3 MB vs 8 MB Cache GECID.com. Страница 1
::>Процессоры >2016 > Как влияет объем кэш-памяти на производительность в играх? Intel Skylake: 3 MB vs 8 MB Cache18-12-2016
Страница 1 Страница 2 Одной страницейПриветствуем вас на сайте GECID.com! Хорошо известно, что тактовая частота и количество ядер процессора напрямую влияют на уровень производительности, особенно в оптимизированных под многопоточность проектах. Мы же решили проверить, какую роль в этом играет кэш-память уровня L3?
Для исследования этого вопроса нам был любезно предоставлен интернет-магазином pcshop.
Если это ощутимо повлияет на производительность, тогда можно будет провести еще один тест с представителем серии Core i5, у которых на борту 6 МБ кэша L3.
Но пока вернемся к текущему тесту. Помогать участникам будет видеокарта MSI GeForce GTX 1070 GAMING X 8G и 16 ГБ оперативной памяти DDR4-2400 МГц. Сравнивать эти системы будем в разрешении Full HD.
Для начала начнем с рассинхронизированных живых геймплев, в которых невозможно однозначно определить победителя. В Dying Light на максимальных настройках качества обе системы показывают комфортный уровень FPS, хотя загрузка процессора и видеокарты в среднем была выше именно в случае Intel Core i7.
Arma 3
Игра DOOM на ультравысоких настройках графики позволила синхронизировать лишь первые несколько кадров, где перевес Core i7 составляет около 10 FPS. Рассинхронизация дельнейшего геймплея не позволяет определить степень влияния кэша на скорость видеоряда. В любом случае частота держалась выше 120 кадров/с, поэтому особого влияния даже 10 FPS на комфортность прохождения не оказывают.
Завершает мини-серию живых геймплеев 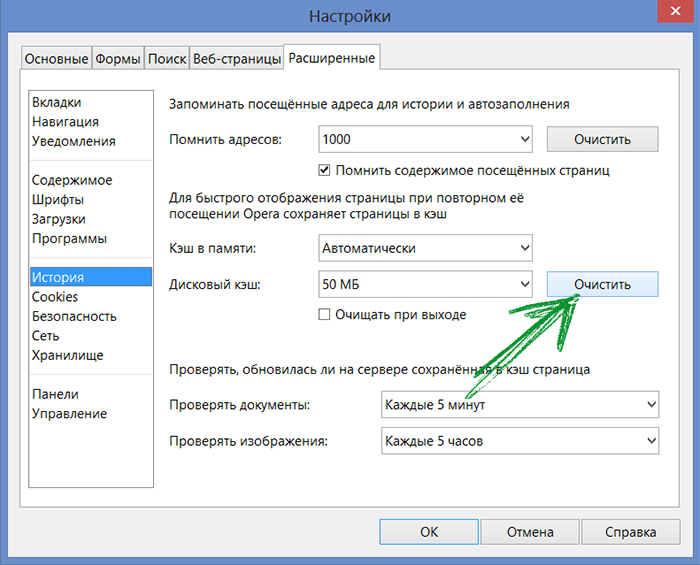
Более информативную картину дают бенчмарки. Например, в GTA V можно увидеть, что за городом преимущество 8 МБ кэша достигает 5-6 кадров/с, а в городе – до 10 FPS благодаря более высокой загрузке видеокарты. При этом сам видеоускоритель в обоих случаях загружен далеко не на максимум, и все зависит именно от CPU.
Третий ведьмак мы запустили с запредельными настройками графики и высоким профилем постобработки. В одной из заскриптованных сцен преимущество Core i7 местами достигает 6-8 FPS при резкой смене ракурса и необходимости подгрузки новых данных. Когда же нагрузка на процессор и видеокарту опять достигают 100%, то разница уменьшается до 2-3 кадров.
Максимальный пресет графических настроек в XCOM 2 не стал серьезным испытанием для обеих систем, и частота кадров находилась в районе 100 FPS. Но и здесь больший объем кэш-памяти трансформировался в прибавку к скорости от 2 до 12 кадров/с. И хотя обоим процессорам не удалось по максимум загрузить видеокарту, вариант на 8 МБ и в этом вопросе местами преуспевал лучше.
Больше всего удивила игра Dirt Rally, которую мы запустили с пресетом очень высоко. В определенные моменты разница доходила до 25 кадров/с исключительно из-за большего объема кэш-памяти L3. Это позволяло на 10-15% лучше загружать видеокарту. Однако средние показатели бенчмарка показали более скромную победу Core i7 — всего 11 FPS.
Интересная ситуация получилась и с Rainbow Six Siege: на улице, в первых кадрах бенчмарка, преимущество Core i7 составляло 10-15 FPS. Внутри помещения загрузка процессоров и видеокарты в обоих случаях достигла 100%, поэтому разница уменьшилась до 3-6 FPS. Но в конце, когда камера вышла за пределы дома, отставание Core i3 опять местами превышало 10 кадров/с. Средний же показатель оказался на уровне 7 FPS в пользу 8 МБ кэша.
Перехитрить производителя. Как разблокировали ядра и кеш у процессоров и конвейеры у видеокарт | Процессоры | Блог
Со времен первых IBM PC между производителями и покупателями появилось противостояние. Производитель хотел подороже продать, покупатель — дешевле купить и получить лучшую производительность или функционал устройства. Давайте вспомним, как пользователи включали заблокированные ядра, кеш и конвейеры на процессорах и видеокартах.
Производитель хотел подороже продать, покупатель — дешевле купить и получить лучшую производительность или функционал устройства. Давайте вспомним, как пользователи включали заблокированные ядра, кеш и конвейеры на процессорах и видеокартах.
Самое наглядное проявление этого — разгон комплектущих: процессора, видеокарты и памяти. Но сегодня я хочу вспомнить моменты, когда удавалось включить дополнительные блоки устройств — кэш или ядра у процессоров, конвейеры у видеокарт. А также случаи, когда с помощью модификации удавалось заставить материнскую плату поддерживать более новые процессоры, чем на которые она проектировалась.
Процессоры и материнские платы
Довольно интересное устройство, которое позволяло установить в материнские платы с разъемом SLOT 1 процессоры, предназначенные под сокет 370. Это «слоткет» или, как его называли у нас — переходник SLOT 1 — сокет 370.
Слоткеты различались качеством изготовления, функциональностью и сложностью. Некоторые переходники позволяли регулировать напряжение ядра процессора (VCore), а например, PowerLeap PL-iP3/T полностью заменял VRM, расположенный на материнской плате.
Некоторые переходники позволяли регулировать напряжение ядра процессора (VCore), а например, PowerLeap PL-iP3/T полностью заменял VRM, расположенный на материнской плате.
Следующая интересная переделка связана с процессорами AMD Athlon XP. У моделей на ядрах Applebred, Thoroughbredи Barton с помощью замыкания определенных ножек или контактов у чипа, удавалось разблокировать множитель процессора, получив аналог нынешних процессоров для разгона серии «K».
Это был довольно сложный процесс, чреватый повреждением процессора. Например, у процессоров AMD Athlon XP на ядрах Thunderbird, Palomino, Spitfire и Morgan разблокировка множителя делалась уже по другим контактам. Дополнительно можно было повысить напряжение на процессоре до максимального (2 вольта).
Но самая интересная и выгодная переделка происходила с процессорами AMD Athlon XP на ядре Thorton. Вооружившись лезвием, клеем и токопроводящим лаком, опытный пользователь мог разблокировать не только множитель, но и дополнительные 256 Кбайт кэша второго уровня, превратив процессор в полный аналог AMD Athlon XP на ядре Barton.
Вооружившись лезвием, клеем и токопроводящим лаком, опытный пользователь мог разблокировать не только множитель, но и дополнительные 256 Кбайт кэша второго уровня, превратив процессор в полный аналог AMD Athlon XP на ядре Barton.
Выпускались и заводские комплекты переходников, которые позволяли замкнуть нужные ножки, но особого распространения они не получили. Например, адаптерXP-TMC от Upgradeware.
Следующая переделка опять связана с продукцией компании AMD. Это был наиболее яркий и заметный способ из всех. У процессоров Phenom II и Athlon II удавалось включить не только кеш, но и заблокированные ядра! Не всегда переделанный процессор становился полноценным и стабильным, но случаев удачной переделки было очень много.
Phenom II X4 8хх — Разблокировались 2 МБ кэша L3
Phenom II X3 7хх — разблокировалось четвёртое ядро.
Phenom II X2 5хх — разблокировались третье и четвертое ядра
Athlon II X4 — разблокировался кэш L3 (при ядре Deneb).
Athlon II X3 — разблокировалось четвёртое ядро (в случае ядра Deneb — кэш L3)
Sempron 130/140/145/150 — разблокировалось второе ядро.
Процессоры Phenom II X4 моделей 650T, 840T, 960Т и 970 Black Edition определенной даты выпуска можно было разблокировать до шестиядерных.
Athlon X2 5000+ — уникальный процессор, имеющий название, уже использовавшееся у процессора под сокет AM2 на ядре Brisbane, однако производился на новом ядре Deneb. Его удавалось разблокировать до четырехядерного Phenom II X4 9хх.
Производители материнских плат с энтузиазмом поддержали разблокировку, встроив специальные функции в материнские платы.
У MSI технология называлась Unlock CPU Core, у GIGABYTE — Auto Unlock, у ASRock — ASRock UCC.
Из более актуальных методов доработки материнских плат хочется отметить возможность разгона неоверклокерских процессоров Intel Skylake.
С помощью перепрошивки специального BIOS снималась блокировка частоты базового тактового генератора у всего модельного ряда Skylake (интеловская защита BCLK Governor). Это позволяло разогнать недорогие LGA1151-процессоры по шине, получив солидный прирост производительности. Но при этом возникал целый ворох проблем, самая скверная из которых — снижение скорости выполнения AVX/AVX2-инструкций.
Еще одна интересная переделка — это возможность установки процессоров Xeon под сокет 771 в материнские платы LGA 775. Путем модификаций BIOS материнских плат, доработки сокета, текстолита процессора и замыканию определенных его ножек удавалось установить недорогие Xeon в массово распространенные материнские платы LGA 775.
До сих пор AliExpress завален этими недорогими, но мощными процессорами, по скорости сравнимыми с Core 2 Quad. Даже сегодня можно собрать систему с четырехядерным процессором и восемью гигабайтами памяти, которая будет комфортно чувствовать себя в серфинге интернета, офисной работе и нетребовательных играх.
Сейчас энтузиастами ведутся работы над материнскими платами разъема LGA 2011 и LGA 2011-3 по расширению списка поддерживаемых процессоров и разгону процессоров, изначально лишенных этой функции. Это позволяет собрать уже серьезную по производительности систему, сопоставимую со средними AMD Ryzen.
Дефицит материнских плат под эти разъемы восполняют китайские производители, наладив выпуск довольно качественных материнских плат HUANAN.
Совсем недавно появились способы переделки материнских плат LGA 1151 на чипсете 100-й и 200-й серии под процессоры Coffee Lake.
Глядя на все эти обширные списки переделок становится понятно, что компания Intel довольно искусственно и бесцеремонно пересаживает пользователей с чипсета на чипсет, которые по сути ничем не отличаются друг от друга. А заблокированный разгон, когда за «K» процессор просятся дополнительные деньги, уже стал всем привычен.
Все это — следствие отсутствия нормальной конкуренции в последние годы. Но теперь процессоры AMD Ryzen все изменили.
Видеокарты
На рынке видеокарт историй с разблокированием функционала было не меньше, и начать хочется с 3dfx Velocity 100. Это был первый случай блокировки функционала видеокарт.
3dfx Velocity 100 отличалась от более старшей модели Voodoo3 1000 тем, что имела отключенный один из двух блоков TMU (Texture Mapping Unit). Путем редактирования всего одной строки в реестре Velocity 100 превращалась в старшую модель — Voodoo3 1000.
Этот способ начала применять и компания ATI, изготавливая на основе полноценного видеочипа Radeon два типа младших видеокарт – Radeon LE и Radeon VE. У Radeon LE отключалась функция HyperZ, а у Radeon VE — T&L (Hardware Transformation & lighting).
В 2003 году часть видеокарт ATI Radeon 9500PROвыпускалась на основе чипа и платы от ATI Radeon 9700 PRO и позволяла осуществить переделку в старшую модель с помощью припаивания дополнительного резистора и перепрошивки BIOS. Потом появилась возможность только программной переделки.
Следующая линейка предтоповых видеокарт, ATI Radeon 9800 SE, могла разблокироваться до полноценной Radeon 9800 PRO.
В 2004 году, выпустив семейство видеокарт GeForce 6ххх, NVIDIA пошла по стопам ATI и начала отключать часть блоков в видеокартах. В NVIDIA GeForce 6800 было программно заблокировано 4 пиксельных и 1 вершинный конвейер, по сравнению со старшей GeForce 6800 ULTRA с формулой 16/6. Путем прошивки отредактированного BIOS и редактирования драйвера через RivaTuner младшая модель становилась идентична старшей.
В NVIDIA GeForce 6800 было программно заблокировано 4 пиксельных и 1 вершинный конвейер, по сравнению со старшей GeForce 6800 ULTRA с формулой 16/6. Путем прошивки отредактированного BIOS и редактирования драйвера через RivaTuner младшая модель становилась идентична старшей.
Конкуренты шестой серии GeForce, ATI Radeon X800 PRO, в некоторых случаях могли с помощью перепрошивки BIOS превратиться в старшую модель — ATI Radeon X800 XT. Однако, 100% результат достигался только при перепрошивки специальной серии ATI Radeon X800 GTO2.
Еще из видеокарт тех лет нужно упомянуть разблокировку GeForce 6200 в GeForce 6600, если ревизия чипа была ниже «А4». Но массовым явлением это уже не было. Как и изредка удававшаяся разблокировка конвейеров в NVIDIA GeForce 9600GSO.
А вот разблокирование AMD RADEON HD 6950 в старшую версию AMD RADEON HD 6970 удавалось заметно чаще. Прошивка в HD 6950 BIOS от старшей модели увеличивало количество потоковых конвейеров с 1408 до 1536, а частоты с 800/1250 МГц до 880/1375 МГц.
Прошивка в HD 6950 BIOS от старшей модели увеличивало количество потоковых конвейеров с 1408 до 1536, а частоты с 800/1250 МГц до 880/1375 МГц.
Потом похожее по простоте решение удавалось провернуть на AMD Radeon R9 290, превращая ее в старшую модель AMD Radeon R9 290X.
Из видеокарт наших дней хотелось бы вспомнить AMD Radeon RX 480 на 4 ГБ. На старте продаж путем перепрошивки BIOS от модели AMD Radeon RX 480 на 8 ГБ иногда удавалось получить четыре дополнительных гигабайта памяти.
А на видеокарте Radeon RX 460, имеющей 896 потоковых процессоров, путем перепрошивки BIOS удавалось получить 1024.
Итоги
Как вы заметили, больше всего в плане разблокировки дополнительных функций пользователей радовала компания AMD. Сейчас она на наших глазах возвращает конкурентную борьбу на рынок процессоров и, быть может мы снова получим возможность включать заблокированный кэш и ядра. Ведь когда идет борьба за пользователей и рынок, такая лотерея обеспечивает прирост довольных покупателей весьма простым методом.
Ведь когда идет борьба за пользователей и рынок, такая лотерея обеспечивает прирост довольных покупателей весьма простым методом.
Устранение проблем с программой запуска Epic Games – Поддержка Epic Games
При наличии проблем в работе программы запуска Epic Games, воспользуйтесь приведёнными ниже способами исправления наиболее часто возникающих ошибок.
Проверьте состояние сервера Epic Games
Посетите страницу состояния сервера Epic Games, чтобы убедиться, что все системы работают корректно. Если программа запуска Epic Games не работает из-за перебоя или системного сбоя, ваша проблема может разрешиться, после возобновления нормальной работы системы.
Проверить на наличие обновлений
Проверьте, есть ли обновления для программы запуска. Для этого выберите «Настройки» (шестерёнка в левом нижнем углу), если вы видите кнопку с надписью: «ПЕРЕЗАПУСТИТЬ И ОБНОВИТЬ», выберите её, чтобы обновить программу запуска.
Очистите веб-кэш программы запуска
Очистка веб-кэша часто решает проблемы с отображением, которые могут помешать
вам использовать программу запуска. Выполните следующие шаги, чтобы очистить
ваш веб-кэш:
Выполните следующие шаги, чтобы очистить
ваш веб-кэш:
Выйдите из программы запуска Epic Games, щёлкнув правой кнопкой мыши значок на панели задач в правом нижнем углу и выбрав в появившемся меню пункт
Нажмите комбинацию Windows + R, введите “%localappdata%” и нажмите клавишу Enter, чтобы открыть окно проводника.
Откройте папку программы запуска Epic Games.
Откройте папку «Сохранённое».
Выберите папку «Веб-кэш» и удалите её.
- Перезагрузите компьютер и запустите программу запуска Epic Games.
Обновите драйверы видеокарты
Чтобы решить проблему сбоя программы запуска, убедитесь, что используются новейшие драйверы видеокарты. Как обновить графические драйверы, описано в этой статье.
Откройте программу запуска от имени администратора
Запуск программы от имени администратора повышает её права, что позволяет
избежать проблем с загрузкой игр. Выполните следующие действия, чтобы
запустить программу от имени администратора:
Выполните следующие действия, чтобы
запустить программу от имени администратора:
- Щёлкните правой кнопкой мыши на ярлыке программы запуска Epic Games.
- Выберите пункт «Запуск от имени администратора».
Переустановите программу запуска Epic Games
В Windows:Примечание. Все ваши установленные игры будут удалены.
Запустите проверку системных файлов, затем переустановите программу запуска Epic Games.
- Выйдите из программы запуска Epic Games, щёлкнув правой кнопкой мыши значок
на панели задач в правом нижнем углу и выбрав в появившемся меню пункт
- Нажмите «Пуск».
- Введите cmd, щёлкните правой кнопкой мыши по командной строке и выберите пункт «Запуск от имени администратора».
- В открывшемся окне введите sfc /scannow и нажмите
клавишу Enter.

Это может занять некоторое время. - Перезагрузите компьютер.
- Нажмите «Пуск».
- Введите «Установка и удаление программ» и нажмите клавишу
- Выберите программу запуска Epic Games из списка программ.
- Нажмите «Удалить».
- Зайдите на сайт www.epicgames.com и нажмите «Загрузить Epic Games» в верхнем правом углу, чтобы скачать последнюю версию установщика программы запуска.

- Закройте программу запуска Epic Games.
- Откройте программу «Мониторинг системы» и убедитесь, что у вас нет запущенных процессов, связанных с программой запуска Epic Games.
- Откройте папку «Приложения».
- Нажмите на программу запуска Epic Games и перетащите её в
- Убедитесь, что во всех следующих каталогах больше нет папок или файлов
программы запуска Epic Games:
- ~/Library/Application Support
- ~/Library/Caches
- ~/Library/Preferences
- ~/Library/Logs
- ~/Library/Cookies
- Зайдите на сайт www. epicgames.com и
нажмите «Загрузить Epic Games» в верхнем правом
углу, чтобы скачать последнюю версию установщика программы запуска.
 epicgames.com и
нажмите «Загрузить Epic Games» в верхнем правом
углу, чтобы скачать последнюю версию установщика программы запуска.
epicgames.com и
нажмите «Загрузить Epic Games» в верхнем правом
углу, чтобы скачать последнюю версию установщика программы запуска.Программа запуска зависает на MacOS 10.15.1 или более ранних версиях
Если ваша программа запуска зависает на MacOS 10.15.1 или более ранней версии, выполните описанные выше действия, чтобы переустановить программу запуска Epic Games на вашем Mac.
Проверьте системные требования
Убедитесь, что ваш компьютер соответствует системным требованиям для работы программы запуска Epic Games. Системные требования для работы программы запуска Epic Games можно найти здесь.
Мигающий значок программы запуска Epic Games на панели задач
Если вы не можете запустить программу запуска Epic Games и видите мигающий значок на панели задач, попробуйте следующие шаги, чтобы устранить эту проблему:
- Щёлкните правой кнопкой мыши на ярлыке программы запуска Epic Games.
- Нажмите «Свойства».
- Выберите «Обычный размер окна» в раскрывающемся меню напротив опции «Окно».
- Выберите вкладку «Совместимость».
- Снимите флажки и нажмите «Применить», затем «ОК».
- Откройте меню «Пуск», затем введите «Параметры обработки изображений» и нажмите клавишу «Ввод».
- В раскрывающемся списке в разделе «Настройки производительности графики» выберите «Классическое приложение».
- Нажмите «Обзор».
- Перейдите в каталог установки программы запуска Epic Games.
По умолчанию это C:/Program Files (x86)/Epic Games/Launcher/Portal/Binaries/Win64. - Щёлкните файл EpicGamesLauncher.exe и выберите пункт «Добавить».
- Нажмите «Параметры».
- Выберите «Энергосбережение».
- Нажмите кнопку «Сохранить».
- Перезапустите программу запуска Epic Games.


Если описанные выше действия не помогли решить вашу проблему, убедитесь, что у вас установлены все последние обновления Windows. Подробные инструкции о том, как это сделать, см. в этой статье.
Объём памяти видеокарты или почему 4 Гб – это не «победа»
Когда среднестатистический пользователь подбирает видеокарту, для новой системы или апгрейда компьютера, то обязательно, решающим фактором при выборе будет объём видеопамяти. И практически всегда, делать это решающим фактором – неуместно и неправильно. В данной статье, мы рассмотрим парадоксальный образец видеокарты с «гипер объёмом» видеопамяти, в сравнении с добротными образцами и обсудим, вышеупомянутую, очень популярную и выгодную для разработчиков характеристику.
Если учитывать факт наличия в видеокарте отдельного процессора – GPU, то будет логично, что здесь будет и своя память. Видеопамять играет роль некого кадрового буфера, в который направляются видеоданные, для дальнейшего считывания и обработки их графическим процессором, а также здесь хранятся текстуры.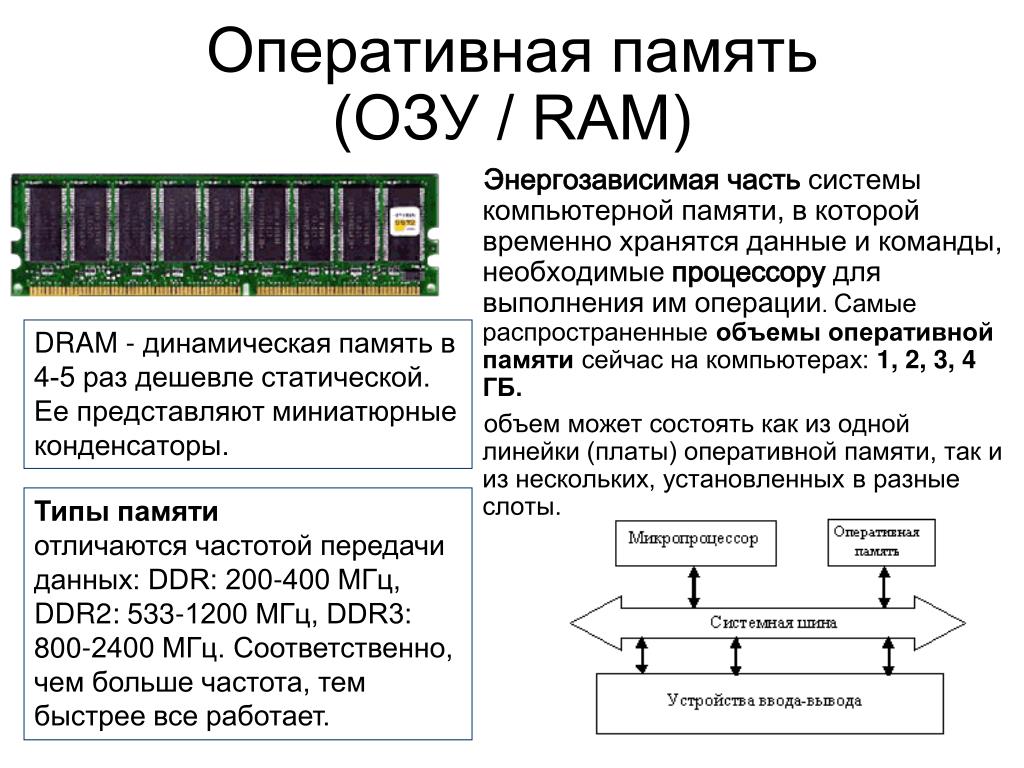
Видеопамять. Больше – не значит лучше
Сравнивая разные образцы видеокарт, пользователь, который практически не разбирается в характеристиках, будет на подсознательном уровне смотреть в сторону моделей с меньшей ценой и большим объёмом видеопамяти. Так как, всем хорошо известен факт – чем больше, тем лучше. Но вот, почему же тогда видеокарта Asus GT630 c 4 Гб видеопамяти стоит 80$, а HD 7850 со «скромным» 1 Гб – 200$? В чем же здесь подвох? Именно на этом и наживаются производители видеокарт, не жалея прибавки объёма видеопамяти, при этом «безбожно» урезая все остальные параметры. Поэтому, «больше» и «практично», в данном случае, не приравниваются.
У Asus GT 630 тип памяти GDDR 3, с шириной шины 128 бит, а у Asus HD 7850 – GDDR 5 с шириной шины 256 бит, что в результате даёт огромную разницу в частотных показателях памяти и общей пропускной способности. У Asus GT 630, эти самые 4 Гб, будут просто простаивать, учитывая другие параметры данной бюджетной видеокарты. Если она сможет загружать хотя бы 512 Мбайт своей же видеопамяти– это уже будет отлично.
Относительно пропускной способности и типов видеопамяти, мы поговорим в отдельных статьях, которые будет подробно описывать эти немаловажные параметры видеокарты.
Сколько нужно видеопамяти?
Будем говорить усреднено, то есть относительно игровой нагрузки, не отклоняясь на рабочую специфику. Сколько используют видеопамяти современные игры? Каждая игра по-разному, но пиковые «запросы» относительно объёма видеопамяти, даже у требовательных игрушек, не такие уж и большие, как может показаться на первый взгляд.
Рис. 2
На рис.2 отображены результаты тестирования с overclockers.ru, которые показывают среднее значение потребления видеопамяти в нескольких десятках игр, у топовых видеокарт на чипах прошлой линейки от AMD и Nvidia. Хорошо видно, что в разрешениях 1920х1080 и ниже, целиком и полностью хватает 1024 Мбайт. А вот для игры в разрешениях 2560х1600, лучше приобрести видеокарту с большим объёмом видеопамяти.
Для ещё более требовательных игр, таких как Crysis 2, рекомендуются видеокарты с 2 Гб видеопамяти.
При этом всём есть нюанс, данные оценки видеопамяти подойдут только для видеокарты Asus HD 7850 из двух ранее нами упомянутых. А вот для Asus GT 630, её «могучие» 4 Гб мало помогут в требовательных играх, так как не могут быть подкреплены, другими характеристиками, такими как та же ПСП.
Объём видеопамяти. Выводы.
Осталось подвести небольшие итоги.
Для видеокарт бюджетного сегмента, стоимостью до 70$, не имеют смысла 1,2, 3, 4 Гб, так как зачастую они позиционируются под не требовательные игры и офисные задачи. Так что, в «бюджетнейшем» диапазоне, рекомендуется покупать видеокарты с объёмом видеопамяти 512Мбайт — 1 Гб (но и это в большинстве случаев будет избыточно).
Также, можно отметить, что для видеокарт средней и выше среднего производительности, которые позиционируется для игры на обычных разрешениях, вплоть до 1920х1080, хватит 1-1,5 Гб (для большинства игр).
Когда речь заходит о топовых и близких к «вершине» видеокартах, стоимостью от 350$, то здесь можно не мелочиться и выбирать видеокарты с объёмом видеопамяти 2 – 3 Гб. Больше 3 Гб, для обычных задач, без специфического уклона, будут также избыточны.
Больше 3 Гб, для обычных задач, без специфического уклона, будут также избыточны.
