Data Mining: что это, задачи, сферы применения, примеры
Термин Data Mining встречается в обиходе все чаще, но иногда его путают с Big Data. РБК Тренды объясняют, как работает добыча данных, почему это целая наука и сколько зарабатывают дата-майнеры
Что такое Data Mining
Data Mining (добыча данных, интеллектуальный анализ данных, глубинный анализ данных или просто майнинг данных) — это процесс, используемый компаниями для превращения необработанных больших данных в полезную информацию. Также для этой технологии используется менее популярный термин «обнаружение знаний в данных» или KDD (knowledge discovery in databases).
Если термином Big Data обозначают все большие данные — как обработанные, так и нет, то Data Mining представляет собой процесс глубокого погружения в эти данные для извлечения ключевых знаний.
Автор термина Data Mining Григорий Пятецкий-Шапиро определял его как процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Используя программное обеспечение для поиска закономерностей в больших пакетах данных, предприятия могут выстраивать маркетинговые стратегии, управлять кредитными рисками, обнаруживать мошенничество, фильтровать спам или даже выявлять настроения пользователей.
Интеллектуальный анализ данных зависит от эффективного сбора, хранения и компьютерной обработки данных. Data Mining считается отдельной дисциплиной в области науки о данных.
Термин «интеллектуальный анализ данных» фигурировал в академических журналах еще в 1970 году, но по-настоящему популярным он стал только в 1990-х после появления интернета. Тогда компаниям потребовалось анализировать большие объемы разнородных данных, чтобы отыскать нетривиальные паттерны и научиться предсказывать поведение клиентов. Обычные модели статистики оказались неспособны справиться с этой задачей.
Первые системы Data Mining предназначались для обработки данных о продажах в супермаркетах по нескольким параметрам, включая их объем по регионам и тип продукта.
Задачи Data Mining
Модели интеллектуального анализа данных применяются для нескольких типов задач:
- прогнозирование: оценка продаж, предсказание нагрузки сервера или его времени простоя;
- риск и вероятность: выбор подходящих заказчиков для целевой рассылки, определение точки баланса для рискованных сценариев, назначение вероятностей по диагнозам или другим результатам;
- рекомендации: определение продуктов, которые будут продаваться вместе, создание рекомендательных сообщений;
- поиск последовательностей: анализ выбора заказчиков во время совершения покупок, прогнозирование их поведения;
- группирование: разделение заказчиков или событий на кластеры, анализ и прогнозирование общих черт этих кластеров.
Где применяют Data Mining
Интеллектуальный анализ данных в основном используется отраслями, обслуживающими потребителей, в том числе в сфере розничной торговли, в финансах и маркетинге.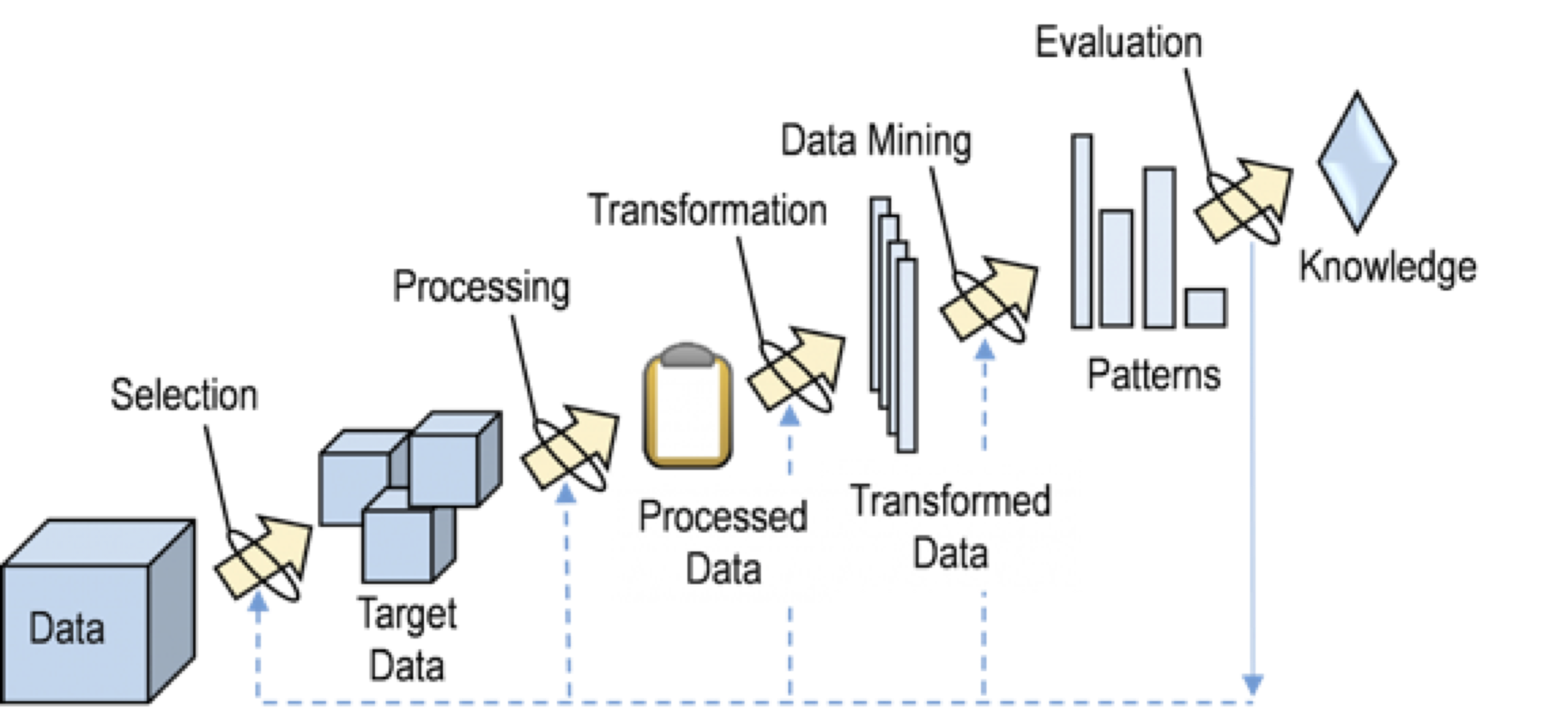 Например, у Сбера существует сервис «Сбор Аналитика», который предоставляет данные по отраслям рынка или территориям на основе анализа денежных потоков населения, продаж товаров и услуг и прочих параметров. Его могут использовать как компании, так и госорганы, чтобы оценить потенциал развития региона.
Например, у Сбера существует сервис «Сбор Аналитика», который предоставляет данные по отраслям рынка или территориям на основе анализа денежных потоков населения, продаж товаров и услуг и прочих параметров. Его могут использовать как компании, так и госорганы, чтобы оценить потенциал развития региона.
Торговля
Торговым сетям Data Mining позволяет анализировать покупательские корзины, чтобы улучшать рекламу, создавать запасы товаров на складах и планировать, как их разложить на витринах, открывать новые магазины и выявлять потребности разных категорий клиентов.
Российская сеть «Лента» проанализировала данные карт лояльности более 90% своих покупателей и поделила аудиторию на определенные сегменты по покупательскому поведению. В частности, ретейлер выделил сегмент покупающих только базовые продукты и мужчин, которые чаще приобретали только напитки и снеки. Это позволило оптимизировать ассортимент и управлять выкладкой и ценами. А Amazon в октябре 2021 года анонсировала инструмент, который предоставит продавцам доступ к информации о том, что в настоящее время ищут покупатели, и тем самым поможет упростить выбор продуктов для продажи.
Банки и телеком
Кредитным организациям Data Mining позволяет выявлять мошенничество с кредитными карточками путем анализа подобных транзакций, а также предлагать различные виды услуг разным группам клиентов. Телеком использует анализ данных, чтобы бороться со спамом и разрабатывать новые тарифы для различных групп абонентов.
Российские сотовые операторы применяют Data Mining для внутренних целей, а также предлагают анализ данных как продукт. Так, «Билайн» в 2020 году запустил новый сервис, который позволяет компаниям получить демографические данные своих клиентов путем дата-майнинга по базам, которые собирает «Вымпелком».
Страхование
Так, австралийской частной страховой компании HCF анализ больших данных позволил за четыре месяца сократить расходы на рекламные рассылки на 25%. Аналитики точно определили тех клиентов, которые с наибольшей вероятностью готовы приобрести более дорогую услугу, и сделали для них отдельную рассылку.
Аналитики точно определили тех клиентов, которые с наибольшей вероятностью готовы приобрести более дорогую услугу, и сделали для них отдельную рассылку.
Производство
Предприятиям анализ больших данных позволяет согласовывать планы поставок с прогнозами спроса, а также обнаруживать проблемы производства на ранних стадиях и успешно инвестировать в бренд. Кроме того, производители могут спрогнозировать износ производственных активов и запланировать техническое обслуживание и ремонт, чтобы не останавливать линию выпуска продукции. Пример применения Data Mining в промышленности — прогнозирование качества изделия в зависимости от параметров технологического процесса.
Российская «Инфосистемы Джет» предлагает интеллектуальную систему поддержки принятия решений Jet Galatea. Она анализирует технологические инструкции и данные, поступающие с датчиков на оборудовании, а затем формирует и выдает рекомендации технологам по оптимальному ведению производственного процесса. Jet Galatea применяют в металлургии, деревообработке, агропроме и добыче полезных ископаемых, чтобы уменьшить расход сырья и увеличить объем продукции.
Социология
Анализ настроений на основе данных социальных сетей позволяет понять, как определенная группа людей относится к конкретной теме. C 2016 года российская полиция использует в некоторых регионах страны систему «Зеус». Она позволяет отслеживать поведение пользователя в соцсети и строит график окружения, устанавливая возможную связь между пользователями на базе анализа друзей, родственников, опосредованных друзей, мест проживания, общих групп, лайков и репостов.
Медицина
Системы Data Mining используются и для постановки медицинских диагнозов. Они построены на основе правил, описывающих сочетания симптомов различных заболеваний. Правила помогают выбирать средства лечения. Например, британский стартап Babylon Heath собирает всю информацию о здоровье клиентов, их образе жизни и привычках, а затем алгоритм строит гипотезы и предлагает варианты обследования, лечения и даже рекомендует конкретных врачей и клиники.
 com)
com)Рекомендательные системы
Подобные системы предназначены для предложения товаров или услуг, которые с большой вероятностью могут быть интересными людям, а также используются для поддержки клиентов. Они работают благодаря дата-майнингу, который осуществляется в реальном времени. Проще говоря, модель постоянно обновляется. Так работают голосовые помощники Alexa от Amazon, Siri от Apple и «Алиса» от «Яндекса». В качестве примера можно привести также службу поддержки такси DiDi, где алгоритм решает до 60% запросов пользователей, поскольку чаще всего они похожи.
Технология и методы Data Mining
Выделяют несколько этапов добычи данных.
- Постановка задачи. Этот шаг включает анализ бизнес-требований, определение области проблемы, метрик, по которым будет выполняться оценка модели, а также определение задач для проекта анализа.

- Подготовка данных: объединение и очистка. Эта работа включает не только удаление ненужных данных, но и поиск в них скрытых зависимостей, определение источников самых точных данных и создание таблицы для анализа.
- Изучение данных.
- Построение моделей.
- Исследование и проверка моделей. Точность их прогнозов можно проверить при помощи специальных средств.
- Развертывание и обновление моделей. Когда модель заработала, ее нужно обновлять по мере поступления новых данных, а затем выполнять их повторную обработку.
Этапы Data Mining
(Фото: predictivesolutions.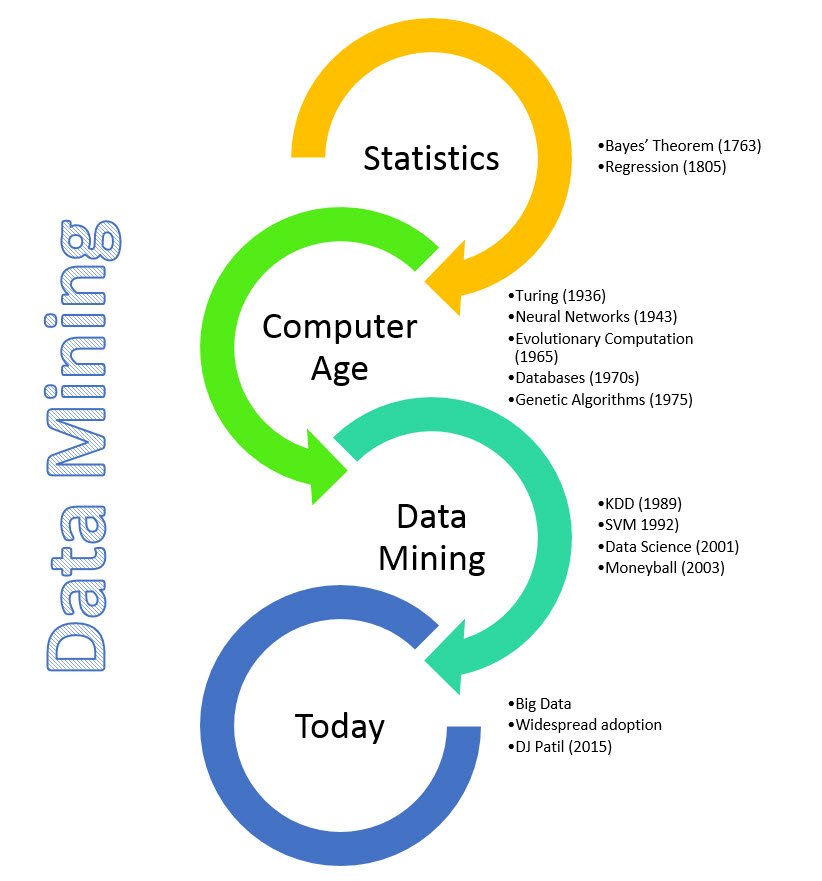 ru)
ru)
Что должен знать и уметь дата-майнер
Специалист по интеллектуальной обработке данных должен иметь глубокие знания в сфере математической статистики, владеть иностранными языками, а также языками программирования. Он обрабатывает большие объемы информации и занимается поиском связей в ней. Специалист использует методики машинного обучения, создает алгоритмы, работает со статистическим анализом. Затем дата-майнер представляет организации результаты своей работы в понятном формате. Исходя из этих презентаций, компания принимает решения.
Работодатели предпочитают специалистов Data Mining с техническим, математическим или естественнонаучным образованием. Университеты предлагают соответствующие направления обучения: «Математика и компьютерные науки», «Прикладная математика и информатика», «Прикладная информатика» и «Системный анализ и управление». Кроме того, азы Data Mining можно изучить на курсах, например, Coursera.
Кроме того, азы Data Mining можно изучить на курсах, например, Coursera.
По данным портала HeadHunter, в октябре 2021 года зарплаты дата-майнеров в России составляли от ₽28 тыс. до ₽250 тыс.
Программы для Data Mining
Существует множество программ, которые могут выполнять задачи Data Mining. Вот некоторые примеры.
- SAS Enterprise Miner — набор методов интеллектуального анализа данных, который применяется для решения таких задач, как обнаружение случаев мошенничества, минимизация финансовых рисков, оценка и прогнозирование потребностей в ресурсах, повышение эффективности маркетинговых кампаний и снижение оттока клиентов. Имеет удобный и понятный интерфейс, позволяющий пользователям самостоятельно создавать модели анализа и прогнозирования. Показывает высокую производительность даже при работе с огромным массивом разрозненных данных.
- Microsoft Analysis Services — предназначен для приложений бизнес-аналитики, анализа данных и создания отчетов. Службы доступны на разных платформах, в том числе на облаке Azure. Предусмотрен механизм для создания собственных алгоритмов и добавления их в качестве новой функции интеллектуального анализа данных.
- SAS Customer Intelligence 360 — это платформа, которая позволяет бизнесу планировать и реализовывать маркетинговые кампании, анализировать их итоги и отслеживать потоки клиентов. Она в реальном времени собирает подробную информацию о действиях клиентов на веб-страницах, в том числе анонимных пользователей, учитывая контекст. Затем платформа дает рекомендации о времени и месте размещения контента на страницах и в мобильных приложениях для конкретного клиента.
 Службы доступны на разных платформах, в том числе на облаке Azure. Предусмотрен механизм для создания собственных алгоритмов и добавления их в качестве новой функции интеллектуального анализа данных.
Службы доступны на разных платформах, в том числе на облаке Azure. Предусмотрен механизм для создания собственных алгоритмов и добавления их в качестве новой функции интеллектуального анализа данных. Многоканальная доставка контента в SAS Customer Intelligence 360
(Фото: blogs. sas.com)
sas.com)
- SAS Credit Scoring — система оценки кредитных рисков и кредитоспособности клиентов. Особенно полезна для банков, компаний финансового сектора и телекома. SAS Credit Scoring анализирует данные потенциального заемщика и представляет готовые рекомендации по выдаче кредита или предоставлению услуги с учетом возможных рисков.
- Board — сочетает функции бизнес-аналитики и корпоративного управления эффективностью. Позволяет предприятиям разрабатывать и поддерживать сложные аналитические и плановые приложения. Также инструмент удобен для составления отчетов, если есть доступ к нескольким источникам данных.
- SAS Revenue Optimization — это набор решений для оптимизации розничных цен, который позволяет определить оптимальную цену в конкретном месте и в конкретное время для формирования конкурентоспособных продаж, запуска промоакций и массовых распродаж. Применяется в ретейле.
- RapidMiner — это открытая платформа для добычи данных с возможностью глубокого обучения алгоритмов, анализа текстов и машинного обучения. RapidMiner можно использовать как на локальных серверах компании, так и в облаке. Платформа популярна в энергетике и промышленности, машиностроении и других отраслях.
 Применяется в ретейле.
Применяется в ретейле.Будущее Data Mining
Рынок систем Data Mining растет. Этому способствует деятельность крупных корпораций: SAS, IBM, Microsoft, Oracle и других. Ожидается, что к 2027 году объем глобального рынка расширенной аналитики вырастет на 23,1% и достигнет отметки в $56,2 млрд.
Последние тенденции в Data Mining включают развитие методов анализа с элементами виртуальной и дополненной реальности, их интеграцию с системами баз данных, добычу биологических данных для инноваций в медицине, веб-майнинг (анализ данных в интернете), анализ данных в реальном времени, а также меры по защите конфиденциальности при добыче данных. Лидеры отрасли считают, что в будущем майнинг данных будет применяться в интеллектуальных приложениях, которые будут встроены в корпоративные хранилища данных.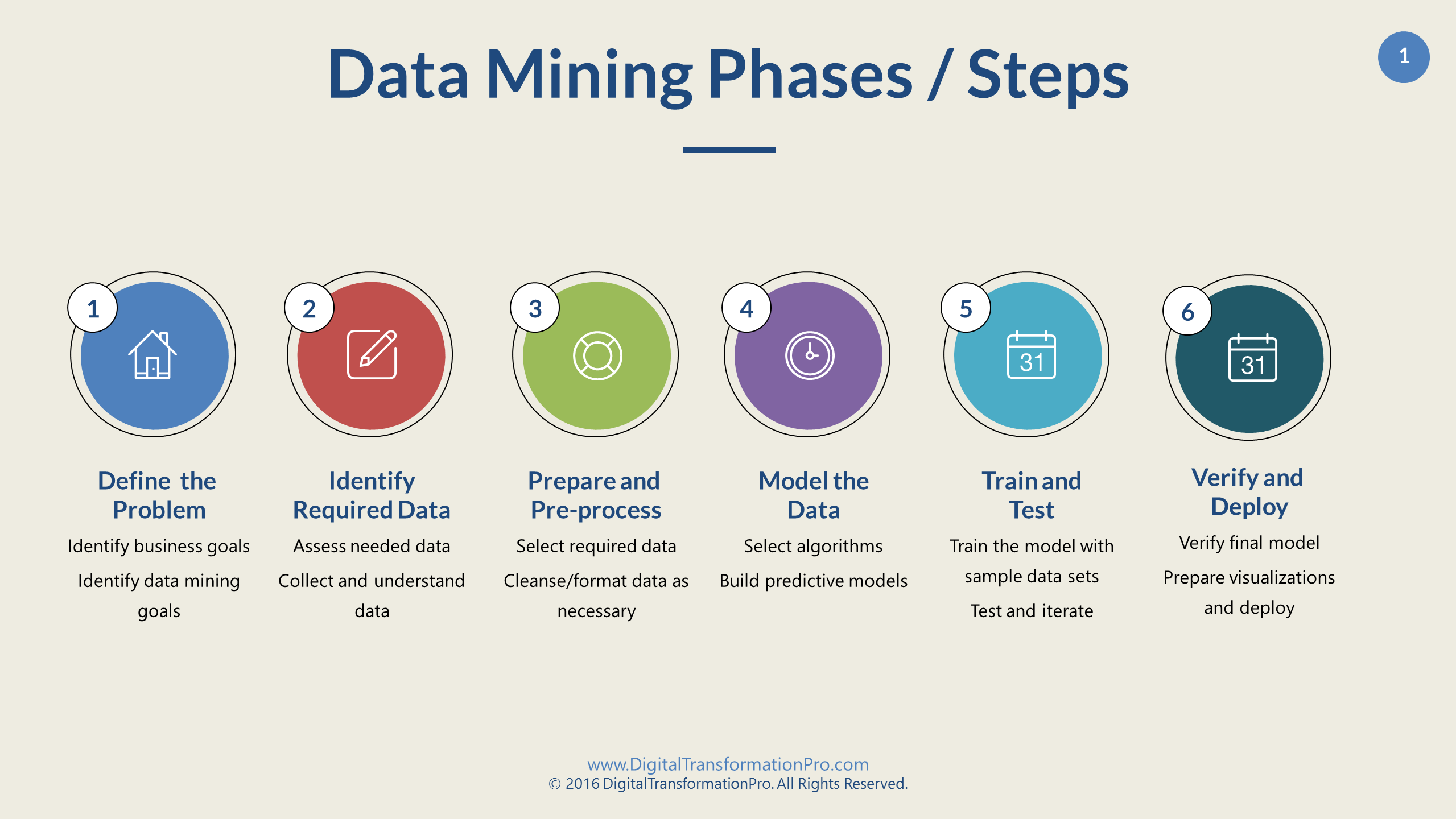
Главной проблемой обнаружения закономерностей в данных является время, которое требуется для перебора информационных массивов. Известные методы либо искусственно ограничивают такой перебор, либо строят целые деревья решений, которые снижают эффективность поиска. Решение этой проблемы остается главной целью разработчиков продуктов для Data Mining.
Технология Data Mining: задачи интеллектуального анализа данных
Data Mining — это способ анализа данных, предназначенный для поиска ранее неизвестных закономерностей в больших массивах информации. Эти закономерности дают возможность принятия эффективных управленческих решений и оптимизации бизнес-процессов.
В данной статье будет рассказано о сферах применения технологии Data Mining.
Области применения методов Data Mining
Методы Data Mining активно применяются в сфере e-commerce, финтехе, IT. Владение инструментами Data Mining дает аналитикам возможность решать самые разнообразные проблемы, например:
-
определения потребностей и желаний клиентов;
-
идентификации клиентов, приносящих максимальную прибыль;
-
повышения лояльности, привлечения и удержание клиентов;
-
анализа эффективности расходов на продвижения товаров и услуг.
