Руководство Batch для начинающих
1- Что такое язык batch?
Batch является языком программирования, используется для создания файлов сценарий которые можно выполнять на операционной системе Windows, обычно эти файлы имею окончание *.bat или *.cmd. При выполнении они открывают окно «Command Prompt», обычно это окно имеет черный фон, белый шрифт.
Файлы batch (*.bat, *.cmd) называются файлами сценарий (script file), они могут содержать команды вмешивающиеся в операционную систему.
Заметьте еще один язык похожий на batch, но использующийся для операционной системы Linux это Shell, с файлами сценарий с окончанием *.sh.
Смотрите так же:
2- Пример начала с Batch
Batch использует @rem чтобы начать строку комментария (Comment), строка комментария используется для записи цели строк команд в программе,и они пропускаются когда выполняется команда.
Чтобы начать с языком Batch, мы создаем файл с названием hello.bat, и пишем команды печатающие на экране строку «Three», «Two», «One», «Hello World!».
hello.bat
@rem My First Batch file!
@echo off
echo Three
echo Two
echo One
echo Hello World!
pause
Двойное нажатие мыши на hello.bat чтобы выполнить (execute) данный файл.
Вы тоже можете выполнить файл Batch из CMD. Открыть программу CMD и CD к папке, содержащей файл необходимый для выполнения.
Выполнить файл hello.bat из CMD:
| Команда | Описание |
| echo | Распечатать строку на экране |
| pause | Приостановить программу, и ждать когда пользователь нажмет на Enter для продолжения. |
@echo on/off
Команда @echo off используется для отключения режима отображения command prompt (напоминание). Данный режим включен (on) по умолчанию. Посмотрим разницу между @echo off и @echo on по изображению ниже:
Вопросы и ответы по AWS Batch
Вопрос. Можно ли использовать бизнес-акселераторы для AWS Batch?
Да, можно использовать Batch, чтобы указать количество и тип необходимых для выполнения ваших заданий бизнес-акселераторов, а также варианты виртуального ЦП и памяти. Все это можно сделать в графе определения задания, изменив входные переменные. AWS Batch масштабирует подходящие для ваших заданий инстансы с учетом необходимых бизнес-акселераторов. Затем они изолируются в соответствии с требованиями для каждого задания, так чтобы только соответствующие контейнеры могли получить к ним доступ.
Вопрос. Для чего необходимо использовать бизнес-акселераторы с AWS Batch?
Используя бизнес-акселераторы с AWS Batch, вы можете в динамическом режиме планировать и распределять задания с учетом всех требований. Batch гарантирует, что для каждого задания будет зарезервировано соответствующее количество бизнес-акселераторов. Batch позволяет при необходимости масштабировать инстансы в сторону увеличения для ускоренной работы EC2, а также масштабировать их в сторону уменьшения после завершения работы, чтобы вы могли спокойно сосредоточиться на своих приложениях. Batch имеет встроенную интеграцию со спотовыми инстансами EC2, что означает, что ускоренное выполнение заданий может обеспечить до 90 % экономии при использовании ускоренных инстансов.
Batch гарантирует, что для каждого задания будет зарезервировано соответствующее количество бизнес-акселераторов. Batch позволяет при необходимости масштабировать инстансы в сторону увеличения для ускоренной работы EC2, а также масштабировать их в сторону уменьшения после завершения работы, чтобы вы могли спокойно сосредоточиться на своих приложениях. Batch имеет встроенную интеграцию со спотовыми инстансами EC2, что означает, что ускоренное выполнение заданий может обеспечить до 90 % экономии при использовании ускоренных инстансов.
Вопрос. Какие бизнес-акселераторы можно использовать с AWS Batch?
В настоящее время можно использовать бизнес-акселераторы графического процессора на ускоренных инстансах серий P и G.
Количество и тип бизнес-акселераторов можно указать в графе определения задания. Вы должны уточнить тип бизнес-акселератора (например, графический процессор – единственный на данный момент поддерживаемый акселератор), а также какое количество акселераторов необходимо для выполнения вашего задания. Выбранный тип бизнес-акселератора должен быть среди типов инстансов, указанных в вычислительных средах. Например, если ваша работа требует 2 графических процессора, то необходимо также указать инстанс семейства P в своей вычислительной среде.
Вы должны уточнить тип бизнес-акселератора (например, графический процессор – единственный на данный момент поддерживаемый акселератор), а также какое количество акселераторов необходимо для выполнения вашего задания. Выбранный тип бизнес-акселератора должен быть среди типов инстансов, указанных в вычислительных средах. Например, если ваша работа требует 2 графических процессора, то необходимо также указать инстанс семейства P в своей вычислительной среде.
Пример из API:
{
«свойства_контейнеров»: {
«виртуальные ЦПУ»: 1,
«изображение»: «nvidia/cuda: версия 9.0»,
«память»: 2048,
«ресурсные_требования»: [
{
«тип»: «графический процессор»,
«значение» : «1»
}
],
Вопрос. Можно ли изменить переменные бизнес-акселератора в определении задания при отправке задания?
При отправке задания вы можете изменить количество и тип бизнес-акселераторов. Вы также можете изменить виртуальные ЦПУ и требования к памяти.
Вопрос. Можно ли использовать ускоренные инстансы для заданий, не требующих акселераторов?
В нынешних условиях Batch по возможности не будет планировать задания, которые не требуют ускорения с помощью ускоренных инстансов. Это делается для того, чтобы избежать случаев, когда долгосрочные задания занимают ускоренные инстансы без использования бизнес-акселератора, что приводит к увеличению расходов. В редких случаях при спотовой цене и наличии ускоренных инстансов необходимого типа Batch может решить, что для выполнения ваших заданий наименее затратным будет применение ускоренного инстанса. При этом неважно, будет использоваться бизнес-акселератор или нет.
Если вы отправите задание в CE, для которого только Batch может запускать ускоренные инстансы, то он будет выполнять задания на указанных инстансах, независимо от необходимости использования бизнес-акселератора.
Вопрос. Как Batch использует ECS AMI, оптимизированный под графические процессоры?
С этого момента инстансы типа P будут запускаться по умолчанию вместе с ECS AMI, оптимизированным под графические процессоры. AMI содержит библиотеки и среды выполнения, необходимые для запуска приложений на базе графических процессоров. При создании CE вы всегда при необходимости сможете указать пользовательский AMI.
AMI содержит библиотеки и среды выполнения, необходимые для запуска приложений на базе графических процессоров. При создании CE вы всегда при необходимости сможете указать пользовательский AMI.
Что такое батч код парфюма и как его проверить
Скопируйте код для вставки в блог
14.04.2021 г.
Далеко не вся информация о продукте доступна на упаковке. Некоторые производители указывают таковую скрыто, в формате батч кода. В большей степени это относится к парфюмерии. Батч код представляет собой некоторую комбинацию цифр, которую наносят прямо на флакон или указывают на специальном стикере. Шифр содержит информацию о дате изготовления продукта и сроке годности такового.
Результат вставки
14.04.2021 г.
Batch Normalization (батч-нормализация) что это такое?
Вам что-нибудь говорит термин
internal covariance shift
Звучит очень
умно, не так ли? И не удивительно. Это понятие в 2015-м году ввели два
сотрудника корпорации Google:
Это понятие в 2015-м году ввели два
сотрудника корпорации Google:
Sergey Ioffe и Christian Szegedy (Иоффе и Сегеди)
решая проблему ускорения процесса обучения НС. И мы сейчас посмотрим, что же они предложили, как это работает и, наконец, что же это за ковариационный сдвиг. Как раз с последнего я и начну.
Давайте предположим, что мы обучаем НС распознавать машины (неважно какие, главное чтобы сеть на выходе выдавала признак: машина или не машина). Но, при обучении мы используем автомобили только черного цвета. После этого, сеть переходит в режим эксплуатации и ей предъявляются машины уже разных цветов:
Как вы понимаете, это не лучшим образом скажется на качестве ее работы. Так вот, на языке математики этот эффект можно выразить так. Начальное распределение цветов (пусть это будут градации серого) обучающей выборки можно описать с помощью вот такой плотности распределения вероятностей (зеленый график):
А распределение
всего множества цветов машин, встречающихся в тестовой выборке в виде синего
графика. Как видите эти графики имеют различные МО и дисперсии. Эта разница
статистических характеристик и приводит к ковариационному сдвигу. И
теперь мы понимаем: если такой сдвиг имеет место быть, то это негативно
сказывается на работе НС.
Как видите эти графики имеют различные МО и дисперсии. Эта разница
статистических характеристик и приводит к ковариационному сдвигу. И
теперь мы понимаем: если такой сдвиг имеет место быть, то это негативно
сказывается на работе НС.
Но это пример внешнего ковариационного сдвига. Его легко исправить, поместив в обучающую выборку нужное количество машин с разными цветами. Есть еще внутренний ковариационный сдвиг – это когда статистическая картина меняется внутри сети от слоя к слою:
Само по себе
такое изменение статистик не несет каких-либо проблем. Проблемы проявляются в
процессе обучения, когда при изменении весов связей предыдущего слоя
статистическое распределение выходных значений нейронов текущего слоя
становится заметно другим. И этот измененный сигнал идет на вход следующего
слоя. Это похоже на то, словно на вход скрытого слоя поступают то машины
черного цвета, то машины красного цвета или какого другого. То есть, весовые
коэффициенты в пределах мини-батча только адаптировались к черным автомобилям,
как в следующем мини-батче им приходится адаптироваться к другому распределению
– красным машинам и так постоянно. В ряде случаев это может существенно снижать
скорость обучения и, кроме того, для адаптации в таких условиях приходится
устанавливать малое значение шага сходимости, чтобы весовые коэффициенты имели
возможность подстраиваться под разные статистические распределения.
То есть, весовые
коэффициенты в пределах мини-батча только адаптировались к черным автомобилям,
как в следующем мини-батче им приходится адаптироваться к другому распределению
– красным машинам и так постоянно. В ряде случаев это может существенно снижать
скорость обучения и, кроме того, для адаптации в таких условиях приходится
устанавливать малое значение шага сходимости, чтобы весовые коэффициенты имели
возможность подстраиваться под разные статистические распределения.
Это описание проблемы, которую, как раз, и выявили сотрудники Гугла, изучая особенности обучения многослойных НС. Решение кажется здесь очевидным: если проблема в изменении статистических характеристик распределения на выходах нейронов, то давайте их стандартизировать, нормализовывать – приводить к единому виду. Именно это и делается при помощи предложенного алгоритма
Batch Normalization
Осталось
выяснить: какие характеристики и как следует нормировать. Из теории
вероятностей мы знаем, что самые значимые из них – первые две: МО и дисперсия.
Так вот, в алгоритме batch normalization их приводят к
значениям 0 и 1, то есть, формируют распределение с нулевым МО и единичной
дисперсией. Чуть позже я подробнее поясню как это делается, а пока ответим на
второй вопрос: для каких величин и в какой момент производится эта нормировка? Разработчики
этого метода рекомендовали располагать нормировку для величин перед
функцией активации:
Из теории
вероятностей мы знаем, что самые значимые из них – первые две: МО и дисперсия.
Так вот, в алгоритме batch normalization их приводят к
значениям 0 и 1, то есть, формируют распределение с нулевым МО и единичной
дисперсией. Чуть позже я подробнее поясню как это делается, а пока ответим на
второй вопрос: для каких величин и в какой момент производится эта нормировка? Разработчики
этого метода рекомендовали располагать нормировку для величин перед
функцией активации:
Но сейчас уже имеются результаты исследований, которые показывают, что этот блок может давать хорошие результаты и после функции активации.
