Нейросети на Форекс и биржах. Как используют Нейросеть в торговле
Искусственная нейронная сеть представляет собой математическую модель, воплощенную в виде компьютерной программы и имитирующую работу центральной нервной системы живых организмов.
Что такое Нейронная сеть и как она работает в торговле на биржах
Понятие «Нейронная сеть» (НС) появилось в ходе изучения процессов, идущих в головном мозге, и попыток их воспроизведения. В настоящее время разработано множество алгоритмов, которые нашли применение во многих областях, где требуется анализ, распознавание и прогнозирование, включая нейросеть для торговли на бирже.
Нейронные сети в торговле на биржах – это системы анализа данных, которые, в отличие от обычных программ, работают не сугубо в рамках прописанного набора действий, а самообучаются в процессе работы благодаря возможностям машинного обучения и тестирования различных исходов и ситуаций на основе прошлых событий. В ходе обучения НС выявляет сложные взаимосвязи, которые непросто рассмотреть в обычных обстоятельствах.
Современные торговые советники и роботы опираются только на один алгоритм и не способны самообучаться. Поэтому при смене рыночной ситуации приходится останавливать работу советника или перенастраивать его алгоритм. Даже в процессе работы советника, он может выдавать много ложных сделок, так как рыночная ситуация может не соответствовать его заданному алгоритму.
Нейросети на Форекс позволят избежать подобных ситуаций. Вернее, предполагается, что позволят. На данный момент сделаны лишь первые шаги в этом направлении. О создании полноценной аналитической системы, которая могла бы самостоятельно переключаться и определять рыночные состояния, а также принимать решения исходя из этого, говорить пока что не приходится.
Что такое нейросети на Форекс
В последние время трейдерское сообщество все чаще обсуждает машинное обучение и нейросети на Форекс и бирже. Эта тема не совсем нова: в докризисные годы были популярны торговые программы на базе НС NeuroSolutions и NeuroShell. Сейчас, после внедрения Google и Microsoft этой технологии в свои переводчики и голосовой поиск, продвинутые трейдеры снова обратили на нее внимание.
Сейчас, после внедрения Google и Microsoft этой технологии в свои переводчики и голосовой поиск, продвинутые трейдеры снова обратили на нее внимание.Нейросеть простыми словами – это система, имитирующая работу головного мозга, способная обучаться и приспосабливаться к меняющимся условиям, а также прогнозировать ситуации. Применительно к торговле на финансовых рынках это означает, что для анализа можно использовать не только котировки, как в случае торговых роботов, но и любые другие данные, которые пользователь сочтет нужными. Кроме того, всю исходную информацию можно комбинировать в любых пропорциях.
Однако нейросети на Форекс все еще недоступны для широких масс трейдеров. Поэтому большинству приходится пока что изучать их работу в теории.
Главной трудностью применения искусственных нейросетей является процесс их обучения. Другим препятствием становится высокая стоимость нейропакетов и в особенности специального оборудования для них – нейрокомпьютеров.
Посмотрите короткое видео о использовании нейросетей в торговле на биржах:
Некоторые американские компании как LBS Capital Management Inc. покупают небольшие нейропакеты и нейрокомпьютеры до $50000 и улучшают свои торговые показатели на американских фондовых индексах S&P 500 или Nasdaq 100.
Схема работы нейронной сети:
Задачи для нейросети
Выборка статистики в качестве обучающего элемента имеет для НС решающее значение. Состав данных может быть очень широким, однако встает вопрос отсеивания ненужной информации. Справиться с фильтрацией входных данных для нейронного советника можно, используя несколько способов.
- Большинство нейропакетов включают опцию определения чувствительности к входной информации. Эта функция позволяет загружать все имеющиеся данные без сортировки, после чего сеть сама покажет, какие данные более приоритетны. Ввиду непрогнозируемости времени обучения НС этот способ далек от оптимального, однако является самым простым.
- Данные проверяются на противоречивость: большое количество взаимоисключающей информации способно полностью блокировать возможность получения сколько-нибудь точного рыночного прогноза.
- Возможно использование нейросетевых программных инструментов, работающих по технологии Data Maining. В основе такого метода обработки информации лежит классификация данных различными способами, включая нечеткую логику.
- Применяются методы корреляционного и кластерного анализа, а также исследование временных рядов, которые дают возможность группировки введенных данных. Также они выявляют отношение числовых показателей друг к другу и их цикличность применительно к отдельным элементам и к группам цифр.


Почему нейронные сети не применяются активно в трейдинге?
Существует несколько довольно простых и нетривиальных объяснений отсутствию популярности таких технологий в современном трейдинге среди широкой массы частных инвесторов. Связано это как с дороговизной подобных пакетов, так и с необходимостью последующего обучения сети.
То есть готовых решений нет. Вам придется все равно заниматься настройками и подготовкой подобных алгоритмов вручную. Кстати для этого потребуются знания в той области, в которой будут применяться нейросети. А ведь многие трейдеры хотят получить в свои руки готовый инструмент, который не требует никаких доработок и, главное, усилий.
В самой популярной торговой платформе для рынка Форекс – MetaTrader пока что нет возможности подключения модулей для нейросетей, хотя попытки уже предпринимались и уже написаны некоторые готовые библиотеки. Сейчас есть возможность подключения программ машинного обучения у платформы Wealth Lab, но программирование данных модулей – задача очень сложная и на данный момент не реализованная.
Еще одна причина связана с тем, что нейросети в целом пока что не пользуются высоким спросом и в других областях.
Полезные статьи:
В каких сферах успешно применяются нейронные сети
Наверняка среди читателей довольно много скептиков в отношении применения подобных технологий в трейдинге, да и в любой другой сфере. Поэтому сейчас мы расскажем о том, где нейронные сети уже применяются, причем довольно успешно.
В Великобритании ученые внедрили такую технологию в медицину для оценки рисков сердечно-сосудистых заболеваний. Причем алгоритмы прошли «обучение» на данных от более чем 300 000 пациентов. В результате, искусственный интеллект оказался даже эффективнее, чем человек.
Используются такие сети и в сфере финансов. В частности, в Японии одна из страховых компаний внедрила специальный алгоритм, который будет изучать медицинские сертификаты и историю болезней, а также перенесенных операций для расчета условий страхования клиентов.
Нейросети успешно применяются сегодня в поисковых алгоритмах Яндекс и Google. Помимо этого, они используются, к примеру, в Amazon. В известнейшей интернет-сети продаж благодаря автоматизации механизма рекомендаций осуществляется 35% продаж.
Помимо этого, они используются, к примеру, в Amazon. В известнейшей интернет-сети продаж благодаря автоматизации механизма рекомендаций осуществляется 35% продаж.
В будущем ожидается, что такие алгоритмы смогут использоваться и для работы так называемых чат ботов и смогут заменить сотрудников Call-центров.
Применяются нейронные сети и на транспорте. В частности, речь идет о беспилотных автомобилях и других разработках в этой отрасли, которые ведутся известными компаниями Google, Yandex, Uber.
Наконец, внедрение искусственного интеллекта наблюдается также в промышленном производстве и сельском хозяйстве.
Плюсы и минусы
А теперь разберемся с преимуществами и недостатками применения нейронных сетей в торговле на бирже.
Одним из главных является то, что системы такого рода постоянно обучаются. Появляются новые данные и нейросети учитывают их в процессе анализа.Второй важный момент – современные системы такого рода могут комбинировать технические и фундаментальные данные. Соответственно, применять подобную методику можно для прогнозирования, к примеру, по системе Прайс экшн и, при этом, исключить влияние фундаментальных факторов на результаты торговли.
Соответственно, применять подобную методику можно для прогнозирования, к примеру, по системе Прайс экшн и, при этом, исключить влияние фундаментальных факторов на результаты торговли.
Что касается недостатков, они также присутствуют. К ним можно отнести, к примеру, то, что если на входе подавались неверные данные, то и результат будет соответствующим.
Наконец, из доступных сегодня систем, построенных на базе нейронных сетей, большинство показывает точность прогнозов в 50-60%. То есть данные методики пока что не отличаются высокой точностью.
Именно по этой причине многие трейдеры полагают, что нейронные сети вообще не работают и их использование в трейдинге бесперспективно. В некотором плане с ними можно согласиться, так как на современном этапе точность таких прогнозов очень низка. Поэтому смысла в них нет никакого. Но в будущем, ситуация может улучшиться.
В любом случае, применение нейронных сетей никогда не отменит необходимость наличия знаний в области трейдинга. Для того, чтобы обучить такую технологию, необходимо понимать как и зачем, а главное чему обучать искусственный интеллект. Даже если и будут готовые решения, они вряд ли полностью заменят трейдера.
Для того, чтобы обучить такую технологию, необходимо понимать как и зачем, а главное чему обучать искусственный интеллект. Даже если и будут готовые решения, они вряд ли полностью заменят трейдера.
Заключение
В статье мы рассказали о том, что такое нейросети и как они применяются на практике в различных сферах. Как видите, в торговле на биржах нейросети сегодня практически не используются, равно как и в трейдинге на Форекс. Однако в будущем ситуация может кардинально поменяться.
Машинное обучение: прогнозируем цены акций на фондовом рынке
Для проекта я использовал две модели нейронных сетей: Многослойный перцептрон Румельхарта (Multilayer Perceptron — MLP) и модель Долгой краткосрочной памяти (Long Short Term Model — LSTM). Кратко расскажу о том, как работают эти модели. Подробнее о MLP читайте в другой статье, а о работе LSTM — в материале Джейкоба Аунгиерса.
MLP — самая простая форма нейронных сетей. Входные данные попадают в модель и с помощью определённых весов значения передаются через скрытые слои для получения выходных данных. Обучение алгоритма происходит от обратного распространения через скрытые слои, чтобы изменить значение весов каждого нейрона. Проблема этой модели — недостаток «памяти». Невозможно определить, какими были предыдущие данные и как они могут и должны повлиять на новые. В контексте нашей модели различия за 10 дней между данными двух датасетов могут иметь значение, но MLP не способны анализировать такие связи.
Входные данные попадают в модель и с помощью определённых весов значения передаются через скрытые слои для получения выходных данных. Обучение алгоритма происходит от обратного распространения через скрытые слои, чтобы изменить значение весов каждого нейрона. Проблема этой модели — недостаток «памяти». Невозможно определить, какими были предыдущие данные и как они могут и должны повлиять на новые. В контексте нашей модели различия за 10 дней между данными двух датасетов могут иметь значение, но MLP не способны анализировать такие связи.
Для этого используется LSTM или Рекуррентные нейронные сети (Recurrent Neural Networks — RNN). RNN сохраняют определённую информацию о данных для последующего использования, это помогает нейронной сети анализировать сложную структуру связей между данными о ценах на акции. Но с RNN возникает проблема исчезающего градиента. Градиент уменьшается, потому что количество слоев повышается и уровень обучения (значение меньше единицы) умножается в несколько раз. Решают эту проблему LSTM, увеличивая эффективность.
Решают эту проблему LSTM, увеличивая эффективность.
Для реализации модели я использовал Keras, потому что там слои добавляются постепенно, а не определяют всю сеть сразу. Так мы можем быстро изменять количество и тип слоёв, оптимизируя нейронную сеть.
Важный этап работы с ценами на акции — нормализация данных. Обычно для этого вы вычитаете среднюю погрешность и делите на стандартную. Но нам нужно, чтобы эту систему можно было использовать в реальной торговле в течение определённого периода времени. Таким образом, использование статистики может быть не самым точным способом нормализации данных. Поэтому я просто разделил все данные на 200 (произвольное число, по сравнению с которым все другие числа малы). И хотя кажется, что такая нормализация ничем не обоснована и не имеет смысла, она эффективна, чтобы убедиться, что веса в нейронной сети не становятся слишком большими.
Начнём с более простой модели — MLP.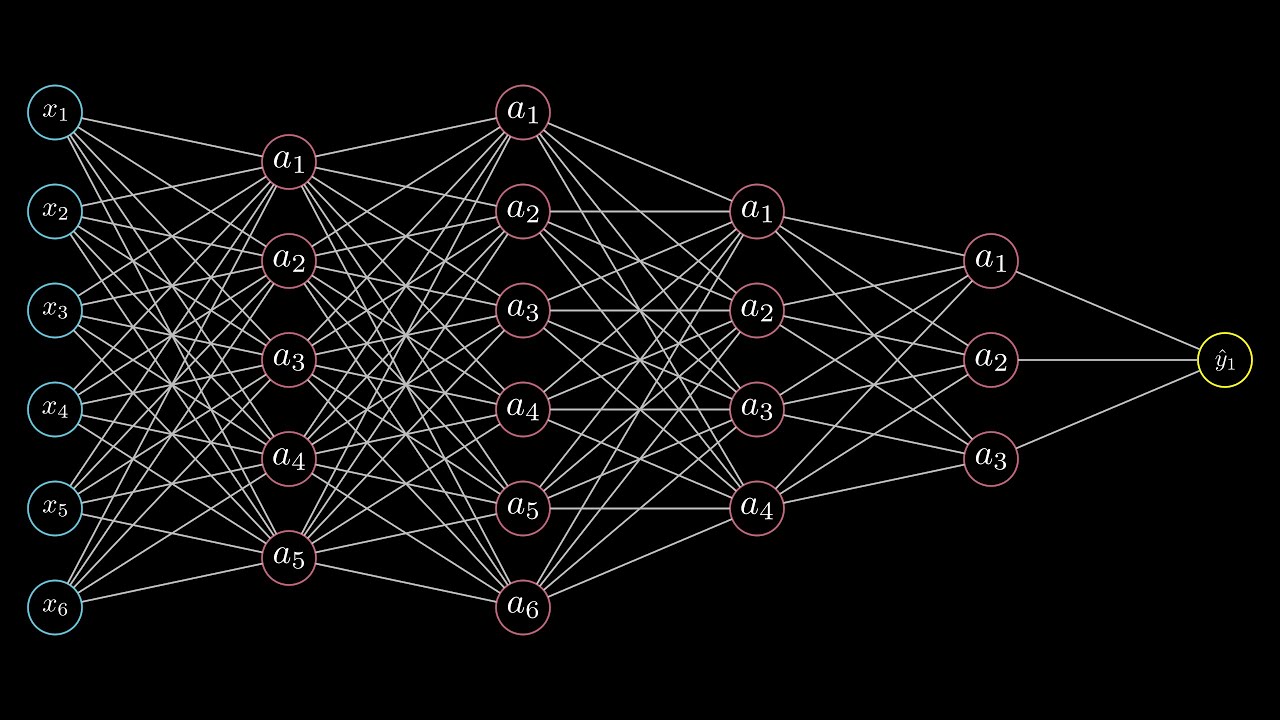 В Keras строится последовательность и поверх неё добавляются плотные слои. Полный код выглядит так:
В Keras строится последовательность и поверх неё добавляются плотные слои. Полный код выглядит так:
С помощью Keras в пяти строках кода мы создали MLP со скрытыми слоями, по сто нейронов в каждом.
А теперь немного об оптимизаторе. Популярность набирает метод Adam (adaptive moment estimation) — более эффективный оптимизационный алгоритм по сравнению с стохастическим градиентным спуском. Есть два других расширения стохастического градиентного спуска — на их фоне сразу видны преимущества Adam:
AdaGrad — поддерживает установленную скорость обучения, которая улучшает результаты при расхождении градиентов (например, при проблемах с естественным языком и компьютерным зрением).
RMSProp — поддерживает установленную скорость обучения, которая может изменяться в зависимости от средних значений недавних градиентов для веса (например, насколько быстро он меняется). Это значит, что алгоритм хорошо справляется с нестационарными проблемами (например, шумы).
Это значит, что алгоритм хорошо справляется с нестационарными проблемами (например, шумы).
Adam объединяет в себе преимущества этих расширений, поэтому я выбрал его.
Теперь подгоняем модель под наши обучающие данные. Keras снова упрощает задачу, нужен только следующий код:
Когда модель готова, нужно проверить её на тестовых данных, чтобы определить, насколько хорошо она сработала. Это делается так:
Информацию, полученную в результате проверки, можно использовать, чтобы оценить способность модели прогнозировать цены акций.
Для модели LSTM используется похожая процедура, поэтому я покажу код и немного объясню его:
Обратите внимание, что для Keras нужны данные определённого размера в зависимости от вашей модели. Очень важно изменить форму массива с помощью NumPy.
Нейронные сети. От мозга до биржи
Нейронная сеть (НС) – массив связанных и совместно функционирующих естественных (биологических) или искусственных нейронов, призванных выполнять определенные задачи. По происхождению и типу нейронов различают биологические (БНС) и искусственные нейронные сети (ИНС).
По происхождению и типу нейронов различают биологические (БНС) и искусственные нейронные сети (ИНС).
СОДЕРЖАНИЕ:
Введение. Искусственный интеллект
1. Биологическая нейронная сеть (БНС)
2. Искусственная нейронная сеть (ИНС)
2.1. Определение
2.2. Искусственный нейрон и функция активации
2.3. Структура, типы и простейший механизм ИНС
3. История создания
4. Предназначение ИНС
4.1. Распознавание
4.2. Классификация
4.3. Принятие решений и управление
4.4. Сжатие данных и ассоциативная память
4.5. Прогнозирование
5. Обучение ИНС
5.1. Виды обучения
5.2. Требования к входной информации
5.3. Ошибка, эпоха и итерация
Примечания и ссылки
Используемые сокращения
ВВЕДЕНИЕ. ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ
Термин «искусственный интеллект», ИИ (artificial intelligence, AI) был введен в 1956 г. американцем Джоном Маккарти. Одно из наиболее точных и адекватных определений ИИ дано в «Толковом словаре по искусственному интеллекту» А. Аверкиным и соавторами[1]. Согласно нему, ИИ – это «свойство интеллектуальных <технических или программных> систем выполнять творческие функции, которые традиционно считаются прерогативой человека».
Аверкиным и соавторами[1]. Согласно нему, ИИ – это «свойство интеллектуальных <технических или программных> систем выполнять творческие функции, которые традиционно считаются прерогативой человека».
Одним из путей «копирования» человека стало изобретение и развитие искусственных нейронных сетей (ИНС). Для того, чтобы яснее понять явление ИНС рассмотрим, какие человеческие опции они призваны подменить.
1. БИОЛОГИЧЕСКАЯ НЕЙРОННАЯ СЕТЬ (БНС)
Под биологической или естественной нейронной сетью Википедия[2] понимает «совокупность нейронов головного и спинного мозга центральной нервной системы и ганглия (узлов, скоплений) периферической нервной системы, связанные или функционально объединенные в нервной системе, и выполняющие специфические физиологические функции».
Упомянутые «специфические физиологические функции» делают людей людьми. Это их интеллектуальная, «мозговая» деятельность, простая и сложная. От первого осмысленного шага ребенка до общей теории относительности скромного служащего патентного бюро Альберта Эйнштейна.
Структурная единица НС – нейрон или неврон (от древнегреческого волокно, нерв[3]). Нейрон – клетка, хранящая информацию и передающая ее с помощью электрических и химических сигналов. Человеческий мозг содержит 90-95 млрд нейронов. Нейронная сеть образуется путем связывания нейронов друг с другом. Место контакта между соседними нейронами именуется синапсом (от греческого соединение, связь)
Как работает биологическая нейронная сеть?
Запускаемый в нее импульс передается от нейрона к нейрону через синапсы химическим или электрическим путем. В первом случае, прохождение сигнала обеспечивается, так называемыми, медиаторами (нейромедиаторами) – биологически активными химическими веществами. При электрическом варианте между нейронами (клетками) путешествуют ионы.
На выходе из БНС импульс от крайних нейронов перебрасывается на эффекторную клетку (клетку мишень), которая исполняет получаемый «приказ».
2. ИСКУССТВЕННАЯ НЕЙРОННАЯ СЕТЬ (ИНС)
2.1. Определение
Искусственная нейронная сеть – «математическая модель с ее программным/аппаратным воплощением, выстроенная по принципу организации и функционирования биологической нейронной сети»[5]. Можно выразиться более понятно и кратко: «ИНС – компьютерная модель мозга человека»[6]. Она имитирует его работу, правда пока, достаточно примитивно.
2.2. Искусственный нейрон и функция активации
Роль естественного нейрона в ИНС выполняет нейрон искусственный, другое название – формальный нейрон. Технически, искусственный нейрон – простейший процессор. Математически – функция, преобразующая линейную комбинацию входных сигналов (значений), получаемых формальным нейроном, в выходные, передаваемые им далее. Функция носит имя функции активации или срабатывания, а также передаточной функции.
К базовым функциям активации относят:
1) Линейную функцию f(x)=k*x (обычно, k=1).
Частный случай – полулинейная функция:
| f(x)= | 0, при x<0 |
| х, при 0<x<1 | |
| 1, при x>1 |
2) Пороговую функцию:
| f(x)= | 0, при x<x0 |
| 1, при x>x0 |
3) Сигмоид (сигмоиду):
f(x)=1/(1+e—x)
4) Гиперболический тангенс:
f(x)=(e2x-1)/(e2x+1)
Важным в архитектуре функций активации является то, что (в большинстве случаев) она должна быть монотонно возрастающей и с областью ее значений [0;1] или [-1;1]. Бывают и исключения.
2.3. Структура, типы и простейший механизм ИНС
Итак, что такое ИНС в первом приближении, и каковы основные принципы ее работы?
Как и в биологической нейронной сети, ИНС – массив связанных между собой нейронов, но нейронов искусственных.
(Далее, по тексту, по умолчанию, под нейронами будут пониматься искусственные нейроны, под нейронной сетью, НС – искусственная нейронная сеть, ИНС, если не оговорено иное)
источник[5]
Нейроны делятся на три вида, в зависимости от их расположения в сети: входные, промежуточные (скрытые или внутренние) и выходные[7]. На картинке, соответственно – зеленые, голубые и желтый. Они формируют слои ИНС: входной, промежуточные и выходной. Входные нейроны являются «прозрачными» для входящей в них информации, передают ее далее, «один к одному», без обработки. Прочие — модифицируют сведения, полученные из предыдущего слоя.
Для определения связи, контакта между искусственными нейронами, аналогично БНС, применяется термин «синапс». Роль синапса в математическом нейроне выполняют веса (коэффициенты), на которые умножаются входные, по отношению к данному нейрону, сигналы (цифровые значения) для подстановки в функцию активации. Вес – единственный параметра синапса ИНС.
Связь (синапс) с положительны весом называется «возбуждающей», с отрицательным – «тормозящей». У каждого нейрона один выход, сигналы с которого могут уходить на неограниченное число входов других нейронов.
Существует великое множество классификаций нейронных сетей: по типу входной информации, по характеру обучения, по характеру настройки синапсов в и т.д.
Одной из базовых представляется разделение ИНС на сети прямого распространения (СПР) и рекуррентные нейронные сети (РНС). В СПР выдерживается единое направление передачи сигнала, от входных нейронов, через промежуточные – к выходным. РНС предполагает частичное отражение (обратную передачу) импульса нейронами данного слоя на слой предыдущий. Далее, в материале рассматриваются только СПР.
Функционирование ИНС рассмотрим на элементарном примере.
источник[6]
Здесь, I1 и I2 – входные, H1 и H2 – промежуточные (скрытые) и O1 – выходной нейроны. Также, для краткости, под I1, I2, H1,H2 и О1 будем понимать математические значения, аргументы для расчета функции активации, «снимаемые» с соответствующих нейронов. Wi (i=1,….6) – синапсы (веса).
Также, для краткости, под I1, I2, H1,H2 и О1 будем понимать математические значения, аргументы для расчета функции активации, «снимаемые» с соответствующих нейронов. Wi (i=1,….6) – синапсы (веса).
Зададим для входящих переменных следующие значения:
I
Отметим, что веса w1, w2 и w4 – отвечают возбуждающим связям, прочие – тормозящим.
В качестве функции активации предлагается использовать сигмоид.
Этап 1
Сигналы от нейронов I1 и I2 поступают на нейроны H1 и H2. (входящая информация H1input и H2input) и обрабатываются ими в исходящую информацию (H1output и H2output).
H1input=I1*w1+I2*w3=1*0,45+0*(-0,12)=0,45.
H2input=I1*w2+I2*w4=1*0,78+0*0,13=0,78.
H1output=sigmoid(0,45)=1/(1+e-0,45)=0,61.
H2output=sigmoid(0,78)=1/(1+e-0,78)=0,69.
Этап 2
Сигналы от нейронов H1 и H2 поступают на нейрон O1. (входящая информация O1input) и обрабатываются им в исходящую информацию (O1output).
O1input=H1output*w5+ H2output*w6=0,61*1,5+0,69*(-2,3)=-0,672.
O1output= sigmoid(-0,672)=1/(1+e0,672)=0,338.
Далее, этот сигнал с соответствующим весом, например, w7, уходит на следующий нейрон.
3. ИСТОРИЯ СОЗДАНИЯ
В 2018 году искусственные нейронные сети отметили 75-летие.
Своему появлению они обязаны двум американским именам: Уоррен Мак-Каллок (Warren Sturgis McCulloch) и Уолтер Питтс (Walter Pitts). В 1943 г. ученые публикуют фундаментальную работу «Логическое исчисление идей, относящихся к нервной активности»[8], положившую начало новому направлению на стыке кибернетики и нейрофизиологии.
В 1943 г. ученые публикуют фундаментальную работу «Логическое исчисление идей, относящихся к нервной активности»[8], положившую начало новому направлению на стыке кибернетики и нейрофизиологии.
Уолтер Питтс (справа)[8]
Для практической реализации идеи ИНС «отец» кибернетики Норберт Винер предложил У. Питтсу вакуумные лампы. Идеальное техническое решение для 1940-х.
Норберт Винер[9]
4. ПРЕДНАЗНАЧЕНИЕ
Для чего Всевышний создал человека и наделил его таким уникальным аппаратом, как нейронная сеть, точно ответить может только сам Творец. Не нам судить об этом.
Искусственные сети проектируют люди и ставят перед ними четкие задачи.
По характеру исполняемых задач, ИНС группируются по следующим магистральным направлениям.
4.1. Распознавание
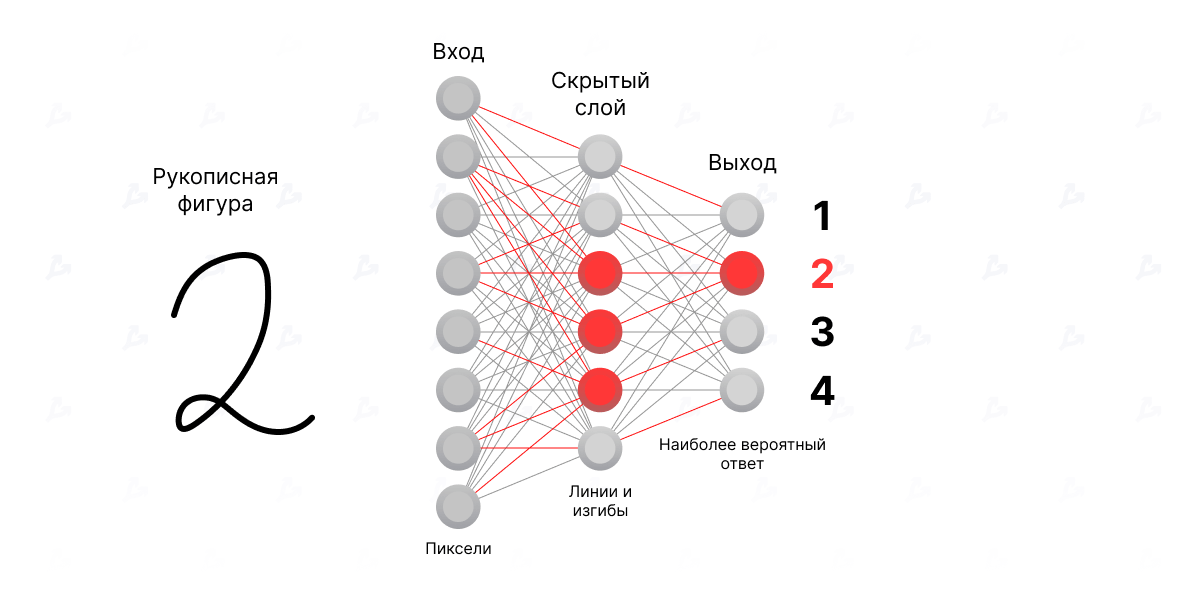
Наиболее простое и популярное применение ИНС в наше время. Нейронная сеть помогает современному гаджету выделить, среди прочих, лицо его владельца и провести идентификацию. Интернет-поисковики с помощью ИНС распределяют картинки по образам, содержащимся в них. Объект для распознавания может быть любой: изображение, звук, текст, символ.
Нейронная сеть помогает современному гаджету выделить, среди прочих, лицо его владельца и провести идентификацию. Интернет-поисковики с помощью ИНС распределяют картинки по образам, содержащимся в них. Объект для распознавания может быть любой: изображение, звук, текст, символ.
4.2. Классификация
Дополняет и расширяет функцию распознавания. То, что узнано и определено должно быть классифицировано. Нейронная сеть отнесет объект исследования к тому или иному классу, в соответствии с набором (вектором) присущих ему признаков.
Например, ИНС поможет кадровой службе вынести решение о соответствии претендента предлагаемой должности при приеме на работу. Набор признаков: от возраста и пола до образования и уровня классификации.
Нейронная сеть отберет оптимальных заемщиков для банка. Анализу подвергнутся платежеспособность, семейное положение, кредитная история и т.д.
4.3. Принятие решений и управление
Расширяет первые два направления. Распознаваться и классифицироваться могут не только привычные объекты, но и целые ситуации. На вход ИНС подаются характеристики состояния исследуемой системы. На выходе – принимаемое решение, встраиваемое в управление системой.
Распознаваться и классифицироваться могут не только привычные объекты, но и целые ситуации. На вход ИНС подаются характеристики состояния исследуемой системы. На выходе – принимаемое решение, встраиваемое в управление системой.
4.4. Сжатие данных и ассоциативная память
ИНС уплотняет и/или восстанавливает память (массивы данных).
С одной стороны, она может, используя тесные связи между элементами анализируемого массива, значительно уплотнить, сжать его, убрав лишние, повторяющиеся сегменты и связи. «Увидеть» главное.
С другой – провести обратную процедуру, своего рода «вспомнить все». Нейросеть воссоздаст полную информацию по ее части или восстановит поврежденные исходные данные. Такая процедура называется авто- или ассоциативной памятью. Работает логический индуктивный метод: рассуждение от частного к общему.
4.5. Прогнозирование
Пожалуй, самое интересное для биржевой торговли.
Основывается на способности нейронной сети предсказывать значения числовых последовательностей (рядов), исходя из предыдущих значений. Прогноз возможен только тогда, когда прошлые тенденции в таких рядах могут, с той или иной степенью вероятности, повториться в будущих трендах. Согласно гипотезе эффективного рынка[10], считается, что для ценных бумаг и иных финансовых активов это приемлемо. Так выстроен весь технический анализ. Для угадывания выигрыша в лотерее – бессмысленно.
