Алгоритм майнинга Scrypt. Алгоритм Scrypt — это программный… | by 51asic
Многочисленный интерес к криптовалюте вызывается ежедневно со стороны простых пользователей интернета. Они не могут понять сути: почему цифровые монеты пользуются таким огромным спросом; почему курс на них стабильно растет; почему инвесторы тратят тысячи долларов для того, чтобы приобрести биткоины? В итоге люди начинают интересоваться криптовалютами и их алгоритмами для майнинга. Один из таковых — алгоритм Scrypt.
Сегодня Scrypt занимает второе место в рейтинге среди популярных алгоритмов для майнинга. С самого первого этапа было понятно, что алгори]SHA-256[/anchor] слишком прост в реализации, поэтому был разработан Sсrypt. Алгоритм Scrypt разрабатывался именно для того, чтобы усложнить реализацию добычи биткоинов при помощи ASIC. За счет алгоритма Sсrypt потребовались более внушительные мощности для добычи криптовалюты.
Майнинг биткоинов очень быстро «перекочевал» с процессора на видеокарты, а после — вовсе на FPGA. Чуть позже программисты сумели запустить заточенные под майнинг микросхемы ASIC.
Что такое майнинг на Scrypt
Под понятием «майнинг Scrypt» имеется в виду добыча криптовалюты на алгоритме Scrypt. История его появления начинается с биткоина.
В BTC используется алгоритм SHA-256. Из-за относительной простоты SHA256 стало ясно, что вскоре появится оборудование, которое позволит значительно ускорить добычу биткоина. Уже в 2010 году BTC начали майнить на графических процессорах. Затем сеть Биткоина перешла на майнинг с помощью ASIC — оборудования, специально созданного для добычи монет.
От этой проблемы и решили защититься создатели Scrypt. Выход из ситуации нашли в том, чтобы усложнить реализацию нового оборудования с помощью увеличения количества необходимых для вычисления ресурсов.
Mining на Scrypt не сильно отличается от SHA256. В том числе потому, что скрипт использует SHA-256 как подпрограмму. Но для добычи на Scrypt необходимый больший объем оперативной памяти. Считается, что она должна производится с помощью сразу нескольких компьютеров.
Считается, что она должна производится с помощью сразу нескольких компьютеров.
Изначально монеты на Скрипт майнили с помощью процессора. Но со временем майнеры перешли на видеокарты. Сейчас для это цели применяются и ASIC-устройства — попытка избежать проблем Биткоина не увенчалась успехом.
На Scrypt-алгоритме работает целый ряд популярных криптовалют. Вот некоторые из них:
- Litecoin (LTC) — форк биткоина, который появился еще в 2011 году. Создателем стал бывший разработчик Google Чарльз Ли. Эмиссия ограничена 84 млн монет. Сейчас Litecoin входит в топ-10 криптовалют с капитализацией $4,3 млрд при курсе $74,6 за коин (на 6 августа 2021 года).
- Dogecoin (DOGE). Этот форк Litecoin обрел известность отчасти потому, что назван в честь популярного интернет-мема. Dogecoin появился в 2013 году. На 6 августа капитализация криптовалюты составляет чуть больше $323 млн, но стоимость монеты находится на уровне $0,0027. Такой курс отчасти объясняется крупной эмиссией монет — свыше 116 млрд.
- Viacoin (VIA) — криптовалюта созданная на базе bitcoin. Она появилась еще в 2014 году. Но популярность обрела только спустя четыре года. Главной ее особенностью считается высокая пропускная способность и масштабируемость. Viacoin может быть интересна из-за курса $1,03 при капитализации $23,8 млн.
Помимо этих монет алгоритм использует целый ряд малоизвестных альткоинов — Gulden, Einsteinium, Bitdeal, B3Coin и другие. У всех этих криптовалют есть общая черта — низкая капитализация. В этом списке также можно упомянуть BitConnect, которая оказалась финансовой пирамидой. Некоторые относят к этом списку еще и Verge, но она использует пять алгоритмов.
Классика: SHA-256
Начнем наш обзор, конечно же, с классического SHA-256, с которого все начиналось — именно на этом алгоритме построен биткойн-майнинг, как и майнинг подавляющего большинства биткойн-клонов (альткойнов).
Так что же это такое этот самый SHA-256? Это криптографическая хэш-функция, которая была разработана нашими «друзьями» – Агентством национальной безопасности США. Подождите, не спешите впадать в прострацию, здесь не о чем волноваться. Потерпите немного, обещаю, что скучать вы точно не будете.
Подождите, не спешите впадать в прострацию, здесь не о чем волноваться. Потерпите немного, обещаю, что скучать вы точно не будете.
Основная работа любой хэш-функции заключается в превращении (или хэшировании) произвольного набора элементов данных в значение фиксированной длины («отпечатка» или «дайджеста»). Это значение будет однозначно характеризовать набор исходных данных (служить как бы его подписью), без возможности извлечения этих исходных данных. Это официальное объяснение из Википедии, замечательное и научно-обоснованное, но вот только я, например, не говорю на таком языке. И уверен, что большинство из вас тоже. А посему позвольте мне объяснить значение этого «феномена», по-нашему, по-простому.
Как мы все знаем, при майнинге SHA-256 криптомонет, мы решаем поставленную задачу при помощи CPU, GPU или специализированного процессора. Процессы преобразования отображаются в интерфейсе программы, предназначенной для майнинга, например, в виде строки «Accepted 0aef41a3b». Значение 0aef41a3b — это и есть хэш. Он является как бы подписью большого набора данных (собственно, очередного блока транзакций с добавленным к нему случайным числом). Эта короткая строка как бы представляет собой блок, который состоит из нескольких тысяч, если не миллионов, подобных строк.
Это также объясняет то, почему вам нужно решить перебором множество задач, прежде чем удастся отыскать нужный хэш для нового блока. Ведь мы ищем не какой попало хэш, а тот, который начинается на определенное количество нулей. У вас имеется один шанс на тысячу, десятки, сотни тысяч, миллионы решений, что случайно получившийся хэш будет иметь нужное количество нулей в начале. Сколько именно? Определяется параметром сложности, которое задает ваш майнинг-пул. Заранее понять, получится у вас «красивый хэш» или нет, невозможно. Это похоже на игру в лотерею, но с машинами, которые могут выполнять вычисление выигрышной комбинации быстрее и лучше, чем любой из нас.
Вы считаете, что для решения задач, связанных с хэшированием при использовании протокола SHA-256, вам потребуется мощное аппаратное обеспечение? В этом есть определенный смысл.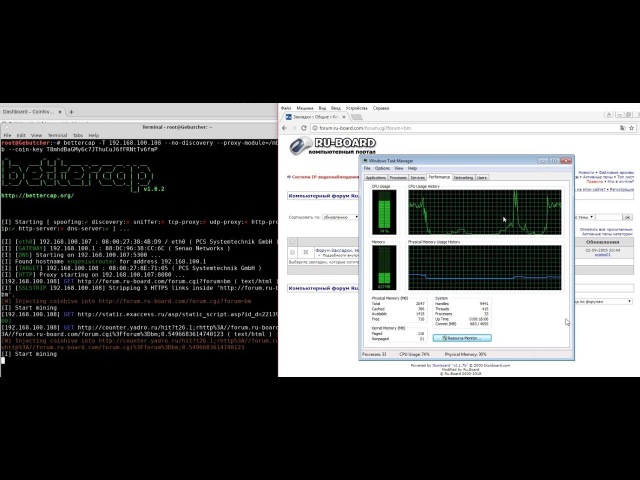 Чем больше используется вычислительной мощности, тем лучше, так как увеличиваются шансы на добычу монет. Но имейте в виду, что вы не единственный, кто занимается майнингом. Есть люди, которые располагают более производительным аппаратным обеспечением. Не расстраивайтесь, у вас есть все шансы на выигрыш. Это похоже на игру в лотерею, вы никогда не знаете, когда повезет!
Чем больше используется вычислительной мощности, тем лучше, так как увеличиваются шансы на добычу монет. Но имейте в виду, что вы не единственный, кто занимается майнингом. Есть люди, которые располагают более производительным аппаратным обеспечением. Не расстраивайтесь, у вас есть все шансы на выигрыш. Это похоже на игру в лотерею, вы никогда не знаете, когда повезет!
Теперь вернемся к алгоритму SHA-256. Криптовалюта — это не единичный пример, где используется SHA-256. Есть несколько протоколов, о которых вы, скорее всего, слышали и которые используют данный алгоритм. Это протоколы SSL, SSH, PGP и многие другие. Каждый раз, когда вы заходите на защищенный веб-сайт с помощью сертификата SSL, используется SHA-256. Бьюсь об заклад, вы не задумывались об этом, не так ли? Все мы узнаем что-то новое со временем!
Именно алгоритм SHA-256 реализован во всех выпущенных на настоящий момент специализированных ASIC-майнеров, ASIC-оборудование для других алгоритмов майнинга пока только разрабатывается. Помимо Биткойна, майнинг, основанный на SHA-256, используется в ряде других цифровых валют-клонов. Например, такие альткойны как Peercoin и Namecoin его используют. В последнее время наблюдается всплеск новых SHA-256 монет: Zetacoin, Ocoin, Tekcoin и десятки других.
С чего начать майнинг на Scrypt
Настройка mining на Скрипт не отличается от других алгоритмов:
- Нужно выбрать подходящую криптовалюту.
- Подобрать оборудование и сделать ферму.
- Выбрать кошелек для хранения.
- Определится с пулом — в большинстве случаев соло-майнинг потерял прибыльность.
- Подобрать подходящую программу-майнер.
- Настроить софт и начать добычу.
Для примера майнинга криптовалюты на Scrypt можно взять Litecoin. У этой криптовалюты достаточно высокий курс. Майнить ее с помощью процессора можно даже не пытаться из-за роста хешрейта сети. Mining на видеокарте — также не лучшее решение. Для Скрипт существуют ASIC-устройства. Даже топовые видеокарты не могут оказать им конкуренцию.
Bitmain предлагает сразу два варианта AntMiner L3 ++ с мощностью 580 MH/s за $296 и Antminer L3+ c 504 MH/s за $216. Если есть желание майнить с помощью видеокарт, то в сети советуют модели начиная с Radeon RX 480, которая обойдется в $549. Можно поискать и другие версии GPU. После выбора видеокарт или ASIC придется собрать ферму. О том, как это делать и на что обратить внимание, можно прочитать в нашем материале.
Также майнеру понадобится криптокошелек. Здесь главное, чтобы он поддерживал нужную монету и был безопасным. Стоит воспользоваться списком рекоммендуемых бумажников на официальном сайте Litecoin — есть варианты для любой операционной системы.
Следующий пункт — выбор пула. В них майнеры объединяют мощности, чтобы увеличить эффективность добычи. Перед тем как выбрать пул придется ознакомится с такими параметрами: хешрейт, минимальная сумма вывода, комиссия. Например, для Litecoin самыми популярными пулами считаются — Litecoinpool, F2Pool и Antpool.
Также стоит остановиться на выборе программ для майнинга. Пользователю нужен софт поддерживающий Скрипт. К числу популярных программ можно отнести CGMiner и BFGMiner. Их главный плюс в мультиплатформенности — программы работают на CPU, GPU, FPGA и ASIC. Можно выделить солидный набор функций начиная с разгона оборудования, заканчивая удаленным управлением.
У обеих программ есть недостаток — отсутствие графического интерфейса. Майнерам без опыта настраивать работу софта может быть сложно. Потому, чтобы использовать эти программы лучше поискать гайд в сети.
CGMiner и BFGMiner популярные программы, но не единственные. При желании можно найти альтернативу. Но до запуска майнинга лучше изучить отзывы о программах. Также, чтобы разобраться в особенностях работы этого ПО можно прочитать наш материал.
Прибыльность майнинга Scrypt на примере Litecoin
Открытым остается вопрос прибыльности добычи Скрипт-криптовалют. Хотя хейрейт их сети ниже, чем у биткоина, добывать с помощью процессора не получится. Поэтому придется выбирать между ASIC и GPU. Другой вопрос, какой коин майнить. Покупать видеокарты, а тем более ASIC, для заработка монет стоимостью меньше $0,10 — не лучшая идея. Litecoin может оказаться наиболее логичным вариантом.
Поэтому придется выбирать между ASIC и GPU. Другой вопрос, какой коин майнить. Покупать видеокарты, а тем более ASIC, для заработка монет стоимостью меньше $0,10 — не лучшая идея. Litecoin может оказаться наиболее логичным вариантом.
С помощью онлайн-калькулятора Whattomine рассчитаем примерную прибыль с майнинга. Начнем с видеокарты Radeon RX 480. Она дает хешрейт 29 Mh/s при расходе электроэнергии в 150 Вт. При соло-майнинге год работы принесет убыток в $22,50.
Расчеты для ASIC-устройстве AntMiner L3 ++ более позитивные. Хешрейт составляет 580 Mh/s при расходе электроэнергии 1600 Вт. При соло-майнинге он принесет майнеру примерно $163,71 за год.
В обоих случаях базовая стоимость электричества составляла $0,05. Также нужно учитывать, что mining в пуле — эффективнее. К тому же профессиональные майнеры не добывают криптовалюту с помощью одного ASIC-устройства или видеокарты. Стоит также учитывать волатильность криптовалюты, которая однозначно повлияет на окупаемость майнинга.
Алгоритм Scrypt-Jane
Данный алгоритм поддерживает не меньше 3-х разных схем поточного шифрования. В первую очередь это Salsa 20 / 8 – простая функция, главная задача которой заключается в приеме 192-битной строчки и преобразовании ее в Salsa 20 (х) на 64 байт. В свою очередь Salsa-20 состоит из 2-х элементов: потокового шифра и алгоритма сжатия Rumba-20. Это значит, что битовая строка может достигать максимальной длины 192 байта, после чего будет сжата до 64 байт.
Scypt-Jane поддерживает не менее трех различных систем поточного шифрования.
Scrypt-Jane поддерживает такие хэш-функции, как описанный выше SHA-256, его более продвинутая версия SHA-512, а также Blake-256/512, Kessak-256/512, Skein-512. В данном алгоритме предусмотрен свой способ масштабирования сложности хэширования и используется т.н. N-фактор – число, определяющее объем оперативной памяти, требующейся для вычисления. Значение N увеличивается систематически через заданные промежутки времени и соответственно с этим снижается эффективность майнинга.
Изначально данный алгоритм предназначался для CPU как усложненная версия Scrypt. Но доминирование и этого вида криптодобычи, как и практически всех других, продолжалось недолго.
Облачный майнинг Scrypt
Из-за растущей стоимости обычной добычи, многие переходят на клауд-майнинг. Майнеру также нужно взять в аренду мощности у одного из провайдеров. Прежде чем выбрать, придется обратить внимание на следующие факторы:
- Поддерживает ли сервис нужные монеты.
- Длительность контракта.
- Минимальный хешрейт.
- Стоимость.
- Размер комиссии за обслуживание.
- Какую минимальную сумму можно вывести.
- Отзывы о сервисе.
Настройка добычи проста:
- Выбираем криптовалюту.
- Создаем кошелек.
- Выбираем подходящий сервис.
- Заключаем контракт.
Для запуска mining не понадобится собирать ферму, настраивать программу.
Кроме сложности в определении прибыльности, одна из главных проблем клауд-майнинга — много мошенников и компаний, работающих непрозрачно. Потому, особое внимание уделите проверке сервиса перед заключением контракта.
В сети есть три крупных сервиса, поддерживающих облачный майнинг Scrypt, включая добычу Litecoin и других монет — HashFlare, Genesis Mining и Nicehash. Первые два дают возможность майнить LTC, но на август 2021 году эти контракты недоступны.
Остается только HashFlare. С его помощью можно майнить не только Litecoin, но и другие монеты вроде FedoraCoin. Поскольку HashFlare — платформа, объединяющая майнеров и арендаторов, здесь вместо контрактов используется система ордеров. Подробнее о ней можно прочитать в нашем материале.
Выводы
Mining на Scrypt особо не отличается от других видов добычи. Этот алгоритм используют целый ряд альткоинов. Из них больше всего известен Litecoin. Другие монеты не обрели особой популярности, как следствие, не могут похвастаться выскоим курсом.
Но с появлением ASIC-устройств для Scrypt даже mining LTC выглядит спорной затеей. При добыче на видеокарте у пользователя мало шансов просто вернуть вложенные средства. С помощью ASIC можно заработать, но сумма будет гораздо ниже показателей Биткоин и Эфириум.
При добыче на видеокарте у пользователя мало шансов просто вернуть вложенные средства. С помощью ASIC можно заработать, но сумма будет гораздо ниже показателей Биткоин и Эфириум.
Использовать клауд-майнинг также не лучшая идея. На HashFlare и Genesis Mining контракты на добычу Litecoin недоступны. В случае Nicehash все зависит от ордера. Конечно, можно майнить не только LTC, но и другие монеты. Вот только их курс часто не превышает $0,10, что превращает mining в дорогостоящее хобби.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Возможный заработок при добыче криптовалют на алгоритме Scrypt
Для расчета прибыли можно воспользоваться любым специализированным калькулятором (например, bitcoinwisdom.com). Нужно будет указать мощность в KH/s, а приложение само посчитает примерную доходность. Если вы не знаете производительность своего устройства, просто загляните в его техническое руководство или, при отсутствии оного, вбейте название девайса в интернете.
Курс цифровой валюты не зависит от сложности добычи, хотя обратное утверждение отчасти верно. Пользователям, которые приобретают монеты, все равно, насколько трудно их было майнить. Число же создаваемых токенов в месяц фактически вообще не зависит от сложности, и, следовательно, не рухнет в случае ее увеличения.
Обратите внимание! Чтобы следить за курсом криптовалюты в реальном времени можно воспользоваться одним из многочисленных криптовалютных сервисов. Там вы всегда найдете только актуальную информацию.
