с чего начать / Хабр
В мире энтерпрайза наступило пресыщение фронтовыми системами, шинами данных и прочими классическими системами, которые внедряли все кому не лень последние 10-15 лет. Но есть один сегмент, который до недавнего времени был в статусе «все хотят, но никто не знает, что это». И это Big Data. Красиво звучит, продвигается топовыми западными компаниями – как не стать лакомым кусочком?
Но пока большинство только смотрит и приценивается, некоторые компании начали активно внедрять решения на базе этого технологического стека в свой IT ландшафт. Важную роль в этом сыграло появление коммерческих дистрибутивов Apache Hadoop, разработчики которых обеспечивают своим клиентам техническую поддержку. Ощутив необходимость в подобном решении, один из наших клиентов принял решение об организации распределенного хранилища данных в концепции Data Lake на базе Apache Hadoop.
Цели проекта
Во-первых, оптимизировать работу департамента управления рисками. До начала работ расчетом факторов кредитного риска (ФКР) занимался целый отдел, и все расчеты производились вручную. Перерасчет занимал каждый раз около месяца и данные, на основе которых он базировался, успевали устареть. Поэтому в задачи решения входила ежедневная загрузка дельты данных в хранилище, перерасчет ФКР и построение витрин данных в BI-инструменте (для данной задачи оказалось достаточно функционала SpagoBI) для их визуализации.
До начала работ расчетом факторов кредитного риска (ФКР) занимался целый отдел, и все расчеты производились вручную. Перерасчет занимал каждый раз около месяца и данные, на основе которых он базировался, успевали устареть. Поэтому в задачи решения входила ежедневная загрузка дельты данных в хранилище, перерасчет ФКР и построение витрин данных в BI-инструменте (для данной задачи оказалось достаточно функционала SpagoBI) для их визуализации.
Во-вторых, обеспечить высокопроизводительные инструменты Data Mining для сотрудников банка, занимающихся Data Science. Данные инструменты, такие как Jupyter и Apache Zeppelin, могут быть установлены локально и с их помощью также можно исследовать данные и производить построение моделей. Но их интеграция с кластером Cloudera позволяет использовать для расчетов аппаратные ресурсы наиболее производительных узлов системы, что ускоряет выполнение задач анализа данных в десятки и даже сотни раз.
В качестве целевого аппаратного решения была выбрана стойка Oracle Big Data Appliance, поэтому за основу был взят дистрибутив Apache Hadoop от компании Cloudera.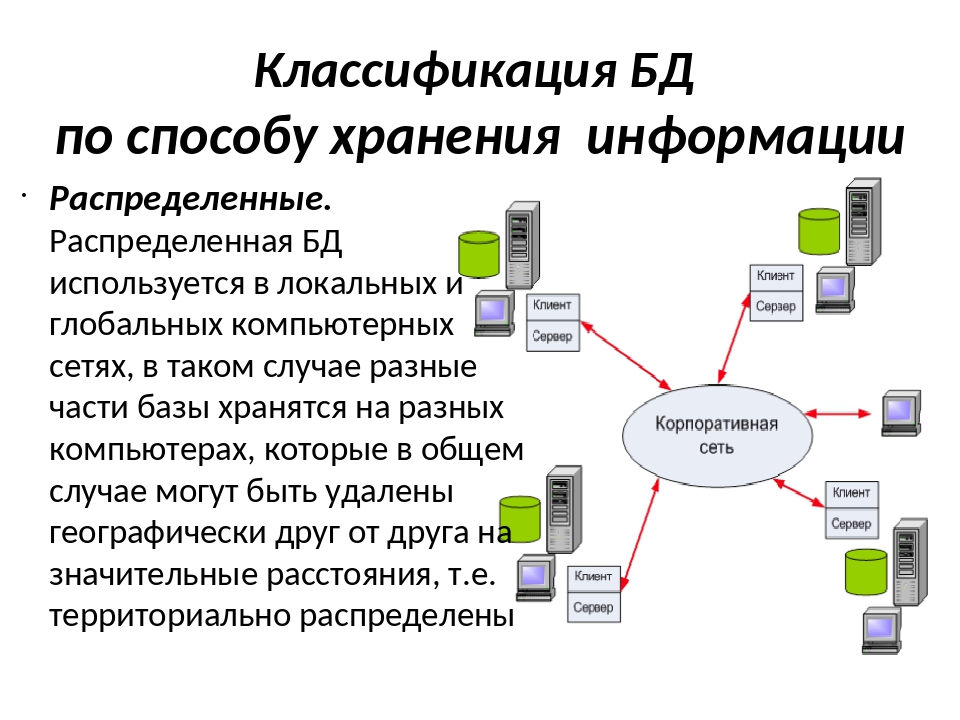 Стойка ехала довольно долго, и для ускорения процесса под данный проект были выделены сервера в приватном облаке заказчика. Решение разумное, но был и ряд проблем, о которых расскажу ниже по тексту.
Стойка ехала довольно долго, и для ускорения процесса под данный проект были выделены сервера в приватном облаке заказчика. Решение разумное, но был и ряд проблем, о которых расскажу ниже по тексту.
В рамках проекта были запланированы следующие задачи:
- Развернуть Cloudera CDH (Cloudera’s Distribution including Apache Hadoop) и дополнительные сервисы, необходимые для работы.
- Произвести настройку установленного ПО.
- Настроить непрерывную интеграцию для ускорения процесса разработки (будет освещена в отдельной статье).
- Установить BI-средства для построения отчетности и инструментов Data Discovery для обеспечения работы датасайентистов (будет освещена в отдельном посте).
- Разработать приложения для загрузки необходимых данных из конечных систем, а также их регулярной актуализации.
- Разработать формы построения отчетности для визуализации данных в BI-средстве.
Компания Neoflex не первый год занимается разработкой и внедрением систем на базе Apache Hadoop и даже имеет свой продукт для визуальной разработки ETL-процессов — Neoflex Datagram.
Ресурсы
До того, как начинать установку, рекомендуется подготовить для нее все необходимое.
Количество и мощность железа напрямую зависит от того, сколько и каких сред потребуется развернуть. Для целей разработки можно установить все компоненты хоть на одну хилую виртуалку, но такой подход не приветствуется.
На этапе пилотирования проекта и активной разработки, когда количество пользователей системы было минимально, было достаточно одной основной среды – это позволяло ускоряться за счет сокращения времени загрузки данных из конечных систем (наиболее частая и долгая процедура при разработке хранилищ данных). Сейчас, когда система стабилизировалась, пришли к конфигурации с тремя средами – тест, препрод и прод (основная).
В приватном облаке были выделены сервера для организации 2 сред – основной и тестовой. Характеристики сред приведены в таблице ниже:
| Назначение | Количество | vCPU | vRAM, Gb | Диски, Gb |
|---|---|---|---|---|
| Основная среда, сервисы Cloudera | 3 | 8 | 64 | 2 200 |
| Основная среда, HDFS | 3 | 22 | 288 | 5000 |
| Основная среда, инструменты Data Discovery | 1 | 16 | 128 | 2200 |
| Тестовая среда, сервисы Cloudera | 1 | 8 | 64 | 2200 |
| Тестовая среда, HDFS | 2 | 22 | 256 | 4000 |
| Основная среда, инструменты Data Discovery | 1 | 16 | 128 | 2200 |
| CI | 2 | 6 | 48 | 1000 |
Позднее основная среда мигрировала на Oracle BDA, а сервера были использованы для организации препрод среды.
Решение о миграции было обоснованным – ресурсов выделенных под HDFS серверов объективно не хватало. Узкими местами стали крохотные диски (что такое 5 Tb для Big Data?) и недостаточно мощные процессоры, стабильно загруженные на 95% при штатной работе задач по загрузке данных. С прочими серверами ситуация обратная – практически все время они простаивают без дела и их ресурсы с большей пользой можно было бы задействовать на других проектах.
С софтом дела обстояли непросто – из-за того, что разработка велась в частном облаке без доступа к интернету, все файлы приходилось переносить через службу безопасности и только по согласованию. В связи с этим приходилось заранее выгружать все необходимые дистрибутивы, пакеты и зависимости.
В этой непростой задаче очень помогала настройка keepcache=1 в файлике /etc/yum.conf (в качестве OS использовался RHEL 7.3) – установить нужное ПО на машине с выходом в сеть намного проще, чем руками выкачивать его из репозиториев вместе с зависимостями 😉
Что потребуется развернуть:
- Oracle JDK (без Java никуда).

- База данных для хранения информации, создаваемой и используемой сервисами CDH (например Hive Metastore). В нашем случае был установлен PostgreSQL версии 9.2.18, но может быть использована любая из поддерживаемых сервисами Cloudera (список отличается для разных версий дистрибутива, см. раздел «Requirements and Supported Versions» официального сайта). Здесь надо заметить, что выбор БД оказался не вполне удачным – Oracle BDA поставляется с БД MySQL (один из их продуктов, перешедший к ним вместе с покупкой Sun) и логичнее было использовать аналогичную базу для других сред, что упростило бы процедуру миграции. Рекомендуется выбирать дистрибутив исходя из целевого аппаратного решения.
- Демон Chrony для синхронизации времени на серверах.
- Cloudera Manager Server.
- Демоны Cloudera Manager.

Подготовка к установке
Перед началом установки CDH стоит провести ряд подготовительных работ. Одна их часть пригодится во время установки, другая упростит эксплуатацию.
Установка и настройка ОС
Прежде всего, стоит подготовить виртуальные (можно и реальные) машины, на которых будет располагаться система: установить на каждую из них операционную систему поддерживаемой версии (список отличается для разных версий дистрибутива, см. раздел «Requirements and Supported Versions» официального сайта), присвоить хостам понятные имена (например, <system_name>master1,2,3…, <system_name>slave1,2,3…), а также разметить диски под файловое хранилища и временные файлы, создаваемые в ходе работы системы.
Рекомендации по разметке следующие:
- На серверах с HDFS создать том хотя бы на 500 Gb для файлов, которые создает YARN в ходе работы задач и помещает в директорию /yarn (куда этот том и надо подмонтировать после установки CDH). Небольшой том (порядка 100 Gb) стоит выделить для ОС, сервисов Cloudera, логов и прочего хозяйства. Все свободное место, которое останется после этих манипуляций, стоит объединить в один большой том и примонтировать к директории /dfs до начала загрузки данных в хранилище. HDFS хранит данные в виде достаточно мелких блоков и лучше лишний раз не заниматься их переносом. Также для удобства последующего добавления дисков рекомендуется использовать LVM – проще будет расширять хранилище (особенно когда оно станет действительно BIG).
- На серверах с сервисами Cloudera можно монтировать все доступное место в корневую директорию – проблем с большими объемами файлов быть не должно, особенно если регулярно чистить логи. Единственное исключение составляет сервер с базой данных, которую используют сервисы Cloudera для своих нужд – на данном сервере имеет смысл разметить отдельный том под директорию, в которой хранятся файлы этой БД (будет зависеть от выбранного дистрибутива). Сервисы пишут довольно умеренно и 500 Gb должно хватить с лихвой. Для подстраховки также можно использовать LVM.
 HDFS хранит данные в виде достаточно мелких блоков и лучше лишний раз не заниматься их переносом. Также для удобства последующего добавления дисков рекомендуется использовать LVM – проще будет расширять хранилище (особенно когда оно станет действительно BIG).
HDFS хранит данные в виде достаточно мелких блоков и лучше лишний раз не заниматься их переносом. Также для удобства последующего добавления дисков рекомендуется использовать LVM – проще будет расширять хранилище (особенно когда оно станет действительно BIG).Настройка http сервера и offline установка пакетов yum и CDH
Поскольку установка софта производится без доступа в интернет, для упрощения установки пакетов рекомендуется поднять HTTP сервер и с его помощью создать локальный репозиторий, который будет доступен по сети. Можно устанавливать весь софт локально с помощью, к примеру, rpm, но при большом количестве серверов и появлении нескольких сред удобно иметь единый репозиторий, из которого можно ставить пакеты без необходимости переносить их руками с машины на машину.
Можно устанавливать весь софт локально с помощью, к примеру, rpm, но при большом количестве серверов и появлении нескольких сред удобно иметь единый репозиторий, из которого можно ставить пакеты без необходимости переносить их руками с машины на машину.
Установка производилась на ОС Red Hat 7.3, поэтому в статье будут приводиться команды, специфичные для нее и других операционных систем на базе CentOS. При установке на других ОС последовательность будет аналогичной, отличаться будут только пакетные менеджеры.
Вот что потребуется сделать:
1. Выбирается машина, на которой будет располагаться HTTP сервер и дистрибутивы.
2. На машине с аналогичной ОС, но подключенной к интернету, выставляем флаг keepcache=1 в файле /etc/yum.conf и устанавливается httpd со всеми зависимостями:
yum install httpdЕсли данная команда не работает, то требуется добавить в список репозиториев yum репозиторий, в котором есть данные пакеты, например, этот —
centos. excellmedia.net/7/os/x86_64
excellmedia.net/7/os/x86_64:
echo -e "\n[centos.excellmedia.net]\nname=excellmedia\nbaseurl=http://centos.excellmedia.net/7/os/x86_64/\nenabled=1\ngpgcheck=0" > /etc/yum.repos.d/excell.repoПосле этого командой
yum repolistпроверяем, что репозиторий подтянулся — в списке репозиториев должен появиться добавленный репозиторий (repo id — centos.excellmedia.net; repo name — excellmedia).
Теперь проверяем, что yum увидел нужные нам пакеты:
yum list | grep httpdЕсли в выводе присутствуют нужные пакеты, то можно установить их приведенной выше командой.
3. Для создания репозитория yum нам потребуется пакет createrepo. Он также есть в указанном выше репозитории и ставится аналогично:
yum install createrepo4.
Как я уже говорил, для работы сервисов CDH требуется база данных. Установим для этих целей PostgreSQL:
yum install postgresql-server5.

Одним из обязательных условий для корректной работы CDH является синхронизация времени на всех серверах, входящих в кластер. Для этих целей используется пакет
chronyd(на тех ОС, где мне приходилось разворачивать CDH, он был установлен по умолчанию). Проверяем его наличие:
chronyd -vЕсли он не установлен, то устанавливаем:
yum install chronyЕсли же установлен, то просто скачиваем:
yumdownloader --destdir=/var/cache/yum/x86_64/7Server/<repo id>/packages chrony6.
Заодно сразу загрузим пакеты, необходимые для установки CDH. Они доступны на сайте
archive.cloudera.com—
archive.cloudera.com/cm///x86_64/cm//RPMS/x86_64/. Можно скачать пакеты руками (cloudera-manager-server и cloudera-manager-daemons) либо по аналогии добавить репозиторий и установить их:
yum install cloudera-manager-daemons cloudera-manager-server7.
После установки пакеты и их зависимости закешируются в папке /var/cache/yum/x86_64/7Server/\/packages. Переносим их на машину, выбранную под HTTP сервер и дистрибутивы, и устанавливаем:
rpm -ivh <имя пакета>8.
Запускаем httpd, делаем его видимым с других хостов нашего кластера, а также добавляем его в список сервисов, запускаемых автоматически после загрузки:
systemctl start httpd
systemctl enable httpd
systemctl stop firewalld # Требуется также сделать для остальных хостов
systemctl disable firewalld # Требуется также сделать для остальных хостов
setenforce 09.
Теперь у нас есть работающий HTTP сервер. Его рабочая директория
/var/www/html. Создадим в ней 2 папки — одну для репозитория yum, другую для парселей Cloudera (об этом чуть позже):
cd /var/www/html
mkdir yum_repo parcels10.
Для работы сервисов Cloudera нам потребуется
Java. На все машины требуется установить JDK одинаковой версии, Cloudera рекомендует Hot Spot от Oracle. Скачиваем дистрибутив с официального сайта (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) и переносим в папку
На все машины требуется установить JDK одинаковой версии, Cloudera рекомендует Hot Spot от Oracle. Скачиваем дистрибутив с официального сайта (http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) и переносим в папку
.
11. Создадим в папке yum_repo репозиторий yum с помощью утилиты createrepo чтобы пакет с JDK стал доступен для установки с машин кластера:
createrepo -v /var/www/html/yum_repo/12.
После создания нашего локального репозитория на каждом из хостов требуется добавить его описание по аналогии с пунктом 2:
echo -e "\n[yum.local.repo]\nname=yum_repo\nbaseurl=http://<имя хоста с httpd>/yum_repo/\nenabled=1\ngpgcheck=0" > /etc/yum.repos.d/yum_repo.repoТакже можно сделать проверки, аналогичные пункту 2.
13. JDK доступен, устанавливаем:
yum install jdk1.8.0_161.x86_64 Для эксплуатации Java потребуется задать переменную JAVA_HOME. Рекомендую сделать ее экспорт сразу после установки, а также записать ее в файлы
Рекомендую сделать ее экспорт сразу после установки, а также записать ее в файлы
и
/etc/default/bigtop-utilsчтобы она автоматически экспортировалась после перезапуска серверов и ее расположение предоставлялось сервисам CDH:
export JAVA_HOME=/usr/java/jdk1.8.0_161
echo "JAVA_HOME=/usr/java/jdk1.8.0_161" >> /etc/environment
export JAVA_HOME=/usr/java/jdk1.8.0_144 >> /etc/default/bigtop-utils14.
Таким же образом устанавливаем chronyd на всех машинах кластера (если, конечно, он отсутствует):
yum install chrony15.
Выбираем хост, на котором будет работать PostgreSQL, и устанавливаем его:
yum install postgresql-server16.
Аналогично, выбираем хост, на котором будет работать Cloudera Manager, и устанавливаем его:
yum install cloudera-manager-daemons cloudera-manager-server17.
Пакеты установлены, можно приступать к настройке ПО перед установкой.
Дополнение:
В ходе разработки и эксплуатации системы потребуется добавлять пакеты к репозиторий yum для их установки на хостах кластера (например дистрибутив Anaconda). Для этого помимо самого переноса файлов в папку yum_repo требуется выполнить следующие действия:
Настройка вспомогательного софта
Настало время сконфигурировать PostgreSQL и создать базы данных для наших будущих сервисов. Данные настройки актуальны для версии CDH 5.12.1, при установке других версий дистрибутива рекомендуется ознакомиться с разделом «Cloudera Manager and Managed Service Datastores» официального сайта.
Для начала произведем инициализации базы данных:
postgresql-setup initdbТеперь настраиваем сетевое взаимодействие с БД. В файле
/var/lib/pgsql/data/pg_hba.confв секции «IPv4 local connections» меняем метод для адреса 127.0.0.1/32 на метод «md5», добавляем метод «trust» и добавляем подсеть кластера с методом «trust»:
vi /var/lib/pgsql/data/pg_hba. conf
pg_hba.conf:
-----------------------------------------------------------------------
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all peer
# IPv4 local connections:
host all all 127.0.0.1/32 md5
host all all 127.0.0.1/32 trust
host all all <cluster_subnet> trust
----------------------------------------------------------------------- conf
pg_hba.conf:
-----------------------------------------------------------------------
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all peer
# IPv4 local connections:
host all all 127.0.0.1/32 md5
host all all 127.0.0.1/32 trust
host all all <cluster_subnet> trust
-----------------------------------------------------------------------
conf
pg_hba.conf:
-----------------------------------------------------------------------
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all peer
# IPv4 local connections:
host all all 127.0.0.1/32 md5
host all all 127.0.0.1/32 trust
host all all <cluster_subnet> trust
-----------------------------------------------------------------------Затем внесем некоторые коррективы в файл /var/lib/pgsql/data/postgres.conf (приведу только те строки, которые надо изменить или проверить на соответствие:
vi /var/lib/pgsql/data/postgres.conf
postgres.conf:
-----------------------------------------------------------------------
listen_addresses = '*'
max_connections = 100
shared_buffers = 256MB
checkpoint_segments = 16
checkpoint_completion_target = 0. 9
logging_collector = on
log_filename = 'postgresql-%a.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
log_timezone = 'W-SU'
datestyle = 'iso, mdy'
timezone = 'W-SU'
lc_messages = 'en_US.UTF-8'
lc_monetary = 'en_US.UTF-8'
lc_numeric = 'en_US.UTF-8'
lc_time = 'en_US.UTF-8'
default_text_search_config = 'pg_catalog.english'
----------------------------------------------------------------------- 9
logging_collector = on
log_filename = 'postgresql-%a.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
log_timezone = 'W-SU'
datestyle = 'iso, mdy'
timezone = 'W-SU'
lc_messages = 'en_US.UTF-8'
lc_monetary = 'en_US.UTF-8'
lc_numeric = 'en_US.UTF-8'
lc_time = 'en_US.UTF-8'
default_text_search_config = 'pg_catalog.english'
-----------------------------------------------------------------------
9
logging_collector = on
log_filename = 'postgresql-%a.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
log_timezone = 'W-SU'
datestyle = 'iso, mdy'
timezone = 'W-SU'
lc_messages = 'en_US.UTF-8'
lc_monetary = 'en_US.UTF-8'
lc_numeric = 'en_US.UTF-8'
lc_time = 'en_US.UTF-8'
default_text_search_config = 'pg_catalog.english'
-----------------------------------------------------------------------После окончания конфигурации требуется создать базы данных (для тех, кому ближе терминология Oracle – схемы) для сервисов, которые будем устанавливать. В нашем случае были установлены следующие сервисы: Cloudera Management Service, HDFS, Hive, Hue, Impala, Oozie, Yarn и ZooKeeper. Из них Hive, Hue и Oozie нуждаются в базах, а также 2 базы потребуются для нужд сервисов Cloudera – одна для сервера Cloudera Manager, другая для менеджера отчетов, входящего в Cloudera Management Service. Запустим и PostgreSQL и добавим его в автозагрузку:
systemctl start postgresql
systemctl enable postgresqlТеперь мы можем подключиться и создать нужные базы:
sudo -u postgres psql
> CREATE ROLE scm LOGIN PASSWORD '<password>';
> CREATE DATABASE scm OWNER scm ENCODING 'UTF8'; # Роль и база Cloudera Manager
> CREATE ROLE rman LOGIN PASSWORD '<password>';
> CREATE DATABASE rman OWNER rman ENCODING 'UTF8'; # Роль и база менеджера отчетов
> CREATE ROLE hive LOGIN PASSWORD '<password>';
> CREATE DATABASE metastore OWNER hive ENCODING 'UTF8'; # Роль и база Hive Metastore
> ALTER DATABASE metastore SET standard_conforming_strings = off; # Рекомендуется для PostgreSQL старше версии 8. 2.23
> CREATE ROLE hue_u LOGIN PASSWORD '<password>';
> CREATE DATABASE hue_d OWNER hue_u ENCODING 'UTF8'; # Роль и база Hue
> CREATE ROLE oozie LOGIN ENCRYPTED PASSWORD '<password>' NOSUPERUSER INHERIT CREATEDB NOCREATEROLE;
> CREATE DATABASE "oozie" WITH OWNER = oozie ENCODING = 'UTF8' TABLESPACE = pg_default LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' CONNECTION LIMIT = -1; # Роль и база Oozie согласно рекомендациям официального сайта:
> \q 2.23
> CREATE ROLE hue_u LOGIN PASSWORD '<password>';
> CREATE DATABASE hue_d OWNER hue_u ENCODING 'UTF8'; # Роль и база Hue
> CREATE ROLE oozie LOGIN ENCRYPTED PASSWORD '<password>' NOSUPERUSER INHERIT CREATEDB NOCREATEROLE;
> CREATE DATABASE "oozie" WITH OWNER = oozie ENCODING = 'UTF8' TABLESPACE = pg_default LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' CONNECTION LIMIT = -1; # Роль и база Oozie согласно рекомендациям официального сайта:
> \q
2.23
> CREATE ROLE hue_u LOGIN PASSWORD '<password>';
> CREATE DATABASE hue_d OWNER hue_u ENCODING 'UTF8'; # Роль и база Hue
> CREATE ROLE oozie LOGIN ENCRYPTED PASSWORD '<password>' NOSUPERUSER INHERIT CREATEDB NOCREATEROLE;
> CREATE DATABASE "oozie" WITH OWNER = oozie ENCODING = 'UTF8' TABLESPACE = pg_default LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8' CONNECTION LIMIT = -1; # Роль и база Oozie согласно рекомендациям официального сайта:
> \qДля других сервисов базы данных создаются аналогично.
Не забываем прогнать скрипт для подготовки базы сервера Cloudera Manager, передав ему на вход данные для подключения к созданной для него базе:
. /usr/share/cmf/schema/scm_prepare_database.sh postgresql scm scm <password>Создание репозитория с файлами CDH
Cloudera предоставляет 2 способа установки CDH – с помощью пакетов (packages) и с помощью парсэлей (parcels). Первый вариант предполагает скачивание набора пакетов с сервисами нужных версий и последующую их установку. Данный способ предоставляет большую гибкость конфигурации кластера, но Cloudera не гарантируют их совместимость. Поэтому более популярен второй вариант установки с использованием парсэлей – заранее сформированных наборов пакетов совместимых версий. Самые свежие версии доступны по следующей ссылке: archive.cloudera.com/cdh5/parcels/latest. Более ранние можно найти уровнем выше. Помимо самого парсэля с CDH требуется скачать manifest.json из той же директории репозитория.
Данный способ предоставляет большую гибкость конфигурации кластера, но Cloudera не гарантируют их совместимость. Поэтому более популярен второй вариант установки с использованием парсэлей – заранее сформированных наборов пакетов совместимых версий. Самые свежие версии доступны по следующей ссылке: archive.cloudera.com/cdh5/parcels/latest. Более ранние можно найти уровнем выше. Помимо самого парсэля с CDH требуется скачать manifest.json из той же директории репозитория.
Для эксплуатации разработанного функционала нам также требовался Spark 2.2, не входящий в парсэль CDH (там доступна первая версия данного сервиса). Для его установки требуется загрузить отдельный парсэль с данным сервисом и соответствующий manifest.json, также доступные в архиве Cloudera.
После загрузки парсэлей и manifest.json требуется перенести их в соответствующие папки нашего репозитория. Создаем отдельные папки для файлов CDH и Spark:
cd /var/www/html/parcels
mkdir cdh sparkПереносим в созданные папки парсэли и файлы manifest. json. Чтобы сделать их доступными для установки по сети выдаем папке с парсэлями соответствующие доступы:
json. Чтобы сделать их доступными для установки по сети выдаем папке с парсэлями соответствующие доступы:
chmod -R ugo+rX /var/www/html/parcelsМожно приступать к установке CDH, о чем я расскажу в следующем посте.
Распределенное хранение данных: от облака до блокчейна
Материал опубликован в рамках совместного спецпроекта ForkLog и Storj Labs «Блокчейн и хранение данных». С полным списком опубликованных материалов можно ознакомиться здесь.
Поиски эффективного применения технологии блокчейн распространяются не только на финансовый сектор и все, что с ним связано, но и на такие сферы, как распределенное хранение данных. Несмотря на достаточно высокую эффективность и популярность, проблемы с традиционными, то есть централизованными, хранилищами по-прежнему существуют.
Одна из самых показательных и громких историй — закрытие файлообменника MegaUpload, сервера которого были физически отключены провайдером LeaseWeb по требованию американских спецслужб.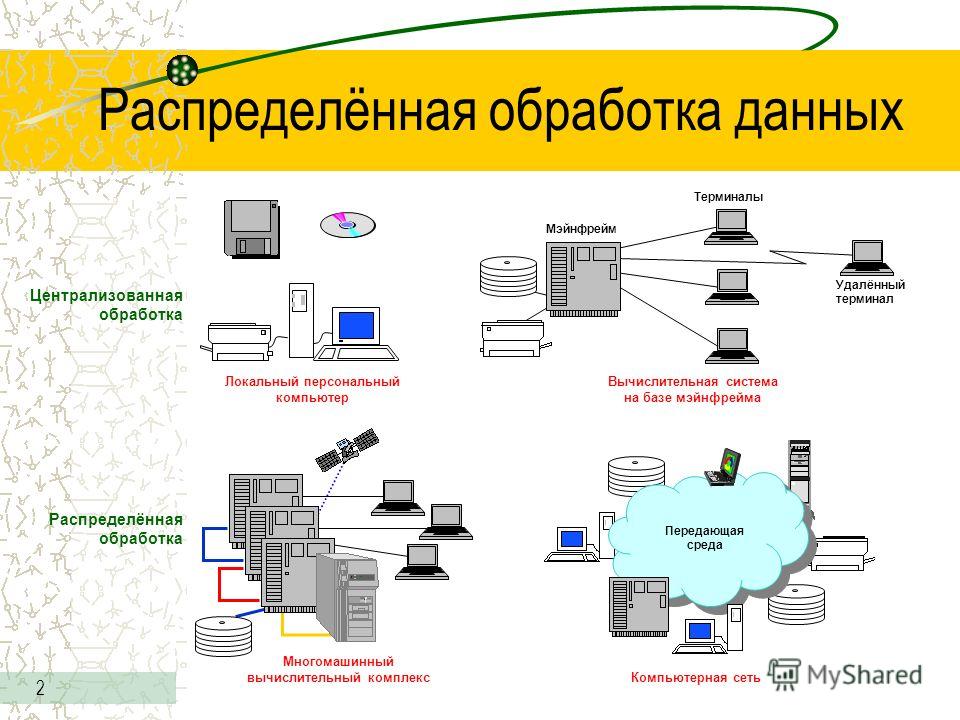 Сами основатели сервиса при этом были арестованы.
Сами основатели сервиса при этом были арестованы.
Неоднократно был скомпрометирован и такой популярный сервис как Dropbox. Примечательно, что в отличие от многих своих централизованных конкурентов Dropbox не использует шифрования данных, в то время как каждое децентрализованное хранилище по умолчанию шифрует данные пользователя.