5. ОБУЧЕНИЕ ИНС
Для того, чтобы нейросеть смогла выполнить ту или иную задачу, ее надо обучить, как человека. Как ребенка, школьника или студента. Сеть «воспитывают», натаскивают, тестируют на обучающей выборке.
Процесс напоминает бэктестинг обычного торгового алгоритма. На вход подаются исторические данные, полученный результат сравнивают с реальным, уже известным, оценивают ошибку. Далее делают поправку в структуре ИНС (связи, веса и пр.), прогоняют по следующему «историческому» отрезку. Результат сравнивают с «идеалом» и вычисляют ошибку. Если есть тенденция к уменьшению погрешности, значит, сеть обучается успешно, в противном случае, что-то не в порядке с ее архитектурой.
Результат сравнивают с «идеалом» и вычисляют ошибку. Если есть тенденция к уменьшению погрешности, значит, сеть обучается успешно, в противном случае, что-то не в порядке с ее архитектурой.
5.1. Виды обучения
Обучение искусственной сети рассматривается, как кибернетический эксперимент. Различают три вида подобных экспериментов[5].
1) Обучение с учителем, Supervised learning.
Принудительный тренинг ИНС на обучающей выборке. Принципиально описан выше. Главное в Supervised learning – участие наставника, экспериментатора, отлаживающего сеть и наличие «правильного ответа» для каждой выборки (выходное пространство решений сети задано). Цель – уменьшение ошибки до адекватного уровня.
2) Обучение без учителя, Unsupervised learning.
Другие названия – самообучение или спонтанное обучение[11].
Сущность метода понятна из определения – сеть обучается сама. Применяется на крупных ИНС, для которых заданы подробные описания объектов обучающей выборки. Процесс тренировки состоит в самостоятельном поиске сетью внутренних связей, закономерностей и зависимостей между объектами.
Процесс тренировки состоит в самостоятельном поиске сетью внутренних связей, закономерностей и зависимостей между объектами.
ИНС лично формирует выходное пространство решений. ИНС, обучающиеся без учителя, получили имя самоорганизующихся.
Один из популярных представителей Unsupervised learning – нейросеть Хопфилда[12]. Особенность сети Хопфилда такова, что при автономном функционировании ее динамика сходится к равновесному положению. Таким образом, ИНС проводит самоотладку.
3) Обучение с подкреплением, Reinforcement learning.
Микс, промежуточное состояние между первым и вторым методами. Вариант смешанного обучения.
Роль учителя выполняет некая среда или модель, но не человек. Ее отклики на решения сети, именуемые сигналами подкрепления[13], выполняют роль корректировочных команд экспериментатора. С другой стороны, ряд сигналов подкрепления продуцируются самими нейронами. Это признак самообучения.
Сведем, приведенное выше, в картинку:
5. 2. Требования к входной информации
2. Требования к входной информации
Для правильной настройки и последующей успешной работы ИНС, подбор входящих данных для обучения имеет важное, если не решающее, значение.
Они должны удовлетворять, в том числе, таким требованиям.
1) Репрезентативность.
Говоря языком социологов и маркетологов[14], обучающая выборка должна представлять все значимые параметры для генеральной совокупности, но не выходить за их пределы. Например, при отладке ИНС для прогноза цены акции, исторические котировки надо брать из одних торговых площадок или учитывать разницу между ними, рассматривать периоды, аналогичные прогнозируемому: сопоставлять даты выхода корпоративной отчетности и макроэкономических статновостей пр.
2) Непротиворечивость.
Для фондового рынка противоречивость будет, в том числе, между данными стабильного и турбулентного рынка (резкое ралли или обвал).
3) Нормализация.
«Размерность» входящих данных должна быть единой или сопоставимой.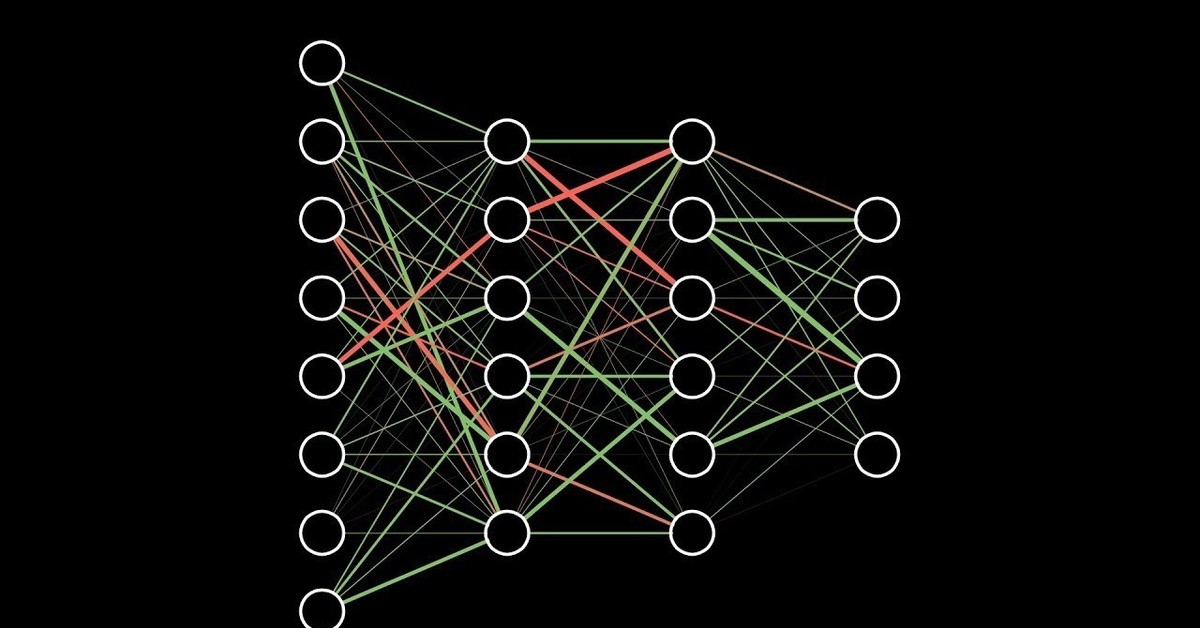 Для функции активации не только область значений (значения функции), но и область ее определения (значения вводимого аргумента х) не должны выходить за отрезок [-1;1]. Иными словами, на вход и на выход подаются числа по модулю, не превышающие 1.
Для функции активации не только область значений (значения функции), но и область ее определения (значения вводимого аргумента х) не должны выходить за отрезок [-1;1]. Иными словами, на вход и на выход подаются числа по модулю, не превышающие 1.
Что же делать, если речь идет о котировках бумаг, выражаемых двух и трехзначными числами или, по крайней мере, больше одного доллара или рубля? Их необходимо привести в нужный формат (размерность). Допустим, взяв обратную величину 1/P, где P – цена акции. Такое действие над числом называется его нормализацией или нормировкой. В итоге, весь ценовой диапазон инструмента ляжет в интервал от почти 0 (при P→+∞, ну очень большие числа, например стоимость акций BRK-A У. Баффетта, $282640,00 за 24.12.18) до 1 при P=$1,00).
Можно подойти и тоньше[6]. Вводить не нормализованный курс акций, а относительное отклонение двух соседних прошлых, «исторических» цен из обучающей выборки. Тогда прогнозируется отклонение от крайнего члена ряда, то есть, от последней известной цены бумаги.
Кроме нормализации, данные могут обрабатываться и другими способами. Непрерывный поток значений переводится в дискретный – квантуется. Или проводится очистка, фильтрование «зашумленной» информации.
5.3. Ошибка, эпоха и итерация
Главный итог обучения искусственной сети – минимальное значение ошибки в ее работе. Конечно, она никогда не будет нулевой. Задача – свести ее к приемлемому уровню. Ошибка – расхождение между поученным и ожидаемым результатом.
В примере из подраздела 2.3 сеть выдала такой результат:
O1output= sigmoid(-0,672)=1/(1+e0,672)=0,338.
Предположим, известное (правильное, заданное) значение равно 1. Ошибка: ∆=1-0,338=0,662 или 66,2%
В процессе тренировки с учителем, ожидаемый результат известен, как одно из исторических данных и погрешность вычисляется после проведения этапа (этапов) тестирования. Обычно, она выражается в процентах (от 0 до 100%) или в долях единицы (от 0 до 1), как кому удобнее. В «боевой» ситуации ожидаемый результат «зашит» в будущее – через минуту, день, неделю, месяц и т.д. Безусловно, если ошибка велика на тесте, то действовать ИНС в реале бессмысленно.
В «боевой» ситуации ожидаемый результат «зашит» в будущее – через минуту, день, неделю, месяц и т.д. Безусловно, если ошибка велика на тесте, то действовать ИНС в реале бессмысленно.
Прогон по выборке получил название «эпохи обучения». Прошли обучающую выборку один раз – сеть «прожила» одну эпоху, два раза – две, n раз – n эпох. Часто, одну эпоху называют одной итерацией, а обучаемые таким образом сети – итерационными. Очевидно, чем больше n, тем система будет более тренированной. Нейросеть продолжает обучаться и в процессе работы. Для нее, как и для любого из нас – «учиться никогда не поздно».
На практике, входные данные при обучении с учителем разделяются на две группы: собственно обучающие и проверочные. Первые используются для тренинга, вторые для оценки ошибки. При этом, проверочные данные в процессе обучения не применяются. После серии итераций значение имеет только уменьшение ошибки на проверочных (тестовых) данных. Если погрешность сжимается на обучающих данных, а на тестовых нет, то сеть «хитрит» и запоминает обучающую информацию. Говорят, что она «переобучена». В таком случае тренировку ИНС останавливают.
Говорят, что она «переобучена». В таком случае тренировку ИНС останавливают.
источник[15]
Насколько успешно искусственная нейросеть может обучаться, демонстрируют ее «интеллектуально-спортивные» достижения. Два года назад на новостных лентах появились сообщения о том, что ИНС AlphaGo выиграла турнир по игре в го у ведущего мирового мастера. Простой перебор вариантов здесь не проходил. Таких вычислительных мощностей пока нет. По крайней мере, они отсутствовали у воспитателей AlphaGo. Сеть должна была непременно научиться играть в го, что она и сделала, в том числе, разыгрывая партии, сама с собой.
6. НЕЙРОСЕТИ В БИРЖЕВОЙ ТОРГОВЛЕ
ИНС – не традиционный алгоритм, который можно написать/запрограммировать. В известном смысле, искусственная сеть – алгоритм с искусственным интеллектом, способный обучаться с наставником или без.
По своей «природе», механическая торговая система не способна самостоятельно перестроиться под изменяющуюся рыночную ситуацию. При смене обстоятельств, советника надо останавливать и менять «начинку» (встроенный алгоритм), во избежание генерации большого количества отрицательных сделок. Корректно обученные и правильно заточенные под среду нейронные сети «живут» вместе с рынком и, в идеале, становятся его органической частью.
При смене обстоятельств, советника надо останавливать и менять «начинку» (встроенный алгоритм), во избежание генерации большого количества отрицательных сделок. Корректно обученные и правильно заточенные под среду нейронные сети «живут» вместе с рынком и, в идеале, становятся его органической частью.
Нейросети могут впитать и задействовать в работе не только котировочный ряд, но и любую информацию фундаментального или технического характера, поступающую на биржу в произвольных пропорциях.
Исключительную важность приобретает процесс отбора таких сведений, чтобы они помогали, а не мешали в функционировании ИНС, не расстраивали ее. В прямом и переносном смысле.
Выставляются пороги чувствительности к входным данным. Сеть анализирует, классифицирует и группирует сообщения. Отсеивается противоречивая, взаимоисключающая информация, способная заблокировать ИНС. Как одна из методик используется Data mining[16].
«Игра стоит свеч»: неверные данные – неверные решения.
Искусственные нейронные сети применяются в трейдинге по ряду направлений, включая моделирование рисков[17]. Но главное – прогнозирование временных рядов.
Упрощенно, задача выглядит следующим образом.
Имеется ряд из к значений исторических (прошлых) цен акции «А»: Pt-1, Pt-2, Pt-3….., Pt—k, отвечающих моментам времени t-1, t-2, t-3…., t-k. От сети требуется найти Pt: цену бумаги в будущий момент времени t.
На входе – четыре точки, на выходе – пятая.
Конечно, как упоминалось выше, только котировками исследуемой акции для прогноза ее будущей стоимости, ограничиваться не стоит. Хорошая сеть работает с индексами тех рынков, где акция обращается, деривативами, базовым активом которых выступает данная акция, другими бумагами представляемого акцией сектора/отрасли и т.д. Любая корректная информация.
Если временной ряд состоит из трех значений цены, каждое из которых отвечает одному торговому дню, то процесс обучения таков.
|
Ряд (итерация) / Прогноз |
Входные данные |
Выходные данные |
|
Ряд 1 |
день 1 – Р1 день 2 – Р2 день 3 – Р3 |
день 4 – Р4 (задано/известно) сравнивается с выходным значением, выдаваемым сетью по выборке (Р1, Р2, Р3) |
|
Ряд 2 |
день 2 – Р2 день 3 – Р3 день 4 – Р4 |
день 5 – Р5 (задано/известно) сравнивается с выходным значением, выдаваемым сетью по выборке (Р2, Р3, Р4) |
|
Ряд 3 |
день 3 – Р3 день 4 – Р4 день 5 – Р5 |
день 6 – Р6 (задано/известно) сравнивается с выходным значением, выдаваемым сетью по выборке (Р3, Р4, Р5) |
|
Прогноз |
день 4 – Р4 день 5 – Р5 день 6 – Р6 |
день 7 – Р7? (не известно) предсказывается сетью по выборке (Р4, Р5, Р6) |
Здесь: день 1, день 2 …,день 6 – «исторические» торговые дни с известными ценами финансового инструмента Р1, Р2…, Р6. Обучающая/тестовая выборка из трех эпох (итераций) понуждает сеть высчитывать цену для четвертого (по порядку) дня по трем предыдущим, сравнивает с известным значением, оценивает ошибку, вносит поправку в веса и связи. И так три раза. Четвертый прогон – предсказание цены Р7 в день 7, допустим – завтра.
Обучающая/тестовая выборка из трех эпох (итераций) понуждает сеть высчитывать цену для четвертого (по порядку) дня по трем предыдущим, сравнивает с известным значением, оценивает ошибку, вносит поправку в веса и связи. И так три раза. Четвертый прогон – предсказание цены Р7 в день 7, допустим – завтра.
Нельзя сказать, что ИНС получили всеобщее признание в торговом сообществе. Какое-то время о них вообще забыли. До 2007 года популярными были программные продукты на нейросетевей основе: NeuroSolutions и NeuroShell.
Проходили сообщения, что инвесткомпания LBS Capital Management Inc. достигает неплохих результатов, используя относительно недорогие нейросетевые пакеты, стоимостью до $50 тыс.
Но, увы, большинство современных ИНС дают низкую точность прогноза. Ошибка в пределах 50-60%. Это много. Ряд экспертов, например, аналитик хедж-фонда NMRQL Стюарт Рид[17], считают, что к ИНС сложился неверный подход. Многие склонны переоценивать их возможности, а некоторые – неправильно строить и эксплуатировать.
Но прогресс неумолим.
В списке профессий, в которых роботы заменят человека в ближайшие 30-50 лет, устойчиво фигурируют биржевые брокеры. Ну и трейдеры, понятно тоже. Просто составители списков не знают разницы. За спиной брокеров и трейдеров маячит тень конкурента.
Искусственной нейронной сети.
Владимир Наливайский
ПРИМЕЧАНИЯ И ССЫЛКИ
- ↑ «Искусственный интеллект», Википедия
- ↑ Нейронная сеть», Википедия
- ↑ «Нейрон», Википедия
- ↑ Синапс», Википедия
- ↑ «Искусственная нейронная сеть», Википедия
- ↑ «Нейронные сети для начинающих. Часть 1» (https://habr.com)
- ↑ «Искусственный нейрон», Википедия
- ↑ «Питтс, Уолтер», Википедия
- ↑ «Винер, Норберт», Википедия
- ↑ «Гипотеза эффективного рынка», Википедия
- ↑ «Обучение без учителя», Википедия
- ↑ «Нейронная сеть Хопфилда», Википедия
- ↑ «Обучение с подкреплением», Википедия
- ↑ «Репрезентативность», Википедия
- ↑ Национальный открытый университет (https://www. intuit.ru)
- ↑ Data mining – интеллектуальный анализ данных, Википедия
- ↑ «Технологии фондового рынка: 10 заблуждений о нейронных сетях» (https://habr.com)
 intuit.ru)
intuit.ru)ИСПОЛЬЗУЕМЫЕ СОКРАЩЕНИЯ
НС – нейронная сеть, нейросеть, коротко – сеть
БНС – биологическая (естественная) нейронная сеть
ИНС – искусственная нейронная сеть, для краткости, по умолчанию – нейросеть или сеть
ИИ – искусственный интеллект
СПР – сети (нейронные) прямого распространения
РНС – рекуррентные нейронные сети
Введение. Нейронные сети задач для прогнозирования курса на валютной бирже
Нейронные сети задач для прогнозирования курса на валютной бирже
курсовая работаавтоматизированная нейронная сеть прогнозирование
Одна из наиболее динамично развивающихся областей современной теории интеллектуальных вычислений (computational intelligence) связана с построением и применением искусственных нейронных сетей.
Нейронные сети — это раздел искусственного интеллекта, в котором для обработки сигналов используются явления, аналогичные происходящим в нейронах живых существ.
Важнейшая особенность нейронной сети, свидетельствующая об ее широких возможностях и огромном потенциале для решения вычислительных задач, состоит в параллельной обработке информации всеми звеньями цепи, что позволяет ускорять процесс обработки информации.
Другое не менее важное свойство нейронной сети — способность к обучению и обобщению накопленных знаний. Нейронная сеть обладает чертами искусственного интеллекта. Натренированная на ограниченном множестве данных сеть способна обобщать полученную информацию и показывать хорошие результаты на данных, не использовавшихся в процессе обучения.
Различные способы объединения нейронов между собой и организации их взаимодействия привели к созданию сетей разных структур.
Среди множества существующих структур сетей в качестве важнейших можно выделить:
многослойный персептрон,
радиальные сети,
сети с самоорганизацией в результате конкуренции нейронов,
сети с самоорганизацией корреляционного типа,
рекуррентные сети, в которых имеются сигналы обратной связи.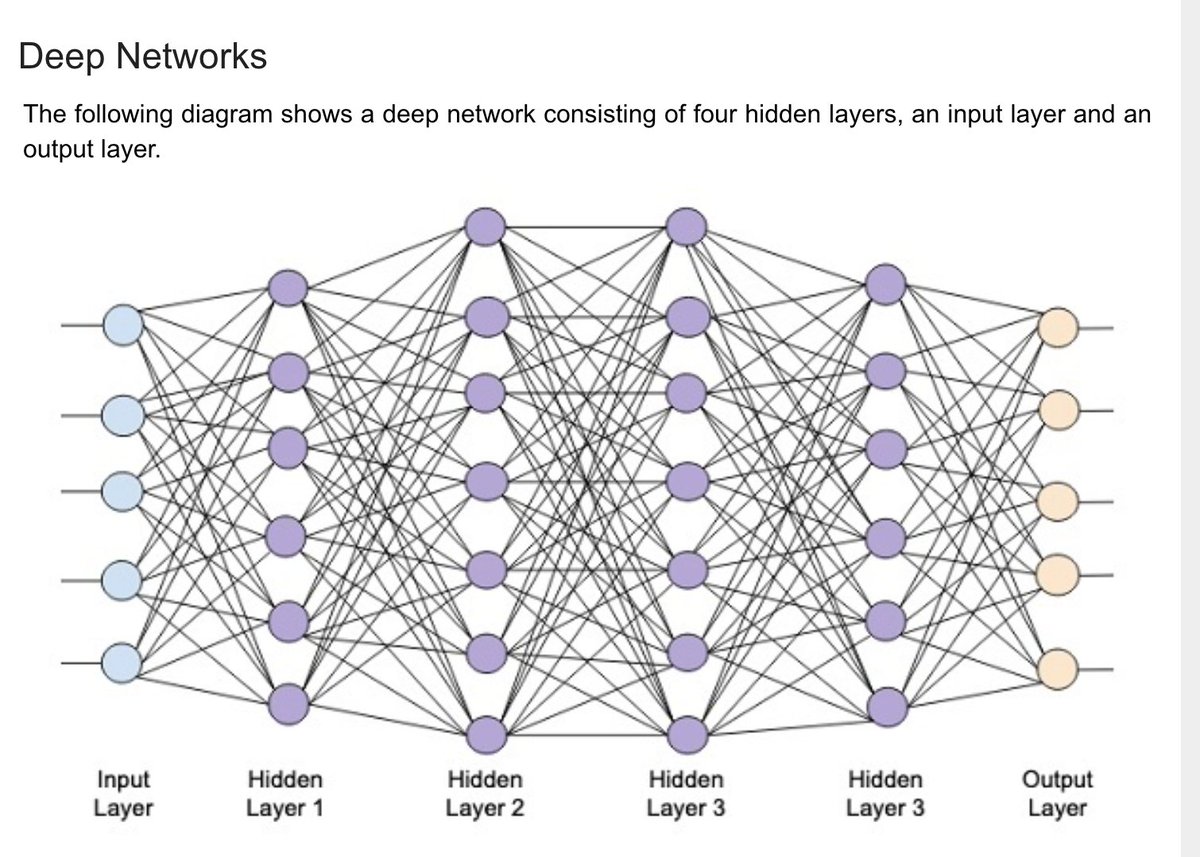
Искусственные нейронные сети в практических приложениях, как правило, используются в качестве подсистемы управления или выработки решений, передающей исполнительный сигнал другим подсистемам, имеющим иную методологическую основу. Задачи, решаемые с помощью нейронных сетей, подразделяются на несколько групп:
аппроксимация;
классификация;
распознавание образов;
прогнозирование;
идентификация;
оценивание;
ассоциативное управление.
В данной работе нейронные сети используются для решения задачи прогнозирования поведения курса валютных пар на валютной бирже Forex с использованием массива числовых данных, содержащего предыдущие значения курса и его колебания на фиксированные моменты времени.
Прогнозирование Цен С Использованием Искусственных Нейронных Сетей
Author
Abstract
Для чего нужно прогнозировать цены? Конечно, первое, что приходит в голову, это для игр на бирже; это, конечно же, верно, ибо зная, какие будут цены и как они будут себя вести в дальнейшем на тот или иной товар/валюту, мы сможем принимать решение покупать или продавать этот товар.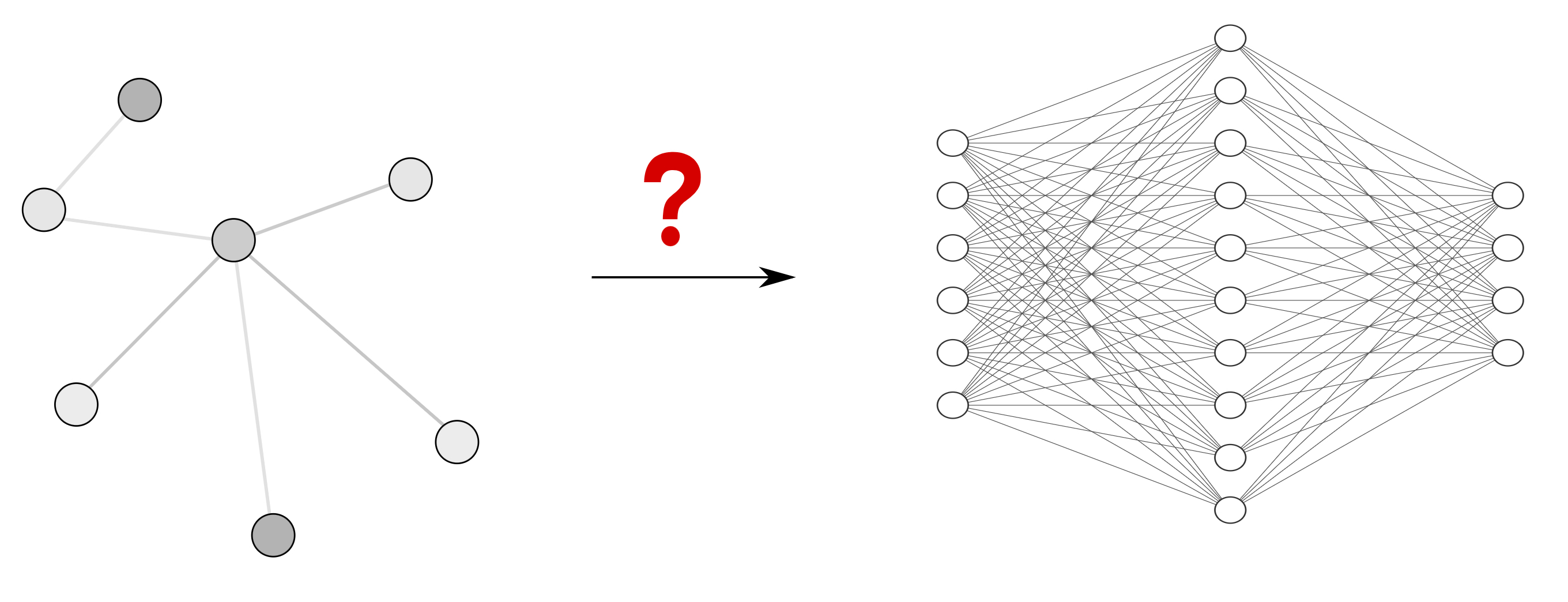 Робот также может за нас принимать подобные решения, оценивая риски, что приведет к успешной игре на бирже с малой степенью участия пользователя, либо вообще исключит его участие. Остается два вопроса: как прогнозировать цены и как оценивать риски. В экономике для прогнозирования, аппроксимации, классификации, выделения скрытых свойств, объектов, явлений, процессов очень эффективно применять искусственные нейронные сети (ИНС). К тому же ИНС способны решать задачи, где невозможно или неэффективно использовать другие методы. Основными предопределяющими условиями их использования является наличие «исторических данных», используя которые нейронная сеть сможет обучиться. В данной статье рассмотрен вариант использования нового средства прогнозирования искусственные нейронные сети.
Робот также может за нас принимать подобные решения, оценивая риски, что приведет к успешной игре на бирже с малой степенью участия пользователя, либо вообще исключит его участие. Остается два вопроса: как прогнозировать цены и как оценивать риски. В экономике для прогнозирования, аппроксимации, классификации, выделения скрытых свойств, объектов, явлений, процессов очень эффективно применять искусственные нейронные сети (ИНС). К тому же ИНС способны решать задачи, где невозможно или неэффективно использовать другие методы. Основными предопределяющими условиями их использования является наличие «исторических данных», используя которые нейронная сеть сможет обучиться. В данной статье рассмотрен вариант использования нового средства прогнозирования искусственные нейронные сети.
Suggested Citation
 Серия 5: Экономика, CyberLeninka;Государственное образовательное учреждение высшего профессионального образования «Адыгейский государственный университет», issue 1 (175), pages 96-100.
Серия 5: Экономика, CyberLeninka;Государственное образовательное учреждение высшего профессионального образования «Адыгейский государственный университет», issue 1 (175), pages 96-100.Download full text from publisher
Corrections
All material on this site has been provided by the respective publishers and authors. You can help correct errors and omissions. When requesting a correction, please mention this item’s handle: RePEc:scn:013827:16967475. See general information about how to correct material in RePEc.
For technical questions regarding this item, or to correct its authors, title, abstract, bibliographic or download information, contact: . General contact details of provider: http://cyberleninka.ru/ .
If you have authored this item and are not yet registered with RePEc, we encourage you to do it here. This allows to link your profile to this item. It also allows you to accept potential citations to this item that we are uncertain about.
It also allows you to accept potential citations to this item that we are uncertain about.
We have no bibliographic references for this item. You can help adding them by using this form .
If you know of missing items citing this one, you can help us creating those links by adding the relevant references in the same way as above, for each refering item. If you are a registered author of this item, you may also want to check the «citations» tab in your RePEc Author Service profile, as there may be some citations waiting for confirmation.
For technical questions regarding this item, or to correct its authors, title, abstract, bibliographic or download information, contact: CyberLeninka (email available below). General contact details of provider: http://cyberleninka.ru/ .
Please note that corrections may take a couple of weeks to filter through the various RePEc services.
5 компаний для инвестирования в искусственный интеллект
Мы и не заметим, как искусственный интеллект станет частью нашей повседневной жизни. Эксперты рынка говорят, что в течение следующих нескольких десятилетий новые технологии приведут к волне экономического роста и окажут положительное влияние на производительность труда. Но не все компании из данной области заслуживают доверие инвесторов.
Эксперты рынка говорят, что в течение следующих нескольких десятилетий новые технологии приведут к волне экономического роста и окажут положительное влияние на производительность труда. Но не все компании из данной области заслуживают доверие инвесторов.
Мы знаем многое как о плюсах, так и о минусах бизнеса таких гигантов из сектора высоких технологий, как Nvidia, Advanced Micro Devices и Tesla. Тем не менее они не связаны напрямую с искусственным интеллектом в отличие от некоторых других компаний из данной отрасли.
Чтобы найти лучшие варианты для инвестирования в искусственный интеллект, эксперты из InvestorPlace отобрали пять компаний с рекомендациями «покупать» и «активно покупать» от лучших аналитиков.
1. Salesforce
Когда гигант облачных вычислений Salesforce.com запустил свою платформу Einstein Analytics в 2017 году, все были в восторге. «У нас больше данных о клиентах, чем когда-либо прежде, и нам нужен искусственный интеллект, чтобы превратить данные в нечто полезное для бизнес-пользователей», – говорит исполнительный директор CRM Арижит Сенгупта.
Читайте: В России появился первый аккредитованный робоэдвайзер
Salesforce хочет стать важной частью быстрорастущего рынка искусственного интеллекта. В сообщении IDC, международной исследовательской и консалтинговой компании, занимающаяся изучением мирового рынка информационных технологий и телекоммуникаций, сказано, что технологии искусственного интеллекта создадут более 800 тысяч новых рабочих мест и добавят $1,1 трлн к мировому ВВП к 2021 году.
Аналитики имеют очень сильный прогноз в отношении акций Salesforce.
2. Microsoft
Microsoft приобрела канадскую компанию Maluuba, проводящую исследования в области искусственного интеллекта, в качестве основного козыря в борьбе по завоеванию данного секторы рынка. Это проект, который занимается обработкой естественного языка с использованием технологий глубокого обучения. Возможно, вы слышали о данной компании, когда она сделала невозможное возможным и с помощью искусственного интеллекта победила в чрезвычайно сложной аркадной видеоигре Ms. Pac-Man. В ходе тестирования искусственный интеллект показал свою способность достигнуть теоретического максимума очков. Ни одному человеку подобного результата достигнуть не удалось.
Pac-Man. В ходе тестирования искусственный интеллект показал свою способность достигнуть теоретического максимума очков. Ни одному человеку подобного результата достигнуть не удалось.