Задачи технологии Data Mining
Технология Data Mining выполняет следующие задачи:
задача классификации — определение категории для каждого объекта исследования. В сфере финтеха такой задачей будет оценка кредитоспособности потенциальных заемщиков. Это поможет снизить риски потери средств при работе с некредитоспособными клиентами;
задача прогнозирования, то есть выявление новых возможных значений в определенной числовой последовательности. В e-commerce такая задача решается для предварительной установки цен в зависимости от сезонов и трендов. Благодаря этому можно прогнозировать уровень продаж;
задача кластеризации (сегментации) — разбивка множества объектов на группы по каким-либо признакам. Так, например, сегментация данных о покупателях интернет-магазина по возрасту, полу или предпочтениям помогает формировать для каждой группы специальные предложения;
задача определения взаимосвязей — выявление частоты встречающихся наборов объектов среди множества наборов. Этот способ помогает, в частности, определить состав потребительской корзины и оптимизировать размещение информации о сопутствующих товарах в интернет-магазине;
Этот способ помогает, в частности, определить состав потребительской корзины и оптимизировать размещение информации о сопутствующих товарах в интернет-магазине;
задача анализа последовательностей — выявление закономерностей в последовательностях событий. Этот анализ можно применять для отслеживания страниц, на которых чаще всего посетители прерывают просмотр сайта. Такой способ работы с данными позволяет устранить недостатки сайтов и повысить его посещаемость;
задача анализа отклонений — определение данных, значительно отличающихся от нормы. Данный анализ используется в финтехе для выявления мошеннических операций с банковскими картами. Он позволяет обеспечить надежную защиту клиентов.
Обучение Data Mining
Анализ данных по технологии Data Mining — это один из необходимых для ведения управленческой деятельности навыков, поэтому ВШБИ НИУ ВШЭ приглашает всех, кто хочет повысить свой профессиональный уровень, пройти переподготовку по программе «Инструментальные средства бизнес-аналитики», в рамках которой проводится теоретическое и практическое обучение сбору и обработке данных с помощью современных цифровых технологий для получения эффективных и нетривиальных управленческих решений.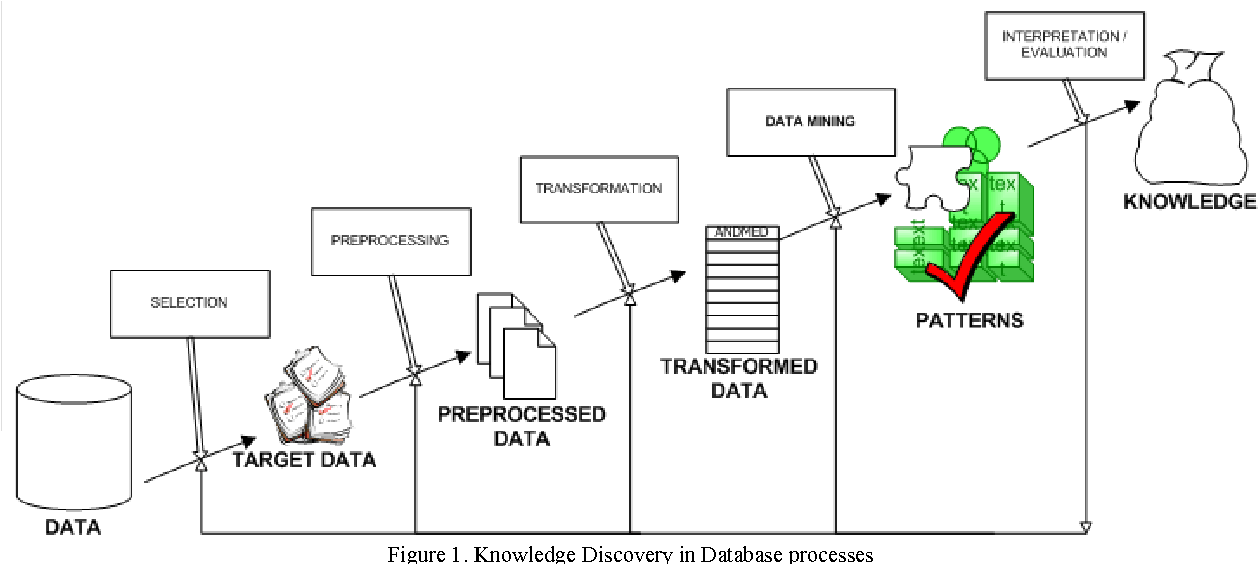
Записаться на обучение по данной программе можно на нашем сайте.
← Назад к списку
Портал Data mining
Мы приветствуем вас на портале Data Mining — уникальном портале, посвященном современным методам Data Mining.
Технологии Data Mining представляют собой мощный аппарат современной бизнес-аналитики и исследования данных для обнаружения скрытых закономерностей и построение предсказательных моделей. Data Mining или добыча знаний основывается не на умозрительных рассуждениях, а на реальных данных.
Рис. 1. Схема применения Data Mining
Problem Definition – Постановка задачи: классификация данных, сегментация, построение предсказательных моделей, прогнозирование.
Data Gathering and Preparation – Сбор и подготовка данных, чистка, верификация, удаление повторных записей.
Model Building – Построение модели, оценка точности.
Knowledge Deployment – Применение модели для решения поставленной задачи.
Data Mining применяется для реализации масштабных аналитических проектов в бизнесе, маркетинге, интернете, телекоммуникациях, промышленности, геологии, медицине, фармацевтике и других областях.
Data Mining позволяет запустить процесс нахождения значимых корреляций и связей в результате просеивания огромного массива данных с использованием современных методов распознавания образов и применения уникальных аналитических технологий, включая деревья принятия решений и классификации, кластеризацию, нейронносетевые методы и другие.
Пользователь, впервые открывший для себя технологию добычи данных, поражается обилию методов и эффективных алгоритмов, позволяющих найти подходы к решению трудных задач, связанных с анализом больших объемов данных.
В целом Data Mining можно охарактеризовать как технологию, предназначенную для поиска в больших объемах данных неочевидных, объективных и практически полезных закономерностей.
В основе Data Mining лежат эффективные методы и алгоритмы, разработанные для анализа неструктурированных данных большого объема и размерности.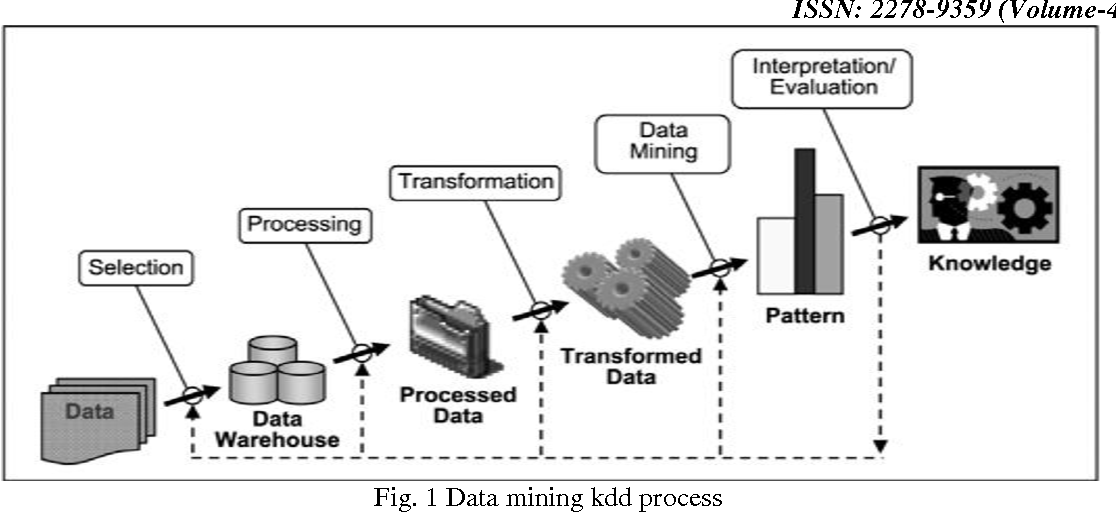
Ключевой момент состоит в том, что данные большого объема и большой размерности представляются лишенными структуры и связей. Цель технологии добычи данных – выявить эти структуры и найти закономерности там, где, на первый взгляд, царит хаос и произвол.
Вот актуальный пример применения добычи данных в фармацевтике и лекарственной индустрии.
Взаимодействие лекарственных веществ — нарастающая проблема, с которой сталкивается современное здравоохранение.
Со временем количество назначаемых лекарств (безрецептурных и всевозможных добавок) возрастает, что делает все более и более вероятным взаимодействие между лекарствами, которое может стать причиной серьезных побочных эффектов, о которых не подозревают врачи и пациенты.
Эта область относится к постклиническим исследованиям, когда лекарство уже выпущено на рынок и интенсивно используется.
Клинические исследования относятся к оценке эффективности препарата, но слабо учитывают взаимодействия данного лекарства с другими препаратами, представленными на рынке.
Исследователи из Стэнфордского Университета в Калифорнии изучили базу данных FDA (Food and Drug Administration — Управление по контролю за пищевыми продуктами и лекарственными препаратами) побочных эффектов лекарств и обнаружили, что два часто используемых препарата – антидепрессант пароксетин и правастатин, используемый для понижения уровня холестерина – увеличивают риск развития диабета, если употребляются совместно.
Исследование по проведению подобного анализа, основанного на данных FDA выявило 47 ранее неизвестных неблагоприятных взаимодействий.
Это замечательно, с той оговоркой, что многие отрицательные эффекты, отмеченные пациентами, остаются не выявленными. Как раз в таком случае сетевой поиск способен себя проявить наилучшим образом.
Академия StatSoft провела тренинг по анализу данных с использованием нейронных сетей для ПАО «Северсталь»
Мы начинаем знакомство с Data Mining, используя замечательные видеоролики Академии Анализа Данных.
Обязательно посмотрите наши ролики, и вы поймете, что такое Data Mining!
Видео 1. Что такое Data Mining?
В вашем браузере отключен JavaScriptДалее познакомьтесь с обзорным видеороликом, из которого вы узнаете, какие методы и алгоритмы реализованы в Data Mining.
Видео 2. Обзор методов добычи данных: деревья принятия решений, обобщенные предсказательные модели, кластеризация и многое другое
В вашем браузере отключен JavaScriptПрежде чем запустить исследовательский проект, мы должны организовать процесс получения данных из внешних источников, сейчас мы покажем, как это делается.
Ролик познакомит вас с уникальной технологией STATISTICA In-place database processing и связью Data Mining с реальными данными.
Видео 3. Порядок взаимодействия с базами данных: графический интерфейс построения SQL запросов технология In-place database processing
В вашем браузере отключен JavaScriptТеперь мы познакомимся с технологиями интерактивного бурения, эффективными при проведении разведочного анализа данных. Сам термин бурение отражает связь технологии Data Mining с геологоразведкой.
Сам термин бурение отражает связь технологии Data Mining с геологоразведкой.
Видео 4. Интерактивное бурение: Разведочные и графические методы для интерактивного исследования данных
В вашем браузере отключен JavaScriptТеперь мы познакомимся с анализом ассоциаций (association rules), эти алгоритмы позволяют находить связи, имеющиеся в реальных данных. Ключевым моментом является эффективность алгоритмов на больших объемах данных.
Результатом алгоритмов анализа связей, например, алгоритма Apriori нахождение правил связей исследуемых объектов с заданной достоверностью, например, 80 %.
В геологии эти алгоритмы можно применять при разведочном анализе полезных ископаемых, например, как признак А связан с признаками В и С.
Вы можете найти конкретные примеры таких решений по нашим ссылкам:
Правило ассоциаций в нефтеразведке
Применение технологий Data Mining в задачах геологоразведки
В розничной торговле алгоритма Apriori или их модификации позволяют исследовать связь различных товаров, например, при продаже парфюмерии (духи – лак – туш для ресниц и т. д.) или товаров разных брендов.
д.) или товаров разных брендов.
Анализ наиболее интересных разделов на сайте также можно эффективно проводить с помощью правил ассоциаций.
Итак, познакомьтесь с нашим следующим роликом.
Видео 5. Правила ассоциаций
В вашем браузере отключен JavaScriptПриведем примеры применения Data Mining в конкретных областях.
Интернет-торговля:
- анализ траекторий покупателей от посещения сайта до покупки товаров
- оценка эффективности обслуживания, анализ отказов в связи с отсутствием товаров
- связь товаров, которые интересны посетителям
Розничная торговля: анализ информации о покупателях на основе кредитных карт, карт скидок и тд.
Типичные задачи розничной торговли, решаемые средствами Data Miningа:
- анализ покупательской корзины;
- создание предсказательных моделей и классификационных моделей покупателей и покупаемых товаров;
- создание профилей покупателей;
- CRM, оценка лояльности покупателей разных категорий, планирование программ лояльности;
- исследование временных рядов и временных зависимостей, выделение сезонных факторов, оценка эффективности рекламных акций на большом диапазоне реальных данных.

Технологии предсказательных моделей (predictive models) позволят построить модели зависимости. Эти модели важны при планировании бизнеса и позволяют оценить, например, при какой стоимости покупок покупателю следует предоставить дисконтную карту с данным процентом скидки и рассчитать далее эффект от предоставления таких скидок, что позволяет сделать бизнес предсказуемым.
Телекоммуникационный сектор открывает неограниченные возможности для применения методов добычи данных, а также современных технологий big data:
- классификация клиентов на основе ключевых характеристик вызовов (частота, длительность и т.д.), частоты смс;
- выявление лояльности клиентов;
- определение мошенничества и др.
Страхование:
- анализ риска. Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам. Известен случай, когда страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания отреагировала на это пересмотром политики скидок семейным клиентам.
- выявление мошенничества. Страховые компании могут снизить уровень мошенничества, отыскивая определенные стереотипы в заявлениях о выплате страхового возмещения, характеризующих взаимоотношения между юристами, врачами и заявителями.
 Известен случай, когда страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания отреагировала на это пересмотром политики скидок семейным клиентам.
Известен случай, когда страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания отреагировала на это пересмотром политики скидок семейным клиентам.Практическое применение добычи данных и решение конкретных задач представлено на следующем нашем видео.
Вебинар 1. Вебинар «Практические задачи Data Mining: проблемы и решения»
В вашем браузере отключен JavaScriptВебинар 2. Вебинар «Data Mining и Text Mining: примеры решения реальных задач»
В вашем браузере отключен JavaScriptБолее глубокие знания по методологии и технологии добычи данных вы можете получить на курсах StatSoft.
Курсы Академии Анализа Данных – это уникальная возможность познакомиться с Добычей Данных из первых рук и понять на конкретных примерах, как работают современные аналитические технологии.
Модели интеллектуального анализа данных (Analysis Services-Data Mining)
- Статья
- Чтение занимает 9 мин
Оцените свои впечатления
Да Нет
Хотите оставить дополнительный отзыв?
Отзывы будут отправляться в корпорацию Майкрософт. Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Отправить
Спасибо!
В этой статье
Область применения: SQL Server Analysis Services Azure Analysis Services Power BI Premium
Модель интеллектуального анализа данных создается путем применения алгоритма к данным. Но это больше, чем алгоритм или контейнер метаданных: это набор данных, статистик и шаблонов, которые можно применять к новым данным для формирования прогнозов и вывода взаимосвязей.
В этом разделе описаны модели интеллектуального анализа данных и возможные варианты их использования: базовая архитектура моделей и структур, свойства моделей интеллектуального анализа данных, способы их создания и применения.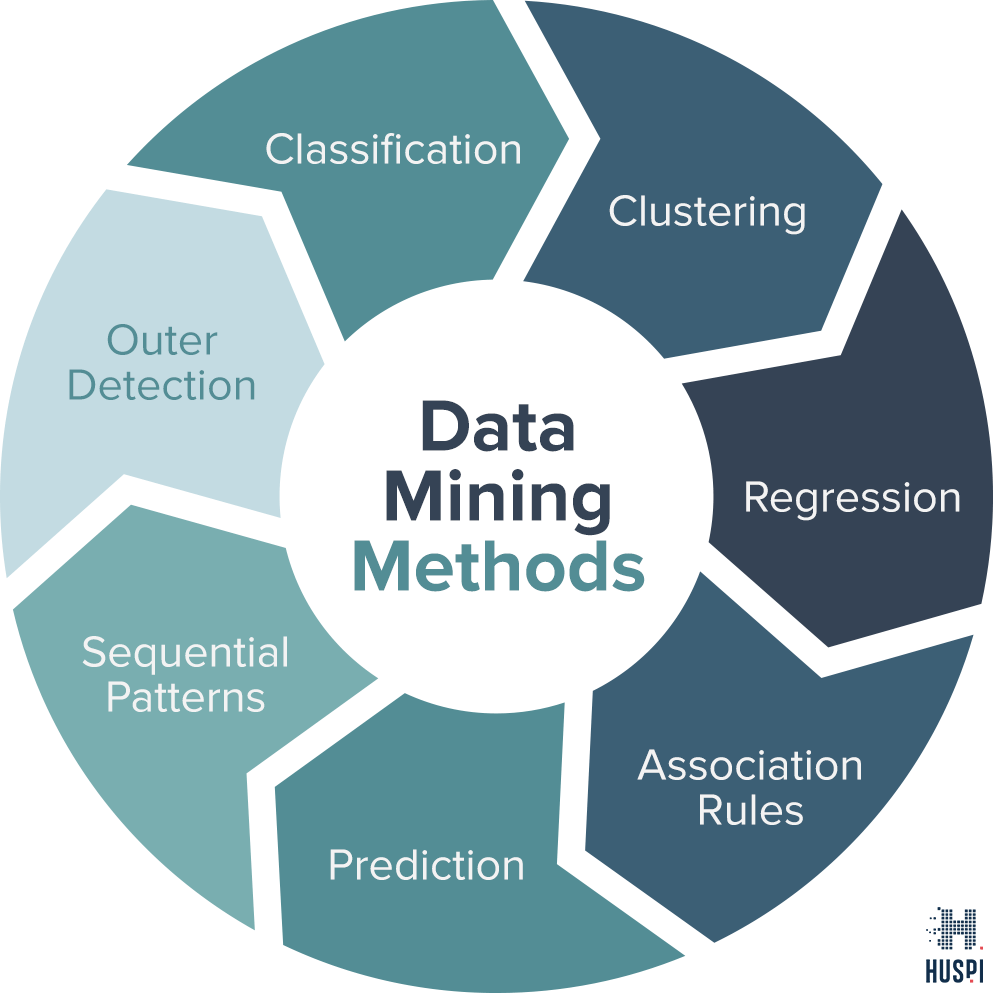
Архитектура модели интеллектуального анализа данных
Определение моделей интеллектуального анализа данных
Свойства модели интеллектуального анализа данных
Столбцы модели интеллектуального анализа данных
Обработка моделей интеллектуального анализа данных
Просмотр и запрос моделей интеллектуального анализа данных
Архитектура модели интеллектуального анализа данных
Модель интеллектуального анализа данных получает данные из структуры интеллектуального анализа данных и анализирует их, применяя алгоритм интеллектуального анализа данных. Структура интеллектуального анализа данных и модель интеллектуального анализа данных являются отдельными объектами. В структуре интеллектуального анализа данных хранятся сведения, определяющие источник данных. Модель интеллектуального анализа данных содержит сведения, полученные по итогам статистической обработки данных, например закономерности, обнаруженные в результате анализа.
Модель интеллектуального анализа данных будет пуста до тех пор, пока не будут обработаны и проанализированы данные, переданные структурой интеллектуального анализа данных. После обработки модель интеллектуального анализа данных содержит метаданные, результаты и привязки к структуре интеллектуального анализа данных.
После обработки модель интеллектуального анализа данных содержит метаданные, результаты и привязки к структуре интеллектуального анализа данных.
Метаданные определяют имя модели и сервер, где она хранится, а также определение модели, включая список столбцов из структуры интеллектуального анализа данных, которые использовались для построения модели, определения всех фильтров, применявшихся при обработке модели, и алгоритм, который использовался для анализа данных. Все эти варианты выбора — столбцы данных и их типы данных, фильтры и алгоритмы — обладают мощным влиянием на результаты анализа.
Например, одни и те же данные можно использовать для создания нескольких моделей, использующих алгоритм кластеризации, алгоритм дерева принятия решений и упрощенный алгоритм Байеса. В каждом из типов моделей создаются различные наборы шаблонов, наборов элементов, правил и формул, которые могут применяться при прогнозировании. Как правило, каждый из алгоритмов анализирует данные по-своему, поэтому содержимое получаемой модели также организуется в различные структуры. В одном из типов моделей данные и шаблоны могут группироваться в кластеры; в модели другого типа данные могут быть упорядочены с помощью деревьев, ветвей и правил, разделяющих и определяющих данные.
В одном из типов моделей данные и шаблоны могут группироваться в кластеры; в модели другого типа данные могут быть упорядочены с помощью деревьев, ветвей и правил, разделяющих и определяющих данные.
Модель также зависит от данных, на которых проводилось ее обучение: даже те модели, обучение которых производилось на основе одной и той же структуры интеллектуального анализа данных, могут выдавать различные результаты, если во время анализа фильтрация данных выполнялась по-разному или использовались разные начальные значения. Однако фактические данные не хранятся в сводной статистике модели, а фактические данные находятся в структуре интеллектуального анализа данных. Если при обучении модели были созданы фильтры данных, то определения фильтров также сохраняются в объекте модели.
Модель содержит набор привязок, указывающих на кэшированные в структуре интеллектуального анализа данные. Если в процессе обработки структуры данные были помещены в кэш и не были удалены из него, то эти привязки позволят выполнять детализацию от результатов к вариантам, образующим несущее множество этих результатов. Фактические данные при этом хранятся в кэше структуры, а не в модели.
Фактические данные при этом хранятся в кэше структуры, а не в модели.
Архитектура модели интеллектуального анализа данных
Определение моделей интеллектуального анализа данных
Чтобы создать модель интеллектуального анализа данных, выполните следующие действия.
Создайте базовую структуру интеллектуального анализа данных и включите в нее столбцы данных, которые могут потребоваться.
Выберите алгоритм, который наилучшим образом подходит для аналитической задачи.
Выберите столбцы из структуры для использования в модели и укажите, как они должны использоваться. какой столбец содержит результат, который необходимо спрогнозировать, какие столбцы предназначены только для ввода и т. д.
Задайте дополнительные параметры для тонкой настройки обработки, проводимой алгоритмом.
Заполните модель данными, выполнив обработку структуры и модели.
Службы Analysis Services предоставляют следующие средства, облегчающие работу с моделями интеллектуального анализа данных.
Мастер интеллектуального анализа данных помогает создать структуру и связанную с ней модель интеллектуального анализа данных. Это самый простой способ. Мастер автоматически создает необходимую структуру интеллектуального анализа данных и помогает настроить важные параметры.
Определение модели можно выполнить с помощью DMX-инструкции CREATE MODEL. В процессе этого автоматически создается необходимая структура. Поэтому данный метод не позволяет повторно использовать существующую структуру. Этот метод следует применять только в том случае, если точно известно, какую модель нужно будет создать, или если необходимо создание скриптов для моделей.
Добавить новую модель интеллектуального анализа данных в существующую структуру можно с помощью DMX-инструкции ALTER STRUCTURE ADD MODEL. Этот метод хорошо подходит для экспериментов с различными моделями, построенными на одном наборе данных.
Модели интеллектуального анализа данных также можно создавать программным образом с помощью объектов AMO или XML для аналитики, а также клиента интеллектуального анализа данных для Excel и других клиентов. Дополнительные сведения см. в следующих разделах:
Дополнительные сведения см. в следующих разделах:
Архитектура модели интеллектуального анализа данных
Свойства модели интеллектуального анализа данных
Каждая модель интеллектуального анализа данных обладает свойствами, которые определяют модель и ее метаданные. В число этих свойств входят имя, описание, дата последней обработки модели, разрешения на модель, а также все фильтры для данных, которые использовались для обучения.
Каждая модель интеллектуального анализа данных также содержит свойства, унаследованные от структуры интеллектуального анализа данных, которые описывают используемые в модели столбцы данных. Если любой из используемых моделью столбцов является вложенной таблицей, то к нему также может применяться отдельный фильтр.
Кроме того, каждая модель интеллектуального анализа данных имеет два специальных свойства: Algorithm и Usage.
Свойство Algorithm определяет алгоритм, используемый для создания модели. Набор доступных алгоритмов зависит от используемого поставщика.
