Паттерн Data Access Object — JavaTutor.net
1 Контекст
2 Проблема
3 Ограничения
4 Решение
4.1 Структура
4.2 Участники и обязанности
4.2.1 BusinessObject
4.2.2 DataAccessObject
4.2.3 DataSource
4.2.4 TransferObject
4.3 Стратегии
4.3.1 Стратегия Automatic DAO Code Generation
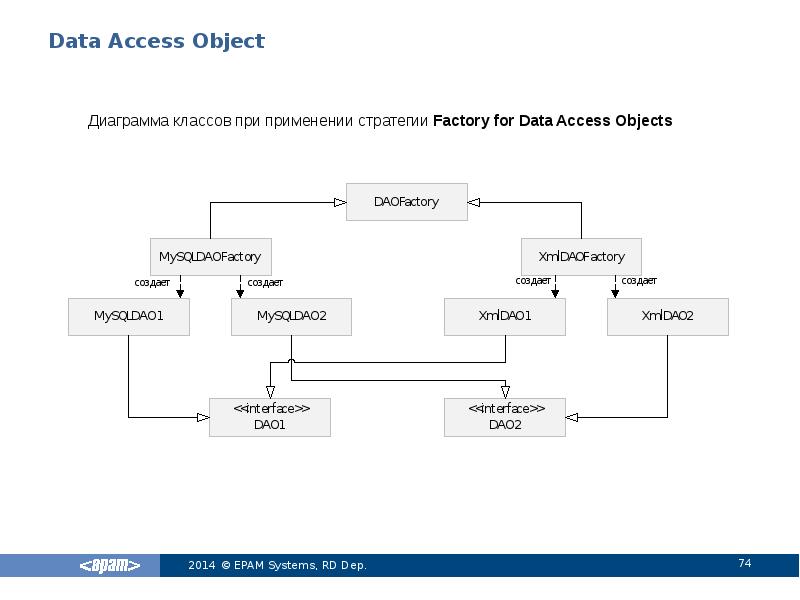
4.3.2 Стратегия Factory for Data Access Objects
5 Выводы
6 Примеры
6.1 Реализация паттерна Data Access Object
6.2 Реализация стратегии Factory for Data Access Objects
6.2.1 Использование паттерна Factory Method
6.2.2 Использование паттерна Abstract Factory
6.2.3 Пример 9.1 Абстрактный класс DAOFactory
6.2.4 Пример 9.2 Конкретная реализация DAOFactory для Cloudscape
6.2.5 Пример 9.3 Базовый DAO-интерфейс для Customer
6.2.6 Пример 9.4 Реализация Cloudscape DAO для Customer
6.
6.2.8 Пример 9.6 Использование DAO и DAO-генератора — код клиента
7 Связанные паттерны
1 Контекст
Способ доступа к данным бывает разным и зависит от источника данных. Способ доступа к персистентному хранилищу, например к базе данных, очень зависит от типа этого хранилища (реляционные базы данных, объектно-ориентированные базы данных, однородные или «плоские» файлы и т.д.) и от конкретной реализации.
2 Проблема
Многие реальные приложения платформы Java 2 Platform, Enterprise Edition (J2EE) должны использовать на некотором этапе персистентные данные. Для этих приложений персистентное хранение реализуется различными механизмами и существуют значительные отличия в API, используемых для доступа к этим механизмам. Другим приложениям может понадобиться доступ к данным, расположенным на разных системах. Например, данные могут находиться на мэйнфреймах, LDAP-репозиториях (Lightweight Directory Access Protocol — облегченный протокол доступа к каталогам) и т.
Обычно приложения совместно используют распределенные компоненты для представления персистентных данных, например, компоненты управления данными. Считается, что приложение использует управляемую компонентом персистенцию (BMP- bean-managed persistence) для своих компонентов управления данными, если эти компоненты явно обращаются к персистентным данным — то есть компонент содержит код прямого доступа к хранилищу данных. Приложение с более простыми требованиями может вместо компонентов управления данными использовать сессионные компоненты или сервлеты с прямым доступом к хранилищу данных для извлечения и изменения данных. Также, приложение могло бы использовать компоненты управления данными с управляемой контейнером персистенцией, передавая, таким образом, контейнеру функции управления транзакциями и деталями персистенции.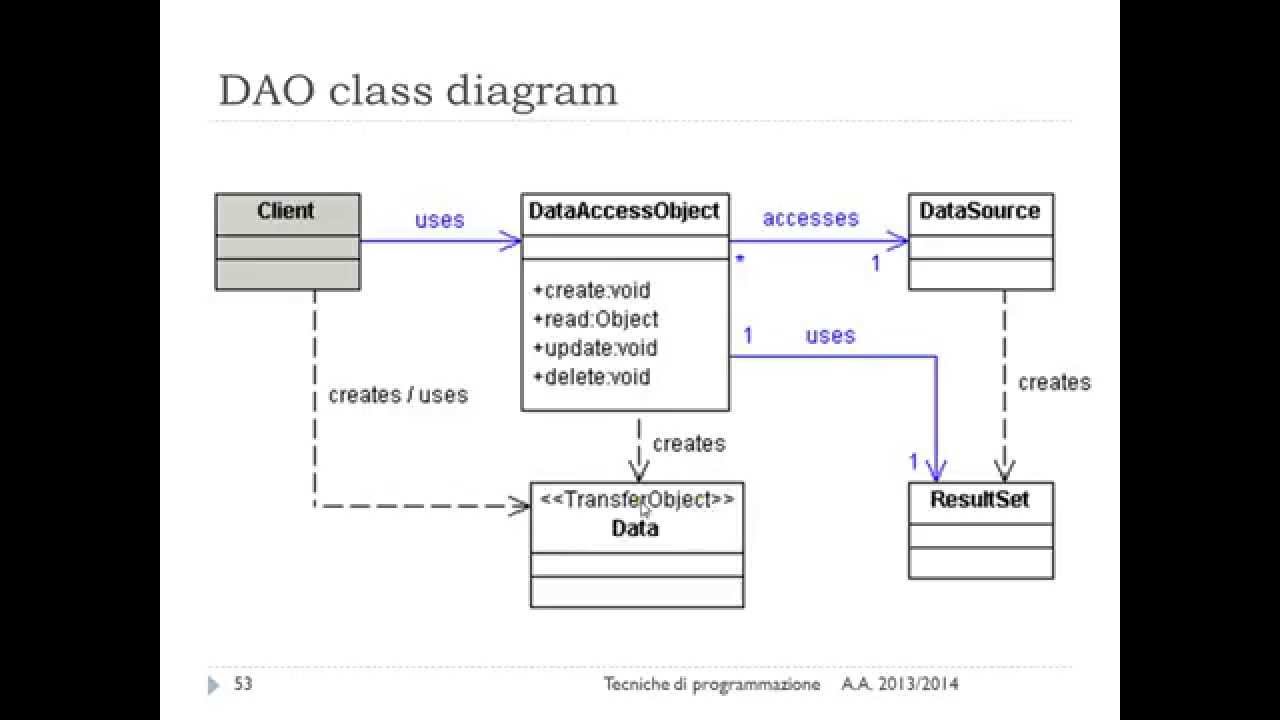
Для доступа к данным, расположенным в системе управления реляционными базами данных (RDBMS), приложения могут использовать JDBC API. JDBC API предоставляет стандартный механизм доступа и управления данными в персистентном хранилище, таком как реляционная база данных. JDBC API позволяет в J2EE-приложениях использовать SQL-команды, являющиеся стандартным средством доступа к RDBMS-таблицам. Однако, даже внутри среды RDBMS фактический синтаксис и формат SQL-команд может сильно зависеть от конкретной базы данных.
Для различных типов персистентных хранилищ существует еще большее число вариантов. Механизмы доступа, поддерживаемые API и функции отличаются для различных типов персистентных хранилищ, таких как RDBMS, объектно-ориентированные базы данных, плоские файлы и т.д. Приложения, которым нужен доступ к данным, расположенным на традиционных или несовместимых системах (например, мэйнфреймы или B2B-службы), часто вынуждены использовать патентованные API. Такие источники данных представляют проблему для приложений и могут потенциально создавать прямую зависимость между кодом приложения и кодом доступа к данным.
3 Ограничения
Компоненты управления данными с управляемой компонентом персистенцией, сессионные компоненты, сервлеты и другие объекты, такие как вспомогательные объекты для JSP-страниц, должны получать и сохранять информацию в персистентных хранилищах и других источниках данных, например традиционных системах, B2B, LDAP и т.

API доступа к персистентному хранилищу данных может зависеть от поставщика продукта. Другие источники данных могут иметь нестандартные или патентованные API. Эти API и их возможности зависят от типа хранилища данных — RDBMS, система управления объектно-ориентированными базами данных (OODBMS), XML-документы, плоские файлы и т.д. Унифицированный API доступа к этим несовместимым системам отсутствует.
Для извлечения или сохранения данных во внешних и/или традиционных системах компоненты обычно используют патентованные API.
Включение в компоненты специфических механизмов доступа и API прямо влияет на переносимость компонентов.
Компоненты должны быть прозрачны для реальной реализации персистентного хранилища или источника данных и обеспечивать легкую миграцию на продукт другого поставщика, на другой тип хранилища и на другой тип источника данных.
4 Решение
Используйте Data Access Object (DAO) для абстрагирования и инкапсулирования доступа к источнику данных.
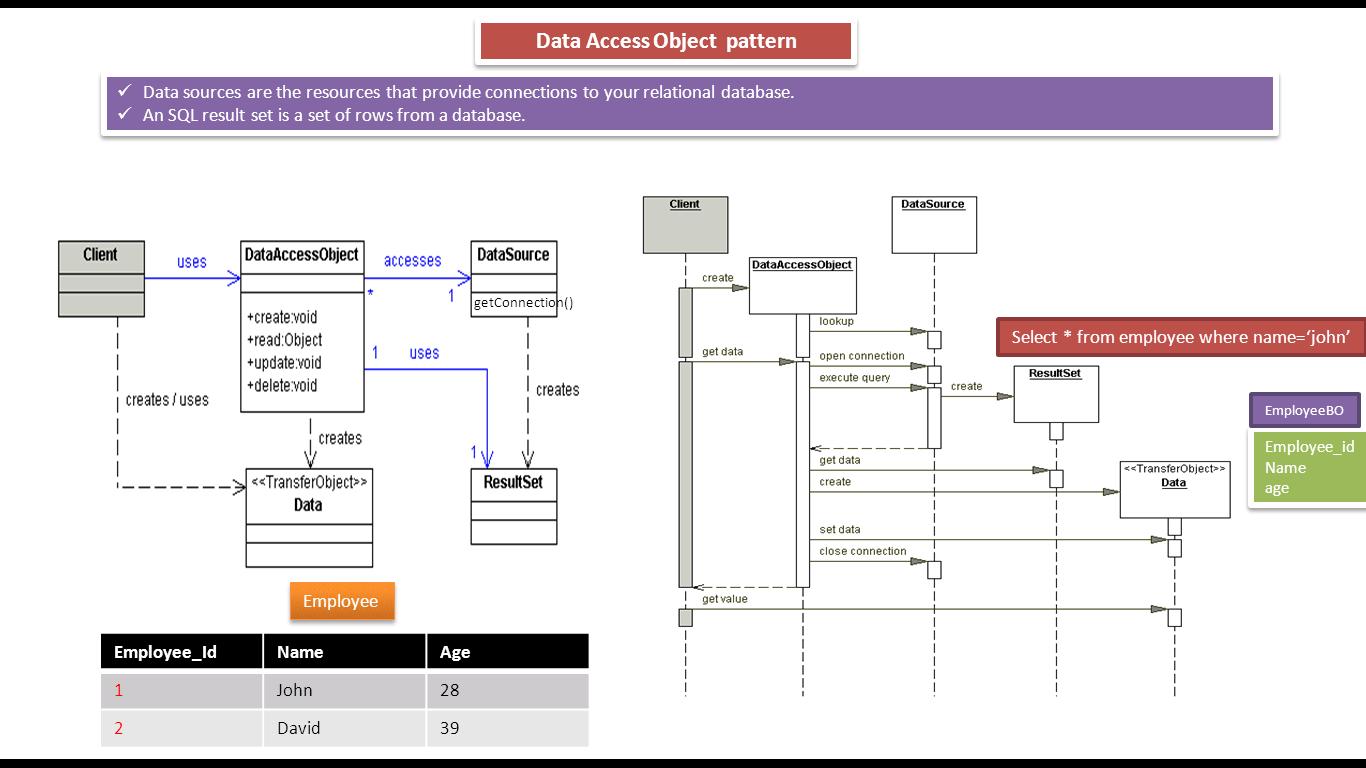
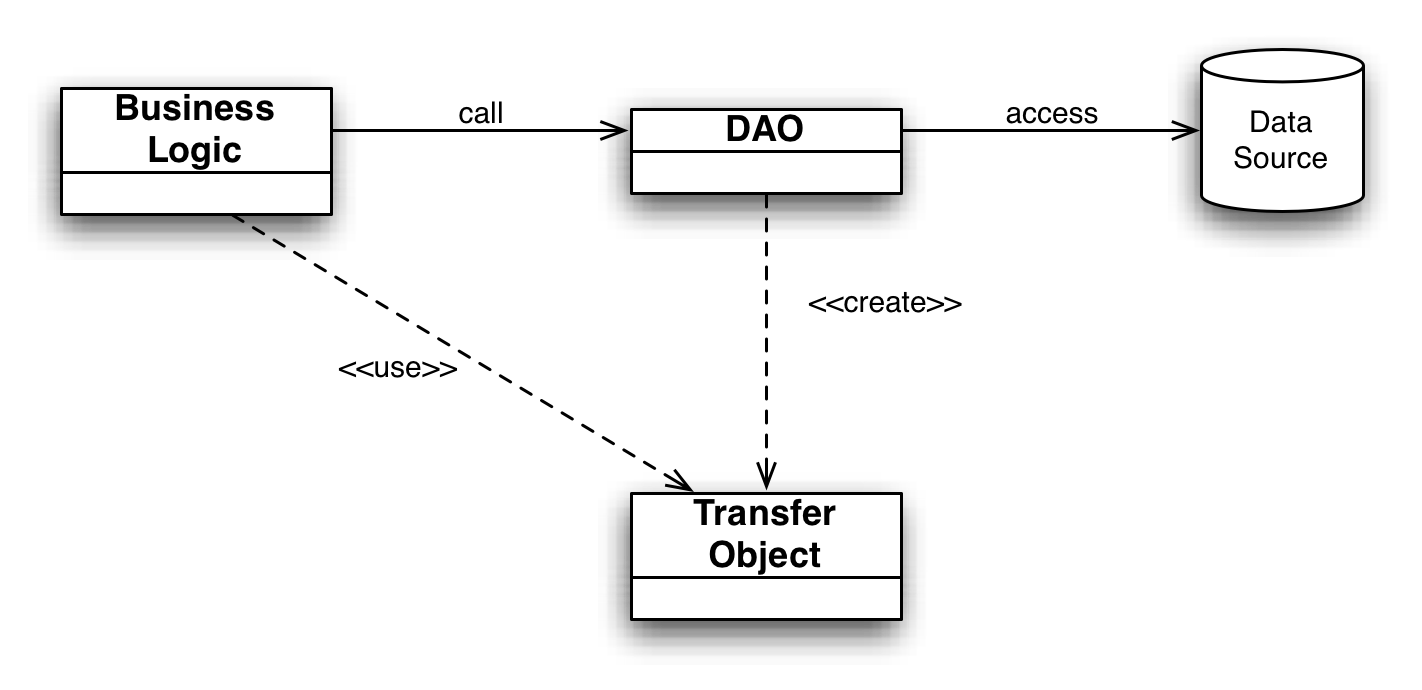
DAO реализует необходимый для работы с источником данных механизм доступа. Источником данных может быть персистентное хранилище (например, RDBMS), внешняя служба (например, B2B-биржа), репозиторий (LDAP-база данных), или бизнес-служба, обращение к которой осуществляется при помощи протокола CORBA Internet Inter-ORB Protocol (IIOP) или низкоуровневых сокетов. Использующие DAO бизнес-компоненты работают с более простым интерфейсом, предоставляемым объектом DAO своим клиентам. DAO полностью скрывает детали реализации источника данных от клиентов. Поскольку при изменениях реализации источника данных представляемый DAO интерфейс не изменяется, этот паттерн дает возможность DAO принимать различные схемы хранилищ без влияния на клиенты или бизнес-компоненты. По существу, DAO выполняет функцию адаптера между компонентом и источником данных.