Но главный вывод в том, что если вы покупаете «средненькую» видеокарту, для «средненьких» игр, то не нужно смотреть «влюблёнными глазами» на модели с большим объёмом видеопамяти, в надежде, что это даст прирост производительности за небольшую цену.
Помощь по Теле2, тарифы, вопросы
Речь идет не о наличности, а о кэш -памяти процессоров и не только. Из объема кэш -памяти торгаши сделали очередной коммерческий фетиш, в особенности с кэшем центральных процессоров и жестких дисков (у видеокарт он тоже есть – но до него пока не добрались). Итак, есть процессор ХХХ с кэшем L2 объемом 1Мб, и точно такой же процессор XYZ с кэшем объемом 2Мб. Угадайте какой лучше? Аа – вот не надо так сразу!
Кэш -память – это буфер, куда складывается то, что можно и/или нужно отложить на потом. Процессор выполняет работу и возникают ситуации, когда промежуточные данные нужно где-то сохранить. Ну конечно в кэше! – ведь он на порядки быстрее, чем оперативная память, т.к. он в самом кристалле процессора и обычно работает на той же частоте. А потом, через какое то время, эти данные он выудит обратно и будет снова их обрабатывать. Грубо говоря как сортировщик картошки на конвейере, который каждый раз, когда попадается что-то другое кроме картошки (морковка ) , бросает ее в ящик. А когда тот полон – встает и выносит его в соседнюю комнату. В этот момент конвейер стоит и наблюдается простой. Объем ящика и есть кэш в данной аналогии. И сколько его надо – 1Мб или 12? Понятно, что если его объем мал придется слишком много времени уделят выносу и будет простой, но с какого то объема его дальнейшее увеличение ничего не даст. Ну будет ящик у сортировщика на 1000кг морковки – да у него за всю смену столько ее не будет и от этого он НЕ СТАНЕТ В ДВА РАЗА БЫСТРЕЕ! Есть еще одна тонкость – большой кэш может вызывать увеличение задержек обращения к нему во-первых, а заодно повышается и вероятность возникновения ошибок в нем, например при разгоне – во-вторых.
Ну конечно в кэше! – ведь он на порядки быстрее, чем оперативная память, т.к. он в самом кристалле процессора и обычно работает на той же частоте. А потом, через какое то время, эти данные он выудит обратно и будет снова их обрабатывать. Грубо говоря как сортировщик картошки на конвейере, который каждый раз, когда попадается что-то другое кроме картошки (морковка ) , бросает ее в ящик. А когда тот полон – встает и выносит его в соседнюю комнату. В этот момент конвейер стоит и наблюдается простой. Объем ящика и есть кэш в данной аналогии. И сколько его надо – 1Мб или 12? Понятно, что если его объем мал придется слишком много времени уделят выносу и будет простой, но с какого то объема его дальнейшее увеличение ничего не даст. Ну будет ящик у сортировщика на 1000кг морковки – да у него за всю смену столько ее не будет и от этого он НЕ СТАНЕТ В ДВА РАЗА БЫСТРЕЕ! Есть еще одна тонкость – большой кэш может вызывать увеличение задержек обращения к нему во-первых, а заодно повышается и вероятность возникновения ошибок в нем, например при разгоне – во-вторых. (о том КАК в этом случае определить стабильность/нестабильность процессора и выяснить что ошибка возникает именно в его кэше, протестировать L1 и L2 – можно прочесть тут.) В-третьих – кэш выжирает приличную площадь кристалла и транзисторный бюджет схемы процессора. То же самое касается и кэш памяти жестких дисков. И если архитектура процессора сильная – у него будет востребовано во многих приложениях 1024Кб кэша и более. Если у вас быстрый HDD – 16Мб или даже 32Мб уместны. Но никакие 64Мб кэша не сделают его быстрее, если это обрезок под названием грин версия (Green WD) с частотой оборотов 5900 вместо положеных 7200, пусть даже у последнего будет и 8Мб. Потом процессоры Intel и AMD по-разному используют этот кэш (вообще говоря AMD более эффективно и их процессоры часто комфортно довольствуются меньшими значениями). Вдобавок у Intel кэш общий, а вот у AMD он персональный у каждого ядра. Самый быстрый кэш L1 у процессоров AMD составляет по 64Кб на данные и инструкции, что вдвое больше, чем у Intel.
(о том КАК в этом случае определить стабильность/нестабильность процессора и выяснить что ошибка возникает именно в его кэше, протестировать L1 и L2 – можно прочесть тут.) В-третьих – кэш выжирает приличную площадь кристалла и транзисторный бюджет схемы процессора. То же самое касается и кэш памяти жестких дисков. И если архитектура процессора сильная – у него будет востребовано во многих приложениях 1024Кб кэша и более. Если у вас быстрый HDD – 16Мб или даже 32Мб уместны. Но никакие 64Мб кэша не сделают его быстрее, если это обрезок под названием грин версия (Green WD) с частотой оборотов 5900 вместо положеных 7200, пусть даже у последнего будет и 8Мб. Потом процессоры Intel и AMD по-разному используют этот кэш (вообще говоря AMD более эффективно и их процессоры часто комфортно довольствуются меньшими значениями). Вдобавок у Intel кэш общий, а вот у AMD он персональный у каждого ядра. Самый быстрый кэш L1 у процессоров AMD составляет по 64Кб на данные и инструкции, что вдвое больше, чем у Intel. Кэш третьего уровня L3 обычно присутствует у топовых процессоров наподобие AMD Phenom II 1055T X6 Socket AM3 2.8GHz или у конкурента в лице Intel Core i7-980X. Прежде всего большие объемы кэша любят игры. И кэш НЕ любят многие профессиональные приложения (см. Компьютер для рендеринга, видеомонтажа и профприложений). Точнее наиболее требовательные к нему вообще равнодушны. Но чего точно не стоит делать, так это выбирать процессор по объему кэша. Старенький Pentium 4 в последних своих проявлениях имел и по 2Мб кэша при частотах работы далеко за 3ГГц – сравните его производительность с дешевеньким двуядерничком Celeron E1***, работающим на частотах около 2ГГц. Он не оставит от старичка камня на камне. Более актуальный пример – высокочастотный двухъядерник E8600 стоимостью чуть не 200$ (видимо из-за 6Мб кэша) и Athlon II X4-620 2,6ГГц, у которого всего 2Мб. Это не мешает Атлону разделать конкурента под орех.
Кэш третьего уровня L3 обычно присутствует у топовых процессоров наподобие AMD Phenom II 1055T X6 Socket AM3 2.8GHz или у конкурента в лице Intel Core i7-980X. Прежде всего большие объемы кэша любят игры. И кэш НЕ любят многие профессиональные приложения (см. Компьютер для рендеринга, видеомонтажа и профприложений). Точнее наиболее требовательные к нему вообще равнодушны. Но чего точно не стоит делать, так это выбирать процессор по объему кэша. Старенький Pentium 4 в последних своих проявлениях имел и по 2Мб кэша при частотах работы далеко за 3ГГц – сравните его производительность с дешевеньким двуядерничком Celeron E1***, работающим на частотах около 2ГГц. Он не оставит от старичка камня на камне. Более актуальный пример – высокочастотный двухъядерник E8600 стоимостью чуть не 200$ (видимо из-за 6Мб кэша) и Athlon II X4-620 2,6ГГц, у которого всего 2Мб. Это не мешает Атлону разделать конкурента под орех.
Как видно на графиках – ни в сложных программах, ни в требовательных к процессору играх никакой кэш не заменит дополнительных ядер. Athlon с 2Мб кэша (красный) легко побеждает Cor2Duo с 6Мб кэша даже при меньшей частота и чуть не вдвое меньшей стоимости. Так же многие забывают, что кэш присутствует в видеокартах, потому что в них, вообще говоря, тоже есть процессоры. Свежий пример видеокарта GTX460, где умудряются не только порезать шину и объем памяти (о чем покупатель догадается) – но и КЭШ шейдеров соответственно с 512Кб до 384Кб (о чем покупатель уже НЕ догадается). А это тоже добавит свой негативный вклад в производительность. Интересно еще будет выяснить зависимость производительности от объема кэша. Исследуем как быстро она растет с увеличением объема кэша на примере одного и того же процессора. Как известно процессоры серии E6*** , E4*** и E2*** отличаются только объемом кэша (по 4, 2 и 1 Мб соответственно). Работая на одинаковой частоте 2400МГц они показывают следующие результаты.
Athlon с 2Мб кэша (красный) легко побеждает Cor2Duo с 6Мб кэша даже при меньшей частота и чуть не вдвое меньшей стоимости. Так же многие забывают, что кэш присутствует в видеокартах, потому что в них, вообще говоря, тоже есть процессоры. Свежий пример видеокарта GTX460, где умудряются не только порезать шину и объем памяти (о чем покупатель догадается) – но и КЭШ шейдеров соответственно с 512Кб до 384Кб (о чем покупатель уже НЕ догадается). А это тоже добавит свой негативный вклад в производительность. Интересно еще будет выяснить зависимость производительности от объема кэша. Исследуем как быстро она растет с увеличением объема кэша на примере одного и того же процессора. Как известно процессоры серии E6*** , E4*** и E2*** отличаются только объемом кэша (по 4, 2 и 1 Мб соответственно). Работая на одинаковой частоте 2400МГц они показывают следующие результаты.
Как видно – результаты не слишком отличаются. Скажу больше – если бы участвовал процессор с объемом 6Мб – результат увеличился бы еще на чуть-чуть, т. к. процессоры достигают насыщения. А вот для моделей с 512Кб падение было бы ощутимым. Другими словами 2Мб даже в играх вполне достаточно. Резюмируя можно сделать такой вывод – кэш это хорошо, когда УЖЕ много всего остального. Наивно и глупо менять скорость оборотов винчестера или количество ядер процессора на объем кэша при равной стоимости, ибо даже самый емкий ящик для сортировки не заменит еще одного сортировщика Но есть и хорошие примеры.. Например Pentium Dual-Core в ранней ревизии по 65-нм процессу имел 1Мб кэша на два ядра (серия E2160 и подобные), а поздняя 45-нм ревизия серии E5200 и дальше имеет уже 2Мб при прочих равных условиях (а главное – ЦЕНЕ). Конечно же стоит выбирать именно последний.
к. процессоры достигают насыщения. А вот для моделей с 512Кб падение было бы ощутимым. Другими словами 2Мб даже в играх вполне достаточно. Резюмируя можно сделать такой вывод – кэш это хорошо, когда УЖЕ много всего остального. Наивно и глупо менять скорость оборотов винчестера или количество ядер процессора на объем кэша при равной стоимости, ибо даже самый емкий ящик для сортировки не заменит еще одного сортировщика Но есть и хорошие примеры.. Например Pentium Dual-Core в ранней ревизии по 65-нм процессу имел 1Мб кэша на два ядра (серия E2160 и подобные), а поздняя 45-нм ревизия серии E5200 и дальше имеет уже 2Мб при прочих равных условиях (а главное – ЦЕНЕ). Конечно же стоит выбирать именно последний.
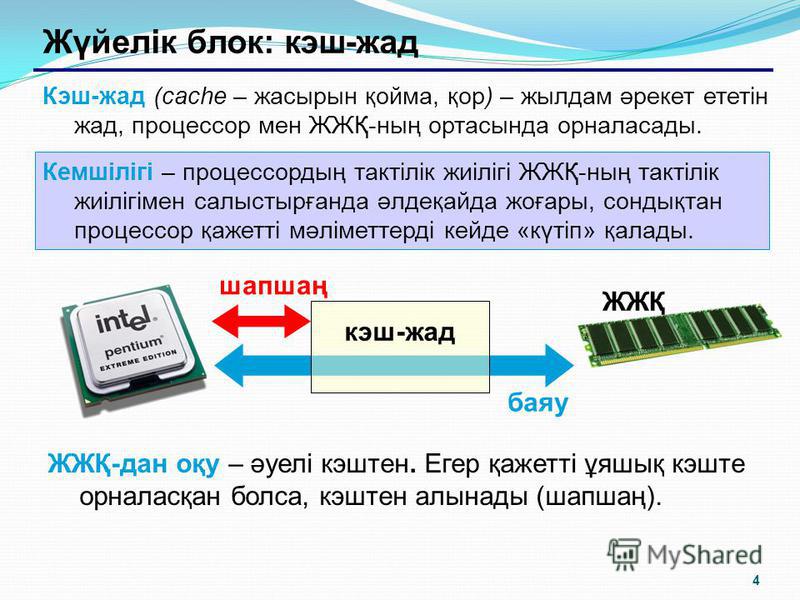
Одним из немаловажных факторов повышающих производительность процессора, является наличие кэш-памяти, а точнее её объём, скорость доступа и распределение по уровням.
Уже достаточно давно практически все процессоры оснащаются данным типом памяти, что ещё раз доказывает полезность её наличия. В данной статье, мы поговорим о структуре, уровнях и практическом назначении кэш-памяти, как об очень немаловажной характеристике процессора
.
В данной статье, мы поговорим о структуре, уровнях и практическом назначении кэш-памяти, как об очень немаловажной характеристике процессора
.
Что такое кэш-память и её структура
Кэш-память – это сверхбыстрая память используемая процессором, для временного хранения данных, которые наиболее часто используются. Вот так, вкратце, можно описать данный тип памяти.
Кэш-память построена на триггерах, которые, в свою очередь, состоят из транзисторов. Группа транзисторов занимает гораздо больше места, нежели те же самые конденсаторы, из которых состоит оперативная память
. Это тянет за собой множество трудностей в производстве, а также ограничения в объёмах. Именно поэтому кэш память является очень дорогой памятью, при этом обладая ничтожными объёмами. Но из такой структуры, вытекает главное преимущество такой памяти – скорость. Так как триггеры не нуждаются в регенерации, а время задержки вентиля, на которых они собраны, невелико, то время переключения триггера из одного состояния в другое происходит очень быстро. Это и позволяет кэш-памяти работать на таких же частотах, что и современные процессоры.
Это и позволяет кэш-памяти работать на таких же частотах, что и современные процессоры.
Также, немаловажным фактором является размещение кэш-памяти. Размещена она, на самом кристалле процессора, что значительно уменьшает время доступа к ней. Ранее, кэш память некоторых уровней, размещалась за пределами кристалла процессора, на специальной микросхеме SRAM где-то на просторах материнской платы. Сейчас же, практически у всех процессоров, кэш-память размещена на кристалле процессора.
Для чего нужна кэш-память процессора?
Как уже упоминалось выше, главное назначение кэш-памяти – это хранение данных, которые часто используются процессором. Кэш является буфером, в который загружаются данные, и, несмотря на его небольшой объём, (около 4-16 Мбайт) в современных процессорах , он дает значительный прирост производительности в любых приложениях.
Чтобы лучше понять необходимость кэш-памяти, давайте представим себе организацию памяти компьютера в виде офиса. Оперативная память будет являть собою шкаф с папками, к которым периодически обращается бухгалтер, чтобы извлечь большие блоки данных (то есть папки). А стол, будет являться кэш-памятью.
А стол, будет являться кэш-памятью.
Есть такие элементы, которые размещены на столе бухгалтера, к которым он обращается в течение часа по несколько раз. Например, это могут быть номера телефонов, какие-то примеры документов. Данные виды информации находятся прямо на столе, что, в свою очередь,увеличивает скорость доступа к ним.
Точно так же, данные могут добавиться из тех больших блоков данных (папок), на стол, для быстрого использования, к примеру, какой-либо документ. Когда этот документ становится не нужным, его помещают назад в шкаф (в оперативную память), тем самым очищая стол (кэш-память) и освобождая этот стол для новых документов, которые будут использоваться в последующий отрезок времени.
Также и с кэш-памятью, если есть какие-то данные, к которым вероятнее всего будет повторное обращение, то эти данные из оперативной памяти, подгружаются в кэш-память. Очень часто, это происходит с совместной загрузкой тех данных, которые вероятнее всего, будут использоваться после текущих данных. То есть, здесь присутствует наличие предположений о том, что же будет использовано «после». Вот такие непростые принципы функционирования.
То есть, здесь присутствует наличие предположений о том, что же будет использовано «после». Вот такие непростые принципы функционирования.
Уровни кэш-памяти процессора
Современные процессоры, оснащены кэшем, который состоит, зачастую из 2–ух или 3-ёх уровней. Конечно же, бывают и исключения, но зачастую это именно так.
В общем, могут быть такие уровни: L1 (первый уровень), L2 (второй уровень), L3 (третий уровень). Теперь немного подробнее по каждому из них:
Кэш первого уровня (L1) – наиболее быстрый уровень кэш-памяти, который работает напрямую с ядром процессора, благодаря этому плотному взаимодействию, данный уровень обладает наименьшим временем доступа и работает на частотах близких процессору. Является буфером между процессором и кэш-памятью второго уровня.
Мы будем рассматривать объёмы на процессоре высокого уровня производительности Intel Core i7-3770K. Данный процессор оснащен 4х32 Кб кэш-памяти первого уровня 4 x 32 КБ = 128 Кб. (на каждое ядро по 32 КБ)
Кэш второго уровня (L2) – второй уровень более масштабный, нежели первый, но в результате, обладает меньшими «скоростными характеристиками». Соответственно, служит буфером между уровнем L1 и L3. Если обратиться снова к нашему примеру Core i7-3770 K, то здесь объём кэш-памяти L2 составляет 4х256 Кб = 1 Мб.
Соответственно, служит буфером между уровнем L1 и L3. Если обратиться снова к нашему примеру Core i7-3770 K, то здесь объём кэш-памяти L2 составляет 4х256 Кб = 1 Мб.
Кэш третьего уровня (L3) – третий уровень, опять же, более медленный, нежели два предыдущих. Но всё равно он гораздо быстрее, нежели оперативная память. Объём кэша L3 в i7-3770K составляет 8 Мбайт. Если два предыдущих уровня разделяются на каждое ядро, то данный уровень является общим для всего процессора. Показатель довольно солидный, но не заоблачный. Так как, к примеру, у процессоров Extreme-серии по типу i7-3960X, он равен 15Мб, а у некоторых новых процессоров Xeon, более 20.
Всем пользователям хорошо известны такие элементы компьютера, как процессор, отвечающий за обработку данных, а также оперативная память (ОЗУ или RAM), отвечающая за их хранение. Но далеко не все, наверное, знают, что существует и кэш-память процессора(Cache CPU), то есть оперативная память самого процессора (так называемая сверхоперативная память).
В чем же состоит причина, которая побудила разработчиков компьютеров использовать специальную память для процессора? Разве возможностей ОЗУ для компьютера недостаточно?
Действительно, долгое время персональные компьютеры обходились без какой-либо кэш-памяти. Но, как известно, процессор – это самое быстродействующее устройство персонального компьютера и его скорость росла с каждым новым поколением CPU. В настоящее время его скорость измеряется миллиардами операций в секунду. В то же время стандартная оперативная память не столь значительно увеличила свое быстродействие за время своей эволюции.
Вообще говоря, существуют две основные технологии микросхем памяти – статическая память и динамическая память. Не углубляясь в подробности их устройства, скажем лишь, что статическая память, в отличие от динамической, не требует регенерации; кроме того, в статической памяти для одного бита информации используется 4-8 транзисторов, в то время как в динамической – 1-2 транзистора. Соответственно динамическая память гораздо дешевле статической, но в то же время и намного медленнее. В настоящее время микросхемы ОЗУ изготавливаются на основе динамической памяти.
Соответственно динамическая память гораздо дешевле статической, но в то же время и намного медленнее. В настоящее время микросхемы ОЗУ изготавливаются на основе динамической памяти.
Примерная эволюция соотношения скорости работы процессоров и ОЗУ:
Таким образом, если бы процессор брал все время информацию из оперативной памяти, то ему пришлось бы ждать медлительную динамическую память, и он все время бы простаивал. В том же случае, если бы в качестве ОЗУ использовалась статическая память, то стоимость компьютера возросла бы в несколько раз.
Именно поэтому был разработан разумный компромисс. Основная часть ОЗУ так и осталась динамической, в то время как у процессора появилась своя быстрая кэш-память, основанная на микросхемах статической памяти. Ее объем сравнительно невелик – например, объем кэш-памяти второго уровня составляет всего несколько мегабайт. Впрочем, тут стоить вспомнить о том, что вся оперативная память первых компьютеров IBM PC составляла меньше 1 МБ.
Кроме того, на целесообразность внедрения технологии кэширования влияет еще и тот фактор, что разные приложения, находящиеся в оперативной памяти, по-разному нагружают процессор, и, как следствие, существует немало данных, требующих приоритетной обработки по сравнению с остальными.
История кэш-памяти
Строго говоря, до того, как кэш-память перебралась на персоналки, она уже несколько десятилетий успешно использовалась в суперкомпьютерах.
Впервые кэш-память объемом всего в 16 КБ появилась в ПК на базе процессора i80386. На сегодняшний день современные процессоры используют различные уровни кэша, от первого (самый быстрый кэш самого маленького объема – как правило, 128 КБ) до третьего (самый медленный кэш самого большого объема – до десятков МБ).
Сначала внешняя кэш-память процессора размещалась на отдельном чипе. Со временем, однако, это привело к тому, что шина, расположенная между кэшем и процессором, стала узким местом, замедляющим обмен данными. В современных микропроцессорах и первый, и второй уровни кэш-памяти находятся в самом ядре процессора.
В современных микропроцессорах и первый, и второй уровни кэш-памяти находятся в самом ядре процессора.
Долгое время в процессорах существовали всего два уровня кэша, но в CPU Intel Itanium впервые появилась кэш-память третьего уровня, общая для всех ядер процессора. Существуют и разработки процессоров с четырехуровневым кэшем.
Архитектуры и принципы работы кэша
На сегодняшний день известны два основных типа организации кэш-памяти, которые берут свое начало от первых теоретических разработок в области кибернетики – принстонская и гарвардская архитектуры. Принстонская архитектура подразумевает единое пространство памяти для хранения данных и команд, а гарвардская – раздельное. Большинство процессоров персональных компьютеров линейки x86 использует раздельный тип кэш-памяти. Кроме того, в современных процессорах появился также третий тип кэш-памяти – так называемый буфер ассоциативной трансляции, предназначенный для ускорения преобразования адресов виртуальной памяти операционной системы в адреса физической памяти.
Упрощенно схему взаимодействия кэш-памяти и процессора можно описать следующим образом. Сначала происходит проверка наличия нужной процессору информации в самом быстром — кэше первого уровня, затем — в кэше второго уровня, и.т.д. Если же нужной информации в каком-либо уровне кэша не оказалось, то говорят об ошибке, или промахе кэша. Если информации в кэше нет вообще, то процессору приходится брать ее из ОЗУ или даже из внешней памяти (с жесткого диска).
Порядок поиска процессором информации в памяти:
Именно таким образом Процессор осуществляет поиск инфоромации
Для управления работой кэш-памяти и ее взаимодействия с вычислительными блоками процессора, а также ОЗУ существует специальный контроллер.
Схема организации взаимодействия ядра процессора, кэша и ОЗУ:
Кэш-контроллер является ключевым элементом связи процессора, ОЗУ и Кэш-памяти
Следует отметить, что кэширование данных – это сложный процесс, в ходе которого используется множество технологий и математических алгоритмов. Среди базовых понятий, применяющихся при кэшировании, можно выделить методы записи кэша и архитектуру ассоциативности кэш-памяти.
Среди базовых понятий, применяющихся при кэшировании, можно выделить методы записи кэша и архитектуру ассоциативности кэш-памяти.
Методы записи кэша
Существует два основных метода записи информации в кэш-память:
- Метод write-back (обратная запись) – запись данных производится сначала в кэш, а затем, при наступлении определенных условий, и в ОЗУ.
- Метод write-through (сквозная запись) – запись данных производится одновременно в ОЗУ и в кэш.
Архитектура ассоциативности кэш-памяти
Архитектура ассоциативности кэша определяет способ, при помощи которого данные из ОЗУ отображаются в кэше. Существуют следующие основные варианты архитектуры ассоциативности кэширования:
- Кэш с прямым отображением – определенный участок кэша отвечает за определенный участок ОЗУ
- Полностью ассоциативный кэш – любой участок кэша может ассоциироваться с любым участком ОЗУ
- Смешанный кэш (наборно-ассоциативный)
На различных уровнях кэша обычно могут использоваться различные архитектуры ассоциативности кэша. Кэширование с прямым отображением ОЗУ является самым быстрым вариантом кэширования, поэтому эта архитектура обычно используется для кэшей большого объема. В свою очередь, полностью ассоциативный кэш обладает меньшим количеством ошибок кэширования (промахов).
Кэширование с прямым отображением ОЗУ является самым быстрым вариантом кэширования, поэтому эта архитектура обычно используется для кэшей большого объема. В свою очередь, полностью ассоциативный кэш обладает меньшим количеством ошибок кэширования (промахов).
Заключение
В этой статье вы познакомились с понятием кэш-памяти, архитектурой кэш-памяти и методами кэширования, узнали о том, как она влияет на производительность современного компьютера. Наличие кэш-памяти позволяет значительно оптимизировать работу процессора, уменьшить время его простоя, а, следовательно, и увеличить быстродействие всей системы.
Приветствуем вас на сайте GECID.com! Хорошо известно, что тактовая частота и количество ядер процессора напрямую влияют на уровень производительности, особенно в оптимизированных под многопоточность проектах. Мы же решили проверить, какую роль в этом играет кэш-память уровня L3?
Для исследования этого вопроса нам был любезно предоставлен интернет-магазином pcshop. ua 2-ядерный процессор с номинальной рабочей частотой 3,7 ГГц и 3 МБ кэш-памяти L3 с 12-ю каналами ассоциативности. В роли оппонента выступил 4-ядерный , у которого были отключены два ядра и снижена тактовая частота до 3,7 ГГц. Объем же кэша L3 у него составляет 8 МБ, и он имеет 16 каналов ассоциативности. То есть ключевая разница между ними заключается именно в кэш-памяти последнего уровня: у Core i7 ее на 5 МБ больше.
ua 2-ядерный процессор с номинальной рабочей частотой 3,7 ГГц и 3 МБ кэш-памяти L3 с 12-ю каналами ассоциативности. В роли оппонента выступил 4-ядерный , у которого были отключены два ядра и снижена тактовая частота до 3,7 ГГц. Объем же кэша L3 у него составляет 8 МБ, и он имеет 16 каналов ассоциативности. То есть ключевая разница между ними заключается именно в кэш-памяти последнего уровня: у Core i7 ее на 5 МБ больше.
Если это ощутимо повлияет на производительность, тогда можно будет провести еще один тест с представителем серии Core i5, у которых на борту 6 МБ кэша L3.
Но пока вернемся к текущему тесту. Помогать участникам будет видеокарта и 16 ГБ оперативной памяти DDR4-2400 МГц. Сравнивать эти системы будем в разрешении Full HD.
Для начала начнем с рассинхронизированных живых геймплев, в которых невозможно однозначно определить победителя. В Dying Light на максимальных настройках качества обе системы показывают комфортный уровень FPS, хотя загрузка процессора и видеокарты в среднем была выше именно в случае Intel Core i7.
Arma 3 имеет хорошо выраженную процессорозависимость, а значит больший объем кэш-памяти должен сыграть свою позитивную роль даже при ультравысоких настройках графики. Тем более что нагрузка на видеокарту в обоих случаях достигала максимум 60%.
Игра DOOM на ультравысоких настройках графики позволила синхронизировать лишь первые несколько кадров, где перевес Core i7 составляет около 10 FPS. Рассинхронизация дельнейшего геймплея не позволяет определить степень влияния кэша на скорость видеоряда. В любом случае частота держалась выше 120 кадров/с, поэтому особого влияния даже 10 FPS на комфортность прохождения не оказывают.
Завершает мини-серию живых геймплеев Evolve Stage 2 . Здесь мы наверняка увидели бы разницу между системами, поскольку в обоих случаях видеокарта загружена ориентировочно на половину. Поэтому субъективно кажется, что уровень FPS в случае Core i7 выше, но однозначно сказать нельзя, поскольку сцены не идентичные.