Список алгоритмов в SQL Server Службы Analysis Servicesсм. в разделе Алгоритмы интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных). Свойство Algorithm применяется к модели интеллектуального анализа данных и может быть задано только один раз для каждой модели. Можно изменить алгоритм позднее, но некоторые столбцы в модели интеллектуального анализа данных могут стать недопустимыми, если они не поддерживаются выбранным алгоритмом. После изменения свойства модели всегда необходимо выполнять повторную обработку модели.Свойство Usage определяет, какие столбцы будут использованы моделью. Можно определить используемый столбец как Входные данные, Прогноз, Только прогноз или Ключ. Свойство Usage применяется к отдельным столбцам модели интеллектуального анализа данных и должно задаваться отдельно для каждого столбца, включенного в модель.
Если структура содержит столбец, который не используется в модели, то для использования задается значение Пропустить. В качестве примера данных, которые могут включаться в структуру интеллектуального анализа данных, но не использоваться при анализе, можно привести имена клиентов или адреса электронной почты. В таком случае к ним можно будет выполнять запросы позднее, но не включать их на этапе анализа.
 Список алгоритмов в SQL Server Службы Analysis Servicesсм. в разделе Алгоритмы интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных). Свойство Algorithm применяется к модели интеллектуального анализа данных и может быть задано только один раз для каждой модели. Можно изменить алгоритм позднее, но некоторые столбцы в модели интеллектуального анализа данных могут стать недопустимыми, если они не поддерживаются выбранным алгоритмом. После изменения свойства модели всегда необходимо выполнять повторную обработку модели.
Список алгоритмов в SQL Server Службы Analysis Servicesсм. в разделе Алгоритмы интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных). Свойство Algorithm применяется к модели интеллектуального анализа данных и может быть задано только один раз для каждой модели. Можно изменить алгоритм позднее, но некоторые столбцы в модели интеллектуального анализа данных могут стать недопустимыми, если они не поддерживаются выбранным алгоритмом. После изменения свойства модели всегда необходимо выполнять повторную обработку модели. Если структура содержит столбец, который не используется в модели, то для использования задается значение Пропустить. В качестве примера данных, которые могут включаться в структуру интеллектуального анализа данных, но не использоваться при анализе, можно привести имена клиентов или адреса электронной почты. В таком случае к ним можно будет выполнять запросы позднее, но не включать их на этапе анализа.
Если структура содержит столбец, который не используется в модели, то для использования задается значение Пропустить. В качестве примера данных, которые могут включаться в структуру интеллектуального анализа данных, но не использоваться при анализе, можно привести имена клиентов или адреса электронной почты. В таком случае к ним можно будет выполнять запросы позднее, но не включать их на этапе анализа.Значения свойств модели интеллектуального анализа данных можно изменить после создания модели. Однако после любого изменения, даже если оно касалось только имени модели интеллектуального анализа данных, необходимо выполнить повторную обработку модели. После повторной обработки модели можно получить другие результаты.
Архитектура модели интеллектуального анализа данных
Столбцы модели интеллектуального анализа данных
Модель интеллектуального анализа данных содержит столбцы данных, получаемые из определенных в структуре интеллектуального анализа данных столбцов. Можно выбрать столбцы из структуры интеллектуального анализа данных, используемые в модели, а также создать копии столбцов из структуры интеллектуального анализа данных, переименовать их или изменять способ их использования. В процессе создания модели также необходимо определить способы использования столбцов в модели. Например, столбец может служить ключом, использоваться для прогноза или вообще пропускаться алгоритмом.
Можно выбрать столбцы из структуры интеллектуального анализа данных, используемые в модели, а также создать копии столбцов из структуры интеллектуального анализа данных, переименовать их или изменять способ их использования. В процессе создания модели также необходимо определить способы использования столбцов в модели. Например, столбец может служить ключом, использоваться для прогноза или вообще пропускаться алгоритмом.
При создании модели вместо автоматического добавления всех доступных столбцов данных рекомендуется внимательно проанализировать данные в структуре и включить в модель лишь те столбцы, анализ которых имеет смысл. Например, не следует включать в модель несколько столбцов с идентичными данными, а также использовать столбцы, содержащие по большей части уникальные значения. Если столбец не подходит для использования, его не нужно удалять из структуры или модели интеллектуального анализа данных. Можно просто установить для столбца флаг, указывающий, что столбец должен пропускаться во время построения модели.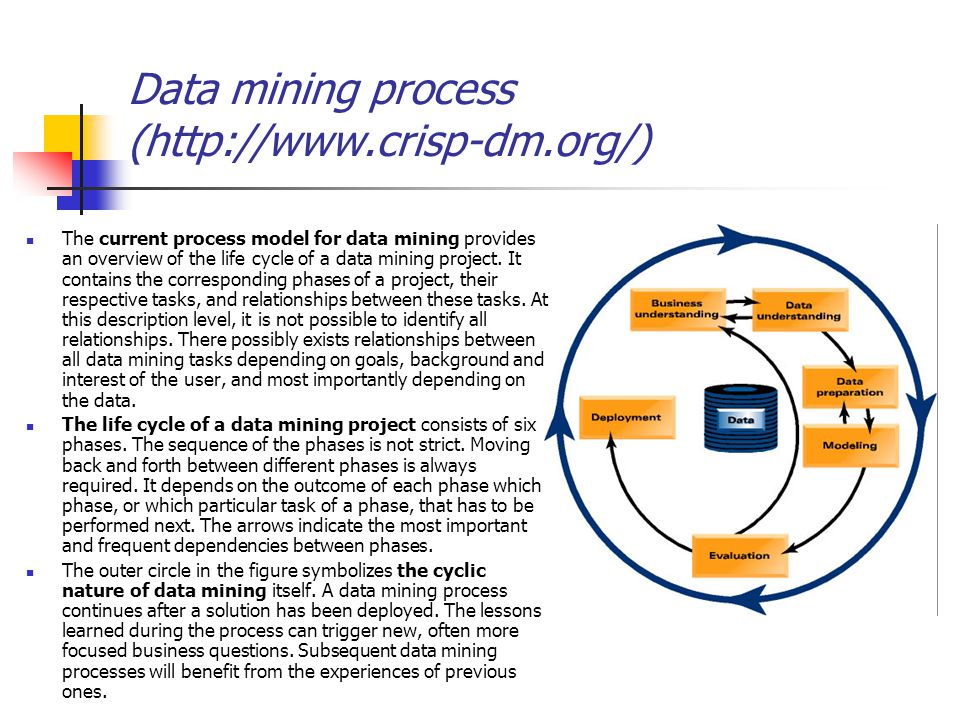 Это означает, что столбец останется в структуре интеллектуального анализа, но не будет использоваться в модели интеллектуального анализа данных. Если детализация из модели в структуру интеллектуального анализа данных включена, то сведения из столбца можно будет извлечь позднее.
Это означает, что столбец останется в структуре интеллектуального анализа, но не будет использоваться в модели интеллектуального анализа данных. Если детализация из модели в структуру интеллектуального анализа данных включена, то сведения из столбца можно будет извлечь позднее.
В зависимости от выбранного алгоритма некоторые столбцы в структуре интеллектуального анализа данных могут оказаться несовместимыми с конкретными типами моделей или вызвать ухудшение качества результатов. Например, если данные содержат числовые данные в непрерывном интервале (например, в столбце дохода), а модели требуются дискретные значения, то может потребоваться преобразовать данные в дискретные значения или исключить их из модели. В некоторых случаях алгоритм автоматически преобразует данные или распределяет их по группам, но результаты таких операций могут оказаться непредсказуемыми или нежелательными. Рассмотрите возможность создания дополнительных копий столбца и проверки применимости различных моделей. Также можно задать для отдельных столбцов флаги, указывающие, что требуется особая обработка. Например, если данные содержат пустые значения (NULL), то для управления их обработкой можно воспользоваться флагом модели. Если определенный столбец в модели должен считаться регрессором, то этого можно добиться с помощью флага модели.
Также можно задать для отдельных столбцов флаги, указывающие, что требуется особая обработка. Например, если данные содержат пустые значения (NULL), то для управления их обработкой можно воспользоваться флагом модели. Если определенный столбец в модели должен считаться регрессором, то этого можно добиться с помощью флага модели.
После создания модели можно вносить изменения, например добавлять или удалять столбцы или изменять имя модели. Однако после любого изменения, даже если оно касалось только метаданных модели, необходимо выполнить повторную обработку модели.
Архитектура модели интеллектуального анализа данных
Обработка моделей интеллектуального анализа данных
Модель интеллектуального анализа данных до обработки представляет собой пустой объект. Во время обработки модели данные, которые были помещены в кэш структурой, передаются через фильтр, если он был определен в модели, и подвергаются анализу в соответствии с заданным алгоритмом. Алгоритм вычисляет набор сводных статистических показателей, описывающих данные, выявляет правила и закономерности в данных, а затем на основе правил и закономерностей производит заполнение модели.
После обработки модель интеллектуального анализа данных содержит ценные сведения о данных и обнаруженных при анализе закономерностях, включая статистические показатели, правила и формулы регрессии. Просмотреть эти сведения можно с помощью пользовательских средств просмотра или создав запросы интеллектуального анализа данных, которые будут извлекать эти сведения и использовать их для анализа и представления.
Архитектура модели интеллектуального анализа данных
Просмотр и запросы моделей интеллектуального анализа данных
После обработки модели ее можно просмотреть с помощью пользовательских средств просмотра, входящих в состав среды SQL Server Data Tools и SQL Server Management Studio. Для
Запросы к модели интеллектуального анализа данных позволяют создавать прогнозы и получать метаданные модели или закономерности, созданные моделью. Для создания запросов используется язык DMX.
См. также
По следующим ссылкам можно получить более конкретную информацию о работе с моделями интеллектуального анализа данных.
См. также:
Объекты баз данных (службы Analysis Services — многомерные данные)
Услуги Data Mining — анализ и извлечение знаний из больших данных
- Стоимость услуги будет зависеть от требований по задаче
- Минимальная стоимость услуги Data Mining от 50 000 ₽
Предобработка
Шесть классов задач анализа данных
Оценка качества полученных результатов
Data Mining
Data Mining представляет собой комплексный анализ исходных данных с помощью методов матстатистики, машинного обучения, моделирования баз знаний. Целью майнинга является получение из массива информации новых, специфичных сведений хорошо показывающиx себя на практике. Data Mining нужен, чтобы:
- Предварительно обработать «сырой» массив
- Управлять базами данных, в том числе мониторить социальные, природные, техногенные процессы и явления для пополнения баз
- Разрабатывать модели и их параметры
- Составлять метрики эффективности
- Выполнять наглядную визуализацию, чтобы люди без серьезной математической подготовки могли анализировать информацию.
В майнинге разработаны разнообразные методы, способы, стратегии. Из-за важности Data Mining регулярно придумываются новые методологии, которые дополняют и расширяют уже созданные.
Для работы с хранилищами и витринами данных, анализа корпоративных массивов информации, предобработки тематических подмножеств агрегированных сведений применяются методы:
- Билла Инмона
- ETL (Extract, Transform, Load – «достать, обработать, загрузить»)
- NoETL (Not only ETL) – ETL с расширенным инструментарием
Ранние способы поиска закономерностей в базах данных основаны на теореме Байеса и регрессионном анализе. Из-за роста компьютерных технологий, увеличения вычислительных мощностей появилось больше возможностей по собиранию, хранению, обработке огромных массивов данных. Поэтому Data Mining дополняется автоматизированными технологиями. Также в майнинге используются наработки в сфере машинного обучения по:
- Правилам принятия решений и представления решающих правил в строгой иерархической структуре
- Кластерному анализу
- Нейронным сетям
- Генетическим алгоритмам
- SVM – методу опорных векторов
Получается, что майнинг массивов необработанных данных включает в себя комбинации способов и инструментов. Поэтому при оказании услуг по Data Mining важно корректно определить методологию, чтобы обнаружить в объеме информации скрытые шаблоны и паттерны, которые принесут практическую пользу. Грамотный майнинг устранит разрыв между прикладными статистическими инструментами и искусственным интеллектом, поможет настроить управление базами данных, разработает алгоритмы обучения и поиска требуемых сведений, обработает объемные информационные массивы.
Поэтому при оказании услуг по Data Mining важно корректно определить методологию, чтобы обнаружить в объеме информации скрытые шаблоны и паттерны, которые принесут практическую пользу. Грамотный майнинг устранит разрыв между прикладными статистическими инструментами и искусственным интеллектом, поможет настроить управление базами данных, разработает алгоритмы обучения и поиска требуемых сведений, обработает объемные информационные массивы.
Этапы извлечения полезных знаний из базы данных
Извлечь данные – получить полные сведения из собранной информации, как структурированной, так и неструктурированной. Полученные знания следует представить в виде, понятном для электронно-вычислительных машин, чтобы ускорить последующую обработку.
Извлечение знаний методически аналогично извлечению информации из текстов (Natural Language Processing – NLP) и ETL, но результат извлечения выходит за рамки создания структурированной информации. Требуется, чтобы отобранные сведения были структурированными, распознавались интеллектуальными информационными системами, преобразовывались в реляционную структуру, позволяли применять репозитории онтологий, давали возможность создавать схемы, которые способны совместно использоваться людьми и программными агентами.
Поэтому в ходе KDD (Knowledge Discovery in Databases – «нахождение знаний в базах данных») необходимо выполнить следующие этапы:
- Определить выборку исходной информации
- Сделать предварительную обработку массива
- Преобразовать полученные данные в удобочитаемый формат
- Извлечь конкретные признаки и обнаружить закономерности
- Интерпретировать данные и дать оценку полученной информации
Из-за разнообразия сфер применения Data Mining требуется использовать варианты KDD, подходящие для конкретной области. Существует межотраслевой стандарт для исследования данных (CRISP-DM), в котором исследовательский цикл делится на шесть фаз. При оказании услуги майнинга по CRISP-DM следует:
- Понять бизнес и определить цели проекта
- Изучить начальные сведения, выявить проблемы с качеством – неполнотой или недостоверностью информации
- Подготовить данные, которые понадобятся для моделирования, привести разнородные и разноформатные сведения к единому формату
- Выбрать методику моделирования, построить модель, протестировать
- Оценить результаты и на основе оценки продумать последующие шаги
- Развернуть модель – составить финальный отчет и при необходимости внедрить полученные знания для решения прикладных задач
Предобработка
По сведениям корпорации IBM, свыше 80% собранных данных хранятся в неструктурированном виде – как текст на естественном языке. Но даже структурированные массивы часто представляются в форме, понятной человеку, а не компьютеру. Чтобы ЭВМ распознавала подобную информацию, ей следует или получить умение мыслить аналогично людям, или научиться имитировать мыслительный процесс.
Но даже структурированные массивы часто представляются в форме, понятной человеку, а не компьютеру. Чтобы ЭВМ распознавала подобную информацию, ей следует или получить умение мыслить аналогично людям, или научиться имитировать мыслительный процесс.
Майнинг текстовой информации, написанной естественным языком, делается с помощью NLP. Data Mining выполняется на нескольких уровнях:
- Поиск словосочетаний
- Определение тематики текста
- Выделение семантических отношений – связи слов и обозначаемых объектов, признаков, действий
Чтобы сделать комплексный анализ, сначала разрабатывают парсер, способный проводить морфологический, грамматический, синтаксический разбор. Затем выполняют онтологический анализ – составляют тематический словарь, определяют взаимосвязи между терминами, рассматривают правила, которые позволят выдавать истинные утверждения. Тогда искусственный интеллект сможет успешно имитировать человеческое мышление.
Но сначала собирают массив данных.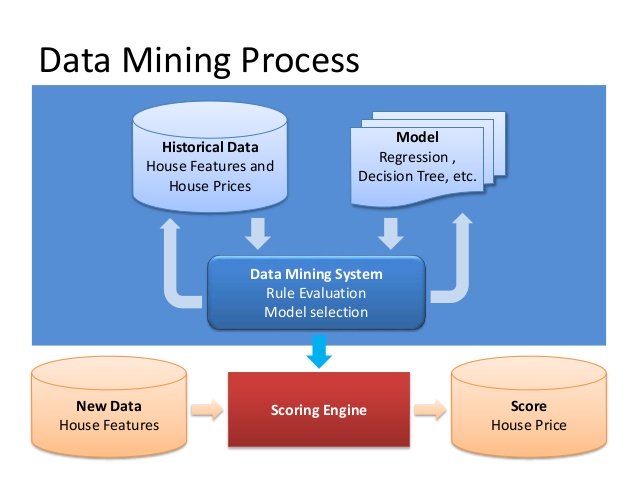 Так как алгоритмы майнинга способны обнаружить только паттерны, которые действительно присутствуют в информации, то массив должен иметь правильный объем. Если набор сведений для изучения окажется кратким, в нем не будет содержаться достаточного количества шаблонов. Если массив будет чересчур объемным, программа не сможет обработать его в течение заданного времени. Поэтому на этапе предобработки следует найти подходящую информацию и очистить ее от «шумов».
Так как алгоритмы майнинга способны обнаружить только паттерны, которые действительно присутствуют в информации, то массив должен иметь правильный объем. Если набор сведений для изучения окажется кратким, в нем не будет содержаться достаточного количества шаблонов. Если массив будет чересчур объемным, программа не сможет обработать его в течение заданного времени. Поэтому на этапе предобработки следует найти подходящую информацию и очистить ее от «шумов».
Шесть классов задач анализа данных
Data Mining решает проблемы следующих типов:
- Поиск аномалий. Методы майнинга позволяют обнаружить выбросы, отклонения, нетипичные изменения в массиве данных. Аномалии могут оказаться как ошибками, так и нестандартными знаниями, которые требуют детального изучения.
- Нахождение зависимостей. Поиск взаимосвязей между переменными дозволяет создавать практически полезные правила ассоциаций. Так, интернет-магазин, собирая сведения о корзинах клиентов и обнаруживая взаимосвязи, узнает, какие товары приобретаются вместе. Это поможет выстроить маркетинговую стратегию по продвижению продукции.
- Обнаружение похожих структур в объемном массиве. Кластерный анализ находит относительно однородные группы в ходе работы алгоритма.
- Классификация новых данных посредством сравнения с уже изученной структурой. Например, почтовые программы способны классифицировать входящее электронное письмо как спам, зная о типовых характеристиках подобных рассылок.
- Установление соответствия между случайными переменными. Регрессионный анализ позволяет найти с минимальными ошибками взаимосвязи в массиве.
- Формирование обобщенных данных на основе детализированных. Суммаризация дает возможность компактно представить информацию, сделать визуализацию, создать наглядные отчеты.
 Это поможет выстроить маркетинговую стратегию по продвижению продукции.
Это поможет выстроить маркетинговую стратегию по продвижению продукции.Оценка качества полученных результатов
Инструменты Data Mining возможно применить некорректно. Из-за неправильного использования методов получатся результаты, которые будут казаться значимыми, но в реальности не смогут предсказать будущее поведение, не повторятся на новой выборке, окажутся бесполезными для практических исследований.
Причинами неграмотного применения майнинга часто становятся отсутствие должной проверки гипотез или изучение чересчур огромного количества гипотетических суждений. Последняя проблема известна в машинном обучении как переобучение.
Чтобы исключить получение некорректных результатов, требуется проводить оценку их качества. Для этого надо проверить, сможет ли алгоритм, уже обученный на определенном наборе данных, верно интерпретировать массив, на котором он ранее не обучался. При обработке новой информации должен получиться результат, который соответствует заданным стандартам.
Допустим, заказана услуга интеллектуального анализа данных для обнаружения спама среди получаемых электронных писем. Тогда сначала разрабатывается алгоритм и запускается в работу на наборе, который содержит образцы «законных» и «незаконных» писем. После окончания обучения алгоритм применяется к массиву e-mail, с которым он еще не сталкивался. Затем производится подсчет – сколько писем ЭВМ рассортировала правильно и какое количество сообщений пометила ошибочно. Для оценки качества используются специальные методы, например, график ROC-кривой.
Для оценки качества используются специальные методы, например, график ROC-кривой.
Когда изученные шаблоны не отвечают требуемым стандартам, приходится переосмысливать работу – точнее составлять выборку, изменять предобработку массива, менять алгоритмы по извлечению паттернов. Если достигается заданный результат, переходят к заключительному шагу – интерпретируют изученные шаблоны и превращают их в знания.
выбор приоритетов и нейронные сети
В течение последнего десятилетия в нефтегазовой отрасли произошла компьютеризация таких процессов, как управление бурением, каротаж высокого разрешения, телеметрия, сбор разнообразных данных на этапе разведки и эксплуатации и многих других. В этом материале мы сосредоточимся на новых аналитических технологиях для нефтедобывающей промышленности.
Построение моделей коллективных данных позволяет изменить способы анализа, моделирования процессов и в целом способствует оптимизации в отрасли. Многие прорывы в поиске месторождений произошли за счет сочетания геологии, петрофизики и геофизики. Сегодня на каждой пробуренной скважине размещены измерительные приборы, которые производят видео, изображения и структурированные данные. Это огромные массивы информации, самой разнообразной, всевозможных типов и масштабов.
Сегодня на каждой пробуренной скважине размещены измерительные приборы, которые производят видео, изображения и структурированные данные. Это огромные массивы информации, самой разнообразной, всевозможных типов и масштабов.
Современные технологии data mining и машинного обучения позволяют работать с большими объемами данных, измеренных в разных шкалах: непрерывной, порядковой, категориальной, с разной частотой дискретизации. Классические методы статистики, имеющей дело с фиксированными наборами данных (выборками), устаревают и должны быть дополнены новыми интеллектуальными технологиями, поскольку подлинная революция в технологии анализа данных уже произошла.
Инженерам, работающим в нефтедобывающей промышленности, data mining дает ответы на многие ключевые вопросы, например:
- в каком направлении следует бурить горизонтальную скважину, чтобы уменьшить риск осложнений;
- как определить набор параметров, оказывающих максимальное влияние на возникновение осложнений;
- какую технологию ВИР следует применять в тех или иных условиях;
- как выбрать смеси для цементирования;
- как выбрать адекватного поставщика и т. д.
 д.
д.Целевые переменные и атрибуты
Первым шагом в создании моделей data mining является определение целевых переменных (target variables) и факторов, влияющих на них. Целевая переменная в контексте машинного обучения – это переменная, которая описывает результат (цель) процесса. Например, 0 – нет осложнений, 1 – есть осложнения.
В анализе данных мы называем такую переменную откликом или зависимой переменной.
В более общей ситуации имеется несколько значений целевой переменной, указывающих на тип осложнений. Например, 0 – нет осложнений, 1 – есть осложнение типа 1, 2 – есть осложнение типа 2 и т.д.
Актуальной технологической задачей является определение набора параметров, которые оказывают максимальное влияние на возникновение осложнения. Для того, чтобы осуществить отбор атрибутов – то есть определить признаки, имеющие наиболее тесные связи с целевой переменной, – нужно задействовать практических работников, инженеров, технологов.
В качестве примера возьмем проект бурения. Разломы и трещины в породе приводят к потерям бурового раствора, тяжелый раствор может разорвать породу, слишком легкий раствор не позволяет подавлять газопроявление, а это приводит к выбросам. Вибрация колонны может повредить оборудование и привести к разрушениям. Поэтому в проекте бурения должны быть учтены многие факторы, включая тип колонны, требования по закачиванию, предыстория и параметры бурового станка, подбор инструмента, оборудования, параметры цементирования и т.д. Ключевым моментом является взаимодействие факторов: они не только действуют на целевую переменную, но и взаимодействуют между собой. Так какие именно переменные следует включить в модель data mining?
Хорошая новость состоит в том, что специалисты в предметной области – инженеры и технологи – могут легко освоить нейросетевой инструмент для решения практических задач.
Итак, обратимся к технологии нейронных сетей.
Нейронные сети
Покажем, как строятся нейронные сети в программе STATISTICA, и убедимся, что делается это просто.
Весь анализ проводится в удобном диалоговом режиме, позволяя пользователю видеть основное направление исследования данных. Даже новичок в аналитике может сделать первые успешные шаги. В качестве примера будем прогнозировать наличие или отсутствие нефти по результатам спектрального анализа.
Шаг 1. Открываем структуру исходных данных
Рисунок 1. Предположим, структура выглядит следующим образом
Столбцы в таблице – это переменные, строки конкретные пробы. Целевой переменной является нефтеносность: наличие/отсутствие нефти (первая переменная). Также имеются переменные, описывающие параметры скважин.
