Введение в RapidMiner / Habr
На данный момент существует много компаний нуждающихся в системах аналитики, но дороговизна и чрезмерная сложность данного ПО в большинстве случаев вынуждает отказаться от идеи построения собственной аналитической системы в пользу простого всем известного экселя. Также дополнительные расходы на обучение сотрудников, поддерживание дорогих систем хранения данных и т.д. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner. RapidMiner (далее просто «майнер») — инструмент созданный для дата майнинга, с основной идеей, что майнер (аналитик) не должен программировать при выполнении своей работы. При этом как известно, для майнинга нужны данные, поэтому его снабдили достаточно хорошим набором операторов решающих большой спектр задач получения и обработки информации из разнообразных источников (базы данных, файлы и т.п.), и можно с уверенностью говорить, что это ещё и полноценный инструмент для ETL.К нашему с вами сожалению, с 6 версии создатели майнера решили начать зарабатывать денежку на продажах этого ПО и сменили лицензию с AGPL на Business Source. Тем не менее 5 версия AGPL и мы можем её использовать свободно и без ограничений. Поэтому в статье будет рассмотрена именно она. Также отметим, что в шестой версии не так много новых операторов и функций (пожалуй самое интересно это поддержка облака), и для большинства задач хватит RapidMiner 5 Community.
Не так давно c официального сайта ссылки на скачивание RapidMiner 5 были удалены, поэтому соберем RM из исходного кода который возьмем в официальном проекте на гитхабе.
Для сборки RapidMiner’a из репозитория нам понадобится
 Зайдем в консоль, перейдем в каталог куда хотели бы поставить майнер, клонируем репозиторий
Зайдем в консоль, перейдем в каталог куда хотели бы поставить майнер, клонируем репозиторийgit clone https://github.com/rapidminer/rapidminer-5.gitследующий шаг соберем проект
ant build
ant release.makePlatformIndependentтеперь запустим майнер
.\scripts\RapidMinerGUI.bat
для линукса соответственно
./scripts/RapidMinerGUI.shПеред вами откроется окно как на картинке справа. Нажимаем на New Process и идем дальше.
Перед тем как на примере посмотреть основные принципы работы с RapidMiner сделаем небольшое введение в его основные понятия.
Процесс
Совокупность операторов соединенных между собой в заданном порядке для выполнения требуемой задачи анализа/обработки данных.
Оператор
Логическая единица процесса. Оператор производит какие то действия над данными, у него есть вход-выход (так называемые «порты»), на вход приходят данные, на выход идут обработанные оператором данные. Таким образом мы можем делать цепочки обработки данных, к примеру — считать транзакции клиентов из БД, найти самые большие, сконвертировать в доллары и выдать результат. При этом можно цепочки параллелить — к примеру в одной мы читаем транзакции из разных БД, а в другой ищем данные клиентов, потом объединяем и получаем результат (при этом также возможно их параллельное исполнение во времени!).
В интерфейсе программы операторам соответствует вкладка Operators — где в иерархии они сгруппированы по функциональному признаку. Чтобы воспользоваться оператором необходимо нажать на него и перенести в рабочую область процесса.
Репозиторий
Место для хранения процессов RM. Может быть локальным, а также удаленным (RapidMiner Server), для которого возможно исполнять процессы на стороне сервера, многопользовательский доступ к процессам/соединениям БД, запуск процессов по расписанию или отдача данных как веб-сервис.
Во вкладе Repositories в RM тут можно увидеть только Samples, DB и Local Repository. Первое как уже понятно из название набор процессов — примеров, DB — текущие соединения к базам данных доступных в майнере (определяются через Tools -> Manage Database Connections) и Local Repository, место для хранения собственных процессов на компьютере.
Контекст процесса
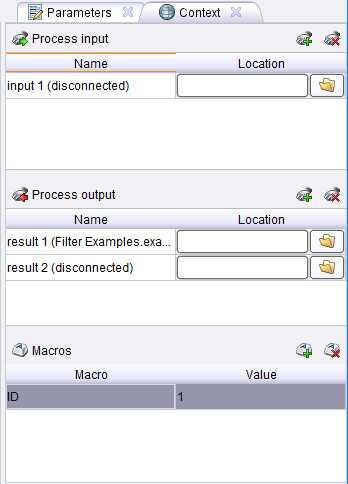
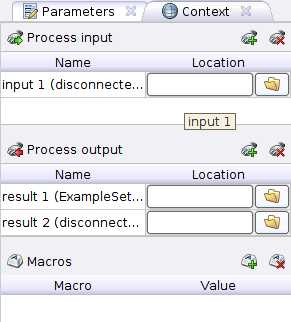 Контексту соответствует вкладка Context где мы можем увидеть три секции:
Контексту соответствует вкладка Context где мы можем увидеть три секции:- Process input
- Process output — тут указывается путь в репозитории, куда будет сохранен результат работы процесса.