Более информативную картину дают бенчмарки. Например, в GTA V можно увидеть, что за городом преимущество 8 МБ кэша достигает 5-6 кадров/с, а в городе — до 10 FPS благодаря более высокой загрузке видеокарты. При этом сам видеоускоритель в обоих случаях загружен далеко не на максимум, и все зависит именно от CPU.
Третий ведьмак мы запустили с запредельными настройками графики и высоким профилем постобработки. В одной из заскриптованных сцен преимущество Core i7 местами достигает 6-8 FPS при резкой смене ракурса и необходимости подгрузки новых данных. Когда же нагрузка на процессор и видеокарту опять достигают 100%, то разница уменьшается до 2-3 кадров.
Максимальный пресет графических настроек в XCOM 2 не стал серьезным испытанием для обеих систем, и частота кадров находилась в районе 100 FPS. Но и здесь больший объем кэш-памяти трансформировался в прибавку к скорости от 2 до 12 кадров/с. И хотя обоим процессорам не удалось по максимум загрузить видеокарту, вариант на 8 МБ и в этом вопросе местами преуспевал лучше.
Больше всего удивила игра Dirt Rally , которую мы запустили с пресетом очень высоко. В определенные моменты разница доходила до 25 кадров/с исключительно из-за большего объема кэш-памяти L3. Это позволяло на 10-15% лучше загружать видеокарту. Однако средние показатели бенчмарка показали более скромную победу Core i7 — всего 11 FPS.
Интересная ситуация получилась и с Rainbow Six Siege : на улице, в первых кадрах бенчмарка, преимущество Core i7 составляло 10-15 FPS. Внутри помещения загрузка процессоров и видеокарты в обоих случаях достигла 100%, поэтому разница уменьшилась до 3-6 FPS. Но в конце, когда камера вышла за пределы дома, отставание Core i3 опять местами превышало 10 кадров/с. Средний же показатель оказался на уровне 7 FPS в пользу 8 МБ кэша.
The Division при максимальном качестве графики также хорошо реагирует на увеличение объема кэш памяти. Уже первые кадры бенчмарка по полной загрузили все потоки Core i3, а вот общая нагрузка на Core i7 составляла 70-80%. Однако разница в скорости в эти моменты составляла всего 2-3 FPS. Чуть позже нагрузка на оба процессора достигла 100%, а разница в определенные моменты уже была за Core i3, но лишь на 1-2 кадра/с. В среднем же она составила около 1 FPS в пользу Core i7.
Однако разница в скорости в эти моменты составляла всего 2-3 FPS. Чуть позже нагрузка на оба процессора достигла 100%, а разница в определенные моменты уже была за Core i3, но лишь на 1-2 кадра/с. В среднем же она составила около 1 FPS в пользу Core i7.
В свою очередь бенчмарк Rise of Tomb Rider при высоких настройках графики во всех трех тестовых сценах наглядно показал преимущество процессора с значительно большим объемом кэш памяти. Средние показатели у него на 5-6 FPS лучше, но если внимательно посмотреть каждую сцену, то местами отставание Core i3 превышает 10 кадров/с.
А вот при выборе пресета с очень высокими настройками возрастает нагрузка на видеокарту и процессоры, поэтому в большинстве своем разница между системами уменьшается до нескольких кадров. И лишь кратковременно Core i7 может показывать более значимые результаты. Средние показатели его преимущества по итогам бенчмарка снизились до 3-4 FPS.
Hitman также меньше подвержен влиянию кэш-памяти L3. Хотя и здесь при ультравысоком профиле детализации дополнительные 5 МБ обеспечили лучшую загрузку видеокарты, превратив это в дополнительные 3-4 кадра/с. Особо критичного влияния на производительность они не оказывают, но из чисто спортивного интереса приятно, что есть победитель.
Хотя и здесь при ультравысоком профиле детализации дополнительные 5 МБ обеспечили лучшую загрузку видеокарты, превратив это в дополнительные 3-4 кадра/с. Особо критичного влияния на производительность они не оказывают, но из чисто спортивного интереса приятно, что есть победитель.
Высокие настройки графики Deus ex: Mankind divided сразу же потребовали максимальной вычислительной мощности от обеих систем, поэтому разница в лучшем случае составляла 1-2 кадра в пользу Core i7, на что указывает и средний показатель.
Повторный запуск при ультравысоком пресете еще сильнее загрузил видеокарту, поэтому влияние процессора на общую скорость стало еще меньшим. Соответственно, разница в кэш-памяти L3 практически не влияла на ситуацию и средний FPS отличался менее чем на полкадра.
По итогам тестирования можно отметить, что влияние кэш-памяти L3 на производительность в играх действительно имеет место, но оно проявляется лишь тогда, когда видеокарта не загружена на полную мощность. В таких случаях можно было бы получить прирост в 5-10 FPS, если бы кэш увеличился в 2,5 раза. То есть ориентировочно получается, что при прочих равных каждый дополнительный МБ кэш-памяти L3 добавляет только 1-2 FPS к скорости отображения видеоряда.
В таких случаях можно было бы получить прирост в 5-10 FPS, если бы кэш увеличился в 2,5 раза. То есть ориентировочно получается, что при прочих равных каждый дополнительный МБ кэш-памяти L3 добавляет только 1-2 FPS к скорости отображения видеоряда.
Так что, если сравнивать соседние линейки, например, Celeron и Pentium, или модели с разным объем кэш-памяти L3 внутри серии Core i3, то основной прирост производительности достигается благодаря более высоким частотам, а потом и наличию дополнительных процессорных потоков и ядер. Поэтому, выбирая процессор, в первую очередь, все же, нужно ориентироваться на основные характеристики, а только потом обращать внимание на объем кэш-памяти.
На этом все. Спасибо за внимание. Надеемся, этот материал был полезным и интересным.
Статья прочитана 26737 раз(а)
| Подписаться на наши каналы | |||||
Кэш — память (кеш , cash , буфер — eng. ) — применяется в цифровых устройствах, как высокоскоростной буфер обмена. Кэш память можно встретить на таких устройствах компьютера как , процессоры, сетевые карты, приводы компакт дисков и многих других.
) — применяется в цифровых устройствах, как высокоскоростной буфер обмена. Кэш память можно встретить на таких устройствах компьютера как , процессоры, сетевые карты, приводы компакт дисков и многих других.
Принцип работы и архитектура кэша могут сильно отличаться.
К примеру, кэш может служить как обычный буфер обмена . Устройство обрабатывает данные и передаёт их в высокоскоростной буфер, где контроллёр передаёт данные на интерфейс. Предназначен такой кэш для предотвращения ошибок, аппаратной проверки данных на целостность, либо для кодировки сигнала от устройства в понятный сигнал для интерфейса, без задержек. Такая система применяется например в CD/DVD приводах компакт дисков.
В другом случае, кэш может служить для хранения часто используемого кода и тем самым ускорения обработки данных. То есть, устройству не нужно снова вычислять или искать данные, что заняло бы гораздо больше времени, чем чтение их из кэш-а. В данном случае очень большую роль играет размер и скорость кэш-а.
Такая архитектура чаще всего встречается на жёстких дисках, и центральных процессорах (CPU ).
При работе устройств, в кэш могут загружаться специальные прошивки или программы диспетчеры, которые работали бы медленней с ПЗУ (постоянное запоминающее устройство).
Большинство современных устройство, используют смешанный тип кэша , который может служить как буфером обмена, как и для хранения часто используемого кода.
Существует несколько очень важных функций, реализуемых для кэша процессоров и видео чипов.
Объединение исполнительных блоков . В центральных процессорах и видео процессорах часто используется быстрый общий кэш между ядрами. Соответственно, если одно ядро обработало информацию и она находится в кэше, а поступает команда на такую же операцию, либо на работу с этими данными, то данные не будут снова обрабатываться процессором, а будут взяты из кэша для дальнейшей обработки. Ядро будет разгружено для обработки других данных. Это значительно увеличивает производительность в однотипных, но сложных вычислениях, особенно если кэш имеет большой объём и скорость.
Это значительно увеличивает производительность в однотипных, но сложных вычислениях, особенно если кэш имеет большой объём и скорость.
Общий кэш , также позволяет ядрам работать с ним напрямую, минуя медленную .
Кэш для инструкций. Существует либо общий очень быстрый кэш первого уровня для инструкций и других операций, либо специально выделенный под них. Чем больше в процессоре заложенных инструкций, тем больший кэш для инструкций ему требуется. Это уменьшает задержки памяти и позволяет блоку инструкций функционировать практически независимо.При его заполнении, блок инструкций начинает периодически простаивать, что замедляет скорость вычисления.
Другие функции и особенности .
Примечательно, что в CPU (центральных процессорах), применяется аппаратная коррекция ошибок (ECC ), потому как небольшая ошибочка в кэше, может привести к одной сплошной ошибке при дальнейшей обработке этих данных.
В CPU и GPU существует иерархия кэш памяти , которая позволяет разделять данные для отдельных ядер и общие. Хотя почти все данные из кэша второго уровня, всё равно копируются в третий, общий уровень, но не всегда. Первый уровень кеша — самый быстрый, а каждый последующий всё медленней, но больше по размеру.
Хотя почти все данные из кэша второго уровня, всё равно копируются в третий, общий уровень, но не всегда. Первый уровень кеша — самый быстрый, а каждый последующий всё медленней, но больше по размеру.
Для процессоров, нормальным считается три и менее уровней кэша. Это позволяет добиться сбалансированности между скоростью, размером кэша и тепловыделением. В видеопроцессорах сложно встретить более двух уровней кэша.
Размер кэша, влияние на производительность и другие характеристики .
Естественно, чем больше кэш , тем больше данных он может хранить и обрабатывать, но тут есть серьёзная проблема.
Большой кеш — это большой бюджет . В серверных процессорах (CPU ), кэш может использовать до 80% транзисторного бюджета. Во первых, это сказывается на конечной стоимости, а во вторых увеличивается энергопотребление и тепловыделение, которое не сопоставимо с увеличенной на несколько процентов производительностью.
Новый подход к кэшированию процессора. Что такое кэш, зачем он нужен и как работает
Приветствуем вас на сайте GECID.com! Хорошо известно, что тактовая частота и количество ядер процессора напрямую влияют на уровень производительности, особенно в оптимизированных под многопоточность проектах. Мы же решили проверить, какую роль в этом играет кэш-память уровня L3?
Для исследования этого вопроса нам был любезно предоставлен интернет-магазином pcshop.ua 2-ядерный процессор с номинальной рабочей частотой 3,7 ГГц и 3 МБ кэш-памяти L3 с 12-ю каналами ассоциативности. В роли оппонента выступил 4-ядерный , у которого были отключены два ядра и снижена тактовая частота до 3,7 ГГц. Объем же кэша L3 у него составляет 8 МБ, и он имеет 16 каналов ассоциативности. То есть ключевая разница между ними заключается именно в кэш-памяти последнего уровня: у Core i7 ее на 5 МБ больше.
Если это ощутимо повлияет на производительность, тогда можно будет провести еще один тест с представителем серии Core i5, у которых на борту 6 МБ кэша L3.
Но пока вернемся к текущему тесту. Помогать участникам будет видеокарта и 16 ГБ оперативной памяти DDR4-2400 МГц. Сравнивать эти системы будем в разрешении Full HD.
Для начала начнем с рассинхронизированных живых геймплев, в которых невозможно однозначно определить победителя. В Dying Light на максимальных настройках качества обе системы показывают комфортный уровень FPS, хотя загрузка процессора и видеокарты в среднем была выше именно в случае Intel Core i7.
Arma 3 имеет хорошо выраженную процессорозависимость, а значит больший объем кэш-памяти должен сыграть свою позитивную роль даже при ультравысоких настройках графики. Тем более что нагрузка на видеокарту в обоих случаях достигала максимум 60%.
Игра DOOM на ультравысоких настройках графики позволила синхронизировать лишь первые несколько кадров, где перевес Core i7 составляет около 10 FPS. Рассинхронизация дельнейшего геймплея не позволяет определить степень влияния кэша на скорость видеоряда. В любом случае частота держалась выше 120 кадров/с, поэтому особого влияния даже 10 FPS на комфортность прохождения не оказывают.
В любом случае частота держалась выше 120 кадров/с, поэтому особого влияния даже 10 FPS на комфортность прохождения не оказывают.
Завершает мини-серию живых геймплеев Evolve Stage 2 . Здесь мы наверняка увидели бы разницу между системами, поскольку в обоих случаях видеокарта загружена ориентировочно на половину. Поэтому субъективно кажется, что уровень FPS в случае Core i7 выше, но однозначно сказать нельзя, поскольку сцены не идентичные.
Более информативную картину дают бенчмарки. Например, в GTA V можно увидеть, что за городом преимущество 8 МБ кэша достигает 5-6 кадров/с, а в городе — до 10 FPS благодаря более высокой загрузке видеокарты. При этом сам видеоускоритель в обоих случаях загружен далеко не на максимум, и все зависит именно от CPU.
Третий ведьмак мы запустили с запредельными настройками графики и высоким профилем постобработки. В одной из заскриптованных сцен преимущество Core i7 местами достигает 6-8 FPS при резкой смене ракурса и необходимости подгрузки новых данных. Когда же нагрузка на процессор и видеокарту опять достигают 100%, то разница уменьшается до 2-3 кадров.
Когда же нагрузка на процессор и видеокарту опять достигают 100%, то разница уменьшается до 2-3 кадров.
Максимальный пресет графических настроек в XCOM 2 не стал серьезным испытанием для обеих систем, и частота кадров находилась в районе 100 FPS. Но и здесь больший объем кэш-памяти трансформировался в прибавку к скорости от 2 до 12 кадров/с. И хотя обоим процессорам не удалось по максимум загрузить видеокарту, вариант на 8 МБ и в этом вопросе местами преуспевал лучше.
Больше всего удивила игра Dirt Rally , которую мы запустили с пресетом очень высоко. В определенные моменты разница доходила до 25 кадров/с исключительно из-за большего объема кэш-памяти L3. Это позволяло на 10-15% лучше загружать видеокарту. Однако средние показатели бенчмарка показали более скромную победу Core i7 — всего 11 FPS.
Интересная ситуация получилась и с Rainbow Six Siege : на улице, в первых кадрах бенчмарка, преимущество Core i7 составляло 10-15 FPS. Внутри помещения загрузка процессоров и видеокарты в обоих случаях достигла 100%, поэтому разница уменьшилась до 3-6 FPS. Но в конце, когда камера вышла за пределы дома, отставание Core i3 опять местами превышало 10 кадров/с. Средний же показатель оказался на уровне 7 FPS в пользу 8 МБ кэша.
Внутри помещения загрузка процессоров и видеокарты в обоих случаях достигла 100%, поэтому разница уменьшилась до 3-6 FPS. Но в конце, когда камера вышла за пределы дома, отставание Core i3 опять местами превышало 10 кадров/с. Средний же показатель оказался на уровне 7 FPS в пользу 8 МБ кэша.
The Division при максимальном качестве графики также хорошо реагирует на увеличение объема кэш памяти. Уже первые кадры бенчмарка по полной загрузили все потоки Core i3, а вот общая нагрузка на Core i7 составляла 70-80%. Однако разница в скорости в эти моменты составляла всего 2-3 FPS. Чуть позже нагрузка на оба процессора достигла 100%, а разница в определенные моменты уже была за Core i3, но лишь на 1-2 кадра/с. В среднем же она составила около 1 FPS в пользу Core i7.
В свою очередь бенчмарк Rise of Tomb Rider при высоких настройках графики во всех трех тестовых сценах наглядно показал преимущество процессора с значительно большим объемом кэш памяти. Средние показатели у него на 5-6 FPS лучше, но если внимательно посмотреть каждую сцену, то местами отставание Core i3 превышает 10 кадров/с.
Средние показатели у него на 5-6 FPS лучше, но если внимательно посмотреть каждую сцену, то местами отставание Core i3 превышает 10 кадров/с.
А вот при выборе пресета с очень высокими настройками возрастает нагрузка на видеокарту и процессоры, поэтому в большинстве своем разница между системами уменьшается до нескольких кадров. И лишь кратковременно Core i7 может показывать более значимые результаты. Средние показатели его преимущества по итогам бенчмарка снизились до 3-4 FPS.
Hitman также меньше подвержен влиянию кэш-памяти L3. Хотя и здесь при ультравысоком профиле детализации дополнительные 5 МБ обеспечили лучшую загрузку видеокарты, превратив это в дополнительные 3-4 кадра/с. Особо критичного влияния на производительность они не оказывают, но из чисто спортивного интереса приятно, что есть победитель.
Высокие настройки графики Deus ex: Mankind divided сразу же потребовали максимальной вычислительной мощности от обеих систем, поэтому разница в лучшем случае составляла 1-2 кадра в пользу Core i7, на что указывает и средний показатель.
Повторный запуск при ультравысоком пресете еще сильнее загрузил видеокарту, поэтому влияние процессора на общую скорость стало еще меньшим. Соответственно, разница в кэш-памяти L3 практически не влияла на ситуацию и средний FPS отличался менее чем на полкадра.
По итогам тестирования можно отметить, что влияние кэш-памяти L3 на производительность в играх действительно имеет место, но оно проявляется лишь тогда, когда видеокарта не загружена на полную мощность. В таких случаях можно было бы получить прирост в 5-10 FPS, если бы кэш увеличился в 2,5 раза. То есть ориентировочно получается, что при прочих равных каждый дополнительный МБ кэш-памяти L3 добавляет только 1-2 FPS к скорости отображения видеоряда.
Так что, если сравнивать соседние линейки, например, Celeron и Pentium, или модели с разным объем кэш-памяти L3 внутри серии Core i3, то основной прирост производительности достигается благодаря более высоким частотам, а потом и наличию дополнительных процессорных потоков и ядер. Поэтому, выбирая процессор, в первую очередь, все же, нужно ориентироваться на основные характеристики, а только потом обращать внимание на объем кэш-памяти.
Поэтому, выбирая процессор, в первую очередь, все же, нужно ориентироваться на основные характеристики, а только потом обращать внимание на объем кэш-памяти.
На этом все. Спасибо за внимание. Надеемся, этот материал был полезным и интересным.
Статья прочитана 19812 раз(а)
| Подписаться на наши каналы | |||||
Насколько важен кэш L3 для процессоров AMD?
Действительно, имеет смысл оснащать многоядерные процессоры выделенной памятью, которая будет использоваться совместно всеми доступными ядрами. В данной роли быстрый кэш третьего уровня (L3) может существенно ускорить доступ к данным, которые запрашиваются чаще всего. Тогда ядрам, если существует такая возможность, не придётся обращаться к медленной основной памяти (ОЗУ, RAM).
По крайней мере, в теории. Недавно AMD анонсировала процессор Athlon II X4 , представляющий собой модель Phenom II X4 без кэша L3, намекая на то, что он не такой и необходимый. Мы решили напрямую сравнить два процессора (с кэшем L3 и без), чтобы проверить, как кэш влияет на производительность.
Мы решили напрямую сравнить два процессора (с кэшем L3 и без), чтобы проверить, как кэш влияет на производительность.
Нажмите на картинку для увеличения.
Как работает кэш?
Перед тем, как мы углубимся в тесты, важно понять некоторые основы. Принцип работы кэша довольно прост. Кэш буферизует данные как можно ближе к вычислительным ядрам процессора, чтобы снизить запросы CPU в более отдалённую и медленную память. У современных настольных платформ иерархия кэша включает целых три уровня, которые предваряют доступ к оперативной памяти. Причём кэши второго и, в частности, третьего уровней служат не только для буферизации данных. Их цель заключается в предотвращении перегрузки шины процессора, когда ядрам необходимо обменяться информацией.
Попадания и промахи
Эффективность архитектуры кэшей измеряется процентом попаданий. Запросы данных, которые могут быть удовлетворены кэшем, считаются попаданиями. Если данный кэш не содержит нужные данные, то запрос передаётся дальше по конвейеру памяти, и засчитывается промах. Конечно, промахи приводят к большему времени, которое требуется для получения информации. В результате в вычислительном конвейере появляются «пузырьки» (простои) и задержки. Попадания, напротив, позволяют поддержать максимальную производительность.
Конечно, промахи приводят к большему времени, которое требуется для получения информации. В результате в вычислительном конвейере появляются «пузырьки» (простои) и задержки. Попадания, напротив, позволяют поддержать максимальную производительность.
Запись в кэш, эксклюзивность, когерентность
Политики замещения диктуют, как в кэше освобождается место под новые записи. Поскольку данные, записываемые в кэш, рано или поздно должны появиться в основной памяти, системы могут делать это одновременно с записью в кэш (write-through) или могут маркировать данные области как «грязные» (write-back), а выполнять запись в память тогда, когда она будет вытесняться из кэша.
Данные в нескольких уровнях кэша могут храниться эксклюзивно, то есть без избыточности. Тогда вы не найдёте одинаковых строчек данных в двух разных иерархиях кэша. Либо кэши могут работать инклюзивно, то есть нижние уровни кэша гарантированно содержат данные, присутствующие в верхних уровнях кэша (ближе к процессорному ядру). У AMD Phenom используются эксклюзивный кэш L3, а Intel следует стратегии инклюзивного кэша. Протоколы когерентности следят за целостностью и актуальностью данных между разными ядрами, уровнями кэшей и даже процессорами.
У AMD Phenom используются эксклюзивный кэш L3, а Intel следует стратегии инклюзивного кэша. Протоколы когерентности следят за целостностью и актуальностью данных между разными ядрами, уровнями кэшей и даже процессорами.
Объём кэша
Больший по объёму кэш может содержать больше данных, но при этом наблюдается тенденция увеличения задержек. Кроме того, большой по объёму кэш потребляет немалое количество транзисторов процессора, поэтому важно находить баланс между «бюджетом» транзисторов, размером кристалла, энергопотреблением и производительностью/задержками.
Ассоциативность
Записи в оперативной памяти могут привязываться к кэшу напрямую (direct-mapped), то есть для копии данных из оперативной памяти существует только одна позиция в кэше, либо они могут быть ассоциативны в n-степени (n-way associative), то есть существует n возможных расположений в кэше, где могут храниться эти данные. Более высокая степень ассоциативности (вплоть до полностью ассоциативных кэшей) обеспечивает наилучшую гибкость кэширования, поскольку существующие данные в кэше не нужно переписывать. Другими словами, высокая n-степень ассоциативности гарантирует более высокий процент попаданий, но при этом увеличивается задержка, поскольку требуется больше времени на проверку всех этих ассоциаций для попадания. Как правило, наибольшая степень ассоциации разумна для последнего уровня кэширования, поскольку там доступна максимальная ёмкость, а поиск данных за пределами этого кэша приведёт к обращению процессора к медленной оперативной памяти.
Другими словами, высокая n-степень ассоциативности гарантирует более высокий процент попаданий, но при этом увеличивается задержка, поскольку требуется больше времени на проверку всех этих ассоциаций для попадания. Как правило, наибольшая степень ассоциации разумна для последнего уровня кэширования, поскольку там доступна максимальная ёмкость, а поиск данных за пределами этого кэша приведёт к обращению процессора к медленной оперативной памяти.
Приведём несколько примеров: у Core i5 и i7 используется 32 кбайт кэша L1 с 8-way ассоциативностью для данных и 32 кбайт кэша L1 с 4-way для инструкций. Понятно желание Intel, чтобы инструкции были доступны быстрее, а у кэша L1 для данных был максимальный процент попаданий. Кэш L2 у процессоров Intel обладает 8-way ассоциативностью, а кэш L3 у Intel ещё «умнее», поскольку в нём реализована 16-way ассоциативность для максимизации попаданий.
Однако AMD следует другой стратегии с процессорами Phenom II X4, где используется кэш L1 с 2-way ассоциативностью для снижения задержек. Чтобы компенсировать возможные промахи ёмкость кэша была увеличена в два раза: 64 кбайт для данных и 64 кбайт для инструкций. Кэш L2 имеет 8-way ассоциативность, как и у дизайна Intel, но кэш L3 у AMD работает с 48-way ассоциативностью. Но решение выбора той или иной архитектуры кэша нельзя оценивать без рассмотрения всей архитектуры CPU. Вполне естественно, что практическое значение имеют результаты тестов, и нашей целью как раз была практическая проверка всей этой сложной многоуровневой структуры кэширования.
Чтобы компенсировать возможные промахи ёмкость кэша была увеличена в два раза: 64 кбайт для данных и 64 кбайт для инструкций. Кэш L2 имеет 8-way ассоциативность, как и у дизайна Intel, но кэш L3 у AMD работает с 48-way ассоциативностью. Но решение выбора той или иной архитектуры кэша нельзя оценивать без рассмотрения всей архитектуры CPU. Вполне естественно, что практическое значение имеют результаты тестов, и нашей целью как раз была практическая проверка всей этой сложной многоуровневой структуры кэширования.
Каждый современный процессор имеет выделенный кэш, которых хранит инструкции и данные процессора, готовые к использованию практически мгновенно. Этот уровень обычно называют первым уровнем кэширования или L1, впервые такой кэш появился у процессоров 486DX. Недавно процессоры AMD стали стандартно использовать по 64 кбайт кэша L1 на ядро (для данных и инструкций), а процессоры Intel используют по 32 кбайт кэша L1 на ядро (тоже для данных и инструкций)
Кэш первого уровня впервые появился на процессорах 486DX, после чего он стал составной функцией всех современных CPU.
Кэш второго уровня (L2) появился на всех процессорах после выхода Pentium III, хотя первые его реализации на упаковке были в процессоре Pentium Pro (но не на кристалле). Современные процессоры оснащаются до 6 Мбайт кэш-памяти L2 на кристалле. Как правило, такой объём разделяется между двумя ядрами на процессоре Intel Core 2 Duo, например. Обычные же конфигурации L2 предусматривают 512 кбайт или 1 Мбайт кэша на ядро. Процессоры с меньшим объёмом кэша L2, как правило, относятся к нижнему ценовому уровню. Ниже представлена схема ранних реализаций кэша L2.
У Pentium Pro кэш L2 находился в упаковке процессора. У последовавших поколений Pentium III и Athlon кэш L2 был реализован через отдельные чипы SRAM, что было в то время очень распространено (1998, 1999).
Последовавшее объявление техпроцесса до 180 нм позволило производителям, наконец, интегрировать кэш L2 на кристалл процессора.
Первые двуядерные процессоры просто использовали существующие дизайны, когда в упаковку устанавливалось два кристалла. AMD представила двуядерный процессор на монолитном кристалле, добавила контроллер памяти и коммутатор, а Intel для своего первого двуядерного процессора просто собрала два одноядерных кристалла в одной упаковке.
AMD представила двуядерный процессор на монолитном кристалле, добавила контроллер памяти и коммутатор, а Intel для своего первого двуядерного процессора просто собрала два одноядерных кристалла в одной упаковке.
Впервые кэш L2 стал использоваться совместно двумя вычислительными ядрами на процессорах Core 2 Duo. AMD пошла дальше и создала свой первый четырёхъядерный Phenom «с нуля», а Intel для своего первого четырёхъядерного процессора вновь использовала пару кристаллов, на этот раз уже два двуядерных кристалла Core 2, чтобы снизить расходы.
Кэш третьего уровня существовал ещё с первых дней процессора Alpha 21165 (96 кбайт, процессоры представлены в 1995) или IBM Power 4 (256 кбайт, 2001). Однако в архитектурах на основе x86 кэш L3 впервые появился вместе с моделями Intel Itanium 2, Pentium 4 Extreme (Gallatin, оба процессора в 2003 году) и Xeon MP (2006).
Первые реализации давали просто ещё один уровень в иерархии кэша, хотя современные архитектуры используют кэш L3 как большой и общий буфер для обмена данными между ядрами в многоядерных процессорах. Это подчёркивает и высокая n-степень ассоциативности. Лучше поискать данные чуть дольше в кэше, чем получить ситуацию, когда несколько ядер используют очень медленный доступ к основной оперативной памяти. AMD впервые представила кэш L3 на процессоре для настольных ПК вместе с уже упоминавшейся линейкой Phenom. 65-нм Phenom X4 содержал 2 Мбайт общего кэша L3, а современные 45-нм Phenom II X4 имеют уже 6 Мбайт общего кэша L3. У процессоров Intel Core i7 и i5 используется 8 Мбайт кэша L3.
