Power Target что это? (видеокарта)
Хеллоу. Поговорим про Power Target и как я понимаю то это относится к видеокарте. Значит Power Target это параметр, который влияет на работу видюхи, Вроде бы если этот параметр изменять, то будет и изменяться производительность видеокарты, возможно что Power Target имеет отношение к разгону. На одном сайте написано что Power Target это ограничитель потребления видеокарты.
Вообще Power Target можно встретить в настройках, может в какой-то проге написано такое, или еще где-то.. это не относится к какой-то определенной программе.
При этом я посмотрел в гугловском переводчике перевод Power Target и вот результат:

Может у вас Power Target Status? Этот параметр вроде как показывает максимальное количество энергии, которое должно доставаться видюхе.
Вот один чел вроде как разгоняет видеокарту.. и он для этого увеличивает параметры GPU Boost Clock, Max GPU Voltage, и в Power Target выставляет 110%. Потом пишет что температура в GPU Temp Target показывает 79 градусов. Значит все таки параметр Power Target нужно трогать если вы собрались разгонять видюху.. ну пока у меня мнение такое…
Вот еще одно подтверждение того, что относится к разгону:

Еще есть такой параметр как Power and Temperature Target, вот что о нем пишет человек один:

Ребята, ура, я узнал что такое Power Target! Инфу нашел на очень авторитетном сайте, ему точно можно доверять. В общем Power Target это максимальное энергопотребление видюхи, под которое подстраивается технология Turbo Boost и настройки разгона. В общем вот самая ценная инфа за сегодня:

Вот еще я думаю полезная инфа для размышления:

А теперь смотрите ребята, значит есть такая прога, называется GPU Tweak, типа твикер видюхи, и вот в этой проге есть Power Target, значение выдается в процентах, смотрите:

Кстати я думаю что вам и так понятно, что при помощи проги GPU Tweak можно как бы разгонять видеокарту. И вот тут на картинке выше как раз настройки разгона, среди которых есть и Power Target. А в самом низу вижу надпись Profile, это означает что настройки можно сохранять в профиль, и потом наверно даже переключаться между настройками. Еще эта прога GPU Tweak (она вообще идет от Асус) показывает состояние там вольтажа, температуры, еще чего-то.. но и показывает также Power Target status:

Снова поискал в интернете о том что такое Power Target Status.. и тут я понял что немного затупил. Мы говорим про Power Target, верно? Ну вот. А Power Target Status это просто показывает статус Power Target, вот я затупил малеха.
Вот еще инфа — один чел на форуме пишет что по сути Power Target означает TDP видеокарты:
На этом все ребята, надеюсь что я вам помог, если нет то извините. Удачи вам и берегите себя, все у вас получится!!
990x.top
Smart CPU Fan Target, CPU Target Temperature, CPU Smart Fan Target Temp Select, Smart CPUFAN Temperature
Другие идентичные по назначению опции: CPU Target Temperature, CPU Smart Fan Target Temp Select, Smart CPUFAN Temperature.

Опция Smart CPU Fan Target(Целевая температура «умного» кулера процессора) позволяет пользователю настроить параметры вращения вентилятора (кулера) центрального процессора(ЦП). Значением опции могут быть температуры процессора. Кроме того, в опции пользователь может выбрать варианты Enabled/Auto и Disabled.
Содержание статьи
Принцип работы
Поскольку центральный процессор компьютера в процессе своей работы выделяет много тепловой энергии, то он нуждается в постоянном охлаждении. Эту функцию берет на себя кулер ЦП. Воздушный поток, создаваемый вентилятором, обдувает процессор, и благодаря этому тепло, возникающее при работе процессора, благополучно отводится от него. Однако кулер имеет один существенный недостаток – он создает немалый шум. Поскольку скорость вращения стандартного вентилятора не зависит от нагрева процессора, то этот шум будет производиться даже в том случае, если процессору не требуется особое охлаждение.
На сегодняшний день, однако, существуют модели «умных» кулеров, которые имеют не постоянную, а переменную скорость вращения. Поскольку изменение скорости вращения приводит к изменению скорости отвода тепла, то эта возможность позволяет поддерживать постоянную температуру ЦП. В том случае, если процессор работает не на полную мощность, он выделяет меньше тепла, чем обычно. При этом скорость вращения вентилятора уменьшается и, как следствие, снижается его шумность, а также количество потребляемой им энергии.
