7 Самая полезная разница между интеллектуальным анализом данных и веб-анализом
Разница между Data Mining и Web Mining
Интеллектуальный анализ данных : это концепция определения значительного шаблона из данных, который дает лучший результат. Выявление закономерностей откуда? Из данных, которые генерируются из систем.
Веб-майнинг . Процесс майнинга данных в сети называется веб-майнингом. Извлечение веб-документов и обнаружение шаблонов из них.
Пример: методы, применяемые для прогнозного анализа. (Прогноз погоды на основе определения закономерностей на основе данных истории)
Позволяет нам понять основные различия между интеллектуальным анализом данных и веб-анализом подробно в этом посте.
аналогия
Золото производится в процессе, называемом добычей золота. Он добывается и очищается от руды. Конечный результат добычи золота — драгоценный металл. Точно так же,
Чтобы получить ключевую информацию (данные, которые стоит) из необработанного источника, применяется метод интеллектуального анализа данных. Здесь шаблон, обнаруженный из необработанного источника данных, считается ценным для аналитика данных / исследователей данных, чтобы приступить к принятию решения, которое влияет на ценность для бизнеса.
Здесь шаблон, обнаруженный из необработанного источника данных, считается ценным для аналитика данных / исследователей данных, чтобы приступить к принятию решения, которое влияет на ценность для бизнеса.
Сбор данных
Проще говоря, интеллектуальный анализ данных — это концепция интеллектуального анализа знаний из различных наборов данных. Извлеченные знания в дальнейшем используются для предоставления прогнозов или рекомендаций. Данные для добычи доступны либо в хранилище данных, либо в других внешних системах. Данные могут быть доступны в разных таблицах с различными поведенческими характеристиками или атрибутами. Чтобы идентифицировать образец, должна быть идентифицирована корреляция между множественными наборами данных.
Шаги в интеллектуальном анализе данных
Поскольку интеллектуальный анализ данных является абстрактным, вот список необходимых шагов,
- Подготовка данных
- Открытие образца
- Построить модели для прогноза / рекомендации (чтобы упомянуть несколько случаев)
- Подводя итог стоимости модели
Веб майнинг
Веб-майнинг является абстрактным, поскольку существует три различных типа майнинга.
- Майнинг веб-контента
- Майнинг веб-структуры
- Майнинг использования веб
Веб-майнинг классы сбора информации
Майнинг веб-контента
Данные с веб-страниц извлекаются для того, чтобы обнаружить различные шаблоны, которые дают значительную информацию. Существует много методов извлечения данных, таких как очистка веб-страниц (например, scrapy и Octoparse — это хорошо известные инструменты, которые выполняют процесс анализа веб-контента.
Один из лучших примеров — чтобы провести мероприятие или какую-либо программу, сначала организация должна проанализировать места (какое место лучше всего подходит для проведения программы, чтобы обеспечить полную посещаемость). Чтобы выполнить эти анализы, нужно собрать информацию о городе, штате и регионе, в которой находится событие от приглашенного. Любые данные о местоположении могут быть извлечены из Интернета. Вот тут-то и появляется майнинг веб-контента.
Майнинг веб-структуры
Данные из гиперссылок, которые ведут на разные страницы, собираются и подготавливаются для обнаружения шаблона. Чтобы просмотреть общедоступный профиль человека из блога или любой другой веб-страницы, есть вероятность, что он вставит свои ссылки в социальных сетях. Таким образом, данные извлекаются не только из одного источника, но и из вложенных страниц через гиперссылки, связанные с каждой страницей. Существуют различные алгоритмы для этого. (Пример: алгоритм PageRank)
Чтобы просмотреть общедоступный профиль человека из блога или любой другой веб-страницы, есть вероятность, что он вставит свои ссылки в социальных сетях. Таким образом, данные извлекаются не только из одного источника, но и из вложенных страниц через гиперссылки, связанные с каждой страницей. Существуют различные алгоритмы для этого. (Пример: алгоритм PageRank)
Веб-майнинг использования:
Когда размещается веб-приложение, создается множество журналов веб-сервера, связанных с пользовательской веб-активностью приложения. Эти журналы рассматриваются как необработанные данные, в результате извлекаются значимые данные и идентифицируются шаблоны.
Например, для любого бизнеса в области электронной коммерции, когда они хотят расширить сферу деятельности или добавить усовершенствование для улучшения качества обслуживания клиентов, веб-активность пользователя через журналы приложений отслеживается и к ним применяется интеллектуальный анализ данных.
Веб-майнинг и интеллектуальный анализ данных являются более или менее похожими методами, но веб-майнинг — это все, что связано с анализом в сети. Интеллектуальный анализ данных не ограничивается Интернетом. Это традиционный процесс, который имеет место для любой аналитики данных.
Интеллектуальный анализ данных не ограничивается Интернетом. Это традиционный процесс, который имеет место для любой аналитики данных.
Говоря о данных из Интернета, есть множество данных, которые можно наблюдать. Это могут быть структурированные данные (данные базы данных извлекаются через API, если они публикуются для общего доступа). Полуструктурированные данные — любая связанная веб-активность или даже журналы сервера. Или даже неструктурированные данные, такие как изображения и т. Д. (Если анализ изображений выполняется)
Сравнение личных данных между интеллектуальным анализом данных и веб-анализом (инфографика)
Ниже приведены 7 лучших сравнений Data Mining и Web Mining.
Ключевые отличия Data Mining от Web Mining
Ниже приведены различия между интеллектуальным анализом данных и веб-интеллектуальным анализом.
Веб-майнинг и анализ данных почти одинаковы, когда дело доходит до определения шаблонов. Но где и в чем отличие веб-майнинга от интеллектуального анализа данных. Какие данные и данные извлекаются откуда? Это два важнейших аспекта, определяющих разницу между интеллектуальным анализом данных и веб-анализом.
Какие данные и данные извлекаются откуда? Это два важнейших аспекта, определяющих разницу между интеллектуальным анализом данных и веб-анализом.
Веб-майнинг относится к интеллектуальному анализу данных, но он ограничен данными, относящимися к сети, и выявлением закономерностей. Интеллектуальный анализ данных — это обширная концепция, которая включает в себя несколько этапов, начиная от подготовки данных до проверки конечных результатов, которые приводят к процессу принятия решений в организации.
Сравнение данных и интеллектуального анализа данных
| Основа для сравнения | Сбор данных | Веб майнинг |
| концепция | Идентификация шаблона по данным, доступным в любых системах. | Идентификация шаблона из веб-данных. |
| Применение / варианты использования | Прогноз погоды с использованием исторических отчетов о погоде | Сканирование данных Хиты / методы PageRank |
| Кто это делает? | Ученые данных Инженеры данных | Ученые данных / Аналитики данных Инженеры данных |
| Процесс | Извлечение данных -> Обнаружение паттернов -> Разработка функции / ее решение (алгоритм) | Тот же процесс, но в Интернете с использованием веб-документов |
| инструменты | Алгоритмы машинного обучения | Пестрый, PageRank, Логи Apache |
| Насколько значительный | Многие организации полагаются на результаты науки о данных для принятия решений.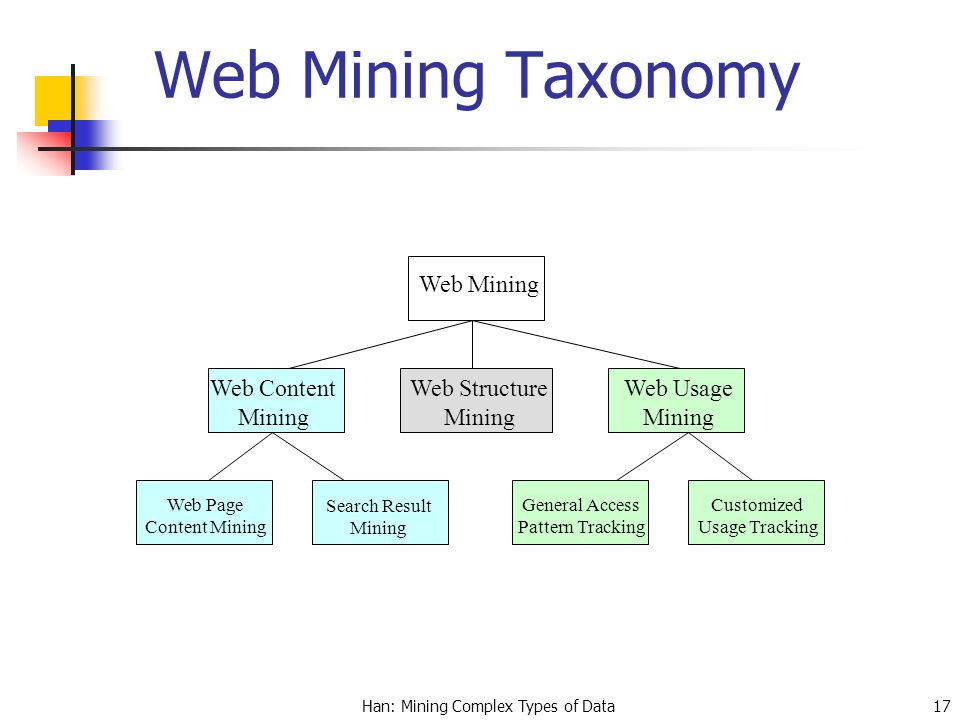 | Извлечение данных из Интернета повлияет на существующий процесс извлечения данных. |
| Навыки и умения | Методы очистки данных, алгоритмы машинного обучения, статистика, вероятность | Знание уровня приложения, Инженерия данных, статистика, вероятность |
Заключение — Data Mining против веб-майнинга
Любые методы майнинга с данными должны обнаружить знания и то, насколько хорошо они могут быть использованы для достижения лучшего результата. Организациям, которые заинтересованы в расширении своего бизнеса и получении высокой прибыли, им нужно принимать множество решений на основе данных, которые в основном доступны в их системах, генерируемых в огромных объемах. Считается, что не все данные дают знания и понимание. Какие, почему и каковы основные вопросы, которые должны думать ученые-аналитики данных, когда они готовятся к выявлению закономерностей. В терминах очень непрофессионала, добыча данных похожа на процесс взбивания молока для производства масла.
Рекомендуемая статья
Это было руководство по интеллектуальному анализу данных и веб-майнингу, их значению, сравнению «голова к голове», основным отличиям, сравнительной таблице и выводам. Вы также можете посмотреть следующие статьи, чтобы узнать больше —
- Data Mining и статистика — какая из них лучше
- 10 мощных шагов к эффективному планированию веб-дизайна
- Интеллектуальный анализ данных и машинное обучение — 10 лучших вещей, которые вам нужно знать
- Лучшие 3 вещи, которые нужно узнать о Data Mining против Text Mining
- Инструменты и методы, используемые в процессе интеллектуального анализа данных
Что такое веб майнинг?
Веб-майнинг — это форма сбора информации, которая применяется к данным, собранным из онлайн-источников. Сбор данных из источников в Интернете позволяет пользователям собирать большие объемы информации для анализа, чтобы принимать ключевые бизнес-решения в онлайн-среде. Например, исследователь может использовать веб-майнинг для сбора информации об использовании определенных ключевых слов в веб-контенте. Кроме того, ритейлеры и другие специалисты по маркетингу используют онлайн-анализ данных для выявления тенденций в веб-трафике, конверсии посетителей сайта в покупателей и других видов использования в сети.
Кроме того, ритейлеры и другие специалисты по маркетингу используют онлайн-анализ данных для выявления тенденций в веб-трафике, конверсии посетителей сайта в покупателей и других видов использования в сети.
С точки зрения сбора, сортировки и анализа данных, веб-майнинг имитирует традиционные операции по сбору данных. Для сравнения, операции веб-майнинга сосредоточены на информации, основанной на веб-технологиях, а не на большом сечении источников информации, таких как автономные компьютерные базы данных, записи клиентов или учетные данные в печатном виде, как это обычно происходит при традиционном интеллектуальном анализе данных. Сосредоточение внимания исключительно на сборе данных из онлайн-источников обеспечивает целенаправленный анализ, необходимый для стратегий онлайн-маркетинга, решений по структуре веб-сайтов и аналогичных решений, связанных с электронной торговлей. Сбор данных с помощью веб-майнинга также предоставляет дополнительные преимущества широкого международного демографического исследования, поскольку веб-сайты со всего мира доступны для исследователей и сборщиков информации.
Профессионально, веб-майнинг подразделяется на три конкретные категории: веб-структура, интеллектуальный анализ и веб-контент. Каждая область фокусируется на конкретной информации, такой как структура и гиперссылки на конкретном веб-сайте, информация о журнале сервера, касающаяся использования посетителями, и конкретный контент, доступный в Интернете. Пакеты и услуги аналитического программного обеспечения для веб-сайтов являются ярким примером анализа использования веб-сайтов, предоставляя веб-мастерам информацию о посещаемости посетителей, используемых результатах поиска, щелчках по ссылкам и времени, потраченном на взаимодействие с конкретными страницами. Анализ структуры, с другой стороны, предоставляет подробную информацию о внутренней структуре конкретного веб-сайта, включая гиперссылки, базы данных и функции запросов.
Для специалистов по маркетингу веб-майнинг предлагает множество применений, связанных с маркетинговой деятельностью. Знание того, как посетители сайта используют конкретный сайт, как конкуренты создают конкурирующий сайт и какой контент уже находится в сети, является ценной информацией. Такая информация помогает ключевым лицам, принимающим решения, разработать маркетинговую стратегию, основанную на ранее проверенных методах и документированной информации.
