Не удается найти страницу | Autodesk Knowledge Network
(* {{l10n_strings.REQUIRED_FIELD}})
{{l10n_strings.CREATE_NEW_COLLECTION}}*
{{l10n_strings.ADD_COLLECTION_DESCRIPTION}}
{{l10n_strings.COLLECTION_DESCRIPTION}} {{addToCollection.description.length}}/500 {{l10n_strings.TAGS}} {{$item}} {{l10n_strings.PRODUCTS}} {{l10n_strings.DRAG_TEXT}}{{l10n_strings.DRAG_TEXT_HELP}}
{{l10n_strings.
{{article.content_lang.display}}
{{l10n_strings.AUTHOR}}Что такое CUDA ядра в видеокарте
Графические ядра CUDA от Nvidia являются аналогом обычного ядра в процессоре. Они оптимизированы для выполнения большего количества операций, которые требует современная графика. На количество ядер CUDA повлияло развитие графики, в особенности сложные настройки, такие как тени, освещение и вот такое все.
Они оптимизированы для выполнения большего количества операций, которые требует современная графика. На количество ядер CUDA повлияло развитие графики, в особенности сложные настройки, такие как тени, освещение и вот такое все.
Уже долгое время технология CUDA является одной из главных особенностей видеокарт GeForce. Однако не все понимают, что это за технология и как она влияет на игры.
В этой статье расскажу и дам короткое объяснение. Так же рассмотрим и другие вопросы, которые могут возникнуть у пользователей.
CUDA это аббревиатура технологии запатентованной Nvidia, означает Compute Unified Device Architecture (Вычислительная Унифицированная Архитектура Устройства). То есть это архитектура — такая форма организации внутреннего устройства ядер в видеокарте. Какая же цель этой технологи? Эффективные параллельные (одновременные) вычисления.
Одно ядро CUDA аналогично
процессорному, с той лишь разницей, что оно проще по своей структуре, однако
их количество очень большое. Типичный игровой процессор имеет от 2 до
16 ядер, а ядер CUDA в видюхе — сотни, даже в бюджетных видеокартах Nvidia. А высокопроизводительные решения
и вовсе насчитывают тысячи.
Типичный игровой процессор имеет от 2 до
16 ядер, а ядер CUDA в видюхе — сотни, даже в бюджетных видеокартах Nvidia. А высокопроизводительные решения
и вовсе насчитывают тысячи.
Работа видеокарты во многом отличается от работы центрального процессора — процессор выступает в роли администратора, который управляет необходимыми операциями, а видеокарта берет на себя выполнения всех тяжелых задач.
Обработка графики требует одновременного выполнения сложных вычислений, именно одновременного. Поэтому в видеокартах и реализовано такое огромное количество ядер CUDA. Учитывая факт оптимизации видеокарт специально для работы с графикой, их ядра намного меньше и проще, чем у более универсальных ядер центрального процессора.
Любые графические вычисления, требующие сложных расчетов, в том числе игры получают значительный прирост от большого количества ядер CUDA. Самым простым примером в играх являются: тени, освещение, часть физической модели, сглаживание, модель затенения окружения (ambient occlusion) и другие.
В отличии от Nvidia с технологией CUDA, их главный конкурент AMD, использует другую технологию — Потоковые процессоры (Stream Processors)
Обе технологии являются собственной разработкой компаний и в них есть различия, однако для обычного пользователя большой разницы между ними нет.
CUDA от Nvidia лучше оптимизированы чем Steam Processors от AMD, но ощутимых различий в графике и производительности о которых вам стоит беспокоится вы не заметите. Это никак не влияет на выбор любого из двух производителей.
Это достаточно сложный вопрос, ответ на который не стоит искать в сухих цифрах характеристик графического адаптера. Количество не даст никаких представлений о производительности.
Многие другие характеристики, например, объем видеопамяти, поколение и скорости шины видеокарты намного важнее, для пользователя, чем данные о ядрах CUDA. Так же не стоит забывать об оптимизации в самих играх.
Лучшим
способом выбора графического адаптера является все таки просмотр тестов производительности, просмотр отзывов людей, которые уже пользуются конкретной видеокартой, анализ рынка в целом, чтобы понять что выбирают покупатели.
Надеюсь, что помог ответить на вопрос о назначении ядер CUDA и развеять все сомнения и заблуждения о данной технологии. Теперь вы знаете что они делают и насколько важны.
Размеры виртуальных машин в Azure, оптимизированных для GPU — Azure Virtual Machines
- Чтение занимает 3 мин
В этой статье
Применимо к: ✔️ виртуальные машины Linux ✔️ виртуальные машины Windows ✔️ гибкие масштабируемые наборы ✔️ универсальные масштабируемые наборы
Размеры виртуальных машин с оптимизацией GPU — это специализированные виртуальные машины с одним, несколькими или дробными GPU. Эти размеры предназначены для рабочих нагрузок с большим объемом вычислений, графической обработки и визуализаций. В этой статье содержатся сведения о количестве и типе GPU, виртуальных ЦП, дисков данных и сетевых адаптеров. Кроме того, для каждого размера виртуальной машины этой группы учитывается пропускная способность хранилища и сети.
Эти размеры предназначены для рабочих нагрузок с большим объемом вычислений, графической обработки и визуализаций. В этой статье содержатся сведения о количестве и типе GPU, виртуальных ЦП, дисков данных и сетевых адаптеров. Кроме того, для каждого размера виртуальной машины этой группы учитывается пропускная способность хранилища и сети.
Размеры серий NCv3 и NC T4_v3 оптимизированы для ресурсоемких приложений с большим объемом вычислений. Примерами являются приложения и имитации на базе CUDA и OpenCL, а также решения ИИ и машинного обучения. Серия NC T4 v3 посвящена рабочим нагрузкам вывода, использующим GPU NVIDIA Tesla T4 и процессор AMD EPYC2 Rome. Серия NCv3 предназначена для высокопроизводительных вычислительных рабочих нагрузок и нагрузок ИИ на базе графического процессора NVIDIA Tesla V100.
Размер серии ND A100 версии 4 ориентирован на масштабируемые приложения для глубокого обучения и ускоренных высокопроизводительных вычислений. В серии ND A100 версии 4 используется 8 GPU NVIDIA A100 TensorCore, для каждого из которых доступно подключение Mellanox InfiniBand HDR 200 Гбит и 40 ГБ памяти GPU.

Размеры серий NV и NVv3 оптимизированы и предназначены для удаленной визуализации, потоковой передачи, игр, кодирования и сценариев VDI, которые используют такие платформы, как OpenGL и DirectX. Эти виртуальные машины работают на базе графического процессора NVIDIA Tesla M60.
Размеры виртуальных машин Серии NVv4 оптимизированы и предназначены для VDI и удаленной визуализации. При использовании секционированных GPU NVv4 предлагает правильный размер для рабочих нагрузок, для которых требуются небольшие ресурсы GPU. Эти виртуальные машины поддерживаются графическим процессором AMD Radeon Instinct MI25. В настоящее время виртуальные машины NVv4 поддерживают только операционную систему на виртуальной машине.
Поддерживаемые операционные системы и драйверы
Чтобы воспользоваться преимуществами GPU виртуальных машин Azure серии N, необходимо установить графические драйверы GPU NVIDIA или AMD.
Для виртуальных машин с GPU NVIDIA расширение драйвера GPU NVIDIA устанавливает необходимые драйверы CUDA или GRID NVIDIA.
Для установки расширения и управления им можно использовать портал Azure или такие инструменты, как Azure PowerShell и шаблоны Azure Resource Manager. Сведения о поддерживаемых операционных системах и этапах развертывания см. в документации по расширению драйвера GPU NVIDIA. Общие сведения о расширениях виртуальных машин см. в статье Расширения и компоненты виртуальных машин Azure.Кроме того, драйверы NVIDIA GPU можно установить вручную. См. статьи Установка драйверов GPU NVIDIA на виртуальных машинах серии N под управлением Windows или Установка драйверов GPU NVIDIA на виртуальных машинах серии N под управлением Linux, чтобы найти сведения о поддерживаемых операционных системах, драйверах, установке и шагах проверки.
Для виртуальных машин, поддерживаемых GPU AMD расширение драйвера GPU AMD устанавливает соответствующие драйверы AMD. Для установки расширения и управления им можно использовать портал Azure или такие инструменты, как Azure PowerShell и шаблоны Azure Resource Manager.
Общие сведения о расширениях виртуальных машин см. в статье Расширения и компоненты виртуальных машин Azure.Кроме того, драйверы AMD GPU можно установить вручную. Сведения о поддерживаемых операционных системах, драйверах, установке и проверке см. в статье Установка драйверов AMD GPU на виртуальных машинах серии N под управлением Windows.
 Для установки расширения и управления им можно использовать портал Azure или такие инструменты, как Azure PowerShell и шаблоны Azure Resource Manager. Сведения о поддерживаемых операционных системах и этапах развертывания см. в документации по расширению драйвера GPU NVIDIA. Общие сведения о расширениях виртуальных машин см. в статье Расширения и компоненты виртуальных машин Azure.
Для установки расширения и управления им можно использовать портал Azure или такие инструменты, как Azure PowerShell и шаблоны Azure Resource Manager. Сведения о поддерживаемых операционных системах и этапах развертывания см. в документации по расширению драйвера GPU NVIDIA. Общие сведения о расширениях виртуальных машин см. в статье Расширения и компоненты виртуальных машин Azure. Общие сведения о расширениях виртуальных машин см. в статье Расширения и компоненты виртуальных машин Azure.