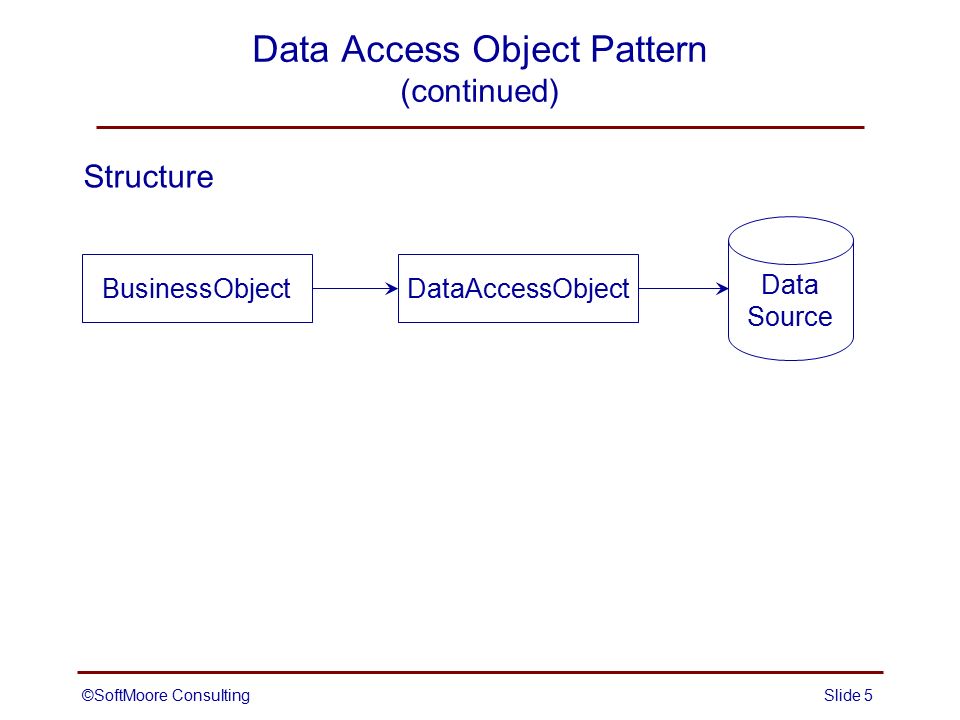
4.1 Структура
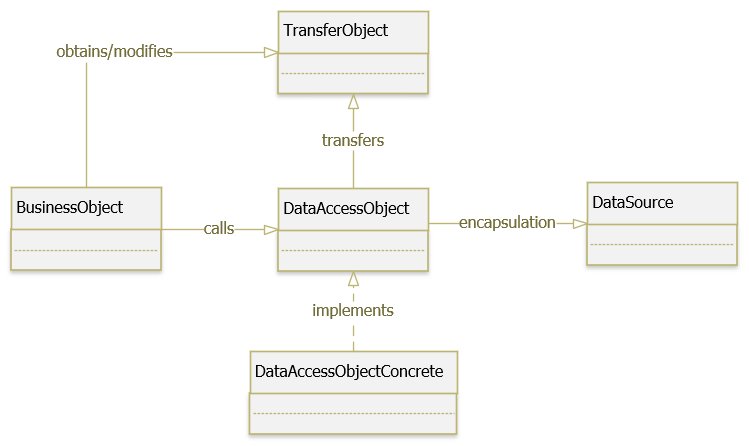
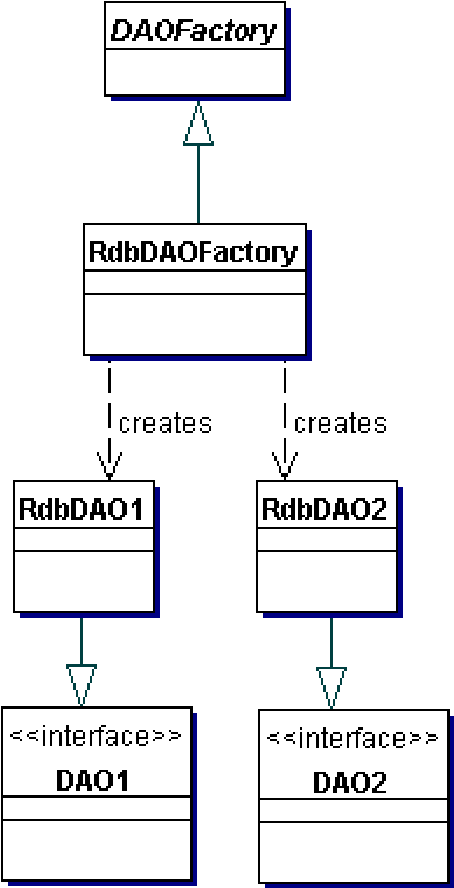
На рисунке 9.1 показана диаграмма классов, представляющая взаимоотношения в паттерне DAO.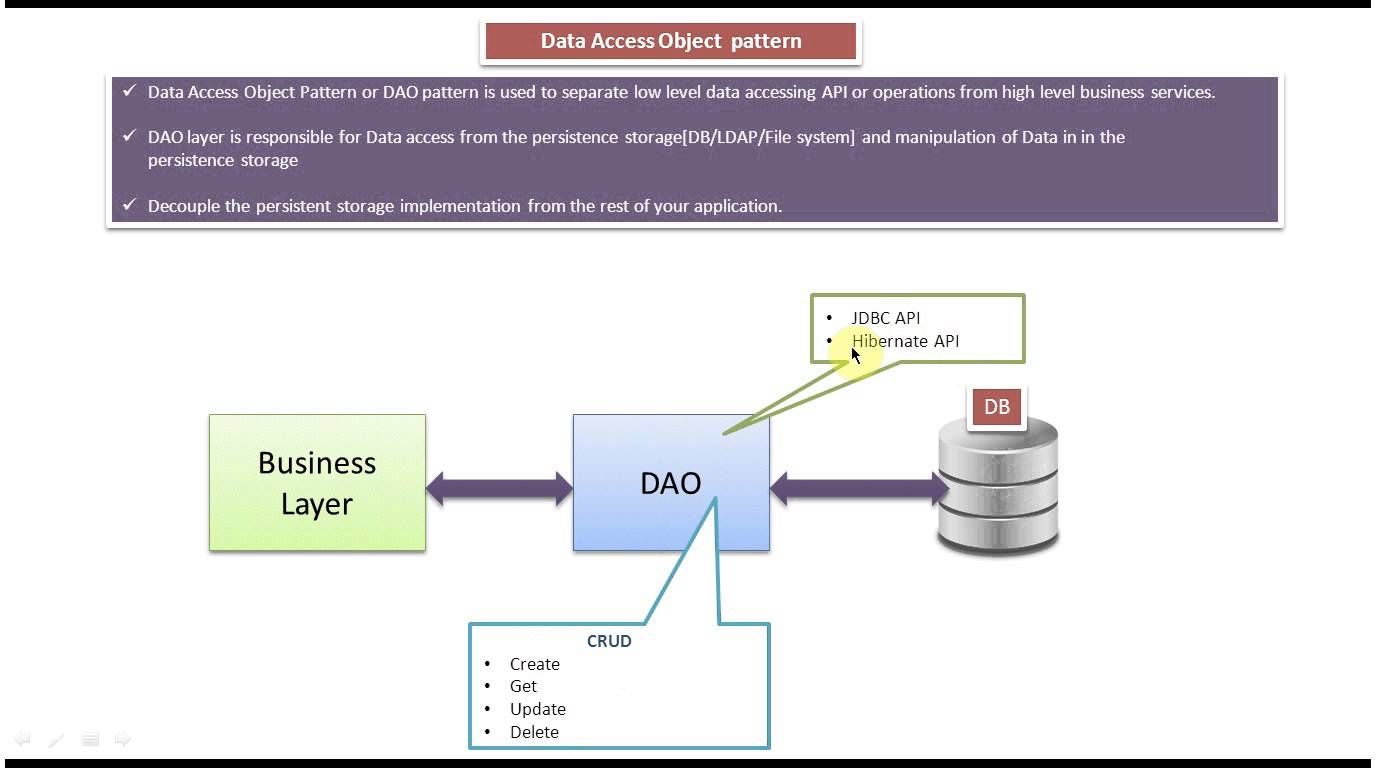
4.2 Участники и обязанности
На рисунке 9.2 представлена диаграмма последовательности действий, показывающая взаимодействия между различными участниками в данном паттерне.
4.2.1 BusinessObject
BusinessObject представляет клиента данных. Это объект, который нуждается в доступе к источнику данных для получения и сохранения данных. BusinessObject может быть реализован как сессионный компонент, компонент управления данными или другой Java-объект, сервлет или вспомогательный компонент.
4.2.2 DataAccessObject
DataAccessObject является первичным объектом данного паттерна. DataAccessObject абстрагирует используемую реализацию доступа к данным для BusinessObject, обеспечивая прозрачный доступ к источнику данных. BusinessObject передает также ответственность за выполнение операций загрузки и сохранения данных объекту DataAccessObject.
4.2.3 DataSource
Представляет реализацию источника данных. Источником данных может быть база данных, например, RDBMS, OODBMS, XML-репозиторий, система плоских файлов и др.
4.2.4 TransferObject
Представляет собой Transfer Object, используемый для передачи данных. DataAccessObject может использовать Transfer Object для возврата данных клиенту. DataAccessObject может также принимать данные от клиента в объекте Transfer Object для их обновления в источнике данных.
4.3 Стратегии
4.3.1 Стратегия Automatic DAO Code Generation
Поскольку BusinessObject соответствует конкретному DAO, есть возможность установить взаимоотношения между BusinessObject, DAO, и применяемыми реализациями (таблицы в RDBMS). После установления взаимоотношений появляется возможность написать простую утилиту для генерации кода, зависящую от приложения, которая может генерировать код для всех нужных приложению объектов DAO. Метаданные для генерации DAO могут определяться разработчиком в файле-дескрипторе.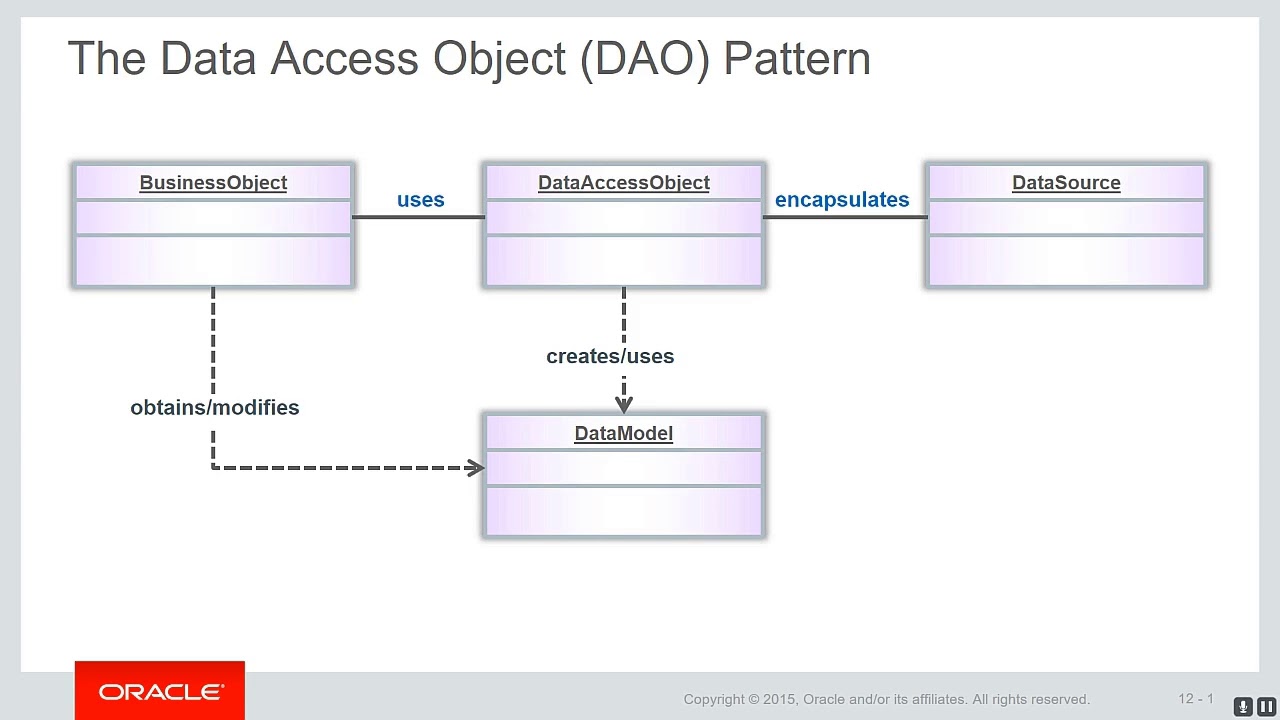
4.3.2 Стратегия Factory for Data Access Objects
Паттерн DAO может быть сделан очень гибким при использовании паттернов Abstract Factory [GoF] и Factory Method [GoF] (см. секцию «Связанные паттерны» в этом разделе).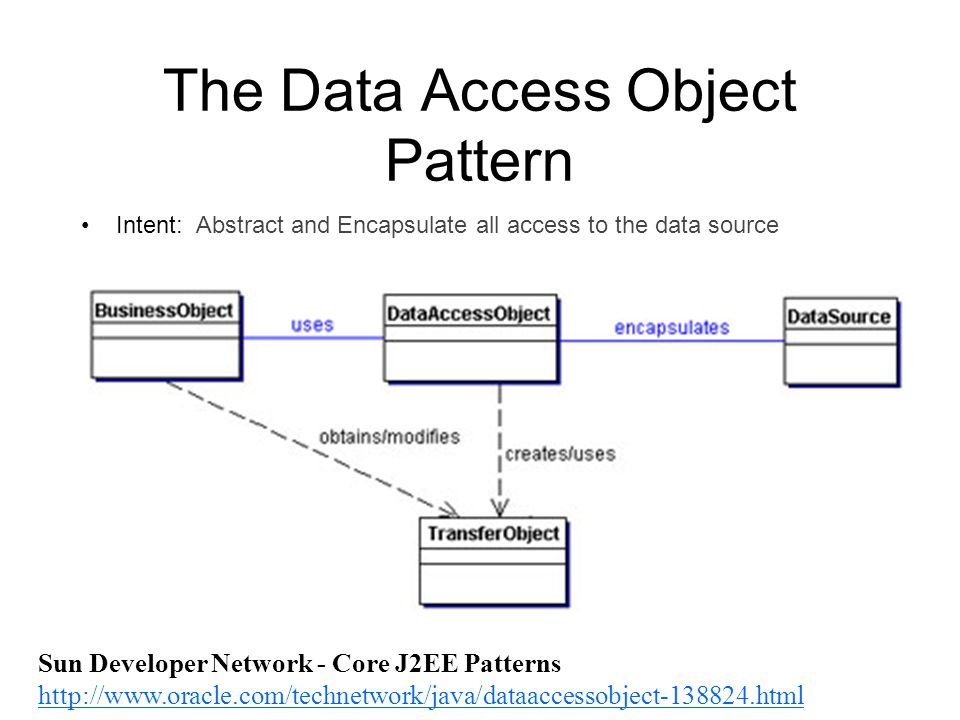
Данная стратегия может быть реализована с использованием паттерна Factory Method для генерации нескольких объектов DAO, которые нужны приложению, в тех случаях, когда применяемое хранилище данных не изменяется при переходе от одной реализации к другой. Диаграмма классов этого случая приведена на рисунке 9.3.