Такая информация помогает ключевым лицам, принимающим решения, разработать маркетинговую стратегию, основанную на ранее проверенных методах и документированной информации.
Колледжи и университеты также используют веб-майнинг с помощью программного обеспечения, которое проверяет, что студенческие документы уникальны и не плагиат. Используя принципы интеллектуального анализа веб-контента, такие помощники оценивают во всем Интернете похожий контент. Преподаватели загружают текст студенческого документа, а затем инструктируют программное обеспечение для плагиата проверить в Интернете похожие фразы или скопированный текст в Интернете. Результаты часто выражаются в процентах от соответствующего текста. Предоставляются ссылки на любые подобные результаты, чтобы инструкторы могли посещать сайты, чтобы определить, действительно ли совпадения были плагиатом.
ДРУГИЕ ЯЗЫКИ
ExxonMobil объявляет о начале производства новых продуктов для горнодобывающей отрасли в России
Техника, применяемая в горнодобывающей промышленности, работает в крайне тяжелых условиях, поэтому используемые здесь масла должны обладать высокими эксплуатационными характеристиками.
Результаты обратной связи, собранной компанией ExxonMobil от крупнейших представителей горнодобывающей промышленности, показали, что значительный сегмент российских предприятий из этой сферы заинтересован в экономически эффективных смазочных материалах высокого качества. Для удовлетворения данной потребности компания ExxonMobil приняла решение о начале производства ряда новых продуктов для потребителей в горнодобывающем секторе на местных предприятиях в России.
Новые моторные и гидравлические масла были специально разработаны в соответствии с требованиями, предъявляемыми к эксплуатации горнодобывающей техники, широко применяющейся в России. Новые продукты призваны помочь потребителям из горнодобывающего сектора снизить совокупную стоимость владения техникой и повысить эффективность ее использования. Применение новых продуктов должно способствовать повышению уровня безопасности людей, работающих с оборудованием, за счет снижения времени контакта с работающей техникой, а также снижению воздействия на окружающую среду за счет увеличения интервалов замены смазочных материалов и уменьшения объемов отработанного масла.
Mobil Delvac™ Mining 15W-40 – моторное масло, разработанное специально для применения в дизельных двигателей с учетом нагрузок, типичных для горнодобывающей промышленности: обладает высокой термической и антиокислительной стабильностью, высокими моющими и диспергирующими свойствами, уменьшает образование отложений и скорость загустевания масла, а также повышает чистоту двигателя и срок службы узлов. Масло рекомендуется к применению в самосвалах, экскаваторах, бульдозерах, внедорожной технике, дизель-генераторах и другой технике, используемой как в горнодобывающей промышленности, так и в других отраслях.
Серия Mobil Hydraulic HVI Ultra — противоизносные гидравлические масла с высокими эксплуатационными характеристиками, разработанные для применения в широком диапазоне температур. Масла обеспечивают надежную защиту пластинчатых, поршневых и шестеренных насосов от износа, обладают оптимальной текучестью при отрицательных температурах, устойчивы к сдвиговым нагрузкам и потере вязкости, а также снижают расходы на утилизацию отработанных продуктов.
Моторное масло Mobil Delvac™ Mining 15W-40 и гидравлические масла серии Mobil Hydraulic HVI Ultra поставляются бестарно (наливом), а также в бочках объемом 208 литров. Подробнее о маслах Mobil для горнодобывающего сектора вы можете узнать на сайте Mobil, а также у сотрудников коммерческого отдела.
О компании ExxonMobil:
ExxonMobil — одна из крупнейших международных открытых акционерных компаний – использует технологии достижения и инновации для удовлетворения растущего энергетического спроса на международном рынке. Компания располагает самыми масштабными в отрасли производственными ресурсами и входит в число крупнейших мировых компаний по переработке, производству и маркетингу нефтепродуктов и продуктов нефтехимии. Более подробную информацию можно получить на exxonmobil.com и на сайте Energy Factor.
Следите за нами в социальных сетях Twitter и LinkedIn.
Майнинг по Превентехи | Cummins Inc.

Заблаговременное выявление проблем позволяет максимально увеличить время безотказной работы
Система PrevenTech® Mining использует возможности установления связи, большие массивы данных, передовые средства анализа данных и технологию «Интернет вещей» (IoT), чтобы обеспечить надежный дистанционный мониторинг работы двигателя и оповещение о возможных проблемах в работе двигателя, используя предупреждения и рекомендации, которые доставляются по электронной почте, телефону и посредством веб-панели мониторинга клиента.
Повышение производительности и сокращение расходов
Позаботьтесь о том, чтобы ваши объекты работали дольше и испытывали меньше отказов и одновременно продлите срок службы двигателя и предупредите появление проблем, связанных с исправностью оборудования, прежде чем их устранение повлечет за собой повышенные расходы.
Оптимизация технического и сервисного обслуживания
Адаптируйте интервалы обслуживания, исходя из фактического использования двигателей на объектах. Следите в режиме реального времени за состоянием горнодобывающего оборудования, чтобы более грамотно планировать простои и проведение ремонтных работ.
Следите в режиме реального времени за состоянием горнодобывающего оборудования, чтобы более грамотно планировать простои и проведение ремонтных работ.
Мониторинг с поддержкой специалистов позаботится о вашем спокойствии
Воспользуйтесь дополнительной функцией поддержки клиентов 24/7 Cummins Care, которая позволяет получать индивидуальные рекомендации по проведению обслуживания в режиме реального времени у специалистов компании Cummins со всего мира.
Гибкие уровни обслуживания в соответствии с вашими требованиями
Система PrevenTech® Mining предлагает три отдельных уровня обслуживания, представленных вариантами «Базовый», «Плюс» и «Премиум». Диапазон предлагаемых функций в рамках этих уровней обслуживания варьируется от обязательного предупреждения о появлении кода неисправности, использования настраиваемых правил и пороговых значений до усовершенствованных алгоритмов прогнозирования Fleetguard FIT™, мониторинга в режиме реального времени специалистами службы Cummins Care и других функций.
Запросить цену или демонстрационную версию
Смотреть брошюру «Обзор PrevenTech®»
Ознакомиться с буклетом по примерам использования PrevenTech®
Построение модели поведения пользователя на веб-ресурсе средствами process mining
Кузнецов Андрей Андреевич
Санкт-Петербургский Политехнический Университет Петра Великого
Институт информационных технологий и управления, студент кафедры Компьютерные интеллектуальные технологии
Kuznetcov Andrei Andreevich
Peter the Great Saint-Petersburg Polytechnic University
institute of computing and control, Student of Intelligent Computer Technologies Department
Библиографическая ссылка на статью:
Кузнецов А.А. Построение модели поведения пользователя на веб-ресурсе средствами process mining // Современные научные исследования и инновации. 2015. № 5. Ч. 2 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2015/05/53873 (дата обращения: 29. 01.2022).
01.2022).
Анализ процессов (process mining) – это относительно новая дисциплина. Основная идея анализа процессов – это выявлять, отслеживать и улучшать реальные (не придуманные) процессы, извлекая знания из журналов событий. [1] Системы логгирования широко применяются в современных информационных системах, как правило, с целью профилактики возникших ошибок и исключений в ходе работы системы.
Методы Process Mining применяются к журналам событий информационных систем. В них отражается реальное выполнение бизнес-процессов через взаимодействие их исполнителей с информационными системами. Применение к ним методов Process Mining позволяет автоматически построить модели бизнес-процессов. Построенные таким образом модели бизнес-процессов отражают реальность и доступны для восприятия и анализа человеком. На основании их анализа могут приниматься решения о внесении изменений в бизнес-процессы и/или о модернизации и настройке информационной системы.
Для построения модели, журнал событий должен иметь как минимум четыре поля[1]:
Событие(activity) – непосредственно какое-то событие, действие, например, авторизация, просмотр страницы;
Время регистрации события (Timestapm) – время начала события;
Идентификатор последовательности событий (Case id) – таким образом идентифицируется последовательность действий.
 В веб-ресурсах в этой роли может выступать идентификатор сессии или ip-адрес;
В веб-ресурсах в этой роли может выступать идентификатор сессии или ip-адрес;Ресурс(Resource) – под ресурсом подразумевается исполнитель, или инициатор активности, это может быть, как пользователь, так и внешняя информационная система;
 В веб-ресурсах в этой роли может выступать идентификатор сессии или ip-адрес;
В веб-ресурсах в этой роли может выступать идентификатор сессии или ip-адрес;Если действия в информационной системе логгируются, то формирование подобного журнала не представляет из себя сложную задачу. Многие системы, например, как moodle, позволяют выгружать журналы событий через административный интерфейс.
Чтобы избежать эффекта паралича анализа требуется осуществить качественную постановку задачи, поскольку работа с данными не имеет однозначных алгоритмов и может быть реализована множественными путями. Об этом же говорят и положения манифеста, написанного IEEE Task Force on Process Mining [2].
Для примера рассмотрим веб-ресурс на основе платформы moodle (https://moodle.org) для образовательных ресурсов. На данном сайте есть доступ к демоверсии этой системы – http://school. demo.moodle.net, заполненной некоторыми курсами и тестовыми пользователями. Постараемся произвести оценку поведения пользователей в рамках демо версии.
demo.moodle.net, заполненной некоторыми курсами и тестовыми пользователями. Постараемся произвести оценку поведения пользователей в рамках демо версии.
Для построения модели будут использованы два инструмента: основной [1] инструмент – ProM (http://www.promtools.org/doku.php) и, коммерческий – Disco (http://fluxicon.com/disco) для сравнения.
Чтобы получить журналы действий из административного интерфейса moodle необходимо авторизоваться под пользователем с необходимыми правами, и в левом меню выбрать администрирование (Site administration), затем отчеты (reports), затем журнал событий (logs). Выгрузить журнал возможно в нескольких форматах, но в используемых инструментах удобнее всего будет работать с csv файлами. Выгружаемый файл будет иметь вид как в таблице 1.
Таблица 1. Формат выгружаемых данных из системы moodle
| Time | User full name | Affected user | Event context | Component | Event name | Description | Origin | IP address |
| 16 Mar, 00:44 | — | — | Page: Choose a role | Page | Course module viewed | The user with id ’0′ viewed the ‘page’ activity with course module id ’44′. | web | 125.164.150.177 |
Можно увидеть, что в файле отсутствует поле «идентификатор последовательности» (case id), его заменит поле «ip address». Стоит отметить, что в реальных ситуациях ip – адрес не может быть надежным идентификатором сессии, так как, например, с одного компьютера могут заходить разные пользователи, хотя и такие случаи возможно рассматривать как единую последовательность. Так же в журнале выводится дата в формате, настроенном в системе, и его придется преобразовывать в более удобный для анализа вид, например, «день.месяц.год часы:минуты» .
В «moodle» под событием (столбец «event name») понимаются действия более абстрактного уровня, и всего насчитывают около нескольких десятков штук, поэтому совместим столбцы «event name» и «event context» в столбец «event» для большей наглядности.
В результате преобразований получим журнал в виде таблицы 2.
Таблица 2. Формат преобразованного журнала событий
Формат преобразованного журнала событий
| Date | User full name | Affected user | Event context | Component | Event name | Description | Origin | IP address | event |
| 16.03.2014 00:00 | Guest user | — | System | System | User has logged in | The user with id ’1′ has logged in. | web | 24. 20.108.104 20.108.104 | User has logged in — System |
Важно отметить, что в реальных журналах событий проблемы могут носить более серьезный характер: шумы, пропущенные действия подробнее рассматривается в [1]. Для примера предполагается, что все полученные журналы событий полностью достоверны.
При анализе журналов событий, зачастую, получаемые модели слабо структурированы и не имеют отличительных особенностей (Рис.1), их называют спагетти подобными(spaghetti-like) моделями [1]. Этот случай не исключение, на рисунке 1 показана модель, полученная из журнала событий за один год.
Рис.1 Спагетти-подобная(spaghetti-like) модель
Для таких моделей рекомендуется использовать Fuzzy miner алгоритм. Алгоритм использует показатели значимости (significance) / корреляции (correlation) в интерактивном режиме упрощая модели процесса до требуемого уровня абстракции. В отличии от эвристического подхода, он может удалить менее важные события (или скрыть их в кластеры), если их сотни. Нечеткая модель не может быть преобразованы в другие типы моделей, но можно использовать её, чтобы анимировать журнал событий на созданной модели, чтобы «почувствовать» поведение процесса [3], поэтому и был сделан выбор в пользу инструментов Disco и ProM, и алгоритма «нечеткого поиска» в частности. Более подробное рассмотрение алгоритма в задачи не входило, подробнее можно изучить в [4].
Нечеткая модель не может быть преобразованы в другие типы моделей, но можно использовать её, чтобы анимировать журнал событий на созданной модели, чтобы «почувствовать» поведение процесса [3], поэтому и был сделан выбор в пользу инструментов Disco и ProM, и алгоритма «нечеткого поиска» в частности. Более подробное рассмотрение алгоритма в задачи не входило, подробнее можно изучить в [4].
Для наглядности и простоты, бралась часть журнала за сутки, в которой содержалось 24 последовательности событий, 105 событий, с 33 классами (видами) событий и 7 исполнителями, так как пробная версия позволяет рассматривать только примерно 100 событий, но этого будет достаточно.
Сначала будет рассматриваться модель, полученная с помощью инструмента Disco.