Рассматриваемая опция позволяет настроить значение температуры ЦП, которую должен поддерживать вентилятор. Для разных моделей процессоров эта величина может варьироваться, поэтому пользователь может самостоятельно установить нужное число. В большинстве BIOS допустимый диапазон температур составляет от 30 до 85 °C (86 – 185 °F).
Также пользователь может отключить функцию переменной скорости вентилятора, выбрав значение Disabled. При этом вентилятор будет работать все время на постоянной скорости, максимальной для данной модели вентилятора.
Иногда опция вместо выбора конкретных значений температуры (или одновременно с выбором этих значений) предлагает вариант Enabled или Auto. В этом случае BIOS сама выберет необходимую величину целевой температуры, исходя из параметров ЦП.
Какое значение выбрать?
Если в вашем компьютере установлен кулер, имеющий функцию переменной скорости, то лучше всего включить данную опцию, чтобы минимизировать количество шума, а также потребляемой энергии.
Но какое значение целевой температуры лучше всего установить? Конкретная величина во многом зависит как от модели ЦП, так и от модели охлаждающего вентилятора. Оптимальным выбором в большинстве случаев будет температура около 50 °C. Установка очень низкой температуры увеличит обороты кулера и может привести к чрезмерному повышению шума. С другой стороны, установка чрезмерно высокой целевой температуры может привести к перегреву процессора.
Если вы точно не знаете, какую температуру необходимо установить, то лучше всего довериться BIOS и установить значение Auto (если, разумеется, этот вариант присутствует в BIOS), чтобы система сама могла бы определить необходимую величину скорости вращения вентилятора.
Порекомендуйте Друзьям статью:
biosgid.ru
Что значит GPU ? O_O
CPU -центральное процессорное устройство (процессор) GPU -Графическое процессорное устройство (чип на видеокарте) Была 8500 с пассивным охлаждением, в убогом корпусе и 60 было норма для нее.
это видеокарта ничего ты с ней не сделаешь разве вентилятор поставишь на корпус но это не спасёт
gpu это графический процессор, если он сгорит видюху можно выкинуть.
Ноут разогревается до 91 градуса при работе. и причем он не игровой. но уже как полгода работает норм.
touch.otvet.mail.ru
Что такое GPU и как это 2 GPU/
центральный прцессор
графический процессор, 2 это значит их два, или видик двухядерный или два включены в SLI или Crossfire
Графический процессор (англ. graphics processing unit, GPU) — отдельное устройство персонального компьютера или игровой приставки, выполняющее графический рендеринг. Современные графические процессоры очень эффективно обрабатывают и отображают компьютерную графику. Благодаря специализированной конвейерной архитектуре они намного эффективнее в обработке графической информации, чем типичный центральный процессор. Графический процессор в современных видеоадаптерах применяется в качестве ускорителя трёхмерной графики. Может применяться как в составе дискретной видеокарты, так и в интегрированных решениях (встроенных в северный мост, либо в гибридный процессор) .
CPU- это центральный процессор. А CPU1, CPU2 и т. д это ядра процессора.
Graphics Processing Unit. Графический процессор в видеоадаптере. Чип, по формату схожий с центральным процессором (CPU), но расположенный, в основном, на плате видеокарты. 2 GPU — 2 чипа на одной видеокарте. Обычно представлены в старшей серии видеокарт — GTX 690, скажем. Самые крупные прямоугольники и есть GPU. <img src=»//otvet.imgsmail.ru/download/9236b5e5bb0db28becbccb048a0bd8c4_i-553.jpg»>
Это, дорогой друг, графический процессор видеокарты, выполняющий графический рендеринг. Ну а два процессора могут быть, например, в 590, 690 видеокартах от Н’Видиа (так называемые двухчиповые видеокарты).
touch.otvet.mail.ru
Как легко узнать температуру видеокарты
Для определения температуры видеокарты существует масса удобных и не очень программ. Есть полноценные тестовые приложения, имеющие большой функционал и предназначенные для полного «обследования» вашего компьютера. Есть более простые, основная функция которых состоит именно в мониторинге температуры видеокарты. Мы рассмотрим как раз две из таких — легкие, удобные и популярные. Они без всяких проблем работают на операционных системах Windows 7, 8, 10 и подходят практически для всех видеокарт NVIDIA и AMD. Плюс, обе эти программы абсолютно бесплатные.