Рисунок 9.3 Стратегия Factory for Data Access Object, использующая Factory Method
Когда используемое хранилище данных может измениться при переходе от одной реализации к другой, данная стратегия может быть реализована с применением паттерна Abstract Factory. Abstract Factory, в свою очередь, может создать и использовать реализацию Factory Method implementation, как рекомендуется в книге «Паттерны проектирования: Элементы повторно используемого объектно-ориентированного программного обеспечения» [GoF]. В этом случае данная стратегия предоставляет абстрактный объект генератора DAO (Abstract Factory), который может создавать конкретные генераторы DAO различного типа, причем каждый генератор может поддерживать различные типы реализаций персистентных хранилищ данных. После получения конкретного генератора для конкретной реализации вы можете использовать его для генерации объектов DAO, поддерживаемых и реализуемых в этой реализации.
После получения конкретного генератора для конкретной реализации вы можете использовать его для генерации объектов DAO, поддерживаемых и реализуемых в этой реализации.
Диаграмма классов этой стратегии представлена на рисунке 9.4. Эта диаграмма классов показывает базовый генератор DAO, являющийся абстрактным классом, который наследуется и реализуется различными конкретными генераторами DAO для поддержки доступа к специфической реализации хранилища данных. Клиент может получить реализацию конкретного генератора DAO, например RdbDAOFactory, и использовать его для получения конкретных объектов DAO, работающих с этой конкретной реализацией хранилища данных. Например, клиент может получить RdbDAOFactory и использовать его для получения конкретных DAO, таких как RdbCustomerDAO, RdbAccountDAO и др. Объекты DAO могут расширять и реализовывать общий базовый класс (показанные как DAO1 и DAO2) и детально описывать требования к DAO для поддерживаемых бизнес-объектов. Каждый конкретный объект DAO отвечает за соединение с источником данных и за получение и управление данными для поддерживаемого им бизнес-объекта.
Пример реализации паттерна DAO и его стратегий приведен в секции «Пример» данного раздела.
Диаграмма последовательности действий, описывающая взаимодействия для этой стратегии, представлена на рисунке 9.5.
5 Выводы
Разрешает прозрачность
Бизнес-объекты могут использовать источник данных, не имея знаний о конкретных деталях его реализации. Доступ является прозрачным, поскольку детали реализации скрыты внутри DAO.
Облегчает миграцию
Уровень объектов DAO облегчает приложению миграцию на другую реализацию базы данных. Бизнес-объекты не знают о деталях реализации используемых данных. Следовательно, процесс миграции требует изменений только в уровне DAO. Более того, при использовании стратегии генератора можно предоставить конкретную реализацию генератора для каждой реализации хранилища данных. В этом случае миграция на другую реализацию хранилища означает предоставление приложению новой реализации генератора.
Уменьшает сложность кода в бизнес-объектах
Поскольку объекты DAO управляют всеми сложностями доступа к данным, упрощается код бизнес-компонентов и других клиентов данных, использующих DAO. Весь зависящий от реализации код (например, SQL-команды) содержится в DAO, а не в бизнес-объекте. Это улучшает читаемость кода и производительность разработки.
Централизует весь доступ к данным в отдельном уровне
Поскольку все операции доступа к данным реализованы в объектах DAO, отдельный уровень доступа к данным может рассматриваться как уровень, изолирующий остальную часть приложения от реализации доступа к данным. Такая централизация облегчает поддержку и управление приложением.
Бесполезна для управляемой контейнером персистенции
Поскольку EJB-контейнер управляет компонентами с управляемой контейнером персистенцией (CMP — container-managed persistence), контейнер автоматически обслуживает весь доступ к хранилищу данных.
Приложения, использующие компоненты управления данными этого типа, не нуждаются в уровне объектов DAO, поскольку сервер приложений обеспечивает эту функциональность. Однако, объекты DAO остаются полезны в случаях, когда необходимо использовать комбинацию CMP (для компонентов управления данными) и BMP (для сессионных компонентов, сервлетов).Добавляет дополнительный уровень
Объекты DAO создают дополнительный уровень объектов между клиентом данных и источником данных, который должен быть разработан и реализован для использования преимуществ, предлагаемых данным паттерном. Но за реализуемые при этом преимущества приходится платить дополнительными усилиями при разработке.
Требуется разработка иерархии классов
При использовании стратегии генератора необходимо разработать и реализовать иерархию конкретных генераторов и иерархию конкретных объектов, производимых генераторами. Эти дополнительные усилия необходимо принимать во внимание, если существует достаточно оснований для реализации такой гибкости.
Это увеличивает сложность разработки. Однако, вы можете сначала реализовать эту стратегию с паттерном Factory Method, а затем, при необходимости, перейти к паттерну Abstract Factory.

 Приложения, использующие компоненты управления данными этого типа, не нуждаются в уровне объектов DAO, поскольку сервер приложений обеспечивает эту функциональность. Однако, объекты DAO остаются полезны в случаях, когда необходимо использовать комбинацию CMP (для компонентов управления данными) и BMP (для сессионных компонентов, сервлетов).
Приложения, использующие компоненты управления данными этого типа, не нуждаются в уровне объектов DAO, поскольку сервер приложений обеспечивает эту функциональность. Однако, объекты DAO остаются полезны в случаях, когда необходимо использовать комбинацию CMP (для компонентов управления данными) и BMP (для сессионных компонентов, сервлетов). Это увеличивает сложность разработки. Однако, вы можете сначала реализовать эту стратегию с паттерном Factory Method, а затем, при необходимости, перейти к паттерну Abstract Factory.
Это увеличивает сложность разработки. Однако, вы можете сначала реализовать эту стратегию с паттерном Factory Method, а затем, при необходимости, перейти к паттерну Abstract Factory.6 Примеры
6.1 Реализация паттерна Data Access Object
Код объекта DAO для персистентного объекта, предоставляющего информацию о клиенте (Customer), представлен в примере 9.4. CloudscapeCustomerDAO создает объект Customer Transfer Object при вызове метода findCustomer().
Код, использующий DAO, показан в примере 9.6. Диаграмма классов этого примера приведена на рисунке 9.6.
6.2 Реализация стратегии Factory for Data Access Objects
6.2.1 Использование паттерна Factory Method
Рассмотрим пример, в котором мы применяем данную стратегию для создания генератором многих объектов DAO для одной реализации базы данных (например, Oracle). Генератор производит такие объекты DAO, как CustomerDAO, AccountDAO, OrderDAO и др. Диаграмма классов для этого примера приведена на рисунке 9. 7.
7.
Рисунок 9.7 Реализация стратегии Factory for DAO, использующей Factory Method
Код генератора DAO (CloudscapeDAOFactory) приведен в примере 9.2.
6.2.2 Использование паттерна Abstract Factory
Рассмотрим пример, в котором мы применяем данную стратегию для трех различных баз данных. В этом случае может быть использован паттерн Abstract Factory. Диаграмма классов этого примера показана на рисунке 9.8. Код в примере 9.1 показывает фрагмент абстрактного класса DAOFactory. Этот генератор производит такие объекты DAO как CustomerDAO, AccountDAO, OrderDAO и др. Данная стратегия использует реализацию Factory Method в генераторах, созданных при помощи Abstract Factory.
Рисунок 9.8 Реализация стратегии Factory for DAO, использующей Abstract Factory
6.2.3 Пример 9.1 Абстрактный класс DAOFactory
// Абстрактный класс DAO Factory
public abstract class DAOFactory {
// Список типов DAO, поддерживаемых генератором
public static final int CLOUDSCAPE = 1;
public static final int ORACLE = 2;
public static final int SYBASE = 3;
. ..
// Здесь будет метод для каждого DAO, который может быть
// создан. Реализовывать эти методы
// должны конкретные генераторы.
public abstract CustomerDAO getCustomerDAO();
public abstract AccountDAO getAccountDAO();
public abstract OrderDAO getOrderDAO();
...
public static DAOFactory getDAOFactory(
int whichFactory) {
switch (whichFactory) {
case CLOUDSCAPE:
return new CloudscapeDAOFactory();
case ORACLE :
return new OracleDAOFactory();
case SYBASE :
return new SybaseDAOFactory();
...
default :
return null;
}
}
} ..
..Код CloudscapeDAOFactory приведен в примере 9.2. Реализации OracleDAOFactory и SybaseDAOFactory аналогичны, за исключением особенностей каждой реализации, таких как JDBC-драйвер, URL базы данных и различий в синтаксисе SQL, если таковые имеются.
6.2.4 Пример 9.2 Конкретная реализация DAOFactory для Cloudscape
// Конкретная реализация DAOFactory для Cloudscape
import java.sql.*;public class CloudscapeDAOFactory extends DAOFactory {
public static final String DRIVER=
"COM.cloudscape.core.RmiJdbcDriver";
public static final String DBURL=
"jdbc:cloudscape:rmi://localhost:1099/CoreJ2EEDB";
// метод для создания соединений к Cloudscape
public static Connection createConnection() {
// Использовать DRIVER и DBURL для создания соединения
// Рекомендовать реализацию/использование пула соединений
}
public CustomerDAO getCustomerDAO() {
// CloudscapeCustomerDAO реализует CustomerDAO
return new CloudscapeCustomerDAO();
}
public AccountDAO getAccountDAO() {
// CloudscapeAccountDAO реализует AccountDAO
return new CloudscapeAccountDAO();
}
public OrderDAO getOrderDAO() {
// CloudscapeOrderDAO реализует OrderDAO
return new CloudscapeOrderDAO();
}
. ..
} ..
..Интерфейс CustomerDAO, показанный в примере 9.3, определяет DAO-методы для персистентного объекта Customer, которые реализованы всеми конкретными реализациями DAO, такими как, CloudscapeCustomerDAO, OracleCustomerDAO и SybaseCustomerDAO. Аналогично (но здесь не приводится) реализуются интерфейсы AccountDAO и OrderDAO, определяющие DAO-методы соответственно для бизнес-объектов Account и Order.
6.2.5 Пример 9.3 Базовый DAO-интерфейс для Customer
// Интерфейс, который должны поддерживать все CustomerDAO
public interface CustomerDAO {
public int insertCustomer(...);
public boolean deleteCustomer(...);
public Customer findCustomer(...);
public boolean updateCustomer(...);
public RowSet selectCustomersRS(...);
public Collection selectCustomersTO(...);
...
}
CloudscapeCustomerDAO реализует CustomerDAO, как показаго в примере 9.4. Реализации других объектов DAO, таких как CloudscapeAccountDAO, CloudscapeOrderDAO, OracleCustomerDAO, OracleAccountDAO, и т. д. — аналогичны.
д. — аналогичны.
6.2.6 Пример 9.4 Реализация Cloudscape DAO для Customer
// Реализация CloudscapeCustomerDAO
// интерфейса CustomerDAO. Этот класс может содержать весь
// специфичный для Cloudscape код и SQL-команды.
// Клиент, таким образом, защищается от необходимости
// знать эти детали реализации.import java.sql.*;public class CloudscapeCustomerDAO implements
CustomerDAO {
public CloudscapeCustomerDAO() {
// инициализация
}
// Следующие методы по необходимости могут использовать
// CloudscapeDAOFactory.createConnection()
// для получения соединения
public int insertCustomer(...) {
// Реализовать здесь операцию добавления клиента.
// Возвратить номер созданного клиента
// или -1 при ошибке
}
public boolean deleteCustomer(...) {
// Реализовать здесь операцию удаления клиента.
// Возвратить true при успешном выполнении, false при ошибке
}
public Customer findCustomer(. ..) {
// Реализовать здесь операцию поиска клиента, используя
// предоставленные значения аргументов в качестве критерия поиска.
// Возвратить объект Transfer Object при успешном поиске,
// null или ошибку, если клиент не найден.
}
public boolean updateCustomer(...) {
// Реализовать здесь операцию обновления записи,
// используя данные из customerData Transfer Object
// Возвратить true при успешном выполнении, false при ошибке
}
public RowSet selectCustomersRS(...) {
// Реализовать здесь операцию выбора клиентов,
// используя предоставленный критерий.
// Возвратить RowSet.
}
public Collection selectCustomersTO(...) {
// Реализовать здесь операцию выбора клиентов,
// используя предоставленный критерий.
// В качестве альтернативы, реализовать возврат
// коллекции объектов Transfer Object.
}
...
} ..) {
..) {Класс Customer Transfer Object показан в примере 9. 5. Он используется объектами DAO для передачи и приема данных от клиентов. Использование объектов Transfer Object детально рассматривалось в паттерне Transfer Object.
5. Он используется объектами DAO для передачи и приема данных от клиентов. Использование объектов Transfer Object детально рассматривалось в паттерне Transfer Object.
6.2.7 Пример 9.5 Customer Transfer Object
public class Customer implements java.io.Serializable {
// переменные-члены
int CustomerNumber;
String name;
String streetAddress;
String city;
...
// методы getter и setter...
...
}В примере 9.6 показано использование генератора DAO и DAO. Если реализация меняется от Cloudscape к другому продукту, необходимо изменить только вызов метода getDAOFactory() в генераторе DAO для получения другого генератора.
6.2.8 Пример 9.6 Использование DAO и DAO-генератора — код клиента
...
// создать требуемый генератор DAO
DAOFactory cloudscapeFactory =
DAOFactory.getDAOFactory(DAOFactory.DAOCLOUDSCAPE);// Создать DAO
CustomerDAO custDAO =
cloudscapeFactory.getCustomerDAO();// создать нового клиента
int newCustNo = custDAO. insertCustomer(...);// найти объект customer. Получить объект Transfer Object.