Рис. 2 Разметка журнала
Disco позволяет разметить (Рис. 2) csv документ и отметить, какие колонки отвечают за такие данные как событие, ресурс, идентификатор последовательности, временная метка и другие данные, а также позволяет не учитывать колонки при рассмотрении.
На рис. 3 показана полная модель поведения, включающая 100% событий и переходов. На ней прямоугольники – события, стрелки – переходы. Более темные прямоугольники и более толстые стрелки обозначают более частые повторения. Цифры – количество действий. Зеленая точка – псевдо-событие начала, красная псевдо-событие конца. Зеленные пунктирные линии – переходы «входа». Красные пунктирные – переходы «выхода»
Рис. 3 Полная модель поведения
Уже из рассмотрения этой модели можно предположить, что пользователей интересуют локализация, просмотр возможностей курсов со стороны авторизованных пользователей и ролевая модель. В модели можно увидеть такое поведение как «Web service function called – System» – это вызов сервисных функций таких как: получение информации о сайте, календарь, или личные сообщения. Наличие этого события говорит о том, что первоначальное предположение о полной достоверности и полноте данных не совсем верно, так как не вся информация «лежит» на поверхности. Но возможности, скрывающиеся под вызовом сервисных функций зачастую есть во всех аналогичных типах веб-ресурсов и не требуют дополнительного внимания при рассмотрении и анализе.
Но возможности, скрывающиеся под вызовом сервисных функций зачастую есть во всех аналогичных типах веб-ресурсов и не требуют дополнительного внимания при рассмотрении и анализе.
Одним из основных инструментов упрощения модели и отображения более высокого уровня абстракции модели является уменьшение количества отображаемых событий и переходов. На рисунках 4 и 5 отображен результат применения этих инструментов: отображены только 30% действий и 40% переходов.
Рис. 4 модель, показывающая 30% действия и 40% переходов
Тут можно сказать, что частично предположения об интересах пользователя подтверждаются, то есть типичный пользователь в основном осматривает возможности ролевой системы, курсы. Вызов сервисных функций не убирается из модели, так как из-за частого повторения события его значимость становится выше [4].
Также, в Disco есть возможность отображения показателей производительности. Примером может служить среднее время перехода от одного действия к другому, однако в текущем контексте веб-ресурса необходимо трактовать как время, проведенное на странице/сервисе отображаемого в модели в виде прямоугольника (Рис. 5). Видно, что пользователь провел больше времени на главной странице, странице выбора роли так как на этих страница отображена основная вводная информация.
5). Видно, что пользователь провел больше времени на главной странице, странице выбора роли так как на этих страница отображена основная вводная информация.
Рис. 5 модель, показывающая 30% действия и 40% переходов, так же, отображающая показатели производительности
Disco позволяет создавать различные фильтры, по времени, атрибутам и т.п.
Рис. 6 отфильтрованная модель, показывающая действия только авторизованных пользователей
На рисунке 6 показан фильтр только по авторизованным пользователям, то есть отображены только те действия, которые выполнялись конкретными пользователями, а не гостем. В итоге, в модели осталось 54% последовательностей и 61% событий от всех.
Присутствует возможность посмотреть полную статистику по журналу, по каждой колонке в отдельности (Рис.7).
Рис. 7 Показатели статистики по ресурсу
Наблюдается, что примерно 44% всех действия выполнялось пользователем «Barbara Gardner», который выполняет роль студента. На данный момент можно с уверенностью сказать, что пользователей демосайта больше всего интересуют возможности курсов именно для студентов.
На данный момент можно с уверенностью сказать, что пользователей демосайта больше всего интересуют возможности курсов именно для студентов.
Также присутствует инструмент подробного просмотра последовательностей (case). На рисунке 8 показан пример последовательности «прохождения теста» в виде последовательности, а на рисунке 9 в виде таблицы.
Рис. 8 Пример последовательности.
Рис. 9 Пример последовательности в виде таблицы.
ProM, в отличии от Disco предоставляет более широкие возможности в методах импорта данных. В ProM реализованы практически все основные инструменты Process Mining в виде плагинов, которых насчитывается более 200. Но несмотря на это ProM в основном работает с журналами только в формате MXML и его приемника – XES. XES – XML-подобный формат одобренный IEEE Task Force on Process Mining и описанный в [5].
Для того чтобы его получить есть несколько способов:
Сразу выгружать в xes из Disco – не лучший вариант, т.
к. когда установлена ограниченная демоверсия мы можем выгрузить только не полный журнал;Через плагин ProM, конвертируя csv в xes – по сути, встроенный XESame в ProM, который может работать только с csv;
Через программу XESame, Поставляемую вместе с ProM – самый универсальный и лучший вариант, так как позволяет подключаться к базе напрямую и создавать журнал необходимого вида «без посредников».
 к. когда установлена ограниченная демоверсия мы можем выгрузить только не полный журнал;
к. когда установлена ограниченная демоверсия мы можем выгрузить только не полный журнал;В примере рассматривается подключения к тестовой базе mysql, с помощью программы XESame и драйвера jdbc:mysql. Необходимые параметры указываются в поле «URL to databse» в виде «драйвер://host/bdname/?properties». Отмечу, что при работе с версией 6.4. возникли проблемы при подключении к mysql базе из-за внутренних «багов» XESame версий 6.4. и старше, что и отметил разработчик в [6], поэтому использовалась версия 6.3. Данные использовались те же, что и в Disco, с той лишь разницей, что csv файл выгружался в тестовую mysql-базу. Объем данных сохранен для наглядности. Более подробно рассмотреть интерфейс можно в [7].
Объем данных сохранен для наглядности. Более подробно рассмотреть интерфейс можно в [7].
Далее в атрибутах и параметрах Log’а и Trac’а (он же Case) описываются имя таблицы, или таблиц, откуда берутся данные и другие необходимые параметры. Далее, помимо основных необходимых параметров журнала, можно добавить свои атрибуты, по необходимости. Подробнее этот вопрос разобран в [8]. Стоит отметить, что, из указанных параметров собирается sql запрос, поэтому имена атрибутов в некоторых версиях программы необходимо обрамлять в кавычки.
Далее запускается выгрузка «Execute Conversion» данных в журнал, с необходимыми параметрами.
При импорте журнала в ProM, можно рассмотреть журнал подробнее по тем или иным статистическим показателям (рис. 10), например, в среднем получается по 4 события на последовательность, а классов событий 3.
Рис. 10 пример некоторых статистических показателей в ProM
В ProM будет использоваться тот же алгоритм, который представлен в виде плагина в меню «actions» [9] под названием «Mine for a Fuzzy Model». В отличии от Disco, в ProM’е реализована ручная настройка порогов и параметров [4] алгоритма нечеткого поиска.
В отличии от Disco, в ProM’е реализована ручная настройка порогов и параметров [4] алгоритма нечеткого поиска.
Рис. 11 модель поведения пользователя в ProM
Модель на рисунке 11 получилась практически идентичной модели в Disco на рисунке 3, только лишь с той разницей, что нет псевдо-конечных и начальных событий (их возможно добавить с помощь другого плагина ProM), то есть получились пять отдельных моделей, отображающих основные последовательности действий. Прямоугольники также – действия, дуги – переходы, только в цвете узлов не отображается частота, а в «насыщенности» цвета дуги отображается её показатели полезности [4]. Основное преимущество нечеткой модели в ProM, что она позволяет динамически формировать кластеры действий по ряду параметров. Одним из самых эффективных способов «упрощения» модели считается [4] удаление узлов по показателю значимости. Если установить значение «Signification cuoff» в «Node filter» равный 0,444, то получим модель как на Рис. 12.
12.
Рис. 12 отфильтрованная модель по значению «Signification cutoff» в «Node filter»
На рисунке 12 оставшиеся 3 маленькие последовательности удалены, так как для анализа ценной информации не несут, кроме как подтверждают необходимость в локализации и работе с курсом и вызовом сервисных функций. Так же можно заметить, что образовались три кластера, которые изображены синими восьмиугольниками в модели. Эти кластеры – совокупность узлов, которых значимость ниже 0.444. То есть на рисунке 12 отображена модель более высокого уровня. Кластеры же можно рассмотреть подробнее двойным нажатием на них в окне ProM (Рис.13). Более светлые узлы и дуги – входящие и исходящие по отношению к кластеру элементы.
Получившиеся кластеры можно назвать как одно действие:
кластер 36 – работа с курсом (или просмотр элементов курса)
кластер 37 – выбор роли
кластер 44 – прохождение теста
Рис.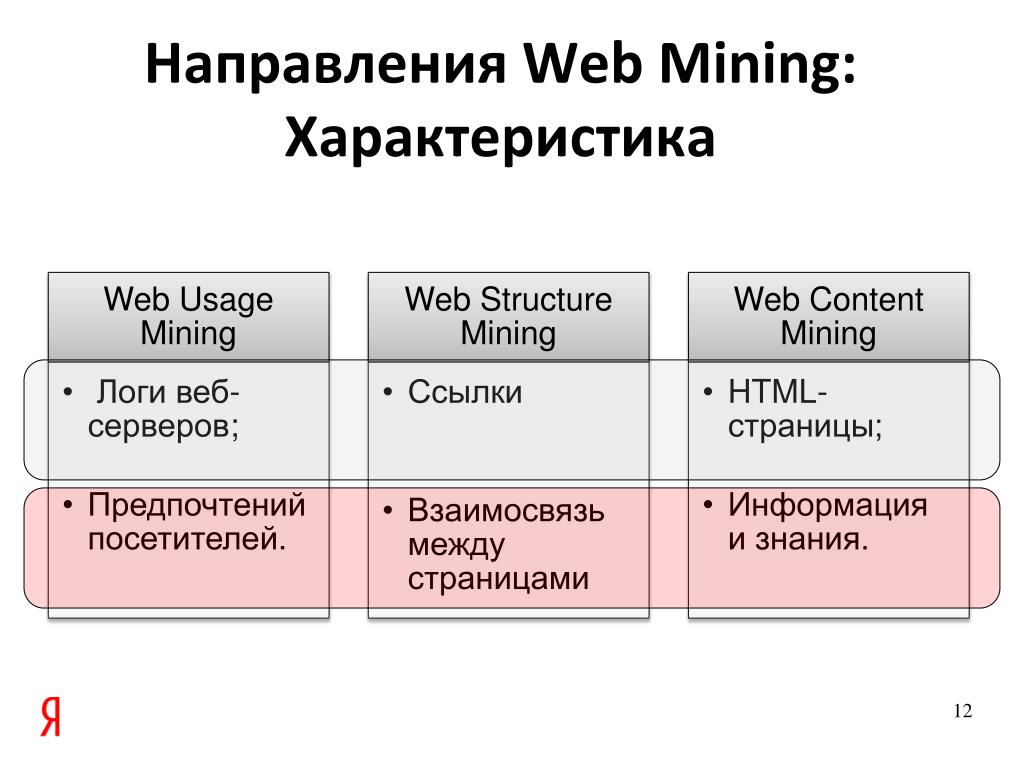 13 сластеры (слева-направо) 36, 37, 44
13 сластеры (слева-направо) 36, 37, 44
Однако у алгоритма нечеткого поиска всетаки тоже есть недостатки [10] , которые проявляются при работе в ProM:
Большие затраты времени: границы каждого порога варьируются от 0 до 1, и таких порогов несколько [4], тем самым порождая тысячи вариантов модели;
Алгоритму не хватает комплексной оценки качества полученной модели
Для решения этих проблем есть плагин «Select Best Fuzzy Instans», задача которого вывести лучший вариант последовательностей из готовой модели процессов. Но результат его работы не всегда координально отличается от первоначальной модели , например, на рис. 14 представлен результат работы этого плагина, он практически идентичен первоначальной модели (Рис. 11).
Рис. 14 результат работы плагина «Select Best Fuzzy Instans»
В примере можно убедиться, что Disco удобнее в использовании для анализа журналов событий, но ограничен не только в выборе алгоритмов анализа, но и лицензией. ProM показал же себя достаточно мощным инструментом, из недостатоков которого можно отметить нестабильность в работе.
ProM показал же себя достаточно мощным инструментом, из недостатоков которого можно отметить нестабильность в работе.
Таким образом, были получены модели поведения пользователей на демосайте, и исходя из этих моделей сделаны выводы, что пользователи, посетившие демосайт в выбранный день были заинтересованы в локализации ресурса, ознакомлении с возможностями курсов для студентов, ролевой модели ресурса.
Пример показывает, что методы анализа событий применимы не только в корпоративной среде.