Генеральный директор Microsoft Сатья Наделла говорит, что хочет «демократизировать искусственный интеллект» и внедрить технологии в такие отрасли, как здравоохранение, образование и промышленность.
После небольшого падения в конце 2018 года акции Microsoft превзошли свои предыдущие максимумы.
3. Alphabet
Исследовательская фирма Quid подсчитала, что Alphabet Inc совершила больше всего покупок в области искусственного интеллекта. Только в первом квартале 2017 года компания заключила 20 сделок по приобретению, включая платформу прогнозной аналитики Kaggle.
Читайте: «Атон» назвал наиболее интересные дивидендные истории
Генеральный директор Google Сундар Пичаи давно говорил о будущем Google, в котором «искусственный интеллект встанет на первое место». На конференции разработчиков Google он представил Google Lens (камеру, которая может распознавать то, что видит) и AutoML. AutoML использует нейронные сети для создания улучшенных нейронных сетей, то есть, по сути, это искусственный интеллект, который способен создавать себя сам.
На конференции разработчиков Google он представил Google Lens (камеру, которая может распознавать то, что видит) и AutoML. AutoML использует нейронные сети для создания улучшенных нейронных сетей, то есть, по сути, это искусственный интеллект, который способен создавать себя сам.
Большинство аналитиков установили для акций Alphabet рекомендацию «покупать». Судя по прогнозам, бумаги компании должны значительно увеличиться в цене.
4. Baidu
Китайская интернет-компания Baidu Inc, известная как «китайский Google», вкладывает большие средства в искусственный интеллект. Руководство фирмы считает, что новые технологии могут дать ей преимущество над местными конкурентами Tencent Holdings и Alibaba Group Holdings.
Всего за 2,5 года Baidu потратила $2,9 млрд на исследования и разработки, при этом большая часть этой суммы ушла на искусственный интеллект. Компания профинансировала исследовательскую группу из 1700 человек и четыре отдельные исследовательские лаборатории. Важно отметить, что Baidu обладает преимуществом в данной отрасли благодаря огромным массивам данных, которые она ежемесячно получает от 665 млн пользователей своей поисковой системы.
Важно отметить, что Baidu обладает преимуществом в данной отрасли благодаря огромным массивам данных, которые она ежемесячно получает от 665 млн пользователей своей поисковой системы.
Торговая война негативно сказалась на акциях Baidu, но у них все еще есть большой потенциал роста.
5. Delphi Automotive
Delphi – международная компания, крупнейший производитель автокомплектующих в мире. Штаб-квартира находится в городе Гиллингем, Великобритания. В недавнем времени фирма переживала сложный период, но к настоящему моменту ситуация нормализовалась.
В прошлом году руководство Delphi решило полностью сосредоточиться на создании электрокаров и автомобилей с функцией самоуправления, что, похоже, наконец стало окупаться. К 2021 году компания в партнерстве с BMW, Intel и Mobileye NV планирует выпустить автомобили с автопилотом.
Лекция 5
Введение: Предсказание как вид бизнеса
В этой главе рассмотрено одно из самых популярных практических приложений
нейросетей — предсказание рыночных временных рядов. В этой области предсказания
наиболее тесно связаны с доходностью, и могут рассматриваться как один из видов
бизнеса.
В этой области предсказания
наиболее тесно связаны с доходностью, и могут рассматриваться как один из видов
бизнеса.
Предсказание финансовых временных рядов — необходимый элемент любой инвестиционной деятельности. Сама идея инвестиций — вложения денег сейчас с целью получения дохода в будущем — основывается на идее прогнозирования будущего. Соответственно, предсказание финансовых временных рядов лежит в основе деятельности всей индустрии инвестиций — всех бирж и небиржевых систем торговли ценными бумагами.
Приведем несколько цифр, иллюстрирующих масштаб этой индустрии предсказаний
(Шарп, 1997). Дневной оборот рынка акций только в США превышает $10 млрд.
Депозитарий DTC (Depositary Trust Company) в США, где зарегестрировано ценных
бумаг на сумму $11 трлн (из общего объема $18 трлн), регистрирует в день сделок
примерно на $250 млрд. Еще более активно идет торговля на мировом валютном рынке
FOREX.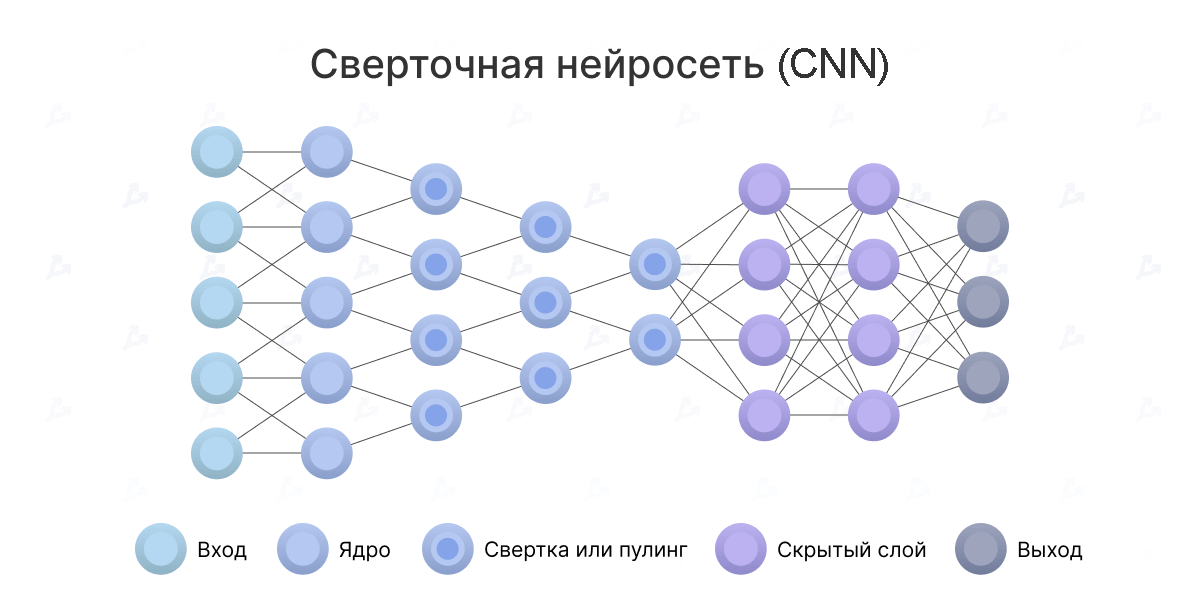 Его дневной оборот превышает $1000 млрд. Это примерно 1/50 всего
совокупного капитала человечества.
Его дневной оборот превышает $1000 млрд. Это примерно 1/50 всего
совокупного капитала человечества.
Известно, что 99% всех сделок — спекулятивные, т.е. направлены не на обслуживание реального товарооборота, а заключены с целью извлечения прибыли по схеме «купил дешевле — продал дороже». Все они основаны на предсказаниях изменения курса участниками сделки. Причем, что немаловажно, предсказания участников каждой сделки противоположны друг другу. Так что объем спекулятивных операций характеризует степень различий в предсказаниях участников рынка, т.е реально — степень непредсказуемости финансовых временных рядов.
Это важнейшее свойство рыночных временных рядов легло в основу теории
«эффективного» рынка, изложенной в диссертации Луи де Башелье
(L.Bachelier) в 1900 г. Согласно этой доктрине, инвестор может надеяться лишь на
среднюю доходность рынка, оцениваемую с помощью индексов, таких как Dow Jones
или S&P500 для Нью-Йоркской биржи. Всякий же спекулятивный доход носит
случайный характер и подобен азартной игре на деньги. В основе непредсказуемости
рыночных кривых лежит та же причина, по которой деньги редко валяются на земле в
людных местах: слишком много желающих их поднять.
Всякий же спекулятивный доход носит
случайный характер и подобен азартной игре на деньги. В основе непредсказуемости
рыночных кривых лежит та же причина, по которой деньги редко валяются на земле в
людных местах: слишком много желающих их поднять.
Теория эффективного рынка не разделяется, вполне естественно, самими участниками рынка (которые как раз и заняты поиском «упавших» денег). Большинство из них уверено, что рыночные временные ряды, несмотря на кажущуюся стохастичность, полны скрытых закономерностей, т.е в принципе хотя бы частично предсказуемы. Такие скрытые эмпирические закономерности пытался выявить в 30-х годах в серии своих статей основатель технического анализа Эллиот (R.Elliott).
В 80-х годах неожиданную поддержку эта точка зрения нашла в незадолго до
этого появившейся теории динамического хаоса. Эта теория построена на
противопоставлении хаотичности и стохастичности (случайности). Хаотические ряды
только выглядят случайными, но, как детерминированный динамический процесс,
вполне допускают краткосрочное прогнозирование. Область возможных предсказаний
ограничена по времени горизонтом прогнозирования, но этого может
оказаться достаточно для получения реального дохода от предсказаний (Chorafas,
1994). И тот, кто обладает лучшими математическими методами извлечения
закономерностей из зашумленных хаотических рядов, может надеяться на большую
норму прибыли — за счет своих менее оснащенных собратьев.
Область возможных предсказаний
ограничена по времени горизонтом прогнозирования, но этого может
оказаться достаточно для получения реального дохода от предсказаний (Chorafas,
1994). И тот, кто обладает лучшими математическими методами извлечения
закономерностей из зашумленных хаотических рядов, может надеяться на большую
норму прибыли — за счет своих менее оснащенных собратьев.
В этой главе мы приведем конкретные факты, подтверждающие частичную предсказуемость финансовых временных рядов, и даже оценим эту предсказуемость численно.
В последнее десятилетие наблюдается устойчивый рост популярности технического анализа — набора эмпирических правил, основанных на различного рода индикаторах поведения рынка. Технический анализ сосредотачивается на индивидуальном поведении данного финансового инструмента, вне его связи с остальными ценными бумагами (Pring, 1991).
Такой подход психологически обоснован сосредоточенностью брокеров именно на
том инструменте, с которым они в данный момент работают. Согласно Александру
Элдеру (A.Elder), известному специалисту по техническому анализу (по своей
предыдущей специальности — психотерапевту), поведение рыночного сообщества имеет
много аналогий с поведением толпы, характеризующимся особыми законами массовой
психологии. Влияние толпы упрощает мышление, нивелирует индивидуальные
особенности и рождает формы коллективного, стадного поведения, более
примитивного, чем индивидуальное. В частности, стадные инстинкты повышают роль
лидера, вожака. Ценовая кривая, по Элдеру, как раз и является таким лидером,
фокусируя на себе коллективное сознание рынка. Такая психологическая трактовка
поведения рыночной цены обосновывает применение теории динамического хаоса.
Частичная предсказуемость рынка обусловлена относительно примитивным
коллективным поведением игроков, которые образуют единую хаотическую
динамическую систему с относительно небольшим числом внутренних степеней
свободы.
Согласно Александру
Элдеру (A.Elder), известному специалисту по техническому анализу (по своей
предыдущей специальности — психотерапевту), поведение рыночного сообщества имеет
много аналогий с поведением толпы, характеризующимся особыми законами массовой
психологии. Влияние толпы упрощает мышление, нивелирует индивидуальные
особенности и рождает формы коллективного, стадного поведения, более
примитивного, чем индивидуальное. В частности, стадные инстинкты повышают роль
лидера, вожака. Ценовая кривая, по Элдеру, как раз и является таким лидером,
фокусируя на себе коллективное сознание рынка. Такая психологическая трактовка
поведения рыночной цены обосновывает применение теории динамического хаоса.
Частичная предсказуемость рынка обусловлена относительно примитивным
коллективным поведением игроков, которые образуют единую хаотическую
динамическую систему с относительно небольшим числом внутренних степеней
свободы.
Согласно этой доктрине, для предсказания рыночных кривых необходимо освободиться от власти толпы, стать выше и умнее ее. Для этого предлагается выработать систему игры, апробированную на прошлом поведении временного ряда и четко следовать этой системе, не поддаваясь влиянию эмоций и циркулирующих вокруг данного рынка слухов. Иными словами, предсказания должны быть основаны на алгоритме, т.е. их можно и даже должно перепоручить компьютеру (LeBeau, 1992). За человеком остается лишь создание этого алгоритма, для чего в его распоряжении имеются многочисленные программные продукты, облегчающие разработку и дальнейшее сопровождение компьютерных стратегий на базе инструментария технического анализа.
Следуя этой логике, почему бы не использовать компьютер и на этапе разработки
стратегии, причем не в качестве ассистента, рассчитывающего известные рыночные
индикаторы и тестирующего заданные стратегии, а для извлечения
оптимальных индикаторов и нахождения оптимальных стратегий по
найденным индикаторам.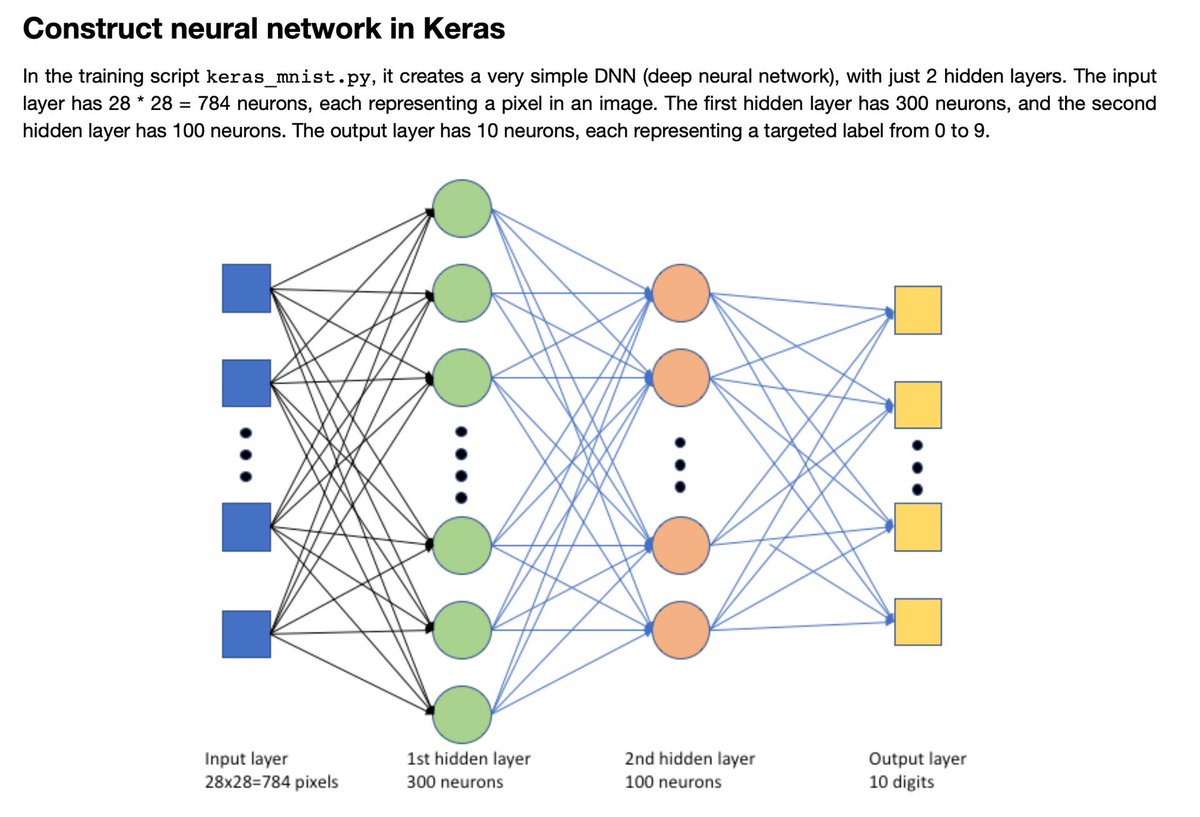 Такой подход — с привлечением технологии нейронных сетей
— завоевывает с начала 90-х годов все больше приверженцев (Beltratti, 1995,
Бэстенс, 1997), т.к. обладает рядом неоспоримых достоинств.
Такой подход — с привлечением технологии нейронных сетей
— завоевывает с начала 90-х годов все больше приверженцев (Beltratti, 1995,
Бэстенс, 1997), т.к. обладает рядом неоспоримых достоинств.
Во-первых, нейросетевой анализ, в отличие от технического, не предполагает никаких ограничений на характер входной информации. Это могут быть как индикаторы данного временного ряда, так и сведения о поведении других рыночных инструментов. Недаром нейросети активно используют именно институциональные инвесторы (например, крупные пенсионные фонды), работающие с большими портфелями, для которых особенно важны корреляции между различными рынками.
Во-вторых, в отличие от теханализа, основанного на общих
рекомендациях, нейросети способны находить оптимальные для данного
инструмента индикаторы и строить по ним оптимальную опять же для
данного ряда стратегию предсказания. Более того, эти стратегии могут быть
адаптивны, меняясь вместе с рынком, что особенно важно для молодых
активно развивающихся рынков, в частности, российского.
Нейросетевое моделирование в чистом виде базируется лишь на данных, не привлекая никаких априорных соображений. В этом его сила и одновременно — его ахиллесова пята. Имеющихся данных может не хватить для обучения, размерность потенциальных входов может оказаться слишком велика. Далее в этой главе мы покажем как для преодоления этих типичных в области финансовых предсказаний трудностей можно воспользоваться опытом, накопленным технического анализом.
Методика предсказания временных рядов
Для начала обрисуем общую схему нейросетевого предсказания временных рядов (Рисунок 39).
Рисунок 39. Схема технологического цикла предсказаний рыночных временных рядов
Далее в этой главе мы кратко обсудим все этапы этой технологической цепочки. Хотя общие принципы нейро-моделирования применимы к данной задаче в полном
объеме, предсказание финансовых временных рядов имеет свою специфику. Именно эти
отличительные черты и будут в большей мере затронуты в этой главе.
Хотя общие принципы нейро-моделирования применимы к данной задаче в полном
объеме, предсказание финансовых временных рядов имеет свою специфику. Именно эти
отличительные черты и будут в большей мере затронуты в этой главе.
Начнем с этапа погружения. Как мы сейчас убедимся, несмотря на то, что предсказания, казалось бы, являются экстраполяцией данных, нейросети, на самом деле, решают задачу интерполяции, что существенно повышает надежность решения. Предсказание временного ряда сводится к типовой задаче нейроанализа — аппроксимации функции многих переменных по заданному набору примеров — с помощью процедуры погружения ряда в многомерное пространство (Weigend, 1994). Например, -мерное лаговое пространство ряда состоит из значений ряда в последовательные моменты времени: .
Для динамических систем доказана следующая теорема Такенса. Если
временной ряд порождается динамической системой, т. е. значения есть произвольная функция
состояния такой системы, существует такая глубина погружения (примерно равная эффективному
числу степеней свободы данной динамической системы), которая обеспечивает
однозначное предсказание следующего значения временного ряда (Sauer,
1991). Таким образом, выбрав достаточно большое можно гарантировать однозначную
зависимость будущего значения ряда от его предыдущих значений: , т.е. предсказание временного
ряда сводится к задаче интерполяции функции многих переменных. Нейросеть далее
можно использовать для восстановления этой неизвестной функции по набору
примеров, заданных историей данного временного ряда.
е. значения есть произвольная функция
состояния такой системы, существует такая глубина погружения (примерно равная эффективному
числу степеней свободы данной динамической системы), которая обеспечивает
однозначное предсказание следующего значения временного ряда (Sauer,
1991). Таким образом, выбрав достаточно большое можно гарантировать однозначную
зависимость будущего значения ряда от его предыдущих значений: , т.е. предсказание временного
ряда сводится к задаче интерполяции функции многих переменных. Нейросеть далее
можно использовать для восстановления этой неизвестной функции по набору
примеров, заданных историей данного временного ряда.
Напротив, для случайного ряда знание прошлого ничего не дает для предсказания будущего. Поэтому, согласно теории эффективного рынка, разброс предсказываемых значений ряда на следующем шаге при погружении в лаговое пространство не изменится.
Отличае хаотической динамики от стохастической (случайной), проявляющееся в
процессе погружения, иллюстрирует Рисунок 40.
Рисунок 40. Проявляющееся по мере погружения ряда различие между случайным процессом и хаотической динамикой
Метод погружения позволяет количественно измерить предсказуемость реальных
финансовых инструментов, т.е. проверить или опровергнуть гипотезу эффективности
рынка. Согласно последней, разброс точек по всем координатам лагового
пространства одинаков (если они — одинаково распределенные независимые случайные
величины). Напротив, хаотическая динамика, обеспечивающая определенную
предсказуемость, должна приводить к тому, что наблюдения будут группироваться
вблизи некоторой гиперповерхности , т.е. экспериментальная выборка
формирует некоторое множество размерности меньшей, чем размерность всего
лагового пространства.
Для измерения размерности можно воспользоваться следующим интуитивно понятным свойством: если множество имеет размерность , то при разбиении его на все более мелкие покрытия кубиками со стороной , число таких кубиков растет как . На этом факте основывается определение размерности множеств уже знакомым нам методом box-counting. Размерность множества точек определяется по скорости возрастания числа ячеек (boxes), содержащих все точки множества. Для ускорения алгоритма размеры берут кратными 2, т.е. масштаб разрешения измеряется в битах.
В качестве примера типичного рыночного временного ряда возьмем такой
известный финансовый инструмент, как индекс котировок акций 500 крупнейших
компаний США, S&P500, отражающий среднюю динамику цен на Нью-Йоркской бирже.
Рисунок 41 показывает динамику индекса на протяжении 679 месяцев. Размерность
(информационная) приращений этого ряда, подсчитанная методом
box-counting, показана на следующем рисунке (Рисунок 42).
|
Рисунок 41. Временной ряд 679 значений индекса S&P500, используемый на протяжении данной главы в качестве примера |
Рисунок 42. Информационая размерность приращений ряда S&P500 |
Как следует из последнего рисунка, в 15-мерном пространстве погружения экспериментальные точки формируют множество размерности примерно 4. Это значительно меньше, чем 15, что мы получили бы исходя из гипотезы эффективного рынка, считающей ряд приращений независимыми случайными величинами.
Таким образом, эмпирические данные убедительно свидетельствуют о наличии
некоторой предсказуемой составляющей в финансовых временных рядах, хотя здесь и
нельзя говорить о полностью детерминированной хаотической динамике.![]() Значит
попытки применения нейросетевого анализа для предсказания рынков имеют под собой
веские основания.
Значит
попытки применения нейросетевого анализа для предсказания рынков имеют под собой
веские основания.
Заметим, однако, что теоретическая предсказуемость вовсе не гарантирует достижимость практически значимого уровня предсказаний. Количественную оценку предсказуемости конкретных рядов дает измерение кросс-энтропии, также возможное с помощью методики box-counting. Для примера приведем измерения предсказуемости приращений индекса S&P500 в зависимости от глубины погружения. Кросс-энтропия , график которой приведен ниже (Рисунок 43), измеряет дополнительную информацию о следующем значении ряда,
обеспеченную знанием прошлых значений этого ряда.
Рисунок 43. Предсказуемость знака приращений ряда индекса S&P500 в зависимости от глубины погружения (ширины «окна»).
 Увеличение глубины погружения свыше 25 сопровождается снижением
предсказуемости.
Увеличение глубины погружения свыше 25 сопровождается снижением
предсказуемости.Далее в этой главе мы оценим какой доход в принципе способен обеспечить такой уровень предсказуемости.
Как иллюстрирует Рисунок 43, увеличение ширины окна погружения ряда приводит в конце концов к понижению предсказуемости — когда повышение размерности входов уже не компенсируется увеличением их информативности. В этом случае, когда размерность лагового пространства слишком велика для данного количества примеров, приходится применять специальные методики формирования пространства признаков с меньшей размерностью. Способы выбора признаков и/или увеличения числа доступных примеров, специфичные для финансовых временных рядов будут описаны ниже.
Для обучения нейросети недостаточно сформировать обучающие наборы
входов-выходов.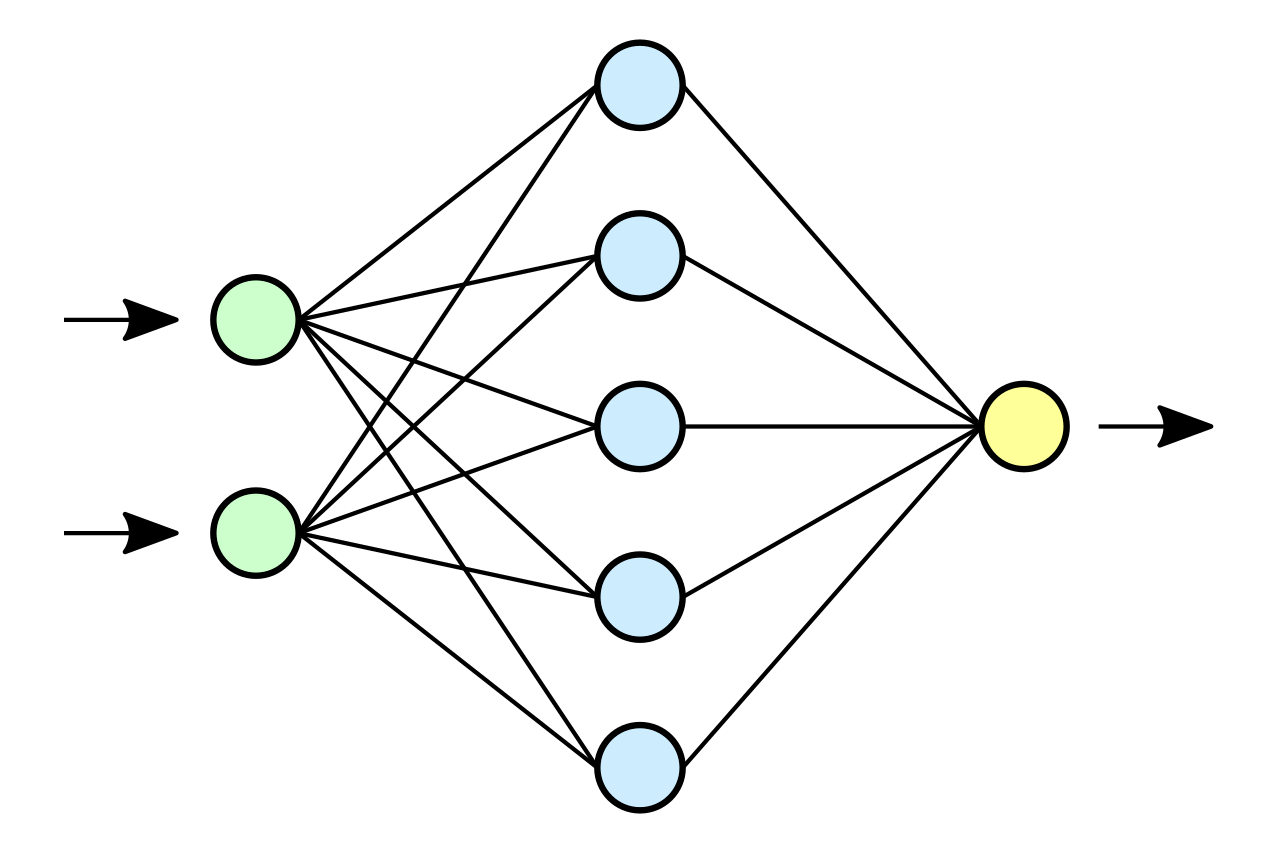 Необходимо также определить ошибку предсказаний сети.
Среднеквадратичная ошибка, используемая по умолчанию в большинстве нейросетевых
приложений, не имеет большого «финансового смысла» для рыночных рядов. Поэтому в
отдельном разделе мы рассмотрим специфичные для финансовых временных рядов
функции ошибки и покажем их связь с возможной нормой прибыли.
Необходимо также определить ошибку предсказаний сети.
Среднеквадратичная ошибка, используемая по умолчанию в большинстве нейросетевых
приложений, не имеет большого «финансового смысла» для рыночных рядов. Поэтому в
отдельном разделе мы рассмотрим специфичные для финансовых временных рядов
функции ошибки и покажем их связь с возможной нормой прибыли.
Например, для выбора рыночной позиции надежное определение знака изменения курса более важно, чем понижение среднеквадратичного отклонения. Хотя эти показатели и связаны между собой, сети оптимизированные по одному из них будут давать худшие предсказания другого. Выбор адекватной функции ошибки, как мы покажем далее в этой главе, должен опираться на некую идеальную стратегию и диктоваться, например, максимизацией прибыли (или минимизацией возможных убытков).
Основная специфика предсказания временных рядов лежит в области предобработки
данных. Процедура обучения отдельных нейросетей стандартена. Как всегда,
имеющиеся примеры разбиваются на три выборки: обучающая,
валидационная и тестовая. Первая используется для обучения, вторая
— для выбора оптимальной архитектуры сети и/или для выбора момента остановки
обучения. Наконец, третья, которая вообще не использовалась в обучении, служит
для контроля качества прогноза обученной нейросети.
Как всегда,
имеющиеся примеры разбиваются на три выборки: обучающая,
валидационная и тестовая. Первая используется для обучения, вторая
— для выбора оптимальной архитектуры сети и/или для выбора момента остановки
обучения. Наконец, третья, которая вообще не использовалась в обучении, служит
для контроля качества прогноза обученной нейросети.
Однако, для сильно зашумленных финансовых рядов существенный выигрыш в надежности предсказаний способно дать использование комитетов сетей. Обсуждением этой методики мы и закончим данную главу.
В литературе имеются свидетельства улучшения качества предсказаний за счет
использования нейросетей с обратными связями. Такие сети могут обладать
локальной памятью, сохраняющей информацию о более далеком прошлом, чем то, что в
явном виде присутствует во входах. Рассмотрение таких архитектур, однако, увело
бы нас слишком далеко от основной темы, тем более, что существуют альтернативные
способы эффективного расширения «горизонта» сети, за счет специальных способов
погружения ряда, рассмотренных ниже.
Формирование пространства признаков
Ключевым для повышения качества предсказаний является эффективное кодирование входной информации. Это особенно важно для труднопредсказуемых финансовых временных рядов. Все рекомендации, описанные в главе о предобработке данных, применимы и здесь. Имеются, однако, и специфичные именно для финансовых временных рядов способы предобработки данных, на которых мы подробно остановимся в данном разделе.