Общие сведения о расширениях виртуальных машин см. в статье Расширения и компоненты виртуальных машин Azure.Рекомендации по развертыванию
Сведения о доступности виртуальных машин серии N по регионам см. на этой странице.
Виртуальные машины серии N поддерживают только модель развертывания с помощью Resource Manager.
Виртуальные машины серии N отличаются типом хранилища Azure, которое поддерживается для их дисков. Виртуальные машины серий NC и NV поддерживают только диски на основе хранилища дисков уровня «Стандартный» (HDD). Все остальные виртуальные машины GPU поддерживают диски виртуальных машин с поддержкой Хранилища дисков категории «Стандартный» и «Премиум» (SSD).
Если вы хотите развернуть большое количество виртуальных машин серии N, мы рекомендуем подписку с оплатой по мере использования или другие варианты покупки.
Если вы используете бесплатную учетную запись Azure, вам доступно ограниченное количество вычислительных ядер Azure.Возможно, вам потребуется увеличить квоту на использование ядер (для каждого региона) в подписке Azure и отдельную квоту для ядер серии NC, NCv2, NCv3, ND, NDv2, NV или NVv2. Чтобы увеличить квоту, отправьте запрос в службу поддержки. Это бесплатная услуга. Ограничения по умолчанию отличаются в зависимости от категории подписки.
 Если вы используете бесплатную учетную запись Azure, вам доступно ограниченное количество вычислительных ядер Azure.
Если вы используете бесплатную учетную запись Azure, вам доступно ограниченное количество вычислительных ядер Azure.Остальные размеры
Дальнейшие действия
Узнайте больше о том, как с помощью единиц вычислений Azure (ACU) сравнить производительность вычислений для различных номеров SKU Azure.
О состоянии глубокого обучения за пределами огороженного сада CUDA | Николай Димоларов
Фото Омара Флореса на Unsplash Если вы исследователь или фанат глубокого обучения и любите использовать Mac в частном или профессиональном порядке, каждый год вы получаете последнее и самое разочаровывающее обновление AMD для вашего графического процессора. Почему разочаровывает? Потому что вы получаете новейший и лучший графический процессор Vega, который, конечно же, не использует CUDA.
Почему разочаровывает? Потому что вы получаете новейший и лучший графический процессор Vega, который, конечно же, не использует CUDA.
Что такое CUDA и почему это так важно?
CUDA® — это платформа параллельных вычислений и модель программирования, разработанная NVIDIA для общих вычислений на графических процессорах (GPU).С CUDA разработчики могут значительно ускорить вычислительные приложения, используя мощь графических процессоров.
Ок. Отлично. Что вам нужно знать, так это то, что это основная базовая технология, которая используется, среди прочего, для ускорения обучения искусственных нейронных сетей (ИНС). Идея состоит в том, чтобы запускать эти дорогостоящие в вычислительном отношении задачи на графическом процессоре, который имеет тысячи оптимизированных ядер графического процессора, которые бесконечно лучше подходят для таких задач по сравнению с процессорами (извините, Intel).Но почему я не могу запустить это на моем модном Macbook середины 2019 года за 7 тысяч долларов с 8 ядрами и графическим процессором Vega 20 на базе HBMI2. Причины. А именно, популярные библиотеки для обучения ИНС, такие как TensorFlow и PyTorch, официально не поддерживают OpenCL. А что такое OpenCL?
Причины. А именно, популярные библиотеки для обучения ИНС, такие как TensorFlow и PyTorch, официально не поддерживают OpenCL. А что такое OpenCL?
OpenCL ™ (Open Computing Language) — открытый, бесплатный стандарт для кроссплатформенного параллельного программирования различных процессоров, используемых в персональных компьютерах, серверах, мобильных устройствах и встраиваемых платформах.
Это в основном , что AMD использует в своих графических процессорах для ускорения графического процессора (CUDA — это проприетарная технология от Nvidia!).По иронии судьбы, графические процессоры на базе Nvidia CUDA могут запускать OpenCL, но, по-видимому, не так эффективно, как карты AMD, согласно этой статье. И чтобы немного узнать здесь: все эти виды работ выполняются под лозунгом «Вычисления общего назначения на графических процессорах» (GPGPU), то есть запускают данные на графических процессорах в качестве основного вычислительного модуля вместо центрального процессора, на случай, если ваши друзья просить. Теперь вернемся к CUDA, TensorFlow и всем остальным модным словечкам.
Теперь вернемся к CUDA, TensorFlow и всем остальным модным словечкам.
Вот состояние реализации OpenCL двух самых популярных библиотек глубокого обучения:
TensorFlow
GitHub Ticket: https: // github.com / tensorflow / tensorflow / issues / 22
Открыт с: 09.11.2015. (Это проблема №22; сейчас мы находимся на # 28961)
Tensorflow заблокировал проблему как «слишком горячую» и ограничил общение с соавторами 26.02.2019. Есть 541 комментарий и нет правопреемника.
Этот снимок экрана первых двух записей в билете GH описывает статус-кво.PyTorch
Билет на GitHub: https://github.com/pytorch/pytorch/issues/488
Открыт с: 18.11.2017 (на самом деле сейчас закрыт с пометкой «требуется обсуждение»)
Этот билет намного разумнее, чем другой.Вот заявление участника исследовательской группы Facebook AI Research:
Мы официально не планируем никакой работы с OpenCL, потому что:
Сама AMD, похоже, движется к HIP / GPUOpen, который имеет транспилятор CUDA (и они сделали некоторая работа по транспилированию бэкэнда Torch).
 Intel переносит значение скорости и оптимизации в MKLDNN. Общая поддержка OpenCL имеет значительно худшую производительность, чем использование CUDA / HIP / MKLDNN там, где это необходимо.
Intel переносит значение скорости и оптимизации в MKLDNN. Общая поддержка OpenCL имеет значительно худшую производительность, чем использование CUDA / HIP / MKLDNN там, где это необходимо.Покопавшись дальше, обнаружил эту проблему с 22.08.2018:
«Заявление об ограничении ответственности: PyTorch AMD все еще находится в разработке, поэтому полное покрытие тестами пока не предоставлено. PyTorch AMD работает поверх стека Radeon Open Compute Stack (ROCm)… »
Введите ROCm (RadeonOpenCompute) — платформу с открытым исходным кодом для вычислений HPC и UltraScale. Изучая это, я обнаружил следующую информацию:
- ROCm включает компилятор HCC C / C ++ на основе LLVM. HCC поддерживает прямую генерацию собственного набора инструкций графического процессора Radeon.
- ROCm создал инструмент переноса CUDA под названием HIP, который может сканировать исходный код CUDA и преобразовывать его в исходный код HIP.
- Исходный код HIP похож на CUDA, но скомпилированный код HIP может работать как на CUDA, так и на графических процессорах AMD через компилятор HCC.
Это похоже на чудовищное усилие. На этом этапе я должен поздравить Nvidia с созданием не только отличной технологии, но и потрясающей (в плохом смысле) технической привязки к своей платформе графического процессора. Престижность. Я не понимаю, почему Google с самого начала решил официально не поддерживать OpenCL. Нет бюджета? Это возвращает нас к замечательному комментарию и мему сверху в выпуске Tensorflow GH.
Итак, в принципе, в какой-то момент все наладится. Может быть. Сегодня вам стоит купить графический процессор Nvidia и сохранить рассудок.
И прежде чем вы скажете, кого волнуют ваши проблемы с Macbook, речь не об этом. Ни один здравомыслящий исследователь искусственного интеллекта не использует Mac для серьезной работы с DL. Речь идет о том факте, что Facebook Inc. и Google Inc., которые продвигают большую часть усилий по разработке DL (с точки зрения цепочки инструментов), решили поддерживать только проприетарный стандарт ускорения GPU и, следовательно, одного производителя видеокарт. Я большой поклонник Nvidia. Я также полностью осведомлен об аргументе «CUDA работает лучше, чем OpenCL» от команды Facebook AI Research из проблемы GitHub, приведенной выше. Тем не менее, я не вижу причин не вкладывать некоторое время и усилия (а у Facebook и Google есть и то, и другое) в поддержку нескольких фреймворков для ускорения графического процессора. А как насчет более абстрактного и открытого интерфейса, чтобы в будущем можно было разработать новый графический процессор или более нишевые фреймворки для ускорения DL?
Я большой поклонник Nvidia. Я также полностью осведомлен об аргументе «CUDA работает лучше, чем OpenCL» от команды Facebook AI Research из проблемы GitHub, приведенной выше. Тем не менее, я не вижу причин не вкладывать некоторое время и усилия (а у Facebook и Google есть и то, и другое) в поддержку нескольких фреймворков для ускорения графического процессора. А как насчет более абстрактного и открытого интерфейса, чтобы в будущем можно было разработать новый графический процессор или более нишевые фреймворки для ускорения DL?
Я также осведомлен о том факте, что оба фреймворка имеют открытый исходный код, и любой может внести свой вклад в них, но давайте посмотрим правде в глаза — оба фреймворка существуют в своем текущем состоянии из-за официальной поддержки (денежной или иной) двух стоящих за ними компаний. .Открытый исходный код, нацеленный только на проприетарную цель, — это не совсем open с открытым исходным кодом. Мы можем лучше!
