Масштабирование базы данных через шардирование и партиционирование / Хабр
Денис Иванов (2ГИС)
Всем привет! Меня зовут Денис Иванов, и я расскажу о масштабировании баз данных через шардирование и партиционирование. После этого доклада у всех должно появиться желание что-то попартицировать, пошардировать, вы поймете, что это очень просто, оно никак жрать не просит, работает, и все замечательно.
Немного расскажу о себе — я работаю в команде WebAPI в компании 2GIS, мы предоставляем API для организаций, у нас очень много разных данных, 8 стран, в которых мы работаем, 250 крупных городов, 50 тыс. населенных пунктов. У нас достаточно большая нагрузка — 25 млн. активных пользователей в месяц, и в среднем нагрузка около 2000 RPS идет на API. Все это располагается в трех датацентрах.
Перейдем к проблемам, которые мы с вами сегодня будем решать. Одна из проблем — это большое количество данных. Когда вы разрабатываете тот или иной проект, у вас в любой момент времени может случиться так, что данных становится очень много.
Я в большей степени расскажу про шардинг. Он бывает вертикальным и горизонтальным. Также бывает такой способ масштабирования как репликация. Доклад «Как устроена MySQL репликация» Андрея Аксенова из Sphinx про это и был. Я эту тему практически не буду освещать.
Перейдем подробнее к теме партицирования (вертикальный шардинг). Как это все выглядит?
У нас есть большая таблица, например, с пользователями — у нас очень много пользователей. Партицирование — это когда мы одну большую таблицу разделяем на много маленьких по какому-либо принципу.

Единственное отличие горизонтального масштабирования от вертикального в том, что горизонтальное масштабирование будет разносить данные по разным инстансам.
Про репликацию я не буду останавливаться, тут все очень просто.
Перейдем глубже к этой теме, и я расскажу практически все о партицировании на примере Postgres’а.
У новости есть идентификатор, есть категория, в которой эта новость расположена, есть автор новости, ее рейтинг и какой-то заголовок — совершенно стандартная таблица, ничего сложного нет.
Как же эту таблицу разделить на несколько? С чего начать?
Всего нужно будет сделать 2 действия над табличкой — это поставить у нашего шарда, например, news_1, то, что она будет наследоваться таблицей news. News будет базовой таблицей, будет содержать всю структуру, и мы, создавая партицию, будем указывать, что она наследуется нашей базовой таблицей.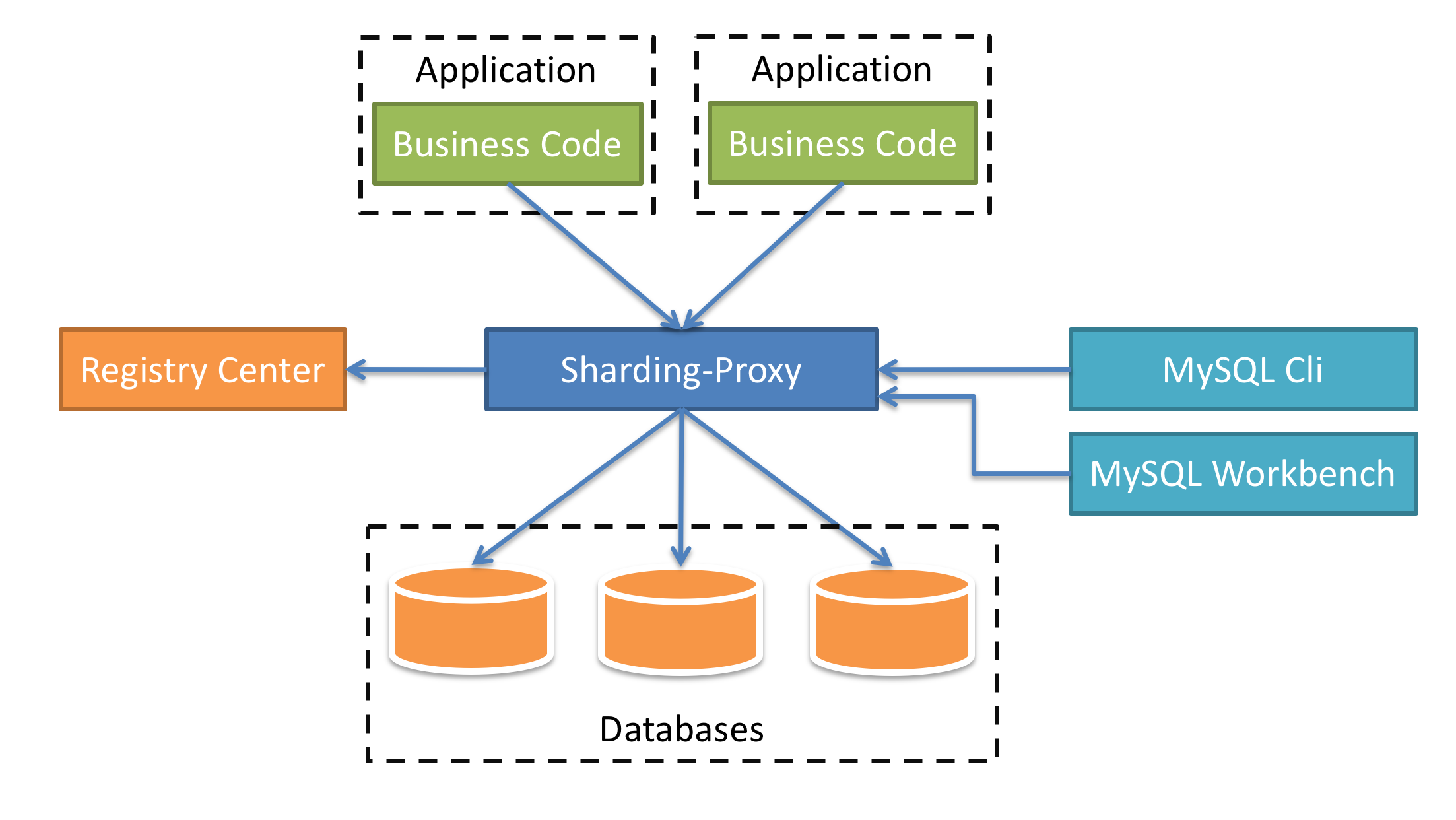
2-ое действие, которое нужно сделать — это поставить ограничения. Это будет проверка, что в эту таблицу будут попадать данные только вот с таким признаком.
В данном случае признак — это category_id=1, т.е. только записи с category_id=1 будут попадать в эту таблицу.
Какие типы проверок бывают для партицированных таблиц?
Бывает строгое значение, т.е. у нас какое-то поле четко равно какому-то полю. Бывает список значений — это вхождение в список, например, у нас может быть 3 автора новости именно в этой партиции, и бывает диапазон значений — это от какого и до какого значения данные будут храниться.
Тут нужно подробнее остановиться, потому что проверка поддерживает оператор BETWEEN, наверняка вы все его знаете.
И так просто его сделать можно. Но нельзя. Можно сделать, потому что нам разрешат такое сделать, PostgreSQL поддерживает такое. Как вы видите, у нас в 1-ую партицию попадают данные между 100 и 200, а во 2-ую — между 200 и 300. В какую из этих партиций попадет запись с рейтингом 200? Не известно, как повезет. Поэтому так делать нельзя, нужно указывать строгое значение, т.е. строго в 1-ую партицию будут попадать значения больше 100 и меньше либо равно 200, и во вторую больше 200, но не 200, и меньше либо равно 300.
Это обязательно нужно запомнить и так не делать, потому что вы не узнаете, в какую из партиций данные попадут. Нужно четко прописывать все условия проверки.
Также не стоит создавать партиции по разным полям, т.е. что в 1-ую партицию у нас будут попадать записи с category_id=1, а во 2-ую — с рейтингом 100.
Опять же, если нам придет такая запись, в которой category_id = 1 и рейтинг =100, то неизвестно в какую из партиций попадет эта запись. Партицировать стоит по одному признаку, по какому-то одному полю — это очень важно.
Партицировать стоит по одному признаку, по какому-то одному полю — это очень важно.
Давайте рассмотрим нашу партицию целиком:
Ваша партицированная таблица будет выглядеть вот так, т.е. это таблица news_1 с признаком, что туда будут попадать записи только с category_id = 1, и эта таблица будет унаследована от базовой таблицы news — все очень просто.
Мы на базовую таблицу должны добавить некоторое правило, чтобы, когда мы будем работать с нашей основной таблицей news, вставка на запись с category_id = 1 попала именно в ту партицию, а не в основную. Мы указываем простое правило, называем его как хотим, говорим, что когда данные будут вставляться в news с category_id = 1, вместо этого будем вставлять данные в news_1. Тут тоже все очень просто: по шаблончику оно все меняется и будет замечательно работать. Это правило создается на базовой таблице.
Таким образом мы заводим нужное нам количество партиций. Для примера я буду использовать 2 партиции, чтобы было проще.
Давайте рассмотрим пример вставки данных:
Данные будем вставлять как обычно, будто у нас обычная большая толстая таблица, т.е. мы вставляем запись с category_id=1 с category_id=2, можем даже вставить данные с category_id=3.
Вот мы выбираем данные, у нас они все есть:
Все, которые мы вставляли, несмотря на то, что 3-ей партиции у нас нет, но данные есть. В этом, может быть, есть немного магии, но на самом деле нет.
Мы также можем сделать соответствующие запросы в определенные партиции, указывая наше условие, т.е.category_id = 1, или вхождение в числа (2, 3).
Все будет замечательно работать, все данные будут выбираться. Опять же, несмотря на то, что с партиции с category_id=3 у нас нет.
Мы можем выбирать данные напрямую из партиций — это будет то же самое, что в предыдущем примере, но мы четко указываем нужную нам партицию. Когда у нас стоит точное условие на то, что нам именно из этой партиции нужно выбрать данные, мы можем напрямую указать именно эту партицию и не ходить в другие. Но у нас нет 3-ей партиции, а данные попадут в основную таблицу.
Хоть у нас и применено партицирование к этой таблице, основная таблица все равно существует. Она настоящая таблица, она может хранить данные, и с помощью оператора ONLY можно выбрать данные только из этой таблицы, и мы можем найти, что эта запись здесь спряталась.
Здесь можно, как видно на слайде, вставлять данные напрямую в партицию. Можно вставлять данные с помощью правил в основную таблицу, но можно и в саму партицию.
Если мы будем вставлять данные в партицию с каким-то чужеродным условием, например, с category_id = 4, то мы получим ошибку «сюда такие данные нельзя вставлять» — это тоже очень удобно — мы просто будем класть данные только в те партиции, которые нам действительно нужно, и если у нас что-то пойдет не так, мы на уровне базы все это отловим.
Тут пример побольше. Можно bulk_insert использовать, т.е. вставлять несколько записей одновременно и они все сами распределятся с помощью правил нужной партиции. Т.е. мы можем вообще не заморачиваться, просто работать с нашей таблицей, как мы раньше и работали. Приложение продолжит работать, но при этом данные будут попадать в партиции, все это будет красиво разложено по полочкам без нашего участия.
Напомню, что мы можем выбирать данные как из основной таблицы с указанием условия, можем, не указывая это условие выбирать данные из партиции. Как это выглядит со стороны explain’а:
У нас будет Seq Scan по всей таблице целиком, потому что туда данные могут все равно попадать, и будет скан по партиции. Если мы будем указывать условия нескольких категорий, то он будет сканировать только те таблицы, на которые есть условия. Он не будет смотреть в остальные партиции. Так работает оптимизатор — это правильно, и так действительно быстрее.
Мы можем посмотреть, как будет выглядеть explain на самой партиции.
Это будет обычная таблица, просто Seq Scan по ней, ничего сверхъестественного. Точно так же будут работать update’ы и delete’ы. Мы можем update’тить основную таблицу, можем также update’ы слать напрямую в партиции. Так же и delete’ы будут работать. На них нужно так же соответствующие правила создать, как мы создавали с insert’ом, только вместо insert написать update или delete.
Перейдем к такой вещи как Index’ы
Индексы, созданные на основной таблице, не будут унаследованы в дочерней таблице нашей партиции. Это грустно, но придется заводить одинаковые индексы на всех партициях. С этим есть что поделать, но придется заводить все индексы, все ограничения, все триггеры дублировать на все таблицы.
Как мы с этой проблемой боролись у себя. Мы создали замечательную утилиту PartitionMagic, которая позволяет автоматически управлять партициями и не заморачиваться с созданием индексов, триггеров с несуществующими партициями, с какими-то бяками, которые могут происходить. Эта утилита open source’ная, ниже будет ссылка. Мы эту утилиту в виде хранимой процедуры добавляем к нам в базу, она там лежит, не требует дополнительных extension’ов, никаких расширений, ничего пересобирать не нужно, т.е. мы берем PostgreSQL, обычную процедуру, запихиваем в базу и с ней работаем.
Эта утилита open source’ная, ниже будет ссылка. Мы эту утилиту в виде хранимой процедуры добавляем к нам в базу, она там лежит, не требует дополнительных extension’ов, никаких расширений, ничего пересобирать не нужно, т.е. мы берем PostgreSQL, обычную процедуру, запихиваем в базу и с ней работаем.
Вот та же самая таблица, которую мы рассматривали, ничего нового, все то же самое.
Как же нам запартицировать ее? А просто вот так:
Мы вызываем процедуру, указываем, что таблица будет news, и партицировать будем по category_id. И все дальше будет само работать, нам больше ничего не нужно делать. Мы так же вставляем данные.
У нас тут три записи с category_id =1, две записи с category_id=2, и одна с category_id=3.
После вставки данные автоматически попадут в нужные партиции, мы можем сделать селекты.
Все, партиции уже создались, все данные разложились по полочкам, все замечательно работает.
Какие мы получаем за счет этого преимущества:
- при вставке мы автоматически создаем партицию, если ее еще нет;
- поддерживаем актуальную структуру, можем управлять просто базовой таблицей, навешивая на нее индексы, проверки, триггеры, добавлять колонки, и они автоматически будут попадать во все партиции после вызова этой процедуры еще раз.


Мы получаем действительно большое преимущество в этом. Вот ссылочка
https://github.com/2gis/partition_magic. На этом первая часть доклада закончена. Мы научились партицировать данные. Напомню, что партицирование применяется на одном инстансе — это тот же самый инстанс базы, где у вас лежала бы большая толстая таблица, но мы ее раздробили на мелкие части. Мы можем совершенно не менять наше приложение — оно точно так же будет работать с основной таблицей — вставляем туда данные, редактируем, удаляем. Так же все работает, но работает быстрее. Приблизительно, в среднем, в 3-4 раза быстрее.
Перейдем ко второй части доклада — это горизонтальный шардинг. Напомню, что горизонтальный шардинг — это когда мы данные разносим по нескольким серверам. Все это делается тоже достаточно просто, стоит один раз это настроить, и оно будет работать замечательно. Я расскажу подробнее, как это можно сделать.
Рассматривать будем такую же структуру с двумя шардами — news_1 и news_2, но это будут разные инстансы, третьим инстансом будет основная база, с которой мы будем работать:
Та же самая таблица:
Единственное, что туда нужно добавить, это CONSTRAINT CHECK, того, что записи будут выпадать только с category_id=1. Так же, как в предыдущем примере, но это не унаследованная таблица, это будет таблица с шардом, которую мы делаем на сервере, который будет выступать шардом с category_id=1. Это нужно запомнить. Единственное, что нужно сделать — это добавить CONSTRAINT.
Так же, как в предыдущем примере, но это не унаследованная таблица, это будет таблица с шардом, которую мы делаем на сервере, который будет выступать шардом с category_id=1. Это нужно запомнить. Единственное, что нужно сделать — это добавить CONSTRAINT.
Мы еще можем дополнительно создать индекс по category_id:
Несмотря на то, что у нас стоит check — проверка, PostgreSQL все равно обращается в этот шард, и шард может очень надолго задуматься, потому что данных может быть очень много, а в случае с индексом он быстро ответит, потому что в индексе ничего нет по такому запросу, поэтому его лучше добавить.
Как настроить шардинг на основном сервере?
Мы подключаем EXTENSION. EXTENSION идет в Postgres’e из коробки, делается это командой CREATE EXTENSION, называется он postgres_fdw, расшифровывается как foreign data wrapper.
Далее нам нужно завести удаленный сервер, подключить его к основному, мы называем его как угодно, указываем, что этот сервер будет использовать foreign data wrapper, который мы указали.
Таким же образом можно использовать для шарда MySql, Oracle, Mongo… Foreign data wrapper есть для очень многих баз данных, т.е. можно отдельные шарды хранить в разных базах.
В опции мы добавляем хост, порт и имя базы, с которой будем работать, нужно просто указать адрес вашего сервера, порт (скорее всего, он будет стандартный) и базу, которую мы завели.
Далее мы создаем маппинг для пользователя — по этим данным основной сервер будет авторизироваться к дочернему. Мы указываем, что для сервера news_1 будет пользователь postgres, с паролем postgres. И на основную базу данных он будет маппиться как наш user postgres.
Я все со стандартными настройками показал, у вас могут быть свои пользователи для проектов заведены, для отдельных баз, здесь нужно именно их будет указать, чтобы все работало.
Далее мы заводим табличку на основном сервере:
Это будет табличка с такой же структурой, но единственное, что будет отличаться — это префикс того, что это будет foreign table, т. е. она какая-то иностранная для нас, отдаленная, и мы указываем, с какого сервера она будет взята, и в опциях указываем схему и имя таблицы, которую нам нужно взять.
е. она какая-то иностранная для нас, отдаленная, и мы указываем, с какого сервера она будет взята, и в опциях указываем схему и имя таблицы, которую нам нужно взять.
Схема по дефолту — это public, таблицу, которую мы завели, назвали news. Точно так же мы подключаем 2-ую таблицу к основному серверу, т.е. добавляем сервер, добавляем маппинг, создаем таблицу. Все, что осталось — это завести нашу основную таблицу.
Это делается с помощью VIEW, через представление, мы с помощью UNION ALL склеиваем запросы из удаленных таблиц и получаем одну большую толстую таблицу news из удаленных серверов.
Также мы можем добавить правила на эту таблицу при вставке, удалении, чтобы работать с основной таблицей вместо шардов, чтобы нам было удобнее — никаких переписываний, ничего в приложении не делать.
Мы заводим основное правило, которое будет срабатывать, если ни одна проверка не сработала, чтобы не происходило ничего. Т.е. мы указываем DO INSTEAD NOTHING и заводим такие же проверки, как мы делали ранее, но только с указанием нашего условия, т. е. category_id=1 и таблицу, в которую данные вместо этого будут попадать.
е. category_id=1 и таблицу, в которую данные вместо этого будут попадать.
Т.е. единственное отличие — это в category_id мы будем указывать имя таблицы. Также посмотрим на вставку данных.