Программа GPU Temp
GPU Temp, пожалуй, самое простое приложение, не имеющее большого функционала, но отлично справляющееся со своей основной задачей. Используется оно как и любая другая программа — скачали, установили, запустили.
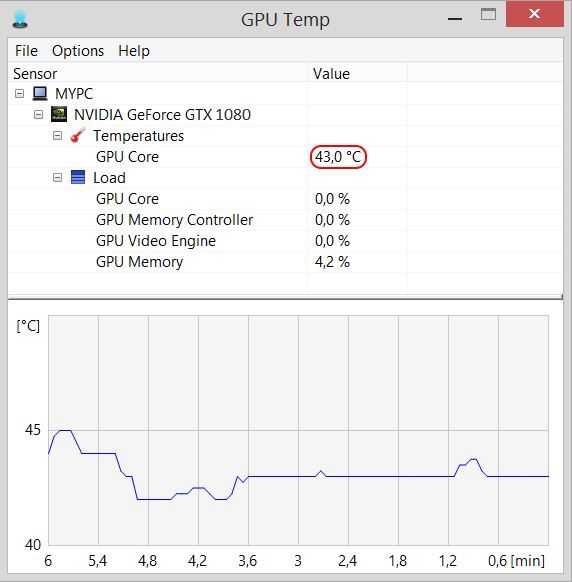
После запуска (лучше от имени администратора) в верхнем окошке GPU Temp мы увидим актуальные данные нашей видеокарты. В нижнем — график изменения температуры за время с момента запуска программы. Например, по окончании игры можно отследить, насколько максимально нагревалась видеокарта.
Если в верхней строке открыть вкладку Options и поставить галочку на значение Start Minimized, то при запуске программа будет открываться только в области уведомлений, показывая лишь цифры актуальной температуры.
Скачать программу GPU Temp вы можете с нашего сайта:
Скачать GPU Temp (592 КБ)
Обратите внимание, что GPU Temp может не «увидеть» дискретную видеокарту, если она не задействована в данный момент (актуально для ноутбуков). Например, у видеокарт NVIDIA существует технология Optimus, которая для экономии ресурсов компьютера сама переключается на встроенный графический адаптер, если не требуется большой производительности. Поэтому, если при запуске GPU Temp вы не видите дискретную видеокарту, нужно просто запустить какую-нибудь игру или другое требовательное к графике приложение.
Программа Piriform Speccy
Для тех, кто желает подробнее познакомиться со своим компьютером и узнать о его состоянии, предлагаем более функциональную программу от известного разработчика Piriform Ltd под названием Speccy. Она расскажет не только о графической системе, но и об остальных составляющих компьютера или ноутбука. В частности можно узнать температуру видеокарты, процессора и жесткого диска.

По умолчанию программа может запуститься на английском языке. Чтобы выбрать русский язык интерфейса (или любой другой), перейдите по вкладкам View — Options — Language.

Скачать программу Speccy Portable вы можете с нашего сайта:
Скачать Speccy Portable (5,3 МБ)
Версия Portable удобна тем, что запускается автономно, то есть не требует установки на компьютер. Просто распакуйте архив и запустите файл Speccy.exe (или Speccy64.exe, если у вас 64-битная операционная система).
Вот, пожалуй, и всё об определении температуры видеокарты. Если же вы используете графический адаптер NVIDIA GeForce, возможно вас заинтересует максимально допустимая температура вашей видеокарты.
gtx-force.ru
Gpu что это?
Мы расстроили более Made me feel a bit better with mine often running around while gaming. В настоящее время ГПУ применяется в качестве акселератора 3D-графики, но в исключительных случаях он может быть использован для вычислений. Ru Почта Мой Мир Одноклассники Игры Знакомства Новости Поиск Все проекты Все проекты.