Что же из себя представляет batch normalization и где тут статистики? Давайте вспомним, что НС обучается пакетами наблюдений – батчами. И для каждого наблюдения из batch на входе каждого нейрона получается свое значение суммы:
Здесь m – это размер
пакета, число наблюдений в батче. Так вот статистики вычисляются для величин V в пределах
одного batch:
Так вот статистики вычисляются для величин V в пределах
одного batch:
И, далее, чтобы вектор V имел нулевое среднее и единичную дисперсию, каждое значение преобразовывают по очевидной формуле:
здесь - небольшое положительное число, исключающее деление на ноль, если дисперсия будет близка к нулевым значениям. В итоге, вектор
будет иметь нулевое МО и почти единичную дисперсию. Но этого недостаточно. Если оставить как есть, то будут теряться естественные статистические характеристики наблюдений между батчами: небольшие изменения в средних значениях и дисперсиях, т.е. будет уменьшена репрезентативность выборки:
Кроме того, сигмоидальная функция активации вблизи нуля имеет практически линейную зависимость, а значит, простая нормировка значений x лишит НС ее нелинейного характера, что приведет к ухудшению ее работы:
Поэтому нормированные величины дополнительно масштабируются и смещаются в соответствии с формулой:
Параметры с
начальными значениями 1 и 0 также подбираются в процессе обучения НС с помощью
того же алгоритма градиентного спуска. То есть, у сети появляются
дополнительные настраиваемые переменные, помимо весовых коэффициентов.
То есть, у сети появляются
дополнительные настраиваемые переменные, помимо весовых коэффициентов.
Далее, величина подается на вход функции активации и формируется выходное значение нейрона. Вот так работает алгоритм batch normalization, который дает следующие возможные эффекты:
- ускорение сходимости к модели обучающей выборки;
- бОльшая независимость обучения каждого слоя нейронов;
- возможность увеличения шага обучения;
- в некоторой степени предотвращает эффект переобучения;
- меньшая чувствительность к начальной инициализации весовых коэффициентов.
Но это лишь возможные эффекты – они могут и не проявиться или даже, наоборот, применение этого алгоритма ухудшит обучаемость НС. Рекомендация здесь такая:
Изначально
строить нейронные сети без batch normalization (или dropout) и если
наблюдается медленное обучение или эффект переобучения, то можно попробовать
добавить batch normalization или dropout, но не оба
вместе.
Реализация batch normalization в Keras
Давайте теперь посмотрим как можно реализовать данный алгоритм в пакете Keras. Для этого существует класс специального слоя, который так и называется:
keras.layers.BatchNormalization
Он применяется к выходам предыдущего слоя, после которого указан в модели НС, например:
model = keras.Sequential([ Flatten(input_shape=(28, 28, 1)), Dense(300, activation='relu'), BatchNormalization(), Dense(10, activation='softmax') ])
Здесь нормализация применяется к выходам скрытого слоя, состоящего из 300 нейронов. Правда в такой простой НС нормализация, скорее, негативно сказывается на обучении. Этот метод обычно помогает при большом числе слоев, то есть, при deep learning.
Batch Normalization. Основы.
Batch Normalization — одна из тех методик (или даже Tips&Tricks), которая существенно упростила тренировку, а следовательно и использование
нейронных сетей в различных задачах. Понятно, что взлет ракетой нейронных сетей, за последние 5+ лет, обязан в основном серьёзному увеличению
возможностей железок. Но удалось бы добиться такого рапространия нейронных сетей, и особенно глубоких нейронных сетей без batch normalization?
Понятно, что взлет ракетой нейронных сетей, за последние 5+ лет, обязан в основном серьёзному увеличению
возможностей железок. Но удалось бы добиться такого рапространия нейронных сетей, и особенно глубоких нейронных сетей без batch normalization?
Главные наблюдаемые достоинства batch normalization это ускорение тренировки (в смысле уменьшения количества итераций для получения нужного качества) и некая допускаемая вольность в подборе параметров: и инициализации весов сети, и learning rate и других метапараметров обучения. Таким образом ценность batch Normalization для нейронных сетей сложно преувеличить, а значит есть смысл разобраться: что это такое и откуда проистекает польза при применении.
И вот тут начинается самое интересное. Ответ на первый вопрос “что это такое?” в целом не вызывает особой сложности (если подойти к делу формально
и определить какие же преобразования добавляются в сетку), а вот про “откуда проистекает польза?” идут жаркие споры. Объяснение, авторов методики
подвергается серьёзной критике.
Мне понравилось как это сформулировано в [3]:
“The practical success of BatchNorm is indisputable. By now, it is used by default in most deep learning models, both in research (more than 6,000 citations) and real-world settings. Somewhat shockingly, however, despite its prominence, we still have a poor understanding of what the effectiveness of BatchNorm is stemming from. In fact, there are now a number of works that provide alternatives to BatchNorm, but none of them seem to bring us any closer to understanding this issue.”
Правда, стоит отметить, что у нас всё глубокое обучение и нейронные сети во многом можно описать теми же словами. Оно вроде работает и мы даже, в принципе, понимаем какие рычаги жать, чтобы ехало в примерно нужном направлении, но многие моменты так до конца и не объясняются.
Заканчивая лирику переходим к конкретике. Начнем разбираться с самого начала, а именно классической статьи [1] где методика BN и была впервые
описана.
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Авторы уже в заголовке статьи [1] анонсируют, что ускорение тренировки связано с тем, что применение BN позволяет уменьшить internal covariate shift. Следовательно, есть смысл разобраться, что такое covariate shift (отложив пока в сторону, что значит internal), а для этого надо обратиться к статье [2] на которую ссылаются авторы [1].
Covariate shift
Допустим у нас есть наблюдаемая величина $x$, и есть, зависящая от $x$, величина $y$. Мы хотим выяснить эту зависимость и научиться по $x$ находить $y$. Зависимость у нас вероятностная, т.е. есть некая условная вероятность, которая определяется при помощи плотности $q(y|x)$. А мы собственно и хотим восстановить эту плотность в виде функции $p(y|x, \theta)$, где $\theta$ это параметры, которые следует подобрать.
Чтобы решить задачу нам выдано некоторое количество пар $\{(x_n, y_n) | n=1,…,N\}$ в качестве тренировочного набора. Чтобы сформировать этот
набор $x_n$ выбирались случайным образом из распределения с плотностью вероятности $q_0(x)$, а $y_n$ из распределения с плотностью вероятности
$q(y | x_n)$. Каким-то образом “натренировав” наши параметры $\theta$ по этому тренировочному набору (не важно каким образом, например, использовав
метод максимального правдоподобия). Мы решаем проверить, что же у нас получилось, а для этого нам выдают второй (проверочный) набор пар
$\{(x’_m, y’_m) | m = 1,…,M\}$, который формируется аналогично первому, вот только $x’_m$ выбираются из распределения с плотностью $q_1(x)$.
Ситуацию, когда $q_0(x) \neq q_1(x)$ в работе [2] называют covariate shift в распределении. При определенных обстоятельствах, такого рода изменение
может дать существенную ошибку на проверочных данных у модели, которая вообще говоря очень хорошо работала на тренировочных.
Чтобы сформировать этот
набор $x_n$ выбирались случайным образом из распределения с плотностью вероятности $q_0(x)$, а $y_n$ из распределения с плотностью вероятности
$q(y | x_n)$. Каким-то образом “натренировав” наши параметры $\theta$ по этому тренировочному набору (не важно каким образом, например, использовав
метод максимального правдоподобия). Мы решаем проверить, что же у нас получилось, а для этого нам выдают второй (проверочный) набор пар
$\{(x’_m, y’_m) | m = 1,…,M\}$, который формируется аналогично первому, вот только $x’_m$ выбираются из распределения с плотностью $q_1(x)$.
Ситуацию, когда $q_0(x) \neq q_1(x)$ в работе [2] называют covariate shift в распределении. При определенных обстоятельствах, такого рода изменение
может дать существенную ошибку на проверочных данных у модели, которая вообще говоря очень хорошо работала на тренировочных.
Рассмотрим следующий пример (который взят из той же [2]).
Пример
Пусть $x \in \mathbb{R}$ и $y \in \mathbb{R}$, при этом зависимость $y$ от $x$ задаётся формулой:
\[y = -x + x^3 + \epsilon\]$\epsilon$ — случайная величина, нормально распределенная с математическим ожиданием $\mu_{\epsilon} = 0$ и среднеквадратичным отклонением
$\sigma_{\epsilon} = 0. 2 \to min\]
2 \to min\]
учитывая изменение распределения переменной $x$. Если воспользоваться этой методикой, то в качестве модели, обученной на тренировочных данных, получим фиолетовую линию на графике:
видно, что она практически совпадает с желтой, а значит мы действительно побороли covariate shift и улучшили предсказательную силу модели на проверочном наборе.
Batch Normalization. Определение.
Разобравшись с тем, что означает covariate shift, возвращаемся к статье [1]. В которой вводится понятие Internal Covariate Shift (ICS) — изменение
распределения входных данных слоя нейронной сети в результате изменения параметров модели в процессе тренировки. Т.е. каждый слой нейронной сети
представляет собой некую функцию, переводящую один случайный вектор в другой, на вход случайный вектор приходит из предыдущего слоя нейронной сети,
соответственно, в процессе тренировки веса предыдущего слоя меняются — значит может поменяться и распределение векторов, которые предыдущий слой
выдаёт. Идея BN в том, чтобы погасить этот самый ICS и за счет этого ускорить тренировку.
Идея BN в том, чтобы погасить этот самый ICS и за счет этого ускорить тренировку.
Мы сейчас не будем углубляться в то, насколько действительно ICS оказывает влияние на скорость тренировки, и борется ли BN с ICS. Позже мы разберем статьи, которые к идеи с ICS относятся с большим скептицизмом и объясняют успех BN совсем другим. Но то, что BN отлично работает подтверждается на практике, поэтому переходим к его описанию
Если теоретическое обоснование BN выглядит “притянутым за уши” (во всяком случае в статье нет каких-то внятных экспериментов, которые бы указывали на то, что до добавления BN сеть страдала от ICS и вот вам статистика, а после перестала, и вот вам другая статистика), то какие практические соображения лежат в основе метода, авторы описывают весьма четко и понятно.
Начинается все c известного метода преобразования случайных векторов, который называется whitening (после применения преобразования данные
становятся похожи на “белый шум”) и формально определяется так: whitening — это такое линейное преобразование, которое переводит случайный вектор
$X$ в случайный вектор $Y$ (той же размерности), таким образом, чтобы у получившегося вектора $Y$ все компоненты имели нулевое математическое
ожидание, были некоррелированы и их дисперсии равнялись единице (иначе говоря у вектора $Y$ была бы единичная ковариационная матрица). 2$ из многомерного (двумерного) нормального распределения, со средним $\mu = ( 1, 0.5 )$ и
ковариационной матрицей:
2$ из многомерного (двумерного) нормального распределения, со средним $\mu = ( 1, 0.5 )$ и
ковариационной матрицей:
Сегенерируем некоторое количество векторов, подчиняющихся этому распределению и отрисуем их на плоскости:
Теперь найдем собственные числа и собственные вектора для матрицы ковариации (если бы мы не знали матрицу ковариации и среднее, то могли бы вычислить приближенное значение из набора векторов):
$\lambda_1 = 2.8, e_1 = (e_{11}, e_{12}) = (0.83205029, -0.5547002)$
$\lambda_2 = 0.2, e_2 = (e_{21}, e_{22}) = (0.5547002, 0.83205029)$
Обозначим:
\[\Phi = \begin{pmatrix} e_{11} / \sqrt{\lambda_1} & e_{12} / \sqrt{\lambda_1} \\ e_{21} / \sqrt{\lambda_2} & e_{22} / \sqrt{\lambda_2} \end{pmatrix}\]и определим линейное преобразование:
\[Y = \Phi \cdot (X — \mu)\]Это преобразование осуществит whitening для исходного набора $X$. При этом $Y$ будет выглядить как-то так:
Покончили с примером, смысл того, что предполагается сделать с данными понятен.