Customer cust = custDAO.findCustomer(...);// изменить значения в Transfer Object.
cust.setAddress(...);
cust.setEmail(...);
// обновить объект customer, используя DAO
custDAO.updateCustomer(cust);// удалить объект customer
custDAO.deleteCustomer(...);
// выбрать всех клиентов одного города
Customer criteria=new Customer();
criteria.setCity("New York");
Collection customersList =
custDAO.selectCustomersTO(criteria);
// возвратить customersList - коллекцию объектов Customer
// Transfer Objects. Проходит по коллекции для
// получения значений.... insertCustomer(...);// найти объект customer. Получить объект Transfer Object.
insertCustomer(...);// найти объект customer. Получить объект Transfer Object.7 Связанные паттерны
Transfer Object
DAO использует Transfer Objects для передачи данных клиентам и от них.
Factory Method [GoF] и Abstract Factory [GoF]
Стратегия Factory for Data Access Objects использует паттерн Factory Method для реализации конкретных генераторов и их продуктов (объектов DAO).
Для дополнительной гибкости, в стратегиях может быть применен паттерн Abstract Factory, как рассматривалось выше.Broker [POSA1]
Паттерн DAO связан с паттерном Broker, который описывает подходы для разделения клиентов и серверов в распределенных системах. Паттерн DAO применяет этот паттерн более конкретно для разделения уровня ресурсов от клиентов и перемещения его в другой уровень, такой как бизнес-уровень, или уровень представлений.
 Для дополнительной гибкости, в стратегиях может быть применен паттерн Abstract Factory, как рассматривалось выше.
Для дополнительной гибкости, в стратегиях может быть применен паттерн Abstract Factory, как рассматривалось выше.Шаблон DAO примеры, достоинства и недостатки Проектирование…
Привет, Вы узнаете про dao, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое dao,шаблон dao,паттерн dao , настоятельно рекомендую прочитать все из категории Проектирование веб сайта или программного обеспечения
1. ОбзорШаблон Data Access Object (DAO) является структурным шаблоном, который позволяет нам изолировать прикладной/бизнес-уровень от постоянного уровня (обычно это реляционная база данных , но это может быть любой другой постоянный механизм) с использованием абстрактного API .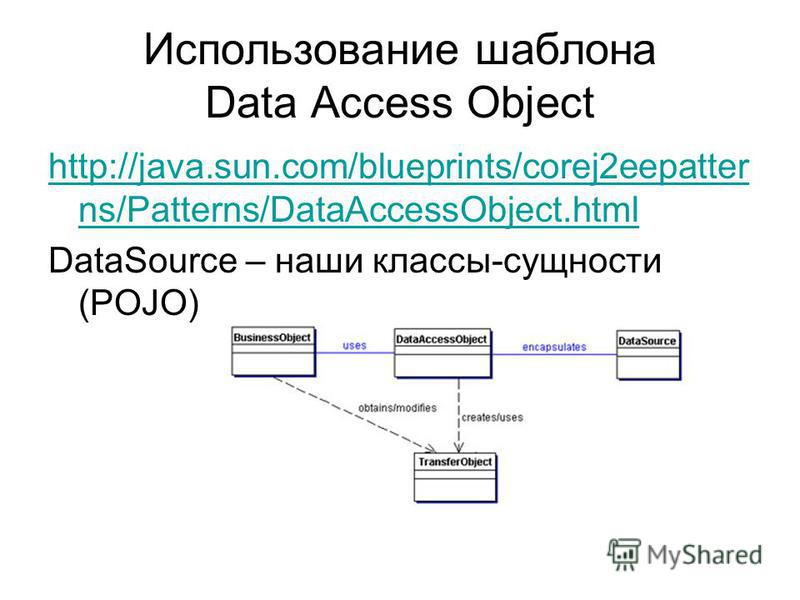
Функциональность этого API заключается в том, чтобы скрыть от приложения все сложности, связанные с выполнением операций CRUD в базовом механизме хранения. Это позволяет обоим слоям развиваться отдельно, ничего не зная друг о друге.
В этом уроке мы углубимся в реализацию шаблона и узнаем, как использовать его для абстрагирования вызовов к Менеджер сущностей JPA .
2. Простая реализацияЧтобы понять, как работает шаблон dao , давайте создадим базовый пример.
Допустим, мы хотим разработать приложение, которое управляет пользователями. Для того чтобы модель домена приложения не зависела от базы данных , мы создадим простой класс DAO, который позаботится о том, чтобы эти компоненты были аккуратно отделены друг от друга .
2.1. Домен Класс
Поскольку наше приложение будет работать с пользователями, нам нужно определить только один класс для реализации его доменной модели:
Класс User представляет собой простой контейнер для пользовательских данных, поэтому он не реализует никакого другого поведения, заслуживающего внимания.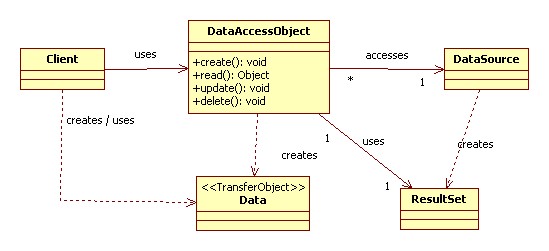
Конечно, самый важный выбор дизайна, который нам нужно сделать здесь, — это как сохранить приложение, использующее этот класс, изолированным от любого механизма персистентности, который может быть реализован в какой-то момент.
Ну, это именно та проблема, которую пытается решить шаблон DAO.
2.2. DAO API
Давайте определим базовый уровень DAO, чтобы мы могли видеть, как он может полностью отделить модель домена от уровня постоянства.
Вот API DAO:
С высоты птичьего полета ясно, что интерфейс Dao определяет абстрактный API, который выполняет операции CRUD над объектами типа T .
Благодаря высокому уровню абстракции, который обеспечивает интерфейс, легко создать конкретную, детальную реализацию, которая работает с объектами User .
2.3. UserDao Класс
Давайте определим пользовательскую реализацию интерфейса Dao :
Класс UserDao реализует все функции, необходимые для извлечения, обновления и удаления объектов User .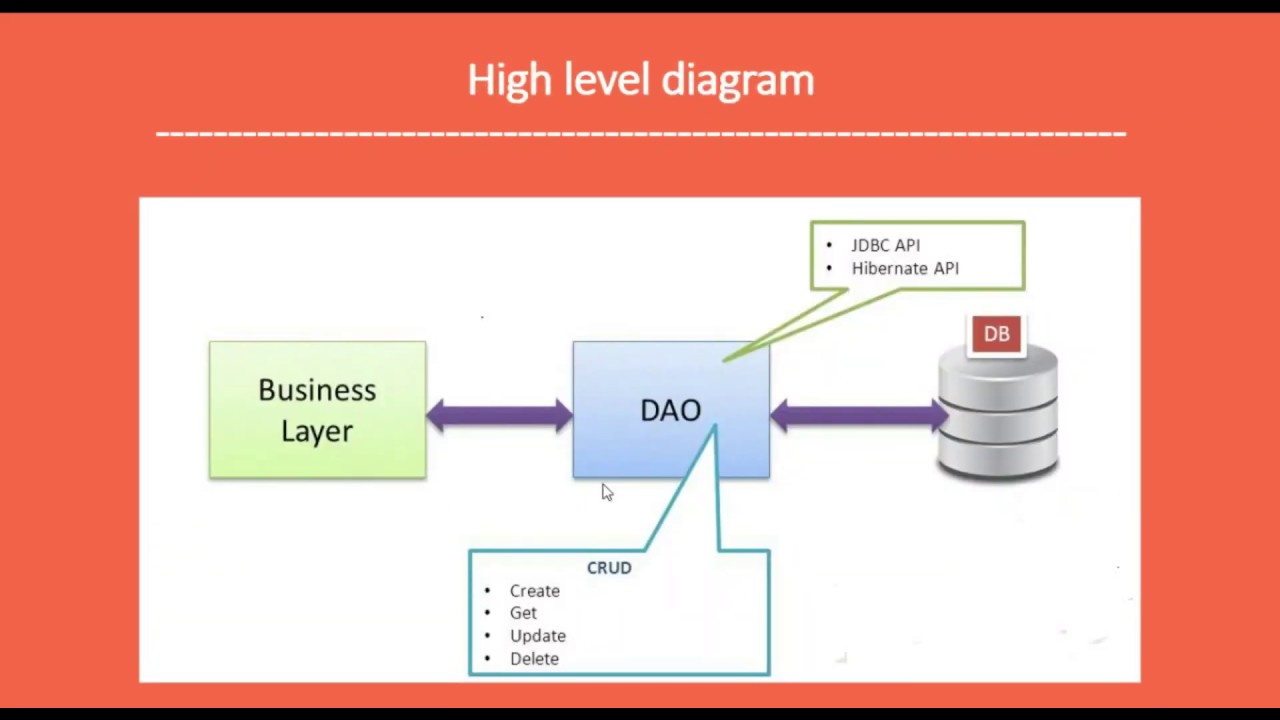
Конечно, легко реорганизовать другие методы, чтобы они могли работать, например, с реляционной базой данных.
Хотя оба класса User и UserDao сосуществуют независимо в одном и том же приложении, нам все еще необходимо выяснить, как последний может использоваться для сохранения уровня персистентности скрытым от логики приложения:
Пример придуман, но в двух словах показывает мотивы, лежащие в основе шаблона DAO . Об этом говорит сайт https://intellect.icu . В этом случае метод main просто использует экземпляр UserDao для выполнения операций CRUD над несколькими объектами User .
-
Наиболее значимым аспектом этого процесса является то, как UserDao скрывает от приложения все низкоуровневые сведения о том, как объекты сохраняются, обновляются и удаляются ** .
3. Использование шаблона с JPA
Среди разработчиков существует общая тенденция думать, что выпуск JPA снизил до нуля функциональность шаблона DAO, поскольку шаблон становится просто еще одним уровнем абстракции и сложности, реализованным поверх уровня, предоставляемого менеджером сущностей JPA.
Безусловно, в некоторых сценариях это действительно так. Несмотря на это , иногда мы просто хотим предоставить нашему приложению только несколько доменных методов API-интерфейса менеджера сущностей. В таких случаях шаблон DAO имеет свое место.
3.1. JpaUserDao Класс
С учетом вышесказанного давайте создадим новую реализацию интерфейса Dao , чтобы мы могли увидеть, как он может инкапсулировать функциональность, предоставляемую менеджером сущностей JPA из коробки:
Кроме того, если мы внимательно посмотрим на класс, мы поймем, как использовать https://en.wikipedia.org/wiki/Composition over inheritance[Composition]и Dependency Инъекция позволяет нам вызывать только методы менеджера сущностей, требуемые нашим приложением.
Проще говоря, у нас есть специализированный API для конкретного домена, а не весь API менеджера сущностей.
3.2. Рефакторинг класса User
В этом случае мы будем использовать Hibernate в качестве реализации по умолчанию для JPA, поэтому мы соответствующим образом проведем рефакторинг класса User :
3. 3. Начальная загрузка JPA Entity Manager программно
3. Начальная загрузка JPA Entity Manager программно
Предполагая, что у нас уже есть работающий экземпляр MySQL, работающий локально или удаленно, и таблица базы данных «пользователи» , заполненная некоторыми записями пользователей, нам нужно получить диспетчер сущностей JPA, чтобы мы могли использовать класс JpaUserDao для выполнения операций CRUD в базе данных.
В большинстве случаев мы выполняем это с помощью типичного файла «persistence.xml», который является стандартным подходом
В этом случае мы воспользуемся подходом xml-less и получим менеджер сущностей с простой Java через удобный https://docs.jboss.org/hibernate/orm/5.0/javadocs/org/hibernate/ . jpa/boot/internal/EntityManagerFactoryBuilderImpl.html[EntityManagerFactoryBuilderImpl] класс.
Для получения подробного объяснения о том, как запустить реализацию JPA с помощью Java, перейдите по ссылке:/java-bootstrap-jpa[эта статья].
3.4. UserApplication Class
Наконец, давайте проведем рефакторинг исходного класса UserApplication , чтобы он мог работать с экземпляром JpaUserDao и выполнять операции CRUD с сущностями User :
Даже когда пример довольно ограничен, он остается полезным для демонстрации того, как интегрировать функциональность шаблона DAO с той, которую предоставляет менеджер сущностей.
В большинстве приложений есть структура DI, которая отвечает за внедрение экземпляра JpaUserDao в класс UserApplication . Для простоты мы опустили детали этого процесса.
Наиболее важный момент, на который следует обратить внимание, заключается в том, как класс JpaUserDao помогает полностью исключить независимость класса UserApplication от того, как уровень персистентности выполняет операции CRUD ** .
Кроме того, мы могли бы поменять MySQL на любую другую СУБД (и даже на плоскую базу данных) в будущем, и все же наше приложение продолжало бы работать как положено, благодаря уровню абстракции, обеспечиваемому интерфейсом Dao и менеджером сущностей ,
Преимущества использования шаблона проектирования DAO
Шаблон проектирования DAO или Data Access Object — хороший пример объектно-ориентированных принципов абстракции и инкапсуляции. Он отделяет логику сохраняемости от отдельного уровня, называемого уровнем доступа к данным, который позволяет приложению безопасно реагировать на изменения в механизме сохраняемости. Например, если вы перейдете от механизма сохранения на основе файлов к базе данных, ваше изменение будет ограничено уровнем доступа к данным и не повлияет на уровень службы или объекты домена. Объект доступа к данным или шаблон DAO в значительной степени стандартен в приложении Java, являясь ядром Java, веб-приложением или корпоративным приложением. Ниже приведены еще несколько преимуществ использования шаблона DAO в приложении Java:
Например, если вы перейдете от механизма сохранения на основе файлов к базе данных, ваше изменение будет ограничено уровнем доступа к данным и не повлияет на уровень службы или объекты домена. Объект доступа к данным или шаблон DAO в значительной степени стандартен в приложении Java, являясь ядром Java, веб-приложением или корпоративным приложением. Ниже приведены еще несколько преимуществ использования шаблона DAO в приложении Java:
-
Шаблон проектирования DAO также обеспечивает низкую связь между различными частями приложения. При использовании шаблона проектирования DAO ваш уровень представления полностью независим от уровня DAO, и только уровень сервиса зависит от него, который также абстрагируется с помощью интерфейса DAO.
-
Шаблон проектирования DAO позволяет тесту JUnit работать быстрее, поскольку он позволяет создавать Mock и избегать подключения к базе данных для запуска тестов. Это улучшает тестирование, потому что проще написать тест с Mock-объектами, а не тест интеграции с базой данных.
В случае возникновения каких-либо проблем при запуске модульного теста вам нужно проверять только код, а не базу данных. Также защищает от проблем с подключением к базе данных и окружающей среды. -
Поскольку шаблон DAO основан на интерфейсе, он также продвигает принцип объектно-ориентированного проектирования «программирование для интерфейса, а не реализация», что приводит к гибкому и качественному коду.
-
Сила шаблона DAO состоит в том, что они позволяют вам создать хороший уровень абстракции реальной системы хранения. Они обеспечивают более объектно-ориентированное представление уровня сохраняемости и четкое разделение между доменом и кодом, который фактически будет выполнять доступ к данным (прямой JDBC, структуры сохраняемости, ORM или даже JPA).
- Общие вызовы для получения объектов.
- После того, как вы настроили общий поток создания / чтения / обновления / удаления, общий макет можно повторить для других DAO.