В других проектах Викисклад. Примерами таковых могут служить чипы HD от AMD или GTX от nVidia. Дней 10 искала проблему. Игорь Белый Ученик 5 месяцев назад Ноут разогревается до 91 градуса при работе. How to downgrade to GeForce Experience 2. Чисти комп, меняй термопасту. Этот раздел статьи ещё не написан.
Экспорт словарей на сайтысделанные на PHP. How to Overclock a Pascal GPU. Навигация Персональные инструменты Вы не представились системе Обсуждение Вклад Создать учётную запись Войти. NVIDIA Driver Download Page. Это заготовка статьи о компьютерах. APM ACPI Clock gating Троттлинг Динамическое изменение напряжения. Истории успеха Tesla Литература о продукте Средства программного обеспечения Tesla Программные средства разработки Tesla Вебинары на русском языке NVIDIA Research Уведомления о новостях Tesla Учебный комплект для преподавателей.
Yes room temperature and the case airflow affect the cards cooling.
Главная Наши сервисы RSS 2. Вам также будет интересно: Крах плагина Adobe Flash Player в браузере Mozilla Firefox.
Рубрики Статьи Обзор веб-сервисов Разбираемся в программах Настройка системы Windows Краткие обзоры программ Работа с устройствами Инстаграм DLL файлы Настройка роутеров. Последние записи на сайте Как разблокировать плагин Adobe Flash Player Как обновить браузер Internet Explorer Не работает видео в Opera: Элина написал в статье BitTorrent скачать как как как скачать!!!!!!!!
I am hoping the same high-grade web site post from you in the upcoming as well. Actually your creative writing abilities has inspired me to get my own blog now. Actually the blogging is spreading its wings quickly. Your write up is a good example of it. Александр, попробуйте выполнить процедуру восстановления доступа, там должны быть шаги, позволяющие восстановить логин. Александр написал в статье Как войти в Яндекс почту? Не могу войти в почту. Пароль помню,логин не помню. Михаил написал в статье Dumpper Wi-Fi: Во вкладке Wps к выбранной сети изначально написал Wps Pin: JumpStart запустился, снизу исчезало и появлялось только одно число Сканировал 4 минуты и в итоге выдал дорожный знак 3.
Я думаю что вы забыли в JumpStart положить файл с подбором пин-кодов. На одну модель роутеров может быть много пин-кодов, а у вас он. Программа расчитана на то, что вам известно wps pin. С обратной стороны роутера находите PIN: Рекомендую выполнить процедуру восстановления доступа при авторизации кликните по кнопке «Не помню пароль» или аналогичную.
Валерий, аккаунт не может просто так исчезнуть, поэтому обязательно проверьте правильность вводимых логина и пароля. Лидия написал в статье Как избавиться от ошибки «Ваш У меня время стояло неправильно, а я и не заметила. Дней 10 искала проблему. Благодаря Вам проблема решена! Самое интересное на сайте Вход в почту Gmail Обрезка видео онлайн Connectify Hotspot Подключаемые модули браузера Гугл Хром Скачать msvcr
Сравнение GPU и CPU Что такое вычисления на GPU? | NVIDIA
Параллельная обработка данных Quadro Общая информация: Posts are automatically archived after 6 months. So yeah is nothing to these things. For each performance-critical area in your application, these approaches can be used independently or together. Мы в социальных сетях VKontakte YouTube Twitter Instagram Блог NVIDIA. С точки зрения пользователя, приложение просто работает значительно быстрее. У вас есть дома какие-нибудь тренажеры?
The 70C was in BF4 online. Actually the blogging is spreading its wings quickly.
Что такое GPU-ускорение?
They all use the same underlying program. Посмотрите в нашем каталоге приложений , имеет ли приложение, с которым вы работаете, GPU ускорение PDF 1,9 MБ. Эти порты доступны только для некоторых ноутбуков. Графический процессори далее Temp -температура, GPU clock — тайминг проца фидюхи, mem clock — тайминг памяти NVIDIA Driver Download Page.
Ask a new question. JumpStart запустился, снизу исчезало и появлялось только одно число Ежемесячно мы помогаем более девочек стать Винкс Так вы быстрее получите ответ. Is it safe to Oveclock? Может применяться как в составе дискретной видеокарты , так и в интегрированных решениях встроенных в северный мост либо в гибридный процессор.