Начнем с того, что в качестве входов и выходов нейросети не следует
выбирать сами значения котировок, которые мы обозначим . Действительно значимыми для
предсказаний являются изменения котировок. Поскольку эти изменения, как
правило, гораздо меньше по амплитуде, чем сами котировки, между
последовательными значениями курсов имеется большая корреляция — наиболее
вероятное значение курса в следующий момент равно его предыдущему значению: .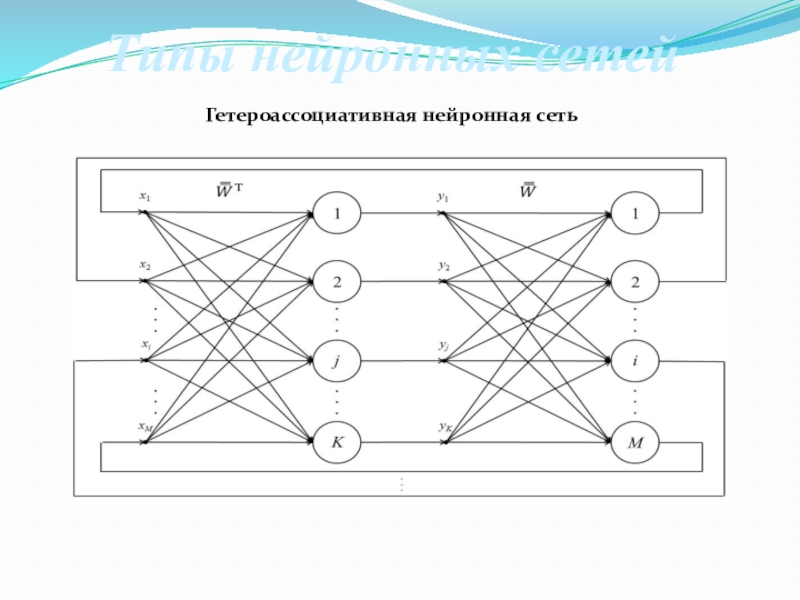 Между тем, как это уже
неоднократно подчеркивалось, для повышения качества обучения следует стремиться
к статистической независимости входов, то есть к отсутствию подобных
корреляций.
Между тем, как это уже
неоднократно подчеркивалось, для повышения качества обучения следует стремиться
к статистической независимости входов, то есть к отсутствию подобных
корреляций.
Поэтому в качестве входных переменных логично выбирать наиболее статистически независимые величины, например, изменения котировок или логарифм относительного приращения . Последний выбор хорош для длительных временных рядов, когда уже заметно влияние инфляции. В этом случае простые разности в разных частях ряда будут иметь различную амплитуду, т.к. фактически измеряются в различных единицах. Напротив, отношения последовательных котировок не зависят от единиц измерения, и будут одного масштаба несмотря на инфляционное изменение единиц измерения. В итоге, большая стационарность ряда позволит использовать для обучения большую историю и обеспечит лучшее обучение.
Отрицательной чертой погружения в лаговое пространство является ограниченный
«кругозор» сети. Технический анализ же, напротив, не фиксирует окно в
прошлом, и пользуется подчас весьма далекими значениями ряда. Например,
утверждается, что максимальные и минимальные значения ряда даже в относительно
далеком прошлом оказывают достаточно сильное воздействие на психологию игроков,
и, следовательно, должны быть значимы для предсказания. Недостаточно широкое
окно погружения в лаговое пространство не способно предоставить такую
информацию, что, естественно, снижает эффективность предсказания. С другой
стороны, расширение окна до таких значений, когда захватываются далекие
экстремальные значения ряда, повышает размерность сети, что в свою очередь
приводит к понижению точности нейросетевого предсказания — уже из-за разрастания
размера сети.
Технический анализ же, напротив, не фиксирует окно в
прошлом, и пользуется подчас весьма далекими значениями ряда. Например,
утверждается, что максимальные и минимальные значения ряда даже в относительно
далеком прошлом оказывают достаточно сильное воздействие на психологию игроков,
и, следовательно, должны быть значимы для предсказания. Недостаточно широкое
окно погружения в лаговое пространство не способно предоставить такую
информацию, что, естественно, снижает эффективность предсказания. С другой
стороны, расширение окна до таких значений, когда захватываются далекие
экстремальные значения ряда, повышает размерность сети, что в свою очередь
приводит к понижению точности нейросетевого предсказания — уже из-за разрастания
размера сети.
Выходом из этой, казалось бы, тупиковой ситуации являются альтернативные
способы кодирования прошлого поведения ряда. Интуитивно понятно, что чем дальше
в прошлое уходит история ряда, тем меньше деталей его поведения влияет на
результат предсказаний. Это обосновано психологией субъективного восприятия
прошлого участниками торгов, которые, собственно, и формируют будущее.
Следовательно, надо найти такое представление динамики ряда, которое имело бы
избирательную точность: чем дальше в прошлое — тем меньше деталей, при
сохранении общего вида кривой. Весьма перспективным инструментом здесь может
оказаться т.н. вейвлетное разложение (wavelet decomposition). Оно эквивалентно
по информативности лаговому погружению, но легче допускает такое сжатие
информации, которое описывает прошлое с избирательной точностью.
Это обосновано психологией субъективного восприятия
прошлого участниками торгов, которые, собственно, и формируют будущее.
Следовательно, надо найти такое представление динамики ряда, которое имело бы
избирательную точность: чем дальше в прошлое — тем меньше деталей, при
сохранении общего вида кривой. Весьма перспективным инструментом здесь может
оказаться т.н. вейвлетное разложение (wavelet decomposition). Оно эквивалентно
по информативности лаговому погружению, но легче допускает такое сжатие
информации, которое описывает прошлое с избирательной точностью.
Подобного рода сжатие информации является примером извлечения из непомерно большого числа входных переменных наиболее значимых для предсказания признаков. Способы систематического извлечения признаков уже были описаны в прошлых главах. Их можно (и нужно) с успехом применять и к предсказанию временных рядов.
Важно только, чтобы способ представления входной информации по возможности
облегчал процесс извлечения признаков. Вейвлетное представление являет собой
пример удачного, с точки зрения извлечения признаков, кодирования (Kaiser,
1995). Например, на следующем рисунке (Рисунок 44) изображен отрезок из 50
значений ряда вместе с его реконструкцией по 10 специальным образом отобранным
вейвлет-коэффициентов. Обратите внимание, что несмотря на то, что для этого
потребовалось в пять раз меньше даных, непосредственное прошлое ряда
восстановлено точно, а более далекое — лишь в общих чертах, хотя максимумы и
минимумы отражены верно. Следовательно, можно с приемлемой точностью описывать
50-мерное окно всего лишь 10-мерным входным вектором.
Вейвлетное представление являет собой
пример удачного, с точки зрения извлечения признаков, кодирования (Kaiser,
1995). Например, на следующем рисунке (Рисунок 44) изображен отрезок из 50
значений ряда вместе с его реконструкцией по 10 специальным образом отобранным
вейвлет-коэффициентов. Обратите внимание, что несмотря на то, что для этого
потребовалось в пять раз меньше даных, непосредственное прошлое ряда
восстановлено точно, а более далекое — лишь в общих чертах, хотя максимумы и
минимумы отражены верно. Следовательно, можно с приемлемой точностью описывать
50-мерное окно всего лишь 10-мерным входным вектором.
Рисунок 44. Пример 50-мерного окна (сплошная линия) и его реконструкции по 10 вейвлет-коэффициентам (о).
Еще один возможный подход — использование в качестве возможных кандидатов в
пространство признаков различного рода индикаторов технического анализа, которые
автоматически подсчитываются в соответствующих программных пакетах (таких как
MetaStock или Windows On Wall Street). Многочисленность этих эмпирических
признаков (Colby, 1988) затрудняет пользование ими, тогда как каждый из них
может оказаться полезным в применении к данному ряду. Описанные ранее методы
позволят отобрать наиболее значимую комбинацию технических индикаторов, которую
и следует затем использовать в качестве входов нейросети.
Многочисленность этих эмпирических
признаков (Colby, 1988) затрудняет пользование ими, тогда как каждый из них
может оказаться полезным в применении к данному ряду. Описанные ранее методы
позволят отобрать наиболее значимую комбинацию технических индикаторов, которую
и следует затем использовать в качестве входов нейросети.
Одним из самых «больных мест» в финансовых предсказаниях является дефицит примеров для обучения нейросети. Финансовые рынки, вообще говоря, не стационарны (особенно российские). Появляются новые финансовые инструменты, для которых еще не накоплена история, изменяется характер торговли на прежних рынках. В этих условиях длина доступных для обучения нейросети временных рядов весьма ограничена.
Однако, можно повысить число примеров, используя для этого те или иные
априорные соображения об инвариантах динамики временного ряда. Это еще
одно физико-математическое понятие, способное значительно улучшить качество
финансовых предсказаний. Речь идет о генерации искусственных примеров,
получаемых из уже имеющихся применением к ним различного рода
преобразований.
Речь идет о генерации искусственных примеров,
получаемых из уже имеющихся применением к ним различного рода
преобразований.
Поясним основную мысль на примере. Психологически оправдано следующее предположение: игроки обращают внимание, в основном, на форму кривой цен, а не на конкретные значения по осям. Поэтому если немного растянуть по оси котировок весь временной ряд, то полученный в результате такого преобразования ряд также можно использовать для обучения наряду с исходным. Мы, таким образом, удвоили число примеров за счет использования априорной информации, вытекающей из психологических особенностей восприятия временных рядов участниками рынка. Более того, мы не просто увеличили число примеров, но и ограничили класс функций, среди которых ищется решение, что также повышает качество предсказаний (если, конечно, использованный инвариант соответствует действительности).
Приведенные ниже результаты вычисления предсказуемости индекса S&P500
методом box-counting (см. Рисунок 45, Рисунок 46) иллюстрируют роль
искусственных примеров. Пространство признаков в данном случае формировалось
методом ортогонализации, описанным в главе о способах предобработки данных. В
качестве входных переменных использовались 30 главных компонент в 100-мерном
лаговом пространстве. Из этих главных компонент были выбраны 7 признаков —
наиболее значимые ортогональные линейные комбинации. Как видно из этих рисунков,
лишь применение искусственных примеров оказалось способным в данном случае
обеспечить заметную предсказуемость.
Рисунок 45, Рисунок 46) иллюстрируют роль
искусственных примеров. Пространство признаков в данном случае формировалось
методом ортогонализации, описанным в главе о способах предобработки данных. В
качестве входных переменных использовались 30 главных компонент в 100-мерном
лаговом пространстве. Из этих главных компонент были выбраны 7 признаков —
наиболее значимые ортогональные линейные комбинации. Как видно из этих рисунков,
лишь применение искусственных примеров оказалось способным в данном случае
обеспечить заметную предсказуемость.
|
Рисунок 45. Предсказуемость знака изменения котировок индекса S&P500 |
Рисунок 46. Предсказуемость знака изменения котировок индекса S&P500 после учетверения числа примеров методом растяжения по оси цен |
Обратите внимание, что использование ортогонального пространства признаков
привело к некоторому повышению предсказуемости по сравнению с обычным способом
погружения: с 0. 12 бит (Рисунок 43) до 0.17 бит (Рисунок 46). Чуть позже, когда
пойдет речь о влиянии предсказуемости на прибыль, мы покажем, что за счет этого
норма прибыли может увеличиться почти в полтора раза.
12 бит (Рисунок 43) до 0.17 бит (Рисунок 46). Чуть позже, когда
пойдет речь о влиянии предсказуемости на прибыль, мы покажем, что за счет этого
норма прибыли может увеличиться почти в полтора раза.
Другой, менее тривиальный, пример удачного использования такого рода
подсказок (hints) для нейросети в каком направлении искать решение —
использование скрытой симметрии в валютной торговле. Смысл этой симметрии в том,
что валютные котировки могут рассмматриваться с двух «точек зрения», например
как ряд DM/$ или как ряд $/DM. Возрастание одного из них соответствует
уменьшению другого. Это свойство можно использовать для удвоения числа примеров:
каждому примеру вида можно добавить его симметричный
аналог . Эксперименты по нейросетевому
предсказанию показали, что для основных валютных рынков учет симметрии поднимает
норму прибыли примерно в два раза, конкретно — с 5% годовых до 10% годовых, с
учетом реальных транзакционных издержек (Abu-Mostafa, 1995).
Измерение качества предсказаний
Хотя предсказание финансовых рядов и сводится к задаче аппроксимации многомерной функции, оно имеет свои особенности как при формировании входов, так и при выборе выходов нейросети. Первый аспект, касающийся входов, мы уже обсудили. Теперь коснемся особенностей выбора выходных переменных. Но прежде ответим на главный вопрос: как измерить качество финансовых предсказаний. Это поможет определить наилучшую стратегию обучения нейросети.
Особенностью предсказния финансовых временных рядов является стремление к получению максимальной прибыли, а не минимизации среднеквадратичного отклонения, как это принято в случае аппроксимации функций.
В простейшем случае ежедневной торговли прибыль зависит от верно угаданого
знака изменения котировки. Поэтому нейросеть нужно ориентировать именно
на точность угадывания знака, а не самого значения. Найдем как связана норма
прибыли с точностью определения знака в простейшей постановке ежедневного
вхождения в рынок (Рисунок 47).
Рисунок 47. Ежедневное вхождение в рынок
Обозначим на момент : полный капитал игрока , относительное изменение котировки , а в качестве выхода сети возьмем степень ее уверенности в знаке этого изменения . Такая сеть с выходной нелинейностью вида обучается предсказывать знак изменения и выдает прогноз знака с амплитудой пропорциональной его вероятности. Тогда возрастание капитала на шаге запишется в виде:
где — доля капитала, «в игре». Выигрыш за все время игры:
нам и предстоит максимизировать, выбрав оптимальный размер ставок . Пусть в среднем игрок угадывает долю знаков и, соответственно, ошибается с вероятностью . Тогда логарифм нормы прибыли,
,
а следовательно и сама прибыль, будет максимальным при значении и составит в среднем:
.
Здесь мы ввели коэффициент . Например, для Гауссова распределения . Степень предсказуемости знака напрямую связана с кросс-энтропией, которую можно оценить a priory методом box-counting. Для бинарного выхода (см. Рисунок 48):
Рисунок 48. Доля правильно угаданных направлений изменений ряда как функция кросс-энтропии знака выхода при известных входах
В итоге получаем следующую оценку нормы прибыли при заданной величине предсказуемости знака , выраженной в битах:
.
То есть, для ряда с предсказуемостью в принципе возможно удвоить
капитал за вхождений в рынок. Так, например,
измеренная выше предсказуемость временного ряда S&P500, равная (см.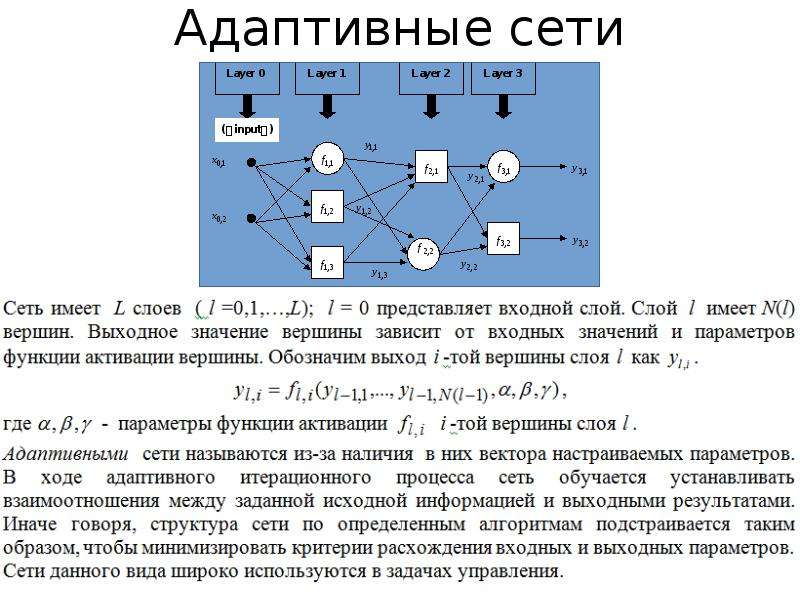 Рисунок 46) предполагает
удвоение капитала в среднем за вхождений в рынок. Таким образом,
даже небольшая предсказуемость знака изменения котировок способна обеспечить
весьма заметную норму прибыли.
Рисунок 46) предполагает
удвоение капитала в среднем за вхождений в рынок. Таким образом,
даже небольшая предсказуемость знака изменения котировок способна обеспечить
весьма заметную норму прибыли.
Подчеркнем, что оптимальная норма прибыли требует достаточно аккуратной игры, когда при каждом вхождении в рынок игрок рискует строго определенной долей капитала:
,
где — типичная при данной волатильности рынка величина выигрыша или проигрыша. Как меньшие, так и большие значения ставок уменьшают прибыль. Причем, чересчур рискованная игра может привести к проигрышу при любой предсказательной способности. Этот факт иллюстрирует Рисунок 49.
Рисунок 49. Зависимость средней нормы прибыли от выбора доли капитала «на кону»
Поэтому приведенные выше оценки дают представление лишь о верхнем пределе
нормы прибыли. Более тщательный анализ с учетом влияния флуктуаций, выходит за
рамки нашего изложения. Качественно понятно, однако, что выбор оптимального
размера контрактов требует оценки точности предсказаний на каждом шаге.
Более тщательный анализ с учетом влияния флуктуаций, выходит за
рамки нашего изложения. Качественно понятно, однако, что выбор оптимального
размера контрактов требует оценки точности предсказаний на каждом шаге.
Если принять, что целью предсказаний финансовых временных рядов является максимизация прибыли, логично настраивать нейросеть именно на этот конечный результат. Например, при игре по описанной выше схеме для обучения нейросети можно выбрать следующую функцию ошибки обучения, усредненную по всем примерам из обучающей выборки:
.
Здесь доля капитала в игре введена в качестве дополнительного выхода сети, настраиваемого в процессе обучения. При таком подходе, первый нейрон, , с функцией активации даст вероятность возрастания или убывания курса, в то время как второй выход сети даст рекомендованную долю капитала в игре на данном шаге.
Поскольку, однако, в соответствии с предыдущим анализом, эта доля должна быть пропорциональна степени уверености предсказания, можно заменить два выхода сети — одним, положив , и ограничиться оптимизацией всего одного глобального параметра минимизирующего ошибку:
Тем самым, появляется возможность регулировать ставку в соответствии с
уровнем риска, предсказываемым сетью. Игра с переменными ставками приносит
большую прибыль, чем игра с фиксированными ставками. Действительно, если
зафиксировать ставку, определив ее по средней предсказуемости, то
скорость роста капитала будет пропорциональна , тогда как если определять
оптимальную ставку на каждом шаге, то — пропорциональна .
Игра с переменными ставками приносит
большую прибыль, чем игра с фиксированными ставками. Действительно, если
зафиксировать ставку, определив ее по средней предсказуемости, то
скорость роста капитала будет пропорциональна , тогда как если определять
оптимальную ставку на каждом шаге, то — пропорциональна .
Использование комитетов сетей
Из-за случайности в выборе начальных значений синаптических весов, предсказания сетей, обученных на одной и той же выборке, будут, вообще говоря, разниться. Этот недостаток (элемент неопределенности) можно превратить в достоинство, организовав комитет нейро-экспертов, состоящий из различных нейросетей. Разброс в предсказаниях экспертов даст представление о степени уверенности этих предсказаний, что можно использовать для правильного выбора стратегии игры.
Легко показать, что среднее значений комитета должно давать лучшие
предсказания, чем средний эксперт из этого же комитета.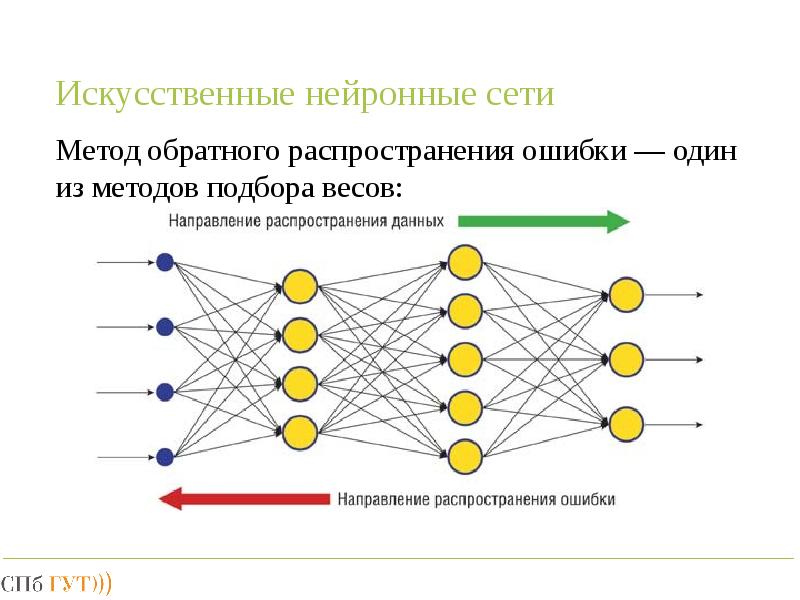 Пусть ошибка -ого эксперта для значения входа
равна . Средняя ошибка комитета всегда
меньше среднеквадратичной ошибки отдельных экспертов в силу неравенства
Коши:
Пусть ошибка -ого эксперта для значения входа
равна . Средняя ошибка комитета всегда
меньше среднеквадратичной ошибки отдельных экспертов в силу неравенства
Коши:
Причем, снижение ошибки может быть довольно заметным. Так, если ошибки отдельных экспертов не коррелируют друг с другом, т.е. , то среднеквадратичная ошибка комитета из экспертов в раз меньше, чем среняя индивидуальная ошибка одного эксперта!
Поэтому, в предсказаниях всегда лучше опираться на средние значения всего комитета. Иллюстрацией этого факта служит Рисунок 50.
Рисунок 50. Норма прибыли на последних 100 значениях ряда sp500 при предсказании комитетом из 10 сетей. Выигрыш комитета (кружки) выше, чем выигрыш среднего эксперта. Счет угаданных знаков для комитета 59:41
Как видно из приведенного выше рисунка, в данном случае выигрыш комитета даже
выше, чем выигрыш каждого из экспертов.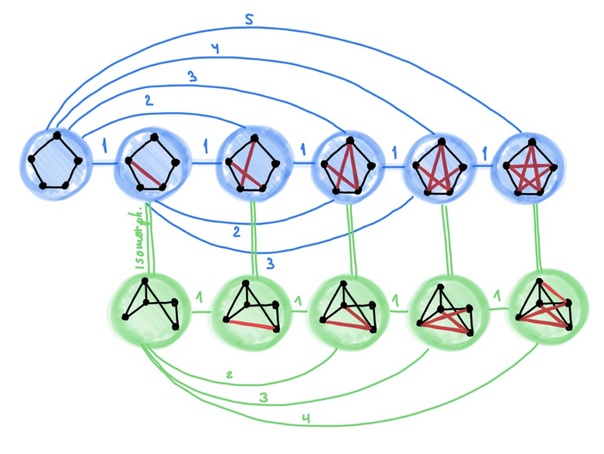 Таким образом, метод комитетов
может существенно повысить качество прогнозирования. Обратите внимание на
абсолютное значение нормы прибыли: капитал комитета возрос в 3.25 раза при 100
вхождениях в рынок (Естественно, эта норма будет ниже при учете транзакционных
издержек).
Таким образом, метод комитетов
может существенно повысить качество прогнозирования. Обратите внимание на
абсолютное значение нормы прибыли: капитал комитета возрос в 3.25 раза при 100
вхождениях в рынок (Естественно, эта норма будет ниже при учете транзакционных
издержек).
Предсказания получены при обучении сети на 30 последовательных экспоненциальных скользящих средних (EMA1 : EMA30) ряда приращений индекса. Предсказывался знак приращения на следующем шаге.
В этом эксперименте ставка была зафиксирована на уровне , близком к оптимальному при данной точности предсказаний (59 угаданных знаков против 41 ошибки) т.е. . На следующем же рисунке приведены результаты более рискованной игры по тем же предсказаниям, а именно — с .
Рисунок 51.
 Норма
прибыли на последних 100 значениях ряда sp500 при тех же предсказаниях
комитета из 10 сетей, но по более рискованной
стратегии.
Норма
прибыли на последних 100 значениях ряда sp500 при тех же предсказаниях
комитета из 10 сетей, но по более рискованной
стратегии.Выигрыш комитета в целом остался на прежнем уровне (чуть увеличился), поскольку данное значение риска так же близко к оптимуму, как и предыдущее. Однако, для большинства сетей, предсказания которых хуже, чем у комитета в целом, такие ставки оказались слишком рискованными, что привело к практически полному их разорению.
Приведенные выше примеры показывают как важно уметь правильно оценить качество предсказания и как можно использовать эту оценку для увеличения прибыльности от одних и тех же предсказаний.
Можно пойти еще дальше и вместо среднего использовать
взвешенное мнение сетей-экспертов. Веса выбираются адаптивно максимизируя
предсказательную способность комитета на обучающей выборке. В итоге, хуже
обученные сети из комитета вносят меньший вклад и не портят предсказания.
В итоге, хуже
обученные сети из комитета вносят меньший вклад и не портят предсказания.
Возможности этого пути иллюстрирует приведенное ниже сравнение предсказаний двух типов комитетов из 25 экспертов (см. Рисунок 52 и Рисунок 53). Предсказания проводились по одной и той же схеме: в качестве входов использовались экспоненциальные скользящие средние приращений ряда с периодами равными первым 10 числам Фибоначчи. По результатам 100 экспериментов взвешенное предсказание дает в среднем превышение правильно угаданных знаков над ошибочным равное примерно 15, тогда как среднее — около 12. Заметим, что общее число повышений курса над понижением за указанный период как раз равно 12. Следовательно, учет общей тенденции к повышению в виде тривиального постоянного предсказания знака «+» дает такой же результат для процента угаданных знаков, что и взвешенное мнение 25 экспертов.
|
Рисунок 52. |
Рисунок 53. Гистограмма сумм угаданных знаков при взвешенных предсказаниях тех же 25 экспертов. Среднее по 100 комитетам = 15.2 при стандартном отклонении 4.9 |
 Гистограмма сумм угаданных знаков при
средних предсказаниях 25 экспертов. Среднее по 100 комитетам = 11.7 при
стандартном отклонении 3.2
Гистограмма сумм угаданных знаков при
средних предсказаниях 25 экспертов. Среднее по 100 комитетам = 11.7 при
стандартном отклонении 3.2
Возможная норма прибыли нейросетевых предсказаний
До сих пор результаты численных экспериментов формулировались нами в виде процента угаданных знаков. Зададимся теперь вопросом о реально достижимой норме прибыли при игре с помощью нейросетей. Полученные выше без учета влияния флуктуаций верхние границы нормы прибыли вряд ли достижимы на практике, тем более, что до сих пор мы не учитывали транзакционных издержек, которые могут свести на нет достигнутую степень предсказуемости.
Действительно, учет комиссионных приводит к появлению отрицательного члена в показателе экспоненты:
.
Причем, в отличае от степени предсказуемости , комиссия входит не квадратично, а линейно. Так, в приведенном выше примере типичные значения предсказуемости не смогут «пересилить» комиссию свыше.
Чтобы дать читателю представление о реальных возможностях нейросей в этой области, приведем результаты автоматического неросетевого трейдинга на трех финансовых инструментах, с различными характерными временами: значения индекса S$P500 с месячными интервалами между отсчетами, дневные котировки немецкой марки DM/$ и часовые отсчеты фьючерсов на акции Лукойл на Российской бирже. Статистика предсказаний набиралась на 50 различных нейросистемах (содержащих комитеты из 50 нейросетей каждая). Сами ряды и результаты по предсказанию знаков на тестовой выборке из 100 последних значений каждого ряда приведены на следующем рисунке.
Рисунок 54.
 Средние
значения и гистограммы количества правильно () и неправильно () угаданных знаков на
тестовых выборках из 100 значений трех реальных финансовых
инструментов.
Средние
значения и гистограммы количества правильно () и неправильно () угаданных знаков на
тестовых выборках из 100 значений трех реальных финансовых
инструментов.Эти результаты подтверждают интуитивно понятную закономерность: ряды тем более предсказуемы, чем меньше времени проходит между его отсчетами. Действительно, чем больше временной масштаб между последовательными значениями ряда, тем больше внешней по отношению к его динамике информации доступно участникам рынка, и, соответственно меньше информации о будущем содержится в самом ряде.
Далее полученные выше предсказания использовались для игры на тестовой
выборке. При этом, размер контракта на каждом шаге выбирался пропорциональным
степени уверенности предсказания, а значение глобального параметра оптимизировалось по обучающей
выборке. Кроме того, в зависимости от своих успехов, каждая сеть в комитете
имела свой плавающий рейтинг, и в предсказаниях на каждом шаге использовалась
лишь «лучшая» в данный момент половина сетей. Результаты таких нейро-трейдеров
показаны на следующем рисунке (Рисунок 55).
Результаты таких нейро-трейдеров
показаны на следующем рисунке (Рисунок 55).
Рисунок 55. Статистика выигрышей по 50 реализациям в зависимости от величины комиссионных. Реалистичные значения комиссионных, показанные пунктиром, определяют область реально достижимых норм прибыли.
Итоговый выигрыш (как и сама стратегия игры), естественно, зависит от
величины комиссионных. Эта зависимость и изображена приведенных выше графиках.
Там, где реалистичные значения комиссионных в выбранных единицах измерений были
известны авторам, они отмечены на рисунке. Уточним, что в этих экспериментах не
учитывалась «квантованность» реальной игры, т.е. то, что величина сделок должна
равняться целому числу типовых контрактов.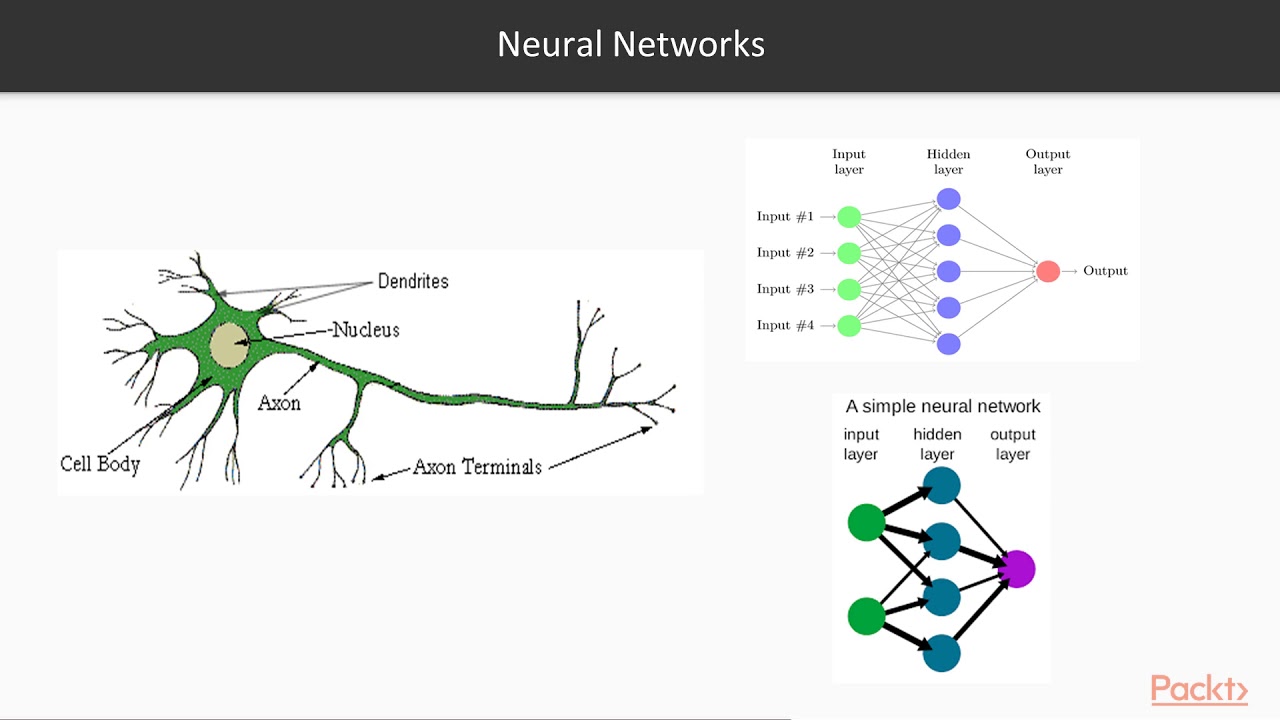 Этот случай соответствует игре
на большом капитале, когда типичные сделки содержат много контрактов. Кроме
того, подразумевалась залоговая форма игры, т.е. норма прибыли исчислялась к
залоговому капиталу, гораздо меньшему, чем масштабы самих контрактов.