Библиографический список
Wil M.P. van der Aalst, Process Mining. Discovery, Conformance and Enhancement of Business Processes, Springer-Verlag Berlin Heidelberg 2011
- Process Mining Manifesto [Электронный ресурс]. URL: http://www.win.tue.nl/ieeetfpm/lib/exe/fetch.php?media=shared:process_mining_manifesto-small.pdf (дата обращения: 20.05.2015)
Christian W. Günther and Wil M.P. van der Aalst. Fuzzy Mining – Adaptive Process Simplification Based on Multi-Perspective Metrics, 2007
- XESame user interface. [Электронный ресурс]. URL: http://www.promtools.org/doku.php?id=gettingstarted:xesameui (дата обращения: 20.05.2015)
J.C.A.M. Buijs. Mapping Data Sources to XES in a Generic Way. Eindhoven, March 2010
- XESame user interface. [Электронный ресурс]. URL: http://www.promtools.org/doku.php?id=gettingstarted:prom6ui (дата обращения: 20.05.2015)
Jiaojiao Xia. Automatic Determination of Graph Simplification Parameter Values for Fuzzy Miner. Eindhoven, October 2010, стр. 29
 [Электронный ресурс]. URL: http://www.promtools.org/doku.php?id=gettingstarted:xesameui (дата обращения: 20.05.2015)
[Электронный ресурс]. URL: http://www.promtools.org/doku.php?id=gettingstarted:xesameui (дата обращения: 20.05.2015)Количество просмотров публикации: Please wait
Все статьи автора «Кузнецов Андрей Андреевич»
Категории содержания веб-ресурсов
Категории содержания веб-ресурсов
Категории содержания веб-ресурсов (далее также «категории») в приведенном ниже списке подобраны таким образом, чтобы максимально полно описать блоки информации, размещенные на веб-ресурсах, с учетом их функциональных и тематических особенностей. Порядок категорий в списке не отражает относительной важности или распространенности категорий в сети Интернет. Названия категорий являются условными и используются лишь для целей программ и веб-сайтов «Лаборатории Касперского». Названия не обязательно соответствуют значению, которое им придает применимое законодательство. Один веб-ресурс может относиться к нескольким категориям одновременно.
Названия категорий являются условными и используются лишь для целей программ и веб-сайтов «Лаборатории Касперского». Названия не обязательно соответствуют значению, которое им придает применимое законодательство. Один веб-ресурс может относиться к нескольким категориям одновременно.
Для взрослых
В общем определении категория включает в себя веб-ресурсы, относящиеся к сексуальной стороне человеческих отношений, философий, секс магазинов и т.д. Это может быть содержимое в любом формате и виде.
Алкоголь, табак, наркотики и психотропы
В общем определении категория включает в себя веб ресурсы, на которых есть упоминание алкоголя, наркотиков, табака в любых видах, в том числе рекламные, исторические, медицинские и обучающие ресурсы. А также веб ресурсы, где описаны или продаются приспособления для употребления указанных веществ.
Насилие
Данная категория включает веб-ресурсы, содержащие фото-, видео- и текстовые материалы, описывающие акты физического или психического насилия над людьми, а также жестокого отношения к животным как цель существования этого контента.
Произведения искусства могут быть исключениями в этой категории.
Нецензурная лексика
Категория включает веб-ресурсы, на которых обнаружены элементы нецензурной брани.
В данную категорию так же попадают веб-ресурсы с лингвистическими и филологическими материалами, содержащими нецензурную лексику в качестве предмета рассмотрения.
Оружие, взрывчатые вещества, пиротехника
Данная категория включает веб-ресурсы, содержащие информацию об оружии, взрывчатых веществах и пиротехнической продукции.
Под «оружием» понимаются устройства, предметы и средства, конструктивно предназначенные для нанесения вреда жизни и здоровью людей и животных и / или выведения из строя техники и сооружений.
Поиск работы
Данная категория включает веб-ресурсы, предназначенные для установления контактов между работодателем и соискателем работы. К ним в частности относятся:
- Веб-сайты кадровых агентств (агентств по трудоустройству и/или агентств по подбору персонала).
- Веб-страницы работодателей, содержащие описание имеющихся вакансий и их преимуществ.
- Независимые порталы, содержащие предложения трудоустройства от работодателей и кадровых агентств.
- Социальные сети профессионального характера, которые в том числе позволяют размещать/находить данные о специалистах, которые не находятся в активном поиске работы.

Средства анонимного доступа
Данная категория включает веб-ресурсы, выступающие в роли посредника для загрузки контента прочих веб-ресурсов с помощью специальных веб-приложений для:
- обхода ограничений администратора локальной сети на доступ к веб-адресам или IP-адресам;
- анонимного доступа к веб-ресурсам, в том числе к веб-ресурсам, которые преднамеренно не принимают HTTP-запросы с определённых IP-адресов или их групп (например, по стране происхождения).
Программное обеспечение, аудио, видео
В общем определении категория включает в себя веб-ресурсы, предоставляющие возможность скачивания соответствующих файлов.
- Торренты
Торрент трекеры и веб ресурсы, помогающие организовать их работу.
- Файловые обменники
Веб-ресурсы, предоставляющие возможность обмена файлами.
- Аудио, видео
Веб-ресурсы, с которых можно загрузить или просмотреть/прослушать аудио или видео файлы.
Азартные игры, лотереи, тотализаторы
Категория охватывает веб-ресурсы, содержащие:
- Азартные игры, предусматривающие денежные взносы за участие.
- Тотализаторы, предусматривающие денежные ставки.
- Лотереи, предусматривающие приобретение лотерейных билетов/номеров.
Общение в сети
В общем определении категория включает в себя веб-ресурсы, позволяющие тем или иным пользователям (зарегистрированным или нет) отправлять персональные сообщения другим пользователям. Существует ряд веб-ресурсов рассчитанных на общение.
- Веб-почта
Веб-почта — исключительно страницы авторизации в почтовом сервисе и страницы почтового ящика, содержащего почтовые сообщения и сопутствующие данные (например, личные контакты).
Для остальных веб-страниц интернет-провайдера, предлагающего почтовый сервис, данная категория не назначается. - Социальные сети
Социальные сети – веб-сайты, предназначенные для построения, отражения и организации контактов между людьми, организациями, государством, требующие в качестве условия участия регистрацию учётной записи пользователя.
- Чаты, форумы
В данную категорию следует относить веб-чаты, а также веб-ресурсы, предназначенные для распространения и поддержки приложений для мгновенного обмена сообщениями, предоставляющих возможность коммуникации в реальном времени. А также форумы – специальные веб сервисы для публичного обсуждения различных тем с сохранением переписки.
- Блоги
Блоги – веб-ресурсы, предназначенные для публичного обсуждения различных тем с помощью специальных веб-приложений, включая блог-платформы (веб-сайты, предоставляющие платные или бесплатные услуги по созданию и обслуживанию блогов).
- Сайты знакомств
Веб ресурсы знакомств, которые помогают организовать знакомства между людьми, в том числе без сексуального подтекста.
 Для остальных веб-страниц интернет-провайдера, предлагающего почтовый сервис, данная категория не назначается.
Для остальных веб-страниц интернет-провайдера, предлагающего почтовый сервис, данная категория не назначается.
Интернет-магазины, банки, платежные системы
В общем определении категория включает в себя веб-ресурсы, предназначенные для проведения любых операций с безналичными денежными средствами в режиме онлайн с помощью специальных веб-приложений. А также веб ресурсы, помогающие снять, сдать, купить или продать недвижимость.
- Интернет-магазины
Интернет-магазины и интернет-аукционы, предназначенные для реализации любых товаров, работ или услуг физическим и/или юридическим лицам, в том числе как веб-сайты магазинов, осуществляющих реализацию исключительно в интернете, так и интернет-представительства обычных магазинов, характерной особенностью которых является возможность оплаты в режиме онлайн.
- Банки
Веб-ресурсы банков.
- Платежные системы
К данной категории относятся следующие веб страницы:
- Специальные веб-страницы банков, предусматривающие услуги интернет-банкинга, включающие безналичные (электронные) переводы между банковскими счетами, открытие банковских вкладов, конвертацию денежных средств, оплату услуг сторонних организаций и т. д.
- Веб-страницы электронных платёжных систем, предоставляющие доступ к персональной учётной записи пользователя.
- Специальные веб-страницы банков, предусматривающие услуги интернет-банкинга, включающие безналичные (электронные) переводы между банковскими счетами, открытие банковских вкладов, конвертацию денежных средств, оплату услуг сторонних организаций и т.
- Криптовалюты и майнинг
Подкатегория включает веб-сайты, предоставляющие сервисы покупки и продажи криптовалют, сервисы информирования о криптовалютах и майнинге.
 д.
д.Компьютерные игры
Данная категория включает веб-ресурсы, посвящённые компьютерным играм разнообразных жанров. А также игровые сообщества и сервисы.
Религии, религиозные объединения
Данная категория включает веб-ресурсы, содержащие материалы об общественных течениях (движениях), объединениях (сообществах) и организациях, подразумевающих наличие религиозной идеологии и/или культа в любых проявлениях.
Новостные ресурсы
Новостные порталы на любые темы, в том числе социальные новости агрегаторы новостей, rss рассылки.
Баннеры
Категория включает веб-ресурсы, содержащие баннеры. Рекламная информация на баннерах может отвлекать пользователей от дел, а загрузка баннеров увеличивает объем трафика.
Региональные ограничения законодательства
- Запрещено законодательством Российской Федерации
- Запрещено законодательством Бельгии
- Запрещено полицией Японии
Веб-ресурсы, предоставляемые по соглашению с японской полицией, только для продуктов японского рынка.
О мальчике Бобби, который любил деньги или ещё раз про добровольно-принудительный веб-майнинг
Опубликовав последнюю заметку об Icinga, я решил поискать в русскоязычном сегменте Интернета последние материалы по теме Icinga и попал на сайт, который уже как-то ранее мне попадался на глаза (ссылку на сайт не привожу намеренно, хотя дальше всё итак будет понятно). Попытавшись просмотреть последние заметки на этом сайте, я обратил внимание на появившуюся через несколько минут звуковую индикацию материнской платы моего компьютера, характерную для ситуаций с перегревом процессора. Это меня несколько смутило, ибо, как я думал, ничего ресурсоёмкого в моей пользовательской сессии в этот момент не выполнялось.
Однако график загрузки процессора сказал мне об обратном. Все 4 ядра моего процессора были нагружены «по самые помидоры»:
Обнаружив то, что источником неистовой нагрузки на систему является веб-браузер, я стал последовательно закрывать его вкладки с разными сайтами до тех пор, пока не стало понятно, какой из сайтов создаёт такую нагрузку. При закрытии вкладки с вредительским сайтом нагрузка падала сразу же.
Беглый просмотр исходного кода страницы показал наличие вызова стороннего скрипта coinhive.min.js с недвусмысленными параметрами:
Сразу вспомнилась статья ESET, на которую я приводил ссылку в Сентябрьском обзоре, никак не думая на тот момент времени, что вскоре сам столкнусь с этим на практике.
Просмотр сетевой активности показал то, что через короткие интервалы времени браузер дёргает файлы, также по всей видимости связанные с работой веб-майнинга
Я подумал, а вдруг администратор сайта даже и не подозревает о наличии этого скрипта.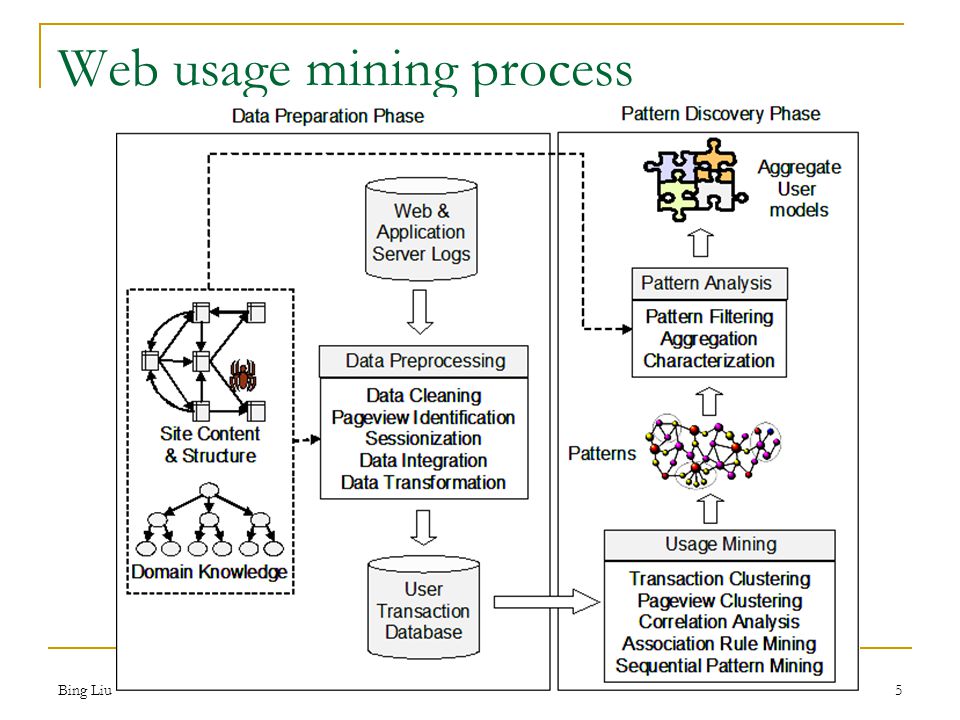 Ведь сайт мог быть взломан злоумышленниками, которые в последствии и внедрили в код сайта свой скрипт. Не смотря на то, что вероятность такой ситуации была крайне не высока, так как этот веб-сайт трудно отнести к категории сайтов с хорошей посещаемостью, я решил задать прямой вопрос администратору сайта, в глубине души надеясь на то, что мои подозрения всё-таки ошибочны. Однако ответ администратора, которого не пришлось долго ждать, меня мягко говоря удивил:
Ведь сайт мог быть взломан злоумышленниками, которые в последствии и внедрили в код сайта свой скрипт. Не смотря на то, что вероятность такой ситуации была крайне не высока, так как этот веб-сайт трудно отнести к категории сайтов с хорошей посещаемостью, я решил задать прямой вопрос администратору сайта, в глубине души надеясь на то, что мои подозрения всё-таки ошибочны. Однако ответ администратора, которого не пришлось долго ждать, меня мягко говоря удивил:
Ну что тут можно ещё добавить? Как говорится, без комментариев. Вспомнилась песенка из старого советского мультфильма О мальчике Бобби, который любил деньги.