Whitening хорошо зарекомендовал себя в том числе, когда мы тренируем нейронные сети, но обычно, при тренировке нейронных сетей он используется на исходных данных. Авторы статьи резонно замечают, что не худо было бы применить нечто похожее и на промежуточных данных, которые приходят на вход слоёв нейронной сети. Однако, возникает две проблемы. Первая, и она же основная, — это крайне дорогое удовольствие, вычислять и применять whitening преобразование для всех слоёв. Вторая, нам бы хотелось, чтобы наша сеть была дифференцируемой функцией (а иначе оптимизировать недифференцируемую функцию будет достаточно проблематично), но введение whitening преобразования дифференцируемость порушит (может и не везде, но и в одном месте будет достаточно). Поэтому предлагается несколько упростить подход и просто нормализовывать данные по каждой компоненте вектора отдельно. Т.е. для вектора $X = (x_1, …, x_d)$ посчитать математическое ожидание и дисперсию для каждой компоненты отдельно и нормализовать его в вектор $\hat X = (\hat x_1, …, \hat x_d)$, используя следующие преобразование:
\[\hat x_k = \frac {(x_k — E(x_k))} {\sqrt{Var(x_k)}}\]Возвращаясь к только что рассмотренному примеру, нормализованные данные $\hat X$ будут выглядеть вот так:
Однако, если просто нормализовывать данные подаваемые на вход слоя (некоторой функции), то мы сужаем возможности того, что слой может представлять,
например, если взять в качестве функции сигмоид, то нормализация данных подаваемых на вход приводит нас в область, где сигмоид почти линейная
функция. Это не хорошо, поэтому вводим два дополнительных параметра $\gamma_k$ и $\beta_k$, которые будут тренироваться вместе с остальными
параметрами сети, и окончательное преобразование будет выглядеть как:
Это не хорошо, поэтому вводим два дополнительных параметра $\gamma_k$ и $\beta_k$, которые будут тренироваться вместе с остальными
параметрами сети, и окончательное преобразование будет выглядеть как:
Замечание. Если мы положим $\gamma_k = \sqrt{Var(x_k)}$ и $\beta_k = E(x_k)$, то получим тождественное преобразование, т.е., в принципе, возможна ситуация, когда вводимая трансформация ничего не изменит вообще.
Итак, авторы определили преобразование $BN_{\gamma, \beta}(x)$, которое добавляется перед каждым слоем нейронной сети (или не перед каждым — это уже вопрос подбора структуры сети). При этом $\gamma, \beta$ — тренируемые параметры, и их черезвычайно много, по паре на каждую компоненту вектора на входе каждого слоя сети. Остаётся пара мелочей.
Первое, во время тренировки мы работаем не со всем тренировочными данными разом, а с данными разделенными на минибатчи. Поэтому во время тренировки
мы нормализуем данные в минибатче, т.е. аппроксимируем математическое ожидание и дисперсии в преобразовании $\hat x$ по каждому минибатчу отдельно.
Поэтому во время тренировки
мы нормализуем данные в минибатче, т.е. аппроксимируем математическое ожидание и дисперсии в преобразовании $\hat x$ по каждому минибатчу отдельно.
Второе, когда сеть используется для вывода, обычно у нас нет ни батчей ни даже минибатчей, поэтому среднее и дисперсию мы сохраняем из тренировки, для этого для каждой компоненты вектора входа каждого слоя мы запоминаем аппроксимированые математическое ожидание и дисперсию, считая скользящую среднюю математического ожидания и дисперсии по минибатчам в процессе тренировки.
Batch Normalization. Практика.
Итак, что такое BN мы определили, разберёмся как её применять. Обычно и полносвязный, и свёрточный слой можно представить в виде:
\[z = g(W\cdot x + b)\]$W$ и $b$ — это параметры линейного преобразования, которые мы тренируем, $g(\cdot)$ — некоторая нелинейная функция (сигмоид, $ReLu(\cdot)$ и т.п.). Вставляем BN перед применением нелинейного преобразования и получается:
\[z = g(\textrm{BN}(W \cdot x))\]Мы убрали сдвиг $b$, потому что, когда мы будем нормализовывать распределение, то $b$ всё равно потеряется, а затем его место займет сдвиг $\beta$ —
параметр BN. Также в [1] авторы объясняют, почему BN не применяется непосредственно к $x$. Обычно $x$ это результат нелинейности с предыдущего слоя,
форма распределения $x$ скорее всего меняется в процессе тренировки и ограничение от BN не помогут убрать covariate shift.
Также в [1] авторы объясняют, почему BN не применяется непосредственно к $x$. Обычно $x$ это результат нелинейности с предыдущего слоя,
форма распределения $x$ скорее всего меняется в процессе тренировки и ограничение от BN не помогут убрать covariate shift.
Чтобы получить максимальный эффект от использования BN в статье [1] предлагается еще несколько изменений в процессе тренировки сети:
Увеличить learning rate. Когда в сеть внедрена BN можно увеличить learning rate и таким образом ускорить процесс оптимизации нейронной сети, при этом избежать расходимости. В сетях без BN при применении больших learning rate за счет увеличения амплитуды градиентов возникает расходимость.
Не использовать dropout слои. BN решает в том числе те же задачи, что и dropout слои, поэтому в сетях где мы применяем BN, можно убрать dropout слои — это ускоряет процесс тренировки при этом переобучения сети не возникает.
Уменьшить вес $L^2$ регуляризации.
 2$ регуляризации в штрафной функции, при этом точность на валидационных данных увеличилась.
2$ регуляризации в штрафной функции, при этом точность на валидационных данных увеличилась.Ускорить убывание learning rate. Поскольку при добавлении в сеть BN скорость сходимости увеличивается, то можно уменьшать learning rate быстрее. (Обычно используется либо экспоненциальное уменьшение веса, либо ступенчатое, и то и другое регулируется двумя параметрами: во сколько раз и через сколько итераций уменьшить learning rate, при применении BN можно сократить число итераций)
Более тщательно перемешивать тренировочные данные, чтобы минибатчи не собирались из одних и тех же примеров.
 2$ регуляризации в штрафной функции, при этом точность на валидационных данных увеличилась.
2$ регуляризации в штрафной функции, при этом точность на валидационных данных увеличилась.Резюмируя. Авторы статьи [1] предложили методику ускорения сходимости нейронной сети. Эта методика доказала свою эффективность, кроме того она
позволяет применять более широкий интервал метапараметров тренировки (например, больший learning rate) и с меньшей аккуратностью подходить к
инициализации весов сети. Объяснение данной методики основывается на понятии ICS, однако, каких-то существенных подтверждений того, что данный метод
действительно позволяет погасить ICS и именно за счет этого улучшить процесс тренировки в статье я не нашел (возможно плохо искал). Есть только некие
теоретические рассуждения, которые не выглядят (на мой взгляд) достаточно убедительно.
Объяснение данной методики основывается на понятии ICS, однако, каких-то существенных подтверждений того, что данный метод
действительно позволяет погасить ICS и именно за счет этого улучшить процесс тренировки в статье я не нашел (возможно плохо искал). Есть только некие
теоретические рассуждения, которые не выглядят (на мой взгляд) достаточно убедительно.
Литература
S. Ioffe, Ch. Szegedy, “Batch Normali;zation: Accelerating Deep Network Training by Reducing Internal Covariate Shift”, arXiv:1502.03167v3, 2015
H. Shimodaira, “Improving predictive inference under covariate shift by weighting the log-likelihood function.”, Journal of Statistical Planning and Inference, 90(2):227–244, October 2000.
Sh. Santurkar, D. Tsipras, A. Ilyas, A. Madry, “How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)”, arXiv:1805.11604v5, 2019
Батч-брю: альтернатива для народа | Нефть
Наверное, Вам уже встречалась новомодная позиция в меню некоторых кофеен третьей волны, именуемая батч-брю? Это не что иное, как фильтр-кофе, регуляр и кофе по-американски, то бишь черный кофе, заваренный методом пролива воды через кофе специальной машиной, но не эспрессо. Откуда взялось, и зачем нужно еще одно определение для этой позиции?
Откуда взялось, и зачем нужно еще одно определение для этой позиции?
Слово регуляр, буквально означающее «как обычно», не прижилось из-за локальных особенностей употребления кофе в разных странах. Даже в США это слово может означать заваренный черный кофе в одних штатах, а в других «как обычно» — это кофе со сливками и сахаром. Под термином фильтр-кофе, благодаря глобализации культуры спешелти кофе, мы уже понимаем все альтернативные методы заваривания. Слово батч-брю тоже пришло к нам из западной спешелти-культуры, и это название напрямую обозначает главную особенность этого напитка: он готовится в больших объемах. Заказав батч-брю, Вы можете быть уверены, что напиток не перепутают ни с каким другим (если, конечно, он есть в меню).
Этот малыш тоже варит батч-брю. (фото: fivesenses.com.au)
Долгое время на батч-брю смотрели косо, но времена меняются. Батч-брю может делать спешелти-кофе простым, постоянным и продуктивным. Так как приготовление батч-брю разгружает бариста, это снижает затраты на оплату труда и увеличивает прибыль заведения. Только задумайтесь, сколько воронок сварит один бариста за час, и сколько чашек он может отдать из термоса с уже готовым напитком? Это также позволяет бариста уделять больше внимания самой важной части сервиса – общению с гостем. Не все хотят и могут ждать воронку по несколько минут, и чашка хорошего батч-брю оставит ничуть не худшее впечатление. Но, как и в случае с любой воронкой, хороший батч-брю получится только под контролем умелого бариста.
Только задумайтесь, сколько воронок сварит один бариста за час, и сколько чашек он может отдать из термоса с уже готовым напитком? Это также позволяет бариста уделять больше внимания самой важной части сервиса – общению с гостем. Не все хотят и могут ждать воронку по несколько минут, и чашка хорошего батч-брю оставит ничуть не худшее впечатление. Но, как и в случае с любой воронкой, хороший батч-брю получится только под контролем умелого бариста.
Итак, Вы решились ввести батч-брю себе в меню. В первую очередь Вам нужна хорошая машина. На сегодняшний день, SCA может порекомендовать 27 машин для домашнего использования, каждую из которых они протестировали. Для заведений с малой проходимостью их может оказаться достаточно, однако если поток за черным кофе предполагается большой, то имеет смысл выбрать более производительные машины. Обращайте внимание на объем, который машина сварит за раз. Даже идеально сваренный фильтр с течением времени превратиться в тыкву.