П.С. Если я пропустил важные новости о поддержке PT / TF и AMD, напишите в комментариях ниже, и я обновлю свою статью. Я бы хотел хороших новостей!
Я бы хотел хороших новостей!
Источники:
https://developer.nvidia.com/cuda-zone, 23.05.2019
https://www.khronos.org/opencl/, 23.05.2019
https://community.amd .com / community / radeon-instinct-accelerators / blog / 2018/11/13 / explore-amd-vega-for-deep-learning, 23.05.2019
CUDA vs OpenCL: что использовать для программирования на GPU
Графические процессоры или графические процессоры за последние годы стали неотъемлемой частью обеспечения вычислительной мощности для высокопроизводительных вычислительных приложений. Программирование GPGPU — это вычисления общего назначения с использованием графического процессора (GPU). Это достигается за счет использования графического процессора вместе с центральным процессором (ЦП) для ускорения вычислений в приложениях, которые традиционно обрабатываются только центральным процессором.Программирование на GPU сейчас включено практически во все отрасли, от ускорения видео, цифровых изображений, обработки аудиосигналов и игр до производства, нейронных сетей и глубокого обучения.
GPGPU по существу влечет за собой разделение нескольких процессов или одного процесса между разными процессорами для ускорения времени, необходимого для завершения. GPGPU использует преимущества программных фреймворков, таких как OpenCL и CUDA, для ускорения определенных функций в программном обеспечении с конечной целью сделать вашу работу быстрее и проще.Графические процессоры делают возможными параллельные вычисления за счет использования сотен встроенных процессорных ядер, которые одновременно обмениваются данными и взаимодействуют для решения сложных вычислительных задач.
CUDA vs OpenCL — два интерфейса, используемых в вычислениях на графическом процессоре, и, хотя оба они имеют некоторые схожие функции, они делают это с использованием разных интерфейсов программирования.
Почему CUDA?
CUDA, что расшифровывается как Compute Unified Device Architecture, представляет собой парадигму параллельного программирования, выпущенную NVIDIA в 2007 году. CUDA при использовании языка, похожего на язык C, используется для разработки программного обеспечения для графических процессоров и огромного множества приложений общего назначения для графических процессоров, которые являются в высшей степени параллельными по своей природе.
CUDA при использовании языка, похожего на язык C, используется для разработки программного обеспечения для графических процессоров и огромного множества приложений общего назначения для графических процессоров, которые являются в высшей степени параллельными по своей природе.
CUDA — это проприетарный API, который поддерживается только графическими процессорами NVIDIA, основанными на архитектуре Tesla. Графические карты, поддерживающие CUDA, — это серии GeForce 8, Tesla и Quadro. Парадигма программирования CUDA представляет собой комбинацию как последовательного, так и параллельного выполнения и содержит специальную функцию C, называемую ядром , которая, проще говоря, представляет собой код C, который одновременно выполняется на видеокарте на фиксированном количестве потоков (подробнее о том, что такое CUDA).
Почему OpenCL?
OpenCL (аббревиатура от Open Computing Language) был запущен Apple и группой Khronos как способ предоставить эталонный тест для гетерогенных вычислений, который не ограничивался только графическими процессорами NVIDIA. OpenCL предлагает переносимый язык для программирования GPU, который использует CPU, GPU, цифровые сигнальные процессоры и другие типы процессоров. Этот переносимый язык используется для разработки программ или приложений, которые являются достаточно общими для работы на существенно разных архитектурах, но при этом достаточно адаптируемы, чтобы позволить каждой аппаратной платформе достичь высокой производительности.
OpenCL предлагает переносимый язык для программирования GPU, который использует CPU, GPU, цифровые сигнальные процессоры и другие типы процессоров. Этот переносимый язык используется для разработки программ или приложений, которые являются достаточно общими для работы на существенно разных архитектурах, но при этом достаточно адаптируемы, чтобы позволить каждой аппаратной платформе достичь высокой производительности.
OpenCL предоставляет портативные, независимые от устройств и производителей программы, которые могут быть ускорены на различных аппаратных платформах. Язык C OpenCL — это ограниченная версия языка C99, которая имеет расширения, подходящие для выполнения кодов параллельных данных на различных устройствах.
Сравнение CUDA и OpenCL
Производительность
OpenCL обеспечивает переносимый язык для программирования графических процессоров, предназначенный для очень несвязанных устройств параллельной обработки.Это никоим образом не означает, что код гарантированно запускается на всех устройствах, если вообще это связано с тем, что большинство из них имеют очень разные наборы функций. Необходимо приложить некоторые дополнительные усилия, чтобы код работал на нескольких устройствах, избегая при этом расширения, зависящего от производителя. В отличие от ядра CUDA, ядро OpenCL может быть скомпилировано во время выполнения, что увеличило бы время работы OpenCL. Однако, с другой стороны, эта своевременная компиляция может позволить компилятору сгенерировать код, который будет лучше использовать целевой графический процессор.
Необходимо приложить некоторые дополнительные усилия, чтобы код работал на нескольких устройствах, избегая при этом расширения, зависящего от производителя. В отличие от ядра CUDA, ядро OpenCL может быть скомпилировано во время выполнения, что увеличило бы время работы OpenCL. Однако, с другой стороны, эта своевременная компиляция может позволить компилятору сгенерировать код, который будет лучше использовать целевой графический процессор.
CUDA, разработан той же компанией, которая разрабатывает оборудование, на котором он выполняет свои функции, поэтому можно ожидать, что он будет лучше соответствовать вычислительным характеристикам графического процессора и, следовательно, будет предлагать больший доступ к функциям и лучшую производительность.
Однако с точки зрения производительности компилятор (и в конечном итоге программист) — это то, что делает каждый интерфейс быстрее, поскольку оба могут полностью использовать оборудование. Производительность будет зависеть от некоторых переменных, включая качество кода, тип алгоритма и тип оборудования.
Реализация поставщиками
На момент написания этой статьи существует только один поставщик реализации CUDA, и это его владелец, NVIDIA.
OpenCL, однако, был реализован огромным количеством поставщиков, включая, но не ограничиваясь:
- AMD: поддерживаются чипы Intel и AMD, а также графические процессоры.
- Radeon 5xxx, 6xxx, серии 7xxx, серии R9xxx поддерживаются
- Все процессоры поддерживают только OpenCL 1.2
- NVIDIA: NVIDIA GeForce 8600M GT, GeForce 8800 GT, GeForce 8800 GTS, GeForce 9400M, GeForce 9600M GT, GeForce GT 120, GeForce GT 130, ATI Radeon 4850, Radeon 4870 и, вероятно, поддерживаются другие.
- Apple (поддерживается только MacOS X)
- Поддерживаются хост-процессоры как вычислительные устройства
- CPU, GPU и «MIC» (Xeon Phi).
Портативность
Это, вероятно, наиболее известное различие между ними, поскольку CUDA работает только на графических процессорах NVIDIA, в то время как OpenCL является открытым отраслевым стандартом и работает на NVIDIA, AMD, Intel и других аппаратных устройствах. Кроме того, OpenCL обеспечивает резервный режим ЦП, и поэтому обслуживание кода проще, в то время как, с другой стороны, CUDA не предоставляет резервный вариант ЦП, что заставляет разработчиков вставлять в свои коды операторы if, которые помогают различать наличие устройства с графическим процессором во время выполнения или его отсутствие.
Кроме того, OpenCL обеспечивает резервный режим ЦП, и поэтому обслуживание кода проще, в то время как, с другой стороны, CUDA не предоставляет резервный вариант ЦП, что заставляет разработчиков вставлять в свои коды операторы if, которые помогают различать наличие устройства с графическим процессором во время выполнения или его отсутствие.
Открытые и коммерческие версии
Еще одно широко известное различие между CUDA и OpenCL заключается в том, что OpenCL имеет открытый исходный код, а CUDA — это проприетарная структура NVIDIA. Это различие имеет свои плюсы и минусы, и общее решение по этому поводу зависит от выбранного вами приложения.
Как правило, если приложение по вашему выбору поддерживает как CUDA, так и OpenCL, использование CUDA — лучший вариант, поскольку в этом сценарии он дает лучшие результаты производительности. Это потому, что NVIDIA предоставляет поддержку высшего качества.Если некоторые приложения основаны на CUDA, а другие имеют поддержку OpenCL, последняя карта NVIDIA поможет вам получить максимальную отдачу от приложений с поддержкой CUDA, имея при этом хорошую совместимость с приложениями, отличными от CUDA.
Однако, если все выбранные вами приложения поддерживают OpenCL, то решение уже принято за вас.
Поддержка нескольких ОС
CUDA может работать в Windows, Linux и MacOS, но только с использованием оборудования NVIDIA. Однако OpenCL доступен для работы практически в любой операционной системе и на большинстве разновидностей оборудования.Когда дело доходит до сравнения поддержки ОС, главным решающим фактором по-прежнему остается оборудование, поскольку CUDA может работать в ведущих операционных системах, в то время как OpenCL работает почти на всех.
Аппаратное различие — вот что действительно определяет сравнение. Поскольку CUDA требует использования только оборудования NVIDIA, тогда как с OpenCL оборудование не указано. У этого различия есть свои плюсы и минусы.