К сожалению, большинство облачных сервисов хранения данных подвержено рискам, вытекающим из централизации, и распределенные системы с изначально заложенным потенциалом к постоянному расширению действительно могут быть гораздо эффективнее как с точки зрения стойкости к цензуре, так и с точки зрения безопасности в целом. И именно в сфере распределенного хранения данных блокчейн может изменить ситуацию кардинально.
Если говорить о децентрализованном хранении данных как таковом, можно разделить его на два типа:
1) Принцип работы облачных хранилищ.
2) Принцип работы торрентов.
В случае с облачными хранилищами такое хранение данных не совсем корректно называть децентрализованным, поскольку в системе всегда есть некий единый оператор, который арендует оборудование у сторонних компаний или располагает собственными серверами. Одна из ключевых проблем современных облачных хранилищ заключается именно в частичной централизации всей системы.
Одна из ключевых проблем современных облачных хранилищ заключается именно в частичной централизации всей системы.
В случае с торрентами файлы могут храниться у обычных пользователей, которые таким образом вносят свой вклад в развитие сети и как бы предоставляют свои услуги по хранению данных в обмен на возможность скачивать файлы от других пользователей. При этом в такой сети могут присутствовать и достаточно крупные сервера, на которых хранится большое количество файлов, поэтому, строго говоря, система такого типа содержит свои риски централизации. Но ключевой недостаток торрентов состоит в отсутствии четко определенных и ощутимых стимулов для участников сети.
И здесь как нельзя кстати можно вспомнить о концепции криптовалюты Permacoin, которая была предложена рабочей группой Microsoft Research еще в 2010 году. Очень упрощенно Permacoin — это протокол, похожий на торрент, с внутренним токеном, который используется для вознаграждения пользователей за хранение данных. Одной из предпосылок к работе над концепцией Permacoin для рабочей группы стало желание утилизировать ресурсы майнеров более полезным образом, чем это происходит в случае с биткоином. Правда, и сам майнинг при этом решении был бы устроен иначе, чем обсчитывание хешей.
Правда, и сам майнинг при этом решении был бы устроен иначе, чем обсчитывание хешей.
Таким образом, возвращаясь к облачным хранилищам и торрентам, будет более корректно и уместно использовать термин «распределенное хранение данных», а не децентрализованное.
И поскольку идея использования блокчейна для распределенного хранения данных лежит на поверхности, на данный момент уже существует несколько проектов, работающих в данном направлении. На сегодняшний день к проектам, которые работают в направлении применения блокчейна для распределенного хранения данных и дистрибуции контента относятся: Storj, Sia, MaidSafe, Decent, LBRY Credits, FileCoin и другие.
STORJ
Проект был запущен в 2014 году. Токен SJCX выпущен через протокол Counterparty, который работает поверх блокчейна биткоина. Стоит отметить, что совсем недавно представители Storj заявили о переносе токена и основной архитектуры проекта на блокчейн Ethereum, поскольку обслуживание в рамках сети биткоина стало обходиться слишком дорого, и, что самое главное, — слишком медленно. Перенос на Ethereum состоится после очередного этапа привлечения средств через Token Sale, который стартует 19 мая.
Перенос на Ethereum состоится после очередного этапа привлечения средств через Token Sale, который стартует 19 мая.
На данный момент цена хранения 1 GB данных при пропускной способности в 30 GB в месяц обходится в $1.51. При этом стоит ожидать, что после переноса проекта на блокчейн Ethereum стоимость хранения данных снизится.
по данным storj.io
Принцип хранения данных в Storj устроен достаточно просто. Файл, загружаемый пользователем в сеть, шифруется так, чтобы доступ к нему был только у владельца. Полученный результат разбивается на несколько частей и отправляется в сеть. Ниже приведена схема, описывающая базовый принцип хранения данных в системе.
Схема, описывающая принцип хранения данных в системе Storj
Процесс предоставления дискового пространства для хранения данных в обмен на токены проекта называется фарминг. На ранней стадии развития проекта, чтобы начать фарминг, нужно было иметь в своем кошельке 10 000 монет SJCX, однако впоследствии это правило отменили.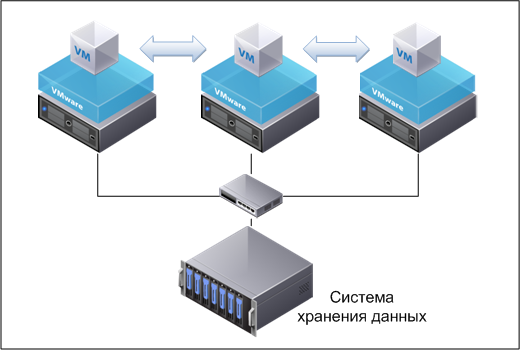
MaidSafe
Команда проекта родом из Шотландии и разрабатывает инфраструктуру для децентрализованного хранения данных c 2006 года. Сама монета MaidSafe существует и торгуется на биржах с 2014 года. Токен был выпущен через протокол MasterCoin, существующий поверх протокола Bitcoin. Стоит сразу отметить, что блокчейн не используется в данном проекте для достижения консенсуса, фактически использование распределенного реестра ограничено выпуском токена и внедрением некоторых дополнительных функций. О том, как может достигаться консенсус без блокчейна, команда опубликовала достаточно подробный и аргументированный пост в официальном блоге проекта еще в 2015 году.
На данный момент на официальном сайте доступна первая альфа-версия проекта, однако точные даты по следующим релизам пока неизвестны. Помимо хранения данных, MaidSafe предлагает безопасный доступ к информации пользователя без взаимодействия с третьей стороной. Простыми словами, никому не нужно хранить записи о файлах пользователя или информации, необходимой для авторизации, соответственно, и доступ к данным и их дешифровке есть только у владельца.
Все файлы, загруженные пользователем в сеть, шифруются и разбиваются на небольшие части, называемые чанками, которые распространяются по всей сети. При этом благодаря сложной системе аутентификации, доступ к итоговому файлу и его чанкам есть только у владельца данных.
Вместо майнинга в сети MaidSafe также используется понятие фарминг, а сам процесс заключается в предоставлении дискового пространства и вычислительных мощностей компьютера для обслуживания сети и хранения файлов, загруженных пользователями. В качестве награды за фарминг пользователи получают токены SafeCoin.
Стоит отметить, что торгуемый на данный момент на биржах токен MAID (MaidSafeCoin) подлежит обмену на токен SafeCoin, а сама процедура обмена будет запущена после окончательного релиза продукта. Учитывая специфику развития биткоина за последние три года, есть вероятность, что этот токен будет выпущен поверх другой блокчейн-системы.
SIA
Проект существует с 2015 года и использует блокчейн, близкий по своим свойствам к блокчейну биткоина. Логика хранения данных у SIA схожа с MaidSafe: файлы пользователя шифруются, разбиваются на части и распределяются по децентрализованной сети. Доступ к файлам пользователя осуществляется через приватный ключ, так что никто кроме владельца не может получить доступ к загруженной в сеть информации. Награда за предоставление дискового пространства распределяется в токенах SIA.
Логика хранения данных у SIA схожа с MaidSafe: файлы пользователя шифруются, разбиваются на части и распределяются по децентрализованной сети. Доступ к файлам пользователя осуществляется через приватный ключ, так что никто кроме владельца не может получить доступ к загруженной в сеть информации. Награда за предоставление дискового пространства распределяется в токенах SIA.
Любопытны и представленные на сайте проекта расчеты о стоимости хранения данных в сети SIA в сравнении с популярными облачными хранилищами. Согласно представленной калькуляции, хранение 1 Тб информации в сети SIA обойдется как минимум в 10 раз дешевле, чем на таких сервисах как Amazon S3 или Microsoft Azure.
по данным sia.tech
Команда проекта даже выпустила отличную и достаточно подробную инфографику, описывающую устройство SIA.
Вместо заключения
На данный момент распределенное хранение данных, наряду с распределенными вычислениями, — один из основных трендов блокчейн-экономики. Многие проекты все еще находятся на ранней стадии разработки и тестировании гипотез, соответственно, о реальной конкуренции с централизованными сервисами хранения пока говорить рано. Но в случае сохранения динамики роста блокчейн-рынка, в скором времени распределенные хранилища на блокчейне будут конкурировать между собой. И основными параметрами конкуренции станут скорость, масштабируемость, безопасность и низкая стоимость услуг.
Но в случае сохранения динамики роста блокчейн-рынка, в скором времени распределенные хранилища на блокчейне будут конкурировать между собой. И основными параметрами конкуренции станут скорость, масштабируемость, безопасность и низкая стоимость услуг.
Нашли ошибку в тексте? Выделите ее и нажмите CTRL+ENTER
Современные распределенные хранилища данных: обзор технологий и перспективы
Сегодня поговорим о том, как лучше хранить данные в мире, где сети пятого поколения, сканеры геномов и беспилотные автомобили производят за день больше данных, чем всё человечество породило в период до промышленной революции. Наш мир генерирует всё больше информации. Какая-то её часть мимолётна и утрачивается так же быстро, как и собирается. Другая должна храниться дольше, а иная и вовсе рассчитана «на века» — по крайней мере, так нам видится из настоящего. Информационные потоки оседают в дата-центрах с такой скоростью, что любой новый подход, любая технология, призванные удовлетворить этот бесконечный «спрос», стремительно устаревают. 40 лет развития распределённых СХД. Первые сетевые хранилища в привычном нам виде появились в 1980-х. Многие из вас сталкивались с NFS (Network File System), AFS (Andrew File System) или Coda. Спустя десятилетие мода и технологии изменились, а распределённые файловые системы уступили место кластерным СХД на основе GPFS (General Parallel File System), CFS (Clustered File Systems) и StorNext. В качестве базиса использовались блочные хранилища классической архитектуры, поверх которых с помощью программного слоя создавалась единая файловая система. Эти и подобные решения до сих пор применяются, занимают свою нишу и вполне востребованы.
40 лет развития распределённых СХД. Первые сетевые хранилища в привычном нам виде появились в 1980-х. Многие из вас сталкивались с NFS (Network File System), AFS (Andrew File System) или Coda. Спустя десятилетие мода и технологии изменились, а распределённые файловые системы уступили место кластерным СХД на основе GPFS (General Parallel File System), CFS (Clustered File Systems) и StorNext. В качестве базиса использовались блочные хранилища классической архитектуры, поверх которых с помощью программного слоя создавалась единая файловая система. Эти и подобные решения до сих пор применяются, занимают свою нишу и вполне востребованы.
Воспользуйтесь нашими услугами
На рубеже тысячелетий парадигма распределённых хранилищ несколько поменялась, и на лидирующие позиции вышли системы с архитектурой SN (Shared-Nothing). Произошёл переход от кластерного хранения к хранению на отдельных узлах, в качестве которых, как правило, выступали классические серверы с обеспечивающим надёжное хранение ПО; на таких принципах построены, скажем, HDFS (Hadoop Distributed File System) и GFS (Global File System).
Ближе к 2010-м заложенные в основу распределённых систем хранения концепции всё чаще стали находить отражение в полноценных коммерческих продуктах, таких как VMware vSAN, Dell EMC Isilon и наша Huawei OceanStor. За упомянутыми платформами стоит уже не сообщество энтузиастов, а конкретные вендоры, которые отвечают за функциональность, поддержку, сервисное обслуживание продукта и гарантируют его дальнейшее развитие. Такие решения наиболее востребованы в нескольких сферах.
Операторы связи
Пожалуй, одними из старейших потребителей распределённых систем хранения являются операторы связи. На схеме видно, какие группы приложений производят основной объём данных. OSS (Operations Support Systems), MSS (Management Support Services) и BSS (Business Support Systems) представляют собой три дополняющих друг друга программных слоя, необходимых для предоставления сервиса абонентам, финансовой отчётности провайдеру и эксплуатационной поддержки инженерам оператора.
Зачастую данные этих слоев сильно перемешаны между собой, и, чтобы избежать накопления ненужных копий, как раз и используются распределённые хранилища, которые аккумулируют весь объём информации, поступающей от работающей сети..png) Хранилища объединяются в общий пул, к которому и обращаются все сервисы.
Хранилища объединяются в общий пул, к которому и обращаются все сервисы.
Наши расчёты показывают, что переход от классических СХД к блочным позволяет сэкономить до 70% бюджета только за счёт отказа от выделенных СХД класса hi-end и использования обычных серверов классической архитектуры (обычно x86), работающих в связке со специализированным ПО. Сотовые операторы уже довольно давно начали приобретать подобные решения в серьезных объёмах. В частности, российское операторы используют такие продукты от Huawei более шести лет.
Да, ряд задач с помощью распределённых систем выполнить не получится. Например, при повышенных требованиях к производительности или к совместимости со старыми протоколами. Но не менее 70% данных, которые обрабатывает оператор, вполне можно расположить в распределённом пуле.
Банковская сфера
В любом банке соседствует множество разношёрстных IT-систем, начиная с процессинга и заканчивая автоматизированной банковской системой. Эта инфраструктура тоже работает с огромным объёмом информации, при этом большая часть задач не требует повышенной производительности и надёжности систем хранения, например разработка, тестирование, автоматизация офисных процессов и пр. Здесь применение классических СХД возможно, но с каждым годом всё менее выгодно. К тому же в этом случае отсутствует гибкость расходования ресурсов СХД, производительность которой рассчитывается из пиковой нагрузки.
Здесь применение классических СХД возможно, но с каждым годом всё менее выгодно. К тому же в этом случае отсутствует гибкость расходования ресурсов СХД, производительность которой рассчитывается из пиковой нагрузки.
При использовании распределённых систем хранения их узлы, по факту являющиеся обычными серверами, могут быть в любой момент конвертированы, например, в серверную ферму и использованы в качестве вычислительной платформы.
Озёра данных
На схеме выше приведён перечень типичных потребителей сервисов data lake. Это могут быть службы электронного правительства (допустим, «Госуслуги»), прошедшие цифровизацию предприятия, финансовые структуры и др. Всем им необходимо работать с большими объёмами разнородной информации.
Эксплуатация классических СХД для решения таких задач неэффективна, так как требуется и высокопроизводительный доступ к блочным базам данных, и обычный доступ к библиотекам сканированных документов, хранящихся в виде объектов. Сюда же может быть привязана, допустим, система заказов через веб-портал. Чтобы всё это реализовать на платформе классической СХД, потребуется большой комплект оборудования под разные задачи. Одна горизонтальная универсальная система хранения вполне может закрывать все ранее перечисленные задачи: понадобится лишь создать в ней несколько пулов с разными характеристиками хранения.
Чтобы всё это реализовать на платформе классической СХД, потребуется большой комплект оборудования под разные задачи. Одна горизонтальная универсальная система хранения вполне может закрывать все ранее перечисленные задачи: понадобится лишь создать в ней несколько пулов с разными характеристиками хранения.
Генераторы новой информации
Количество хранимой в мире информации растёт примерно на 30% в год. Это хорошие новости для поставщиков систем хранения, но что же является и будет являться основным источником этих данных?
Десять лет назад такими генераторами стали социальные сети, это потребовало создания большого количества новых алгоритмов, аппаратных решений и т. д. Сейчас выделяются три главных драйвера роста объёмов хранения. Первый — cloud computing. В настоящее время примерно 70% компаний так или иначе используют облачные сервисы. Это могут быть электронные почтовые системы, резервные копии и другие виртуализированные сущности.
Вторым драйвером становятся сети пятого поколения..jpg) Это новые скорости и новые объёмы передачи данных. По нашим прогнозам, широкое распространение 5G приведёт к падению спроса на карточки флеш-памяти. Сколько бы ни было памяти в телефоне, она всё равно кончается, а при наличии в гаджете 100-мегабитного канала нет никакой необходимости хранить фотографии локально.
Это новые скорости и новые объёмы передачи данных. По нашим прогнозам, широкое распространение 5G приведёт к падению спроса на карточки флеш-памяти. Сколько бы ни было памяти в телефоне, она всё равно кончается, а при наличии в гаджете 100-мегабитного канала нет никакой необходимости хранить фотографии локально.
К третьей группе причин, по которым растёт спрос на системы хранения, относятся бурное развитие искусственного интеллекта, переход на аналитику больших данных и тренд на всеобщую автоматизацию всего, чего только можно.
Особенностью «нового трафика» является его неструктурированность. Нам надо хранить эти данные, никак не определяя их формат. Он требуется лишь при последующем чтении. К примеру, банковская система скоринга для определения доступного размера кредита будет смотреть выложенные вами в соцсетях фотографии, определяя, часто ли вы бываете на море и в ресторанах, и одновременно изучать доступные ей выписки из ваших медицинских документов. Эти данные, с одной стороны, всеобъемлющи, а с другой — лишены однородности.
Океан неструктурированных данных
Какие же проблемы влечет за собой появление «новых данных»? Первейшая среди них, конечно, сам объём информации и расчётные сроки её хранения. Один только современный автономный автомобиль без водителя каждый день генерирует до 60 Тбайт данных, поступающих со всех его датчиков и механизмов. Для разработки новых алгоритмов движения эту информацию необходимо обработать за те же сутки, иначе она начнёт накапливаться. При этом храниться она должна очень долго — десятки лет. Только тогда в будущем можно будет делать выводы на основе больших аналитических выборок.
Одно устройство для расшифровки генетических последовательностей производит порядка 6 Тбайт в день. А собранные с его помощью данные вообще не подразумевают удаления, то есть гипотетически должны храниться вечно.
Наконец, всё те же сети пятого поколения. Помимо собственно передаваемой информации, такая сеть и сама является огромным генератором данных: журналов действий, записей звонков, промежуточных результатов межмашинных взаимодействий и пр.
Всё это требует выработки новых подходов и алгоритмов хранения и обработки информации. И такие подходы появляются.
Технологии новой эпохи
Можно выделить три группы решений, призванных справиться с новыми требованиями к системам хранения информации: внедрение искусственного интеллекта, техническая эволюция носителей данных и инновации в области системной архитектуры. Начнём с ИИ.
В новых решениях Huawei искусственный интеллект используется уже на уровне самого хранилища, которое оборудовано ИИ-процессором, позволяющим системе самостоятельно анализировать своё состояние и предсказывать отказы. Если СХД подключить к сервисному облаку, которое обладает значительными вычислительными способностями, искусственный интеллект сможет обработать больше информации и повысить точность своих гипотез.
Помимо отказов, такой ИИ умеет прогнозировать будущую пиковую нагрузку и время, остающееся до исчерпания ёмкости. Это позволяет оптимизировать производительность и масштабировать систему ещё до наступления каких-либо нежелательных событий..jpg)
Теперь об эволюции носителей данных. Первые флеш-накопители были выполнены по технологии SLC (Single-Level Cell). Основанные на ней устройства были быстрыми, надёжными, стабильными, но имели небольшую ёмкость и стоили очень дорого. Роста объёма и снижения цены удалось добиться путём определённых технических уступок, из-за которых скорость, надёжность и срок службы накопителей сократились. Тем не менее тренд не повлиял на сами СХД, которые за счёт различных архитектурных ухищрений в целом стали и более производительными, и более надёжными.
Но почему понадобились СХД класса All-Flash? Разве недостаточно было просто заменить в уже эксплуатируемой системе старые HDD на новые SSD того же форм-фактора? Потребовалось это для того, чтобы эффективно использовать все ресурсы новых твердотельных накопителей, что в старых системах было попросту невозможно.
Компания Huawei, например, для решения этой задачи разработала целый ряд технологий, одной из которых стала FlashLink, позволившая максимально оптимизировать взаимодействия «диск — контроллер».
Интеллектуальная идентификация дала возможность разложить данные на несколько потоков и справиться с рядом нежелательных явлений, таких как WA (write amplification). Вместе с тем новые алгоритмы восстановления, в частности RAID 2.0+, повысили скорость ребилда, сократив его время до совершенно незначительных величин.
Отказ, переполненность, «сборка мусора» — эти факторы также больше не влияют на производительность системы хранения благодаря специальной доработке контроллеров.
А ещё блочные хранилища данных готовятся встретить NVMe. Напомним, что классическая схема организации доступа к данным работала так: процессор обращался к RAID-контроллеру по шине PCI Express. Тот, в свою очередь, взаимодействовал с механическими дисками по SCSI или SAS. Применение NVMe на бэкенде заметно ускорило весь процесс, однако несло в себе один недостаток: накопители должны были иметь непосредственное подключение к процессору, чтобы обеспечить тому прямой доступ в память.
Следующей фазой развития технологии, которую мы наблюдаем сейчас, стало применение NVMe-oF (NVMe over Fabrics). Что касается блочных технологий Huawei, они уже сейчас поддерживают FC-NVMe (NVMe over Fibre Channel), и на подходе NVMe over RoCE (RDMA over Converged Ethernet). Тестовые модели вполне функциональны, до официальной их презентации осталось несколько месяцев. Заметим, что всё это появится и в распределённых системах, где «Ethernet без потерь» будет весьма востребован.
Что касается блочных технологий Huawei, они уже сейчас поддерживают FC-NVMe (NVMe over Fibre Channel), и на подходе NVMe over RoCE (RDMA over Converged Ethernet). Тестовые модели вполне функциональны, до официальной их презентации осталось несколько месяцев. Заметим, что всё это появится и в распределённых системах, где «Ethernet без потерь» будет весьма востребован.
Дополнительным способом оптимизации работы именно распределённых хранилищ стал полный отказ от зеркалирования данных. Решения Huawei больше не используют n копий, как в привычном RAID 1, и полностью переходят на механизм EC (Erasure coding). Специальный математический пакет с определённой периодичностью вычисляет контрольные блоки, которые позволяют восстановить промежуточные данные в случае их потери.
Механизмы дедупликации и сжатия становятся обязательными. Если в классических СХД мы ограничены количеством установленных в контроллеры процессоров, то в распределённых горизонтально масштабируемых системах хранения каждый узел содержит всё необходимое: диски, память, процессоры и интерконнект.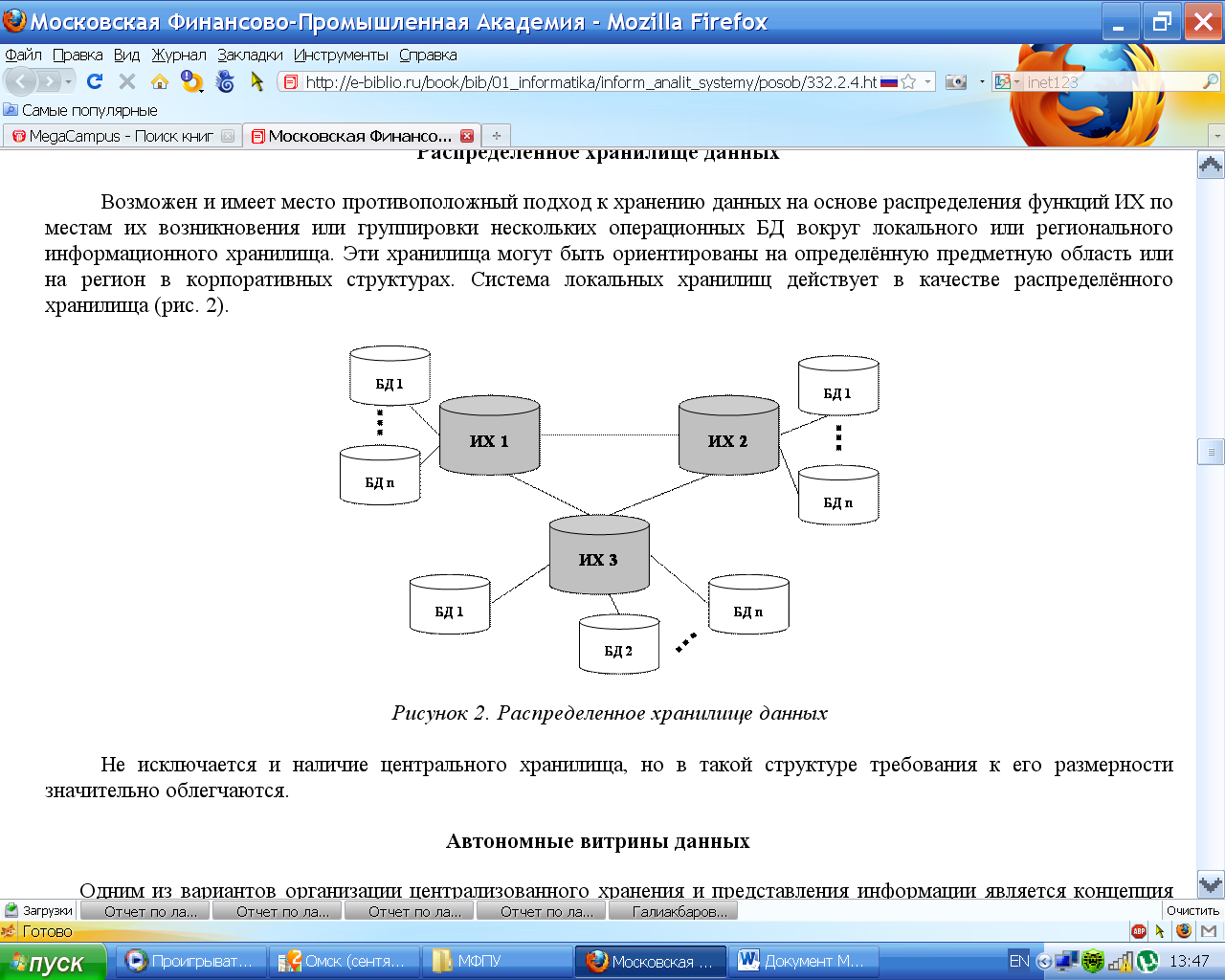 Этих ресурсов достаточно, чтобы дедупликация и компрессия оказывали на производительность минимальное влияние.
Этих ресурсов достаточно, чтобы дедупликация и компрессия оказывали на производительность минимальное влияние.
И об аппаратных методах оптимизации. Здесь снизить нагрузку на центральные процессоры удалось с помощью дополнительных выделенных микросхем (или выделенных блоков в самом процессоре), играющих роль TOE (TCP/IP Offload Engine) или берущих на себя математические задачи EC, дедупликации и компрессии.
Новые подходы к хранению данных нашли воплощение в дезагрегированной (распределённой) архитектуре. В системах централизованного хранения имеется фабрика серверов, по Fibre Channel подключённая к SAN с большим количеством массивов. Недостатками такого подхода являются трудности с масштабированием и обеспечением гарантированного уровня услуги (по производительности или задержкам). Гиперконвергентные системы используют одни и те же хосты — как для хранения, так и для обработки информации. Это даёт практически неограниченный простор масштабирования, но влечёт за собой высокие затраты на поддержание целостности данных.
В отличие от обеих вышеперечисленных, дезагрегированная архитектура подразумевает разделение системы на вычислительную фабрику и горизонтальную систему хранения. Это обеспечивает преимущества обеих архитектур и позволяет практически неограниченно масштабировать только тот элемент, производительности которого не хватает.
От интеграции к конвергенции
Классической задачей, актуальность которой последние 15 лет лишь росла, является необходимость одновременно обеспечить блочное хранение, файловый доступ, доступ к объектам, работу фермы для больших данных и т. д. Вишенкой на торте может быть ещё, например, система бэкапа на магнитную ленту.
На первом этапе унифицировать удавалось только управление этими услугами. Разнородные системы хранения данных замыкались на какое-либо специализированное ПО, посредством которого администратор распределял ресурсы из доступных пулов. Но так как аппаратно эти пулы были разными, миграция нагрузки между ними была невозможна. На более высоком уровне интеграции объединение происходило на уровне шлюза. При наличии общего файлового доступа его можно было отдавать через разные протоколы.
На более высоком уровне интеграции объединение происходило на уровне шлюза. При наличии общего файлового доступа его можно было отдавать через разные протоколы.
Самый совершенный из доступных нам сейчас методов конвергенции подразумевает создание универсальной гибридной системы. Именно такой, какой должна стать наша OceanStor 100D. Универсальный доступ использует те же самые аппаратные ресурсы, логически разделённые на разные пулы, но допускающие миграцию нагрузки. Всё это можно сделать через единую консоль управления. Таким способом нам удалось реализовать концепцию «один ЦОД — одна СХД».
Стоимость хранения информации сейчас определяет многие архитектурные решения. И хотя её можно смело ставить во главу угла, мы сегодня обсуждаем «живое» хранение с активным доступом, так что производительность тоже необходимо учитывать. Ещё одним важным свойством распределённых систем следующего поколения является унификация. Ведь никто не хочет иметь несколько разрозненных систем, управляемых из разных консолей. Все эти качества нашли воплощение в новой серии продуктов Huawei OceanStor Pacific.
Все эти качества нашли воплощение в новой серии продуктов Huawei OceanStor Pacific.
Массовая СХД нового поколения
OceanStor Pacific отвечает требованиям надёжности на уровне «шести девяток» (99,9999%) и может использоваться для создания ЦОД класса HyperMetro. При расстоянии между двумя дата-центрами до 100 км системы демонстрируют добавочную задержку на уровне 2 мс, что позволяет строить на их основе любые катастрофоустойчивые решения, в том числе и с кворум-серверами.
Продукты новой серии демонстрируют универсальность по протоколам. Уже сейчас OceanStor 100D поддерживает блочный доступ, объектовый доступ и доступ Hadoop. В ближайшее время будет реализован и файловый доступ. Нет нужды хранить несколько копий данных, если их можно выдавать через разные протоколы.
Казалось бы, какое отношение концепция «сеть без потерь» имеет к СХД? Дело в том, что распределённые системы хранения данных строятся на основе быстрой сети, поддерживающей соответствующие алгоритмы и механизм RoCE. Дополнительно увеличить скорость сети и снизить задержки помогает поддерживаемая нашими коммутаторами система искусственного интеллекта AI Fabric. Выигрыш производительности СХД при активации AI Fabric может достигать 20%.
Дополнительно увеличить скорость сети и снизить задержки помогает поддерживаемая нашими коммутаторами система искусственного интеллекта AI Fabric. Выигрыш производительности СХД при активации AI Fabric может достигать 20%.