Этот случай соответствует игре
на большом капитале, когда типичные сделки содержат много контрактов. Кроме
того, подразумевалась залоговая форма игры, т.е. норма прибыли исчислялась к
залоговому капиталу, гораздо меньшему, чем масштабы самих контрактов.
Приведенные выше результаты свидетельствуют о перспективности нейросетевого
трейдинга, по крайней мере на «коротких» временных масштабах. Более того, в силу
самоподобия финансовых временных рядов (Peters, 1994), норма прибыли за
единицу времени будет тем выше, чем меньше характерное время трейдинга.
Таким образом, автоматические нейросетевые трейдеры оказываются наиболее
эффективны при торговле в реальном времени, где как раз наиболее заметны их
преимущества над обычными брокерами: неутомляемость, неподверженность эмоциям,
потенциально гораздо более высокая скорость реагирования. Обученная нейросеть,
подсоединенная к электронной системе торгов, может принимать решения еще до
того, как брокер-человек успеет распознать изменения графика котировок на своем
терминале.
Заключение
Подытожим результаты этой главы. Во-первых, мы показали, что (по крайней мере некоторые) рыночные временные ряды частично предсказуемы. Как и любой другой вид нейроанализа, предсказание временных рядов требует достаточно сложной и тщательной предобработки данных. Однако, работа с временными рядами имеет свою специфику, которую можно использовать для увеличения прибыли. Это касается как выбора входов (использование специальных способов представления данных), так и выбора выходов и использования специфических функционалов ошибки. Наконец, мы показали, насколько выгоднее может быть использование комитетов нейро-экспертов по сравнению с отдельными нейросетями, и представили данные о реальных нормах прибыли на нескольких реальных финансовых инструментах.
Прогноз индийского фондового рынка с использованием искусственных нейронных сетей на тиковых данных | Финансовые инновации
В этом исследовании мы использовали варианты ИНС для прогнозирования цены акций. {\boldsymbol{T}}\boldsymbol{e} $$
{\boldsymbol{T}}\boldsymbol{e} $$
(2)
, где J — матрица Якоби, а e — вектор сетевых ошибок.{\boldsymbol{T}}\boldsymbol{e} $$
(4)
Если значение скаляра μ равно нулю, этот алгоритм будет подобен методу Ньютона, который использует аппроксимацию матрицы Гессе. Если скаляр μ станет большим, этот алгоритм будет похож на градиентный спуск с малым размером шага. Но метод Ньютона намного ближе и быстрее вблизи минимума ошибки. Итак, главная цель — как можно быстрее перейти к методу Ньютона.Таким образом, уменьшение μ после каждого успешного шага приводит к урезанию функции качества. μ будет увеличиваться только тогда, когда есть какое-либо улучшение функции качества на любом предварительном шаге, как показано на рис. 2. Следовательно, на каждой итерации функция качества всегда уменьшается.
Рис. 2
2 Блок-схема LM-алгоритма
Одним из существенных достоинств LM-подхода является то, что он работает аналогично градиентному поиску и методу Ньютона для больших значений µ и малых значений µ соответственно.Алгоритм LM объединяет лучшие качества алгоритма наискорейшего спуска и метода Гаусса-Ньютона. Кроме того, многие из их ограничений удалось избежать. В частности, этот алгоритм эффективно решает проблему медленной сходимости (Hagan & Menhaj, 1994).
Теория масштабированного сопряженного градиента
В алгоритме обратного распространения веса корректируются в направлении наискорейшего спуска (отрицательное значение градиента), поскольку функция качества быстро убывает в этом направлении.Но быстрое снижение функции качества в этом направлении не всегда означает скорейшую сходимость. Поиск выполняется по сопряженным направлениям в алгоритмах сопряженного градиента, таким образом, как правило, достигается более быстрая сходимость, чем в направлении наискорейшего спуска. Чтобы найти длину обновленного размера шага взвешивания, большинство алгоритмов используют скорость обучения. Но размер шага изменяется на каждой итерации в большинстве алгоритмов сопряженного градиента. Следовательно, чтобы уменьшить функцию качества, поиск выполняется по направлению сопряженного градиента, чтобы найти размер шага.
Чтобы найти длину обновленного размера шага взвешивания, большинство алгоритмов используют скорость обучения. Но размер шага изменяется на каждой итерации в большинстве алгоритмов сопряженного градиента. Следовательно, чтобы уменьшить функцию качества, поиск выполняется по направлению сопряженного градиента, чтобы найти размер шага.
Основное преимущество масштабированного сопряженного градиента заключается в том, что он не выполняет линейный поиск на каждой итерации по сравнению со всеми другими алгоритмами сопряженного градиента. При линейном поиске сетевые отклики всех обучающих входных данных вычисляются несколько раз для каждого поиска, который требует значительных вычислительных ресурсов. Таким образом, чтобы избежать трудоемкого поиска строк, Moller (1993) разработал алгоритм масштабированного сопряженного градиента (SCG). Алгоритм Scaled Conjugate Gradient (SCG) — это контролируемый алгоритм, который полностью автоматизирован.Он не включает никаких критических параметров, зависящих от пользователя, и работает намного быстрее, чем метод обратного распространения Левенберга-Марквардта. Мы можем использовать этот алгоритм на любом наборе данных, если чистые входные, весовые и передаточные функции данного набора данных имеют производную функцию. Производные производительности относительно переменной смещения X и веса рассчитываются с использованием обратного распространения. Таким образом, он избегает поиска строки на каждой итерации для аппроксимации размера шага масштабирования с помощью алгоритма LM (Hagan et al., 1996).
Мы можем использовать этот алгоритм на любом наборе данных, если чистые входные, весовые и передаточные функции данного набора данных имеют производную функцию. Производные производительности относительно переменной смещения X и веса рассчитываются с использованием обратного распространения. Таким образом, он избегает поиска строки на каждой итерации для аппроксимации размера шага масштабирования с помощью алгоритма LM (Hagan et al., 1996).
Фаза обучения останавливается при возникновении любого из следующих условий:
Если достигнуто максимальное количество повторений.
Если превышено максимальное время.
Производительность снижена до целевого значения.
Если градиент производительности ниже минимального градиента.
Если производительность проверки превысила максимальное количество отказов с момента последнего снижения (при использовании проверки).

Теория байесовской регуляризации
Байесовские регуляризованные искусственные нейронные сети (BRANN) устраняют или сокращают потребность в длительной перекрестной проверке. Следовательно, работайте более надежно, чем стандартное обратное распространение.Байесовская регуляризация — это математический процесс, который преобразует нелинейную регрессию в «правильную» статистическую задачу наподобие гребневой регрессии. Ключевым преимуществом этого алгоритма является то, что он учитывает вероятностный характер весов в сети, связанных с данным набором данных. Вероятность переобучения резко возрастает по мере добавления в нейронную сеть большего количества скрытых слоев нейронов. Таким образом, для точки остановки требуется набор проверки. В этом алгоритме все неразумные сложные модели наказываются путем обнуления дополнительных весов связей.Сеть будет обучать и вычислять нетривиальные веса. По мере роста сети некоторые параметры будут стремиться к константе. Кроме того, волатильность и шум на фондовых рынках приводят к вероятности переобучения базовых сетей обратного распространения ошибки. Но байесовские сети более экономны и, как правило, снижают вероятность переобучения и устраняют необходимость в шаге проверки. Поэтому количество доступных данных для обучения увеличивается (Jonathon, 2013).
В этом алгоритме все неразумные сложные модели наказываются путем обнуления дополнительных весов связей.Сеть будет обучать и вычислять нетривиальные веса. По мере роста сети некоторые параметры будут стремиться к константе. Кроме того, волатильность и шум на фондовых рынках приводят к вероятности переобучения базовых сетей обратного распространения ошибки. Но байесовские сети более экономны и, как правило, снижают вероятность переобучения и устраняют необходимость в шаге проверки. Поэтому количество доступных данных для обучения увеличивается (Jonathon, 2013).
Байесовская регуляризация имеет те же критерии использования, что и алгоритм Scale Conjugate Gradient Backpropagation.Этот алгоритм минимизирует веса и линейную комбинацию квадратов ошибок. Для хороших свойств обобщения сети этот алгоритм модифицирует линейные комбинации (Guresen et al., 2011; Hagan & Menhaj, 1999). Эта байесовская регуляризация происходит в рамках алгоритма Левенберга-Марквардта.
Комплексный обзор глубоких нейронных сетей для фондового рынка: потребности, вызовы и будущие направления
https://doi. org/10.1016/j.eswa.2021.114800Получить права и контент
org/10.1016/j.eswa.2021.114800Получить права и контентОсновные моменты
- •
Обсуждается необходимость глубоких нейронных сетей для предсказания цен на акции и трендов.
- •
CNN, DQN, RNN, LSTM, GRU, ESN, DNN, RBM и DBN анализируются для прогнозирования запасов.
- •
Проводится экспериментальное сравнение девяти моделей и анализируются результаты.
- •
Прогностическая эффективность рассматриваемых моделей сравнивается с существующим подходом.
- •
Также представлены проблемы и потенциальные направления будущих исследований.
Abstract
Фондовый рынок был привлекательным полем для большого числа организаторов и инвесторов для получения полезных прогнозов.Фундаментальные знания о фондовом рынке можно использовать с техническими индикаторами для изучения различных аспектов финансового рынка; также наблюдалось влияние различных событий, финансовых новостей и/или мнений на решения инвесторов и, следовательно, на рыночные тенденции. Такую информацию можно использовать для надежных прогнозов и повышения прибыльности. Вычислительный интеллект появился с помощью различных методов глубоких нейронных сетей (DNN) для решения сложных проблем фондового рынка.В этой статье мы стремимся рассмотреть значение и необходимость DNN в области прогнозирования цен на акции и тенденций; мы обсудим применимость вариаций DNN к временным данным фондового рынка, а также расширим наше исследование, включив в него гибридные, а также метаэвристические подходы с DNN. Мы наблюдаем потенциальные ограничения для предсказания фондового рынка с использованием различных DNN. Чтобы обеспечить экспериментальную оценку, мы также проводим серию экспериментов по прогнозированию фондового рынка с использованием девяти моделей, основанных на глубоком обучении; мы анализируем влияние этих моделей на прогнозирование данных фондового рынка.Мы также оцениваем производительность отдельных моделей с разным количеством функций. Мы обсуждаем проблемы, а также потенциальные направления будущих исследований и завершаем наш обзор экспериментальным исследованием.
Такую информацию можно использовать для надежных прогнозов и повышения прибыльности. Вычислительный интеллект появился с помощью различных методов глубоких нейронных сетей (DNN) для решения сложных проблем фондового рынка.В этой статье мы стремимся рассмотреть значение и необходимость DNN в области прогнозирования цен на акции и тенденций; мы обсудим применимость вариаций DNN к временным данным фондового рынка, а также расширим наше исследование, включив в него гибридные, а также метаэвристические подходы с DNN. Мы наблюдаем потенциальные ограничения для предсказания фондового рынка с использованием различных DNN. Чтобы обеспечить экспериментальную оценку, мы также проводим серию экспериментов по прогнозированию фондового рынка с использованием девяти моделей, основанных на глубоком обучении; мы анализируем влияние этих моделей на прогнозирование данных фондового рынка.Мы также оцениваем производительность отдельных моделей с разным количеством функций. Мы обсуждаем проблемы, а также потенциальные направления будущих исследований и завершаем наш обзор экспериментальным исследованием. Это исследование можно отнести к последним перспективам прогнозирования фондового рынка на основе DNN, в основном охватывающим исследования, охватывающие период с 2017 по 2020 год.
Это исследование можно отнести к последним перспективам прогнозирования фондового рынка на основе DNN, в основном охватывающим исследования, охватывающие период с 2017 по 2020 год.
Ключевые слова
ключевые слова
Глубокая нейронная сеть
Глубокая нейронная сеть
Рекуррентная нейронная сеть
рецидивирующая нейронная сеть
Вызовы
Проблемы исследования
Рекомендуемые статьи на будущее
Рекомендуемые статьи Статьи (0)
Смотреть полный текст© 2021 Elsevier Ltd.Все права защищены.
Рекомендуемые статьи
Ссылки на статьи
Краткосрочное предсказание тренда цен на фондовом рынке с использованием комплексной системы глубокого обучения | Журнал больших данных
В этом разделе мы представляем предлагаемые методы и дизайн предлагаемого решения. Кроме того, мы также представляем дизайн архитектуры, а также детали алгоритма и реализации.
Постановка задачи
Мы проанализировали наилучший возможный подход к прогнозированию краткосрочных ценовых трендов с различных аспектов: проектирование признаков, знание финансовой области и алгоритм прогнозирования.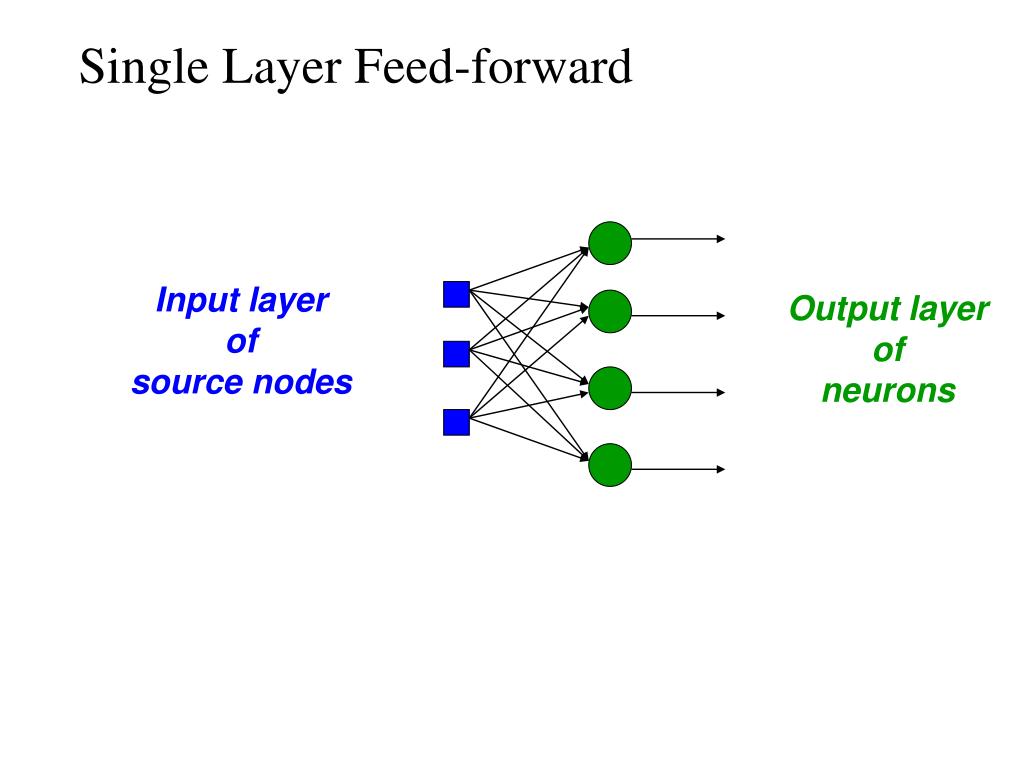 Затем мы рассмотрели три исследовательских вопроса в каждом аспекте соответственно: как инженерия признаков может повысить точность прогнозирования модели? Как выводы из финансовой области помогают разработке модели прогнозирования? И каков наилучший алгоритм для прогнозирования краткосрочных ценовых трендов?
Затем мы рассмотрели три исследовательских вопроса в каждом аспекте соответственно: как инженерия признаков может повысить точность прогнозирования модели? Как выводы из финансовой области помогают разработке модели прогнозирования? И каков наилучший алгоритм для прогнозирования краткосрочных ценовых трендов?
Первый исследовательский вопрос касается разработки признаков. Мы хотели бы знать, как метод выбора признаков влияет на производительность моделей прогнозирования. Из обилия предыдущих работ можно сделать вывод, что данные о ценах на акции содержат высокий уровень шума, а также существуют корреляции между признаками, что делает предсказание цены заведомо сложным.Это также основная причина, по которой в большинстве предыдущих работ инженерная часть была представлена как модуль оптимизации.
Второй вопрос исследования — оценка эффективности результатов, полученных нами в финансовой сфере. В отличие от предыдущих работ, помимо общей оценки моделей данных, таких как затраты на обучение и баллы, наша оценка будет подчеркивать эффективность недавно добавленных функций, которые мы извлекли из финансовой области. Мы вводим некоторые особенности из финансовой области.В то время как мы получили только некоторые конкретные выводы из предыдущих работ, и связанные с ними необработанные данные необходимо обработать в полезные функции. После извлечения связанных функций из финансовой области мы объединяем эти функции с другими общими техническими показателями, чтобы исключить функции с более высоким значением. Существует множество функций, которые считаются эффективными в финансовой сфере, и мы не сможем охватить их все. Таким образом, как правильно преобразовать результаты из финансовой области в модуль обработки данных нашей системы, является скрытым исследовательским вопросом, на который мы пытаемся ответить.
Мы вводим некоторые особенности из финансовой области.В то время как мы получили только некоторые конкретные выводы из предыдущих работ, и связанные с ними необработанные данные необходимо обработать в полезные функции. После извлечения связанных функций из финансовой области мы объединяем эти функции с другими общими техническими показателями, чтобы исключить функции с более высоким значением. Существует множество функций, которые считаются эффективными в финансовой сфере, и мы не сможем охватить их все. Таким образом, как правильно преобразовать результаты из финансовой области в модуль обработки данных нашей системы, является скрытым исследовательским вопросом, на который мы пытаемся ответить.
Третий исследовательский вопрос: какие алгоритмы мы собираемся моделировать для наших данных? Из предыдущих работ исследователи прилагали усилия для точного прогнозирования цены. Мы разбиваем задачу на предсказание тренда, а затем на точное число. В данной статье основное внимание уделяется первому шагу.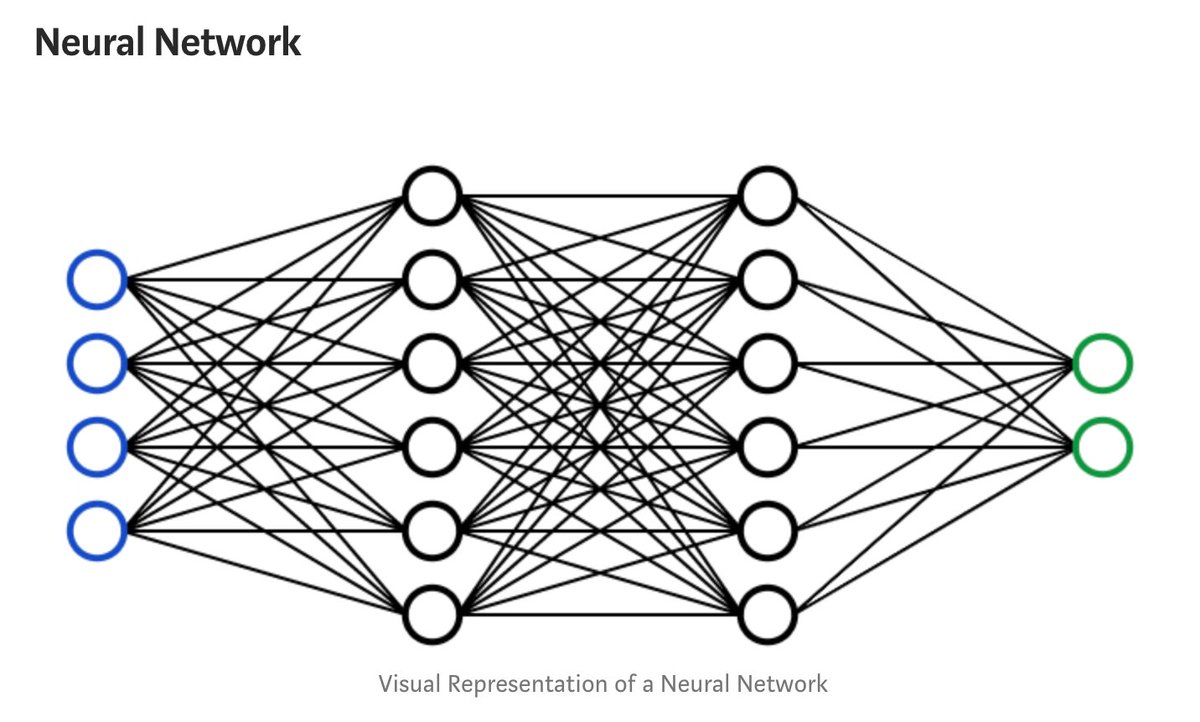 Следовательно, цель была преобразована для решения проблемы бинарной классификации, в то же время находя эффективный способ устранения негативного эффекта, вызванного высоким уровнем шума. Наш подход состоит в том, чтобы разложить сложную проблему на подзадачи, которые имеют меньше зависимостей, и решить их одну за другой, а затем скомпилировать решения в модель ансамбля в качестве вспомогательной системы для инвестирования эталонного поведения.
Следовательно, цель была преобразована для решения проблемы бинарной классификации, в то же время находя эффективный способ устранения негативного эффекта, вызванного высоким уровнем шума. Наш подход состоит в том, чтобы разложить сложную проблему на подзадачи, которые имеют меньше зависимостей, и решить их одну за другой, а затем скомпилировать решения в модель ансамбля в качестве вспомогательной системы для инвестирования эталонного поведения.
В предыдущих работах исследователи использовали различные модели для прогнозирования тенденций цен на акции. Хотя большинство наиболее эффективных моделей основаны на методах машинного обучения, в этой работе мы сравним наш подход с более эффективными моделями машинного обучения в оценочной части и найдем решение для этого исследовательского вопроса.
Предлагаемое решение
Высокоуровневую архитектуру предлагаемого нами решения можно разделить на три части. Во-первых, это часть выбора функций, чтобы гарантировать высокую эффективность выбранных функций. Во-вторых, мы изучаем данные и выполняем уменьшение размерности. И последняя часть, которая является основным вкладом нашей работы, заключается в построении прогнозной модели целевых запасов. На рис. 2 показана высокоуровневая архитектура предлагаемого решения.
Во-вторых, мы изучаем данные и выполняем уменьшение размерности. И последняя часть, которая является основным вкладом нашей работы, заключается в построении прогнозной модели целевых запасов. На рис. 2 показана высокоуровневая архитектура предлагаемого решения.
Высокоуровневая архитектура предлагаемого решения
Существуют способы классификации различных категорий запасов. Некоторые инвесторы предпочитают долгосрочные вложения, тогда как другие проявляют больший интерес к краткосрочным вложениям.Обычно отчеты, связанные с акциями, показывают среднюю производительность, в то время как цена акций резко растет; это одно из явлений, указывающих на то, что прогнозирование цен на акции не имеет фиксированных правил, поэтому необходимо найти эффективные функции перед обучением модели на данных.
В этом исследовании мы фокусируемся на прогнозировании краткосрочного ценового тренда. В настоящее время у нас есть только необработанные данные без меток. Итак, самым первым шагом является маркировка данных. Мы отмечаем ценовой тренд, сравнивая текущую цену закрытия с ценой закрытия n торговых дней назад, диапазон n составляет от 1 до 10, поскольку наше исследование сосредоточено на краткосрочной перспективе.Если ценовой тренд идет вверх, мы отмечаем его как 1 или 0 в обратном случае. Чтобы быть более конкретным, мы используем индексы из индексов n − 1 th дня, чтобы предсказать ценовой тренд n th дня.
Итак, самым первым шагом является маркировка данных. Мы отмечаем ценовой тренд, сравнивая текущую цену закрытия с ценой закрытия n торговых дней назад, диапазон n составляет от 1 до 10, поскольку наше исследование сосредоточено на краткосрочной перспективе.Если ценовой тренд идет вверх, мы отмечаем его как 1 или 0 в обратном случае. Чтобы быть более конкретным, мы используем индексы из индексов n − 1 th дня, чтобы предсказать ценовой тренд n th дня.
Согласно предыдущим работам, некоторые исследователи, применявшие как знания в финансовой области, так и технические методы к биржевым данным, использовали правила для фильтрации высококачественных акций. Мы ссылались на их работы и использовали их правила, чтобы внести свой вклад в наш дизайн расширения функций.
Однако, чтобы обеспечить наилучшую производительность модели прогнозирования, мы сначала рассмотрим данные. В необработанных данных содержится большое количество признаков; если мы включим в наше рассмотрение все функции, это не только резко увеличит вычислительную сложность, но также вызовет побочные эффекты, если мы захотим выполнять обучение без учителя в дальнейших исследованиях.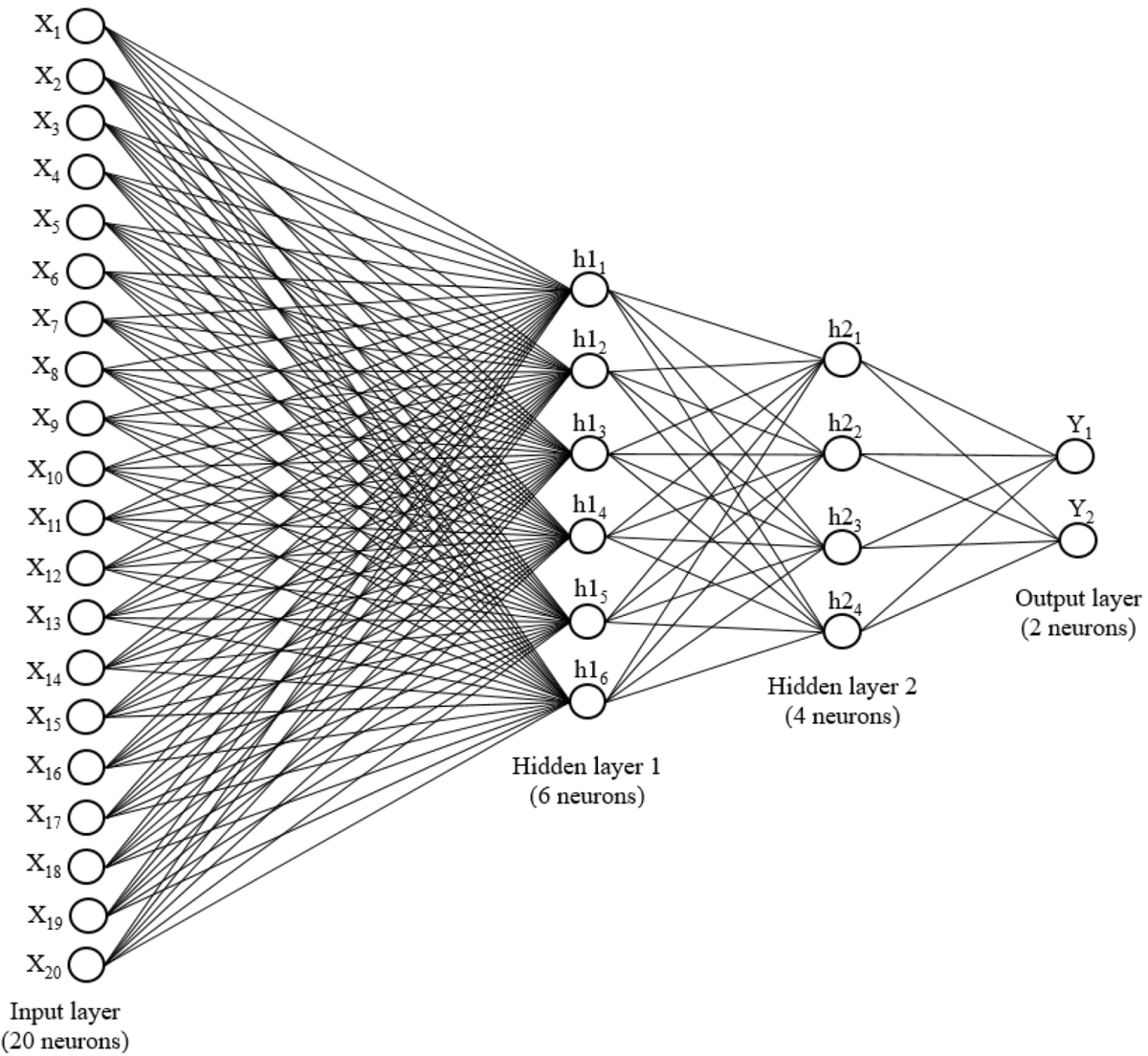 Таким образом, мы используем рекурсивное исключение функций (RFE), чтобы убедиться, что все выбранные функции эффективны.
Таким образом, мы используем рекурсивное исключение функций (RFE), чтобы убедиться, что все выбранные функции эффективны.
Мы обнаружили, что большинство предыдущих работ в технической области анализировали все акции, в то время как в финансовой области исследователи предпочитают анализировать конкретный сценарий инвестиций, чтобы заполнить пробел между двумя областями, мы решили применить функцию расширение на основе выводов, которые мы собрали в финансовой области, прежде чем мы начнем процедуру RFE.
Поскольку мы планируем моделировать данные во временные ряды, чем больше признаков, тем сложнее будет процедура обучения. Таким образом, мы будем использовать уменьшение размерности с помощью рандомизированного PCA в начале предлагаемой нами архитектуры решения.
Детальная разработка технического проекта
В этом разделе представлена разработка детального технического проекта как комплексного решения, основанного на использовании, объединении и настройке нескольких существующих методов предварительной обработки данных, разработки признаков и глубокого обучения. На рис. 3 представлен подробный технический проект от обработки данных до прогнозирования, включая исследование данных. Мы разбиваем контент по основным процедурам, и каждая процедура содержит алгоритмические шаги. Детали алгоритма подробно описаны в следующем разделе. Содержание этого раздела будет сосредоточено на иллюстрации рабочего процесса данных.