Библиотеки
Библиотеки являются ключевыми для вычислений на графических процессорах, поскольку они предоставляют доступ к набору функций, которые уже настроены для использования преимуществ параллелизма данных. CUDA очень силен в этой категории, поскольку он поддерживает шаблоны и бесплатные необработанные математические библиотеки, которые воплощают высокопроизводительные математические процедуры:
CUDA очень силен в этой категории, поскольку он поддерживает шаблоны и бесплатные необработанные математические библиотеки, которые воплощают высокопроизводительные математические процедуры:
- cuBLAS — Полная библиотека BLAS
- cuRAND — Библиотека генерации случайных чисел (ГСЧ)
- cuSPARSE — Библиотека разреженных матриц
- NPP — Примитивы производительности для обработки изображений и видео
- cuFFT — Библиотека быстрых преобразований Фурье
- Thrust — Шаблонные параллельные алгоритмы и структуры данных
- h — Библиотека с плавающей запятой C99
OpenCL имеет альтернативы, которые можно легко создать и которые в последнее время созрели, но ничего подобного библиотекам CUDA.Примером этого является ViennaCL. Библиотеки AMD OpenCL также имеют дополнительный бонус, заключающийся в том, что они работают не только на устройствах AMD, но и на всех совместимых с OpenCL устройствах
.Сообщество
Это часть сравнения, которое охватывает поддержку, долговечность, приверженность и т. Д. Каждой структуры. Хотя эти вещи сложно измерить, просмотр форумов дает представление о том, насколько велико сообщество. Количество тем на форумах NVIDIA CUDA поразительно больше, чем на форумах AMD OpenCL.Однако в последние годы на форумах OpenCL увеличилось количество тем, и следует также отметить, что CUDA существует уже давно.
Д. Каждой структуры. Хотя эти вещи сложно измерить, просмотр форумов дает представление о том, насколько велико сообщество. Количество тем на форумах NVIDIA CUDA поразительно больше, чем на форумах AMD OpenCL.Однако в последние годы на форумах OpenCL увеличилось количество тем, и следует также отметить, что CUDA существует уже давно.
Технические характеристики
CUDA позволяет разработчикам писать свое программное обеспечение на C или C ++, потому что это только платформа и модель программирования, а не язык или API. Распараллеливание достигается за счет использования ключевых слов CUDA.
С другой стороны, OpenCl не позволяет писать код на C ++, однако он предоставляет среду, напоминающую язык программирования C для работы, и позволяет напрямую работать с ресурсами GPU.
Таблица сравнения
| Сравнение | CUDA | OpenCL |
| Производительность | Нет явного преимущества, зависит от качества кода, типа оборудования и других переменных | Нет явного преимущества, зависит от качества кода, типа оборудования и других переменных |
| Внедрение поставщика | Реализуется только NVIDIA | Реализовано ТОННАМИ производителей, включая AMD, NVIDIA, Intel, Apple, Radeon и т.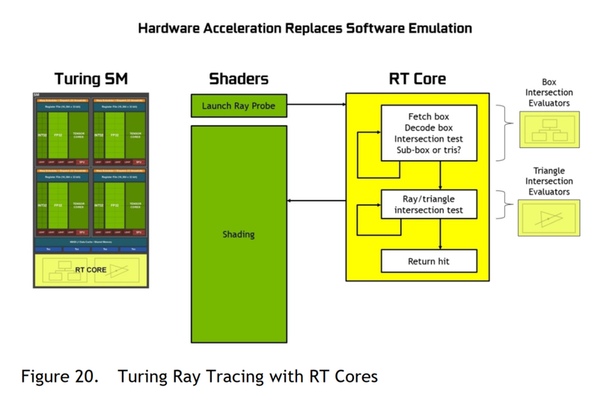 Д. Д. |
| Портативность | Работает только с оборудованием NVIDIA | Может быть перенесен на другое оборудование, если не используются расширения, специфичные для поставщика |
| Открытый исходный код и коммерческое использование | Собственный фреймворк NVIDIA | Стандарт с открытым исходным кодом |
| Поддержка ОС | Поддерживается ведущими операционными системами, единственное отличие — должно использоваться оборудование NVIDIA | Поддерживается в различных операционных системах |
| Библиотеки | Имеет обширные библиотеки высокой производительности | Имеет большое количество библиотек, которые можно использовать на любом оборудовании, совместимом с OpenCL, но не такое обширное, как CUDA | .
| Сообщество | Имеет более крупное сообщество | Имеет растущее сообщество не такое большое, как CUDA |
| Технические характеристики | Не язык, а платформа и модель программирования, обеспечивающая распараллеливание с использованием ключевых слов CUDA | Не позволяет писать код на C ++, но работает на языке программирования C, похожем на среду |
Как выбрать
Поддержка графического процессора дает огромные преимущества для вычислительной мощности и приложений. CUDA и OpenCL являются ведущими фреймворками на момент написания. CUDA, являющаяся проприетарной платформой NVIDIA, не поддерживается во многих приложениях, как OpenCL, но там, где она поддерживается, эта поддержка обеспечивает беспрецедентную производительность. Хотя OpenCL, который поддерживается в большем количестве приложений, не дает такого же повышения производительности там, где поддерживается, как CUDA.
CUDA и OpenCL являются ведущими фреймворками на момент написания. CUDA, являющаяся проприетарной платформой NVIDIA, не поддерживается во многих приложениях, как OpenCL, но там, где она поддерживается, эта поддержка обеспечивает беспрецедентную производительность. Хотя OpenCL, который поддерживается в большем количестве приложений, не дает такого же повышения производительности там, где поддерживается, как CUDA.
(более новые) при поддержке CUDA имеют высокую производительность OpenCL для экземпляров, CUDA не поддерживается.Общее эмпирическое правило заключается в том, что если в экземпляре подавляющее большинство приложений и оборудования, которые вы выбрали, поддерживаются OpenCL, то OpenCL должен быть вашим выбором.
Независимо от того, что вы выберете, Incredibuild может помочь вам ускорить ваши компиляции и тесты, ведущие к улучшению вычислений, будь то создание контента, машинное обучение, обработка сигналов и множество других ресурсоемких рабочих нагрузок. Взгляните на наш пример использования MediaPro — это пример того, как мы можем ускорить ваши компиляции и тесты до доли времени (в данном случае более чем в 6 раз быстрее).
Взгляните на наш пример использования MediaPro — это пример того, как мы можем ускорить ваши компиляции и тесты до доли времени (в данном случае более чем в 6 раз быстрее).
потоковых процессоров против ядер CUDA [ответ 2021]
Потоковые процессоры AMD и ядра CUDA NVIDIA служат одной цели, но работают по-разному, в основном из-за различий в архитектуре графических процессоров.
Эти характеристики не идеальны для сравнения графических процессоров разных производителей, но они могут обеспечить ожидаемую производительность конкретного будущего графического процессора.
Если посмотреть на две разные видеокарты от двух разных производителей, таких как AMD и NVIDIA (на самом деле нет других известных компаний), может быть сложно сравнить их и получить точную оценку их производительности.
Существует много доступной информации, такой как частота ядра графического процессора, частота памяти, видеопамять, транзисторы и т. Д., Но маловероятно, что вы найдете в этом много пользы. Еще одна информация, с которой вы можете регулярно сталкиваться, — это потоковых процессора или ядер CUDA .
Д., Но маловероятно, что вы найдете в этом много пользы. Еще одна информация, с которой вы можете регулярно сталкиваться, — это потоковых процессора или ядер CUDA .
Что именно означают эти термины? Можете ли вы сравнить одно с другим? Означает ли большее количество потоковых процессоров лучшую производительность, чем меньшее количество ядер CUDA? Короче нет.
Эти двое выполняют одинаковые или, по крайней мере, очень похожие роли в видеокарте, но все они сильно отличаются друг от друга.Вы не можете напрямую сравнивать AMD и NVIDIA GPU только на основе этой информации, поскольку эти две функции не идентичны.
Что такое ядра графического процессора?
Чтобы лучше понять значение этих двух терминов, вам необходимо точно понять, что такое ядра графического процессора.
Если вы знакомы с компьютерными технологиями, вы, вероятно, слышали о компьютерных процессорах или процессорах с несколькими ядрами. И Intel, и AMD предлагают многоядерные процессоры: Intel i5 , i7 или AMD R5 , R7 и т. Д.В большинстве случаев процессоры имеют от двух до восьми ядер.
Д.В большинстве случаев процессоры имеют от двух до восьми ядер.
Есть еще так называемые «нити», но это уже другое дело.
Эти ядра позволяют компьютерным процессорам эффективно выполнять многозадачность. Чем больше ядер у компьютера, тем больше вещей он может обрабатывать одновременно. Современный высокопроизводительный 16-поточный ЦП может запускать несколько игр и программ одновременно, не беспокоясь.
ЯдраGPU работают аналогично ядрам CPU, но они не такие мощные и интуитивно понятные.Видеокарта требует огромной мощности для обработки огромного количества задач. Вместо того, чтобы сосредоточить мощность всего нескольких ядер на работе операционной системы или программного обеспечения, несколько ядер часто работают над миллионами задач.
Например, дисплей с разрешением 1920 × 1080 имеет более двух миллионов пикселей. Чтобы сформировать изображение на дисплее 1080p , ядра графического процессора должны обрабатывать эти миллионы пикселей. Этот процесс повторяется несколько раз каждую секунду для обеспечения плавного просмотра.