- Macros — это глобальная переменная доступная в процессе из любого места. Может принимать в качестве значения только строки или числа.
Отметим, что Process input и Process output обозначены в процессе кружками по границе процесса с надписями inp и res. Чтобы воспользоваться данными из входа или сохранить их нужно соединить соответствующий кружок с входом/выходом операторов.
Самое лучшее обучение — практика. Сделаем небольшой процесс на основе которого увидим основные принципы работы с майнером.
Небольшая задачка
Вы директор небольшой компании, которая занимается созданием сайтов, промышленным дизайном и т.д. Достаточно часто, ввиду большого количества заказов и недостатка сотрудников вы нанимаете фрилансеров из разных стран (т.к. клиенты со всего мира) и исправно вносите информацию о выполненных работах в эксель табличку указывая имя исполнителя, род работы, дату оплаты, сумму и валюту оплаты. В какой то момент вам захотелось получить сумму затрат, в рублях (на курс ЦБ), которую вы понесли в разбивке по видам работ на конкретную дату (более интересные случаи — разбивка по месяцам, сотрудникам остаются на собственные эксперименты).
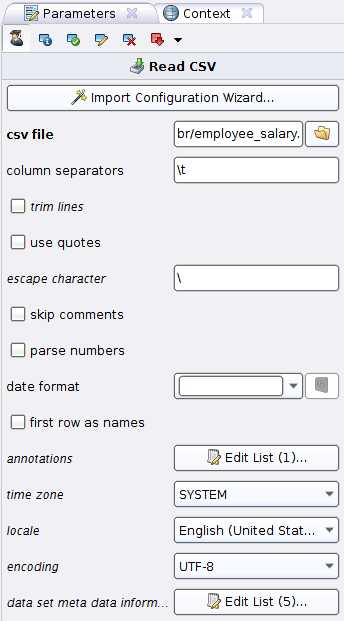 Первое, что мы сделаем, это сохраним наш эксель файлик в формате CSV и откроем его на чтение в RapidMiner’e. Для этого, возьмем оператор Read CSV (Import -> Data -> Read CSV) и перетянем его в рабочую область процесса. Далее нажимаем на него и видим справа настройки оператора. Нажмём на значок открытой папочки , в диалоговом окне выбираем требуемый нам файл (используемый CSV в примере можно скачать по ссылке)
Первое, что мы сделаем, это сохраним наш эксель файлик в формате CSV и откроем его на чтение в RapidMiner’e. Для этого, возьмем оператор Read CSV (Import -> Data -> Read CSV) и перетянем его в рабочую область процесса. Далее нажимаем на него и видим справа настройки оператора. Нажмём на значок открытой папочки , в диалоговом окне выбираем требуемый нам файл (используемый CSV в примере можно скачать по ссылке)Обратим внимание на нажатую кнопку — режим эксперта. В нём доступны дополнительные параметры для операторов, как правило нужные почти всегда и помечаемые курсивом.
Выставляем параметры как на картинке справа и жмем на Edit list справа от
Как можно догадаться тут мы выставляем названия колонок, галочка ставится, чтобы исключить или включить колонку из результата парсинга, тип и роль. Роли отличные от attribute могут понадобиться в майнинге, в обычном же случае они как правило не требуются.