На рис. 3 представлен подробный технический проект от обработки данных до прогнозирования, включая исследование данных. Мы разбиваем контент по основным процедурам, и каждая процедура содержит алгоритмические шаги. Детали алгоритма подробно описаны в следующем разделе. Содержание этого раздела будет сосредоточено на иллюстрации рабочего процесса данных.
Детальный технический проект предлагаемого решения
На основе обзора литературы мы выбираем наиболее часто используемые технические индексы, а затем вводим их в процедуру расширения функций, чтобы получить расширенный набор функций.Мы выберем наиболее эффективные функции и из расширенного набора функций. Затем мы передадим данные с i выбранными функциями в алгоритм PCA, чтобы уменьшить размерность до j функций. После того, как мы получим наилучшую комбинацию i и j , мы обрабатываем данные для окончательного набора функций и вводим их в модель LSTM [10], чтобы получить результат прогнозирования ценового тренда.
Новизна предлагаемого нами решения заключается в том, что мы будем не только применять технический метод к необработанным данным, но и выполнять расширения функций, которые используются инвесторами на фондовом рынке.Подробная информация о расширении функций приведена в следующем подразделе. Опыт, полученный в результате применения и оптимизации решений на основе глубокого обучения в [37, 38], был учтен при разработке и настройке решения для проектирования функций и глубокого обучения в этой работе.
Применение расширения функции
Первая основная процедура на рис. 3 — это расширение функции. В этом блоке входными данными являются наиболее часто используемые технические показатели, выведенные из смежных работ. Тремя методами расширения функций являются максимальное и минимальное масштабирование, поляризация и вычисление процента флуктуаций.Не все технические индексы применимы ко всем трем методам расширения функций; эта процедура применяет только значимые методы расширения для технических индексов. Мы выбираем значимые методы расширения, глядя на то, как рассчитываются индексы. Технические индексы и соответствующие методы расширения функций показаны в таблице 2.е., входные данные с выходными данными и подача в блок RFE в качестве входных данных на следующем шаге.
Мы выбираем значимые методы расширения, глядя на то, как рассчитываются индексы. Технические индексы и соответствующие методы расширения функций показаны в таблице 2.е., входные данные с выходными данными и подача в блок RFE в качестве входных данных на следующем шаге.
Применение рекурсивного исключения функций
После описанного выше расширения функций мы исследуем наиболее эффективные функции i с помощью алгоритма рекурсивного исключения функций (RFE) [6]. Мы оцениваем все признаки по двум атрибутам, коэффициенту и важности признака. Мы также ограничиваем функции, которые удаляются из пула, одной, что означает, что мы будем удалять одну функцию на каждом этапе и сохранять все соответствующие функции.Тогда выход блока RFE будет входом следующего шага, который относится к PCA.
Применение анализа главных компонентов (PCA)
Самым первым шагом перед использованием PCA является предварительная обработка признаков. Потому что некоторые функции после RFE представляют собой данные в процентах, а другие — очень большие числа, т. е. выходные данные RFE представлены в разных единицах. Это повлияет на результат извлечения главного компонента. Таким образом, перед подачей данных в алгоритм PCA [8] необходима предварительная обработка признаков.Мы также иллюстрируем сравнение эффективности и методов в разделе «Результаты».
е. выходные данные RFE представлены в разных единицах. Это повлияет на результат извлечения главного компонента. Таким образом, перед подачей данных в алгоритм PCA [8] необходима предварительная обработка признаков.Мы также иллюстрируем сравнение эффективности и методов в разделе «Результаты».
После выполнения предварительной обработки признаков следующим шагом является подача обработанных данных с выбранными признаками и в алгоритм PCA, чтобы уменьшить масштаб матрицы признаков до j признаков. Этот шаг должен сохранить как можно больше эффективных функций и в то же время устранить вычислительную сложность обучения модели. В этой исследовательской работе также оценивается наилучшая комбинация i и j, , которая имеет относительно лучшую точность предсказания, в то же время сокращая потребление вычислительных ресурсов.Результат также можно найти в разделе «Результаты». После шага PCA система получит измененную матрицу с j столбцов.
Подгонка модели с долговременной кратковременной памятью (LSTM)
PCA уменьшила размеры входных данных, в то время как предварительная обработка данных является обязательной перед подачей данных в слой LSTM. Причина добавления шага предварительной обработки данных перед моделью LSTM заключается в том, что входная матрица, образованная основными компонентами, не имеет временных шагов. В то время как одним из наиболее важных параметров обучения LSTM является количество временных шагов.Следовательно, мы должны смоделировать матрицу с соответствующими временными шагами как для набора данных для обучения, так и для тестирования.
Причина добавления шага предварительной обработки данных перед моделью LSTM заключается в том, что входная матрица, образованная основными компонентами, не имеет временных шагов. В то время как одним из наиболее важных параметров обучения LSTM является количество временных шагов.Следовательно, мы должны смоделировать матрицу с соответствующими временными шагами как для набора данных для обучения, так и для тестирования.
После выполнения части предварительной обработки данных последний шаг — передать данные обучения в LSTM и оценить производительность с использованием данных тестирования. Как вариант нейронной сети RNN, даже с одним слоем LSTM, структура NN по-прежнему остается глубокой нейронной сетью, поскольку она может обрабатывать последовательные данные и запоминать свои скрытые состояния во времени. Слой LSTM состоит из одного или нескольких блоков LSTM, а блок LSTM состоит из ячеек и вентилей для выполнения классификации и прогнозирования на основе данных временных рядов.
Структура LSTM состоит из двух слоев. Входная размерность определяется j после алгоритма PCA. Первый слой — это входной слой LSTM, а второй слой — выходной слой. Конечным результатом будет 0 или 1, указывающий, идет ли результат прогнозирования тренда цены акций вниз или вверх, в качестве вспомогательного предложения для инвесторов принять следующее инвестиционное решение.
Обсуждение дизайна
Расширение возможностей является одной из новинок предлагаемой нами системы прогнозирования ценовых тенденций.В процедуре расширения функций мы используем технические индексы для взаимодействия с методами эвристической обработки, полученными от инвесторов, что заполняет пробел между областью финансовых исследований и областью технических исследований.
Поскольку мы предложили систему прогнозирования ценовых трендов, проектирование признаков чрезвычайно важно для окончательного результата прогнозирования. Не только метод расширения функции полезен, чтобы гарантировать, что мы не пропустим потенциально коррелированную функцию, но также необходим метод выбора функции для объединения эффективных функций.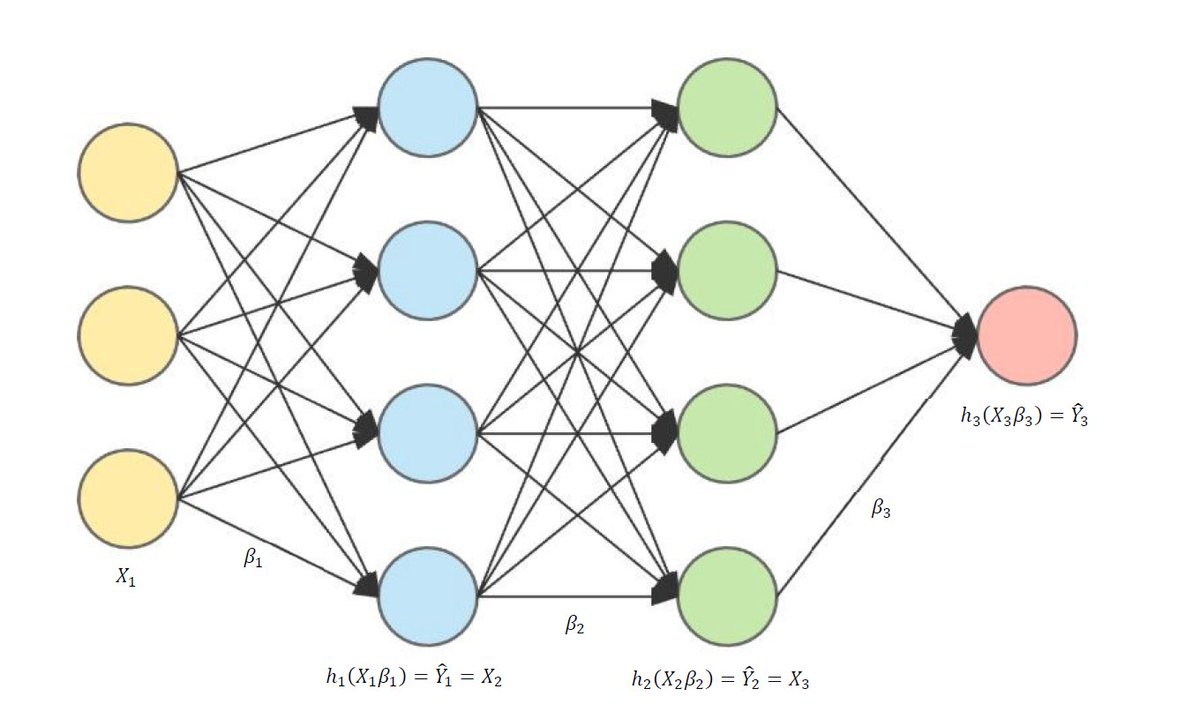 Чем больше нерелевантных признаков будет введено в модель, тем больше будет шума. Каждая основная процедура тщательно продумана и вносит свой вклад в разработку всей системы.
Чем больше нерелевантных признаков будет введено в модель, тем больше будет шума. Каждая основная процедура тщательно продумана и вносит свой вклад в разработку всей системы.
Помимо разработки функций, мы также используем LSTM, современный метод глубокого обучения для прогнозирования временных рядов, который гарантирует, что модель прогнозирования может захватывать как сложные скрытые шаблоны, так и шаблоны, связанные с временными рядами.
Известно, что стоимость обучения моделей глубокого обучения высока как с точки зрения времени, так и с точки зрения оборудования; Еще одним преимуществом нашей системы является процедура оптимизации — PCA.Он может сохранить основные компоненты функций при уменьшении масштаба матрицы функций, тем самым помогая системе сэкономить затраты на обучение при обработке матрицы функций больших временных рядов.
Разработка алгоритма
В этом разделе представлены подробные сведения об алгоритмах, которые мы создали, используя и адаптируя различные существующие методы.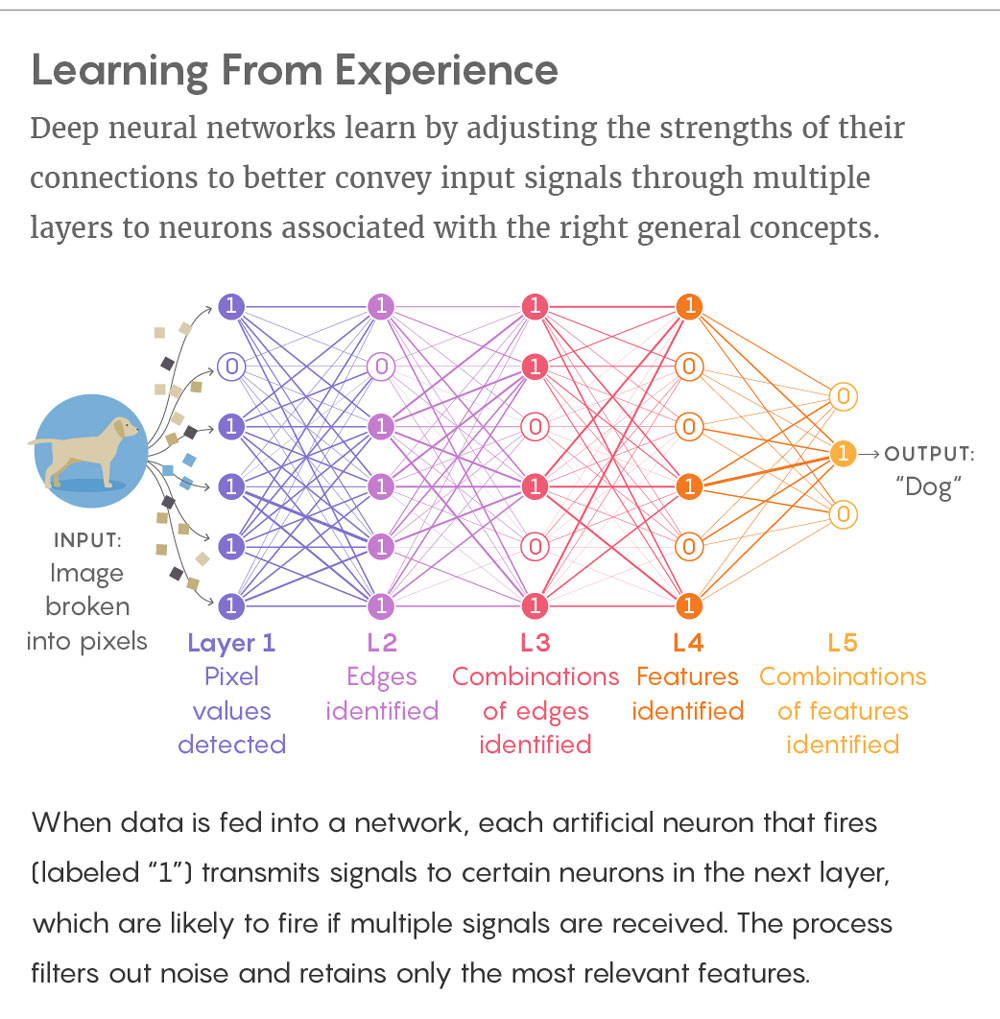 Подробно о терминологиях, параметрах, а также оптимизаторах. В легенде в правой части рис. 3 мы отмечаем шаги алгоритма в виде восьмиугольников, все их можно найти в этом разделе «Разработка алгоритма».
Подробно о терминологиях, параметрах, а также оптимизаторах. В легенде в правой части рис. 3 мы отмечаем шаги алгоритма в виде восьмиугольников, все их можно найти в этом разделе «Разработка алгоритма».
Прежде чем углубиться в этапы алгоритма, вот краткое введение в предварительную обработку данных: поскольку мы пройдем через алгоритмы обучения с учителем, нам также необходимо запрограммировать основную истину. Основная истина этого исследования запрограммирована путем сравнения цены закрытия текущей торговой даты с ценой закрытия предыдущей торговой даты, с которой пользователи хотят сравнить. Обозначьте рост цен как 1, в противном случае основная истина будет помечена как 0. Поскольку эта исследовательская работа сосредоточена не только на прогнозировании ценового тренда за определенный период времени, но и на краткосрочной перспективе в целом, обработка основной истины осуществляется в соответствии с диапазон торговых дней.Хотя алгоритмы не будут меняться в зависимости от длины срока предсказания, мы можем рассматривать длину срока как параметр.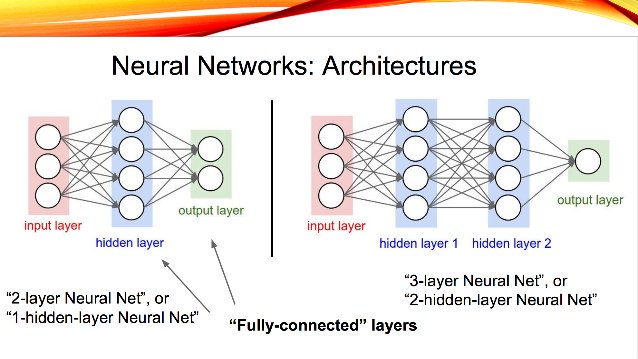
Алгоритмическая деталь проработана, соответственно первый алгоритм представляет собой инженерную часть гибридных признаков для подготовки качественных данных для обучения и тестирования. Он соответствует блокам Feature extension, RFE и PCA на рис. 3. Второй алгоритм — это блок процедуры LSTM, включающий предварительную обработку данных временных рядов, построение NN, обучение и тестирование.
Алгоритм 1. Краткосрочное предсказание тренда цен на фондовом рынке — применение разработки признаков с использованием FE + RFE + PCA
Функция FE соответствует блоку расширения функции.Для процедуры расширения функций мы применяем три различных метода обработки, чтобы перевести результаты из финансовой области в технический модуль в нашей системе. Хотя не все индексы применимы для расширения, мы только выбираем правильный метод(ы) для определенных функций для выполнения расширения функции (FE) в соответствии с таблицей 2.
Метод нормализации сохраняет относительную частоту терминов и преобразует технические индексы в диапазоне [0, 1]. Поляризация — это хорошо известный метод, часто используемый реальными инвесторами. Иногда они предпочитают учитывать, выше или ниже нуля значение технического индекса. Мы программируем некоторые функции, используя метод поляризации, и готовимся к RFE.Максимально-минимальное (или минимальное-максимальное) масштабирование [35] – это метод преобразования, часто используемый в качестве альтернативы масштабированию с нулевым средним и единичной дисперсией. Другим известным используемым методом является процент колебания, и мы преобразуем процент колебания технических индексов в диапазон [- 1, 1].
Поляризация — это хорошо известный метод, часто используемый реальными инвесторами. Иногда они предпочитают учитывать, выше или ниже нуля значение технического индекса. Мы программируем некоторые функции, используя метод поляризации, и готовимся к RFE.Максимально-минимальное (или минимальное-максимальное) масштабирование [35] – это метод преобразования, часто используемый в качестве альтернативы масштабированию с нулевым средним и единичной дисперсией. Другим известным используемым методом является процент колебания, и мы преобразуем процент колебания технических индексов в диапазон [- 1, 1].
Функция RFE() в первом алгоритме относится к рекурсивному исключению признаков. Прежде чем мы выполним уменьшение масштаба обучающих данных, мы должны убедиться, что выбранные нами функции эффективны. Неэффективные функции не только снижают точность классификации, но и усложняют вычисления.Для части выбора функций мы выбираем рекурсивное исключение функций (RFE). Как поясняется в [45], процесс рекурсивного устранения признаков можно разделить на алгоритм ранжирования, повторную выборку и внешнюю проверку.
Для алгоритма ранжирования он подбирает модель по характеристикам и ранжирует по важности для модели. Мы устанавливаем параметр, чтобы сохранить i номеров функций, и на каждой итерации выбора функций сохраняется Si функций с наивысшим рейтингом, затем переделываем модель и снова оцениваем производительность, чтобы начать другую итерацию.Алгоритм ранжирования в конечном итоге определит лучшие функции Si .
Известно, что алгоритм RFE страдал от проблемы переобучения. Чтобы устранить проблему переобучения, мы запустим алгоритм RFE несколько раз на случайно выбранных акциях в качестве тренировочного набора и обеспечим, чтобы все выбранные нами функции имели высокий вес. Эта процедура называется повторной выборкой данных. Повторная выборка может быть построена как шаг оптимизации как внешний слой алгоритма RFE.
Последняя часть нашего алгоритма разработки гибридных функций предназначена для целей оптимизации.Для уменьшения масштаба матрицы обучающих данных мы применяем рандомизированный анализ основных компонентов (PCA) [31], прежде чем мы решим особенности модели классификации.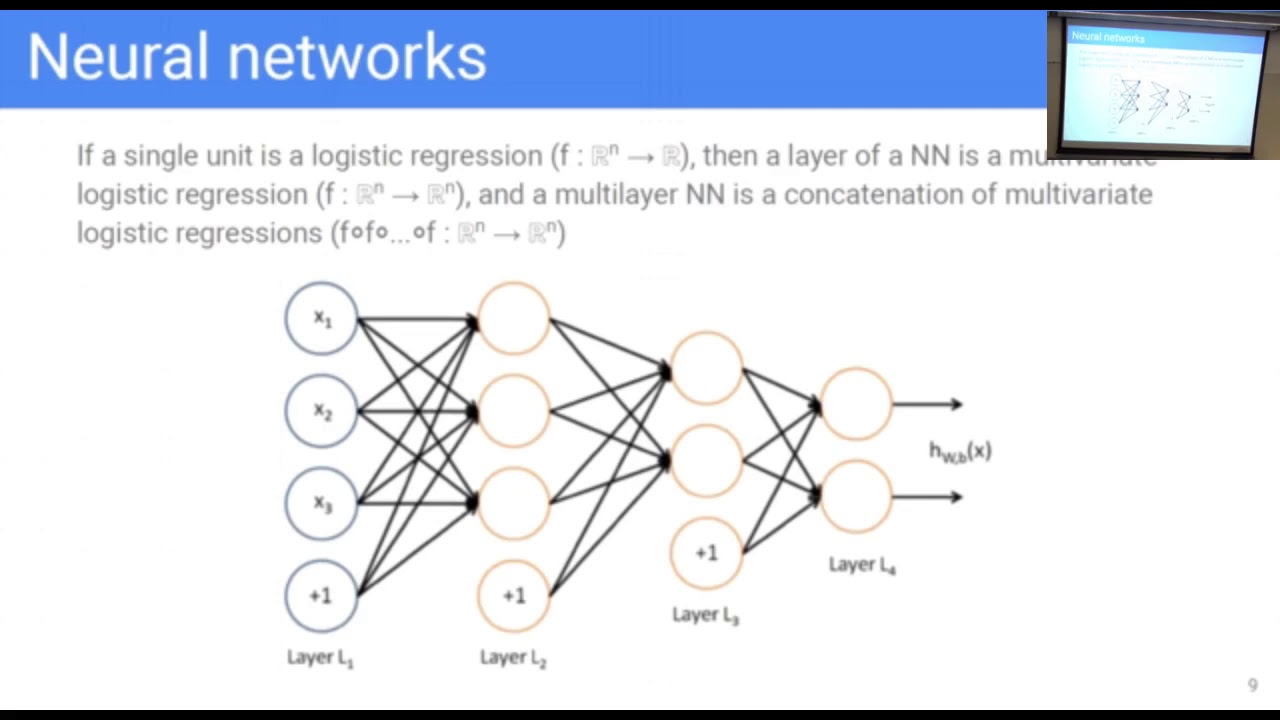
Финансовые коэффициенты котируемой компании используются для представления способности роста, способности зарабатывать, платежеспособности и т. д. Каждый финансовый коэффициент состоит из набора технических показателей, каждый раз, когда мы добавляем технический показатель (или функцию), добавляется еще один столбец данных в матрицу данных и приведет к низкой эффективности обучения и избыточности.Если в обучающие данные включены нерелевантные или менее релевантные функции, это также снизит точность классификации.
Приведенное выше уравнение представляет собой объяснительную способность главных компонент, извлеченных методом PCA для исходных данных. Если ACR ниже 85%, метод PCA непригоден из-за потери исходной информации. Поскольку ковариационная матрица чувствительна к порядку величины данных, перед выполнением PCA должна быть предусмотрена процедура стандартизации данных.{*} = (X_{ij} — \overline{{X_{j} }} )/s_{j}\), где \(\overline{{X_{j} }}\) представляет собой среднее значение, и \(s_{j}\) — стандартное отклонение.
Массив fe_array определен в соответствии с таблицей 2, номера строк соответствуют функциям, столбцы 0, 1, 2, 3 примечания для методов расширения нормализации, поляризации, шкалы максимума–минимума и процента флуктуации соответственно. Затем мы заполняем значения для массива по правилу, где 0 означает, что нет необходимости расширять, а 1 — если функции требуют применения соответствующих методов расширения.Окончательный алгоритм предварительной обработки данных с использованием RFE и PCA можно проиллюстрировать как Алгоритм 1.
Алгоритм 2: Модель прогнозирования ценового тренда с использованием LSTM
После извлечения главного компонента мы получим матрицу с уменьшенным масштабом, что означает i наиболее эффективные функции преобразуются в j основных компонентов для обучения модели прогнозирования. Мы использовали модель LSTM и добавили процедуру преобразования для нашего набора данных о ценах на акции. Подробная схема алгоритма показана на алгоритме 2. Функция TimeSeriesConversion () преобразует матрицу главных компонентов во временные ряды путем смещения кадра входных данных в соответствии с количеством временных шагов [3], т. е. длиной терма в данном исследовании. Обработанный набор данных состоит из входной последовательности и прогнозной последовательности. В этом исследовании параметр LAG равен 1, потому что модель ежедневно определяет характер колебаний характеристик. Между тем, N_TIME_STEPS варьируется от 1 торгового дня до 10 торговых дней.Функции DataPartition(), FitModel(), EvaluateModel() являются обычными шагами без настройки. Проект структуры NN, решение оптимизатора и другие параметры проиллюстрированы в функции ModelCompile() .
Функция TimeSeriesConversion () преобразует матрицу главных компонентов во временные ряды путем смещения кадра входных данных в соответствии с количеством временных шагов [3], т. е. длиной терма в данном исследовании. Обработанный набор данных состоит из входной последовательности и прогнозной последовательности. В этом исследовании параметр LAG равен 1, потому что модель ежедневно определяет характер колебаний характеристик. Между тем, N_TIME_STEPS варьируется от 1 торгового дня до 10 торговых дней.Функции DataPartition(), FitModel(), EvaluateModel() являются обычными шагами без настройки. Проект структуры NN, решение оптимизатора и другие параметры проиллюстрированы в функции ModelCompile() .
Прогнозирование движения фондового рынка с использованием нейронной сети, применяемой к общедоступному набору данных Deutsche Börse
Отказ от ответственности
Этот пост в блоге и связанный с ним репозиторий Github не являются советами по торговле и не побуждают людей торговать автоматически.
Введение
Исходный код предиктора акций на Github
Используя нейронную сеть, примененную к общедоступному набору данных Deutsche Börse, мы реализовали подход для прогнозирования будущих движений цен на акции с использованием тенденций за предыдущие 10 минут. Наша мотивация заключалась в том, чтобы получить представление об этом наборе данных и создать архитектуру и подход, на основе которых мы можем выполнять итерации. Мы также планировали, что эта работа поможет всем, кто хочет начать работу с машинным обучением и анализом данных с помощью общедоступного набора данных Deutsche Börse.
Мы начали с того, что задались вопросом, действительно ли возможно угадать, будет ли торгуемая акция расти или падать в цене, учитывая информацию о ее недавних ценах с течением времени?
Рис. 1. Пример поминутного движения цены акций в последующие дни [акции BMW на 26 марта 2018 г.]
Движение цен акций демонстрирует шум от одного момента к другому. В то время как данный общий тренд может быть восходящим, мы можем видеть временные спады на этом пути.Прогнозирование этих колебаний и угадывание их направления является ключевой частью задачи, которую мы перед собой ставим. Для этого мы применили нейросетевые подходы к общедоступному набору данных (PDS) от Deutsche Börse. Мы выбрали этот подход из-за присущей нейронным сетям гибкости в выражении нескольких моделей, от очень простых до сложных. В то же время мы признали, что ключевым недостатком нейронных сетей является то, что они игнорируют выбросы, которые могут иметь огромное значение в этой области как рыночные события «Черный лебедь».
В то время как данный общий тренд может быть восходящим, мы можем видеть временные спады на этом пути.Прогнозирование этих колебаний и угадывание их направления является ключевой частью задачи, которую мы перед собой ставим. Для этого мы применили нейросетевые подходы к общедоступному набору данных (PDS) от Deutsche Börse. Мы выбрали этот подход из-за присущей нейронным сетям гибкости в выражении нескольких моделей, от очень простых до сложных. В то же время мы признали, что ключевым недостатком нейронных сетей является то, что они игнорируют выбросы, которые могут иметь огромное значение в этой области как рыночные события «Черный лебедь».
PDS — это бесплатный и общедоступный набор данных, состоящий из агрегированной торговой информации от торговых систем XETRA и EUREX, которые включают в себя ряд типов ценных бумаг, детализированных с поминутной детализацией и обновляемых практически в режиме реального времени. на той же частоте. Мы решили сосредоточиться на работе исключительно с долевыми ценными бумагами, которые предоставляются как часть компонента XETRA PDS. Активность каждой акции имеет подробную торговую информацию на поминутном уровне, включая объемы и максимальные, минимальные, начальные и конечные цены.По сути, данные здесь такие же, как и для клиентов, только с задержкой на несколько минут и агрегированы.
Активность каждой акции имеет подробную торговую информацию на поминутном уровне, включая объемы и максимальные, минимальные, начальные и конечные цены.По сути, данные здесь такие же, как и для клиентов, только с задержкой на несколько минут и агрегированы.
Если бы мы обладали способностью предсказывать, пойдет ли цена акции вверх или вниз в следующую минуту, основываясь на анализе ее исторического поведения, теоретически у нас был бы один компонент торговой стратегии. Однако способности предсказывать движение цены недостаточно, чтобы алгоритмически зарабатывать деньги на фондовом рынке. Другие соображения связаны с торговыми издержками, проскальзыванием, налогами и управлением рисками в целом.
Первоначально мы решили прогнозировать конечную цену в следующую минуту, потому что набор данных организован на поминутной основе, и мы хотели быть как можно ближе к прогнозу «в реальном времени». В ходе нашего анализа мы обнаружили, что предсказание направления конечной цены на одну или несколько минут в будущем затруднено из-за наличия большого количества шума. Наши репозитории содержат дополнительные записные книжки, подробно описывающие эффективность прогнозирования статистики распределения, такой как средняя конечная цена, за временные интервалы.Их легче предсказать, чем конечную цену, и они практически более значимы.
Наши репозитории содержат дополнительные записные книжки, подробно описывающие эффективность прогнозирования статистики распределения, такой как средняя конечная цена, за временные интервалы.Их легче предсказать, чем конечную цену, и они практически более значимы.
Здесь мы описываем наш подход, от преобразования данных и проведения исследовательского анализа данных до применения нейронных сетей к задаче прогнозирования фондового рынка. Эта работа предназначена для того, чтобы служить базовым введением в общедоступный набор данных и вдохновить другие проекты, основанные на нем. Его можно обобщить на другие наборы данных, в том числе на другие фондовые рынки, включая криптовалюты.
Мы использовали очень упрощенную торговую стратегию и показали, что она может приносить положительную «идеальную» прибыль. Наше определение доходности было просто определено как разница между текущей и предыдущей ценой по сравнению с предыдущей ценой, в то время как в финансах доход измеряется через альфу, которая зависит от рыночного индекса или эталона. Мы также не учитывали торговые издержки, проскальзывания или интеграцию с нашими торговыми стратегиями. Поэтому результат оптимистичен и может быть неприменим на практике.
Мы также не учитывали торговые издержки, проскальзывания или интеграцию с нашими торговыми стратегиями. Поэтому результат оптимистичен и может быть неприменим на практике.
Мы считаем нашу работу лишь отправной точкой в сложной области. Мы будем признательны за любые отзывы, отправленные путем регистрации вопросов Github относительно методологии, заметных упущений или советов о том, как улучшить код.
Эта работа явно не является советом по торговле и не побуждает людей торговать автоматически.