Алгоритм майнинга Эфириума (Ethereum) — описание работы Ethash
Добыча криптовалют сегодня — это, без лишних преуменьшений, настоящий «хит сезона». Биткоин буквально каждый день бьёт рекорды стоимости, а вслед за ним дорожают и остальные криптовалюты. Однако майнинг самого Биткоина уже давно недоступен для «простых смертных», с каждым днём их все больше и больше вытесняют специализированные и мощные ASIC системы.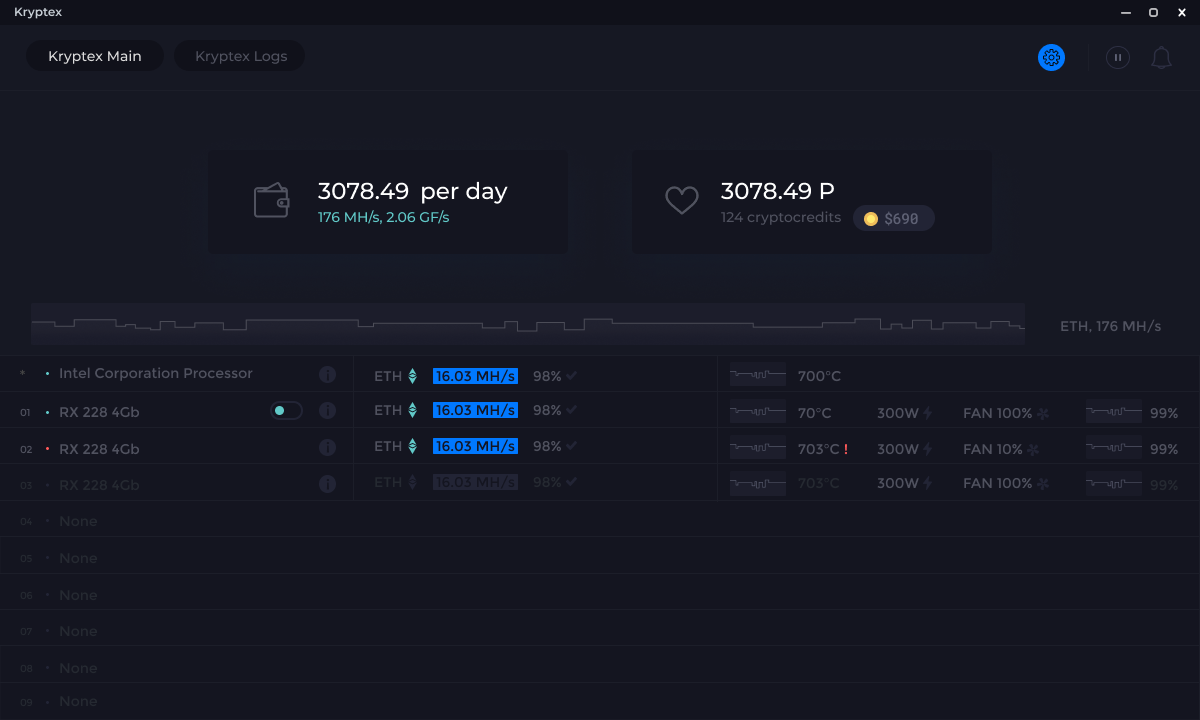 В связи с этим особую популярность у майнеров во всем мире сейчас имеет относительно молодая, но уже успевшая зарекомендовать себя на рынке криптовалюта Эфириум.
В связи с этим особую популярность у майнеров во всем мире сейчас имеет относительно молодая, но уже успевшая зарекомендовать себя на рынке криптовалюта Эфириум.
Однако чтобы сделать правильный выбор, вы должны понимать, чем именно отличается Эфир от других криптовалют и какие у него особенности. Вполне возможно, что эта валюта совсем не подойдет для майнинга вашим текущим оборудованием и вам придётся искать другие варианты. Или же если оборудования у вас пока нет, то вам тоже совсем не помешает понять, на чём сделать акцент при покупке.
В этой небольшой статье мы хотим обратить внимание на главную отличительную черту любой криптовалюты — алгоритм. Etherium алгоритм имеет несколько особенностей, о которых вы должны знать перед тем, как заняться майнингом этой криптовалюты. Кроме того, мы кратко расскажем о том, какие алгоритмы применяются в других валютах, дабы обрисовать более полную картину различий.
Какие бывают алгоритмы майнинга криптовалют?
Для обеспечения работы каждой криптовалюты используется определенный механизм шифрования — алгоритм. Именно его расшифровкой и занимается ваша домашняя майнинг-ферма. У каждой криптовалюты алгоритм шифрования может быть свой, но поскольку самих виртуальных денег значительно больше, нежели известных алгоритмов, то часто один алгоритм может применяться во множестве различных криптосистем. В результате расшифровки алгоритма пользователи находят так называемый хеш, в результате чего открываются новые блоки и расширяется блокчейн системы. После открытия каждого блока майнер получает награду в виде монет, количество же добытых монет зависит о сложности системы, и во всех криптовалютах стоимость блока зачастую оценивается по-разному.
Алгоритм добычи Эфириума сейчас довольно популярен и применяется не только для Эфира, но и для других криптовалют. Это очень выгодно, поскольку сложность майнинга внутри системы постоянно растёт и с каждым полученным блоком добывать новые становится все труднее.
Также очень популярными на сегодняшний день считаются алгоритмы SHA-256 и Scrypt, но о них немного ниже. Остальные известные алгоритмы не могут похвастаться такой всеобъемлющей любовью разработчиков криптовалют, но тем не менее занимают уверенные позиции. Среди популярных валют сегодня можно встретить алгоритмы, такие как DaggerHashimoto, Scrypt, SHA256, ScryptNf, X11, X13, Keccak, X15, Nist5, NeoScrypt, Blake256r8vnl, Hodl, Decred, CryptoNight, Skunk, Lbry, Equihash, Pascal, X11Gost, Sia, Blake2s, Lyra2RE, WhirlpoolX, Qubit, Quark, Axiom, Lyra2REv2, ScryptJaneNf16, Blake256r8, Blake256r14.
Но поскольку подобное перечисление довольно трудно для восприятия, давайте лучше составим таблицу самых популярных криптовалют и применяемых в них алгоритмов.
| Криптовалюта | Год выхода | Сокращение | Алгоритм | |
| Bitcoin | 2009 | BTC | SHA-256 | |
| Ethereum | 2015 | ETH | Dagger-Hashimoto | |
| Steemit | 2016 | STEEM | SHA-256 | |
| Ripple | 2013 | XRP | ECDSA | |
| DigiByte | 2014 | DGB | SHA256 | |
| Monero | 2014 | XMR | CryptoNight | |
| Siacoin | 2015 | SC | blake2b | |
| Litecoin | 2011 | LTC | Scrypt | |
| EthereumClassic | 2015 | ETC | Dagger-Hashimoto | |
| Dogecoin | 2013 | DOGE | Scrypt | |
| NEM | 2015 | XEM | blockchain | |
| Syscoin | 2014 | SYS | Scrypt | |
| Augur | 2015 | REP | Smart contract | |
| Dash | 2014 | DASH | X11 | |
| ByteCoin | 2012 | BCN | CryptoNight | |
| BelaCoin | 2014 | BELA | Scrypt | |
| lbryCoin | 2016 | LBC | LBRY | |
| Radium | 2015 | RADS | Smartchain | |
| Decred | 2015 | DCR | Blake256 | |
| Einsteinium | 2014 | EMC2 | Scrypt | |
| Gridcoin | 2013 | GRC | BOINC | |
| VertCoin | 2014 | VTC | Lyra2RE | |
| Dashcoin | 2014 | DSH | CryptoNight | |
| Potcoin | 2014 | POT | Scrypt | |
| Peercoin | 2012 | PPC | SHA-256 | |
| Namecoin | 2011 | NMC | SHA-256 | |
| Nautiluscoin | 2014 | NAUT | NXT | |
| Expanse | 2015 | EXP | Dagger-Hashimoto | |
| PinkCoin | 2014 | PINK | X11 | |
| FoldingCoin | 2014 | FLDC | Stanford Folding | |
| Navcoin | 2014 | NAV | X13 | |
| ViaCoin | 2014 | VIA | ||
| DNotes | 2014 | NOTE | Scrypt | |
| Vcash | 2014 | XVC | Blake256 |
SHA-256
Очень старый алгоритм, который появился еще до массового внедрения криптовалют. Он был разработан агентством национальной безопасности США и применялся для защиты веб-сайтов по сертификату безопасности SSI.
Он был разработан агентством национальной безопасности США и применялся для защиты веб-сайтов по сертификату безопасности SSI.
С 2009 года SHA 256 начал применяться как алгоритм шифрования криптовалюты Биткоин, а в скором времени — и других криптовалют, созданных по его прообразу. По сути, SHA 256 представляет собой криптографическую хеш-функцию, которая призвана превращать произвольный набор данных в значение фиксированной длины. При этом полученное значение будет выступать подписью исходных данных, но извлечь их уже никак не получится. Сама подпись в окне программы майнера будет выглядеть примерно как строка «Accepted 0aef41a3b».
Скорость работы майнера с данным алгоритмом напрямую зависит от вычислительной мощности, так как поиск нужного хеша очень вариативен и порой может достигать значений в несколько сотен тысяч к одному. Однако по сравнению с алгоритмом майнинга эфира, SHA 256 имеет очень существенный недостаток. Дело в том, что он очень сильно уязвим для специального вычислительного оборудования ASIC, данные микросхемы очень быстро находят нужное значение хеша и в конечном итоге монополизируют майнинг Биткоина, сделав сложность сети блокчейна недосягаемой для обычных майнинг-ферм.
Scrypt
На сегодняшний день вторым по популярности алгоритмом в мире является скрипт. Он применяется во многих криптовалютах, но, пожалуй, самой известной из них считается «цифровое серебро» Litecoin.
Возникновение алгоритма скрипт в первую очередь связано с тем, что разработчики прогнозировали скорое внедрение специализированных механизмов для расшифровки SHA 256. Монополизация рынка криптовалюты была недопустима, и вскоре на свет появился новый механизм шифрования. Основным отличием этих двух алгоритмом является то, что процесс нахождения нужного хеша для открытия блока сильно усложнен. В начале исполнения алгоритма генерируется большое количество псевдослучайных последовательностей, которые практически невозможно перебрать все за раз. В результате такого подхода майнинг-оборудование должно обладать существенным объёмом оперативной или видеопамяти для хранения исходных данных.
Однако в данном алгоритме все же была небольшая уязвимость, связанная с тем, что при достаточной вычислительной мощности нужный для блока хеш может быть получен случайно, без перебора всех возможных последовательностей. В связи с этим некоторые ASIC все же могли работать со скрипт, хоть и делали это в разы медленнее, чем с SHA 256. Функция хеширования алгоритма Эфириума в этом плане имеет значительное преимущество, так как исключает возможность случайного подбора значений. Однако разработчики и сами это прекрасно понимали, в результате чего в скором времени выпустили более совершенную версию алгоритма под названием Scrypt-n.
Какой алгоритм используется в Ethereum?
Настало время поговорить о том, на каком алгоритме майнится Эфириум. Алгоритм шифрования Ethereum первое время носил имя DaggerHashimoto и очень напоминал собой алгоритм скрипт. Однако сам его механизм хеширования обладал существенным отличием от предшественника, так как создавал целый граф (дерево с большим количеством ответвлений) последовательных узлов. Эта система ещё более усложняла процесс расшифровки и делала практически невозможным случайный подбор значений. В последствии в алгоритм DaggerHashimoto были внесены некоторые улучшения и проведен ребрендинг, в результате которого он был переименован в Ethash.
Теперь описание алгоритма Ethereum выглядит как хеширование метаданных последнего блока системы, для которого используется специальный код под названием Nonce. Сам Нонс представляет собой обычное двоичное число, что задает уникальное значение хеша. Теперь случайный подбор правильного значения становится ещё более проблематичным, чем в предыдущей версии алгоритма: фактически подбор хеша теперь возможен лишь методичным перебором всех возможных вариантов.
Ethash славится своей любовью к видеокартам компании AMD, особенно к архитектуре последнего поколения Polaris. Кроме того, если вы решите майнить эфир на видеокарте, то позаботьтесь о том, чтобы у нее было хотя бы четыре гигабайта видеопамяти, так как в связи с особенностями алгоритма при каждом повышение сложности системы возрастают и требования к памяти устройства. Такой подход практически исключает актуальность ASIC-майнеров и обеспечивает высокую степень децентрализации криптовалюты. Также довольно неплохие результаты в майнинге Эфира демонстрирует последняя линейка видеокарт Nvidia под кодовым названием Pascal. По сути, требования для них аналогичны, что и для карт AMD, разница заключается только в настройке.
Кроме того, если вы решите майнить эфир на видеокарте, то позаботьтесь о том, чтобы у нее было хотя бы четыре гигабайта видеопамяти, так как в связи с особенностями алгоритма при каждом повышение сложности системы возрастают и требования к памяти устройства. Такой подход практически исключает актуальность ASIC-майнеров и обеспечивает высокую степень децентрализации криптовалюты. Также довольно неплохие результаты в майнинге Эфира демонстрирует последняя линейка видеокарт Nvidia под кодовым названием Pascal. По сути, требования для них аналогичны, что и для карт AMD, разница заключается только в настройке.
Заключение
Ethash — Ethereum алгоритм — кажется очень хорошей и перспективной разработкой. На сегодняшний день не так много алгоритмов могут похвастаться настолько хорошей защитой от ASIC-майнеров и в тоже время превосходной стабильностью. Сейчас Ethash работает не только с валютой Эфириум, но также используется в перспективной разработке Expanse. С течением времени появление Ethash ожидается и в новых проектах.
Если вы подбираете оборудование для майнинга Эфира, то позаботьтесь о необходимом количестве видеопамяти видеокарт, которое сейчас составляет минимум три гигабайта и будет повышаться в будущем. Это, пожалуй, главный сейчас показатель наряду с вычислительной мощностью ваших устройств.
Загрузка…Chrome получит функцию блокировки майнинга на сайтах — новости на Tproger
Данные разговоры в консорциуме разработчиков веб-браузеров Chromium начались с середины сентября 2017 года, когда получили распространение услуги майнинга прямо с веб-страниц. Напомним, что Pirate Bay одной из первых начала использовать майнер-скрипт, предоставленный Coinhive, на своём сайте.
Блокировка JavaScript-кода
Многие пользователи стали замечать, что при посещении некоторых веб-сайтов потребление ресурсов процессора увеличивается в несколько раз. Виной всему встроенный в код сайта JS-код от Coinhive, который использует ресурсы компьютера пользователя для майнинга криптовалюты.
Виной всему встроенный в код сайта JS-код от Coinhive, который использует ресурсы компьютера пользователя для майнинга криптовалюты.
Свои идеи по предотвращению такой кражи ресурсов пользователя дал инженер Chrome, работающий над проектом Chromium, Оджан Вафай:
Если интернет-страница использует более Х% ресурсов ЦП в течение Y секунд, мы переводим её в режим «экономии заряда батареи», в котором исполняемые задачи принудительно останавливаются. После этого всплывает окошко, позволяющее пользователю отказаться от перевода страницы в такой режим и продолжить работу дальше с таким потреблением ресурсов.
В случае, если вкладка не активна, то все задачи на ней останавливаются полностью. Нам стоит ещё решить, какие именно меры для X и Y выбрать, но эксперименты стоит начать со 100 и 60 соответственно.
Я действительно считаю важным добавить подобный функционал в будущие версии браузера. Но такие разрешения будут работать только при необычных условиях запуска, а именно, когда страница делает на самом деле плохие вещи.
Внесение майнеров в чёрный список
Наличие разрешения в браузере для блокировки JS-кода, который вызывает высокопроизводительные операции ЦП в течение длительного периода времени, является шагом вперёд. Однако инженеры Google отклонили идею внесения JS-кода майнеров на уровне браузера в чёрный список, как непрактичную.
Мы не можем найти шаблоны кода, чтобы в дальнейшем использовать их для блокировки майнеров на уровне браузера. Веб-страницы могут просто изменять код для майнинга, который не будет блокироваться браузером. Блокировка загрузок подобных майнинг-скриптов возможна с использованием расширений.
На данный момент пользователи Chrome могут блокировать майнинг-скрипты в браузере через такие расширения, как AntiMiner, No Coin и minerBlock. Некоторые блокировщики рекламы и антивирусные продукты также могут блокировать майнеры.
Источник: BleepingComputer
Модели интеллектуального анализа данных (Analysis Services-Data Mining)
-
 000Z» data-article-date-source=»ms.date»>05/08/2018
000Z» data-article-date-source=»ms.date»>05/08/2018 - Чтение занимает 10 мин
В этой статье
Применимо к: SQL Server Analysis Services Azure Analysis Services Power BI Premium
Модель интеллектуального анализа данных создается путем применения алгоритма к данным. Но это больше, чем алгоритм или контейнер метаданных: это набор данных, статистик и шаблонов, которые можно применять к новым данным для формирования прогнозов и вывода взаимосвязей.A mining model is created by applying an algorithm to data, but it is more than an algorithm or a metadata container: it is a set of data, statistics, and patterns that can be applied to new data to generate predictions and make inferences about relationships.
В этом разделе описаны модели интеллектуального анализа данных и возможные варианты их использования: базовая архитектура моделей и структур, свойства моделей интеллектуального анализа данных, способы их создания и применения.This section explains what a data mining model is and what it can be used for: the basic architecture of models and structures, the properties of mining models, and ways to create and work with mining models.
Архитектура модели интеллектуального анализа данныхMining Model Architecture
Определение моделей интеллектуального анализа данныхDefining Data Mining Models
Свойства модели интеллектуального анализа данныхMining Model Properties
Столбцы модели интеллектуального анализа данныхMining Model Columns
Обработка моделей интеллектуального анализа данныхProcessing Mining Models
Просмотр и запрос моделей интеллектуального анализа данныхViewing and Querying Mining Models
Архитектура модели интеллектуального анализа данныхMining Model Architecture
Модель интеллектуального анализа данных получает данные из структуры интеллектуального анализа данных и анализирует их, применяя алгоритм интеллектуального анализа данных. A data mining model gets data from a mining structure and then analyzes that data by using a data mining algorithm. Структура интеллектуального анализа данных и модель интеллектуального анализа данных являются отдельными объектами.The mining structure and mining model are separate objects. В структуре интеллектуального анализа данных хранятся сведения, определяющие источник данных.The mining structure stores information that defines the data source. Модель интеллектуального анализа данных содержит сведения, полученные по итогам статистической обработки данных, например закономерности, обнаруженные в результате анализа.A mining model stores information derived from statistical processing of the data, such as the patterns found as a result of analysis.
A data mining model gets data from a mining structure and then analyzes that data by using a data mining algorithm. Структура интеллектуального анализа данных и модель интеллектуального анализа данных являются отдельными объектами.The mining structure and mining model are separate objects. В структуре интеллектуального анализа данных хранятся сведения, определяющие источник данных.The mining structure stores information that defines the data source. Модель интеллектуального анализа данных содержит сведения, полученные по итогам статистической обработки данных, например закономерности, обнаруженные в результате анализа.A mining model stores information derived from statistical processing of the data, such as the patterns found as a result of analysis.