Я специально выделил несуществующие партиции, т.к. эти данные по нашему условию не попадут никуда, т.е. у нас указано, что мы ничего не будем делать, если не нашлось никакого условия, потому что это VIEW, это не настоящая таблица, туда данные вставить нельзя. В том условии мы можем написать, что данные будут вставляться в какую-то третью таблицу, т.е. мы можем завести что-то типа буфера или корзины и INSERT INTO делать в ту таблицу, чтобы там копились данные, если вдруг каких-то партиций у нас нет, и данные стали приходить, для которых нет шардов.
Выбираем данные
Обратите внимание на сортировку идентификаторов — у нас сначала выводятся все записи из первого шарда, затем из второго. Это происходит из-за того, что postgres ходит по VIEW последовательно. У нас указаны select’ы через UNION ALL, и он именно так исполняет — посылает запросы на удаленные машины, собирает эти данные и склеивает, и они будут отсортированы по тому принципу, по которому мы эту VIEW создали, по которому тот сервер отдал данные.
Делаем запросы, какие мы делали ранее из основной таблицы с указанием категории, тогда postgres отдаст данные только из второго шарда, либо напрямую обращаемся в шард.
Так же, как и в примерах выше, только у нас разные сервера, разные инстансы, и все точно так же работает как работало раньше.
Посмотрим на explain.
У нас foreign scan по news_1 и foreign scan по news_2, так же, как было с партицированием, только вместо Seq Scan-а у нас foreign scan — это удаленный скан, который выполняется на другом сервере.
Партицирование — это действительно просто, стоит всего лишь несколько действий совершить, все настроить, и оно все будет замечательно работать, не будет просить есть. Можно так же работать с основной таблицей, как мы работали ранее, но при этом у нас все красиво лежит по полочкам и готово к масштабированию, готово к большому количеству данных. Все это работает на одном сервере, и при этом мы получаем прирост производительности в 3-4 раза, за счет того, что у нас объем данных в таблице сокращается, т. к. это разные таблицы.
к. это разные таблицы.
Шардинг — лишь немного сложнее партицирования, тем, что нужно настраивать каждый сервер по отдельности, но это дает некое преимущество в том, что мы можем просто бесконечное количество серверов добавлять, и все будет замечательно работать.
Контакты
Блог компании 2ГИС
Принципы шардинга реляционных баз данных | by Igor Olemskoi | Southbridge
Когда ваша база данных небольшая (10 ГБ), вы можете легко добавить больше ресурсов и таким образом масштабировать ее. Однако, поскольку таблицы растут, нужно подумать и о других способах масштабирования базы данных.
С одной стороны шардинг — лучший способ масштабирования. Он позволяет линейно масштабировать ресурсы базы данных, памяти и диска, дробя базу данных на более мелкие части. С другой стороны целесообразность использования шаринга — спорная тема. Интернет полон советов по шардингу, от «масштабирования инфраструктуры базы данных» до «почему вы никогда не используете шардинг». Итак, вопрос в том, какую сторону принять.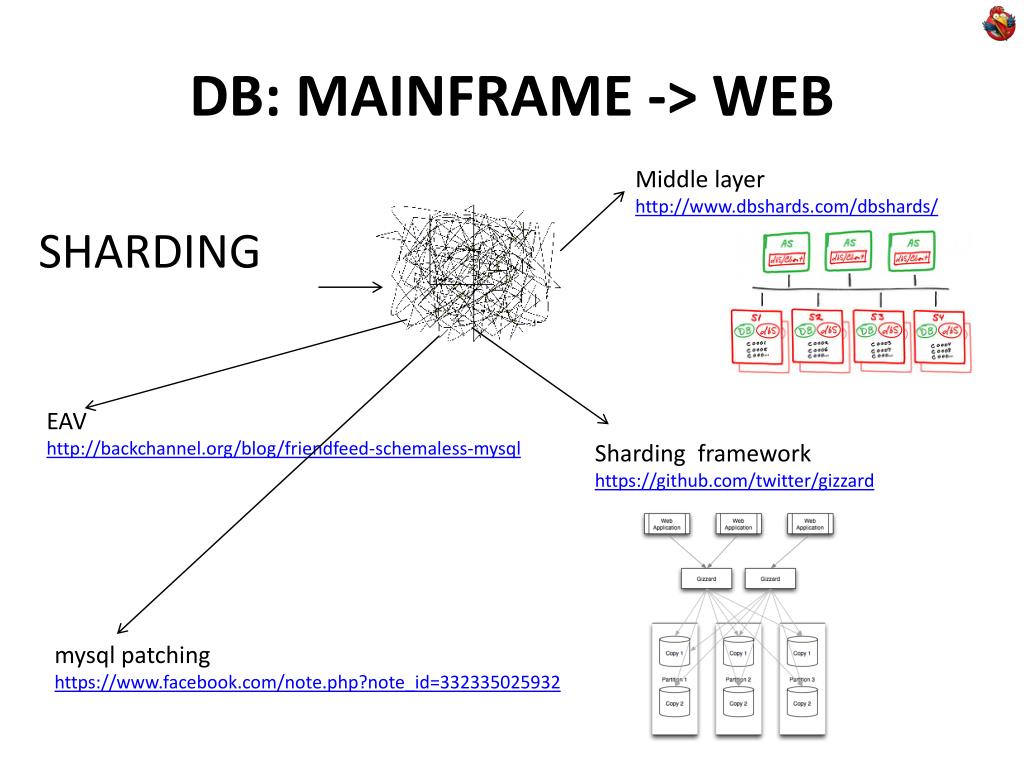
Всегда, когда возникал вопрос шардинга, ответ был «раз на раз не приходится». Теория шардинга проста: выберите один ключ (столбец), который равномерно распределяет данные. Убедитесь, что большинство запросов могут быть решены с помощью этого ключа. Эта теория проста, но только до того момента, пока вы не приступите к практике.
В Citus мы помогли сотням команд, когда они обращались к шардингу баз данных. С получением опыта мы обнаружили, что имеются ключевые шаблоны.
В этой статье мы сначала рассмотрим ключевые параметры, которые влияют на успех шардинга, а затем раскроем основную причину, по которой мнения о шардинге столь разные. Когда дело доходит до шардинга базы данных, на успех в большей степени влияет тип приложения, которое вы создаете.
На успех шардинга базы данных влияют 3 ключевых параметра. На диаграмме они показаны на трех осях, а также приведены примеры известных компаний.
Ось X на диаграмме показывает тип рабочей нагрузки. Эта ось начинается с транзакционных нагрузок слева и продолжается организацией хранилищ данных. Изменения этой оси более заметны при шардинге.
Изменения этой оси более заметны при шардинге.
Ось Z демонстрирует еще один важный параметр — нахождение в жизненном цикле приложения. Сколько таблиц у вас есть в базе данных (10, 100, 1000) или как долго приложение находится в производстве? Приложение, запущенное на PostgreSQL в течение нескольких месяцев, будет легче шардироваться, чем приложение, которое было в производстве в течение многих лет.
В Citus мы обнаружили, что большинство пользователей имеют достаточно развитые приложения. Когда приложение развито, ось У становится критической. К сожалению, изменения этой оси не так заметны, как изменения остальных осей. Фактически большинство статей, которые противоречат выводам о фрагментации, предоставляют свои рекомендации в контексте одного типа приложения.
Ось У на диаграмме показывает наиболее важный параметр при шардинге баз данных — тип приложения. В верхней части этой оси находятся приложения B2B, модели данных которых более удобны для фрагментации. В нижней части этой оси — приложения B2C, такие как Amazon и Facebook, которые требуют больше работы. Далее мы расскажем о различиях трех известных компаний.
Далее мы расскажем о различиях трех известных компаний.
Хорошим примером приложения для B2B является программное обеспечение CRM. Когда вы создаете CRM-приложение, такое как Salesforce, ваше приложение будет обслуживать других клиентов. Например, компания GE Aviation будет одним из ваших клиентов, использующих Salesforce.
В GE Aviation есть пользователи, которые входят в свою панель мониторинга компании. GE также фиксирует:
потенциальных клиентов, с которыми они могут вести бизнес,
контакты/людей, которые уже известны и с которыми установлены деловые отношения,
счета, которые представляют бизнес-единицы и у которых есть работающие на них контакты,
возможности, которые являются событиями продаж, связанными с учетной записью и одного или нескольких контактов.
Сопоставление этих сложных соотношений выглядит следующим образом:
График выглядит сложным. Но изучив график, можно заметить, что большинство таблиц происходит из таблицы клиентов. Графы можно преобразовать, добавив столбец customer_id ко всем таблицам.
С помощью этого простого преобразования у базы данных теперь есть хороший ключ оглавления: customer_id. Он равномерно распределяет данные, и большинство запросов к базе данных будут включать ключ клиента. Кроме того, вы можете размещать таблицы в client_id и продолжать использовать ключевые функции реляционной базы данных, такие как транзакция, объединение таблиц и ограничение внешнего ключа.
Другими словами, если у вас есть приложение B2B, характер ваших данных дает вам фундаментальное преимущество при шардинге.
Amazon.com — хороший пример расширенного приложения B2C. Если бы вы строили сайт Amazon.com сегодня, у вас было бы несколько концепций для рассмотрения. Во-первых, пользователь приходит на ваш сайт и начинает смотреть продукты: книги, электронику. Когда пользователь посещает страницу продукта, скажем, Harry Potter 7, он видит информацию каталога, связанную с этим продуктом. Пример информации о каталоге включает автора, цену, обложку и другие изображения.
Когда пользователь регистрируется на веб-сайте, он получает доступ к данным, связанным с пользователем. Пользователь должен быть аутентифицирован, может писать отзывы о любимых продуктах и добавлять элементы в корзину покупок. В какой-то момент пользователь решает сделать покупку и размещает заказ. Заказ обрабатывается, забирается со склада и отправляется.
Пользователь должен быть аутентифицирован, может писать отзывы о любимых продуктах и добавлять элементы в корзину покупок. В какой-то момент пользователь решает сделать покупку и размещает заказ. Заказ обрабатывается, забирается со склада и отправляется.
При сопоставлении отношений в реляционнной базе данных вы обнаружите, что они отличаются от примера Salesforce одной важной чертой. У вас нет единого измерения, которое является центром всех отношений, а есть как минимум три: каталог, пользователь и данные заказа.
При фрагментации данных типа B2C один из вариантов заключается в преобразовании приложения в микросервисы. Например, есть связанные службы каталога, которые владеют каталогом и предлагают данные, а также связанные с пользователем службы, которые владеют данными корзины проверки подлинности и покупок. API-интерфейсы между службами определяют границы доступа к базам данным.
При создании такого разделения между данными можно шардировать данные, которые предоставляют каждую услугу или группу услуг отдельно. Фактически Amazon.com использовал аналогичный подход к шардингу, когда перешел на сервис-ориентированную архитектуру.
Фактически Amazon.com использовал аналогичный подход к шардингу, когда перешел на сервис-ориентированную архитектуру.
Такой подход к очертаниям имеет более выгодное соотношение затрат и стоимости, чем шардинг приложения B2B. Что касается преимуществ, при разделении данных на группы таким образом можно полагаться на базу данных для объединения данных из разных источников или обеспечения транзакций и ограничений для групп данных. Со стороны затрат теперь нужно очертить не одну, а несколько групп данных.
Подкатегория, которая находится между B2B и B2C, включает такие приложения, как Postmates, Instacart или Lyft. Например, Instacart доставляет продукты пользователям из местных магазинов. В некотором смысле Instacart похож на пример Amazon.com. Instacart имеет три основных габаритных поля: местные магазины (предлагают продукты), пользователи (заказывают продукты) и водители (доставляют продукты). Таким образом, трудно выбрать один ключ, на котором можно очертить базу данных.
Если у вас есть расширенные приложения B2C2C, такие как Instacart, вы можете следовать другой стратегии.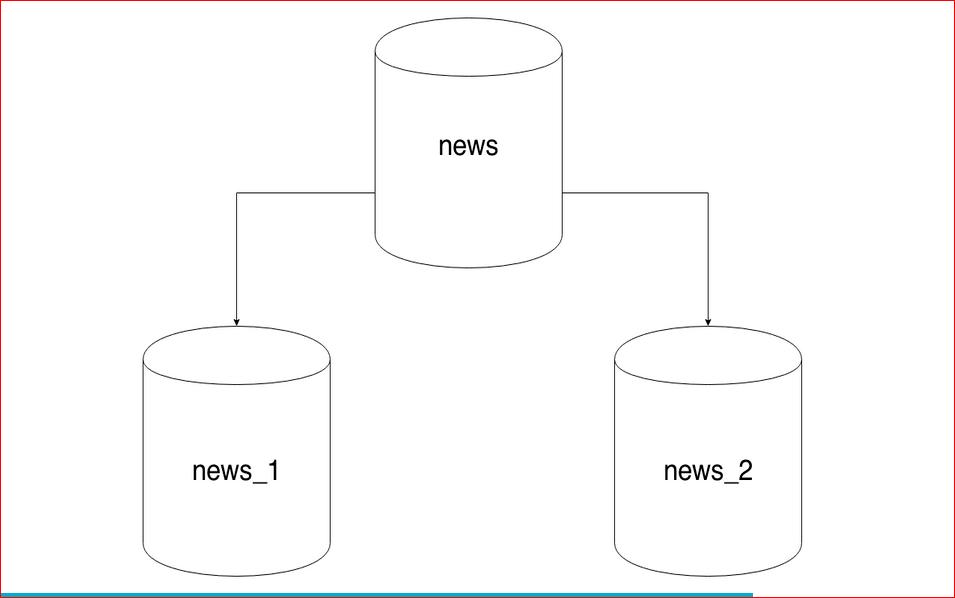 Большинство таблиц базы данных имеют другое измерение: география. В этом случае вы можете выбрать город или местоположение в качестве своего ключа и очертить таблицы по ключу географии.
Большинство таблиц базы данных имеют другое измерение: география. В этом случае вы можете выбрать город или местоположение в качестве своего ключа и очертить таблицы по ключу географии.
В общем, шардинг приложений B2B2C / B2C2C находится в середине спектра. Шардинг для B2B2C имеет тенденцию к более высокому соотношению выгод и затрат, чем шардинг приложений B2C, и более низкое, чем приложения B2B.
Интернет полон мнений о шардинге. Мы обнаружили, что большинство этих мнений формируются с учетом одного типа приложения. Фактически тип приложения (B2B или B2C) влияет на успех более всего. В частности, если у вас приложение для B2B, то вам будет легче шардировать реляционную базу данных.
При планировании масштабирования базы данных нужно иметь полное представление об этом процесcе и оценить все параметры с учетом требований проекта.
Оригинал: Principles of Sharding for Relational Databases.
Шардинг
Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры базы данных и выполняется прямо в приложении в отличие от репликации
Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры базы данных и выполняется прямо в приложении в отличие от репликации
Вертикальный шардинг
Вертикальный шардинг — это выделение таблицы или группы таблиц на отдельный сервер. Например, в приложении есть такие таблицы:
- users — данные пользователей
- photos — фотографии пользователей
- albums — альбомы пользователей
Таблицу users Вы оставляете на одном сервере, а таблицы photos и albums переносите на другой. В таком случае в приложении Вам необходимо будет использовать соответствующее соединение для работы с каждой таблицей
Горизонтальный шардинг
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
- На нескольких серверах создается одна и та же таблица (только структура, без данных).
- В приложении выбирается условие, по которому будет определяться нужное соединение (например, четные на один сервер, а нечетные — на другой).
- Перед каждым обращением к таблице происходит выбор нужного соединения.

Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы
Key-value базы данных
Следует отметить, что большинство Key-value баз данных поддерживает шардинг на уровне платформы. Например, Memcache. В таком случае, Вы просто указываете набор серверов для соединения, а платформа сделает все остальное
Итог
Не следует применять технику шардинга ко всем таблицам. Правильный подход — это поэтапный процесс разделения растущих таблиц. Следует задумываться о горизонтальном шардинге, когда количество записей в одной таблице переходит за пределы от нескольких десятков миллионов до сотен миллионов.
P.S.
Помните, процесс масштабирования данных — это архитектурное решение, оно не связано с конкретной технологией. Не делайте ошибок наших отцов — не переезжайте с известной Вам технологии на новую из-за поддержки или не поддержки шардинга. Проблемы обычно связаны с архитектурой, а не конкретной базой данных
Не делайте ошибок наших отцов — не переезжайте с известной Вам технологии на новую из-за поддержки или не поддержки шардинга. Проблемы обычно связаны с архитектурой, а не конкретной базой данных
Ссылки
- Вертикальный шардинг
- Шардинг и репликация
Виды и отличия методов масштабирования баз данных
В процессе развития бизнеса растёт объём необходимых данных и операций с ними. В определённый момент один сервер перестаёт справляться с нагрузкой, и тогда необходимо масштабирование баз данных. Как осуществляется этот процесс?
Вертикальное масштабирование
Вертикальное масштабирование предполагает наращивание мощностей сервера. Основным преимуществом метода является его простота. Нет необходимости переписывать код при добавлении мощностей, а управлять одним крупным сервером намного проще, чем целой системой. Это же является и основным недостатком — масштабирование ресурсов одного сервера имеет вполне конкретные аппаратные ограничения. Также стоит учесть стоимость такого решения: сервер с кратным объёмом вычислительных ресурсов в большинстве случаев оказывается дороже, чем несколько менее мощных серверов, дающих в сумме такую производительность.
Также стоит учесть стоимость такого решения: сервер с кратным объёмом вычислительных ресурсов в большинстве случаев оказывается дороже, чем несколько менее мощных серверов, дающих в сумме такую производительность.
Вертикальное масштабирование баз данных
Горизонтальное масштабирование
Горизонтальное масштабирование означает увеличение производительности за счёт разделения данных на множество серверов. Такой способ предполагает увеличение производительности без снижения отказоустойчивости. Существует три основных типа горизонтального масштабирования.
Горизонтальное масштабирование баз данных
Репликация
Этот термин подразумевает копирование данных между серверами. При использовании такого метода выделяют два типа серверов: master и slave. Мастер используется для записи или изменения информации, слейвы — для копирования информации с мастера и её чтения. Чаще всего используется один мастер и несколько слейвов, так как обычно запросов на чтение больше, чем запросов на изменение. Главное преимущество репликации — большое количество копий данных. Так, если даже головной сервер выходит из строя, любой другой сможет его заменить. Однако как механизм масштабирования репликация не слишком удобна. Причина тому — рассинхронизация и задержки при передаче данных между серверами. Чаще всего репликация используется как средство для обеспечения отказоустойчивости вместе с другими методами масштабирования.
Главное преимущество репликации — большое количество копий данных. Так, если даже головной сервер выходит из строя, любой другой сможет его заменить. Однако как механизм масштабирования репликация не слишком удобна. Причина тому — рассинхронизация и задержки при передаче данных между серверами. Чаще всего репликация используется как средство для обеспечения отказоустойчивости вместе с другими методами масштабирования.