Возникает вопрос, как защищаться от подобного рода «предпринимателей».
Если речь идёт о компьютере под управлением Windows, то многие современные антивирусные программы уже знают об подобном типе угроз и своевременно блокируют подобное содержимое. Например, имеющийся в моём распоряжении компьютер под управлением Windows 10 с работающим антивирусным пакетом Symantec Endpoint Protection v14 среагировал вполне оперативно и утащил «каку» из кэша Internet Explorer:
Помимо этого, для некоторых веб-браузеров, например Mozilla Firefox, имеются расширения, такие как No Coin, которые по заверению разработчиков способны автоматически блокировать подобный тип угроз. Я сам не использовал подобные расширения, так как не являюсь приверженцем того, чтобы обвешивать браузер всяческими расширениями без крайней необходимости. Поэтому на своей домашней Linux-системе я быстро решил проблему с майнинг-сервисом CoinHive, добавив в файл /etc/hosts запись-«заглушку»:
Я сам не использовал подобные расширения, так как не являюсь приверженцем того, чтобы обвешивать браузер всяческими расширениями без крайней необходимости. Поэтому на своей домашней Linux-системе я быстро решил проблему с майнинг-сервисом CoinHive, добавив в файл /etc/hosts запись-«заглушку»:
После этого достаточно очистить кэш веб-браузера и можно без вышеописанных симптомов посещать «говно-сайты», использующие CoinHive-майнер. Хотя идеологически более правильным решением, на мой взгляд, будет отказ от посещения сайтов, администраторы которых себе позволяют подобные «фокусы» с максимальной оглаской проблемы для их анти-рекламы. Как гласит перефразированная народная мудрость, скупой должен заплатить дважды, а тупой — трижды.
Поделиться ссылкой на эту запись:
ПохожееВеб-майнинг — обзор
9.6 Веб-майнинг
Всемирная паутина — это огромное хранилище текста. Почти весь он отличается от обычного «простого» текста тем, что содержит явную структурную разметку. Некоторая разметка является внутренней и указывает на структуру или формат документа; другая разметка является внешней и определяет явные гипертекстовые ссылки между документами. Оба этих источника информации дают дополнительные возможности для анализа веб-документов. Веб-майнинг похож на интеллектуальный анализ текста, но использует дополнительную информацию и часто улучшает результаты, извлекая выгоду из существования тематических каталогов и другой информации в Интернете.
Некоторая разметка является внутренней и указывает на структуру или формат документа; другая разметка является внешней и определяет явные гипертекстовые ссылки между документами. Оба этих источника информации дают дополнительные возможности для анализа веб-документов. Веб-майнинг похож на интеллектуальный анализ текста, но использует дополнительную информацию и часто улучшает результаты, извлекая выгоду из существования тематических каталогов и другой информации в Интернете.
Учитывать внутреннюю разметку. Интернет-ресурсы, которые содержат реляционные данные — телефонные справочники, каталоги продуктов и т. д. — используют команды форматирования языка гипертекстовой разметки (HTML), чтобы четко представить содержащуюся в них информацию пользователям Интернета. Однако извлечь данные из таких ресурсов в автоматическом режиме достаточно сложно. Для этого программные системы используют простые модули синтаксического анализа, называемые оболочками , для анализа структуры страницы и извлечения необходимой информации. Если обертки кодируются вручную, что часто и происходит, то это тривиальный вид интеллектуального анализа текста, поскольку он опирается на страницы, имеющие фиксированную, заранее определенную структуру, из которой информация может быть извлечена алгоритмически.Но страницы редко подчиняются правилам. Их структуры различаются; веб-сайты развиваются. Ошибки, незначительные для человека, полностью искажают автоматические процедуры извлечения. Когда происходят изменения, ручная настройка оболочки может стать кошмаром, который включает в себя изучение существующего кода и его исправление таким образом, чтобы не вызвать поломки где-либо еще.
Если обертки кодируются вручную, что часто и происходит, то это тривиальный вид интеллектуального анализа текста, поскольку он опирается на страницы, имеющие фиксированную, заранее определенную структуру, из которой информация может быть извлечена алгоритмически.Но страницы редко подчиняются правилам. Их структуры различаются; веб-сайты развиваются. Ошибки, незначительные для человека, полностью искажают автоматические процедуры извлечения. Когда происходят изменения, ручная настройка оболочки может стать кошмаром, который включает в себя изучение существующего кода и его исправление таким образом, чтобы не вызвать поломки где-либо еще.
Ввод обертки индукция — автоматическое обучение оберток на примерах. Входные данные представляют собой обучающий набор страниц вместе с кортежами, представляющими информацию, полученную с каждой страницы.Результатом является набор правил, которые извлекают кортежи путем анализа страницы. Например, он может искать определенные разделители HTML — границы абзаца (  от ключевых элементов информации и узнать последовательность, в которой представлены сущности. Это может быть достигнуто путем перебора всех вариантов разделителей, останавливаясь при обнаружении согласованной оболочки.Тогда распознавание будет зависеть только от минимального набора сигналов, обеспечивающих некоторую защиту от постороннего текста и маркеров на входе. В качестве альтернативы можно последовать совету Эпикура в конце раздела 5.9 (стр. 186) и найти надежную оболочку, которая использует несколько сигналов для защиты от случайных изменений. Большим преимуществом автоматической индукции обертки является то, что когда ошибки вызваны стилистическими вариантами, их просто добавить к обучающим данным и повторно создать новую оболочку, которая их учитывает.Индукция обертки уменьшает проблемы с распознаванием, когда происходят небольшие изменения, и значительно упрощает создание новых наборов правил извлечения, когда структуры радикально меняются.
от ключевых элементов информации и узнать последовательность, в которой представлены сущности. Это может быть достигнуто путем перебора всех вариантов разделителей, останавливаясь при обнаружении согласованной оболочки.Тогда распознавание будет зависеть только от минимального набора сигналов, обеспечивающих некоторую защиту от постороннего текста и маркеров на входе. В качестве альтернативы можно последовать совету Эпикура в конце раздела 5.9 (стр. 186) и найти надежную оболочку, которая использует несколько сигналов для защиты от случайных изменений. Большим преимуществом автоматической индукции обертки является то, что когда ошибки вызваны стилистическими вариантами, их просто добавить к обучающим данным и повторно создать новую оболочку, которая их учитывает.Индукция обертки уменьшает проблемы с распознаванием, когда происходят небольшие изменения, и значительно упрощает создание новых наборов правил извлечения, когда структуры радикально меняются.
Одна из проблем Интернета заключается в том, что в нем много мусора. Чтобы отделить зерна от плевел, основатели Google ввели показатель под названием PageRank; он также используется в различных формах другими поисковыми системами и во многих других приложениях для веб-майнинга. Он пытается измерить престиж веб-страницы или сайта, где престиж , согласно определению словаря, означает «высокое положение, достигнутое благодаря успеху или влиянию».Есть надежда, что это хороший способ определить авторитет, определяемый как «признанный источник экспертной информации или совета». Напомним, что алгоритм PageRank был указан ранее в таблице 9.1 как один из 10 лучших алгоритмов интеллектуального анализа данных, единственный, с которым мы до сих пор не сталкивались. Возможно, сомнительно, следует ли его классифицировать как алгоритм интеллектуального анализа данных, но все же его стоит описать.
Чтобы отделить зерна от плевел, основатели Google ввели показатель под названием PageRank; он также используется в различных формах другими поисковыми системами и во многих других приложениях для веб-майнинга. Он пытается измерить престиж веб-страницы или сайта, где престиж , согласно определению словаря, означает «высокое положение, достигнутое благодаря успеху или влиянию».Есть надежда, что это хороший способ определить авторитет, определяемый как «признанный источник экспертной информации или совета». Напомним, что алгоритм PageRank был указан ранее в таблице 9.1 как один из 10 лучших алгоритмов интеллектуального анализа данных, единственный, с которым мы до сих пор не сталкивались. Возможно, сомнительно, следует ли его классифицировать как алгоритм интеллектуального анализа данных, но все же его стоит описать.
Ключ — внешняя разметка в виде гиперссылок. В сетевом сообществе люди вознаграждают за успех ссылками.Если вы ссылаетесь на мою страницу, это, вероятно, потому, что вы находите ее полезной и информативной — это успешная веб-страница. Если на нее ссылается множество людей, это указывает на престиж: моя страница успешна и влиятельна. Посмотрите на рис. 9.1, на котором показана крошечная часть Интернета, включая ссылки между страницами. Какие из них вы считаете наиболее авторитетными? Страница F имеет пять входящих ссылок, что указывает на то, что пять человек сочли ее заслуживающей ссылки, поэтому есть большая вероятность, что эта страница является более авторитетной, чем другие. B является вторым лучшим, с четырьмя ссылками.
Если на нее ссылается множество людей, это указывает на престиж: моя страница успешна и влиятельна. Посмотрите на рис. 9.1, на котором показана крошечная часть Интернета, включая ссылки между страницами. Какие из них вы считаете наиболее авторитетными? Страница F имеет пять входящих ссылок, что указывает на то, что пять человек сочли ее заслуживающей ссылки, поэтому есть большая вероятность, что эта страница является более авторитетной, чем другие. B является вторым лучшим, с четырьмя ссылками.
РИСУНОК 9.1. Запутанная «паутина».
Простой подсчет ссылок является грубой мерой. Некоторые веб-страницы имеют тысячи исходящих ссылок, в то время как другие имеют всего одну или две. Более редкие ссылки более разборчивы и должны учитываться больше, чем другие. Ссылка с вашей страницы на мою дает больше престижа, если на вашей странице мало исходящих ссылок. На рис. 9.1 множество ссылок, происходящих со страницы A , означают, что каждая из них имеет меньший вес просто потому, что A является плодовитым компоновщиком. С точки зрения F , ссылки из D и E могут быть более ценными, чем ссылки из A . Есть еще один фактор: ссылка более ценна, если она идет с престижной страницы. Ссылка с B на F может быть лучше, чем другие в F , потому что B более престижна. Правда, в этом факторе присутствует определенная замкнутость, и без дальнейшего анализа неясно, можно ли его заставить работать.Но ведь может.
С точки зрения F , ссылки из D и E могут быть более ценными, чем ссылки из A . Есть еще один фактор: ссылка более ценна, если она идет с престижной страницы. Ссылка с B на F может быть лучше, чем другие в F , потому что B более престижна. Правда, в этом факторе присутствует определенная замкнутость, и без дальнейшего анализа неясно, можно ли его заставить работать.Но ведь может.
Вот подробности. Мы определяем PageRank страницы как число от 0 до 1, которое измеряет ее престиж. Каждая ссылка на страницу влияет на ее PageRank. Сумма, которую он вносит, равна PageRank ссылающейся страницы, деленной на количество исходящих с нее ссылок. PageRank любой страницы рассчитывается путем суммирования этого количества по всем ссылкам. Значение D на рис. 9.1 рассчитывается путем добавления одной пятой значения A (поскольку он имеет пять исходящих ссылок) к половине значения C .
Простой итерационный метод используется для устранения кажущейся круговой природы вычислений. Начните со случайного присвоения начального значения каждой странице. Затем пересчитайте PageRank каждой страницы, просуммировав соответствующие величины, описанные ранее, по входящим ссылкам. Если исходные значения рассматривать как приближение к истинному значению PageRank, то новые значения являются лучшим приближением. Продолжайте, генерируя третье приближение, четвертое и так далее. На каждом этапе пересчитывайте PageRank для каждой страницы в Интернете.Остановитесь, когда для каждой страницы следующая итерация даст почти такой же PageRank, как и предыдущая.
С учетом двух модификаций, обсуждаемых позже, эта итерация гарантированно сойдется, причем довольно быстро. Хотя точные детали окутаны тайной, сегодняшние поисковые системы, вероятно, ищут точность для окончательных значений между 10 -9 и 10 -12 . В раннем эксперименте сообщалось о 50 итерациях для гораздо меньшей версии Интернета, чем та, которая существует сегодня, до того, как детали стали коммерческими; теперь требуется в несколько раз больше итераций. Считается, что Google запускает программы в течение нескольких дней для расчета PageRank для всей сети, и эта операция выполняется — или, по крайней мере, раньше — каждые несколько недель.
Считается, что Google запускает программы в течение нескольких дней для расчета PageRank для всей сети, и эта операция выполняется — или, по крайней мере, раньше — каждые несколько недель.
Есть две проблемы с расчетом, который мы описали. Вероятно, у вас есть ментальная картина того, как PageRank течет через запутанную «паутину» на рис. 9.1, попадая на страницу через входящие ссылки и покидая ее через исходящие. Что делать, если внутренних ссылок нет (страница H )? Или нет исходящих ссылок (страница G )?
Чтобы операционализировать эту картину, представьте себе веб-серфера, который наугад щелкает ссылки.Он берет текущую страницу, случайным образом выбирает исходящую ссылку и переходит на целевую страницу этой ссылки. Вероятность получения какой-либо конкретной ссылки меньше, если исходящих ссылок много, а это именно то поведение, которое мы хотим получить от PageRank. Оказывается, PageRank данной страницы пропорционален вероятности того, что пользователь, случайно ищущий, попадет на эту страницу.