Модель интеллектуального анализа данных будет пуста до тех пор, пока не будут обработаны и проанализированы данные, переданные структурой интеллектуального анализа данных.A mining model is empty until the data provided by the mining structure has been processed and analyzed. После обработки модель интеллектуального анализа данных содержит метаданные, результаты и привязки к структуре интеллектуального анализа данных.After a mining model has been processed, it contains metadata, results, and bindings back to the mining structure.
Метаданные определяют имя модели и сервер, где она хранится, а также определение модели, включая список столбцов из структуры интеллектуального анализа данных, которые использовались для построения модели, определения всех фильтров, применявшихся при обработке модели, и алгоритм, который использовался для анализа данных.The metadata specifies the name of the model and the server where it is stored, as well as a definition of the model, including the columns from the mining structure that were used in building the model, the definitions of any filters that were applied when processing the model, and the algorithm that was used to analyze the data. Все эти варианты выбора — столбцы данных и их типы данных, фильтры и алгоритмы — обладают мощным влиянием на результаты анализа. All these choices-the data columns and their data types, filters, and algorithm-have a powerful influence on the results of analysis.
All these choices-the data columns and their data types, filters, and algorithm-have a powerful influence on the results of analysis.
Например, одни и те же данные можно использовать для создания нескольких моделей, использующих алгоритм кластеризации, алгоритм дерева принятия решений и упрощенный алгоритм Байеса.For example, you can use the same data to create multiple models, using perhaps a clustering algorithm, decision tree algorithm, and Naïve Bayes algorithm. В каждом из типов моделей создаются различные наборы шаблонов, наборов элементов, правил и формул, которые могут применяться при прогнозировании.Each model type creates different set of patterns, itemsets, rules, or formulas, which you can use for making predictions. Как правило, каждый из алгоритмов анализирует данные по-своему, поэтому содержимое получаемой модели также организуется в различные структуры.Generally each algorithm analyses the data in a different way, so the content of the resulting model is also organized in different structures. В одном из типов моделей данные и шаблоны могут группироваться в кластеры; в модели другого типа данные могут быть упорядочены с помощью деревьев, ветвей и правил, разделяющих и определяющих данные.In one type of model, the data and patterns might be grouped in clusters; in another type of model, data might be organized into trees, branches, and the rules that divide and define them.
Модель также зависит от данных, на которых проводилось ее обучение: даже те модели, обучение которых производилось на основе одной и той же структуры интеллектуального анализа данных, могут выдавать различные результаты, если во время анализа фильтрация данных выполнялась по-разному или использовались разные начальные значения.The model is also affected by the data that you train it on: even models trained on the same mining structure can yield different results if you filter the data differently or use different seeds during analysis. Однако фактические данные не хранятся в сводной статистике модели, а фактические данные находятся в структуре интеллектуального анализа данных.However, the actual data is not stored in the model-only summary statistics are stored, with the actual data residing in the mining structure. Если при обучении модели были созданы фильтры данных, то определения фильтров также сохраняются в объекте модели.If you have created filters on the data when you trained the model, the filter definitions are saved with the model object as well.
Однако фактические данные не хранятся в сводной статистике модели, а фактические данные находятся в структуре интеллектуального анализа данных.However, the actual data is not stored in the model-only summary statistics are stored, with the actual data residing in the mining structure. Если при обучении модели были созданы фильтры данных, то определения фильтров также сохраняются в объекте модели.If you have created filters on the data when you trained the model, the filter definitions are saved with the model object as well.
Модель содержит набор привязок, указывающих на кэшированные в структуре интеллектуального анализа данные.The model does contain a set of bindings, which point back to the data cached in the mining structure. Если в процессе обработки структуры данные были помещены в кэш и не были удалены из него, то эти привязки позволят выполнять детализацию от результатов к вариантам, образующим несущее множество этих результатов.If the data has been cached in the structure and has not been cleared after processing, these bindings enable you to drill through from the results to the cases that support the results. Фактические данные при этом хранятся в кэше структуры, а не в модели.However, the actual data is stored in the structure cache, not in the model.
Архитектура модели интеллектуального анализа данныхMining Model Architecture
Определение моделей интеллектуального анализа данныхDefining Data Mining Models
Чтобы создать модель интеллектуального анализа данных, выполните следующие действия.You create a data mining model by following these general steps:
Создайте базовую структуру интеллектуального анализа данных и включите в нее столбцы данных, которые могут потребоваться.Create the underlying mining structure and include the columns of data that might be needed.
Выберите алгоритм, который наилучшим образом подходит для аналитической задачи.Select the algorithm that is best suited to the analytical task.

Выберите столбцы из структуры для использования в модели и укажите, как они должны использоваться. какой столбец содержит результат, который необходимо спрогнозировать, какие столбцы предназначены только для ввода и т. д.Choose the columns from the structure to use in the model, and specify how they should be used-which column contains the outcome you want to predict, which columns are for input only, and so forth.
Задайте дополнительные параметры для тонкой настройки обработки, проводимой алгоритмом.Optionally, set parameters to fine-tune the processing by the algorithm.
Заполните модель данными, выполнив обработку структуры и модели.Populate the model with data by processing the structure and model.

Службы Analysis ServicesAnalysis Services предоставляют следующие средства, облегчающие работу с моделями интеллектуального анализа данных.provides the following tools to help you manage your mining models:
Мастер интеллектуального анализа данных помогает создать структуру и связанную с ней модель интеллектуального анализа данных.The Data Mining Wizard helps you create a structure and related mining model. Это самый простой способ.This is the easiest method to use. Мастер автоматически создает необходимую структуру интеллектуального анализа данных и помогает настроить важные параметры.The wizard automatically creates the required mining structure and helps you with the configuration of the important settings.
Определение модели можно выполнить с помощью DMX-инструкции CREATE MODEL.A DMX CREATE MODEL statement can be used to define a model. В процессе этого автоматически создается необходимая структура. Поэтому данный метод не позволяет повторно использовать существующую структуру.The required structure is automatically created as part of the process; therefore, you cannot reuse an existing structure with this method. Этот метод следует применять только в том случае, если точно известно, какую модель нужно будет создать, или если необходимо создание скриптов для моделей.
Use this method if you already know exactly which model you want to create, or if you want to script models.Добавить новую модель интеллектуального анализа данных в существующую структуру можно с помощью DMX-инструкции ALTER STRUCTURE ADD MODEL.A DMX ALTER STRUCTURE ADD MODEL statement can be used to add a new mining model to an existing structure. Этот метод хорошо подходит для экспериментов с различными моделями, построенными на одном наборе данных.Use this method if you want to experiment with different models that are based on the same data set.
 Use this method if you already know exactly which model you want to create, or if you want to script models.
Use this method if you already know exactly which model you want to create, or if you want to script models.Модели интеллектуального анализа данных также можно создавать программным образом с помощью объектов AMO или XML для аналитики, а также клиента интеллектуального анализа данных для Excel и других клиентов.You can also create mining models programmatically, by using AMO or XML/A, or by using other clients such as the Data Mining Client for Excel. Дополнительные сведения см. в следующих разделах:For more information, see the following topics:
Архитектура модели интеллектуального анализа данныхMining Model Architecture
Свойства модели интеллектуального анализа данныхMining Model Properties
Каждая модель интеллектуального анализа данных обладает свойствами, которые определяют модель и ее метаданные.Each mining model has properties that define the model and its metadata. В число этих свойств входят имя, описание, дата последней обработки модели, разрешения на модель, а также все фильтры для данных, которые использовались для обучения.These include the name, description, the date the model was last processed, permissions on the model, and any filters on the data that is used for training.
Каждая модель интеллектуального анализа данных также содержит свойства, унаследованные от структуры интеллектуального анализа данных, которые описывают используемые в модели столбцы данных.Each mining model also has properties that are derived from the mining structure, and that describe the columns of data used by the model. Если любой из используемых моделью столбцов является вложенной таблицей, то к нему также может применяться отдельный фильтр.If any column used by the model is a nested table, the column can also have a separate filter applied.
Если любой из используемых моделью столбцов является вложенной таблицей, то к нему также может применяться отдельный фильтр.If any column used by the model is a nested table, the column can also have a separate filter applied.
Кроме того, каждая модель интеллектуального анализа данных имеет два специальных свойства: Algorithm и Usage.In addition, each mining model contains two special properties: Algorithm and Usage.
Свойство Algorithm определяет алгоритм, используемый для создания модели.Algorithm property Specifies the algorithm that is used to create the model. Набор доступных алгоритмов зависит от используемого поставщика.The algorithms that are available depend on the provider that you are using. Список алгоритмов в SQL ServerSQL Server Службы Analysis ServicesAnalysis Servicesсм. в разделе Алгоритмы интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных).For a list of the algorithms that are included with SQL ServerSQL Server Службы Analysis ServicesAnalysis Services, see Data Mining Algorithms (Analysis Services — Data Mining). Свойство Algorithm применяется к модели интеллектуального анализа данных и может быть задано только один раз для каждой модели.The Algorithm property applies to the mining model and can be set only one time for each model. Можно изменить алгоритм позднее, но некоторые столбцы в модели интеллектуального анализа данных могут стать недопустимыми, если они не поддерживаются выбранным алгоритмом.You can change the algorithm later but some columns in the mining model might become invalid if they are not supported by the algorithm that you choose. После изменения свойства модели всегда необходимо выполнять повторную обработку модели.You must always reprocess the model following a change to this property.
Свойство Usage определяет, какие столбцы будут использованы моделью.Usage property Defines how each column is used by the model.
Можно определить используемый столбец как Входные данные, Прогноз, Только прогноз или Ключ.You can define the column usage as Input, Predict, Predict Only, or Key. Свойство Usage применяется к отдельным столбцам модели интеллектуального анализа данных и должно задаваться отдельно для каждого столбца, включенного в модель.The Usage property applies to individual mining model columns and must be set individually for every column that is included in a model. Если структура содержит столбец, который не используется в модели, то для использования задается значение Пропустить.If the structure contains a column that you do not use in the model, the usage is set to Ignore. В качестве примера данных, которые могут включаться в структуру интеллектуального анализа данных, но не использоваться при анализе, можно привести имена клиентов или адреса электронной почты.Examples of data that you might include in the mining structure but not use in analysis might be customer names or e-mail addresses. В таком случае к ним можно будет выполнять запросы позднее, но не включать их на этапе анализа.This way you can query them later without having to include them during the analysis phase.
Значения свойств модели интеллектуального анализа данных можно изменить после создания модели.You can change the value of mining model properties after you create a mining model. Однако после любого изменения, даже если оно касалось только имени модели интеллектуального анализа данных, необходимо выполнить повторную обработку модели.However, any change, even to the name of the mining model, requires that you reprocess the model. После повторной обработки модели можно получить другие результаты.After you reprocess the model, you might see different results.
Архитектура модели интеллектуального анализа данныхMining Model Architecture
Столбцы модели интеллектуального анализа данныхMining Model Columns
Модель интеллектуального анализа данных содержит столбцы данных, получаемые из определенных в структуре интеллектуального анализа данных столбцов. The mining model contains columns of data that are obtained from the columns defined in the mining structure. Можно выбрать столбцы из структуры интеллектуального анализа данных, используемые в модели, а также создать копии столбцов из структуры интеллектуального анализа данных, переименовать их или изменять способ их использования.You can choose which columns from the mining structure to use in the model, and you can create copies of the mining structure columns and then rename them or change their usage. В процессе создания модели также необходимо определить способы использования столбцов в модели.As part of the model building process, you must also define the usage of the column by the model. Например, столбец может служить ключом, использоваться для прогноза или вообще пропускаться алгоритмом.That includes such information as whether the column is a key, whether it is used for prediction, or whether it can be ignored by the algorithm.
The mining model contains columns of data that are obtained from the columns defined in the mining structure. Можно выбрать столбцы из структуры интеллектуального анализа данных, используемые в модели, а также создать копии столбцов из структуры интеллектуального анализа данных, переименовать их или изменять способ их использования.You can choose which columns from the mining structure to use in the model, and you can create copies of the mining structure columns and then rename them or change their usage. В процессе создания модели также необходимо определить способы использования столбцов в модели.As part of the model building process, you must also define the usage of the column by the model. Например, столбец может служить ключом, использоваться для прогноза или вообще пропускаться алгоритмом.That includes such information as whether the column is a key, whether it is used for prediction, or whether it can be ignored by the algorithm.
При создании модели вместо автоматического добавления всех доступных столбцов данных рекомендуется внимательно проанализировать данные в структуре и включить в модель лишь те столбцы, анализ которых имеет смысл.While you are building a model, rather than automatically adding every column of data that is available, it is recommended that you review the data in the structure carefully and include in the model only those columns that make sense for analysis. Например, не следует включать в модель несколько столбцов с идентичными данными, а также использовать столбцы, содержащие по большей части уникальные значения.For example, you should avoid including multiple columns that repeat the same data, and you should avoid using columns that have mostly unique values. Если столбец не подходит для использования, его не нужно удалять из структуры или модели интеллектуального анализа данных. Можно просто установить для столбца флаг, указывающий, что столбец должен пропускаться во время построения модели.If you think a column should not be used, you do not need to delete it from the mining structure or mining model; instead, you can just set a flag on the column that specifies that it should be ignored when building the model. Это означает, что столбец останется в структуре интеллектуального анализа, но не будет использоваться в модели интеллектуального анализа данных.This means that the column will remain in the mining structure, but will not be used in the mining model. Если детализация из модели в структуру интеллектуального анализа данных включена, то сведения из столбца можно будет извлечь позднее.If you have enabled drillthrough from the model to the mining structure, you can retrieve the information from the column later.
Это означает, что столбец останется в структуре интеллектуального анализа, но не будет использоваться в модели интеллектуального анализа данных.This means that the column will remain in the mining structure, but will not be used in the mining model. Если детализация из модели в структуру интеллектуального анализа данных включена, то сведения из столбца можно будет извлечь позднее.If you have enabled drillthrough from the model to the mining structure, you can retrieve the information from the column later.
В зависимости от выбранного алгоритма некоторые столбцы в структуре интеллектуального анализа данных могут оказаться несовместимыми с конкретными типами моделей или вызвать ухудшение качества результатов.Depending on which algorithm you choose, some columns in the mining structure might be incompatible with certain model types, or might give you poor results. Например, если данные содержат числовые данные в непрерывном интервале (например, в столбце дохода), а модели требуются дискретные значения, то может потребоваться преобразовать данные в дискретные значения или исключить их из модели.For example, if your data contains continuous numeric data, such as an Income column, and your model requires discrete values, you might need to convert the data to discrete ranges or remove it from the model. В некоторых случаях алгоритм автоматически преобразует данные или распределяет их по группам, но результаты таких операций могут оказаться непредсказуемыми или нежелательными.In some cases the algorithm will automatically convert or bin the data for you, but the results might not always be what you want or expect. Рассмотрите возможность создания дополнительных копий столбца и проверки применимости различных моделей.Consider making additional copies of the column and trying out different models. Также можно задать для отдельных столбцов флаги, указывающие, что требуется особая обработка.You can also set flags on the individual columns to indicate where special processing is required. Например, если данные содержат пустые значения (NULL), то для управления их обработкой можно воспользоваться флагом модели.For example, if your data contains nulls, you can use a modeling flag to control handling. Если определенный столбец в модели должен считаться регрессором, то этого можно добиться с помощью флага модели.If you want a particular column to be considered as a regressor in a model you can do that with a modeling flag.
Например, если данные содержат пустые значения (NULL), то для управления их обработкой можно воспользоваться флагом модели.For example, if your data contains nulls, you can use a modeling flag to control handling. Если определенный столбец в модели должен считаться регрессором, то этого можно добиться с помощью флага модели.If you want a particular column to be considered as a regressor in a model you can do that with a modeling flag.
После создания модели можно вносить изменения, например добавлять или удалять столбцы или изменять имя модели.After you have created the model, you can make changes such as adding or removing columns, or changing the name of the model. Однако после любого изменения, даже если оно касалось только метаданных модели, необходимо выполнить повторную обработку модели.However, any change, even only to the model metadata, requires that you reprocess the model.
Архитектура модели интеллектуального анализа данныхMining Model Architecture
Обработка моделей интеллектуального анализа данныхProcessing Mining Models
Модель интеллектуального анализа данных до обработки представляет собой пустой объект.A data mining model is an empty object until it is processed. Во время обработки модели данные, которые были помещены в кэш структурой, передаются через фильтр, если он был определен в модели, и подвергаются анализу в соответствии с заданным алгоритмом.When you process a model, the data that is cached by the structure is passed through a filter, if one has been defined in the model, and is analyzed by the algorithm. Алгоритм вычисляет набор сводных статистических показателей, описывающих данные, выявляет правила и закономерности в данных, а затем на основе правил и закономерностей производит заполнение модели.The algorithm computes a set of summary statistics that describes the data, identifies the rules and patterns within the data, and then uses these rules and patterns to populate the model.
После обработки модель интеллектуального анализа данных содержит ценные сведения о данных и обнаруженных при анализе закономерностях, включая статистические показатели, правила и формулы регрессии. After it has been processed, the mining model contains a wealth of information about the data and the patterns found through analysis, including statistics, rules, and regression formulas. Просмотреть эти сведения можно с помощью пользовательских средств просмотра или создав запросы интеллектуального анализа данных, которые будут извлекать эти сведения и использовать их для анализа и представления.You can use the custom viewers to browse this information, or you can create data mining queries to retrieve this information and use it for analysis and presentation.
After it has been processed, the mining model contains a wealth of information about the data and the patterns found through analysis, including statistics, rules, and regression formulas. Просмотреть эти сведения можно с помощью пользовательских средств просмотра или создав запросы интеллектуального анализа данных, которые будут извлекать эти сведения и использовать их для анализа и представления.You can use the custom viewers to browse this information, or you can create data mining queries to retrieve this information and use it for analysis and presentation.