Это подчёркивает и высокая n-степень ассоциативности. Лучше поискать данные чуть дольше в кэше, чем получить ситуацию, когда несколько ядер используют очень медленный доступ к основной оперативной памяти. AMD впервые представила кэш L3 на процессоре для настольных ПК вместе с уже упоминавшейся линейкой Phenom. 65-нм Phenom X4 содержал 2 Мбайт общего кэша L3, а современные 45-нм Phenom II X4 имеют уже 6 Мбайт общего кэша L3. У процессоров Intel Core i7 и i5 используется 8 Мбайт кэша L3.
Современные четырёхъядерные процессоры имеют выделенные кэши L1 и L2 для каждого ядра, а также большой кэш L3, являющийся общим для всех ядер. Общиё кэш L3 также позволяет обмениваться данными, над которыми ядра могут работать параллельно.
Кэш — память (кеш , cash , буфер — eng.) — применяется в цифровых устройствах, как высокоскоростной буфер обмена. Кэш память можно встретить на таких устройствах компьютера как , процессоры, сетевые карты, приводы компакт дисков и многих других.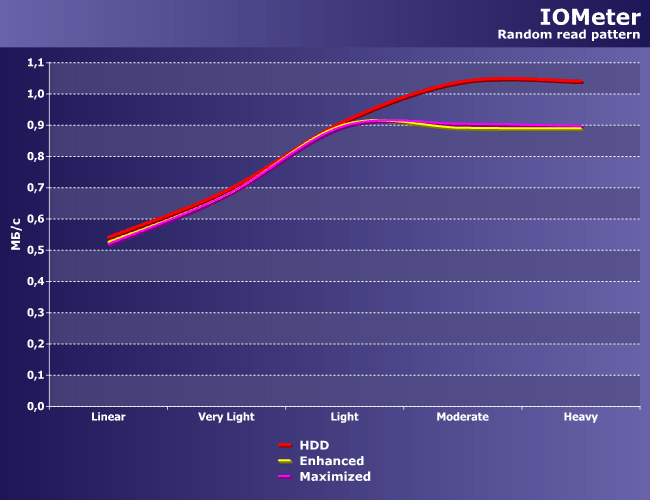
Принцип работы и архитектура кэша могут сильно отличаться.
К примеру, кэш может служить как обычный буфер обмена . Устройство обрабатывает данные и передаёт их в высокоскоростной буфер, где контроллёр передаёт данные на интерфейс. Предназначен такой кэш для предотвращения ошибок, аппаратной проверки данных на целостность, либо для кодировки сигнала от устройства в понятный сигнал для интерфейса, без задержек. Такая система применяется например в CD/DVD приводах компакт дисков.
В другом случае, кэш может служить для хранения часто используемого кода и тем самым ускорения обработки данных. То есть, устройству не нужно снова вычислять или искать данные, что заняло бы гораздо больше времени, чем чтение их из кэш-а. В данном случае очень большую роль играет размер и скорость кэш-а.
Такая архитектура чаще всего встречается на жёстких дисках, и центральных процессорах (CPU ).
При работе устройств, в кэш могут загружаться специальные прошивки или программы диспетчеры, которые работали бы медленней с ПЗУ (постоянное запоминающее устройство).
Большинство современных устройство, используют смешанный тип кэша , который может служить как буфером обмена, как и для хранения часто используемого кода.
Существует несколько очень важных функций, реализуемых для кэша процессоров и видео чипов.
Объединение исполнительных блоков . В центральных процессорах и видео процессорах часто используется быстрый общий кэш между ядрами. Соответственно, если одно ядро обработало информацию и она находится в кэше, а поступает команда на такую же операцию, либо на работу с этими данными, то данные не будут снова обрабатываться процессором, а будут взяты из кэша для дальнейшей обработки. Ядро будет разгружено для обработки других данных. Это значительно увеличивает производительность в однотипных, но сложных вычислениях, особенно если кэш имеет большой объём и скорость.
Общий кэш , также позволяет ядрам работать с ним напрямую, минуя медленную .
Кэш для инструкций. Существует либо общий очень быстрый кэш первого уровня для инструкций и других операций, либо специально выделенный под них. Чем больше в процессоре заложенных инструкций, тем больший кэш для инструкций ему требуется. Это уменьшает задержки памяти и позволяет блоку инструкций функционировать практически независимо.При его заполнении, блок инструкций начинает периодически простаивать, что замедляет скорость вычисления.
Чем больше в процессоре заложенных инструкций, тем больший кэш для инструкций ему требуется. Это уменьшает задержки памяти и позволяет блоку инструкций функционировать практически независимо.При его заполнении, блок инструкций начинает периодически простаивать, что замедляет скорость вычисления.
Другие функции и особенности .
Примечательно, что в CPU (центральных процессорах), применяется аппаратная коррекция ошибок (ECC ), потому как небольшая ошибочка в кэше, может привести к одной сплошной ошибке при дальнейшей обработке этих данных.
В CPU и GPU существует иерархия кэш памяти , которая позволяет разделять данные для отдельных ядер и общие. Хотя почти все данные из кэша второго уровня, всё равно копируются в третий, общий уровень, но не всегда. Первый уровень кеша — самый быстрый, а каждый последующий всё медленней, но больше по размеру.
Для процессоров, нормальным считается три и менее уровней кэша. Это позволяет добиться сбалансированности между скоростью, размером кэша и тепловыделением. В видеопроцессорах сложно встретить более двух уровней кэша.
Это позволяет добиться сбалансированности между скоростью, размером кэша и тепловыделением. В видеопроцессорах сложно встретить более двух уровней кэша.
Размер кэша, влияние на производительность и другие характеристики .
Естественно, чем больше кэш , тем больше данных он может хранить и обрабатывать, но тут есть серьёзная проблема.
Большой кеш — это большой бюджет . В серверных процессорах (CPU ), кэш может использовать до 80% транзисторного бюджета. Во первых, это сказывается на конечной стоимости, а во вторых увеличивается энергопотребление и тепловыделение, которое не сопоставимо с увеличенной на несколько процентов производительностью.
Всем пользователям хорошо известны такие элементы компьютера, как процессор, отвечающий за обработку данных, а также оперативная память (ОЗУ или RAM), отвечающая за их хранение. Но далеко не все, наверное, знают, что существует и кэш-память процессора(Cache CPU), то есть оперативная память самого процессора (так называемая сверхоперативная память).
В чем же состоит причина, которая побудила разработчиков компьютеров использовать специальную память для процессора? Разве возможностей ОЗУ для компьютера недостаточно?
Действительно, долгое время персональные компьютеры обходились без какой-либо кэш-памяти. Но, как известно, процессор – это самое быстродействующее устройство персонального компьютера и его скорость росла с каждым новым поколением CPU. В настоящее время его скорость измеряется миллиардами операций в секунду. В то же время стандартная оперативная память не столь значительно увеличила свое быстродействие за время своей эволюции.
Вообще говоря, существуют две основные технологии микросхем памяти – статическая память и динамическая память. Не углубляясь в подробности их устройства, скажем лишь, что статическая память, в отличие от динамической, не требует регенерации; кроме того, в статической памяти для одного бита информации используется 4-8 транзисторов, в то время как в динамической – 1-2 транзистора. Соответственно динамическая память гораздо дешевле статической, но в то же время и намного медленнее. В настоящее время микросхемы ОЗУ изготавливаются на основе динамической памяти.
Соответственно динамическая память гораздо дешевле статической, но в то же время и намного медленнее. В настоящее время микросхемы ОЗУ изготавливаются на основе динамической памяти.
Примерная эволюция соотношения скорости работы процессоров и ОЗУ:
Таким образом, если бы процессор брал все время информацию из оперативной памяти, то ему пришлось бы ждать медлительную динамическую память, и он все время бы простаивал. В том же случае, если бы в качестве ОЗУ использовалась статическая память, то стоимость компьютера возросла бы в несколько раз.
Именно поэтому был разработан разумный компромисс. Основная часть ОЗУ так и осталась динамической, в то время как у процессора появилась своя быстрая кэш-память, основанная на микросхемах статической памяти. Ее объем сравнительно невелик – например, объем кэш-памяти второго уровня составляет всего несколько мегабайт. Впрочем, тут стоить вспомнить о том, что вся оперативная память первых компьютеров IBM PC составляла меньше 1 МБ.
Кроме того, на целесообразность внедрения технологии кэширования влияет еще и тот фактор, что разные приложения, находящиеся в оперативной памяти, по-разному нагружают процессор, и, как следствие, существует немало данных, требующих приоритетной обработки по сравнению с остальными.
История кэш-памяти
Строго говоря, до того, как кэш-память перебралась на персоналки, она уже несколько десятилетий успешно использовалась в суперкомпьютерах.
Впервые кэш-память объемом всего в 16 КБ появилась в ПК на базе процессора i80386. На сегодняшний день современные процессоры используют различные уровни кэша, от первого (самый быстрый кэш самого маленького объема – как правило, 128 КБ) до третьего (самый медленный кэш самого большого объема – до десятков МБ).
Сначала внешняя кэш-память процессора размещалась на отдельном чипе. Со временем, однако, это привело к тому, что шина, расположенная между кэшем и процессором, стала узким местом, замедляющим обмен данными. В современных микропроцессорах и первый, и второй уровни кэш-памяти находятся в самом ядре процессора.
В современных микропроцессорах и первый, и второй уровни кэш-памяти находятся в самом ядре процессора.
Долгое время в процессорах существовали всего два уровня кэша, но в CPU Intel Itanium впервые появилась кэш-память третьего уровня, общая для всех ядер процессора. Существуют и разработки процессоров с четырехуровневым кэшем.
Архитектуры и принципы работы кэша
На сегодняшний день известны два основных типа организации кэш-памяти, которые берут свое начало от первых теоретических разработок в области кибернетики – принстонская и гарвардская архитектуры. Принстонская архитектура подразумевает единое пространство памяти для хранения данных и команд, а гарвардская – раздельное. Большинство процессоров персональных компьютеров линейки x86 использует раздельный тип кэш-памяти. Кроме того, в современных процессорах появился также третий тип кэш-памяти – так называемый буфер ассоциативной трансляции, предназначенный для ускорения преобразования адресов виртуальной памяти операционной системы в адреса физической памяти.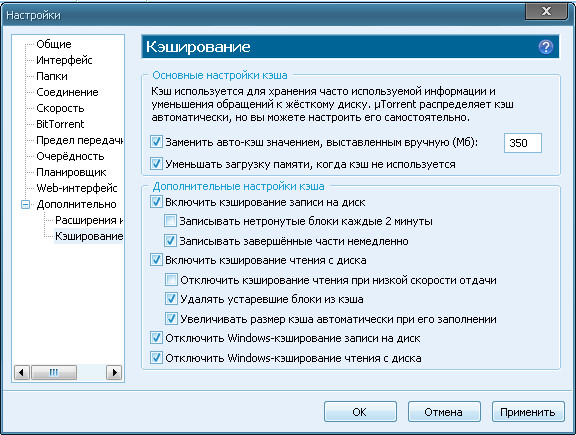
Упрощенно схему взаимодействия кэш-памяти и процессора можно описать следующим образом. Сначала происходит проверка наличия нужной процессору информации в самом быстром — кэше первого уровня, затем — в кэше второго уровня, и.т.д. Если же нужной информации в каком-либо уровне кэша не оказалось, то говорят об ошибке, или промахе кэша. Если информации в кэше нет вообще, то процессору приходится брать ее из ОЗУ или даже из внешней памяти (с жесткого диска).
Порядок поиска процессором информации в памяти:
Именно таким образом Процессор осуществляет поиск инфоромации
Для управления работой кэш-памяти и ее взаимодействия с вычислительными блоками процессора, а также ОЗУ существует специальный контроллер.
Схема организации взаимодействия ядра процессора, кэша и ОЗУ:
Кэш-контроллер является ключевым элементом связи процессора, ОЗУ и Кэш-памяти
Следует отметить, что кэширование данных – это сложный процесс, в ходе которого используется множество технологий и математических алгоритмов. Среди базовых понятий, применяющихся при кэшировании, можно выделить методы записи кэша и архитектуру ассоциативности кэш-памяти.
Среди базовых понятий, применяющихся при кэшировании, можно выделить методы записи кэша и архитектуру ассоциативности кэш-памяти.
Методы записи кэша
Существует два основных метода записи информации в кэш-память:
- Метод write-back (обратная запись) – запись данных производится сначала в кэш, а затем, при наступлении определенных условий, и в ОЗУ.
- Метод write-through (сквозная запись) – запись данных производится одновременно в ОЗУ и в кэш.
Архитектура ассоциативности кэш-памяти
Архитектура ассоциативности кэша определяет способ, при помощи которого данные из ОЗУ отображаются в кэше. Существуют следующие основные варианты архитектуры ассоциативности кэширования:
- Кэш с прямым отображением – определенный участок кэша отвечает за определенный участок ОЗУ
- Полностью ассоциативный кэш – любой участок кэша может ассоциироваться с любым участком ОЗУ
- Смешанный кэш (наборно-ассоциативный)
На различных уровнях кэша обычно могут использоваться различные архитектуры ассоциативности кэша. Кэширование с прямым отображением ОЗУ является самым быстрым вариантом кэширования, поэтому эта архитектура обычно используется для кэшей большого объема. В свою очередь, полностью ассоциативный кэш обладает меньшим количеством ошибок кэширования (промахов).
Кэширование с прямым отображением ОЗУ является самым быстрым вариантом кэширования, поэтому эта архитектура обычно используется для кэшей большого объема. В свою очередь, полностью ассоциативный кэш обладает меньшим количеством ошибок кэширования (промахов).
Заключение
В этой статье вы познакомились с понятием кэш-памяти, архитектурой кэш-памяти и методами кэширования, узнали о том, как она влияет на производительность современного компьютера. Наличие кэш-памяти позволяет значительно оптимизировать работу процессора, уменьшить время его простоя, а, следовательно, и увеличить быстродействие всей системы.
Кэш -промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше идёт быстрее, чем выборка исходных данных из оперативной (ОЗУ) и быстрее внешней (жёсткий диск или твердотельный накопитель) памяти, за счёт чего уменьшается среднее время доступа и увеличивается общая производительность компьютерной системы.
Ряд моделей центральных процессоров (ЦП) обладают собственным кэшем, для того чтобы минимизировать доступ к оперативной памяти (ОЗУ), которая медленнее, чем регистры. Кэш-память может давать значительный выигрыш в производительности, в случае когда тактовая частота ОЗУ значительно меньше тактовой частоты ЦП. Тактовая частота для кэш-памяти обычно ненамного меньше частоты ЦП.
Кэш центрального процессора разделён на несколько уровней. В универсальном процессоре в настоящее время число уровней может достигать 3. Кэш-память уровня N+1 как правило больше по размеру и медленнее по скорости доступа и передаче данных, чем кэш-память уровня N.
Самой быстрой памятью является кэш первого уровня — L1-cache. По сути, она является неотъемлемой частью процессора, поскольку расположена на одном с ним кристалле и входит в состав функциональных блоков. В современных процессорах обычно кэш L1 разделен на два кэша, кэш команд (инструкций) и кэш данных (Гарвардская архитектура). Большинство процессоров без L1 кэша не могут функционировать. L1 кэш работает на частоте процессора, и, в общем случае, обращение к нему может производиться каждый такт. Зачастую является возможным выполнять несколько операций чтения/записи одновременно. Латентность доступа обычно равна 2?4 тактам ядра. Объём обычно невелик — не более 384 Кбайт.
L1 кэш работает на частоте процессора, и, в общем случае, обращение к нему может производиться каждый такт. Зачастую является возможным выполнять несколько операций чтения/записи одновременно. Латентность доступа обычно равна 2?4 тактам ядра. Объём обычно невелик — не более 384 Кбайт.
Вторым по быстродействию является L2-cache — кэш второго уровня, обычно он расположен на кристалле, как и L1. В старых процессорах — набор микросхем на системной плате. Объём L2 кэша от 128 Кбайт до 1?12 Мбайт. В современных многоядерных процессорах кэш второго уровня, находясь на том же кристалле, является памятью раздельного пользования — при общем объёме кэша в nM Мбайт на каждое ядро приходится по nM/nC Мбайта, где nC количество ядер процессора. Обычно латентность L2 кэша, расположенного на кристалле ядра, составляет от 8 до 20 тактов ядра.
Кэш третьего уровня наименее быстродействующий, но он может быть очень внушительного размера — более 24 Мбайт. L3 кэш медленнее предыдущих кэшей, но всё равно значительно быстрее, чем оперативная память. В многопроцессорных системах находится в общем пользовании и предназначен для синхронизации данных различных L2.
В многопроцессорных системах находится в общем пользовании и предназначен для синхронизации данных различных L2.
Иногда существует и 4 уровень кэша, обыкновенно он расположен в отдельной микросхеме. Применение кэша 4 уровня оправдано только для высоко производительных серверов и мейнфреймов.
Проблема синхронизации между различными кэшами (как одного, так и множества процессоров) решается когерентностью кэша. Существует три варианта обмена информацией между кэш-памятью различных уровней, или, как говорят, кэш-архитектуры: инклюзивная, эксклюзивная и неэксклюзивная.
Читайте также…
На что влияет частота памяти видеокарты
Видеопамять — одна из самых главных характеристик видеокарты. Она имеет очень сильное влияние на общую производительность, качество выдаваемой картинки, её разрешение, и главным образом на пропускную способность видеокарты, о которой вы узнаете, прочитав данную статью.
Читайте также: На что влияет процессор в играх
Влияние частоты видеопамяти
Специальная встроенная в видеокарту оперативная память называется видеопамятью и в своей аббревиатуре вдобавок к DDR (удвоенная передача данных) содержит букву G в начале. Это даёт понять, что речь идёт именно о GDDR (графическая удвоенная передача данных), а не о каком-то другом типе оперативной памяти. Данный подтип ОЗУ обладает более высокими частотами по сравнению с обычной оперативной памятью, установленной в любой современный компьютер, и обеспечивает достаточное быстродействие графического чипа в целом, давая ему возможность работать с большими объёмами данных, которые нужно обработать и вывести на экран пользователя.
Пропускная способность памяти
Тактовая частота видеопамяти непосредственно влияет на её пропускную способность (ПСП). В свою очередь, высокие значения ПСП часто помогают добиться лучших результатов в производительности большинства программ, где необходимо участие или работа с 3D-графикой — компьютерные игры и программы для моделирования и создания трёхмерных объектов являются подтверждением данному тезису.
Читайте также: Определяем параметры видеокарты
Ширина шины памяти
Тактовая частота видеопамяти и её влияние на производительность видеокарты в целом находится в прямой зависимости от другого, не менее важного компонента графических адаптеров — ширины шины памяти и её частоты. Из этого следует, что при выборе графического чипа для вашего компьютера необходимо обращать внимание и на эти показатели, чтобы не разочароваться в общем уровне производительности своей рабочей или игровой компьютерной станции. При невнимательном подходе легко попасть на удочку маркетологов, установивших в новый продукт своей компании 4 ГБ видеопамяти и 64-битную шину, которая будет очень медленно и неэффективно пропускать через себя такой огромный поток видеоданных.
Необходимо соблюдение баланса между частотой видеопамяти и шириной её шины. Современный стандарт GDDR5 позволяет сделать эффективную частоту видеопамяти в 4 раза большей от её реальной частоты. Можете не переживать, что вам постоянно придётся осуществлять подсчёты эффективной производительности видеокарты в голове и держать эту простую формулу умножения на четыре в уме — производитель изначально указывает умноженную, то есть настоящую частоту памяти видеокарты.
В обычных, не предназначенных для специальных вычислений и научной деятельности графических адаптерах используются шины памяти от 64 до 256 бит шириной. Также в топовых игровых решениях может встретиться шина шириной в 352 бита, но одна только цена подобной видеокарты может составлять стоимость полноценного ПК средне-высокого уровня производительности.
Если вам нужна «затычка» под слот для видеокарты на материнской плате для работы в офисе и решения исключительно офисных задач по типу написания отчёта в Word, создания таблицы в Excel (ведь даже просмотр видео с такими характеристиками будет затруднителен), то вы можете с уверенностью приобретать решение с 64-битной шиной.
В любых других случаях необходимо обращать внимание на 128-битную шину или 192, а лучшим и самым производительным решением будет шина памяти в 256 бит. Такие видеокарты в большинстве своём имеют достаточный запас видеопамяти с высокой её частотой, но бывают и недорогие исключения с 1 ГБ памяти, чего для сегодняшнего геймера уже недостаточно и надо иметь как минимум 2 ГБ карточку для комфортной игры или работы в 3D-приложении, но тут уж можно смело следовать принципу «чем больше, тем лучше».
Расчёт ПСП
К примеру, если у вас есть видеокарта оснащённая памятью GDDR5 с эффективной тактовой частотой памяти 1333 МГц (чтобы узнать реальную частоту памяти GDDR5, необходимо эффективную поделить на 4) и с 256-битной шиной памяти, то она будет быстрее видеокарты с эффективной частотой памяти 1600 Мгц, но с шиной в 128 бит.
Чтобы рассчитать пропускную способность памяти и затем узнать, насколько производительный у вас видеочип, необходимо прибегнуть к данной формуле: ширину шины памяти умножаем на частоту памяти и полученное число делим на 8, ведь именно столько бит в байте. Полученное число и будет нужным нам значением.
Вернёмся к нашим двум видеокартам из примера выше и рассчитаем их пропускную способность: у первой, лучшей видеокарты, но с меньшим показателем тактовой частоты видеопамяти она будет следующей — (256*1333)/8 = 42,7 ГБ в секунду, а у второй видеокарты всего лишь 25,6 ГБ в секунду.
Вы также можете установить программу TechPowerUp GPU-Z, которая способна выводить развёрнутую информацию об установленном в ваш компьютер графическом чипе, в том числе и объём видеопамяти, её частоту, битность шины и пропускную способность.
Читайте также: Ускоряем работу видеокарты
Вывод
Исходя из информации выше, можно понять, что частота видеопамяти и её влияние на эффективность работы находится в прямой зависимости от ещё одного фактора — ширины памяти, вместе с которой они создают значение пропускной способности памяти. Она и влияет на скорость и количество передаваемых данных в видеокарте. Надеемся, что эта статья помогла вам узнать что-то новое о строении и работе графического чипа и дала ответы на интересующие вопросы.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТМы не можем найти эту страницу
(* {{l10n_strings.REQUIRED_FIELD}})
{{l10n_strings.CREATE_NEW_COLLECTION}}*
{{l10n_strings. ADD_COLLECTION_DESCRIPTION}}
ADD_COLLECTION_DESCRIPTION}}
{{l10n_strings.DRAG_TEXT_HELP}}
{{l10n_strings.ЯЗЫК}} {{$select.selected.display}} {{article. content_lang.display}}
content_lang.display}}
{{l10n_strings.AUTHOR_TOOLTIP_TEXT}}
{{$select.selected.display}} {{l10n_strings.CREATE_AND_ADD_TO_COLLECTION_MODAL_BUTTON}} {{l10n_strings.CREATE_A_COLLECTION_ERROR}}Понимание кэшей GPU — RasterGrid
Ранее мы исследовали различные типы памяти, доступные для доступа с помощью графического процессора, но лишь немного затронули тему кешей. В этой статье мы исправим это, взглянув на различные кэши, доступные на современных графических процессорах, чтобы оценить их роль в системе. Полное понимание поведения кэша графического процессора позволяет разработчикам лучше использовать его и, таким образом, повышать производительность своих графических или вычислительных приложений.
В этой статье мы исправим это, взглянув на различные кэши, доступные на современных графических процессорах, чтобы оценить их роль в системе. Полное понимание поведения кэша графического процессора позволяет разработчикам лучше использовать его и, таким образом, повышать производительность своих графических или вычислительных приложений.
Как и в предыдущей статье, наше основное внимание будет сосредоточено на дискретных графических процессорах и их иерархии кэш-памяти, но иногда мы также будем касаться интегрированных реализаций, таких как APU и SoC.Однако перед этим стоит потратить немного времени на понимание общих целей кэшей и того, как они обычно организуются в иерархии.
Введение
На протяжении всей истории компьютеров вычислительная мощность увеличивалась быстрее, чем скорость доступа к памяти, и поскольку этот разрыв и, следовательно, стоимость доступа к памяти увеличивались, возникла необходимость вводить промежуточные высокоскоростные ресурсы хранения между процессором и памятью, чтобы способный снабжать первый данными с достаточной скоростью, поэтому появились процессорные кеши.
Основным преимуществом кэшей является то, что они обеспечивают буферизацию, и в этом смысле кэши и буферы служат схожим целям:
- Уменьшить задержку путем считывания данных из памяти большими порциями в надежде, что последующие обращения к данным будут адресоваться к ближайшим местоположениям
- Увеличить пропускную способность путем объединения нескольких небольших передач в более крупные и более эффективные запросы к памяти
Это достигается путем кэши, хранящие данные в блоках, называемых строками кэша , которые обычно имеют размер от 32 до 512 байт, а операции с памятью выполняются в единицах строк кэша, в то время как отдельные обращения, выполняемые кодом, выполняемым на процессоре, обычно меньше этого ( е.г. 4 байта).
Дополнительная цель кэшей по сравнению с буферами заключается в том, что они также направлены на повышение производительности повторного доступа к одним и тем же данным, поскольку кэши сохраняют копию подмножества данных в памяти, поэтому последующие обращения к данным, уже находящимся в кэше, не выполняются. не требует дорогостоящей транзакции доступа к памяти. Конечно, кэши имеют намного меньшую емкость, чем объем памяти системы, поэтому кэшированных в настоящее время набора данных постоянно изменяются в соответствии с шаблоном доступа к памяти исполняемого кода и политикой замены, реализованной кэшем.
не требует дорогостоящей транзакции доступа к памяти. Конечно, кэши имеют намного меньшую емкость, чем объем памяти системы, поэтому кэшированных в настоящее время набора данных постоянно изменяются в соответствии с шаблоном доступа к памяти исполняемого кода и политикой замены, реализованной кэшем.
При создании приложений, дружественных к кэшу, цель состоит в том, чтобы максимизировать частоту попаданий в кэш , т. е. процент обращений к данным, которые могут быть обслужены из данных в кэше, тем самым повышая общую производительность. Это особенно важно для кода графического процессора, поскольку графическим процессорам необходимо обслуживать тысячи имитируемых потоков с данными по сравнению с центральными процессорами, которые обычно должны делать это не более чем для пары десятков потоков.
Чтобы понять иерархию кэша графического процессора, мы сначала рассмотрим иерархию кэша одного из первых потребительских многоядерных процессоров: Intel Core 2 Duo.
в настоящее время имеют более сложную иерархию кэша, поскольку они обычно имеют кэш L2 для каждого ядра и дополнительный кэш L3, совместно используемый ядрами (иногда даже кэш L4), чтобы хранить еще больше данных ближе к тому месту, где это необходимо, но мы выбрали Core 2 Duo, потому что его иерархия кеша отражает суть организации кеша многоядерного процессора. В частности, многоядерные процессоры всегда имеют как минимум два уровня кэшей:
.- Кэш ближайшего уровня является частным для ядра процессора
- Кэш последнего уровня является общим для всех ядер процессора
Кроме того, первый уровень состоит из двух кэшей, один из которых предназначен для кэширования инструкций, а другой — для кэширования данных. чтобы признать различия в шаблонах использования между кодом и данными, поскольку код доступен только для чтения с точки зрения ядра процессора, а поток инструкций обычно следует определенным шаблонам доступа, в то время как данные доступны для чтения/записи, и шаблон доступа может быть произвольным в общем случае .
Неудивительно, что современные графические процессоры используют очень похожие иерархии кэшей с одним ключевым отличием: у них намного больше ядер. Однако эта, казалось бы, небольшая разница имеет множество последствий.