Теперь становится очевидной проблема, связанная со страницей без исходящих ссылок: это утечка PageRank, потому что когда посетители заходят, они не могут выйти.В более общем смысле набор страниц может ссылаться друг на друга, но не на что-либо другое. Эта кровосмесительная группа также является поглотителем PageRank: случайный пользователь попадает в ловушку. И страница без внутренних ссылок? Случайные серферы никогда не достигают его. На самом деле, они никогда не достигают какой-либо группы страниц, которые не имеют входящих ссылок из остальной части Интернета, даже если у них могут быть внутренние ссылки и исходящие ссылки на Интернет в целом.
Эти две проблемы означают, что описанное выше итеративное вычисление не сходится, как мы утверждали ранее.Но решение простое: телепортация . С некоторой небольшой вероятностью просто заставьте посетителя попасть на случайно выбранную страницу, а не перейти по ссылке с той, на которой он находится. Это решает обе проблемы. Если серферы застряли на G , они в конечном итоге телепортируются оттуда. И если они не смогут добраться до H с помощью серфинга, они в конечном итоге телепортируются туда.
Если серферы застряли на G , они в конечном итоге телепортируются оттуда. И если они не смогут добраться до H с помощью серфинга, они в конечном итоге телепортируются туда.
Вероятность телепортации сильно влияет на скорость сходимости итеративного алгоритма и на точность его результатов.В крайнем случае, если бы он был равен 1, что означает, что посетитель всегда телепортируется, структура ссылок не повлияла бы на PageRank, и не было бы необходимости в итерации. Если бы он был равен 0 и серфер никогда не телепортировался, расчет вообще не сходился бы. В ранних опубликованных экспериментах использовалась вероятность телепортации 0,15; некоторые предполагают, что поисковые системы немного увеличивают его, чтобы ускорить конвергенцию.
Вместо того, чтобы телепортироваться на случайно выбранную страницу, вы можете выбрать предопределенную вероятность для каждой страницы и — как только вы решили телепортироваться — использовать эту вероятность, чтобы определить, куда приземлиться. Это не влияет на расчет. Но это влияет на результат. Если бы страница была подвергнута дискриминации, получив меньшую вероятность, чем другие, она получила бы меньший PageRank, чем заслуживает. Это дает операторам поисковых систем возможность влиять на результаты вычислений — возможность, которую они, вероятно, используют для дискриминации определенных сайтов (например, тех, которые, по их мнению, пытаются получить несправедливое преимущество, используя систему PageRank). Это материал, из которого сделаны судебные иски.
Это не влияет на расчет. Но это влияет на результат. Если бы страница была подвергнута дискриминации, получив меньшую вероятность, чем другие, она получила бы меньший PageRank, чем заслуживает. Это дает операторам поисковых систем возможность влиять на результаты вычислений — возможность, которую они, вероятно, используют для дискриминации определенных сайтов (например, тех, которые, по их мнению, пытаются получить несправедливое преимущество, используя систему PageRank). Это материал, из которого сделаны судебные иски.
Веб-майнинг все еще актуален?
Поделиться этой статьей
В прошлую среду французская полиция закрыла крупный ботнет, который смог установить вредоносное ПО на более чем 850 000 компьютеров. Эта сеть частично использовалась для распространения программ-вымогателей и кражи данных. Однако он также использовался для криптоджекинга, позволяя злоумышленникам добывать Monero на компьютерах своих жертв.
Трехлетняя операция принесла злоумышленникам криптовалюту на миллионы долларов. Хотя точные цифры до сих пор неясны, криптоджекинг становится растущей тенденцией. На самом деле, ранее в этом году Каперски сообщал, что корпоративный трафик, связанный с майнингом криптовалюты, вырос в 200 раз за последний год — и в основном виноват криптоджекинг.
Хотя точные цифры до сих пор неясны, криптоджекинг становится растущей тенденцией. На самом деле, ранее в этом году Каперски сообщал, что корпоративный трафик, связанный с майнингом криптовалюты, вырос в 200 раз за последний год — и в основном виноват криптоджекинг.
Однако сценарии веб-майнинга, которые часто используются криптоджекерами, работают не так хорошо. Эти скрипты позволяют операторам веб-сайтов добывать криптовалюты, используя мощность ЦП посетителей сайта.
CoinHive, один очень популярный скрипт, был закрыт в начале этого года из-за падения прибыли и постоянных изменений в схеме майнинга Monero.Это оставило криптоджекеров на один инструмент в их распоряжении меньше, и теперь они вынуждены искать альтернативы.
Новые веб-майнеры
Доступно несколько различных сценариев майнинга, и легко увидеть, какие сценарии наиболее популярны. PublicWWW позволяет нам искать фрагменты кода — метод, который Binance Academy и Bad Packets Report использовали в прошлом для выявления популярных скриптов майнинга. Это показывает нам, сколько сайтов размещает каждый конкретный скрипт майнинга, как показано ниже:
Это показывает нам, сколько сайтов размещает каждый конкретный скрипт майнинга, как показано ниже:
Несмотря на закрытие, CoinHive по-прежнему лидирует в гонке. Bad Packets говорит, что CoinHive был активен на 30 000 сайтов в конце 2018 года, а Binance говорит, что в феврале этого года он был активен на 15 000.
Даже сегодня не менее 6000 сайтов все еще пытаются использовать CoinHive. Наиболее вероятное объяснение заключается в том, что многие сайты просто не обновлялись после закрытия CoinHive.
Между тем существуют также альтернативные скрипты майнинга, которые требуют согласия пользователей на майнинг. JSECoin используется не менее чем на 1500 сайтах, и он майнит только в том случае, если посетители соглашаются. AuthedMine, майнер, созданный CoinHive, присутствует как минимум на 1000 страниц, хотя сейчас он не существует.
Другие скрипты представляют собой смешанную сумку. DeepMiner присутствует как минимум на 1750 сайтах. CoinImp присутствует как минимум на 100 сайтах, хотя эту цифру легко недооценить, поскольку код для встраивания трудно определить точно.Наконец, Cryptoloot и Moonify имеют очень незначительное присутствие, и их можно найти примерно на 20 страницах каждая — тем не менее, они являются жизнеспособными инструментами для веб-майнинга.
Вас взломали?
Эти данные просто отражают обычные попытки веб-майнинга и не отражают, ведутся ли какие-либо крупномасштабные атаки. Многие из сайтов, найденных на PublicWWW, просто управляются веб-операторами, которые используют мощность вашего компьютера для майнинга криптовалюты на время вашего посещения.
Хотя криптоджекинг может доставлять небольшие неудобства, сам по себе он редко опасен.
На самом деле эти данные, вероятно, не показывают каких-либо сложных атак. Например, в 2017 году злоумышленники внедрили скрипты майнинга в частные сети Wi-Fi Starbucks. Позже, в 2018 году, злоумышленники внедрили скрипт в программу преобразования текста в речь, которая достигла сразу 4000 государственных сайтов. Если подобные атаки происходят сегодня, возможно, нет никакой возможности узнать об этом.
Позже, в 2018 году, злоумышленники внедрили скрипт в программу преобразования текста в речь, которая достигла сразу 4000 государственных сайтов. Если подобные атаки происходят сегодня, возможно, нет никакой возможности узнать об этом.
Кроме того, наши данные не показывают, какие крипто-майнеры больше всего наносят ущерб посетителям веб-сайтов — они показывают только, сколько веб-сайтов используют скрипты майнинга.Возможно, некоторые скрипты популярны у операторов веб-сайтов, сайты которых получают большой трафик. Кроме того, некоторые скрипты не работают на полную мощность или позволяют настроить это.
Судя по этим цифрам, веб-майнинг и криптоджекинг, вероятно, переживают спад. Недавнее исследование показывает, что прибыль довольно скромная, и что средний криптоджекер зарабатывает около 5,80 долларов в день на каждом веб-сайте. Таким образом, кажется, что рост криптоджекинга может быть связан с его заманчивым имиджем, а не с фактической прибыльностью.
Поделиться этой статьей
Информация на этом веб-сайте или доступ через него получен из независимых источников, которые мы считаем точными и надежными, но Decentral Media, Inc. не делает заявлений и не гарантирует своевременность, полноту или точность какой-либо информации на этом веб-сайте или доступ через него Веб-сайт. Decentral Media, Inc. не является инвестиционным консультантом. Мы не даем индивидуальных советов по инвестициям или других финансовых советов. Информация на этом веб-сайте может быть изменена без предварительного уведомления.Некоторая или вся информация на этом веб-сайте может устареть, стать неполной или неточной. Мы можем, но не обязаны обновлять любую устаревшую, неполную или неточную информацию.
не делает заявлений и не гарантирует своевременность, полноту или точность какой-либо информации на этом веб-сайте или доступ через него Веб-сайт. Decentral Media, Inc. не является инвестиционным консультантом. Мы не даем индивидуальных советов по инвестициям или других финансовых советов. Информация на этом веб-сайте может быть изменена без предварительного уведомления.Некоторая или вся информация на этом веб-сайте может устареть, стать неполной или неточной. Мы можем, но не обязаны обновлять любую устаревшую, неполную или неточную информацию.
Вы никогда не должны принимать инвестиционное решение об ICO, IEO или других инвестициях на основе информации на этом веб-сайте, и вы никогда не должны интерпретировать или иным образом полагаться на какую-либо информацию на этом веб-сайте в качестве инвестиционного совета. Мы настоятельно рекомендуем вам проконсультироваться с лицензированным консультантом по инвестициям или другим квалифицированным финансовым специалистом, если вы ищете инвестиционный совет по ICO, IEO или другим инвестициям.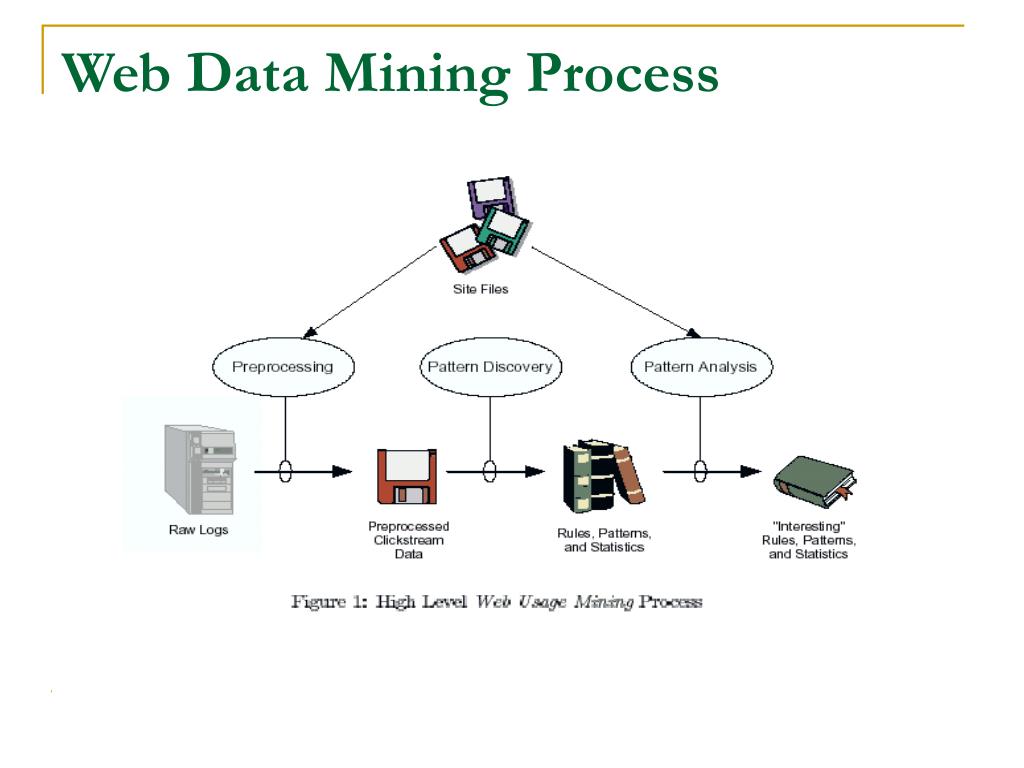 Мы не принимаем компенсацию ни в какой форме за анализ или отчетность по любым ICO, IEO, криптовалютам, валюте, токенизированным продажам, ценным бумагам или товарам.
Мы не принимаем компенсацию ни в какой форме за анализ или отчетность по любым ICO, IEO, криптовалютам, валюте, токенизированным продажам, ценным бумагам или товарам.
См. полные условия.