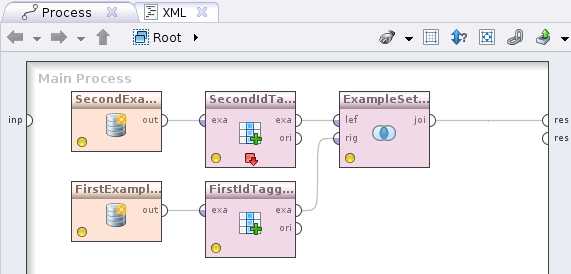
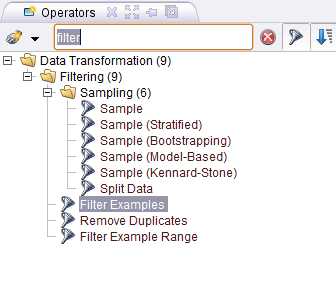
Нажимаем Apply и переходим к следующему шагу. Добавим оператор Filter examples (Data Transformation -> Filtering), его вход соединим с выходом Read CSV, а выход с выходом процесса обозначенным кружочком и надписью res. У вас получится такая картина
 С помощью добавленного оператора мы выберем записи только на указанную дату которую объявим как макрос процесса. Идем на вкладку
С помощью добавленного оператора мы выберем записи только на указанную дату которую объявим как макрос процесса. Идем на вкладку
Так вкладка Context на данном шаге у вас будет выглядеть как на картинке справа. Макрос (напомню, т.е. глобальную переменную) мы определили и теперь воспользуемся им для фильтра записей по дате из нашего CSVшничка. Жмем на оператор Filter Examples выбираем в condition class attribute_value_filter и в parameter string пишем: date = %{date}. Слева мы указали название колонки по которой происходит фильтрация, по центру операция проверки на равенство и справа взятие значения из макроса.
Посмотрим, что получилось. Жмём на кнопочку запуска процесса и майнер переключившись на Result perspective (если этого не произошло нажмите на ) отобразит отфильтрованные данные на 30 июля 2012 года.
Первый результат получен, но нам хотелось бы видеть затраты в рублях по курсу ЦБ РФ. Переключаемся на Design Perspective нажатием на и добавляем оператор Open file (Utility -> Files -> Open file). Нажимаем на него и выставляем следующие настройки
Где url: http://www.cbr.ru/scripts/XML_daily.asp?date_req=%{date}
Обратим внимание, что мы подставили макрос в параметр оператора.
Получить данные мы получим, но что-то должно их преобразовать в ExampleSet — т.е. таблицу с данными. В первом случае эту роль выполнял Read CSV, а сейчас как не трудно догадаться мы воспользуемся Read XML (Import -> Data -> Read XML). Тянем оператор, соединяем его вход с выходом оператора Open file и делаем следующие настройки (если вы испытываете трудности с xpath воспользуйтесь мастером импорта нажав наImport configuration wizard).
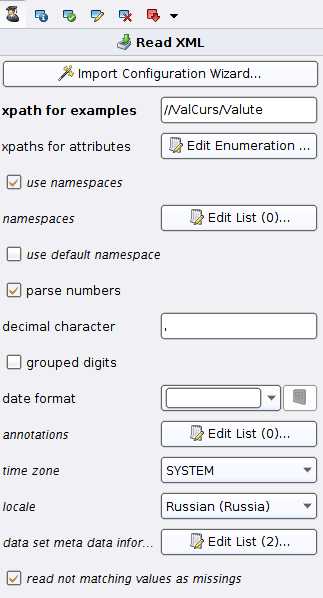 Обратите внимание, что выставлена галочка parse numbers и разделителем целой и дробной части выставлена запятая.
Обратите внимание, что выставлена галочка parse numbers и разделителем целой и дробной части выставлена запятая.
Value[1]/text() — стоимость в рублях единицы валюты
CharCode[1]/text() — буквенный код валюты
Теперь необходимо выставить типы значений для атрибутов. Для этого нажимаем на Edit list справа от data set meta datainformation и выставляем как на картинке ниже
На данном этапе мы имеем процесс который у вас должен выглядеть так
Пришло время сделать конвертацию валют в отфильтрованных по дате данным. Для этого, как можно догадаться, нам потребуется каким то образом объединить котировки и данные. В этом нам поможет оператор
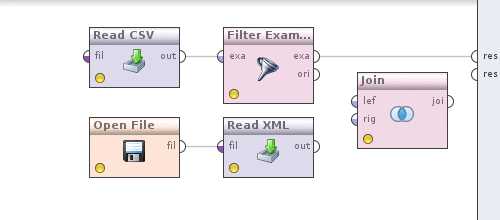
Теперь нажмем на оператор Join и определим как именно будут объединятся данные. Убираем галочку use id attribute as key, так как объединение у нас происходит по полю currency, появится новый параметр key attributes нажмем слева от него наEdit list, в диалоге Add entry и в обоих полях пропишем —
Мы все ближе к заветной цели — узнать сколько же мы потратили в рублях на наши задачи. Остался последний штрих, собственно сама конвертация. Добавим в процесс оператор Generate Attributes (Data Transformation -> Attribute Set Reduction and Transformation -> Generation) и соединим его вход с выходом оператора Join, а первый выход около которого написано exp (сокращенно ExampleSet)к выходу процесса. Как понятно из названия оператора его задача добавить новый атрибут, для этого нажмем на оператор и справа в его настройках на Edit list, кнопка напротив function descriptions. Дадим название атрибуту и как его считать
Сохраняем изменения и выполняем процесс, наш результат
Ура! Вот она заветная цифра затрат в рублях которую мы понесли по курсу ЦБ на дату оплаты. Развить данную задачу можно очень далеко, к примеру сделать вывод информации за месяц, в группировке по типу работ, исполнителю или датам. В общем, простор фантазии.