Этот процесс повторяется несколько раз каждую секунду для обеспечения плавного просмотра.
Это упрощенное объяснение того, что такое потоковые процессоры или ядра CUDA. Технология графических процессоров намного сложнее.
Они не равны
Процессоры AMD Streamи ядра CUDA NVIDIA не равны и не сопоставимы. Это связано с тем, что у двух брендов есть свои особые архитектуры графических процессоров.
Процесс изготовления совершенно другой, потому что у обеих сторон есть секретная формула.
Эти два термина представляют собой торговые марки, призванные повысить узнаваемость среди потребителей.Ядра CUDA — это то, что NVIDIA решила назвать процессорами своих графических процессоров. То же самое и с AMD.
В чем смысл фирменных ядер графического процессора?
Если эти два типа ядер графического процессора нельзя сравнивать, почему они вообще получили фирменные наименования? Почему обычные потребители должны беспокоиться о ядрах CUDA или потоковых процессорах?
Одним из преимуществ является то, что он позволяет сравнивать видеокарты одной марки.
Например, RTX 3080 и RTX 3070 от NVIDIA и основаны на одной и той же архитектуре Ampere.Первый имеет 8704 ядра CUDA, а второй — 5888. С этими числами вы можете предположить, что RTX 3080 быстрее, и вы поступите правильно.
Однако информация, которую вы можете получить из этого типа спецификации, не очень точна. Если вы не знакомы с прошлыми или нынешними линейками и выпусками графических процессоров, эти цифры не принесут вам много пользы. Не рекомендуется уделять слишком много времени официальным спецификациям.
Как сравнить графические процессоры
Понять, как работают видеокарты и как они построены, непросто.Это сложный вопрос. Вот почему большинству случайных потребителей и геймеров не стоит особо беспокоиться об этом.
Если вы ищете надежный способ сравнить производительность видеокарт, есть более простое решение. Забудьте о спецификациях, цифрах или другой подобной информации.
Вместо этого вам следует посмотреть официальные или сторонние результаты тестов. Тесты дадут вам представление о том, какой именно FPS вы можете ожидать в определенных играх. С этой информацией намного проще сравнивать графические процессоры AMD и NVIDIA.
Тесты дадут вам представление о том, какой именно FPS вы можете ожидать в определенных играх. С этой информацией намного проще сравнивать графические процессоры AMD и NVIDIA.
Найти эти эталоны теперь очень просто, поскольку существует бесчисленное количество статей, видео и веб-сайтов, которые предоставляют такую информацию.
AIO против воздушного охлаждения — какой тип охлаждения лучше всего подходит для вашего процессора?
Подготовка кодов для LUMI: преобразование приложений CUDA в HIP
Изображение: Adobe Stock
В первом сообщении блога «Давайте представим: LUMI» мы обсудили высокоуровневые спецификации LUMI, программный стек и какие модели программирования можно использовать для запуска кодов с ускорением на GPU в системе.В этой статье мы более подробно рассмотрим HIP, который является прямым ответом AMD на CUDA. Поскольку существует множество существующих приложений для графических процессоров, использующих CUDA, нам нужен способ их перевода для работы на LUMI, и в этой статье мы обсудим шаги, необходимые для этого.
Что такое HIP?
Как уже упоминалось, HIP — это ответ AMD на CUDA, в то время как код CUDA может работать только на графических процессорах Nvidia, программы, использующие HIP, могут работать как на графических процессорах AMD, так и на графических процессорах Nvidia. Синтаксис HIP API очень похож на CUDA API, а уровень абстракции тот же, что и перенос между ними двумя простыми, и мы рассмотрим практические способы сделать это ниже.
В настоящее время HIP поддерживает большой набор тех же функций, что и CUDA, но некоторые из них не поддерживаются, большинство функций, которые не поддерживаются, представляют собой новые функции, представленные в более поздних версиях CUDA.
На стороне AMD HIP является частью вычислительного стека AMD под названием Radeon Open Compute, ROCm. Стек ROCm включает в себя все, от компилятора для оборудования AMD GPU до низкоуровневых оптимизированных библиотек для оборудования AMD. Большое различие здесь заключается в том, что HIP — это части, которые переносятся между оборудованием AMD и Nvidia, тогда как остальная часть стека ROCm предназначена для оборудования AMD.
Разъяснение терминологии
Способ, которым HIP обрабатывает аппаратное обеспечение графического процессора, такой же, как и в CUDA, поэтому терминология очень похожа. Ядра выполняются как сетки блоков, и каждый блок содержит заданное количество потоков, основное отличие состоит в том, что в CUDA мы называем 32 потока, выполняющиеся одновременно, как деформацию, но в номенклатуре HIP это волновой фронт, а на AMD аппаратное количество одновременно выполняемых потоков — 64.
Количество потоков, включенных в волновой фронт, определяется используемым оборудованием, а не кодом HIP или CUDA, при запуске кода на оборудовании AMD волновой фронт состоит из 64 потоков, однако при запуске кода HIP на оборудовании Nvidia это только 32 потока.
Для выполнения ядер графического процессора мы используем специальные переменные, цель которых — идентифицировать поток в сетке, такими ключевыми словами являются threadIdx.x, blockIdx.x и т. Д. Для CUDA и HIP мы используем одни и те же термины в отношении ядер, в то время как для OpenCL используются разные имена для этого, но это выходит за рамки этой публикации.
Таблица 1: Терминология для CUDA и HIP
Код ядра
Обычно код ядра выглядит одинаково для CUDA и HIP, и поддерживаются одни и те же функции языка C ++.Доступны те же квалификаторы памяти __ , __ и __ , __ и т. Д. HIP также поддерживает большинство математических функций, которые используются в CUDA, последнюю информацию можно найти в документации ROCm.
Однако есть некоторые различия, с которыми могут встречаться некоторые коды, все функции текстурной и поверхностной памяти недоступны в HIP, те же самые инструкции перемешивания деформации не поддерживаются, однако, начиная с ROCm 4.1, теперь доступны кооперативные группы в HIP-коде и встроенном PTX. код работать не будет.В дополнение к этому есть некоторые незначительные отличия, точные отличия можно найти в руководстве по программированию HIP.
API (API времени выполнения)
API среды выполнения HIP обычно отражает API CUDA, просто заменяя текст cuda в вызове на hip. в большинстве случаев дает вам эквивалентный вызов среды выполнения HIP. В таблице 2 показано простое сравнение того, как меняются вызовы между HIP и CUDA, версия HIP, естественно, также будет включать различные файлы заголовков для API среды выполнения.Бывают случаи, когда преобразование не является прямым, в некоторых случаях определенные аргументы необходимо передавать по-разному, но обычно, если есть эквивалентный вызов HIP, вопрос просто заключается в замене cuda на hip , и вызов будет работать.
в большинстве случаев дает вам эквивалентный вызов среды выполнения HIP. В таблице 2 показано простое сравнение того, как меняются вызовы между HIP и CUDA, версия HIP, естественно, также будет включать различные файлы заголовков для API среды выполнения.Бывают случаи, когда преобразование не является прямым, в некоторых случаях определенные аргументы необходимо передавать по-разному, но обычно, если есть эквивалентный вызов HIP, вопрос просто заключается в замене cuda на hip , и вызов будет работать.
Таблица 2: Различия между CUDA и HIP API
Одно из основных отличий в настоящее время заключается в том, как запускаются ядра. CUDA использует специальный синтаксис с угловыми скобками, то есть kernelName <<< gird, block >>>, тогда как в HIP запуск ядер выполняется с помощью обычного вызова функции hipLaunchKernelGGL, который в качестве аргумента принимает имя ядра, сетку и размер блока, и т.п.В таблице 3 показаны различные способы запуска ядер.
Таблица 3: Запуск ядра
Библиотеки
AMD портировала многие известные библиотеки графических процессоров для работы со своими графическими процессорами, как правило, они бывают двух видов. Версия библиотек HIP работает так же, как и API среды выполнения HIP, вызовы очень похожи на версии CUDA, а затем коды, которые их используют, могут работать как на оборудовании AMD, так и на Nvidia. В фоновом режиме будет вызываться соответствующая базовая библиотека в зависимости от оборудования, для которого скомпилирован код.Например, в системе Nvidia hipBLAS будет вызывать cuBLAS, тогда как в системах AMD hipBLAS будет вызывать соответствующие библиотеки AMD, в данном случае rocBLAS. Когда имя библиотеки начинается с roc, что означает, что это собственная библиотека для графических процессоров AMD, интерфейс для них может несколько отличаться от версий HIP и CUDA. В таблице 4 перечислены некоторые библиотеки с их эквивалентами CUDA, HIP и ROCm, полный и актуальный список можно найти на веб-сайте библиотек ROCm.
Таблица 4: Библиотеки
Переносимость HIP
Преимущество кода, преобразованного в HIP, заключается в том, что он работает как на оборудовании AMD, так и на Nvidia, поэтому вы все равно можете запускать преобразованный код на существующем оборудовании.То, как это достигается, аккуратно скрыто от пользователя, вы просто передаете код компилятору hipcc , и он позаботится о компиляции кода для правильной платформы. Выбор архитектуры, для которой он строится, можно контролировать с помощью переменных среды, в основном переменная HIP_PLATFORM сообщит компилятору, на какую архитектуру ориентироваться.