Шаг 2. Начало моделирования. Открываем модуль «Нейронные сети Statistica», выбираем метод анализа.
Рисунок 2. Стартовое окно нейронных сетей Statistica
Целевая переменная принимает два значения: 0 и 1, поэтому выбираем метод классификации в разделе Анализ, нажимаем ОК.
Шаг 3. Выбираем переменные и задаем параметры анализа.
Прежде всего указываем, какие переменные являются целевыми, какие факторы влияют на нее. Переменная нефтеносность является целевой, остальные переменные независимые или входные. Задача в том, чтобы оценить, как входные переменные влияют на целевую переменную.
Рисунок 3. Окно выбора переменных
Шаг 5. В следующем окне выбираем подвыборки для обучения сети.
Рисунок 4. Задание подвыборок
Основные принципы обучения и критерии остановки
Это ключевой момент для понимания машинного обучения. Мы не можем обучать сеть до бесконечности, предъявляя все имеющиеся данные, сеть обучается до достижения минимума ошибок. Поэтому нужно разделить исходные данные на выборки: обучающую, контрольную, тестовую.
Отмечу, что эмпирический подход предполагает раннюю остановку процесса обучения сети, чтобы не допустить переобучения. Необходимо использовать набор валидаций для контроля точности обучения, это достигается с помощью контрольной выборки. Как только ошибка на выборке, контролирующей обучение, начинает возрастать, процесс обучения прекращается.
Необходимо использовать набор валидаций для контроля точности обучения, это достигается с помощью контрольной выборки. Как только ошибка на выборке, контролирующей обучение, начинает возрастать, процесс обучения прекращается.
Тестовая выборка провидит проверку построенной и обученной сети, т.е. сети с найденными параметрами, на отдельном тестовом множестве.
Сеть обучается на выборке, составляющей обычно 70% наблюдений, процесс обучения контролируется на контрольной выборке (15% процентов наблюдений), построенная сеть проверяется на тестовой выборке (также 15% процентов наблюдений).
В отдельной вкладке можно выбрать тип сети, количество сетей для обучения и сохранения, функцию ошибок. Обычно используется сумма квадратов отклонений наблюдаемых и предсказанных значений, а также кросс-энтропия.
Рисунок 5. Окно спецификаций сетей
В этом диалоговом окне можно выбрать радиальные базисные функции и многослойные персептроны. Архитектура многослойных персептронов включает три вида нейронных слоёв: входной слой – NeuralInputs, скрытый слой – Hidden_NeuralLayer и выходной слой – NeuralOutputs.
Поток информации проходит от входных нейронов к выходным, формируя результат анализа.
В первых опытах с сетями рекомендуется использовать предопределенные настройки, которые впоследствии можно изменить, например, увеличить сложность сети, изменить число скрытых нейронов в многослойном персептроне, выбрать различные функции активации.
После того как основные параметры сети выбраны, запускаем процесс обучения.
Результаты определения нефтеносности на обучающей выборке показаны на рис. 6.
Рисунок 6. Результаты классификации
В этой таблице показана сеть MLP – многослойный персептрон, имеющий 173 входа и результаты сети на обучающей выборке.
Итак, сеть построена, вы оценили качество ее работы, теперь ее можно сохранить и использовать в деле!
Уверен, работа с нейронными сетями Statistica доставит вам удовольствие.
Углубленные и начальные курсы по анализу данных с помощью нейронных сетей также представлены в Академии Анализа Данных, пишите: academy@statsoft. ru.
ru.
|
Автор: Владимир БоровиковCEO StatSoft |
OLAP и Data Mining — Трюки и приемы в Microsoft Excel
Повсеместное использование компьютеров привело к пониманию важности задач, связанных с анализом накопленной информации с целью извлечения новых знаний. Возникла потребность в создании хранилищ данных и систем поддержки принятия решений, основанных в том числе на методах теории искусственного интеллекта. Действительно, управление предприятием, банком, различные сферы бизнеса, в том числе электронного, немыслимы без процессов накопления, анализа, выявления определенных закономерностей и зависимостей, прогнозирования тенденций и рисков. Именно давний интерес авторов к методам, алгоритмическим моделям и средствам их реализации, используемым на этапе анализа данных, явился причиной подготовки данной книги.
В книге представлены наиболее перспективные направления анализа данных: хранение информации, оперативный и интеллектуальный анализ. Подробно рассмотрены методы и алгоритмы интеллектуального анализа. Кроме описания популярных и известных методов анализа приводятся оригинальные результаты. В частности, разд. 7.4 подготовлен С. И. Елизаровым.
Подробно рассмотрены методы и алгоритмы интеллектуального анализа. Кроме описания популярных и известных методов анализа приводятся оригинальные результаты. В частности, разд. 7.4 подготовлен С. И. Елизаровым.
Книга ориентирована на студентов и специалистов, интересующихся современными методами анализа данных. Наличие в приложениях материала, посвященного нейронным сетям и генетическим алгоритмам, делает книгу самодостаточной. Как пособие, книга в первую очередь предназначена для бакалавров и магистров, обучающихся по направлению «Информационные системы». Кроме того, книга будет полезна специалистам, занимающимся разработкой корпоративных информационных систем. Подробное описание методов и алгоритмов интеллектуального анализа позволит использовать книгу не только для ознакомления с данной областью применения информации систем, но и для разработки конкретных систем.
В книге освещены основные направления в области анализа данных: организация хранилища данных, оперативный (OLAP) и интеллектуальный (Data Mining) анализ данных.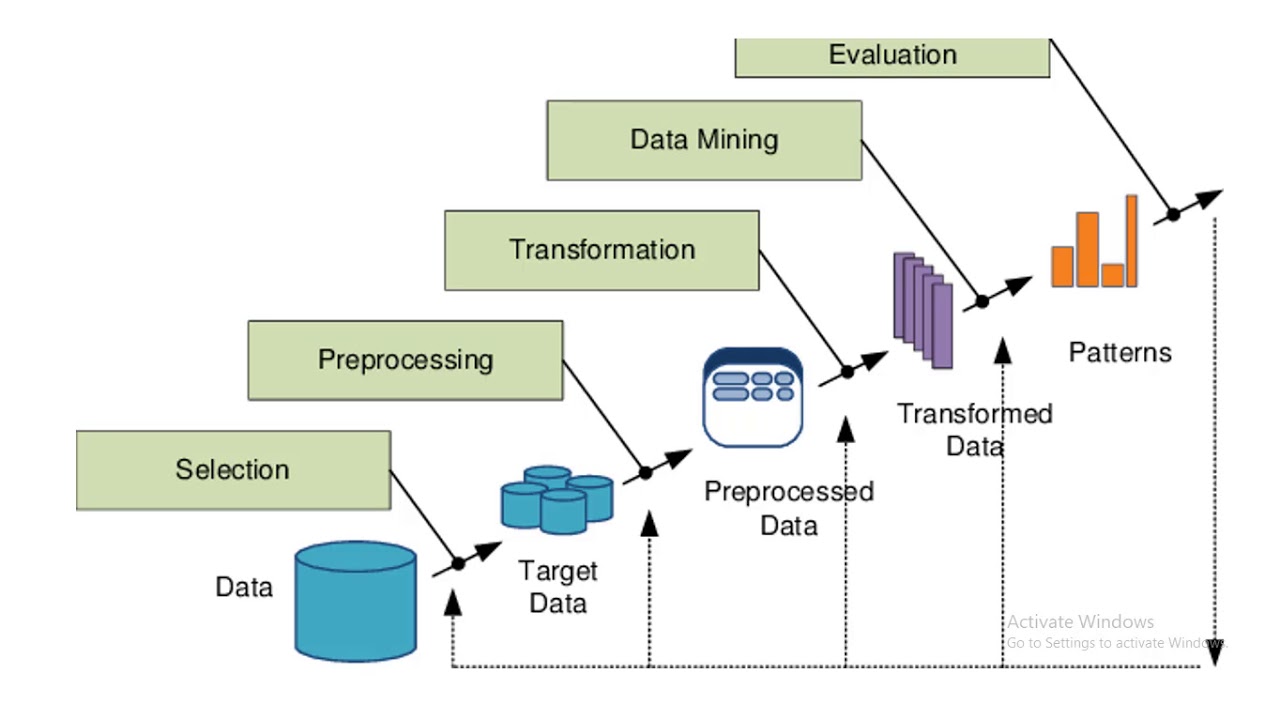 Приведено описание методов и алгоритмов решения основных задач анализа: классификации, кластеризации и др. Описание идеи каждого метода дополняется конкретным примером его применения. Представлены стандарты и библиотека алгоритмов Data Mining. Первые четыре главы книги, содержащие общую информацию о современных направлениях анализа данных, будут полезны руководителям предприятий, планирующим внедрение и использование методов анализа данных.
Приведено описание методов и алгоритмов решения основных задач анализа: классификации, кластеризации и др. Описание идеи каждого метода дополняется конкретным примером его применения. Представлены стандарты и библиотека алгоритмов Data Mining. Первые четыре главы книги, содержащие общую информацию о современных направлениях анализа данных, будут полезны руководителям предприятий, планирующим внедрение и использование методов анализа данных.
Что такое интеллектуальный анализ данных? | IBM
Узнайте о интеллектуальном анализе данных, который объединяет статистику и искусственный интеллект для анализа больших наборов данных для обнаружения полезной информации.
Что такое интеллектуальный анализ данных?
Интеллектуальный анализ данных, также известный как обнаружение знаний в данных (KDD), — это процесс выявления закономерностей и другой ценной информации из больших наборов данных. Учитывая эволюцию технологий хранилищ данных и рост больших данных, внедрение методов интеллектуального анализа данных быстро ускорилось за последние пару десятилетий, помогая компаниям преобразовывать их необработанные данные в полезные знания. Однако, несмотря на то, что эта технология постоянно развивается для обработки данных в крупном масштабе, лидеры по-прежнему сталкиваются с проблемами масштабируемости и автоматизации.
Однако, несмотря на то, что эта технология постоянно развивается для обработки данных в крупном масштабе, лидеры по-прежнему сталкиваются с проблемами масштабируемости и автоматизации.
Data Mining улучшил процесс принятия решений в организации за счет глубокого анализа данных. Методы интеллектуального анализа данных, лежащие в основе этого анализа, можно разделить на две основные цели; они могут либо описать целевой набор данных, либо они могут предсказать результаты с помощью алгоритмов машинного обучения. Эти методы используются для организации и фильтрации данных, выявляя наиболее интересную информацию, от обнаружения мошенничества до поведения пользователей, узких мест и даже нарушений безопасности.
В сочетании с инструментами анализа и визуализации данных, такими как Apache Spark, погружение в мир интеллектуального анализа данных никогда не было таким простым, а получение важной информации стало еще быстрее. Достижения в области искусственного интеллекта продолжают ускорять внедрение в различных отраслях.
Процесс интеллектуального анализа данных
Процесс интеллектуального анализа данных включает в себя ряд шагов от сбора данных до визуализации для извлечения ценной информации из больших наборов данных. Как упоминалось выше, методы интеллектуального анализа данных используются для создания описаний и прогнозов целевого набора данных.Специалисты по обработке данных описывают данные, наблюдая закономерности, ассоциации и корреляции. Они также классифицируют и группируют данные с помощью методов классификации и регрессии и выявляют выбросы для вариантов использования, таких как обнаружение спама.
Интеллектуальный анализ данных обычно состоит из четырех основных этапов: постановка целей, сбор и подготовка данных, применение алгоритмов интеллектуального анализа данных и оценка результатов.
1. Установите бизнес-цели: Это может быть самая сложная часть процесса интеллектуального анализа данных, и многие организации тратят слишком мало времени на этот важный этап.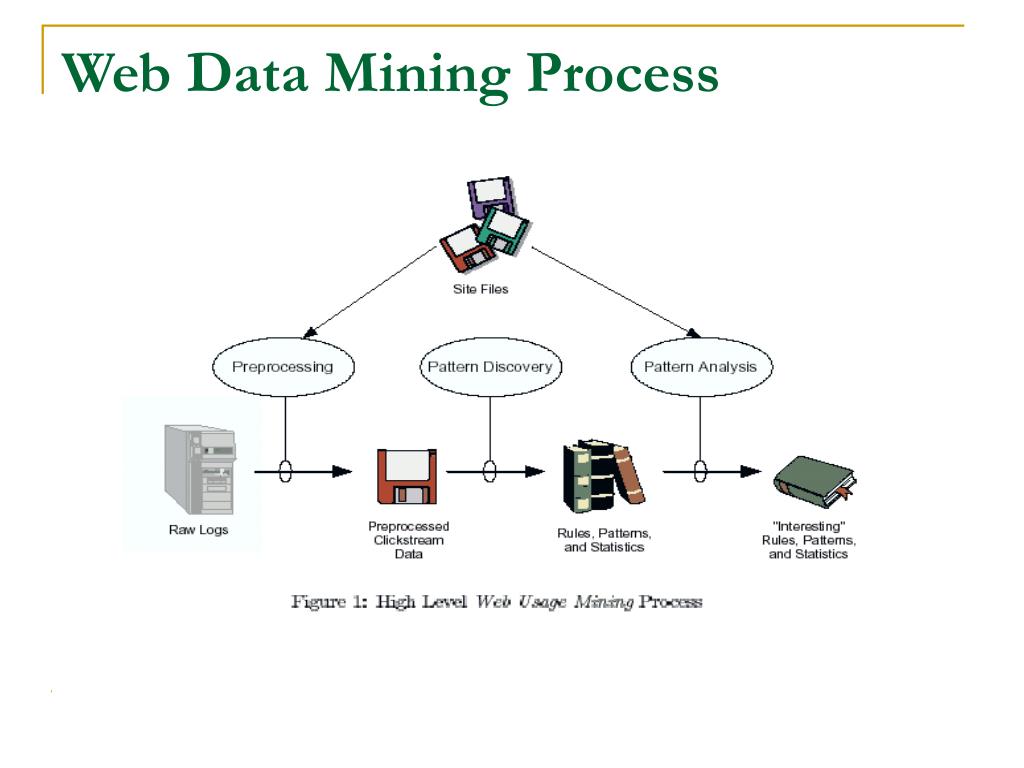 Специалистам по обработке данных и заинтересованным сторонам бизнеса необходимо работать вместе, чтобы определить бизнес-проблему, которая помогает информировать вопросы о данных и параметры для данного проекта. Аналитикам также может потребоваться дополнительное исследование, чтобы надлежащим образом понять бизнес-контекст.
Специалистам по обработке данных и заинтересованным сторонам бизнеса необходимо работать вместе, чтобы определить бизнес-проблему, которая помогает информировать вопросы о данных и параметры для данного проекта. Аналитикам также может потребоваться дополнительное исследование, чтобы надлежащим образом понять бизнес-контекст.
2. Подготовка данных: После определения масштабов проблемы специалистам по данным легче определить, какой набор данных поможет ответить на соответствующие вопросы для бизнеса. Как только они соберут соответствующие данные, данные будут очищены, удалив любой шум, такой как дубликаты, пропущенные значения и выбросы.В зависимости от набора данных может потребоваться дополнительный шаг для уменьшения количества измерений, поскольку слишком большое количество функций может замедлить любые последующие вычисления. Специалисты по обработке данных будут стремиться сохранить наиболее важные предикторы, чтобы обеспечить оптимальную точность любых моделей.
3. Построение модели и анализ закономерностей: В зависимости от типа анализа специалисты по обработке данных могут исследовать любые интересные взаимосвязи данных, такие как последовательные шаблоны, правила ассоциации или корреляции.Хотя высокочастотные шаблоны имеют более широкое применение, иногда отклонения в данных могут быть более интересными, выделяя области потенциального мошенничества.
Алгоритмы глубокого обучения также могут применяться для классификации или кластеризации набора данных в зависимости от доступных данных. Если входные данные помечены (т.е. контролируемое обучение), модель классификации может использоваться для категоризации данных или, альтернативно, может применяться регрессия для прогнозирования вероятности конкретного назначения. Если набор данных не помечен (т.е. обучение без учителя), отдельные точки данных в обучающем наборе сравниваются друг с другом, чтобы выявить основные сходства, группируя их на основе этих характеристик.
4. Оценка результатов и внедрение знаний: После агрегирования данных результаты необходимо оценить и интерпретировать. При окончательном оформлении результатов они должны быть достоверными, новыми, полезными и понятными. Когда этот критерий соблюден, организации могут использовать эти знания для реализации новых стратегий, достигая намеченных целей.
Методы интеллектуального анализа данных
Data Mining работает с использованием различных алгоритмов и методов для превращения больших объемов данных в полезную информацию. Вот некоторые из наиболее распространенных:
Правила связывания: Правило связывания — это основанный на правилах метод поиска взаимосвязей между переменными в заданном наборе данных. Эти методы часто используются для анализа рыночной корзины, позволяя компаниям лучше понять взаимосвязь между различными продуктами.Понимание потребительских привычек клиентов позволяет компаниям разрабатывать более эффективные стратегии перекрестных продаж и механизмы рекомендаций.
Нейронные сети: В первую очередь используются для алгоритмов глубокого обучения, нейронные сети обрабатывают данные обучения, имитируя взаимосвязь человеческого мозга через слои узлов. Каждый узел состоит из входов, весов, смещения (или порога) и выхода. Если это выходное значение превышает заданный порог, он «запускает» или активирует узел, передавая данные на следующий уровень в сети.Нейронные сети изучают эту функцию отображения посредством обучения с учителем, настраиваясь на основе функции потерь в процессе градиентного спуска. Когда функция стоимости равна нулю или близка к нему, мы можем быть уверены в точности модели и дадим правильный ответ.
Дерево решений: Этот метод интеллектуального анализа данных использует методы классификации или регрессии для классификации или прогнозирования потенциальных результатов на основе набора решений. Как следует из названия, он использует древовидную визуализацию для представления потенциальных результатов этих решений.
K-ближайший сосед (KNN): K-ближайший сосед, также известный как алгоритм KNN, представляет собой непараметрический алгоритм, который классифицирует точки данных на основе их близости и связи с другими доступными данными. Этот алгоритм предполагает, что похожие точки данных могут быть найдены рядом друг с другом. В результате он пытается вычислить расстояние между точками данных, обычно через евклидово расстояние, а затем присваивает категорию на основе наиболее часто встречающейся категории или среднего значения.
Приложения для интеллектуального анализа данных
Методы интеллектуального анализа данных широко используются в группах бизнес-аналитики и анализа данных, помогая им извлекать знания для своей организации и отрасли.Вот некоторые примеры использования интеллектуального анализа данных:
Продажи и маркетинг
Компании собирают огромное количество данных о своих клиентах и перспективах. Наблюдая за демографией потребителей и поведением пользователей в Интернете, компании могут использовать данные для оптимизации своих маркетинговых кампаний, улучшения сегментации, предложений перекрестных продаж и программ лояльности клиентов, что позволяет повысить рентабельность инвестиций в маркетинг.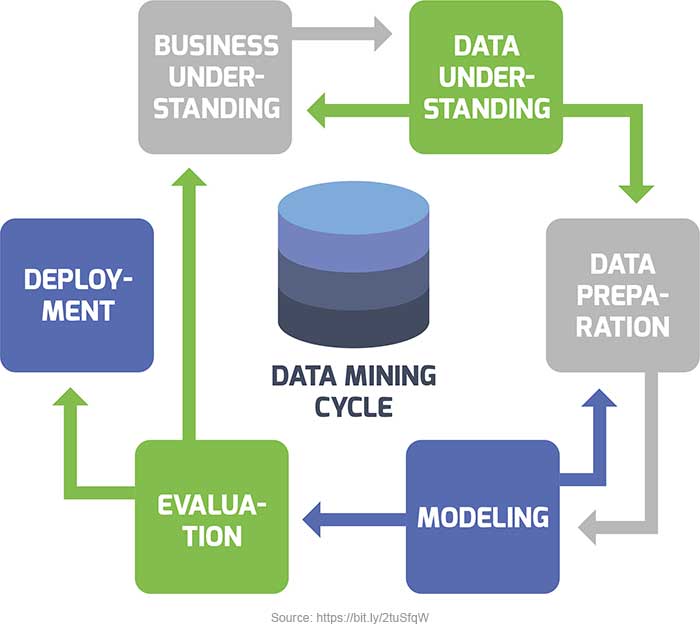 Прогнозный анализ также может помочь командам установить ожидания своих заинтересованных сторон, предоставляя оценки доходности от любого увеличения или уменьшения маркетинговых инвестиций.
Прогнозный анализ также может помочь командам установить ожидания своих заинтересованных сторон, предоставляя оценки доходности от любого увеличения или уменьшения маркетинговых инвестиций.
Образование
Образовательные учреждения начали сбор данных, чтобы понять, в каком контингенте учащихся, а также какие условия благоприятствуют успеху. По мере того, как курсы продолжают переноситься на онлайн-платформы, они могут использовать различные параметры и показатели для наблюдения и оценки производительности, такие как нажатие клавиши, профили студентов, классы, университеты, затраченное время и т. Д.
Операционная оптимизация
Process Mining использует методы интеллектуального анализа данных для сокращения затрат на выполнение операционных функций, что позволяет организациям работать более эффективно.Эта практика помогла выявить дорогостоящие узкие места и улучшить процесс принятия решений бизнес-лидерами.
Обнаружение мошенничества
Хотя часто встречающиеся закономерности в данных могут дать командам ценную информацию, наблюдение за аномалиями данных также полезно, помогая компаниям в обнаружении мошенничества.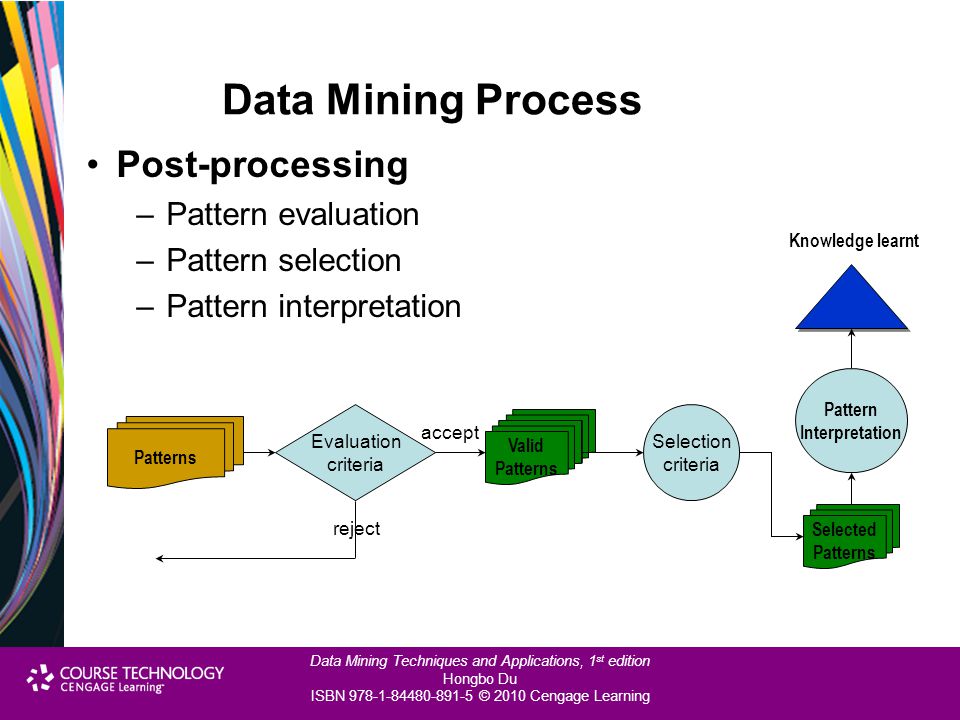 Хотя это хорошо известный вариант использования в банковских и других финансовых учреждениях, компании, работающие на основе SaaS, также начали применять эти методы для удаления поддельных учетных записей пользователей из своих наборов данных.