Что же представляет собой новый узел распределённой СХД OceanStor Pacific? Решение форм-фактора 5U включает в себя 120 накопителей и может заменить три классических узла, что даёт более чем двукратную экономию места в стойке. За счёт отказа от хранения копий КПД накопителей ощутимо возрастает (до +92%).
Мы привыкли к тому, что программно-определяемая СХД — это специальное ПО, устанавливаемое на классический сервер. Но теперь для достижения оптимальных параметров это архитектурное решение требует и специальных узлов. В его состав входят два сервера на базе ARM-процессоров, управляющие массивом трёхдюймовых накопителей.
Эти серверы мало подходят для гиперконвергентных решений. Во-первых, приложений для ARM достаточно мало, а во-вторых, трудно соблюсти баланс нагрузки. Мы предлагаем перейти к раздельному хранению: вычислительный кластер, представленный классическими или rack-серверами, функционирует отдельно, но подключается к узлам хранения OceanStor Pacific, которые также выполняют свои прямые задачи. И это себя оправдывает.
Мы предлагаем перейти к раздельному хранению: вычислительный кластер, представленный классическими или rack-серверами, функционирует отдельно, но подключается к узлам хранения OceanStor Pacific, которые также выполняют свои прямые задачи. И это себя оправдывает.
Для примера возьмём классическое решение для хранения больших данных с гиперконвергентной системой, занимающее 15 серверных стоек. Если распределить нагрузку между отдельными вычислительными серверами и узлами СХД OceanStor Pacific, отделив их друг от друга, количество необходимых стоек сократится в два раза! Это снижает затраты на эксплуатацию дата-центра и уменьшает совокупную стоимость владения. В мире, где объём хранимой информации растет на 30% в год, подобными преимуществами не разбрасываются.
Автор: denisdubinin3
Источник: https://habr.com/
Воспользуйтесь нашими услугами
Понравилась статья? Тогда поддержите нас, поделитесь с друзьями и заглядывайте по рекламным ссылкам!
база данных, кеш, файловое хранилище
Современные приложения оперируют различными типами данных, которые хранятся в базах данных (БД). Это могут быть целочисленные, строковые, бинарные, дата-временные и другие. Такие базы данных, как MySQL или PostgreSQL, могут хранить в себе любые объёмы самых различных данных, но эффективно ли размещать в одном экземпляре всё подряд? Мы опытным путём разделили данные на три категории: часто используемые, текстово-числовые и файловые. В часто используемые попадают те данные, к которым наиболее часто обращаются пользователи. Файловые — это все файлы, в основном картинки, видео и архивы.
Это могут быть целочисленные, строковые, бинарные, дата-временные и другие. Такие базы данных, как MySQL или PostgreSQL, могут хранить в себе любые объёмы самых различных данных, но эффективно ли размещать в одном экземпляре всё подряд? Мы опытным путём разделили данные на три категории: часто используемые, текстово-числовые и файловые. В часто используемые попадают те данные, к которым наиболее часто обращаются пользователи. Файловые — это все файлы, в основном картинки, видео и архивы.
Для каждой категории мы используем отдельное хранилище — такой подход повышает эффективность работы с данными.
Управление ИТ услугами
Реляционное хранилище
Главным местом хранения данных любого приложения является реляционная база данных. SimpleOne использует PostgreSQL для текстово-числовых данных. Эта реляционная система управления базами данных выбрана за стабильность и надёжность, а также множество встроенных инструментов для работы с таблицами и дополнительных модулей. База данных открыто распространяется, имеет огромное комьюнити и постоянно развивается. Например, мы используем встроенный инструмент глобального поиска, и он отлично работает в нашей системе, нет необходимости разрабатывать собственные решения или искать дополнительные расширения. В будущем, с развитием нашей платформы, PostgreSQL всегда сможет удовлетворить наши запросы.
База данных открыто распространяется, имеет огромное комьюнити и постоянно развивается. Например, мы используем встроенный инструмент глобального поиска, и он отлично работает в нашей системе, нет необходимости разрабатывать собственные решения или искать дополнительные расширения. В будущем, с развитием нашей платформы, PostgreSQL всегда сможет удовлетворить наши запросы.
Кеш
Как бы быстро ни работала реляционная система управления базами данных, есть способ сделать работу платформы ещё быстрее — настроить кеширование самых часто используемых данных. Использовать данные из кеша более экономично, чем каждый раз обращаться к PostgreSQL. Для кеширования мы используем БД Redis, это нереляционная база данных, которая размещает информацию в оперативной памяти сервера. Redis выбрали за его простоту, удобство использования, возможность кластеризации и шардирования. Когда нам становится недостаточно одного сервера для кеша, мы добавляем дополнительные в кластер и тем самым увеличиваем производительность.
Чтобы кеш работал эффективно, он должен содержать часто используемые, но редко обновляемые данные, для этого все запросы к БД анализируются по частоте запросов. Данные в кеше могут храниться только до момента их обновления, затем кеш освобождается и перезаписывается новой информацией. Чтобы не происходило постоянного процесса стирания-записи, для кеширования выбираются те данные, которые обновляются редко. Например, это могут быть агрегаты.
Агрегаты — это сложные объекты, которые имеют много связей. Чтобы собрать агрегат и показать его пользователю, необходимо сделать несколько обращений к БД. Если агрегат целиком поместить в кеш, не надо будет каждый раз тратить время и ресурсы на его сборку. В качестве примера агрегата, помещаемого в кеш, можно назвать систему управления таблицами. Агрегат содержит элементы управления колонками и столбцами, фильтры, сортировщики, кнопки и формы. Все эти элементы описаны в различных таблицах, формируют один объект и редко обновляются. Содержимое самой таблицы, напротив, регулярно изменяется.
Если взять такой агрегат и целиком поместить в Redis, то для его загрузки не надо будет обращаться к PostgreSQL, такая операция станет выполняться значительно быстрее. А динамично обновляющиеся данные в таблицу будут по-прежнему загружаться напрямую из базы данных.
Если все данные записывать в базу данных, то её размер будет стремительно увеличиваться, время доступа расти, а поиск замедляться. Поэтому все файлы мы храним в отдельном S3-хранилище.
MinIO по S3
S3 — это протокол доступа к неструктурированным данным, разработанный компанией Amazon для своего продукта AWS S3. Компания создала распределённое хранилище, написала для него API и предоставила к нему доступ. Протокол стал настолько популярным, что многие компании выпустили свои версии хранилищ, совместимых с S3. Для SimpleOne мы используем сервер MinIO, который нативно работает с данным протоколом. Взаимодействие платформы с MinIO реализовано с помощью инструментария AWS SDK.
Среди аналогичных продуктов, таких как OpenStack Swift, мы выбрали MinIO, так как его возможностей нам достаточно, а отсутствие лишних компонентов не перегружает систему и не мешает работать. MinIO — живой проект, постоянно развивается и имеет хорошую перспективу. С другой стороны, если его возможностей нам в какой-то момент будет недостаточно, мы всегда сможем смигрировать на другую аналогичную платформу без вмешательства в код программы, так как инструменты взаимодействия по протоколу S3 для всех одинаковы.
Схема: SimpleOne + AWS SDKИспользование такого хранилища позволяет предоставить пользователям доступ к файлам по http, то есть дать ссылку на файл, а также разграничить права доступа, разложить файлы по корзинам, осуществить резервное копирование данных, кластеризовать и шардировать. Предоставление доступа к файлам осуществляется напрямую, без необходимости перемещения файла на другие серверы.
Наше хранилище S3, так же как и другие сервисы платформы, работает из контейнера Docker, с помощью технологии контейнеров происходит и взаимодействие между сервисами: backend-сервером, frontend-серером и другими. В зависимости от сложности проекта и числа пользователей мы можем запускать несколько контейнеров на одном сервере или разнести их по отдельным физическим машинам. Технология Docker позволяет автоматически масштабировать систему и динамично перераспределять нагрузку тем контейнерам, у которых в настоящий момент полная загрузка. В любой момент можно подключить дополнительный сервер — распределить нагрузку и повысить производительность системы.
В зависимости от сложности проекта и числа пользователей мы можем запускать несколько контейнеров на одном сервере или разнести их по отдельным физическим машинам. Технология Docker позволяет автоматически масштабировать систему и динамично перераспределять нагрузку тем контейнерам, у которых в настоящий момент полная загрузка. В любой момент можно подключить дополнительный сервер — распределить нагрузку и повысить производительность системы.
Почему распределённая система хранения данных эффективнее
Существует несколько причин высокой эффективности такой системы — как скоростных, так и архитектурных.
Например, такая система отлично масштабируется. Когда пользователь загружает файл на платформу, он попадает на backend-сервер. Таких серверов может быть несколько, а обращение идёт по единому URL-адресу. Предугадать, на который из них этот файл загрузится, невозможно. Когда пользователю вновь потребуется этот файл, его может не оказаться в Сети: сервер завис, остановлен или недоступен по другим причинам..png) Поэтому сразу после загрузки файла система перекладывает его на выделенный сервер хранения S3, формирует ссылку и передаёт её клиенту для возможности независимой загрузки.
Поэтому сразу после загрузки файла система перекладывает его на выделенный сервер хранения S3, формирует ссылку и передаёт её клиенту для возможности независимой загрузки.
На хранилище S3 можно размещать файлы любых форматов и любого размера, это никак не сказывается на производительности самого хранилища, но значительно разгружает веб-сервер. Когда на S3 заканчивается место, мы всегда можем добавить диски или подключить дополнительную систему хранения данных без каких-либо структурных и программных изменений.
Схема работы с S3Заключение
Распределённое хранение данных — это быстро и удобно. Правильно настроенные системы кеширования и файлового хранения в S3 позволили нам улучшить масштабирование и повысить скорость работы с данными более чем на 50%. Мы использовали открытые системы и протоколы, а также стандартные SDK и API — это позволило сократить сроки разработки, упростить техническую поддержку. Тем самым мы получили возможность сменить программные компоненты без вмешательства в код платформы. Для создания SimpleOne мы используем современные технологии и решения, чтобы сделать платформу, удобную как для конечных пользователей, так и для разработчиков и администраторов.
Для создания SimpleOne мы используем современные технологии и решения, чтобы сделать платформу, удобную как для конечных пользователей, так и для разработчиков и администраторов.
☸️ Распределенное хранение данных в Kubernetes – IT is good
Kubernetes отлично подходит для приложений без учета их состояния.
Разверните свое приложение, масштабируйте его до сотен экземпляров, будьте счастливы.
Но как вы управляете хранилищем?
Как мы можем гарантировать, что каждое из наших сотен приложений получит надежное, быстрое и дешевое хранилище?
Давайте возьмем типичный кластер Kubernetes с несколькими узлами (серверами Linux), которые обеспечивают несколько копий нашего приложения:
Обратите внимание на наши грустные, неиспользованные диски!
Kubernetes, безусловно, приносит много побед, но разве мы больше являемся системными администраторами, если не управляем огромными RAID-массивами?
Persistent Volume Claims
В Kubernetes мы определяем PersistentVolumeClaims, чтобы запросить нашу систему хранения.
Проще говоря, приложение «требует» немного памяти, и система отвечает настраиваемым способом:
App1 – > VolumeClaim
К сожалению, большинство облачных провайдеров стремятся использовать простоту Kubernetes, «отвечая» на ваш запрос хранилища, подключая Cloud Storage (например, Amazon EBS).
У этой стратегии есть ряд недостатков для потребителей:
- Производительность и стоимость: производительность томов EBS (и других поставщиков облачных вычислений) зависит от его размера – это означает, что меньший диск – это то же самое, что и более медленный диск.
- Характеристики: поставщики облачных услуг обычно предлагают жесткие диски, SDD и опцию «подготовленного ввода-вывода». Это ограничивает системных администраторов в их системах хранения. Где находится резервная копия? А как насчет NVMe? Как диск подключен к серверу, на котором работает мой код?
- Переносимость / блокировка: EBS – это EBS, а постоянные диски Google – это постоянные диски Google. Поставщики облачных услуг настойчиво пытаются привязать вас к своим платформам и обычно прячут инструменты файловой системы, которые мы знаем и любим за облачной системой моментальных снимков.
 Поставщики облачных услуг настойчиво пытаются привязать вас к своим платформам и обычно прячут инструменты файловой системы, которые мы знаем и любим за облачной системой моментальных снимков.
Поставщики облачных услуг настойчиво пытаются привязать вас к своим платформам и обычно прячут инструменты файловой системы, которые мы знаем и любим за облачной системой моментальных снимков.Итак … Что нам тогда нужно, так это система управления хранилищем данных с открытым исходным кодом, которая будет работать в любом кластере Kubernetes и может преобразовывать кучи дисков в пулы хранения, доступные для наших подов!
Введите Rook.io
Что такое Rook?
С веб-сайта Rook:
Облачное хранилище с открытым исходным кодом для Kubernetes» с «Хранилищем готовых файлов, блоков и объектов».
Если говорить о маркетинге, Rook – это версия AWS EBS и S3 с открытым исходным кодом, которую вы можете установить в свои кластеры.
Это также бэкэнд для системы хранения KubeSail, и именно так мы создаем RAID-массивы для поддержки приложений наших пользователей!
Rook и Ceph
Rook – это система, которая находится в вашем кластере и отвечает на запросы на хранение, но сама она не является системой хранения.
Хотя это немного усложняет ситуацию, вы должны чувствовать себя хорошо, потому что, хотя Rook и новичок, система хранения, которую он использует под капотом, закалена и далека от бета-тестирования.
Мы будем использовать Ceph, которому около 15 лет, который используется и разрабатывается такими компаниями, как Canonical, CERN, Cisco, Fujitsu, Intel, Red Hat и SanDisk.
Это очень далеко от Kubernetes-Hipster, несмотря на то, как круто выглядит проект Rook!
Учитывая, что Rook версии 1.0 и Ceph поддерживают некоторые из самых важных в мире наборов данных, я бы сказал, что настало время обрести уверенность и вернуть контроль над нашим хранилищем данных!
Я буду строить RAID-массивы в 2020-х годах, и никто не сможет меня остановить!
Установка
Я не буду концентрироваться на первоначальной установке здесь, так как руководство по Rook простое.
После установки Rook мы создадим несколько компонентов:
- CephCluster, который отображает узлы и их диски в нашу новую систему хранения.
- CephBlockPool, который определяет, как хранить данные, включая количество реплик, которые мы хотим.
- StorageClass, который определяет способ использования хранилища из CephBlockPool.
Давайте начнем с CephCluster:
#?filename=ceph-cluster.yaml&mini=true&noApply=true
---
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
mon:
count: 3
allowMultiplePerNode: false
storage:
useAllNodes: false
useAllDevices: true
location:
config:
osdsPerDevice: "1"
directories:
- path: /opt/rook
nodes:
- name: "my-storage-node-1"
- name: "my-storage-node-2"
- name: "my-storage-node-3"
Здесь важно отметить, что CephCluster – это, по сути, карта, на которой показаны ноды и какие диски или каталоги на этих узлах будут использоваться для хранения данных.
Многие учебные пособия будут предлагать useAllNodes:true, что мы настоятельно не рекомендуем.
Вместо этого мы рекомендуем управлять меньшим пулом поднаборов «storage workers» – это позволяет позже использовать различные типы систем (например, очень медленные диски) без случайного / неосознанного добавления его в пул хранения.
Мы будем предполагать, что /opt/rook является точкой монтирования, но Rook может использовать неформатированные диски, а также каталоги.
Еще одно замечание: mon – система мониторинга Rook.
Мы настоятельно рекомендуем запускать по крайней мере три и гарантировать, что allowMultiplePerNode имеет значение false.
Теперь наш кластер выглядит так:
Кстати, вы наверняка захотите взглянуть на поды, работающие в пространстве имен rook-ceph!
Вы найдете свои OSD (Object-Storage-Device) поды, а также поды мониторинга и агента, живущие в этом пространстве имен.
Давайте создадим наш CephBlockPool и StorageClass, который он использует:
#?filename=ceph-blockpool. yaml&mini=true&noApply=true
---
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: my-storage-pool
namespace: rook-ceph
spec:
failureDomain: osd
replicated:
size: 2
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: my-storage
provisioner: rook.io/block
parameters:
pool: my-storage-pool
 yaml&mini=true&noApply=true
---
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: my-storage-pool
namespace: rook-ceph
spec:
failureDomain: osd
replicated:
size: 2
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: my-storage
provisioner: rook.io/block
parameters:
pool: my-storage-pool
yaml&mini=true&noApply=true
---
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: my-storage-pool
namespace: rook-ceph
spec:
failureDomain: osd
replicated:
size: 2
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: my-storage
provisioner: rook.io/block
parameters:
pool: my-storage-pool
Мы подождем, пока наш CephCluster будет установлен – а вы уже можете взглянуть на созданный вами объект CephCluster:
➜ kubectl -n rook-ceph get cephcluster rook-ceph -o json | jq .status.ceph.health
"HEALTH_OK"Теперь мы готовы сделать запрос на хранение!
Теперь мы можем запросить хранилище несколькими стандартными способами.#?filename=ceph-pvc. yaml&mini=true&noApply=true
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-data
spec:
accessModes:
- ReadWriteOnce
# Use our new ceph storage:
storageClassName: my-storage
resources:
requests:
storage: 1000Mi
 yaml&mini=true&noApply=true
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-data
spec:
accessModes:
- ReadWriteOnce
# Use our new ceph storage:
storageClassName: my-storage
resources:
requests:
storage: 1000Mi
yaml&mini=true&noApply=true
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-data
spec:
accessModes:
- ReadWriteOnce
# Use our new ceph storage:
storageClassName: my-storage
resources:
requests:
storage: 1000Mi
➜ kubectl get pv --watch
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS AGE
pvc-... 1000Mi RWO Delete Bound default/test-data my-storage 13mИтак, поехали!
Удобная, довольно простая в использовании, нативная система хранения Kubernetes.
Мы можем принести свои собственные диски, мы можем использовать любой облачный провайдер … Свобода!
Поделитесь статьей:
10 минут, чтобы понять: распределенное решение для хранения данных для 100 миллионов пользователей!
Нажмите на «Выбор задней части технологии«Выберите« Топ общего числа »
Техническая статья отправлена в первый раз!
Автор:Северный код города Сельское хозяйство Алекс
segmentfault.
 com/a/1190000019460946
com/a/1190000019460946Толкатьрекомендуючитатьчитать(Нажмите, чтобы прочитать чтение)
1. Агрегация контента Scraphboot
2. Интервью Вопрос Содержание Агрегация
3. Режим дизайна Агрегация контента
4. Сортировка алгоритма Содержание агрегации
5. Многопоточная агрегация контента
Распределенные базы данных и распределенные хранения являются крупнейшими и крупными проблемами в распределенных системах, а также является наиболее подверженным проблемам. Интернет-компании решают только проблему хранения распределенных данных, могут поддерживать приток более 100 миллионов пользователей.
Далее вы потратите десять минут, чтобы освоить следующие три аспекта:
Репликация MySQL: в том числе репликация Master-Slave и основная копия;
Фрагмент данных: принцип фрагментации данных, схема фрагментации и расширение фрагментационной базы данных;
Несколько программ распределенного развертывания базы данных.

Во-первых, MySQL Copy
1. Mysql Master-Place Copy
Репликация Mysql Master-Slave — скопировать данные в основной базе данных MySQL в базу данных.
Основная цель состоит в том, чтобы добиться разделения записи с чтением базы данных, операция записи в режиме ожидания основной базы данных, доступом к работе с чтением в базе данных, что позволяет базу данных иметь более мощную емкость доступа, поддержать больше пользователей.
Его основной принцип репликации: когда клиент приложения отправляет команду обновления в базу данных, база данных будет записывать эту команду обновления в Binlog, а затем прочитайте этот журнал из Binlog из Binlog по другому потоку, а затем скопируйте его с сервера с сервера с сервера После того, как вы получите этот журнал обновления с сервера, добавьте его в свой собственный журнал реле, затем выполните темы из другого SQL из журнала реле. Этот новый журнал и повторно выполните его в локальной базе данных.
Это когда клиентское приложение выполняет команду обновления, эта команда выполняется синхронно в основной базе данных и из базы данных, что позволяет основную базу данных копировать из базы данных, что позволяет одни и те же данные из базы данных и основной базы данных.
2. MySQL Один Главный Больше от копии
Репликация MySQL’s Master-Slave — это механизм синхронизации данных. В дополнение к копированию данных в основной базе данных в базу данных подчиненной базы данных, вы также можете скопировать данные из основной базы данных для нескольких из базы данных, то есть так называемого основного MySQL Больше от копии.
Когда несколько баз данных связаны с основной базой данных, скопируйте журнал BINLOG в основной базе данных, чтобы несколько из базы данных. Выполняя журналы, дайте каждому из данных из базы данных и данных в основной базе данных. Операции по обновлению данных в этом указывают на то, что все обновления базы данных, в дополнение к операциям по чтению данных, такие как SELECT, другие вставки, удаление, обновление записи DML-записи и создания таблицы, выпадают, удаленные таблицы и т. Д. Операция DDL также может быть синхронно скопирована в базу данных.
3. Одно главное от копирования преимуществ
У одного из людей четырех преимуществ от репликации, соответственно, и специализируются на специальных машинах, простых в использовании.
а. Распространение нагрузки
Распространите операции только для чтения в нескольких из базы данных для распределения нагрузки на несколько серверов.
б. Специальная машина
Различные типы запросов могут быть использованы для разных типов запросов.
с. Легко остыть
Даже если база данных копируется мастером, в некоторых экстремальных случаях. Также возможно заставить серверы данных во всем центре обработки данных, которые будут потеряны. Поэтому обычно многие компании сделают данные холодными, но есть сложная точка при переносе охлаждения, заключается в том, что если база данных написана, данные охлаждения могут быть неполными, а файл данных может быть в поврежденном состоянии. Резервное копирование времени отключения может быть достигнуто с помощью копии из копирования. Необходимо только отключить процесс репликации данных данных, файл закрыт, то файл данных скопирован, и копия вновь вписывается после завершения копии.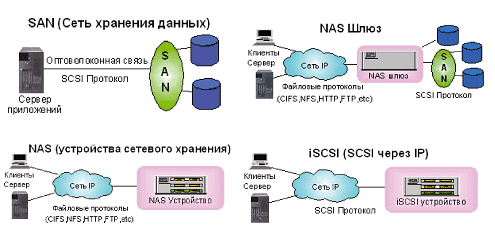
д. очень доступны
Если сервер опустится, до тех пор, пока вы не отправляете запрос, у вас не будет проблем. Когда этот сервер восстановлен, запрос перенаправляется на этот сервер. Таким образом, в случае большинства определенное влияние на всю систему очень мало.
4. Основная копия MySQL
Тем не менее, хост способен реализовать только эти преимущества с сервера. Когда основная база данных недоступна, данные все еще не переписаны, поскольку данные не могут быть записаны на верхнюю часть сервера, читается с сервера. Оф.
Чтобы решить проблему наличия основного сервера, мы можем использовать основную схему MySQL. Так называемая схема первичной копии относится к обоим серверам в качестве главного сервера, и операции записи, полученные на любом сервере, скопированы на другой сервер.
В качестве основного копирования схема основного мастера, когда клиентская программа выполняет операции обновления данных на первичном сервере A, основной сервер A будет записывать операцию обновления в журнал Binlog. Затем Binlog синхронизирует журнал данных на первичный сервер B, пишет в журнал реле сервера основного сервера, а затем включить журнал реле, чтобы получить журнал обновлений в журнале реле, выполните операции SQL для записи в локальную базу данных сервера базы данных B. Обновление на сервере B также копирует сервер A на сервер A BINLOG на сервер A, а затем обновлять данные в сервере A через журнал реле.
Затем Binlog синхронизирует журнал данных на первичный сервер B, пишет в журнал реле сервера основного сервера, а затем включить журнал реле, чтобы получить журнал обновлений в журнале реле, выполните операции SQL для записи в локальную базу данных сервера базы данных B. Обновление на сервере B также копирует сервер A на сервер A BINLOG на сервер A, а затем обновлять данные в сервере A через журнал реле.
Таким образом, любой из серверов A или B принимает операцию записи данных, будет обновляться на другой сервер, а владелец базы данных реализован. Основная копия может улучшить запись системы, а можно реализовать высокую доступность операций записи.
5. Восстановление основной неудачи MySQL
Как разобраться с сервером базы данных, если основная копия реализована с использованием сервера MySQL
При нормальных обстоятельствах пользователь записывается на первичный сервер A, то данные копируются с A на первичный сервер B. Когда основной сервер A недействителен, операция записи отправляется на основной сервер B, а данные копируются с сервера B на сервер.
Процесс обслуживания основного сбоя заключается в следующем:
В начале все первичные серверы могут быть использованы нормально. Когда основной сервер A является недействительным, приложение обнаруживает, что основной сервер A a Failed, обнаружение этого сбоя может занять несколько секунд или несколько минут, то приложение должно быть Неверный перевод, отправьте операцию записи на основной сервер B, отправьте операцию чтения на сервер B в верхнюю часть сервера.
Через некоторое время сервер должен восстановить данные, потерянные во время сбоя, что означает синхронизировать данные с сервера с сервера с сервера B. После того, как синхронизация завершена, система вернется к обычному. На этот раз B сервер B является основным сервером доступа пользователя, а сервер используется в качестве резервного сервера.
6.mysql Скопируйте меры предосторожности
Примите заметку при использовании MySQL для первичной копии следующим образом:
а. Не выполняйте операции записи данных одновременно для двух баз данных, потому что эта ситуация вызывает конфликт данных.
b. Copy — это просто возможность читать и обработать данные и не увеличивает возможность писать возможности параллелизма и хранения системы.
с. Обновление структуры таблицы данных приводит к огромной задержке синхронизации.
Вам необходимо обновить работу структуры таблицы, не пишите в Binlog, чтобы закрыть бинлог обновленной структуры таблицы. Если вы хотите обновить структуру таблицы, вы должны вручную выполнить операцию обновления структуры таблицы данных по операции и техническому обслуживанию инженера DBA.
Во-вторых, фрагментация данных
Репликация данных может улучшить только возможности для чтения данных, и не может улучшить способность операции записи данных и емкость хранения данных, то есть не улучшает общее количество баз данных в базе данных. Если операция записи нашей базы данных также должна быть выполнена, или наша таблица данных особенно велика, а один сервер даже не хранит таблицу. Раствор является фрагментацией данных.
Введение фракции данных
а. Главная цель:Разделите лист данных в меньшую часть, разные хранилища листов на разных серверах, путем фрагментации, используя несколько серверов для хранения таблицы данных, избегайте одного хранения данных для хранения данных о материальном хранилище и доступа.
Главная цель:Разделите лист данных в меньшую часть, разные хранилища листов на разных серверах, путем фрагментации, используя несколько серверов для хранения таблицы данных, избегайте одного хранения данных для хранения данных о материальном хранилище и доступа.
б. Основные характеристики:Сервер базы данных не зависит, не разделяйте никакой информации, даже если некоторые сбои сервера не влияют на доступность всей системы. Вторая функция состоит в том, чтобы найти ломтик путем фрагментации, что означает, что фрагментация хранится на какой сервер продолжается, который должен посмотреть, на котором проверяется сервер, который рассчитывается по ключу фрагмента для алгоритма маршрутизации. В операторе SQL вы можете получить доступ к конкретному серверу, не подключая все серверы, связываясь с другими серверами.
C. Основной принцип:Разделение данных каким-то образом, как правило, является алгоритмом маршрутизации ключевого ключа Shard.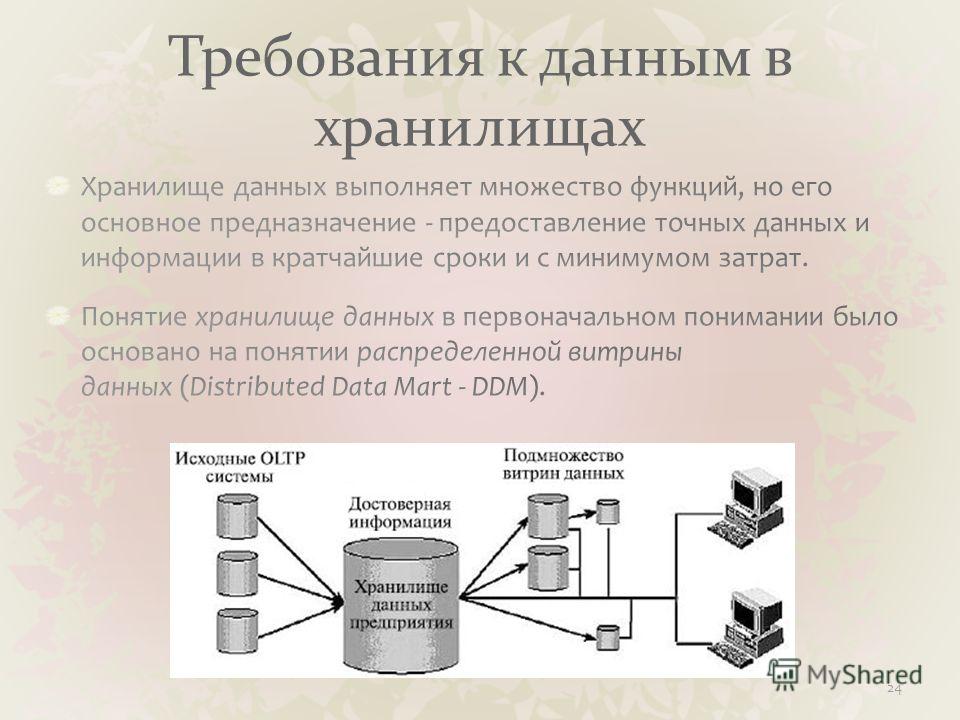 Через клавишу фрагмента расчет проводится в соответствии с некоторыми алгоритмом маршрутизации, так что каждый сервер хранится только.