Копнув немного дальше, при компиляции для оборудования Nvidia компилятор hipcc просто вызовет компилятор nvcc для создания кода для этих графических процессоров.На этой платформе заголовки времени выполнения будут также просто вызывать соответствующие вызовы API времени выполнения CUDA. Это означает, что на платформе Nvidia вы также можете предоставить только заголовки времени выполнения и использовать обычный компилятор nvcc для компиляции кода, заголовки по умолчанию будут вызывать функции CUDA API.
На платформах AMD GPU среда выполнения HIP затем свяжется с соответствующими аппаратными вызовами AMD, на этих платформах компилятор hipcc позаботится о компиляции кода.В этом случае компилятор hipcc основан на clang, поэтому вы можете убедиться, что код компилируется с clang для упрощения перехода на оборудование AMD.
Рисунок 1: Диаграмма использования HIP на разных графических процессорах
Если при преобразовании кода вы также переименовываете свои файлы .cu в .cpp, вам нужно будет передать компилятору Nvidia дополнительный аргумент -x cu, чтобы он искал код устройства в обычных файлах .cpp.
Как «модифицировать» свой код?
Программный стек AMD включает инструменты, которые автоматически преобразуют существующий код CUDA в HIP, эти инструменты используются для «преобразования» кодов CUDA.Есть два основных инструмента, а также несколько вспомогательных скриптов, которые упрощают преобразование всей базы кода. Первый инструмент основан на Perl-скрипте и называется hipify-perl , а второй — на компиляторе Clang и называется hipify-clang . Оба инструмента работают с кодами C / C ++, но не с Fortran, мы обсудим подходы, которые можно использовать для Fortran позже.
Первый инструмент основан на Perl-скрипте и называется hipify-perl , а второй — на компиляторе Clang и называется hipify-clang . Оба инструмента работают с кодами C / C ++, но не с Fortran, мы обсудим подходы, которые можно использовать для Fortran позже.
Hipify-perl
Более простой в использовании инструмент — это инструмент hipify-perl , он будет пытаться изменить код CUDA с помощью основных методов поиска и замены, строка cuda в вызовах API заменяется на hip, это и, однако, немного умнее. также добавит соответствующие заголовки, а для вызовов HIP с разными аргументами он попытается исправить это.В большинстве случаев скрипту удастся выполнить всю конвертацию, но всегда следует проверять правильность перевода.
В простейшей форме инструмент просто распечатает переведенную версию любого переданного ему файла. Добавление аргумента — inplace к вызову инструмента заменит содержимое файла переведенным содержимым и в то же время создаст копию файла с расширением . prehip, которая содержит исходный код. Таким образом, вы можете скомпилировать свой код с такими же именами файлов, а затем, если вы хотите изменить исходный исходный код, измените файл mult.c.prehip и снова запустите инструмент hipify-perl. Еще один полезный аргумент в пользу инструмента hipify-perl — аргумент — print-stats . Это распечатает статистику о том, что сделал инструмент, сколько вызовов он нашел и преобразовал.
prehip, которая содержит исходный код. Таким образом, вы можете скомпилировать свой код с такими же именами файлов, а затем, если вы хотите изменить исходный исходный код, измените файл mult.c.prehip и снова запустите инструмент hipify-perl. Еще один полезный аргумент в пользу инструмента hipify-perl — аргумент — print-stats . Это распечатает статистику о том, что сделал инструмент, сколько вызовов он нашел и преобразовал.
Hipify-clang
Hipify-clang — это более продвинутый инструмент для выполнения преобразования, он основан на компиляторе clang и, таким образом, может иметь больше контекста для кода при выполнении преобразования, чем простой поиск / замена.Поскольку этот инструмент основан на clang, он содержит предупреждение о том, что код должен быть совместимым, что означает, что иногда вам нужно добавлять заголовки, определения и т. Д., Чтобы убедиться, что код может быть скомпилирован.
Hipconvertinplace-perl / clang
Для преобразования больших баз кода инструменты AMD поставляются с удобными сценариями, которые могут преобразовывать весь код в определенном каталоге. Инструмент снова поставляется в двух вариантах: hipconvertinplace-perl.sh, , который будет вызывать hipify-perl для преобразования, и hipconvertinplace.sh , который использует hipify-clang. В этом разделе мы рассмотрим только первый инструмент, поскольку perl-скрипта часто бывает достаточно для преобразования в большинстве случаев.
Инструмент снова поставляется в двух вариантах: hipconvertinplace-perl.sh, , который будет вызывать hipify-perl для преобразования, и hipconvertinplace.sh , который использует hipify-clang. В этом разделе мы рассмотрим только первый инструмент, поскольку perl-скрипта часто бывает достаточно для преобразования в большинстве случаев.
Сценарий hipconvertinplace-perl.sh выполняет hipify-perl с параметрами –inplace и –print-stats для всего каталога, который используется в качестве аргумента, или, если он вызывается без аргумента, будет использоваться текущий каталог. Например, если мы хотим изменить каталог с именем src, мы должны позвонить:
$ hipconvertinplace-perl.sh src
Эта команда преобразует все соответствующие файлы и распечатает статистику для каждого файла, включая сводку.
Hipifying код C / C ++
Далее у нас есть два примера того, как два кода, выполняющих saxpy, то есть одинарной точности A * X + Y, могут быть преобразованы из CUDA в HIP. Первый пример включает код ядра для выполнения вычислений, тогда как второй использует cuBLAS для операции.
Первый пример включает код ядра для выполнения вычислений, тогда как второй использует cuBLAS для операции.
В этом примере файл saxpycuda.cpp включает код saxpy, написанный на CUDA, он состоит из нескольких вызовов выделения памяти и копирования, а также ядра и кода для его запуска. Чтобы преобразовать его, эти вызовы API CUDA должны быть переведены в HIP.
Используя программу hipify-perl , мы модифицируем код с помощью следующего вызова:
$ hipify-perl –inplace –print-stats saxpycuda.cpp Из выходных данных мы видим, что скрипт выполнил 14 преобразований в HIP, скрипт также распечатывает, сколько вызовов он нашел и преобразовал. В случае, если он столкнется с вызовом, который не может преобразовать, он также распечатает это как предупреждение в этом состоянии. В сценарий преобразования также добавлены операторы include для заголовка hip_runtime. Ядро остается точно таким же, поскольку ни один из используемых там кодов не отличается между HIP и CUDA, обычно это так. Таблица 5: Преобразование с помощью hipify-perl из saxpy с CUDA в saxpy с HIP При компиляции преобразованного кода код просто передается в оболочку компилятора hipcc: hipcc -o csaxpy_hip saxpycuda.cpp В этом случае компиляция работает одинаково на платформах AMD и Nvidia. Второй пример, который у нас есть, — это использование saxpy из cuBLAS, в этом случае помимо преобразования вызовов CUDA API в HIP нам также необходимо преобразовать вызовы cuBLAS в hipBLAS, к счастью, инструменты hipify также могут преобразовывать эти вызовы библиотеки. $ hipify-perl –inplace –print-stats saxpy.cpp Из отчета мы видим, что инструмент выполнил 12 замен, 4 — для операций с памятью, 6 — для библиотечных операций, таких как cuBLAS и т. Д. Из выходных данных, показанных в таблице 7, мы видим, что вызовы cuBLAS были преобразованы и соответствующий заголовок был включен. Таблица 6: Преобразование с помощью hipify-perl из saxpy с CUBLAS в saxpy с hipBLAS Для компиляции мы снова используем hipcc, и нам также нужно связать код с hipblas.Это означает, что для компиляции мы будем использовать: hipcc -o saxpy_hip saxpy.cpp -I / path_to_hipblas / include / -L / path_to_hipblas / lib / -lhipblas Опять же, компиляция работает одинаково на платформах AMD и Nvidia. в Fortran может быть реализован различными способами, мы намерены осветить наиболее важные из них в следующей статье, это будет включать преобразование Fortran, который использует код CUDA по-разному, в HIP. В конце концов, преобразование кода CUDA в HIP обычно довольно просто, с загвоздкой в том, что самые передовые функции CUDA не поддерживаются, но могут поддерживаться в будущем. Программный стек AMD GPU поставляется с инструментами, которые значительно ускоряют процесс преобразования по сравнению с его выполнением вручную. Посмотрите коды CUDA и HIP на Github. Авторы: Джордж Маркоманолис, ведущий научный сотрудник по высокопроизводительным вычислениям в CSC — IT Center for Science Ltd.и Фредрик Робертсен, технологический стратег в CSC — IT Center for Science Ltd. В прошлом году я купил свой ноутбук и в спешке купил вместе с ним графический процессор AMD. Через несколько месяцев я понял, что во время игры частота кадров падает, и он довольно легко нагревается. Хорошо, для меня это не большая проблема, так как я мало играю в игры. В основном я использую свой ноутбук для программирования. Недавно я начал изучать программирование на основе искусственного интеллекта и собирался создать свой первый проект на основе искусственного интеллекта, не подозревая о том, что AMD собирается меня бросить. Все мы знаем, что искусственный интеллект — это грядущая реальность, которая повысила спрос на обработку все большего количества данных для получения значимых результатов. Если вы относитесь к тому типу людей, которые любят ИИ и машинное обучение, и создание собственной модели ИИ — ваша следующая цель, то первое и самое главное — у вас должен быть ноутбук с хорошим графическим процессором для обучения вашей модели машинного обучения ( о чем я не знал).