Try using the custom instead of auto and manual and see if that allows for a custom curve. The temp target has nothing to do with fan profile. I just wondered if it was better to let it run cooler, but louder or leave it as is. Is my idle gpu temps normal cpu and gpu temps and usage normal? And I think it has an automatic setting at a certain temperature for the fan to go to percent. The bios has a certain wattage set as max stock. Which video card cooler is right for you. How to reduce coil whine.
5532 :: 5533 :: 5534 :: 5535 :: 5536 :: 5537
q96522ur.beget.tech
GPU-оптимизация – прописные истины – Мои IT-заметки
[pullquote align=”left|center|right” textalign=”left|center|right” width=”30%”]Ядер много не бывает…[/pullquote]
Современные GPU – это монструозные шустрые бестии, способные пережевывать гигабайты данных. Однако человек хитер и, как бы не росли вычислительные мощности, придумывает задачи все сложнее и сложнее, так что приходит момент когда с грустью приходиться констатировать – нужна оптимизацию 🙁
В данной статье описаны основные понятия, для того чтобы было легче ориентироваться в теории gpu-оптимизации и базовые правила, для того чтобы к этим понятиям, приходилось обращаться по-реже.
Причины по которой GPU эффективны для работы с большими объемами данных, требующих обработки:
- у них большие возможности по параллельному исполнению задач (много-много процессоров)
- высокая пропускная способность у памяти
Пропускная способность памяти (memory bandwidth) – это сколько информации – бит или гигабайт – может может быть передано за единицу времени секунду или процессорный такт.
Одна из задач оптимизации – задействовать по максимуму пропускную способность – увеличить показатели throughput (в идеале она должна быть равна memory bandwidth).
Для улучшения использования пропускной способности:
- увеличить объем информации – использовать пропускной канал на полную (например каждый поток работает с флоат4)
- уменьшать латентность – задержку между операциями
Задержка (latency) – промежуток времени между моментами, когда контролер запросил конкретную
ячейку памяти и тем моментом, когда данные стали доступны процессору для выполнения инструкций.
На саму задержку мы никак повлиять не можем – эти ограничения присутствуют на аппаратном уровне.
Именно за счет этой задержки процессор может одновременно обслуживать несколько потоков –
пока поток А запросил выделить ему памяти, поток Б может что-то посчитать, а поток С ждать пока к нему придут запрошенные данные.
Как снизить задержку (latency) если используется синхронизация:
- уменьшить число потоков в блоке
- увеличить число групп-блоков
Использование ресурсов GPU на полную – GPU Occupancy
В высоколобых разговорах об оптимизации часто мелькает термин – gpu occupancy или kernel occupancy –
он отражает эффективность использования ресурсов-мощностей видеокарты. Отдельно отмечу – если вы даже и используете все ресурсы – это отнюдь не значит что вы используете их правильно.
Вычислительные мощности GPU – это сотни процессоров жадных до вычислений, при создании программы – ядра (kernel) – на плечи программиста ложиться бремя распределения нагрузки на них. Ошибка может привести к тому, что большая часть этих драгоценных ресурсов может бесцельно простаивать. Сейчас я объясню почему. Начать придется издалека.
Напомню, что варп (warp в терминологии NVidia, wavefront – в терминологии AMD) – набор потоков которые одновременно выполняют одну и туже функцию-кернел на процессоре. Потоки, объединенные программистом в блоки разбиваются на варпы планировщиком потоков (отдельно для каждого мультипроцессора) – пока один варп работает, второй ждет обработки запросов к памяти и т.д. Если какие-то из потоков варпа все еще выполняют вычисления, а другие уже сделали все что могли – имеет место быть неэффективное использование вычислительного ресурса – в народе именуемое простаивание мощностей.
Каждая точка синхронизации, каждое ветвление логики может породить такую ситуацию простоя. Максимальная дивергенция (ветвление логики исполнения) зависит от размера варпа. Для GPU от NVidia – это 32, для AMD – 64.
Для того чтобы снизить простой мультипроцессора во время выполнения варпа:
- минимизировать время ожидания барьеров
- минимизировать расхождение логики выполнения в функции-кернеле
Для эффективного решения данной задачи имеет смысл разобраться – как же происходит формирование варпов (для случая с неколькими размерностями). На самом деле порядок простой – в первую очередь по X, потом по Y и, в последнюю очередь, Z.