Через клавишу фрагмента расчет проводится в соответствии с некоторыми алгоритмом маршрутизации, так что каждый сервер хранится только.
2. Фрагментация данных в реализации жесткого кодирования
В качестве примера фрагментация данных реализована путем применения жесткого кодирования. Предполагая, что наша база данных разделяет таблицу данных в соответствии с идентификатором пользователя, логика фрагментации заключается в том, что идентификатор пользователя хранится на сервере 2, и идентификатор пользователя хранится на сервере 1. Затем, когда приложение кодируется, расчет HASH может быть непосредственно через идентификатор пользователя, обычно остаток расчета. Если остаток является нечетным числом, подключитесь к серверу 2, если остаток является четным числом, подключитесь к серверу 1, чтобы слайд таблицы пользователей на обоих серверах.
Этот хардкодированный основной недостаток заключается в том, что логика лозунга базы данных реализуется самим приложением, и приложение должно быть связано с логикой фрагмента базы данных, которая не способствует обслуживанию и расширению приложений..png) Простое решение состоит в том, чтобы сохранить сопоставление отношения снаружи.
Простое решение состоит в том, чтобы сохранить сопоставление отношения снаружи.
3. Настольная карта Внешнее хранение
Когда приложение подключено к базе данных для операций SQL, приложение отображается запросом внешнего хранилища данных, к которому необходимо подключить сервер, а затем соответствующий сервер выполняет соответствующую операцию в соответствии с количеством возвращенного сервера. В этом примере сервер пользователя ID = 33 — 2, сервер поиска пользователя ID = 94 также является 2, который записывает данные на соответствующий фрагмент сервера в соответствии с числом пользовательского сервера для поиска, подключающих соответствующий сервер.
4. Проблемы и решения фрагментов данных
Фрагмент базы данных сталкивается с проблемами:
В настоящее время существуют некоторые специальные промежуточные программы по распределенной базе данных, чтобы решить эти проблемы, описанные выше, относительно известные mycat. MyCat — это посвященная промежуточное программное обеспечение распределенной базы данных.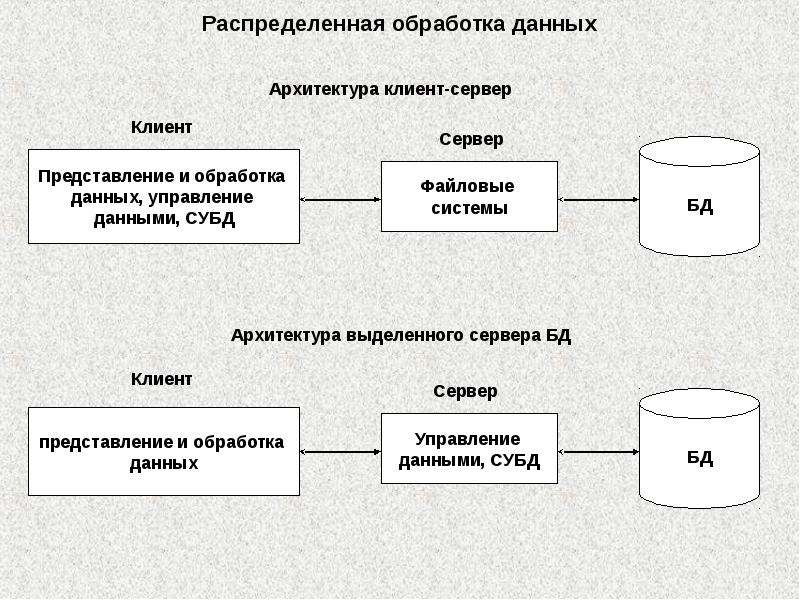 Приложение подключено к MyCat, как подключение базы данных, а фрагментация данных полностью передана MyCat.
Приложение подключено к MyCat, как подключение базы данных, а фрагментация данных полностью передана MyCat.
В этом примере есть три сервера баз данных Shard, серверы баз данных DN1, DN2 и DN3, и их правила их фрагмента фрагментированы на основе PROV. Итак, когда мы выполняем операцию запроса «Выбрать * из заказов, где POV = ‘Wuhan’» myCat составит эту операцию SQL на узел сервера DN1 на основе правил Shard. DN1 После выполнения операций запроса данных MyCat возвращается в приложение. Используя распределенную базу данных, такую как MyCat, приложение может использовать фрагментационную базу данных, которая может быть прозрачно недостижимой. В то же время mycat также поддерживает совместное соединение запросов и транзакцию баз данных фрагментационных баз данных в определенную степень.
5. Различное расширение базы данных телескопический
Сначала объем данных не слишком много, и два сервера базы данных достаточно. Но, поскольку данные растут, может потребоваться добавить третий четвертый пятый или более сервер.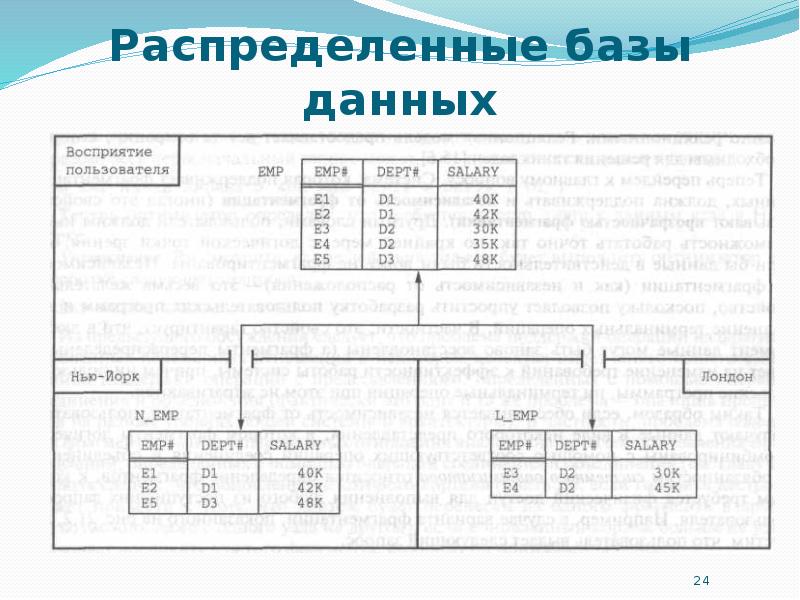 Во время увеличения сервера правила абраза должны быть изменены. После изменения правил фрагментации данные, используемые для ранее записанных в исходную базу данных. Согласно новым правилам осколки, может потребоваться получить доступ к новому серверу, поэтому требуется миграция данных.
Во время увеличения сервера правила абраза должны быть изменены. После изменения правил фрагментации данные, используемые для ранее записанных в исходную базу данных. Согласно новым правилам осколки, может потребоваться получить доступ к новому серверу, поэтому требуется миграция данных.
Независимо от того, является ли это алгоритм маршрутизации правил изменения фрагментов или миграция данных является большей проблемой и сложной вещью. Следовательно, на практике является фрагментация данных использует логическую базу данных, то есть, что, хотя только два сервера могут завершить хранилище среза данных, он все еще логически разрезан в несколько логических баз данных. Конкретные методы работы, эта статья не должна быть разработана.
В-третьих, решение развертывания базы данных
1. Одноместный сервис и одиночная база данных
Это самая простая программа развертывания. Серверы приложений могут иметь несколько, но их завершение является одной функцией. Множество серверов, которые заполняют одну функцию, доступны с помощью балансировки нагрузки..png) Они соединяют только один сервер базы данных, который является архитектурным методом, когда система приложений относительно низкая.
Они соединяют только один сервер базы данных, который является архитектурным методом, когда система приложений относительно низкая.
2. Главное хлопнуть
Если у вас есть более высокие требования к наличию системы и производительности доступа базы данных, вы можете использовать основную телескопию для репликации через базу данных. Через репликацию мастера-раб, осознайте большинство. Работа записи сервера приложений подключена к главной базе данных, а операция чтения читается с сервера.
3. Два веб-сервиса и две базы данных
Поскольку бизнес более сложный, чтобы обеспечить более высокие возможности обработки базы данных, могут быть выполнены данные. Библиотеки Data Business B логичны, на основе функциональных расщеплений, хранится различными целями таблиц данных на различных физических базах данных.
В этом примере есть услуги по категории продуктов и пользовательские услуги, два кластера серверов приложений и соответственно разделены на два, одна называемая база данных категории, пользовательская база данных. Каждая база данных все еще использует репликацию Master-Plave. Через путь ветвей бизнеса входит больше хранения базы данных в той же системе, и она также обеспечивает более мощные возможности доступа к данным, но также облегчает систему, а сцепление системы ниже.
Каждая база данных все еще использует репликацию Master-Plave. Через путь ветвей бизнеса входит больше хранения базы данных в той же системе, и она также обеспечивает более мощные возможности доступа к данным, но также облегчает систему, а сцепление системы ниже.
4. Интегрированный план развертывания
Различные решения используются в соответствии с различными характеристиками доступа к данным. Например, база данных категории может соответствовать всем требованиям доступа через репликацию Master-Slave. Однако, если количество пользователей особенно большим, мастер-рабская копия или первичная копия или хранение данных и давление доступа к операции записи могут быть сохранены в настоящее время, пользовательская база данных может быть сохранена. В то же время каждая база данных Slice также развернута с использованием мастера от репликации.
Вышеуказанная схема развертывания для распределенных баз данных, если ваше приложение не является для использования реляционной базы данных, вы также можете выбрать базу данных NoSQL, база данных NoSQL предоставляет более мощные возможности хранения данных и одновременными читателями. Но база данных NoSQL может столкнуться с проблемой несоответствия в связи с ограничением принципа CAP. Решение несоответствия данных, можно решить слиянием временем Timestamm, Client Sention и несколькими механизмами, такими как голосование для достижения окончательной консистенции.
Но база данных NoSQL может столкнуться с проблемой несоответствия в связи с ограничением принципа CAP. Решение несоответствия данных, можно решить слиянием временем Timestamm, Client Sention и несколькими механизмами, такими как голосование для достижения окончательной консистенции.
——THE END——
Вышеприведенное взято из «Организация окончания ALI ende», «Распределенное хранение данных)
Главный преподаватель: Ли Жихуй, бывший технический эксперт Alibaba
Смотрите здесь, обратите внимание на один?
Основные сведения о моделях хранилищ данных — Azure Application Architecture Guide
- Статья
- Чтение занимает 11 мин
Оцените свои впечатления
Да Нет
Хотите оставить дополнительный отзыв?
Отзывы будут отправляться в корпорацию Майкрософт. Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Отправить
Спасибо!
В этой статье
Современные бизнес-системы управляют большими объемами разнородных данных. Такая разнородность означает, что единственное хранилище данных редко будет оптимальным решением. Вместо этого часто лучше хранить различные типы данных в разных хранилищах данных, каждое из которых направлено на определенную рабочую нагрузку или шаблон использования. Термин многоязычное хранение обозначает решения, в которых сочетаются разные технологии хранилища данных. Поэтому важно понимать основные модели хранения и их компромиссы.
Выбор правильного хранилища данных, соответствующего всем требованиям, является для проекта ключевым решением. Выбирать приходится буквально из сотен реализаций баз данных SQL и NoSQL. Хранилища данных обычно различают по методам структурирования данных и типам поддерживаемых операций. В этой статье описаны несколько самых распространенных моделей хранилища. Обратите внимание, что некоторые технологии хранилища данных поддерживают несколько моделей хранилища. Например, реляционная СУБД поддерживает технологии хранилища пар «ключ — значение» или графов. На самом деле, существует общая тенденция поддержки нескольких моделей , в которой одна система базы данных поддерживает несколько моделей. Но узнать о других моделях будет полезно в любом случае.
Выбирать приходится буквально из сотен реализаций баз данных SQL и NoSQL. Хранилища данных обычно различают по методам структурирования данных и типам поддерживаемых операций. В этой статье описаны несколько самых распространенных моделей хранилища. Обратите внимание, что некоторые технологии хранилища данных поддерживают несколько моделей хранилища. Например, реляционная СУБД поддерживает технологии хранилища пар «ключ — значение» или графов. На самом деле, существует общая тенденция поддержки нескольких моделей , в которой одна система базы данных поддерживает несколько моделей. Но узнать о других моделях будет полезно в любом случае.
Хранилища данных, включенные в одну категорию, не обязательно предоставляют одинаковый набор возможностей. Большинство хранилищ данных выполняют обработку запросов и данных на стороне сервера. Иногда эта функция встроена в подсистему хранилища данных. В других случаях функции обработки данных вынесены в отдельный модуль или несколько модулей для обработки и анализа. Хранилища данных также поддерживают разные интерфейсы программного доступа и управления.
Хранилища данных также поддерживают разные интерфейсы программного доступа и управления.
Для начала вам следует решить, какая модель хранилища отвечает вашим требованиям. Затем найдите конкретное хранилище данных в этой категории, учитывая такие факторы, как набор функций, стоимость и простота управления.
Реляционные СУБД
Реляционные базы данных хранят данные в наборе двумерных таблиц со строками и столбцами. большинство поставщиков предоставляют диалект язык SQL (SQL) для получения и управления данными. Как правило, реляционная СУБД реализует для обновления информации транзакционно согласованный механизм, который соответствует модели ACID (Atomic = атомарность, Consistent = согласованность, Isolated = изоляция, Durable = устойчивость).
Реляционная СУБД часто поддерживает модель «схема для записи». В этой схеме сначала определяется структура данных, а затем она применяется для всех операций чтения или записи.
Эта модель очень полезна, если важны надежные гарантии согласованности, где все изменения являются атомарными, а транзакции всегда оставляют данные в согласованном состоянии. Однако объект РСУБД обычно не может горизонтально масштабироваться без сегментирования данных каким бы то ни было образом. Кроме того, данные в RDBMS должны быть нормализованы, что не подходит для каждого набора данных.
Однако объект РСУБД обычно не может горизонтально масштабироваться без сегментирования данных каким бы то ни было образом. Кроме того, данные в RDBMS должны быть нормализованы, что не подходит для каждого набора данных.
Службы Azure
Рабочая нагрузка
- Записи часто создаются и обновляются.
- Несколько операций должны выполниться в одной транзакции.
- Связи задаются по ограничениям базы данных.
- Индексы используются для оптимизации производительности запросов.
Тип данных
- Данные имеют высокую степень нормализации.
- Схемы базы данных требуются и принудительно применяются.
- Для данных в базе данных настроена связь «многие ко многим».
- Ограничения определяются в схеме и применяются к любым данным в базе данных.
- Данные требуют высокого уровня целостности. Индексы и связи требуют осторожного использования.
- Данные требуют строгой согласованности. Транзакции осуществляются таким образом, который гарантирует, что все данные полностью согласованы для всех пользователей и процессов
- Размер отдельных записей данных мал для среднего размера.
Примеры
- Управление запасами
- управление заказами;
- база данных отчетов;
- Учет
Хранилище пар «ключ — значение»
Хранилище ключей и значений связывает каждое значение данных с уникальным ключом. Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком. В большинстве реализаций атомарной операцией считается чтение или запись одного значения.
Приложение может хранить произвольные данные в виде набора значений. Приложение должно предоставлять любые сведения о схеме. Хранилище ключей и значений просто извлекает или сохраняет значение по ключу.
Хранилища ключей и значений оптимизированы для приложений, выполняющих простые поиски, но менее подходят, если необходимо запрашивать данные в разных хранилищах ключей и значений. Хранилища ключей и значений также не оптимизируются для запросов по значению.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.
Службы Azure
Рабочая нагрузка
- Доступ к данным осуществляется с помощью одного ключа, например словаря.
- Соединения, блокировки или объединения не нужны.
- Механизмы статистической обработки не используются.
- Как правило, вторичные индексы не используются.
Тип данных
- Каждый ключ связан с одним значением.
- Схема не применяется.
- Сущности не связаны.
Примеры
- Кэширование данных
- Управление сеансом
- Управления параметрами и профилями пользователя
- Рекомендации по продуктам и реклама
Базы данных документов
В базе данных документов хранится коллекция документов, в которой каждый документ состоит из именованных полей и данных. Данные могут быть простыми значениями или сложными элементами, такими как списки и дочерние коллекции. Документы извлекаются с помощью уникальных ключей.
Документы извлекаются с помощью уникальных ключей.
Как правило, документ содержит данные для одной сущности, например клиента или заказа. Документ может содержать сведения, которые будут распределяться по нескольким реляционным таблицам в RDBMS. Документы не должны иметь одинаковую структуру. Приложения могут сохранять в документах различные данные по мере изменения бизнес-требований.
Служба Azure
Рабочая нагрузка
- Операции вставки и обновления являются общими.
- Нет объектно-реляционной несогласованности. Документы можно эффективнее сопоставить со структурами объектов, используемыми в коде приложения.
- Отдельные документы извлекаются и записываются как единый блок.
- Данным требуется индекс по нескольким полям.
Тип данных
- Данными можно управлять не нормализованно.
- Размер отдельных блоков данных документа относительно невелик.
- Тип каждого документа может использовать собственную схему.
- Документы могут содержать дополнительные поля.
- Данные документа полуструктурированные. Это означает, что типы данных каждого поля не строго определены.

Примеры
- Каталог продукции
- Управление содержимым
- Управление запасами
Графовые базы данных
База данных графов хранит сведения двух типов: узлы и грани. Границы указывают связи между узлами. Узлы и края могут иметь свойства, предоставляющие сведения об этом узле или крае, аналогичные столбцам в таблице. Грани могут иметь направление, указывающее на характер связи.
Graph базы данных могут эффективно выполнять запросы по сети узлов и ребер, а также анализировать связи между сущностями. На следующей схеме представлена база данных персонала организации, структурированная в виде графа. Сущности являются сотрудниками и отделами, а границы обозначают связи отчетов и отделы, в которых работают сотрудники.
Эта структура позволяет легко выполнять такие запросы, как «найти всех сотрудников, которые напрямую или косвенно сообщать Сара» или «Кто работает в одном отделе с Джон?» Для больших диаграмм с большим количеством сущностей и связей можно очень быстро выполнять очень сложные анализы.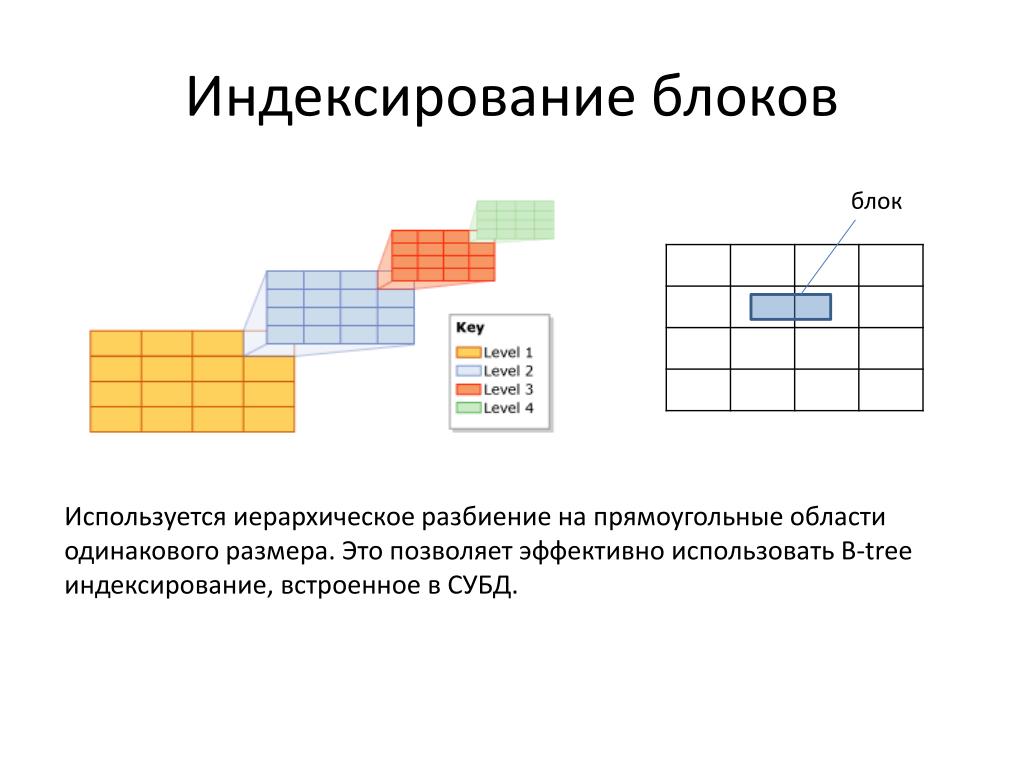 Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.
Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.
Службы Azure
Рабочая нагрузка
- Сложные связи между элементами данных, включающие много прыжков между связанными элементами данных.
- Связи между элементами данных динамические и изменяются со временем.
- Отношения между объектами являются привилегированными. Для обхода не требуются внешние ключи и соединения.
Тип данных
- Узлы и связи.
- Узлы похожи на строки таблицы или документы JSON.
- Связи так же важны, как и узлы, и явно предоставляются на языке запросов.
- Составные объекты, такие как пользователь с несколькими телефонными номерами, как правило, разделяются на несколько отдельных небольших узлов в сочетании с переходными связями.
Примеры
- Организационные диаграммы
- Графы социальных сетей
- Обнаружение мошенничества.
- Системы рекомендаций
аналитика данных.

Хранилища аналитики данных предоставляют решения для масштабной параллельной обработки, хранения и анализа данных. Данные распределяются по нескольким серверам для повышения масштабируемости. Большие форматы файлов данных, такие как файлы-разделители (CSV), Parquetи ORC , широко используются в аналитике данных. исторические данные обычно хранятся в хранилищах данных, таких как хранилище blob-объектов или Azure Data Lake Storage 2-го поколения, доступ к которым осуществляется с помощью Azure синапсе, кирпичей данных или HDInsight в качестве внешних таблиц. Типичный сценарий использования данных, хранящихся как Parquet-файлы, для повышения производительности описан в статье использование внешних таблиц с синапсе SQL.
Службы Azure
Рабочая нагрузка
- аналитика данных.
- Корпоративная бизнес-аналитика
Тип данных
- Исторические данные из нескольких источников.
- Обычно денормализовано в схеме типа «звезда» или «снежинка», состоящей из таблиц фактов и измерений.
- Как правило, новые данные загружаются по расписанию.
- Таблицы измерений часто включают в себя несколько исторических версий сущности, называемых медленно изменяющимися измерениями.

Примеры
- Корпоративное хранилище данных
Базы данных столбцов
Базы данных столбцов хранят распределяют данные по строкам и столбцам. База данных столбцов в простейшей форме почти неотличима от реляционной базы данных, по крайней мере организационно. Настоящим преимуществом базы данных столбцов является способность денормализованно структурировать разреженные данные.
Базу данных столбцов можно представить как набор табличных данных со строками и столбцами, в которых столбцы разделяются на определенные группы или семейства столбцов. Каждое семейство столбцов включает набор логически связанных столбцов, которые обычно извлекаются или управляются как единое целое. Другие данные, которые используются в других процессах, хранятся отдельно в других семействах столбцов. В семейство столбцов можно динамически добавить новые столбцы, а строки могут быть разреженными (то есть строки не обязаны иметь значение для каждого столбца).
В семейство столбцов можно динамически добавить новые столбцы, а строки могут быть разреженными (то есть строки не обязаны иметь значение для каждого столбца).
На следующей диаграмме представлен пример таблицы с двумя семействами столбцов: Identity и Contact Info. Данные для одной сущности имеют одинаковые ключи строк во всех семействах столбцов. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории баз данных. Семейства столбцов очень хорошо подходят для хранения структурированных изменчивых данных.
В отличие от хранилища пар «ключ — значение» и баз данных документов, большинство хранилищ столбцов используют для упорядоченного хранения данных сами значения ключей, а не хэш-коды от них. Многие реализации позволяют создавать индексы по определенным столбцам в семействе столбцов. Индексы позволяют получать данные по значениям столбцов, а не ключам строки.
Чтение и запись одной строки для одного семейства столбцов обычно являются атомарными операциями. Но некоторые реализации поддерживают атомарность для всей строки, распределенной по нескольким семействам столбцов.
Службы Azure
Рабочая нагрузка
- В большинстве баз данных столбцов операции записи выполняются очень быстро.
- Операции обновления и удаления выполняются редко.
- Предназначены для обеспечения доступа с высокой пропускной способностью и малой задержкой.
- Поддерживают простой доступ с выполнением запроса к конкретному набору полей в большой записи.
- Высокая масштабируемость.
Тип данных
- Данные хранятся в таблицах, состоящих из ключевого столбца и одного или нескольких наборов столбцов.
- Определенные столбцы изменяются в зависимости от отдельных строк.
- Доступ к отдельным ячейкам осуществляется с использованием команд GET и PUT.
- Несколько строк возвращаются с использованием команды проверки.

Примеры
- Рекомендации
- Personalization
- Данные от датчиков
- Телеметрия
- Messaging
- Анализ социальных сетей
- Веб-аналитика
- Мониторинг активности
- Прогнозные данные и другие данные временных рядов
Базы данных поисковой системы
База данных поисковой системы позволяет приложениям искать сведения, хранящиеся во внешних хранилищах данных. База данных поисковой системы может индексировать большие объемы данных и предоставлять доступ к этим индексам практически в режиме реального времени.
В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных. Индексирование может выполняться по модели извлечения, то есть по требованию базы данных, или по модели передачи, то есть по команде из кода внешнего приложения.
Поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые поисковые системы поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например,
Некоторые поисковые системы поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, dogs будет считаться соответствием для pets) и морфологии (поиск любых однокоренных слов).
Служба Azure
Рабочая нагрузка
- Индексы данных из нескольких источников и служб.
- Запросы являются специализированными и могут быть сложными.
- Требуется полнотекстовый поиск.
- Требуется специализированный запрос на самообслуживание.
Тип данных
- Частично структурированный или неструктурированный текст
- Текст со ссылкой на структурированные данные
Примеры
- Каталоги продуктов
- Поиск на сайте
- Ведение журнала
Базы данных временных рядов
Данные временных рядов — это набор значений, упорядоченных по времени. Базы данных временных рядов обычно собираются большие объемы данных в режиме реального времени из большого числа источников. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией. Несмотря на то, что записи, записываемые в базу данных временных рядов, обычно невелики, часто встречается большое количество записей, а общий размер данных может быстро увеличиваться.
Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией. Несмотря на то, что записи, записываемые в базу данных временных рядов, обычно невелики, часто встречается большое количество записей, а общий размер данных может быстро увеличиваться.
Служба Azure
Рабочая нагрузка
- Записи обычно добавляются последовательно по времени.
- Большая часть операций (95–99 %) — это операции записи.
- Обновления происходят редко.
- Удаление выполняется в пакетном режиме. Удаляются смежные блоки или записи.
- Данные считываются последовательно в порядке возрастания или убывания времени, как правило, параллельно.
Тип данных
- Отметка времени используется в качестве механизма сортировки первичного ключа и.
- Теги могут определять дополнительные сведения о типе, источнике и другие сведения о записи.
Примеры
- Мониторинг и телеметрия событий.
- Данные датчиков или другие данные Интернета вещей.

Хранилище объектов
Хранилище объектов оптимизировано для хранения и извлечения больших двоичных объектов (изображения, файлы, видео- и аудиопотоки, объекты данных и документы приложений большого размера, образы дисков для виртуальных машин). Большие файлы данных также используются в этой модели, например файл разделителя (CSV), Parquetи ORC. Хранилища объектов могут управлять очень большими объемами неструктурированных данных.
Служба Azure
Рабочая нагрузка
- Определяется ключом.
- Содержимое обычно является ресурсом-контейнером, таким как разделитель, изображение или видеофайл.
- Содержимое должно быть устойчивым и внешним для любого уровня приложения.
Тип данных
- Данные большого размера.
- Значение является непрозрачным.
Примеры
- Изображения, видео, офисные документы, PDF-файлы
- Статический HTML, JSON, CSS
- Файлы журнала и аудита
- Резервные копии базы данных
Общие файлы
В некоторых случаях самой эффективной системой хранения и извлечения данных будут простые неструктурированные файлы. Использование общих файловых ресурсов позволяет использовать их совместно через компьютерную сеть. Если созданы необходимые механизмы для поддержки безопасности и одновременного доступа, такое совместное использование данных позволяет распределенным службам с высокой степенью масштабируемости предоставлять доступ к данным для базовых низкоуровневых операций, то есть для простых запросов на чтение и запись.
Использование общих файловых ресурсов позволяет использовать их совместно через компьютерную сеть. Если созданы необходимые механизмы для поддержки безопасности и одновременного доступа, такое совместное использование данных позволяет распределенным службам с высокой степенью масштабируемости предоставлять доступ к данным для базовых низкоуровневых операций, то есть для простых запросов на чтение и запись.
Служба Azure
Рабочая нагрузка
- Миграция из имеющихся приложений, взаимодействующих с файловой системой.
- Требуется интерфейс SMB.
Тип данных
- Файлы в наборе папок иерархической структуры.
- Доступны в стандартных библиотеках ввода-вывода.
Примеры
- Устаревшие файлы
- Общее содержимое доступно в нескольких виртуальных машинах или экземплярах приложения
Теперь с этим пониманием различных моделей хранения данных следует оценить рабочую нагрузку и приложение и решить, какое хранилище данных будет соответствовать вашим потребностям. Используйте Дерево принятия решений для хранения данных , чтобы помочь в этом процессе.
Используйте Дерево принятия решений для хранения данных , чтобы помочь в этом процессе.
Введение в распределенное хранилище данных | Квентин Труонг
Все, что вам нужно знать для эффективного использования распределенных хранилищ данных!
Данные, хранящиеся на кварце — используются с разрешения Microsoft.Данные — это основа сегодняшнего дня! Он поддерживает все, от ваших любимых видеороликов о кошках до миллиардов финансовых транзакций, которые происходят каждый день. В основе всего этого лежит распределенное хранилище данных.