Экстракция вкусовых веществ заканчивается, как только кофе перестает контактировать с водой, но это не значит, что химический состав не будет меняться дальше. Хлорогеновые кислоты, содержащиеся в любом кофе, при его остывании активно распадаются на более простые, но более горькие и резкие по вкусу кислоты. Некоторые машины оборудованы специальной нагревательной поверхностью для сервировочного чайника. Она поможет замедлить спад температуры, но не защитит наш кофе от другого его врага – кислорода. Наилучшим сосудом для батч-брю является герметичный термос, соразмерный его объему. Чем больше в термосе кофе, тем меньше пространства остается для кислорода, и тем медленнее он будет окисляться. Идеальным вариантом для кофейни будет такой аппарат, который сварит кофе не более чем на час. Помните, лучше варить чаще, но понемногу, чем один раз и на весь день.
Хлорогеновые кислоты, содержащиеся в любом кофе, при его остывании активно распадаются на более простые, но более горькие и резкие по вкусу кислоты. Некоторые машины оборудованы специальной нагревательной поверхностью для сервировочного чайника. Она поможет замедлить спад температуры, но не защитит наш кофе от другого его врага – кислорода. Наилучшим сосудом для батч-брю является герметичный термос, соразмерный его объему. Чем больше в термосе кофе, тем меньше пространства остается для кислорода, и тем медленнее он будет окисляться. Идеальным вариантом для кофейни будет такой аппарат, который сварит кофе не более чем на час. Помните, лучше варить чаще, но понемногу, чем один раз и на весь день.
Вари батч-брю, и гости к тебе потянуться
Определившись с объемом на выходе, нужно определиться и с размером корзины. SCA рекомендует соотношение кофе:вода в районе 60 грамм кофе на 1 литр воды. Для оптимального протекания кофейная таблетка (слой кофе) должна иметь глубину 3-5 сантиметров, в противном случае мы рискуем избыточным образованием каналов, либо чрезмерно длительным временем контакта. Так или иначе, это испортит экстракцию. Если Вы решитесь варить батч-брю часто и мало, убедитесь, что вы берете не слишком мало кофе для Вашей машины. Если ее корзина окажется слишком велика, обратитесь к поставщику за корзиной поменьше.
Так или иначе, это испортит экстракцию. Если Вы решитесь варить батч-брю часто и мало, убедитесь, что вы берете не слишком мало кофе для Вашей машины. Если ее корзина окажется слишком велика, обратитесь к поставщику за корзиной поменьше.
Какие параметры нас интересуют помимо производительности? Самые примитивные машины обладают одной лишь кнопкой включения. Они нагревают залитую в них воду до температуры кипения и разбрызгивают ее через так называемый душ над корзиной с кофе, пока вода не закончится. Такие машины не дают практически никакого контроля над процессом, а составление рецепта сводятся только к количеству кофе и тонкости помола. Более продвинутые машины позволяют точно отстроить температуру, количество проливов и их объем, а также дают возможность предсмачивания и лучше распределяют воду. Таким образом, они позволяют достичь более равномерной экстракции и более точечно настроить вкус. Если такая роскошь не вписывается в Ваш бюджет, то добиться вкусной чашки можно и с обычными машинами, но придется попотеть и проявить креативность:
- Машина не умеет в предсмачивание? Попробуйте сначала залить воду в корзину с кофе из чайника в соотношении 3:1 и тщательно размешайте кофе ложкой, а остальной объем пусть доливает машина.
- Вода из душа льется только в центр, игнорируя остальной кофе? Попробуйте извлекать и вращать корзину с кофе в перерывах между проливами для лучшего распределения воды.
- Мы также пробовали накрывать кофе сверху большим бумажным фильтром по размеру таблетки. Это также может помочь распределять воду по всей поверхности.

Кстати, о помоле. Базовой рекомендацией является как можно более крупный помол, позволяющий закончить протекание примерно к 6 минутам. Известный в кофейном сообществе Скотт Рао, автор таких книг как «Пособие профессионального баристы» и «Компаньон обжарщика», считает, что если Ваш помол для батч-брю не находится в пределах 15% от самой дальней от нуля отметки на кофемолке, то что-то в Вашей системе идет не так. Если для того, чтобы добиться насыщенности, Вам приходиться уменьшать помол, то вероятна одна из следующих проблем: жернова на кофемолке изрядно затупились, глубина кофейной таблетки слишком мала, не хватает времени контакта с водой, вода не охватывает всю поверхность кофе, либо не хватает предсмачивания в самом начале заваривания.
Разумеется, не стоит забывать об обслуживании машины. Как и в любом другом способе заваривания, качество напитка напрямую зависит от того, какой водой вы его приготовили. В случае с батч-брю отдельное внимание стоит уделять жесткости воды: слишком жесткая вода будет оставлять большие отложения накипи на бойлере, тогда как мягкая, кислотная вода может со временем разъесть его стены. Так или иначе, Вы рискуете заметно сократить срок службы вашей машины, если невнимательно отнесетесь к выбору воды. Также помните про поддержание чистоты, особенно если варите кофе в термос. На его внутренних стенках будет скапливаться кофейный налет, который испортит вкус кофе, оказавшегося там впоследствии, поэтому позаботьтесь о наличии специальных чистящих средств для кофейных машин.
Чистая машина — чистый кофе. (фото: urnex.com)
Батч-брю в Вашей кофейне при правильном подходе увеличит прибыль и привлечет больше людей к качественному кофе. Выбирайте машину исходя из бюджета и потребностей, не бойтесь экспериментировать и не забывайте следить за ней, тогда гости непременно вернуться к Вам за чашечкой черного кофе.
Батч терминал сбора данных
C этим понятием мы часто сталкиваемся в процессе покупки оборудования для автоматизации магазинов или складов.
Итак, в жесточайшей борьбе с конкурентами, предприниматели организовывают новые методы ведения бизнеса и контроля товаров. Люди, проходя через кассу любого крупного супермаркета или даже магазина, не замечают портативные терминалы, которые напоминают с виду типичные смартфоны.
Немногие знают, что это так называемые портативные терминалы сбора данных(ТСД) — устроиства, совмещающие в себе функции коммуникатора и обычного сканера штрих-кодов.
Является надежным, эффективным помощником товароведа, складского работника, мерчендайзера и других представителей разнообразных отраслей.
Суть процесса работы с ТСД заключается в считывании информации со штрих-кодов, благодаря чему достигается большая скорость и новый качественный уровень работы торговых точек. Причем, особенно процесс инвентаризации товара упрощается и ускоряется.
В недалеком будущем многие фирмы получат возможность автоматизировать технологические процессы.
Существуют два типа ТСД: батч-терминалы (от англ. batch — пакет данных) и радиотерминалы.
Накопительный батч-терминал сбора данных, основан на базе определенного оборудования и имеет ограничения памяти. Стоит заметить,что придется время от времени подключать его к крэдлу, т.к. нужно считывать информацию или обновлять данные.
Радиотерминалы используют популярную беспроводную сеть wi fi. Этот вид терминалов обеспечивает непрерывный обмен информацией между устройством и компьютером, содержащим базу данных.
Данное оборудование обеспечивает полный онлайн контроль товаров и автоматизацию производства, а также бухгалтерский учет. По виду радиотерминалы подразделяются на:
- переносные – популярны и практичны
- и стационарные, крепящиеся на стационарные рабочие места или на колесную технику (погрузчики) для сбора данных.
Существует огромное количество производителей, выпускающих продукцию соответствующего качества и отвечающее поставленным задачам и планам предприятия. При выборе оборудования следует прежде всего определить, где будет располагаться терминал.
При выборе оборудования следует прежде всего определить, где будет располагаться терминал.
В закрытых помещениях, где отсутствует беспроводная сеть, лучшим и удобным вариантом будет batch терминалы сбора данных. Благо ассортимент имеется.
На базе офиса или цеха, с развернутой сетью wifi подойдет радиотерминал(например,хорошо зарекомендовал себя wifi терминал сбора данных motorola).
Основанная на открытых стандартах внутренняя архитектура терминала обеспечивает защиту капиталовложений, предоставляя возможность наращивания функциональных возможностей ТСД и его настройку в зависимости от потребностей бизнеса.
Внимания заслуживают продукты motorola(symbol), такие как motorola mc1000 и motorola mt2070.
Эти устройства, созданные для пакетной обработки в розничной торговле или дистрибьюторских центрах, помогут увеличить точность и эффективность труда.
Следует заметить, что motorola mc2070 новое слово в классе мобильных батч-терминалов, эта современная модель работает по batch-технологии через USB и RS232 интерфейсы.
Пакетная обработка: Введение — BMC Software
Проще говоря, пакетная обработка — это процесс, посредством которого компьютер выполняет пакеты заданий, часто одновременно, в непрерывном последовательном порядке. Это также команда, которая обеспечивает вычисление больших заданий небольшими частями для повышения эффективности в процессе отладки.
У этой команды много названий, включая автоматизацию рабочих нагрузок (WLA) и планирование заданий. Как и большинство вещей в программировании, он со временем меняется. К счастью, эти изменения сделали пакетную обработку заданий более сложной и эффективной.Для многих предприятий это необходимый компонент их ежедневного успеха.
В этой статье мы предоставим обзор пакетной обработки, рассмотрим варианты использования, а также преимущества и недостатки, а затем предложим рекомендации по определению того, подходит ли вам пакетная обработка.
Эволюция пакетной обработки
Сегодня определяющей характеристикой пакетной обработки является отсутствие взаимодействия с пользователем. Есть несколько ручных процессов, чтобы запустить его. Это часть того, что делает его таким успешным и эффективным, но так было не всегда.Пакетная обработка началась с использования перфокарт, которые составлялись в таблицы, чтобы сообщать компьютерам, что делать. Часто колоды или партии карт обрабатывались одновременно. Эта практика восходит к 1890 году, когда Герман Холлерит создал перфокарты для обработки данных переписи населения. Работая в Бюро переписи населения США, он разработал систему, с помощью которой карта, которую он пробивал вручную, считывалась электромеханическим устройством. Вскоре Холлерит создал небольшую компанию, известную сегодня как IBM.
Есть несколько ручных процессов, чтобы запустить его. Это часть того, что делает его таким успешным и эффективным, но так было не всегда.Пакетная обработка началась с использования перфокарт, которые составлялись в таблицы, чтобы сообщать компьютерам, что делать. Часто колоды или партии карт обрабатывались одновременно. Эта практика восходит к 1890 году, когда Герман Холлерит создал перфокарты для обработки данных переписи населения. Работая в Бюро переписи населения США, он разработал систему, с помощью которой карта, которую он пробивал вручную, считывалась электромеханическим устройством. Вскоре Холлерит создал небольшую компанию, известную сегодня как IBM.
Перфокарты произвели революцию в бизнесе, но это было тогда.За последние два десятилетия пакетная обработка продолжила свое развитие. Специалисты по вводу данных больше не нужны. Большинство функций пакетной обработки включаются без взаимодействия и выполняются в соответствии с заданными временными потребностями. Некоторые задания выполняются в режиме реального времени с функциями ежедневного мониторинга и отчетности, другие выполняются немедленно.
Зависимости и мониторы в пакетной обработке
Современная пакетная обработка использует оповещения управления на основе исключений для уведомления нужных людей о возникновении проблем.Это позволяет менеджерам свободно работать без регулярной проверки хода выполнения партий. Идея состоит в том, что менеджерам вообще не нужно регистрироваться, если только они не получат оповещение о критическом исключении.