Когерентность кэша
Тот факт, что кэши хранят в памяти локальные копии данных, имеющие свои канонические версии, создает проблему несогласованности данных. Например, если одно ядро изменяет данные, хранящиеся в частном кэше данных ядра, то другие ядра могут не увидеть это обновление, потому что они просматривают ту же ячейку памяти через свои собственные кэши.Кроме того, если устройство изменяет данные в памяти, это обновление может быть не сразу видно ни одному из ядер процессора, поскольку они могут считывать устаревшие данные из одного из кэшей в иерархии.
ЦП решают эту проблему за счет наличия протоколов когерентности кэша между различными кэшами и шиной памяти, которые используют отслеживание шины или другие решения для обнаружения обновлений данных и соответствующей синхронизации/аннулирования кэшированных данных (например, см. протоколы MOESI и MESIF). Это имеет смысл для ЦП, которые имеют относительно небольшое количество вычислительных ядер, и это своего рода необходимость поддерживать эффективный обмен данными между программами, работающими на произвольных ядрах/потоках ЦП, из-за гибкости модели программирования, которая обычно работает в условиях предположение о когерентной системе памяти.
протоколы MOESI и MESIF). Это имеет смысл для ЦП, которые имеют относительно небольшое количество вычислительных ядер, и это своего рода необходимость поддерживать эффективный обмен данными между программами, работающими на произвольных ядрах/потоках ЦП, из-за гибкости модели программирования, которая обычно работает в условиях предположение о когерентной системе памяти.
В случае графических процессоров количество ядер (вычислительных единиц/потоковых мультипроцессоров) намного больше, и поэтому реализация протоколов когерентности кэша будет слишком дорогой как с точки зрения площади кристалла, так и с точки зрения производительности. В результате кэши графического процессора обычно несогласованны и требуют явного сброса и/или аннулирования кэшей для повторной когерентности (т. е. для согласованного представления данных между ядрами графического процессора и/или другими устройствами). Однако на практике это не представляет проблемы из-за особой модели программирования графических процессоров, в которой практически нет возможности/необходимости для высокочастотного обмена данными между шейдерами/ядрами, работающими на разных ядрах графического процессора. Конкретно:
Конкретно:
- вызовы шейдеров в рамках отдельных команд отрисовки или отправки вычислений, которые выполняются на разных ядрах графического процессора, могут отображать несогласованные представления одних и тех же данных памяти, если только не используются согласованные ресурсы (см. далее) или не создаются барьеры памяти в шейдере, которые очищают/аннулируют данные для каждого ядра. кэши
- последующие команды отрисовки или отправки вычислений могут видеть несогласованные представления одних и тех же данных памяти, если только через API не выдаются соответствующие барьеры памяти, которые очищают/аннулируют соответствующие кэши
- команды и операции графического процессора, выполняемые другими устройствами (например,г. чтения/записи ЦП) могут видеть несогласованные представления одних и тех же данных памяти, если только для их синхронизации не используются соответствующие примитивы синхронизации (например, барьеры или семафоры), которые неявно вставляют необходимые барьеры памяти
Это, конечно, не набор формальных правил, а просто приблизительное изложение того, чего ожидать, а отдельные API-интерфейсы программирования графических процессоров могут иметь разные правила, поведение по умолчанию и инструменты синхронизации.
Кэш команд ядра
Мы начнем изучать кэши графических процессоров для каждого ядра с кэша инструкций шейдера, так как он проще.
Хотя модель программирования и, следовательно, аппаратная реализация графических процессоров сильно отличается от модели ЦП, основные строительные блоки и используемые ими методы не так уж отличаются. Например, распространенные архитектуры графических процессоров используют блоки обработки SIMD, но вместо того, чтобы использовать их для включения векторных инструкций из отдельных потоков, они используют модель выполнения SIMT (Single Instruction Multiple Thread), где каждая дорожка практически выполняет отдельный поток (вызов шейдера). .Это отличная модель для графических процессоров, поскольку они обычно запускают относительно простые программы с большим набором рабочих элементов, поэтому они выигрывают от возможности планировать инструкции для группы потоков вместе, а не планировать их по отдельности. Группа потоков, которые выполняются совместно в этом режиме SIMT (часто синхронно), образуют волну (wavefront в терминологии AMD, warp в терминологии NVIDIA, подгруппа в терминологии Vulkan).
Кроме того, аналогично функциям одновременной многопоточности (SMT) ЦП (например,г. Hyper-Threading), графические процессоры также могут иметь несколько волн, работающих на одном ядре. Это позволяет увеличить количество независимых инструкций в конвейере, но, что более важно, позволяет графическому процессору выполнять инструкции других волн, пока волна ожидает данных из памяти/кэшей/и т. д. На практике на одном ядре графического процессора могут выполняться тысячи потоков, хотя в большинстве случаев только по очереди. Например:
- Вычислительный блок AMD GCN (CU) может выполнять 40 волн, по 64 потока в каждом, всего до 2560 потоков на CU до 2048 потоков / SM
Эффективное количество потоков, которые могут выполняться на любом конкретном ядре графического процессора, на практике может быть намного меньше из-за различных факторов, но обсуждение этого вопроса выходит за рамки этой статьи.
Однако важно отметить, что, несмотря на огромное количество потоков, работающих на одном ядре GPU, обычно все они выполняют один и тот же код. Для потоков одной волны это верно по определению из-за модели выполнения SIMT. На самом деле, один и тот же код довольно часто выполняется по волнам от нескольких ядер графического процессора, поскольку количество рабочих элементов, над которыми выполняется программа в типичной рабочей нагрузке графического процессора, даже больше, чем то, что может поместиться на одном ядре графического процессора (например, .г. полноэкранный просмотр изображения в формате Full HD приводит к более чем 2 миллионам вызовов потоков).
Это означает, что небольшой кэш инструкций на ядро более чем удовлетворителен, даже учитывая огромное количество потоков, выполняемых на одном ядре GPU. Некоторые графические процессоры идут еще дальше и совместно используют кеш инструкций для нескольких ядер графического процессора (например, архитектура AMD GCN использует один кэш инструкций размером 32 КБ для кластера до 4 вычислительных блоков).
С точки зрения производительности следует иметь в виду, что на графических процессорах промах кэша инструкций может привести к остановке тысяч потоков вместо одного, как в случае с ЦП, поэтому, как правило, настоятельно рекомендуется, чтобы код шейдера/ядра был достаточно мал, чтобы полностью поместиться в этот кеш.
Кэш данных на ядро
Каждое ядро графического процессора обычно имеет один или несколько выделенных кэшей данных шейдеров. В более ранних конструкциях графических процессоров шейдеры могли только считывать данные из памяти, но не записывать в них, поскольку обычно шейдерам для выполнения своих задач требовался только доступ к входным данным текстуры и буфера, поэтому кэши данных для каждого ядра традиционно были доступны только для чтения. Однако более поздние архитектуры, адаптированные для гибких вычислительных операций GPGPU, должны были поддерживать разрозненные записи в память, поэтому возникла необходимость в кэше данных для чтения/записи. Эти кэши обычно используют политику сквозной записи , т. е. записи немедленно распространяются на следующий уровень кэша.
Эти кэши обычно используют политику сквозной записи , т. е. записи немедленно распространяются на следующий уровень кэша.
Типичный размер кэша данных ядра графического процессора составляет от 16 КБ до 128 КБ, что сравнимо с обычным размером кэша данных L1 32 КБ, используемым большинством ЦП. Однако нельзя забывать, что этот кэш данных обслуживает значительно большее количество потоков, чем в случае с CPU, и хотя все потоки на ядре GPU обычно выполняют один и тот же код, а потоки внутри одной волны даже выполняют одну и ту же инструкцию в любой момент времени. с учетом времени им все еще обычно нужно читать разные адреса.Это делает емкость кэша данных для каждого кода графических процессоров намного меньше, чем у их эквивалентов ЦП, как показано в таблице ниже:
| процессор CORE | размер кэша данных | максимальные потоки | емкость / нить | .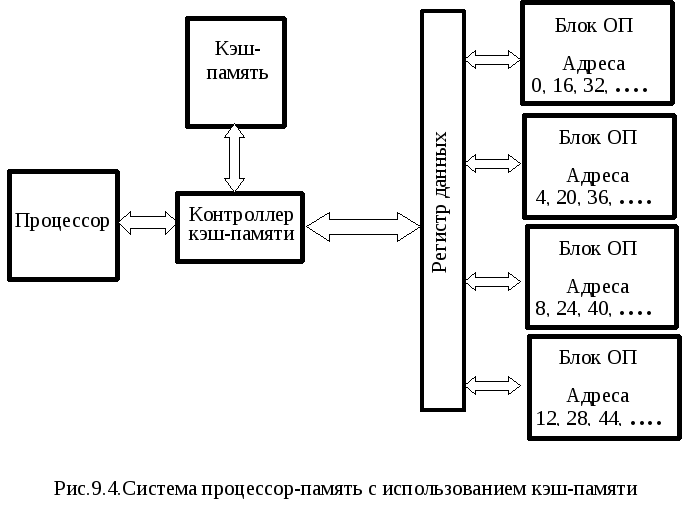 | 9012 (4 волны) Емкость / нить (Максимальные волны) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AMD GCN CU | 16 КБ | 2560 (40x 64 волны) | 64 байта | 6.4 байта | |||||||||||||
| AMD RDNA DCU | 2x 16 Kb | 2560 (80x 32 -2 Широкие волны) | 256 байт | 12.8 BYTES | |||||||||||||
| NVIDIA PASCAL SM | 24 KB | 2048 (64x 32 -2 широкие волны) | 192 байт | 12 байт | |||||||||||||
| NVIDIA Volta SM (Config a) | 32 Kb | 2048 | 2048 (64x 32 -2 Широкие волны) | 256 BYTES | 16 байт | ||||||||||||
| NVIDIA Volta SM (Config B) | 64 KB | 64 KB | 2048 | 2048 (64x 32) | 512 BYTES | 32 байта | |||||||||||
| NVIDIA Volta SM C) | 96 КБ | 2048 (64x 32 волны) | 768 байт | 48 байт |

ПРИМЕЧАНИЕ. Кэш данных NVIDIA Volta L1 может работать с различной емкостью (см. далее).
Как видно, размер кэша данных на ядро графических процессоров часто довольно мал, чтобы его можно было использовать для традиционного кэширования при высокой занятости волн, т. е. для повышения производительности повторных обращений к одному и тому же месту памяти просто за счет огромного количества потоки, которые могут выполняться на одном ядре графического процессора, поскольку они неизбежно вытесняют данные друг друга из кеша. Это означает, что кеш данных для каждого ядра обычно действует больше как объединяющий буфер для операций с памятью, чем как типичный кеш.Например. 32-разрядная волна, выполняемая на ядре RDNA, при этом каждый поток обращается к элементу из массива с 4-байтовыми элементами, по одному на рабочий элемент, приведет к выборке одной 128-байтовой строки кэша, при условии, что базовый адрес массива соответствует выровнены.
Однако существует важный класс шаблонов доступа, где проявляется истинное преимущество кэширования: если есть перекрытие между ячейками памяти, к которым обращаются потоки одной и той же волны или другие волны на одном и том же ядре графического процессора. Хотя такие шаблоны доступа не являются чем-то необычным и в общем случае, на самом деле это почти всегда имеет место при выполнении поиска текстур с фильтрацией, поскольку тексельный отпечаток 2×2 извлекается для создания выборки текстуры с билинейной фильтрацией в формате e.г. поток фрагментного шейдера будет иметь перекрытия с текселями, необходимыми для 8 «соседних» потоков фрагментного шейдера. Таким образом, в этих случаях средний показатель попаданий в кэш может быть около 75%, а иногда даже выше.
ПРИМЕЧАНИЕ. Билинейные контуры текселей 2×2, сэмплированные соседними фрагментами, накладываются друг на друга.
Таким образом, повторное использование кэшированных данных на графических процессорах обычно не происходит во временной области, как в случае с центральными процессорами (т.е. последующие инструкции одного и того же потока, обращающиеся к одним и тем же данным несколько раз), а скорее в пространственной области (т.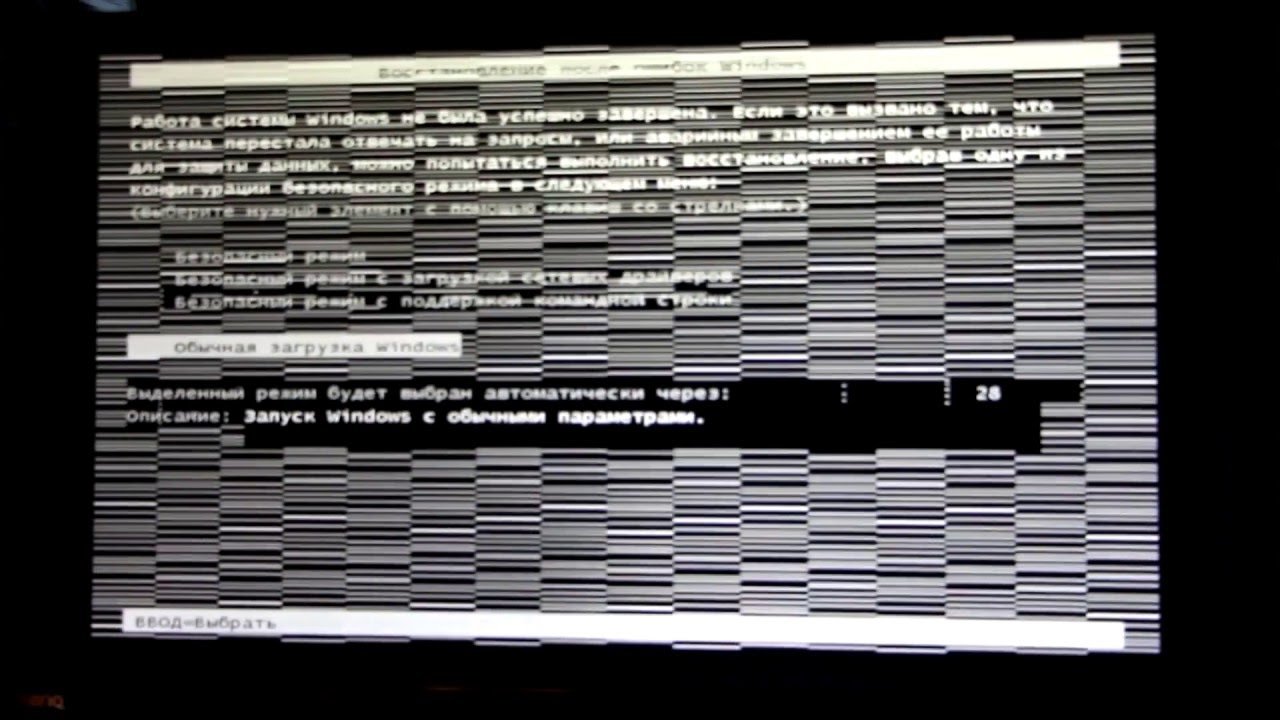 е. инструкции разных потоков на одном и том же ядре, обращающихся к одним и тем же данным). Соответственно, использование памяти в качестве временного хранилища и использование кэширования для быстрого повторного доступа — не лучшая идея для графических процессоров, в отличие от центральных процессоров. Однако на практике это компенсируется большим объемом регистров и доступностью разделяемой памяти.
е. инструкции разных потоков на одном и том же ядре, обращающихся к одним и тем же данным). Соответственно, использование памяти в качестве временного хранилища и использование кэширования для быстрого повторного доступа — не лучшая идея для графических процессоров, в отличие от центральных процессоров. Однако на практике это компенсируется большим объемом регистров и доступностью разделяемой памяти.
Крайний случай повторного использования данных между потоками — это когда всем потокам одной или нескольких волн необходимо прочитать данные с одного и того же адреса.Это довольно распространено, поскольку шейдеры/ядра часто обращаются к постоянным данным или другим низкочастотным данным (например, к данным рабочей группы в вычислительных шейдерах). Чтобы повысить производительность таких обращений, многие графические процессоры имеют выделенные единые кэши данных (иногда называемые скалярными или константными кэшами). Преимущество наличия отдельного кеша для этой цели заключается в том, что он гарантирует, что такие низкочастотные данные не будут вытеснены из кеша данных высокочастотным доступом к данным, что в противном случае произошло бы, если бы они были сохранены в том же кеше под общая политика замены.
Подобно коду, такие однородные данные часто распределяются не только между волнами в пределах одного ядра GPU, но и между волнами нескольких ядер GPU, так что это еще один кеш, который является хорошим кандидатом на совместное использование несколькими ядрами GPU (например, архитектура AMD GCN). совместно использует один скалярный кэш размером 16 КБ в кластере до 4 вычислительных блоков).
Кэш-память устройства
Кэш на уровне ядра и другие кэши более низкого уровня графических процессоров обслуживаются кэшем на уровне устройства, который обеспечивает согласованные кэшированные данные между ядрами, и обычно это последний уровень кэша в иерархии с несколькими заметными исключениями.Это кеш чтения/записи, который обычно также поддерживает атомарные операции. Фактически, все атомарные операции с данными, поддерживаемыми памятью, выполняемые шейдерами/ядрами, обрабатываются здесь, пропуская при этом кэши более низкого уровня. Таким образом, атомарные операции по определению когерентны между потоками, работающими на разных ядрах графического процессора, хотя это не гарантирует, что при обычном чтении будут видны результаты атомарных операций, поскольку они будут по-прежнему обслуживаться по умолчанию из кэшей данных для каждого ядра.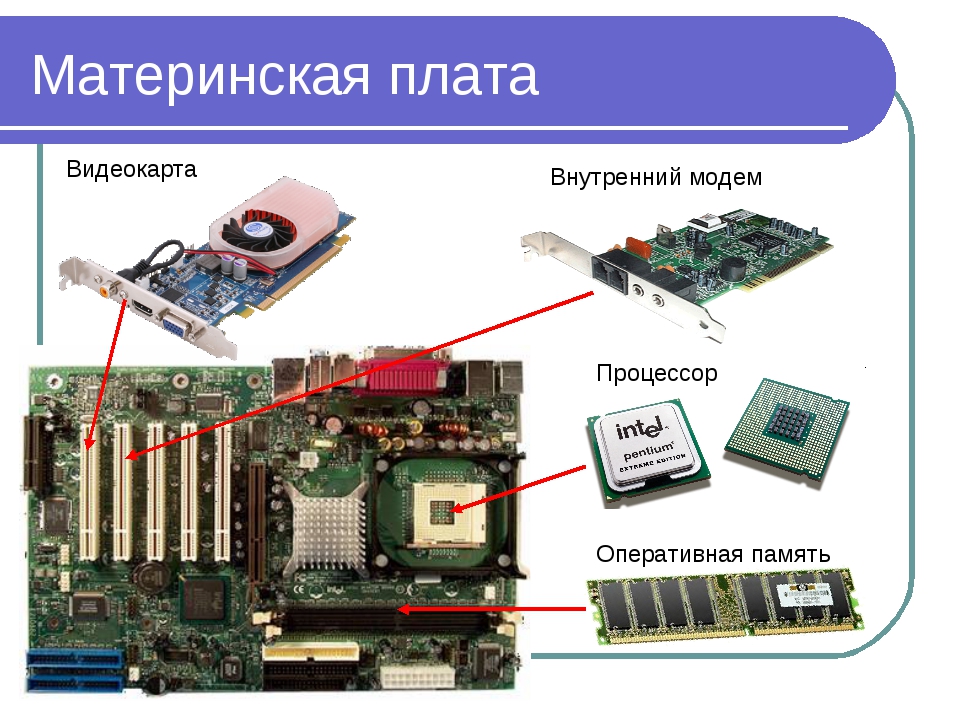
Чтобы поддерживать согласованный доступ к изменяемым данным, совместно используемым несколькими ядрами, графические процессоры обычно имеют специальные инструкции или варианты инструкций для обхода непоследовательных кэшей для каждого ядра даже для обычных неатомарных операций чтения или записи.Хотя не все API-интерфейсы программирования графических процессоров предоставляют такой детальный контроль, всегда есть какой-то механизм, обеспечивающий такой согласованный доступ к ресурсу. Например, GLSL использует квалификатор «когерентный», чтобы пометить весь ресурс как всегда доступный через операции с памятью, которые обходят кеши, несогласованные между ядрами графического процессора.
Эта функция удобна не только тогда, когда вызовы шейдеров в рамках одной команды отрисовки или отправки вычислений должны когерентно обмениваться изменяемыми данными, но также и для обмена данными между последующими командами, поскольку с помощью когерентных операций с памятью на уровне устройства мы можем избежать необходимости сбрасывать/ аннулировать кэши для каждого ядра между командами, что устраняет некоторые или все задержки/пузыри, связанные с синхронизацией, между зависимыми операциями.
Естественно, использование когерентных операций с памятью может отрицательно сказаться на производительности, поскольку мы отказываемся от преимуществ кэшей более низкого уровня, однако для типичного доступа к данным для каждого потока пусть это будет чтение входных данных или запись выходных данных, когда запросы по всей волне объединяются. в транзакции данных размером со всю строку кэша, не должно быть дополнительных накладных расходов. На самом деле это довольно распространено в случае шейдеров/ядер обработки изображений, где каждая волна обрабатывает соответствующий 2D-фрагмент изображения, или других преобразований, когда потоки каждой волны считывают или записывают непрерывный, выровненный диапазон входных или выходных данных (обычно расположены в виде структуры массивов).
Объединенный, выровненный по строке кэша (пунктирные линии) доступ к данным из волн шириной 16.ПРИМЕЧАНИЕ. Сопоставление потока с данными не обязательно должно быть взаимно однозначным (например, массив[threadID]).

Этот метод оптимизации обычно дает преимущества, если существует достаточное количество независимой работы, которую можно запланировать для выполнения между рабочими нагрузками «производитель» и «потребитель», которые выполняют совместное использование данных посредством последовательной записи и чтения, соответственно, поскольку он позволяет использовать завершение- только зависимость между ними, без операций управления кешем, таких как очистка/аннулирование кешей для каждого ядра (т.г. операция ожидания события Vulkan без барьера памяти).
Также стоит отметить, что некоторые архитектуры имеют дополнительные кэши между общим кэшем устройства и кэшем каждого ядра (например, новый кэш L1, присутствующий в архитектуре AMD RDNA), однако это не должно влиять на достоверность этого метода в целом.
Но вернемся к кешу устройства, если посмотреть на его размер, он все еще относительно мал, так как даже если мы сравним типичные размеры на высокопроизводительных графических процессорах, их размер 4-6 МБ довольно мал по сравнению с размером кеша L3 процессоров. который служит той же цели, за заметным исключением нового «Big Navi» от AMD, который имеет дополнительный уровень кэш-памяти устройства с гигантской емкостью 128 МБ, но это больше компенсирует его относительно узкую шину памяти, а не выполняет традиционную роль кэш-памяти графических процессоров устройства.
который служит той же цели, за заметным исключением нового «Big Navi» от AMD, который имеет дополнительный уровень кэш-памяти устройства с гигантской емкостью 128 МБ, но это больше компенсирует его относительно узкую шину памяти, а не выполняет традиционную роль кэш-памяти графических процессоров устройства.
| GPU | GPU | Устройство широкий кеш | Max Threads | Емкость / резьба | (4 волн / ядра) Емкость / резьба (Максимальные волны) |
|---|---|---|---|---|---|
| AMD Polaris 20 (GCN | 2 МБ | 92160 (2560 x 36 CU) | 227.5 BYTES | 22.75 BYTES | |
| AMD Navi 10 (RDNA) | 4 MB | 102400 (2560 x 40 CU) | 819. 2 байт 2 байт | 40.96 байт | |
| NVIDIA GP100 (Паскаль) | 4 МБ | 122880 (2048 х 60 СМ) | 546,13 байт | 34,13 байт | |
| NVIDIA GV100 (Вольта) | 6 МБ | 163840 | 163840 (2048 x 80 см) | 614.4 Байты | 38.4 BYTES |
Как видно, эти объемы кэша на поток, скорее всего, будут полезны для традиционного кэширования, хотя это все же показывает, что графические процессоры в первую очередь предназначены для обработки огромного количества относительно небольших элементов данных по сравнению с центральными процессорами, которые обычно работают со значительными объемами данных. большие наборы данных с использованием меньшего количества потоков.
большие наборы данных с использованием меньшего количества потоков.
В примечании о APU и SoC: графические процессоры, установленные на таком оборудовании, обычно не имеют выделенного кэша на уровне устройства, вместо этого они совместно используют кэш последнего уровня с ЦП.
Общая память
В современных графических процессорах каждое ядро имеет собственную общую память, которая в основном используется для обмена данными между вычислительными потоками (или вызовами вычислительных шейдеров), принадлежащими одной рабочей группе, и даже поддерживает атомарные операции. Общая память — это не кэш, а тип оперативной памяти, но мы тем не менее упоминаем ее здесь, потому что она служит той же цели, что и кэши, в том смысле, что она позволяет хранить повторно используемые данные рядом с процессорами.
Разница между кэшами и блокнотной памятью заключается в том, что в то время как кэши автоматически управляют набором данных, которые они в настоящее время хранят, блокнотная память управляется прикладным программным обеспечением, поэтому код шейдера/ядра может явно передавать данные между памятью и блокнотом.
Еще одна причина, по которой мы упоминаем общую память, заключается в том, что NVIDIA предложила интересную идею объединения кэша данных L1 и общей памяти в один компонент. Этот подход впервые появился в их архитектуре Kepler, хотя в этой архитектуре все еще был отдельный кэш текстур только для чтения.Максвелл и Паскаль объединили кеш данных L1 и кеш текстур, но у них был отдельный раздел с общей памятью (по аналогии с решением AMD). Наконец, начиная с архитектуры Volta, унифицированный кэш данных и общая память являются частью единого компонента.
Эволюция кэшей данных для каждого ядра и общей памяти в ядрах графических процессоров NVIDIA.SMEM: разделяемая память
L1$: L1 кэш данных чтения-записи
TEX$ : кэш текстуры только для чтения
Это решение позволяет NVIDIA динамически разделять этот комбинированный компонент хранилища данных на различные размеры, зарезервированные для кэша данных и использования общей памяти. В архитектуре Ampere можно использовать все 128 КБ (или 192 КБ) кэша данных ядра в случае, если не требуется общая память, что может быть в случае рабочих нагрузок, связанных только с графикой. Кроме того, это, вероятно, также позволяет NVIDIA напрямую загружать данные из кэша L2 в общую память, учитывая, что они обслуживаются тем же компонентом, что и кэш данных L1, однако невозможно проверить это, поскольку ISA NVIDIA (архитектура набора инструкций) не публичный.
В архитектуре Ampere можно использовать все 128 КБ (или 192 КБ) кэша данных ядра в случае, если не требуется общая память, что может быть в случае рабочих нагрузок, связанных только с графикой. Кроме того, это, вероятно, также позволяет NVIDIA напрямую загружать данные из кэша L2 в общую память, учитывая, что они обслуживаются тем же компонентом, что и кэш данных L1, однако невозможно проверить это, поскольку ISA NVIDIA (архитектура набора инструкций) не публичный.
Также есть заслуживающие внимания идеи, связанные с общей памятью на графических процессорах AMD.В частности, помимо общей памяти для каждого ядра, графические процессоры LDS (локальный общий доступ к данным), AMD GCN и RDNA также имеют общую память устройства, называемую GDS (глобальный общий доступ к данным), которая работает аналогично, но позволяет обмениваться данными между всеми устройствами. потоки, работающие на любом из ядер графического процессора, включая быстрые, глобальные, неупорядоченные атомарные операции. К сожалению, на сегодняшний день ни один API программирования GPU не предоставляет прямой доступ к GDS.
К сожалению, на сегодняшний день ни один API программирования GPU не предоставляет прямой доступ к GDS.