В этой статье мы узнаем , что такое распределенное хранилище данных , , почему нам это нужно, и , как использовать его эффективно.Эта статья предназначена для помощи в разработке приложений, поэтому мы рассмотрим только то, что разработчиков приложений должны знать. Сюда входят основные основы, общие ошибки, с которыми сталкиваются разработчики, и различия между различными распределенными хранилищами данных.
Эта статья не требует каких-либо знаний о распределенных системах! Программирование и опыт работы с базами данных помогут, но вы также можете просто искать темы по мере того, как мы к ним подходим. Давайте начнем!
Распределенное хранилище данных — это система, которая хранит и обрабатывает данные на нескольких машинах.
Как разработчик, вы можете думать о распределенном хранилище данных как о том, как вы храните и извлекаете данные приложений, показатели, журналы и т. Д. Некоторые популярные распределенные хранилища данных, с которыми вы, возможно, знакомы, — это MongoDB, Amazon Web Service S3 и Google. Гаечный ключ облачной платформы.
На практике существует множество видов распределенных хранилищ данных. Обычно они предоставляются в виде сервисов, управляемых поставщиками облачных услуг, или продуктов, которые вы развертываете самостоятельно. Вы также можете создать свое собственное хранилище данных с нуля или поверх других хранилищ данных.
Почему бы просто не использовать хранилища данных на одном компьютере? Чтобы по-настоящему понять, нам сначала нужно осознать масштаб и повсеместность сегодняшних данных. Давайте посмотрим на некоторые конкретные цифры:
- Steam имел пик в 18,5 миллионов одновременных пользователей, развернул серверы с 2,7 петабайтами SSD и предоставил пользователям 15 эксабайт в 2018 году¹.
- Nasdaq в 2020 году обработал пик в 113 миллиардов записей за один день, увеличившись в среднем по сравнению с 30 миллиардами всего двумя годами ранее².
- Kellogg’s, компания по производству хлопьев, в 2014 году обрабатывала 16 терабайт в неделю только в результате смоделированной рекламной деятельности.
Честно говоря, невероятно, сколько данных мы используем. Каждый из этих битов тщательно хранится и где-то обрабатывается. Это где-то наши распределенные хранилища данных.
Хранилища данных на одном компьютере просто не могут удовлетворить эти требования. Поэтому вместо этого мы используем распределенные хранилища данных, которые предлагают ключевые преимущества в производительности , масштабируемости и надежности . Давайте разберемся, что на самом деле означают эти преимущества.
Поэтому вместо этого мы используем распределенные хранилища данных, которые предлагают ключевые преимущества в производительности , масштабируемости и надежности . Давайте разберемся, что на самом деле означают эти преимущества.
Производительность, масштабируемость и надежность
Производительность — это то, насколько хорошо машина может выполнять работу.
Производительность критична. Существует бесчисленное количество исследований, которые количественно оценивают и показывают влияние задержек на срок до 100 мс⁴ на бизнес. Медленное время отклика не только расстраивает людей — они приводят к снижению трафика, продаж и, в конечном итоге, доходов⁵.
К счастью, мы можем контролировать производительность нашего приложения. В случае хранилищ данных на одной машине часто бывает достаточно просто перейти на более быструю машину. Если этого недостаточно или вы полагаетесь на распределенное хранилище данных, тогда в игру вступают другие формы масштабируемости.
Если этого недостаточно или вы полагаетесь на распределенное хранилище данных, тогда в игру вступают другие формы масштабируемости.
Масштабируемость — это способность увеличивать или уменьшать ресурсы инфраструктуры.
Приложения сегодня часто испытывают быстрый рост и цикличность использования. Чтобы удовлетворить эти требования к нагрузке, мы «масштабируем» наши распределенные хранилища данных. Это означает, что мы предоставляем больше или меньше ресурсов по запросу по мере необходимости. Масштабируемость бывает двух форм.
- Горизонтальное масштабирование означает добавление или удаление компьютеров (также известных как машины или узлы).
- Вертикальное масштабирование означает изменение ЦП, ОЗУ, емкости хранилища или другого оборудования машины.
Благодаря горизонтальному масштабированию распределенные хранилища данных могут превосходить хранилища данных на одном компьютере. Распределяя работу по сотням компьютеров, совокупная система имеет более высокую производительность и надежность. В то время как распределенные хранилища данных в основном полагаются на горизонтальное масштабирование, вертикальное масштабирование используется вместе для оптимизации общей производительности и стоимости⁶.
Распределяя работу по сотням компьютеров, совокупная система имеет более высокую производительность и надежность. В то время как распределенные хранилища данных в основном полагаются на горизонтальное масштабирование, вертикальное масштабирование используется вместе для оптимизации общей производительности и стоимости⁶.
Диапазон масштабирования варьируется от ручного до полностью управляемого. Некоторые продукты имеют ручного масштабирования , где вы сами обеспечиваете дополнительную емкость. Другие автоматическое масштабирование на основе таких показателей, как оставшаяся емкость хранилища. Наконец, некоторые сервисы выполняют масштабирование, даже если разработчик даже не задумывается об этом, например S3 от Amazon Web Service.
Независимо от подхода, все службы имеют некоторые ограничения, которые нельзя увеличить, например максимальный размер объекта.Вы можете проверить квоты в документации, чтобы увидеть эти жесткие ограничения. Вы можете проверить онлайн-тесты, чтобы увидеть, какая производительность достижима на практике.
Вы можете проверить онлайн-тесты, чтобы увидеть, какая производительность достижима на практике.
Надежность — это вероятность безотказности⁷.
Некоторые приложения настолько важны для нашей жизни, что даже секунды отказа недопустимы. Эти приложения не могут использовать хранилища данных на одном компьютере из-за неизбежных сбоев оборудования и сети, которые могут поставить под угрозу всю службу. Вместо этого мы используем распределенные хранилища данных, потому что они могут приспособиться к сбоям отдельных компьютеров или сетевых путей.
Чтобы быть высоконадежной, система должна быть одновременно доступной и отказоустойчивой.
- Доступность — это процент времени, в течение которого служба доступна и нормально отвечает на запросы.
- Отказоустойчивость — это способность выдерживать аппаратные и программные сбои. Полная отказоустойчивость невозможна ».
Хотя на первый взгляд доступность и отказоустойчивость могут показаться одинаковыми, на самом деле они совершенно разные. Посмотрим, что будет, если один у вас есть, а другого нет.
Посмотрим, что будет, если один у вас есть, а другого нет.
- Доступно, но не отказоустойчиво: Рассмотрим систему, которая выходит из строя каждую минуту, но восстанавливается в течение миллисекунд. Пользователи могут получить доступ к сервису, но длительные задания никогда не успевают закончиться.
- Отказоустойчивый, но недоступный: Рассмотрим систему, в которой половина узлов постоянно перезагружается, а остальные стабильны. Если емкость стабильных узлов недостаточна, то некоторые запросы придется отклонять.
Takeaway
Для разработчика приложений ключевым моментом является то, что распределенные хранилища данных могут масштабировать производительность и надежность далеко за пределы отдельных компьютеров. Загвоздка в том, что у них есть предостережения относительно того, как они работают, что может ограничить их потенциал.
Давайте рассмотрим, что разработчикам приложений необходимо знать о том, как работают распределенные хранилища данных — о разделении, маршрутизации запросов и репликации. Эти основы дадут вам представление о поведении и характеристиках распределенных хранилищ данных.Это поможет вам понять предостережения, компромиссы и то, почему у нас нет распределенного хранилища данных, которое бы превосходно во всем.
Эти основы дадут вам представление о поведении и характеристиках распределенных хранилищ данных.Это поможет вам понять предостережения, компромиссы и то, почему у нас нет распределенного хранилища данных, которое бы превосходно во всем.
Разбиение на разделы
Наши наборы данных часто слишком велики для хранения на одной машине. Чтобы преодолеть это, мы разбиваем наших данных на более мелкие подмножества, которые отдельные машины могут хранить и обрабатывать. Есть много способов разделить данные, каждый со своими компромиссами. Два основных подхода — это вертикальное и горизонтальное разделение.
Изображение автора Вертикальное разбиение означает разделение данных по связанным полям¹¹. Поля могут быть связаны по многим причинам. Это могут быть свойства какого-то общего объекта. Это могут быть поля, к которым запросы обычно обращаются вместе. Это могут быть даже поля, к которым с одинаковой периодичностью обращаются или пользователи с аналогичными разрешениями.![]() Точный способ вертикального разделения данных между машинами в конечном итоге зависит от свойств вашего хранилища данных и шаблонов использования, для которых вы оптимизируете.
Точный способ вертикального разделения данных между машинами в конечном итоге зависит от свойств вашего хранилища данных и шаблонов использования, для которых вы оптимизируете.
Горизонтальное разбиение (также известное как сегментирование ) — это когда мы разделяем данные на подмножества с одинаковой схемой¹¹. Например, мы можем горизонтально разделить таблицу реляционной базы данных, сгруппировав строки в сегменты, которые будут храниться на разных машинах. Мы разделяем данные, когда одна машина не может обработать ни объем данных, ни загрузку запросов для этих данных. Стратегии сегментирования делятся на две категории: алгоритмические и динамические, но существуют гибриды.
Изображение автора Алгоритмическое сегментирование определяет, какому сегменту выделить данные, в зависимости от функции ключа данных. Например, при сохранении URL-адресов сопоставления данных «ключ-значение» в HTML мы можем диапазон разделить наши данные, разделив пары «ключ-значение» в соответствии с первой буквой URL-адреса.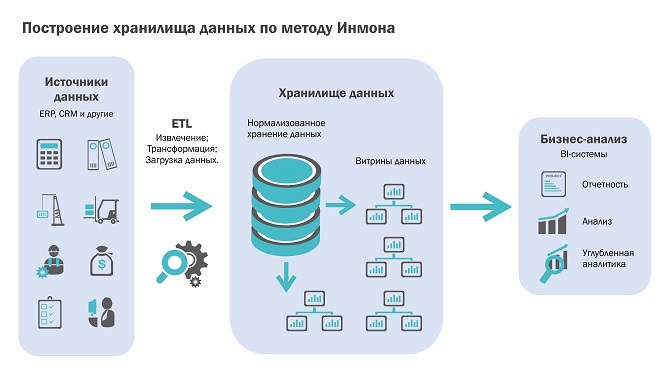 Например, все URL-адреса, начинающиеся с «A», будут идти на первом компьютере, «B» — на втором и так далее. Существует бесчисленное множество стратегий, каждая из которых имеет разные компромиссы.
Например, все URL-адреса, начинающиеся с «A», будут идти на первом компьютере, «B» — на втором и так далее. Существует бесчисленное множество стратегий, каждая из которых имеет разные компромиссы.
Динамическое сегментирование явно выбирает расположение данных и сохраняет это расположение в таблице поиска. Для доступа к данным мы консультируемся с сервисом с помощью таблицы поиска или проверяем локальный кеш. Таблицы поиска могут быть довольно большими, и поэтому они могут иметь таблицы поиска, указывающие на вспомогательные таблицы поиска, такие как B + -Tree¹². Динамическое сегментирование более гибкое, чем алгоритмическое сегментирование¹³.
Разбиение на разделы на практике довольно сложно и может создать множество проблем, о которых вам нужно знать.К счастью, некоторые распределенные хранилища данных справятся со всей этой сложностью за вас. Другие справляются с некоторыми или ничего.
- Осколки могут иметь неровных данных размеров. Это обычное явление в алгоритмическом сегментировании, когда функцию сложно выполнить правильно. Мы смягчаем это, адаптируя стратегию сегментирования к данным.
- Осколки могут иметь точек доступа , где одни данные запрашиваются по величине чаще, чем другие. Например, подумайте, насколько чаще вы будете запрашивать знаменитостей в социальной сети, чем обычные люди.Здесь могут помочь тщательный дизайн схемы, кеши и реплики.
- Перераспределение данных для обработки добавления или удаления узлов из системы затруднено при поддержании высокой доступности.
- Индексы также могут потребовать секционирования. Индексы могут индексировать сегмент, на котором он хранится (локальный индекс), или он может индексировать весь набор данных и быть секционированным (глобальный индекс). Каждый имеет свои компромиссы.
- Транзакции между разделами могут работать, или они могут быть отключены, медленными или непоследовательными, что может сбивать с толку. Это особенно сложно при создании собственного распределенного хранилища данных из хранилищ данных одного компьютера.
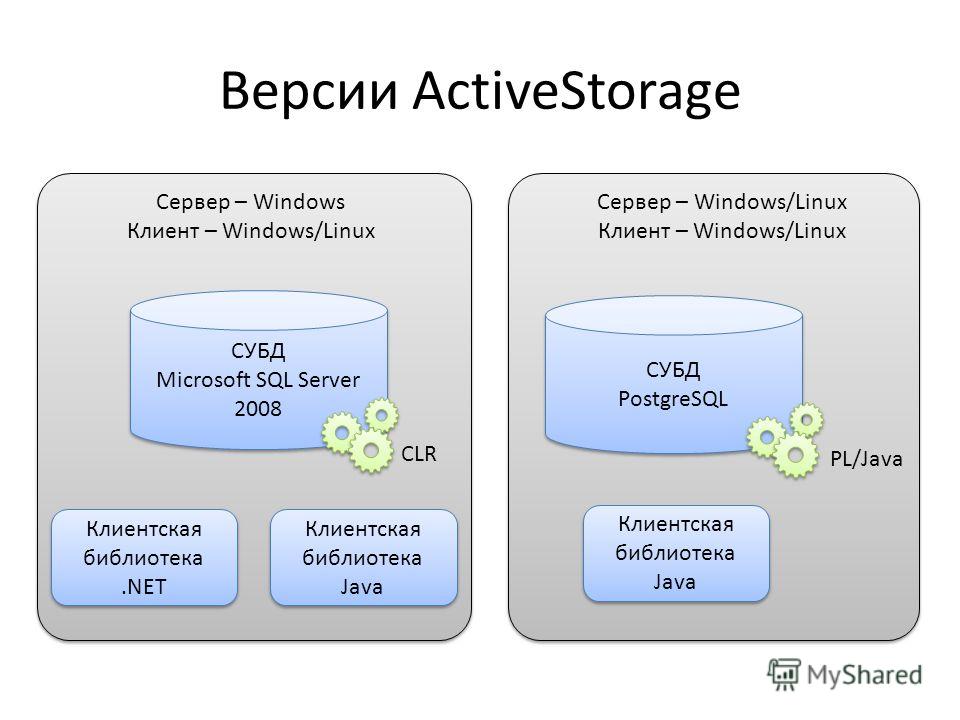 Это обычное явление в алгоритмическом сегментировании, когда функцию сложно выполнить правильно. Мы смягчаем это, адаптируя стратегию сегментирования к данным.
Это обычное явление в алгоритмическом сегментировании, когда функцию сложно выполнить правильно. Мы смягчаем это, адаптируя стратегию сегментирования к данным. Это особенно сложно при создании собственного распределенного хранилища данных из хранилищ данных одного компьютера.
Это особенно сложно при создании собственного распределенного хранилища данных из хранилищ данных одного компьютера.Маршрутизация запросов
Разделение данных — это только часть дела. Нам по-прежнему нужно направлять запросы от клиента на правильный серверный компьютер. Маршрутизация запросов может происходить на разных уровнях программного стека. Давайте посмотрим на три основных случая.
- Разделение на стороне клиента — это когда клиент хранит логику принятия решения о том, какой внутренний узел запрашивать.Преимуществом является концептуальная простота, а недостатком — то, что каждый клиент должен реализовывать логику маршрутизации запросов.
- Разделение на основе прокси — это когда клиент отправляет все запросы на прокси. Затем этот прокси определяет, какой серверный узел запрашивать. Это может помочь уменьшить количество одновременных подключений на ваших внутренних серверах и отделить логику приложения от логики маршрутизации.
- Разделение на основе сервера — это когда клиент подключается к любому внутреннему узлу, и этот узел будет обрабатывать, перенаправлять или пересылать запрос.
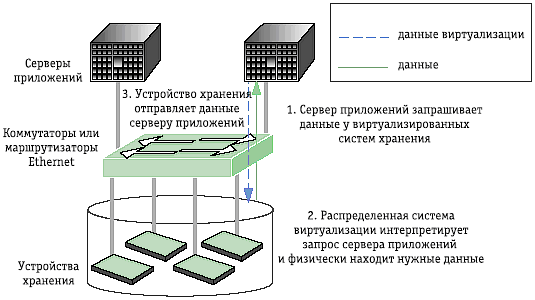
На практике маршрутизация запросов обрабатывается большинством распределенных хранилищ данных. Обычно вы настраиваете клиента, а затем запрашиваете его с помощью клиента. Однако, если вы создаете собственное распределенное хранилище данных или используете такие продукты, как Redis, которые не обрабатывают его, вам необходимо принять это во внимание¹⁴.
Репликация
Последняя концепция, которую мы рассмотрим, — это репликация. Репликация означает хранение нескольких копий одних и тех же данных. Это дает много преимуществ.
- Избыточность данных: Когда оборудование неизбежно выходит из строя, данные не теряются из-за наличия другой копии.
- Доступность данных: Клиенты могут получить доступ к данным с любой реплики. Это увеличивает устойчивость к сбоям в работе центра обработки данных и разделению сети.
- Повышенная пропускная способность чтения: Есть больше машин, которые могут обслуживать данные, поэтому общая емкость выше.
- Уменьшение сетевой задержки: Клиенты могут получить доступ к ближайшей к ним реплике, уменьшая сетевую задержку.
 Это увеличивает устойчивость к сбоям в работе центра обработки данных и разделению сети.
Это увеличивает устойчивость к сбоям в работе центра обработки данных и разделению сети.Реализация репликации требует сложных протоколов консенсуса и исчерпывающего анализа сценариев сбоев.К счастью, разработчикам приложений обычно достаточно знать, где и когда реплицируются данные.
Где реплицируются данные варьируются от центра обработки данных до зон, регионов или даже континентов. Реплицируя данные близко друг к другу, мы минимизируем сетевую задержку при обновлении данных между машинами. Однако, реплицируя данные дальше друг от друга, мы защищаемся от сбоев центра обработки данных, сетевых разделов и потенциально уменьшаем сетевую задержку при чтении.
При репликации данные могут быть синхронными или асинхронными.
- Синхронная репликация означает, что данные копируются во все реплики перед ответом на запрос. Это дает преимущество в обеспечении идентичных данных на всех репликах за счет более высокой задержки записи.
- Асинхронная репликация означает, что данные хранятся только на одной реплике до ответа на запрос. Это дает преимущество более быстрой записи с недостатками более слабой согласованности данных и возможной потери данных.
Takeaway
Разделение, маршрутизация запросов и репликация являются строительными блоками распределенного хранилища данных. Разные реализации проявляются как разные функции и свойства, между которыми вы делаете компромиссы.
Распределенные хранилища данных — это все особые снежинки, каждая со своим уникальным набором функций. Мы сравним их, сгруппировав различия по категориям и рассмотрев основы каждой из них. Это поможет вам узнать, какие вопросы задавать и о чем читать дальше в будущем.
Это поможет вам узнать, какие вопросы задавать и о чем читать дальше в будущем.
Модель данных
Первое отличие, которое следует учитывать, — это модель данных. Модель данных — это тип данных и способ их запроса. Общие типы включают
- Документ: Вложенные коллекции документов JSON. Запрос с ключами или фильтрами.
- Пары «ключ-значение»: Пары «ключ-значение». Запрос с ключом.
- Реляционная: Таблицы строк с явной схемой. Запрос с SQL.
- Двоичный объект: Произвольные двоичные капли.Запрос с ключом.
- Файловая система: Каталоги файлов. Запрос с путем к файлу.
- График: Узлы с краями. Запрос на языке запросов графа.
- Сообщение: Группы пар ключ-значение, такие как JSON или Python dict. Запрос из очереди, темы или отправителя.
- Временной ряд: Данные упорядочены по метке времени. Запрос с помощью SQL или другого языка запросов.
- Текст: Текст произвольной формы или журналы.Запрос на языке запросов.

Различные модели данных предназначены для разных ситуаций. Хотя вы можете просто хранить все как двоичный объект, это будет неудобно при запросе данных и разработке приложения. Вместо этого используйте модель данных, которая лучше всего соответствует вашему типу запросов. Например, если вам нужен быстрый и простой поиск небольших фрагментов данных, используйте пары «ключ-значение». Мы предоставим более подробную информацию о предполагаемом использовании в таблице ниже.
Обратите внимание, что некоторые хранилища данных являются многомодельными, что означает, что они могут эффективно работать с несколькими моделями данных.
Гарантии
Различные хранилища данных предоставляют разные «гарантии» поведения.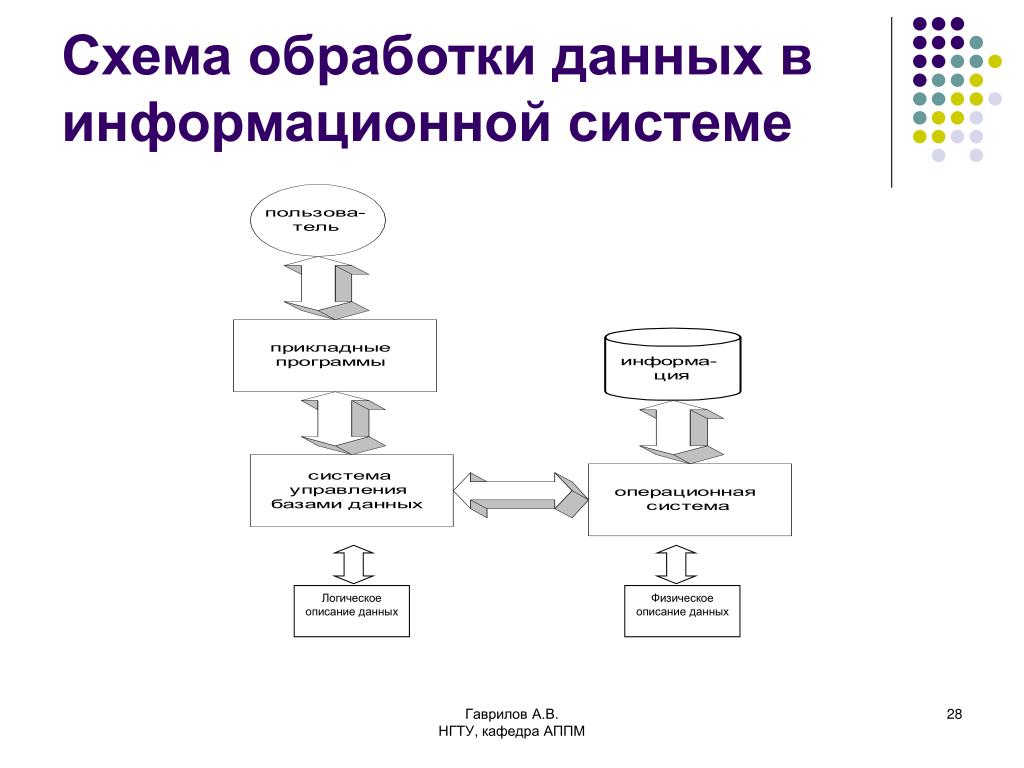 Хотя вам технически не нужны гарантии для разработки надежных приложений, строгие гарантии значительно упрощают проектирование и внедрение. Общие гарантии, с которыми вы столкнетесь, следующие:
Хотя вам технически не нужны гарантии для разработки надежных приложений, строгие гарантии значительно упрощают проектирование и внедрение. Общие гарантии, с которыми вы столкнетесь, следующие:
- Согласованность — это то, выглядят ли данные одинаково для всех читателей и являются ли они актуальными. Обратите внимание, что термин «согласованность» по иронии судьбы сильно перегружен — убедитесь, о каком типе согласованности идет речь¹⁵.
- Доступность — есть ли у вас доступ к своим данным.
- Долговечность — это надежность и целостность хранимых данных.
Некоторые поставщики услуг даже по контракту гарантируют уровень обслуживания, такой как доступность 99,99%, посредством соглашения об уровне обслуживания (SLA). Если они не соблюдают соглашение, вы обычно получаете некоторую компенсацию.
Экосистема
Экосистема (интеграции, инструменты, вспомогательное программное обеспечение и т.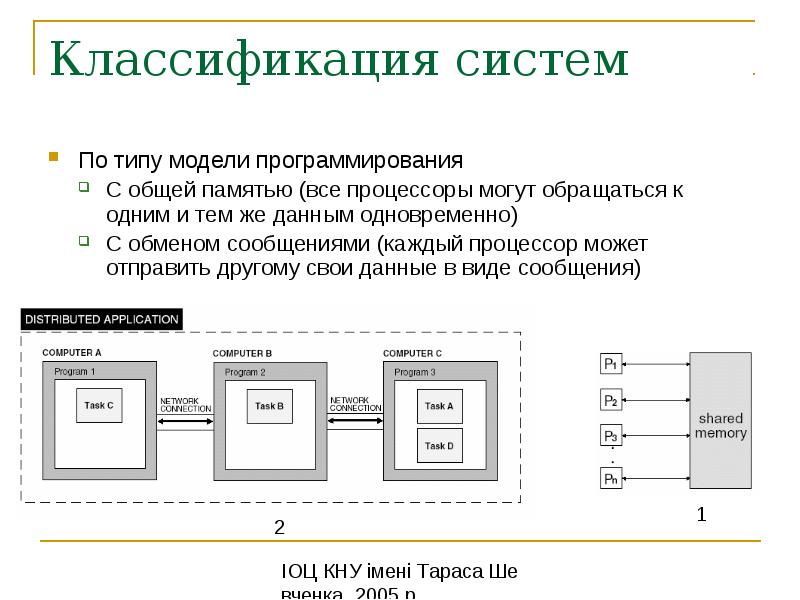 Д.) имеет решающее значение для вашего успеха с распределенным хранилищем данных. Необходимо проверить простые вопросы, например, какие SDK доступны и какие типы тестирования поддерживаются. Если вам нужны такие функции, как соединители баз данных, мобильная синхронизация, ORM, буферы протоколов, геопространственные библиотеки и т. Д., Вам необходимо подтвердить, что они поддерживаются. Эта информация будет в документации и блогах.
Д.) имеет решающее значение для вашего успеха с распределенным хранилищем данных. Необходимо проверить простые вопросы, например, какие SDK доступны и какие типы тестирования поддерживаются. Если вам нужны такие функции, как соединители баз данных, мобильная синхронизация, ORM, буферы протоколов, геопространственные библиотеки и т. Д., Вам необходимо подтвердить, что они поддерживаются. Эта информация будет в документации и блогах.
Безопасность
Ответственность за безопасность разделяется между вами и вашим поставщиком продукта / услуги.Ваши обязанности будут зависеть от того, какой частью стека вы управляете.
Если вы используете распределенное хранилище данных в качестве службы, вам может потребоваться только настроить некоторые политики идентификации и доступа, аудит и безопасность приложений. Однако, если вы создадите и развернете все это, вам нужно будет справиться со всем, включая безопасность инфраструктуры, сетевую безопасность, шифрование в состоянии покоя / при передаче, управление ключами, исправление и т..jpg) Д. Проверьте «модель совместной ответственности» для вашего хранилища данных, чтобы понять это из.
Д. Проверьте «модель совместной ответственности» для вашего хранилища данных, чтобы понять это из.
Соответствие
Соответствие может быть важным отличием. Многие приложения должны соответствовать законам и постановлениям, касающимся обработки данных. Если вам необходимо соблюдать политики безопасности, такие как FEDRAMP, PCI-DSS, HIPAA или любые другие, ваше распределенное хранилище данных также должно соответствовать.
Кроме того, если вы дали обещания клиентам относительно хранения данных, их резидентности или изоляции данных, вам может потребоваться распределенное хранилище данных со встроенными для этого функциями.
Цена
Стоимость разных хранилищ данных разная. Некоторые хранилища данных взимают плату исключительно в зависимости от объема хранилища, в то время как другие учитывают серверы и лицензионные сборы. В документации обычно есть калькулятор цен, который можно использовать для оценки счета. Обратите внимание: хотя на первый взгляд может показаться, что некоторые хранилища данных стоят дороже, они вполне могут компенсировать это экономией времени на проектирование и эксплуатацию.
Takeaway
Распределенные хранилища данных уникальны. Мы можем понять и сравнить их различные функции с помощью документации, блогов, тестов, калькуляторов цен или поговорив с профессиональной службой поддержки и создав прототипы.
Теперь мы знаем тонну о распределенных хранилищах данных абстрактно. Давайте свяжем это вместе и посмотрим на настоящие инструменты!
Вариантов на первый взгляд бесконечное, а лучшего, к сожалению, нет. Каждое распределенное хранилище данных предназначено для разных целей и должно соответствовать вашему конкретному варианту использования. Чтобы понять различные типы, ознакомьтесь со следующей таблицей. Не торопитесь и сосредоточьтесь на общих типах и вариантах использования.
Архитектура II: Распределенные хранилища данных
Это вопрос, который нами движет, Neo
Почему у AWS так много вариантов хранения данных? Какой мне подходит? Это часто задаваемые вопросы клиентов. В этой серии блогов, состоящей из трех частей, я попытаюсь внести некоторую ясность. В первой части я обсудил основы высокой доступности и то, как избыточность является распространенным способом ее достижения. Я также вкратце упомянул, что обеспечение избыточности на уровне данных создает новые проблемы. В этой второй части серии блогов я обсуждаю некоторые из тех проблем и общих компромиссов, которые вам необходимо учитывать при их преодолении. Третья часть этой серии блогов будет опираться на эту информацию и обсуждать конкретные варианты хранения данных AWS и для каких рабочих нагрузок оптимизирован каждый вариант хранения.Прочитав все три части этой серии блогов, вы сможете оценить богатство предложений по хранению данных AWS и научитесь выбирать правильный вариант для правильной рабочей нагрузки.