Полезные материалы
habr.com
RapidMiner — платформа для анализа больших данных
К концу XXI века объем информации превысит 4,22 йоттабайт (или 4,22*1024 степени). А объем интернет-трафика перешел уже отметку в один зеттабайт и через пару лет составит несколько зетттабайт. Эту информацию необходимо обработать и представить в читаемый вид.
Но для этих задач необходимо нанять дорогостоящих специалистов, купить специализированное программное обеспечение. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner. RapidMiner (далее просто «майнер») — инструмент, созданный для дата майнинга, с основной идеей, что майнер (аналитик) не должен программировать при выполнении своей работы. При этом как известно, для майнинга нужны данные, поэтому его снабдили достаточно хорошим набором операторов решающих большой спектр задач получения и обработки информации из разнообразных источников (базы данных, файлы и т.п.), и можно с уверенностью говорить, что это ещё и полноценный инструмент для ETL ( Extract, Transform, Load).

RapidMiner — это мощная и многопользовательская платформа, она служит для создания, передачи и обслуживания наукоемких данных. Платформа RapidMiner предлагает больше функций, чем любое другое визуальное решение, плюс она открыта и расширяема для поддержки всех потребностей научных данных.
Унифицированная платформа RapidMiner ускоряет создание полных аналитических рабочих процессов — от подготовки данных до моделирования до развертывания бизнеса — в единой среде, значительно повышая эффективность и сокращая время, необходимое для проектов в области данных.
Профессиональная лицензия платная. В стандартной лицензии AGPL доступно 10,000 колонок и ограничение в один логический процесс.
- Хороший GUI. По сути, каждый функциональный блок собран в кубик. Ничего нового в подходе, но очень крутое исполнение. Обычно разница между классическим программированием и визуальным сильно бьёт по функциональности. Например, в SPSS Modeler всего 50 узлов, а тут целых 250 в базовой загрузке.
- Есть хорошие инструменты подготовки данных. Обычно предполагается, что данные готовятся где-то ещё, но тут уже есть готовый ETL (получение и трансформация). В том же коммерческом SPSS возможностей для подготовки куда меньше.
- Расширяемость. Есть язык программирования R. Полностью интегрированы операторы система WEKA.
- Дружит с Hadoop (отдельное платное расширение с незамысловатым названием Radoop), причём как с чистым, так и с коммерческими реализациями.
- Архитектурно данные снаружи. Ставим платформу, грузим данные и начинаем смотреть, где какие кореляции, что можем спрогнозировать. Это и плюс, и минус, почему — ниже.
- Кроме IDE есть ещё сервер. Rapid Miner Studio создаёт процессы, а на сервере их можно публиковать. Что-то типа Cron — сервер знает, какой процесс когда запускать, с какой частой, что делать, если где-то что-то отвалилось, кто отвечает за каждый из процессов, кому как отдавать ресурсы, куда выгружать результаты.
- А ещё сервер же умеет сразу строить минимальные отчёты. Можно выгружать не в XLS, а рисовать графику прямо там. Это нравится маркетингу маленьких проектов.
- Быстрое развитие. Только поднялся серьезный шум вокруг Apache Spark — через месяц интегрировали.
Если сравнивать RapidMiner c другими программами, то у RM гораздо шире функциональные возможности по обработке, банально больше узлов. С другой стороны, в IBM SPSS есть режимы «автопилота». Авто-модели (Auto Numeric, Auto Classifier) — перебирают несколько возможных моделей с разными параметрами, выбирают несколько лучших. Не сильно опытный аналитик может построить на таком адекватную модель. Она почти наверняка будет уступать в точности построенным опытным специалистом, но есть сам факт — можно построить модель ничего не понимая в этом. В RM есть аналог (Loop and Deliver Best), но он все же требует хотя бы выбрать модели и критерии выбора лучшего. Автоматическая предобработка данных (Auto Data Prep) — другая известная фишка SPSS — иначе и чуть более муторно реализована в RapidMiner. В SPSS сборка данных выполняется одним узлом Automated Data Preparation, галочками проставляется, что нужно сделать с данными. В RapidMiner — собирается из атомарных узлов в произвольной последовательности.