- Он также консолидирует, где может идти конкретная часть вашего кода. Отделяет бизнес-логику от других компонентов вашего кода.
- абстрактное разделение
- единая точка определения для таблицы БД — Отображение атрибутов объекта
- прозрачная возможность реализации DAO для других типов хранилищ
- разработать шаблон интерфейса, которому следуют все DAO
- разработка более или менее стандартного тестового класса JUnit для результатов DAO в лучшем тестовом покрытии
- полный контроль над спецификой
- нет потери производительности из-за слишком общего решения
- Абстракция для реальной реализации доступа к базе данных отделяет стратегию доступа к данным от бизнес-логики пользователя. Это позволило нам выбрать краткосрочную стратегию реализации (шаблон Spring JDBC) для начальной фазы проекта с возможностью перехода на IBATIS или Hibernate позже. (Выбор, который мы не можем сделать в настоящее время. )
- Такое разделение дает значительные преимущества тестируемости, так как вся реализация доступа к данным может быть смоделирована в модульном тестировании. (Это, наверное, самое большое преимущество)
- Объединение этого со Spring позволяет нам внедрить любую реализацию БД в выбранную нами систему (хотя это, возможно, больше говорит о DI, чем о шаблоне DAO).
 В случае возникновения каких-либо проблем при запуске модульного теста вам нужно проверять только код, а не базу данных. Также защищает от проблем с подключением к базе данных и окружающей среды.
В случае возникновения каких-либо проблем при запуске модульного теста вам нужно проверять только код, а не базу данных. Также защищает от проблем с подключением к базе данных и окружающей среды.
 )
)Недостатки использования шаблона DAO
- это еще один слой, который усложняет системы … Но я думаю, это цена, которую нужно заплатить за то, чтобы не привязывать свой код к базовому API сохраняемости.
- Это не самая гибкая вещь.
- Если вы хотите отложить загрузку некоторых дочерних объектов, вам придется либо смешивать DAO с другими слоями, либо принимать меры предосторожности при попытке получить ленивые объекты.
- Если вы напишете DAO от руки, код может стать утомительным и повторяющимся.
- много шаблонного кода
 Заключение
ЗаключениеВ этой статье мы подробно рассмотрели ключевые концепции шаблона DAO, как реализовать его в Java и как использовать его поверх менеджера сущностей JPA.
См. также
На этом все! Теперь вы знаете все про dao, Помните, что это теперь будет проще использовать на практике. Надеюсь, что теперь ты понял что такое dao,шаблон dao,паттерн dao и для чего все это нужно, а если не понял, или есть замечания, то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Проектирование веб сайта или программного обеспечения
DAO vs ORM (hibernate) паттерн
ORM и DAO-ортогональные понятия. Один из них связан с тем, как объекты сопоставляются с таблицами базы данных, другой-это шаблон проектирования для записи объектов, которые обращаются к данным. Вы не выбираете ‘between’ из них. Вы можете иметь ORM и DAO-это одно и то же приложение, точно так же, как вам не нужно ORM, чтобы использовать шаблон DAO.
Тем не менее, хотя вам никогда ничего не нужно , вы должны использовать DAOs. Шаблон поддается модульному коду. Вы держите всю свою логику настойчивости в одном месте (разделение проблем, борьба с дырявыми абстракциями). Вы позволяете себе тестировать доступ к данным отдельно от rest приложения. И вы позволяете себе протестировать rest приложения, изолированного от доступа к данным (т. Е. Вы можете издеваться над своим DAOs).
Кроме того, следовать шаблону DAO легко, даже если реализация доступа к данным может быть затруднена. Таким образом, это стоит вам очень мало (или ничего), и вы получаете много.
EDIT — Что касается вашего примера, ваш метод входа в систему должен быть в некотором роде AuthenticationService. Вы можете обрабатывать исключения там (в методе входа в систему). Если бы вы использовали Spring, он мог бы управлять кучей вещей для вас: (1) транзакции, (2) внедрение зависимостей. Вам не нужно было бы писать свои собственные транзакции или фабрики dao, вы могли бы просто определить границы транзакций вокруг своих методов обслуживания и определить свои реализации DAO как бобы, а затем подключить их к своему сервису.![]()
EDIT2
Основная причина использования шаблона заключается в разделении проблем. Это означает, что весь ваш код сохранения находится в одном месте. Побочным эффектом этого является возможность тестирования и ремонтопригодность, а также тот факт, что это облегчает последующее переключение реализаций. Если вы строите Hibernate на основе DAOs, вы можете абсолютно манипулировать сеансом в DAO, это то, что вы должны делать. Анти-шаблон-это когда код, связанный с сохраняемостью, происходит за пределами уровня сохраняемости (закон протекающих абстракций).
Транзакции немного сложнее. На первый взгляд может показаться, что транзакции связаны с постоянством, и это так. Но они связаны не только с настойчивостью. Транзакции также относятся к вашим услугам, поскольку ваши методы обслуживания должны определять «единицу работы», что означает, что все, что происходит в методе обслуживания, должно быть атомарным. Если вы используете hibernate транзакции, то вам придется написать код транзакции hibernate за пределами вашего DAOs, чтобы определить границы транзакций вокруг служб, использующих множество методов DAO.
Но обратите внимание, что транзакции могут быть независимыми от вашей реализации-вам нужны транзакции независимо от того, используете вы hibernate или нет. Также обратите внимание, что вам не нужно использовать механизм транзакций hibernate-вы можете использовать транзакции на основе контейнеров, транзакции JTA и т. Д.
Без сомнения, если вы не используете Spring или что-то подобное, транзакции будут болезненными. Я настоятельно рекомендую использовать Spring для управления вашими транзакциями или спецификацию EJB, в которой, как я полагаю , вы можете определять транзакции вокруг ваших сервисов с помощью аннотаций.
Проверьте следующие ссылки для транзакций на основе контейнеров.
Транзакции, управляемые контейнерами
Сеансы И Транзакции
Из этого я заключаю, что вы можете легко определить транзакции за пределами DAOs на уровне обслуживания, и вам не нужно писать код транзакции.
Другая (менее элегантная) альтернатива состоит в том, чтобы поместить все атомарные единицы работы в DAOs. Вы могли бы иметь CRUD DAOs для простых операций, а затем более сложные DAOs, которые выполняют более одной операции CRUD. Таким образом, ваши программные транзакции останутся в DAO, а ваши службы будут вызывать более сложные DAOs, и вам не придется беспокоиться о транзакциях.
Вы могли бы иметь CRUD DAOs для простых операций, а затем более сложные DAOs, которые выполняют более одной операции CRUD. Таким образом, ваши программные транзакции останутся в DAO, а ваши службы будут вызывать более сложные DAOs, и вам не придется беспокоиться о транзакциях.
Следующая ссылка является хорошим примером того, как шаблон DAO может помочь вам упростить код
AO против ORM(hibernate) шаблон
(thanx @ daff )
Обратите внимание, как определение интерфейса делает так, что ваша бизнес-логика заботится только о поведении UserDao. Его не волнует реализация. Вы можете написать DAO, используя hibernate, или просто JDBC. Таким образом, вы можете изменить реализацию доступа к данным, не затрагивая rest вашей программы.
Блог сурового челябинского программиста: О спорном паттерне DAO
В последние годы, после выхода спецификации Java EE 6, среди разработчиков и архитекторов информационных систем развернулась нешуточная дискуссия на тему паттерна DAO. Некоторые архитекторы и евангелисты уверены, что данный паттерн устарел и является избыточным решением в эпоху инъектируемого сразу в EJB- или CDI-компоненты JPA EntityManager’а. Другие же упорно настраивают на необходимости его применения.
Некоторые архитекторы и евангелисты уверены, что данный паттерн устарел и является избыточным решением в эпоху инъектируемого сразу в EJB- или CDI-компоненты JPA EntityManager’а. Другие же упорно настраивают на необходимости его применения.
@Stateless
public class MyDocumentService implements DocumentService {
@PersistenceContext
private EntityManager em;
// ...
}
Давайте попробуем разобраться в данном вопросе.
Паттерн DAO предназначен для отделения взаимодействия с хранилищем данных от бизнес-логики приложения. Т.е. вся логика, отвечающая за сохранение, изменение, извлечение сущностей выносится в отдельные DAO-классы, а код, инкапсулирующий бизнес-логику приложения (т.н. сервисы), взаимодействует с этими классами, а не непосредственно с хранилищем данных. Такой подход обеспечивает гибкость в выборе подсистемы хранения для приложения. Если необходимо перейти с использования ORM на прямое взаимодействие с базой данных посредством JDBC или отказаться от использования внутреннего хранилища данных для приложения и перейти на взаимодействие с системой управления мастер-данными посредством веб-сервисов, то достаточно только заменить реализацию DAO.

Все прекрасно и звучит красиво, но как известно бесплатного супа не бывает. Поддержка конструкции «интерфейс сервиса — сервис — интерфейс DAO — одна или несколько реализаций DAO» довольно утомительна. Чтобы добавить новую операцию в сервис, в общем случае необходимо сделать следующее:
- Добавить метод в интерфейс сервиса.
- Добавить метод в реализацию сервиса.
- Добавить метод в интерфейс DAO.
- Добавить метод в одну или несколько реализаций DAO.
При этом большинство методов сервисов будут иметь подобную реализацию:
public class MyDocumentService implements DocumentService {
private DocumentDao documentDao;
@Transational
public Document getDocumentById(Long id) {
return documentDao.getDocumentById(id);
}
//...
@Transactional
public void saveDocument(Document document) {
documentDao.save(document);
}
}
Т.е. логики практически нет, но зато добавление новой бизнес-операции выливается в четыре рутинных действия, выполнять которые быстро надоедает всем без исключения разработчикам.

Но важно даже не это, в конце концов человек ко всему привыкает. Главное то, что выполнять их не зачем, прозрачной смены подсистемы хранения паттерн DAO на самом деле не предоставляет. Каждый рекламируемый вариант замены реализации DAO (переключение между ORM и JDBC, между реляционными СУБД и NoSQL, между СУБД и веб-сервисами и т.д.) имеет свои подводные камни и практически всегда требует внесения изменений в слой бизнес-логики.
1. Переключение между ORM и JDBC. ORM-фреймворки, в отличие от JDBC реализуют прозрачное хранение (т.н. transparent persistence). Если после загрузки объекта в сессию обратиться к его сеттерам, то после синхронизации сессии с базой данных эти изменения будут отражены в ней. При использовании же JDBC такой прозрачности нет, поэтому любые изменения необходимо явно синхронизировать с базой данных посредством вызова соответствующих методов DAO, а значит требуется добавить обращение к этим методами в слой бизнес-логики, т. к. ранее, при использовании ORM, они отсутствовали.
к. ранее, при использовании ORM, они отсутствовали.
2. Переключение с традиционной реляционной СУБД на NoSQL-хранилище тоже не всегда можно сделать прозрачно. Большинство NoSQL-хранилищ не поддерживают транзакции в терминах ACID. Бизнес-логику, реализуемую в сервисах, придется адаптировать к нетранзакционному хранилищу. Например, для повышения быстродействия мы могли исключить некоторые проверки из бизнес-логики, надеясь, что в СУБД отработают ограничения целостности, а в случае их нарушения будет выброшено исключение и произойдет откат транзакции. Если же транзакции нет, то изменения, выполненные до момента выбрасывания исключения, сохранятся в БД, что приведет к нарушению целостности данных.
3. Аналогичные соображения можно высказать и относительно перехода с использования реляционной СУБД на взаимодействие с внешним хранилищем посредством веб-сервисов. Контекст транзакции по веб-сервисам без использования специальных техник, таких как WS-AtomicTransaction, не передается, а применение данных техник не всегда возможно, а там где возможно ведет к существенному снижению производительности.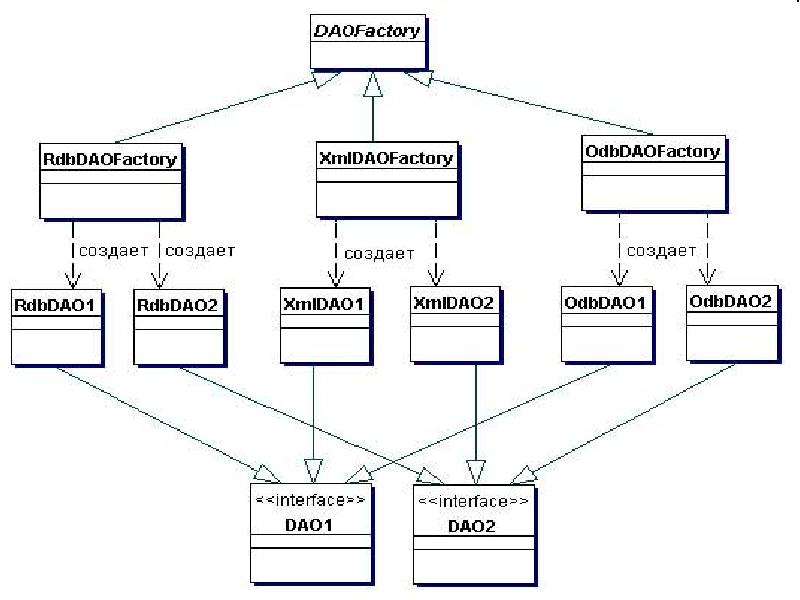
4. Общее соображение. Давайте подумаем, что делать, если необходимо заменить слой хранения в сервисе частично. Предположим, что часть справочников будет подгружаться из системы управления мастер-данными (МДМ), а часть по прежнему храниться в СУБД. Нужно ли создавать композитные DAO-классы, в которых часть методов оперирует с МДМ, а остальные — с СУБД (т.е. по сути, произвести не расширение системы классов, а модификацию конкретного класса, тем самым нарушив принцип открытости-закрытости SOLID), или лучше инжектировать в сервис две реализации одного и того же DAO, затем три и т.д.?
Выводы
Радикальная смена подсистемы хранения только посредством использования паттерна DAO — миф. Как правило такая замена повлечет за собой и модификацию бизнес-логики. Максимум что можно сделать посредством данного паттерна — обеспечить переход на другую реализацию в рамках одной технологии. Например, сменить производителя и, соответственно, используемый диалект языка SQL в рамках технологии «реляционные СУБД». Т.е. перейти с Oracle на DB2 при использовании JDBC посредством паттерна DAO можно, а замена Oracle на Cassandra скорее всего потребует изменений и в слое бизнес-логики. Но заменить диалект СУБД при использовании ORM можно посредством изменения одной строчки в конфигурации. Более радикальные изменения потребуют модификации бизнес-логики и в случае использования структуры из «интерфейс сервиса — тело сервиса — интерфейс DAO — одна или несколько реализаций DAO«, и в случае простой инъекции Entity Manager‘а в сервис.
Т.е. перейти с Oracle на DB2 при использовании JDBC посредством паттерна DAO можно, а замена Oracle на Cassandra скорее всего потребует изменений и в слое бизнес-логики. Но заменить диалект СУБД при использовании ORM можно посредством изменения одной строчки в конфигурации. Более радикальные изменения потребуют модификации бизнес-логики и в случае использования структуры из «интерфейс сервиса — тело сервиса — интерфейс DAO — одна или несколько реализаций DAO«, и в случае простой инъекции Entity Manager‘а в сервис.