Веб-майнинг: прошлое, настоящее и будущее
Действия
‘) var buybox = document.querySelector(«[data-id=id_»+ метка времени +»]»).родительский узел ;[].slice.call(buybox.querySelectorAll(«.вариант-покупки»)).forEach(initCollapsibles) функция initCollapsibles(подписка, индекс) { var toggle = подписка.querySelector(«.цена-варианта-покупки») подписка.classList.remove(«расширенный») var form = подписка.querySelector(«.форма-варианта-покупки») var priceInfo = подписка. querySelector(«.Информация о цене»)
var PurchaseOption = переключатель.родительский элемент если (переключить && форма && priceInfo) {
toggle.setAttribute(«роль», «кнопка»)
toggle.setAttribute(«tabindex», «0») toggle.addEventListener («щелчок», функция (событие) {
var expand = toggle.getAttribute(«aria-expanded») === «true» || ложный
toggle.setAttribute(«aria-expanded», !expanded)
форма.скрытый = расширенный
если (! расширено) {
покупкаOption.classList.add(«расширенный»)
} еще {
покупкаOption.classList.remove(«расширенный»)
}
priceInfo.hidden = расширенный
}, ложный)
}
} функция initKeyControls() {
документ.
querySelector(«.Информация о цене»)
var PurchaseOption = переключатель.родительский элемент если (переключить && форма && priceInfo) {
toggle.setAttribute(«роль», «кнопка»)
toggle.setAttribute(«tabindex», «0») toggle.addEventListener («щелчок», функция (событие) {
var expand = toggle.getAttribute(«aria-expanded») === «true» || ложный
toggle.setAttribute(«aria-expanded», !expanded)
форма.скрытый = расширенный
если (! расширено) {
покупкаOption.classList.add(«расширенный»)
} еще {
покупкаOption.classList.remove(«расширенный»)
}
priceInfo.hidden = расширенный
}, ложный)
}
} функция initKeyControls() {
документ. addEventListener(«keydown», функция (событие) {
if (document.activeElement.classList.contains(«цена-варианта-покупки») && (event.code === «Пробел» || event.code === «Enter»)) {
если (document.activeElement) {
событие.preventDefault()
документ.activeElement.click()
}
}
}, ложный)
} функция InitialStateOpen() {
var buyboxWidth = buybox.смещениеШирина
;[].slice.call(buybox.querySelectorAll(«.опция покупки»)).forEach(функция (опция, индекс) {
var toggle = option.querySelector(«.цена-варианта-покупки»)
var form = option.querySelector(«.форма-варианта-покупки»)
var priceInfo = option.querySelector(«.Информация о цене»)
если (buyboxWidth > 480) {
переключить.
addEventListener(«keydown», функция (событие) {
if (document.activeElement.classList.contains(«цена-варианта-покупки») && (event.code === «Пробел» || event.code === «Enter»)) {
если (document.activeElement) {
событие.preventDefault()
документ.activeElement.click()
}
}
}, ложный)
} функция InitialStateOpen() {
var buyboxWidth = buybox.смещениеШирина
;[].slice.call(buybox.querySelectorAll(«.опция покупки»)).forEach(функция (опция, индекс) {
var toggle = option.querySelector(«.цена-варианта-покупки»)
var form = option.querySelector(«.форма-варианта-покупки»)
var priceInfo = option.querySelector(«.Информация о цене»)
если (buyboxWidth > 480) {
переключить. щелчок()
} еще {
если (индекс === 0) {
переключать.щелчок()
} еще {
toggle.setAttribute («ария-расширенная», «ложь»)
form.hidden = «скрытый»
priceInfo.hidden = «скрытый»
}
}
})
} начальное состояниеОткрыть() если (window.buyboxInitialized) вернуть
window.buyboxInitialized = истина initKeyControls()
})()
щелчок()
} еще {
если (индекс === 0) {
переключать.щелчок()
} еще {
toggle.setAttribute («ария-расширенная», «ложь»)
form.hidden = «скрытый»
priceInfo.hidden = «скрытый»
}
}
})
} начальное состояниеОткрыть() если (window.buyboxInitialized) вернуть
window.buyboxInitialized = истина initKeyControls()
})()Data Mining World Wide Web
За последние несколько лет World Wide Web стал важным источником информации и одновременно популярной платформой для бизнеса.Веб-майнинг можно определить как метод использования методов и алгоритмов интеллектуального анализа данных для извлечения полезной информации непосредственно из Интернета, такой как веб-документы и службы, гиперссылки, веб-контент и журналы сервера. Всемирная паутина содержит большое количество данных, которые являются богатым источником для интеллектуального анализа данных. Цель интеллектуального анализа данных в Интернете состоит в том, чтобы искать закономерности в веб-данных путем сбора и изучения данных, чтобы получить представление.
Всемирная паутина содержит большое количество данных, которые являются богатым источником для интеллектуального анализа данных. Цель интеллектуального анализа данных в Интернете состоит в том, чтобы искать закономерности в веб-данных путем сбора и изучения данных, чтобы получить представление.
Что такое веб-майнинг?
Веб-майнинг можно широко рассматривать как применение адаптированных методов интеллектуального анализа данных в Интернете, тогда как интеллектуальный анализ данных определяется как применение алгоритма для обнаружения шаблонов в основном структурированных данных, встроенных в процесс обнаружения знаний .Веб-майнинг имеет отличительное свойство предоставлять набор различных типов данных. Интернет имеет множество аспектов, которые приводят к различным подходам к процессу майнинга, например, веб-страницы состоят из текста, веб-страницы связаны гиперссылками, а действия пользователей можно отслеживать с помощью журналов веб-сервера. Эти три функции приводят к различию между тремя областями: анализ веб-контента, анализ веб-структуры, анализ использования сети.
Существует три типа интеллектуального анализа данных:
1.Добыча веб-контента:
Интеллектуальный анализ веб-контента может использоваться для извлечения полезных данных, информации и знаний из содержимого веб-страницы. При анализе веб-контента каждая веб-страница рассматривается как отдельный документ. Пользователь может воспользоваться полуструктурированным характером веб-страниц, поскольку HTML предоставляет информацию, касающуюся не только макета, но и логической структуры. Основной задачей интеллектуального анализа контента является извлечение данных, когда структурированные данные извлекаются из неструктурированных веб-сайтов.Цель состоит в том, чтобы облегчить агрегирование данных по различным веб-сайтам с использованием извлеченных структурированных данных. Интеллектуальный анализ веб-контента можно использовать для выделения тем в Интернете. Например, если какой-либо пользователь ищет определенную задачу в поисковой системе, то пользователь получит список предложений.
2. Структурированный веб-майнинг:
Интеллектуальный анализ веб-структуры можно использовать для поиска структуры гиперссылки. Он используется для определения того, что данные либо ссылаются на веб-страницы, либо на сеть с прямыми ссылками.В анализе веб-структур человек рассматривает Интернет как ориентированный граф, где веб-страницы являются вершинами, связанными с гиперссылками. Наиболее важным приложением в этом отношении является поисковая система Google, которая оценивает ранжирование своих результатов в первую очередь с помощью алгоритма PageRank. Он характеризует страницу как исключительно релевантную, когда она часто связана с другими тесно связанными страницами. Методологии анализа структуры и содержания обычно комбинируются. Например, структурированный веб-майнинг может быть полезен организациям для регулирования сети между двумя коммерческими сайтами.
3. Анализ использования Интернета:
Интеллектуальный анализ использования Интернета используется для извлечения полезных данных, информации и знаний из записей веб-журналов и помогает распознавать шаблоны доступа пользователей к веб-страницам. В майнинге, при использовании веб-ресурсов, человек думает о записях запросов посетителей веб-сайта, которые часто собираются в виде журналов веб-сервера. В то время как содержание и структура набора веб-страниц соответствуют намерениям авторов страниц, отдельные запросы демонстрируют, как потребители видят эти страницы.Интеллектуальный анализ использования Интернета может раскрыть отношения, которые не были предложены создателем страниц.
В майнинге, при использовании веб-ресурсов, человек думает о записях запросов посетителей веб-сайта, которые часто собираются в виде журналов веб-сервера. В то время как содержание и структура набора веб-страниц соответствуют намерениям авторов страниц, отдельные запросы демонстрируют, как потребители видят эти страницы.Интеллектуальный анализ использования Интернета может раскрыть отношения, которые не были предложены создателем страниц.
Некоторые из методов выявления и анализа шаблонов использования Интернета приведены ниже:
I. Анализ сессий и посетителей:
Анализ предварительно обработанных данных может быть выполнен при анализе сеанса, который включает записи гостей, дни, время, сеансы и т. д. Эти данные можно использовать для анализа поведения посетителя.
После этого анализа создается документ, который содержит сведения о повторно посещаемых веб-страницах, общих входах и выходах.
II. OLAP (онлайн-аналитическая обработка):
OLAP выполняет многомерный анализ расширенных данных.
OLAP может выполняться для различных частей данных, связанных с журналом, за определенный период.
Инструменты OLAP можно использовать для определения важных показателей бизнес-аналитики
90 150 проблем в веб-майнинге: 90 143Сеть претендует на невероятные ресурсы и открытия знаний, основываясь на следующих наблюдениях:
- Сложность веб-страниц:
Страницы сайта не имеют единой структуры.Они чрезвычайно сложны по сравнению с традиционными текстовыми документами. В цифровой библиотеке Интернета огромное количество документов. Эти библиотеки не организованы в соответствии с определенным порядком.
- Интернет является динамическим источником данных:
Данные в интернете быстро обновляются. Например, новости, климат, покупки, финансовые новости, спорт и так далее.
- Разнообразие клиентских сетей:
Клиентская сеть в Интернете быстро расширяется. У этих клиентов разные интересы, опыт и цели использования. Есть более ста миллионов рабочих станций, которые связаны с Интернетом, и их число продолжает стремительно расти.
У этих клиентов разные интересы, опыт и цели использования. Есть более ста миллионов рабочих станций, которые связаны с Интернетом, и их число продолжает стремительно расти.
Считается, что конкретного человека обычно интересует небольшая часть сети, тогда как остальная часть сети содержит данные, которые не знакомы пользователю и могут привести к нежелательным результатам.
Сеть огромна и быстро увеличивается.Похоже, что сеть слишком велика для хранения данных и интеллектуального анализа данных.
Анализ структур ссылок в Интернете для распознавания авторитетных веб-страниц:
Сеть состоит из страниц, а также гиперссылок, указывающих с одной страницы на другую. Когда создатель веб-страницы создает гиперссылку, показывающую другую веб-страницу, это можно рассматривать как авторизацию создателя другой страницы. Единая авторизация данной страницы различными создателями в Интернете может указывать на важность страницы и, естественно, может способствовать обнаружению авторитетных веб-страниц. Данные о веб-ссылках предоставляют обширные данные о релевантности, качестве и структуре веб-контента и, таким образом, являются богатым источником веб-интеллектуального анализа.
Данные о веб-ссылках предоставляют обширные данные о релевантности, качестве и структуре веб-контента и, таким образом, являются богатым источником веб-интеллектуального анализа.
Применение веб-майнинга:
Веб-майнинг имеет обширное применение из-за различных вариантов использования Интернета. Список некоторых приложений веб-майнинга приведен ниже.
- Инструмент маркетинга и конверсии
- Анализ данных о выполнении сайта и приложений.
- Анализ поведения аудитории
- Анализ эффективности рекламы и кампаний.
- Тестирование и анализ сайта.
Интеллектуальный анализ структуры веб-сайта: повышение видимости веб-сайта
Интернет представляет собой огромный набор документов, связанных гипертекстовыми ссылками, созданными разработчиками веб-сайтов. Однако публикация в Интернете — это больше, чем просто создание страницы на сайте; обычно это также включает в себя ссылки на другие страницы в Интернете.
Растущий объем данных, доступных в Интернете, предоставляет огромное количество полезной информации, которую можно обработать для получения полезных знаний.Эта тенденция привела к «веб-майнингу» как к новой развивающейся дисциплине.
В широком смысле веб-майнинг можно определить как обнаружение и анализ полезной информации из всемирной паутины. Это очень активная область исследований, которая включает применение методов интеллектуального анализа данных к содержанию, структуре и использованию веб-ресурсов.
Несмотря на то, что он основан на интеллектуальном анализе данных, веб-интеллектуальный анализ имеет много уникальных характеристик. Например, источниками веб-майнинга являются веб-документы, которые можно представить в виде ориентированного графа, состоящего из узлов документа и гиперссылок.В то время как источник интеллектуального анализа данных ограничивается структурными данными в базах данных, в веб-интеллектуальном анализе могут быть идентифицированы различные шаблоны с учетом содержания документов, структуры, заданной гиперссылками, или способа просмотра веб-страниц.
Есть три общих области веб-майнинга; интеллектуальный анализ контента, интеллектуальный анализ структуры и интеллектуальный анализ использования:
- Интеллектуальный анализ веб-контента (WCM) занимается обнаружением знаний в веб-контенте, включая текст, гипертекст, изображения, аудио и видео.Последние достижения в области интеллектуального анализа мультимедийных данных обещают расширить доступ к изображениям, звуку, видео и т. д.
- Интеллектуальный анализ веб-структуры (WSM) обычно работает со структурой гиперссылок веб-страниц. WSM фокусируется на наборах страниц, начиная от одного веб-сайта и заканчивая Интернетом в целом. WSM использует дополнительную информацию, содержащуюся в гипертексте.
- Интеллектуальный анализ использования Интернета (WUM) фокусируется на записях запросов, сделанных посетителями веб-сайта, которые чаще всего собираются в журнале веб-сервера.Содержание и структура веб-страниц, и, в частности, одного веб-сайта, отражают намерения авторов и дизайнеров страниц, а также лежащую в их основе информационную архитектуру.

Интеллектуальный анализ веб-структур
Задача WSM состоит в том, чтобы разобраться со структурой гиперссылок внутри самого Интернета. Растущий интерес к веб-майнингу привел к возобновлению интереса к анализу ссылок, который включает в себя гипертекст и веб-майнинг, реляционное обучение и индуктивное логическое программирование, а также интеллектуальный анализ графов.Оценка и улучшение структуры ссылок имеет решающее значение для понимания общей структуры веб-сайта и определения того, где информация сконцентрирована или отсутствует.
При работе с анализом ссылок можно выделить несколько направлений исследований. Классификация на основе ссылок связана с предсказанием категории веб-страницы на основе слов, встречающихся на странице, ссылок между страницами, текста привязки, тегов html и других возможных атрибутов, найденных на веб-странице. Алгоритм Google PageRank является такой существующей метрикой, используемой для оценки веб-страниц, и является важным компонентом поисковой системы Google.