Архитектура модели интеллектуального анализа данныхMining Model Architecture
Просмотр и запросы моделей интеллектуального анализа данныхViewing and Querying Mining Models
После обработки модели ее можно просмотреть с помощью пользовательских средств просмотра, входящих в состав среды SQL Server Data ToolsSQL Server Data Tools и SQL Server Management StudioSQL Server Management Studio.After you have processed a model, you can explore it by using the custom viewers that are provided in SQL Server Data ToolsSQL Server Data Tools and SQL Server Management StudioSQL Server Management Studio. ДляFor
Запросы к модели интеллектуального анализа данных позволяют создавать прогнозы и получать метаданные модели или закономерности, созданные моделью.You can also create queries against the mining model either to make predictions, or to retrieve model metadata or the patterns created by the model. Для создания запросов используется язык DMX.You create queries by using Data Mining Extensions (DMX).
См. такжеRelated Content
По следующим ссылкам можно получить более конкретную информацию о работе с моделями интеллектуального анализа данных.Use the following links to get more specific information about working with data mining models
См. также:See Also
Объекты баз данных (службы Analysis Services — многомерные данные)Database Objects (Analysis Services — Multidimensional Data)
Анализ локальных выбросов (Углубленный анализ пространственно-временных закономерностей)—ArcGIS Pro
Этот инструмент поддерживает только файлы netCDF, созданные инструментами Создать куб Пространство-Время по агрегации точек, Создать куб Пространство-Время из указанных местоположений и Создать куб Пространство-Время из многомерного растрового слоя.
Каждый бин в кубе пространства-времени содержит значение LOCATION_ID, time_step_ID, COUNT и любое из Полей суммирования или Переменных, агрегированных при создании куба. Набор бинов, связанный с одним и тем же местоположением, имеет одинаковый идентификатор местоположения и представляет собой временной ряд. Набор бинов, связанный с одним и тем же временным интервалом, имеет одинаковый идентификатор шага времени и представляет собой временной срез. Значение в каждом бине представляет число инцидентов или записей, которые присутствуют в определенном местоположении и определенном временном интервале.
Данный инструмент анализирует переменную во Входном кубе пространства-времени netCDF, используя пространственно-временную реализацию статистики Anselin Локальный индекс Морана I.
Выходные объекты добавляются на панель Таблице содержания и представляют обобщенный результат анализа пространства-времени для всех проанализированных местоположений. Если вы укажете Полигональную маску анализа, будут проанализированы только те местоположения, которые попадают в пределы маски анализа; в ином случае будут проанализированы местоположения, которые имеют как минимум одну точку в как минимум одном временном интервале.
Кроме создания Выходных объектов, отчет об анализе записывается в виде сообщений, которые появляются в нижней части панели Геообработка во время выполнения этого инструмента. Вы можете получить доступ к сообщениям, переместив курсор мыши на индикатор выполнения, щелкнув на всплывающую кнопку или развернув раздел сообщений на панели Геообработка. Вы можете также получить доступ к сообщениям предыдущего запуска инструмента с помощью Истории геообработки на панели Каталог.
Инструмент Анализ локальных выбросов идентифицирует статистически значимые кластеры и выбросы в контексте пространства и времени. См. раздел Более подробно о работе инструмента Анализ локальных выбросов, чтобы получить дополнительные сведения об определениях выходных категорий по умолчанию и об алгоритмах, использующихся в этом инструменте анализа.
См. раздел Более подробно о работе инструмента Анализ локальных выбросов, чтобы получить дополнительные сведения об определениях выходных категорий по умолчанию и об алгоритмах, использующихся в этом инструменте анализа.
Для идентификации кластеров и выбросов в кубе пространства-времени, инструмент использует пространственно-временную интерпретацию статистики Anselin Локальный индекс Морана I, при этом значение каждого бина сопоставляется со значениями в соседних бинах.
Чтобы идентифицировать бины, которые будут включены в каждую окрестность анализа, инструмент сначала выявляет бины, которые попадают в заданное Определение пространственных взаимоотношений. Затем для каждого бина определяются бины, расположенные в том же местоположении, но в пределах N предшествующих временных шагов, где N – Временной шаг окрестности, указанный во входных параметрах.
Выбор параметра Определение пространственных взаимоотношений должен отражать внутренние отношения между пространственными объектами, которые вы анализируете. Чем более точно вы сможете смоделировать взаимодействие пространственных объектов в пространстве, тем более точные результаты вы получите. Рекомендации см. в разделе Выбор определения пространственных взаимоотношений: рекомендации.
По умолчанию для параметра Определение пространственных взаимоотношений устанавливается Фиксированное расстояние. Бин считается соседним, если его центроид попадает в указанные вами пределы Расстояния окрестности, а его временной интервал попадает в пределы Временного шага окрестности. Если вы не указываете Расстояние окрестности, оно будет рассчитано по умолчанию на основании пространственного распределения ваших данных. Если вы не указываете Интервал временного шага, то инструмент будет использовать значение по умолчанию, которое составляет 1 интервал временного шага.
Параметр Число соседей может замещать Расстояние соседства для опции Фиксированное расстояние либо расширять поиск соседей для опций Только соседние ребра и Углы соседних ребер. В этих случаях Число соседей используется, как минимальное значение. Например, если вы зададите Фиксированное расстояние с опцией Расстояние соседства равным 10, и значение 3 для параметра Количество соседей, то у каждого из бинов будет минимум по 3 пространственных соседа, даже если для того, чтобы найти их, пришлось бы увеличить Расстояние соседства. Расстояние увеличивается только в тех случаях, где минимальное Количество соседей не найдено. Точно так же с опциями смежности: для бинов с меньшим этого числа смежных соседей будут выбраны дополнительные соседи на основе близости центроидов.
Значение Временного шага окрестности – это количество интервалов временных шагов, включенных в окрестность анализа. Если интервал временного шага в вашем кубе составляет 3 месяца, и вы указали значение 2 для параметра Временной шаг окрестности – все бины, расположенные в пределах Определения пространственных взаимоотношений и все связанные с ними бины в двух предшествующих интервалах временных шагов (в совокупности 9 месяцев) будут включены в окрестность анализа.
Перестановки используются для определения вероятности нахождения актуального пространственного распределения анализируемых значений. Для каждой перестановки, значения, окружающие каждый бин, перераспределяются в случайном порядке, затем вычисляется значение локального индекса Морана I. Результат референсного распределения значений затем сравнивается с наблюдаемым индексом Морана I для определения вероятного нахождения наблюдаемого значения в случайном распределении. По умолчанию используется 499 перестановок; однако распределение случайной выборки улучшается при увеличении числа перестановок, что повышает точность псевдо p-значений.
Если параметр Число перестановок имеет значение 0, в результате получается обычное p-значение, вместо псевдо p-значения.
Перестановки, используемые этим инструментом, могут пользоваться преимуществом увеличения производительности, доступным в системе, использующей несколько CPU (или многоядерные CPU). Инструмент по умолчанию будет использовать 50% доступных процессоров, но количество используемых процессоров может быть увеличено или уменьшено с помощью настройки среды Коэффициент параллельной обработки. Увеличение скорости обработки особенно заметно в больших кубах пространство-время или при запуске инструмента с большим количеством перестановок.
Слой Полигональной маски анализа может содержать один или несколько полигонов, определяющих область анализа. Эти полигоны определяют область, в которой могут встретиться анализируемые точки, и исключают области, в которых точки для анализа не встречаются. Например, если вы анализируете ограбления в жилых кварталах, вы можете использовать Полигональную маску анализа чтобы исключить крупные водоемы, парки и другие области, где нет жилых домов.
Полигон маски для анализа пересекается с экстентом Входного куба Пространство-Время, но не выходит за пределы куба.
Если Полигональная маска анализа, которую вы используете для задания области изучения, покрывает область, выходящую за границы экстента входных объектов, которые были использованы для первоначального создания куба, может потребоваться заново создать куб, используя эту Полигональную маску анализа как параметр среды Экстент. Это позволит гарантировать, что вся область, покрываемая Полигональной маской анализа, будет включена в инструмент Анализ локальных выбросов. Используя Полигональную маску анализа в качестве параметра среды Экстент во время создания куба можно гарантировать, что куб будет соответствовать экстенту Полигональной маски анализа.
- Number of Outliers
- Percentage of Outliers
- Number of Low Clusters
- Percentage of Low Clusters
- Number of Low Outliers
- Percentage of Low Outliers
- Number of High Clusters
- Percentage of High Clusters
- Number of High Outliers
- Percentage of High Outliers
- Местоположения с No Spatial Neighbors
- Местоположения с Outlier in the Most Recent Time Step
- Cluster Outlier Type
- и дополнительная суммарная статистика
Cluster Outlier Type будет всегда обозначать статистически значимые кластеры и выбросы для 95-процентного доверительного интервала, а значения в этом поле будут приведены только для статистически значимых бинов. Эта значимость отражает Коррекцию FDR.
Чтобы обеспечить наличие по крайней мере 1 временного соседства для каждого местоположения, Локальный индекс Морана не вычисляется для первого временного среза. Значения бинов в первом временном срезе, тем не менее, включаются в вычисление глобального среднего.
Запуск инструмента Анализ локальных выбросов позволяет добавить результаты обратно в файл netCDF, представляющий Входной куб Пространство-Время. Каждый бин анализируется совместно с бинами в ближайшей окрестности для измерения кластеризации как высокого, так и низкого значений, и для определения пространственных и временных выбросов в этих кластерах. В результате этого анализа получается локальный индекс Морана I, псевдо p-значение (или p-значение, если не используются перестановки), и кластер или тип выброса (CO_TYPE) для каждого бина в кубе Пространство-Время.
Сводные расчеты по переменным, которые добавляются ко Входному кубу Пространство-Время , перечислены ниже:
| Имя переменной | Описание | Измерение |
|---|---|---|
OUTLIER_{ANALYSIS_VARIABLE}_INDEX | Вычисленный локальный индекс I Морана. | Три измерения: одно значение локального индекса I Морана для каждого бина в кубе пространство-время. |
OUTLIER_{ANALYSIS_VARIABLE}_PVALUE | Статистика Anselin Локальный индекс I Морана псевдо p-значение или p-значение, измеряющее статистическую значимость значения локального индекса Морана I. | Три измерения: одно p-значение или псевдо p-значение для каждого бина в кубе пространство-время. |
OUTLIER_{ANALYSIS_VARIABLE}_TYPE | Полученный тип категории, позволяющий различить статистически значимый кластер высоких значений (HH), кластер низких значений (LL), выброс, в котором высокое значение окружено в основном низкими значениями (HL) и выброс, в котором низкое значение окружено в основном высокими значениями (LH). | Три измерения: один кластер или тип выброса для каждого бина в кубе пространство-время. Бины классифицируются с применением коррекции FDR. |
OUTLIER_{ANALYSIS_VARIABLE} _HAS_SPATIAL_NEIGHBORS | Обозначает местоположения, не имеющие пространственных соседей, а также те, которые основываются только на временных соседях. | Два измерения: одна классификация для каждого местоположения. Анализ местоположений, не имеющих пространственных соседей, проводит к вычислениям, основанных только на временных соседях. |

«Классификация, регрессия и другие алгоритмы Data Mining с использованием R»
Друзья!
Владимир Кириллович и я рады представить вашему вниманию новый результат нашей совместной работы — книгу «Классификация, регрессия и другие алгоритмы Data Mining с использованием R».
В книге рассмотрена широкая совокупность методов построения статистических моделей классификации и регрессии для откликов, измеренных в альтернативной, категориальной и метрической шкалах. Подробно рассматриваются деревья решений, машины опорных векторов с различными разделяющими поверхностями, нелинейные формы дискриминантного анализа, искусственные нейронные сети и т.д. Показана технология применения таких методов бутстреп-агрегирования деревьев решений, как бэггинг, случайный лес и бустинг. Представлены различные методы построения ансамблей моделей для коллективного прогнозирования. Особое внимание уделяется сравнительной оценке эффективности и поиску оптимальных областей значений гиперпараметров моделей с использованием пакета caret. Рассматриваются такие алгоритмы Data Mining, как генерация ассоциативных правил и анализ последовательностей. Отдельная глава посвящена методам многомерной ординации данных и различным алгоритмам кластерного анализа.
Отдельная глава посвящена методам многомерной ординации данных и различным алгоритмам кластерного анализа.
Описание указанных методов сопровождается многочисленными примерами из различных областей на основе общедоступных исходных данных. Представлены несложные скрипты на языке R, дающие возможность читателю легко воспроизвести все расчеты.
Книга может быть использована в качестве учебного пособия по статистическим методам для студентов и аспирантов высших учебных заведений.
Книга распространяется совершенно бесплатно. Ее PDF-версию и соответствующие приложения можно скачать по следующим двум официальным адресам:
Кроме того, книга опубликована в виде отдельного сайта по адресу:
Мы будем благодарны за любые ваши замечания и пожелания касательно этой работы — отправляйте их, пожалуйста, по электронной почте stok1946[«собака»]gmail.com и/или rtutorialsbook[«собака»]gmail.com
Сергей Мастицкий, Владимир Шитиков
P.S.: Как отмечено выше, книга распространяется бесплатно. Однако если она окажется вам полезной и вы сочтете уместным отблагодарить авторов за их работу, вы можете перечислить любую сумму, воспользовавшись следующей кнопкой (все транзакции выполняются в безопасном режиме через систему электронных платежей PayPal; наличие у вас аккаунта в этой системе необязательно):
Создайте собственный алгоритм майнинга блокчейна в Go! | by Coral Health
Учитывая недавнее повальное увлечение майнингом Биткойн и Эфириум, легко задаться вопросом, о чем идет речь. Новички в этой сфере слышат дикие истории о людях, которые заполняют склады графическими процессорами, зарабатывая криптовалюты на миллионы долларов в месяц. Что такое майнинг криптовалюты? Как это работает? Как я могу попробовать написать собственный алгоритм майнинга?
В этом посте мы рассмотрим каждый из этих вопросов, а завершим вас уроком о том, как написать собственный алгоритм майнинга.Алгоритм, который мы вам покажем, называется Proof of Work , который является основой для Биткойн и Эфириум, двух самых популярных криптовалют. Не волнуйтесь, мы вскоре объясним, как это работает.
Не волнуйтесь, мы вскоре объясним, как это работает.
Что такое майнинг криптовалюты?
Криптовалюты должны иметь дефицит, чтобы быть ценными. Если бы кто-нибудь мог производить столько биткойнов, сколько он хотел в любое время, биткойн был бы бесполезен как валюта (подождите, разве Федеральный резерв не делает этого? * Facepalm *).Алгоритм Биткойн выдает некоторое количество Биткойнов победившему члену своей сети каждые 10 минут, при этом максимальная поставка будет достигнута примерно через 122 года. Этот график выпуска также в определенной степени контролирует инфляцию, так как весь фиксированный запас не выпускается в начале. Со временем медленно выпускаются новые.
Процесс, посредством которого определяется победитель и выдается биткойн, требует, чтобы победитель выполнил некоторую «работу» и соревновался с другими, которые также выполняли эту работу. Этот процесс называется , добыча , потому что он аналогичен золотодобытчику, который тратит некоторое время на работу и в конечном итоге (и мы надеемся) находит немного золота.
Алгоритм Биткойн заставляет участников или узлы выполнять эту работу и соревноваться друг с другом, чтобы гарантировать, что Биткойн не будет выпущен слишком быстро.
Как работает майнинг?
Быстрый поиск в Google «как работает майнинг биткойнов?» заполняет ваши результаты множеством страниц, объясняющих, что майнинг биткойнов запрашивает у узла (вас или вашего компьютера) номер для решения сложной математической задачи . Хотя технически это верно, просто назвать это «математической» задачей невероятно банально и банально.Очень интересно понять, как майнинг работает под капотом. Нам нужно немного разобраться в криптографии и хешировании, чтобы узнать, как работает майнинг.
Краткое введение в криптографические хэши
Односторонняя криптография принимает читаемый человеком ввод, такой как «Hello world», и применяет к нему функцию (то есть математическую задачу) для получения не поддающегося расшифровке вывода. Эти функции (или алгоритмы) различаются по характеру и сложности. Чем сложнее алгоритм, тем сложнее его реконструировать.Таким образом, криптографические алгоритмы очень эффективны для защиты таких вещей, как пароли пользователей и военные коды.
Давайте посмотрим на пример SHA-256, популярного криптографического алгоритма. Этот веб-сайт хеширования позволяет легко вычислять хеши SHA-256. Давайте хэшируем «Hello world» и посмотрим, что мы получим:
Попробуйте хешировать «Hello world» снова и снова. Каждый раз вы получаете один и тот же хэш. В программировании получение одного и того же результата снова и снова при одном и том же вводе называется идемпотентностью .
Фундаментальным свойством криптографических алгоритмов является то, что их чрезвычайно сложно реконструировать, чтобы найти входные данные, но чрезвычайно легко проверить выходные данные. Например, используя хэш SHA-256 выше, для кого-то должно быть тривиальным применение хеш-алгоритма SHA-256 к «Hello world», чтобы проверить, действительно ли он дает такой же результирующий хеш, но это должно быть очень сложно чтобы взять полученный хеш и получить из него «Hello world». Вот почему этот тип криптографии называется односторонним .
Биткойн использует Double SHA-256 , который просто применяет SHA-256 снова к хешу SHA-256 «Hello world». Для наших примеров в этом руководстве мы будем использовать только SHA-256.
Майнинг
Теперь, когда мы понимаем, что такое криптография, мы можем вернуться к майнингу криптовалюты. Биткойну нужно найти способ заставить участников, которые хотят зарабатывать биткойны, «работать», чтобы биткойны не выпускались слишком быстро. Биткойн достигает этого, заставляя участников хешировать множество комбинаций букв и цифр до тех пор, пока результирующий хеш не будет содержать определенное количество ведущих «0».
Например, вернитесь на хеш-сайт и введите хэш «886». Он создает хеш с 3 нулями в качестве префикса.
Он создает хеш с 3 нулями в качестве префикса.
Но как мы узнали, что «886» дает что-то с тремя нулями? В этом-то и дело. До написания этого блога у нас не было . Теоретически нам пришлось бы проработать целую кучу комбинаций букв и цифр и протестировать результаты, пока мы не получим ту, которая соответствует требованию трех нулей. Чтобы дать вам простой пример, мы уже работали заранее, чтобы понять, что хеш «886» дает 3 ведущих нуля.
Тот факт, что любой может легко проверить, что «886» дает что-то с 3 ведущими нулями , доказывает , что мы проделали кропотливую работу по тестированию и проверке большого количества букв и цифр, чтобы получить этот результат. Так что, если бы я был первым, кто получил этот результат, я бы заработал биткойн за , доказав , что я выполнил эту работу — доказательство состоит в том, что любой может быстро проверить, что «886» дает количество нулей, которое, как я утверждаю, дает. Вот почему алгоритм консенсуса Биткойн называется Proof-of-Work .