В этой серии блогов, состоящей из трех частей, я попытаюсь внести некоторую ясность. В первой части я обсудил основы высокой доступности и то, как избыточность является распространенным способом ее достижения. Я также вкратце упомянул, что обеспечение избыточности на уровне данных создает новые проблемы. В этой второй части серии блогов я обсуждаю некоторые из тех проблем и общих компромиссов, которые вам необходимо учитывать при их преодолении. Третья часть этой серии блогов будет опираться на эту информацию и обсуждать конкретные варианты хранения данных AWS и для каких рабочих нагрузок оптимизирован каждый вариант хранения.Прочитав все три части этой серии блогов, вы сможете оценить богатство предложений по хранению данных AWS и научитесь выбирать правильный вариант для правильной рабочей нагрузки.
Что вообще не так с реляционными базами данных?
Как многие из вас, вероятно, знают, технология реляционных баз данных (RDB) существует с 1970-х годов и была де-факто стандартом структурированного хранилища до конца 1990-х годов. RDB проделали отличную работу по поддержке транзакционных рабочих нагрузок с высокой согласованностью на протяжении многих десятилетий и по-прежнему остаются сильными.Со временем эта известная технология приобрела новые возможности в ответ на запросы клиентов, такие как хранилище больших двоичных объектов, хранилище XML / документов, полнотекстовый поиск, выполнение кода в базе данных, хранилище данных с его звездообразной схемой и геопространственные расширения. Пока все можно было сжать в определении реляционной схемы и поместилось в одном блоке, это можно было сделать в реляционной базе данных.
RDB проделали отличную работу по поддержке транзакционных рабочих нагрузок с высокой согласованностью на протяжении многих десятилетий и по-прежнему остаются сильными.Со временем эта известная технология приобрела новые возможности в ответ на запросы клиентов, такие как хранилище больших двоичных объектов, хранилище XML / документов, полнотекстовый поиск, выполнение кода в базе данных, хранилище данных с его звездообразной схемой и геопространственные расширения. Пока все можно было сжать в определении реляционной схемы и поместилось в одном блоке, это можно было сделать в реляционной базе данных.
Затем произошла коммерциализация Интернета, которая радикально изменила ситуацию, сделав реляционные базы данных недостаточными для всех потребностей хранения.Доступность, производительность и масштаб становились не менее важными, а иногда и более важными, чем согласованность.
Производительность всегда была важна, но с появлением коммерциализации Интернета изменился масштаб. Оказывается, для достижения масштабной производительности требуются другие методы и технологии, чем то, что было приемлемо в доинтернетовскую эпоху. Реляционные базы данных были построены на основе понятия ACID (атомарность, согласованность, изоляция, долговечность), и самый простой способ достичь ACID — это хранить все в одном устройстве.Следовательно, традиционный подход RDB к масштабированию заключался в увеличении масштаба, или, говоря простым языком, для получения большей коробки.
Оказывается, для достижения масштабной производительности требуются другие методы и технологии, чем то, что было приемлемо в доинтернетовскую эпоху. Реляционные базы данных были построены на основе понятия ACID (атомарность, согласованность, изоляция, долговечность), и самый простой способ достичь ACID — это хранить все в одном устройстве.Следовательно, традиционный подход RDB к масштабированию заключался в увеличении масштаба, или, говоря простым языком, для получения большей коробки.
Ой-ой, я думаю, мне нужна коробка побольше
Решение просто получить коробку побольше было подходящим, пока Интернет не принес нагрузку, с которой не справилась бы даже одна коробка. Это заставило инженеров изобретать хитроумные методы преодоления ограничений, присущих одной коробке. Существует множество различных подходов, каждый со своими плюсами и минусами: мастер-реплика, кластеризация, объединение таблиц и секционирование, а также сегментирование (что, возможно, является частным случаем разделения).
Еще одним фактором, способствовавшим распространению вариантов хранения данных, была доступность. Пользователи систем, предшествующих Интернету, обычно находились внутри организации, что позволяло планировать простои в нерабочее время, и даже незапланированные отключения имели ограниченный радиус действия. Коммерческий Интернет тоже изменил это: теперь каждый, у кого есть доступ к Интернету, стал потенциальным пользователем, поэтому незапланированные простои потенциально имели большой радиус действия, а глобальный характер Интернета затруднял определение нерабочих часов и запланированных простоев.
В первой части этой серии блогов я обсуждал роль избыточности в достижении высокой доступности. Однако применительно к уровню хранения данных избыточность создает новый набор интересных проблем. Наиболее распространенный способ применения избыточности на уровне базы данных — это конфигурация «главный / реплика».
Эта, казалось бы, простая установка имеет одно огромное отличие от традиционной реляционной базы данных с одним блоком: теперь у нас есть несколько блоков, разделенных сетью. Когда происходит запись в базу данных, нам теперь нужно решить, когда считать ее завершенной: как только она сохраняется на главном сервере или только после того, как она сохраняется в реплике (или даже n репликах, если мы хотим более высокую доступность — проверьте первую часть этой серии блогов, чтобы увидеть, как добавление еще одного блока повлияет на общую доступность). Если мы решим, что достаточно сохранить его на главном сервере, мы рискуем потерять данные, если мастер выйдет из строя до репликации данных. Если мы решим подождать, пока данные будут реплицированы, мы понесем штраф за задержку.В редких случаях, когда реплика может не работать, нам нужно определить, принять ли запись в любом случае или отклонить.
Когда происходит запись в базу данных, нам теперь нужно решить, когда считать ее завершенной: как только она сохраняется на главном сервере или только после того, как она сохраняется в реплике (или даже n репликах, если мы хотим более высокую доступность — проверьте первую часть этой серии блогов, чтобы увидеть, как добавление еще одного блока повлияет на общую доступность). Если мы решим, что достаточно сохранить его на главном сервере, мы рискуем потерять данные, если мастер выйдет из строя до репликации данных. Если мы решим подождать, пока данные будут реплицированы, мы понесем штраф за задержку.В редких случаях, когда реплика может не работать, нам нужно определить, принять ли запись в любом случае или отклонить.
Таким образом, из мира согласованности по умолчанию мы вошли в мир, где согласованность является выбором. В этом мире мы могли бы выбрать так называемую конечную согласованность, когда состояние реплицируется на нескольких узлах, но не каждый узел имеет полное представление обо всем состоянии.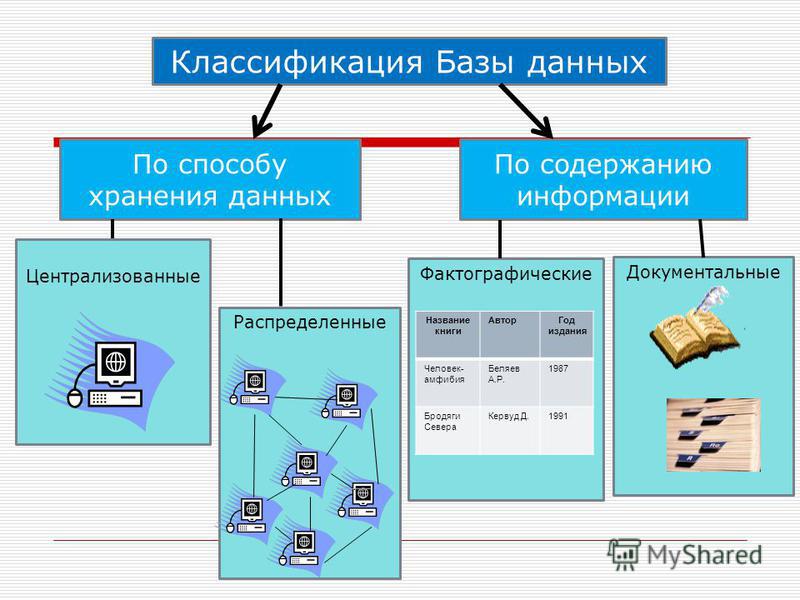 В нашем примере конфигурации выше, если мы решили считать запись завершенной, как только она попадает на мастер (или мастер и любую одну реплику, но не обязательно и то, и другое), то мы выбираем конечную согласованность.Это неизбежно, потому что каждая запись в конечном итоге будет реплицирована на каждую реплику. Но в любой момент времени, если мы запрашиваем одну из реплик, у нас нет гарантии, что она содержит все записи, сделанные до этого момента.
В нашем примере конфигурации выше, если мы решили считать запись завершенной, как только она попадает на мастер (или мастер и любую одну реплику, но не обязательно и то, и другое), то мы выбираем конечную согласованность.Это неизбежно, потому что каждая запись в конечном итоге будет реплицирована на каждую реплику. Но в любой момент времени, если мы запрашиваем одну из реплик, у нас нет гарантии, что она содержит все записи, сделанные до этого момента.
Давайте примерим эту новую насадку
Напомним, когда хранилище данных реплицируется (также называется секционированным), состояние системы распределяется. Это означает, что мы покидаем комфортную провинцию ACID и вступаем в дивный новый мир CAP.Гипотеза CAP была представлена доктором Эриком Брюером из Калифорнийского университета в Беркли в 2000 году. В своей простейшей форме она выглядит следующим образом: распределенная система должна искать компромисс между согласованностью, доступностью и допуском к разделению, и она может достичь только двух результатов..png) из трех.
из трех.
CAP Conjecture расширил дискуссию о хранении данных за пределы ACID и вдохновил на создание многих технологий нереляционных баз данных. Через десять лет после того, как он представил свою гипотезу CAP, д-р.Брюэр выпустил пояснение, в котором говорилось, что его первоначальная концепция «выберите два из трех» была значительно упрощена, чтобы открыть дискуссию и помочь вывести ее за рамки ACID. Однако это большое упрощение привело к многочисленным неверным истолкованиям и недоразумениям. В более тонкой интерпретации CAP все три измерения считаются диапазонами, а не логическими значениями. Также понятно, что распределенные системы большую часть времени работают в несекционированном режиме, и в этом случае им необходимо найти компромисс между согласованностью и производительностью / задержкой.В редких случаях, когда разделение действительно происходит, системе приходится выбирать между согласованностью и доступностью.
Вернемся к нашему примеру с мастером / репликой: если мы решим считать запись завершенной только тогда, когда данные реплицируются повсюду (также известная как синхронная репликация), мы будем отдавать предпочтение согласованности за счет задержки записи.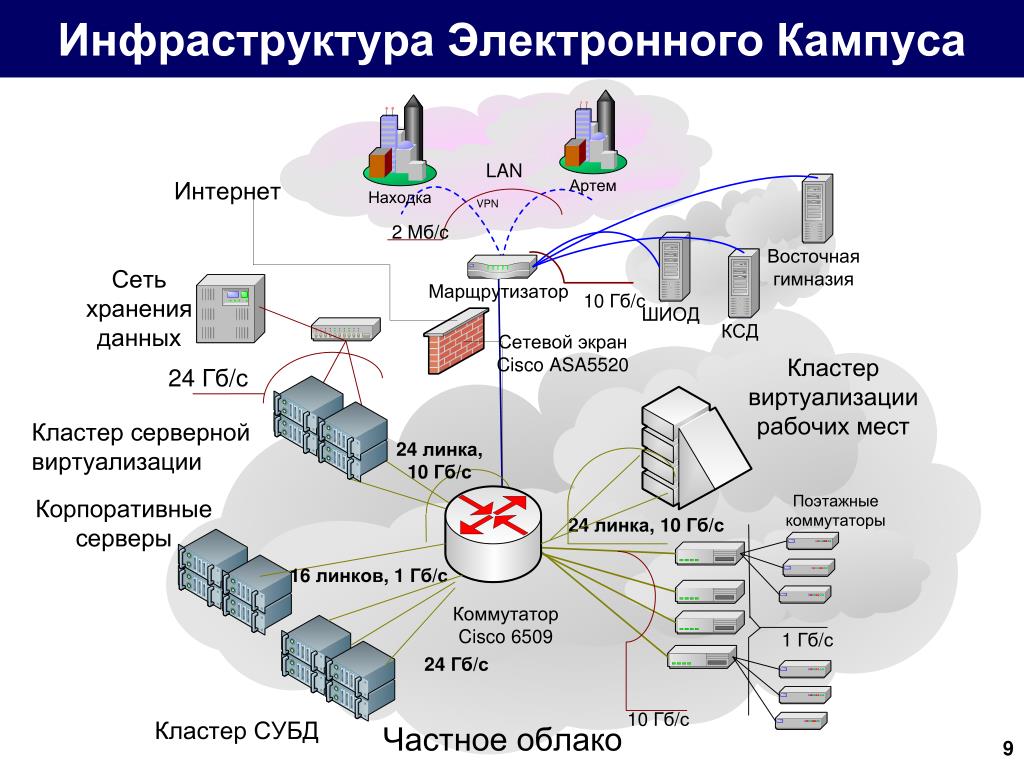 С другой стороны, если мы решим считать запись завершенной, как только она сохраняется на главном сервере, и позволить репликации происходить в фоновом режиме (также известном как асинхронная репликация), мы будем отдавать предпочтение производительности, а не согласованности.
С другой стороны, если мы решим считать запись завершенной, как только она сохраняется на главном сервере, и позволить репликации происходить в фоновом режиме (также известном как асинхронная репликация), мы будем отдавать предпочтение производительности, а не согласованности.
Когда происходит разделение сети, распределенные системы переходят в специальный режим разделения, в котором они достигают компромисса между согласованностью и доступностью. Вернемся к нашему примеру: реплики могут продолжать обслуживать запросы даже после потери связи с мастером, предпочитая доступность, а не согласованность. Или мы можем выбрать, что мастер должен прекратить принимать записи, если он теряет связь с репликами, тем самым предпочитая согласованность доступности. В эпоху коммерческого Интернета выбор последовательности обычно означает потерю доходов, поэтому многие системы выбирают доступность.В этом случае, когда система возвращается в свое нормальное состояние, она может войти в режим восстановления, в котором все накопленные несоответствия будут устранены и воспроизведены.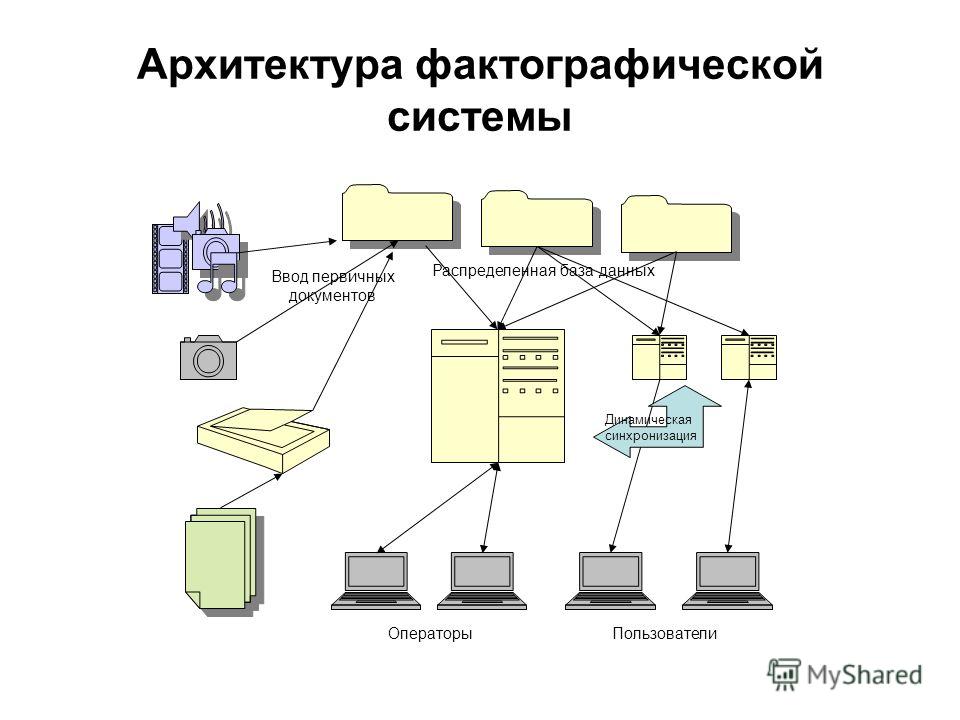
Раз уж мы говорим о режиме восстановления, стоит упомянуть тип конфигурации распределенного хранилища данных, называемый master-master (или active-active). В этой настройке записи могут выполняться в нескольких режимах, а затем взаимно реплицироваться. С такой системой усложняется даже обычный режим, потому что если два обновления одного и того же фрагмента данных происходят примерно в одно и то же время на двух разных главных узлах, как вы их согласовываете? И если такой системе придется восстанавливаться из разделенного состояния, дела обстоят еще хуже.Хотя можно иметь работающую конфигурацию мастер-мастер и есть некоторые продукты, которые упрощают эту задачу, я советую избегать этого, если только в этом нет крайней необходимости. Есть много способов достичь хорошего баланса производительности и доступности, которые не требуют высокой стоимости мастер-мастер.
Общие шаблоны многих современных хранилищ данных
Один из распространенных подходов, обеспечивающих хорошее сочетание производительности / масштабируемости и доступности, — это объединение секционирования и репликации в конфигурацию (или, скорее, в шаблон).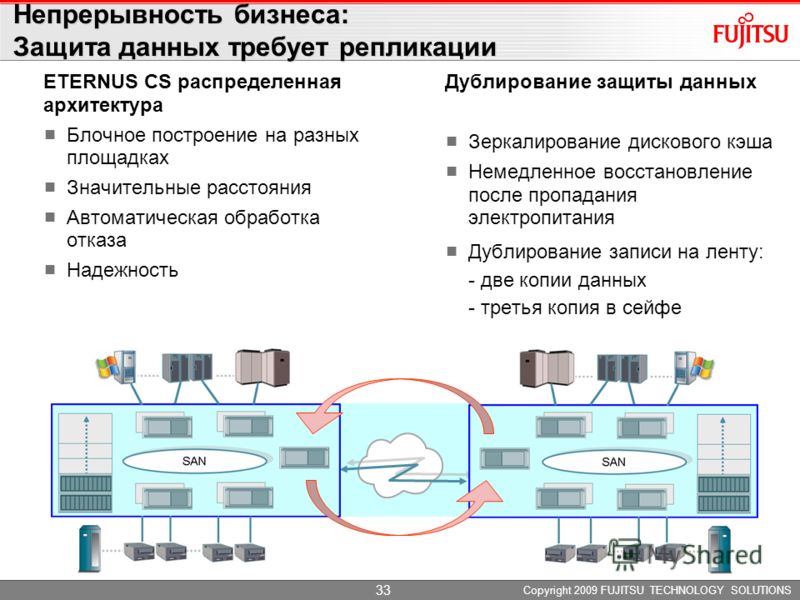 Иногда это называют набором многораздельных реплик.
Иногда это называют набором многораздельных реплик.
Будь то Hadoop или кластер MongoDB, они по существу соответствуют этому шаблону, как и многие сервисы хранения данных AWS. Cassandra, основанная на принципах, изложенных в знаменитом техническом документе Amazon Dynamo, делает еще один шаг вперед, где каждый узел в кластере может быть диспетчером, а каждый узел в наборе реплик может быть мастером для конкретной записи. Это устраняет потенциальные точки сбоев на уровне диспетчера и мастера, делая общую архитектуру еще более устойчивой.Давайте рассмотрим некоторые общие характеристики секционированного набора реплик:
- Данные разделены (т. Е. Разбиты) по нескольким узлам (или, скорее, кластерам узлов). Ни один раздел не содержит всех данных. Запись должна идти только в один раздел. Множественные записи потенциально могут идти в несколько разделов и, следовательно, должны быть независимыми друг от друга. Сложные транзакционные записи с несколькими записями (и, следовательно, потенциально с несколькими разделами) не приветствуются, поскольку они могут связать всю систему.
- Максимальный объем данных, который может обработать один раздел, может стать потенциальным узким местом. Если раздел достигает предела пропускной способности, добавление дополнительных разделов и разделение трафика между ними помогает решить проблему. Таким образом, вы можете масштабировать этот тип системы, добавляя больше разделов.
- Ключ раздела используется для распределения данных по разделам. Вам необходимо тщательно выбирать ключ раздела, чтобы операции чтения и записи были как можно более равномерно «распределены» по всем разделам.Если операции чтения / записи кластеризованы, они могут превысить пропускную способность определенного раздела и повлиять на производительность всей системы, в то время как другие разделы будут использоваться недостаточно. Это известно как проблема «горячего раздела».
- Данные реплицируются на нескольких хостах. Это могут быть полностью отдельные наборы реплик для каждого раздела или наложение нескольких наборов реплик поверх одной и той же группы хостов. Количество репликаций фрагмента данных часто называют фактором репликации.
- Эта конфигурация имеет встроенную функцию высокой доступности: данные реплицируются на несколько хостов. Теоретически отказ нескольких хостов, меньший, чем коэффициент репликации, не повлияет на доступность всей системы.

 Количество репликаций фрагмента данных часто называют фактором репликации.
Количество репликаций фрагмента данных часто называют фактором репликации.Все это совершенство, с его встроенной масштабируемостью и высокой доступностью, имеет свою цену: это уже не ваш Swiss Army Knife, единая система управления реляционными базами данных (RDBMS). Это сложная система с множеством движущихся частей, требующих управления, и параметров, требующих точной настройки.Для установки, настройки и обслуживания этих систем требуется специальный опыт. Кроме того, необходима инфраструктура мониторинга и оповещения, чтобы они не спали. Вы, конечно, можете сделать это самостоятельно, но это будет непросто, и вы можете не сделать это правильно ни в первый раз, ни во второй.
Чтобы помочь нашим клиентам получить доступ к масштабируемым и доступным хранилищам данных без дополнительных затрат на управление, AWS предлагает различные услуги по управлению данными / хранилищами. Поскольку существует множество различных измерений для оптимизации, не существует единого волшебного хранилища данных, а есть набор служб, каждая из которых оптимизирована для определенного типа рабочей нагрузки.В следующей статье блога я рассмотрю варианты хранилищ данных, предлагаемые AWS, и расскажу, для чего каждый из них оптимизирован (а не оптимизирован).
Поскольку существует множество различных измерений для оптимизации, не существует единого волшебного хранилища данных, а есть набор служб, каждая из которых оптимизирована для определенного типа рабочей нагрузки.В следующей статье блога я рассмотрю варианты хранилищ данных, предлагаемые AWS, и расскажу, для чего каждый из них оптимизирован (а не оптимизирован).
Такое разрастание хранилищ данных, хотя и вызывает некоторые головные боли, связанные с выбором, — действительно хорошая вещь. Нам просто нужно выйти за рамки нашего традиционного представления о хранилище данных для всей нашей системы и принять образ мышления, предполагающий использование множества различных хранилищ данных в системе, каждое из которых обслуживает рабочую нагрузку, для которой оно лучше всего подходит.Например, мы могли бы использовать следующую комбинацию:
- Высокопроизводительная очередь приема для входящего потока обращений
- Система на основе Hadoop для обработки потока обращений
- Облачное объектное хранилище для недорогого долгосрочного хранения сжатых ежедневных дайджестов потока
- Реляционная база данных для метаданных, которую мы могли бы использовать для обогащения данных о посещениях.
- Кластер хранилищ данных для аналитики
- Поисковый кластер для произвольного поиска

Все вышеперечисленное может быть частью единой подсистемы, названной что-то вроде платформы аналитики веб-сайта.
Сводка
а. Коммерческий Интернет принес с собой требования к масштабируемости и доступности, которые больше не могли быть удовлетворены с помощью швейцарского армейского ножа РСУБД.
г. Добавление горизонтального масштабирования и избыточности к хранилищу данных увеличивает сложность, усложняет ACID, заставляет рассматривать компромиссы CAP и создает много интересных возможностей для оптимизации и специализации.
г. Используйте несколько хранилищ данных в вашей системе, каждое из которых обслуживает ту рабочую нагрузку, для которой оно наиболее подходит.
г. Современные хранилища данных представляют собой сложные системы, требующие специальных знаний и накладных расходов на управление. С AWS вы можете получить преимущества специализированного хранилища данных без этих накладных расходов.
Современные хранилища данных представляют собой сложные системы, требующие специальных знаний и накладных расходов на управление. С AWS вы можете получить преимущества специализированного хранилища данных без этих накладных расходов.
— обзор
3.3 Хранение данных
Большие данные предъявляют строгие требования к хранению и управлению.Традиционно инфраструктура хранения данных используется для хранения, управления, поиска и анализа данных с помощью структурированных СУБД. В настоящее время данные уже рассматриваются как новый вид активов, поэтому устройства хранения данных становятся все более важными. Хранение больших данных — это хранение и управление массивными наборами данных для обеспечения надежности и доступности доступа к данным. В этой части мы обсудим важные вопросы, включая массивные системы хранения, распределенные системы хранения и механизмы хранения больших данных.С одной стороны, ожидается, что системы хранения будут предоставлять услуги хранения информации с надежной емкостью хранения, а с другой стороны, такие системы должны обеспечивать мощный интерфейс доступа для запроса и анализа большого объема данных.
Многие системы хранения созданы для удовлетворения потребностей в больших объемах данных. Существующие технологии массового хранения можно классифицировать как хранилище с прямым подключением (DAS) и сетевое хранилище, а сетевое хранилище можно дополнительно разделить на сетевое хранилище (NAS) и сеть хранения данных (SAN).DAS состоит из различных жестких дисков, которые напрямую связаны с серверами. Однако DAS полезен только при небольшом масштабе серверов, поскольку каждое устройство использует определенный объем ресурсов ввода-вывода и управляется отдельным прикладным программным обеспечением. Поэтому DAS в основном используется на персональных компьютерах и малогабаритных серверах. Напротив, NAS — это вспомогательное запоминающее устройство в сети. В NAS данные передаются в виде файлов через концентратор или коммутатор в сети. В то время как NAS ориентирован на сеть, SAN специально разработан для хранения данных в масштабируемой сети с интенсивным использованием полосы пропускания.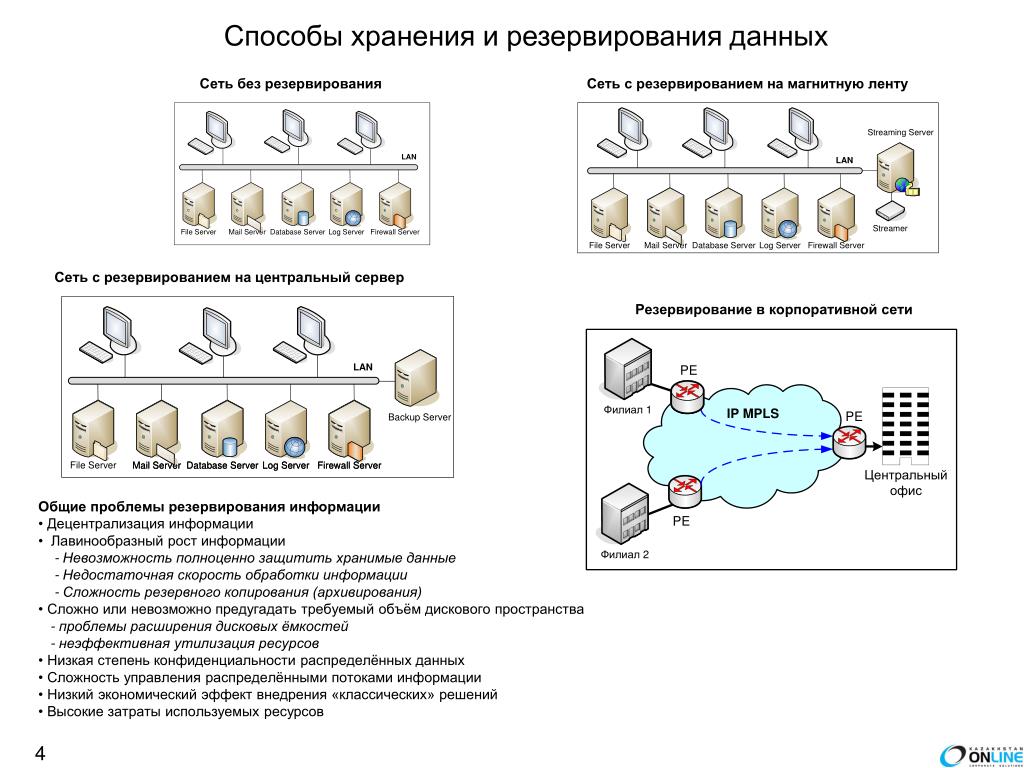
В целом систему хранения данных можно разделить на три части: дисковый массив, подсистемы подключения и сети, а также программное обеспечение для управления хранением. Дисковый массив — это основа системы хранения и фундаментальная гарантия хранения данных. Подсистемы связи и сети обеспечивают связь между одним или несколькими дисковыми массивами и серверами. Программное обеспечение для управления хранением данных выполняет совместное использование данных, аварийное восстановление и другие задачи управления хранением данных на нескольких серверах.
Разработка крупномасштабной распределенной системы хранения для больших данных также является сложной задачей.Чтобы использовать распределенную систему для хранения больших объемов данных, необходимо учитывать следующие факторы:
Согласованность : распределенная система хранения требует нескольких серверов для совместного хранения данных. Поскольку серверов много, вероятность сбоев серверов возрастет. Чтобы справиться со сбоями, данные обычно делятся на несколько частей, которые сохраняются на разных серверах для обеспечения доступности. Однако сбои сервера в параллельном хранилище могут вызвать несогласованность между разными копиями одних и тех же данных.В заключение, согласованность означает, что несколько копий одних и тех же данных должны быть идентичными.
Чтобы справиться со сбоями, данные обычно делятся на несколько частей, которые сохраняются на разных серверах для обеспечения доступности. Однако сбои сервера в параллельном хранилище могут вызвать несогласованность между разными копиями одних и тех же данных.В заключение, согласованность означает, что несколько копий одних и тех же данных должны быть идентичными.