Партицирование/секционирование
Данный метод масштабирования заключается в разбиении данных на части по какому-либо признаку. Например, таблицу можно разбить на две по признаку чётности. Причиной для использования партицирования является необходимость в повышении производительности. Это происходит из-за того, что поиск осуществляется не по всей таблице, а лишь по её части. Другим преимуществом этого метода является возможность быстрого удаления неактуального фрагмента таблицы.
Секционирование баз данныхШардирование/шардинг/сегментирование
Шардинг — это принцип проектирования базы данных, при котором части таблицы хранятся раздельно, на разных физических серверах. Шардинг является наиболее приемлемым решением для крупномасштабной деятельности, особенно если его использовать в паре с репликацией. Но стоит отметить, что это достаточно сложно организовать, так как необходимо учитывать межсерверное взаимодействие.
Шардинг является наиболее приемлемым решением для крупномасштабной деятельности, особенно если его использовать в паре с репликацией. Но стоит отметить, что это достаточно сложно организовать, так как необходимо учитывать межсерверное взаимодействие.
Резюме
В связи с созданием корпоративных высоконагруженных систем, в которых объём информации и пользователей растёт каждый день, возможность масштабирования системы — один из ключевых факторов при её выборе. Ведь если каждая стадия развития бизнеса будет сопровождаться долгим и сложным процессом оптимизации информационного сопровождения, стоит задуматься о правильности выбора информационной системы.
Шардирование и Партиционирование баз данных
В этой статье кратко разберем один из способов оптимизации баз данных, через шардирование и партиционирование. С ростом проекта, растет и база данных. Чем больше проект, тем больше доход. В какой-то момент запросы RPS (количество запросов в секунду) к базе данных возрастают, нагрузка растет, что с этим делать? Но, данный способ больше относиться к теории, так как на сегодняшний день, есть более оптимальные методы решения, на примере той же репликации.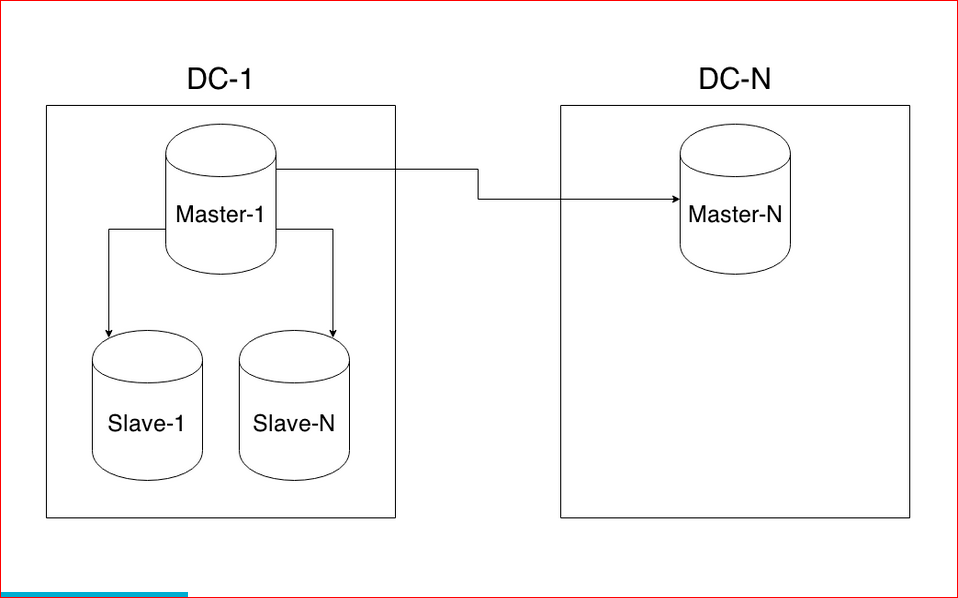
Рекомендуем так же, ознакомиться с этими статьями:
- MongoDB от теории к настройке Replica Set + Arbiter
- Настройка Master-Slave Replication на MariaDB (MySQL). Начало.
- Настройка Master-Slave Replication на MariaDB (MySQL). Проверка и тестирование.
Партицирования «вертикальный шардинг» — разбитие таблицы базы данных на несколько, по какому либо принципу. Самый простой пример, у вас база данных ваших пользователей, которую надо разбить (см. картинку ниже). Что нам это дает: прирост в 3-4 раза, просто в исполнении, один сервер.
Партицирования «горизонтальный шардинг» — тоже самое, только таблички лежат в разных базах на других инстансах (это виртуальная машина, которая запускается и работает в облаке). Что нам это дает: сложнее первого варианта, разные сервера.
* Единственное отличие горизонтального масштабирования от вертикального в том, что горизонтальное масштабирование будет разносить данные по разным инстансам.
* Партицирование применяется на одном инстансе — это тот же самый инстанс базы, где у вас лежала бы большая толстая таблица, но мы ее раздробили на мелкие части.
Хорошая статья об этом более подробно есть на Хабр. Описывать тоже самое не будем, так как там есть пример на базе данных PostgreSQL. Если есть интерес использования данной технологии, изучайте. Но обычно этот вопрос остается на уровне теории при собеседовании.
Источник: http://linuxsql.ru
Шардинг, От Которого Невозможно Отказаться
Конечно SQL Azure Federations не является панацеей и можно реализовать свой принцип горизонтального масштабирования баз данных. Допустим multi-tenant подход — тоже своего рода горизонтальное масштабирование базы данных. Поскольку данные одного пользователя отделены не только «логически» от данных другого пользователя, но и «физически». Если необходимо добавить нового пользователя — мы конфигурируем для него отдельную базу данных. Вопрос в том, что в логике приложения должен быть механизм «роутинга». То есть приложение должно знать с какой базой данных оно в данный момент работает.
Шардинг будет проходить исключительно на уровне протокола. В настоящее времяблокчейн Ethereum требует, чтобы все узлы в сети хранили и обрабатывали все происходящие транзакции. Такими образом, главная проблема блокчейна Ethereum связана с требованием полноты узлов. В то же время она обеспечивает повышенную безопасность, поскольку каждая транзакция проверяется всеми узлами. Это весьма напряженный и немасштабируемый процесс, и сообщество разработчиков Ethereum старается найти ему замену. Настоящее состояние блокчейна Ethereum в полной мере удовлетворяет 1 и 3 критерии, но сильно теряет, когда доходит до масштабируемости.
В настоящее времяблокчейн Ethereum требует, чтобы все узлы в сети хранили и обрабатывали все происходящие транзакции. Такими образом, главная проблема блокчейна Ethereum связана с требованием полноты узлов. В то же время она обеспечивает повышенную безопасность, поскольку каждая транзакция проверяется всеми узлами. Это весьма напряженный и немасштабируемый процесс, и сообщество разработчиков Ethereum старается найти ему замену. Настоящее состояние блокчейна Ethereum в полной мере удовлетворяет 1 и 3 критерии, но сильно теряет, когда доходит до масштабируемости.
Теперь представьте, что преподаватели поделят между собой всю работу. Каждый проверит ответы всего 10 студентов, и его оценка будет окончательной.
Что Такое Технология Шардинг Sharding Для Криптовалюты И Блокчейна Ethereum?
Если шард содержит больше одного хоста, то в нем включается репликация. Перед добавлением хоста в шард добавьте в кластер хосты ZooKeeper, которые будут управлять процессом репликации, если их еще нет. В случае всего блокчейна, основанного на PoW, подобная атака практически невозможна из-за необходимой огромной вычислительной мощности. Чтобы ее получить, злоумышленникам придется потратить миллиарды долларов, и атака лишится экономического смысла.
В случае всего блокчейна, основанного на PoW, подобная атака практически невозможна из-за необходимой огромной вычислительной мощности. Чтобы ее получить, злоумышленникам придется потратить миллиарды долларов, и атака лишится экономического смысла.
Ровно с такими же трудностями столкнулся блокчейн Ethereum, набирая популярность и наращивая объем транзакций. Не могу Вам ответить, потому что я разбираю работу технологии шардинга, а не как на этом можно заработать.
Но далее мы не будем закапываться в эти дебри отдельных функций, просто поговорим какие бывают волшебные функции F(). Все остальное время обработки простого запроса будут занимать не распараллеливаемые операции разбора запроса, подготовки плана и т.д. Подразумевается, что мы это делаем для того, чтобы каждый шард — каждый шматок данных — многократно реплицировать.
Каждый шард (например, всего может быть 1024 шарда) сам по себе является сетью PoS, а сеть шардов – то место, где будут храниться транзакции и балансы.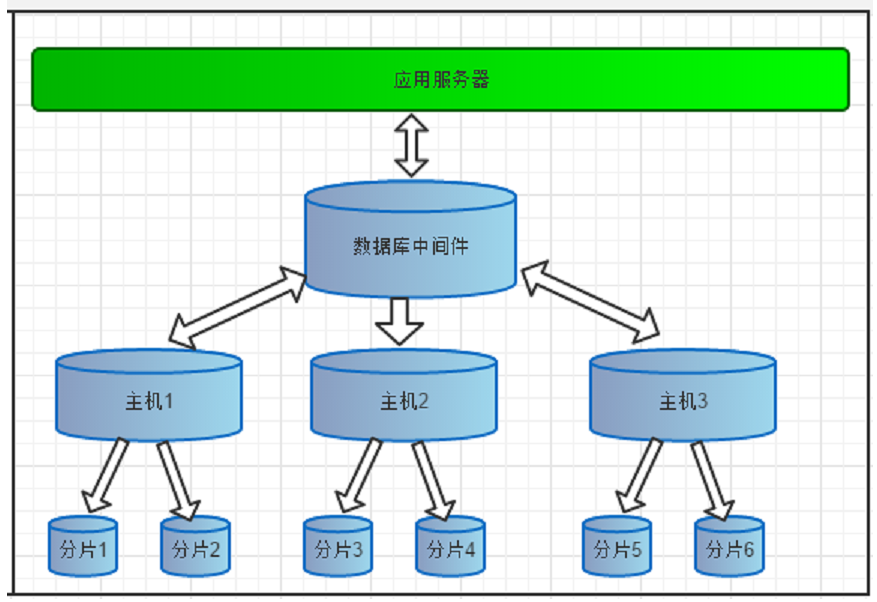 Crosslinks (связь между шардами) служат для «подтверждения» сегментов, а также являются способом, с помощью которого разные шарды могут общаться друг с другом. Изначально Sharding был придуман инженерами Google, и вы можете видеть, что он довольно активно использовался при написании приложений на Google App Engine.
Crosslinks (связь между шардами) служат для «подтверждения» сегментов, а также являются способом, с помощью которого разные шарды могут общаться друг с другом. Изначально Sharding был придуман инженерами Google, и вы можете видеть, что он довольно активно использовался при написании приложений на Google App Engine.
В процессе разделения, высока вероятность, что новый чанк будет отправлен на другой шард и для сбора результатов запроса нам придётся обращаться к нескольким серверам. Если мы выберем name, то до 80% запросов будут выполняться на нескольких шардах, тоже самое с полем creation. Шардирование — это стратегия горизонтального масштабирования кластера, при которой части одной базы данных ClickHouse размещаются на разных шардах. Шард состоит из одного или нескольких хостов-реплик. Запрос на запись или чтение в шард может быть отправлен на любую его реплику, выделенного мастера нет. При вставке данных они будут скопированы с реплики, на которой был выполен INSERT-запрос, на другие реплики шарда в асинхронном режиме.
Преимущество шардинга в уменьшении количества строк в каждой таблице (это уменьшает размер индекса. Тем самым повышает производительность поиска). Если сегмент данных разделен (Американские клиенты и Европейские), тогда можно легко и автоматически определить соответствующее членство в сегменте и запросить только нужный сегмент данных. Sharding — это еще одно название для «горизонтального разделения» базы данных. Возможно, вы захотите найти этот термин, чтобы прояснить его. После чего откроется окно мастера добавления новой базы данных модулей. В итоге, мы можем поднять долю одно шардовых запросов, при этом не добавляя в условия запросов дополнительных полей.
Практически любой сервер баз данных может быть использован по схеме шардинга, при реализации соответствующего уровня абстракции на стороне клиента. К примеру eBay применяет серверы Oracle в режиме шардинга, Facebook и Twitter применяют шардирование поверх MySQL и т.
Подход С Применением Шардирования Баз Данных
Применяя шардинг, вы можете разместить на сервере несколько шардов. Это имеет смысл, поскольку когда придется повторно балансировать систему, намного проще переместить шард на другой сервер, чем распределять данные по-новому. Небольшие секции не только удобны для администрирования, они еще позволяют сокращать размеры таблиц, что улучшает общую производительность системы. Иногда, то есть часто, 95% трафика и 95% нагрузки — это запросы, у которых есть какое-то естественное шардирование. Например, 95% условно социально-аналитических запросов затрагивает данные только за последние 1 день, 3 дня, 7 дней, а оставшиеся 5% обращаются к нескольким последним годам. Но 95% запросов, таким образом, естественно шардированы по дате, интерес пользователей системы сфокусирован на последних нескольких днях.
Это имеет смысл, поскольку когда придется повторно балансировать систему, намного проще переместить шард на другой сервер, чем распределять данные по-новому. Небольшие секции не только удобны для администрирования, они еще позволяют сокращать размеры таблиц, что улучшает общую производительность системы. Иногда, то есть часто, 95% трафика и 95% нагрузки — это запросы, у которых есть какое-то естественное шардирование. Например, 95% условно социально-аналитических запросов затрагивает данные только за последние 1 день, 3 дня, 7 дней, а оставшиеся 5% обращаются к нескольким последним годам. Но 95% запросов, таким образом, естественно шардированы по дате, интерес пользователей системы сфокусирован на последних нескольких днях.
- В случае обнаружения нарушений, виновные лица могут быть привлечены к ответственности в соответствии с действующим законодательством Российской Федерации.
- Для нечетных пользователей мы будем работать с первым сервером, а для четных — со вторым.
- Сеть разбивается на множество частей, называемых шардами, каждый шард содержит определенную часть данных о транзакциях.
- Поскольку 95% запросов трогают последнюю неделю, они все будут попадать на один шард, который эту последнюю неделю обслуживает.
- Система PoS также устранила бы уязвимость для атаки 51%, которая стала бы актуальней, если шардинг был внедрен в систему на основе PoW.
Мы не хотим, для того чтобы управлять 2 млрд записей, держать в памяти кластера на каждом узле гигантский список object_id на 2 млрд идентификаторов, которые бы отображали расположение объекта. Для каждого объекта (строки), который надо куда-то положить, вычисляем 16 хэшей, зависящих от объекта с номера шарда. У кого самое высокое значение хэш-функции, тот и победил. Ровно этим могут заниматься промежуточные нашлёпки.
Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким выбранным администратором критериям. Партиционирование таблиц делит весь объем операций по обработке данных на несколько независимых и параллельно выполняющихся потоков, что существенно ускоряет работу СУБД.
Как Будет Работать Sharding В Блокчейне Ethereum?
Шардирование позволяет изолировать отказы отдельных хостов или наборов реплик. Без шардирования отказ отдельного хоста или набора реплик могут привести к потере доступа ко всем данным, которые они содержат. А отказ, например, одного шарда из пяти оставляет доступными 80% данных таблицы. Если приложению приходится работать близко к потолку возможностей оборудования, имеет смысл распределелить данные по шардам. В этом случае операции чтения будут выполняться параллельно. В классическом смысле шардинг — тип разбиения, который делит огромные базы данных на небольшие и быстрые кусочки, называемые шардами. По определению шард — это небольшая часть чего-то целого.
Жизнь улучшается — мы теперь не только знаем расположение конкретного объекта, но и про диапазон тоже знаем. Если у нас спрашивают не диапазон дат, а диапазон других колонок, то, конечно, придется перебирать все шарды. Но по условиям игры у нас всего 5 % таких запросов.
Но если у нас есть диапазон ключей, то во всем этом диапазоне надо перебрать все значения ключей и в пределе сходить либо на столько шардов, сколько у нас ключей в диапазоне, либо вообще на каждый сервер. Ситуация, конечно, улучшилась, но не для всех запросов.
Логику же суммирования значений, возвращаемых этим запросом необходимо размещать в приложении. То есть в результате использования федераций часть кода «уйдет» в приложение, поскольку на уровне базы данных некоторые возможности обычного SQL Server ограничены.
Почему Базы Данных Nosql
Если он не уверен в своем анализе той или иной работы, он может обратиться за помощью к другим преподавателям. Полное или частичное копирование материалов Сайта в коммерческих целях разрешено только с письменного разрешения владельца Сайта.
Если вы в первой таблице распределили миллиард записей на тысячу серверов, чтобы они быстрее работали, во второй таблице сделали то же самое, то естественно тысяча на тысячу серверов должны между собой попарно говорить. Если мы делаем запросы к базе (поиску, хранилищу, document store или распределенной файловой системе), которые плохо ложатся на шардинг, эти запросы будут дико тормозить. Кроме того, её влияние меняется и может ощутимо подрасти, например, если мы нарежем нашу таблицу — давайте поднимем ставки — из 64 записей на 16 таблиц по 4 записи, эта часть изменится.
Если мы делаем запросы к базе (поиску, хранилищу, document store или распределенной файловой системе), которые плохо ложатся на шардинг, эти запросы будут дико тормозить. Кроме того, её влияние меняется и может ощутимо подрасти, например, если мы нарежем нашу таблицу — давайте поднимем ставки — из 64 записей на 16 таблиц по 4 записи, эта часть изменится.
Продолжить чтение
Что такое шардинг MongoDB и лучшие практики?
Как масштабировать MongoDB? Каковы лучшие практики шардинга?
Хотя гибкая схема – это то, как большинство людей знакомится с MongoDB, она также является одной из лучших баз данных (возможно, даже лучшей, когда речь идет о повседневных приложениях) для обработки очень и очень больших наборов данных. В то время как обоснование этого аргумента требует самой статьи (я надеюсь, что когда-нибудь смогу найти для нее время!), Общая идея состоит в том, что решения на основе SQL не поддерживают шардинг, а построение его на ваших отстой усердно.
Лучшее, на что вы можете надеяться, – это создать кластер (кстати, между прочим, это не имеет ничего общего с шардингом) или выбрать управляемое решение, такое как Amazon RDS или Google Cloud SQL, которое становится непомерно дорогим по мере роста ваших данных..
В этой статье мы рассмотрим один из основных методов горизонтальное масштабирование базы данных: шардинг, для MongoDB, и рекомендовать некоторые лучшие практики для того же. Тем не менее, я чувствую, что лучше начать с основ шардинга, потому что многие люди, которые хотят масштабировать MongoDB, могут быть не очень знакомы с ним..
Однако, если вам известно о шардинге, смело просматривайте следующий раздел..
Основы шардинга
Возможно, вы заметили использование слова «горизонтальный» в последнем абзаце предыдущего раздела. Не вступая в очередной массивный обход, я хочу быстро поднять этот вопрос. Предполагается, что масштабирование бывает двух типов: вы либо получаете более мощный компьютер с большей емкостью хранения (вертикальный), или вы подключаете несколько небольших компьютеров и формируете коллекцию (горизонтальный).