Анализ социальных сетей
Как правило, анализ социальных сетей (SNA) часто используется для изучения анализа ссылок. SNA представляет собой набор исследовательских процедур для выявления структур в социальных системах на основе отношений между компонентами системы, также называемыми узлами.
СНС возникла в результате использования математических моделей графов, применяемых при анализе социальных отношений между субъектами. В социологии акторы обычно моделируют отдельных людей, группы и иногда автономные устройства.Социальная сеть состоит из конечного набора или наборов акторов и определенного на них отношения или отношений. Это сложная система, которая характеризуется большим количеством динамически взаимосвязанных объектов и соединяет объекты любым типом связи, подразумевающим одноранговые отношения. СНС можно рассматривать как расширение или обобщение стандартных методов анализа данных и прикладной статистики, которые обычно фокусируются на элементах наблюдения и их характеристиках.
«Три ключевых метода повышения видимости веб-сайтов — это SEO, реклама в поисковых системах и платное включение.
Несмотря на то, что существуют альтернативы, основанные на анализе контента, по сравнению с другими веб-методами, такими как анализ на основе контента, относительное преимущество анализа гиперссылок заключается в том, что он позволяет изучить, каким образом веб-сайты формируют определенные виды отношений с другими посредством гиперссылки. Использование этой информации в сочетании с другими веб-анализами может способствовать пониманию того, почему и как определенные типы контента появляются на веб-сайтах.
Повышение наглядности, удобства использования и доступности
Внутренняя структура веб-сайта тесно связана с такими вопросами, как доступность и навигация по сайту.Функции навигации позволяют посетителю получить легкий доступ к интересующей его информации, как внутренней, так и внешней по отношению к сайту. Он включен в качестве одной из особенностей дизайна корпоративных веб-сайтов, наряду с презентацией, безопасностью, скоростью и отслеживанием. Качество веб-сайта также повышается, если он легко узнаваем и доступен для пользователей. На самом деле доступность является частью индексов веб-оценки.
Качество веб-сайта также повышается, если он легко узнаваем и доступен для пользователей. На самом деле доступность является частью индексов веб-оценки.
Организация веб-сайта также имеет важное значение для удобства использования. Это относится к тому, «насколько хорошо и легко пользователь без формального обучения может взаимодействовать с информационной системой или веб-сайтом».Улучшенная структура веб-ссылок позволяет посетителям легче перемещаться по веб-сайтам, а также быстрее направлять их в нужное место. Хотя юзабилити веб-сайта можно оценить с помощью различных подходов, таких как когнитивное прохождение, цепи Маркова или методы опроса, все они обусловлены структурой веб-сайта. Следовательно, дизайнеры веб-сайтов должны учитывать выявленные шаблоны структуры веб-сайта для повышения удобства использования.
Еще одно важное следствие относится к поисковой оптимизации (SEO), поскольку значительное большинство поисковых запросов в Интернете используют поисковую систему в качестве начальной точки входа. Три ключевых метода повышения видимости веб-сайтов — это SEO, реклама в поисковых системах и платное включение.
Три ключевых метода повышения видимости веб-сайтов — это SEO, реклама в поисковых системах и платное включение.
SEO включает в себя принятие методов, которые улучшают рейтинг веб-сайта, когда пользователь вводит релевантные ключевые слова в поисковой системе; реклама в поисковой системе относится к покупке отображаемых позиций в платной области листинга поисковой системы; а платное включение означает оплату поисковым системам за включение сайта в их органические списки. SEO обычно считается наиболее эффективным, поскольку поисковики уделяют меньше внимания коммерческому контенту, чем органическим спискам.
Структура сайта напрямую влияет на то, насколько хорошо он будет восприниматься поисковыми системами. Поисковые системы посылают программы, известные как «роботы», «пауки» или «краулеры», для изучения Интернета и выяснения того, что находится на сайтах. Мало того, они используют алгоритмы для обработки данных, возвращаемых им поисковыми роботами, и для определения релевантности и популярности сайтов, которые будут перечислены на их результирующих страницах. Структура сайта важна, потому что она всегда будет влиять на то, как «сканеры» увидят его и его содержимое.
Структура сайта важна, потому что она всегда будет влиять на то, как «сканеры» увидят его и его содержимое.
службы SEO согласны с тем, что если есть три или более ссылок на каждую страницу с других на сайте, то можно сказать, что он хорошо структурирован для поисковой оптимизации. Если структура сайта сдерживает количество внутренних ссылок, то он плохо структурирован. Сканеры должны иметь возможность прочитать как можно больше страниц, и эти ссылки — это пути, по которым им придется идти. Сайт должен быть структурирован таким образом, чтобы обеспечить простую и доступную навигацию по карте сайта и обратно.Можно сказать, что удобная для пользователя структура сайта хорошо работает с точки зрения поисковых роботов. Это означает, что ранжирование страницы результатов поисковой системы может быть улучшено с помощью хорошей структуры сайта. Страница результатов в поисковой системе дает пользователю первое представление о содержании после того, как он ввел текст в поле запроса и нажал Enter. Структуру веб-сайта можно рассматривать как один из инструментов SEO, находящихся в распоряжении веб-дизайнеров, чтобы сделать веб-сайты видимыми на странице результатов поисковой системы.
Структуру веб-сайта можно рассматривать как один из инструментов SEO, находящихся в распоряжении веб-дизайнеров, чтобы сделать веб-сайты видимыми на странице результатов поисковой системы.
Используя SNA, дизайнеры веб-сайтов могут определить способы повышения удобства использования веб-сайта, что, в свою очередь, принесет пользу посетителям веб-сайта.Они также могут проверить, является ли структура их веб-сайта такой, какой они ее задумывали. Наконец, веб-сайты должны быть структурированы таким образом, чтобы поисковые системы могли просматривать их содержимое.
Июль 2011 г.
Это сокращенная версия «Изучения структуры веб-сайта с использованием анализа социальных сетей», которая первоначально появилась в Internet Research , Volume 21 Number 2, 2011.
Авторы: М. Р. Мартинес-Торрес, Серхио Л.Торал, Беатрис Паласиос и Федерико Барреро.
Веб-аналитика и майнинг | Информатика
Веб-аналитика и майнинг
MET CS 688 (4 кредита)
Курс «Веб-аналитика и добыча полезных ископаемых» охватывает области веб-аналитики, интеллектуального анализа текста, интеллектуального анализа данных в Интернете и практических областей применения. Часть курса, посвященная веб-аналитике, изучает показатели веб-сайтов, их содержание, поведение пользователей и отчетность. Модуль интеллектуального анализа текста охватывает анализ текста, включая извлечение содержимого, сопоставление строк, кластеризацию, классификацию и системы рекомендаций.Модуль веб-анализа изучает, как поисковые роботы обрабатывают и индексируют содержимое веб-сайтов, как работает поиск и как ранжируются результаты. Области применения майнинга в социальной сети будут тщательно изучены. Лабораторный курс. Требования: MET CS 544 или MET CS 555 или эквивалентные знания, или согласие инструктора.
Часть курса, посвященная веб-аналитике, изучает показатели веб-сайтов, их содержание, поведение пользователей и отчетность. Модуль интеллектуального анализа текста охватывает анализ текста, включая извлечение содержимого, сопоставление строк, кластеризацию, классификацию и системы рекомендаций.Модуль веб-анализа изучает, как поисковые роботы обрабатывают и индексируют содержимое веб-сайтов, как работает поиск и как ранжируются результаты. Области применения майнинга в социальной сети будут тщательно изучены. Лабораторный курс. Требования: MET CS 544 или MET CS 555 или эквивалентные знания, или согласие инструктора.
2021FALLMETCS688 A1, с 7 сентября по 7 декабря 2021 г.
| Дней | Старт | Конец | Тип | , корп. | Комната |
|---|---|---|---|---|---|
| Т | 09:00 | 11:45 | МЕТ | 122 |
2021FALLMETCS688 A2, со 2 сентября по 9 декабря 2021 года
| Дней | Старт | Конец | Тип | , корп. | Комната |
|---|---|---|---|---|---|
| Р | 18:00 | 20:45 | КРУЖКА | 205 |
2021FALLMETCS688 O1, с 7 сентября по 25 октября 2021 года
| Дней | Старт | Конец | Тип | , корп. | Комната |
|---|---|---|---|---|---|
| ARR | Подлежит уточнению | Подлежит уточнению |
2022SPRGMETCS688 A1, с 25 января по 3 мая 2022 г.
| Дней | Старт | Конец | Тип | , корп. | Комната |
|---|---|---|---|---|---|
| Т | 09:00 | 11:45 | МЕТ | 122 |
2022SPRGMETCS688 A2, с 20 января по 28 апреля 2022 года
| Дней | Старт | Конец | Тип | , корп. | Комната |
|---|---|---|---|---|---|
| Р | 18:00 | 20:45 | Хар | 312 |
2022SPRGMETCS688 O2, с 14 марта по 1 мая 2022 года
| Дней | Старт | Конец | Тип | , корп. | Комната |
|---|---|---|---|---|---|
| ARR | Подлежит уточнению | Подлежит уточнению | КОМНАТА |
Что такое веб-майнинг — определение, значение и примеры
Определение:
веб-майнинг
— это процесс использования методов и алгоритмов интеллектуального анализа данных для извлечения информации непосредственно из Интернета или через веб-документы. и веб-службы, гиперссылки и журналы сервера.Цель интеллектуального анализа данных в Интернете — поиск закономерностей в веб-данных путем сбора и анализа информации, чтобы получить представление о тенденциях, отрасли и пользователях в целом.
Типы веб-анализа:
- Веб-анализ контента: Процесс извлечения полезной информации из содержимого веб-страниц и веб-документов, которые в основном представляют собой текст, изображения, аудио- или видеофайлы.
- Анализ веб-структуры: Процесс анализа структуры узлов и связи веб-сайта с использованием теории графов. К этому можно добавить две вещи: структуру веб-сайта с точки зрения того, как он соединяется с другими сайтами, и структуру документа самой веб-страницы с точки зрения того, как каждая страница соединяется.
- Анализ использования Интернета: Процесс извлечения шаблонов и информации из журналов сервера для получения информации о действиях пользователей, их источниках, количестве пользователей, нажимавших на элемент на сайте, и типах действия, происходящие на сайте.
 К этому можно добавить две вещи: структуру веб-сайта с точки зрения того, как он соединяется с другими сайтами, и структуру документа самой веб-страницы с точки зрения того, как каждая страница соединяется.
К этому можно добавить две вещи: структуру веб-сайта с точки зрения того, как он соединяется с другими сайтами, и структуру документа самой веб-страницы с точки зрения того, как каждая страница соединяется.Веб-майнинг по сравнению сИнтеллектуальный анализ данных
При сравнении веб-интеллектуального анализа данных с традиционным интеллектуальным анализом данных необходимо учитывать три основных отличия:
- Масштаб: В традиционном интеллектуальном анализе данных обработка 1 миллиона записей из базы данных требует большого объема работы. В веб-майнинге даже 10 миллионов страниц не будут очень большим числом.
- Доступ: При добыче данных корпоративной информации данные являются частными и часто требуют прав доступа для их чтения. Для веб-майнинга данные являются общедоступными и редко требуют прав доступа.Однако веб-майнинг имеет дополнительные ограничения из-за неявного соглашения в отношении веб-мастеров об автоматическом доступе к этим данным. Это неявное соглашение заключается в том, что веб-мастер разрешает сканерам доступ к полезным данным на веб-сайте, и вместо этого сканер обещает не перегружать сайт и может привлечь больше трафика на веб-страницу после публикации поискового индекса. При веб-майнинге такого индекса часто нет, а это означает, что сканер должен быть очень осторожным в процессе сканирования, чтобы не создавать проблем для веб-мастера.
- Структура: Традиционная задача интеллектуального анализа данных получает информацию из базы данных, которая обеспечивает определенный уровень явной структуры. Типичной задачей веб-интеллектуального анализа данных является обработка неструктурированных или частично структурированных данных с веб-страниц. Несмотря на то, что базовая информация для веб-страниц поступает из базы данных, она часто скрыта форматом HTML.
 Для веб-майнинга данные являются общедоступными и редко требуют прав доступа.Однако веб-майнинг имеет дополнительные ограничения из-за неявного соглашения в отношении веб-мастеров об автоматическом доступе к этим данным. Это неявное соглашение заключается в том, что веб-мастер разрешает сканерам доступ к полезным данным на веб-сайте, и вместо этого сканер обещает не перегружать сайт и может привлечь больше трафика на веб-страницу после публикации поискового индекса. При веб-майнинге такого индекса часто нет, а это означает, что сканер должен быть очень осторожным в процессе сканирования, чтобы не создавать проблем для веб-мастера.
Для веб-майнинга данные являются общедоступными и редко требуют прав доступа.Однако веб-майнинг имеет дополнительные ограничения из-за неявного соглашения в отношении веб-мастеров об автоматическом доступе к этим данным. Это неявное соглашение заключается в том, что веб-мастер разрешает сканерам доступ к полезным данным на веб-сайте, и вместо этого сканер обещает не перегружать сайт и может привлечь больше трафика на веб-страницу после публикации поискового индекса. При веб-майнинге такого индекса часто нет, а это означает, что сканер должен быть очень осторожным в процессе сканирования, чтобы не создавать проблем для веб-мастера.