Когда дело доходит до графического процессора, есть два громких имени — NVidia и AMD. Оба всегда были соперниками в области графических процессоров, но все мы знаем, что NVidia — бесспорный король в этой области. AMD также имеет долгую историю производства хороших процессоров, но когда дело касается графических процессоров, AMD не может сравниться с NVidia. Но все же AMD удалось создать хорошие графические процессоры, которые сделают эту работу за вас. Если у вас на ноутбуке стоит NVidia, то у вас все пройдет гладко. Если вы приобрели графическую карту AMD, вам придется нелегко. NVidia имеет поддержку CUDA для ускорения обработки графики и задач обучения модели глубоких нейронных сетей. Установка CUDA для задач машинного обучения похожа на легкую прогулку. AMD также предоставила среду платформы ROCm для всех типов графических процессоров, но эта среда является новой и поддерживает не все оборудование. CUDA — это платформа параллельных вычислений и модель программирования, разработанная NVIDIA для общих вычислений на графических процессорах (GPU). С помощью CUDA разработчики могут значительно ускорить вычислительные приложения, используя мощь графических процессоров. CUDA Toolkit от NVIDIA предоставляет все необходимое для разработки приложений с ускорением на GPU. CUDA Toolkit включает библиотеки с ускорением на GPU, компилятор, инструменты разработки и среду выполнения CUDA. ROCm — универсальная платформа для вычислений с ускорением на GPU. ROCm даже предоставляет инструменты для переноса кода CUDA, зависящего от поставщика, в формат ROCm, не зависящий от поставщика, что делает массивный массив исходного кода, написанный для CUDA, доступным для оборудования AMD и других аппаратных сред. CUDA Toolkit доступен как для платформ Windows, так и для Linux, тогда как ROCm отказался от пользователей Windows, обеспечивая поддержку только для пользователей Linux. ROCm практически не пользуется поддержкой сообщества, так как он был недавно разработан, и потребуется время, чтобы создать свое сообщество. Интернет наводнен поддержкой CUDA, что облегчает жизнь пользователям NVidia. Когда я начал создавать свою первую модель распознавания изображений, мне нужно было обучить мою модель на огромном наборе данных. AMD ничего не заявила о поддержке Windows, и мы тоже не очень оптимистичны по этому поводу. Потребуется несколько лет, чтобы сообщество поддержало ROCm. А пока у нас остается только один вариант — купить графические процессоры NVidia. Если вы покупаете новый графический процессор, вы могли заметить количество ядер CUDA / потоковых процессоров в графическом процессоре AMD / NVIDIA. В чем разница между ними и почему их так много? Вот что вам нужно знать о ядрах NVIDIA CUDA и процессорах AMD Stream. Что делает их такими особенными, так это то влияние, которое они оказывают на графические процессоры, и какой из них более мощный. Так же, как у CPU есть свои ядра, у GPU тоже есть свои ядра. Как и в случае ядер ЦП, чем больше ядер NVIDIA CUDA или потоковых процессоров AMD у графического процессора, тем он мощнее. Это означает, что у вас есть два разных графических процессора из одной серии или одной архитектуры. Тот, у которого больше всего ядер CUDA или потоковых процессоров, является более мощным графическим процессором. ядер CUDA и процессоры AMD Stream.Благодаря им вы можете просматривать изображения или даже играть в игры на своем ноутбуке или настольном компьютере . могут обрабатывать изображения и видео. Но графические процессоры намного лучше подходят для этой задачи. Они такие же, но разные. Начнем с того, что между ними общего. Как упоминалось ранее, AMD называет свои ядра графическими процессорами потоковыми процессорами, а NVIDIA называет свои ядра CUDA. Раньше NVIDIA называла их потоковыми процессорами, но позже они изменили это название. Все дело в брендинге. Они одинаковы по своим функциям, только два больших технологических гиганта называют их по-разному. Теперь о различиях. Именно здесь на помощь приходит архитектура графического процессора. Архитектура графического процессора — это то, как различные компоненты графического процессора соединяются вместе. Это как построить дом. Это может быть дом с двумя, пятью или одной спальней.Вы также можете включить или исключить только кирпичи или дерево. Так устроена архитектура GPU. Графические процессоры NVIDIA и AMD имеют разные архитектуры. Даже в пределах одной марки графических процессоров ваша архитектура различается между семействами или сериями. Примером может служить GTX 1660 Ti с архитектурой NVIDIA Turing и GTX 1070 с архитектурой Pascal. Итак, у разных компаний будут разные архитектуры графических процессоров. Различия в архитектуре графических процессоров означают различия между процессорами AMD Stream и ядрами NVIDIA CUDA. меньше по размеру и работают на более низких частотах, в то время как ядра NVIDIA CUDA больше и работают на более высоких частотах. Потоковые процессоры AMD ядра NVIDIA CUDA Работайте на более низких частотах Работайте на высоких частотах Маленький по размеру Большой размер Да, количество ядер NVIDIA CUDA и процессоров AMD Stream имеет огромное значение. Если вы сравниваете два графических процессора одной компании и одной архитектуры. Тот, у кого больше процессоров CUDA / Stream, будет более мощным. RTX 3070 будет иметь больше ядер CUDA, чем RTX 3060. Но есть одна загвоздка. Невозможно сравнить производительность двух графических процессоров, если они принадлежат разным сериям или компаниям, использующим только количество потоковых процессоров или только ядра CUDA.Это связано с тем, что у каждой компании есть собственная архитектура графического процессора, которую они используют. Вот почему вы не можете использовать ядра CUDA или потоковые процессоры только для определения мощности графического процессора. Это причина, по которой существуют тесты. Прекрасным примером являются GTX 1070 и RTX 2060. Оба имеют одинаковое количество ядер CUDA. Согласно пользовательскому тесту , RTX 2060 превосходит GTX 1070 на 6 процентов. Да, чем больше ядер CUDA или потоковых процессоров у графического процессора, тем он мощнее.Только если он принадлежит к той же семье. Использование количества потоковых процессоров AMD и ядер NVIDIA CUDA для определения мощности графического процессора — верный способ сделать неверные выводы. Это возвращает нас к архитектуре GPU. Основная причина разницы в производительности графических процессоров. Можно ли преобразовать количество ядер NVIDIA CUDA в потоковые процессоры AMD? Е …… НЕТ !!! Невозможно преобразовать количество ядер NVIDIA CUDA в потоковые процессоры AMD.Таких формул нет. Это даже невозможно. Вот почему. Да, хотя мы сказали, что они одинаковы, т.е. имеют одинаковую функцию при обработке пикселей. Таким образом, вы не можете преобразовать 1920 ядер NVIDIA CUDA в X потоковых процессоров или наоборот.Это все равно, что сказать, что вы хотите преобразовать процессор Intel в процессор AMD. Несмотря на то, что они оба являются процессорами, вы не можете этого сделать. Единственный верный способ узнать, что лучше, — это протестировать графические процессоры. Бенчмаркинг — единственный способ узнать, какой из них более эффективен. Вот это для ядер NVIDIA CUDA Vs. Процессоры AMD Stream. Их функции схожи, но способ их реализации NVIDIA и AMD приводит к некоторым отличиям. Кроме того, потоковые процессоры AMD и ядра NVIDIA CUDA позволяют определить мощность графического процессора.Хотя это применимо только в том случае, если они принадлежат к одной архитектуре или семейству графических процессоров. Вам также может понравиться Добро пожаловать в Classic Industries ® v7.0 Первый выбор Америки в области восстановления Выберите год
Все Years19281929193019311932193319341935193619371938193919401941194219431944194519461947194819491950195119521953195419551956195719581959196019611962196319641965196619671968196919701971197219731974197519761977197819791980198119821983198419851986198719881989191199219931994199519961997199819992000200120022003200420052006200720082009201020112012201320142015201620172018 Выберите «Сделать»
Все марки Выбрать модель