Если сравнивать с SAS. По возможностям «сделать что угодно» RM выше, но, в конечном итоге, с помощью какой-то матери и некоторых усложнений можно получить тот же результат и в SAS. Но здесь совершенно другой подход — придётся переучиваться, если вы привыкли к SAS. Ещё SAS предоставляет множество вертикальных решений — банки, ритейл. Платформа разговаривает с пользователем на его бизнес-языке. RM более абстрактен, в нём придётся самому формулировать, что есть что.
Процесс в RapidMiner представляет собой набор операторов, соединенных последовательно между собой. Есть операторы, которые считывают данные из файла, есть операторы, которые производят фильтр по определенным признакам, есть операторы, которые записывают результат в файл, и многие другие.
Оператор — это логическая единица, которая может производить какое-то действие над данными. Оператор имеет вход и выход. На входе поступают сырые данный, на выходе получаются обработанные данные. Все операторы доступны в левой колонке и отсортированы по функциональному признаку.
Еще одна интересная особенность RapidMiner от IBM SPSS и SAS. В RapidMiner есть макросы — это параметры работы процесса, которые можно использовать в любой его точке (т.е они являются глобальными переменными). Например, в качестве макроса можно использовать имя файла, дату его создания, среднее значение какого-либо атрибута данных, наилучшую достигнутую точность, номер итерации, последнее время запуска процесса.
Место для хранения процессов RM. Может быть локальным, а также удаленным (RapidMiner Server), для которого возможно исполнять процессы на стороне сервера, многопользовательский доступ к процессам/соединениям БД, запуск процессов по расписанию или отдача данных как веб-сервис.
Кроме Макроса во вкладке контекст присутствуют параметры process input и process output.
process input- данных, подающиеся на вход. Может быть указан путь откуда вытаскивать данные.
process output. — данные, которые передаются к следующему процессу. Может быть указан путь для сохранения данных.

После создания процесса и его запуска можно построить графики разброса величин и многое другое.


Кроме скачивания дистрибутива программы с официального сайта https://my.rapidminer.com/nexus/account/index.html#downloads , также можно скачать git репозиторий и собрать проект с помощью apache ant.
git clone https://github.com/rapidminer/rapidminer-5.git
ant build
ant release.makePlatformIndependent

businessarchitecture.ru
16. Возможности Rapid Miner для работы с данными.
С википедии:
RapidMiner (прежнее название YALE) — среда для проведения экспериментов и решения задач машинного обученияиинтеллектуального анализа данных. Эксперименты описываются в виде суперпозиций произвольного числа произвольным образом вложенных операторов, и легко строятся средствами визуального графического интерфейсаRapidMiner-а.
RapidMiner — открытый программный продукт, свободно распространяемый под лицензией GNU AGPLv3.
RapidMiner может работать и как отдельное приложение, и как «интеллектуальный движок», встраиваемый в другие приложения, включая коммерческие.
Приложениями RapidMiner-а могут быть как исследовательские (модельные), так и прикладные (реальные) задачи интеллектуального анализа данных, включая анализ текста(text mining),анализ мультимедиа(multimedia mining),анализ потоков данных(data stream mining).
Функциональные возможности
RapidMiner предоставляет более 400 операторов для всех наиболее известных методов машинного обучения, включая ввод и вывод, предварительную обработку данных и визуализацию.
RapidMiner интегрирует в себя < операторы WEKA.
Имеется встроенный язык сценариев, позволяющий выполнять массивные серии экспериментов.
Концепция многоуровневого представления данных (multi-layered data view) обеспечивает эффективную и прозрачную работу с данными.
Графическая подсистема обеспечивает многомерную визуализацию данных и моделей.
Имеется пошаговый учебник, включающий популярное введение в машинное обучениеиинтеллектуальный анализ данных.
Реализация и технологии
Программное обеспечение написано целиком на Java, поэтому работает во всех основных операционных системах.
Для представления экспериментов как суперпозиций операторов применяется язык XML.
Встраивание в другие приложения осуществляется посредством Java API.
Поддерживаются механизмы плагинов (plugin) и расширений (extension).
История
Начальная версия была разработана в 2001 году группой Искусственного Интеллекта технологического иниверситета в Дортмунде (Artificial Intelligence Unit of Dortmund University of Technology).
Начиная с 2004 года исходные коды RapidMiner-а доступны на SourceForge.