Хотя это хорошо известный вариант использования в банковских и других финансовых учреждениях, компании, работающие на основе SaaS, также начали применять эти методы для удаления поддельных учетных записей пользователей из своих наборов данных.
Data Mining и IBM
Станьте партнером IBM, чтобы начать свой последний проект по интеллектуальному анализу данных. IBM Watson Discovery анализирует ваши данные в режиме реального времени, чтобы выявить скрытые закономерности, тенденции и взаимосвязи между различными частями контента. Используйте методы интеллектуального анализа данных, чтобы получить представление о поведении клиентов и пользователей, проанализировать тенденции в социальных сетях и электронной коммерции, найти первопричины проблем и многое другое. В ваших скрытых идеях есть неиспользованная ценность для бизнеса. Начните работу с IBM Watson Discovery уже сегодня.
Зарегистрируйте бесплатную учетную запись Watson Discovery в IBM Cloud, где вы получите доступ к приложениям, искусственному интеллекту и аналитике, а также сможете создавать с помощью тарифных планов 40+ Lite.
Чтобы узнать больше о решении IBM для хранилища данных, зарегистрируйтесь в IBMid и создайте бесплатную учетную запись IBM Cloud сегодня.
Что такое интеллектуальный анализ данных?
Что такое интеллектуальный анализ данных?Интеллектуальный анализ данных — это процесс сортировки больших наборов данных для выявления закономерностей и взаимосвязей, которые могут помочь в решении бизнес-проблем посредством анализа данных.Методы и инструменты интеллектуального анализа данных позволяют предприятиям прогнозировать будущие тенденции и принимать более обоснованные бизнес-решения.
Интеллектуальный анализ данных — ключевая часть аналитики данных в целом и одна из основных дисциплин в науке о данных, которая использует передовые методы аналитики для поиска полезной информации в наборах данных. На более детальном уровне интеллектуальный анализ данных — это шаг в процессе обнаружения знаний в базах данных (KDD), методологии науки о данных для сбора, обработки и анализа данных. Интеллектуальный анализ данных и KDD иногда называют взаимозаменяемыми, но чаще они рассматриваются как разные вещи.
Интеллектуальный анализ данных и KDD иногда называют взаимозаменяемыми, но чаще они рассматриваются как разные вещи.
Интеллектуальный анализ данных — важнейший компонент успешных аналитических инициатив в организациях. Информация, которую он генерирует, может использоваться в приложениях бизнес-аналитики (BI) и расширенной аналитики, которые включают анализ исторических данных, а также в приложениях аналитики в реальном времени, которые исследуют потоковые данные по мере их создания или сбора.
Эффективный интеллектуальный анализ данных помогает в различных аспектах планирования бизнес-стратегий и управления операциями.Это включает в себя функции, ориентированные на клиентов, такие как маркетинг, реклама, продажи и поддержка клиентов, а также производство, управление цепочкой поставок, финансы и HR. Интеллектуальный анализ данных поддерживает обнаружение мошенничества, управление рисками, планирование кибербезопасности и многие другие критически важные бизнес-сценарии. Он также играет важную роль в здравоохранении, правительстве, научных исследованиях, математике, спорте и многом другом.
Он также играет важную роль в здравоохранении, правительстве, научных исследованиях, математике, спорте и многом другом.
Процесс интеллектуального анализа данных: как это работает?
Интеллектуальный анализ данных обычно выполняется специалистами по обработке данных и другими квалифицированными специалистами в области бизнес-аналитики и аналитики.Но это также может быть выполнено хорошо разбирающимися в данных бизнес-аналитиками, руководителями и работниками, которые действуют как гражданские специалисты по данным в организации.
Его основные элементы включают машинное обучение и статистический анализ, а также задачи управления данными, выполняемые для подготовки данных к анализу. Использование алгоритмов машинного обучения и инструментов искусственного интеллекта (AI) автоматизировало большую часть процесса и упростило добычу массивных наборов данных, таких как базы данных клиентов, записи транзакций и файлы журналов с веб-серверов, мобильных приложений и датчиков.
Использование алгоритмов машинного обучения и инструментов искусственного интеллекта (AI) автоматизировало большую часть процесса и упростило добычу массивных наборов данных, таких как базы данных клиентов, записи транзакций и файлы журналов с веб-серверов, мобильных приложений и датчиков.
Процесс интеллектуального анализа данных можно разбить на четыре основных этапа:
- Сбор данных. Идентифицируются и собираются релевантные данные для приложения аналитики. Данные могут находиться в разных исходных системах, хранилище данных или озере данных, все более распространенном репозитории в средах больших данных, которые содержат смесь структурированных и неструктурированных данных. Также могут использоваться внешние источники данных. Независимо от того, откуда поступают данные, специалист по данным часто перемещает их в озеро данных для оставшихся этапов процесса.
- Подготовка данных . Этот этап включает в себя набор шагов по подготовке данных к добыче. Он начинается с исследования данных, профилирования и предварительной обработки, за которыми следует работа по очистке данных для исправления ошибок и других проблем с качеством данных. Преобразование данных также выполняется для обеспечения согласованности наборов данных, если только специалист по анализу данных не хочет анализировать нефильтрованные необработанные данные для конкретного приложения.
- Анализ данных. После подготовки данных специалист по данным выбирает соответствующий метод интеллектуального анализа данных, а затем реализует один или несколько алгоритмов для выполнения интеллектуального анализа.В приложениях машинного обучения алгоритмы обычно должны быть обучены на выборочных наборах данных, чтобы искать искомую информацию, прежде чем они будут работать с полным набором данных.
- Анализ и интерпретация данных. Результаты интеллектуального анализа данных используются для создания аналитических моделей, которые могут помочь в принятии решений и других бизнес-действиях. Специалист по анализу данных или другой член группы по науке о данных также должен сообщить результаты своим руководителям и пользователям, часто с помощью визуализации данных и использования методов рассказывания историй.
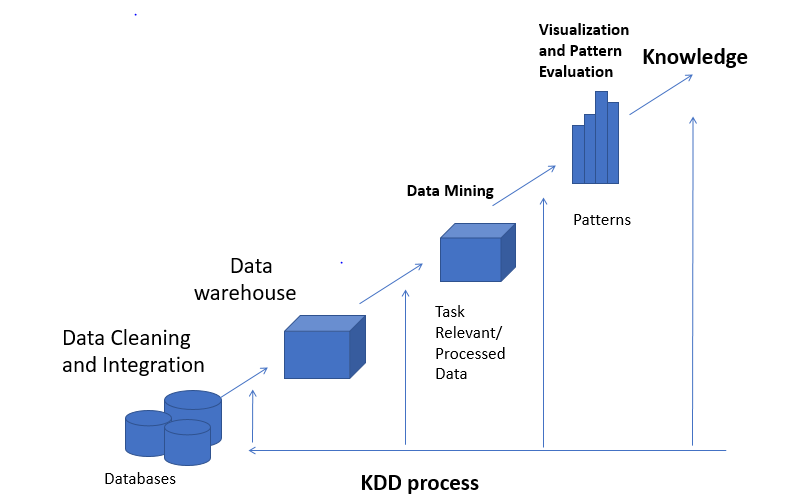 Он начинается с исследования данных, профилирования и предварительной обработки, за которыми следует работа по очистке данных для исправления ошибок и других проблем с качеством данных. Преобразование данных также выполняется для обеспечения согласованности наборов данных, если только специалист по анализу данных не хочет анализировать нефильтрованные необработанные данные для конкретного приложения.
Он начинается с исследования данных, профилирования и предварительной обработки, за которыми следует работа по очистке данных для исправления ошибок и других проблем с качеством данных. Преобразование данных также выполняется для обеспечения согласованности наборов данных, если только специалист по анализу данных не хочет анализировать нефильтрованные необработанные данные для конкретного приложения.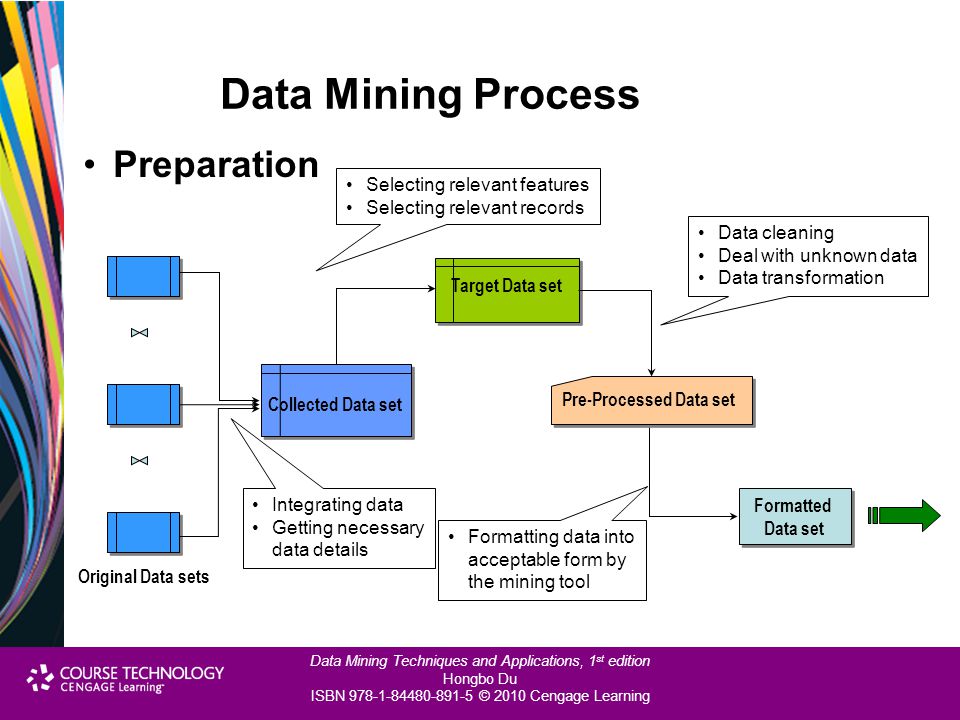 Специалист по анализу данных или другой член группы по науке о данных также должен сообщить результаты своим руководителям и пользователям, часто с помощью визуализации данных и использования методов рассказывания историй.
Специалист по анализу данных или другой член группы по науке о данных также должен сообщить результаты своим руководителям и пользователям, часто с помощью визуализации данных и использования методов рассказывания историй.Для сбора данных для различных приложений науки о данных можно использовать различные методы. Распознавание образов — это распространенный вариант использования интеллектуального анализа данных, который обеспечивается несколькими методами, как и обнаружение аномалий, которое направлено на выявление резко отклоняющихся значений в наборах данных. Популярные методы интеллектуального анализа данных включают следующие типы:
- Ассоциация правил майнинга. В интеллектуальном анализе данных правила ассоциации — это операторы «если-то», которые определяют отношения между элементами данных. Критерии поддержки и уверенности используются для оценки взаимосвязей — поддержка измеряет, как часто связанные элементы появляются в наборе данных, в то время как уверенность отражает, сколько раз утверждение «если-то» было точным.
- Классификация. Этот подход присваивает элементы в наборах данных различным категориям, определенным как часть процесса интеллектуального анализа данных.Деревья решений, наивные байесовские классификаторы, k-ближайший сосед и логистическая регрессия — вот некоторые примеры методов классификации.
- Кластеризация. В этом случае элементы данных с общими характеристиками группируются в кластеры как часть приложений интеллектуального анализа данных. Примеры включают кластеризацию k-средних, иерархическую кластеризацию и модели гауссовой смеси.
- Регрессия. Это еще один способ поиска взаимосвязей в наборах данных путем вычисления прогнозируемых значений данных на основе набора переменных. Примеры — линейная регрессия и многомерная регрессия. Деревья решений и некоторые другие методы классификации также могут использоваться для регрессий.
- Анализ последовательности и пути. Данные также могут быть добыты для поиска шаблонов, в которых определенный набор событий или значений приводит к более поздним.
- Нейронные сети. Нейронная сеть — это набор алгоритмов, имитирующих деятельность человеческого мозга. Нейронные сети особенно полезны в приложениях для распознавания сложных образов, включающих глубокое обучение, более сложное ответвление машинного обучения.
 Критерии поддержки и уверенности используются для оценки взаимосвязей — поддержка измеряет, как часто связанные элементы появляются в наборе данных, в то время как уверенность отражает, сколько раз утверждение «если-то» было точным.
Критерии поддержки и уверенности используются для оценки взаимосвязей — поддержка измеряет, как часто связанные элементы появляются в наборе данных, в то время как уверенность отражает, сколько раз утверждение «если-то» было точным. Примеры — линейная регрессия и многомерная регрессия. Деревья решений и некоторые другие методы классификации также могут использоваться для регрессий.
Примеры — линейная регрессия и многомерная регрессия. Деревья решений и некоторые другие методы классификации также могут использоваться для регрессий. Инструменты интеллектуального анализа данных доступны от большого числа поставщиков, как правило, как часть программных платформ, которые также включают в себя другие виды анализа данных и инструменты расширенной аналитики. Ключевые функции, предоставляемые программным обеспечением интеллектуального анализа данных, включают возможности подготовки данных, встроенные алгоритмы, поддержку прогнозного моделирования, среду разработки на основе графического интерфейса пользователя и инструменты для развертывания моделей и оценки их эффективности.
Поставщики, предлагающие инструменты для интеллектуального анализа данных, включают Alteryx, AWS, Databricks, Dataiku, DataRobot, Google, h3O.ai, IBM, Knime, Microsoft, Oracle, RapidMiner, SAP, SAS Institute и Tibco Software и другие.
Для добычи данных также могут использоваться различные бесплатные технологии с открытым исходным кодом, включая DataMelt, Elki, Orange, Rattle, scikit-learn и Weka. Некоторые поставщики программного обеспечения также предоставляют варианты с открытым исходным кодом. Например, Knime сочетает платформу аналитики с открытым исходным кодом с коммерческим программным обеспечением для управления приложениями для обработки данных, в то время как такие компании, как Dataiku и h3O.ai, предлагают бесплатные версии своих инструментов.
Преимущества интеллектуального анализа данных В целом, бизнес-преимущества интеллектуального анализа данных связаны с повышенной способностью обнаруживать скрытые закономерности, тенденции, корреляции и аномалии в наборах данных. Эту информацию можно использовать для улучшения принятия бизнес-решений и стратегического планирования за счет сочетания традиционного анализа данных и прогнозной аналитики.
Эту информацию можно использовать для улучшения принятия бизнес-решений и стратегического планирования за счет сочетания традиционного анализа данных и прогнозной аналитики.
Конкретные преимущества интеллектуального анализа данных включают следующее:
- Более эффективный маркетинг и продажи. Data Mining помогает маркетологам лучше понимать поведение и предпочтения клиентов, что позволяет им создавать целевые маркетинговые и рекламные кампании. Аналогичным образом отделы продаж могут использовать результаты интеллектуального анализа данных для повышения коэффициента конверсии потенциальных клиентов и продажи дополнительных продуктов и услуг существующим клиентам.
- Лучшее обслуживание клиентов. Благодаря интеллектуальному анализу данных компании могут быстрее выявлять потенциальные проблемы с обслуживанием клиентов и предоставлять агентам контакт-центра актуальную информацию для использования при звонках и онлайн-чатах с клиентами.
- Улучшенное управление цепочкой поставок. Организации могут определять рыночные тенденции и более точно прогнозировать спрос на продукцию, что позволяет им лучше управлять запасами товаров и материалов. Менеджеры цепочки поставок также могут использовать информацию из интеллектуального анализа данных для оптимизации складских операций, распределения и других логистических операций.
- Увеличение времени безотказной работы. Извлечение операционных данных с датчиков на производственных машинах и другом промышленном оборудовании поддерживает приложения для профилактического обслуживания для выявления потенциальных проблем до их возникновения, помогая избежать незапланированных простоев.
- Сильнее Управление рисками . Риск-менеджеры и руководители предприятий могут лучше оценивать финансовые, юридические, кибербезопасные и другие риски компании и разрабатывать планы по управлению ими.
- Снижение затрат. Data Mining помогает сократить расходы за счет повышения операционной эффективности бизнес-процессов и сокращения избыточности и потерь корпоративных расходов.

В конечном итоге инициативы по интеллектуальному анализу данных могут привести к увеличению доходов и прибыли, а также к конкурентным преимуществам, которые выделяют компании среди их конкурентов.
Отраслевые примеры интеллектуального анализа данныхВот как организации в некоторых отраслях используют интеллектуальный анализ данных как часть аналитических приложений:
- Розничная торговля. Интернет-магазины собирают данные о клиентах и записи о посещениях, чтобы помочь им нацелить маркетинговые кампании, рекламу и рекламные предложения на отдельных покупателей. Интеллектуальный анализ данных и прогнозное моделирование также обеспечивают работу механизмов рекомендаций, которые предлагают посетителям веб-сайтов возможные покупки, а также действия по управлению запасами и цепочкой поставок.
- Финансовые услуги. Банки и компании, выпускающие кредитные карты, используют инструменты интеллектуального анализа данных для построения моделей финансовых рисков, обнаружения мошеннических транзакций и проверки ссуд и заявок на получение кредита. Интеллектуальный анализ данных также играет ключевую роль в маркетинге и в выявлении потенциальных возможностей увеличения продаж с существующими клиентами.
- Страхование. Страховщики полагаются на интеллектуальный анализ данных, чтобы помочь в ценообразовании страховых полисов и принятии решения об утверждении приложений полисов, включая моделирование рисков и управление ими для потенциальных клиентов.
- Производство. Приложения Data Mining для производителей включают в себя усилия по увеличению времени безотказной работы и операционной эффективности на производственных предприятиях, производительности цепочки поставок и безопасности продукции.
- Развлечения. Службы потоковой передачи выполняют интеллектуальный анализ данных, чтобы анализировать, что пользователи смотрят или слушают, и давать персонализированные рекомендации, основанные на привычках просмотра и прослушивания людей.
- Здравоохранение. Data Mining помогает врачам диагностировать заболевания, лечить пациентов и анализировать рентгеновские снимки и другие результаты медицинской визуализации.Медицинские исследования также сильно зависят от интеллектуального анализа данных, машинного обучения и других форм аналитики.

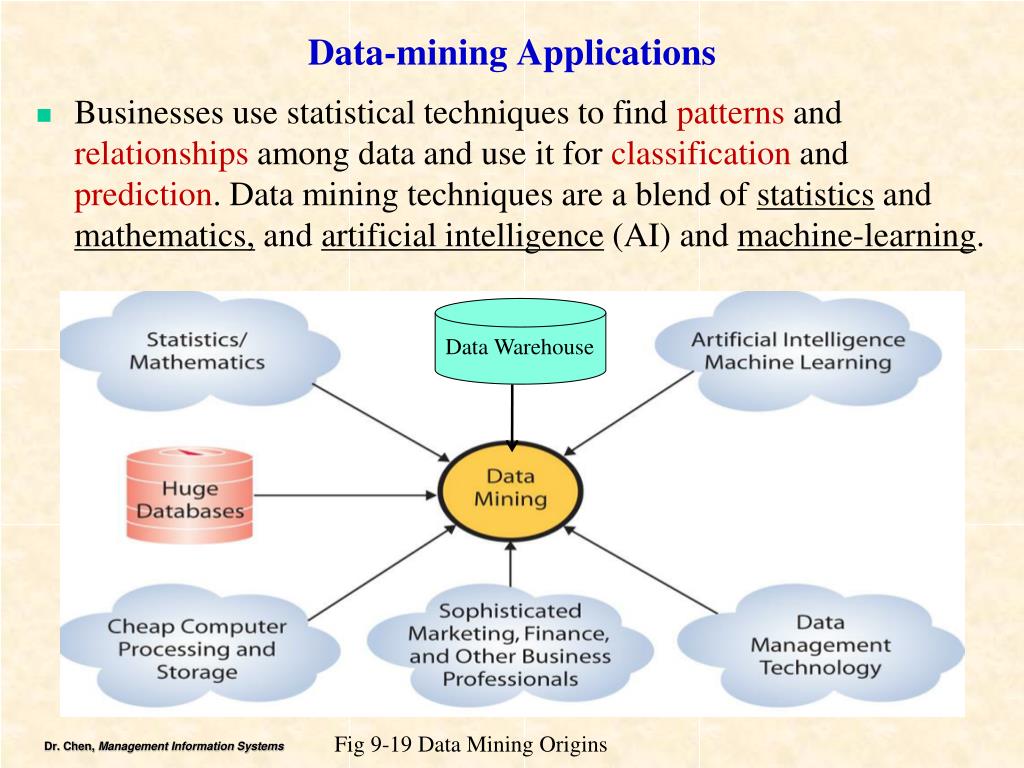 Службы потоковой передачи выполняют интеллектуальный анализ данных, чтобы анализировать, что пользователи смотрят или слушают, и давать персонализированные рекомендации, основанные на привычках просмотра и прослушивания людей.
Службы потоковой передачи выполняют интеллектуальный анализ данных, чтобы анализировать, что пользователи смотрят или слушают, и давать персонализированные рекомендации, основанные на привычках просмотра и прослушивания людей. Интеллектуальный анализ данных иногда рассматривается как синоним аналитики данных. Но в основном это рассматривается как особый аспект аналитики данных, который автоматизирует анализ больших наборов данных для обнаружения информации, которую иначе невозможно было бы обнаружить. Затем эту информацию можно использовать в процессе обработки и анализа данных, а также в других приложениях бизнес-аналитики и аналитики.
Хранилище данных поддерживает усилия по интеллектуальному анализу данных, предоставляя репозитории для наборов данных. Традиционно исторические данные хранятся в корпоративных хранилищах данных или меньших витринах данных, созданных для отдельных бизнес-единиц или для хранения определенных подмножеств данных. Однако теперь приложения интеллектуального анализа данных часто обслуживаются озерами данных, в которых хранятся как исторические, так и потоковые данные, и основаны на платформах больших данных, таких как Hadoop и Spark, базах данных NoSQL или службах хранения облачных объектов.
История и происхождение интеллектуального анализа данных Технологии хранилищ данных, бизнес-аналитики и аналитики начали появляться в конце 1980-х — начале 1990-х годов, обеспечивая повышенную способность анализировать растущие объемы данных, которые организации создавали и собирали. Термин интеллектуальный анализ данных использовался к 1995 году, когда в Монреале проходила Первая международная конференция по открытию знаний и интеллектуальному анализу данных.
Мероприятие спонсировалось Ассоциацией по развитию искусственного интеллекта (AARI), которая также проводила конференцию ежегодно в течение следующих трех лет.С 1999 года конференция, широко известная как KDD 2021 и т. Д., Была организована в основном SIGKDD, специальной группой по обнаружению знаний и интеллектуальному анализу данных в рамках Ассоциации вычислительной техники.
Технический журнал Data Mining and Knowledge Discovery опубликовал свой первый выпуск в 1997 году. Изначально он выходил ежеквартально, теперь он публикуется раз в два месяца и содержит рецензируемые статьи по теориям, методам и практикам интеллектуального анализа данных и поиска знаний.Еще одно издание, American Journal of Data Mining and Knowledge Discovery , было выпущено в 2016 году.
Что такое интеллектуальный анализ данных: определение, примеры, инструменты и методы (для начинающих)
Интеллектуальный анализ данных жизненно важен для бизнес-операций во многих отраслях. Компании используют интеллектуальный анализ данных для управления рисками, прогнозирования потребностей в ресурсах, прогнозирования продаж клиентов, обнаружения мошенничества и повышения скорости отклика на свои маркетинговые усилия.
Компании используют интеллектуальный анализ данных для управления рисками, прогнозирования потребностей в ресурсах, прогнозирования продаж клиентов, обнаружения мошенничества и повышения скорости отклика на свои маркетинговые усилия.
Согласно отчету MicroStrategy о глобальном состоянии корпоративной аналитики (PDF 11 МБ), 60 процентов респондентов использовали аналитику для экономии денег, 57 процентов использовали ее для реализации стратегии и изменений, а 52 процента стремились улучшить финансовые показатели.
Пожалуй, самый известный процесс интеллектуального анализа данных называется CRISP-DM или межотраслевой стандартный процесс интеллектуального анализа данных.