Исключения определяются системой зависимостей и мониторов, которые необходимы для программного обеспечения:
- Зависимости — это события, запускающие пакетную обработку. Это может быть то, что клиент размещает онлайн-заказ или пользователь запрашивает новые расходные материалы, инициируя генерацию запроса системой.. Зависимость запустила пакетную обработку.
- Мониторы ищут отклонения в партии. Возможно, выполнение одной работы занимает больше времени, чем обычно. Следующее задание не может начаться до тех пор, пока не завершится предыдущее. Если это вызывает необычную задержку, монитор поймает ее, сгенерирует исключение и отправит его менеджеру.
 Если это вызывает необычную задержку, монитор поймает ее, сгенерирует исключение и отправит его менеджеру.
Если это вызывает необычную задержку, монитор поймает ее, сгенерирует исключение и отправит его менеджеру.Когда использовать пакетную обработку
При использовании пакетной обработки могут возникнуть задержки. Однако во многих ситуациях такая задержка перед началом передачи данных не представляет большой проблемы — процессы, использующие эту функцию, не являются критически важными в данный конкретный момент.
Пакетную обработку следует рассматривать в ситуациях, когда:
- Передача и результаты в режиме реального времени не имеют решающего значения
- Необходимо обрабатывать большие объемы данных
- Доступ к данным осуществляется пакетами, а не потоками
- Сложные алгоритмы должны иметь доступ ко всему пакету
- Таблицы в реляционных базах данных должны быть объединены
- Работа повторяется
Преимущества пакетной обработки
Существует ряд причин, по которым компании внедряют системы пакетной обработки. Владельцы бизнеса должны учитывать общее влияние при принятии решения о новом программном обеспечении для своей организации.
Владельцы бизнеса должны учитывать общее влияние при принятии решения о новом программном обеспечении для своей организации.
Скорость при меньших затратах
Поскольку для пакетной обработки не требуются специалисты по вводу данных, это помогает снизить эксплуатационные расходы, которые предприятия тратят на рабочую силу. Кроме того, для работы не требуется никакого дополнительного оборудования, кроме компьютера.
На самом деле, использование пакетной обработки может снизить зависимость компании от другого дорогостоящего оборудования, что делает его относительно недорогим решением, помогающим предприятиям экономить деньги и время.Без возможности ошибки пользователя пакетные процессы выполняются максимально эффективно. Результатом является быстрая и точная обработка и менеджеры, которые могут уделять больше времени повседневным операциям.
Автономные функции
Системы пакетной обработки данных работают в автономном режиме, поэтому, когда рабочий день заканчивается, системы пакетной обработки продолжают работать в фоновом режиме. Это дает менеджерам полный контроль над тем, когда запускать процессы.
Это дает менеджерам полный контроль над тем, когда запускать процессы.
Программное обеспечение можно настроить на ночную обработку определенных пакетов, что является удобным решением для компаний, которые не хотят, чтобы автоматическая загрузка мешала повседневной деятельности.
Простое автоматическое управление
У менеджеров достаточно работы без входа в систему каждый час для проверки своих партий. Система уведомлений на основе исключений современного программного обеспечения для пакетной обработки позволяет менеджерам легко выполнять свою работу, не беспокоясь о том, правильно ли работает их программное обеспечение и выполняются ли пакеты. Если есть проблема, уведомления отправляются нужным людям для ее решения. Менеджеры могут использовать подход невмешательства, полагая, что их программное обеспечение для пакетной обработки выполняет свою работу.
Простота
По сравнению с обработкой в режиме реального времени или потоковой обработкой пакетная обработка значительно проще: она не требует постоянной системной поддержки для ввода данных или уникального оборудования. После установки и настройки пакетная система не требует тяжелого технического обслуживания, что делает ее решением с относительно низким порогом входа.
После установки и настройки пакетная система не требует тяжелого технического обслуживания, что делает ее решением с относительно низким порогом входа.
Недостатки пакетной обработки
Хотя пакетная обработка отлично подходит для многих сценариев, владельцы также должны учитывать эти компоненты, которые могут быть недостатками для некоторых компаний.
Развертывание и обучение
Как и в случае с любой новой технологией, управление этими системами требует определенной подготовки. Менеджеры, которые не знакомы, должны понимать, что запускает пакет, как планировать их и что означают уведомления об исключениях, среди прочего.
Комплексная отладка
При возникновении ошибки менеджеры также должны знать, как ее исправить. Понятно, что отладка систем пакетной обработки может быть сложной. Вам, вероятно, понадобится штатный сотрудник, который специализируется на этих системах; в противном случае ожидайте дополнительных затрат всякий раз, когда вам понадобится помощь внешнего консультанта.
Стоимость
В то время как большинство предприятий экономят деньги на рабочей силе и оборудовании, когда они переходят на пакетную обработку, некоторые предприятия изначально не нуждаются в специалистах по вводу данных или дорогостоящем оборудовании. Для этих предприятий стоимость некоторых систем пакетной обработки может показаться неосуществимой.
Пакетная обработка и потоковая обработка
Учитывая преимущества обеих технологий, многие организации сталкиваются с дилеммой: что лучше: пакетная обработка или потоковая обработка? Хотя четкий ответ может быть идеальным, не существует единственного варианта, который был бы идеальным решением для каждого случая, а оптимальный метод варьируется в зависимости от потребностей, компании и конкретной ситуации.
Благодаря способности обрабатывать большие объемы данных одновременно, даже миллионы записей, которые хранятся и накапливаются в течение дня, пакетная обработка является хорошим вариантом для задач, которые могут подождать до окончания рабочего дня. Примеры:
Примеры:
- Все счета-фактуры
- Процессы расчета заработной платы
- Все отдельные транзакции, которые финансовая фирма может отправлять в течение любой заданной недели
Потоковая обработка, с другой стороны, полезна для процессов или системы, которые зависят от доступа к данным в режиме реального времени.Имея возможность почти мгновенно анализировать потоковые данные, этот метод лучше подходит для сценариев, в которых события происходят часто и близко друг к другу, и не может ждать до вечера, пока компьютеры не будут простаивать. Этот тип обработки лучше всего использовать для таких задач, как кибербезопасность и обнаружение мошенничества, поскольку их необходимо сразу же обнаружить, чтобы снизить риски.
Многие организации пришли к выводу, что сочетание пакетной и потоковой обработки является наиболее выгодным для рабочих процессов, при этом каждый метод используется по мере необходимости.
Нужна ли мне пакетная обработка?
Если вы все еще сомневаетесь, подходит ли вам пакетная обработка, подумайте о примерах, где вы можете использовать эту функцию в своем бизнесе. Есть ли пробелы, которые вы могли бы заполнить с помощью автоматизации?
Есть ли пробелы, которые вы могли бы заполнить с помощью автоматизации?
Вот некоторые из них:
- Процессы начисления заработной платы и табели учета рабочего времени
- Банковские выписки
- Выставление счетов по отдельным позициям
- Поток, аналитика и обработка транзакций
- Исследования и отчеты 90 и Fulfillment
- Other Requests
Как правило, если вы регулярно выполняете большие вычислительные задания вручную, есть большая вероятность, что правильное программное обеспечение для пакетной обработки может стать ключом к высвобождению большего количества времени и денег для вашей организации.
Есть также несколько вопросов, которые следует учитывать при принятии решения о том, нужна ли вашей компании пакетная обработка:
- Как обеспечить правильное выполнение ручных операций? Есть ли у вас система для определения того, что они были отправлены и обработаны в правильном порядке?
- У вас есть задания, ожидающие начала, которые зависят от завершения другого? Есть ли у вас система для отслеживания каждой работы до ее завершения или которая знает, когда будет выполнена первая работа?
- Вы вручную проверяете наличие новых файлов? Достаточно ли часто ваш скрипт зацикливается, чтобы быть эффективным при проверке файлов?
- Есть ли на вашем сервере текущая настройка с повторными попытками на уровне задания? Какое влияние он оказывает? Вы бы выиграли от меньшей нагрузки на сервер?
- Как вы отслеживаете зависимости между серверами? Откуда вы знаете, что зависимый сервер будет доступен, когда это необходимо?
Автоматизируйте планирование заданий для вашей компании
Современные системы призваны освободить менеджеров от повседневных мелочей, предотвратить ошибки пользователей и способствовать быстрому и эффективному выполнению заданий с минимальным контролем. Пакетная обработка имеет дополнительный эффект экономии денег почти для всех компаний, которые ее внедряют.
Пакетная обработка имеет дополнительный эффект экономии денег почти для всех компаний, которые ее внедряют.
Однако, как отмечалось выше, не обошлось без соображений. Компании, у которых нет ИТ-персонала для реализации успешного плана развертывания и обслуживания, по-прежнему могут извлечь выгоду из пакетной обработки, но им следует подготовиться к тому, чтобы инвестировать время и деньги в партнерство с ИТ-специалистами, чтобы обеспечить успешный запуск и удобство работы конечных пользователей.
BMC для автоматизации рабочих нагрузок
Дополнительные сведения по этой теме см. в нашем блоге по автоматизации рабочих нагрузок BMC.Готовы узнать, что BMC может сделать для вашей компании? Изучите автоматизацию рабочих нагрузок, включая пакетную обработку, с помощью Control-M.
Используйте современный подход к пакетной обработке
Оркестрация рабочих процессов приложений — это современный подход к пакетной обработке, который может предотвратить производственные сбои для своевременного предоставления услуг каждый раз. Загрузить электронную книгу › ›
Загрузить электронную книгу › ›Эти сообщения являются моими собственными и не обязательно отражают позицию, стратегию или мнение BMC.
Видите ошибку или есть предложение? Пожалуйста, сообщите нам об этом по электронной почте blogs@bmc.ком.
Что такое пакетная служба AWS? — AWS Batch
AWS Batch помогает выполнять рабочие нагрузки пакетных вычислений в облаке AWS. Пакетные вычисления — распространенный способ разработчиков, ученых и инженеров для доступа к большим объемам вычислительных ресурсов. Пакетная служба AWS удаляет недифференцированная тяжелая работа по настройке и управлению необходимой инфраструктурой, аналогичная традиционной пакетной обработке вычислительное программное обеспечение. Эта служба может эффективно выделять ресурсы в ответ на отправленные задания, чтобы устранить ограничения емкости, снизить затраты на вычисления и быстро получить результаты.
Будучи полностью управляемым сервисом, AWS Batch помогает запускать рабочие нагрузки пакетных вычислений любого масштаба. Пакетная обработка AWS
автоматически выделяет вычислительные ресурсы и оптимизирует распределение рабочей нагрузки в зависимости от количества и масштаба
рабочие нагрузки. С AWS Batch нет необходимости устанавливать или управлять программным обеспечением для пакетных вычислений, поэтому вы можете сосредоточить свое время
по анализу результатов и решению задач.
Пакетная обработка AWS
автоматически выделяет вычислительные ресурсы и оптимизирует распределение рабочей нагрузки в зависимости от количества и масштаба
рабочие нагрузки. С AWS Batch нет необходимости устанавливать или управлять программным обеспечением для пакетных вычислений, поэтому вы можете сосредоточить свое время
по анализу результатов и решению задач.
Компоненты пакета AWS
AWS Batch упрощает выполнение пакетных заданий в нескольких зонах доступности в пределах региона.Вы можете создать пакетную службу AWS вычислительных сред в новом или существующем облаке VPC. После того, как вычислительная среда запущена и связана с очередью заданий, вы можете определить определения заданий, которые указывают, какие образы контейнеров Docker запускать ваши задания. Образы контейнеров хранятся в реестрах контейнеров и извлекаются из них, которые могут существовать как в вашем AWS, так и за его пределами. инфраструктура.