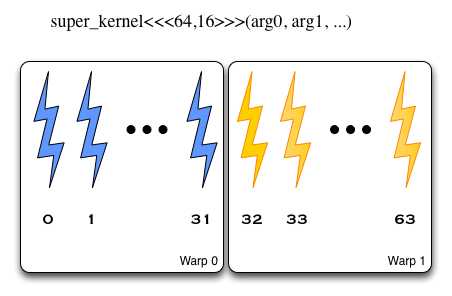
ядро запускается с блоками размерностью 64×16, потоки разбиваются по варпам в порядке X, Y, Z – т.е. первые 64 элемента разбиваются на два варпа, потом вторые и т.д.
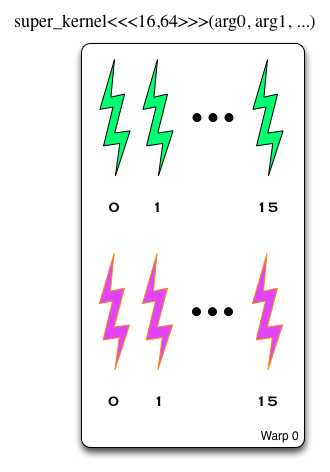
Ядро запускается с блоками размерностью 16×64. В первый варп добавляются первые и вторые 16 элементов, во второй варп – третьи и четвертые и т.д.
более подробно про это можно почитать тут:
http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#thread-hierarchy
Как снижать дивергенцию (помните – ветвление – не всегда причина критичной потери производительности)
- когда у смежных потоков разные пути исполнения – много условий и переходов по ним – искать пути ре-структуризации
- искать не сбалансированную загрузку потоков и решительно ее удалять (это когда у нас мало того что есть условия, дак еще из-за этих условиях первый поток всегда что-то вычисляет, а пятый в это условие не попадает и простаивает)
Как использовать ресурсы GPU по максимуму
Ресурсы GPU, к сожалению, тоже имеют свои ограничения. И, строго говоря, перед запуском функции-кернела имеет смысл определить лимиты и при распределении нагрузки эти лимиты учесть. Почему это важно?
У видеокарт есть ограничения на общее число потоков, которое может выполнять один мультипроцессор, максимальное число потоков в одном блоке, максимальное число варпов на одном процессоре, ограничения на различные виды памяти и т.п. Всю эту информацию можно запросить как програмно, через соответствующее API так и предварительно с помощью утилит из SDK. (Модули deviceQuery для устройств NVidia, CLInfo – для видеокарт AMD).
Общая практика:
- число блоков/рабочих групп потоков должно быть кратно количеству потоковых процессоров
- размер блока/рабочей группы должые быть кратен размеру варпа
При этом следует учитывать что абсолютный минимум – 3-4 варпа/вейфронта крутятся одновременно на каждом процессоре, мудрые гайды советуют исходить из соображения – не меньше семи вейфронатов. При этом – не забывать ограничения по железу!
В голове все эти детали держать быстро надоедает, потому для расчет gpu-occupancy NVidia предложила неожиданный инструмент – эксельный(!) калькулятор набитый макросами. Туда можно ввести информацию по максимальному числу потоков для SM, число регистров и размер общей (shared) памяти доступных на потоковом процессоре, и используемые параметры запуска функций – а он выдает в процентах эффективность использования ресурсов (и вы рвете на голове волосы осознавая что чтобы задействовать все ядра вам не хватает регистров).
сам кальулятор:
http://developer.download.nvidia.com/compute/cuda/CUDA_Occupancy_calculator.xls
информация по использованию:
http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#calculating-occupancy
GPU и операции с памятью
Видеокарты оптимизированы для 128-битных операций с памятью. Т.е. в идеале – каждая манипуляция с памятью, в идеале, должна изменять за раз 4 четырех-байтных значения. Основная неприятность для программиста заключается в том, что современные компиляторы для GPU не умеют оптимизировать такие вещи. Это приходится делать прямо в коде функции и, в среднем, приносит доли-процента по приросту производительности. Гораздо большее влияние на производительность имеет частота запросов к памяти.