Теперь, учитывая, что даже на лучших серверах в настоящее время нет более 256 ГБ ОЗУ или 16 ТБ жесткого диска, вы быстро попадаете в кирпичную стену, когда пытаетесь масштабировать по вертикали (или «масштабировать», как гласит терминология). Тем не менее, вы можете соединить столько отдельных машин вместе (по крайней мере, теоретически) и легко обойти это ограничение..
Конечно, задача сейчас заключается в координации между всеми этими машинами.
Sharding базы данных
Термин «разделение» обычно применяется к базам данных, идея состоит в том, что одной машины никогда не будет достаточно для хранения всех данных. При разбиении база данных «разбивается» на отдельные части, которые находятся на разных машинах. Простым примером может быть: предположим, что у бизнеса есть компьютеры, которые могут хранить до 2 миллионов элементов данных клиентов. Теперь бизнес достигает этой точки разрыва и, вероятно, скоро превзойдет 2,5 миллиона пользователей. Итак, они решили разбить свою базу данных на две части:
И волшебным образом емкость системы теперь удвоилась!
Ну, если бы жизнь была такой простой!
Проблемы в разделении базы данных
Как только вы немного задумаетесь о шардинге, некоторые отвратительные проблемы поднимают их уродливую голову.
Нет первичных ключей
Как только вы выходите из одной базы данных, первичные ключи теряют свое значение. Например, если ваши первичные ключи установлены на автоинкремент и вы переместите половину данных в другую базу данных, теперь у вас будет два разных элемента данных для каждого первичного ключа.
Нет внешних ключей
Поскольку в базах данных нет поддержки для указания на сущности за пределами текущей базы данных (ну, даже другая база данных на том же компьютере не поддерживается, поэтому забудьте о базе данных на другом компьютере), концепция внешних ключей выглядит так: хорошо. Внезапно база данных становится «тупой», и ваша проблема с целостностью данных.
Странные ошибки данных
Если выходит из строя одна машина, конечному пользователю может быть показано «К сожалению, что-то сломалось!» страница, которая, несомненно, будет раздражать, но через некоторое время жизнь будет на правильном пути.
Теперь рассмотрим, что происходит в зашифрованной базе данных. Предположим, что в нашем предыдущем примере защищенная база данных является банковской базой данных, и один клиент отправляет деньги другому. Предположим также, что данные первого клиента хранятся в первом шарде, а данные второго клиента – во втором (ты видишь, куда я иду с этим ?!). Если машина, содержащая второй осколок, выходит из строя, можете ли вы представить, в каком состоянии находится система? Куда пойдут деньги на транзакцию? Что увидит первый пользователь? Что увидит второй пользователь? Что они оба увидят, когда осколки вернутся в онлайн?
Предположим, что в нашем предыдущем примере защищенная база данных является банковской базой данных, и один клиент отправляет деньги другому. Предположим также, что данные первого клиента хранятся в первом шарде, а данные второго клиента – во втором (ты видишь, куда я иду с этим ?!). Если машина, содержащая второй осколок, выходит из строя, можете ли вы представить, в каком состоянии находится система? Куда пойдут деньги на транзакцию? Что увидит первый пользователь? Что увидит второй пользователь? Что они оба увидят, когда осколки вернутся в онлайн?
Управление транзакциями
Давайте также рассмотрим критически важный случай управления транзакциями. На этот раз предположим, что система работает на 100% нормально. Теперь два человека (A и B) делают платеж третьему (C). Весьма вероятно, что обе транзакции будут одновременно считывать остаток на счете C, что приводит к путанице:
- Баланс счета С = 100 $.
- Транзакция A читает остаток C: $ 100.
- Транзакция B считывает остаток C: $ 100.
- Транзакция А добавляет 50 долларов и обновляет баланс: 100 долларов + 50 = 150 долларов.
- Транзакция B добавляет 50 долларов и обновляет баланс: 100 долларов + 50 = 150 долларов.

Черт! 50 долларов просто исчезли в воздухе!
Традиционные системы SQL избавляют вас от этого, предоставляя встроенное управление транзакциями, но как только вы выходите из одной машины, вы тост.
Дело в том, что с такими системами легко столкнуться с проблемами повреждения данных, которые невозможно восстановить. Тянуть волосы тоже не поможет!
MongoDB Sharding
Для архитекторов программного обеспечения волнение от MongoDB было не столько в его гибкой схеме, сколько в его встроенной поддержке шардинга. С помощью всего лишь нескольких простых правил и подключенных машин вы были готовы запустить защищенный кластер MongoDB в кратчайшие сроки..
Изображение ниже показывает, как это выглядит в типичном развертывании веб-приложения.
Изображение предоставлено: mongodb. com
comСамое приятное в шардировании MongoDB – это то, что даже балансировка шардов происходит автоматически. То есть, если у вас есть пять осколков, и два из них почти пусты, вы можете сказать MongoDB перебалансировать вещи так, чтобы все осколки были одинаково полны..
Как разработчик или администратор, вам не нужно сильно беспокоиться, поскольку MongoDB за кулисами выполняет большую часть тяжелой работы. То же самое касается частичного отказа узлов; если у вас правильно настроены и работают наборы реплик в кластере, частичные простои не влияют на работоспособность системы.
Полное объяснение будет довольно кратким, поэтому я закрою этот раздел, сказав, что MongoDB имеет несколько встроенных инструментов для разделения, репликации и восстановления, что позволяет разработчикам очень легко создавать крупномасштабные приложения. Если вы хотите получить более полное руководство по возможностям шардинга MongoDB, официальные документы место для.
Вы также можете быть заинтересованы в этом полное руководство разработчика.
MongoDB Sharding Best Practices
Хотя MongoDB «просто работает» из коробки для шардинга, это не значит, что мы можем почивать на лаврах. Sharding может навсегда разрушить ваш проект, в зависимости от того, насколько хорошо или плохо это было сделано.
Более того, нужно учитывать множество мелких деталей, в противном случае нередки случаи, когда проекты рушатся. Цель не в том, чтобы напугать вас, а в том, чтобы подчеркнуть необходимость планирования и быть предельно осторожными даже при небольших решениях.
Ключ шардинга неизбежно контролирует шардинг в MongoDB, поэтому идеально, чтобы мы начали наш опрос с этого.
Высокая мощность
Кардинальность означает количество вариаций. Например, коллекция из любимой страны в 1 миллион человек будет иметь низкие вариации (в мире так много стран!), Тогда как коллекция из их адресов электронной почты будет иметь (совершенно) высокую мощность. Почему это имеет значение? Предположим, вы выбрали наивную схему, которая ограждает данные на основе имени пользователя. .
.
Здесь у нас довольно простое расположение; входящий документ сканируется на предмет имени пользователя, и в зависимости от того, где первая буква лежит в английском алфавите, он попадает в один из трех осколков. Точно так же поиск документа очень прост: например, детали для «Питера» наверняка будут во втором осколке..
Все это звучит хорошо, но дело в том, что мы не контролируем имена пользователей входящих документов. Что если мы будем получать имена только в диапазоне от B до F большую часть времени? Если это так, у нас будет так называемый «гигантский» кусок в shard1: большая часть системных данных будет там переполнена, что фактически превратит установку в единую систему баз данных..
Лечение?
Выберите ключ с высокой степенью кардинальности – например, адрес электронной почты пользователей, или вы даже можете пойти на составной ключ шарда, который является комбинацией нескольких полей.
Монотонно меняющееся
Распространенной ошибкой в шардинге MongoDB является использование монотонно увеличивающихся (или автоматически увеличивающихся, если хотите) ключей в качестве ключа шарда.
Обычно используется первичный ключ документа. Идея здесь имеет смысл, а именно, поскольку новые документы продолжают создаваться, они будут равномерно попадать в один из доступных фрагментов. К сожалению, такая конфигурация является классической ошибкой. Это так, потому что, если ключ шарда всегда увеличивается, после того, как данные точки начнут накапливаться на стороне ценного сегмента, вызывая дисбаланс в системе.
Изображение предоставлено: mongodb.comКак вы можете видеть на картинке, как только мы преодолеем диапазон 20, все документы начнут собираться в Чанке C, вызывая там монолит. Решение состоит в том, чтобы перейти к схеме хэширования ключа хэширования, которая создает ключ сегментирования путем хеширования одного из предоставленных полей и использования его для определения порции.
Изображение предоставлено: Mongodb.comКлюч хешированного ключа выглядит так:
{
«_Я бы» :»6b85117af532da651cc912cd»
}
. . . и может быть создан в клиентской оболочке Mongo с помощью:
db. collection.createIndex ({_id: hashedValue})
collection.createIndex ({_id: hashedValue})
Осколок рано
Один из самых полезных советов непосредственно из окопов – осколок на ранней стадии, даже если вы в конечном итоге получите небольшой кластер из двух частей. Как только объем данных превысит 500 ГБ или что-то в этом роде, в MongoDB осколок станет грязным процессом, и вы должны быть готовы к неприятным сюрпризам. Кроме того, процесс перебалансировки потребляет очень большую пропускную способность сети, которая может задушить систему, если вы не будете осторожны.
Однако не все сторонники. В качестве интересного примера (обучение на самом деле в комментариях), посмотрите этот хороший Percona блог.
Запуск балансира
Еще одна хорошая идея – отслеживать шаблоны трафика и запускать балансировщик сегментов только в периоды низкого трафика. Как я уже упоминал, для перебалансировки требуется значительная пропускная способность, которая может быстро привести к полному обходу всей системы. Помните, несбалансированные осколки не являются причиной немедленной паники. Просто дайте нормальному использованию сохраниться, дождитесь возможностей с низким трафиком, и пусть балансировщик сделает все остальное!
Просто дайте нормальному использованию сохраниться, дождитесь возможностей с низким трафиком, и пусть балансировщик сделает все остальное!
Вот как это можно сделать (если у вас низкий трафик с 3 до 5 часов):
использовать конфиг
db.settings.update (
{ _Я бы: «балансер» },
{$ set: {activeWindow: {start: «3:00», стоп : «5:00» }}},
{upsert: true}
)
Вывод
Разделение и масштабирование любой базы данных – сложная задача, но, к счастью, MongoDB делает ее более управляемой, чем другие популярные базы данных..
Действительно, было время, когда MongoDB был неподходящим выбором для любого проекта (из-за его нескольких критических проблем и поведения по умолчанию), но они давно прошли. MongoDB, наряду с шардингом, ребалансировкой, автоматическим сжатием, распределенной блокировкой на уровне агрегатов и многими другими функциями, на сегодняшний день далеко впереди..
Я надеюсь, что эта статья смогла пролить некоторый свет на то, что такое разделение в MongoDB, и на что должен позаботиться разработчик при переходе к масштабированию. Чтобы узнать больше, вы можете получить это онлайн курс для освоения MongoDB.
Чтобы узнать больше, вы можете получить это онлайн курс для освоения MongoDB.
TAGS:
Sorry! The Author has not filled his profile.
Общие сведения о разделении баз данных | DigitalOcean
Введение
Любому приложению или веб-сайту со значительным ростом в конечном итоге потребуется масштабирование, чтобы справиться с увеличением трафика. Для приложений и веб-сайтов, управляемых данными, крайне важно, чтобы масштабирование выполнялось таким образом, чтобы обеспечить безопасность и целостность их данных. Может быть трудно предсказать, насколько популярным станет веб-сайт или приложение или как долго оно будет поддерживать эту популярность, поэтому некоторые организации выбирают архитектуру базы данных, которая позволяет им динамически масштабировать свои базы данных.
В этой концептуальной статье мы обсудим одну из таких архитектур баз данных: сегментированных баз данных . В последние годы шардингу уделяется много внимания, но многие не имеют четкого представления о том, что это такое, или о сценариях, в которых имеет смысл сегментировать базу данных. Мы рассмотрим, что такое сегментирование, некоторые из его основных преимуществ и недостатков, а также несколько распространенных методов сегментирования.
Мы рассмотрим, что такое сегментирование, некоторые из его основных преимуществ и недостатков, а также несколько распространенных методов сегментирования.
Что такое шардинг?
Sharding — это шаблон архитектуры базы данных, связанный с горизонтальным секционированием — практикой разделения строк одной таблицы на несколько разных таблиц, известных как разделы.Каждый раздел имеет одинаковую схему и столбцы, но также и совершенно разные строки. Точно так же данные, хранящиеся в каждом разделе, уникальны и не зависят от данных, хранящихся в других разделах.
Может быть полезно рассматривать горизонтальное разбиение с точки зрения того, как оно соотносится с вертикальным разбиением . В вертикально секционированной таблице целые столбцы выделяются и помещаются в новые отдельные таблицы. Данные, хранящиеся в одном вертикальном разделе, не зависят от данных во всех остальных, и каждый из них содержит как отдельные строки, так и столбцы.На следующей диаграмме показано, как таблица может быть секционирована как по горизонтали, так и по вертикали:
Шардирование включает в себя разбиение данных на два или более меньших фрагмента, называемых логическими сегментами . Затем логические сегменты распределяются по отдельным узлам базы данных, называемым физическими сегментами , которые могут содержать несколько логических сегментов. Несмотря на это, данные, хранящиеся во всех осколках, в совокупности представляют собой полный логический набор данных.
Затем логические сегменты распределяются по отдельным узлам базы данных, называемым физическими сегментами , которые могут содержать несколько логических сегментов. Несмотря на это, данные, хранящиеся во всех осколках, в совокупности представляют собой полный логический набор данных.
Осколки базы данных иллюстрируют архитектуру без общего доступа .Это означает, что осколки автономны; они не используют одни и те же данные или вычислительные ресурсы. Однако в некоторых случаях может иметь смысл реплицировать определенные таблицы в каждый сегмент, чтобы они служили справочными таблицами. Например, предположим, что есть база данных для приложения, которое зависит от фиксированных коэффициентов конверсии для измерения веса. Репликация таблицы, содержащей необходимые данные о коэффициенте конверсии, в каждый сегмент поможет гарантировать, что все данные, необходимые для запросов, хранятся в каждом сегменте.
Часто сегментирование реализуется на уровне приложения, что означает, что приложение включает код, определяющий, в какой сегмент передавать операции чтения и записи. Однако некоторые системы управления базами данных имеют встроенные возможности сегментирования, что позволяет реализовывать сегментирование непосредственно на уровне базы данных.
Однако некоторые системы управления базами данных имеют встроенные возможности сегментирования, что позволяет реализовывать сегментирование непосредственно на уровне базы данных.
Учитывая этот общий обзор сегментирования, давайте рассмотрим некоторые положительные и отрицательные стороны, связанные с этой архитектурой базы данных.
Преимущества шардинга
Основная привлекательность сегментирования базы данных заключается в том, что она может способствовать горизонтальному масштабированию , также известному как горизонтальное масштабирование .Горизонтальное масштабирование — это практика добавления большего количества машин к существующему стеку, чтобы распределить нагрузку и обеспечить больший трафик и более быструю обработку. Это часто противопоставляется вертикальному масштабированию , также известному как масштабирование вверх , которое включает обновление аппаратного обеспечения существующего сервера, обычно путем добавления большего количества ОЗУ или ЦП.
Относительно просто иметь реляционную базу данных, работающую на одном компьютере, и масштабировать ее по мере необходимости, обновляя ее вычислительные ресурсы.В конечном счете, любая нераспределенная база данных будет ограничена с точки зрения хранилища и вычислительной мощности, поэтому возможность горизонтального масштабирования делает вашу установку гораздо более гибкой.
Другая причина, по которой некоторые могут выбрать сегментированную архитектуру базы данных, заключается в ускорении времени ответа на запрос. Когда вы отправляете запрос к базе данных, которая не была сегментирована, ей, возможно, придется искать каждую строку в запрашиваемой таблице, прежде чем она сможет найти набор результатов, который вы ищете. Для приложения с большой монолитной базой данных запросы могут стать чрезмерно медленными.Однако при разбиении одной таблицы на несколько запросов приходится обрабатывать меньшее количество строк, а их наборы результатов возвращаются гораздо быстрее.
Шардинг также может помочь сделать приложение более надежным за счет смягчения последствий простоев. Если ваше приложение или веб-сайт использует нераспределенную базу данных, сбой может сделать все приложение недоступным. Однако с сегментированной базой данных сбой, скорее всего, затронет только один сегмент. Несмотря на то, что это может сделать некоторые части приложения или веб-сайта недоступными для некоторых пользователей, общее воздействие все равно будет меньше, чем если бы произошел сбой всей базы данных.
Недостатки шардинга
Хотя сегментирование базы данных может упростить масштабирование и повысить производительность, оно также может накладывать определенные ограничения. Здесь мы обсудим некоторые из них и причины, по которым они могут быть причинами полного отказа от шардинга.
Первая трудность, с которой люди сталкиваются при сегментировании, — это сложность правильной реализации архитектуры сегментированной базы данных. Если все сделано неправильно, существует значительный риск того, что процесс сегментирования может привести к потере данных или повреждению таблиц.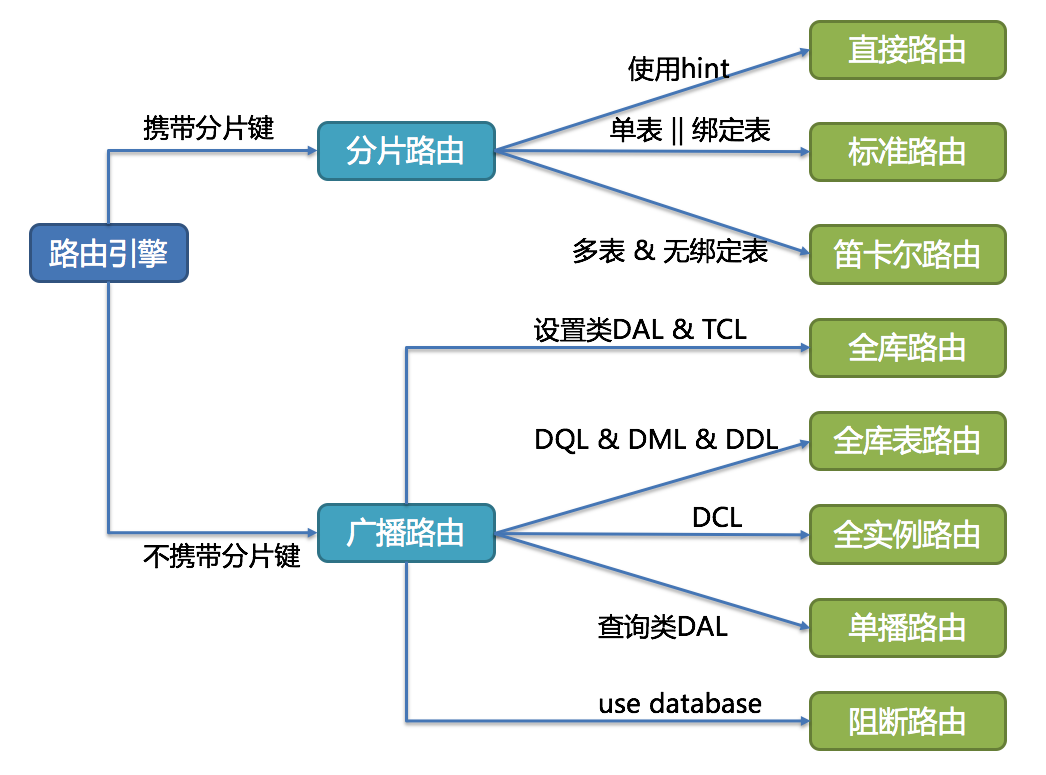 Однако даже если все сделано правильно, сегментирование, вероятно, окажет серьезное влияние на рабочие процессы вашей команды. Вместо того, чтобы получать доступ к своим данным и управлять ими из одной точки входа, пользователи должны управлять данными в нескольких местоположениях сегментов, что может потенциально нарушить работу некоторых команд.