UPD: Статья вызвала некий резонанс. В обсуждении на форуме JavaTalks есть интересные мысли, но, как впрочем и ожидалось, дискуссия в конце концов свелась к переходу на личности и мнениям, что кто DAO не пишет, тому стоит перейти на другой язык программирования. Ситуация характерная для русскоязычной аудитории. Не служил — не мужик, че. Однако и в комментариях к данной заметке, и на форуме был высказан ряд соображений в пользу данного паттерна, достойных внимания.
- В приложении присутствует сложная логика доступа к данным и мы хотим эту логику тестировать. При этом хорошо, если у нас приложение переносимое между СУБД, тогда можем запускать тесты на какой-нибудь h3, если же приложение не переносимо, то придется запускать целевую СУБД, что во-первых, может быть медленне, а во-вторых, требует существенного усложнения окружения разработчика. В качестве контраргумента можно высказать следующее: если запросы инкапсулированы в одном месте приложения, например в мэпинге myBatis или вынесены в именованные запросы JPA, то их можно протестировать и без отдельного слоя DAO. Он будет нужен, если логика доступа к данным, не бизнес-логика, несколько сложнее, чем выполнение одного запроса на один метод, например, реализован поиск по нескольким источникам данных или шардинг, т.е. когда в банальном getById выполняется несколько запросов. Тогда в DAO действительно есть смысл.
- DAO облегчает модульное тестирование не слоя доступа к данным, а вышележащего слоя бизнес-логики. Можно сделать моки на объекты DAO и тестировать только логику. Если в проекте действительно используются модульные тесты бизнес-логики, то подход имеет право на жизнь.
- Если у заказчика много денег и он готов оплачивать отдельную команду, разрабатывающую слой DAO. Странная ситуация, но один товарищ на форуме отметил, что работает уже во второй компании, в которой процесс разработки построен таким образом. На мой взгляд это какой-то крайний случай следования паттернам. Более приближенной к реальности является ситуация, когда есть выделенные программисты СУБД, которые пишут слой доступа к данным на языке СУБД, а разработчики среднего слоя (мы с вами) просто вызывают соответствующие хранимые процедуры, представления, или отправляют подсказанные им запросы.
- Пример из моей практики. Интеграционное приложение, в котором логика одна: перелей из пустого в порожнее и залогируй, а типов данных много. Тогда действительно разумно сделать сервис с одним методом, принимающий на вход два объекта-DAO: один отвечает за извлечение данных данного типа из одной информационной системы, другой — за их сохранение в соответствующей информационной системе. Здесь мы получаем все преимущества, приписываемые паттерну DAO: и переносимость, только не между источниками данных, а между информационными потоками, и полиморфизм, когда несколько классов, каждый из которых работает со своим типом данных, реализуют обобщенный интерфейс, а сервис, инкапсулирующий в себе бизнес-логику, работает только с этим интерфейсом. Сами DAO я немного описывал в своих предыдущих заметках (раз и два). Но такой подход весьма нишевый, далеко не в каждом приложении одна логика выпролняется над несколькими типами данных.
 Можно сделать моки на объекты DAO и тестировать только логику. Если в проекте действительно используются модульные тесты бизнес-логики, то подход имеет право на жизнь.
Можно сделать моки на объекты DAO и тестировать только логику. Если в проекте действительно используются модульные тесты бизнес-логики, то подход имеет право на жизнь.UPD 13.11.2014: Сейчас на практике получаю опыт миграции приложения с одной реляционной СУБД на другую и одной и той же СУБД между аппаратно/программными платформами. Надо сказать, что поведение СУБД зачастую бывавет очень разным. Дилемму «версионник-блокировочник» знают все, но в данном случае различия тоньше. При этом использование даже такого развитого ORM, как Hibernate, неспособно помочь. Приходится использовать нативные запросы и привлекать опытных DBA. Это я пишу к тому, что даже если вы протестировали ваше DAO на какой-нибудь In-Memory СУБД, то далеко не факт, что на промышленной системе код будет работать. Но тесты будут зелеными, некоторым это греет душу, да.
Понравилось сообщение — подпишитесь на блог
Паттерны/шаблоны проектирования
Паттерны (или шаблоны) проектирования описывают типичные способы решения часто встречающихся проблем при проектировании программ.
Каталог паттерновСписок из 22-х классических паттернов, сгруппированых по предназначению.
Польза паттерновВы можете вполне успешно работать, не зная ни одного паттерна. Но зная паттерны, вы получаете ещё один инструмент в свой личный набор профессионала.
КлассификацияПаттерны отличаются по уровню сложности, охвата и детализации проектируемой системы. Кроме этого, их можно поделить на три группы, относительно решаемых проблем.
История паттерновКто и когда придумал паттерны? Можно ли использовать язык паттернов вне разработки программного обеспечения?
Критика паттерновТак ли паттерны хороши на самом деле? Всегда ли можно их использовать? Почему, иногда, паттерны бывают вредными?
Погружение в ПаттерныЭлектронная книга о паттернах и принципах проектирования. Доступна в PDF/EPUB/MOBI. Включает в себя архив с примерами на 9 языках программирования.
JDBC, Hibernate, Maven Flashcards | Quizlet
Существует 4 варианта генерации первичных ключей1. GenerationType.AUTO является типом генерации по умолчанию и позволяет поставщику персистентности выбрать стратегию генерации.
Если вы используете Hibernate в качестве поставщика персистентности, он выбирает стратегию генерации на основе конкретного диалекта базы данных. Для большинства популярных баз данных он выбирает GenerationType.SEQUENCE .
2. GenerationType.IDENTITY-самый простой в использовании, но не самый лучший с точки зрения производительности . Он опирается на автоматически увеличивающийся столбец базы данных и позволяет базе данных генерировать новое значение при каждой операции вставки. С точки зрения базы данных это очень эффективно, поскольку столбцы автоматического приращения сильно оптимизированы и не требуют никаких дополнительных операторов.
Этот подход имеет существенный недостаток, если вы используете Hibernate. Hibernate требует значения первичного ключа для каждой управляемой сущности и поэтому должен немедленно выполнить инструкцию insert. Этот предотвращает использование различных методов оптимизации, таких как пакетирование JDBC.
3. GenerationType.SEQUENCE использует последовательность базы данных для генерации уникальных значений. Для получения следующего значения из последовательности базы данных требуются дополнительные операторы select. Но это не имеет никакого значения воздействие для большинства применений .
Если вы не предоставите никакой дополнительной информации, Hibernate запросите следующее значение из последовательности по умолчанию. Вы можете изменить это , обратившись к имени @SequenceGenerator в генераторе атрибут аннотации @GeneratedValue . Аннотация @SequenceGenerator позволяет определить имя генератора, имя и схему последовательности базы данных, а также размер распределения последовательности.
4. GenerationType.TABLE используется очень редко . Он имитирует последовательность путем хранения и обновления ее текущего значения в таблице базы данных, которая требует использования пессимистических блокировок, которые ставят все операции в последовательном порядке. Это замедляет ваше приложение, и поэтому вы должны предпочесть GenerationType.SEQUENCE, если ваша база данных поддерживает последовательности, что делают большинство популярных баз данных.
lec-14-DAO-v001
Пример реализации шаблонов
DAO и Session Facsade
Основы разработки | 20 |
корпоративных
WEB приложений на языке Java
ОБСУЖДАЕМЫЕ ВОПРОСЫ
•Паттерны Data Access Object (или DAO) и
Session Facade
•Пример реализации DAO
•Классы сущности, представляющие модель
•Особенности реализации
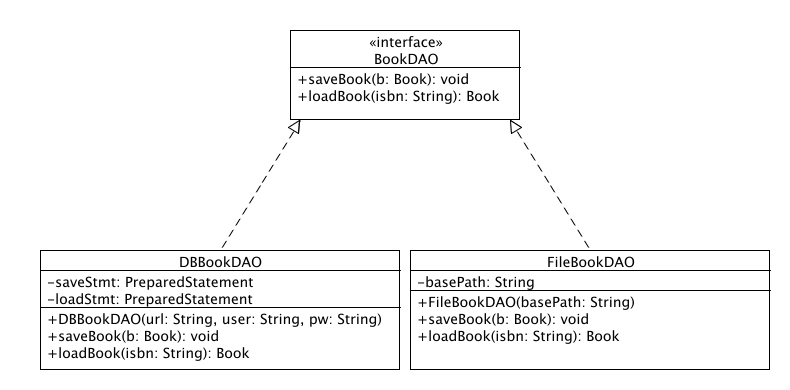
•Интерфейс BookStoreDAO
•Класс DerbyDAO
•Класс AuthorService
ПАТТЕРНЫ DAO И SESSION FACADE
Код компонентов, которые осуществляют обработку данных, может совмещать бизнес логику с логикой доступа к данным.
Это делает трудным замену или модификацию ресурсов данных приложения.
Кроме того, одни и те же компоненты приложения, обрабатывающие данные могут использовать, как разные типы источников (например, базы данных и XML файлы), так и разные методы их использования (например, базы данных разных вендоров).
Решение проблемы разделения специфики хранения и обработки предлагают паттерны DAO и Session Facade
ПАТТЕРН SESSION FACADE
Большинство бизнес процессов содержат сложные манипуляции с бизнес классами.
Бизнес классы участвуют во множестве бизнес процессов или в рабочем потоке.
Сложные процессы, которые вовлекают множество бизнес объектов могут приводить к тесному взаимодействию между этими классами и в результате снижать гибкость и ясность конструирования.
Сложные взаимоотношения между низкоуровневыми бизнес компонентами делают клиентов сложными для написания.
ПАТТЕРН SESSION FAÇADE
(ПРОДОЛЖЕНИЕ)
Шаблон Session Facade («фасад сеанса») определяет высокоуровневый компонент, который содержит и централизует сложные взаимодействия между низкоуровневыми бизнес компонентами.
Session Facade может быть реализован как сеансовый компонент EJB или простой сессионный бин. Он обеспечивает клиентов одним интерфейсом для поддержки функциональности приложения или подмножества объектов приложения.
ПАТТЕРН SESSION FACADE (СХЕМА)
Объект Session Facade также может действовать
как Mediator между бизнес объектами, отделяя их программные интерфейсы друг от друга.
В нашем случае, когда мы не используем EJB компоненты, наши службы будут реализованы в виде POJO далеко не идеально, но достаточно, чтобы показать возможность реализации.
ПАТТЕРН SESSION FACADE (ОКОНЧАНИЕ)
Объекты Session Facade управляют запросами, приходящими от презентационного узла и для выполнения бизнес логики приложения могут вызывать другие объекты Enterprise Session Beans, которые выполняют транзакции, тогда как Entity компоненты представляют бизнес данные в виде набора атрибутов.
Session Facade абстрагирует взаимодействия бизнес объектов и обеспечивает уровень служб, предоставляющий только необходимые интерфейсы. Таким образом, он скрывает от клиента (от презентационного слоя, в данном случае) сложность взаимоотношений между участниками этих взаимодействий.
Session Facade управляет взаимодействиями между объектами бизнес данных и бизнес служб, участвующих в рабочем процессе, и инкапсулирует связанную с этим бизнес-логику.
ПАТТЕРН DATA ACCESS OBJECT (DAO)
Отделяет обработку данных, от механизма доступа к данным
Адаптирует API доступа к специфическим ресурсам данных клиентского интерфейса
Паттерн DAO позволяет модифицировать механизм доступа к данным независимо от кода, который использует данные, а также обеспечивает:
Абстрагирование и инкапсуляцию механизмов доступа к данным
Большую гибкость при разработке
Независимость от способа доступа, предоставленного вендором
Независимость реализации доступа к ресурсам
Легкую миграция на JPA
Улучшение расширяемости
Предотвращает необходимость не нужных передач данных между узлами реализаций зависимых объектов, как легких, классов постоянства
ОБЪЕКТЫ, РЕАЛИЗУЮЩИЕ ПАТТЕРН DAO ОБЫЧНО РАЗМЕЩАЮТСЯ НА БИЗНЕС УЗЛЕ
DataAccessObject
является первичным объектом данного паттерна.
DataAccessObject абстрагирует используемую реализацию доступа к данным для BusinessObject, обеспечивая прозрачный доступ к источнику данных. BusinessObject передает также ответственность за выполнение операций загрузки и сохранения данных объекту DataAccessObject.
ПАТТЕРН DAO (ПРОДОЛЖЕНИЕ)
Паттерн DAO попадает в категорию структурных шаблонов, поскольку он описывает – как один бизнес объект может быть разделен на несколько объектов, выполняющих разные роли (объекты извлекающие данные из источников и объекты, использующие эти данные), а также описывает — как эти объекты могут быть скомбинированы для формирования большого модуля бизнес узла.
Паттерн DAO не описывает то, как создавать объекты базы данных или — как передаются данные между объектами.
В каталоге шаблонов J2EE DAO помещен в группу шаблонов осуществляющих интеграцию, поскольку он используется для интеграции бизнес объектов с различными типами источников данных.
Сохранение данных на Android, Глава 8: Шаблон DAO
Heads up … Вы читаете эту книгу бесплатно, а некоторые части этой главы показаны в виде зашифрованного текста.
Вы можете разблокировать оставшуюся часть этой книги и весь наш каталог книг и видео с подпиской raywenderlich.com Professional.
В предыдущей главе вы узнали о различных типах отношений, таких как «один к одному» , «один ко многим» и «многие ко многим» .Вы также узнали, как создавать их с помощью аннотаций.
Теперь вы узнаете, как извлекать, вставлять, удалять и обновлять данные из вашей базы данных с помощью Database Access Objects .
Попутно вы также узнаете:
- Что такое DAO и как они работают.
- Как создавать DAO с помощью аннотаций комнат.
- Как предварительно заполнить базу данных с помощью класса поставщика.
- Как выполнить INSERT INTO запросов с использованием аннотированных методов
@Insert. - Как выполнить DELETE FROM запросов с использованием аннотированных методов
@Delete. - Как использовать аннотацию
@Queryдля чтения данных из базы данных.
Готовы? Нырнуть в!
Начало работы
Загрузите начальный проект, прилагаемый к этой главе, и откройте его с помощью Android Studio 3.4 или более поздней версии. После того, как Gradle завершит сборку вашего проекта, найдите время, чтобы ознакомиться с кодом. Если вы до сих пор следили за происходящим, вы уже должны быть знакомы с проектом, поскольку он такой же, как последний проект из предыдущей главы.Если вы только начинаете, вот краткое описание кода:
- Пакет data содержит два пакета: db и model . Пакет db содержит класс
QuestionDatabase, который определяет вашу базу данных Room. Пакет model содержит ваши сущности:ВопросиОтвет. - Пакет view содержит все ваши действия:
MainActivity,QuestionActivityиResultActivity.
Now Build and Запустите приложение , чтобы убедиться, что все работает правильно:
Круто! Теперь вы готовы приступить к созданию некоторых объектов доступа к базе данных для управления данными.
Использование DAO для запроса данных
Объекты доступа к базе данныхобычно известны как DAO . DAO — это объекты, которые обеспечивают доступ к данным вашего приложения, и именно они делают Room настолько мощным, поскольку абстрагируют большую часть сложности взаимодействия с реальной базой данных.Использование DAO вместо построителей запросов или прямых запросов упрощает взаимодействие с вашей базой данных. Вы избегаете всех трудностей, связанных с отладкой построителей запросов, если что-то ломается, и все мы знаем, насколько сложным может быть SQL! Они также обеспечивают лучшее разделение проблем для создания более структурированного приложения и повышения его тестируемости.