Прочие тайники
До сих пор мы говорили только о кэшах, используемых для ускорения доступа к памяти, выполняемого шейдерными ядрами, но графические процессоры обычно используют другие кэши, которые обслуживают различные аппаратные компоненты с фиксированными функциями, которые реализуют определенные этапы или функции графического конвейера.Примером такого кэша является кэш атрибутов вершин, который традиционно использовался для кэширования значений атрибутов вершин перед отправкой соответствующих вызовов вершинного шейдера. В настоящее время из-за повышенной программируемости этапов обработки геометрии обычно нет необходимости в таком выделенном кэше, поскольку чтение данных атрибутов часто происходит из шейдеров, явно или неявно, особенно в случае современных конвейеров геометрии, использующих тесселяцию, геометрию. шейдеры или сетчатые шейдеры.
На другом конце графического конвейера у нас обычно есть другой набор кэшей, обычно называемый кэшами ROP (растровые операции) или RB (серверная часть рендеринга), которые обеспечивают кэширование операций присоединения кадрового буфера (целевого объекта рендеринга). Они по-прежнему существуют в современных графических процессорах с непосредственным режимом рендеринга (IMR) (не путать с немедленным режимом OpenGL API), потому что операции с буфером кадра имеют достаточно специфические шаблоны доступа из-за того, как работает растеризация, чтобы оправдать индивидуальное решение, которое обеспечивает наилучшую производительность для конкретного использования.Кроме того, доступ к памяти фреймбуфера на графических процессорах IMR обычно происходит отдельно от выполнения фрагментного шейдера, выдаваемого выделенными блоками ROP, которые обеспечивают несколько других функций (например, смешивание и обеспечение того, чтобы обновления фреймбуфера происходили в соответствии с входящим порядком примитивов).
Они по-прежнему существуют в современных графических процессорах с непосредственным режимом рендеринга (IMR) (не путать с немедленным режимом OpenGL API), потому что операции с буфером кадра имеют достаточно специфические шаблоны доступа из-за того, как работает растеризация, чтобы оправдать индивидуальное решение, которое обеспечивает наилучшую производительность для конкретного использования.Кроме того, доступ к памяти фреймбуфера на графических процессорах IMR обычно происходит отдельно от выполнения фрагментного шейдера, выдаваемого выделенными блоками ROP, которые обеспечивают несколько других функций (например, смешивание и обеспечение того, чтобы обновления фреймбуфера происходили в соответствии с входящим порядком примитивов).
Обычно в графическом процессоре имеется несколько кэшей ROP, каждый из которых обслуживает одну или несколько единиц ROP, и, как правило, каждый кэш ROP состоит из отдельного кэша глубины/трафарета и цвета, опять же из-за особых потребностей вложений глубины/трафарета по сравнению с вложениями цвета. Эти кэши, опять же, обычно несовместимы по отношению к своим собратьям, включая кэши шейдеров для каждого ядра, и они могут поддерживаться или не поддерживаться тем же кэшем (ами) на уровне устройства, что и кэши для каждого ядра.
Эти кэши, опять же, обычно несовместимы по отношению к своим собратьям, включая кэши шейдеров для каждого ядра, и они могут поддерживаться или не поддерживаться тем же кэшем (ами) на уровне устройства, что и кэши для каждого ядра.
До появления вычислительных шейдеров наиболее распространенной операцией синхронизации кэша графического процессора была синхронизация операций записи, выполняемых через кэши ROP, с операциями чтения, выполняемыми через кэши шейдеров каждого ядра (рендеринг в текстуру, а затем результаты чтения, например, отображение теней, карты отражений). ). Такие зависимости данных по-прежнему распространены, даже несмотря на то, что в настоящее время вычислительные шейдеры чаще используются для обработки пространства изображения (например, шейдеры).г. постобработка, отложенное затенение/освещение), поэтому лучше держать кэши ROP как можно ближе к кэшам шейдеров для каждого ядра в иерархии кэшей. Таким образом, неудивительно, что графические процессоры, которые традиционно не поддерживали свои кэши ROP с кэшем на уровне устройства, перешли к дизайну, в котором они есть.
, распространенные в мобильных SoC, работают по-другому, поэтому у них нет кэшей ROP, как у графических процессоров IMR.Эти графические процессоры разбивают пространство буфера кадра на сетку тайлов и выполняют растеризацию и обработку фрагментов/пикселей для каждого тайла отдельно. Этот подход позволяет им минимизировать количество обращений к внешней памяти, которые GPU должен выполнять во время обработки фрагмента/пикселя, загружая данные кадрового буфера, соответствующие каждому тайлу перед обработкой тайла, а затем сохраняя результаты обратно в память после этого. Хранилище, в котором находятся данные кадрового буфера обрабатываемого тайла, обычно называется встроенной/локальной памятью тайла.
Тайловая память обычно функционирует как блокнотная память, аналогичная разделяемой памяти, на самом деле вполне вероятно, что фактические реализации используют одно и то же физическое хранилище для обоих. Это оперативная память, потому что хранящиеся в ней данные явно контролируются приложением, хотя и не всегда напрямую. В частности, графический API Vulkan предоставляет специальные функции для управления тем, когда, как и какие данные загружаются в память тайлов из видеопамяти или сохраняются из памяти тайлов в видеопамять.Приложение управляет поведением с помощью операций загрузки/сохранения каждого вложения и других параметров объектов прохода рендеринга Vulkan.
Это оперативная память, потому что хранящиеся в ней данные явно контролируются приложением, хотя и не всегда напрямую. В частности, графический API Vulkan предоставляет специальные функции для управления тем, когда, как и какие данные загружаются в память тайлов из видеопамяти или сохраняются из памяти тайлов в видеопамять.Приложение управляет поведением с помощью операций загрузки/сохранения каждого вложения и других параметров объектов прохода рендеринга Vulkan.
Наконец, также стоит отметить, что современные графические процессоры используют адресацию виртуальной памяти, поэтому они также используют отдельную кэш-иерархию резервных буферов трансляции (TLB) для ускорения трансляции виртуальных адресов в физические. В интегрированных решениях иерархия TLB может использоваться совместно с ЦП, в то время как в случае дискретных графических процессоров на кристалле всегда есть выделенная иерархия TLB.
Заключение
Нам удалось охватить ключевые аспекты иерархии кеша графических процессоров, их сравнение с иерархией кеша ЦП, а также основные различия в дизайне и реализации между ними. Мы также видели, как эти различия влияют на модель программирования, в частности, что непоследовательные кэши графического процессора требуют особого внимания со стороны разработчика приложений, когда речь идет о синхронизации данных между рабочими элементами и последующими командами отрисовки и вычисления.
Мы также видели, как эти различия влияют на модель программирования, в частности, что непоследовательные кэши графического процессора требуют особого внимания со стороны разработчика приложений, когда речь идет о синхронизации данных между рабочими элементами и последующими командами отрисовки и вычисления.
созданы для разных типов задач. ЦП запускают только несколько потоков параллельно, но каждый из них имеет большой и сложный код и наборы данных, с которыми они работают, в то время как графические процессоры выполняют на порядки большее количество потоков одновременно, но, как правило, большинство из них используют один и тот же код и имеют доступ к относительно небольшому объему данных на поток. Из-за этого, несмотря на сходство фактических иерархий кэшей, используемых двумя типами процессоров, фактическая схема использования кэшей на практике существенно различается.Помнить об этом имеет первостепенное значение для достижения хорошей производительности и часто является причиной того, почему наивные порты алгоритмов, ориентированных на ЦП, плохо работают на графических процессорах.
Помимо кешей, мы также говорили о различных типах оперативной памяти, доступных в современных графических процессорах, и о том, как они дополняют кеши для дальнейшего повышения производительности доступа к данным.
Вся информация, представленная в этой статье, относящаяся к конкретным типам, иерархиям и размерам кэша графических процессоров, была собрана на основе технических документов по архитектуре и других общедоступных материалов, выпущенных поставщиками оборудования для соответствующего графического процессора или поколения графических процессоров.Для дальнейшего чтения, пожалуйста, ознакомьтесь со списком ниже:
Видеокарта NVIDIA 6200 64 МБ Turbo Cache 104969 : Electronics
В настоящее время недоступен.
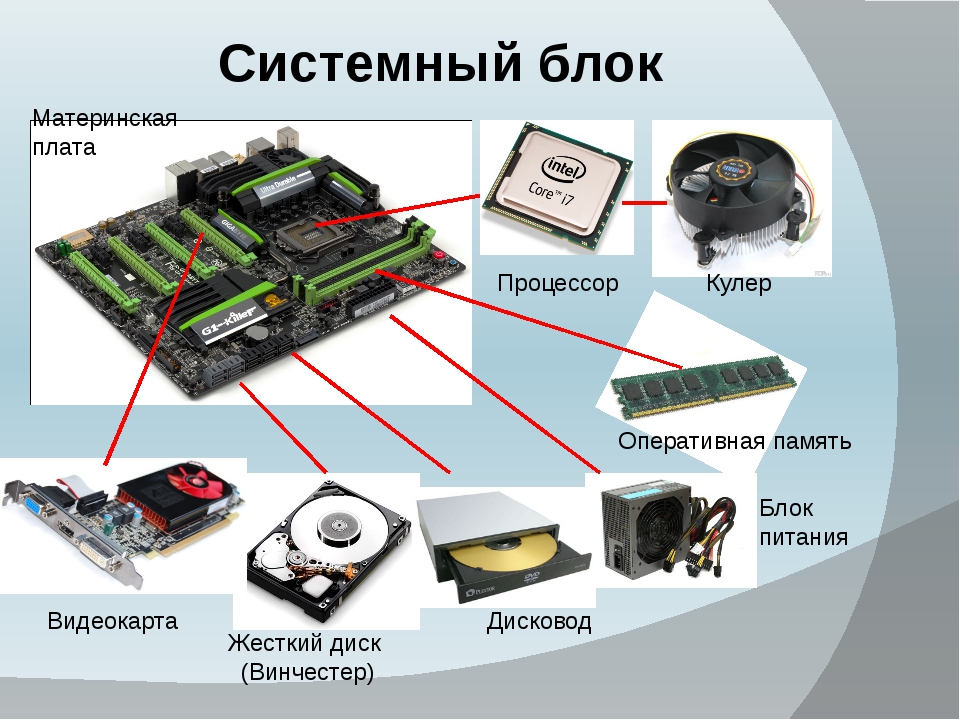
Мы не знаем, когда этот товар снова появится в наличии.
| Бренд | NVIDIA |
| графический процессор Производитель | NVIDIA |
| RAM RAM | 64 МБ |
| графический карточный интерфейс | PCI-E |
— обзор
OpenCL на графическом процессоре AMD Radeon HD7970
Графический процессор — это совершенно другая цель для кода OpenCL по сравнению с ЦП. Читатель должен помнить, что графический процессор в первую очередь предназначен для эффективной визуализации трехмерной графики. Эта цель приводит к значительному изменению приоритетов ресурсов и, следовательно, к значительно отличающейся от ЦП архитектуре. На современных графических процессорах это различие сводится к нескольким основным функциям, из которых следующие три были рассмотрены в главе 3:
Читатель должен помнить, что графический процессор в первую очередь предназначен для эффективной визуализации трехмерной графики. Эта цель приводит к значительному изменению приоритетов ресурсов и, следовательно, к значительно отличающейся от ЦП архитектуре. На современных графических процессорах это различие сводится к нескольким основным функциям, из которых следующие три были рассмотрены в главе 3:
- •
Широкое выполнение одной инструкции с несколькими данными (SIMD): выполняется гораздо большее количество исполнительных блоков. одна и та же инструкция для разных элементов данных.
- •
Интенсивная многопоточность: поддержка большого количества одновременных контекстов потоков на данном вычислительном ядре графического процессора.
- •
Аппаратная блокнотная память: Буферизация физической памяти находится исключительно под контролем программиста.
Ниже приведены дополнительные отличия, более тонкие, но интересные, поскольку они создают возможности для обеспечения улучшений с точки зрения задержки диспетчеризации работы и связи: аппаратные нити.
Постановка задач и диспетчеризация с аппаратным управлением: управление очередью работ и балансировка нагрузки на оборудовании.
Поддержка аппаратной синхронизации снижает накладные расходы на синхронизацию выполнения нескольких контекстов потоков на заданном ядре SIMD, обеспечивая мелкомодульную связь при низких затратах.
Графические процессоры обеспечивают обширную аппаратную поддержку для диспетчеризации задач, поскольку они глубоко укоренились в мире трехмерной графики. Игровые рабочие нагрузки включают в себя управление сложными графами задач, возникающими из-за чередования работы в графическом конвейере.Как показано на общей диаграмме AMD Radeon HD7970 на рис. 3.11, архитектура состоит из командного процессора и генератора групп на переднем плане, который передает сформированные группы паре аппаратных планировщиков. Эти два планировщика распределяют вычислительные нагрузки по 32 ядрам, разбросанным по всему устройству, каждое из которых содержит один скалярный блок и четыре векторных блока. Для графических рабочих нагрузок AMD включает дополнительный набор блоков аппаратного ускорителя ниже командного процессора:
Для графических рабочих нагрузок AMD включает дополнительный набор блоков аппаратного ускорителя ниже командного процессора:
- •
Тесселятор: Тесселяция — это процесс создания меньших треугольников из больших для масштабирования сложности модели во время выполнения.
- •
Сборщик геометрии: упаковывает геометрическую информацию для обработки шейдерами.
- •
Растеризатор: преобразует векторные данные в растровый формат.
- •
Иерархический Z-процессор: Поддерживает иерархическое представление глубины сцены для снижения нагрузки за счет возможности раннего отклонения пикселей в зависимости от глубины.
Вместе эти блоки позволяют оборудованию планировать рабочие нагрузки, как показано на рис. 6.5. Чтобы получить высокий уровень ускорения производительности, связанный с вычислениями на GPU, планирование должно быть очень эффективным. Накладные расходы на планирование потоков должны оставаться низкими, поскольку фрагменты работы, собранные входной сборкой, могут быть очень маленькими — например, один треугольник, состоящий из нескольких пикселей. Этот объем работы сам по себе не позволит использовать машину, но помните, что полный графический конвейер очень быстро собирает, растрирует и затеняет большое количество треугольников одновременно.Мы можем видеть упрощенную версию такого расписания на рис. 6.5. Обратите внимание, что неиспользованное время вычислений, обозначенное пробелом на рисунке, будет легко заполняться при одновременной обработке нескольких треугольников. Это хороший пример того, почему GPU предназначен для обработки с высокой пропускной способностью и, следовательно, почему рабочие нагрузки должны правильно сопоставляться с базовым оборудованием для достижения хорошей производительности.
Этот объем работы сам по себе не позволит использовать машину, но помните, что полный графический конвейер очень быстро собирает, растрирует и затеняет большое количество треугольников одновременно.Мы можем видеть упрощенную версию такого расписания на рис. 6.5. Обратите внимание, что неиспользованное время вычислений, обозначенное пробелом на рисунке, будет легко заполняться при одновременной обработке нескольких треугольников. Это хороший пример того, почему GPU предназначен для обработки с высокой пропускной способностью и, следовательно, почему рабочие нагрузки должны правильно сопоставляться с базовым оборудованием для достижения хорошей производительности.
Рисунок 6.5. Аппаратно-управляемое расписание для набора задач, выполняемых на небольшой единице работы графического процессора.Когда многие из этих рабочих нагрузок запланированы вместе, аппаратное обеспечение можно использовать очень эффективно.
Для OpenCL большая часть этого оборудования для растеризации и сборки не требуется, поскольку диспетчеры предопределены с большими размерами, и их нужно только собрать в соответствующие рабочие группы и аппаратные потоки для запуска на устройстве. Однако, чтобы обеспечить эффективную работу высококонвейерного командного процессора и генератора заданий и достичь высоких уровней производительности на графическом процессоре, нам необходимо:
Однако, чтобы обеспечить эффективную работу высококонвейерного командного процессора и генератора заданий и достичь высоких уровней производительности на графическом процессоре, нам необходимо:
- •
Обеспечить много работы для каждой диспетчеризации ядра.
- •
Пакетные задания вместе.
Обеспечивая достаточный объем работы в каждом ядре, мы гарантируем, что конвейер генерации групп всегда занят, чтобы у него всегда было больше работы для планировщиков волн, а у планировщиков всегда было больше работы для передачи на SIMD единицы. По сути, мы хотим создать большое количество потоков, чтобы занять машину: как обсуждалось ранее, GPU — это машина с высокой пропускной способностью.
Второй пункт относится к механизму очередей OpenCL.Когда среда выполнения OpenCL выбирает обработку работы в рабочей очереди, связанной с устройством, она просматривает задачи в очереди с целью выбора подходящего большого фрагмента для обработки. Из этого набора задач он строит командный буфер работы для графического процессора на языке, понятном командному процессору, находящемуся перед конвейером графического процессора. Этот процесс состоит из (1) создания очереди, (2) размещения ее где-то в памяти, (3) сообщения устройству, где она находится, и (4) запроса устройства на ее обработку.Такая последовательность операций требует времени, вызывая относительно большую задержку для одного блока работы. В частности, поскольку графический процессор работает за драйвером, работающим в пространстве ядра, этот процесс требует ряда переключений контекста в пространство ядра и из него, чтобы позволить графическому процессору начать работу. Как и в случае ЦП, где переключение контекста между потоками стало бы значительным накладным расходом, переключение в режим ядра и подготовка очередей для слишком мелких единиц работы неэффективны. Существуют довольно постоянные накладные расходы на диспетчеризацию рабочей очереди и дополнительные накладные расходы на обработку в зависимости от объема работы в ней.
Из этого набора задач он строит командный буфер работы для графического процессора на языке, понятном командному процессору, находящемуся перед конвейером графического процессора. Этот процесс состоит из (1) создания очереди, (2) размещения ее где-то в памяти, (3) сообщения устройству, где она находится, и (4) запроса устройства на ее обработку.Такая последовательность операций требует времени, вызывая относительно большую задержку для одного блока работы. В частности, поскольку графический процессор работает за драйвером, работающим в пространстве ядра, этот процесс требует ряда переключений контекста в пространство ядра и из него, чтобы позволить графическому процессору начать работу. Как и в случае ЦП, где переключение контекста между потоками стало бы значительным накладным расходом, переключение в режим ядра и подготовка очередей для слишком мелких единиц работы неэффективны. Существуют довольно постоянные накладные расходы на диспетчеризацию рабочей очереди и дополнительные накладные расходы на обработку в зависимости от объема работы в ней. Эти накладные расходы должны быть преодолены за счет запуска очень больших ядер или длинных последовательностей ядер. В любом случае цель состоит в том, чтобы увеличить объем работы, выполняемой для каждого экземпляра обработки очереди.
Эти накладные расходы должны быть преодолены за счет запуска очень больших ядер или длинных последовательностей ядер. В любом случае цель состоит в том, чтобы увеличить объем работы, выполняемой для каждого экземпляра обработки очереди.
Многопоточность и система памяти
На рис. 6.6 показана приблизительная иерархия памяти системы, содержащей ЦП AMD FX8150 и ГП AMD Radeon HD7970. Иерархия кэша ЦП в этой настройке устроена так, чтобы уменьшить задержку одного потока доступа к памяти: любая значительная задержка приведет к остановке этого потока и снижению эффективности выполнения.Поскольку конструкция ядер графического процессора использует многопоточность и широкий SIMD для максимизации пропускной способности за счет задержки, система памяти аналогичным образом разработана для максимизации пропускной способности для удовлетворения этой пропускной способности с некоторыми затратами на задержку.
Рисунок 6.6. Приблизительные значения пропускной способности для различных уровней иерархии памяти как для ЦП AMD FX8150, так и для графического процессора AMD Radeon HD7970. Обратите особое внимание на низкую пропускную способность экспресс-шины PCI по сравнению с другими уровнями, особенно кэшами, по обеим сторонам интерфейса.
Обратите особое внимание на низкую пропускную способность экспресс-шины PCI по сравнению с другими уровнями, особенно кэшами, по обеим сторонам интерфейса.
Ограниченное кэширование, связанное с широкополосной памятью GDDR5 в конструкции Radeon, стало возможным благодаря следующему:
LDS обеспечивает доступ для чтения/записи с высокой пропускной способностью и малой задержкой, управляемый программистом. Эта форма программируемого повторного использования данных менее расточительна, а также более эффективна с точки зрения площади и энергопотребления, чем кэширование с аппаратным управлением.Ограниченный доступ к ненужным данным (данные, которые загружаются в кэш, но не используются) означает, что LDS может иметь меньшую емкость, чем эквивалентный кэш. Кроме того, снижение потребности в управляющей логике и структурах тегов приводит к уменьшению площади на единицу емкости.
Аппаратно управляемая многопоточность в ядрах графического процессора позволяет аппаратному обеспечению компенсировать задержку памяти. Чтобы выполнить доступ к памяти, поток, работающий на модуле SIMD, временно удаляется из этого модуля и помещается в отдельный контроллер памяти.Поток не возобновляется на SIMD до тех пор, пока доступ к памяти не возобновится. Для достижения высоких уровней производительности и использования должно выполняться достаточно большое количество потоков. Во многих приложениях может потребоваться четыре или более волновых фронта на блок SIMD или 16 на ядро (вычислительный блок). Каждый блок SIMD может поддерживать до 10 волновых фронтов, из которых 40 активны на вычислительном блоке. Чтобы обеспечить быстрое переключение, состояние волнового фронта сохраняется в регистрах, а не в кэше. Каждый передаваемый волновой фронт потребляет ресурсы, поэтому увеличение количества активных волновых фронтов для покрытия задержки должно быть сбалансировано с использованием регистров и LDS.
Чтобы выполнить доступ к памяти, поток, работающий на модуле SIMD, временно удаляется из этого модуля и помещается в отдельный контроллер памяти.Поток не возобновляется на SIMD до тех пор, пока доступ к памяти не возобновится. Для достижения высоких уровней производительности и использования должно выполняться достаточно большое количество потоков. Во многих приложениях может потребоваться четыре или более волновых фронта на блок SIMD или 16 на ядро (вычислительный блок). Каждый блок SIMD может поддерживать до 10 волновых фронтов, из которых 40 активны на вычислительном блоке. Чтобы обеспечить быстрое переключение, состояние волнового фронта сохраняется в регистрах, а не в кэше. Каждый передаваемый волновой фронт потребляет ресурсы, поэтому увеличение количества активных волновых фронтов для покрытия задержки должно быть сбалансировано с использованием регистров и LDS.
Кэши, присутствующие в системе, обеспечивают механизм фильтрации для объединения сложных собранных шаблонов доступа для чтения и разрозненной записи в векторных операциях с памятью в максимально возможные блоки. Большие векторные чтения, возникающие в результате хорошо структурированного доступа к памяти, гораздо более эффективны для системы на основе DRAM, требуя меньшего временного кэширования, чем распределенные во времени меньшие чтения, возникающие из наиболее общего кода ЦП.
Большие векторные чтения, возникающие в результате хорошо структурированного доступа к памяти, гораздо более эффективны для системы на основе DRAM, требуя меньшего временного кэширования, чем распределенные во времени меньшие чтения, возникающие из наиболее общего кода ЦП.
На рисунке 6.6 показана шина PCI Express как соединение между процессором и графическим процессором.Весь трафик между процессором и, следовательно, основной памятью и графическим процессором должен проходить через этот канал. Поскольку пропускная способность PCI Express значительно ниже, чем доступ к DRAM, и даже ниже, чем возможности встроенных буферов, это может стать серьезным узким местом в приложении, сильно зависящем от связи. В приложении OpenCL нам нужно минимизировать количество и размер операций копирования памяти по отношению к ядрам, которые мы ставим в очередь. Трудно добиться хорошей производительности в приложении, которое должно работать на дискретном графическом процессоре, если это приложение имеет тесную петлю обратной связи, включающую копирование данных туда и обратно по шине PCI Express. В главе 7 более подробно обсуждаются компромиссы, связанные с оптимизацией перемещения данных.
В главе 7 более подробно обсуждаются компромиссы, связанные с оптимизацией перемещения данных.
Выполнение инструкций на архитектуре HD7970
Идея программирования SIMD-архитектуры с использованием модели дорожек обсуждалась ранее. В каждом вычислительном блоке или ядре HD7970 планировщик инструкций может планировать до 5 инструкций в каждом цикле для скалярного блока, одного из блоков SIMD, блока памяти или других аппаратных устройств со специальными функциями.
В предыдущих устройствах, таких как архитектура HD6970, представленная в предыдущем издании книги, управление потоком управлялось автоматически ветвящимся устройством.Эта конструкция привела к очень специализированному механизму выполнения, который несколько отличался от других векторных архитектур, представленных на рынке. В дизайне HD7970 реализована более явная интеграция скалярного и векторного кода пошагово, как это делает ЦП x86 при интеграции операций SSE или AVX.
Механизм SIMD выполняет 64-разрядные логические объекты SIMD, называемые волновыми фронтами. Каждый волновой фронт использует декодирование одной инструкции и имеет свой собственный поток инструкций и может рассматриваться как отдельный контекст аппаратного потока.64 рабочих элемента в волновом фронте выполняются в течение четырех тактовых циклов на 16-полосном аппаратном блоке SIMD. Различные волновые фронты выполняются в разных точках своих потоков команд. Все разветвления выполняются на уровне детализации волнового фронта.
Каждый волновой фронт использует декодирование одной инструкции и имеет свой собственный поток инструкций и может рассматриваться как отдельный контекст аппаратного потока.64 рабочих элемента в волновом фронте выполняются в течение четырех тактовых циклов на 16-полосном аппаратном блоке SIMD. Различные волновые фронты выполняются в разных точках своих потоков команд. Все разветвления выполняются на уровне детализации волнового фронта.
Любая возможность субволнового (расходящегося) ветвления требует ограничения ISA последовательностью операций маскирования и демаскирования. Результатом является очень явная последовательность блоков инструкций, которые выполняются до тех пор, пока не будут пройдены все необходимые пути. Такое расхождение в выполнении создает неэффективность, поскольку в любой момент времени активна только часть векторного блока, однако возможность поддерживать такой поток управления улучшает программируемость, устраняя необходимость для программиста вручную векторизовать код. Очень похожие проблемы возникают при разработке для конкурирующих архитектур, таких как дизайн NVIDIA GTX580, и характерны для производства программного обеспечения для широких векторных архитектур, будь то ручная, компиляторная, аппаратная векторизация или где-то посередине.
Очень похожие проблемы возникают при разработке для конкурирующих архитектур, таких как дизайн NVIDIA GTX580, и характерны для производства программного обеспечения для широких векторных архитектур, будь то ручная, компиляторная, аппаратная векторизация или где-то посередине.
Ниже приведен пример кода, предназначенного для работы на вычислительном блоке HD7970 (см. спецификацию ISA для Южных островов [cite]SI-ISA[/cite]). Возьмем очень простое ядро, которое будет расходиться на волновом фронте любой ширины больше единицы: (0) == 0 ) {
out[get_global_id(0)] = in[get_global_id(0)];
} else {
out[get_global_id(0)] = 0;
}
}
Хотя это тривиальное ядро, оно позволит нам увидеть, как компиляция сопоставляет его с ISA, и косвенно, как эта ISA будет вести себя на оборудовании.Когда мы скомпилируем это для HD7970, мы получаем следующее:
Si_Asic Main
ASIC (Si_asic)
Тип (CS)
49
S0, S [4: 7], 0x04
s_buffer_load_dword s1, с [4: 7], 0x18
s_waitcnt lgkmcnt (0)
s_min_u32 s0, s0, 0x0000ffff
v_mov_b32 v1, s0
v_mul_i32_i24 v1, S12, V1
v_add_i32 v0, vcc, v0, v1
v_add_i32 v0, vcc, s1, v0
s_buffer_load_dword s0, s [8:11], 0x00
S_BUFFER_LOLD_DWORD S1, S [8 : 11], 0x04
V_CMP_EQ_I32 S [4: 5], V0, 0
S_AND_SAVEEXEC_B64 S [4: 5], S [4: 5]
V_LSHLREV_B32 V1, 2, V0
s_cbranch_execz label_0016
- 9000 2 s_waitcnt lgkmcnt (0)
v_add_i32 v1, vcc, s0, v1
s_load_dwordx4 s [8:11], s [2: 3], 0x50
S_WAITCNT LGKMCNT (0)
tbuffer_load_format_x v1, v1, s [8:11], 0 Offen
Формат: [buf_data_format_32, buf_num_format_float]
Label_0016:
S_ANDN2_B64 EXEC, S [4: 5], EXEC
V_MOV_B32 V1, 0
S_MOV_B64 EXEC, S [4: 5]
V_LSHLREV_B32 V0, 2, V0
S_WAITCNT LGKMCNT (0)
V_ADD_I32 V0, VCC, S1, V0
s_load_dwordx4 s[0:3], s[2:3], 0x58
s_waitcnt vmcnt(0) & lgkmcnt(0)
tbuffer_store_ offen
формат: [BUF_DATA_FORMAT_32,BUF_NUM_FORMAT_FLOAT]
s_en dpgm
end
Этот код можно рассматривать, как и код OpenCL, для представления одной полосы выполнения: одного рабочего элемента. Однако, в отличие от языка более высокого уровня, здесь мы видим комбинацию скалярных операций (с префиксом s_), предназначенных для выполнения на скалярном блоке ядра графического процессора, который мы видим на рис. 6.7, и векторных операций (с префиксом v_), которые выполняются. через одну из векторных единиц.