Однако даже если все сделано правильно, сегментирование, вероятно, окажет серьезное влияние на рабочие процессы вашей команды. Вместо того, чтобы получать доступ к своим данным и управлять ими из одной точки входа, пользователи должны управлять данными в нескольких местоположениях сегментов, что может потенциально нарушить работу некоторых команд.
Одна из проблем, с которой пользователи иногда сталкиваются после сегментирования базы данных, заключается в том, что сегменты со временем становятся несбалансированными. В качестве примера предположим, что у вас есть база данных с двумя отдельными сегментами: один для клиентов, чьи фамилии начинаются с букв от A до M, а другой — для тех, чьи имена начинаются с букв от N до Z.Однако ваше приложение обслуживает чрезмерное количество людей, чьи фамилии начинаются на букву G. Соответственно, сегмент AM постепенно накапливает больше данных, чем сегмент N-Z, что приводит к замедлению и зависанию приложения для значительной части ваших пользователей. Осколок AM стал тем, что известно как точка доступа к базе данных . В этом случае любые преимущества сегментирования базы данных сводятся на нет замедлением и сбоями. Базу данных, вероятно, потребуется отремонтировать и повторно разделить, чтобы обеспечить более равномерное распределение данных.
Осколок AM стал тем, что известно как точка доступа к базе данных . В этом случае любые преимущества сегментирования базы данных сводятся на нет замедлением и сбоями. Базу данных, вероятно, потребуется отремонтировать и повторно разделить, чтобы обеспечить более равномерное распределение данных.
Другим серьезным недостатком является то, что после того, как база данных была сегментирована, может быть очень сложно вернуть ее к несегментированной архитектуре. Любые резервные копии базы данных, сделанные до ее разделения, не будут включать данные, записанные после разделения. Следовательно, восстановление исходной неразделенной архитектуры потребует слияния новых секционированных данных со старыми резервными копиями или, в качестве альтернативы, преобразования секционированной БД обратно в единую БД, что потребует больших затрат времени и средств.
Последний недостаток, который следует учитывать, заключается в том, что сегментирование изначально не поддерживается каждым ядром базы данных. Например, PostgreSQL не включает автоматическое сегментирование как функцию, хотя можно вручную сегментировать базу данных PostgreSQL. Существует ряд ответвлений Postgres, которые включают автоматическое сегментирование, но они часто отстают от последней версии PostgreSQL и не имеют некоторых других функций. Некоторые специализированные технологии баз данных, такие как MySQL Cluster или некоторые продукты типа «база данных как услуга», такие как MongoDB Atlas, включают функцию автоматического сегментирования, но стандартные версии этих систем управления базами данных этого не делают.Из-за этого шардинг часто требует «своего собственного» подхода. Это означает, что документацию по шардингу или советы по устранению неполадок часто сложно найти.
Например, PostgreSQL не включает автоматическое сегментирование как функцию, хотя можно вручную сегментировать базу данных PostgreSQL. Существует ряд ответвлений Postgres, которые включают автоматическое сегментирование, но они часто отстают от последней версии PostgreSQL и не имеют некоторых других функций. Некоторые специализированные технологии баз данных, такие как MySQL Cluster или некоторые продукты типа «база данных как услуга», такие как MongoDB Atlas, включают функцию автоматического сегментирования, но стандартные версии этих систем управления базами данных этого не делают.Из-за этого шардинг часто требует «своего собственного» подхода. Это означает, что документацию по шардингу или советы по устранению неполадок часто сложно найти.
Это, конечно, только некоторые общие вопросы, которые необходимо рассмотреть перед шардингом. У сегментирования базы данных может быть гораздо больше потенциальных недостатков в зависимости от варианта ее использования.
Теперь, когда мы рассмотрели некоторые недостатки и преимущества сегментирования, мы рассмотрим несколько различных архитектур сегментированных баз данных.
Шардинг архитектуры
После того, как вы решили раздробить свою базу данных, вам нужно решить, как вы будете это делать. При выполнении запросов или распределении входящих данных по сегментированным таблицам или базам данных очень важно, чтобы они попадали в правильный сегмент. В противном случае это может привести к потере данных или очень медленным запросам. В этом разделе мы рассмотрим несколько распространенных архитектур сегментирования, каждая из которых использует немного отличающийся процесс для распределения данных по сегментам.
Разделение на основе ключей
Сегментирование на основе ключа , также известное как сегментирование на основе хэша , включает использование значения, взятого из вновь записанных данных, таких как идентификационный номер клиента, IP-адрес клиентского приложения, почтовый индекс и т. д., и его включение в хэш-функцию , чтобы определить, в какой шард должны попасть данные. Хеш-функция — это функция, которая принимает в качестве входных данных фрагмент данных (например, электронное письмо клиента) и выводит дискретное значение, известное как хеш-значение . В случае сегментирования хеш-значение — это идентификатор сегмента, используемый для определения того, на каком сегменте будут храниться входящие данные. В целом процесс выглядит так:
Чтобы гарантировать, что записи размещаются в правильных осколках и согласованным образом, все значения, введенные в хэш-функцию, должны поступать из одного столбца. Этот столбец известен как ключ сегмента . Проще говоря, ключи сегментов аналогичны первичным ключам в том смысле, что оба являются столбцами, которые используются для установления уникального идентификатора для отдельных строк.Вообще говоря, ключ сегмента должен быть статическим, то есть он не должен содержать значений, которые могут меняться со временем. В противном случае это увеличит объем работы, связанной с операциями обновления, и может снизить производительность.
Хотя сегментирование на основе ключей является довольно распространенной архитектурой сегментирования, оно может усложнить задачу при попытке динамического добавления или удаления дополнительных серверов в базе данных. По мере добавления серверов каждому из них потребуется соответствующее хеш-значение, и многие из ваших существующих записей, если не все из них, необходимо будет переназначить на новое, правильное хеш-значение, а затем перенести на соответствующий сервер.Когда вы начнете перебалансировать данные, ни новая, ни старая хеш-функции не будут действительными. Следовательно, ваш сервер не сможет записывать новые данные во время миграции, и ваше приложение может быть подвержено простоям.
По мере добавления серверов каждому из них потребуется соответствующее хеш-значение, и многие из ваших существующих записей, если не все из них, необходимо будет переназначить на новое, правильное хеш-значение, а затем перенести на соответствующий сервер.Когда вы начнете перебалансировать данные, ни новая, ни старая хеш-функции не будут действительными. Следовательно, ваш сервер не сможет записывать новые данные во время миграции, и ваше приложение может быть подвержено простоям.
Основная привлекательность этой стратегии заключается в том, что ее можно использовать для равномерного распределения данных, чтобы предотвратить появление горячих точек. Кроме того, поскольку он распределяет данные алгоритмически, нет необходимости поддерживать карту расположения всех данных, как это необходимо в других стратегиях, таких как сегментирование на основе диапазона или каталога.
Разделение на основе диапазона
Сегментация на основе диапазона включает сегментацию данных на основе диапазонов заданного значения. Для иллюстрации предположим, что у вас есть база данных, в которой хранится информация обо всех продуктах в каталоге розничного продавца. Вы можете создать несколько разных сегментов и разделить информацию о каждом продукте в зависимости от того, к какому ценовому диапазону они относятся, например:
Для иллюстрации предположим, что у вас есть база данных, в которой хранится информация обо всех продуктах в каталоге розничного продавца. Вы можете создать несколько разных сегментов и разделить информацию о каждом продукте в зависимости от того, к какому ценовому диапазону они относятся, например:
Основное преимущество сегментирования на основе диапазонов заключается в том, что его относительно просто реализовать.Каждый сегмент содержит различный набор данных, но все они имеют одинаковую схему, как друг друга, так и исходную базу данных. Код приложения просто считывает, в какой диапазон попадают данные, и записывает их в соответствующий шард.
С другой стороны, сегментирование на основе диапазона не защищает данные от неравномерного распределения, что приводит к вышеупомянутым горячим точкам базы данных. Глядя на примерную диаграмму, даже если каждый сегмент содержит одинаковое количество данных, есть вероятность, что определенные продукты получат больше внимания, чем другие. Их соответствующие осколки, в свою очередь, получат непропорционально большое количество чтений.
Их соответствующие осколки, в свою очередь, получат непропорционально большое количество чтений.
Разделение на основе каталогов
Чтобы реализовать сегментирование на основе каталогов , необходимо создать и поддерживать таблицу поиска , которая использует ключ сегмента для отслеживания того, какой сегмент содержит какие данные. Короче говоря, таблица поиска — это таблица, содержащая статический набор информации о том, где можно найти определенные данные. На следующей диаграмме показан упрощенный пример сегментирования на основе каталогов:
Здесь столбец Зона доставки определен как ключ сегмента.Данные из ключа сегмента записываются в таблицу поиска вместе с любым сегментом, в который должна быть записана каждая соответствующая строка. Это похоже на сегментирование на основе диапазона, но вместо того, чтобы определять, в какой диапазон попадают данные ключа сегмента, каждый ключ привязан к своему конкретному сегменту. Сегментирование на основе каталогов является хорошим выбором по сравнению с сегментированием на основе диапазонов в тех случаях, когда ключ сегмента имеет низкую кардинальность и для сегмента не имеет смысла хранить диапазон ключей. Обратите внимание, что он также отличается от сегментирования на основе ключа тем, что не обрабатывает ключ сегмента с помощью хеш-функции; он просто сверяет ключ с таблицей поиска, чтобы увидеть, куда нужно записать данные.
Сегментирование на основе каталогов является хорошим выбором по сравнению с сегментированием на основе диапазонов в тех случаях, когда ключ сегмента имеет низкую кардинальность и для сегмента не имеет смысла хранить диапазон ключей. Обратите внимание, что он также отличается от сегментирования на основе ключа тем, что не обрабатывает ключ сегмента с помощью хеш-функции; он просто сверяет ключ с таблицей поиска, чтобы увидеть, куда нужно записать данные.
Основная привлекательность сегментирования на основе каталогов заключается в его гибкости. Архитектуры сегментирования на основе диапазонов ограничивают вас указанием диапазонов значений, в то время как архитектуры на основе ключей ограничивают вас использованием фиксированной хеш-функции, которую, как упоминалось ранее, может быть чрезвычайно сложно изменить позже. С другой стороны, сегментирование на основе каталогов позволяет вам использовать любую систему или алгоритм, который вы хотите назначать элементам данных для сегментов, и с помощью этого подхода относительно легко динамически добавлять сегменты.
Хотя сегментирование на основе каталогов является наиболее гибким из обсуждаемых здесь методов сегментирования, необходимость подключения к таблице поиска перед каждым запросом или записью может отрицательно сказаться на производительности приложения. Кроме того, таблица поиска может стать единственной точкой отказа: если она будет повреждена или иным образом выйдет из строя, это может повлиять на возможность записи новых данных или доступа к существующим данным.
Должен ли я осколок?
Вопрос о том, следует ли реализовывать сегментированную архитектуру базы данных, почти всегда является предметом споров.Некоторые рассматривают сегментирование как неизбежный результат для баз данных, достигающих определенного размера, в то время как другие считают его головной болью, которой следует избегать, если в этом нет крайней необходимости, из-за операционной сложности, которую добавляет сегментирование.
Из-за этой дополнительной сложности сегментирование обычно выполняется только при работе с очень большими объемами данных.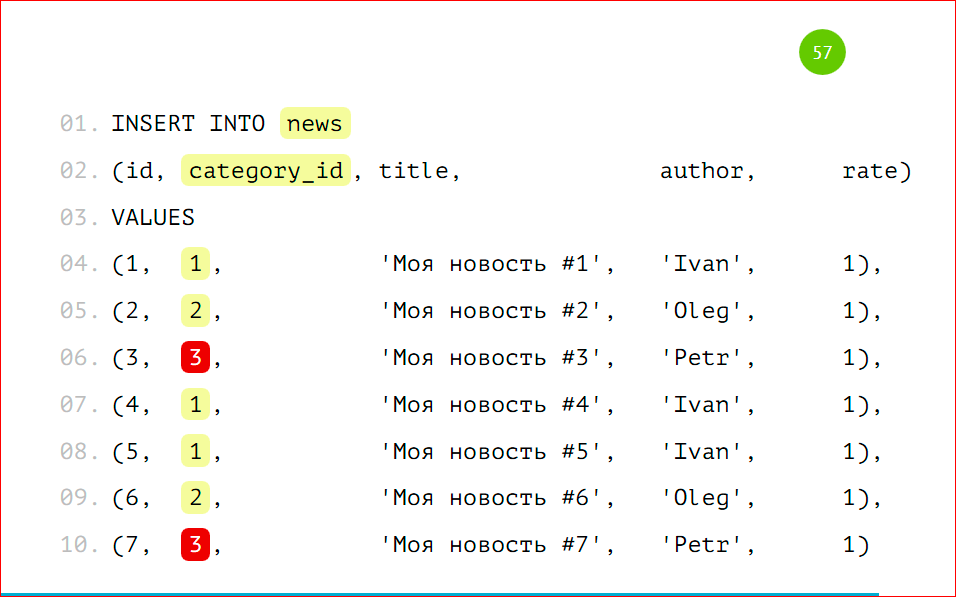 Вот несколько распространенных сценариев, в которых может быть полезно сегментировать базу данных:
Вот несколько распространенных сценариев, в которых может быть полезно сегментировать базу данных:
- Объем данных приложения увеличивается и превышает емкость хранилища одного узла базы данных.
- Объем операций записи или чтения в базу данных превышает возможности одного узла или его реплик чтения, что приводит к увеличению времени отклика или тайм-аутам.
- Пропускная способность сети, необходимая приложению, превышает пропускную способность, доступную для одного узла базы данных и любых реплик чтения, что приводит к замедлению времени отклика или тайм-аутам.
Перед шардингом следует исчерпать все остальные варианты оптимизации базы данных. Некоторые оптимизации, которые вы, возможно, захотите рассмотреть, включают:
- Настройка удаленной базы данных .Если вы работаете с монолитным приложением, в котором все его компоненты находятся на одном сервере, вы можете повысить производительность своей базы данных, переместив ее на отдельный компьютер. Это не добавляет такой сложности, как сегментирование, поскольку таблицы базы данных остаются нетронутыми. Тем не менее, он по-прежнему позволяет вертикально масштабировать базу данных отдельно от остальной инфраструктуры.
- Реализация кэширования . Если производительность чтения вашего приложения вызывает у вас проблемы, кэширование — это одна из стратегий, которая может помочь улучшить ее.Кэширование включает в себя временное хранение данных, которые уже были запрошены в памяти, что позволяет вам получить к ним гораздо более быстрый доступ позже.
- Создание одной или нескольких реплик чтения . Другая стратегия, которая может помочь улучшить производительность чтения, включает копирование данных с одного сервера базы данных ( первичный сервер ) на один или несколько вторичных серверов . После этого каждая новая запись отправляется на первичный, а затем копируется на вторичные серверы, а чтение выполняется исключительно на вторичные серверы. Такое распределение операций чтения и записи не позволяет какой-либо одной машине брать на себя слишком большую нагрузку, помогая предотвратить замедление работы и сбои. Обратите внимание, что создание реплик чтения требует больше вычислительных ресурсов и, следовательно, стоит больше денег, что может быть серьезным ограничением для некоторых.
- Обновление до более крупного сервера . В большинстве случаев масштабирование сервера базы данных до машины с большим количеством ресурсов требует меньше усилий, чем сегментирование. Как и в случае создания реплик чтения, обновленный сервер с большим количеством ресурсов, вероятно, будет стоить больше денег.Соответственно, вам следует изменять размер только в том случае, если это действительно окажется вашим лучшим вариантом.
 Это не добавляет такой сложности, как сегментирование, поскольку таблицы базы данных остаются нетронутыми. Тем не менее, он по-прежнему позволяет вертикально масштабировать базу данных отдельно от остальной инфраструктуры.
Это не добавляет такой сложности, как сегментирование, поскольку таблицы базы данных остаются нетронутыми. Тем не менее, он по-прежнему позволяет вертикально масштабировать базу данных отдельно от остальной инфраструктуры. Такое распределение операций чтения и записи не позволяет какой-либо одной машине брать на себя слишком большую нагрузку, помогая предотвратить замедление работы и сбои. Обратите внимание, что создание реплик чтения требует больше вычислительных ресурсов и, следовательно, стоит больше денег, что может быть серьезным ограничением для некоторых.
Такое распределение операций чтения и записи не позволяет какой-либо одной машине брать на себя слишком большую нагрузку, помогая предотвратить замедление работы и сбои. Обратите внимание, что создание реплик чтения требует больше вычислительных ресурсов и, следовательно, стоит больше денег, что может быть серьезным ограничением для некоторых. Имейте в виду, что если ваше приложение или веб-сайт превысит определенный предел, ни одной из этих стратегий будет недостаточно для повышения производительности. В таких случаях шардинг действительно может быть лучшим вариантом для вас.
Заключение
Sharding может стать отличным решением для тех, кто хочет масштабировать свою базу данных по горизонтали. Однако это также значительно усложняет работу приложения и создает больше потенциальных точек отказа.Кому-то сегментирование может быть необходимо, но время и ресурсы, необходимые для создания и обслуживания сегментированной архитектуры, могут перевесить преимущества для других.
Прочитав эту концептуальную статью, вы должны получить более четкое представление о плюсах и минусах шардинга. Двигаясь вперед, вы можете использовать эту информацию, чтобы принять более обоснованное решение о том, подходит ли архитектура сегментированной базы данных для вашего приложения.
Разделение базы данных: концепции и примеры
Архитектуры и типы сегментирования
Хотя существует множество различных методов сегментирования, мы рассмотрим четыре основных типа: ранжированное/динамическое сегментирование, алгоритмическое/хешированное сегментирование, сегментирование на основе сущностей/связей и географическое. основанный на шардинге.
основанный на шардинге.