Это процедура из шести шагов для превращения данных в аналитическую информацию. Модель работает так:
Понимание бизнеса
Это отправная точка. Какие у вас есть вопросы? Что вы хотите узнать из своих данных? Компании и организации сначала должны определить свои цели, в том числе, какие идеи они хотят извлечь или проблемы, которые они хотят решить, используя собранные данные.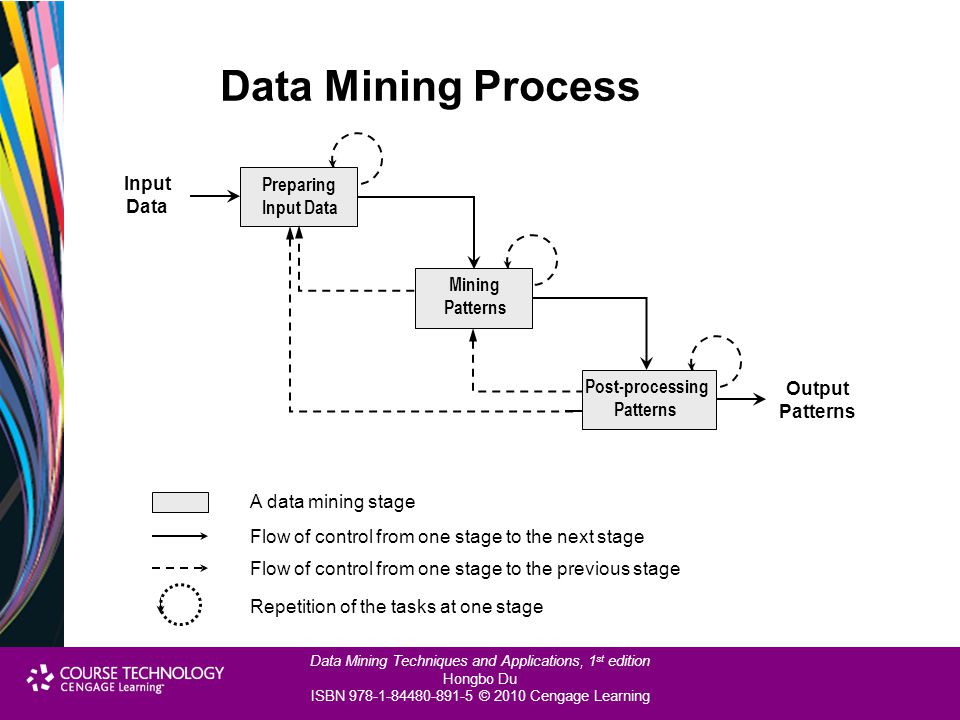 Определение целей проекта важно для сбора правильных данных для анализа.
Определение целей проекта важно для сбора правильных данных для анализа.
Понимание данных
После того, как цель определена, пора определить данные. Не все точки данных, хранящиеся на сервере или в облаке, подходят для каждого проекта. Определение правильных данных для поиска экономит время и избавляет от потенциальных хлопот, связанных с повторным отслеживанием шагов позже.
На этом этапе данные собираются из нескольких источников в зависимости от решаемой проблемы. Компания ищет исторические данные о продажах определенного товара? Тип кредитной карты, используемой для совершения покупки? Были ли товары куплены в магазине или в Интернете? Каждый тип данных может быть релевантным — или нет — в зависимости от проекта.
Эта часть процесса также важна для проверки качества данных. Перед переходом к следующему этапу можно исправить отсутствующие, ошибочные или повторяющиеся данные.
Подготовка данных
Подготовка данных считается наиболее сложным этапом интеллектуального анализа данных, на который часто уходит не менее половины времени и усилий проекта. Именно на этом этапе выбираются, очищаются и сортируются наиболее полезные данные для учета ошибок или несоответствий в коде. Данные из нескольких источников можно объединять, организовывать или корректировать по-разному, чтобы подготовиться к следующему этапу: моделированию.
Именно на этом этапе выбираются, очищаются и сортируются наиболее полезные данные для учета ошибок или несоответствий в коде. Данные из нескольких источников можно объединять, организовывать или корректировать по-разному, чтобы подготовиться к следующему этапу: моделированию.
Моделирование
Теперь данные начинают обретать форму. Майнеры данных могут использовать различные модели (способы организации данных) для создания решений. Например, модели могут стремиться обнаруживать закономерности или аномалии в данных или использовать данные для прогнозирования результата. Компании будут выбирать модель на основе типа данных, которые они анализируют, конкретных требований проекта и преследуемых целей.
Для получения разных результатов на одном и том же наборе данных можно использовать несколько методов моделирования.Компании редко отвечают на свои вопросы по интеллектуальному анализу данных, используя только одну модель.
Оценка На этом этапе исследователи данных оценивают, дали ли модели удовлетворительный ответ на заданный вопрос и содержат ли результаты какие-либо неожиданные или уникальные выводы.
Если первоначальный вопрос остается без ответа, может потребоваться новая модель или данные могут быть изменены. Если результаты соответствуют их критериям, проект переходит к завершающей фазе.
Развертывание
На данный момент компании ответили на заданный ими вопрос.В примере с цветочным магазином, возможно, модель предлагала увеличенный заказ из-за прошлых продаж и ожидаемого потребительского спроса. Флорист может использовать эти знания, чтобы иметь под рукой достаточно цветов, когда прибывает крупное мероприятие.
Почему интеллектуальный анализ данных важен для бизнеса?
Проще говоря, интеллектуальный анализ данных улучшает бизнес; он может сэкономить деньги, обеспечить конкурентное преимущество, улучшить качество обслуживания клиентов и выявить новых клиентов и источники доходов.
Согласно опросу MicroStrategy (PDF 11 МБ), 63 процента респондентов заявили, что аналитика повысила эффективность и производительность их компании, 57 процентов заявили, что она помогает им быстрее принимать решения, а 51 процент отметили улучшение финансовых показателей.
Интеллектуальный анализ данных — это открытие — отсюда и этот термин, и его отношение к добыче драгоценных материалов. А в потребительском мире, перегруженном данными, компаниям нужны эффективные способы проанализировать эти данные, чтобы найти актуальные решения, по которым можно предпринять действия. Они могут настроить все данные, которые они генерируют, чтобы узнать, кто покупает их продукты, где они их покупают и как продавать больше.
Одно из основных преимуществ интеллектуального анализа данных — скорость. Десятилетия назад для анализа больших наборов данных требовались недели или месяцы.Банкам и компаниям, выпускающим кредитные карты, пришлось просмотреть миллионы записей, чтобы обнаружить мошенничество или ошибки. Благодаря достижениям в области нейронных сетей, машинного обучения и искусственного интеллекта эти огромные наборы данных теперь можно анализировать за часы или минуты. Более совершенные инструменты и методы интеллектуального анализа данных помогли собрать разрозненные данные в удобные для использования группы, как никогда раньше.
Данные можно разделить на два основных формата: структурированные и неструктурированные. Структурированные данные состоят из чисел, которые мы распознаем в таблице или электронной таблице Excel, например, данные о продажах за последний месяц и запасы за этот месяц.Между тем неструктурированные данные существуют в разных форматах, таких как текст или видео. Он включен в электронные письма, сообщения в социальных сетях, фотографии и даже спутниковые снимки.
Компаниям, безусловно, необходимо оценивать структурированные данные, но интеллектуальный анализ неструктурированных данных — быстро развивающееся предприятие. Согласно опросу Forbes, более 95 процентов предприятий говорят, что им нужны более эффективные способы управления неструктурированными данными.
Как интеллектуальный анализ данных используется в различных отраслях?
Для чего используется интеллектуальный анализ данных? А кто им пользуется? На самом деле интеллектуальный анализ данных можно применить к любой отрасли, которая генерирует данные и хочет их использовать.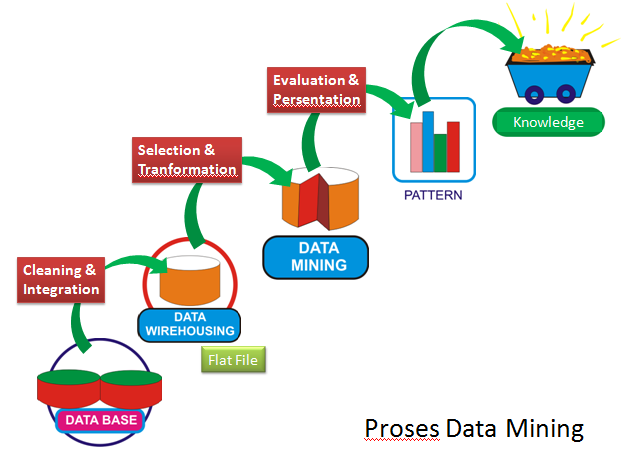 Пока у вас есть доступ к данным и любопытство, чтобы узнать смысл или ответить на вопросы, интеллектуальный анализ данных может помочь вам найти свой путь.
Пока у вас есть доступ к данным и любопытство, чтобы узнать смысл или ответить на вопросы, интеллектуальный анализ данных может помочь вам найти свой путь.
Вот несколько примеров того, как интеллектуальный анализ данных используется в конкретных отраслях.
Здравоохранение
Интеллектуальный анализ данных уже много лет используется в здравоохранении. Врачи используют более эффективные методы лечения, основанные на данных, полученных в ходе клинических испытаний и исследований пациентов. Больницы и клиники могут улучшить результаты лечения и безопасность пациентов, сократив расходы и время отклика.Интеллектуальный анализ данных может даже сопоставлять пациентов с врачами на основе отчетов об успешной диагностике.
Банки и финансы
Одним из первых применений интеллектуального анализа данных было обнаружение мошенничества с кредитными картами. Финансовые компании также используют свои миллиарды транзакций, чтобы измерить, как клиенты экономят и инвестируют деньги, что позволяет им предлагать новые услуги и постоянно проверять риски.
Розничная торговля
Розничные торговцы имеют огромное количество данных о клиентах (тенденции покупок, предпочтения и привычки расходов среди них), которые они пытаются использовать для увеличения будущих продаж.Розничные компании, которые не делают выводов на основе интеллектуального анализа данных, рискуют отстать от конкурентов.
Страхование
Обнаружение мошенничества — важный компонент страховой отрасли, но страховщики также используют данные для управления рисками, понимания причин потери клиентов и более эффективной оценки своих продуктов. Например, компания по страхованию автомобилей может изучить пробег и количество аварий в определенном регионе, чтобы определить, следует ли повышать или понижать ставки для клиентов, которые там живут.
СМИ и телекоммуникации
Медиа и телекоммуникационные компании располагают множеством данных о предпочтениях потребителей, включая программы, которые они смотрят, книги, которые они читают, и видеоигры, в которые они играют. Имея эти данные, компании могут нацеливать программы на потребителей по вкусу, региону или другим факторам. Они даже могут предложить средства массовой информации для использования — подход, который освоили такие компании, как Netflix.
Имея эти данные, компании могут нацеливать программы на потребителей по вкусу, региону или другим факторам. Они даже могут предложить средства массовой информации для использования — подход, который освоили такие компании, как Netflix.
Образование
Измеряя данные об успеваемости учащихся, преподаватели полагают, что они могут предсказать, когда учащиеся могут бросить школу, еще до того, как учащиеся об этом задумаются.Кроме того, эти данные могут помочь педагогам воздействовать на учащихся из групп риска и потенциально удерживать их в школе.
Производство
Производители используют данные для согласования своих производственных графиков со спросом, обеспечивая наличие продуктов на полках магазинов (или виртуальных), когда они нужны. Это помогает максимизировать производство в критические моменты и прогнозировать, когда сборочные линии могут нуждаться в обслуживании.
Транспорт
Безопасность является основным фактором интеллектуального анализа данных в транспортной отрасли. Города и сообщества могут проводить исследования дорожного движения, чтобы определять самые загруженные дороги и перекрестки. Компании, занимающиеся общественным транспортом, могут анализировать данные, чтобы определить наиболее загруженные зоны и время в пути.
Города и сообщества могут проводить исследования дорожного движения, чтобы определять самые загруженные дороги и перекрестки. Компании, занимающиеся общественным транспортом, могут анализировать данные, чтобы определить наиболее загруженные зоны и время в пути.
Что такое интеллектуальный анализ данных? | TIBCO Software
Почему интеллектуальный анализ данных важен и где он используется?
Объем данных, которые производятся каждый год, феноменально огромен. И то, что уже является колоссальной цифрой, удваивается каждые два года. Цифровая вселенная состоит примерно на 90 процентов из неструктурированных данных, но это не означает, что чем больше объем информации, тем лучше знания.Интеллектуальный анализ данных призван изменить это, и с его помощью предприятия могут:
- Организованно анализируйте множество повторяющейся информации.
- Извлеките соответствующую информацию и максимально используйте ее для достижения лучших результатов.
- Ускорьте темпы принятия обоснованных решений.

Вы найдете интеллектуальный анализ данных центральным элементом аналитики в самых разных секторах. Вот посмотрите, как некоторые из них его используют.
Промышленность связи
Отрасль коммуникаций, маркетинговая или другая, очень конкурентоспособна и имеет дело с клиентом, которого тянут в нескольких разных направлениях.Использование методов интеллектуального анализа данных для понимания и анализа огромных объемов данных помогает этому сектору создавать целевые кампании, которые обеспечивают большее количество успешных продаж и взаимодействий с клиентами.
Страховой сектор
Этому сектору часто приходится иметь дело с проблемами соблюдения нормативных требований, широким спектром мошенничества, оценкой рисков и управлением ими, а также удержанием клиентов на конкурентном рынке. Благодаря интеллектуальному анализу данных страховые компании могут лучше оценивать продукты и создавать лучшие варианты для существующих клиентов, одновременно поощряя регистрацию новых.
Сектор образования
Наблюдения за успеваемостью учащихся на основе данных позволяют преподавателям уделять им более персонализированное внимание там, где это необходимо. Стратегии вмешательства могут быть построены на раннем этапе для групп учащихся, которым они могут понадобиться.
Обрабатывающая промышленность
Выход из строя производственной линии или падение качества могут привести к огромным потерям для любой обрабатывающей промышленности. Благодаря интеллектуальному анализу данных компании смогут лучше планировать свои цепочки поставок.Это означает, что можно выявлять и устранять возможные поломки на раннем этапе, проверка качества может быть более интенсивной, а производственные линии сталкиваются с минимальными нарушениями.
Банковское дело
Банковский сектор в значительной степени полагается на интеллектуальный анализ данных и автоматизированные алгоритмы, которые помогают разобраться в миллиардах транзакций, которые происходят в финансовой системе. Благодаря этому финансовые организации смогут увидеть рыночные риски с высоты птичьего полета, быстрее обнаруживать мошенничество, контролировать соблюдение нормативных требований и обеспечивать оптимальную отдачу от своих маркетинговых инвестиций.
Благодаря этому финансовые организации смогут увидеть рыночные риски с высоты птичьего полета, быстрее обнаруживать мошенничество, контролировать соблюдение нормативных требований и обеспечивать оптимальную отдачу от своих маркетинговых инвестиций.
Сектор розничной торговли
Учитывая астрономическое количество розничных транзакций, существует множество данных, которые сектор может использовать для лучшего понимания своих потребителей. Интеллектуальный анализ данных помогает им развиваться, улучшая отношения с клиентами, оптимизируя маркетинговые кампании и прогнозируя продажи.
Процесс интеллектуального анализа данных
Как показано ниже, процесс интеллектуального анализа данных состоит из четырех основных этапов.
Определение проблемы
Первым шагом в любом проекте интеллектуального анализа данных является понимание целей и требований.Это должно быть определено с точки зрения бизнеса, а также должен иметься базовый план реализации. Если бизнес-проблема заключается в возможности продавать больше — проблема интеллектуального анализа данных будет заключаться в том, «какой тип клиента, вероятно, совершит покупки продукта?» Реализация начинается с создания модели на основе таких данных, как предыдущие отношения с клиентами и атрибуты, включая демографические данные, размер семьи, возраст, место жительства и многое другое.
Если бизнес-проблема заключается в возможности продавать больше — проблема интеллектуального анализа данных будет заключаться в том, «какой тип клиента, вероятно, совершит покупки продукта?» Реализация начинается с создания модели на основе таких данных, как предыдущие отношения с клиентами и атрибуты, включая демографические данные, размер семьи, возраст, место жительства и многое другое.
Сбор и подготовка данных
Второй этап охватывает сбор и исследование данных.Изучение собранных данных даст вам представление о том, насколько точно они подходят для решения вашей бизнес-проблемы. На этом этапе можно решить отказаться от некоторых параметров данных или ввести несколько новых. Здесь можно решить проблемы с качеством данных и отсканировать их на предмет возможных закономерностей в данных.
Этап подготовки данных охватывает такие задачи, как выбор таблицы, случая и атрибута. Он также включает в себя очистку и преобразование данных, удаление дубликатов, стандартизацию вводимых заголовков и другую проверку данных.
Построение и оценка модели
На третьем этапе выбираются и применяются различные методы моделирования, а параметры калибруются до оптимального уровня. На этом начальном этапе построения модели лучше всего работать с небольшим, хорошо продуманным набором данных. Еще раз оценить, как модель решает бизнес-проблему, — хорошая идея. На этом этапе можно добавить любые формы улучшения.
Развертывание моделиНа заключительном этапе развертывания на основе собранных данных могут быть получены идеи и полезная информация.Затем эти знания можно применить в целевой среде. Развертывание может включать применение модели к любым новым данным, извлечение деталей модели, интеграцию моделей в приложения и многое другое.
Проблемы интеллектуального анализа данных
Без сомнения, интеллектуальный анализ данных — это мощный процесс, но он сопряжен с определенными проблемами, особенно с учетом того, что он имеет дело с растущими объемами сложных больших данных.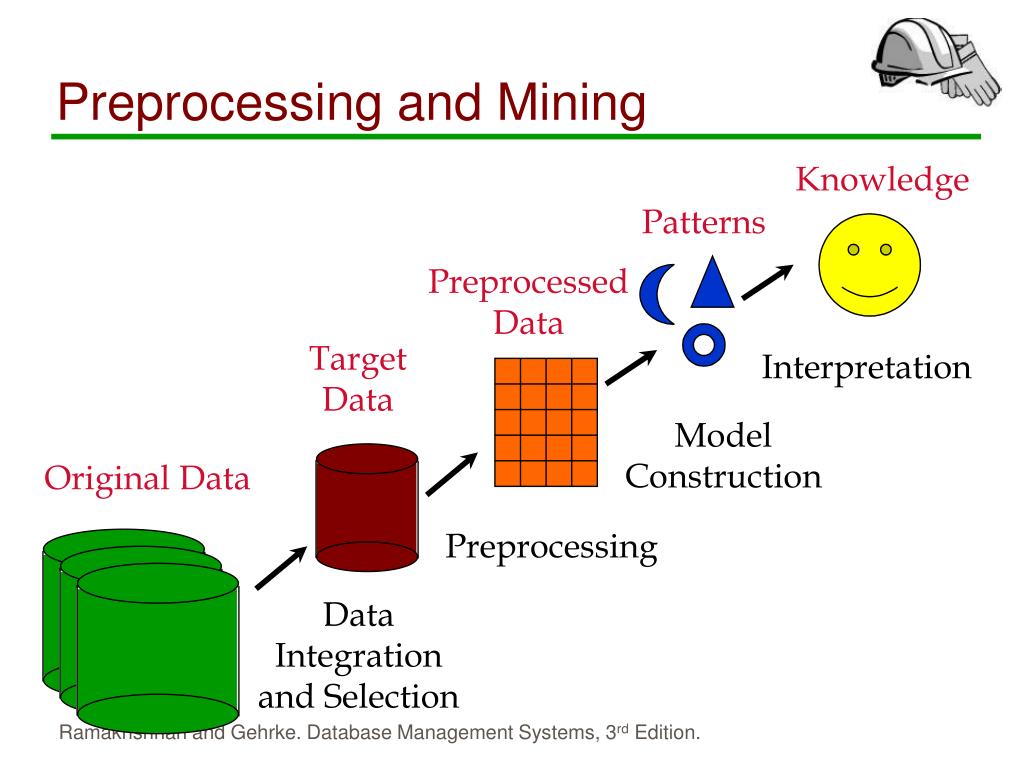 Сбор и анализ всех этих данных только усложняются.Вот некоторые из наиболее серьезных проблем, связанных с интеллектуальным анализом данных:
Сбор и анализ всех этих данных только усложняются.Вот некоторые из наиболее серьезных проблем, связанных с интеллектуальным анализом данных:
Большие данные
Когда дело доходит до больших данных, возникают четыре основных проблемы:
- Объем: большие объемы данных связаны с проблемами хранения. Кроме того, при просмотре таких больших объемов данных возникает проблема нахождения правильных данных. Обработка происходит медленнее, когда инструменты интеллектуального анализа данных имеют дело с таким объемом.
- Разнообразие: В данный момент собирается и хранится огромное количество разнообразных данных.Инструменты интеллектуального анализа данных должны уметь обрабатывать многие виды форматов данных, что может быть проблемой.
- Скорость: скорость, с которой данные могут быть собраны в наши дни, намного выше, чем когда-то, что потенциально может создавать проблемы.
- Правдивость: точность таких огромных объемов данных может быть сложной задачей, особенно с учетом факторов объема, разнообразия и скорости передачи данных. Основная проблема в этом случае — сбалансировать количество данных с качеством данных.
 Основная проблема в этом случае — сбалансировать количество данных с качеством данных.
Основная проблема в этом случае — сбалансировать количество данных с качеством данных.Модели с переустановкой
Они сложны и используют слишком много независимых переменных, чтобы сделать прогноз. Риск переобучения увеличивается с увеличением объема и разнообразия. В результате модель начинает показывать естественные ошибки в выборке вместо отображения основных тенденций. Уменьшение количества переменных приводит к нерелевантной модели, а добавление слишком большого количества ограничивает модель. Задача состоит в том, чтобы найти правильную модерацию используемых переменных и их баланс с точки зрения точности прогнозов.
Стоимость шкалы
С увеличением объема и скорости компании необходимо работать над масштабированием моделей, чтобы в полной мере использовать преимущества интеллектуального анализа данных. Для этого компаниям необходимо инвестировать в ряд мощных вычислительных мощностей, серверов и программного обеспечения. Это не всегда может быть легким делом для компаний.
Конфиденциальность и безопасность
Требования к хранилищам постоянно растут, и компании обращаются к облаку для своих нужд. Но с этим возникает необходимость в мерах безопасности высокого уровня для данных.Когда принимаются меры по обеспечению конфиденциальности и безопасности данных, должен вступить в силу ряд внутренних правил и положений. Это требует изменения стиля работы, а для многих это крутая кривая обучения.
Соответствующие данные имеют решающее значение для функционирования любого бизнеса в эти конкурентные времена. Интеллектуальный анализ данных помогает организациям лучше разрабатывать стратегию. Интеллектуальный анализ данных — ключ к тому, чтобы помочь предприятиям получить это преимущество. Главное — делать это правильно.