Рисунок 6.7. Вычислительный блок/ядро на архитектуре Radeon HD7970. Вычислительный блок состоит из скалярного процессора и четырех 16-полосных модулей SIMD. Каждый модуль SIMD обрабатывает волновой фронт из 64 элементов в течение четырех циклов.64 КБ векторных регистров разделены между четырьмя ядрами SIMD, что обеспечивает высокую пропускную способность доступа.
Если внимательно посмотреть на структуру кода, то мы увидим:
Операция сравнения векторов, по всему фронту волны мы сравниваем локальный id с константой 0.
v_cmp_eq_i32 s[4:5], v0 , 0
затем манипулирует маской выполнения, обрабатывая результат сравнения и обновляя скалярный регистр текущим значением маски. Кроме того, эта операция гарантирует, что регистр скалярного кода условия (SCC) установлен: это то, что вызовет условный переход.
Кроме того, эта операция гарантирует, что регистр скалярного кода условия (SCC) установлен: это то, что вызовет условный переход.
s_and_saveexec_b64 s[4:5], s[4:5]
Целью этого является то, что если какая-либо дорожка волнового фронта должна была войти в if, то условного перехода не произойдет. Если условного перехода не происходит, код войдет в часть if условного оператора. Если дорожке не нужно входить в часть if, скалярный модуль выполнит ветвь, и управление перейдет к части else.
s_cbranch_execz label_0016
Если ветвь if выполняется, векторная загрузка (загрузка из буфера t или текстуры, показывающая графическое наследие ISA: tbuffer_load_format_x) загружает ожидаемые данные в векторный регистр , v1. Обратите внимание, что операция tbuffer_store была исключена компилятором, поэтому мы видим ее только один раз в скомпилированном коде, тогда как в исходном коде OpenCL C мы видели два.
В ветке else поведение ожидаемое: те дорожки, которые не выполнили ветку if, должны выполняться здесь. В частности, маска выполнения заменяется текущей маской NAND с исходной сохраненной маской и становится активной:
В частности, маска выполнения заменяется текущей маской NAND с исходной сохраненной маской и становится активной:
s_andn2_b64 exec, s[4:5], exec
И затем v1 загружается с 0, что это то, что мы ожидаем от исходного кода OpenCL C.
v_mov_b32 v1, 0
Нет ветки, чтобы пропустить ветку else. Похоже, что в этом случае компилятор решил, что, поскольку в ветке else нет нагрузки для выполнения, накладные расходы на простое маскирование операций и обработку всего раздела как предикатного выполнения являются эффективным решением, так что ветвь else будет всегда выполняться и просто обычно не обновлять v1.Маска выполнения обновляется (s_mov_b64 exec, s[4:5]), и код выполняется. Какая бы из двух операций записи в v1 ни была верна для текущей векторной дорожки, она будет сохранена в памяти.
Очевидно, это очень простой пример. С глубоко вложенными ifs код маски может быть усложнен длинными последовательностями хранения масок и операций AND с новыми кодами условий, сужая набор выполняемых дорожек на каждом этапе до тех пор, пока, наконец, не потребуются скалярные ветви. На каждом этапе сужения эффективность выполнения снижается, и в результате хорошо структурированный код, выполняющий одну и ту же инструкцию по всему вектору, жизненно важен для эффективного использования архитектуры.Именно сложный набор процедур управления масками и других векторных операций отличает эту ISA от CPU ISA, такой как SSE, а не абстрактное понятие наличия гораздо большего количества ядер.
На каждом этапе сужения эффективность выполнения снижается, и в результате хорошо структурированный код, выполняющий одну и ту же инструкцию по всему вектору, жизненно важен для эффективного использования архитектуры.Именно сложный набор процедур управления масками и других векторных операций отличает эту ISA от CPU ISA, такой как SSE, а не абстрактное понятие наличия гораздо большего количества ядер.
Схема модуля SIMD, выполняющего этот код, показана на рис. 6.7. Каждый блок SIMD содержит 32-портовый LDS с задержкой в четыре операции и атомарными блоками на своем интерфейсе. Эти атомарные единицы означают, что невозвратные атомарные операции могут выполняться в LDS одновременно с арифметическими операциями, выполняемыми в ALU, что обеспечивает дополнительный параллелизм.Два волновых фронта от разных блоков SIMD на одном ядре могут быть объединены вместе в 32 банках блока LDS. Чтение или запись из одного или обоих волновых фронтов, активных на интерфейсе LDS, могут конфликтовать, и конфликтующие операции чтения или записи воспроизводятся в течение нескольких циклов, пока все операции не будут завершены. При чтении это может привести к остановке ALU.
При чтении это может привести к остановке ALU.
Переход от VLIW Execution
Более ранние архитектуры AMD, описанные в предыдущем издании книги, страдали от более сложной и трудной для чтения ISA.Частично это произошло из-за несвязанного скалярного модуля с высокой задержкой выполнения, а частично из-за использования выполнения VLIW. В то время как на HD7970 инструкции могут быть динамически запланированы для четырех блоков SIMD в вычислительном блоке, на более ранних устройствах эти четыре (или даже пять) блоков SIMD выполнялись синхронно по расписанию инструкций, сгенерированному компилятором. В целом это изменение должно привести к меньшему количеству пузырей в расписании инструкций, однако оно приводит к одному важному отличию в отображении OpenCL от того, что мы видели в прошлом.Использование встроенных векторных типов OpenCL ранее рекомендовалось как способ увеличить арифметическую интенсивность функции и упаковать больше арифметических операций близко друг к другу для заполнения пакета VLIW.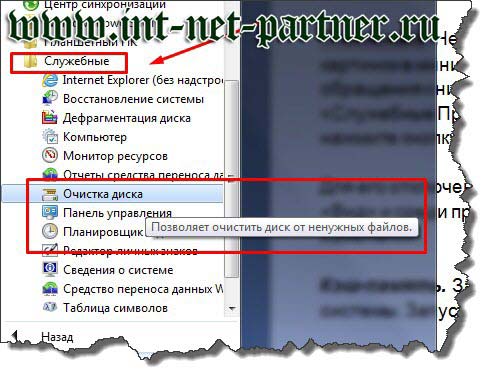
Например, для архитектуры HD6970 в ISA можно увидеть следующую инструкцию:
17 y: ADD ____, R1.x, PV16.x
z: ADD T0.z, R1.x, -PV16.x
18 x: MOV R1.x, R0.w
y: MOV R1.y, R0.w
z: MOV R1.z, R0.w
w: MUL_e ____, R4.x, PV17.y
Это пара пакетов инструкций, каждый из которых содержит до четырех операций. Первый из них заполнен только наполовину: здесь в дело вступают векторные операции. Кроме того, доступ к четырем банкам регистрового файла, которые мы видим на рис. 6.7, осуществлялся из четырех слотов VLIW (с некоторой гибкостью), так что векторные переменные оптимально хранится. Архитектурное изменение четырех динамически планируемых блоков SIMD мы видим на рисунке 6.7 означает, что дополнительные арифметические инструкции могут не понадобиться, скорее это можно рассматривать как чисто арифметический вопрос интенсивности. Что еще более важно, использование короткого вектора OpenCL использует несколько последовательных регистров, и без выигрыша с точки зрения эффективности упаковки регистров это может привести к чрезмерному использованию файла регистров. Обратите внимание, что четыре волновых фронта активны в пространстве, которое раньше занимал один: с дополнительными промежуточными регистрами для соответствия.
Обратите внимание, что четыре волновых фронта активны в пространстве, которое раньше занимал один: с дополнительными промежуточными регистрами для соответствия.
Распределение ресурсов
Каждый модуль SIMD на графическом процессоре включает в себя фиксированный объем регистра и дискового пространства LDS.На каждом вычислительном блоке имеется 256 КБ регистров. Эти регистры разделены на четыре банка, так что на модуль SIMD приходится 256 регистров, каждый из которых имеет ширину 64 дорожки и 32 бита на дорожку. Эти регистры будут разделены в зависимости от количества волновых фронтов, выполняемых на модуле SIMD. На каждом вычислительном блоке имеется 64 КБ LDS, доступных в виде 32-банков SRAM с произвольным доступом. LDS делится между количеством рабочих групп, выполняющихся на вычислительном блоке, на основе запросов на выделение локальной памяти, сделанных в ядре, и с помощью механизма передачи параметров во время выполнения OpenCL.
При выполнении одного ядра на каждом вычислительном блоке, что является стандартным сопоставлением при запуске программы OpenCL, мы можем столкнуться с узким местом в ресурсах, как показано на рис. 6.8. На этой диаграмме мы видим две рабочие группы, каждая из которых содержит два волновых фронта, где каждому рабочему элементу (и, следовательно, увеличенному волновому фронту) требуется 42 векторных регистра, доля в 50 скалярных регистрах, а рабочей группе требуется 24 КБ LDS. Это выделение четырех волновых фронтов на вычислительную единицу ограничено требованиями LDS рабочей группы и ниже минимального количества волновых фронтов, которые нам нужно запустить на устройстве, чтобы поддерживать его занятость, поскольку только с одним волновым фронтом на модуль SIMD у нас нет возможности переключаться на замену, когда волновой фронт выполняет скалярный код или операции с памятью.Если мы сможем увеличить количество волновых фронтов, работающих на SIMD-модуле, до четырех или более, у нас будет больше шансов сохранить занятость скалярных и векторных модулей во время потока управления и, в частности, задержку памяти, где чем больше запущенных потоков, тем лучше наша работа. скрытая задержка.
6.8. На этой диаграмме мы видим две рабочие группы, каждая из которых содержит два волновых фронта, где каждому рабочему элементу (и, следовательно, увеличенному волновому фронту) требуется 42 векторных регистра, доля в 50 скалярных регистрах, а рабочей группе требуется 24 КБ LDS. Это выделение четырех волновых фронтов на вычислительную единицу ограничено требованиями LDS рабочей группы и ниже минимального количества волновых фронтов, которые нам нужно запустить на устройстве, чтобы поддерживать его занятость, поскольку только с одним волновым фронтом на модуль SIMD у нас нет возможности переключаться на замену, когда волновой фронт выполняет скалярный код или операции с памятью.Если мы сможем увеличить количество волновых фронтов, работающих на SIMD-модуле, до четырех или более, у нас будет больше шансов сохранить занятость скалярных и векторных модулей во время потока управления и, в частности, задержку памяти, где чем больше запущенных потоков, тем лучше наша работа. скрытая задержка. Поскольку в этом случае мы ограничены LDS, увеличение количества волновых фронтов на рабочую группу до трех было бы хорошим началом, если это целесообразно для алгоритма. В качестве альтернативы, уменьшение выделения LDS позволило бы нам запустить третью рабочую группу на каждом вычислительном блоке, что очень полезно, если один фронт волны ожидает барьеров или обращений к памяти и, следовательно, не на модуле SIMD в данный момент.
Поскольку в этом случае мы ограничены LDS, увеличение количества волновых фронтов на рабочую группу до трех было бы хорошим началом, если это целесообразно для алгоритма. В качестве альтернативы, уменьшение выделения LDS позволило бы нам запустить третью рабочую группу на каждом вычислительном блоке, что очень полезно, если один фронт волны ожидает барьеров или обращений к памяти и, следовательно, не на модуле SIMD в данный момент.
Рисунок 6.8. Выделение ресурсов одной вычислительной единицы для рабочих нагрузок OpenCL. Учитывая рабочую группу из 128 рабочих элементов, для которой требуется 24 КБ LDS и где для каждого рабочего элемента требуется 42 векторных регистра и 50 скалярных регистров, мы можем разместить две рабочие группы и, следовательно, четыре волновых фронта на каждом модуле SIMD: мы ограничены доступностью LDS, в то время как емкость регистра практически не используется.
Каждый фронт волны запускается на одном модуле SIMD и остается там до завершения. Любой набор волновых фронтов, являющихся частью одной и той же рабочей группы, остается вместе на одном вычислительном блоке. Причина этого должна быть ясна, когда вы видите объем хранилища состояния, требуемый этой группе: в этом случае мы видим 24 КБ LDS и 84 КБ регистров на рабочую группу. Это значительный объем данных, которые необходимо сбросить в память и перенести на другое ядро. В результате, когда контроллер памяти выполняет операцию чтения или записи с высокой задержкой, если нет другого фронта волны с работой ALU, которую можно было бы выполнить, готовую к планированию на SIMD-модуле, аппаратное обеспечение будет бездействовать.
Причина этого должна быть ясна, когда вы видите объем хранилища состояния, требуемый этой группе: в этом случае мы видим 24 КБ LDS и 84 КБ регистров на рабочую группу. Это значительный объем данных, которые необходимо сбросить в память и перенести на другое ядро. В результате, когда контроллер памяти выполняет операцию чтения или записи с высокой задержкой, если нет другого фронта волны с работой ALU, которую можно было бы выполнить, готовую к планированию на SIMD-модуле, аппаратное обеспечение будет бездействовать.
Что такое кэш-память в моем компьютере
Слово «кэш» могло появляться в ваших разговорах о компьютерах, производительности и, в частности, о памяти.Но что это на самом деле означает и почему это важно?
Понимание кэша и кэш-памяти может помочь вам сделать лучший выбор для обслуживания вашего компьютера, чтобы вы могли продолжать выполнять задачи с максимальной эффективностью. В этом руководстве вы узнаете, что такое кэш-память и как она влияет на повседневное использование компьютера.
Определение кэш-памяти компьютера
Кэш — это временная память, официально называемая «кэш-память ЦП». Эта чиповая функция вашего компьютера позволяет вам получать доступ к некоторой информации быстрее, чем если бы вы обращались к ней с основного жесткого диска вашего компьютера.Данные из программ и файлов, которые вы используете чаще всего, хранятся в этой временной памяти, которая также является самой быстрой памятью на вашем компьютере.
Кэш и ОЗУ
Когда вашему компьютеру требуется быстрый доступ к данным, но он не может найти их в кеше, он будет искать их в оперативной памяти (ОЗУ). Оперативная память является основным типом хранилища компьютерных данных, в котором хранится информация и программные процессы. Он находится дальше от процессора, чем кэш-память, и не такой быстрый; кеш на самом деле в 100 раз быстрее, чем стандартная оперативная память. Если кеш такой быстрый, то почему не все данные хранятся там? Кэш-хранилище ограничено и очень дорого для своего пространства, поэтому имеет смысл хранить только наиболее часто используемые данные там, а все остальное оставить в оперативной памяти.
Другие варианты использования термина «кэш»
«Кэш» также используется для обозначения любого временного сбора данных в аппаратном или программном обеспечении. Например, регулярное техническое обслуживание предполагает регулярную перезагрузку компьютера, маршрутизатора и модема, чтобы «очистить кеш», что позволит вашим устройствам быстрее загружать программы.Когда вы заходите в свою историю Google, чтобы стереть файлы cookie браузера и выполнить поиск, одним из вариантов является очистка «кэшированных изображений».
Когда специалисты по компьютерам говорят о «кеше», они, скорее всего, имеют в виду кэш-память.
Как кэш-память влияет на производительность
Как кэш-память ускоряет ваши вычисления? Мы уже знаем, что он может получать доступ к часто используемым данным с максимальной эффективностью. Однако решить, какие данные он хранит в кеше, само по себе почти искусство.
Компьютер ждет, пока вы начнете использовать данные, а затем каталогизирует копии данных, к которым вы обращаетесь снова и снова, в свою специальную библиотеку кэш-памяти. Этот процесс называется «кэшированием». Чем больше вы что-то используете, тем больше вероятность того, что его копия окажется в вашем кеше.
Этот процесс называется «кэшированием». Чем больше вы что-то используете, тем больше вероятность того, что его копия окажется в вашем кеше.Попадания и промахи
Затем, когда вы выполняете задачу, требующую этой информации, компьютер сначала проверяет кэш-память. Если он есть, это называется «хит», и вы достигнете максимальной производительности. Если данных нет, это «промах», и ваш компьютер будет искать их на жестком диске или в оперативной памяти более длинным и медленным путем.
Что делать, если мой кэш заполнен?
Несмотря на то, что кэширование может ускорить работу компьютера, если кэш-память переполняется, оно может наоборот замедлить работу. Важно запускать задачи обслуживания на вашем ПК, потому что некоторые из этих функций избавят его память от временных файлов, которые ему, вероятно, больше не нужны. То же самое относится и к вашему интернет-браузеру, который хранит еще больше данных в кеше, что может привести к зависанию вашего ПК. Если вы просрочили очистку истории браузера или временных интернет-файлов, не откладывайте.
Объяснение уровней кэша
Кэш-памяти тоже не одно большое ведро. Компьютер может присваивать данные одному из двух уровней.
Кэш уровня 1
Кэш уровня 1 (L1) — это кэш, встроенный в ваш ЦП. Он оценивает данные, к которым только что обращался ваш ЦП, и определяет, что, вероятно, вы скоро снова получите к ним доступ. Итак, она попадает в кеш L1, потому что это первое место, которое ваш компьютер проверит в следующий раз, когда вам понадобится эта информация. Это самый быстрый из уровней кэша.
Кэш уровня 2
Кэш уровня 2 (L2) также называется «вторичным кешем». Это то, куда ваш компьютер отправляется, когда не может найти ваши данные (или получает «промах») после поиска в кеше L1. Уровень 2 обычно находится на карте памяти в непосредственной близости от процессора.
Кэш-память на диске
Вы также найдете кэш-память на жестком диске. Это называется «дисковым кешем». Это самый медленный из всех уровней кэша, так как он берет данные с жесткого диска, чтобы поместить их в оперативную память. В ОЗУ также может храниться информация об аксессуарах и периферийных устройствах компьютера, таких как DVD-привод, в периферийном кэше.
Кэш графического процессора
Получение необходимых данных для рендеринга графики должно происходить очень быстро, поэтому имеет смысл использовать только систему кэширования. Если графика вашего компьютера интегрирована, она будет обрабатываться графическим процессором (GPU), который объединен с CPU в одном чипе. Обе функции работают с одними и теми же ресурсами, поэтому кеш-память графического процессора также ограничена. Отдельная выделенная графическая карта (также называемая «дискретной графикой») будет отделена от ЦП и также будет иметь собственный кеш-память.Самые быстрые игровые компьютеры будут иметь выделенную графическую карту с достаточными хранилищами кэша, встроенными прямо в графический процессор, чтобы избежать задержек или заиканий в интенсивных играх.Как покупать с учетом кеша
Большинство людей не покупают новый компьютер, думая о кеше. Тем не менее, это стоит отметить, если вы заинтересованы в максимально плавной работе компьютера с меньшими задержками и задержками, особенно при одновременном запуске нескольких процессов. К дополнительным параметрам кэш-памяти относятся размер кэша и задержка.
Тем не менее, это стоит отметить, если вы заинтересованы в максимально плавной работе компьютера с меньшими задержками и задержками, особенно при одновременном запуске нескольких процессов. К дополнительным параметрам кэш-памяти относятся размер кэша и задержка.
Размер
Да, это правда, что больший кэш вмещает больше данных. Но это также медленнее, поэтому есть компромисс в производительности. Кроме того, компьютеры созданы для распределения данных по приоритетам в разных кэшах. Вот почему у них есть уровни кеша. Если в кеше L1 недостаточно места, он может сохранить его в кеше L2. В результате размер кеша не должен быть основным фактором при совершении покупок.
Задержка
При доступе к данным задержка рассматривается как «скорость». Сколько времени требуется вашему компьютеру, чтобы добраться до этого кеша памяти L2? Если это меньший кеш, это будет быстрее.Кэш L2 объемом 6 МБ будет иметь повышенную задержку по сравнению с кешем 3 МБ. Компьютеры более высокого класса используют мультисистемный подход, который размещает данные в дополнительных кэшах меньшего размера. Это решает проблему хранения большего количества информации с меньшей общей задержкой.
Это решает проблему хранения большего количества информации с меньшей общей задержкой.
Заключение
Учитывая все характеристики, которые необходимо учитывать при покупке компьютера, ваше решение о покупке, вероятно, будет зависеть не только от кэш-памяти. Вместо этого вы будете покупать ЦП или ГП, поскольку именно там происходят процессы кэширования.
С учетом множества других соображений, оказывающих большее влияние на общую производительность ЦП, они, скорее всего, приведут к вашей покупке гораздо больше, чем кеш-память.При покупке процессора учитывайте цену, тактовую частоту, количество ядер, количество потоков и совместимость с вашей материнской платой или видеокартой. Для получения дополнительной информации о покупке процессора ознакомьтесь с нашей статьей о лучших процессорах для бизнеса или лучших процессорах для игр. Хотя полезно знать, как работает кэш, но если вы покупаете высококлассный игровой компьютер или бизнес-ноутбук, вы, скорее всего, получите доступ к наиболее производительным вариантам кэш-памяти по умолчанию. Если вы планируете обновить свой ЦП, вы можете учитывать кеш при выборе ЦП, подходящего для вашего компьютера.
Если вы планируете обновить свой ЦП, вы можете учитывать кеш при выборе ЦП, подходящего для вашего компьютера.
Об авторе
Линси Кнерл является автором статьи для HP® Tech Takes. Линси — писатель со Среднего Запада, оратор и член ASJA. Она стремится помогать потребителям и владельцам малого бизнеса использовать свои ресурсы с помощью новейших технических решений.Популярные продукты HP
Значение кэш-памяти жесткого диска в играх
Возможно, вы знаете или не знаете, что все части вашего компьютера работают вместе, чтобы повлиять на результат ваших процессов.Эффективность и состояние вашего жесткого диска могут привести к тому, что ваш компьютер будет работать медленно или плавно, в зависимости от того, есть ли какие-либо проблемы, которые необходимо решить. И каждая часть жесткого диска выполняет свою функцию, чтобы обеспечить бесперебойную работу вашего компьютера. Имейте в виду, что каждая часть, хотя и индивидуальна, одинаково важна для функциональности вашего устройства. И некоторые особенности вашего жесткого диска могут быть диагностированы при попытке выяснить, почему ваша игра работает не так гладко, как должна быть.
И некоторые особенности вашего жесткого диска могут быть диагностированы при попытке выяснить, почему ваша игра работает не так гладко, как должна быть.
Одной из таких функций, в частности, является кэш жесткого диска. Кэш жесткого диска влияет на игру несколькими специфическими способами. Во-первых, это замедляет время загрузки карт, уровней и роликов. Во-вторых, это может уменьшить графический потенциал ваших игр. Наконец, в играх с открытым миром это может вызвать общую задержку и замедление при перемещении или загрузке вещей в игре. Однако кеш жесткого диска — не единственный симптом жесткого диска, который может привести к снижению производительности в играх. В этой статье мы поговорим о том, что такое кеш жесткого диска, подробно расскажем о стратегиях решения этой проблемы с задержкой, предложим решения и порассуждаем о том, что может замедлять работу ваших игр.
Что такое кэш жесткого диска? Кэш жесткого диска некоторые называют «буфером», так как это буквальный буфер, который работает на вашем жестком диске. По сути, он пытается обслуживать и использовать временную память для вашего жесткого диска, поскольку одновременно записывает заметки для постоянного хранения на вращающиеся пластины. В некотором смысле кэш жесткого диска действует точно так же, как оперативная память, но он создан специально для вашего жесткого диска, а не является отдельным физическим элементом. Кэш существует потому, что на жестких дисках есть маленькие микроскопические контроллеры, которые помогают обрабатывать данные и содержимое определенным образом.Он фильтрует то, что входит и выходит из диска, подобно почкам, фильтрующим то, что входит и выходит из тела. Кэш — это то, что работает с этими микроконтроллерами, чтобы временно удерживать память, поскольку она постоянно обрабатывается.
По сути, он пытается обслуживать и использовать временную память для вашего жесткого диска, поскольку одновременно записывает заметки для постоянного хранения на вращающиеся пластины. В некотором смысле кэш жесткого диска действует точно так же, как оперативная память, но он создан специально для вашего жесткого диска, а не является отдельным физическим элементом. Кэш существует потому, что на жестких дисках есть маленькие микроскопические контроллеры, которые помогают обрабатывать данные и содержимое определенным образом.Он фильтрует то, что входит и выходит из диска, подобно почкам, фильтрующим то, что входит и выходит из тела. Кэш — это то, что работает с этими микроконтроллерами, чтобы временно удерживать память, поскольку она постоянно обрабатывается.
Возможно, вы знакомы с термином «буферизация» на YouTube. Вы когда-нибудь пытались посмотреть видео, а затем оно внезапно останавливается, потому что оно должно буферизоваться? Как правило, когда видео замедляется, это происходит из-за того, что ваше соединение внезапно стало медленным или плохим, и видеопроигрыватель должен собрать больше данных, прежде чем он сможет воспроизводиться плавно. Это тот же процесс, который происходит в кэше жесткого диска, что позволяет диску буферизоваться во время обработки данных. И когда вы играете в свою любимую видеоигру, будь то командный файтинг или ролевая игра с открытым миром, если вы испытываете моменты задержки или медлительности, это, вероятно, связано с буферизацией кеша жесткого диска и вызывает задержки в обработке данных. твоя память.
Это тот же процесс, который происходит в кэше жесткого диска, что позволяет диску буферизоваться во время обработки данных. И когда вы играете в свою любимую видеоигру, будь то командный файтинг или ролевая игра с открытым миром, если вы испытываете моменты задержки или медлительности, это, вероятно, связано с буферизацией кеша жесткого диска и вызывает задержки в обработке данных. твоя память.
Когда ваша игра загружается, она загружается из файлов, которые уже существуют на вашем жестком диске.Это наиболее заметная проблема медленного жесткого диска с низким объемом кэш-памяти. Если вы когда-либо застревали в лобби в ожидании загрузки карты, это могло быть связано с тем, что чей-то жесткий диск работает с перегрузкой и работает недостаточно быстро. Правильно — медленные кэши других людей могут повлиять на вас и ваше игровое время. Вы когда-нибудь были в раунде League of Legends и застряли на экране загрузки перед матчем, потому что у одного из членов вашей команды очень высокий пинг? Вероятно, они страдают либо от плохого соединения, либо от неуклюжего жесткого диска с чрезвычайно низким объемом кэш-памяти, который работает сверхурочно для правильной буферизации игры. Вот почему время загрузки у всех разное, в зависимости от типа жесткого диска, его состояния и игры, в которую он играет.
Вот почему время загрузки у всех разное, в зависимости от типа жесткого диска, его состояния и игры, в которую он играет.
При игре в одиночные игры с интенсивной графикой вы заметите медленное время задержки, если ваш жесткий диск фрагментирует большие файлы. Такие игры, как Fallout 4, и даже MMORPG, такие как World of Warcraft, могут испытывать резкие задержки, если ваш жесткий диск пытается одновременно фрагментировать большие файлы. Играя в MMO, вы можете увидеть отставание, когда группа игроков одновременно входит в одну и ту же область.Это связано с тем, что ваш жесткий диск усердно работает, пытаясь сохранить всю эту новую память, в то время как изменения и перемещения происходят быстро и в режиме реального времени.