Но что, если мне просто повезло и я получил 3 ведущих нуля с первой попытки? Это крайне маловероятно, и случайный узел, который успешно добывает блок (доказывает, что они выполнили свою работу) с первой попытки, перевешивается миллионами других, которым пришлось потрудиться, чтобы найти желаемый хеш. Давай, попробуй. Введите любую другую комбинацию букв и цифр на хеш-сайте. Спорим, у вас не будет трех ведущих нулей.
Требования Биткойна немного сложнее, чем это (намного больше ведущих нулей!), И он может динамически корректировать требования, чтобы гарантировать, что требуемая работа не будет слишком легкой или слишком сложной.Помните, что он нацелен на выпуск биткойнов каждые 10 минут, поэтому, если слишком много людей занимается майнингом, необходимо усложнить доказательство работы, чтобы компенсировать это. Это называется , корректировка сложности . Для наших целей регулировка сложности будет означать только требование большего количества ведущих нулей.
Итак, вы можете видеть, что алгоритм консенсуса Биткойн намного интереснее, чем просто «решение математической задачи»!
Теперь, когда у нас есть необходимый фон, давайте создадим нашу собственную программу Blockchain с алгоритмом Proof-of-Work.Мы напишем его на Go, потому что мы используем его здесь, в Coral Health, и, честно говоря, он потрясающий.
Прежде чем продолжить, мы рекомендуем прочитать нашу оригинальную запись в блоге Кодируйте свой собственный блокчейн менее чем за 200 строк Go! Это не требование, но мы быстро рассмотрим некоторые из приведенных ниже примеров. Обратитесь к исходному сообщению, если вам нужны более подробные сведения. Если вы уже знакомы с этой исходной публикацией, перейдите к разделу «Подтверждение работы» ниже.
Архитектура
У нас будет сервер Go, на котором для простоты мы поместим весь наш код в один главный сервер .перейти файл. Этот файл предоставит нам всю необходимую логику блокчейна (включая Proof of Work) и будет содержать все обработчики для наших REST API. Эти данные блокчейна неизменны; нам нужны только запросы GET и POST . Мы будем делать запросы через браузер для просмотра данных через GET , и мы будем использовать Postman для POST новых блоков ( curl тоже отлично работает).
Импорт
Начнем с нашего стандартного импорта.Обязательно возьмите следующие пакеты с go get
github.com/davecgh/go-spew/spew красиво распечатывает ваш блокчейн в Терминале
github.com/gorilla/mux удобный слой для подключения ваш веб-сервер
github.com/joho/godotenv считывает переменные среды из файла .env в корневом каталоге
Давайте создадим файл .env в нашем корневом каталоге, который просто хранит одну переменную среды, которая нам понадобится позже.![]() Поместите одну строку в свой файл
Поместите одну строку в свой файл .env : ADDR = 8080
Сделайте объявление пакета и определите свой импорт в main.go в корневом каталоге:
эта диаграмма. Блоки в цепочке блоков проверяются путем сравнения предыдущего хэша в блоке с хэшем предыдущего блока. Таким образом сохраняется целостность цепочки блоков и как злоумышленник не может изменить историю цепочки блоков.
ударов в минуту — это ваша частота пульса или ударов в минуту. Мы будем использовать количество ударов в минуту вашего пульса в качестве данных, которые мы помещаем в наши блоки. Просто положите два пальца на внутреннюю сторону запястья и посчитайте, сколько раз вы получите удары в минуту, и запомните это число.
Некоторая базовая сантехника
Давайте добавим нашу модель данных и другие переменные, которые нам понадобятся при импорте в main.go
сложность — это константа, определяющая количество нулей в начале хеша.Чем больше нулей нам нужно получить, тем сложнее найти правильный хеш. Начнем с нуля.
Блок — это модель данных каждого блока. Не беспокойтесь о Nonce , мы скоро объясним это.
Blockchain — это часть Block , которая представляет нашу полную цепочку.
Сообщение — это то, что мы отправим, чтобы сгенерировать новый блок , используя запрос POST в нашем REST API.
Мы объявляем мьютекс , который мы будем использовать позже, чтобы предотвратить скачки данных и убедиться, что блоки не генерируются одновременно.
Веб-сервер
Давайте быстро подключим наш веб-сервер. Давайте создадим функцию run , которую мы вызовем из main позже, которая будет строить наш сервер. Мы также объявим наши обработчики маршрутов в makeMuxRouter () . Помните, что все, что нам нужно, это
Помните, что все, что нам нужно, это GET для получения цепочки блоков и POST для добавления новых блоков. Блокчейны неизменяемы, поэтому нам не нужно редактировать или удалять.
httpAddr: = os.Getenv ("ADDR") будет извлекать порт : 8080 из нашего .env , который мы создали ранее. Мы сможем получить доступ к нашему приложению через http: // localhost: 8080 в нашем браузере.
Давайте напишем наш обработчик GET для печати нашей цепочки блоков в нашем браузере. Мы также добавим быстрый ответ с функцией JSON , которая возвращает нам сообщения об ошибках в формате JSON, если какой-либо из наших вызовов API вызывает ошибку.
Помните, если мы идем слишком быстро, обратитесь к нашей исходной публикации , в которой каждый из этих шагов объясняется более подробно.
Теперь напишем наш обработчик POST . Так мы добавляем новые блоки. Мы делаем запрос POST с помощью Postman, отправляя тело JSON, например. {«BPM»: 60} с по http: // localhost: 8080 с вашим ранее измеренным пульсом.
Обратите внимание на блокировку и разблокировку мьютекса . Нам нужно заблокировать его перед записью нового блока, иначе множественная запись создаст гонку данных. Внимательный читатель заметит функцию generateBlock .Это наша ключевая функция, которая будет обрабатывать наше Доказательство работы. Мы скоро к этому вернемся.
Основные функции блокчейна
Давайте подключим наши основные функции блокчейна, прежде чем мы перейдем к Proof of Work. Мы добавим функцию isBlockValid , которая следит за тем, чтобы наши индексы увеличивались правильно, и наш PrevHash нашего текущего блока и Hash предыдущего блока совпадают.
Мы также добавим функцию calculateHash , которая генерирует хеши, необходимые для создания Hash и PrevHash . Это просто хэш SHA-256 нашего объединенного индекса, отметки времени, BPM, предыдущего хеша и
Это просто хэш SHA-256 нашего объединенного индекса, отметки времени, BPM, предыдущего хеша и Nonce (мы объясним, что это такое, через секунду).
Давайте перейдем к алгоритму майнинга или Proof of Work. Мы хотим убедиться, что Proof of Work завершено, прежде чем мы позволим добавить новый блок Block в цепочку блоков . Давайте начнем с простой функции, которая проверяет, соответствует ли хэш, сгенерированный во время Proof of Work, установленным нами требованиям.
Наши требования будут следующими:
- Хэш, сгенерированный нашим Proof of Work, должен начинаться с определенного количества нулей
- Количество нулей определяется постоянной трудностью
- Мы можем усложнить решение Proof of Work, увеличив сложность
Запишите эту функцию, isHashValid :
Go предоставляет удобные Repeat и HasPrefix функции в своем пакете strings .Мы определяем переменную с префиксом как повторение нулей, определяемых нашей сложностью . Затем мы проверяем, начинается ли хеш с этих нулей, и возвращаем True , если это так, и False , если нет.
Теперь давайте создадим нашу функцию generateBlock .
Мы создаем newBlock , который берет хэш предыдущего блока и помещает его в PrevHash , чтобы обеспечить непрерывность нашей цепочки блоков. Большинство других полей должны быть очевидны:
-
Индексприращений -
Временная метка— это строковое представление текущего времени -
BPM— это ваша частота пульса, которую вы измерили ранее -
Сложностьпросто взята из константа в верхней части нашей программы.Мы не будем использовать это поле в этом руководстве, но его полезно иметь, если мы проводим дополнительную проверку и хотим убедиться, что сложность согласуется с результатами хеширования (т. е. результат хеширования имеет N нулей в префиксе, поэтому сложность также должна быть равна N, или цепь нарушена)
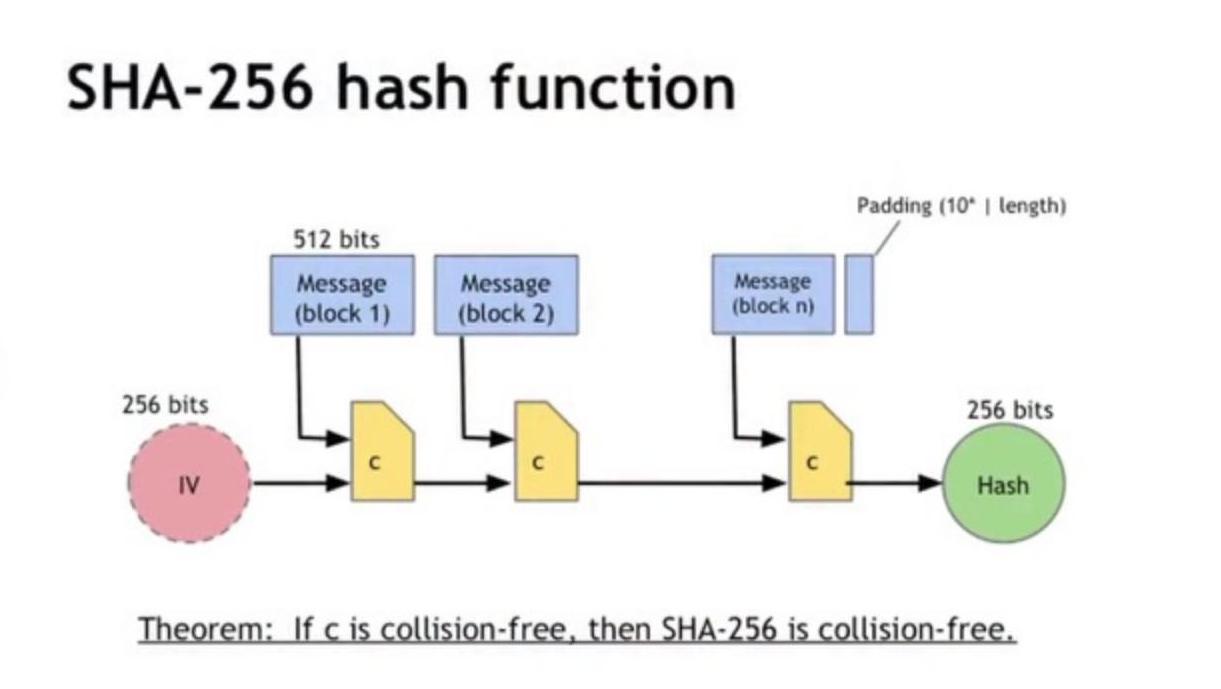 е. результат хеширования имеет N нулей в префиксе, поэтому сложность также должна быть равна N, или цепь нарушена)
е. результат хеширования имеет N нулей в префиксе, поэтому сложность также должна быть равна N, или цепь нарушена) Цикл для является критически важным элементом в этой функции. Давайте рассмотрим, что здесь происходит:
- Мы возьмем шестнадцатеричное представление
iи установим ему значениеNonce.Нам нужен способ добавить изменяющееся значение к нашему хешу, который мы создаем из нашей функцииcalculateHash, поэтому, если мы не получаем нужное нам начальное число нулей, мы можем повторить попытку с новым значением. Это изменяющееся значение, которое мы добавляем к нашей объединенной строке вcalculateHashназывается «Nonce» - В нашем цикле мы вычисляем хэш с
iи Nonce, начиная с 0, и проверяем, начинается ли результат. с количеством нулей, как определено нашей постояннойсложностью.Если этого не произошло, мы вызываем следующую итерацию цикла с увеличенным значением Nonce и пробуем снова. - Мы добавили 1-секундный спящий режим, чтобы смоделировать время, необходимое для решения Proof of Work
- Мы продолжаем цикл до тех пор, пока не получим желаемое количество ведущих нулей, что означает, что мы успешно выполнили Proof of Work. Тогда и только тогда мы позволяем добавить наш
Blockкblockchainчерез нашhandleWriteBlockобработчик
Мы закончили писать все наши функции, поэтому давайте завершим нашу основную функцию сейчас:
С godotenv .Load () мы загружаем нашу переменную среды, которая представляет собой просто порт : 8080 , к которому мы будем обращаться из нашего браузера.
Подпрограмма go создает наш генезисный блок, поскольку нам нужно снабдить наш блокчейн отправной точкой.
Мы запускаем наш веб-сервер с помощью нашей функции run () , которую мы создали ранее.
Вот готовый код полностью.
Давай попробуем этого малыша!
Запустите свою программу с помощью go run main.go
Затем посетите http: // localhost: 8080 в своем браузере:
Наш генезис-блок был создан для нас.Теперь откройте Postman и давайте отправим запрос POST по тому же маршруту с нашим BPM (частотой пульса), который мы использовали ранее в теле JSON.
После того, как мы отправим запрос смотрим, что происходит в вашем терминале . Вы увидите, как ваша машина с пыхтением создает новые хэши с увеличивающимися значениями Nonce, пока, наконец, не найдет результат с требуемым количеством ведущих нулей!
Когда Proof of Work решен, мы получаем полезное сообщение о выполнении работы! , и мы можем проверить хэш, чтобы убедиться, что он действительно начинается с того количества нулей, которое мы установили в сложности .Это означает, что теоретически новый блок, который мы пытались добавить с BPM = 60, теперь должен был быть добавлен в нашу цепочку блоков.
Давайте обновим наш браузер и проверим:
УСПЕХ! Наш второй блок был добавлен в наш генезисный блок. Это означает, что мы успешно отправили наш блок в запросе POST , который запустил процесс майнинга, и ТОЛЬКО после того, как Proof of Work был решен, он был добавлен в нашу цепочку блоков!
Отличная работа! То, что вы только что узнали, действительно имеет большое значение.Proof of Work — это основа для Биткойн, Ethereum и многих крупнейших блокчейн-платформ. То, что мы только что прошли, нетривиально; в то время как мы использовали низкую сложность для демонстрационных целей, увеличение сложности до высокого числа составляет ровно , как работают готовые к производству блокчейны Proof of Work.
Теперь, когда вы хорошо понимаете ключевой компонент технологии блокчейн, вам решать, куда двигаться дальше. Мы рекомендуем следующее:
Если вы готовы сделать еще один шаг, попробуйте узнать о Proof of Stake .В то время как большинство блокчейнов используют Proof of Work в качестве алгоритма консенсуса, Proof of Stake привлекает все больше и больше внимания. Широко распространено мнение, что Ethereum перейдет от Proof of Work к Proof of Stake в будущем.
Чтобы узнать больше о Coral Health и о том, как мы используем блокчейн для продвижения индивидуальных медицинских исследований, посетите наш веб-сайт.
Объяснение алгоритма Litecoin Scrypt — Mycryptopedia
Объяснение алгоритма Litecoin ScryptПоследнее обновление: 18 декабря 2018 г.
Scrypt — это хеш-функция, которая впервые была использована криптовалютой Litecoin в качестве альтернативы более известной хеш-функции SHA-256.Scrypt и SHA-256 используются в качестве алгоритмов майнинга в протоколах Litecoin и Bitcoin соответственно. Оба работают в рамках механизма консенсуса доказательства выполнения работы, когда майнер должен найти значение nonce (переменная, выбранная майнером), так что, когда заголовок блока кандидата хешируется, результирующий результат равен или ниже, чем заданная цель. Цель — это мера того, насколько сложно майнеру создать действительный блок; чем ниже целевое значение, тем сложнее майнеру сгенерировать действительный блок.И наоборот, чем выше целевое значение, тем проще майнеру сгенерировать действительный блок. Время генерации блока Litecoin составляет 2,5 минуты, поэтому цель будет автоматически регулировать сложность, чтобы успешный блок создавался майнером каждые 2,5 минуты.
Например, если одноразовый номер должен быть переменной «12345», он будет помещен в хешируемый заголовок блока, например:
Где x = выходное значение хеш-функции,
x = Scrypt (заголовок блока)
Если результирующее выходное значение хеш-функции, в данном случае «x», оказывается выше целевого значения, майнер должен повторить попытку.Затем майнер меняет одноразовый номер на другую переменную, например «» и помещает его в заголовок блока . , если результирующее выходное значение хэша оказывается ниже целевого, блок майнера затем ретранслируется на узлы Litecoin в сети для проверки.
Скрипт и SHA-256Хэш-функции Scrypt и SHA-256 требуют больших вычислительных ресурсов, поскольку обе требуют необработанной вычислительной мощности для генерации большого количества возможных решений для соответствующих функций.Например, согласно BitInfoCharts, на момент написания текущая скорость хеширования в сети Litecoin составляет 146 TH / s. Это означает, что каждую секунду майнеры по протоколу Litecoin выполняют 146 триллионов хеш-вычислений. Однако, что отличает функцию Scrypt от функции SHA-256, так это то, что она также требует интенсивной памяти . Scrypt требует много памяти, потому что эти сгенерированные числа не только требуют от майнеров быстрой генерации чисел, но и хранятся в оперативной памяти (ОЗУ) процессора, к которой затем необходимо получить доступ перед отправкой результата.
Что касается общей мощности хеширования, протоколы на основе Scrypt имеют более низкую скорость хеширования, чем протоколы на основе SHA-256. В настоящее время, согласно Blockchain.info, скорость хеширования протокола Биткойн составляет примерно 45000000000 TH / с, что значительно больше, чем у Litecoin.
Зачем нужен Scrypt?Хеш-функция Scrypt была первоначально реализована командой разработчиков Litecoin, чтобы избежать возможности майнинга в сети Litecoin так называемых специализированных интегральных схем (ASIC).При майнинге криптовалют у пользователей обычно есть выбор между: CPU, GPU или ASIC-майнером.
ASICв вычислительном отношении превосходят процессоры и графические процессоры, т.е. они могут генерировать больше хэшей в секунду. Таким образом, майнеры, которые используют любое другое устройство, кроме ASIC, для майнинга криптовалюты, оказываются в невыгодном положении. Однако алгоритм интеллектуального анализа данных Scrypt был введен для предотвращения майнинга ASIC, поскольку этот алгоритм требует большого объема памяти; Первоначально майнеры ASIC не подходили для майнинга по протоколам на основе Scrypt, и, таким образом, майнеры, которые использовали центральные и графические процессоры, могли оставаться конкурентоспособными.