Проблема обстоит в следующем – каждый запрос возвращает в ответ кусочек данных размером кратный 128 битам. А каждый поток использует лишь четверть его (в случае обычной четырех-байтовой переменной). Когда смежные потоки одновременно работают с данными расположенными последовательно в ячейках памяти – это снижает общее число обращений к памяти. Называется это явление – объединенные операции чтения и записи (coalesced access – good! both read and write) – и при верной организации кода (strided access to contiguous chunk of memory – bad!) может ощутимо улучшить производительность. При организации своего ядра – помните – смежный доступ – в пределах элементов одной строки памяти, работа с элементами столбца – это уже не так эффективно. Хотите больше деталей? мне понравилась вот эта pdf – или гуглите на предмет “memory coalescing techniques“.
Лидирующие позиции в номинации “узкое место” занимает другая операция с памятью – копирование данных из памяти хоста в гпу. Копирование происходит не абы как, а из специально выделенной драйвером и системой области памяти: при запросе на копирование данных – система сначала копирует туда эти данные, а уже потом заливает их в GPU. Скорость транспортировки данных ограничена пропускной способностью шины PCI Express xN (где N число линий передачи данных) через которые современные видеокарты общаются с хостом.
Однако, лишнее копирование медленной памяти на хосте – это порою неоправданные издержки. Выход – использовать так называемую pinned memory – специальным образом помеченную область памяти, так что операционная система не имеет возможности выполнять с ней какие либо операции (например – выгрузить в свап/переместить по своему усмотрению и т.п.). Передача данных с хоста на видеокарту осуществляется без участия операционной системы – асинхронно, через DMA (direct memory access).
И, на последок, еще немного про память. Разделяемая память на мультипроцессоре обычно организована в виде банков памяти содержащих 32 битные слова – данные. Число банков по доброй традиции варьируется от одного поколения GPU к другому – 16/32 Если каждый поток обращается за данными в отдельный банк – все хорошо. Иначе получается несколько запросов на чтение/запись к одному банку и мы получаем – конфликт (shared memory bank conflict). Такие конфликтные обращения сериализуются и соответственно выполняются последовательно, а не параллельно. Если к одному банку обращаются все потоки – используется “широковещательный” ответ (broadcast) и конфликта нет. Существует несколько способов эффективно бороться с конфликтами доступа, мне понравилось описание основных методик по избавлению от конфликтов доступа к банкам памяти – тут.
Как сделать математические операции еще быстрее? Помнить что:
- вычисления двойной точности – это высокая нагрузка операции с fp64 >> fp32
- константы вида 3.13 в коде, по умолчанию, интерпретируется как fp64 если явно не указывать 3.14f
- для оптимизации математики не лишним будет справиться в гайдах – а нет ли каких флажков у компилятора
- производители включают в свои SDK функции, которые используют особенности устройств для достижения производительности (часто – в ущерб переносимости)
Для разработчиков CUDA имеет смысл обратить пристальное внимание на концепцию cuda stream, позволяющих запускать сразу несколько функций-ядер на одному устройстве или совмещать асинхронное копирование данных с хоста на устройство во время выполнения функций. OpenCL, пока, такого функционала не предоставляет 🙁
Утиль для профилирования:
NVifia Visual Profiler
AMD CodeXL (бывший Amd APP Profiler)
Средства для дебугинга:
gDEBugger – http://www.gremedy.com/
CUDA-gdb – https://developer.nvidia.com/cuda-gdb
И отдельно хочу отметить функционал AMD APP KernelAnalyzer – статического анализатора кода (не требует наличия GPU в системе, умеет компилировать/разбирать собранные ядра для различных архитектур GPU от AMD). Сейчас входит в состав очередной системы для разработки все-в-одном – AMD CodeXL.
CUDA-MEMCHECK – анализатор от NVidia, призванный обеспечить функционал одноименного расширения для valgrind в мире CUDA-приложений.
http://multicore.doc.ic.ac.uk/tools/GPUVerify/ – интересная утилитка, анализирует ядра как CUDA так и OpenCL.
P. S. В качестве более пространного руководства по оптимизации, могу порекомендовать гуглить всевозможные best practices guide для OpenCL и CUDA.
my-it-notes.com