Более
подробно, более неформальным языком: Вот
интерфейс.  Вы
закидываете данные, а потом просто
перетаскиваете операторы в GUI, формируя
процесс обработки данных. От вас —
только понимание того, что вы делаете.
Весь код берёт на себя среда. «Под капот»
можно, конечно, залезть, но в большинстве
случаев это просто не надо.
Вы
закидываете данные, а потом просто
перетаскиваете операторы в GUI, формируя
процесс обработки данных. От вас —
только понимание того, что вы делаете.
Весь код берёт на себя среда. «Под капот»
можно, конечно, залезть, но в большинстве
случаев это просто не надо.
Важные фичи
Хороший GUI. По сути, каждый функциональный блок собран в кубик. Ничего нового в подходе, но очень крутое исполнение. Обычно разница между классическим программированием и визуальным сильно бьёт по функциональности. Например, в SPSS Modeler всего 50 узлов, а тут целых 250 в базовой загрузке.
Есть хорошие инструменты подготовки данных. Обычно предполагается, что данные готовятся где-то ещё, но тут уже есть готовый ETL. В том же коммерческом SPSS возможностей для подготовки куда меньше.
Расширяемость. Есть старый добрый язык R. Полностью интегрированы операторы система WEKA. В общем, это не «детский сад» и не закрытый фреймворк. Надо будет спуститься на низкий уровень — без проблем.
Дружит с Hadoop (отдельное платное расширение с незамысловатым названием Radoop), причём как с чистым, так и с коммерческими реализациями. То есть когда вы решите молотить не табличку XLS с демо-набором данных, а боевую БД, да еще и при помощи модного ныне Apache Spark — всё сразу встанет как надо. Самое приятное — писать код не надо. Можно в майнере аналитиком написать скрипт через всё тот же GUI и отдать в обработку.
Архитектурно данные снаружи. Ставим платформу, грузим данные и начинаем смотреть, где какие кореляции, что можем спрогнозировать. Это и плюс, и минус, почему — ниже.
Кроме IDE есть ещё сервер. Rapid Miner Studio создаёт процессы, а на сервере их можно публиковать. Что-то типа планировщика — сервер знает, какой процесс когда запускать, с какой частой, что делать, если где-то что-то отвалилось, кто отвечает за каждый из процессов, кому как отдавать ресурсы, куда выгружать результаты. В общем, все-все-все современные плюшки.
А ещё сервер же умеет сразу строить минимальные отчёты. Можно выгружать не в XLS, а рисовать графику прямо там. Это нравится маркетингу маленьких компаний и удобно для небольших проектов. И, естественно, это очень недорого (даже в коммерческой версии) в сравнении с Моделлером и SAS. Но — сразу говорю — области применения у них разные.
Быстрое развитие. Только поднялся серьезный шум вокруг Apache Spark — через пару месяцев вышел релиз о поддержке базового функционала.
Минусы
Деньги. С 2011 года в опенсорс уходит предпоследняя версия продукта. С выходом новой предыдущая становится опенсорсной. Cтартер не позволяет строить процессы, обработка которых съест больше гигибайта оперативной памяти. Триал две недели.
Компания по Гартнеру не самая большая. Это плохо для внедрения и поддержки, потому что своими силами они это делать не могут. С другой стороны, всё это для больших бизнесов по политике компании отдаётся на интеграторов (то есть, как раз нам).
Авторитет компании пока не накоплен — внедрений не так много, молодая. За SAS ещё никого не увольняли, даже если бюджет в три раза выше, а здесь имя не на слуху.
Плохо с консалтингом, нет формализованных процессов техподдержки. Предполагается, что это всё делают, опять же, интеграторы. Мы и делаем, но с точки зрения большого бизнеса нельзя не упомянуть про эту особенность.
Не все вещи анализируются на сервере, в некоторых случаях платформа пробует агрегировать данные на локальной машине. Это плохо, когда модель требует всей базы, то есть когда нельзя взять и прогнать алгоритм на небольшом куске данных. Предполагается, что вы используете Hadoop или аналог для решения этой проблемы. Там всё есть.
Аналитика классических баз данных (то, что не Big Data по критерию многообразия) на шаг позади классических решений. То есть если вы захотите сделать предагрегацию перед выгрузкой in-database, то это нужно задать ручками явно, сам RapidMiner до этого не догадается.
Задачи Итак, перед нами чистое поле для решения любых задач. Наиболее частые в России, решающиеся такими инструментами — это:
Анализ транзакций (например, банковских) для противодействия мошенничеству.