Подготовка данных
Мы начали с извлечения данных из корзины PDS AWS S3 и изучения их структуры.Данные приходят со следующими полями:
| Имя столбца | Описание данных | Словарь данных |
|---|---|---|
| ISIN | ISIN ценной бумаги | строка |
| Мнемоника | Тикер фондовой биржи | строка |
| Описание безопасности | Описание безопасности | строка |
| Тип безопасности | Тип защиты | строка |
| Валюта | Валюта, в которой продается продукт | строка |
| Идентификатор безопасности | Уникальный идентификатор для каждого контракта | интервал |
| Дата | Дата торгового периода | Дата |
| Время | Минута торгов, к которой относится данная запись | время (чч:мм) |
| Начальная цена | Торговая цена на начало периода | поплавок |
| Максимальная цена | Максимальная цена за период | поплавок |
| Минимальная цена | Минимальная цена за период | поплавок |
| Конечная цена | Торговая цена на конец периода | поплавок |
| Торговый объем | Общая стоимость сделок | поплавок |
| Количество сделок | Количество отдельных сделок за период | интервал |
Таблица1. Характеристики данных PDS XETRA
Характеристики данных PDS XETRA
Используя Python 2.5 и библиотеку Pandas, мы установили шаги, необходимые для помещения временных рядов XETRA в правильно отформатированный фрейм данных, а затем создали конвейер преобразования данных для стандартизации вывода данных для любого ввода из PDS.
Мы использовали этот конвейер для создания рабочей базы данных для задач анализа и прогнозирования, содержащей 50 крупнейших по объему сделок акций за дни с января по март 2018 г., за исключением тех, по которым в указанный период времени не было сделок.
После подготовки этого сообщения в блоге после проверки трейдером мы обратили внимание на то, что нам необходимо скорректировать эти данные для разделения, дивидендов и исключения из списка, чтобы обеспечить лучший торговый сигнал при тестировании на исторических данных. В будущих демонстрациях мы планируем учесть эти предложения.
Исследовательский анализ
В общем, прежде чем выполнять какую-либо форму машинного обучения, нам необходимо тщательно изучить данные. Поскольку мы не являемся экспертами в области финансового рынка, мы должны составить представление о поведении и характеристиках данных с нуля.
Поскольку мы не являемся экспертами в области финансового рынка, мы должны составить представление о поведении и характеристиках данных с нуля.
Мы ожидаем, что этот анализ и прилагаемые к нему записные книжки будут полезны неспециалистам, но экспертам они могут показаться очевидными. Мы также признаем, что кванты могут ожидать увидеть графики автокорреляции и тесты на сезонность и стационарность, но они оставлены для будущей работы, поскольку для нейронных сетей они в значительной степени имеют ограниченное применение.
В этой работе мы не учитывали дробление или делистинг, поскольку на протяжении всего исследования мы использовали лучшие по объему акции, что должно иметь низкую вероятность того, что это произойдет.
Мы начали с изучения основных характеристик: MaxPrice, MinPrice, StartPrice, EndPrice, TradedVolume и NumberOfTrades.
Рис. 2. Ценовые характеристики акций BMW с 8:00 до 15:00 26 марта 2018 г.
Рис. 3: TradedVolume для акций BMW с 8:00 до 15:00 26 марта 2018 г.
3: TradedVolume для акций BMW с 8:00 до 15:00 26 марта 2018 г.
Рис. 4. Число сделок по акциям BMW с 8:00 до 15:00 26 марта 2018 г.
Данные были преобразованы в сглаженные 15-минутные интервалы для более удобного наблюдения тенденций с использованием библиотеки Pandas для дискретизации временных рядов и вычисления медианных значений.Мы не сравнивали с экспоненциально взвешенной скользящей средней, поскольку важно было выявить модели, которые можно было бы легко интерпретировать. После проверки мы обнаружили следующее важное поведение:
- В нисходящих тенденциях EndPrice имеет тенденцию быть ближе к MinPrice, чем MaxPrice, и ниже StartPrice.
- В восходящих тенденциях EndPrice имеет тенденцию быть ближе к MaxPrice, чем MinPrice, и выше StartPrice.
Аналогично,
- При нисходящем тренде StartPrice ближе к MaxPrice, чем к MinPrice.
- В восходящих тенденциях StartPrice имеет тенденцию быть ближе к MinPrice, чем MaxPrice.
Рис. 5. Связь между MinPrice, MaxPrice и EndPrice
Такое поведение привело к решению сгенерировать новый признак направления движения запаса, который мы назвали Элемент направления (DF). Математически это определяется как:
DF = (МаксЦена[t-1] — КонечнаяЦена[t-1]) — (КонечнаяЦена[t-1] — МинимальнаяЦена[t-1])
Или просто:
DF = Максимальная цена[t-1] — Минимальная цена[t-1] — 2(Конечная цена[t-1])
Глядя на функцию направления, вы можете видеть, что она просто описывает, ближе ли EndPrice для данной минуты торговли акциями к MaxPrice или MinPrice минуты.Мы полагали, что эта метрика может функционировать как упрощенный, но эффективный показатель спроса или предложения и, следовательно, относится к восходящим или нисходящим тенденциям в цене акций с течением времени. После некоторых исследований мы обнаружили, что эта функция аналогична концепциям ранее существовавшего технического индикатора «Линия накопления/распределения» и известной торговой стратегии «молот».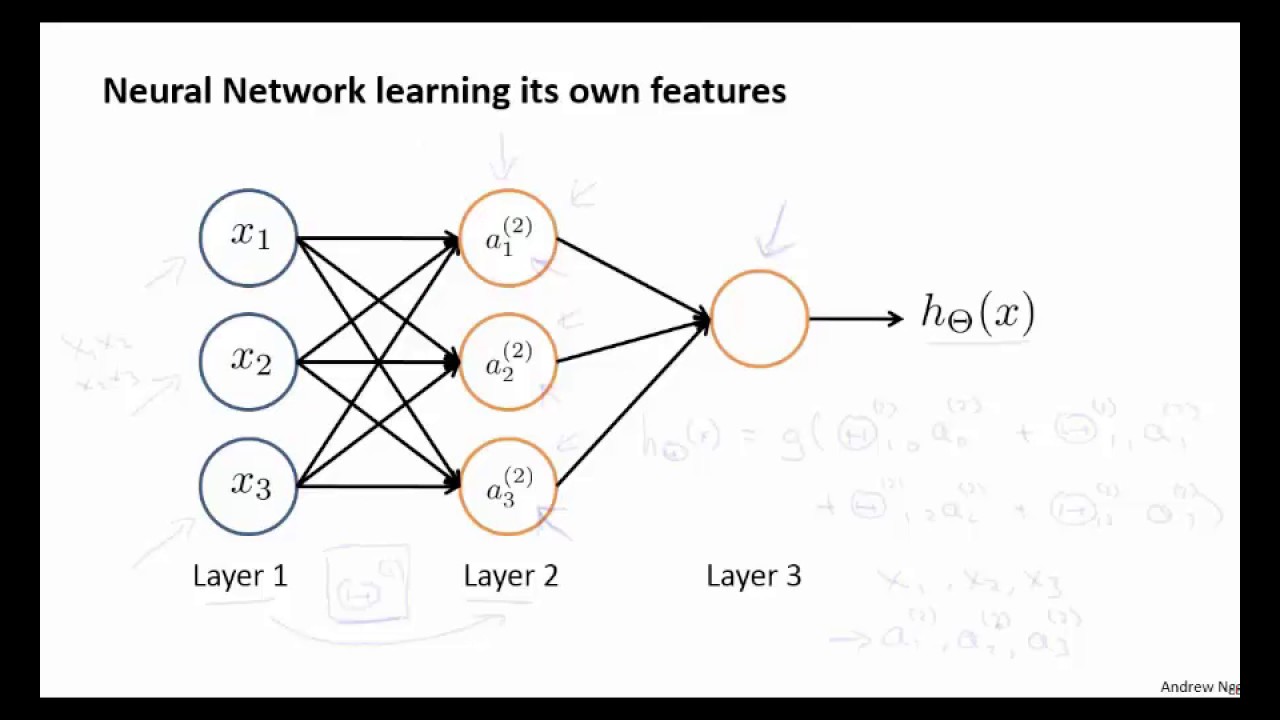
Здесь мы обнаружили, что в этом конкретном случае характеристика направления коррелирует (0,33) со скоростью возврата в следующую минуту.Мы не сравнивали эту производительность с другими существующими индикаторами финансового технического анализа, такими как RSI, MACD, A/D, полосы Боллинджера и т. д., но мы хотели бы провести такие сравнения в будущем.
Как обсуждалось ранее, норма доходности была просто определена как относительная величина движения EndPrice от одной минуты к другой, также известная как простая доходность за один период для цены P в момент времени t:
R = (P[t+1] — P[t])/P[t]
Мы использовали это определение, потому что его легко интерпретировать как изменение в процентах и оно не требует финансовых знаний.Кроме того, мы могли легко нормализовать данные, что было важно, поскольку мы использовали несколько акций.
Было обнаружено, что сила корреляции характеристики направления с нормой доходности зависит от периода времени, для которого она рассчитывается. Другими словами, в определенные периоды было обнаружено, что характеристика направления сильно коррелирует с нормой доходности, а в другие периоды времени и с другими акциями — нет. Это не является неожиданным, учитывая, сколько факторов влияет на цену акций. Мы предполагаем, что это связано с микроструктурой рынка.Хотя дискретность наших измерений фиксируется поминутно, акции движутся с разной скоростью в разное время. Мы также обнаружили, что та же функция направления имеет более сильную и стабильную корреляцию со средней конечной ценой на 30 минут вперед. Это подтверждает сложность попыток предсказать точную конечную цену по сравнению со средней ценой. Конечная цена содержит гораздо больше шума.
Другими словами, в определенные периоды было обнаружено, что характеристика направления сильно коррелирует с нормой доходности, а в другие периоды времени и с другими акциями — нет. Это не является неожиданным, учитывая, сколько факторов влияет на цену акций. Мы предполагаем, что это связано с микроструктурой рынка.Хотя дискретность наших измерений фиксируется поминутно, акции движутся с разной скоростью в разное время. Мы также обнаружили, что та же функция направления имеет более сильную и стабильную корреляцию со средней конечной ценой на 30 минут вперед. Это подтверждает сложность попыток предсказать точную конечную цену по сравнению со средней ценой. Конечная цена содержит гораздо больше шума.
Прогнозирование движения цены акций с помощью нейронной сети
Мы разработали простой нейросетевой подход с использованием Keras и Tensorflow, чтобы предсказать, будет ли акция расти или падать в цене в следующую минуту, учитывая информацию за предыдущие десять минут. Заметное отличие от других подходов заключается в том, что мы объединили данные по всем 50 акциям и запустили сеть на наборе данных без идентификаторов акций. Набор данных состоит из записей, в которых прогнозируемой переменной является движение (вверх или вниз), а функции извлекаются за последние 10 минут. Мы обнаружили, что нормализация признаков имеет решающее значение.
Заметное отличие от других подходов заключается в том, что мы объединили данные по всем 50 акциям и запустили сеть на наборе данных без идентификаторов акций. Набор данных состоит из записей, в которых прогнозируемой переменной является движение (вверх или вниз), а функции извлекаются за последние 10 минут. Мы обнаружили, что нормализация признаков имеет решающее значение.
Мы оценили не только то, сколько правильных прогнозов может дать модель, но и то, какой общий доход от торговой стратегии она может принести.Мы сравнили его с рядом эвристических стратегий, чтобы понять, насколько хорошо он работает по сравнению с более простыми альтернативами. Общий набор использованных стратегий:
- Случайная торговая стратегия, при которой решение о покупке или продаже на следующую минуту генерируется случайным образом.
- Стратегия «всегда вверх», при которой прогнозируется, что цена всегда пойдет вверх, поэтому всегда происходит покупка на следующую минуту.
- Стратегия «всегда вниз», при которой прогнозируется, что цена всегда пойдет вниз, поэтому всегда происходит продажа в следующую минуту.
- «Всезнающая» стратегия, при которой движение цены всегда предсказывается правильно, а покупка и продажа происходят надлежащим образом. Это дает максимально возможную прибыль от рынка.
- Стратегия, основанная на DirectionFeature (на основе DF), где
- Если DF положительный (т.е. EndPrice ближе к MaxPrice), покупайте акции на следующую минуту.
- Если DF отрицательный (т.е. EndPrice ближе к MinPrice), продать акции на следующую минуту.
- Стратегия, основанная на нейронной сети, которая на заданную минуту выдает прогнозируемое направление движения цены на следующую минуту, используя показатель прогноза.Этот показатель может иметь значение от -1 до 1. В общем случае
- Если оценка >0, предположим, что цена вырастет в следующую минуту, и купим акции
- Если счет равен 0, предположим, что цена не изменится в следующую минуту, и мы не торгуем
- Если оценка <0, предположите, что цена упадет в следующую минуту, и продайте акции.


Каждая стратегия, включая нейросеть, каждую минуту выделяла 1 евро на действия по покупке и продаже.Если решение было правильным, доход от 1 евро рассчитывался и добавлялся к общей сумме возврата. В случае ошибки убыток будет вычтен из общей суммы дохода. Это, конечно, чрезвычайно упрощенный подход, который не использует «портфель» акций и не принимает во внимание транзакционные издержки, но может сказать нам, как стратегии будут работать по отношению друг к другу. Здесь наша цель состояла в том, чтобы дать немедленную осмысленную интерпретацию прогнозов без использования ретроспективного тестирования. В будущей работе мы хотели бы сравнить эти методы с устоявшимися стратегиями, такими как экспоненциальная скользящая средняя, и базовыми линиями, такими как «Купи и держи» и MACD.
Мы создали три набора данных из полного набора данных для обучения, проверки и тестирования. Обучающая выборка состояла из 60% данных (120 дней) и использовалась для обучения модели.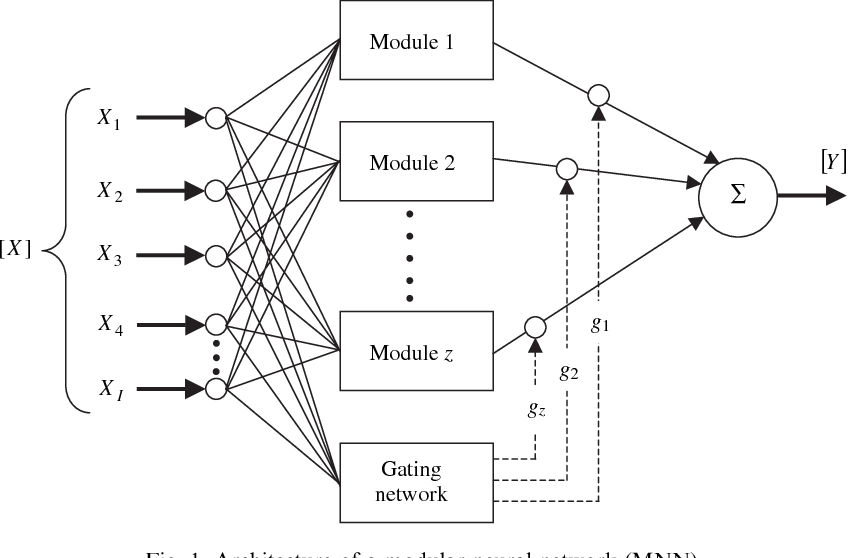 Проверочный набор, 5% данных (10 дней), использовался для оценки процесса обучения без предоставления характеристик модели, чтобы избежать переобучения. Тестовый набор состоял из оставшихся 35% данных (70 дней) и использовался для оценки модели в целом в этих задачах прогнозирования. Общий набор проверки + обучения был создан с использованием первых 130 дней, затем из него были отобраны 10 дней для создания набора проверки.Тестовый набор был создан из данных за последние 70 дней. Наш тест на тестовых данных вне выборки, вперед.
Проверочный набор, 5% данных (10 дней), использовался для оценки процесса обучения без предоставления характеристик модели, чтобы избежать переобучения. Тестовый набор состоял из оставшихся 35% данных (70 дней) и использовался для оценки модели в целом в этих задачах прогнозирования. Общий набор проверки + обучения был создан с использованием первых 130 дней, затем из него были отобраны 10 дней для создания набора проверки.Тестовый набор был создан из данных за последние 70 дней. Наш тест на тестовых данных вне выборки, вперед.
Затем мы обработали данные, опираясь на полученный ранее опыт и создав дополнительные шаги. Мы удалили все строки, в которых присутствовали значения «Н/Д», которые встречались там, где не было сделок, и чаще всего встречались в начале и конце торгового дня. Затем мы объединили данные об акциях за каждый день с окончанием торгов предыдущего дня, чтобы построить непрерывный временной ряд.Это не привело к перерывам в торговле, но позволило нам построить более простую и надежную модель. Мы также обрезали экстремальные выбросы, поскольку для хорошей работы нейронных сетей значения должны быть ограничены. Мы поняли, что модель не будет обучена отображать экстремальные движения, но компромисс был оправданным, поскольку нас больше интересовало предсказание направления движения, а не значения.
Мы также обрезали экстремальные выбросы, поскольку для хорошей работы нейронных сетей значения должны быть ограничены. Мы поняли, что модель не будет обучена отображать экстремальные движения, но компромисс был оправданным, поскольку нас больше интересовало предсказание направления движения, а не значения.
Затем был рассчитан набор признаков, который включал:
- Индикатор
- Конечная Цена
- Минимальная цена
- Максимальная цена
- Линейные комбинации EndPrice, MinPrice и MaxPrice
- Скользящее сглаженное стандартное отклонение EndPrice, рассчитанное с использованием оконных данных за предыдущие десять минут.
- Знак (+ или -) вычисляемой доходности.
Архитектура нейронной сети была построена как простая двухслойная плотная модель со штрафом L2 для предотвращения переобучения. В будущем могут быть построены и испытаны более сложные модели. Поскольку индикатор сам по себе является линейной комбинацией переменных компонентов, также возможно, что нейронная сеть может синтезировать его как функцию в скрытой единице.
| Торговая стратегия | Возврат (Евро) | % от макс.Возможный возврат |
|---|---|---|
| Всеведущий | 1638,60 | 100,00 |
| Нейронная сеть | 238.01 | 14,53 |
| Индикатор | 99,23 | 6,05 |
| Всегда вниз | 2,82 | 0,00 |
| Случайный | 1,35 | 0,00 |
| Всегда на связи | -2.82 | 0,00 |
Таблица 2. Эффективность торговых стратегий на тестовом наборе, измеренная и ранжированная по убыванию общей доходности.
Всезнающий подход дал максимально возможную прибыль в размере 1638,60 евро, полученную из этого набора данных. Чтобы понять это число, его следует разделить на количество акций и дней, и вы получите дневную норму доходности в день. Стратегия нейронной сети достигла 14,5% от теоретического максимума, что является очень обнадеживающим результатом для первого шага в этой области (это не следует рассматривать как генерацию 14.5% превышение, однако). Примечательно, что подход, основанный на индикаторах, достиг прибыли в 6% от максимума, что означает, что он сам по себе может быть хорошим предсказателем движения акций. Обратите внимание, что эти цифры представляют собой не доходность на финансовом рынке, а проценты от теоретического максимума. Числа полезны только для сравнения моделей между собой, но не для принятия обоснованных решений, будет ли модель полезна для торговой стратегии. Мы используем эту упрощенную стратегию, чтобы иметь более интерпретируемую метрику, чем частота ошибок, и мы не рекомендуем торговать по такой упрощенной стратегии.В идеале нам нужно проверить это на большем количестве временных рядов и акций, прежде чем делать убедительные выводы об эффективности этих подходов; тем не менее, они обещают первые результаты.
Стратегия нейронной сети достигла 14,5% от теоретического максимума, что является очень обнадеживающим результатом для первого шага в этой области (это не следует рассматривать как генерацию 14.5% превышение, однако). Примечательно, что подход, основанный на индикаторах, достиг прибыли в 6% от максимума, что означает, что он сам по себе может быть хорошим предсказателем движения акций. Обратите внимание, что эти цифры представляют собой не доходность на финансовом рынке, а проценты от теоретического максимума. Числа полезны только для сравнения моделей между собой, но не для принятия обоснованных решений, будет ли модель полезна для торговой стратегии. Мы используем эту упрощенную стратегию, чтобы иметь более интерпретируемую метрику, чем частота ошибок, и мы не рекомендуем торговать по такой упрощенной стратегии.В идеале нам нужно проверить это на большем количестве временных рядов и акций, прежде чем делать убедительные выводы об эффективности этих подходов; тем не менее, они обещают первые результаты.
Индикатор и нейросетевые стратегии торговали только на тех минутах, которые соответствовали условиям для торговли, а не на всех минутах. Стратегия, основанная на индикаторах, торговала 1 436 174 раза, тогда как нейронная сеть торговала 2 128 392 раза, что на 48% чаще, что указывает на то, что нейронная сеть может использовать больше ситуаций, чем стратегия, основанная на индикаторах.
В таблице 3 приведена разбивка производительности нейросетевого подхода с разбивкой по процентилям оценки прогноза; так, например, прогнозы в пределах 10% лучших абсолютных оценок прогнозов достигли точности 58,8% и охватили 7,7% всех сделок. Это дает нам представление о том, как точность меняется с оценками, что можно использовать для дальнейшей настройки производительности.
| Процентили оценки прогноза | Точность (%) | Процент ответивших (%) | Достигнутая нормализованная доходность (евро) |
|---|---|---|---|
| 10 | 58. 8 8 | 7,7 | 0,000437 |
| 20 | 57,6 | 15,5 | 0,000350 |
| 30 | 56,6 | 23,3 | 0,000299 |
| 40 | 56,0 | 31,2 | 0,000262 |
| 50 | 55,5 | 39,3 | 0,000233 |
| 60 | 55.1 | 46,9 | 0,000212 |
| 70 | 54,7 | 54,8 | 0,000192 |
| 80 | 54,3 | 62,6 | 0,000175 |
| 90 | 53,9 | 70,4 | 0,000160 |
Таблица 3. Производительность нейронной сети при прогнозировании движения запасов
Обратите внимание, что Достигнутый нормализованный доход на сделку ниже, чем типичные транзакционные издержки на сделку. Ясно, что это означает, что в действительности мы будем работать с чистыми убытками. На практике вы будете торговать только тогда, когда ожидаете, что величина изменения цены будет больше, чем стоимость. При более сложной торговой стратегии это будет принято во внимание.
Ясно, что это означает, что в действительности мы будем работать с чистыми убытками. На практике вы будете торговать только тогда, когда ожидаете, что величина изменения цены будет больше, чем стоимость. При более сложной торговой стратегии это будет принято во внимание.
Дополнительная работа также показала, что разные акции и разные дни показывали разные результаты, когда речь шла о прогнозах движения цены. Неясно, является ли это результатом каких-то фундаментальных отличий или просто фазой поведения некоторых акций.Чтобы определить это, потребуется дополнительная работа.
Резюме
Мы показали, что можем использовать нейронную сеть для прогнозирования будущих движений акций в общедоступном наборе данных Deutsche Boerse, и использовали это как основу упрощенной торговой стратегии. Используемая здесь модель нейронной сети намеренно проста, и существует ряд моделей и методов, которые могут дать лучшие результаты.
Long-Short Term Memory (LSTM) и сверточные слои — многообещающие кандидаты, которые могут позволить нам использовать данные далеко за пределами предыдущих 10 минут. Другой подход заключается в создании сети, которая использует цены других акций для прогнозирования стоимости друг друга, особенно тех, которые, как известно, коррелируют. Применение типичных приемов нейронной сети, таких как настройка гиперпараметров, также должно повысить производительность. Построение модели, которая настраивается на дисперсию признаков во временном ряду, вместо того, чтобы нормализовать все признаки перед их передачей в сеть, также может быть потенциальным путем.
Другой подход заключается в создании сети, которая использует цены других акций для прогнозирования стоимости друг друга, особенно тех, которые, как известно, коррелируют. Применение типичных приемов нейронной сети, таких как настройка гиперпараметров, также должно повысить производительность. Построение модели, которая настраивается на дисперсию признаков во временном ряду, вместо того, чтобы нормализовать все признаки перед их передачей в сеть, также может быть потенциальным путем.
Другие идеи включают использование торговых объемов и количества сделок (как определено в наборе данных PDS) в качестве характеристик модели, использование моделей с несколькими входами и несколькими выходами, которые могут одновременно учиться прогнозировать как объемы, так и цены, и использование глобального рынка. тренды прошлых дней или месяцев в качестве предикторов.
Мы считаем, что для максимизации прибыли можно проделать большую работу, опираясь на нашу простую торговую стратегию. Очевидной областью является попытка предсказать величины ценовых движений вместе с неопределенностями, что позволит стратегии делать более крупные ставки, когда величина высока, а неопределенность низка. Внедрение моделирования проскальзываний по методу Монте-Карло и торговых издержек также помогло бы разработать стратегию, лучше подходящую для реальной торговли, которую можно было бы полностью протестировать на исторических данных. Мы также хотели бы отказаться от простого определения доходности, используемого здесь, и использовать альфа-канал в соответствии с текущей практикой в отрасли.Мы также хотели бы сравнить оцениваемые здесь стратегии с устоявшимися в отрасли, чтобы понять их эффективность по сравнению с проверенными подходами.
Очевидной областью является попытка предсказать величины ценовых движений вместе с неопределенностями, что позволит стратегии делать более крупные ставки, когда величина высока, а неопределенность низка. Внедрение моделирования проскальзываний по методу Монте-Карло и торговых издержек также помогло бы разработать стратегию, лучше подходящую для реальной торговли, которую можно было бы полностью протестировать на исторических данных. Мы также хотели бы отказаться от простого определения доходности, используемого здесь, и использовать альфа-канал в соответствии с текущей практикой в отрасли.Мы также хотели бы сравнить оцениваемые здесь стратегии с устоявшимися в отрасли, чтобы понять их эффективность по сравнению с проверенными подходами.
После тщательных экспериментов с различными прогностическими функциями и наблюдения различных эффектов в разные торговые дни и акции мы считаем, что наша работа показывает лишь многообещающую нижнюю границу проблемы прогнозирования и понимания движения цен акций. В то же время это интересный полигон для идей в области машинного обучения.Движения цен действуют в разных масштабах для разных акций и торговых дней. Наблюдаемые эффекты нелинейны с поворотной точкой, которая меняет локальный или глобальный тренд. Это резко контрастирует со многими задачами машинного обучения, где данные стационарны, а многие эффекты суммируются.
В то же время это интересный полигон для идей в области машинного обучения.Движения цен действуют в разных масштабах для разных акций и торговых дней. Наблюдаемые эффекты нелинейны с поворотной точкой, которая меняет локальный или глобальный тренд. Это резко контрастирует со многими задачами машинного обучения, где данные стационарны, а многие эффекты суммируются.
Мы надеемся, что эта работа вдохновит вас на новые проекты по прогнозированию фондового рынка, особенно с использованием общедоступного набора данных DBG и его поминутной детализации. Мы с нетерпением ждем дальнейших результатов от сообщества машинного обучения в этой области.
Приложение
Сезонное разложение
На этапе исследования мы использовали сезонную декомпозицию, чтобы начать понимать данные о запасах как временной ряд. Этот метод разбивает данный временной ряд на 3 компонента:
- Тенденция, показывающая, как данные изменяются с течением времени после исключения сезонности.
- Сезонность, которая является базовой моделью, которой может следовать ряд данных, если он имеет какой-либо сезонный компонент, такой как дневной, недельный или месячный цикл.
- Остаток, который отражает оставшуюся часть временного ряда после вычитания трендовых и сезонных компонентов.

Мы применили это к временному ряду отдельных акций, чтобы изучить их основную природу.
Используя информацию о ценах, мы обнаружили, что, хотя сезонные компоненты обычно демонстрируют четкий дневной цикл с сильными базовыми тенденциями, величина остатков относительно велика. Это подтвердило нам, что использование простой сезонной модели для прогнозирования цен не даст хороших результатов.
Рис. 6: Пример сезонного разложения
Кластеризация
Также на этапе исследования мы стремились определить, демонстрируют ли акции сходство с точки зрения ценовых тенденций с течением времени и можно ли их сгруппировать в соответствии с этим. Известно, что движение цен на акции часто коррелирует с другими акциями. Мы попытались создать простую кластеризацию акций, рассчитав корреляцию движения конечной цены каждой акции с движениями других акций с течением времени и визуализировав результаты.Наша мотивация заключалась в том, что, используя движение цен других акций, мы могли лучше предсказать движение цены целевой акции.
Известно, что движение цен на акции часто коррелирует с другими акциями. Мы попытались создать простую кластеризацию акций, рассчитав корреляцию движения конечной цены каждой акции с движениями других акций с течением времени и визуализировав результаты.Наша мотивация заключалась в том, что, используя движение цен других акций, мы могли лучше предсказать движение цены целевой акции.
Мы построили матрицу парной корреляции для временных рядов акций, вычислив корреляцию Пирсона для каждой пары акций в нашем полном наборе данных и сохранив ее в массиве элементов 100×100. Затем, используя разложение по сингулярным значениям (SVD), мы сократили количество измерений, описывающих каждую акцию, со 100 до 50. Это дает более «сжатое» представление векторного пространства и может помочь процессу кластеризации дать лучшие результаты.Мы применили алгоритм кластеризации HDBSCAN к векторам с минимальным числом кластеров, равным 2. Затем это было визуализировано с помощью алгоритма T-SNE для представления кластеров в двух измерениях.
Рис. 7. Пример кластеризации акций
Алгоритм создал 4 кластера с 9 акциями, которые были классифицированы как выбросы. Мы видим один большой кластер из 74 акций и вторичный кластер из 12 акций. Два других кластера имеют номера всего 4 и 2 соответственно.Мы видим, что большинство акций ведут себя одинаково, и что другие кластеры объясняют большинство других. Возможно, можно усовершенствовать этот подход к кластеризации для поиска более мелких кластеров, но эти результаты были иллюстративными для наших исследовательских целей.
Генерация и тестирование функций
Помимо изучения индикатора, мы разработали методологию с высокой пропускной способностью для выявления существующих и созданных функций с прогнозирующей силой в отношении нормы прибыли в EndPrice в следующую минуту.
Подход был основан на идее ранжирования объектов по их корреляции со скоростью изменения EndPrice в следующую минуту. Чтобы увеличить широту исследования, мы создали новые функции, применяя преобразования к функциям, таким как «МинМакс», «Оконный режим» и «Скорость изменения», и ранжировали их как функции сами по себе. В результате было создано около 3000 функций и такое же количество сравнений.
В результате было создано около 3000 функций и такое же количество сравнений.
Мы наблюдали несколько характеристик, таких как объем, коррелирующий с абсолютной нормой доходности, но не с направлением дельты.Другими словами, эти характеристики можно использовать для предсказания величины предстоящих ценовых изменений, но не для того, будут ли они отрицательными или положительными. Однако ничто не превзошло индикатор, основанный на EndPrice, MaxPrice и MinPrice. Мы ожидали, что объемы каким-то образом коррелируют с доходностью, поскольку знали, что высокочастотные трейдеры часто используют разницу в лимитных ордерах на покупку и продажу в книге ордеров, чтобы предвидеть направление цены. Эта информация не является частью PDS, в некоторой степени используется только том в качестве прокси.
Мы обнаружили, что акции по-разному коррелируют с ценой, что указывает на диапазон поведения во временном ряду акций. Мы также заметили, что большинство корреляций, хотя и сильные для определенного дня или акции, могут полностью поменять знак на другой день или другую акцию. Это основа парной торговли, где, если линейная комбинация акций является стационарной, мы можем сформировать стратегию, основанную на торговле их корзиной.