Доступность : поскольку в распределенных системах хранения используются мультисерверы, отказы серверов неизбежны. Доступность означает, что вся система не подвергается серьезному воздействию с точки зрения чтения и записи.
Допуск разделения : как упоминалось выше, существует сеть, которая соединяет несколько серверов в распределенной системе хранения. Кроме того, иногда могут происходить сбои сетевого канала / узла, что приводит к разделению.Распределенная система хранения является толерантной к разделам, если она все еще работает, когда сеть разделена.
Говоря о распределенных системах хранения, нельзя игнорировать теорию CAP.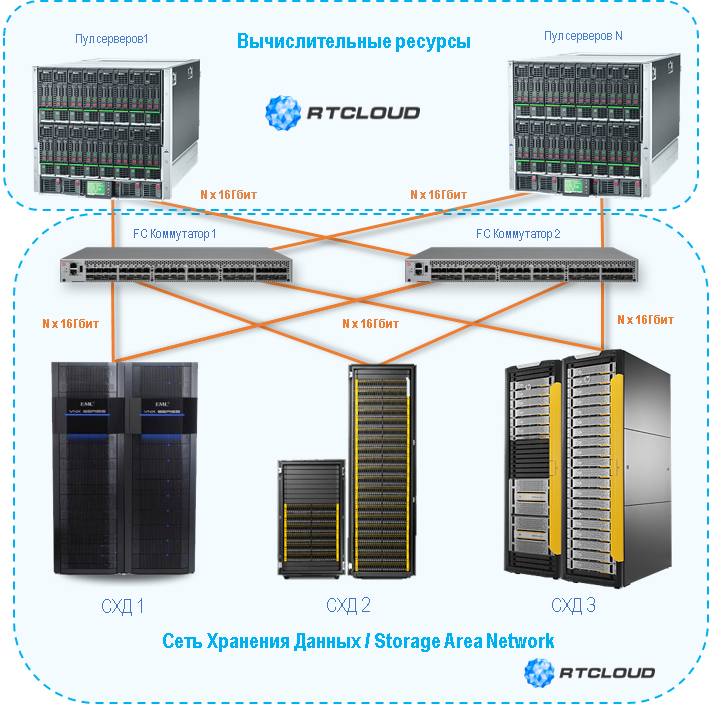 Теория, подтвержденная в 2002 году, показала, что распределенная система не может одновременно удовлетворять требованиям согласованности, доступности и устойчивости к разделению, что означает, что одновременно могут быть удовлетворены не более двух из них. Теперь, когда согласованность, доступность и устойчивость к разделению не могут быть достигнуты одновременно, мы можем игнорировать одно из трех требований в соответствии с различными целями и условиями проектирования.Это означает, что у нас могут быть системы CA, системы CP и системы AP. Системы CA не поддерживают разделение на разделы и не могут работать при сбоях сети. Поэтому использование систем CA на одном сервере — хороший выбор. Например, некоторые традиционные маломасштабные реляционные базы данных могут поддерживаться системами CA, где согласованность и доступность гарантированы. Однако системы CA не могут быть расширены для использования мультисерверов. Чтобы обеспечить крупномасштабное хранилище, необходимо соблюдать допуск на разделы.
Теория, подтвержденная в 2002 году, показала, что распределенная система не может одновременно удовлетворять требованиям согласованности, доступности и устойчивости к разделению, что означает, что одновременно могут быть удовлетворены не более двух из них. Теперь, когда согласованность, доступность и устойчивость к разделению не могут быть достигнуты одновременно, мы можем игнорировать одно из трех требований в соответствии с различными целями и условиями проектирования.Это означает, что у нас могут быть системы CA, системы CP и системы AP. Системы CA не поддерживают разделение на разделы и не могут работать при сбоях сети. Поэтому использование систем CA на одном сервере — хороший выбор. Например, некоторые традиционные маломасштабные реляционные базы данных могут поддерживаться системами CA, где согласованность и доступность гарантированы. Однако системы CA не могут быть расширены для использования мультисерверов. Чтобы обеспечить крупномасштабное хранилище, необходимо соблюдать допуск на разделы.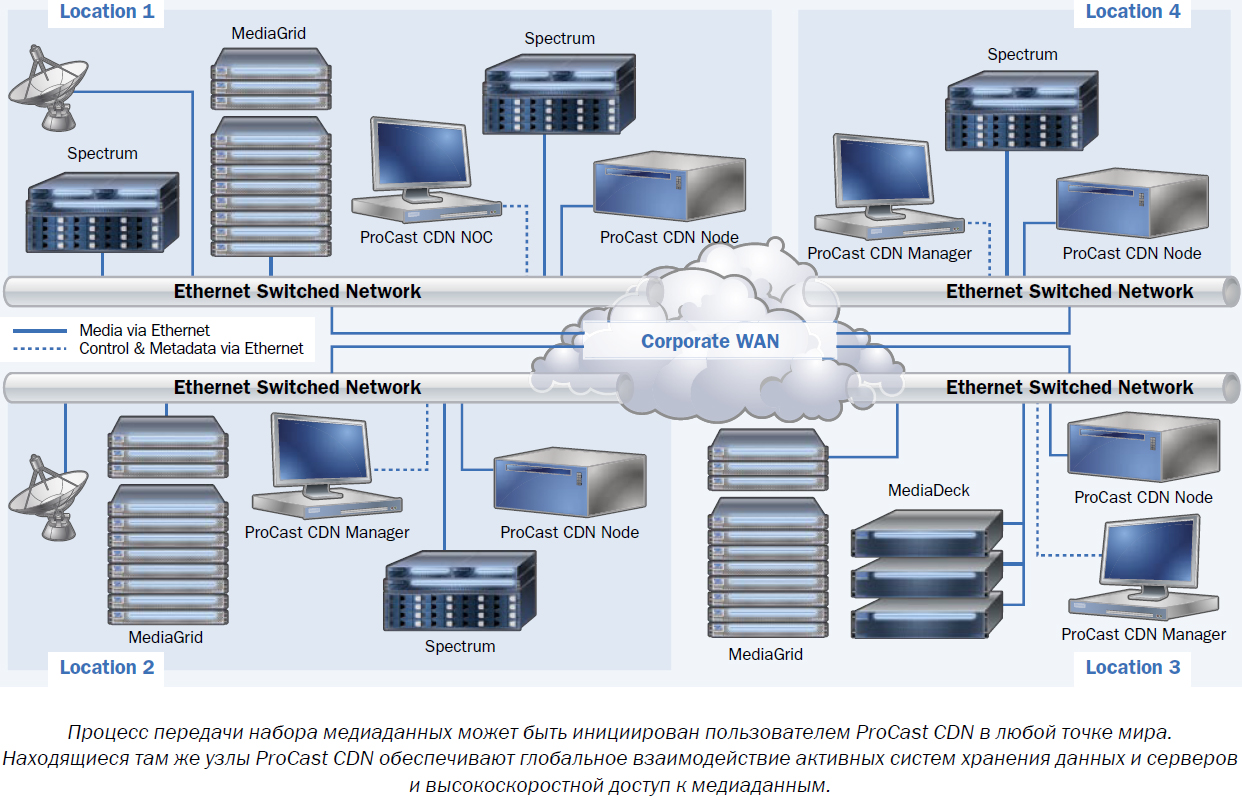 По сравнению с системами CA, системы CP обеспечивают устойчивость к перегородкам.В целом системы CP полезны для сценариев с умеренной нагрузкой, но предъявляют строгие требования к точности данных. BigTable и Hbase — это два экземпляра систем CP. Кроме того, системы AP обеспечивают устойчивость к разделам. Однако системы AP гарантируют только конечную согласованность, а не сильную согласованность. Поэтому системы AP в основном применяются в сценариях с частыми запросами, но низкими требованиями к точности. Такие сценарии можно найти в системах онлайн-сервисов социальных сетей (SNS), где существует много одновременных запросов к данным, но допустимо определенное количество ошибок данных.
По сравнению с системами CA, системы CP обеспечивают устойчивость к перегородкам.В целом системы CP полезны для сценариев с умеренной нагрузкой, но предъявляют строгие требования к точности данных. BigTable и Hbase — это два экземпляра систем CP. Кроме того, системы AP обеспечивают устойчивость к разделам. Однако системы AP гарантируют только конечную согласованность, а не сильную согласованность. Поэтому системы AP в основном применяются в сценариях с частыми запросами, но низкими требованиями к точности. Такие сценарии можно найти в системах онлайн-сервисов социальных сетей (SNS), где существует много одновременных запросов к данным, но допустимо определенное количество ошибок данных.
Что касается механизмов хранения, существующие механизмы можно разделить на три восходящих уровня: файловые системы, системы баз данных и модели программирования. Файловые системы являются основой приложений на верхних уровнях. Среди существующих файловых систем GFS — одна из самых успешных, она производится Google. GFS — это расширяемая распределенная файловая система, разработанная для крупномасштабных, распределенных приложений с большим объемом данных. Он состоит из дешевых стандартных серверов для обеспечения отказоустойчивости и предоставляет высокопроизводительные услуги.Кроме того, GFS выполняет более частое чтение, чем запись в крупномасштабных файловых приложениях. Однако единственная точка отказа и низкая производительность для небольших файлов — основные ограничения GFS. Появились и другие файловые системы, удовлетворяющие другим ограничениям. Например, HDFS и Kosmosfs — две файловые системы, разработанные на основе открытых исходных кодов GFS. У Microsoft есть свой Cosmos для поддержки своего поискового и рекламного бизнеса. Alibaba разработала TFS и FastDFS для торговых систем, а у Facebook есть Haystack, который хорошо справляется с хранением большого количества изображений небольшого размера.Таким образом, после многих лет исследований распределенные файловые системы стали зрелой областью.
GFS — это расширяемая распределенная файловая система, разработанная для крупномасштабных, распределенных приложений с большим объемом данных. Он состоит из дешевых стандартных серверов для обеспечения отказоустойчивости и предоставляет высокопроизводительные услуги.Кроме того, GFS выполняет более частое чтение, чем запись в крупномасштабных файловых приложениях. Однако единственная точка отказа и низкая производительность для небольших файлов — основные ограничения GFS. Появились и другие файловые системы, удовлетворяющие другим ограничениям. Например, HDFS и Kosmosfs — две файловые системы, разработанные на основе открытых исходных кодов GFS. У Microsoft есть свой Cosmos для поддержки своего поискового и рекламного бизнеса. Alibaba разработала TFS и FastDFS для торговых систем, а у Facebook есть Haystack, который хорошо справляется с хранением большого количества изображений небольшого размера.Таким образом, после многих лет исследований распределенные файловые системы стали зрелой областью. Итак, продолжим фокусироваться на двух других уровнях.
Итак, продолжим фокусироваться на двух других уровнях.
За последние 30 лет технология баз данных развивалась. Многие системы баз данных разработаны для обработки наборов данных в различных масштабах и поддержки различных приложений. В эпоху больших данных традиционные реляционные базы данных теряют эффективность при обработке массивных наборов данных. Базы данных NoSQL (то есть нетрадиционные реляционные базы данных) становятся все более популярной темой для исследований в области хранения больших данных.Некоторые основные особенности баз данных NoSQL включают гибкие режимы, поддержку простого и легкого копирования, простой API, согласованность в конечном итоге и поддержку больших объемов данных, что делает базы данных NoSQL основной технологией для больших данных. В этом разделе есть три основные базы данных NoSQL: базы данных с ключом, базы данных, ориентированные на столбцы, и базы данных, ориентированные на документы, каждая из которых основана на определенных моделях данных.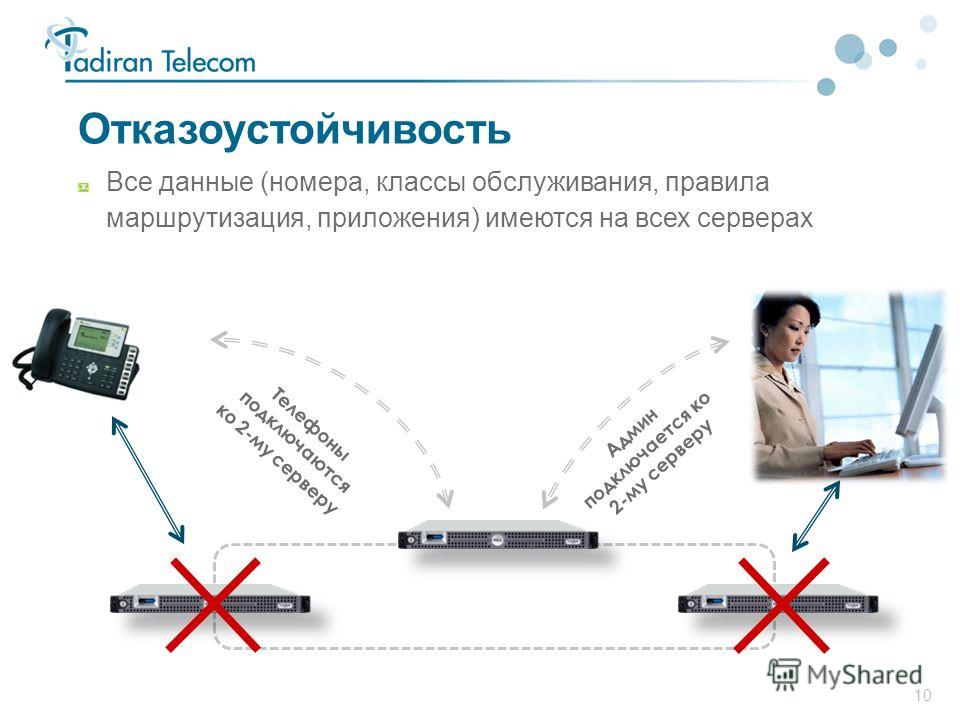
В базах данных типа «ключ-значение» хранятся данные, соответствующие парам «ключ-значение». Каждый ключ в базе данных должен быть уникальным, чтобы запрашиваемые значения могли определяться ключами.Такие базы данных имеют простую структуру и могут работать с высокой расширяемостью и меньшим временем отклика на запросы по сравнению с традиционными базами данных. Некоторые из основных баз данных типа «ключ-значение» включают Dynamo от Amazon, Voldemort Redis, Tokyo Canbinet и Tokyo Tyrant, Memcached и Memcache DB, Riak и Scalaris и т. Д. По сравнению с хранилищем ключ-значение, хранилище документов может поддерживать более сложные формы данных, а не просто учитывая ключи и ценности. Поскольку документы не соответствуют строгим режимам, нет необходимости выполнять миграцию режима.Кроме того, пары ключ-значение по-прежнему можно сохранять. MongoDB, SimpleDB и CouchDB — три представителя документных баз данных. Что касается баз данных, ориентированных на столбцы, они отличаются от традиционных реляционных баз данных, поскольку они хранят и обрабатывают данные в соответствии со столбцами, отличными от строк. И столбцы, и строки в базах данных, ориентированных на столбцы, сегментированы на несколько узлов для обеспечения возможности расширения. Базы данных, ориентированные на столбцы, в основном созданы на основе Google BigTable, которая представляет собой распределенную структурированную систему хранения данных, предназначенную для обработки данных уровня PB на тысячах коммерческих серверов.
И столбцы, и строки в базах данных, ориентированных на столбцы, сегментированы на несколько узлов для обеспечения возможности расширения. Базы данных, ориентированные на столбцы, в основном созданы на основе Google BigTable, которая представляет собой распределенную структурированную систему хранения данных, предназначенную для обработки данных уровня PB на тысячах коммерческих серверов.
Теперь мы продолжаем говорить о моделях программирования. Традиционно у нас есть несколько параллельных моделей, включая MPI и OpenMP, для поддержки параллельных программ. Однако такие модели становятся неадекватными при работе с массивными наборами данных. Недавно были предложены некоторые новые модели параллельного программирования для эффективного повышения производительности NoSQL и уменьшения разрыва в производительности по сравнению с реляционными базами данных. Такие модели стали краеугольным камнем технологии больших данных.
MapReduce — одна из самых популярных моделей программирования в области больших данных..jpg) Это позволяет большому количеству кластеров коммерческих серверов реализовать параллельные вычисления и распределение. В MapReduce есть только две функции, map и reduce, обе из которых должны быть реализованы пользователями. Функция карты отвечает за обработку входных пар ключ-значение и генерацию промежуточных пар ключ-значение. Затем эти промежуточные пары «ключ-значение» объединяются в соответствии с ключами и передаются в функцию уменьшения, которая дополнительно сжимает набор значений в меньший набор.Одним из преимуществ MapReduce является то, что он освобождает программистов от сложных этапов разработки параллельных приложений. Программистам нужно учитывать только две функции. Самая первая структура MapReduce плохо справлялась с несколькими наборами данных в задаче, что было смягчено некоторыми недавними улучшениями. Однако инфраструктура MapReduce поддерживает только непрозрачные функции сопоставления и сокращения, что делает ее неспособной содержать все общие операции. Как следствие, разработчикам приходится тратить дополнительное время на реализацию основных функций, которые обычно трудно поддерживать или повторно использовать.
Это позволяет большому количеству кластеров коммерческих серверов реализовать параллельные вычисления и распределение. В MapReduce есть только две функции, map и reduce, обе из которых должны быть реализованы пользователями. Функция карты отвечает за обработку входных пар ключ-значение и генерацию промежуточных пар ключ-значение. Затем эти промежуточные пары «ключ-значение» объединяются в соответствии с ключами и передаются в функцию уменьшения, которая дополнительно сжимает набор значений в меньший набор.Одним из преимуществ MapReduce является то, что он освобождает программистов от сложных этапов разработки параллельных приложений. Программистам нужно учитывать только две функции. Самая первая структура MapReduce плохо справлялась с несколькими наборами данных в задаче, что было смягчено некоторыми недавними улучшениями. Однако инфраструктура MapReduce поддерживает только непрозрачные функции сопоставления и сокращения, что делает ее неспособной содержать все общие операции. Как следствие, разработчикам приходится тратить дополнительное время на реализацию основных функций, которые обычно трудно поддерживать или повторно использовать. Для повышения эффективности программирования были разработаны некоторые языковые системы, такие как Scope of Microsoft, Pig Latin of Yahoo, Hive of Facebook и Sawzall из Google.
Для повышения эффективности программирования были разработаны некоторые языковые системы, такие как Scope of Microsoft, Pig Latin of Yahoo, Hive of Facebook и Sawzall из Google.
Вдохновленные вышеупомянутыми моделями программирования, другие исследования также были сосредоточены на режимах программирования для более сложных вычислительных задач, таких как итерационные вычисления, вычисления отказоустойчивой памяти, инкрементные вычисления и принятие решений по управлению потоком данных, связанных с данными.
Что такое распределенная база данных? {Особенности, преимущества и недостатки}
Введение
Распределенные базы данных используются для горизонтального масштабирования и предназначены для удовлетворения требований рабочей нагрузки без необходимости вносить изменения в приложение базы данных или вертикальное масштабирование отдельной машины.
Распределенные базы данных решают различные проблемы , такие как доступность, отказоустойчивость, пропускная способность, задержка, масштабируемость и многие другие проблемы, которые могут возникнуть при использовании одного компьютера и одной базы данных.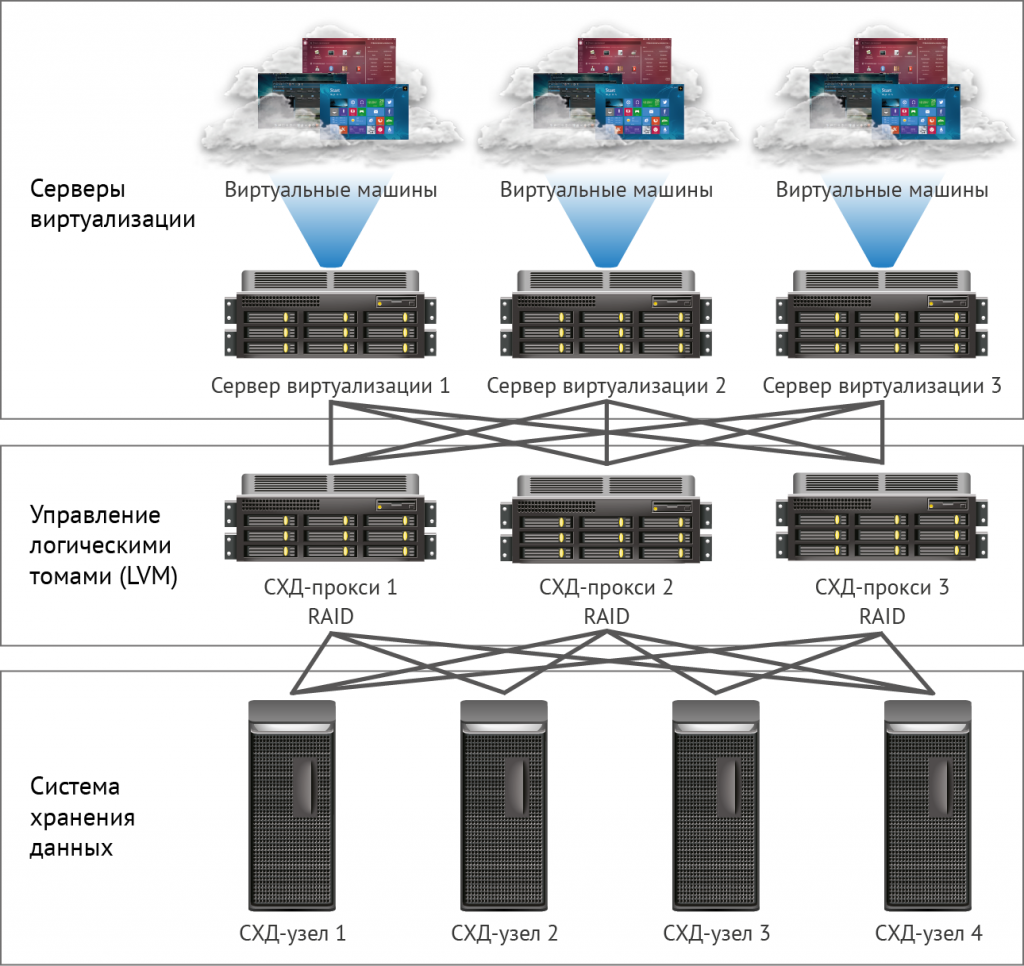
Из этой статьи вы узнаете, что такое распределенные базы данных, а также их преимущества и недостатки.
Определение распределенной базы данных
Распределенная база данных представляет собой несколько взаимосвязанных баз данных, распределенных по нескольким сайтам, связанным сетью.Поскольку все базы данных подключены, они отображаются для пользователей как единая база данных.
Распределенные базы данных используют несколько узлов. Они масштабируются по горизонтали и развивают распределенную систему. Больше узлов в системе обеспечивает большую вычислительную мощность, большую доступность и решает проблему единой точки отказа.
Различные части распределенной базы данных хранятся в нескольких физических местах , а требования к обработке распределяются между процессорами на нескольких узлах базы данных.
Централизованная распределенная система управления базами данных ( DDBMS ) управляет распределенными данными, как если бы они хранились в одном физическом месте. DDBMS синхронизирует все операции с данными между базами данных и гарантирует, что обновления в одной базе данных автоматически отражаются в базах данных на других сайтах.
DDBMS синхронизирует все операции с данными между базами данных и гарантирует, что обновления в одной базе данных автоматически отражаются в базах данных на других сайтах.
Функции распределенной базы данных
Некоторые общие особенности распределенных баз данных:
- Независимость от местоположения — Данные физически хранятся на нескольких сайтах и управляются независимой СУБД.
- Распределенная обработка запросов — Распределенные базы данных отвечают на запросы в распределенной среде, которая управляет данными на нескольких сайтах. Запросы высокого уровня преобразуются в план выполнения запроса для упрощения управления.
- Распределенное управление транзакциями — Обеспечивает согласованную распределенную базу данных с помощью протоколов фиксации, методов распределенного управления параллелизмом и методов распределенного восстановления в случае множества транзакций и сбоев.
- Полная интеграция — Базы данных в коллекции обычно представляют собой единую логическую базу данных, и они взаимосвязаны.
- Связывание с сетью — Все базы данных в коллекции связаны сетью и взаимодействуют друг с другом.
- Обработка транзакций — Распределенные базы данных включают обработку транзакций, которая представляет собой программу, включающую в себя набор одной или нескольких операций с базой данных. Обработка транзакций — это атомарный процесс, который либо выполняется полностью, либо не выполняется вовсе.
Распределенные типы баз данных
Есть два типа распределенных баз данных:
Однородный
Однородная распределенная база данных — это сеть из идентичных баз данных , хранящихся на нескольких сайтах. Сайты имеют одинаковую операционную систему, DDBMS и структуру данных, что делает их легко управляемыми.
Однородные базы данных позволяют пользователям беспрепятственно получать доступ к данным из каждой из баз данных.
На следующей диаграмме показан пример однородной базы данных:
Гетерогенный
Гетерогенная распределенная база данных использует различных схем , операционных систем, DDBMS и различных моделей данных.
В случае гетерогенной распределенной базы данных конкретный сайт может полностью не знать о других сайтах, что приводит к ограниченному сотрудничеству при обработке запросов пользователей. Ограничение состоит в том, почему переводы необходимы для установления связи между сайтами.
На следующей диаграмме показан пример гетерогенной базы данных:
Распределенное хранилище баз данных
Распределенное хранилище базы данных управляется двумя способами:
Реплика
При репликации базы данных системы хранят копий данных на разных сайтах .Если вся база данных доступна на нескольких сайтах, это полностью избыточная база данных.
Преимущество репликации базы данных состоит в том, что увеличивает доступность данных на различных сайтах и позволяет обрабатывать параллельные запросы запросов.
Однако репликация базы данных означает, что данные требуют постоянного обновления и синхронизации с другими сайтами для поддержания точной копии базы данных. Любые изменения, внесенные на одном сайте, должны быть записаны на других сайтах, в противном случае возникнут несоответствия.
Любые изменения, внесенные на одном сайте, должны быть записаны на других сайтах, в противном случае возникнут несоответствия.
Постоянные обновления вызывают большие накладные расходы на сервер и усложняют управление параллелизмом, поскольку необходимо проверять множество параллельных запросов на всех доступных сайтах.
Фрагментация
Когда дело доходит до фрагментации хранилища распределенной базы данных, отношения фрагментированы, что означает, что они разбиты на более мелкие части . Каждый из фрагментов хранится на разных сайтах, где это необходимо.
Предварительное условие для фрагментации — убедиться, что фрагменты могут быть позже реконструированы в исходное отношение без потери данных.
Преимущество фрагментации в том, что нет копий данных , что предотвращает несогласованность данных.
Есть два типа фрагментации:
- Горизонтальная фрагментация — Схема отношения фрагментирована на группы строк, и каждая группа (кортеж) назначается одному фрагменту.
- Вертикальная фрагментация — Схема отношений фрагментирована на более мелкие схемы, и каждый фрагмент содержит общий ключ-кандидат, чтобы гарантировать соединение без потерь.
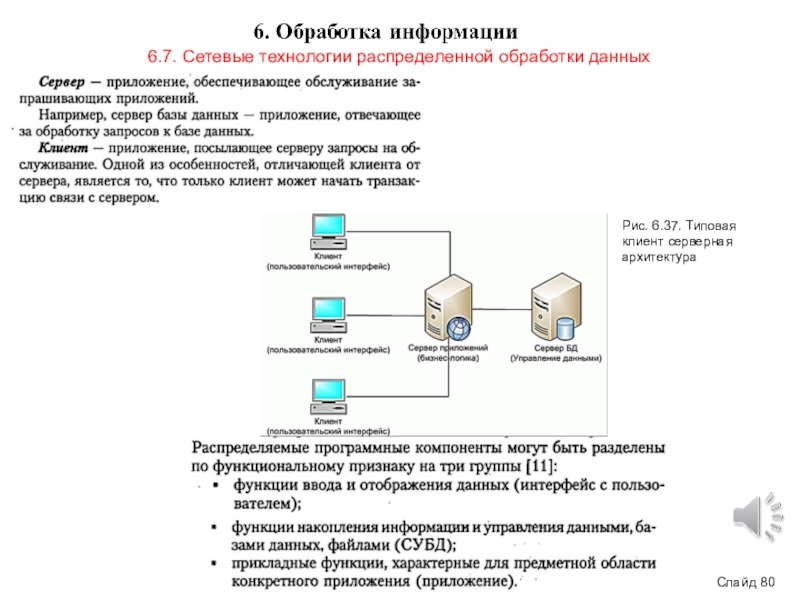
Примечание: В некоторых случаях возможно сочетание фрагментации и репликации.
Преимущества и недостатки распределенной базы данных
Ниже приведены некоторые ключевые преимущества и недостатки распределенных баз данных:
| Преимущества | Недостатки |
|---|---|
| Модульная разработка | Дорогостоящее программное обеспечение |
| Надежность | Большие накладные расходы |
| Более низкие затраты на передачу данных | 907 распределение
Преимущества и недостатки подробно описаны в следующих разделах.
Преимущества
- Модульная разработка . Модульное развитие распределенной базы данных подразумевает, что система может быть расширена до новых местоположений или единиц путем добавления новых серверов и данных к существующей установке и подключения их к распределенной системе без прерывания. Этот тип расширения не вызывает перебоев в работе распределенных баз данных.
 Этот тип расширения не вызывает перебоев в работе распределенных баз данных.
Этот тип расширения не вызывает перебоев в работе распределенных баз данных.- Надежность . Распределенные базы данных предлагают большую надежность по сравнению с централизованными базами данных.В случае отказа базы данных в централизованной базе данных система полностью останавливается. В распределенной базе данных система функционирует даже при возникновении сбоев, обеспечивая только снижение производительности до тех пор, пока проблема не будет решена.
- Снижение затрат на связь . Локальное хранение данных снижает затраты на обмен данными в распределенных базах данных. Локальное хранение данных невозможно в централизованных базах данных.