Вакансии
Единица работы (например, сценарий оболочки, исполняемый файл Linux или образ контейнера Docker), которую вы отправляете
Пакет AWS. У него есть имя, и он работает как контейнерное приложение на ресурсах AWS Fargate или Amazon EC2 в ваших вычислительных ресурсах.
среду, используя параметры, указанные в определении задания. Задания могут ссылаться на другие задания по имени или идентификатору.
и может зависеть от успешного завершения других работ. Дополнительные сведения см. в разделе Работа.
Определения заданий
Определение задания указывает, как должны выполняться задания. Вы можете думать об определении работы как о плане для
ресурсы в вашей работе.Вы можете предоставить своей работе роль IAM, чтобы предоставить доступ к другим ресурсам AWS. Вы тоже
укажите требования как к памяти, так и к процессору. Определение задания также может управлять свойствами контейнера, средой
переменные и точки монтирования для постоянного хранилища. Многие спецификации в определении работы могут быть переопределены.
путем указания новых значений при отправке отдельных заданий. Дополнительные сведения см. в разделе Определения заданий
Дополнительные сведения см. в разделе Определения заданий
Очереди заданий
Когда вы отправляете пакетное задание AWS, вы отправляете его в определенную очередь заданий, где задание находится до тех пор, пока оно не будет запланировано на вычислительную среду.Вы связываете одну или несколько вычислительных сред с очередью заданий. Вы также можете назначать значения приоритета для этих вычислительных сред и даже для самих очередей заданий. Например, вы можете иметь очередь с высоким приоритетом, в которую вы отправляете срочные задания, и очередь с низким приоритетом для заданий, которые могут выполняться в любое время, когда вычислительные ресурсы дешевле.
Вычислительная среда
Вычислительная среда — это набор управляемых или неуправляемых вычислительных ресурсов, которые используются для выполнения заданий.С участием
управляемых вычислительных средах можно указать желаемый тип вычислений (Fargate или EC2) на нескольких уровнях детализации. Вы можете настроить вычислительные среды, в которых используется конкретный тип экземпляра EC2, конкретная модель, например
Вы можете настроить вычислительные среды, в которых используется конкретный тип экземпляра EC2, конкретная модель, например c5.2xlarge или m5.10xlarge . Или вы можете выбрать только указать, что вы хотите использовать
новейшие типы экземпляров. Вы также можете указать минимальное, желаемое и максимальное количество виртуальных ЦП для среды.
вместе с суммой, которую вы готовы заплатить за спотовый инстанс в процентах от цены инстанса по требованию.
и целевой набор подсетей VPC.AWS Batch эффективно запускает, управляет и завершает типы вычислений по мере необходимости. Ты
также может управлять вашими собственными вычислительными средами. Таким образом, вы несете ответственность за настройку и масштабирование экземпляров.
в кластере Amazon ECS, который AWS Batch создает для вас. Дополнительные сведения см. в разделе вычислительная среда.
Начало работы
Начните работу с AWS Batch, создав определение задания, вычислительную среду и очередь заданий в AWS Batch. консоль.
консоль.
Мастер первого запуска AWS Batch дает возможность создать вычислительную среду, очередь заданий и отправка образца работы Hello World.Если у вас уже есть образ Docker, который вы хотите запустить в AWS Batch, вы можете создать определение задания с этим изображением и вместо этого отправьте его в свою очередь. Дополнительные сведения см. в разделе Начало работы с AWS Batch.
Периодический процесс – обзор
1 ВВЕДЕНИЕ
Периодический процесс широко используется в химической, биохимической, фармацевтической и сельскохозяйственной промышленности. Их гибкость для производства дорогостоящих продуктов во время коротких производственных кампаний объясняет их широкое использование.При высокой степени автоматизации управление периодическим процессом является довольно сложной задачей. Это объясняется сочетанием их конечной длительности, нелинейного поведения, естественной нестационарности и многокритериальности критериев. За последнее десятилетие были разработаны некоторые методы и инструменты для мониторинга периодического процесса. Для периодических процессов эти инструменты включают многофакторный анализ основных компонентов (MPCA) и многофакторный метод наименьших квадратов (MPLS) (P. Nomikos, and J.F.MacGrregor, 1994; T. Kourti, J.Lee and J.F.MacGregor, 1995). Они извлекают основную информацию из данных, используя многомерный статистический анализ. В этом документе MPCA будет применяться для мониторинга и диагностики ошибок в пакетном процессе. Метод по существу строит статистическую модель MPCA в соответствии с нормальными переменными процесса вокруг их средних траекторий. Затем он сравнивает отклонение новой партии от средней траектории с моделью MPCA. Любое отклонение от модели, которое нельзя статистически отнести к обычному изменению процесса, указывает на то, что новая партия имеет низкое качество.
Для периодических процессов эти инструменты включают многофакторный анализ основных компонентов (MPCA) и многофакторный метод наименьших квадратов (MPLS) (P. Nomikos, and J.F.MacGrregor, 1994; T. Kourti, J.Lee and J.F.MacGregor, 1995). Они извлекают основную информацию из данных, используя многомерный статистический анализ. В этом документе MPCA будет применяться для мониторинга и диагностики ошибок в пакетном процессе. Метод по существу строит статистическую модель MPCA в соответствии с нормальными переменными процесса вокруг их средних траекторий. Затем он сравнивает отклонение новой партии от средней траектории с моделью MPCA. Любое отклонение от модели, которое нельзя статистически отнести к обычному изменению процесса, указывает на то, что новая партия имеет низкое качество.
Метод MPCA поддерживается предположением о том, что все траектории данных в пакетном процессе согласованы. Статистическая модель строится с использованием этих данных равной продолжительности. Но многие ситуации отличаются. Общая продолжительность партий и продолжительность различных стадий внутри партий неодинаковы. Обычно различия между партиями могут влиять на статистическую модель и даже на диагностику неисправностей. Таким образом, одной из важных задач является обеспечение согласованности всех данных процесса.
Общая продолжительность партий и продолжительность различных стадий внутри партий неодинаковы. Обычно различия между партиями могут влиять на статистическую модель и даже на диагностику неисправностей. Таким образом, одной из важных задач является обеспечение согласованности всех данных процесса.
Распространенной проблемой при распознавании произнесенных слов являются несинхронизированные режимы.Одно и то же слово может быть произнесено с разной продолжительностью и интенсивностью в разной ситуации и разными говорящими; Система распознавания речи должна уметь их классифицировать. Этот процесс завершается извлечением признаков из речевых сигналов. Динамическая деформация времени (DTW) — это метод гибкой схемы сопоставления с образцом. Он переводит, сжимает и расширяет пары паттернов таким образом, что сходные черты внутри двух паттернов сопоставляются (C. Myers, L.R.Rabiner, and A.E.Rosenberg.1980; H.F.Silverman, and D.П. Морган.1990). DTW широко используется для распознавания устной речи. Точно так же DTW имеет возможность синхронизировать две траектории из пакетного процесса и обеспечивает элегантное решение проблемы синхронизации пакетных траекторий.
Точно так же DTW имеет возможность синхронизировать две траектории из пакетного процесса и обеспечивает элегантное решение проблемы синхронизации пакетных траекторий.
В этом документе предлагается метод CMPCA для мониторинга и диагностики неисправностей в периодическом процессе. Это основано на сочетании MPCA и DTW. DTW может синхронизировать все данные из пакетного процесса. Чтобы построить модель MPCA, в первую очередь должны быть согласованы обычные исторические данные.Затем можно построить модель CMPCA, которая не только сохраняет информацию о данных, но и позволяет избежать остатков модели. Кроме того, новые пакетные данные также размещаются с использованием DTW, а затем проецируются на модель CMPCA для диагностики ошибок.
Организация этой статьи выглядит следующим образом. Сначала дается краткий обзор стандартной процедуры MPCA, после чего следует введение в анализ DTW. Методология CMPCA с использованием DTW детально разработана и предназначена для диагностики неисправностей в пакетных процессах на примерах последовательности. Наконец, выводы и обсуждения приведены в последнем разделе.
Наконец, выводы и обсуждения приведены в последнем разделе.
Что такое пакетная обработка? — Определение и примеры — Видео и стенограмма урока
Другой способ взаимодействия с пользователем
В отличие от работы с ПК или планшетом, когда для выполнения команд используется мышь или сенсорный экран с большим цветным дисплеем, пакетная обработка сильно отличается. В соответствии с моделью пакетной обработки группа из одной или нескольких программ, называемая заданием , будет выполнять определенный набор задач , которые не требуют, чтобы пользователь управлял ими.Часто говорят, что эти программы работают в фоновом режиме компьютера, поскольку во время их выполнения пользователю не предоставляется взаимодействие, отображение или обратная связь.
Результатами этих заданий могут быть отчеты об инвентаризации и продажах, сложные исследовательские расчеты, платежные чеки или отчеты о счетах за коммунальные услуги, такие как счет за воду или поставщика сотовой связи. Поскольку взаимодействие с пользователем отсутствует, вся необходимая информация, необходимая для выполнения задания, должна быть указана до запуска задания или быть доступной на соответствующем этапе в порядке выполнения задания.Когда задание завершено, могут быть инициированы различные действия, такие как сообщения владельцу задания или распечатка сгенерированных отчетов. Дополнительные задания можно запускать даже на основе результатов предыдущих заданий.
Поскольку взаимодействие с пользователем отсутствует, вся необходимая информация, необходимая для выполнения задания, должна быть указана до запуска задания или быть доступной на соответствующем этапе в порядке выполнения задания.Когда задание завершено, могут быть инициированы различные действия, такие как сообщения владельцу задания или распечатка сгенерированных отчетов. Дополнительные задания можно запускать даже на основе результатов предыдущих заданий.
Если нужная информация не готова, когда это необходимо, или полностью отсутствует, задание может занять больше времени, чем обычно, или может вызвать ошибку и завершиться до завершения обработки. Если задание не может быть выполнено успешно, системный оператор получит предупреждающее сообщение и должен будет устранить неполадки, где что-то пошло не так, или попросить программиста просмотреть этот шаг в задании, просмотрев журналы, коды ошибок или файлы входных данных.
Во многих случаях задания настраиваются на запуск по предварительно заданному расписанию в зависимости от выполняемой задачи. Некоторые задания, например обработка кредитных карт для владельцев магазинов, могут выполняться ежедневно в конце рабочего дня, когда все продажи за день отправляются в банк для регистрации. Другие задания, такие как счета за коммунальные услуги, будут выполняться реже, ежемесячно или даже ежеквартально, поскольку более целесообразно, чтобы эти счета обрабатывались и отправлялись реже. В конце концов, вы не хотели бы получать счет за мобильный телефон каждую неделю.Это было бы довольно подавляющим!
Некоторые задания, например обработка кредитных карт для владельцев магазинов, могут выполняться ежедневно в конце рабочего дня, когда все продажи за день отправляются в банк для регистрации. Другие задания, такие как счета за коммунальные услуги, будут выполняться реже, ежемесячно или даже ежеквартально, поскольку более целесообразно, чтобы эти счета обрабатывались и отправлялись реже. В конце концов, вы не хотели бы получать счет за мобильный телефон каждую неделю.Это было бы довольно подавляющим!