Ранжированное/динамическое сегментирование
Ранжированное сегментирование или динамическое сегментирование берет поле в записи в качестве входных данных и на основе предопределенного диапазона выделяет эту запись соответствующему сегменту. Для сегментирования с диапазоном требуется наличие таблицы поиска или службы, доступной для всех запросов или операций записи. Например, рассмотрим набор данных с идентификаторами в диапазоне от 0 до 50. Простая таблица поиска может выглядеть следующим образом:
| Диапазон | Идентификатор сегмента |
| [0, 20) | А |
| [20, 40] | Б |
| [40, 50] | С |
Поле, на котором основан диапазон, также известно как ключ сегмента.Естественно, выбор ключа сегмента, а также диапазонов имеют решающее значение для обеспечения эффективности сегментирования на основе диапазонов. Неправильный выбор ключа сегмента приведет к несбалансированности сегментов, что приведет к снижению производительности. Эффективный ключ сегмента позволит нацеливать запросы на минимальное количество сегментов. В нашем примере выше, если мы запрашиваем все записи с идентификаторами 10-30, то нужно будет запрашивать только осколки A и B.
Неправильный выбор ключа сегмента приведет к несбалансированности сегментов, что приведет к снижению производительности. Эффективный ключ сегмента позволит нацеливать запросы на минимальное количество сегментов. В нашем примере выше, если мы запрашиваем все записи с идентификаторами 10-30, то нужно будет запрашивать только осколки A и B.
Двумя ключевыми атрибутами эффективного ключа сегмента являются высокая кардинальность и хорошо распределенная частота . Кардинальность относится к числу возможных значений этого ключа. Если ключ сегмента имеет только три возможных значения, то может быть максимум три сегмента. Частота относится к распределению данных по возможным значениям. Если 95% записей встречаются с одним значением ключа сегмента, то из-за этой точки доступа 95% записей будут размещены в одном сегменте. Учитывайте оба эти атрибута при выборе ключа сегмента.
Сегментирование на основе диапазона — это простой для понимания метод горизонтального разделения, но его эффективность будет сильно зависеть от наличия подходящего ключа сегмента и выбора соответствующих диапазонов. Кроме того, служба поиска может стать узким местом, хотя объем данных достаточно мал, поэтому обычно это не проблема.
Кроме того, служба поиска может стать узким местом, хотя объем данных достаточно мал, поэтому обычно это не проблема.
Алгоритмическое/хешированное сегментирование
Алгоритмическое сегментирование или хешированное сегментирование берет запись в качестве входных данных и применяет к ней хэш-функцию или алгоритм, который генерирует выходное значение или хэш-значение. Затем этот вывод используется для размещения каждой записи в соответствующем сегменте.
Функция может принимать любое подмножество значений в записи в качестве входных данных.Возможно, самым простым примером хэш-функции является использование оператора модуля с количеством осколков, как показано ниже:
Значение хэша=ID % Число осколков
Это похоже на сегментирование на основе диапазона — набор полей определяет отнесение записи к данному осколку. Хеширование входных данных обеспечивает более равномерное распределение по сегментам, даже если нет подходящего ключа сегмента и нет необходимости поддерживать таблицу поиска. Однако есть несколько недостатков.
Однако есть несколько недостатков.
Во-первых, операции запроса для нескольких записей с большей вероятностью будут распределены по нескольким сегментам.В то время как ранжированное сегментирование отражает естественную структуру данных в сегментах, хэшированное сегментирование обычно игнорирует смысл данных. Это отражается в увеличении числа операций широковещательной передачи.
Во-вторых, повторное использование может быть дорогостоящим. Любое обновление количества сегментов, скорее всего, потребует перебалансировки всех сегментов для перемещения записей. Сделать это, избежав отключения системы, будет сложно.
Шардинг на основе сущностей/отношений
Шардинг на основе сущностей хранит связанные данные вместе на одном физическом сегменте.В реляционной базе данных (например, PostgreSQL, MySQL или SQL Server) связанные данные часто распределяются по нескольким различным таблицам.
Например, рассмотрим случай базы данных покупок с пользователями и способами оплаты. У каждого пользователя есть набор способов оплаты, который тесно связан с этим пользователем. Таким образом, совместное хранение связанных данных в одном сегменте может снизить потребность в широковещательных операциях и повысить производительность.
У каждого пользователя есть набор способов оплаты, который тесно связан с этим пользователем. Таким образом, совместное хранение связанных данных в одном сегменте может снизить потребность в широковещательных операциях и повысить производительность.
Сегментация на основе географии
Сегментация на основе географии или геошардинг также хранит связанные данные вместе на одном сегменте, но в этом случае данные связаны по географии.По сути, это ранжированное сегментирование, при котором ключ сегмента содержит географическую информацию, а сами сегменты имеют географическую привязку.
Например, рассмотрим набор данных, в котором каждая запись содержит поле «страна». В этом случае мы можем повысить общую производительность и уменьшить задержку системы, создав сегмент для каждой страны или региона и сохранив соответствующие данные в этом сегменте. Это простой пример, и есть много других способов размещения ваших геошардов, которые выходят за рамки этой статьи.
Разделение базы данных против разделения: в чем разница?
В этом сообщении защитник разработчиков SingleStore Джо Карлссон объясняет различия между сегментированием и секционированием базы данных. Оба являются методами разбиения большого набора данных на более мелкие подмножества, но есть различия. В этой статье рассматривается, когда использовать каждый из них или даже комбинировать их для приложений с интенсивным использованием данных.
Введение:
Если вы потратили время на изучение методов масштабируемой архитектуры баз данных, скорее всего, вы сталкивались с терминами «сегментирование» и «разделение».Так в чем же разница между этими двумя понятиями? Теперь, на первый взгляд, эти два термина и понятия могут показаться довольно похожими. Это связано с тем, что сегментирование и секционирование связаны с разбиением большого набора данных на более мелкие подмножества. Разница в том, что шардинг подразумевает, что данные распределяются между несколькими компьютерами, а секционирование — нет. Рассмотрим подробно каждую концепцию.
Рассмотрим подробно каждую концепцию.
Что такое разделение?
Секционирование — это процесс базы данных, при котором очень большие таблицы делятся на несколько более мелких частей.Разбивая большую таблицу на более мелкие отдельные таблицы, запросы, которые обращаются только к части данных, могут выполняться быстрее, поскольку для сканирования требуется меньше данных. Основная цель секционирования — помочь в обслуживании больших таблиц и сократить общее время отклика на чтение и загрузку данных для определенных операций SQL.
Вертикальное секционирование
Вертикальное секционирование таблицы в основном используется для повышения производительности SQL Server, особенно в тех случаях, когда запрос извлекает все столбцы из таблицы, содержащей несколько очень широких текстовых или BLOB-столбцов.В этом случае для сокращения времени доступа столбцы BLOB можно разделить на отдельные таблицы. Другим примером является ограничение доступа к конфиденциальным данным, например. пароли, информация о зарплате и т. д. Вертикальное секционирование разбивает таблицу на две или более таблиц, содержащих разные столбцы:
пароли, информация о зарплате и т. д. Вертикальное секционирование разбивает таблицу на две или более таблиц, содержащих разные столбцы:
Когда разбивать таблицу на разделы?
Вот несколько советов о том, когда следует разбивать таблицу на разделы:
Таблицы размером более 2 ГБ всегда следует рассматривать как кандидаты на разделение.
Таблицы, содержащие исторические данные, в которых новые данные добавляются в самый новый раздел. Типичным примером является историческая таблица, в которой обновляются данные только за текущий месяц, а остальные 11 месяцев доступны только для чтения.
Когда содержимое таблицы необходимо распределить по различным типам устройств хранения.

Что такое шардинг?
Разделение на самом деле является типом разделения базы данных, а точнее, горизонтальным разделением. Разделение — это репликация [копирование] схемы, а затем разделение данных на основе ключа сегмента на отдельный экземпляр сервера базы данных для распределения нагрузки.Каждая распределенная таблица имеет ровно один ключ сегмента. Ключ сегмента может содержать любое количество столбцов. В SingleStore при запуске CREATE TABLE для создания таблицы можно указать ключ сегмента для таблицы.
Ключ сегмента таблицы определяет, в каком разделе хранится данная строка таблицы. Когда вы выполняете запрос INSERT, узел вычисляет хеш-функцию значений в столбце или столбцах, которые составляют ключ сегмента, который создает номер раздела, в котором должна храниться строка
. Затем узел направляет операцию INSERT на соответствующий компьютер узла и раздел.
Например, в приведенной ниже таблице ключ сегмента содержит только первый столбец. Все люди с одинаковым именем будут храниться в одном разделе.
Все люди с одинаковым именем будут храниться в одном разделе.
Когда разбивать таблицу?
Разделение данных может значительно повысить производительность базы данных. Ниже приведены некоторые примеры того, как сегментирование может помочь повысить производительность:
- Уменьшенный размер индекса — поскольку таблицы разделены и распределены по нескольким серверам, общее количество строк в каждой таблице в каждой базе данных уменьшается. Это уменьшает размер индекса, что обычно повышает производительность поиска.
Распределить базу данных по нескольким компьютерам — сегмент базы данных можно разместить на отдельном оборудовании, а несколько сегментов можно разместить на нескольких компьютерах. Это позволяет распределить базу данных по большому количеству машин, что значительно повышает производительность.
Сегментация данных по географическому признаку.
, американских клиентов), то можно будет легко и автоматически определить принадлежность к соответствующему сегменту и запросить только соответствующий сегмент.
 , американских клиентов), то можно будет легко и автоматически определить принадлежность к соответствующему сегменту и запросить только соответствующий сегмент.
, американских клиентов), то можно будет легко и автоматически определить принадлежность к соответствующему сегменту и запросить только соответствующий сегмент.Когда НЕ разбивать таблицу?
Разделение следует использовать только тогда, когда все другие варианты оптимизации не подходят. Введенная сложность сегментирования базы данных вызывает следующие потенциальные проблемы:
Сложность SQL — увеличение количества ошибок, поскольку разработчикам приходится писать более сложный SQL для обработки логики сегментирования
Дополнительное программное обеспечение, которое разделяет, балансирует, целостность может быть нарушена
Единственная точка отказа — повреждение одного фрагмента из-за проблем с сетью/аппаратным обеспечением/системой приводит к сбою всей таблицы.
Сложность отказоустойчивого сервера. На отказоустойчивых серверах должны быть копии групп сегментов базы данных.
Сложность резервных копий.
Резервные копии баз данных отдельных сегментов должны быть согласованы с резервными копиями других сегментов.Операционная сложность. Добавление/удаление индексов, добавление/удаление столбцов, изменение схемы становится намного сложнее.
 Резервные копии баз данных отдельных сегментов должны быть согласованы с резервными копиями других сегментов.
Резервные копии баз данных отдельных сегментов должны быть согласованы с резервными копиями других сегментов.К счастью, SingleStore справляется с большинством этих дополнительных сложностей, связанных с сегментированием ваших данных, так что вам не о чем беспокоиться!
Шардинг vs.Разделение: в чем разница?
Разделение — это общий термин, который просто означает разделение ваших логических объектов на разные физические объекты для обеспечения производительности, доступности или какой-либо другой цели. «Горизонтальное разбиение» или сегментирование — это репликация схемы и последующее разделение данных на основе ключа сегмента.
И последнее замечание: вы можете комбинировать методы секционирования и сегментирования базы данных. На самом деле иногда для приложений, интенсивно использующих данные, требуется использование обеих стратегий.
Дополнительные ресурсы:
Как работает разделение данных в распределенной базе данных SQL
Примечание редактора: этот пост был обновлен 28 августа 2020 г. , чтобы включить новые функции сегментирования, доступные начиная с YugabyteDB 2.2
, чтобы включить новые функции сегментирования, доступные начиная с YugabyteDB 2.2
Предприятия всех размеров внедряют быструю модернизацию пользовательских приложений в рамках своей более широкой стратегии цифровой трансформации. Инфраструктура реляционной базы данных (RDBMS), на которую полагаются такие приложения, внезапно должна поддерживать гораздо большие объемы данных и объемы транзакций. Однако в таких сценариях монолитная СУБД имеет тенденцию быстро перегружаться. Одним из наиболее распространенных архитектурных шаблонов, используемых для масштабирования СУБД, является «сегментирование» данных. В этом блоге мы узнаем, что такое сегментирование и как его можно использовать для масштабирования базы данных SQL.Мы также рассмотрим плюсы и минусы распространенных архитектур сегментирования, а также рассмотрим, как сегментирование реализовано в распределенной базе данных SQL, такой как YugabyteDB.
Что такое совместное использование данных?
Шардинг — это процесс разбиения больших таблиц на более мелкие фрагменты, называемые сегментами , которые распределяются по нескольким серверам. Сегмент — это, по сути, горизонтальный раздел данных, который содержит подмножество общего набора данных и, следовательно, отвечает за обслуживание части общей рабочей нагрузки.Идея состоит в том, чтобы распределить данные, которые не помещаются на одном узле, в кластер из 90 123 90 124 узлов базы данных. Разделение также называется горизонтальным разделением . Различие между горизонтальным и вертикальным исходит из традиционного табличного представления базы данных. Базу данных можно разделить по вертикали — с сохранением разных столбцов таблицы в отдельной базе данных или по горизонтали — с сохранением строк одной и той же таблицы в нескольких узлах базы данных.
Сегмент — это, по сути, горизонтальный раздел данных, который содержит подмножество общего набора данных и, следовательно, отвечает за обслуживание части общей рабочей нагрузки.Идея состоит в том, чтобы распределить данные, которые не помещаются на одном узле, в кластер из 90 123 90 124 узлов базы данных. Разделение также называется горизонтальным разделением . Различие между горизонтальным и вертикальным исходит из традиционного табличного представления базы данных. Базу данных можно разделить по вертикали — с сохранением разных столбцов таблицы в отдельной базе данных или по горизонтали — с сохранением строк одной и той же таблицы в нескольких узлах базы данных.
Рис. 1. Разделение данных по вертикали и горизонтали (Источник: Medium)
Зачем разбивать базу данных?
Бизнес-приложения, основанные на монолитной СУБД, по мере своего роста сталкиваются с узкими местами.При ограниченных ресурсах ЦП, емкости хранилища и памяти неизбежно страдают пропускная способность запросов и время отклика. Когда дело доходит до добавления ресурсов для поддержки операций базы данных, вертикальное масштабирование (также известное как масштабирование вверх) имеет свой собственный набор ограничений и в конечном итоге достигает точки убывающей отдачи.
Когда дело доходит до добавления ресурсов для поддержки операций базы данных, вертикальное масштабирование (также известное как масштабирование вверх) имеет свой собственный набор ограничений и в конечном итоге достигает точки убывающей отдачи.
С другой стороны, горизонтальное секционирование таблицы означает большую вычислительную мощность для обслуживания входящих запросов, и, следовательно, вы получаете более быстрое время ответа на запрос и построение индекса. Благодаря постоянной балансировке нагрузки и набора данных между дополнительными узлами сегментирование также позволяет использовать дополнительную емкость.Кроме того, сеть небольших и более дешевых серверов может оказаться более рентабельной в долгосрочной перспективе, чем поддержка одного большого сервера.
Помимо решения проблем масштабирования, сегментирование потенциально может смягчить последствия незапланированных простоев. Во время простоя все данные в нераспределенной базе данных недоступны, что может быть разрушительным или просто катастрофическим. При правильном выполнении сегментирование может обеспечить высокую доступность: даже если один или два узла, на которых размещено несколько сегментов, отключены, остальная часть базы данных по-прежнему доступна для операций чтения/записи, пока другие узлы (на которых размещены оставшиеся сегменты) работают в режиме ожидания. различные домены отказов.В целом сегментирование может увеличить общую емкость хранилища кластера, ускорить обработку и обеспечить более высокую доступность при меньших затратах, чем вертикальное масштабирование.
При правильном выполнении сегментирование может обеспечить высокую доступность: даже если один или два узла, на которых размещено несколько сегментов, отключены, остальная часть базы данных по-прежнему доступна для операций чтения/записи, пока другие узлы (на которых размещены оставшиеся сегменты) работают в режиме ожидания. различные домены отказов.В целом сегментирование может увеличить общую емкость хранилища кластера, ускорить обработку и обеспечить более высокую доступность при меньших затратах, чем вертикальное масштабирование.
Опасности ручного шардинга
Сегментирование, включая создание сегментов первого дня и ребалансировку сегментов второго дня, при полной автоматизации может быть благом для приложений с большими объемами данных. К сожалению, монолитные базы данных, такие как Oracle, PostgreSQL, MySQL, и даже более новые распределенные базы данных SQL, такие как Amazon Aurora, не поддерживают автоматическое сегментирование.Это означает, что сегментирование вручную на уровне приложения должно выполняться, если вы хотите продолжать использовать эти базы данных. Конечным результатом является значительное увеличение сложности разработки. Ваше приложение теперь имеет дополнительную логику сегментирования, чтобы точно знать, как распределяются ваши данные и как их получить. Вы также должны решить, какой подход к сегментированию использовать, сколько сегментов создать и сколько узлов использовать. А также учитывайте ключ сегмента и даже изменения подхода к сегментированию, если ваш бизнес нуждается в изменении.
Конечным результатом является значительное увеличение сложности разработки. Ваше приложение теперь имеет дополнительную логику сегментирования, чтобы точно знать, как распределяются ваши данные и как их получить. Вы также должны решить, какой подход к сегментированию использовать, сколько сегментов создать и сколько узлов использовать. А также учитывайте ключ сегмента и даже изменения подхода к сегментированию, если ваш бизнес нуждается в изменении.
Одной из самых серьезных проблем при ручном сегментировании является неравномерное распределение сегментов. Непропорциональное распределение данных может привести к тому, что сегменты станут несбалансированными: некоторые будут перегружены, а другие останутся относительно пустыми. Лучше не накапливать слишком много данных на шарде, потому что точка доступа может привести к замедлению работы и сбоям сервера. Эта проблема также может возникнуть из-за небольшого набора сегментов, из-за чего данные распределяются по слишком небольшому числу сегментов. Это допустимо в средах разработки и тестирования, но не в рабочей среде.Неравномерное распределение данных, горячие точки и хранение данных на слишком малом количестве сегментов могут привести к истощению ресурсов сегментов и серверов.
Это допустимо в средах разработки и тестирования, но не в рабочей среде.Неравномерное распределение данных, горячие точки и хранение данных на слишком малом количестве сегментов могут привести к истощению ресурсов сегментов и серверов.
Наконец, шардинг вручную может усложнить рабочие процессы. Резервные копии теперь должны выполняться для нескольких серверов. Миграция данных и изменения схемы должны быть тщательно скоординированы, чтобы гарантировать, что все осколки имеют одну и ту же копию схемы. Без достаточной оптимизации объединение баз данных на нескольких серверах может быть крайне неэффективным и трудным для выполнения.
Распространенные архитектуры автоматического сегментирования
Шардинг существует уже давно, и на протяжении многих лет различные архитектуры и реализации шардинга использовались для создания крупномасштабных систем.В этом разделе мы рассмотрим три наиболее распространенных из них.