Однако с течением времени первоначальная «устойчивость к ASIC» алгоритма майнинга Scrypt исчезла. Были разработаны ASIC с поддержкой Scrypt, которые позволяют эффективно майнить любую криптовалюту, использующую алгоритм Scrypt. Следовательно, процессоры и графические процессоры больше не являются действующими инструментами майнинга в сети Litecoin из-за их меньшей вычислительной мощности по сравнению с ASIC.
майнеров на основе Scrypt и новая гонка вооружений криптовалюты
Производители планируют поставлять оборудование на основе scrypt, которое ускорит майнинг и снизит накладные расходы на электроэнергию для альтернативного алгоритма криптовалюты.Может ли это спровоцировать новую гонку вооружений криптовалюты?
Большинство криптовалют, добываемых компьютерами, используют алгоритм «доказательства работы», призванный заставить их доказать, что они вложили вычислительные мощности в производство монет. Биткойн использует SHA – 256, но многие альтернативные монеты (альткойны) используют другую систему, называемую scrypt.
Одно из самых больших различий между scrypt и SHA-256 заключается в том, что первый сильно зависит от вычислительных ресурсов, помимо самого процессора, в частности памяти.И наоборот, SHA-256 этого не делает. Это затрудняет масштабирование систем на основе scrypt и использование больших вычислительных мощностей, поскольку им придется использовать пропорциональный объем памяти, а это дорого.
«Это затрудняет параллельное выполнение множества экземпляров scrypt на видеокарте, например, — сказал Чарльз Ли, изобретатель litecoin, добавив:
«Это также означает, что стоимость производства ASIC scrypt будет значительно дороже, чем стоимость ASIC SHA-256.”
Тем не менее, некоторые компании начинают рекламировать оборудование, предназначенное для майнинга криптовалютных монет, например, Lee. Один из них — Crypto Industries, расположенный в Лондоне, Великобритания. Вскоре будут запущены предварительные заказы на три разных бокса: Isis, блок с пропускной способностью 1MH / sec, Osiris со скоростью 5MH / sec и Horus с 10MH / sec.
Майк Кулар, соучредитель компании, работал менеджером по маркетингу, прежде чем уйти с работы, чтобы торговать монетами на постоянной основе. Он майнил SHA-256 и монеты на основе scrypt с настройкой на 20 GPU, но, по его словам, это обходилось ему в 600 фунтов стерлингов в месяц.
«Что важно, так это эффективность мощности, которую вы отдаете машине», — сказал Кулар. «Используя наши машины, вы повышаете энергоэффективность на 2–300%».
Майнинговые устройстваCrypto Industries основаны на микросхемах программируемой вентильной матрицы (FPGA) от Xilinx и будут обеспечивать энергопотребление в наихудшем случае 150 Вт, 750 Вт и 1,5 кВт соответственно, согласно спецификациям компании.
Память
Однако, учитывая требования scrypt, мощность — не единственный решающий параметр.Память тоже важна. По словам Кулара, пропускная способность памяти зависит от количества контактов ввода-вывода (IO) на чипах. В FGPA, как и в ASIC, технологический узел (размер транзисторов, который определяет, сколько логических вентилей поместится на кремнии) по-прежнему важен, но не так важен, как в биткойнах. «Ворота не являются решающим фактором. Речь идет о выводах ввода-вывода », — сказал Кулар, добавив, что платы FGPA будут иметь пропускную способность памяти 24,8 ГБ / сек на плату.
СистемыCrypto Industries будут иметь несколько плат, управляемых Raspberry Pi.Это запустит модифицированную версию программного обеспечения для майнинга с открытым исходным кодом CGMiner, модифицированную для работы с программным обеспечением scrypt для майнинга на ПЛИС. Пользователи смогут получить к нему доступ через браузер или загрузить свои конфигурации с помощью предварительно отформатированного текстового документа на USB-накопителе.
Фирма со временем будет выпускать поддержку различных монет на основе scrypt посредством обновлений прошивки, но сначала она будет иметь возможность переключаться между Litecoin и Feathercoin, но надеется получить 30-40 различных валют в течение месяца с момента первой поставки. и там сказано, что это очень близко к предзаказу.
Есть и другие компании, планирующие предложить специализированное оборудование для майнинга на основе скриптов. ASIC может быть сложно реализовать для scrypt, но это возможно. Ли сказал:
«Использование ASIC не обязательно делает майнинг недоступным. На самом деле все наоборот. Благодаря ASIC каждый может приобрести оборудование для майнинга и запустить его ».
«Проблема в том, что крупные игроки могут позволить себе покупать оборудование для майнинга на миллион долларов дешевле, чем маленькие игроки.Так что это может задеть маленьких игроков, поскольку майнинг биткойнов / лайткойнов — это, по сути, гонка вооружений », — добавил он.
Также в разработке находятся несколько ASIC-майнеров. Компания scrypt Asic International (SAI), котирующаяся на CryptoStocks на прошлой неделе, переоборудовала свой первый дизайн еще до того, как он был отправлен, выйдя за рамки того, что она называла «технологией преобразования графического процессора», к тому, что, по ее словам, является дизайном ASIC. Согласно сообщениям на сайте Cryptostocks, он будет предлагать свои оригинальные машины Unit 1 под названием «minis» со скоростью 2,5 МГц / сек за 800 фунтов стерлингов.Согласно его веб-сайту, новые блоки unit 1 должны предлагать 5 MH / sec за 1500 фунтов стерлингов.
Затем есть Alpha Technologies, которая не отвечала на письма от CoinDesk, но перешла от идеи размещения чипов GPU в коробке к FGPA (хотя на ее веб-сайте это также называется ASIC). Он указывает 5MH / sec при 200 Вт.
Однако ни одна из этих компаний не осуществила поставки, и, несмотря на их онлайн-обещания надежности, у них нет заслуг. Но KnCMiner умеет. Компания, которая уже поставляет свои биткойн-майнеры ASIC, планирует выпустить майнинговый продукт на основе скрипта.Но пока об этом мало что известно. «Мы не можем обнародовать многие из этих деталей, поскольку еще не закончили дизайн», — сказал CoinDesk соучредитель Сэм Коул.
Есть желающие?
Вопрос в том, кто купит эти майнеры? Будут ли эти альткойны (среди которых лайткойн является наиболее популярным) достаточно популярными, чтобы побудить людей инвестировать в дополнительное оборудование для майнинга?
Продукты майнера scrypt от Crypto Industries.«Рост Litecoin последует за ростом биткойнов. До тех пор, пока основные продавцы не начнут поддерживать litecoin, нужно пройти несколько шагов », — сказал Ли, добавив, что для поддержки litecoin потребуется платежный процессор.«Но прежде чем они это сделают, им нужен способ обменять лайткойны на различные валюты. Это означает, что для обеспечения ликвидности необходима поддержка со стороны крупных бирж ».
Он надеется, что Mt. Gox выполнит свое обещание ввести поддержку Litecoin, а также надеется на аналогичные шаги со стороны Bitstamp и BTC China. «Так что очень скоро litecoin сделает первый серьезный шаг к поддержке продавцов».
Майнеры на основеScrypt могут быть относительно новым явлением, но раннее участие и риск может окупиться, если litecoin получит надежную торговую и платежную инфраструктуру и начнет набирать обороты.Прямо сейчас скорость хеширования лайткойнов составляет около 25 ГГц / сек, а это означает, что вам придется купить 25 больших ящиков Horus Crypto Industries (и заплатить за 37,5 кВт), чтобы получить 1% мощности сети.
Litecoin — не единственная монета, основанная на скрипте, но самая популярная. Если бы лайткойны продавались с наценкой, покупка майнера могла бы быть более простым немедленным предложением для клиентов. Однако с начала июля эта валюта неуклонно падала в цене по отношению к BTC, а также по отношению к доллару.
Однако те, кто покупает сейчас, могут надеяться, что они будут готовы к майнингу, когда цена вернется в норму. А пока у них будет возможность переключаться между лайткойном и другими монетами на основе скрипта. Когда на эти системы открываются предзаказы, будет интересно следить за спросом.
Association Rule Mining с помощью априорного алгоритма в Python
Извлечение правил ассоциации — это метод определения взаимосвязей между различными элементами. Возьмем пример Супермаркета, где покупатели могут покупать самые разные товары.Как правило, покупатели покупают по определенной схеме. Например, матери с младенцами покупают детские товары, такие как молоко и подгузники. Девицы могут покупать косметику, а холостяки — пиво, чипсы и т. Д. Короче говоря, транзакции связаны с закономерностью. Большую прибыль можно получить, если можно будет определить взаимосвязь между товарами, купленными в разных транзакциях.
Например, если товары A и B покупаются вместе чаще, можно предпринять несколько шагов для увеличения прибыли.Например:
- A и B могут быть размещены вместе, так что, когда покупатель покупает один из продуктов, ему не нужно далеко уходить, чтобы купить другой продукт.
- Люди, которые покупают один из продуктов, могут быть нацелены с помощью рекламной кампании на покупку другого.
- На эти продукты могут быть предложены коллективные скидки, если покупатель купит их оба.
- И A, и B можно упаковать вместе.
Процесс определения ассоциаций между продуктами называется интеллектуальным анализом правил ассоциации.
Алгоритм априори для майнинга ассоциативных правил
Различные статистические алгоритмы были разработаны для реализации интеллектуального анализа ассоциативных правил, и Apriori является одним из таких алгоритмов. В этой статье мы изучим теорию, лежащую в основе алгоритма Априори, а позже реализуем алгоритм Априори на Python.
Теория априорного алгоритма
Алгоритм Априори состоит из трех основных компонентов:
Мы объясним эти три концепции на примере.
Предположим, у нас есть запись о 1 тысяче транзакций клиентов, и мы хотим найти поддержку, уверенность и подъем для двух элементов, например бургеры и кетчуп. Из тысячи транзакций 100 содержат кетчуп, а 150 — гамбургеры. Из 150 транзакций, в которых был куплен бургер, 50 транзакций также содержат кетчуп. Используя эти данные, мы хотим найти поддержку, уверенность и подъем.
Поддержка
Поддержка относится к популярности элемента по умолчанию и может быть рассчитана путем деления количества транзакций, содержащих конкретный элемент, на общее количество транзакций.Предположим, мы хотим найти поддержку по пункту B. Это можно рассчитать как:
Поддержка (B) = (Транзакции, содержащие (B)) / (Всего транзакций)
Например, если из 1000 транзакций 100 транзакций содержат кетчуп, то поддержка элемента кетчупа может быть рассчитана как:
Поддержка (кетчуп) = (транзакции, содержащие кетчуп) / (всего транзакций)
Поддержка (кетчуп) = 100/1000
= 10%
Уверенность
Уверенность относится к вероятности того, что предмет B также будет куплен, если предмет A куплен.Его можно рассчитать, найдя количество транзакций, в которых A и B покупаются вместе, разделенное на общее количество транзакций, в которых был куплен A. Математически это можно представить как:
Уверенность (A → B) = (транзакции, содержащие оба (A и B)) / (транзакции, содержащие A)
Возвращаясь к нашей проблеме, у нас было 50 транзакций, в которых Burger и Ketchup были куплены вместе. Пока в 150 транзакциях покупаются бургеры. Тогда мы можем найти вероятность покупки кетчупа при покупке гамбургера, которая может быть представлена как уверенность Burger -> Ketchup и может быть математически записана как:
Уверенность (Бургер → Кетчуп) = (Транзакции, содержащие и (Бургер, и Кетчуп)) / (Транзакции, содержащие А)
Уверенность (Бургер → Кетчуп) = 50/150
= 33.3%
Вы можете заметить, что это похоже на то, что вы видите в наивном байесовском алгоритме, однако эти два алгоритма предназначены для разных типов проблем.
Подъемник
Лифт (A -> B) относится к увеличению доли продаж B при продаже A. Подъем (A -> B) можно рассчитать путем деления уверенности (A -> B) на поддержки (B) . Математически это можно представить как:
Подъем (A → B) = (Уверенность (A → B)) / (Поддержка (B))
Возвращаясь к нашей проблеме с бургерами и кетчупом, Lift (Burger -> Ketchup) можно рассчитать как:
Лифт (Бургер → Кетчуп) = (Уверенность (Бургер → Кетчуп)) / (Поддержка (Кетчуп))
Лифт (Бургер → Кетчуп) = 33.3/10
= 3,33
Lift в основном говорит нам, что вероятность покупки бургера и кетчупа вместе в 3,33 раза больше, чем вероятность покупки просто кетчупа. Повышение, равное 1, означает, что нет никакой связи между продуктами A и B. Повышение более 1 означает, что товары A и B с большей вероятностью будут куплены вместе. Наконец, показатель Lift менее 1 относится к случаю, когда два продукта вряд ли будут куплены вместе.
шагов, задействованных в априорном алгоритме
Для больших наборов данных могут быть сотни элементов в сотнях тысяч транзакций.Алгоритм Apriori пытается извлечь правила для каждой возможной комбинации элементов. Например, рост может быть рассчитан для элемента 1 и элемента 2, элемента 1 и элемента 3, элемента 1 и элемента 4, а затем элемента 2 и элемента 3, элемента 2 и элемента 4, а затем комбинаций элементов, например п.1, п.2 и п.3; аналогично пунктам 1, 2 и 4 и так далее.
Как видно из приведенного выше примера, этот процесс может быть очень медленным из-за количества комбинаций. Чтобы ускорить процесс, нам необходимо выполнить следующие шаги:
- Установите минимальное значение поддержки и уверенности.Это означает, что нас интересует только поиск правил для элементов, которые имеют определенное существование по умолчанию (например, поддержку) и имеют минимальное значение для совместной встречаемости с другими элементами (например, достоверность).
- Извлеките все подмножества, имеющие более высокое значение поддержки, чем минимальный порог.
- Выберите все правила из подмножеств со значением достоверности выше минимального порога.
- Упорядочите правила в порядке убывания Lift.
Реализация априорного алгоритма с Python
Хватит теории, пришло время увидеть алгоритм Априори в действии.В этом разделе мы будем использовать алгоритм Apriori, чтобы найти правила, которые описывают связи между различными продуктами при 7500 транзакциях в течение недели во французском розничном магазине. Набор данных можно скачать по следующей ссылке:
https://drive.google.com/file/d/1y5DYn0dGoSbC22xowBq2d4po6h2JxcTQ/view?usp=sharing
Еще один интересный момент заключается в том, что нам не нужно писать скрипт для расчета поддержки, уверенности и подъемной силы для всех возможных комбинаций элементов.Мы будем использовать готовую библиотеку, в которой весь код уже реализован.
Библиотека, о которой я говорю, апиори, и ее исходный код можно найти здесь. Я предлагаю вам загрузить и установить библиотеку в путь по умолчанию для ваших библиотек Python, прежде чем продолжить.
Примечание. Все сценарии в этой статье были выполнены с использованием Spyder IDE для Python.
Чтобы реализовать алгоритм априори в Python, выполните следующие действия:
Импортировать библиотеки
Первым шагом, как всегда, является импорт необходимых библиотек.Для этого выполните следующий сценарий:
импортировать numpy как np
импортировать matplotlib.pyplot как plt
импортировать панд как pd
из апиори импорт априори
В приведенном выше скрипте мы импортируем библиотеки pandas, numpy, pyplot и apriori.
Импорт набора данных
Теперь давайте импортируем набор данных и посмотрим, с чем мы работаем. Загрузите набор данных и поместите его в папку «Datasets» на диске «D» (или измените код ниже, чтобы он соответствовал пути к файлу на вашем компьютере) и выполните следующий сценарий:
store_data = pd.read_csv ('D: \\ Наборы данных \\ store_data.csv')
Давайте вызовем функцию head () , чтобы посмотреть, как выглядит набор данных:
store_data.head ()
Фрагмент набора данных показан на скриншоте выше. Если вы внимательно посмотрите на данные, мы увидим, что заголовок на самом деле является первой транзакцией. Каждая строка соответствует транзакции, а каждый столбец соответствует элементу, купленному в этой конкретной транзакции. NaN говорит нам, что элемент, представленный столбцом, не был куплен в этой конкретной транзакции.
В этом наборе данных нет строки заголовка. Но по умолчанию функция pd.read_csv обрабатывает первую строку как заголовок. Чтобы избавиться от этой проблемы, добавьте параметр header = None в функцию pd.read_csv , как показано ниже:
store_data = pd.read_csv ('D: \\ Datasets \\ store_data.csv', header = None)
Теперь выполните функцию head () :
store_data.head ()
В обновленных выходных данных вы увидите, что первая строка теперь обрабатывается как запись, а не как заголовок, как показано ниже:
Теперь мы воспользуемся алгоритмом Apriori, чтобы выяснить, какие товары обычно продаются вместе, чтобы владелец магазина мог принять меры по размещению связанных товаров вместе или рекламировать их вместе, чтобы увеличить прибыль.
Обработка данных
Библиотека Apriori, которую мы собираемся использовать, требует, чтобы наш набор данных был в форме списка списков, где весь набор данных представляет собой большой список, а каждая транзакция в наборе данных является внутренним списком во внешнем большом списке. В настоящее время у нас есть данные в виде фрейма данных pandas. Чтобы преобразовать наш фреймворк pandas в список списков, выполните следующий скрипт:
записей = []
для i в диапазоне (0, 7501):
records.append ([str (store_data.values [i, j]) для j в диапазоне (0, 20)])
Применение априори
Следующим шагом является применение алгоритма априори к набору данных. Для этого мы можем использовать класс apriori , который мы импортировали из библиотеки apyori.
Для работы класса apriori требуются некоторые значения параметров. Первый параметр — это список списка, из которого вы хотите извлечь правила. Второй параметр — это параметр min_support . Этот параметр используется для выбора элементов со значениями поддержки, превышающими значение, указанное в параметре.Затем параметр min_confidence фильтрует те правила, степень достоверности которых превышает порог достоверности, заданный параметром. Аналогично, параметр min_lift указывает минимальное значение подъема для правил из краткого списка. Наконец, параметр min_length указывает минимальное количество элементов, которое вы хотите включить в свои правила.
Предположим, что нам нужны правила только для тех товаров, которые покупаются не менее 5 раз в день, или 7 x 5 = 35 раз в неделю, поскольку наш набор данных рассчитан на период в одну неделю.Поддержка этих элементов может быть рассчитана как 35/7500 = 0,0045. Минимальная достоверность правил — 20% или 0,2. Точно так же мы указываем значение подъема как 3 и, наконец, min_length равно 2, поскольку в наших правилах нам нужно как минимум два продукта. Эти значения в основном выбираются произвольно, так что вы можете поиграть с этими значениями и посмотреть, какое различие это имеет в правилах, которые вы возвращаетесь.