Получение максимальной отдачи от компьютерных ресурсов
Пакетная обработка также позволяет предприятиям максимально эффективно использовать свое компьютерное оборудование, выполняя задания в нерабочее время. В течение дня сотрудники используют сеть и серверы для выполнения своей работы, и когда они идут домой в конце дня, эти ресурсы обычно простаивают до следующего утра. Предприятия могут использовать пакетную обработку, чтобы воспользоваться этим временем простоя, сохраняя свои сложные операции по созданию и обработке отчетов для так называемого непикового времени, планируя выполнение этих заданий после того, как люди ушли домой на вечер. Ресурсы, которые в противном случае простаивали бы, работают всю ночь, позволяя компаниям быть более эффективными и получать максимальную отдачу от своих инвестиций в вычислительную мощность. На следующий день, когда сотрудники возвращаются, результаты этих работ ждут людей для просмотра и использования по мере необходимости.
Другие компании могут предпочесть выполнение пакетных заданий в обычные рабочие часы и будут использовать сложные инструменты планирования и мониторинга, чтобы гарантировать, что задания не потребляют слишком много ресурсов и не мешают работе офисных работников.Например, процесс планирования и выполнения может запускать задания в том порядке, в котором они были отправлены, следуя модели «первым поступил — первым обслужен», часто называемой для краткости FIFO . Конечно, это означает, что если сложное или большое задание отправляется и начинает выполняться, многим меньшим заданиям нужно дождаться завершения, прежде чем их можно будет запустить.
Чтобы обойти эту распространенную проблему, планировщики могут отдавать приоритет небольшим заданиям, для выполнения которых требуется меньше ресурсов, чтобы они могли выполняться быстрее и не задерживались из-за других, более сложных заданий. Приоритет также может быть установлен при отправке пакетного задания, что позволяет предоставить этому заданию больше или меньше вычислительных ресурсов для его выполнения.
Приоритет также может быть установлен при отправке пакетного задания, что позволяет предоставить этому заданию больше или меньше вычислительных ресурсов для его выполнения.
Рассмотрим ситуацию, когда задание, которое генерирует зарплату для организации, было неожиданно задержано или во время его выполнения возникла ошибка. Владелец этого задания может повторно отправить его и настроить его выполнение с более высоким приоритетом, чтобы гарантировать, что оно попадет в начало очереди, и использует больше вычислительной мощности, чтобы гарантировать своевременное завершение.И наоборот, владелец задания может установить для своего пакетного задания более низкий приоритет, если его работа не требуется своевременно, и владелец не хочет негативно влиять на других пользователей системы.
Краткий обзор урока
Вот и все. Пакетная обработка позволяет запускать задание с минимальным вмешательством человека или без него в соответствии с заданными расписаниями и приоритетами, пока имеется информация, необходимая для выполнения задания. Кроме того, вычислительные ресурсы теперь можно использовать 24 часа в сутки, помогая компаниям получать максимально возможную отдачу от своих инвестиций в технологии.
Кроме того, вычислительные ресурсы теперь можно использовать 24 часа в сутки, помогая компаниям получать максимально возможную отдачу от своих инвестиций в технологии.
Когда несколько заданий конкурируют за одни и те же ресурсы, необходимые для выполнения их задач, операторы могут устанавливать разные уровни приоритета, чтобы позволить одному заданию использовать больше или меньше вычислительной мощности. Это гарантирует, что те задания, которые важны для бизнес-операций, будут поставлены на первое место, что позволит своевременно предоставлять бизнес-данные, услуги, процессы и результаты.
Использовать пакетную установку Apex | Начальная точка Salesforce
Чтобы написать класс Batch Apex, ваш класс должен реализовать базу данных.Пакетный интерфейс и включает следующие три метода:
начало Используется для сбора записей или объектов, которые должны быть переданы интерфейсному методу execute для обработки. Этот метод вызывается один раз в начале задания Batch Apex и возвращает либо объект Database. QueryLocator, либо объект Iterable, содержащий записи или объекты, переданные заданию.
QueryLocator, либо объект Iterable, содержащий записи или объекты, переданные заданию.
В большинстве случаев QueryLocator выполняет трюк с помощью простого запроса SOQL для создания области объектов в пакетном задании.Но если вам нужно сделать что-то сумасшедшее, например прокрутить результаты вызова API или предварительно обработать записи перед передачей в метод execute, вы можете проверить ссылку «Пользовательские итераторы» в разделе «Ресурсы».
С помощью объекта QueryLocator обходится ограничение регулятора на общее количество записей, извлекаемых с помощью запросов SOQL, и вы можете запрашивать до 50 миллионов записей. Однако при использовании Iterable по-прежнему применяется ограничение регулятора на общее количество записей, извлекаемых с помощью запросов SOQL.
выполнить Выполняет фактическую обработку каждого фрагмента или «пакета» данных, переданных методу. Размер пакета по умолчанию составляет 200 записей. Не гарантируется, что пакеты записей будут выполняться в том порядке, в котором они получены из метода start.
- Ссылка на объект Database.BatchableContext.
- Список объектов sObject, например List
, или список параметризованных типов. Если вы используете базу данных.QueryLocator, используйте возвращенный список.
Используется для выполнения операций постобработки (например, отправки электронного письма) и вызывается один раз после обработки всех пакетов.
Вот как выглядит скелет класса Batch Apex:
открытый класс MyBatchClass реализует Database.Batchable{ public (Database.QueryLocator | Iterable ) start(Database.BatchableContext bc) { // собираем пакеты записей или объектов, которые нужно передать для выполнения } публичное недействительное выполнение (база данных.BatchableContext bc, List записи){ // обрабатываем каждую партию записей } публичная недействительная отделка (Database.
 BatchableContext bc) {
// выполняем любые операции постобработки
}
}
BatchableContext bc) {
// выполняем любые операции постобработки
}
} Что такое серийное производство в производстве?
Существует множество подходов, которые могут быть использованы производителями, когда речь идет об усовершенствовании производственных процессов. Один из таких методов называется серийным производством.
Но что такое серийное производство, каковы преимущества (и недостатки) его использования и чем оно отличается от других стратегий? Мы ответили на эти вопросы и объяснили, как программное обеспечение может сделать этот метод еще более эффективным.
Что такое серийное производство?Серийное производство – это метод, при котором группа идентичных продуктов производится одновременно (а не по одному). Производитель должен решить, насколько большой будет партия и как часто эти партии будут производиться.
Каждая партия вместе проходит отдельные этапы производственного процесса.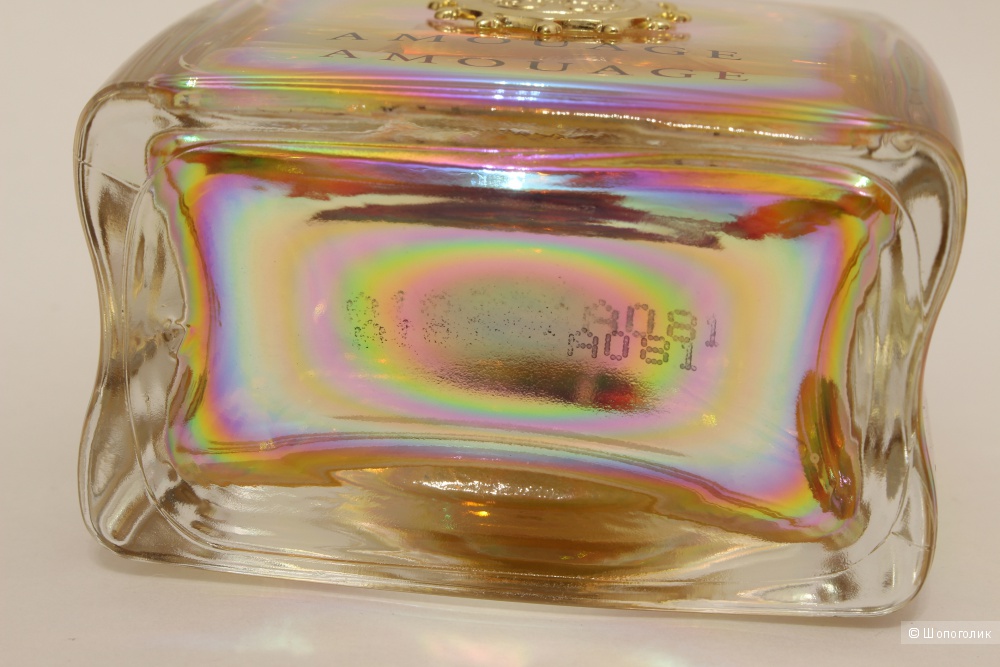 Это означает, что другая партия не может начать стадию, если предыдущая все еще находится в этой части цикла.
Это означает, что другая партия не может начать стадию, если предыдущая все еще находится в этой части цикла.
Каждая партия может быть разной, так как производители могут принять решение об изменении спецификаций от одной группы продуктов к другой. Возможно, необходимо изменить цвет или размер этой конкретной группы (в зависимости от предпочтений, указанных в конкретном заказе).
Проверка качества может проводиться после каждого этапа производственного цикла. Кроме того, между партиями можно тестировать оборудование, чтобы убедиться в отсутствии проблем с производительностью. Такая гибкость невозможна при использовании некоторых других подходов.
Важно изучить эти противоположные методы, чтобы определить, какой из них лучше всего соответствует потребностям вашего бизнеса. Но будет справедливо сказать, что серийное производство хорошо подходит для малых и средних производителей по причинам, к которым мы вернемся.
Каковы основные особенности серийного производства?- Подходит для выращивания МСП
- Гибкий метод производства
- Каждая партия проходит все этапы производства вместе
- Контроль качества может осуществляться между партиями
- Подходит для поддержания разумного уровня запасов
- Может быть много времени простоя между партиями
Преимущества
- Экономия денег
Этот метод полезен для небольших компаний, так как можно сэкономить деньги благодаря более низким эксплуатационным расходам. Оборудование работает не постоянно, а только при производстве партии.
Также дешевле покупать материалы оптом, чем в меньшем количестве. Если вы готовитесь к большой партии, поставщики, скорее всего, предложат вам более выгодную сделку для крупного заказа.
Это также снижает нагрузку на ваше оборудование и рабочую силу, если продукты создаются большими группами, так как это эффективнее (и быстрее), чем производство товаров по отдельности.
- Сокращение отходов
По сравнению с крупномасштабными методами существует немного больше места для ошибок.Если производителю необходимо создать большое количество продукта, но он разбивает его на более мелкие партии, будет меньше отходов, если, например, в одной из этих партий будут бракованные изделия.
Точно так же, если продукт плохо продается, производители не стремятся производить слишком большое количество. Они могут внести изменения, пока не стало слишком поздно. Запасы можно поддерживать на разумном уровне, что также снижает затраты на хранение.
Запасы можно поддерживать на разумном уровне, что также снижает затраты на хранение.
- Большая гибкость
Если бы в отрасли возникла новая тенденция или если бы волна сезонного спроса вступила в силу, серийное производство позволяет настраивать изделия от одного производственного цикла к другому (вместо того, чтобы иметь неизменный предмет для длительный период времени).
Недостатки
- Потерянное время
Можно утверждать, что серийное производство вызывает много простоев между партиями, когда оборудование не используется.
Оборудование должно быть выключено в конце одного цикла, и иногда требуется некоторое время для его перенастройки (при подготовке к следующей партии).