Все модели Ваш универсальный источник высококачественных кузовных панелей на рынке. Эта заводская замена задней панели пола Restorer’s Choice ™ идеальна, когда заржавела только задняя панель пола / пространство для ног.Замените заржавевший оригинальный поддон на эту совершенно новую панель с правильными контурами и черным электрофоретическим покрытием (EDP или E-coat) для превосходной долговременной защиты от коррозии, готовой к подготовке, грунтовке и покраске без снятия изоляции. Продукт Mopar Authentic Restoration ™ устанавливается с правой (пассажирской) стороны. Примечание: поставляется негабаритного. Области применения: 1970 Barracuda 1970 ‘Cuda Приобретая репродуктивные детали и аксессуары у Classic Industries®, вы можете быть уверены, что каждый продукт, на котором изображен символ Restorer’s Choice ™, изготовлен в соответствии с точными спецификациями, соответствует требованиям завода и является вашей гарантией качественный. Если поддон пола поврежден или имеет злокачественные образования в нескольких местах, просто замените поддон целиком сразу. Эта копия Restorer’s Choice ™ оригинального поддона переднего пола предлагает меньше хлопот с установкой и отсутствие зашитых швов, что обеспечивает более чистую реставрацию, большую прочность и долговечность, чем может предложить лоскутное одеяло из деталей из листового металла.Изготовлен из стали калибра OE со всеми исходными контурами и деталями, имеет черное электрофоретическое покрытие (EDP или E-coat) для превосходной долговременной защиты от коррозии и готово к подготовке, грунтовке и окраске без снятия изоляции. Продукт Mopar Authentic Restoration ™ Важно: это только передняя часть. Область заднего пространства для ног не включена. Примечание: Доставка грузовым автотранспортом. Области применения: 1970 Barracuda 1970 ‘Cuda 1970 Challenger Приобретая воспроизводимые детали и аксессуары у Classic Industries®, вы можете быть уверены, что каждый продукт, на котором изображен символ Restorer’s Choice ™, изготовлен в соответствии с точными спецификациями, соответствует задумке завода и является вашим гарантия качества. Замените проржавевшую кастрюлю переднего пола этой качественной копией. Эта панель, изготовленная в соответствии с заводскими спецификациями, имеет правильный фланец на стороне коромысла поддона пола и закрывает только переднее сиденье и переднюю нишу для ног.Продукт Mopar Authentic Restoration ™ обладает правильными контурами, сливными отверстиями и черным электрофоретическим покрытием (EDP или E-coat) для превосходной долгосрочной защиты от коррозии и готов к подготовке, грунтовке и покраске без снятия изоляции. Примечание: поставляется вдвое большего размера. Применения: 1970 Barracuda 1970 ‘Cuda 1970 Challenger / p> Эта заводская замена задней панели пола Restorer’s Choice ™ идеальна, когда заржавела только задняя панель пола / пространство для ног.Замените заржавевший оригинальный поддон на эту совершенно новую панель с правильными контурами и черным электрофоретическим покрытием (EDP или E-coat) для превосходной долговременной защиты от коррозии, готовой к подготовке, грунтовке и покраске без снятия изоляции. Продукт Mopar Authentic Restoration ™ устанавливается с левой стороны (со стороны водителя). Примечание: поставляется негабаритного. Области применения: 1970 Barracuda 1970 ‘Cuda Приобретая репродуктивные детали и аксессуары у Classic Industries®, вы можете быть уверены, что каждый продукт, на котором изображен символ Restorer’s Choice ™, изготовлен в соответствии с точными спецификациями, соответствует требованиям завода и является вашей гарантией качественный. Замените проржавевшую кастрюлю переднего пола этой качественной копией. Эта панель, изготовленная в соответствии с заводскими спецификациями, имеет правильный фланец на стороне коромысла поддона пола и закрывает только переднее сиденье и переднюю нишу для ног.Продукт Mopar Authentic Restoration ™ обладает правильными контурами, сливными отверстиями и черным электрофоретическим покрытием (EDP или E-coat) для превосходной долгосрочной защиты от коррозии и готов к подготовке, грунтовке и покраске без снятия изоляции. Примечание: поставляется вдвое большего размера. Применения: 1970 Barracuda 1970 ‘Cuda 1970 Challenger / p> Теперь вы можете заменить туннельную часть в области переключателя, не заменяя весь поддон пола.Предлагаем эту качественную штампованную панель для ремонта рабочего места на установке переключателя. Mopar Authentic Restoration ™ … Этот заводской заменяющий поддон заднего сиденья Restorer’s Choice ™ отштампован из стали калибра OE со всеми новыми инструментами для точной замены оригинала.Имеет правильные контуры, предустановленные сливные пробки и … Эти заводские сменные распорки опоры пола приварены к передней и задней части передней панели пола для обеспечения дополнительной структурной поддержки.Изготовлен из штампованной стали, которая по качеству повторяет оригинал, … Узнайте, что говорят клиенты о Classic Industries
информация: преобразовано 14 CUDA-> HIP refs (ошибка: 0 init: 0 версия: 0 устройство: 0 контекст: 0 модуль: 0 память: 7 virtual_memory : 0 адресация: 0 поток: 0 событие: 0 external_resource_interop: 0 stream_memory: 0 выполнение: 0 график: 0 занятость: 0 текстура: 0 поверхность: 0 одноранговый узел: 0 графика: 0 профилировщик: 0 openGL: 0 D3D9: 0 D3D10: 0 D3D11: 0 VDPAU: 0 EGL: 0 поток: 0 комплекс: 0 библиотека: 0 device_library: 0 device_function: 3 include: 0 include_cuda_main_header: 0 type: 0 literal: 0 numeric_literal: 3 define: 0 extern_shared: 0 kernel_launch: 1)
предупреждать: 0 LOC: 40 in ‘saxpycuda. cpp ’
cpp ’
hipMemcpy 3
hipFree 2
hipMemcpyHostToDevice 2
hipMalloc 2
hipLaunchKernelGGL 1
hipMemcpyD![]()
Как и в предыдущем случае, мы просто вызываем hipify-perl для преобразования кода:
информация: преобразовано 12 ссылок CUDA-> HIP (ошибка: 0 init: 0 версия: 0… библиотека: 6… include_cuda_main_header: 1 тип: 1)
warn: 0 LOC: 35 in ‘saxpy.cpp ’
hipFree 2
hipMalloc 2 
Код Hipify Fortran
Код графического процессора Преобразование CUDA в HIP несложно
![]()
графических процессоров AMD и вещи, о которых вам никто не расскажет | Шекхаром | Аналитика Vidhya
 ИИ требует большой вычислительной мощности для обучения модели. Вот где ЦП — отстой, а графические процессоры делают свое дело. Графические процессоры имеют архитектуру, отличную от ЦП, они работают параллельно, а ЦП — последовательно. GPU значительно сокращает время, необходимое для обучения модели.
ИИ требует большой вычислительной мощности для обучения модели. Вот где ЦП — отстой, а графические процессоры делают свое дело. Графические процессоры имеют архитектуру, отличную от ЦП, они работают параллельно, а ЦП — последовательно. GPU значительно сокращает время, необходимое для обучения модели.
 Модульная конструкция позволяет любому поставщику оборудования создавать драйверы, поддерживающие стек ROCm. ROCm также интегрирует несколько языков программирования и упрощает добавление поддержки других языков.
Модульная конструкция позволяет любому поставщику оборудования создавать драйверы, поддерживающие стек ROCm. ROCm также интегрирует несколько языков программирования и упрощает добавление поддержки других языков. Обучение модели с использованием ЦП заняло несколько часов.Я перешел на графический процессор, но, поскольку я пользователь Windows, я не могу использовать ROCm для своей графической карты AMD. Для меня это почти как труп.
Обучение модели с использованием ЦП заняло несколько часов.Я перешел на графический процессор, но, поскольку я пользователь Windows, я не могу использовать ROCm для своей графической карты AMD. Для меня это почти как труп. ядер NVIDIA CUDA против потоковых процессоров AMD
NVIDIA CUDA Cores против AMD Stream Processors
 AMD называет свои ядра потоковыми процессорами, а NVIDIA называет свои ядра CUDA (Compute Unified Device Architecture).Эти ядра графического процессора также известны как пиксельные процессоры или пиксельные конвейеры.
AMD называет свои ядра потоковыми процессорами, а NVIDIA называет свои ядра CUDA (Compute Unified Device Architecture).Эти ядра графического процессора также известны как пиксельные процессоры или пиксельные конвейеры. Для чего нужны ядра NVIDIA CUDA и потоковые процессоры AMD?
За обработку пикселей отвечают Поскольку они были буквально созданы для обработки изображений и пикселей.
Поскольку они были буквально созданы для обработки изображений и пикселей. Различия между ядрами NVIDIA CUDA и потоковыми процессорами AMD
 Stream Processors, Repair Laws» src=»https://www.youtube.com/embed/O5FwrlZXTzc?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> Ядра NVIDIA CUDA против потоковых процессоров AMD
Stream Processors, Repair Laws» src=»https://www.youtube.com/embed/O5FwrlZXTzc?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> Ядра NVIDIA CUDA против потоковых процессоров AMD Имеет ли большое значение количество ядер NVIDIA CUDA и потоковых процессоров AMD?
 Как и у процессора, чем больше ядер, тем он мощнее. Та же логика применима к графическим процессорам.
Как и у процессора, чем больше ядер, тем он мощнее. Та же логика применима к графическим процессорам.
Сколько ядер CUDA равно потоковому процессору?
 NVIDIA и AMD использовали разные подходы к созданию и реализации их в своих архитектурах графических процессоров.
NVIDIA и AMD использовали разные подходы к созданию и реализации их в своих архитектурах графических процессоров. Последние мысли
 Надежный способ сравнить производительность — проверить их тесты.
Надежный способ сравнить производительность — проверить их тесты. AMD — Авто Металл Прямая | Детали 1970 Plymouth Cuda
и запасных частей и принадлежностей Панели AMD изготовлены из стали надлежащего калибра и имеют все правильные оригинальные зажимы, выступы, фланцы, изгибы и швы. Каждый раз, когда прототип панели снимается с новой оснасткой, он тестируется и дорабатывается до тех пор, пока не будет достигнута качественная подгонка и отделка. С панелями корпуса AMD вы можете быть уверены, что получаете качественную деталь.
Панели AMD изготовлены из стали надлежащего калибра и имеют все правильные оригинальные зажимы, выступы, фланцы, изгибы и швы. Каждый раз, когда прототип панели снимается с новой оснасткой, он тестируется и дорабатывается до тех пор, пока не будет достигнута качественная подгонка и отделка. С панелями корпуса AMD вы можете быть уверены, что получаете качественную деталь.
Первый выбор Америки в области восстановления и повышения производительности Запасные части и аксессуары