Выполните следующий сценарий:
association_rules = apriori (записи, min_support = 0.0045, min_confidence = 0,2, min_lift = 3, min_length = 2)
Association_results = список (Association_rules)
Во второй строке здесь мы конвертируем правила, найденные классом apriori , в список , так как в этой форме легче просматривать результаты.
Просмотр результатов
Давайте сначала найдем общее количество правил, добытых классом apriori . Выполните следующий скрипт:
печать (len (association_rules))
Приведенный выше сценарий должен вернуть 48.Каждому пункту соответствует одно правило.
Давайте напечатаем первый элемент в списке association_rules , чтобы увидеть первое правило. Выполните следующий скрипт:
печать (правила_связи [0])
Результат должен выглядеть так:
RelationRecord (items = frozenset ({'light cream', 'chicken'}), support = 0.004532728969470737, orders_statistics [OrderedStatistic (items_base = frozenset ({'light cream'}), items_add = frozenset ({'chicken'}) , уверенность = 0.2229057, подъемник = 4,84395061728395)])
Первый элемент в списке — это сам список, содержащий три элемента. Первый элемент списка показывает продукты в правиле.
Например, из первого пункта видно, что легкие сливки и курицу обычно покупают вместе. Это имеет смысл, поскольку люди, которые покупают легкие сливки, внимательно относятся к тому, что они едят, поэтому они с большей вероятностью будут покупать курицу, то есть белое мясо, а не красное мясо, то есть говядину. Или это может означать, что в рецептах курицы обычно используются легкие сливки.
Значение поддержки для первого правила — 0,0045. Это число рассчитывается путем деления количества транзакций, содержащих легкие сливки, на общее количество транзакций. Уровень достоверности для правила составляет 0,2905, что показывает, что из всех транзакций, содержащих легкие сливки, 29,05% транзакций также содержат курицу. Наконец, повышение на 4,84 говорит нам о том, что вероятность того, что курица будет куплена покупателями, которые покупают легкие сливки, в 4,84 раза выше, чем вероятность продажи курицы по умолчанию.
Следующий скрипт более наглядно отображает правило, поддержку, уверенность и рост для каждого правила:
для элемента в association_rules:
# первый индекс внутреннего списка
# Содержит базовый элемент и добавляет элемент
пара = элемент [0]
items = [x вместо x в паре]
print ("Правило:" + items [0] + "->" + items [1])
# второй индекс внутреннего списка
print ("Поддержка:" + str (элемент [1]))
#third индекс списка, расположенный на 0-м
# третьего индекса внутреннего списка
print ("Уверенность:" + str (элемент [2] [0] [2]))
print ("Lift:" + str (элемент [2] [0] [3]))
print ("=====================================")
Если вы выполните приведенный выше сценарий, вы увидите все правила, возвращаемые классом apriori .Первые четыре правила, возвращаемые классом apriori , выглядят следующим образом:
Правило: легкие сливки -> курица
Поддержка: 0.004532728969470737
Уверенность: 0,2229057
Подъемник: 4.84395061728395
=====================================
Правило: сливочно-грибной соус -> эскалоп
Поддержка: 0.0057325689126
Уверенность: 0,3006993006993007
Лифт: 3.7696715049
=====================================
Правило: эскалоп -> паста
Поддержка: 0.005865884548726837
Уверенность: 0,3728813559322034
Лифт: 4.700811850163794
=====================================
Правило: говяжий фарш -> зелень и перец
Поддержка: 0,015997866951073192
Уверенность: 0,3234501347708895
Лифт: 3,2919938411349285
=====================================
Первое правило мы уже обсуждали. Теперь обсудим второе правило. Второе правило гласит, что грибной сливочный соус и эскалоп покупают часто. Поддержка сливочно-грибного соуса 0,0057. Доверие для этого правила составляет 0,3006, что означает, что из всех транзакций, содержащих гриб, 30.06% транзакций также могут содержать эскалоп. Наконец, подъем 3,79 показывает, что эскалоп с большей вероятностью будет куплен покупателями сливочно-грибного соуса на 3,79 по сравнению с продажей по умолчанию.
Заключение
Алгоритмы интеллектуального анализа правил ассоциации, такие как Apriori, очень полезны для поиска простых ассоциаций между нашими элементами данных. Их легко реализовать, и они обладают высокой объясняемостью. Однако для более сложных аналитических данных, таких как те, которые используются Google или Amazon и т. Д., используются более сложные алгоритмы, такие как рекомендательные системы. Однако вы, вероятно, видите, что этот метод — очень простой способ получить базовые ассоциации, если это все, что вам нужно.
Разъяснение 10 лучших алгоритмов интеллектуального анализа данных
Раймонд Ли.
Сегодня я собираюсь объяснить на простом английском языке 10 самых влиятельных алгоритмов интеллектуального анализа данных, за которые проголосовали 3 отдельные группы в этом обзоре.
Как только вы узнаете, что они из себя представляют, как они работают, что они делают и где их найти, я надеюсь, что у вас будет этот пост в блоге как трамплин, чтобы узнать еще больше о интеллектуальном анализе данных.
Чего мы ждем? Давайте начнем!
Вот алгоритмы:
- 1. C4.5
- 2. k-средство
- 3. Машины опорных векторов
- 4. Априори
- 5. EM
- 6. PageRank
- 7. AdaBoost
- 8. кНН
- 9. Наивный байесовский
- 10. КОРЗИНА
Мы также предоставляем интересные ресурсы в конце.
1. C4.5Что он делает? C4.5 строит классификатор в виде дерева решений. Для этого C4.5 предоставляется набор данных, представляющих уже классифицированные вещи.
Подождите, а что за классификатор? Классификатор — это инструмент интеллектуального анализа данных, который берет набор данных, представляющих то, что мы хотим классифицировать, и пытается предсказать, к какому классу принадлежат новые данные.
Какой пример? Конечно, предположим, что набор данных содержит группу пациентов. Мы знаем разные вещи о каждом пациенте, такие как возраст, пульс, артериальное давление, VO 2 max, семейный анамнез и т. Д.Это так называемые атрибуты.
Сейчас:
Учитывая эти атрибуты, мы хотим предсказать, заболеет ли пациент раком. Пациент может попасть в 1 из 2 классов: заболеет раком или не заболеет раком. C4.5 сообщается класс для каждого пациента.
А вот и сделка:
Используя набор атрибутов пациента и соответствующий класс пациента, C4.5 строит дерево решений, которое может предсказать класс для новых пациентов на основе их атрибутов.
Круто, а что такое дерево решений? Изучение дерева решений создает нечто похожее на блок-схему для классификации новых данных.Используя тот же пример пациента, один конкретный путь на блок-схеме может быть:
- Пациент болел раком
- Пациент экспрессирует ген, сильно коррелированный с больными раком
- Больной опухоль
- Размер опухоли пациента превышает 5 см
Итог:
В каждой точке блок-схемы есть вопрос о значении некоторого атрибута, и в зависимости от этих значений он или она классифицируются. Вы можете найти множество примеров деревьев решений.
Это контролируемое или неконтролируемое? Это обучение с учителем, поскольку набор обучающих данных помечен классами. Используя пример с пациентом, C4.5 не узнает самостоятельно, что пациент заболеет раком или не заболеет раком. Сначала мы сказали ему, он сгенерировал дерево решений, а теперь он использует дерево решений для классификации.
Вам может быть интересно, чем C4.5 отличается от других систем дерева решений?
- Во-первых, C4.5 использует информационный выигрыш при генерации дерева решений.
- Во-вторых, хотя другие системы также включают обрезку, C4.5 использует однопроходный процесс обрезки, чтобы уменьшить чрезмерную подгонку. Обрезка приводит ко многим улучшениям.
- В-третьих, C4.5 может работать как с непрерывными, так и с дискретными данными. Насколько я понимаю, он делает это путем указания диапазонов или пороговых значений для непрерывных данных, тем самым превращая непрерывные данные в дискретные.
- Наконец, неполные данные обрабатываются по-своему.
Зачем использовать C4.5? Возможно, самым лучшим аргументом в пользу деревьев решений является их простота интерпретации и объяснения.Кроме того, они довольно быстрые, довольно популярные, а вывод удобочитаем.
Где используется? Популярную реализацию Java с открытым исходным кодом можно найти на OpenTox. Orange, инструмент визуализации и анализа данных с открытым исходным кодом для интеллектуального анализа данных, реализует C4.5 в своем классификаторе дерева решений.
Классификаторы хороши, но обязательно ознакомьтесь со следующим алгоритмом кластеризации…
2. k-средствоЧто он делает? k-means создает k групп из набора объектов, чтобы члены группы были более похожи.Это популярный метод кластерного анализа для изучения набора данных.
Погодите, что такое кластерный анализ? Кластерный анализ — это семейство алгоритмов, предназначенных для формирования групп, при которых члены группы более похожи, чем члены, не входящие в группу. Кластеры и группы являются синонимами в мире кластерного анализа.
Есть такой пример? Конечно, предположим, что у нас есть данные о пациентах. В кластерном анализе это можно назвать наблюдениями.Мы знаем разные вещи о каждом пациенте, такие как возраст, пульс, артериальное давление, VO 2 max, холестерин и т. Д. Это вектор, представляющий пациента.
Внешний вид:
Вы можете представить вектор как список чисел, которые мы знаем о пациенте. Этот список также можно интерпретировать как координаты в многомерном пространстве. Пульс может иметь одно измерение, кровяное давление — другое измерение и так далее.
Вам может быть интересно:
Учитывая этот набор векторов, как мы сгруппируем вместе пациентов с одинаковым возрастом, пульсом, кровяным давлением и т. Д.?
Хотите узнать самое лучшее?
Вы указываете k-средство, сколько кластеров вам нужно.Об остальном позаботится K-means.
Как k-means позаботится об остальном? k-means имеет множество вариантов оптимизации для определенных типов данных.
На высоком уровне все они делают что-то вроде этого:
- k-means выбирает точки в многомерном пространстве для представления каждого из k кластеров. Их называют центроидами.
- Каждый пациент будет ближе всего к 1 из этих k центроидов. Будем надеяться, что не все они будут ближе всего к одному и тому же, поэтому они сформируют кластер вокруг своего ближайшего центроида.
- У нас есть k кластеров, и каждый пациент теперь является членом кластера. Затем
- k-means находит центр для каждого из k кластеров на основе его членов кластера (да, используя векторы пациентов!).
- Этот центр становится новым центроидом кластера.
- Поскольку центроид теперь находится в другом месте, пациенты теперь могут быть ближе к другим центроидам. Другими словами, они могут изменить членство в кластере.
- Шаги 2–6 повторяются до тех пор, пока центроиды не перестанут меняться и членство в кластерах не стабилизируется.Это называется конвергенцией.
Это контролируемое или неконтролируемое? Это зависит от обстоятельств, но большинство классифицирует k-среднее как неконтролируемое. Помимо указания количества кластеров, k-означает «изучает» кластеры самостоятельно, без какой-либо информации о том, к какому кластеру принадлежит наблюдение. k-средства могут быть частично контролируемыми.
Зачем нужны k-средства? Не думаю, что у многих возникнут проблемы с этим:
Ключевым преимуществом k-means является его простота.Его простота означает, что он в целом быстрее и эффективнее других алгоритмов, особенно для больших наборов данных.
Становится лучше:
k-средних можно использовать для предварительной кластеризации массивного набора данных с последующим более дорогостоящим кластерным анализом на подкластерах. k-средства также можно использовать для быстрой «игры» с k и исследования, есть ли упущенные закономерности или отношения в наборе данных.
Не все гладко:
Двумя ключевыми недостатками k-средних являются его чувствительность к выбросам и чувствительность к первоначальному выбору центроидов.И последнее, о чем следует помнить, — k-means разработан для работы с непрерывными данными — вам нужно будет проделать несколько уловок, чтобы заставить его работать с дискретными данными.
Где используется? Тонна реализаций кластеризации k-средних доступна в Интернете:
Если деревья решений и кластеризация вас не впечатлили, вам понравится следующий алгоритм.
3. Машины опорных векторовЧто он делает? Машина опорных векторов (SVM) изучает гиперплоскость для классификации данных на 2 класса.На высоком уровне SVM выполняет ту же задачу, что и C4.5, за исключением того, что SVM вообще не использует деревья решений.
Ого, гипер-что? Гиперплоскость — это функция, подобная уравнению для прямой, y = mx + b . Фактически, для простой задачи классификации всего с двумя элементами гиперплоскость может быть линией.
Оказывается…
SVM может выполнять трюк для проецирования ваших данных в более высокие измерения. Однажды спроецированный в более высокие измерения…
… SVM определяет лучшую гиперплоскость, которая разделяет ваши данные на 2 класса.
У вас есть пример? Безусловно, самый простой пример, который я нашел, начинается с связки красных и синих шаров на столе. Если шарики не слишком перемешаны, вы можете взять палку и, не перемещая шарики, разделить их палкой.
Вы видите:
Когда на стол добавляется новый шар, вы можете предсказать его цвет, зная, на какой стороне клюшки он находится.
Что означают шары, стол и клюшка? Шары представляют собой точки данных, а красный и синий цвета представляют 2 класса.Палочка представляет собой простейшую гиперплоскость — линию.
А что самое крутое?
SVM определяет функцию гиперплоскости.
Что делать, если все станет сложнее? Верно, часто так и поступают. Если шарики перемешать, прямая палка не подойдет.
Вот обходной путь:
Быстро поднимите стол, подбрасывая шары в воздух. Пока шары находятся в воздухе и правильно подброшены, вы используете большой лист бумаги, чтобы разделять шары в воздухе.
Вам может быть интересно, не обман ли это:
Нет, поднятие таблицы эквивалентно отображению ваших данных в более высокие измерения. В этом случае мы переходим от двухмерной поверхности стола к трехмерным шарам в воздухе.
Как это делает SVM? Используя ядро, мы получаем хороший способ работать в более высоких измерениях. Большой лист бумаги по-прежнему называется гиперплоскостью, но теперь это функция плоскости, а не линии. Замечание Юваля: когда мы оказываемся в трехмерном пространстве, гиперплоскость должна быть плоскостью, а не линией.
Я нашел эту визуализацию очень полезной:
Reddit также имеет 2 отличных темы по этому поводу в субреддитах ELI5 и ML.
Как шары на столе или в воздухе соотносятся с реальными данными? У шара на столе есть место, которое мы можем указать с помощью координат. Например, мяч может находиться на расстоянии 20 см от левого края и 50 см от нижнего края. Другой способ описать мяч — это координаты (x, y) или (20, 50). x и y — два измерения мяча.
Вот сделка:
Если бы у нас был набор данных пациента, каждого пациента можно было бы описать различными измерениями, такими как пульс, уровень холестерина, артериальное давление и т. Д. Каждое из этих измерений является измерением.
Итог:
SVM делает свое дело, отображает их в более высокое измерение, а затем находит гиперплоскость для разделения классов.
Маржа часто ассоциируется с SVM? Кто они такие? Запас — это расстояние между гиперплоскостью и двумя ближайшими точками данных из каждого соответствующего класса.В примере с мячом и столом расстояние между клюшкой и ближайшим красным и синим мячом является полем.
Ключ:
SVM пытается максимизировать запас, чтобы гиперплоскость находилась так же далеко от красного шара, как и синий шар. Таким образом, снижается вероятность ошибочной классификации.
Откуда SVM получил свое название? В примере с мячом и столом гиперплоскость равноудалена от красного и синего мячей. Эти шары или точки данных называются опорными векторами, потому что они поддерживают гиперплоскость.
Это контролируемое или неконтролируемое? Это обучение с учителем, поскольку набор данных используется для первого обучения SVM классам. Только тогда SVM сможет классифицировать новые данные.
Зачем нужна SVM? SVM вместе с C4.5, как правило, являются двумя классификаторами, которые следует попробовать в первую очередь. Ни один классификатор не будет лучшим во всех случаях из-за теоремы о запрете бесплатного обеда. Кроме того, некоторые недостатки — выбор ядра и интерпретируемость.
Где используется? Существует множество реализаций SVM.Некоторые из самых популярных — это scikit-learn, MATLAB и, конечно же, libsvm.
Следующий алгоритм — один из моих любимых…
Как майнить с f2pool с помощью NiceHash
NiceHash — это платформа обмена хешрейтом, где майнеры могут приобретать хешрейт для различных алгоритмов для майнинга через пулы майнинга f2pool.
Хешрейт, приобретенный у NiceHash, будет отображаться как одна машина для майнинга после подключения к f2pool. В стандартной конфигурации f2pool будет считать его стандартной машиной для майнинга и делегировать ей несоответствующие задачи по майнингу, что приведет к высокому проценту отказов.
В этом руководстве мы покажем вам, как настроить параметры майнинга для успешного майнинга с использованием хешрейта, арендованного у NiceHash!
Конфигурация
Чтобы начать майнинг с помощью f2pool, вам необходимо настроить следующие параметры в NiceHash:
Имя пользовательского пула : любое имя по вашему выбору
Алгоритм : алгоритм, используемый для майнинга вашей монеты (см. Таблицу ниже)
Имя хоста Stratum или IP : URL-адрес сервера f2pool
Порт : порт для сервера f2pool
Имя пользователя : Ваше имя пользователя f2pool или адрес кошелька
Пароль : Введите пароль в точности так, как он указан в таблице ниже; для паролей с пометкой Anything допускается любая последовательность символов
| Монета | Алгоритм | Страта | Порт | Имя пользователя | Пароль |
|---|---|---|---|---|---|
| Биткойн | SHA256 | btc.f2pool.com | 3333 | имя пользователя f2pool | fd = 524288 |
| Эфириум | Даггерхасимото | eth.f2pool.com | 6688 | имя пользователя f2pool | d = 40 |
| Грин | GrinCuckaroo29 | grin29.f2pool.com | 13654 | имя пользователя f2pool | d = 8 |
| Грин | GrinCuckaroo31 | оскал31.f2pool.com | 13654 | имя пользователя f2pool | d = 8 |
| Decred | Блейк256r14 | dcr.f2pool.com | 5730 | адрес кошелька | Все, что угодно |
| Балка | Балка | beam.f2pool.com | 5000 | адрес кошелька | Все, что угодно |
| Равенкоин | X16Rv2 | ворон.f2pool.com | 3636 | адрес кошелька | d = 32 |
| AE | CuckooCycle | ae.f2pool.com | 7898 | адрес кошелька | d = 1024 |
| DigiByte | sha256 | dgb-sha256d.f2pool.com | 11110 | адрес кошелька | d = 4611686018427387904 или d = 9223372036854775808 |
| DigiByte | scrypt | dgb-scrypt.f2pool.com | 11111 | адрес кошелька | d = 2748774 |
| DigiByte | кубит | dgb-qubit.f2pool.com | 11114 | адрес кошелька | d = 68719476736 |
Обратите внимание
Полный список серверов пула для майнинга f2pool для восьми монет, поддерживаемых для майнинга NiceHash, доступен здесь.