Разделение хэша
Сегментирование хэша берет значение ключа сегмента и генерирует из него хеш-значение. Затем значение хеш-функции используется для определения того, в каком сегменте должны находиться данные. С помощью единого алгоритма хеширования, такого как ketama, хеш-функция может равномерно распределять данные по серверам, снижая риск возникновения горячих точек. При таком подходе данные с близкими ключами шарда вряд ли будут размещены на одном шарде. Таким образом, эта архитектура отлично подходит для целевых операций с данными.
Затем значение хеш-функции используется для определения того, в каком сегменте должны находиться данные. С помощью единого алгоритма хеширования, такого как ketama, хеш-функция может равномерно распределять данные по серверам, снижая риск возникновения горячих точек. При таком подходе данные с близкими ключами шарда вряд ли будут размещены на одном шарде. Таким образом, эта архитектура отлично подходит для целевых операций с данными.
Рисунок 2. Сегментирование хэша
Разделение диапазона
Разбиение по диапазонам разделяет данные на основе диапазонов значения данных (так называемого пространства ключей). Ключи осколков с близкими значениями с большей вероятностью попадают в один и тот же диапазон и на одни и те же осколки. Каждый сегмент по существу сохраняет одну и ту же схему из исходной базы данных. Разделение становится таким же простым, как определение соответствующего диапазона данных и размещение его в соответствующем сегменте.
Рисунок 3: Сегментирование диапазона
Сегментирование диапазона позволяет выполнять эффективные запросы, которые считывают целевые данные в пределах непрерывного диапазона или запросов диапазона. Однако сегментация диапазона требует, чтобы пользователь априори выбрал ключи сегмента, а неправильно выбранные ключи сегмента могут привести к появлению горячих точек в базе данных.
Однако сегментация диапазона требует, чтобы пользователь априори выбрал ключи сегмента, а неправильно выбранные ключи сегмента могут привести к появлению горячих точек в базе данных.
Хорошим эмпирическим правилом является выбор ключей сегментов, которые имеют большое количество элементов, низкую частоту повторения и не увеличиваются и не уменьшаются монотонно. Без надлежащего выбора ключа сегмента данные могут быть неравномерно распределены по сегментам, а определенные данные могут запрашиваться чаще, чем другие, что создает потенциальные системные узкие места в сегментах, которые получают большую рабочую нагрузку.
Идеальным решением для фрагментов разного размера является автоматическое разделение и слияние сегментов. Если сегмент становится слишком большим или содержит часто используемую строку, то разбиение сегмента на несколько сегментов и их последующая перебалансировка по всем доступным узлам приводит к повышению производительности. Точно так же обратный процесс может быть предпринят, когда слишком много мелких осколков.
Георазметка
При сегментировании на основе географических данных (т.н. с учетом местоположения) данные сначала разбиваются в соответствии с указанным пользователем столбцом, который сопоставляет сегменты диапазона с определенными регионами и узлами в этих регионах.Затем внутри заданного региона данные сегментируются с использованием либо хеширования, либо сегментирования диапазона. Например, кластер, который охватывает 3 региона в США, Великобритании и ЕС, может полагаться на столбец Country_Code таблицы User для сопоставления строки пользователя с ближайшим регионом, соответствующим правилам GDPR.
Шардинг в YugabyteDB
YugabyteDB — это сверхустойчивая, высокопроизводительная, географически распределенная база данных SQL с автоматическим сегментированием, созданная на основе Google Spanner. В настоящее время он поддерживает разбиение хэшей и диапазонов.Гео-разделение — это активная функция, находящаяся в стадии разработки. Каждый сегмент данных называется планшетом и находится на соответствующем планшетном сервере.
Разделение хэша
Для разделения хэшей таблицам выделяется хеш-пространство от 0x0000 до 0xFFFF (2-байтовый диапазон), вмещающее до 64 КБ планшетов в очень больших наборах данных или размерах кластера. Рассмотрим таблицу с 16 планшетами, как показано на рисунке 4. Мы берем общее хеш-пространство [от 0x0000 до 0xFFFF) и делим его на 16 сегментов — по одному для каждого планшета.
Рисунок 4: Сегментирование хэша в YugabyteDB
В операциях чтения/записи первичные ключи сначала преобразуются во внутренние ключи и соответствующие им хеш-значения. Операция обслуживается путем сбора данных с соответствующих планшетов. (Рисунок 3)
Рисунок 5. Выбор планшета для использования в YugabyteDB
В качестве примера предположим, что вы хотите вставить ключ k со значением v в таблицу, как показано на рис. 6, вычисляется хэш-значение k, затем выполняется поиск соответствующего планшета, а затем — соответствующего сервера планшетов. .Затем запрос отправляется непосредственно на этот планшетный сервер для обработки.
.Затем запрос отправляется непосредственно на этот планшетный сервер для обработки.
Рисунок 6. Сохранение значения k в YugabyteDB
Разделение диапазона
Таблицы SQL могут быть созданы с директивами ASC и DESC для первого столбца первичного ключа, а также для первого из индексированных столбцов. Это приведет к тому, что данные будут храниться в выбранном порядке на одном планшете. Эту единственную таблетку можно разделить автоматически (как только она достигнет определенного размера) или вручную, когда это необходимо.Для высокопроизводительных рабочих нагрузок с хорошо известными точками разделения можно добавить предложение SPLIT AT во время создания таблицы, чтобы указать точные диапазоны.
Георазметка
Георазбиение на уровне строк находится в стадии активной разработки. Проектная документация и текущий статус доступны на GitHub.
Резюме
Data sharding — это решение для бизнес-приложений с большими наборами данных и потребностями в масштабировании. Существует множество архитектур сегментирования на выбор, каждая из которых предоставляет различные возможности.Прежде чем остановиться на архитектуре сегментирования, необходимо определить потребности и требования к рабочей нагрузке вашего приложения. Ручного сегментирования следует избегать в большинстве случаев, учитывая значительное увеличение сложности логики приложения. YugabyteDB — это распределенная база данных SQL с автоматическим сегментированием, которая сегодня поддерживает как хэширование, так и сегментирование диапазона. Поддержка гео-разделения появится в ближайшее время. В этом руководстве вы можете увидеть автоматическое разбиение YugabyteDB в действии.
Существует множество архитектур сегментирования на выбор, каждая из которых предоставляет различные возможности.Прежде чем остановиться на архитектуре сегментирования, необходимо определить потребности и требования к рабочей нагрузке вашего приложения. Ручного сегментирования следует избегать в большинстве случаев, учитывая значительное увеличение сложности логики приложения. YugabyteDB — это распределенная база данных SQL с автоматическим сегментированием, которая сегодня поддерживает как хэширование, так и сегментирование диапазона. Поддержка гео-разделения появится в ближайшее время. В этом руководстве вы можете увидеть автоматическое разбиение YugabyteDB в действии.
Что дальше?
- Подробно сравните YugabyteDB с такими базами данных, как CockroachDB, Google Cloud Spanner и MongoDB.
- Начните работу с YugabyteDB в macOS, Linux, Docker и Kubernetes.
- Свяжитесь с нами, чтобы узнать больше о лицензировании, ценах или запланировать технический обзор.
Обзор Oracle Sharding
Oracle Sharding — это функция масштабируемости и доступности для подходящих приложений OLTP. Он обеспечивает распространение и репликацию данных в пуле баз данных Oracle, которые не используют совместно аппаратное или программное обеспечение.
Приложения воспринимают пул баз данных как единую логическую базу данных.Приложения могут эластично масштабировать данные, транзакции и пользователей до любого уровня на любой платформе, добавляя базы данных (сегменты) в пул. Oracle Database 12c Release 2 (12.2.0.1) поддерживает масштабирование до 1000 сегментов.
На следующем рисунке показаны основные архитектурные компоненты Oracle Sharding:
Разделенная база данных (SDB) — единая логическая база данных Oracle, горизонтально разделенная на пул физических баз данных Oracle (сегментов), которые не используют совместно аппаратное или программное обеспечение
Сегменты — независимые физические базы данных Oracle, в которых размещается подмножество сегментированной базы данных
Глобальная служба — службы базы данных, обеспечивающие доступ к данным в SDB
Каталог сегментов — база данных Oracle, которая поддерживает автоматическое развертывание сегментов, централизованное управление сегментированной базой данных и запросы к нескольким сегментам
Директора сегментов — сетевые прослушиватели, обеспечивающие высокопроизводительную маршрутизацию соединений на основе ключа сегментирования
Пулы соединений — во время выполнения действуют как директора сегментов, направляя запросы к базе данных через соединения в пуле
Интерфейсы управления — GDSCTL (утилита командной строки) и Oracle Enterprise Manager (GUI)
Разделенная база данных и осколки
Сегменты — это независимые базы данных Oracle, размещенные на серверах баз данных, которые имеют собственные локальные ресурсы: ЦП, память и диск.Для осколков не требуется общего хранилища.
Сегментированная база данных — это набор сегментов. Все осколки могут быть размещены в одном регионе или могут быть размещены в разных регионах. Регион в контексте Oracle Sharding представляет собой центр обработки данных или несколько центров обработки данных, которые находятся в непосредственной близости от сети.
Сегментыреплицируются для обеспечения высокой доступности (HA) и аварийного восстановления (DR) с помощью технологий репликации Oracle, таких как Data Guard.Для высокой доступности резервные сегменты могут быть размещены в том же регионе, что и основные сегменты. Для аварийного восстановления резервные сегменты расположены в другом регионе.
Глобальная служба
Глобальная служба является расширением понятия традиционной службы базы данных. Все свойства традиционных служб баз данных поддерживаются для глобальных служб. Для сегментированных баз данных задаются дополнительные свойства для глобальных сервисов — например, роль базы данных, допустимое запаздывание репликации, соответствие регионов между клиентами и шардами и так далее.Для рабочей нагрузки транзакций чтения-записи создается одна глобальная служба для доступа к данным из любого основного сегмента в SDB. Для высокодоступных сегментов, использующих Active Data Guard, можно создать отдельную глобальную службу только для чтения.
Каталог осколков
Каталог фрагментов — это база данных Oracle специального назначения, которая является постоянным хранилищем данных конфигурации SDB и играет ключевую роль в централизованном управлении сегментированной базой данных.Все изменения конфигурации, такие как добавление и удаление сегментов и глобальных служб, инициируются в каталоге сегментов. Все DDL в SDB выполняются путем подключения к каталогу сегментов.
Каталог осколков также содержит основную копию всех дублированных таблиц в SDB. Каталог сегментов использует материализованные представления для автоматической репликации изменений в дублирующихся таблицах во всех сегментах. База данных каталога сегментов также действует как координатор запросов, используемый для обработки запросов с несколькими сегментами и запросов, в которых не указан ключ сегментирования.
Рекомендуется использовать Oracle Data Guard для обеспечения высокой доступности каталога сегментов. Доступность каталога сегментов не влияет на доступность SDB. Выход из строя каталога сегмента влияет только на возможность выполнения операций обслуживания или запросов к нескольким сегментам в течение короткого периода времени, необходимого для завершения автоматического переключения на резервный каталог сегмента. Транзакции OLTP продолжают маршрутизироваться и выполняться SDB, и на них не влияет сбой каталога.
Директор осколков
В Oracle Database 12c появился глобальный диспетчер служб для маршрутизации соединений в зависимости от роли базы данных, нагрузки, задержки репликации и местоположения. В рамках поддержки Oracle Sharding глобальные менеджеры служб поддерживают маршрутизацию соединений на основе местоположения данных. Глобальный менеджер служб в контексте Oracle Sharding известен как директор сегмента.
Директор сегмента — это конкретная реализация глобального диспетчера служб, который действует как региональный прослушиватель для клиентов, подключающихся к SDB.Директор поддерживает текущую карту топологии SDB. На основе ключа сегментирования, переданного во время запроса на подключение, директор направляет подключения к соответствующему сегменту.
Для типичной SDB набор директоров сегментов устанавливается на выделенных недорогих стандартных серверах в каждом регионе. Для достижения высокой доступности разверните несколько директоров сегментов. В Oracle Database 12c Release 2 вы можете развернуть до 5 директоров сегментов в заданном регионе.
Ниже приведены ключевые возможности директоров сегментов:
Поддерживать данные времени выполнения о конфигурации SDB и доступности сегментов
Измерение задержки сети между своим и другими регионами
Действовать как региональный прослушиватель для подключения клиентов к SDB
Управление глобальными службами
Выполнить балансировку нагрузки соединения
Пулы соединений
База данных Oracle поддерживает пул соединений в драйверах доступа к данным, таких как OCI, JDBC и ODP.СЕТЬ. В Oracle 12c Release 2 эти драйверы могут распознавать ключи сегментирования, указанные как часть запроса на подключение. Точно так же универсальный пул соединений Oracle (UCP) для клиентов JDBC может распознавать ключи сегментирования, указанные в URL-адресе соединения. Oracle UCP также позволяет клиентам приложений сторонних производителей, таким как Apache Tomcat и WebSphere, работать с Oracle Sharding.
Клиенты Oracle используют информацию о маршрутизации кэша UCP для прямой маршрутизации запроса к базе данных в соответствующий сегмент на основе ключей сегментирования, предоставленных приложением.Такая маршрутизация запросов к базе данных, зависящая от данных, устраняет дополнительные сетевые переходы, уменьшая задержку транзакций для приложений OLTP большого объема.
Информация о маршрутизации кэшируется во время первоначального подключения к сегменту, которое устанавливается с помощью директора сегмента. Последующие запросы к базе данных на сегментирование ключей в кэшированном диапазоне направляются непосредственно на сегмент, минуя директора сегмента.
Как и UCP, директор сегмента может обрабатывать ключ сегментирования, указанный в строке подключения, и кэшировать информацию о маршрутизации.Однако UCP направляет запросы к базе данных, используя уже установленное соединение, в то время как директор сегмента направляет запросы на подключение к сегменту. Кэш маршрутизации автоматически обновляется, когда сегмент становится недоступным или происходят изменения в топологии сегментирования. Для высокопроизводительной маршрутизации, зависящей от данных, Oracle рекомендует использовать пул соединений при доступе к данным в SDB.
Интерфейсы управления для SDB
Вы можете развертывать, управлять и отслеживать базы данных Oracle Sharded с помощью двух интерфейсов: Oracle Enterprise Manager Cloud Control и GDSCTL.
Cloud Control позволяет управлять жизненным циклом сегментированной базы данных с помощью графического пользовательского интерфейса. Вы можете управлять SDB и отслеживать ее доступность и производительность, а также выполнять такие задачи, как добавление и развертывание сегментов, служб, директоров сегментов и других компонентов сегментирования.
GDSCTL — это интерфейс командной строки, предоставляющий простой декларативный способ указания конфигурации SDB и автоматизации ее развертывания. Для создания SDB требуется всего несколько команд GDSCTL, например:
Команда GDSCTL DEPLOY автоматически создает сегменты и соответствующие им прослушиватели.Кроме того, эта команда автоматически развертывает конфигурацию репликации, используемую для высокой доступности на уровне сегмента, указанную администратором.
Как работает шардинг. Это продолжение прошлого блога… | by Jeeyoung Kim
Это продолжение моего последнего поста почему я люблю базы данных
Ваше приложение неожиданно становится популярным. Трафик и данные начинают расти, и ваша база данных с каждым днем становится все более перегруженной.Люди в Интернете говорят вам масштабировать базу данных с помощью сегментирования, но вы на самом деле не знаете, что это значит. Вы начинаете проводить какое-то исследование и натыкаетесь на этот пост.
Добро пожаловать!
Разделение — это метод разделения и хранения одного логического набора данных в нескольких базах данных. Распределяя данные между несколькими машинами, кластер систем баз данных может хранить больший набор данных и обрабатывать дополнительные запросы. Разделение необходимо, если набор данных слишком велик для хранения в одной базе данных.Более того, многие стратегии сегментирования позволяют добавлять дополнительные машины. Разделение позволяет кластеру базы данных масштабироваться вместе с ростом его данных и трафика.
Разделение также называется горизонтальным разделением . Различие по горизонтали по сравнению с по вертикали исходит из традиционного табличного представления базы данных. База данных может быть разделена по вертикали — хранение разных таблиц и столбцов в отдельной базе данных или по горизонтали — хранение строк одной и той же таблицы в нескольких узлах базы данных.
Иллюстрированный пример вертикального и горизонтального разбиения# Пример вертикального разбиения
fetch_user_data(user_id) -> db["USER"].fetch(user_id)
fetch_photo(photo_id) -> db["PHOTO"].fetch (photo_id)
# Пример горизонтального разделения
fetch_user_data(user_id) -> user_db[user_id % 2].fetch(user_id)
Вертикальное разделение очень специфично для домена. Вы проводите логическое разделение данных вашего приложения, сохраняя их в разных базах данных.Он почти всегда реализуется на уровне приложения — фрагмент кода маршрутизации считывает и записывает в назначенную базу данных.
Напротив, при сегментировании однородные данные разбиваются на несколько баз данных. Как видите, такой алгоритм легко обобщается. Вот почему сегментирование может быть реализовано либо на уровне приложения, либо на уровне базы данных . Во многих базах данных сегментирование является первоклассной концепцией, и база данных знает, как хранить и извлекать данные в кластере.Почти все современные базы данных изначально сегментированы. Cassandra, HBase, HDFS и MongoDB — популярные распределенные базы данных. Яркими примерами современных баз данных без сегментирования являются Sqlite, Redis (в разработке), Memcached и Zookeeper.
Существуют различные стратегии распределения данных по нескольким базам данных. Каждая стратегия имеет свои плюсы и минусы в зависимости от различных предположений, которые делает стратегия. Крайне важно понимать эти предположения и ограничения. Операциям может потребоваться выполнить поиск во многих базах данных, чтобы найти запрошенные данные.Они называются операциями между разделами и обычно неэффективны. Горячие точки — еще одна распространенная проблема — неравномерное распределение данных и операций. Горячие точки в значительной степени нейтрализуют преимущества шардинга.
Sharding усложняет программирование и эксплуатацию вашего приложения. Вы теряете удобство доступа к данным приложения в одном месте. Управление несколькими серверами усложняет работу. Прежде чем начать, посмотрите, можно ли избежать сегментирования или отложить его.
Получите более дорогой аппарат . Емкость хранилища растет со скоростью закона Мура. От Amazon вы можете получить сервер с 6,4 ТБ SDD, 244 ГБ ОЗУ и 32 ядрами. Даже в 2013 году Stack Overflow работает на одном сервере MS SQL. (Некоторые могут возразить, что разделение Stack Overflow и Stack Exchange является формой сегментирования)
Если ваше приложение ограничено производительностью чтения, вы можете добавить кэши или базы данных реплики . Они обеспечивают дополнительные возможности чтения без существенного изменения вашего приложения.