Клиентская аналитика. Это самая горячая тема. Проще всего и выгоднее всего бывает выстроить модель оттока клиентов и отмечать флагом тех, кто к этому готов. Для рынка телекомов, например, переход абонента куда-то ещё — это трагедия, потому что людей больше не становится. Поэтому за флажок «клиент может убежать» они готовы платить реальные деньги.
Персональные рекомендации. Это любит розница — что кому предложить. Как раз тот случай, когда вы только-только не купили презервативы, а про вас уже запомнили, что через несколько месяцев нужно давать скидки на детское питание.
Прогнозирование поставок и продаж. При том, что есть готовые пакеты для этого, RapidMiner тупо дешевле. Не надо покупать Боинг, если у вас средний бизнес. И не надо покупать тот же JDA (он стоит как два Боинга). Нет, там всё очень круто и по возможностям, и по интеграции — но банально мало кто может позволить себе это купить.
Текстовая аналитика — о чём люди пишут. Например, анализ эмоционального оттенка отзывов или комментариев в автоматическом режиме. Это «50 жаловались на связь в Волгограде по улице Победы», «20 похвалили сервис», «Основная причина недовольства абонентов — частые разрывы соединения» и так далее.
Часто бывает нужна готовая интеграция на уровне базы и веб-сервисов. По сути, тут ничего не надо писать, задаётся только частота опроса, какие модель и процесс использовать, и кто потребитель. Для асинхронных или месячных отчётов ещё проще, есть даже подтягивания данных из Дропбокса для совсем малого бизнеса и готовая интеграция с Амазоновскими сервисами.
Коммерческий RapidMiner очень хорошо работает с большими данными. Exadata и Vertica — классические базы данных 2.0 или массивно-параллельные СУБД — поддерживаются «во все тяжкие».
RapidMiner vs IBM SPSS Modeler У RM гораздо шире функциональные возможности по обработке, банально больше узлов. С другой стороны, в SPSS есть режимы «автопилота». Авто-модели (Auto Numeric, Auto Classifier) — перебирают несколько возможных моделей с разными параметрами, выбирают несколько лучших. Не сильно опытный аналитик может построить на таком адекватную модель. Она почти наверняка будет уступать в точности построенным опытным специалистом, но есть сам факт — можно построить модель ничего не понимая в этом. В RM есть аналог (Loop and Deliver Best), но он все же требует хотя бы выбрать модели и критерии выбора лучшего. Автоматическая предобработка данных (Auto Data Prep) — другая известная фишка SPSS — иначе и чуть более муторно реализована в RapidMiner. В SPSS сборка данных выполняется одним узлом Automated Data Preparation, галочками проставляется, что нужно сделать с данными. В RapidMiner — собирается из атомарных узлов в произвольной последовательности.
studfiles.net
рапид майнинг — Лучшее видео смотреть онлайн
Опубликовано: 50 лет назад
8 881 просмотр
Опубликовано: 2 часа назад
23 616 просмотров
Опубликовано: 4 часа назад
1 566 просмотров
Опубликовано: 5 часов назад
9 просмотров
Опубликовано: меньше минуты назад
119 просмотров
Опубликовано: меньше минуты назад
35 просмотров
Опубликовано: меньше минуты назад
133 просмотра
Опубликовано: 2 часа назад
270 361 просмотр
Опубликовано: 5 часов назад
57 просмотров
Опубликовано: меньше минуты назад
5 просмотров
Опубликовано: меньше минуты назад
63 просмотра
Опубликовано: 50 лет назад
97 569 просмотров
Опубликовано: 50 лет назад
5 707 просмотров
Опубликовано: 5 часов назад
18 просмотров
Опубликовано: 3 часа назад
355 просмотров
Опубликовано: 2 часа назад
21 просмотр
Опубликовано: меньше минуты назад
396 просмотров
Опубликовано: меньше минуты назад
208 просмотров
Опубликовано: 1 час назад
45 просмотров
luchshee-video.ru
Подробно о Битс рапид майнинг
В наше время слова «Майнинг», «Блокчейн», «Биткоины» раздаются буквально отовсюду: от пассажиров трамвая до серьёзных бизнесменов и депутатов Госдумы. Разобраться во всех тонкостях и подводных камнях этих и смежных понятий сложно, однако в базе данных на нашем сайте Вы быстро найдёте исчерпывающую информацию, касающуюся всех аспектов.