Начни майнинг сегодня!
Вы готовы к работе.
Пока вы успешно отправите свой хешрейт, вы будете получать выплаты от f2pool.
Чтобы быть в курсе последних новостей и разработок PoW, подписывайтесь на нас в Twitter!
Удачного майнинга!
Прикладные науки | Бесплатный полнотекстовый | Параллельный подход для частого анализа подграфов в одном большом графе с использованием Spark
1. Введение
Многие отношения между объектами в различных приложениях, таких как химия, биоинформатика, компьютерное зрение, социальные сети, поиск текста и веб-анализ, могут быть представлены вид графиков.Частый анализ подграфов (FSM) - хорошо изученная проблема в области интеллектуального анализа графов, которая способствует развитию многих сценариев реальных приложений, таких как механизмы предложения розничной торговли [1], сети межбелкового взаимодействия [2], прогнозирование отношений [3], вторжение обнаружение [4], прогнозирование событий [5], анализ тональности текста [6], классификация изображений [7] и т. д. Например, поиск частых подграфов из графа массового взаимодействия событий [8] может помочь найти повторяющиеся модели взаимодействия между людьми. или организации, которые могут быть интересны социологам.Существует две широкие категории частого интеллектуального анализа подграфов: (i) конечный автомат на основе транзакций графа; и (ii) автомат на основе одного графа [9]. В графовом автомате на основе транзакций входные данные представляют собой набор графов малого или среднего размера, называемых транзакциями, то есть базу данных графов. В автомате на основе одного графа входные данные составляют один очень большой граф. Задача конечного автомата - перечислить все подграфы с поддержкой выше минимального порога поддержки. Графический автомат на основе транзакций использует поддержку подсчета на основе транзакций, в то время как конечный автомат на основе графа использует подсчет на основе вхождений.Поиск частых подграфов в одном графе более сложен и требует вычислений, поскольку несколько экземпляров идентичных подграфов могут перекрываться. В этой статье мы сосредотачиваемся на частом поиске подграфов в одном большом графе. «Узким местом» для алгоритмов частого поиска подграфов на одном большом графе является вычислительная сложность, вызванная двумя основными операциями: (i) эффективное создание всех подграфов с помощью различный размер; и (ii) оценка изоморфизма подграфов (оценка поддержки), i.е., определение того, является ли график точным совпадением с другим. Пусть N и n - количество вершин входного графа G и подграфа S соответственно. Обычно сложность генерации подграфа составляет O (2N2), а оценка поддержки - O (Nn). Таким образом, общая сложность алгоритма конечного автомата составляет O (2N2 · Nn), что экспоненциально с точки зрения размера проблемы. В последние годы было предложено множество алгоритмов для конечного автомата на основе одного графа. Тем не менее, большинство из них являются последовательными алгоритмами, которые требуют много времени для добычи больших наборов данных, включая SiGraM (анализ единственного графа) [10], GERM (майнер правил эволюции графа) [11] и GraMi (анализ графов) [12].Между тем, исследователи также использовали методы параллельных и распределенных вычислений для ускорения вычислений, в которых в основном используются две параллельные вычислительные структуры: Map-Reduce [13,14,15,16,17,18] и MPI (интерфейс передачи сообщений) [ 19]. Все существующие реализации параллельных алгоритмов конечных автоматов MapReduce основаны на Hadoop [20] и предназначены для транзакций графа, а не для одного графа, что часто приводит к узким местам ввода-вывода (ввод и вывод), поскольку им приходится тратить много времени на перемещение данных. / обрабатывает диск и извлекает из него во время итерации алгоритмов.Кроме того, некоторые из этих алгоритмов не могут поддерживать майнинг через расширение подграфов [14,15]. Другими словами, пользователи должны указать размер подграфа в качестве входных данных. Кроме того, хотя методы, основанные на MPI, такие как DistGraph [19], обычно имеют хорошую производительность, они ориентированы на тесно взаимосвязанные машины HPC (High Performance Computing), которые менее доступны для большинства людей. Кроме того, для алгоритмов на основе MPI сложно объединить несколько алгоритмов машинного обучения или интеллектуального анализа данных в один конвейер от распределенного хранилища данных до выбора функций и обучения, что является обычным для машинного обучения.Отказоустойчивость также остается на усмотрение разработчика приложения. В этой статье мы предлагаем алгоритм параллельного анализа частых подграфов в одном большом графе с использованием инфраструктуры Apache Spark, который называется SSiGraM. Spark [21] - это платформа распределенных вычислений общего назначения, аналогичная MapReduce, которая предоставляет пользователям высокоуровневый интерфейс для создания приложений. В отличие от предыдущих платформ MapReduce, таких как Hadoop, Spark в основном хранит промежуточные данные в памяти, эффективно сокращая количество операций ввода / вывода на диск.Кроме того, преимущества конструкции «конвейеров машинного обучения» [22] в Spark заключаются в том, что мы можем не только эффективно добывать частые подграфы, но и легко комбинировать процесс добычи с другими алгоритмами машинного обучения, такими как классификация, кластеризация или рекомендации. Стремясь решить две вычислительные задачи FSM, мы проводим расширение подграфа и оценку поддержки для всех распределенных рабочих узлов кластера. Для расширения подграфов наш подход генерирует все подграфы параллельно с помощью FFSM-Join (Fast Frequent Subgraph Mining) и FFSM-Extend, предложенного Huan et al.[23], что является эффективным решением для перебора подграфов-кандидатов. При вычислении поддержки подграфов мы принимаем модель задачи удовлетворения ограничений (CSP), предложенную в [12], в качестве метода оценки поддержки. Поддержка CSP удовлетворяет свойству закрытия вниз (DCP), также известному как антимонотонность (или свойство Apriori), что означает, что подграф g является частым тогда и только тогда, когда все его подграфы являются частыми. В результате мы используем стратегию поиска в ширину (BFS) в нашем алгоритме SSiGraM.На каждой итерации сгенерированные подграфы распределяются между каждым исполнителем в кластере Spark для решения CSP. Затем редкие подграфы удаляются, а оставшиеся частые подграфы передаются на следующую итерацию для генерации подграфов-кандидатов. На практике оценка поддержки более сложна, чем расширение подграфа, и будет занимать большую часть времени в процессе добычи. В результате, помимо параллельного майнинга, наш алгоритм SSiGraM также использует стратегию эвристического поиска и три новых оптимизации: балансировку нагрузки, предварительную отсечку перед поиском и отсечение сверху вниз в процессе подсчета поддержки, что значительно повышает производительность.Примечательно, что SSiGraM также может применяться к ориентированным графам, интеллектуальному анализу взвешенных подграфов или анализу неопределенных графов с небольшими изменениями, представленными в [24,25]. Таким образом, наш основной вклад в частый поиск подграфов в одном большом графе состоит из трех частей:Во-первых, мы предлагаем SSiGraM, новый алгоритм параллельного интеллектуального анализа частых подграфов в одном большом графе с использованием Spark, который отличается от алгоритма SSiGraM. Параллельные алгоритмы на основе Hadoop MapReduce и MPI. SSiGraM также можно легко комбинировать с данными нижнего распределенного хранилища Hadoop и другими алгоритмами машинного обучения.
Во-вторых, мы проводим параллельное расширение подграфа и подсчет поддержки, соответственно, стремясь к двум основным этапам с высокой вычислительной сложностью при частом поиске подграфов. Кроме того, мы предлагаем стратегию эвристического поиска и три оптимизации для вспомогательных вычислений.
В-третьих, проводятся обширные экспериментальные оценки производительности с использованием четырех реальных графиков. Предложенный алгоритм SSiGraM превосходит метод GraMi как минимум на порядок при той же выделенной памяти.
2. Формализм
Граф G = (V, E) определяется как набор вершин (узлов) V, которые соединены между собой набором ребер (связей) E ⊆V × V [26].Помеченный граф также состоит из функции разметки L, помимо V и E, которая присваивает метки V и E. Обычно графы, используемые в автомате, считаются простыми графами, т. Е. Невзвешенными и ненаправленными помеченными графами без циклы и отсутствие множественных связей между любыми двумя отдельными узлами [27]. Чтобы упростить представление, наш SSiGraM проиллюстрирован неориентированным графом с одной меткой для каждого узла и ребра. Тем не менее, как упоминалось выше, SSiGraM также может быть расширен для поддержки ориентированных или взвешенных графов.Далее вводится ряд широко используемых определений, используемых далее в этой статье. Определение 1.(Маркированный график): Помеченный граф может быть представлен как G = (V, E, LV, LE, φ), где V - набор вершин, E⊆V × V a набор граней. LV и LE - это наборы меток вершин и ребер соответственно. ϕ - функция-метка, определяющая отображения V → LV и E → LE.
Определение 2.(Подграф): Даны два графика G1 = (V1, E1, LV1, LE1, φ1) и G2 = (V2, E2, LV2, LE2, φ2), G1 является подграфом группы G2 тогда и только тогда, когда (i) V1⊆V2 и ∀v∈V1, φ1 (v) = φ2 (v); (ii) E1⊆E2 и ∀ (u, v) ∈E1, φ1 (u, v) = φ2 (u, v).G2 также называют суперграфом G1.
Определение 3.(Изоморфизм подграфов): Пусть G1 = (V1, E1, LV1, LE1, φ1) - подграф G. Подграф G1 изоморфен графу G, если и только если существует другой подграф G2 = (V2, E2, LV2, LE2, φ2) ⊆G и биекция f: V1 → V2, удовлетворяющая: (i) ∀u∈V1, φ1 (u) = φ2 (f (u)); (ii) ∀ (u, v) ∈E1⇔ (f (u), f (v)) ∈E2; и (iii) ∀ (u, v) ∈E1, φ1 (u, v) = φ2 (f (u), f (v)). G2 также называют вложением G1 в G.
Например, на рисунке 1a показан помеченный граф графа взаимодействия событий.Метки узлов представляют тип участника события (например, GOV: правительство) в кодах CAMEO (наблюдение за конфликтом и посредничеством) [28], а метки края представляют тип события [28] между двумя участниками. На рис. 1б, в показаны два подграфа рис. 1а. Рисунок 1b (v1−3v2−9v3) имеет три изоморфизма относительно графа (a): u2−3u4−9u5, u6−3u5−9u4 и u7−3u8−9u10. Определение 4. (Частый подграф в одиночном графе): Для помеченного одиночного графа G и минимального порога поддержки τ проблема частого поиска подграфов определяется как поиск всех подграфов Gi в G,Sup (Gi, G) ≥τ, ∀Gi∈S,
где S обозначает множество подграфов в G с носителем, большим или равным τ.Для подграфа G1 и входного графа G простой способ вычислить носитель G1 в графе G - это подсчитать все его изоморфизмы G1 в G [29]. К сожалению, такой метод не удовлетворяет свойству закрытия вниз (DCP), поскольку бывают случаи, когда подграф появляется меньше раз, чем его надграф. Например, на рисунке 1a граф с одним узлом REF (Refugee) появляется три раза, а его суперграф REF-3GOV - четыре раза. Без DCP пространство поиска не может быть сокращено, и исчерпывающий поиск неизбежен [30].Чтобы решить эту проблему, мы используем поддержку на основе минимального изображения (MNI), которая является антимонотонной, введенной в [31]. Определение 5. (Поддержка MNI): Для подграфа G1 пусть ∑ (S) = {ϕ1, ϕ2,…, ϕm} обозначает множество всех изоморфизмов / вложений G1 во входной граф G. Поддержка MNI подграфа G1 в G основана на количестве уникальных узлов во входном графе G, на которые отображается узел подграфа G1 = (V1, E1), который определяется как:SupMNI (G1, G) = minv∈V1 {| Φ (v) |},
где Φ (v) - множество уникальных отображений для каждого v∈V1, обозначаемых какΦ (v) = ⋃i = 1 | ∑ (S) | ϕi (v).
На рисунке 2 показаны четыре изоморфизма подграфа G1≡A-B-C-A во входном графе. Например, один из изоморфизмов ϕ = {u1, u4, u6, u8}, показанный во втором столбце на рисунке 2c. Есть четыре изоморфизма для подграфа G1 на рисунке 2b. Следовательно, множество уникальных отображений для вершины v1 есть {u1, u2, u8}. Число уникальных отображений по всем вершинам подграфа {v1, v2, v3, v4} равно 3, 3, 2 и 2 соответственно. Таким образом, поддержка MNI для G1 равна SupMNI (G1, G) = min {3,3,2,2} = 2. Определение 6.(Матрица смежности): Матрица смежности графа Gi с n вершинами определяется как матрица M × n, в которой каждый диагональный элемент соответствует отдельной вершине в Gi и заполнен меткой этой вершины и каждая недиагональная (для неориентированного графа верхний треугольник всегда является зеркалом нижнего треугольника) запись в нижней части треугольника соответствует паре вершин в Gi и заполнена меткой ребра между двумя вершинами и ноль, если края нет.
Определение 7. (Максимальная правильная подматрица): Для матрицы A am × m матрица B × n является максимальной собственной подматрицей матрицы A, если и только если B получается путем удаления последней ненулевой записи из A. Для Например, последний ненулевой элемент M2 на рисунке 3 - это y в нижней строке. Определение 8. (Каноническая матрица смежности): Пусть матрица M обозначает матрицу смежности графа Gi. Код (M) представляет собой код M, который определяется как последовательность, образованная объединением нижних треугольных элементов M (включая элементы по диагонали) слева направо и сверху вниз соответственно.Каноническая матрица смежности (CAM) графа Gi - это матрица, которая производит максимальный код с использованием лексикографического порядка [23]. Очевидно, максимальная собственная подматрица САМ также является САМ. На рисунке 3 показаны три матрицы смежности M1, M2, M3 для графа G1 слева. После применения стандартного лексикографического порядка у нас есть Код (M1): aybyxb0y0c00y0d> Код (M2): aybyxb00yd0y00c> Код (M3): bxby0d0y0cyy00a. Фактически, M1 - это каноническая матрица смежности G1. Определение 9. (Субоптимальный CAM): Для данного графа G субоптимальная каноническая матрица смежности (субоптимальная CAM) G является матрицей смежности M группы G, так что ее максимальная собственная подматрица N является CAM графа что N представляет.[23]. CAM также является неоптимальным CAM. Правильный субоптимальный CAM обозначается как субоптимальный CAM, который не является CAM графа, который он представляет.5. Выводы. сложность частого извлечения подграфов. Кроме того, мы также предлагаем стратегию эвристического поиска и три оптимизации для вспомогательных вычислений.Наконец, проводятся обширные экспериментальные оценки производительности с четырьмя наборами графических данных, показывающими эффективность предложенного алгоритма SSiGraM.
В настоящее время параллельное выполнение ведется в масштабе каждого сгенерированного подграфа. Когда подграф включает узел с очень большой степенью, SSiGraM не перейдет к следующей итерации, пока исполнитель не завершит вычисление поддержки этого подграфа. В будущем мы планируем разработать стратегию, которая разбивает задачу оценки для этого типа подграфа на всех исполнителей, что еще больше увеличивает скорость поиска.
6. Обсуждение
Предлагаемый в этой статье алгоритм применяется к автомату для одного большого определенного графа данных, в котором каждое ребро определенно существует. Однако неопределенные графики также являются обычным явлением и имеют практическое значение в реальном мире, например, в телекоммуникационных или электрических сетях. В модели неопределенного графа [33] каждое ребро графа связано с вероятностью количественной оценки вероятности того, что это ребро существует в графе. Обычно существование ребер считается независимым.Также существует два типа конечных автоматов на неопределенных графах: на основе транзакций и на основе одного графа. Большинство существующих работ по конечным автоматам на неопределенных графах разрабатывается на настройках транзакций, т. Е. На множественных малых / средних неопределенных графах. Автомат для транзакций неопределенного графа в рамках ожидаемой семантики считает подграф частым, если его ожидаемая поддержка превышает пороговое значение. Репрезентативные алгоритмы включают в себя интеллектуальный анализ шаблонов неопределенного подграфа (MUSE) [34], взвешенный MUSE (WMUSE) [35], индекс неопределенного графа (UGRAP) [36] и интеллектуальный анализ шаблонов неопределенного подграфа в рамках вероятностной семантики (MUSE-P) [37].Они предлагаются в рамках ожидаемой семантики или вероятностной семантики. Здесь мы в основном обсуждаем измерение неопределенности и применения методов, предложенных в этой статье, с учетом одного неопределенного графика. Измерение неопределенности важно при рассмотрении неопределенного графика. Комбинируя помеченный граф из определения 1 в этой статье, неопределенный граф представляет собой кортеж Gu = (G, P), где G - размеченный граф с основной цепью, а P: E → (0,1] - функция вероятности, которая присваивает каждому ребру e с вероятностью существования, обозначаемой P (e), e∈E.Неопределенный граф Gu влечет 2 | E | Всего возможных графов, каждый из которых является структурой Gu, может существовать как. Вероятность существования Gi можно вычислить с помощью совместного распределения вероятностей:P (Gu⇒Gi) = ∏e∈EGiP (e) ∏e∈EG / EGi (1 − P (e)).
Вообще говоря, автомат на одном неопределенном графе также можно разделить на две фазы: расширение подграфа и оценка поддержки. Фаза расширения подграфа такая же, как и для конечного автомата на магистральном графе G. Таким образом, методы, используемые в этой статье, такие как каноническая матрица смежности для представления подграфов и параллельное расширение для расширения подграфов, могут использоваться в одном неопределенном графе.
Самая большая разница заключается в фазе оценки поддержки. Поддержка подграфа g в неопределенном графе Gu измеряется ожидаемой поддержкой. Простая процедура для вычисления ожидаемой поддержки - это создание всех подразумеваемых графов, вычисление и агрегирование поддержки подграфа в каждом подразумеваемом графе и, наконец, получение ожидаемой поддержки, что может быть выполнено с помощью модели CSP, используемой в этой статье.