Большой многотерабайтный жесткий диск предотвратит фрагментацию, что увеличит время загрузки в однопользовательских играх. Наконец, в игре с открытым миром, а также в некоторых шутерах от первого лица игра будет загружать уровни во время игры. Подумайте о такой игре, как Skyrim: с такой массивной картой вы не сможете загрузить всю карту, не исчерпав оперативной памяти. Вот почему карта может загружаться для вас только понемногу. Таким образом, когда ваш компьютер ищет файлы во время игры, медленный жесткий диск может негативно повлиять на время загрузки игры.
Вот почему карта может загружаться для вас только понемногу. Таким образом, когда ваш компьютер ищет файлы во время игры, медленный жесткий диск может негативно повлиять на время загрузки игры.
Кэш жесткого диска также может повлиять на графику вашей игры. Готовы поспорить, вы видели игры с серьезными проблемами с частотой кадров, когда горы просто появляются из ниоткуда. Это особенно распространено в играх 64-битной эпохи. Когда вы играете в современные компьютерные игры, ваша система запускает графически интенсивные программы и визуализирует огромное количество визуальных данных во время игры.Это почти полностью делается вашей видеокартой. Если у вас возникли проблемы с графикой, это первое, что нужно устранить. Однако вы обнаружите, что медленный жесткий диск — или старый жесткий диск, находящийся на грани сбоя, — также будет ограничивать графическую производительность вашей системы. Более быстрый кэш жесткого диска и более надежный жесткий диск улучшат качество графики в ваших играх. Иногда может потребоваться замена жесткого диска, чтобы игры снова работали без сбоев.Вы заслуживаете оптимальной производительности и бесперебойной работы игр.
Иногда может потребоваться замена жесткого диска, чтобы игры снова работали без сбоев.Вы заслуживаете оптимальной производительности и бесперебойной работы игр.
Игры с открытым миром становятся все более популярными на рынке игр для крупных студий. Это отлично подходит для геймеров, которым нужен большой выбор способов игры, но вашей машине невероятно сложно отображать эту графику на лету. Это может вызвать некоторое отставание. Учтите, что ваш жесткий диск постоянно загружает файлы и отображает их, пока вы играете в игру с открытым миром. По этой причине вам нужен надежный жесткий диск с большим объемом кэш-памяти — тогда ваш диск сможет легко вызывать файлы, которые вы недавно использовали.Поскольку в игре с открытым миром нужно вызвать так много файлов, это важно при игре в игры с гигантской картой. Попытка загрузить слишком большую часть карты за один раз может оказаться слишком большой для вашего жесткого диска и может привести к сбою игры или даже всего вашего компьютера.
Иногда бывает сложно разобраться с кешем жесткого диска. Потому что для многих других неигровых процессов важно увеличить скорость вашего диска. Вы можете улучшить свою функциональность с помощью отличного кеша.Жесткие диски от природы не быстрые; на самом деле, они чаще всего являются самой медленной частью вашего компьютера. Кэширование — это то, что ускоряет его. Он почти лжет остальной части компьютера, заставляя его думать, что память уже записана, в то время как остальная часть жесткого диска работает за кулисами, чтобы постоянно записывать ее так быстро, как только может. Запись данных занимает много времени, потому что жесткий диск использует для записи физические части. В то время как большинство компьютерных процессов выполняются в электронном и цифровом виде, здесь для записи на диски используются реальные физические методы.
Кэшированные данные будут взяты жестким диском, когда он начнет их записывать. Но вместо того, чтобы положить все эти данные на свои пластины сразу, он сообщит остальному компьютеру, что задача уже выполнена. Это заставляет компьютер отправлять еще больше данных, которые кэшируются и запускают совершенно новый процесс. Тем не менее, это наиболее важный элемент кэширования, поскольку он позволяет вашему компьютеру считать, что процесс уже завершен, поэтому он может перейти к следующей задаче для вас. Представьте, если бы вам пришлось ждать, пока ваш жесткий диск завершит запись каждой части информации, которую вы отправляете на него, прежде чем вы сможете перейти к следующему.Это была бы поистине архаичная система!
Это заставляет компьютер отправлять еще больше данных, которые кэшируются и запускают совершенно новый процесс. Тем не менее, это наиболее важный элемент кэширования, поскольку он позволяет вашему компьютеру считать, что процесс уже завершен, поэтому он может перейти к следующей задаче для вас. Представьте, если бы вам пришлось ждать, пока ваш жесткий диск завершит запись каждой части информации, которую вы отправляете на него, прежде чем вы сможете перейти к следующему.Это была бы поистине архаичная система!
Как видите, кеш может помочь свести к минимуму время ожидания при рендеринге карты в играх с открытым миром или при загрузке частоты кадров для командной игры FPS. Однако кэш не всегда идеален. В то время как жесткий диск делает все возможное, чтобы записать все данные, в то время как ваш кеш лежит на остальной части вашего компьютера, иногда это не удается. Это может произойти, если ваш компьютер внезапно выключится. Тогда ваш кеш ничем не лучше ОЗУ, который удалит все эти энергозависимые данные хранилища, и вам придется начинать все сначала, когда вы снова включите компьютер. Очевидно, что размер кеша может помочь избежать этой проблемы. Чем больше ваш кеш, тем более плавно он будет работать и тем лучше он будет временно хранить и удерживать данные по мере их записи на жесткий диск. Только не выключайте компьютер!
Очевидно, что размер кеша может помочь избежать этой проблемы. Чем больше ваш кеш, тем более плавно он будет работать и тем лучше он будет временно хранить и удерживать данные по мере их записи на жесткий диск. Только не выключайте компьютер!
Размер кеша — не единственное, что нужно учитывать, если вы хотите повысить производительность своих игр. Ваши скорости передачи влияют на кеш жесткого диска, поэтому давайте посмотрим на них. Есть две метрики, которые следует учитывать: скорость серийной съемки и скорость чтения.Пакетная скорость — это измерение, показывающее, сколько времени требуется для отправки данных в ваш кэш. Скорость чтения — это время, необходимое для записи данных на сам диск. Для игр скорость пакетной передачи будет влиять на производительность ваших игр, потому что чем выше скорость пакетной передачи, тем лучше ваша система будет вызывать сохраненные данные с вашего жесткого диска. Скорость чтения будет влиять на то, сколько времени потребуется для установки игр и сохранения файлов, но если вы играете онлайн, ищите жесткие диски с высокой скоростью передачи данных.
Время доступа — еще одна составляющая вашего жесткого диска, которую следует учитывать при выборе модели.Он измеряется в миллисекундах (мс), поэтому на самом деле вы хотите, чтобы этот показатель был низким — чем меньше миллисекунд, тем меньше времени требуется для выполнения задачи. Скорость доступа измеряет, сколько времени требуется жесткому диску для поиска необходимых файлов, и обычно составляет от 10 до 15 мс. Помните, что модели с более высокой скоростью доступа будут иметь более низкий показатель в списке.
ЗаключениеВ заключение, кеш вашего жесткого диска хранит большие файлы, необходимые для игры — это как таблица со всеми вашими важными файлами.Кэш похож на оперативную память жесткого диска, временно хранящую информацию, в то время как ваш жесткий диск начинает записывать ее постоянно. Однако вам нужно большое табличное пространство для хранения всех ваших файлов. Чем больше места за столом, тем лучше. Это улучшит производительность во время загрузки, уменьшит отставание графики и устранит сбои в играх с открытым миром. Хотя вы ничего не можете сделать со случайным товарищем по команде, который может страдать от серьезных проблем с кэшем, вы можете быть уверены, что ваш собственный компьютер будет работать без сбоев и сможет загрузить командную игру как можно быстрее.Однако кэш — не единственное, что влияет на скорость вашего жесткого диска. Скорость жесткого диска также определяется скоростью серийной съемки, скоростью чтения и временем доступа. Эти три показателя определяют, насколько быстро ваш жесткий диск может получить доступ к файлам в кэше. Когда вы собираете свой собственный компьютер, обязательно учитывайте размер кеша вашего жесткого диска и скорость, с которой он извлекает файлы.
Глоссарий технических терминов
Последнее обновление: 27 марта 2008 г.
Глоссарий технических терминов
2D
2D означает двухмерный.Это обычно используется для описания дисплея режим видеокарты, когда она не в 3D режим. Большинство программ, таких как текстовые процессоры, веб-браузеры и операционные системный пользовательский интерфейс работает в 2D-режиме, хотя некоторые с продвинутым пользователем интерфейсы могут работать в 3D-режиме. Программы нравятся многим играм и многим программы визуализации работают в 3D режиме.
3D
3D означает трехмерность. Это обычно используется для описания режим отображения видеокарты при отображении трехмерных объектов как и во многих играх, инженерных и трехмерных программах.Большинство операционные системы в настоящее время (2006 г.) работают в 2D режим, но некоторые новые начинают поддерживать 3D-интерфейсы пользователя.
АГП
Своего рода расширение слот. AGP расшифровывается как ускоренный графический порт. Это более быстрая версия PCI, который был разработан для ускорения передачи данных видеокарты. переводы. Новые компьютеры используют более быстрые и гибкие PCI-Express x16 слоты для видеокарт.
аналог
В контексте компьютеров аналог — это метод представления данных с непрерывный диапазон значений.Аналоговое напряжение колеблется между минимальным и максимальные значения для представления данных. Например, монитор VGA использует аналоговое напряжение для представления яркости цветового компонента, который делает до изображения. Большинство вещей внутри компьютера цифровой а не аналог. Аналоговые значения обычно не используются. Аналог используется для контролировать такие вещи, как изображение на ЭЛТ монитор или звук, воспроизводимый через динамики. Но даже в этих случаях большая часть компьютерной обработки этих сигналов осуществляется в цифровом виде. преобразуется в аналоговый непосредственно перед включением монитора или динамика.Когда аналоговый данные передаются по кабелю, точность данных ухудшается до некоторой степень. Данные ухудшаются даже при отправке через высококачественные экранированные кабели. Это отличается от цифровой передачи, когда данные (за исключением серьезные проблемы) полученные данные идентичны переданным.
БИОС
BIOS — это сокращение от Basic Input Output System. Ваш BIOS — это программа, которая контролирует базовую функциональность различных аппаратных средств в вашем компьютер.Системная плата BIOS позволяет изменять такие параметры, как скорость вашего ОЗУ, скорость вашего АГП порт, как твой Слоты расширения работа и т. д. Вы можете найти основную информацию о BIOS материнских плат здесь. Видеокарты также есть биосы.
бит
Бит — это сокращение от двоичной цифры. Это наименьшая единица хранения в компьютер. Он имеет два возможных значения: 0 и 1. Компьютеры используют биты для хранения отслеживать вещи. Поскольку бит может хранить только два значения, вы должны сгруппировать связка битов вместе для хранения большего количества значений.Например, байт состоит из восьми битов и может хранить все целые числа от 0 до 255. В наши дни на компьютерах много памяти, поэтому вы, скорее всего, столкнетесь с вещи как мегабайты и гигабайты.
ботинок
Ботинок — это сокращение от бутстрап.
бутстрап
Начальная загрузка относится к процессу загрузки и запуска операционной системы. система. Оно происходит от фразы «подтягиваться за bootstraps». Для краткости его часто называют «boot».Холодная загрузка — это бутстрап что происходит сразу после включения компьютера. Теплый ботинок происходит, когда операционная система перезагружается без включения компьютер выключен.
байт
Байт состоит из восьми биты. Байт достаточно велик, чтобы содержать все целые числа от 0 до 255. Байты стандартная единица хранения, используемая в компьютерах. Современные компьютеры, как правило, имеют много байтов ОЗУ, место на жестком диске и т. д., поэтому объем памяти, как правило, указывается в мегабайты или гигабайты.
кэш
Кэш — это небольшой объем высокоскоростной памяти, в котором хранится копия данных. который хранится в низкоскоростной памяти. Кэш хранит копии наиболее часто используемые данные. Когда к данным необходимо получить доступ, он использует быстрый кэш, если это возможно, и использует более медленную память только в том случае, если данные не в кэше. В результате доступ к кэшированным данным существенно ускоряется. А Процессор имеет кеш, в котором есть копии некоторых данных, хранящихся в системная плата ОЗУ.Большинство процессоров на самом деле имеют как минимум два кэша: основной кэш (кэш L1 или кэш-память). Кэш уровня 1) является самым быстрым, а вторичный кеш (кэш L2 или уровень 2 cache) медленнее и обычно намного больше. Когда ЦП обращается к данным, он обращается к данным в первичном кэше, если это возможно. Если это не в первичный кеш, затем он пробует вторичный кеш. Если его нет ни в одном из кеши, то он должен получить доступ к гораздо более медленной оперативной памяти материнской платы.
ЦП
ЦП означает центральный процессор.Это основной кремниевый чип на системная плата который выполняет универсальную обработку для компьютера. Большинство процессоров в ПК производятся Intel или AMD.
ЭЛТ
CRT расшифровывается как электронно-лучевая трубка. Компьютерные ЭЛТ-мониторы — это старый стиль те, которые используют трубки телевизионного типа для отображения изображений. ЭЛТ большие, тяжелые и потребляют много энергии по сравнению с ЖК мониторы. ЭЛТ-мониторы могут отображать достаточно четкие изображения при многих разрешения экрана. ЖК-мониторы идеально резкие только в своем родном разрешении (или родные разрешения, разделенные на 2, 3 и т. д.) и отображать другие разрешения относительно плохо.
ГДР
DDR — сокращение от двойной скорости передачи данных. Синхронные микросхемы памяти работают на заданная тактовая частота. Память с одной скоростью передачи данных может обращаться к одному значению за такт. Так микросхема памяти с одной скоростью передачи данных 100 МГц имеет пиковую скорость доступа к данным 100 миллионов обращений в секунду. Память DDR может обращаться к двум значениям за такт. Итак, Чип памяти DDR 100 МГц имеет пиковую скорость доступа к данным 200 миллионов обращений. в секунду. Другими распространенными формами памяти DDR являются DDR-II и GDDR3.Они имеют отличаются техническими характеристиками, чем обычная DDR, но они также имеют доступ к двум значений за такт.
драйвер устройства
Драйвер устройства — это программное обеспечение, которое позволяет получить доступ к аппаратному обеспечению. За например, вы должны установить драйвер устройства принтера для операционной системы чтобы можно было пользоваться принтером.
цифровой
В контексте компьютеров цифровой — это метод представления данных с дискретный диапазон значений. Это в отличие от аналог который представляет данные с непрерывным диапазоном значений.Большинство вещей внутри компьютер цифровой, а не аналоговый. Аналоговые значения обычно не использовал. Аналог используется для управления такими вещами, как изображение на ЭЛТ монитор или звук, воспроизводимый через динамики. Но даже в этих случаях большая часть компьютерной обработки этих сигналов осуществляется в цифровом виде. преобразуется в аналоговый непосредственно перед включением монитора или динамика. Данные передается по кабелю в цифровом виде (за исключением серьезных проблем) не теряет точность. Полученные данные идентичны переданным данным.Аналоговый передача, с другой стороны, страдает от некоторого ухудшения при прохождении через кабель.
адаптер дисплея
Видеоадаптер — это аппаратное обеспечение, которое отображает изображения на вашем мониторе. Срок «адаптер дисплея» может относиться как к видеокартам, так и к встроенной графике.
драйвер дисплея
Драйвер дисплея — это программное обеспечение, которое позволяет другим программам получать доступ и использовать адаптер дисплея. Ты должен быть установлен драйвер дисплея, чтобы ваш видеоадаптер работал ничего, кроме самых основных операций.Большинство операционных систем имеют драйвер дисплея по умолчанию, который будет работать с большинством видеоадаптеров, но имеет ограниченный функционал. Чтобы использовать более продвинутые функции, такие как три размерная графика, полный драйвер дисплея, разработанный для этого конкретного должен быть установлен видеоадаптер.
драйвер
Драйвер является коротким для устройства Водитель.
ДВИ
DVI — это цифровой видеостандарт, введенный в 1999 году. DVI означает цифровой визуальный интерфейс.DVI находится в процессе замены VGA как наиболее распространенный способ подключения мониторов к компьютерам. DVI был создан для предоставить стандартный способ передачи изображения в цифровом виде, а не в в аналог форма, используемая VGA. DVI используется почти исключительно в ЖК панели. ЭЛТ которые принимают цифровые входы DVI, встречаются крайне редко. ЭЛТ, которые поддерживают DVI — это, как правило, высококачественные мониторы, которые пытаются избежать качества изображения. ухудшение качества кабеля VGA из-за передачи данных в цифровом виде.DVI разъем также опционально поддерживает аналоговые видеосигналы. Дополнительную информацию о DVI см. эта страница.
ЕДИД
EDID означает расширенные идентификационные данные дисплея. Когда видеокарта хочет узнать о возможностях монитора, он считывает EDID из монитор. Данные EDID содержат такую информацию, как разрешающая способность и Частота обновления поддерживаемых режимов экрана. Он также сообщает, является ли монитор цифровым или аналог, а также многие другие подробности о мониторе.
плата расширения
Карта, которая подключается к расширению слот на материнской плате для добавления устройства к компьютеру. Карты расширения могут быть такие вещи, как видеокарты, сетевые платы, звуковые карты и т.д.
слот расширения
Разъем на материнской плате, который принимает расширение карту для добавления устройства к компьютеру. Наиболее распространенные виды расширения слоты AGP, PCI, и PCI-Express.
ГБ/с
ГБ/с означает гигабайты в секунду.А гигабайт примерно миллиард байт (на самом деле это 1 073 741 824 байта). Таким образом, 1 ГБ/с — это примерно миллиард байтов в секунду.
ГГц
ГГц — это сокращение от гигагерца. Гигагерц — это миллиард (1 000 000 000) циклов в секунду. Различные тактовые частоты в компьютере измеряются в гигагерцах. За например, 3,2 ГГц Процессор работает со скоростью 3,2 миллиарда (3 200 000 000) циклов в секунду.
гигабайт
Гигабайт — это чуть больше миллиарда байт (на самом деле это 1 073 741 824 байта). байт).Размер жестких дисков часто указывается в гигабайтах.
ГП
GPU означает графический процессор. Это кремниевый чип на адаптер дисплея, который выполняет графические расчеты. В настоящее время большинство графических процессоров производится Intel. NVIDIA или ATI. Другие производители включают VIA, SiS и Matrox.
графический драйвер
Графический драйвер аналогичен драйверу дисплея.
Гц
Гц это сокращение от герц. Герц — это единица измерения циклов в секунду.Например, видеомонитор с частота обновления экрана 75 Гц обновляет экран 75 раз в секунду.
встроенная графика
Интегрированная графика означает, что аппаратное обеспечение, отображающее изображения на монитор встроен в материнскую плату. Он встроен в материнскую плату для снижения затрат. Интегрированная графика также имеет тенденцию быть медленнее, чем видеокарты и имеют менее развитую функциональность.
встроенное видео
Интегрированное видео означает, что аппаратное обеспечение, которое отображает изображения на монитор встроен в материнскую плату.Он встроен в материнскую плату для снижения затрат. Интегрированное видео также имеет тенденцию быть медленнее, чем видеокарты и имеют менее развитую функциональность.
ЖК-дисплей
LCD означает жидкокристаллический дисплей. ЖК-мониторы компьютера новее плоские панели, которые используют плоскую ЖК-панель для отображения изображений. ЖК-панели меньше, легче и потребляют меньше энергии, чем ЭЛТ мониторы. ЖК-мониторы, работающие с исходным разрешением (или родные разрешения, разделенные на 2, 3 и т. д.) отображать гораздо более четкие изображения, чем ЭЛТ-мониторы, но ЖК-мониторы плохо отображают изображения при других разрешениях.
Светодиод
LED означает светоизлучающий диод. Светодиод представляет собой небольшой твердотельный источник света. Большинство маленьких лампочек на компьютере — это светодиоды, потому что они дешевы и не выгорай.
мегабайт
Мегабайт — это немногим больше миллиона байт (на самом деле это 1 048 576). байт). Количество ОЗУ в компьютере часто указывается в мегабайтах.
МБ/с
МБ/с означает мегабайты в секунду.А мегабайт примерно миллион байт (на самом деле это 1 048 576 байт). Таким образом, 1 МБ/с — это примерно миллион байтов в секунду.
МГц
МГц — это сокращение от мегагерц. Мегагерц — это миллион (1 000 000) циклов в второй. Различные тактовые частоты в компьютере измеряются в мегагерцах. За например, 400 МГц графический процессор на видеокарте работает со скоростью 400 миллионов (400 000 000) циклов в секунду.
материнская плата
Это главная печатная плата вашего компьютера.Он держит ПРОЦЕССОР, основная память и слоты расширения.
разгон
Установка тактовой частоты чипа выше предполагаемого значения называется разгон. Это увеличивает скорость чипа, но также нагревает его. и может вызвать проблемы со стабильностью. Это может даже сократить срок службы чип, если он слишком сильно разогнан. Люди разгоняются, чтобы делать части своих компьютеры работают быстрее без необходимости покупать более дорогие чипы, которые официально поддерживают более высокие тактовые частоты.
PCI
Своего рода расширение слот. PCI означает межсоединение периферийных компонентов. Слоты PCI могут быть используется для добавления к компьютеру всевозможных устройств, включая видеокарты, сетевые платы и дисковые контроллеры. Слоты расширения PCI не принимают PCI-Экспресс расширение открытки.
PCI-Экспресс
Своего рода расширение слот. PCI-Express — это более быстрый слот, чем PCI. Слоты PCI-Express можно использовать для подключения к компьютеру любых устройств. включая видеокарты, сетевые платы и дисковые контроллеры.Есть разные размеры слоты расширения PCI-Express. Слоты PCI-Express x16 используются для видеокарт. Слоты PCI-Express x1 используются для самых разных устройств. Слоты расширения PCI-Express не поддерживают расширение PCI открытки.
PCI-Express x16
Это своего рода PCI-Экспресс Слот расширения который обычно используется для удержания видеокарты. Часть «x16» относится к количеству дорожек. Этот вид слотов имеет 16 дорожек. Каждая дорожка может считывать данные с пиковым значением 250 МБ/с и напишите в 250 МБ/с одновременно.В результате слоты PCI-Express x16 могут читать 4 ГБ/с и пиши в 4 ГБ/с.
пикселей
Пиксель — это сокращение от элемента изображения. Вы можете сделать довольно хорошую версию изображения путем создания двумерного массива маленьких квадратов и сохранения один цвет в каждом квадрате. Каждый из маленьких квадратов является пикселем. Картинка с разрешением 640 на 480 пикселей состоит из 640 столбцов, где каждый столбец имеет высоту 480 пикселей. Это изображение содержит 640 х 480 пикселей или 307 200 пикселей.Чем больше пикселей в изображении, тем оно четче. А Версия изображения 1280 на 960 имеет в два раза больше столбцов и в два раза больше строки и выглядит намного четче, чем изображение 640 на 480.
ОЗУ
Оперативная память — это всего лишь память компьютера. Ваш компьютер содержит много чипов оперативной памяти, где он хранит информацию. Основная память в вашем компьютере, вероятно, хранится на картах памяти, каждая из которых содержит 256 МБ или более. Ваша видеокарта также содержит чипы оперативной памяти, где хранится информация, используемая для рисования изображений на вашем монитор.Оперативная память на самом деле означает оперативную память, но это не так. важно для его текущего использования.
перезагрузка
Перезагрузка компьютера означает, что компьютер выключается, а затем бутстрапы снова операционная система. Перезагрузка выполняется после внесения изменений что требует перезагрузки операционной системы.
частота обновления экрана
Изображение экрана, которое вы видите на мониторе компьютера, многократно перерисовывается Второй. Скорость, с которой перерисовывается все изображение на экране, называется частота обновления экрана.Обычно это выражается в циклах в секунду или герцах. ЭЛТ отображать изображение, стреляя пучком электронов в люминофоры на передней поверхности ЭЛТ-трубки. Люминофоры некоторое время светятся после попадания электроны. Изображение люминофора яркое после рисования, а затем быстро исчезает. Если изображение ЭЛТ перерисовывается слишком медленно, то изображение мерцает заметно. Для стандартного компьютерного ЭЛТ частота обновления 60 Гц плохо мерцает достаточно, чтобы вызвать зрительное напряжение у большинства людей. 75 Гц едва мерцает, а 85 Гц считается свободным от мерцания.ЖК-дисплеи отображать свое изображение на экране, используя совершенно другую технологию, которая не мерцание. Есть еще некоторая польза в увеличении частоты обновления ЖК-дисплея, если вы хотите, чтобы он отображал быстро меняющиеся изображения, как это видно во многих играх. Но для по большей части 60 Гц является приемлемой частотой обновления для ЖК-дисплеев.
разрешение экрана
Экранное изображение, отображаемое на мониторе компьютера, на самом деле является двухмерным. массив пикселей. Количество пикселей, используемых для отображения изображения, называется разрешением экрана.Обычно выражается как количество пикселей по горизонтали (количество столбцы пикселей) и количество пикселей по вертикали (количество строк пикселей). Например, разрешение экрана 640 X 480 (произносится как «640 на 480»). имеет ширину 640 пикселей и высоту 480 пикселей. Чем больше пикселей, тем четче изображение, поэтому разрешение экрана 800 х 600 четче, чем 640 х 480.
пониженная частота
Установка тактовой частоты микросхемы ниже ее предполагаемого значения называется разгон.Это делает чип более холодным и замедляет его работу. Это обычно вниз, чтобы попытаться устранить проблемы. Если разгон решает проблема, то обычно это означает, что микросхема повреждена или перегревается.
распаковать
Разархивирование — это сокращение от процесса распаковки файла, который был сжат с помощью метода сжатия ZIP. Windows XP имеет встроенный почтовый файл программное обеспечение для декомпрессии. Один из способов разархивировать в XP — щелкнуть правой кнопкой мыши по zip-архиву. файл, а затем выберите «Извлечь все…». Это позволяет выбрать каталог назначения, а затем распакуйте в него файлы. Если молния файл выглядит как каталог, затем двойной щелчок по zip-файлу открывает файл в качестве каталога, который позволяет получить доступ к сжатым файлам. Ты сможешь также используйте множество бесплатных или условно-бесплатных программных утилит для сжатия и распаковки zip файлы. WinZip и WinRAR — два популярных варианта.
VGA
VGA — давно используемый видеостандарт, который был представлен в 1987 году.VGA стойки для массива видеографики. На самом деле VGA — это название основного чипа на оригинальный VGA видеокарта представлен IBM. Со временем VGA стал более распространенным термин, относящийся к конкретному стандарту видеокарты, который включает в себя VGA выходной разъем. Разъем VGA по-прежнему широко используется, но находится в стадии процесс вытеснения более новым разъемом DVI. Разъем VGA иногда называют разъемом HD-15 или DSub-15. разъем. Дополнительную информацию о VGA см. эта страница.
видеоплата
Видеоплата такая же, как видеокарта
видеокарта
Видеокарта – это карта расширения который отображает изображения на вашем мониторе.
видеодрайвер
Видеодрайвер такой же, как драйвер дисплея.
видеопамять
Видеопамять относится к микросхемам памяти на видеокарте. Текущие (2006 г.) видеокарты обычно имеют от 64 МБ до 512 МБ видеопамяти.
zip-файл
ZIP-файл — это файл, сжатый с помощью сжатия ZIP. метод.Распаковка zip-файла называется распаковка. Windows XP имеет встроенный почтовый файл программное обеспечение для декомпрессии. Один из способов разархивировать в XP — щелкнуть правой кнопкой мыши по zip-архиву. файл, а затем выберите «Извлечь все…». Это позволяет выбрать каталог назначения, а затем распакуйте в него файлы. Если молния файл выглядит как каталог, затем двойной щелчок по zip-файлу открывает файл в качестве каталога, который позволяет получить доступ к сжатым файлам. Ты сможешь также используйте множество бесплатных или условно-бесплатных программных утилит для сжатия и распаковки zip файлы.WinZip и WinRAR — два популярных варианта.