Вертикальное разделение по функциональности. Двоичные BLOB-объекты, как правило, занимают много места и изолированы в приложении. Хранение файлов в S3 может снизить нагрузку на хранилище. Другие функции, такие как полнотекстовый поиск, теги и аналитика, лучше всего выполнять в отдельных базах данных.
Не все может нуждаться в сегментировании. Часто лишь несколько таблиц занимают большую часть дискового пространства. Очень мало пользы дает сегментирование небольших таблиц с сотнями строк.Сосредоточьтесь на больших столах.
Чтобы сравнить плюсы и минусы каждой стратегии сегментирования, я буду использовать следующие принципы.
Как данные считываются — Базы данных используются для хранения и извлечения данных. Если нам вообще не нужно читать данные, мы можем просто записать их в /dev/null . Если нам нужно только время от времени обрабатывать данные в пакетном режиме, мы можем добавить их в один файл и периодически сканировать их. Требования к извлечению данных (или их отсутствие) сильно влияют на стратегию сегментирования.
Как распределяются данные — Если у вас есть кластер компьютеров, работающих вместе, важно обеспечить равномерное распределение данных и работы. Неравномерная нагрузка вызывает проблемы с хранилищем и производительностью. Некоторые базы данных перераспределяют данные динамически, в то время как другие ожидают, что клиенты будут равномерно распределять данные и обращаться к ним.
После использования сегментирования перераспределение данных становится серьезной проблемой. После того, как ваша база данных будет сегментирована, вполне вероятно, что данные будут быстро расти.Добавление дополнительного узла становится обычной рутиной. Это может потребовать изменений в конфигурации и перемещения больших объемов данных между узлами. Это увеличивает как производительность, так и операционную нагрузку.
Многие базы данных имеют собственную терминологию. Следующие термины используются повсюду для описания различных алгоритмов.
Осколок или Ключ раздела — это часть первичного ключа, которая определяет способ распределения данных. Ключ раздела позволяет эффективно извлекать и изменять данные, направляя операции в нужную базу данных.Записи с одним и тем же ключом раздела хранятся в одном узле. Логический сегмент — это набор данных, использующих один и тот же ключ раздела. Узел базы данных, иногда называемый физическим сегментом , содержит несколько логических сегментов.
Один из способов классификации сегментирования — алгоритмический и динамический. При алгоритмическом сегментировании клиент может определить базу данных данного раздела без посторонней помощи. При динамическом сегментировании отдельная служба локатора отслеживает разделы среди узлов.
Алгоритмически сегментированная база данных с простой функцией сегментированияАлгоритмически сегментированные базы данных используют функцию сегментирования (partition_key) -> database_id для поиска данных. Простая функция сегментирования может быть « hash(key) % NUM_DB ».
Чтение выполняется в пределах одной базы данных, пока задан ключ раздела. Запросы без ключа раздела требуют поиска на каждом узле базы данных. Неразделенные запросы не масштабируются по отношению к размеру кластера, поэтому они не рекомендуются.
Алгоритмическое сегментирование распределяет данные только по своей функции сегментирования. Он не учитывает размер полезной нагрузки или использование пространства. Для равномерного распределения данных каждый раздел должен иметь одинаковый размер. Мелкозернистые разделы уменьшают количество горячих точек — одна база данных будет содержать много разделов, и сумма данных между базами данных, вероятно, будет статистически одинаковой. По этой причине алгоритмическое сегментирование подходит для баз данных типа «ключ-значение» с однородными значениями.
Повторное разделение данных может быть сложной задачей.Это требует обновления функции шардинга и перемещения данных по кластеру. Делать и то, и другое одновременно, сохраняя согласованность и доступность, сложно. Умный выбор функции сегментирования может уменьшить объем передаваемых данных. Последовательное хеширование является таким алгоритмом.
Примеры таких систем включают Memcached. Memcached не сегментируется сам по себе, но ожидает, что клиентские библиотеки будут распространять данные внутри кластера. Такую логику довольно легко реализовать на уровне приложения.
Схема динамического сегментирования, использующая секционирование на основе диапазонов.При динамическом сегментировании внешняя служба локатора определяет расположение записей. Он может быть реализован несколькими способами. Если количество ключей разделов относительно невелико, локатор может быть назначен отдельному ключу. В противном случае один локатор может адресовать диапазон ключей разделов.
Для чтения и записи данных клиентам необходимо сначала обратиться к службе локатора. Работа с первичным ключом становится довольно тривиальной.Другие запросы также становятся эффективными в зависимости от структуры локаторов. В примере с ключами секции на основе диапазона запросы диапазона эффективны, поскольку служба локатора уменьшает количество баз данных-кандидатов. Запросы без ключа раздела потребуют поиска во всех базах данных.
Динамическое сегментирование более устойчиво к неравномерному распределению данных. Локаторы можно создавать, разделять и переназначать для перераспределения данных. Однако перемещение данных и обновление локаторов необходимо выполнять одновременно.У этого процесса есть много краеугольных случаев с множеством интересных теоретических, операционных и реализационных задач.
Служба локатора становится единой точкой разногласий и сбоев. Каждой операции с базой данных необходим доступ к ней, поэтому производительность и доступность являются обязательными. Однако локаторы нельзя кэшировать или просто реплицировать. Устаревшие локаторы будут направлять операции в неправильные базы данных. Неправильно направленные записи особенно опасны — они становятся недоступными для обнаружения после решения проблемы с маршрутизацией.
Так как влияние неправильно маршрутизируемого трафика настолько разрушительно, многие системы выбирают решение с высокой согласованностью. Для хранения этих данных используются алгоритмы консенсуса и синхронные репликации. К счастью, данные локатора, как правило, невелики, поэтому вычислительные затраты, связанные с таким тяжеловесным решением, обычно невелики.
Благодаря своей надежности динамическое сегментирование используется во многих популярных базах данных. HDFS использует узел имен для хранения метаданных файловой системы. К сожалению, узел имени является единственной точкой отказа в HDFS. Apache HBase разбивает ключи строк на диапазоны. Сервер диапазона отвечает за хранение нескольких регионов. Информация о регионе хранится в Zookeeper для обеспечения согласованности и избыточности. В MongoDB ConfigServer хранит информацию о сегментировании, а mongos выполняет маршрутизацию запросов. ConfigServer использует синхронную репликацию для обеспечения согласованности. Когда сервер конфигурации теряет избыточность, он переходит в режим только для чтения в целях безопасности. Обычные операции базы данных не затрагиваются, но сегменты нельзя создавать или перемещать.
Entity Groups разделяет все связанные таблицы вместеПредыдущие примеры ориентированы на операции ключ-значение. Однако многие базы данных имеют более выразительные возможности запросов и манипуляций. Традиционные функции РСУБД, такие как соединения, индексы и транзакции, упрощают приложение.
Концепция групп сущностей очень проста. Храните связанные объекты в одном разделе, чтобы обеспечить дополнительные возможности в одном разделе. В частности:
- Запросы в пределах одного физического сегмента эффективны.
- Внутри сегмента может быть достигнута более строгая семантика согласованности.
Это популярный подход к сегментированию реляционной базы данных. В типичном веб-приложении данные естественно изолированы для каждого пользователя. Разделение по пользователям обеспечивает масштабируемость сегментирования, сохраняя при этом большую часть его гибкости. Обычно он начинается как простое решение для конкретной компании, в котором операции по перераспределению выполняются разработчиками вручную. Зрелые решения, такие как Vitess от Youtube и Jetpants от Tumblr, могут автоматизировать большинство оперативных задач.
Запросы, охватывающие несколько разделов, обычно имеют более слабые гарантии согласованности, чем запросы из одного раздела. Они также имеют тенденцию быть неэффективными, поэтому такие запросы следует выполнять с осторожностью.
Однако конкретный запрос между разделами может потребоваться часто и эффективно. В этом случае данные должны храниться в нескольких разделах для поддержки эффективного чтения. Например, сообщения чата между двумя пользователями могут храниться дважды — с разбивкой по отправителям и получателям.Все сообщения, отправленные или полученные данным пользователем, хранятся в одном разделе. В общем случае может потребоваться дублирование отношений «многие ко многим» между разделами.
Группы сущностей могут быть реализованы либо алгоритмически, либо динамически. Обычно они реализуются динамически, поскольку общий размер группы может сильно различаться. Здесь применяются те же предостережения относительно обновления локаторов и перемещения данных. Вместо отдельных таблиц необходимо перемещать всю группу сущностей вместе.
Примером такой системы является Google Megastore .Megastore публично доступен через API хранилища данных Google App Engine.
Базы данных, ориентированные на столбцы, разбивают данные по ключам строк.Базы данных, ориентированные на столбцы, являются расширением хранилищ ключей и значений. Они добавляют выразительности группам сущностей с иерархическим первичным ключом . Первичный ключ состоит из пары (ключ строки, ключ столбца) . Записи с одним и тем же ключом раздела хранятся вместе. Запросы диапазона для столбцов, ограниченных одной секцией, эффективны. Вот почему в DynamoDB ключ столбца называется ключом диапазона .
Эта модель популярна с середины 2000-х годов. Ограничение, налагаемое иерархическими ключами, позволяет базам данных реализовывать механизмы сегментирования, не зависящие от данных, и эффективные механизмы хранения. Между тем, иерархические ключи достаточно выразительны, чтобы представлять сложные отношения. Базы данных, ориентированные на столбцы, могут эффективно моделировать такие проблемы, как временные ряды.
Базы данных, ориентированные на столбцы, можно сегментировать либо алгоритмически, либо динамически. С небольшими и многочисленными небольшими разделами они имеют ограничения, аналогичные хранилищам ключ-значение.В противном случае больше подойдет динамический шардинг.
Термин база данных столбцов теряет популярность. И HBase, и Cassandra когда-то позиционировали себя как столбцовые базы данных, но теперь это не так. Если бы мне сегодня нужно было классифицировать эти системы, я бы назвал их иерархическими хранилищами «ключ-значение», поскольку это их самая отличительная черта.
Первоначально опубликованный в 2005 году, Google BigTable популяризировал базы данных, ориентированные на столбцы, среди общественности. Apache HBase — это подобная BigTable база данных, реализованная поверх экосистемы Hadoop.Apache Cassandra ранее описывала себя как базу данных столбцов — записи хранились в семействах столбцов с ключами строк и столбцов. CQL3, последний API для Cassandra, представляет плоскую модель данных — (ключ раздела, ключ столбца) — это просто составной первичный ключ. Dynamo от Amazon популяризировал высокодоступные базы данных. Amazon DynamoDB — это предложение Dynamo по принципу «платформа как услуга». DynamoDB использует (хеш-ключ, ключ диапазона) в качестве первичного ключа.
Многие предостережения обсуждались выше.Однако есть и другие распространенные проблемы, на которые следует обратить внимание при использовании многих стратегий.
Логический сегмент (данные, использующие один и тот же ключ раздела) должен помещаться на одном узле. Это наиболее важное допущение, и его труднее всего изменить в будущем . Логический сегмент — это атомарная единица хранения, которая не может охватывать несколько узлов. В такой ситуации кластеру базы данных фактически не хватает места. Наличие более мелких разделов смягчает эту проблему, но усложняет как базу данных, так и приложение.Кластер должен управлять дополнительными разделами, и приложение может выполнять дополнительные операции между разделами.
Многие веб-приложения разбивают данные по пользователям. Со временем это может стать проблемой, так как приложение аккумулирует опытных пользователей с большим объемом данных. Например, служба электронной почты может иметь пользователей с терабайтами электронной почты. Для этого данные одного пользователя разбиваются на разделы. Эта миграция обычно очень сложна, поскольку она делает недействительными многие основные предположения о базовой модели данных.
Иллюстрация точки доступа в конце диапазона разделов даже после многочисленных разделений осколков.Несмотря на то, что динамическое сегментирование более устойчиво к несбалансированным данным, непредвиденная рабочая нагрузка может снизить его эффективность. В схеме секционирования по диапазонам вставка данных в порядке ключа секции создает горячие точки. Только последний диапазон получит вставки. Этот диапазон разделов будет разделяться по мере того, как он становится большим. Однако из разделенных диапазонов только последний диапазон получит дополнительные записи.Пропускная способность записи кластера эффективно сводится к одному узлу. MongoDB, HBase и Google Datastore не одобряют этого.
В случае динамического шардинга плохо иметь большое количество локаторов. Поскольку к локаторам обращаются часто, они обычно обслуживаются непосредственно из ОЗУ. Узлу имени HDFS требуется не менее 150 байт памяти на файл для его метаданных, поэтому хранение большого количества файлов является непомерно высоким. Многие базы данных выделяют фиксированный объем ресурсов для каждого диапазона разделов.HBase рекомендует около 20–200 регионов на сервер.
Существует множество тем, тесно связанных с шардингом, которые здесь не рассматриваются. Репликация является важнейшей концепцией в распределенных базах данных для обеспечения надежности и доступности. Репликация может выполняться независимо от сегментирования или тесно связана со стратегиями сегментирования.
Детали перераспределения данных важны. Как упоминалось ранее, обеспечение синхронизации данных и локаторов во время перемещения данных является сложной проблемой.Многие методы делают компромисс между согласованностью, доступностью и производительностью. Например, разделение регионов HBase — это сложный многоэтапный процесс. Что еще хуже, требуется короткое время простоя во время разделения региона.
Все это не волшебство. Все становится логично, если учесть, как данные хранятся и извлекаются. Запросы между разделами неэффективны, и многие схемы сегментирования пытаются минимизировать количество операций между разделами. С другой стороны, разделы должны быть достаточно гранулированными, чтобы равномерно распределять нагрузку между узлами.Найти правильный баланс может быть сложно. Конечно, лучшее решение в программной инженерии — вообще избежать проблемы. Как уже говорилось ранее, есть много успешных веб-сайтов, работающих без сегментирования. Посмотрите, сможете ли вы отсрочить или вообще избежать проблемы.
Удачной базы данных!
Простой обзор В 2021 году
Понимание гравитации облаков в 5 простых пунктах
Что такое облачная гравитация в данных?Что делать с облачной гравитацией в данных?Важность облачной гравитации в предприятияхПроблемы с облачной гравитацией в данныхКак справиться с облачной гравитацией в данных 1.Что такое облачная гравитация в данных? Представьте ситуацию, когда вы работаете с приложением, работающим с большими объемами данных, и вам необходимо передать это приложение одному из ваших коллег для дальнейшего улучшения. Это перемещение данных к тому, которое вы хотите, может стать громоздким и дорогим. Этот эффект называется Data Gravity. Гравитация данных — это в основном метафора, используемая для обозначения утомления или трудностей, с которыми приходится сталкиваться в ситуации. Термин Data Gravity был придуман или дан Дэйвом МакКрори.Гравитация облака в данных также может быть выведена из термина гравитация, когда данные становятся тяжелее, и из-за гравитации становится трудно перемещать данные из источника в пункт назначения. Обычно для решения этого вопроса используются облачные сервисы хранения, такие как Dropbox или Google Drive. 2. Как использовать Cloud Gravity в данных? Первым шагом является создание архитектуры на основе масштабируемой платформы NAS, которая обеспечивает интеграцию/консолидацию данных. Платформа должна поддерживать широкий спектр традиционных и новейших рабочих нагрузок и приложений, которые ранее использовались для различных типов хранилищ.С помощью этой платформы можно управлять данными в одном месте и использовать все приложения и вычислительную мощность для данных. 3. Важность облачной гравитации для предприятий Чтобы убедиться, что информация, которую предоставляет организация, является точной, актуальной и актуальной, организация должна эффективно управлять данными. Если не следовать политикам, правилам и процедурам взаимодействия, огромное количество наборов данных в хранилище данных или другом наборе данных может стать неуправляемым.в худшем случае это может оказаться бесполезным. Владельцы приложений могут вернуться к использованию данных, которыми они владеют, для принятия решений, что приведет к бесполезным решениям, принятым для одного или нескольких приложений. Интеграция данных в большей степени страдает из-за гравитации облака в данных, особенно когда мы пытаемся унифицировать системы и уменьшить потери ресурсов из-за ошибок. 4. Проблемы с облачной гравитацией в данных 1) Задержка. Задержка, как следует из названия, это время, необходимое для перемещения данных от источника к месту назначения.Естественно, что большой набор данных потребует, чтобы его приложение было близким. т. е. на своей орбите, но если это не так, существует более высокая вероятность того, что пользователю придется столкнуться с проблемами задержки. Скорость имеет решающее значение для успешных бизнес-операций, и увеличение задержки из-за увеличения гравитации данных просто недопустимо. Предприятие должно убедиться, что и объем производства, и рабочая нагрузка уравновешиваются объемом данных. Это означает перемещение приложений в одну и ту же область, чтобы свести к минимуму задержку и повысить производительность труда.2) Недостаток переносимости. Из вышеизложенного совершенно очевидно, что гравитация данных увеличивает размер наборов данных. И чем больше набор данных, тем сложнее перемещать данные из источника в пункт назначения. Для организаций это довольно утомительная работа по переносу своих наборов данных, поскольку наборы данных организации постоянно растут и с течением времени становятся все тяжелее. Следовательно, Data Gravity влияет на бизнес в целом. 5. Как работать с данными Cloud Gravity In Гравитация данных — это вполне логичная реальность.Лучший способ справиться с гравитацией данных — это правильное управление данными, управление и интеграция. Управление данными — мы знаем о важности управления в организации. Таким образом, это слишком важно при работе с большим количеством данных. Управление данными обычно включает в себя принятие решений о том, следует ли хранить данные в облачных службах хранения данных или использовать локальное приложение для ведения учета всех данных организации. Управление данными. Управление данными является ключевым элементом управления данными.Как следует из названия, управление данными играет роль ответственности и подотчетности в отношении данных. Это функция, которая отвечает за преодоление проблем, возникающих из-за Data Gravity и других подобных проблем. Интеграция данных. Интеграция данных, как следует из названия, консолидирует все данные в одном месте и повышает производительность приложений и систем. Вывод После изучения вышеупомянутой информации становится совершенно очевидным, как Data Gravity влияет на хранение данных в компаниях.По мере того, как мы продвигаемся вперед с постоянно развивающимися технологиями, мы также сталкиваемся с новыми проблемами. Но поскольку мы люди, мы пытаемся найти решения практически для каждой проблемы, с которой сталкиваемся. Если говорить об основной идее Data Gravity, то основной недостаток, с которым сталкивается пользователь при использовании Data Gravity, заключается в необходимости меньшей близости источника и пункта назначения. Чем больше будет расстояние или вес, тем больше будет время, необходимое для выполнения указанной работы. Программа сертификации аспирантов Jigsaw Academy по облачным вычислениям приближает тех, кто стремится к облачным технологиям, к работе своей мечты.Курс совместной сертификации длится 6 месяцев, проводится онлайн и поможет вам стать полноценным профессионалом в области облачных вычислений. ТАКЖЕ ЧИТАЙТЕ Горизонтальное и вертикальное масштабирование: упрощение различий (2021 г.) Привязка к поставщику? Руководство для начинающих в 4 основных пунктах
.