@Dao
interface QuizDao {
}
@Insert (onConflict = OnConflictStrategy.ЗАМЕНЯТЬ)
забавная вставка (вопрос: вопрос)
@Insert (onConflict = OnConflictStrategy.REPLACE)
забавная вставка (ответ: Ответ)
@Query («УДАЛИТЬ ИЗ вопросов»)
весело clearQuestions ()
@Delete
fun deleteQuestion (вопрос: вопрос)
@Query ("ВЫБРАТЬ * ИЗ вопросов ORDER BY question_id") // 1
весело getAllQuestions (): Список <Вопрос>
@Transaction // 2
@Query ("ВЫБРАТЬ * ИЗ вопросов") // 3
весело getQuestionAndAllAnswers (): Список
абстрактная забавная викторинаDao (): QuizDao
@ База данных (
entity = [(Вопрос :: класс), (Ответ :: класс)],
версия = 1
)
абстрактный класс QuizDatabase: RoomDatabase () {
абстрактная забавная викторинаDao (): QuizDao
}
Создание класса поставщика
Теперь, когда ваши методы DAO готовы, вы создадите класс провайдера, который вам понадобится позже, для предварительного заполнения вашей базы данных. Создайте новый класс в пакете data , назовите его QuestionInfoProvider и добавьте следующий метод:
приватное развлечение initQuestionList (): MutableList {
val questions = mutableListOf <Вопрос> ()
questions.add (
Вопрос(
1,
«Какой из следующих языков обычно не используется для разработки приложений Android»)
)
вопросов.добавлять(
Вопрос(
2,
"В чем смысл жизни?")
)
ответьте на вопросы
}
приватное развлечение initAnswersList (): MutableList {
val answers = mutableListOf <Ответ> ()
ответы.добавить (Ответ (
1,
1,
истинный,
"Джава"
))
answers.add (Ответ (
2,
1,
ложный,
«Котлин»
))
answers.add (Ответ (
3,
1,
ложный,
"Рубин"
))
answers.add (Ответ (
4,
2,
истинный,
«42»
))
answers.add (Ответ (
5,
2,
ложный,
«35»
))
answers.add (Ответ (
6,
2,
ложный,
«7»
))
вернуть ответы
}
var questionList = initQuestionList ()
var answerList = initAnswersList ()
объект QuestionInfoProvider {
var questionList = initQuestionList ()
var answerList = initAnswersList ()
приватное развлечение initQuestionList (): MutableList {
val questions = mutableListOf <Вопрос> ()
questions.add (
Вопрос(
1,
«Какой из следующих языков обычно не используется для разработки приложений Android»))
вопросов.добавлять(
Вопрос(
2,
"В чем смысл жизни?"))
ответьте на вопросы
}
приватное развлечение initAnswersList (): MutableList {
val answers = mutableListOf <Ответ> ()
answers.add (Ответ (
1,
1,
истинный,
"Джава"
))
answers.add (Ответ (
2,
1,
ложный,
«Котлин»
))
answers.add (Ответ (
3,
1,
ложный,
"Рубин"
))
answers.add (Ответ (
4,
2,
истинный,
«42»
))
ответы.добавить (Ответ (
5,
2,
ложный,
«35»
))
answers.add (Ответ (
6,
2,
ложный,
«7»
))
вернуть ответы
}
}
Тестирование базы данных
Хотя пользовательский интерфейс вашего приложения еще не работает, вы все равно можете взаимодействовать с базой данных, выполняя некоторые тесты, такие как добавление или удаление вопросов, чтобы проверить ее работоспособность.
@RunWith (AndroidJUnit4 :: класс)
класс QuizDaoTest {// 1
@ Правило
@JvmField
правило val: TestRule = InstantTaskExecutorRule () // 2
частная база данных lateinit var: QuizDatabase // 3
приватный lateinit var quizDao: QuizDao // 4
}
@ До
fun setUp () {
val context: Context = InstrumentationRegistry.getInstrumentation (). context // 1
пытаться {
database = Room.inMemoryDatabaseBuilder (контекст, QuizDatabase :: class.java) // 2
.allowMainThreadQueries () // 3
.строить()
} catch (e: Exception) {
Log.i (this.javaClass.simpleName, e.message) // 4
}
quizDao = database.quizDao () // 5
}
@Test
fun testInsertQuestion () {
// 1
val previousNumberOfQuestions = quizDao.getAllQuestions (). размер
// 2
val question = Question (1, «Как вас зовут?»)
quizDao.insert (вопрос)
// 3
значение numberOfQuestions = quizDao.getAllQuestions (). size
// 4
значение numberOfNewQuestions =
numberOfQuestions - previousNumberOfQuestions
// 5
Assert.assertEquals (1, numberOfNewQuestions)
// 6
quizDao.clearQuestions ()
// 7
Assert.assertEquals (0, quizDao.getAllQuestions (). Размер)
}
@Test
fun testClearQuestions () {
for (вопрос в QuestionInfoProvider.questionList) {
quizDao.insert (вопрос)
}
Утверждать.assertTrue (quizDao.getAllQuestions (). isNotEmpty ())
Log.d ("testData", quizDao.getAllQuestions (). ToString ())
quizDao.clearQuestions ()
Assert.assertTrue (quizDao.getAllQuestions (). IsEmpty ())
}
@ После
fun tearDown () {
база данных.Закрыть()
}
Ключевые моменты
Куда идти дальше?
Теперь вы знаете, как создавать DAO для взаимодействия с вашей базой данных. Вы можете загрузить окончательный проект, открыв приложение к этой главе, и если вы хотите узнать больше о DAO в Room, вы можете изучить следующие ресурсы:
В чем разница между шаблонами DAO и репозиторием?
DAO - это абстракция персистентности данных .
Репозиторий - это абстракция коллекции объектов .
DAO будет считаться более близким к базе данных, часто ориентированным на таблицы.
Репозиторий будет считаться ближе к домену, работая только с агрегированными корнями.
Репозиторий может быть реализован с использованием DAO , но вы не сделаете наоборот.
Кроме того, репозиторий обычно представляет собой более узкий интерфейс. Это должен быть просто набор объектов с Get (id) , Find (ISpecification) , Add (Entity) .
Такой метод, как Update , подходит для DAO , но не для репозитория - при использовании репозитория изменения сущностей обычно отслеживаются отдельным UnitOfWork.
Кажется обычным видеть реализации, называемые репозиторием , которые на самом деле больше похожи на DAO , и поэтому я думаю, что есть некоторая путаница в различиях между ними.
Хорошо, думаю, я смогу лучше объяснить то, что я написал в комментариях :). Таким образом, в принципе, вы можете видеть и то, и другое как одно и то же, хотя DAO является более гибким шаблоном, чем репозиторий. Если вы хотите использовать оба, вы должны использовать репозиторий в своих DAO. Я объясню каждый из них ниже:
РЕПОЗИТОРИЙ:
Это хранилище объектов определенного типа - оно позволяет вам искать объекты определенного типа, а также сохранять их. Обычно он обрабатывает ТОЛЬКО один тип объектов. Э.г. AppleRepository позволит вам выполнить AppleRepository.findAll (критерии) или AppleRepository.save (juicyApple) .
Обратите внимание, что в репозитории используются термины модели домена (не термины БД - ничего не связанное с тем, как данные где-либо сохраняются).
Репозиторий, скорее всего, будет хранить все данные в одной таблице, тогда как шаблон этого не требует. Тот факт, что он обрабатывает только один тип данных, делает его логически связанным с одной основной таблицей (если используется для сохранения БД).
DAO - объект доступа к данным (другими словами - объект, используемый для доступа к данным)
DAO - это класс, который находит данные для вас (в основном это средство поиска, но обычно оно также используется для хранения данных). Шаблон не ограничивает вас хранением данных одного и того же типа, поэтому вы можете легко получить DAO, который находит / хранит связанные объекты.
Например. вы можете легко получить UserDao, который предоставляет такие методы, как
Коллекция <Разрешение> findPermissionsForUser (String userId)
Пользователь findUser (String userId)
Коллекция <Пользователь> findUsersForPermission (разрешение на доступ)
Все они связаны с пользователем (и безопасностью) и могут быть указаны в том же самом DAO.Это не относится к репозиторию.
Наконец
Обратите внимание, что оба шаблона действительно означают одно и то же (они хранят данные и абстрагируют доступ к ним, и оба они выражены ближе к модели предметной области и почти не содержат ссылки на БД), но способ их использования может немного отличаться, DAO будучи немного более гибким / универсальным, в то время как репозиторий немного более конкретен и ограничивает только тип.
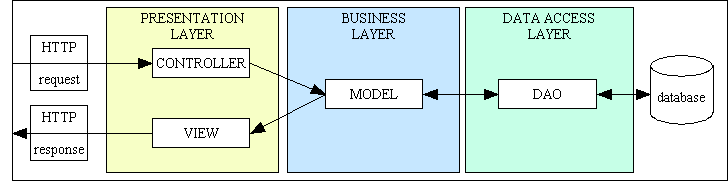
DAO и шаблон репозитория - это способы реализации уровня доступа к данным (DAL).Итак, сначала начнем с DAL.
Объектно-ориентированные приложения, которые обращаются к базе данных, должны иметь некоторую логику для обработки доступа к базе данных. Чтобы код оставался чистым и модульным, рекомендуется выделить логику доступа к базе данных в отдельный модуль. В многоуровневой архитектуре этим модулем является DAL.
До сих пор мы не говорили ни о какой конкретной реализации: только об общем принципе, согласно которому логика доступа к базе данных помещается в отдельный модуль.
Теперь, как мы можем реализовать этот принцип? Что ж, один из известных способов реализации этого, в частности, с такими фреймворками, как Hibernate, - это шаблон DAO.
Шаблон DAO - это способ создания DAL, где обычно каждый объект домена имеет свой собственный DAO. Например, User и UserDao , Appointment и AppointmentDao и т. Д. Пример DAO с Hibernate: http://gochev.blogspot.ca/2009/08/hibernate-generic-dao.html.
Тогда что такое шаблон репозитория? Как и DAO, шаблон репозитория также является способом достижения DAL. Главное в шаблоне репозитория заключается в том, что с точки зрения клиента / пользователя он должен выглядеть или вести себя как коллекция.Под поведением коллекции подразумевается не то, что она должна быть создана, например, Collection collection = new SomeCollection () . Вместо этого это означает, что он должен поддерживать такие операции, как добавление, удаление, содержание и т. Д. В этом суть шаблона репозитория.
На практике, например, в случае использования Hibernate, шаблон репозитория реализуется с помощью DAO. То есть экземпляр DAL может быть одновременно экземпляром шаблона DAO и шаблона репозитория.
Шаблон репозиторияне обязательно строится поверх DAO (как некоторые могут предположить).Если DAO разработаны с интерфейсом, поддерживающим вышеупомянутые операции, то это экземпляр шаблона репозитория. Подумайте об этом: если DAO уже предоставляют набор операций, подобных коллекции, то зачем нужен дополнительный слой поверх него?
Структура шаблона объекта доступа к данным
Контекст 1
... четыре этапа помогают нам подойти и организовать процесс построения модуля / подсистемы хранения и извлечения нашего приложения, где фактическая реализация является последней задачей, для которой другие формальные доступны инструменты, помогающие разработчикам выполнять это эффективно и без ошибок.Одним из таких концептуальных инструментов являются шаблоны проектирования программного обеспечения. Программный шаблон - это повторяемое программное решение определенного типа проблемы, которое оказалось одновременно эффективным и простым [10]. Применение шаблонов проектирования программного обеспечения в процессе проектирования и разработки системы помогает сократить усилия по разработке и предотвращает появление общих или известных ошибок. В следующих подразделах будут представлены некоторые программные шаблоны, связанные с доступом к базе данных. Шаблон Value Object (VO) представляет собой абстракцию состояния или значения постоянного объекта в домене [10].Структура шаблона показана на рисунке 1 с использованием языка моделирования UML [3]. Шаблон VO абстрагирует постоянные свойства бизнес-концепции как элементы, которые будут сохранены в постоянном хранилище (RDB). Доступ к этим данным ограничен и осуществляется через вызовы функций, которые могут быть доступны только для чтения (функции / методы «доступа») или чтения-записи (функции / методы «обновления»). Шаблон объекта доступа к данным (DAO), структура которого показана на рисунке 2, скрывает взаимодействие с постоянным хранилищем (базой данных) от остальной системы или приложения, отделяя бизнес-логику от логики сохранения [10].В таком случае DAO является элементом системы, который будет предоставлять внутренний API для восстановления / хранения данных ВО, абстрагируя внешний источник хранения (обычно, в наших примерах, реляционная база данных, но это может быть любой другой носитель). . Это программная часть системы, которая, например, будет вызывать стандартный API для доступа к базе данных с помощью ODBC, или же будет работать с ней напрямую с помощью собственного драйвера или специальной реализации доступа к базе данных. Шаблон DAO сочетает в себе функции, обычно идентифицируемые с двумя разными шаблонами программного обеспечения: • Шаблон адаптера [10], поскольку он обеспечивает интерфейс для сохранения.• Заводской шаблон [10], поскольку он создает (восстанавливает, а также сохраняет) виртуальные организации, что делает его независимым от источника данных для остальной системы. DAO может даже использовать другие DAO, если имеет дело со сложной VO, состоящей из более чем одной базовой VO, как показано на рисунке 3. Паттерн Фасад обеспечивает единый интерфейс для набора компонентов в системе. Таким образом, клиентам не нужно знать все детали и сложности системы: они просто взаимодействуют с фасадом, у которого есть удобные методы для удовлетворения их потребностей.Использование фасадов в качестве интерфейсов для функциональности системы (или ее части) отделяет ее от клиентов, позволяя сделать модификации прозрачными (поскольку это затронет только внутреннее устройство фасада). Помимо удобной точки доступа к набору логически связанных вариантов использования, фасад также может представлять рабочий процесс. Это подразумевает большую гибкость (и простоту) в разработке системы, потому что могут быть созданы разные фасады (столько, сколько нужно), каждый из которых представляет собой один, хорошо спроектированный API для конкретных целей.Erlang - это распределенный параллельный функциональный язык программирования без конструкций, вызывающих побочные эффекты (за исключением потоковой связи - процессов -). Значения в Erlang (то есть неприводимые выражения) варьируются от чисел и атомов (символьные строчные константы) до сложных структур данных (списки, кортежи - аналогично структурам C -) и функциональных значений. В отсутствие системы статических типов списки и кортежи могут содержать любое допустимое значение. Записи также предоставляются как полезный синтаксический сахар для доступа к кортежам по имени, а не по позиции.Функция Erlang определяется набором уравнений, каждое из которых устанавливает различный набор ограничений, основанных, главным образом, на структуре аргументов (сопоставление с образцом). Итеративное управление осуществляется с помощью рекурсии, и выражения быстро оцениваются. Функции сгруппированы в модули, и подмножество этих функций можно экспортировать, объявляя как имя функции, так и арность, для использования в других модулях. Таким образом, модули Erlang являются элементами единицы реализации на этом языке (например, классы в Java), и, таким образом, каждый объект значения в системе, представляющий бизнес-объекты приложения, соответствует модулю (см. Фрагмент кода 3), экспортирующему подходящие функции доступа и обновления.Как мы ранее указывали в разделе 3.2, для каждого класса, представляющего бизнес-объект, реализуется модуль DAO. В разделе 4 исходного кода показано абстрактное и общее представление Erlang DAO. В этой статье мы проанализировали, изучили и представили ситуацию доступа к реляционной базе данных из среды Erlang. В настоящее время реляционные базы данных являются наиболее часто используемым типом баз данных, и даже несмотря на то, что на рынке существуют другие, более новые и более сложные модели баз данных, реляционные СУБД вряд ли потеряют свое преобладание, по крайней мере, в ближайшие годы.Что касается Erlang, мы считаем его очень интересной платформой для разработки, особенно при наличии определенных требований (надежность, отказоустойчивость, высокая доступность, надежность, возможность распространения, параллелизм, простота обслуживания ...). Таким образом, мы исследовали различные решения, доступные при объединении среды разработки Erlang / OTP с хранилищем реляционной СУБД. Изложенная здесь методология проектирования может применяться независимо от деталей этапа реализации.Тем не менее, только тщательный анализ рабочей нагрузки приложений, бизнес-сценариев использования и характера как операций с данными, так и характера данных, вместе со зрелостью технологического решения, предоставит достаточно суждений для каждого случая, чтобы выбрать между альтернативами доступа к базе данных. Благодарности: Эта работа была частично поддержана MEyC TIN2005-08986 и XUGA ...
db - The Empire DAO-Pattern
Большинству бизнес-приложений требуется доступ к данным, которые доступны из постоянного хранилища, и по-прежнему наиболее популярным типом хранилища являются системы управления реляционными базами данных (СУБД) на основе SQL.Доступ к реляционным системы баз данных стали доступны на Java через JDBC интерфейс, для которого все основные поставщики баз данных обеспечить реализацию. Хотя JDBC прост в использовании на низком уровне, многие ручная работа требуется для эффективно управлять передачей данных от бизнес-объектов и к ним.