- Отсутствие специализации
Невозможно создать полностью уникальный предмет, если отдельный покупатель предъявляет особые требования.
- Дороже, чем более мелкие методы производства
Затраты на хранение, связанные с серийным производством, будут выше (по сравнению с небольшим производством). Кроме того, вся партия может быть потеряна, если произойдет ошибка.
Тем не менее, серийное производство обеспечивает хороший баланс между более мелкими и крупными методами, возможно, достигая лучшего из обоих миров (и идеально подходит для производственного малого и среднего бизнеса, стремящегося к расширению).
Серийное производство в сравнении с непрерывным производством в сравнении с конвейерным производствомНепрерывное производство
Непрерывное производство, в отличие от серийного производства, является стратегией непрерывного производства.Это означает, что процесс никогда не останавливается, и нет перерывов между различными этапами создания продукта.
Единственный раз, когда производство будет остановлено, это будет очень редкое техническое обслуживание (или если потребуется замена оборудования). Примером организации, которая может использовать непрерывное производство, является химический завод или производитель бумаги.
Примером организации, которая может использовать непрерывное производство, является химический завод или производитель бумаги.
Одним из основных преимуществ этой стратегии является получение большого объема продукции за короткий промежуток времени.Существует также огромная согласованность с производимыми предметами, что хорошо, если клиенты ожидают, что каждый продукт будет производиться на одном уровне.
Недостатком этого метода является то, что для установки всего оборудования требуются большие первоначальные инвестиции. Непрерывное производство может дополнительно генерировать большое количество отходов. Если спрос на продукт внезапно упадет, у предприятия будет слишком много запасов, с которыми он не сможет справиться.
Сборочное производство
Конвейерное производство является одним из самых популярных методов массового производства товаров.Отдельные части продукта добавляются на каждом отдельном этапе производства, таким образом собирая продукт до его завершения.
Эти различные части добавляются сотрудником или машиной, и весь процесс происходит последовательно. Самый очевидный пример бизнеса, который бы реализовал это, — автопроизводитель.
Преимущество конвейерного производства заключается в том, что оно, возможно, дешевле, чем некоторые другие методы. Это связано с тем, что производственный цикл разбит на более простые этапы, а это означает, что низкооплачиваемый сотрудник (или менее сложная машина) может выполнять отдельные этапы.
Так же, как и непрерывное производство, эта стратегия позволяет создавать большие объемы запасов, которые впоследствии могут увеличить доход, если существует соответствующий спрос. Но опять же, как и в случае с непрерывным производством, существует множество возможностей для образования отходов.
Дефект может быть не обнаружен до тех пор, пока не будет произведено огромное количество продукции, что обойдется производителю в большие деньги. Падение спроса также приведет к целому ряду непроданных товаров.
помогает устранить многие очевидные недостатки, связанные с серийным производством, позволяя значительно повысить эффективность.
Этот тип программного решения объединяет все ваши бизнес-функции, обеспечивая точность, согласованность и актуальность данных. Эти данные позволяют иметь полное представление о запасах, продажах и финансах.
Это позволяет вам прогнозировать спрос и, следовательно, размер партий, которые вам необходимо произвести.
Все эти дополнительные сведения о спросе, финансовом состоянии и складских запасах позволяют повысить производительность (что компенсирует потери времени между партиями продукции).
Благодаря полной синхронности между операциями многие процессы, связанные с цепочкой поставок, могут быть автоматизированы. Программное обеспечение для производства имеет функцию планирования производства, что означает, что работу можно планировать, а сотрудники могут постоянно контролировать любую текущую деятельность.
Персонал может отслеживать отдельные продукты на протяжении всего цикла с помощью серийной нумерации и отслеживания партий. Функция спецификации позволяет создавать сложные конфигурации продукта.
Объединяя офисный и заводской цеха, программное обеспечение для производства помогает малым предприятиям расти.Этот рост может обеспечить ресурсы и уверенность, необходимые для того, чтобы попробовать что-то вроде серийного производства, что само по себе будет способствовать дальнейшему расширению.
Если вы хотите продолжить чтение на похожие темы, ознакомьтесь с другими нашими статьями ниже. Или, если вы заинтересованы во внедрении метода серийного производства (и хотите оптимизировать свои операции в одной унифицированной системе), взгляните на наше производственное программное обеспечение, которое предназначено для малых и средних производителей.
Что такое пакетный поток? — Непрерывный поток и альтернативы
Непрерывный поток и периодический поток — это две разные производственные модели, используемые в производственных условиях. Хотя у обоих есть свои преимущества, пакетный поток часто менее эффективен и более подвержен ошибкам, чем непрерывный поток.
Хотя у обоих есть свои преимущества, пакетный поток часто менее эффективен и более подвержен ошибкам, чем непрерывный поток.
В этом сообщении блога мы рассмотрим, что такое пакетный поток и некоторые из его основных недостатков.
Определение пакетного потока
Пакетный поток подразумевает, что каждая уникальная партия выполняется в одном рабочем центре до того, как вся партия будет перемещена в следующий рабочий центр.
В этом процессе последующие партии должны ждать, пока текущая партия не переместится на следующий рабочий центр.
Производственный процесс является одним из факторов успеха бизнеса. Пакетный поток является одним из важных и успешных производственных процессов.
Благодаря этому процессу производитель может производить несколько продуктов одновременно.
Преимущества пакетного процесса
- Снижает первоначальные затраты на установку.
- Позволяет легко и дешево реализовать всю систему оборудования для периодической обработки.
- Позволяет настроить каждый процесс отдельно.
- Подходит для фармацевтической, редкометаллической, пищевой и упаковочной промышленности.
- Нет необходимости концентрироваться на одном типе продукта. Следовательно, увеличивается гибкость для производства других видов продукции.

Периодический процесс очень подходит для производства одежды и сезонных продуктов.
Благодаря этому процессу текстильная промышленность может производить одежду разных цветов и размеров.
Недостатки
Поток порций подходит не для всех видов промышленности. Поэтому мы должны знать его недостатки.
- Его стоимость обработки высока
- Пакетный поток требует времени и энергии
- Оборудование, используемое в периодическом процессе, требует больше места.
- Для перемещения товаров из одного места в другое требуются дополнительные рабочие.
Пример процесса пакетного потока
Например, предположим, что текстильная промышленность поставляет в отель полотенца, простыни, наволочки, необходимые для их бизнеса. Благодаря пакетному процессу легко выполнять заказы этого отеля.
Благодаря пакетному процессу легко выполнять заказы этого отеля.
Легко произвести 200 простыней, 1000 больших наволочек, 700 маленьких наволочек, 500 штор и т. д. с помощью одного комплекта оборудования.
Благодаря гибкости периодического процесса текстильная промышленность может немедленно удовлетворить потребности конкретного отеля.
Точно так же для таких предприятий, как выпечка печенья, выпечка самосы, приготовление сэндвичей, периодический процесс является хорошим выбором.
Поскольку эти предприятия должны поставлять свою продукцию, когда она свежая, поскольку у нее короткий срок годности, следовательно, в этом случае имеет смысл серийное производство.
Предположим, что компания, занимающаяся выпечкой печенья, производит печенье с большим сроком хранения, тогда непрерывный процесс эффективен.
Какие продукты производятся с использованием периодического потока?
Продукция, производимая с использованием периодического потока, — хлебобулочные изделия, компьютерные микросхемы, одежда, газеты, журналы, книги, электротовары, джиговые изделия.
Как повысить эффективность пакетного потока?
Пакетный поток менее эффективен по сравнению с непрерывным потоком. Но каким-то образом вы можете повысить эффективность пакетного потока, выполнив следующие шаги.
Уменьшить возможности вида продукции
Если вы производите от 16 до 20 видов печенья, задайте себе вопрос, выгодно ли производить от 16 до 20 видов печенья?. Затем просмотрите спрос на файлы cookie.
Найдите быстродействующие файлы cookie и создайте файлы cookie только этого типа.Затем удалите медленные, менее прибыльные типы файлов cookie.
Тем не менее, вы хотите производить все виды, а затем увеличить время производства медленного печенья, чтобы получить больше заказов во время процесса.
Переместить сотрудников во время переключения
Предположим, что у вас есть 15 сотрудников на производстве партии, и вам нужно изменить настройку для другой партии.
В это время оставьте только одного или двух сотрудников для изменения настроек и временно переведите других работников на другую работу, пока настройки не изменятся.
Сотрудники используют это время для уборки помещения, помощи другим сотрудникам.
Увеличьте стоимость специальной партии
Некоторые клиенты просят индивидуальные или уникальные продукты. Так что эта партия требует некоторых дополнительных настроек. Но, с другой стороны, это уменьшает количество переключений. Следовательно, взимайте дополнительную плату за эти продукты.
Внедрение бережливого производства
Метод бережливого производства помогает сократить время переключения. Это уменьшает расточительный процесс.
Непрерывный процесс
В этом процессе одна рабочая единица перемещается между всеми этапами без перерывов во времени. Здесь движение продуктов или единиц происходит непрерывно.
Преимущества непрерывного потока:
- Экономия времени и энергии
- Помогает сэкономить деньги за счет сокращения складских запасов и транспортных расходов
- Улучшает качество продукта за счет легкого выявления неисправности
- Повышает производительность
- Эффективно удовлетворяет потребности клиентов по сравнению с периодическим процессом
В чем разница между пакетным и непрерывным потоком?
На приведенном выше рисунке показано время, затрачиваемое как на периодические, так и на непрерывные процессы. Время, необходимое для первого продукта в периодическом процессе, составляет 21 мин. На изготовление одной партии из 10 изделий уходит 30 минут.
Время, необходимое для первого продукта в периодическом процессе, составляет 21 мин. На изготовление одной партии из 10 изделий уходит 30 минут.
Время, необходимое для получения первого продукта в непрерывном процессе, составляет 3 минуты. Следовательно, производство десяти продуктов занимает 12 минут.
Ниже приведены существенные различия между периодическим и непрерывным потоком.
- Стоимость оборудования высока при непрерывном процессе и низка при периодическом процессе.
- В периодическом процессе трудно поддерживать хорошее качество продукции, поскольку дефекты не выявляются до тех пор, пока вся партия не будет завершена.В то время как в непрерывном процессе легко найти дефект в продукте, потому что в этом процессе один продукт перемещается между каждой стадией процесса.
- Производительность меньше в непрерывном потоке, но выше в периодическом процессе.
- Выключение происходит чаще в пакетном процессе, тогда как в непрерывном процессе это происходит редко.
- Пакетный процесс очень прост в управлении. Но обращение с непрерывным потоком затруднено.
- Для непрерывного потока требуется большое рабочее место, тогда как для периодического потока требуется небольшое рабочее место.

Заключение
Подводя итог, можно сказать, что пакетный поток — это система, которая лучше всего подходит для производственных и сборочных процессов. Он использует концепцию «размера партии», чтобы заставить всю группу единиц проходить через производство одновременно, чтобы минимизировать затраты за счет снижения уровня запасов (для чего требуется больше места) и избегания времени наладки между этапами.
Системы с непрерывным потоком также популярны, потому что они обеспечивают лучшее обслуживание клиентов, позволяя быстрее реагировать в периоды пиковой нагрузки, сокращать потребность в рабочей силе на каждом этапе процесса и идти в ногу с изменениями спроса или конструкции продукта, не прерывая операции.
В некоторых отраслях требуется периодический поток, например, в фармацевтике, пищевой промышленности, а также в производстве чувствительных и редких металлов.