Что такое интеллектуальный анализ данных? Как это работает, методы и примеры
В повседневной деятельности компания собирает данные о продажах, клиентах, производстве, сотрудниках, маркетинговой деятельности и многом другом.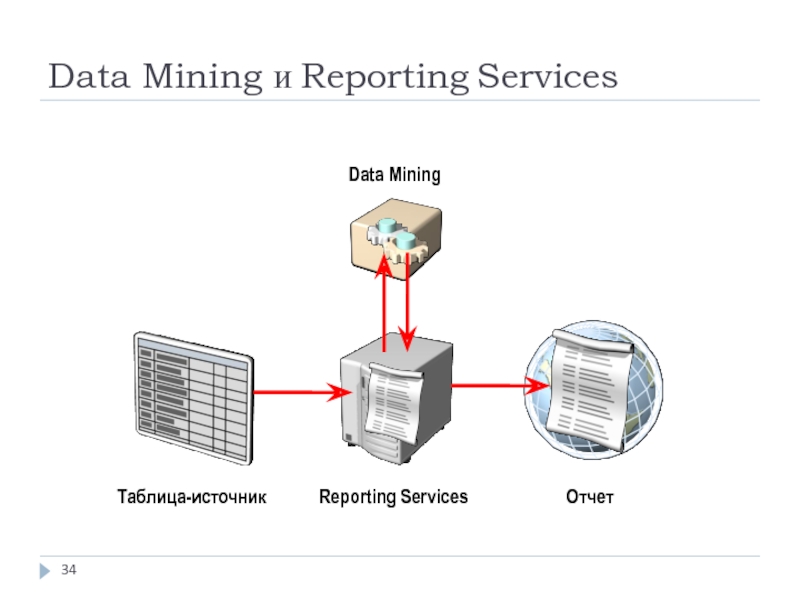 Интеллектуальный анализ данных может помочь предприятиям извлекать больше пользы из этого критически важного актива компании. Знания, полученные с помощью интеллектуального анализа данных, могут стать полезной информацией, которую бизнес может использовать для улучшения маркетинга, прогнозирования покупательских тенденций, обнаружения мошенничества, фильтрации электронных писем, управления рисками, увеличения продаж и улучшения отношений с клиентами.
Интеллектуальный анализ данных может помочь предприятиям извлекать больше пользы из этого критически важного актива компании. Знания, полученные с помощью интеллектуального анализа данных, могут стать полезной информацией, которую бизнес может использовать для улучшения маркетинга, прогнозирования покупательских тенденций, обнаружения мошенничества, фильтрации электронных писем, управления рисками, увеличения продаж и улучшения отношений с клиентами.
Поскольку методы интеллектуального анализа данных требуют больших наборов данных для получения надежных результатов, в прошлом они использовались в основном крупными предприятиями. Но появление больших общедоступных наборов данных — например, сообщения в социальных сетях, прогнозы погоды и тенденции, модели трафика — может сделать интеллектуальный анализ данных полезным для многих малых предприятий, которые могут комбинировать такие внешние данные со своей собственной информацией и собирать их вместе для получения ценной информации. В то же время инструменты интеллектуального анализа данных становятся дешевле и проще в использовании, что делает их более доступными для малых предприятий.
В то же время инструменты интеллектуального анализа данных становятся дешевле и проще в использовании, что делает их более доступными для малых предприятий.
Что такое интеллектуальный анализ данных?
Data Mining — это набор технологий, процессов и аналитических подходов, объединенных воедино, чтобы получить представление о бизнес-данных, которое можно использовать для принятия более эффективных решений. Он объединяет статистику, искусственный интеллект и машинное обучение для поиска закономерностей, взаимосвязей и аномалий в больших наборах данных.
С помощью интеллектуального анализа данных компания может обнаруживать закономерности в текущем поведении клиентов, которые могут быть не очевидны для человека-аналитика. Он также может предсказывать будущие тенденции. Например, применительно к новому набору данных о потенциальных клиентах модель, основанная на текущих клиентах, может предсказать, какие потенциальные клиенты с наибольшей вероятностью станут будущими клиентами.
Ключевые выводы
- Интеллектуальный анализ данных объединяет статистику, искусственный интеллект и машинное обучение для поиска закономерностей, взаимосвязей и аномалий в больших наборах данных.
- Организация может анализировать свои данные для улучшения многих аспектов своего бизнеса, хотя этот метод особенно полезен для улучшения продаж и отношений с клиентами.
- Интеллектуальный анализ данных может использоваться для поиска взаимосвязей и закономерностей в текущих данных, а затем применять их к новым данным для прогнозирования будущих тенденций или обнаружения аномалий, таких как мошенничество.
Определение интеллектуального анализа данных
В многоэтапном итеративном процессе интеллектуальный анализ данных создает модели, которые автоматически ищут закономерности и взаимосвязи в больших наборах данных, а затем используют эту информацию для описания взаимосвязей в данных или прогнозирования будущих тенденций.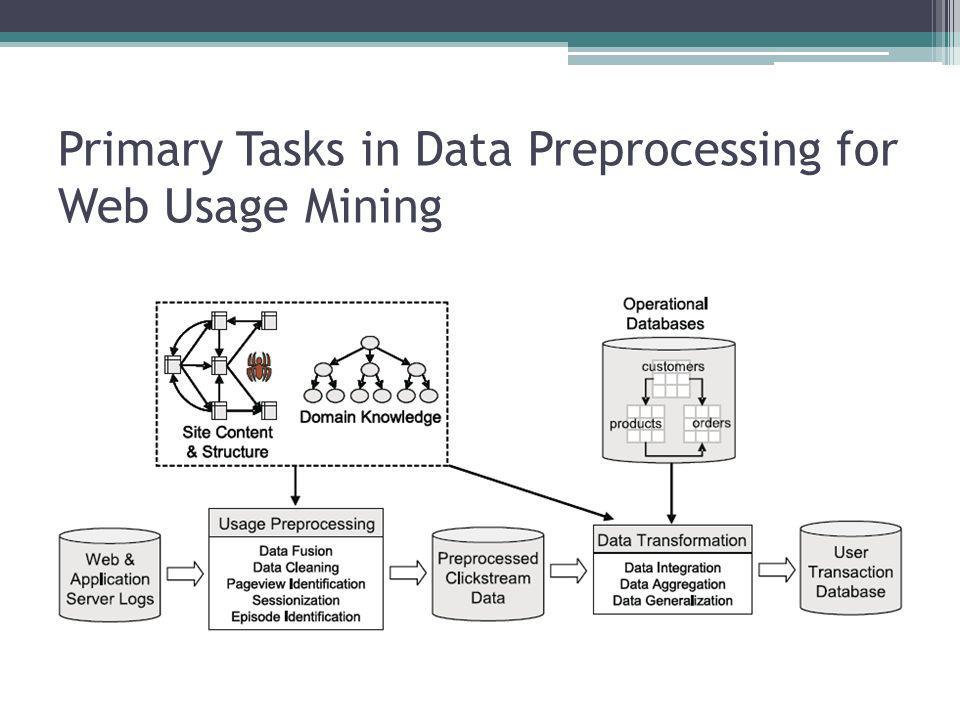 По этой причине интеллектуальный анализ данных также иногда называют обнаружением знаний в данных или KDD. Часто анализ выполняется специалистом по данным, но новые программные инструменты позволяют другим применять некоторые методы интеллектуального анализа данных.
По этой причине интеллектуальный анализ данных также иногда называют обнаружением знаний в данных или KDD. Часто анализ выполняется специалистом по данным, но новые программные инструменты позволяют другим применять некоторые методы интеллектуального анализа данных.
Как работает интеллектуальный анализ данных
Data Mining основывается на концепции прогнозного моделирования. Предположим, организация хочет достичь определенного результата. Анализируя набор данных, в котором известен этот результат, методы интеллектуального анализа данных могут, например, построить программную модель, которая анализирует новые данные для прогнозирования вероятности аналогичных результатов.Вот обзор:
Начать с историческими данными
Допустим, компания хочет узнать о лучших потенциальных клиентах в новой маркетинговой базе данных. Он начинает с изучения своих клиентов.
Анализировать исторические данные
Программное обеспечениесканирует собранные данные, используя комбинацию алгоритмов статистики, искусственного интеллекта и машинного обучения, выявляя закономерности и взаимосвязи в данных.
Правила записи
Когда закономерности и взаимосвязи обнаруживаются, программа выражает их в виде правил. Правило может заключаться в том, что большинство клиентов в возрасте от 51 до 65 лет делают покупки два раза в неделю и наполняют свои корзины свежими продуктами, в то время как клиенты в возрасте от 21 до 50, как правило, делают покупки один раз в неделю и покупают больше упакованных продуктов.
Применить правила
Здесь модель интеллектуального анализа данных применяется к новой маркетинговой базе данных.
Если компания занимается поставкой упакованных продуктов питания, она будет искать людей в возрасте от 21 до 50 лет.

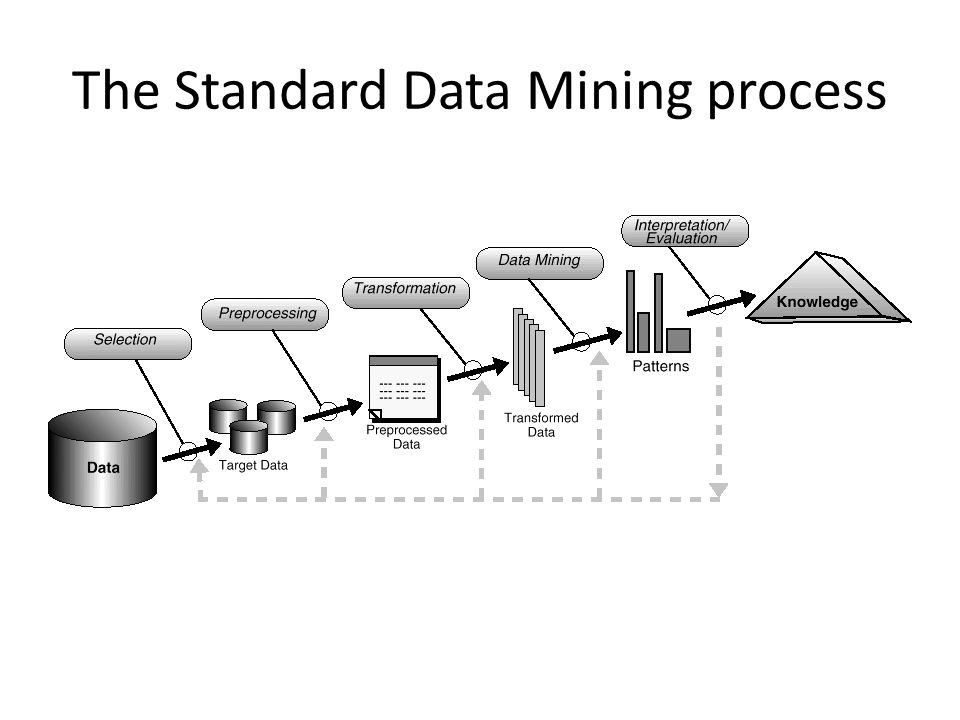 Если компания занимается поставкой упакованных продуктов питания, она будет искать людей в возрасте от 21 до 50 лет.
Если компания занимается поставкой упакованных продуктов питания, она будет искать людей в возрасте от 21 до 50 лет.Для чего нужен интеллектуальный анализ данных?
Интеллектуальный анализ данных находит в данных скрытые взаимосвязи и закономерности, которые люди-аналитики и другие методы анализа могут упустить. Выводы, которые он раскрывает, могут помочь бизнесу принимать более обоснованные решения, например, увеличивать прибыль или повышать эффективность маркетинга. Но важно понимать, что интеллектуальный анализ данных обнаруживает закономерности, а не причинно-следственные связи.Это не уменьшает потребность организации в аналитиках, которые разбираются в бизнесе, разбираются в данных и разбираются в методах и процессах интеллектуального анализа данных. Только такие эксперты могут оценить ценность шаблонов, которые обнаруживает интеллектуальный анализ данных, и использовать их с пользой для бизнеса.
Почему важен интеллектуальный анализ данных?
Все больше продуктов становятся цифровыми, как и больше платежных операций и взаимодействий с клиентами. По мере того, как это происходит, все больше компаний обнаруживают, что их данные, часто уже хранящиеся в хранилище данных и ожидающие анализа, столь же ценны, как и их продукты и услуги.В этом контексте интеллектуальный анализ данных дает компаниям конкурентное преимущество, помогая быстро находить бизнес-идеи, скрытые во всех данных всех этих цифровых бизнес-транзакций. Преимущества практически безграничны. Понимание поведения клиентов может привести к появлению новых продуктов, услуг или маркетинговых идей. Обнаружение вторжений может предотвратить серьезную кражу данных клиентов.
По мере того, как это происходит, все больше компаний обнаруживают, что их данные, часто уже хранящиеся в хранилище данных и ожидающие анализа, столь же ценны, как и их продукты и услуги.В этом контексте интеллектуальный анализ данных дает компаниям конкурентное преимущество, помогая быстро находить бизнес-идеи, скрытые во всех данных всех этих цифровых бизнес-транзакций. Преимущества практически безграничны. Понимание поведения клиентов может привести к появлению новых продуктов, услуг или маркетинговых идей. Обнаружение вторжений может предотвратить серьезную кражу данных клиентов.
Кто использует интеллектуальный анализ данных?
Любая компания может использовать интеллектуальный анализ данных, но те, у кого большие наборы данных, получат более надежные результаты.Паттерны и отношения, обнаруженные с тысячами клиентов, с большей вероятностью позволят точно предсказать будущее поведение клиентов, чем те, которые обнаружены только с сотнями или десятками. Но рынок также расширяется, поскольку большие наборы данных становятся общедоступными, а технологии интеллектуального анализа данных становятся менее дорогими и более доступными даже для тех, кто не имеет опыта анализа данных.
Но рынок также расширяется, поскольку большие наборы данных становятся общедоступными, а технологии интеллектуального анализа данных становятся менее дорогими и более доступными даже для тех, кто не имеет опыта анализа данных.
Итак, хотя интеллектуальный анализ данных традиционно использовался в отраслях, которые генерируют большой объем данных, например, в индустрии кредитных карт, здравоохранении или разведке нефти и газа, он также получает все большее распространение в образовании, управлении взаимоотношениями с клиентами и маркетинге, среди многих других. другие.
Ключевые концепции интеллектуального анализа данных
Как и во многих других областях, интеллектуальный анализ данных использует собственный словарь в качестве ярлыков для определения важных понятий. Знание этих концепций важно для освоения интеллектуального анализа данных и понимания того, что он может сделать для бизнеса.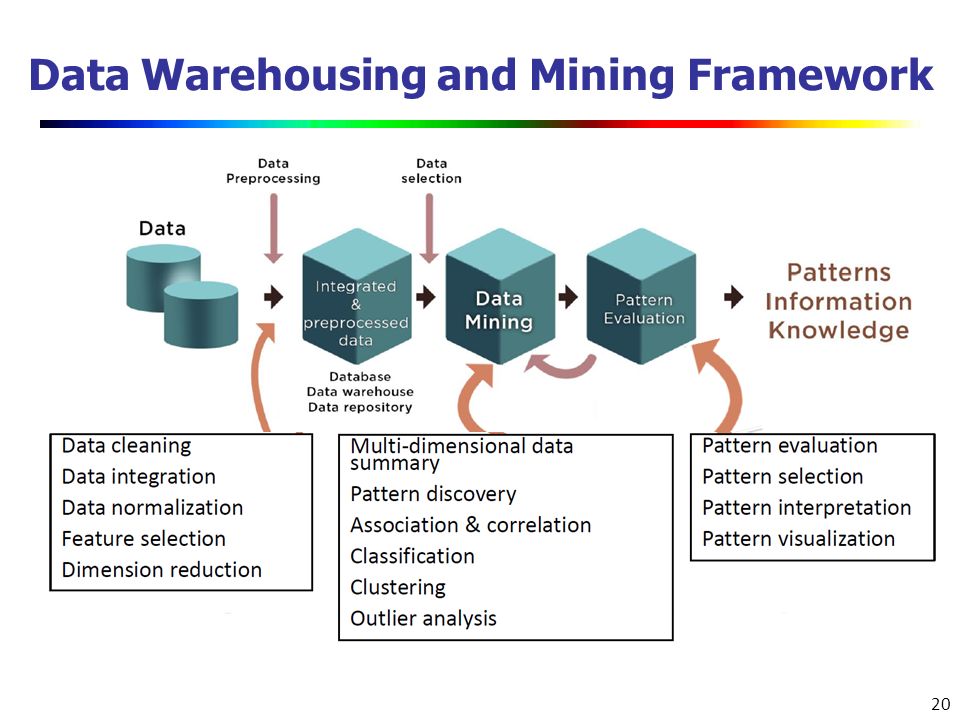
Очистка данных: Также называется очисткой данных. Процесс исправления ошибок и упущений в данных перед их анализом.
Модель: Обнаружение взаимосвязей между данными, часто выражаемых в виде правил.
Цель: Цель интеллектуального анализа данных, например, выявление ценных клиентов.
Предикторы: Связанные данные, ведущие к цели.
Случай: Конкретный экземпляр данных, например, информация о конкретном клиенте, который вставляется в модель для определения его взаимосвязи с целью.Например, вернется ли этот покупатель для повторных продаж?
Анализ рыночной корзины: Выявление покупательского поведения клиентов на основе прошлых моделей покупок, часто с использованием данных, собранных в рамках программ лояльности компании.
Машинное обучение: Алгоритмы, использующие известные случаи для обнаружения других подобных или идентичных случаев в больших наборах данных.

Методы интеллектуального анализа данных
В зависимости от целей компании в области интеллектуального анализа данных используются различные методы для создания моделей, которые соответствуют желаемым результатам.Модели можно использовать для описания текущих данных, прогнозирования будущих тенденций или помощи в обнаружении аномалий данных.
Описательная модель: Описательная аналитика находит закономерности и взаимосвязи в текущих данных.
Модель прогнозирования: Используется для прогнозирования будущих результатов, например, является ли соискатель кредита высокой степенью риска, или для составления финансовых прогнозов, например предстоящих продаж.
Анализ выбросов: Используется для поиска аномалий, то есть данных, которые не вписываются в шаблоны.Анализ выбросов особенно полезен при обнаружении мошенничества, обнаружении сетевых вторжений и уголовных расследований.

Преимущества интеллектуального анализа данных
Data Mining может принести большие выгоды компаниям, обнаруживая закономерности и взаимосвязи в данных, которые уже собирает компания, и объединяя эти данные с внешними источниками. Вот лишь некоторые из потенциальных преимуществ, которые интеллектуальный анализ данных может принести бизнесу. Результаты интеллектуального анализа данных часто демонстрируются на информационных панелях в программном обеспечении для бизнеса, которое объединяет метрики и ключевые показатели эффективности и отображает их с помощью простых для понимания визуальных элементов.
Оптимальная цена продукта / услуги: Использование интеллектуального анализа данных для анализа взаимодействия переменных ценообразования, таких как спрос, эластичность, распределение и восприятие бренда, может помочь бизнесу устанавливать цены, которые максимизируют прибыль.
Улучшенный маркетинг: Интеллектуальный анализ данных может помочь компании получить больше пользы от своих маркетинговых кампаний, сегментируя клиентов с различным поведением, оптимизируя взаимодействие по сегментам или обеспечивая понимание, помогающее в разработке персонализированного рекламного объявления.Результаты рекламных кампаний часто можно продемонстрировать на информационных панелях продаж.
Повышенная продуктивность сотрудников: Анализ моделей поведения сотрудников и просмотр ключевых показателей эффективности на панелях управления персоналом может привести к разработке стратегий повышения вовлеченности и производительности сотрудников.
Улучшение удержания клиентов: Понимание поведения клиентов может улучшить отношения с ними, сокращая отток.
Повышенная рентабельность: Производственные затраты, например, можно снизить с помощью множества различных анализов интеллектуального анализа данных, от понимания ценового поведения поставщиков до лучшего понимания моделей покупательского поведения клиентов.
Более высокое качество продукции / услуг: Выявление и устранение областей, в которых наблюдается нестабильность качества, может снизить возврат продукции.


Проблемы конфиденциальности
Ни одна организация не должна начинать инициативу по интеллектуальному анализу данных, включающую информацию о клиентах и сотрудниках, без тщательного рассмотрения потенциальных проблем конфиденциальности и этических вопросов, которые могут возникнуть.Алгоритмы интеллектуального анализа данных могут находить закономерности и взаимосвязи, которые могут привести к идентификации людей, даже если в процессе сбора данных принимаются меры для защиты их конфиденциальности. Следовательно, любая организация, планирующая использовать интеллектуальный анализ данных, в котором задействованы люди, должна включать экспертов по конфиденциальности и этике, которые помогут направлять их работу с самого начала проекта.
Процесс интеллектуального анализа данных
Интеллектуальный анализ данных — это итеративный процесс, который обычно начинается с заявленной бизнес-цели, например повышения продаж, удержания клиентов или эффективности маркетинга.Процесс работает путем сбора данных, разработки цели и применения методов интеллектуального анализа данных. Выбранная тактика может варьироваться в зависимости от цели, но эмпирический процесс интеллектуального анализа данных остается неизменным.
Определите цель: Хотите узнать больше о своих клиентах? Хотите сократить производственные затраты? Хотите увеличить доход? Вы хотите обнаружить мошенничество? Чтобы приступить к работе, четко определите желаемый результат внедрения интеллектуального анализа данных.
Соберите данные: Интеллектуальный анализ данных может ответить на все эти вопросы, но для каждого из них требуется свой набор данных.
Часто данные поступают из нескольких баз данных, например, клиенты и заказы.Очистить данные: После выбора данные обычно необходимо очистить, переформатировать и проверить.
Ознакомьтесь с данными: Ознакомьтесь с данными, выполнив базовый статистический анализ и построив наглядные графики и диаграммы.Именно здесь аналитики определяют переменные, которые, по их мнению, наиболее важны для достижения цели, и начинают формировать гипотезы, которые приводят к модели.
Построение модели: Построение модели — это то место, где процесс интеллектуального анализа данных является наиболее итеративным. Аналитики выбирают один или несколько технологических подходов, обсуждаемых в следующем разделе, и применяют один или несколько к добываемым данным. Возможные подходы лучше подходят для разных вопросов.
Результатом этого шага является поиск подхода к технологии интеллектуального анализа данных, который дает наиболее полезные результаты.Это может потребовать повторения третьего шага, потому что некоторые модели требуют, чтобы данные были отформатированы определенным образом.Подтвердите результаты: Какие бы методы не использовались, изучите результаты, чтобы убедиться в их точности. Если нет, вернитесь к шагу № 5 — перестройте модель.
Реализуйте модель: Используйте открытия для достижения исходной бизнес-цели.
 Часто данные поступают из нескольких баз данных, например, клиенты и заказы.
Часто данные поступают из нескольких баз данных, например, клиенты и заказы.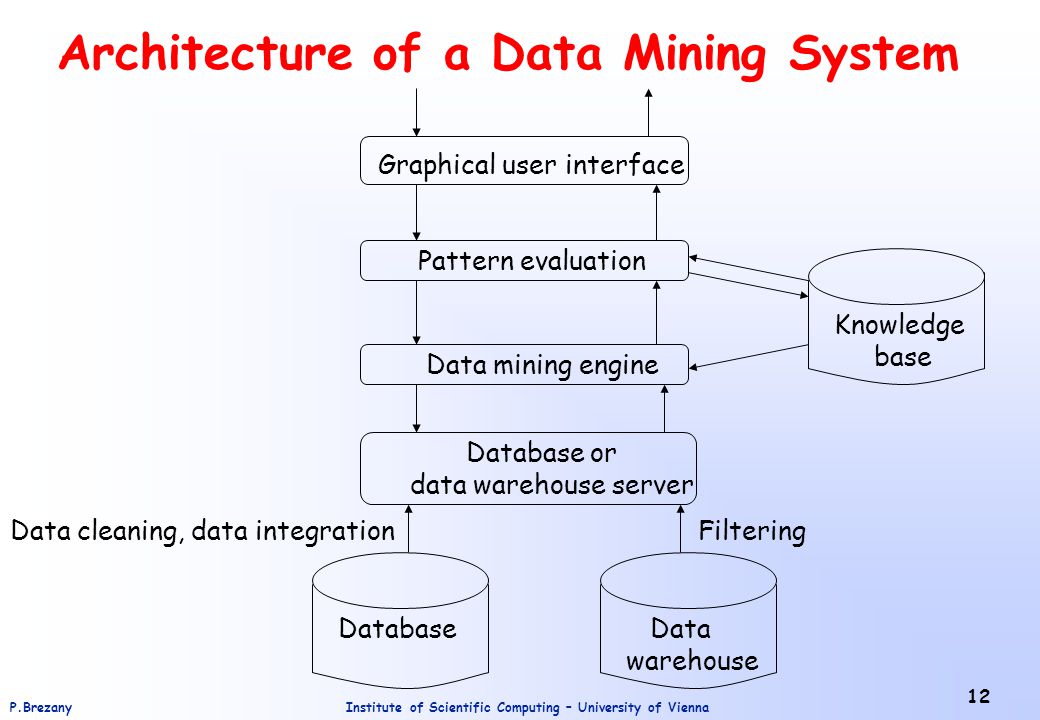 Результатом этого шага является поиск подхода к технологии интеллектуального анализа данных, который дает наиболее полезные результаты.Это может потребовать повторения третьего шага, потому что некоторые модели требуют, чтобы данные были отформатированы определенным образом.