За прошедшие годы появилось несколько компонентов, расширяющих JDBC в чтобы упростить передачу и обработку данных, а также сделать код независимым от диалекта SQL базовой системы баз данных.За основной принцип, по которому такие решения с сохранением могут работать, Sun определила шаблон, описывающий, как использовать объект доступа к данным (DAO) для абстрагирования и инкапсуляции всего доступа к источнику данных: шаблон объекта доступа к данным (DAO).
Однако шаблон DAO, как и большинство популярных компонентов сохраняемости, таких как Hibernate, фокусируется только на данных. Но мы
думаю, что в большинстве случаев для реализации приложения требуется от 5 до 10% всех атрибутов сущности.
логика.Остальное просто передается из базы данных клиенту - например, Пользователь
интерфейс - и наоборот.
С другой стороны, метаданные, например, точность значения, максимальный размер поля или
поле обязательно или нет,
часто требуется для отображения, ввода и проверки данных. Без управления метаданными такая информация обычно
разделить и повторить на всех уровнях приложения. С предоставлением метаданных эта избыточность сокращается, что
в свою очередь, упрощает разработку и сокращает объем необходимого тестирования.
Empire-db был разработан с нуля для работы с данными и метаданными. Для поддержки метаданных Empire-db расширяет традиционный доступ к данным Шаблон объекта (DAO) представляет новый информационный объект данных (DIO) . DIO - это контейнер для всех метаданные, относящиеся к определенному атрибуту объекта. Добавлена специальная поддержка для общей модели данных и некоторый вид определенные атрибуты метаданных, но вы также можете добавить свои собственные.
Вот как выглядит расширенный шаблон DAO Empire-db:
Помимо объекта информации о данных, есть еще два заметных отличия от классический паттерн DAO:
- Empire-db работает с динамическими, а не статическими компонентами JavaBeans.
У динамических bean-компонентов нет геттеров и сеттеров для каждого отдельного свойства, как у обычных JavaBeans. Вместо этого используется один универсальный метод получения и установки, который принимает желаемое поле в качестве параметра. В целях для обеспечения безопасности типов Empire-db использует ссылку на объект столбца вместо строки для адресации запрошенного атрибута.
В качестве преимущества нет необходимости изменять объектный компонент при добавлении новых атрибутов в модель данных. и вы можете легко переопределить геттер и сеттер для общей обработки. - Объект доступа к данным Empire-db только использует объекты данных и не создает их.
Идея состоит в том, что вы можете расширить свои объекты данных и реализовать логику, зависящую от сущности. Так что вместо перенос и копирование всех полей данных в ваши бизнес-объекты, вы также можете использовать их непосредственно в или как объекты вашего бизнеса.
| [1] | Цзин-Хуан Ю, Цзы-Мэн Чжоу.Компоненты и развитие в системе больших данных: обзор. Журнал электронной науки и техники, 2019, 17 (1): 51-72. DOI: 10.11989 / JEST.1674-862X.80926105 |
| [2] | Юон-Чан Линь, Ян-Те Ли, Чен-Ян Чэн. ( r , QI) -Трансформация: обратимая анонимность данных на основе числового типа данных в базе данных, переданной на аутсорсинг.Журнал электронной науки и техники, 2017, 15 (3): 222-230. DOI: 10.11989 / JEST.1674-862X.60804020 |
| [3] | Хун-Ли Чен, Яо-Дун Цзоу, Бо-Чен Тай, Су-Чуанг Ли, Йен-Нун Хуанг, Чиа-Му Ю, Ю-Шиан Чиу. Разработка и применение технологии деидентификации данных в условиях больших данных. Журнал электронной науки и техники, 2017, 15 (3): 231-239. DOI: 10.11989 / JEST.1674-862X.60804064 |
| [4] | Нямсурен Ваанчиг, Вэй Чен, Чжи-Гуан Цинь. Контроль доступа на основе атрибутов с эффективным и безопасным отзывом атрибутов для облачной службы обмена данными. Журнал электронной науки и техники, 2017, 15 (1): 90-98. DOI: 10.11989 / JEST.1674-862X.5121616 |
| [5] | Пэн Ю, Юн Чжан, Син-Хуа Лю, Пэн Чжао, Сунь Ли, Жуй-Ци Ван, Шу-Мин Сунь, Гуан-Лей Ли, Ю-Яо Цюй, Линь Ли. Новый шаблон топологии для смешанной микросети переменного и постоянного тока. Журнал электронной науки и техники, 2016, 14 (3): 281-286. DOI: 10.11989 / JEST.1674-862X.605022 |
| [6] | Вэнь-Мин Пан, Цинь Чжан, Цзя-Фэн Чен, Хао-Юань Ван, Цзя-Чун Кан.Маломощный дизайн передачи данных по Ethernet. Журнал электронной науки и техники, 2014, 12 (4): 371-375. DOI: 10.3969 / j.issn.1674-862X.2014.04.006 |
| [7] | Вэй-Лян Тай, Чарльз С. Н. Ван, Филип С. Ю. Шеу, Джеффри Дж. П. Цай. Скрытие данных в ДНК для подтверждения прав на сорта растений. Журнал электронной науки и техники, 2013, 11 (1): 38-43. DOI: 10.3969 / j.issn.1674-862X.2013.01.008 |
| [8] | Ю-Чан Ли, Вэй-Ченг Ву. Технология последовательного шаблона для визуального обнаружения пожара. Журнал электронной науки и техники, 2012, 10 (3): 276-280. DOI: 10.3969 / j.issn.1674-862X.2012.03.014 |
| [9] | Кэ Ли, Цзинь Сюй, Цзян-Сюн Ли, Го-Шэн Хуан, Мин Чжоу, Цун-Конг Цяо, Хай-Шэн Ван.Модель данных хранилища EHR на основе HL7 RIM. Журнал электронной науки и техники, 2012, 10 (4): 334-341. DOI: 10.3969 / j.issn.1674-862X.2012.04.009 |
| [10] | Цин-Цян Хэ, Ю-Хун Лян, Бин-Чжун Ван. Синтез паттернов и оптимизация поляризации конической решетки. Журнал электронной науки и техники, 2011, 9 (1): 71-77. DOI: 10.3969 / j.issn.1674-862X.2011.01.013 |
| [11] | Мукеш Мотвани, Ракхи Мотвани, Фредерик Харрис мл. Параметрическая оценка наборов данных отслеживания движения. Журнал электронной науки и техники, 2010, 8 (3): 215-222. DOI: 10.3969 / j.issn.1674-862X.2010.03.004 |
| [12] | Сюй Лэй, Пин Ян, Пэн Сюй, Тие-Цзюнь Лю, Де-Чжун Яо. Общий классификатор ансамбля пространственных образов и его применение в интерфейсе мозг-компьютер. Журнал электронной науки и техники, 2009, 7 (1): 17-21. |
| [13] | Чэн Чжан, Кэ-Ан Чен, Го-Юэ Чен.Расчет диаграммы направленности и анализ характеристик для круглой решетки со сферическими перегородками. Журнал электронной науки и техники, 2009, 7 (3): 240-245. |
| [14] | Ван Бин-чжун, Сяо Шао-цю, Чжан Юн, Ян Сюэ-сон, У Вэй-ся. Исследования реконфигурируемой антенны в CEMLAB в UESTC. Журнал электронной науки и техники, 2006, 4 (3): 225-231. |
| [15] | Лю Синь, XIONG You-lun. Улучшение создания тестовых шаблонов на основе SAT. Журнал электронной науки и техники, 2005, 3 (2): 134-139. |
| [16] | ЮАНЬ Хун, ЧЭН Хуа-фу, Яо Дэ-чжун. Новая общая линейная модель свертки для обработки данных фМРТ. Журнал электронной науки и техники, 2005, 3 (1): 68-71. |
| [17] | ЧЖЭН Фанвэй, ХУАН Цзюньцай, ШЕ Кун, ЧЖОУ Минтянь. Поиск островов патогенности в геномных данных с помощью ICA. Журнал электронной науки и техники, 2004, 2 (1): 58-62. |
| [18] | Лю Се, Лю Синь-песня, Ян Фэн, Бай Инь-цзе. Разработка и реализация новой модели прогнозирования доступа к файлам в Linux.Журнал электронной науки и техники, 2004, 2 (2): 36-41. |
| [19] | LüWen, TONG Ling, CHEN Guang-ju. MEM в обработке данных измерений. Журнал электронной науки и техники, 2004, 2 (2): 53-55. |
| [20] | ЯО Хай-цюн, Н.И. Гуй-цян. Исследование архитектурного стиля адаптивной объектной модели.Журнал электронной науки и техники, 2004, 2 (4): 16-20. |
Документ без названия
Документ без названияПроблема
Как веб-приложения подключаются к базе данных для получения данных? Большинство веб-приложений требуют большого объема данных, а это значит, что база данных необходима. Как именно это вписывается в парадигму MVC, где все строго разделено. Итак, краткий ответ заключается в том, что данные являются частью модельной части парадигмы MVC.
Более сложный ответ включает сложности, возникающие при взаимодействии с моделью отношений сущностей, которую используют современные базы данных. Как сущности соотносятся с объектами, которые создаются в веб-приложениях? Отношения и таблицы содержат информацию, которая формирует объекты. Существует способ формировать объекты из этих отношений, и решение представляет собой шаблон проектирования объектов доступа к данным (DAO).
Веб-приложения могут также получать доступ к другим постоянным хранилищам, таким как системы LDAP и ERP.
Решение
Шаблон проектирования Data Access Object используется для доступа к данным из постоянных источников (реляционная база данных или другие веб-службы).
DAO действует как мост между постоянными источниками данных и веб-приложением. Они также помогают в переводе реляционной модели в объектно-ориентированную модель.
Шаблон проектирования DAO - это набор классов и интерфейсов, которые позволяют установить мост между постоянным источником данных и веб-приложением.
Обычно, когда приложению необходимо использовать данные из базы данных, оно вызывает DAO. DAO выполнит необходимый запрос и создаст объекты из набора результатов.
Как найти решение?
Шаблон проектирования DAO может быть реализован с помощью следующих элементов:
- А заводской класс ДАО
- Интерфейс DAO
- Конкретный класс, реализующий интерфейс DAO
- Объекты передачи данных (иногда называемые объектами значений)
Класс фабрики DAO сгенерирует класс, реализующий правильный конкретный класс, реализующий интерфейс DAO.Интерфейс DAO необходим, потому что можно использовать несколько хранилищ данных. Объект передачи данных - это объект, который возвращается из класса DAO.
Вот пример иерархии классов для абстрактной фабричной реализации шаблона DAO.
DAOFactory - это абстрактный класс, который будут расширены низшими классами. Каждый из классов, расширяющих класс DAOFactory, предназначен для разных постоянных хранилищ данных. В данном случае их три: cloudscape, oracle и sybase.Каждая из этих фабрик создает объекты DAO, которые запускают правильные запросы для этого конкретного хранилища данных и реализуют интерфейс CustomerDAO, поэтому все они имеют одинаковые методы. Затем объекты DAO создают объекты Customer, которые используются бизнес-логикой.
Следующая лекция будет посвящена Hibernate, фреймворку с открытым исходным кодом для взаимодействия с множеством хранилищ данных.
Источники:
Салливан, Шон. «Расширенное программирование DAO». 07 октября 2003 г. IBM Developerworks. 15 апреля 2009 г.
Sun Microsystems. «Объект доступа к данным». 2002. Core J2EE Patterns. , 14 апреля 2009 г.
DAO Pattern в примере Java | Блог
Шаблон DAO в Java
Чтобы продолжить тему подключения к базе данных в Java, необходимо взглянуть на шаблон DAO, который облегчает работу с базой данных.
Основная идея паттерна Data Access Object (DAO) состоит в том, чтобы скрыть все внутренние операции подключения к базе данных и объединить их в один основной класс. Это может быть необходимо, когда программа состоит из нескольких сущностей, связанных друг с другом, и было бы очень сложно и неэффективно устанавливать соединение с каждой сущностью каждый раз.
На этом этапе необходимо создать несколько шаблонов кода, написанных один раз и выполняемых из разных мест программы.Чтобы лучше понять, как это устроено, давайте рассмотрим пример.
Представьте, что у нас есть штат, представляющий собой таблицу, хранящую примитивную информацию о каждом члене компании (имя, адрес электронной почты, статус). Чтобы разделить операции подключения к базе данных и создания и выполнения операторов, они жестко запрограммированы в методах соответствующих классов. У нас есть интерфейс staffDAO, который содержит прототипы функций, переопределенные в классе staffDAOImpl.
Кроме того, метод подключения разделен на отдельные классы для облегчения доступа в случае необходимости.
Программа может вставлять, обновлять и удалять элементы в базе данных.
Этот пример
довольно обычный, но он помогает понять, как работает шаблон DAO.
Листинг кода
Класс для установления соединения
Главный класс всей программы
Код Выход
Класс сущности для персонала
Интерфейс StaffDAO
Реализация методов интерфейса
В этом удивительном и уникальном примере вы можете найти инструкции о том, как работать с шаблоном Java DAO.Образец был написан тщательно по правилам программирования. Поверьте, с этим шаблоном DAO в примере Java вы выполните свою задачу намного быстрее.
Если вы сомневаетесь, справитесь ли вы со своими заданиями или нет, обратитесь к нам.