Ищем дополнительную информацию в базах данных:
Битс рапид майнинг
Базы онлайн-проектов:
Данные с выставок и семинаров:
Данные из реестров:
Дождитесь окончания поиска во всех базах.
По завершению появится ссылка для доступа к найденным материалам.
Вкратце же все необходимые знания будут изложены в этой статье.
Итак, начать стоит с блокчейна. Суть его в том, что компьютеры объединяются в единую сеть через совокупность блоков, содержащую автоматически зашифрованную информацию, попавшую туда. Вместе эти блоки образуют базу данных. Допустим, Вы хотите продать дом. Оформив документы, необходимо идти к нотариусу, затем в присутствии его, заверив передачу своей подписью, Вам отдадут деньги. Это долго, да и к тому же нужно платить пошлину.
Благодаря технологии блокчейна достаточно:
- Договориться.
- Узнать счёт получателя.
- Перевести деньги на счёт получателя.
…и не только деньги. Можно оформить электронную подпись и отправлять документы, любую другую информацию, в том числе и конфиденциальную. Опять же, не нужны нотариусы и другие чиновники: достаточно идентифицироваться Вам и получателю (будь то частное лицо или госучреждение) в своём компьютере.
Транзакция проходит по защищённому каналу связи, никто не видит (в том числе банки и государство), кто, что и кому перевёл.
Возможность взломать исключена из-за огромного количества блоков, описанных выше. Для хакера нужно подобрать шифр для каждого блока, что физически нереально.
Другие возможности использования блокчейна:
- Страхование;
- Логистика;
- Оплата штрафов
- Регистрация браков и многое другое.
С блокчейном тесно связано понятие криптовалюта. Криптовалюта — это новое поколение децентрализованной цифровой валюты, созданной и работающей только в сети интернет. Никто не контролирует ее, эмиссия валюты происходит посредством работы миллионов компьютеров по всему миру, используя программу для вычисления математических алгоритмов.
Вкратце это выглядит так:
1. Вы намереваетесь перевести кому-то деньги.
2. Генерируется математический код, проходящий через уже известные Вам блоки.
3. Множество компьютеров (часто представляющих собой совокупность их, с мощными процессорами и как следствие большей пропускной способностью) обрабатывают цифровую информацию, передавая их на следующие блоки, получая за это вознаграждение (некоторые транзакции можно совершать бесплатно)
4. Математический код доходит до электронного кошелька получателя, на его балансе появляются деньги.
Опять же, как это в случае с блокчейном, переводы криптовалют никем не контролируются.
Хотя база данных открыта, со всеми адресами переводящих и получающих деньги, но владельца того или иного адреса, с которого осуществляется перевод, никто не знает, если только хозяин сам не захочет рассказать.
Работающих по подобному принципу валют много. Самой знаменитой является, конечно, биткоин. Также популярны эфириум, ритл, лайткоины, нумитсы, неймкоины и многие другие. Разница у них в разном типе шифрования, обработки и некоторых других параметрах.
Зарабатывают на технологии передачи денег майнеры.
Это люди, создавшие упомянутую выше совокупность компьютерных видеокарт, которая генерирует новые блоки, передающие цифровую информацию — биткоины (или ритлы, или любую другую криптовалюту). За это они получают вознаграждение в виде той же самой криптовалюты.
Существует конкуренция между майнерами, т.к. технология с каждой транзакции запрограммировано усложняется. Сначала можно было майнить с одного компьютера (2008 год), сейчас же такую валюту как биткоин физическим лицам уже просто невыгодно: нужно очень много видеокарт (их все вместе называют фермами), с огромными вычислительными мощностями. Для этого снимаются отдельные помещения, затраты электроэнергии для работы сравнимы с затратами промышленных предприятий.
Зато можно заработать на других, менее популярных, но развивающихся криптовалютах. Также различают соло майнинг и пул майнинг. Соло — это создание своей собственной фермы, прибыль забирается себе. Пул же объединяет других людей с такими же целями. Заработать можно гораздо больше, но придётся уже делиться со всеми.
Перспективами использования технологии блокчейна вообще и криптовалют в частности заинтересовались как и физические лица, так и целые государства.
В Японии криптовалюта узаконена. В России в следующем году собираются принять нормативно-правовые акты о легализации блокчейна, переводов криптовалюты и майнинга. Планируется перевод некоторых операций в рамки блокчейна. Имеет смысл изучить это подробнее, и, при желании, начать зарабатывать. Очевидно, что сейчас информационные технологии будут развиваться и входить в нашу жизнь всё больше и больше.
safe-crypto.me