Результатом этого шага является поиск подхода к технологии интеллектуального анализа данных, который дает наиболее полезные результаты.Это может потребовать повторения третьего шага, потому что некоторые модели требуют, чтобы данные были отформатированы определенным образом.Технология интеллектуального анализа данных
Большая часть интеллектуального анализа данных использует хорошо известные алгоритмы, которые объединяют, сегментируют, связывают и классифицируют данные. Каждый метод строит модель, которая затем используется для описания текущих данных или прогнозирования результатов для новых случаев данных.
Классификация: Присваивает данные нескольким категориям или классам. Например, соискатель кредита может быть отнесен к категории низкого, среднего или высокого риска.Обычно категории для модели предопределяются на основе предыдущего анализа данных.
Обнаружение аномалий: Форма классификации, использующая машинное обучение для обнаружения данных, не соответствующих классу. Например, обнаружение аномалий используется для обнаружения списаний с мошеннических кредитных карт.
Кластеризация: Обозначает группы похожих данных. Например, кластеризацию можно использовать для поиска клиентов с похожими покупательскими привычками.
Связь: Создает вероятность одновременного возникновения нескольких событий. Одно из приложений — это «анализ корзины», который определяет, когда два или более товара часто покупаются вместе.
Регрессия: Используя набор данных, значения которого известны, методы регрессии пытаются предсказать значение на основе нескольких атрибутов. Например, регрессия может предсказывать продажи на основе рекламных долларов, месяцев, посещений веб-сайтов и других финансовых атрибутов.
Нейронные сети: Форма искусственного интеллекта, которая имитирует человеческий мозг для поиска взаимосвязей в данных. Нейронные сети имеют множество приложений, например, для прогнозирования поведения клиентов.

Сценарии и примеры использования интеллектуального анализа данных
По мере того, как отдельные организации собирают большие объемы данных, становится доступным больше общедоступных наборов данных, а технологии интеллектуального анализа данных становятся более простыми в использовании и менее дорогостоящими, потенциальные приложения интеллектуального анализа данных расширяются. Примеры улучшения процессов и получения преимуществ интеллектуального анализа данных можно найти в нескольких бизнес-сегментах. И легко экстраполировать эти варианты использования, чтобы представить, как ваша организация может развернуть интеллектуальный анализ данных. Вот лишь некоторые из бесчисленных способов, которыми интеллектуальный анализ данных уже используется.
Примеры улучшения процессов и получения преимуществ интеллектуального анализа данных можно найти в нескольких бизнес-сегментах. И легко экстраполировать эти варианты использования, чтобы представить, как ваша организация может развернуть интеллектуальный анализ данных. Вот лишь некоторые из бесчисленных способов, которыми интеллектуальный анализ данных уже используется.
Банковское дело: Интеллектуальный анализ данных используется для прогнозирования успешных соискателей кредита, а также для обнаружения мошенничества с кредитными картами.
Розничная торговля: Создавайте эффективные рекламные объявления на основе прошлых ответов.
Страхование: Прогнозирование вероятности и стоимости будущих бедствий на основе прошлых ураганов или торнадо.
Продуктовые магазины: Проанализируйте рыночные корзины, чтобы найти продукты, обычно покупаемые вместе.
Проведение рекламной акции для одного товара может улучшить продажи другого товара по его нормальной цене.Производство: Осуществляйте своевременное выполнение заказов, прогнозируя, когда следует заказать новые расходные материалы или когда оборудование может выйти из строя.
Управление взаимоотношениями с клиентами: Определите характеристики клиентов, которые переходят к конкурентам, а затем предложите специальные предложения для удержания других клиентов с такими же характеристиками.
Безопасность: Методы обнаружения вторжений используют интеллектуальный анализ данных для выявления аномалий, которые могут быть взломами сети.
 Проведение рекламной акции для одного товара может улучшить продажи другого товара по его нормальной цене.
Проведение рекламной акции для одного товара может улучшить продажи другого товара по его нормальной цене.История и эволюция интеллектуального анализа данных
На протяжении веков люди вручную анализировали данные, чтобы найти закономерности. Развитие цифровых информационных технологий и баз данных, начавшееся в 1950-х годах, конечно же, изменило правила игры для такого анализа. Термин «интеллектуальный анализ данных» вошел в употребление примерно в 1990 году, когда исследования технологий и методов, описанных выше, нашли практическое применение в сообществе компьютерных баз данных. Популярность интеллектуального анализа данных выросла в основном из-за того, что он продемонстрировал ценность для компаний.
Развитие цифровых информационных технологий и баз данных, начавшееся в 1950-х годах, конечно же, изменило правила игры для такого анализа. Термин «интеллектуальный анализ данных» вошел в употребление примерно в 1990 году, когда исследования технологий и методов, описанных выше, нашли практическое применение в сообществе компьютерных баз данных. Популярность интеллектуального анализа данных выросла в основном из-за того, что он продемонстрировал ценность для компаний.
Сегодня большие хранилища данных с информацией, собранной из нескольких источников в различных форматах, в сочетании с большей емкостью хранилища и более быстрыми компьютерами, позволяют даже небольшим компаниям пользоваться преимуществами интеллектуального анализа данных.Алгоритмы интеллектуального анализа данных также стали более сложными. Например, относительно новые методы машинного обучения могут вывести отношения, не обнаруженные предыдущими алгоритмами.
Будущее интеллектуального анализа данных
Фундаментальные технологии, лежащие в основе интеллектуального анализа данных — вычисления, базы данных, хранилища данных, нейронные сети, машинное обучение и искусственный интеллект — продолжают становиться более мощными, менее дорогими и простыми в использовании.![]() Таким образом, они становятся более доступными для многих других — и более мелких — предприятий.Итак, общее будущее интеллектуального анализа данных состоит в том, что он будет находить все более широкое применение во многих других и более разнообразных видах бизнеса.
Таким образом, они становятся более доступными для многих других — и более мелких — предприятий.Итак, общее будущее интеллектуального анализа данных состоит в том, что он будет находить все более широкое применение во многих других и более разнообразных видах бизнеса.
Тем временем становится доступным все больше данных о мире, в котором мы живем, что открывает потенциал для развития будущих методов интеллектуального анализа данных, специально предназначенных для анализа того, что мы сейчас считаем нетрадиционными данными. Это включает видео, аудио и изображения; географические и пространственные данные; и данные мобильного телефона, и они часто хранятся в так называемом озере данных.Подобно хранилищу данных, озера данных являются хранилищами информации, но данные не должны быть структурированы и хранятся в естественном или необработанном формате.
В обозримом будущем интеллектуальный анализ данных включает его потенциальное использование во всем: от обыденных — подумайте о том, чтобы найти лучшие авиабилеты на данный момент или лучшие цены на портативные генераторы в Лонг-Айленде, штат Нью-Йорк, — до глубоких, таких как новые методы лечения или открытия природа Вселенной.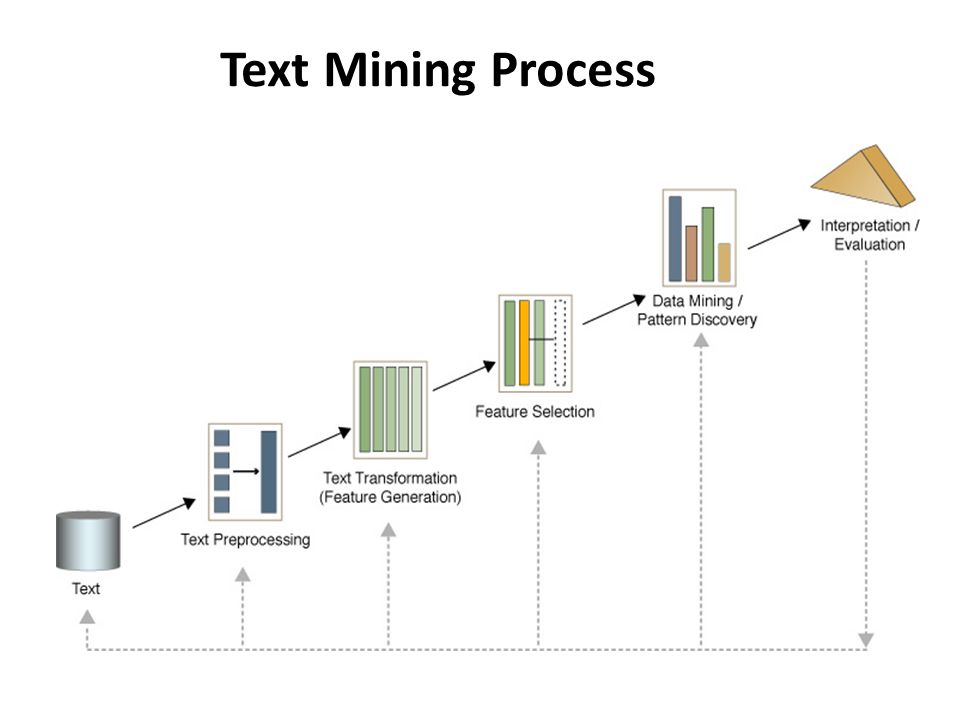
Программное обеспечение и инструменты для интеллектуального анализа данных
В прошлом специалистам по анализу данных приходилось использовать такие языки программирования, как R и Python, в приложениях для интеллектуального анализа данных. Однако теперь есть инструменты, которые упрощают интеллектуальный анализ данных, а программное обеспечение может выполнять многие из необходимых задач и помогать выявлять правила и другие выводы из ваших данных. В эти инструменты обычно включены графические возможности для визуализации результатов на предварительно настроенных и настраиваемых информационных панелях бизнес-аналитики.
Совсем недавно программное обеспечение облачных хранилищ данных стало доступным для компаний, которые в противном случае не смогли бы позволить себе интеллектуальный анализ данных или иметь ИТ-инфраструктуру, необходимую для его поддержки. Эти инструменты представляют собой значительное упрощение того, что требуется организации для проведения интеллектуального анализа данных. Они могут хранить собственные данные компании в том же репозитории, что и внешние данные, и могут включать как структурированные, так и частично структурированные данные. Они также представляют собой шаг вперед в вычислительной мощности, а это означает, что анализ интеллектуального анализа данных может выполняться быстрее, чем раньше.
Они могут хранить собственные данные компании в том же репозитории, что и внешние данные, и могут включать как структурированные, так и частично структурированные данные. Они также представляют собой шаг вперед в вычислительной мощности, а это означает, что анализ интеллектуального анализа данных может выполняться быстрее, чем раньше.
Объединив все данные организации в одном хранилище, компания может получить более полное и целостное представление о своих операциях. А за счет включения данных, полученных извне, и их интеллектуального анализа вместе с внутренними данными, бизнес может открыть для себя новые возможности.
Заключение
Интеллектуальный анализ данных открывает компаниям возможности для повышения своей прибыли за счет выявления закономерностей и взаимосвязей в данных, которые они уже собирают.Его преимущества доказаны во всех отраслях. Между тем технологии, необходимые для интеллектуального анализа данных, становятся более автоматизированными, более простыми в использовании и менее дорогими, что делает их более доступными для небольших организаций. Будущие возможности интеллектуального анализа данных ограничены только воображением компании.
Будущие возможности интеллектуального анализа данных ограничены только воображением компании.
Часто задаваемые вопросы по интеллектуальному анализу данных
Что вы подразумеваете под интеллектуальным анализом данных?
Data Mining объединяет статистику, искусственный интеллект и машинное обучение для поиска закономерностей, взаимосвязей и аномалий в больших наборах данных.На основе этих знаний компания может выявить текущее поведение и предсказать будущие тенденции.
Для чего используется интеллектуальный анализ данных?
Знания, полученные с помощью интеллектуального анализа данных, можно использовать практически неограниченными способами — ограниченными только наличием данных и воображением организации, чтобы их использовать. Сегодня интеллектуальный анализ данных используется для улучшения маркетинга, прогнозирования покупательских тенденций, обнаружения мошенничества, фильтрации электронных писем, управления рисками, увеличения продаж и улучшения отношений с клиентами.
Какие навыки требуются для интеллектуального анализа данных?
Специалисты по обработке данных разработали сложные алгоритмы интеллектуального анализа данных, которые теперь реализованы в программном обеспечении, что позволяет компаниям без специальных знаний добывать свои данные. Но интеллектуальный анализ данных по-прежнему требует аналитиков, которые понимают природу бизнеса, а также данные, которые бизнес генерирует или получает из внешних источников.
Что такое интеллектуальный анализ данных и его типы?
Data Mining может использоваться для описания текущих закономерностей и взаимосвязей в данных, прогнозирования будущих тенденций или обнаружения аномалий или выбросов данных.Для этого используются три основные модели или типы: описательная модель, которая находит закономерности и взаимосвязи в текущих данных; прогностическая модель, которая используется для предсказания будущих результатов; и анализ выбросов, который обнаруживает аномалии — данные, которые не укладываются в шаблон.
Что такое интеллектуальный анализ данных? — DATAVERSITY
Data Mining — это более старая (а теперь родственная) подгруппа машинного обучения и искусственного интеллекта, которая работает с большими наборами данных.Он использует технологии распознавания образов со статистическими и математическими методами для прогнозирования бизнес-тенденций и поиска полезных моделей. «Интеллектуальный анализ данных также известен как обнаружение знаний в данных (KDD)». Компонент интеллектуального анализа данных, интеллектуального анализа текста, анализирует документы с анализом текста, автоматически классифицируя контент по онтологиям, которые можно легко найти.
Методы интеллектуального анализа данных и текста включают:
- Профилирование: Определение норм и обнаружение аномалий
- Сокращение данных : Замена большого набора данных меньшим набором, который содержит большую часть важной информации в большом наборе, для упрощения обработки и анализа
- Ассоциация: Связывание и обучение без присмотра, «чтобы найти взаимосвязи между элементами обучения на основе транзакций, в которых они участвуют. Это включает «частый поиск наборов элементов, обнаружение правил и рыночный анализ»
- Кластеризация: Группирование элементов вместе по общим характеристикам (например, сегментация клиентов)
- Самоорганизующиеся карты : Анализ кластеров с использованием методов нейронной сети
 Это включает «частый поиск наборов элементов, обнаружение правил и рыночный анализ»
Это включает «частый поиск наборов элементов, обнаружение правил и рыночный анализ»Обычно интеллектуальный анализ данных выполняет компьютерный язык Python. Интеллектуальный анализ данных обещает стать более эффективным, поскольку методы и инструменты для работы с большими данными продолжают совершенствоваться. Подобно прогрессу, достигнутому в прогнозировании того, когда и где ударит шторм или ураган, интеллектуальный анализ данных продолжает улучшаться, например.г. индивидуальный интеллектуальный анализ данных для конкретного бизнеса.
Другие определения интеллектуального анализа данных включают:- «Процесс, в котором предприятия просматривают данные, чтобы найти соответствующую информацию». (Дэвид Андерсон)
- «Процесс обнаружения значимых корреляций, закономерностей и тенденций путем просеивания больших объемов данных, хранящихся в репозиториях. Интеллектуальный анализ данных использует технологии распознавания образов, а также статистические и математические методы.(Gartner IT Glossary)
- «Процесс обнаружения полезных закономерностей и тенденций в больших наборах данных». (OReilly)
- «Быстро развивающаяся область, которая занимается разработкой методов, помогающих менеджерам разумно использовать« электронные хранилища ». (MIT)
- «Незаменимая технология для предприятий и исследователей во многих областях. Опираясь на работу в таких областях, как статистика, машинное обучение, распознавание образов, базы данных и высокопроизводительные вычисления, интеллектуальный анализ данных извлекает полезную информацию.”(MIT Press).
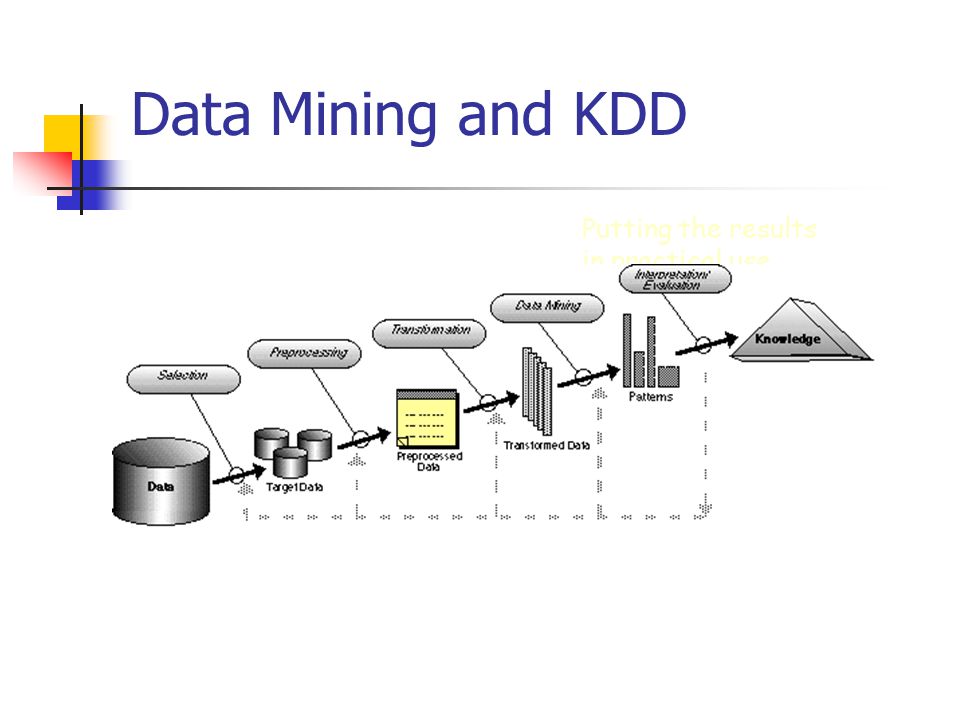 (Дэвид Андерсон)
(Дэвид Андерсон)- Розничный торговец, который «нашел способ точно определить, какие клиенты впервые, вероятно, станут долгосрочными спонсорами»
- Страховая компания, которая сократила расходы и ускорила обслуживание клиентов после того, «обнаружив, какие офисы обрабатывают определенные общие типы требований более эффективно, чем любые другие. другое »
- Правоохранительный орган отказался от неэффективного процесса определения приоритетности дел и работал над чем-то лучшим.
- « Производитель обнаружил предупреждающие признаки разлива химикатов, предоставив информацию, необходимую для предотвращения будущих аварий, защиты окружающей среды и избежания дорогостоящих капиталовложений и судебных разбирательств »
 другое »
другое »- Помогите избежать дорогостоящих ошибок
- Сделайте обработку данных более актуальной
- Выявите пробелы в
- Увеличьте прибыль
- Прогнозируйте краткосрочное движение цен
Изображение используется по лицензии Shutterstock.com
Интеллектуальный анализ данных в бизнес-аналитике
Проще говоря, интеллектуальный анализ данных — это процесс, который компании используют для превращения необработанных данных в полезную информацию.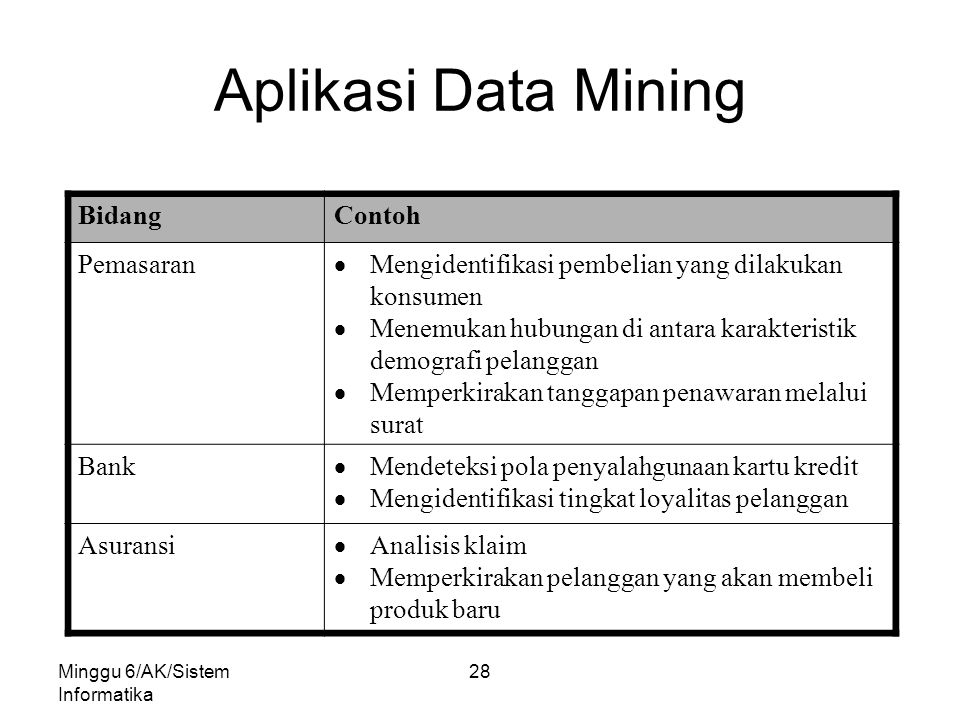 Они используют программное обеспечение для поиска закономерностей в больших пакетах данных, чтобы больше узнать о клиентах. Он извлекает информацию из наборов данных и сравнивает ее, чтобы помочь бизнесу принимать решения. В конечном итоге это помогает им разрабатывать стратегии, увеличивать продажи, эффективно продвигать рынок и т. Д.
Они используют программное обеспечение для поиска закономерностей в больших пакетах данных, чтобы больше узнать о клиентах. Он извлекает информацию из наборов данных и сравнивает ее, чтобы помочь бизнесу принимать решения. В конечном итоге это помогает им разрабатывать стратегии, увеличивать продажи, эффективно продвигать рынок и т. Д.
Интеллектуальный анализ данных иногда путают с машинным обучением и анализом данных, но все эти термины очень разные и уникальны.
Хотя и интеллектуальный анализ данных, и машинное обучение используют шаблоны и аналитику, интеллектуальный анализ данных ищет шаблоны, которые уже существуют в данных, в то время как машинное обучение выходит за рамки предсказания будущих результатов на основе данных. В интеллектуальном анализе данных «правила» или закономерности неизвестны с самого начала. Во многих случаях машинного обучения машине дается правило или переменная для понимания данных. Кроме того, интеллектуальный анализ данных полагается на вмешательство и решения человека, но машинное обучение предназначено для запуска человеком, а затем обучения само по себе. Существует много общего между интеллектуальным анализом данных и машинным обучением, процессы машинного обучения часто используются в интеллектуальном анализе данных для автоматизации этих процессов.
Существует много общего между интеллектуальным анализом данных и машинным обучением, процессы машинного обучения часто используются в интеллектуальном анализе данных для автоматизации этих процессов.
Точно так же анализ данных и интеллектуальный анализ данных не взаимозаменяемые термины. Интеллектуальный анализ данных используется в аналитике данных, но это не одно и то же. Интеллектуальный анализ данных — это процесс получения информации из больших наборов данных, а аналитика данных — это когда компании берут эту информацию и погружаются в нее, чтобы узнать больше. Анализ данных включает в себя проверку, очистку, преобразование и моделирование данных.Конечная цель анализа — обнаружение полезной информации, обоснование выводов и принятие решений.
Интеллектуальный анализ данных, анализ данных, искусственный интеллект, машинное обучение и многие другие термины объединены в процессы бизнес-аналитики, которые помогают компании или организации принимать решения и больше узнавать о своих клиентах и потенциальных результатах.