Это основа парной торговли, где, если линейная комбинация акций является стационарной, мы можем сформировать стратегию, основанную на торговле их корзиной.
Кредиты
Мы благодарны нашим рецензентам Originate за их отзывы и Аджаю Мансухани за его объяснения того, как трейдинг работает на практике.
Ссылка на репозиторий Github
Искусственные нейронные сети для прогнозирования фондового рынка: всесторонний обзор
Действия
‘) var buybox = document.querySelector(«[data-id=id_»+ метка времени +»]»).parentNode ;[].slice.call(buybox.querySelectorAll(«.вариант-покупки»)).forEach(initCollapsibles) функция initCollapsibles(подписка, индекс) { var toggle = подписка.querySelector(«.Цена-варианта-покупки») подписка.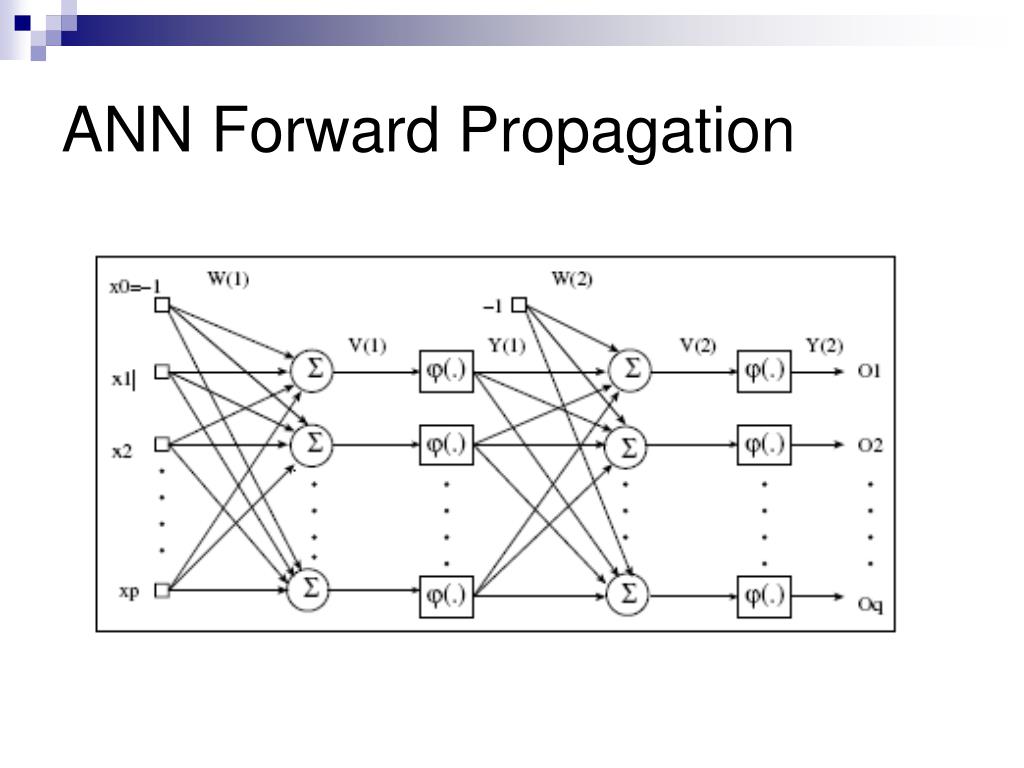 classList.remove(«расширенный»)
var form = подписка.querySelector(«.форма-варианта-покупки») если (форма) {
вар formAction = form.getAttribute(«действие»)
form.setAttribute(«действие», formAction.replace(«/checkout», «/cart»))
document.querySelector(«#ecommerce-scripts»).addEventListener(«load», bindModal(form, formAction, timestamp, index), false)
} var priceInfo = подписка.селектор запросов(«.Информация о цене»)
var PurchaseOption = toggle.parentElement если (переключить && форма && priceInfo) {
toggle.setAttribute(«роль», «кнопка»)
toggle.setAttribute(«tabindex», «0») toggle.addEventListener («щелчок», функция (событие) {
var expand = toggle.
classList.remove(«расширенный»)
var form = подписка.querySelector(«.форма-варианта-покупки») если (форма) {
вар formAction = form.getAttribute(«действие»)
form.setAttribute(«действие», formAction.replace(«/checkout», «/cart»))
document.querySelector(«#ecommerce-scripts»).addEventListener(«load», bindModal(form, formAction, timestamp, index), false)
} var priceInfo = подписка.селектор запросов(«.Информация о цене»)
var PurchaseOption = toggle.parentElement если (переключить && форма && priceInfo) {
toggle.setAttribute(«роль», «кнопка»)
toggle.setAttribute(«tabindex», «0») toggle.addEventListener («щелчок», функция (событие) {
var expand = toggle. getAttribute(«aria-expanded») === «true» || ложный
переключать.setAttribute(«расширенная ария», !расширенная)
form.hidden = расширенный
если (! расширено) {
покупкаOption.classList.add(«расширенный»)
} еще {
покупкаOption.classList.remove(«расширенный»)
}
priceInfo.hidden = расширенный
}, ложный)
}
} функция bindModal (форма, formAction, метка времени, индекс) {
var weHasBrowserSupport = окно.выборка && Array.from функция возврата () {
var Buybox = EcommScripts ? EcommScripts.Buybox : ноль
var Modal = EcommScripts ? EcommScripts.Modal : ноль if (weHasBrowserSupport && Buybox && Modal) {
var modalID = «ecomm-modal_» + метка времени + «_» + индекс var modal = новый модальный (modalID)
модальный.
getAttribute(«aria-expanded») === «true» || ложный
переключать.setAttribute(«расширенная ария», !расширенная)
form.hidden = расширенный
если (! расширено) {
покупкаOption.classList.add(«расширенный»)
} еще {
покупкаOption.classList.remove(«расширенный»)
}
priceInfo.hidden = расширенный
}, ложный)
}
} функция bindModal (форма, formAction, метка времени, индекс) {
var weHasBrowserSupport = окно.выборка && Array.from функция возврата () {
var Buybox = EcommScripts ? EcommScripts.Buybox : ноль
var Modal = EcommScripts ? EcommScripts.Modal : ноль if (weHasBrowserSupport && Buybox && Modal) {
var modalID = «ecomm-modal_» + метка времени + «_» + индекс var modal = новый модальный (modalID)
модальный. domEl.addEventListener(«закрыть», закрыть)
функция закрыть () {
form.querySelector(«кнопка[тип=отправить]»).фокус()
} форма.setAttribute(
«действие»,
formAction.replace(«/checkout», «/cart?messageOnly=1»)
) form.addEventListener(
«Отправить»,
Буйбокс.перехват формы отправки (
Buybox.fetchFormAction(окно.fetch),
Buybox.triggerModalAfterAddToCartSuccess(модальный),
консоль.лог,
),
ложный
) document.
domEl.addEventListener(«закрыть», закрыть)
функция закрыть () {
form.querySelector(«кнопка[тип=отправить]»).фокус()
} форма.setAttribute(
«действие»,
formAction.replace(«/checkout», «/cart?messageOnly=1»)
) form.addEventListener(
«Отправить»,
Буйбокс.перехват формы отправки (
Buybox.fetchFormAction(окно.fetch),
Buybox.triggerModalAfterAddToCartSuccess(модальный),
консоль.лог,
),
ложный
) document. body.appendChild(modal.domEl)
}
}
} функция initKeyControls() {
документ.addEventListener(«keydown», функция (событие) {
if (document.activeElement.classList.contains(«цена-варианта-покупки») && (event.code === «Пробел» || event.code === «Enter»)) {
если (document.activeElement) {
событие.preventDefault()
документ.activeElement.click()
}
}
}, ложный)
} функция InitialStateOpen() {
var buyboxWidth = buybox.смещениеШирина
;[].slice.call(buybox.querySelectorAll(«.опция покупки»)).forEach(функция (опция, индекс) {
var toggle = option.querySelector(«.
body.appendChild(modal.domEl)
}
}
} функция initKeyControls() {
документ.addEventListener(«keydown», функция (событие) {
if (document.activeElement.classList.contains(«цена-варианта-покупки») && (event.code === «Пробел» || event.code === «Enter»)) {
если (document.activeElement) {
событие.preventDefault()
документ.activeElement.click()
}
}
}, ложный)
} функция InitialStateOpen() {
var buyboxWidth = buybox.смещениеШирина
;[].slice.call(buybox.querySelectorAll(«.опция покупки»)).forEach(функция (опция, индекс) {
var toggle = option.querySelector(«. цена-варианта-покупки»)
var form = option.querySelector(«.форма-варианта-покупки»)
var priceInfo = option.querySelector(«.Информация о цене»)
если (buyboxWidth > 480) {
переключить.щелчок()
} еще {
если (индекс === 0) {
переключать.щелчок()
} еще {
toggle.setAttribute («ария-расширенная», «ложь»)
form.hidden = «скрытый»
priceInfo.hidden = «скрытый»
}
}
})
} начальное состояниеОткрыть() если (window.buyboxInitialized) вернуть
window.buyboxInitialized = истина initKeyControls()
})()
цена-варианта-покупки»)
var form = option.querySelector(«.форма-варианта-покупки»)
var priceInfo = option.querySelector(«.Информация о цене»)
если (buyboxWidth > 480) {
переключить.щелчок()
} еще {
если (индекс === 0) {
переключать.щелчок()
} еще {
toggle.setAttribute («ария-расширенная», «ложь»)
form.hidden = «скрытый»
priceInfo.hidden = «скрытый»
}
}
})
} начальное состояниеОткрыть() если (window.buyboxInitialized) вернуть
window.buyboxInitialized = истина initKeyControls()
})()Могут ли нейронные сети предсказывать фондовый рынок, просто читая газеты?
Говорят, что рынки управляются случайностью, но это не означает, что они на 100% случайны и, следовательно, совершенно непредсказуемы. В конце концов, за инвестициями всегда стоят люди, и многие из них принимают решения, основываясь на том, что они читают в газетах. Мы попытаемся оценить доходность временного ряда, а именно Биткойн, , используя только текстовые данные из соответствующих статей. BERT, сеть глубокого обучения НЛП, будет использоваться для анализа тональности текста.
В конце концов, за инвестициями всегда стоят люди, и многие из них принимают решения, основываясь на том, что они читают в газетах. Мы попытаемся оценить доходность временного ряда, а именно Биткойн, , используя только текстовые данные из соответствующих статей. BERT, сеть глубокого обучения НЛП, будет использоваться для анализа тональности текста.
Я выбрал биткойн для этого эксперимента, так как его стоимость имеет огромную волатильность и очень подвержена изменениям из-за внезапных ажиотажей и страхов, обычно отражаемых в газетах.Хотя Биткойн — это криптовалюта, а не акция, строго говоря, его можно покупать и продавать одним и тем же способом. Это делает его полностью подходящим для наших нужд.
Текстовая регрессия: что мы делаем?
Идея этого поста состоит в том, чтобы использовать НЛП для регрессии текста. Этот метод состоит из кодирования входного текста в виде числовых векторов , а затем их использования для проведения регрессионного анализа и оценки выходного значения .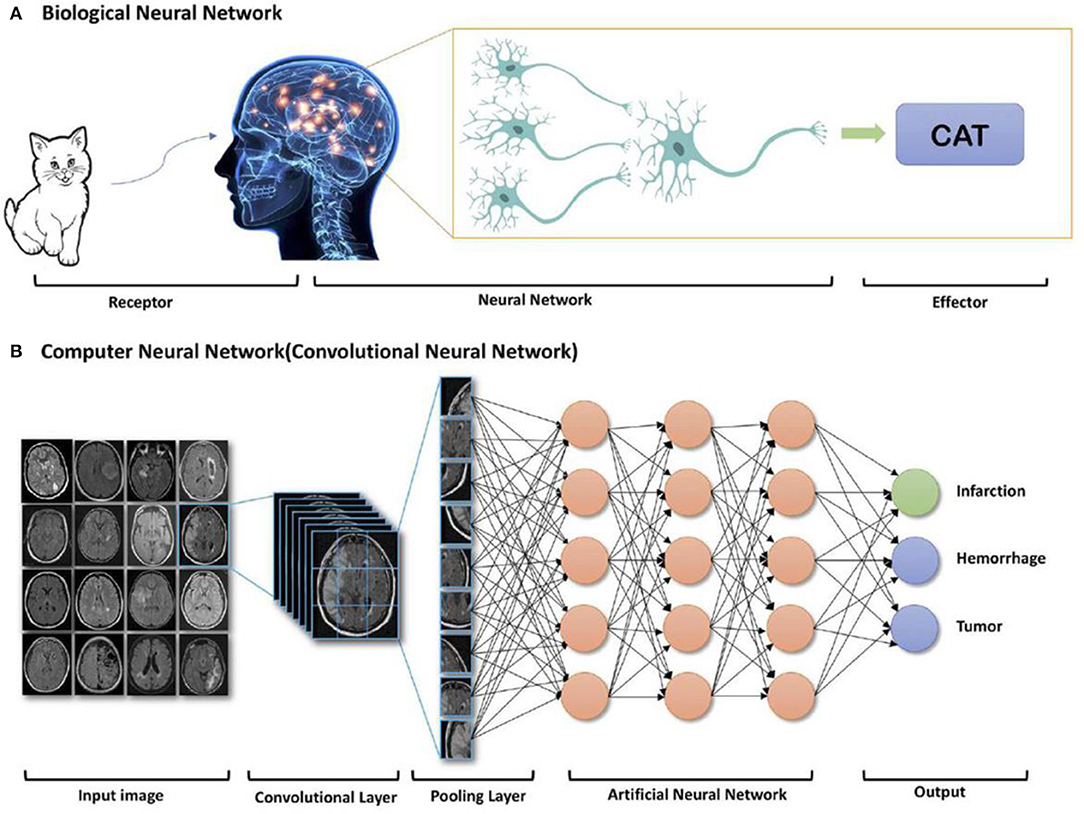 В нашем случае входными данными будет текст из статей, связанных с Биткойном, закодированный и преобразованный с помощью BERT , а целевым значением будут возвраты близких значений Биткойна на дату публикации таких статей.
В нашем случае входными данными будет текст из статей, связанных с Биткойном, закодированный и преобразованный с помощью BERT , а целевым значением будут возвраты близких значений Биткойна на дату публикации таких статей.
Проверка биографических данных: что такое BERT?
BERT (представления двунаправленного кодировщика от трансформеров) — это нейронная сеть, предназначенная для решения любой задачи НЛП. Разработанный исследователями из Google, он вскоре стал современным, побив рекорды во многих различных тестах НЛП (бумага).
Сети языкового моделирования обычно обучаются путем случайного маскирования слов в каждом предложении и попытки предсказать их с учетом предыдущих или последующих.Например, маскируем слово « мат » в предложении:
«Кошка сидела на ____».
Сеть попытается угадать слово «мат», зная предыдущие. Учитывая миллионы упорядоченных предложений, эти сети учатся точно предсказывать пустые места, глядя на текст либо до, либо после замаскированного слова , , но не оба . Если вы обучаете сеть информацией с обеих сторон, модель будет переобучать, поскольку вы будете неявно указывать ответ на нее при обучении с другими предложениями.Именно здесь вступает в игру основная новинка BERT, поскольку она предназначена для изучения замаскированных слов из текста до и после (именно это означает двунаправленность). BERT преодолевает эту трудность, используя две техники Masked LM (MLM) и Prediction Next Sentence Prediction (NSP), которые выходят за рамки этого поста. Это позволяет BERT иметь гораздо более глубокое понимание языкового контекста, чем предыдущие решения.
Если вы обучаете сеть информацией с обеих сторон, модель будет переобучать, поскольку вы будете неявно указывать ответ на нее при обучении с другими предложениями.Именно здесь вступает в игру основная новинка BERT, поскольку она предназначена для изучения замаскированных слов из текста до и после (именно это означает двунаправленность). BERT преодолевает эту трудность, используя две техники Masked LM (MLM) и Prediction Next Sentence Prediction (NSP), которые выходят за рамки этого поста. Это позволяет BERT иметь гораздо более глубокое понимание языкового контекста, чем предыдущие решения.
Создание набора данных
Чтобы получить статьи, связанные с биткойнами, я использовал несколько замечательных пакетов Python, которые оказались очень удобными, например, поиск Google и новости.Первый эмулирует поиск в Google и извлекает набор URL-адресов. Последний извлекает много информации из статьи (дата публикации, авторы, основной заголовок, основной текст и т. д.) по URL-адресу.
д.) по URL-адресу.
Объединив эти два параметра, я получил 5 лучших статей на английском языке, которые появились в новостях Google, введя поисковый запрос: «Биткойн | Криптовалюта» на каждый день между 2019-01-01 и 2020-03-19 .
Возможность имитации поиска в Google гарантирует, что первые статьи, которые появляются в списке, являются наиболее релевантными, и можно предположить, что те, которые оказали большее влияние.Черта между двумя ключевыми словами в поисковом запросе действует как функция ИЛИ. Всего я собрал датасет из 2210 статей. Вот вам небольшая выборка:
Анализ настроений с помощью BERT
А вот и самое интересное, пришло время извлечь тональность всего текста, который мы только что собрали. BERT — тяжеловес, когда дело доходит до вычислительных ресурсов, поэтому после некоторых тестов я решил работать только с текстом в заголовке и описании каждой статьи . Я разбил все эти куски текста на предложения. В конце концов, мой набор данных состоял из набора предложений, сгруппированных по дням их публикации. Я использовал версию BERT, доступную в виде преобразователя Huggingface, который предварительно обучен для анализа настроений по обзорам продуктов . Учитывая обзор продукта, он предсказывает его «настроение» в виде количества звезд (от 1 до 5). Несмотря на то, что текст обзора продукта и текст газеты довольно сильно различаются, мы увидим, что эта модель работает на наших данных на удивление хорошо.Вот вам пример:
Я разбил все эти куски текста на предложения. В конце концов, мой набор данных состоял из набора предложений, сгруппированных по дням их публикации. Я использовал версию BERT, доступную в виде преобразователя Huggingface, который предварительно обучен для анализа настроений по обзорам продуктов . Учитывая обзор продукта, он предсказывает его «настроение» в виде количества звезд (от 1 до 5). Несмотря на то, что текст обзора продукта и текст газеты довольно сильно различаются, мы увидим, что эта модель работает на наших данных на удивление хорошо.Вот вам пример:
предложение = «Фьючерсы на биткойн торгуются ниже спотовой цены криптовалюты» предложение_ids = tokenizer.encode (предложение) bert_model.predict([sentence_ids]) # 1 звезда 2 звезды 3 звезды 4 звезды 5 звезд [[ 0,62086743 0,7408671 0,599566 -0,50914824 -1,2169912 ]]
Преобразователь состоит из двух частей: основная модель , отвечающая за прогнозирование настроений, и токенизатор , используемый для преобразования предложения в идентификаторы, которые модель может понять. Токенизатор делает это, просматривая каждое слово в словаре и заменяя его его идентификатором. Прежде чем делать прогнозы для всех наших предложений в нашем наборе данных, мы должны убедиться, что модель понимает самые важные слова, связанные с биткойнами. После подсчета слов в предложениях на основе набора ключевых слов я добавил эти термины в токенизатор [‘биткойн’, ‘криптовалюта’, ‘крипто’, ‘криптовалюты’, ‘блокчейн’] , который был назначен конкретным идентификаторам. . Добавление этих терминов позволяет сети различать их как отдельные слова, иначе все они были бы заменены идентификатором «неизвестных слов».
Токенизатор делает это, просматривая каждое слово в словаре и заменяя его его идентификатором. Прежде чем делать прогнозы для всех наших предложений в нашем наборе данных, мы должны убедиться, что модель понимает самые важные слова, связанные с биткойнами. После подсчета слов в предложениях на основе набора ключевых слов я добавил эти термины в токенизатор [‘биткойн’, ‘криптовалюта’, ‘крипто’, ‘криптовалюты’, ‘блокчейн’] , который был назначен конкретным идентификаторам. . Добавление этих терминов позволяет сети различать их как отдельные слова, иначе все они были бы заменены идентификатором «неизвестных слов».
5-звездочные прогнозы доходности акций
После этого BERT сделал 5-звездочные прогнозы для всех предложений, как если бы они были обзорами продуктов, доступных на Amazon. Я вычислил средние значения каждой из звезд для предложений, которые принадлежали каждому дню, и обучил простую сеть LSTM на полученных данных.
определение lstm_model (n_steps):
n_звезд = 5
модель = Последовательный()
model. add(LSTM(100, input_shape = (n_steps, n_stars), return_sequences = True))
модель.добавить (TimeDistributed (Dense (20, активация = 'elu')))
model.add(Свести())
model.add (плотный (1, активация = 'элу'))
model.compile (потеря = 'mean_squared_error', оптимизатор = 'адам')
печать (модель.резюме())
модель возврата
 add(LSTM(100, input_shape = (n_steps, n_stars), return_sequences = True))
модель.добавить (TimeDistributed (Dense (20, активация = 'elu')))
model.add(Свести())
model.add (плотный (1, активация = 'элу'))
model.compile (потеря = 'mean_squared_error', оптимизатор = 'адам')
печать (модель.резюме())
модель возврата
add(LSTM(100, input_shape = (n_steps, n_stars), return_sequences = True))
модель.добавить (TimeDistributed (Dense (20, активация = 'elu')))
model.add(Свести())
model.add (плотный (1, активация = 'элу'))
model.compile (потеря = 'mean_squared_error', оптимизатор = 'адам')
печать (модель.резюме())
модель возврата
Я обучил модель на прошлогодних данных (статьи между
от 01.01.2019 и 11.01.2019) и протестировал ее на данных за 2020 год (до 19.03). Поиграв некоторое время с гиперпараметрами сети, мы получили следующий результат.
Что только что произошло?
Я знаю, это далеко не идеально.Но если вы посмотрите повнимательнее, вы заметите, что есть тенденции, которые были признаны BERT и дуэтом LSTM. Прогнозы начинаются в ноябре и совпадают с реальными сериями. Рождество — это полный беспорядок, поскольку наша модель продолжает предсказывать нисходящий тренд, когда биткойн резко растет.![]() Затем мы можем увидеть, как модель реагирует и достигает максимума, который прекрасно совпадает с таковым в реальной серии. Про прогнозы на начало марта комментариев нет. Правда, такую резкую перемену трудно предвидеть (даже газетам?).
Затем мы можем увидеть, как модель реагирует и достигает максимума, который прекрасно совпадает с таковым в реальной серии. Про прогнозы на начало марта комментариев нет. Правда, такую резкую перемену трудно предвидеть (даже газетам?).
В общем, модель может более или менее точно предсказать небольших пиков и спадов. Это очень хороший знак, если принять во внимание, что модель не использует в качестве ввода ничего, кроме текста . Взгляните на рисунок с необработанными доходами ниже. Качество наших данных не очень хорошее. В конце концов, мы используем 5 лучших статей, которые являются более «релевантными» по мнению Google (что бы это ни значило). Если бы мы собирали текст более тщательно, мы, вероятно, получили бы лучшие результаты.
Сырая и прогнозируемая доходность за тестовый период
Тесла: второе мнение
Мне было любопытно, как этот подход поведет себя в другом случае. Тесла — это акции, которые ведут себя довольно безумно. Илон Маск пишет загадочный твит, и акции TSLA трясутся. Это идеально подходит для нашего эксперимента. Я следовал точно такому же процессу. Во-первых, я получил 5 лучших статей за каждый день. Затем я передал текст через BERT и в конце применил сеть LSTM. Вот результаты:
Илон Маск пишет загадочный твит, и акции TSLA трясутся. Это идеально подходит для нашего эксперимента. Я следовал точно такому же процессу. Во-первых, я получил 5 лучших статей за каждый день. Затем я передал текст через BERT и в конце применил сеть LSTM. Вот результаты:
Мы можем видеть, как прогнозы модели следуют начавшемуся восходящему тренду, определяя некоторые долины в январе и феврале.Таким образом, он полностью игнорирует падение цен в марте (но кто это предвидел, верно?). Здесь у вас есть необработанные результаты:
Доходы Tesla по сравнению с доходами, предсказанными нашей модельюКлючевые выводы
В LSTM использовались последовательности из 10 временных шагов (то есть с использованием данных за последние 10 дней для прогнозирования завтрашней доходности). При использовании большего или меньшего количества временных шагов прогнозы становились нестабильными. Чтобы добиться стабильности, мы могли бы использовать разницу в цене в течение нескольких дней в качестве целевого значения вместо доходности. Другой вариант — разработать стратегию, предсказывающую фиксированный рост в зависимости от позитивности или негативности настроений. В заключение этого поста я хочу выделить следующие моменты:
Другой вариант — разработать стратегию, предсказывающую фиксированный рост в зависимости от позитивности или негативности настроений. В заключение этого поста я хочу выделить следующие моменты:
- Похоже, что новостных статей иногда влияют на движений рынка.
- BERT — чрезвычайно мощная сеть , способная решать многие задачи НЛП, в том числе анализ настроений.
- Модели НЛП, основанные на новостных данных, могут быть полезны для дополнения стратегий инвестиционного портфеля .
Чтобы проверить код, используемый для этого сообщения, взгляните на мой репозиторий Github
. Система искусственного интеллекта— использование нейронных сетей с глубоким обучением — превосходит фондовый рынок в моделировании
Исследователи из Италии объединили новую науку о сверточных нейронных сетях (CNN) с глубоким обучением — дисциплиной в рамках искусственного интеллекта — для создания системы прогнозирования рынка с потенциалом большей прибыли и меньшими потерями, чем предыдущие попытки использовать методы ИИ для управлять портфелями акций.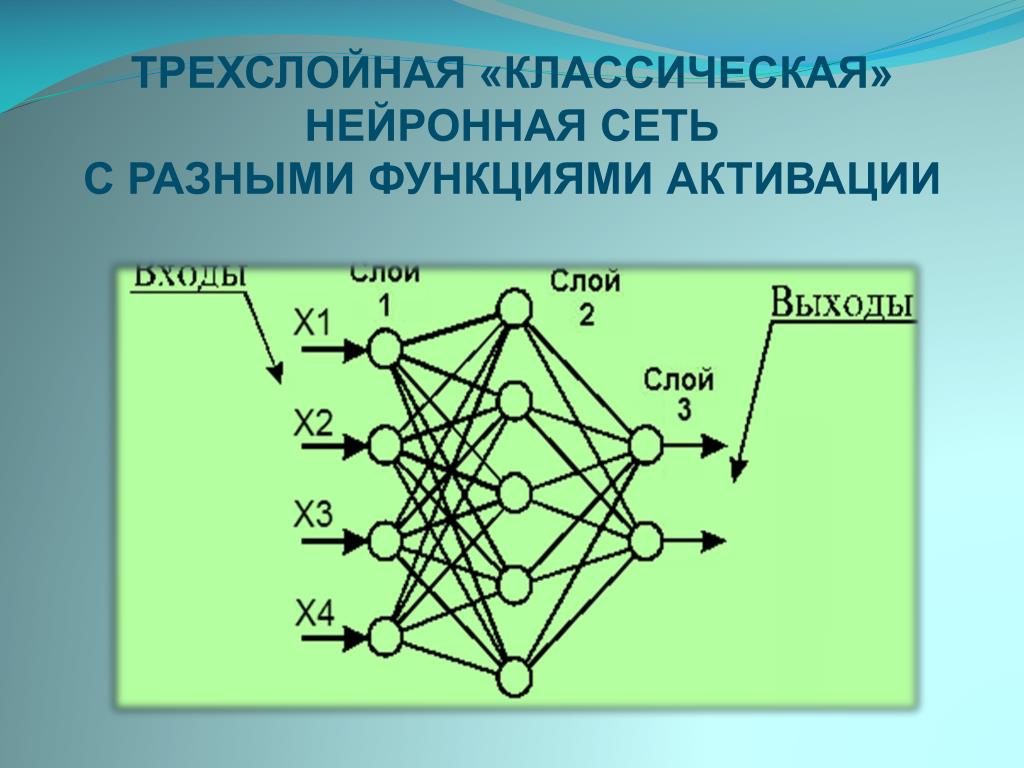 Команда под руководством профессора Сильвио Барра из Университета Кальяри опубликовала свои выводы в IEEE/CAA Journal of Automatica Sinica .
Команда под руководством профессора Сильвио Барра из Университета Кальяри опубликовала свои выводы в IEEE/CAA Journal of Automatica Sinica .
Команда из Университета Кальяри приступила к созданию управляемой ИИ стратегии «купи и держи» (B&H) — системы принятия решения о том, следует ли предпринять одно из трех возможных действий — долгосрочное действие (покупка акций и их продажа до рынок закрывается), короткое действие (продажа акций, а затем покупка их обратно до закрытия рынка) и удержание (решение не инвестировать в акции в этот день).В основе предлагаемой ими системы лежит автоматизированный цикл анализа многоуровневых изображений, созданных на основе текущих и прошлых рыночных данных. Старые системы B&H основывали свои решения на машинном обучении — дисциплине, которая в значительной степени опирается на прогнозы, основанные на прошлой производительности.
Позволив предлагаемой ими сети анализировать текущие данные, наложенные на прошлые данные, они делают шаг вперед в прогнозировании рынка, допуская тип обучения, который более точно отражает интуицию опытного инвестора, а не робота.Предлагаемая ими сеть может корректировать свои пороги покупки/продажи в зависимости от того, что происходит как в настоящий момент, так и в прошлом. Учет современных факторов повышает доходность как по сравнению со случайным угадыванием, так и с алгоритмами торговли, не способными к обучению в реальном времени.
Чтобы подготовить свою CNN к эксперименту, исследовательская группа использовала данные S&P 500 с 2009 по 2016 год. S&P 500 широко считается лакмусовой бумажкой здоровья всего мирового рынка.
Сначала предложенная ими торговая система предсказывала рынок с точностью около 50 процентов, или достаточно точно, чтобы безубыточность в реальной ситуации.Они обнаружили, что краткосрочные выбросы, которые неожиданно оказались лучше или хуже, порождают фактор, который они назвали «случайностью». Понимая это, они добавили пороговые элементы управления, что в конечном итоге значительно стабилизировало их метод.
«Уменьшение случайности приводит к двум простым, но важным последствиям», — сказал профессор Барра. «Когда мы проигрываем, мы, как правило, проигрываем очень мало, а когда мы выигрываем, мы, как правило, выигрываем значительно».
По словам проф.Барра, так как другие уже используемые методы автоматической торговли делают рынки все более и более сложными для прогнозирования.
Ссылка: «Глубокое обучение и кодирование временных рядов в изображения для финансового прогнозирования» Сильвио Барра, Сальваторе Марио Карта, Андреа Коррига, Алессандро Себастьян Подда и Диего Рефоргиато Рекуперо, май 2020 г., IEEE/CAA Journal of Automatica Sinica .
DOI: 10.1109/JAS.2020.1003132