- Лучшее реагирование .Эффективное распределение данных в системе распределенных баз данных обеспечивает более быстрый ответ, когда запросы пользователей выполняются локально. В централизованных базах данных запросы пользователей проходят через центральный компьютер, который обрабатывает все запросы. В результате увеличивается время ответа, особенно при большом количестве запросов.
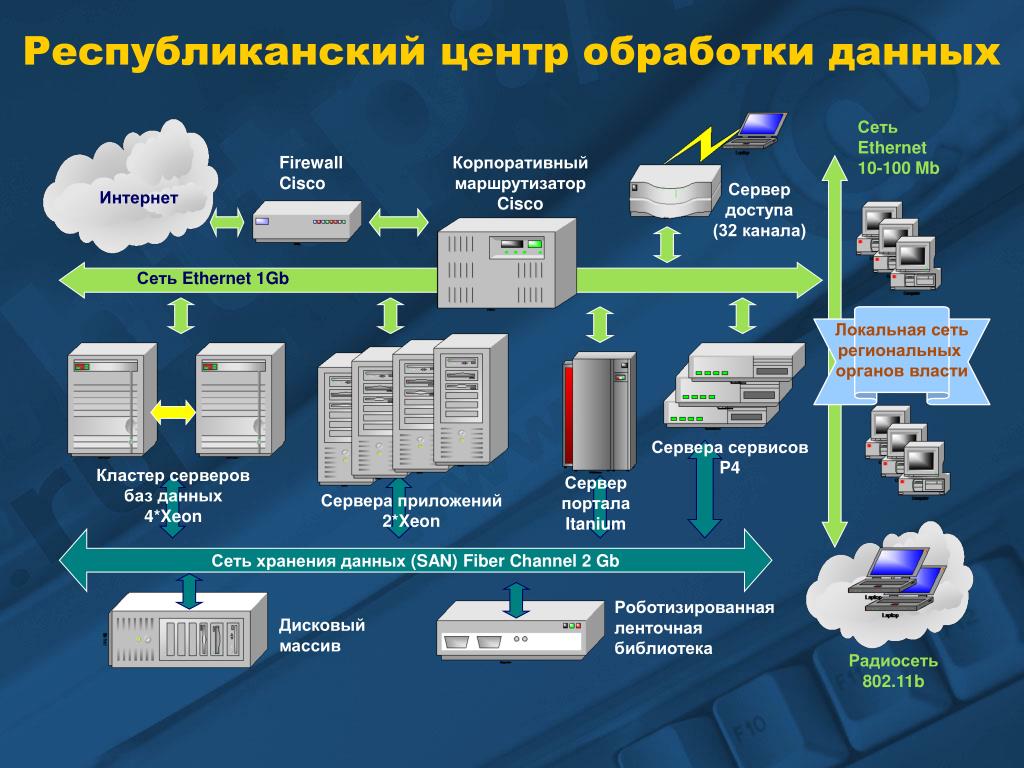 В результате увеличивается время ответа, особенно при большом количестве запросов.
В результате увеличивается время ответа, особенно при большом количестве запросов.Недостатки
- Дорогостоящее программное обеспечение . Обеспечение прозрачности данных и координации между несколькими сайтами часто требует использования дорогостоящего программного обеспечения в системе распределенных баз данных.
- Большие накладные расходы . Многие операции на нескольких сайтах требуют многочисленных вычислений и постоянной синхронизации, когда используется репликация базы данных, что вызывает большие накладные расходы на обработку.
- Целостность данных . Возможной проблемой при использовании репликации базы данных является целостность данных, которая нарушается при обновлении данных на нескольких сайтах.
- Неправильное распространение данных . Отзывчивость на запросы пользователей во многом зависит от правильного распределения данных. Это означает, что скорость отклика может быть снижена, если данные неправильно распределены между несколькими сайтами.
 Это означает, что скорость отклика может быть снижена, если данные неправильно распределены между несколькими сайтами.
Это означает, что скорость отклика может быть снижена, если данные неправильно распределены между несколькими сайтами.Примечание: Рассмотрите возможность использования многомодельной базы данных. Многомодельные базы данных предоставляют единый механизм для различных типов баз данных.
Заключение
Теперь вы знаете, что такое распределенные базы данных и как они работают.
Распределенные базы данных обладают значительными преимуществами по сравнению с централизованными базами данных. Прочитав эту статью, вы сможете выбрать для себя правильный тип базы данных.
🤔 Объясните, что такое распределенное хранилище — и как оно перестает работать для github / uilicious / cloud / и т. Д.
Плохой месяц для системных администраторов (октябрь 2018 г.), сначала youtube, затем github
Для начала: # спасибо ребятам из github за исправление их систем. Нелегко поддерживать и поддерживать крупномасштабные системы в рабочем состоянии (будучи там сам)
И очевидно, что хотя распределенное хранилище данных используется повсеместно в облаке, не многие разработчики действительно это понимают. ..
..
Итак, что такое распределенное хранилище? Почему его используют все крупные облачные провайдеры? И почему и как они терпят неудачу?
Распределенное хранилище здесь коллективно означает «Распределенное хранилище данных», также называемое «Распределенные базы данных» и «Распределенная файловая система».
И используется в различных формах — от тренда NoSQL до самого известного — хранилища AWS S3.
Основная концепция заключается в формировании избыточности в хранилище данных путем разделения данных на несколько частей и обеспечения наличия реплик на нескольких физических серверах (часто с разной емкостью хранилища).
Реплицированный том GlusterFSРеплика данных может храниться в виде точных полных копий или сжиматься на несколько частей с использованием кода стирания
Потому что код стирания, шифрование, биты четности включает сложную математику для объяснения того, как они работают, и не сильно меняет концепции в этой статье, кроме сжатия данных.
 Я бы просто использовал неточные «реплики», чтобы сэкономить нам обоим лекцию по математике
Я бы просто использовал неточные «реплики», чтобы сэкономить нам обоим лекцию по математикеНезависимо от используемого метода хранения это помогает гарантировать, что на Y серверах хранится X копий данных.Где X <= Y (например, 3 реплики на 5 серверах).
В крупномасштабных системах вопрос не в том, «выйдет ли из строя» сервер, а в том, «когда». В конце концов, учитывая количество оборудования, это в значительной степени статистический факт.
И вы действительно не хотите, чтобы такая крупномасштабная система выходила из строя всякий раз, когда чихает единственный сервер.
Это сильно отличается от того, что раньше было более распространенным — резервирование дисков на одном сервере (например, RAID 1), которое защищает данные от сбоя жесткого диска.
Если все сделано правильно, распределенные системы хранения помогают выдержать простои системы, такие как полный отказ сервера, выброс всей серверной стойки или даже экстремальный ядерный взрыв в центре обработки данных.
Или, как выразился xkcd …
Ну, это зависит … отчасти причина того, что существует так много разных распределенных систем, заключается в том, что все системы образуют своего рода компромисс, который отдает предпочтение одному атрибуту над другим.Примеры включают гарантии задержки или ACID.
И одним из наиболее распространенных компромиссов для распределенных систем является принятие значительных накладных расходов, связанных с координацией данных между несколькими серверами. Поэтому, когда речь идет об отдельном серверном узле, сравниваемом с нераспределенными системами, они, как правило, проигрывают.
Однако взамен они получают горизонтальную масштабируемость, такую как возможность охвата тысячи узлов.
Типичный пример, с которым могли столкнуться многие разработчики: загрузка одного большого файла в облачное хранилище может быть несколько медленной.Однако, с другой стороны, они могут загружать столько файлов одновременно, сколько позволяет их кошелек, потому что нагрузка будет распределяться между несколькими серверами.
Или для ЦЕРНа (вы знаете, гигантского Большого адронного коллайдера) это означает 11000 серверов с 200 ПБ данных, передающих более 200 Гбит / с. На сегодняшний день обнаружено нулевое количество черных дыр,
год.Так что да, одиночный сервер «медленный». Для «быстрой» мультисерверности у вас есть параллелизм с распределением реплик между ними.
Не вдаваясь в общие принципы работы какой-либо одной распределенной системы.
Когда часть данных записывается в систему клиентской программой, ее реплики синхронно создаются в различных других узлах в процессе.
При чтении фрагмента данных клиент получает данные либо из одной из реплик, либо из нескольких реплик, где окончательный результат определяется большинством голосов.
Если какая-либо реплика оказывается поврежденной или отсутствующей из-за сбоя, ее реплика удаляется из системы.И новая реплика создается и помещается на другой сервер, если он доступен.
Это происходит либо при чтении, либо в процессе фоновой проверки.Решение о том, какие данные действительны или повреждены, и где должны находиться данные каждой реплики, обычно принимает «главный узел» или «большинством голосов». А иногда для выбора, куда реплики попадают «случайно».
Тем не менее, одна из наиболее важных повторяющихся вещей, которые следует принимать во внимание, — это системное требование о наличии большинства голосов для многих операций, среди всех избыточностей для работы системы.
 Это происходит либо при чтении, либо в процессе фоновой проверки.
Это происходит либо при чтении, либо в процессе фоновой проверки.Во-первых … это зависит от вашего определения отказа …
Одно из больших преимуществ распределенной системы — это то, что во многих случаях, когда выходит из строя один узел или реплика, за кулисами появляется инженер по надежности системы (или системный администратор), который заменяет затронутые серверы без ведома пользователей.
Это, вероятно, один из самых недооцененных и неблагодарных аспектов работы.
 Никто не знает, что происходит.Официально это уже произошло дважды в Uilicious в этом году, и я уверен, что для инфраструктуры размером с Google и Amazon это будет происходить ежедневно. Итак #hugops
Никто не знает, что происходит.Официально это уже произошло дважды в Uilicious в этом году, и я уверен, что для инфраструктуры размером с Google и Amazon это будет происходить ежедневно. Итак #hugopsЕще одна вещь, на которую следует обратить внимание, — это определение отказа с точки зрения бизнеса. Постоянная потеря всех ваших данных о клиентах намного хуже, чем переход, скажем, в режим только для чтения или даже сбой системы.
В частности, для github, если пользователям еще предстоит продвинуть свои коммиты — они прекрасно понимают, что им нужно сохранить локальную копию данных для последующей загрузки.Однако, если они уже загрузили, они могут удалить свою локальную копию, чтобы освободить место для своих ноутбуков с хранилищем SSD <1 ТБ.
Следовательно, многие такие системы спроектированы так, чтобы сначала выключаться или переходить в режим только для чтения, когда вместо этого потребуется длительное ручное восстановление, чтобы гарантировать безопасность данных. Что по замыслу является «частичным отказом».
И наконец … Закон Мерфи … означает, что иногда несколько узлов или сегментов вашей сетевой инфраструктуры выходят из строя. Вы столкнетесь с ситуациями, когда теряется большинство голосов.
В облачных системах это обычно означает замену реплики новым экземпляром.
Однако, в зависимости от сетевой инфраструктуры и размера набора данных, время является серьезным препятствием.
Например, для замены одного узла 8 ТБ на гигабитное соединение (или 800 мегабит в секунду эффективно) потребуется примерно 22,2 часа или 1 целый день с округлением в большую сторону. И это при условии оптимальной скорости передачи, которая приведет к насыщению системы. Чтобы система продолжала работать без заметных простоев, мы можем вдвое снизить скорость передачи данных, увеличив время, необходимое до 2 полных дней.
Естественно, в игру вступят более сложные факторы, такие как 10-гигабитные соединения или скорость жесткого диска.
Однако суть остается прежней: замена поврежденной реплики в «большом» узле хранения вряд ли происходит мгновенно.
Вот почему вы также увидите твиты с ETA о том, сколько времени потребуется для синхронизации данных в кластере.
И для записи, учитывая, что они, вероятно, используют кластер с несколькими петабайтами, синхронизируя данные день «постный»
И иногда в эти долгие 48 часов ситуация для системного администратора становится напряженной.При конфигурации с тремя репликами не будет места для ошибок, если будет поддерживаться большинство из двух исправных узлов. Для конфигурации с 5 репликами будет передышка 1.
И когда большинство голосов потеряно, произойдет одно из трех:
- Разделенный мозг: в результате получается запутанный кластер
- Режим только для чтения: чтобы система не имела двух разных наборов данных (и, следовательно, разделенного мозга)
- Жесткий сбой системы: некоторые системы предпочитают вызывать серьезный сбой, а не вызывать расщепление мозга.
Разделение мозга начинается, когда ваш кластер начинает разделяться на 2 сегмента. Ваша система начнет видеть две разные версии одних и тех же данных, поскольку кластер выходит из синхронизации.
Чаще всего это происходит, когда из-за сбоя сети половина кластера оказывается изолированной от другой половины.
Что произойдет впоследствии, если произойдет изменение данных, так это то, что половина системы будет обновлена, а другая половина будет устаревшей.
Это «нормально», пока другая половина не вернется в сеть.И данные могут быть не синхронизированы или даже изменены из-за использования с другой половиной кластера.
Обе половины начнут утверждать, что они «настоящие» данные, и проголосуют против «второй половины». И, как и в случае с любой системой голосования, которая застряла в тупике, никакой работы не происходит.
Оба: Я настоящий!Это может произойти даже с нечетным количеством реплик. Например, если одна реплика имеет критический сбой и решает «не голосовать»
К счастью, большинство распределенных систем при правильной настройке спроектировано таким образом, чтобы в первую очередь предотвратить возникновение разделения мозга.Обычно они бывают 3-х видов.
Главный узел, который принимает все окончательные решения (однако это может привести к отказу одной точки отказа главного узла. Некоторые системы отключаются к голосованию за новый главный узел, если это происходит).
Серьезный сбой системы для предотвращения такого расщепления мозга. Пока весь кластер не будет синхронизирован, выполняйте резервное копирование должным образом; Это гарантирует, что не будут показаны «устаревшие» данные.
Блокировка системы только для чтения; Наиболее распространенным признаком этого является отображение устаревших данных на определенных узлах в режиме только для чтения.
Последний является наиболее распространенным для большинства распределенных систем, также замечен в недавнем отключении github
Заметным исключением были бы системы распределенного кеширования, такие как hazelcast: которые использовали бы подход данных с «последней» временной меткой для решения проблем с разделением мозга.
Это может быть «нормально» в случае использования кэширования, и это сделано намеренно, но это может стать большой проблемой для более устойчивой системы хранения, поскольку это приведет к отбрасыванию данных.Во многих случаях для разрешения этой ситуации потребуется принятие решения, зависящего от контекста, либо программистом, либо системным администратором.
Ну вы, наверное, уже
В наши дни большинство экземпляров AWS или GCP начального уровня используют для своих жестких дисков ту или иную форму «блочного хранилища», то есть распределенную систему хранения.
Более известным было бы объектное хранилище, такое как сам S3 и практически любое облачное хранилище. Даже для выделенных серверов большинство систем резервного копирования, таких как системы, предоставляемые linode и digital ocean, используют некоторую форму распределенного хранилища.
Помимо облачных сервисов, существует множество развертываний с открытым исходным кодом, в которых используется распределенное хранилище. Практически вся база данных NoSQL, даже сама kubernetes, потому что она поставляется с распределенным хранилищем ключей и значений ETCD.
Впоследствии для заметных конкретных приложений существуют Cockroach DB (SQL), GlusterFS (файловое хранилище), Elasticsearch (NoSQL), Hadoop (большие данные). Даже mysql можно развернуть в такой конфигурации, известной как групповая репликация. Или как вариант через галера.
Возможность использовать такие распределенные системы и не думать об этом — это, в конечном счете, то, за что вы платите «облачным налогом» — за того, кто за кулисами решает эти проблемы за вас.
Облако — это не волшебство, кому-то действительно нужно, чтобы оно работалоБудьте спокойны и #hugops — дайте им время, они, вероятно, используют его в меру своих возможностей. Даже самые лучшие из нас могут совершать одни и те же ошибки.
Особая благодарность: @feliciahsieh за помощь в проверке и исправлении всех моих ужасных запятых и грамматики.
Uilicious — это простое и надежное решение для автоматизации тестирования пользовательского интерфейса для веб-приложений. Зарегистрироваться на нашу бесплатную пробную версию и написать тестовые сценарии для проверки вашей распределенной системы можно так же просто, как и сценарий ниже.
{% gist https://gist.github.com/PicoCreator/127df587b8cd1e3c373461e5393d2afb%}
Или, как вариант, такой тест …
Кошачье вскармливание: плохое тестирование котят в почтовом ящике XD
ОБНОВЛЕНИЕ: Теперь это преобразовано в серию, часть 2 которой распространяется на распределенные системы хранения.
Эта статья дублируется на dev.to
. Для комментариев и обсуждения, пожалуйста, делайте это на dev.to вместо
Стратегия распределенного хранения данных на основе LOP
Zhang, Y .; и др .: Системы параллельной обработки больших данных: обзор. Proc. IEEE 104 (11), 2114–2136 (2016)
Статья Google Scholar
Polato, I .; и др.: Комплексный взгляд на исследования Hadoop — систематический обзор литературы. J. Netw. Comput. Прил. 46 , 1–25 (2014). Автор 1, А .; Автор 2, Б. Название книги , 3-е изд .; Издатель: Местоположение издателя, Страна, 2008 г .; С. 154–196
Challa, J.S .; и др .: DD-Rtree: динамическая распределенная структура данных для эффективного распределения данных между узлами кластера для алгоритмов пространственного анализа данных. В: Международная конференция IEEE по большим данным (Big Data), 2016 г. IEEE (2016)
Cangir, O.F .; Cankur, O .; Озсой, А .: Таксономия технологий распределенного хранения на основе блокчейна. Инф. Процесс. Manag. 58 (5), 102627 (2021)
Артикул Google Scholar
Fan, W .; и др .: Метод поддержания согласованности данных в микросервисной архитектуре. В: 4-я Международная конференция IEEE по безопасности больших данных в облаке (BigDataSecurity), 2018 г., Международная конференция IEEE по высокопроизводительным и интеллектуальным вычислениям (HPSC) и Международная конференция IEEE по интеллектуальным данным и безопасности (IDS). IEEE Computer Society (2018)
Benerjee, K.G .; Гупта, М.К .: Выбор разнородных распределенных систем хранения между стоимостью хранения и ремонта.Вероятно. Инф. Трансм. 57 (1), 33–53 (2021)
Артикул Google Scholar
Ruty, G .; Baccouch, H .; Нгуен, В. и др.: Полное кэширование реплик на основе популярности для распределенных систем хранения с стиранием. Clust. Comput. 2021 , 1–14 (2021)
Google Scholar
Холл Р.Дж .: Инструменты для прогнозирования надежности крупномасштабных систем хранения.ACM Trans. Хранение (TOS) 12 (4), 1–30 (2016)
Артикул Google Scholar
Круглик, С .; Фролов А .: Теоретико-информационный подход к надежным распределенным системам хранения. J. Commun. Technol. Избрать. 65 (12), 1505–1516 (2020)
Артикул Google Scholar
Ю., Л .; и др .: Стохастическая балансировка нагрузки для управления виртуальными ресурсами в центрах обработки данных.IEEE Trans. Облачные вычисления. 8 (2), 459–472 (2016)
Статья Google Scholar
Kaur, S .; Шарма, Т .: Эффективная балансировка нагрузки с использованием улучшенной техники центральной балансировки нагрузки. В: 2-я Международная конференция по изобретательским системам и контролю, 2018 г. (ICISC). IEEE (2018)
Qin, X.P .; Wang, H.J .; Li, F.R .; и др .: Новый ландшафт технологий управления данными. J. Softw. 24 (2), 175–197 (2013)
Статья Google Scholar
Mishra, S .; Суман, A.C .: Эффективный метод разделения больших объемов многомерных данных для параллельных алгоритмов кластеризации (2016). arXiv: 1609.06221
Alarabi, L .; Mokbel, M.F .; Муслех, М .: St-hadoop: структура mapreduce для пространственно-временных данных. ГеоИнформатика 22 (4), 785–813 (2018)
Статья Google Scholar
Mahmud, M.S .; и др .: Обзор методов разделения данных и выборки для поддержки анализа больших данных.Большие данные Мин. Аналит. 3 (2), 85–101 (2020)
Артикул Google Scholar
Emara, X.Z.T.Z .; Он, C.W.H .: Модель данных с разбиением на случайную выборку для анализа больших данных (2017). arXiv: 1712.04146
Alsmirat, M .; Jararweh, Y .; Аль-Айюб, М .: Ускорение запросов DBLP с помощью hadoop и spark // Серия конференций IOP: материаловедение и инженерия. IOP Publ. 459 (1), 012003 (2018)
Google Scholar
Hu, X .; Xu, H .; Jia, J .; и др.: Исследования по распределенному хранению и оптимизации запросов гетерогенных метеорологических данных из нескольких источников. В: Материалы Международной конференции по облачным вычислениям и Интернету вещей 2018 г. ACM, стр. 12–18 (2018)
Xue, J .; Xu, C .; Бай, Л .: DStore: распределенная система для внешнего хранения и поиска данных. Futur. Gener. Comput. Syst. 99 , 106–114 (2019)
Статья Google Scholar
Коломвацос, К .: Распределенная проактивная интеллектуальная схема для обеспечения качества крупномасштабной обработки данных. Вычислительная техника 101 (11), 1687–1710 (2019)
Статья Google Scholar
Rafique, A .; Van Landuyt, D .; Джоузен, В .: Persist: промежуточное программное обеспечение для управления данными на основе политик для многопользовательских Saas-сервисов, использующих объединенное облачное хранилище. J. Grid Comput. 16 (2), 165–194 (2018)
Статья Google Scholar
Rafique, A .; Van Landuyt, D .; Truyen, E .; Reniers, V .; Джоузен, В .: СФЕРА: самоадаптирующееся промежуточное программное обеспечение для управления данными на основе политик для федеративных облаков. J. Internet Serv. Прил. 10 (1), 1–19 (2019)
Статья Google Scholar
Ли Р. и др .: TrajMesa: распределенная система управления данными траектории на основе NoSQL. IEEE Trans. Знай. Data Eng. (2021 г.). https://doi.org/10.1109/TKDE.2021.3079880
Статья Google Scholar
Li, R .; Он, H .; Wang, R .; Ruan, S .; Sui, Y .; Bao, J .; Чжэн, Й .: Trajmesa: распределенный механизм хранения nosql для больших данных о траектории. В: 2020 г., 36-я международная конференция IEEE по инженерии данных (ICDE). IEEE, pp. 2002–2005 (2020)
Ye, X .; Tang, Y .; Lin, Y .; Chen, Z .; Zhang, Z .; Чен, Р .: Исследование и реализация временного индекса TD index. Sci. Грех. (Инф.) 8 (45), 1025–1045 (2015)
Google Scholar
Ye, X.P .; Tang, Y .; Zhang, Z.B .; Chen, Z.Y .; Лин, Ю.К .: Исследование и реализация на основе семантики кооперативного временного индекса XML. J. Comput. 37 (9), 1911–1921 (2014)
Google Scholar
Ye, X.P .; Tang, Y .; Lin, Y.C .; Chen, Z.Y .; Чжан, З.Б .: Исследование и применение структуры данных временного квазипорядка. J. Softw. 25 (11), 2587–2601 (2014)
MATH Google Scholar
Аллен, Дж. Ф .: Сохранение знаний о временных интервалах. Читать. Qual. Причина. Phys. Syst. 26 (11), 361–372 (1990)
Google Scholar
Распределенное хранилище данных Facebook для социальной сети
Обсуждение на Hacker News
В ближайшие несколько недель статьи будут основаны на исследовании VLDB 2021 (или связаны с ним) — на горизонте одна из моих любимых системных конференций SOSP. Как всегда, не стесняйтесь обращаться в Twitter с отзывами или предложениями о статьях для чтения! Эти бумажные обзоры можно еженедельно доставлять вам на почту, или вы можете подписаться на ленту Atom.
TAO: распределенное хранилище данных Facebook для социальной сети
Это первая часть из двух частей, посвященных TAOTAO, что означает «Ассоциации и объекты»: ассоциации — это ребра в графе, а объекты — это узлы. , Оптимизированная для чтения и согласованная со временем база данных графов Facebook. В отличие от других графовых баз данных, TAO фокусируется исключительно на обслуживании и кэшировании ограниченного набора запросов приложений в масштабе (в отличие от систем, ориентированных на анализ данных). Кроме того, система основана на опыте масштабирования MySQL и кэша памяти, как обсуждалось в предыдущем обзоре статьи.
Первая статья в серии посвящена исходной статье TAO, описывающей мотивацию построения системы, ее архитектуру и инженерные уроки, извлеченные на этом пути. Вторая часть посвящена исследованию, относящемуся к TAO, опубликованному в этом году на VLDB — RAMP-TAO: Layering Atomic Transactions в онлайн-хранилище данных TAO Facebook. В этом новом документе описывается дизайн и реализация транзакций поверх существующей крупномасштабной распределенной системы — задача, усложняющаяся требованием, чтобы приложения постепенно переходили на новую функциональность и чтобы работа по поддержке транзакций имела ограниченное влияние на производительность существующих приложений.
Каков вклад газеты?
Исходный документ TAO вносит три вклада: характеризует и мотивирует реализацию графической базы данных, подходящей для интенсивного чтения трафика Facebook, предоставляет модель данных и API разработчика для вышеупомянутой базы данных и описывает архитектуру, которая позволила масштабировать базу данных.
Мотивация
Статья начинается с раздела, описывающего мотивацию первоначального развития TAO. Когда Facebook был первоначально разработан, MySQL использовался в качестве хранилища данных для графа.По мере масштабирования сайта перед базами данных MySQL был добавлен слой кэша памяти для облегчения нагрузки.
Хотя вставка кэша памяти в стек работала в течение некоторого периода времени, в статье упоминаются три основные проблемы с реализацией: неэффективных списков ребер , логики распределенного управления и дорогостоящей согласованности чтения после записи .
Неэффективные списки кромок
Разработчики приложений в Facebook использовали крайних списков для представления совокупности информации в графе — например, списка дружеских отношений, которые есть у пользователя (каждая дружба — это ребро в графе, а пользователи — узлы).К сожалению, поддержание этих списков в memcache было неэффективным — memcache — это простое хранилище значений ключей без поддержки списков, что означает, что общие функции, связанные со списками, аналогичны тем, которые поддерживаются в Redis. неэффективно. Если список необходимо обновить (например, удалить дружбу), логика обновления списка будет сложной — в частности, часть логики, связанная с координацией обновления списка между несколькими копиями одного и того же данные в нескольких центрах обработки данных.
Распределенная логика управления
Управляющая логика (в контексте архитектуры хранилища графов Facebook) означает способность управлять доступом к системе. До внедрения TAO хранилище данных графа имело распределенную логику управления — клиенты напрямую связывались с узлами кэша памяти, и не было единой точки управления для доступа клиентов к системе. Это свойство затрудняет защиту от непослушных клиентов и грохочущих стад.
Дорогая согласованность чтения после записи
Согласованность чтения после записи означает, что если клиент записывает данные, а затем выполняет чтение данных, клиент должен увидеть результат выполненной записи. Если в системе нет этого свойства, пользователи могут быть сбиты с толку: «Почему кнопка« Мне нравится », которую они только что нажали, не регистрируется при перезагрузке страницы?».
Обеспечение согласованности чтения после записи было дорогостоящим и сложным для системы на основе кэша памяти Facebook, которая использовала базы данных MySQL с репликацией главный / подчиненный для передачи записей в базу данных между центрами обработки данных.В то время как Facebook разработал внутреннюю технологию, как описано в моем предыдущем обзоре статьи, Масштабирование Memcache в Facebook. для потоковой передачи изменений между базами данных существующие системы, которые использовали комбинацию MySQL и кэша памяти, полагались на сложную логику аннулирования кеша. Например, последователи будут пересылать чтения для ключей кэша, недействительных при записи в базу данных лидера, увеличивая нагрузку и вызывая потенциально медленную межрегиональную связь. . это повлекло за собой накладные расходы на сеть. Цель этой новой системы — избежать этих накладных расходов (с подходом, описанным позже в документе).
Модель данных и API
TAO является в конечном итоге последовательным Для описания возможной согласованности (и связанных тем!) Я настоятельно рекомендую этот пост от Вернера Фогельса. оптимизированное для чтения хранилище данных для графика Facebook.
В нем хранятся две сущности — объектов и ассоциаций (отношения между объектами). Теперь мы узнаем, почему хранилище данных графа называется TAO — это сокращение от «Ассоциации и объекты».
В качестве примера того, как объектов и связей используются для моделирования данных, рассмотрим две общие функции социальных сетей:
- Дружба между пользователями : пользователи в базе данных хранятся как объектов , а отношения между пользователями — ассоциаций .
- Check-ins : пользователь и место, где они регистрируются, являются объектами . Между ними существует связь , чтобы показать, что данный пользователь зарегистрировался в данном месте.
Объекты и ассоциации имеют разные представления в базе данных:
- Каждый объект в базе данных имеет идентификатор и тип.
- Каждая ассоциация содержит идентификаторы объектов, связанных данным ребром, а также тип ассоциации (отметка, дружба и т. Д.). Кроме того, у каждой ассоциации есть отметка времени, которая используется для запроса (описана позже в обзоре статьи).
Метаданные «ключ-значение» могут быть связаны как с объектами, так и с ассоциациями, хотя возможные ключи и тип значения ограничены типом объекта или ассоциации.
Для обеспечения доступа к этим данным TAO предоставляет три основных API: Object API , Association API и Association Querying API .
Два из трех ( Object API и Association API ) обеспечивают операции создания, чтения, обновления и удаления для отдельных объектов.
В отличие от этого API Association Querying API предоставляет интерфейс для выполнения общих запросов на графике. Методы запроса позволяют разработчикам приложений извлекать ассоциации для данного объекта и типа (потенциально ограничиваясь временным диапазоном или набором объектов, на которые указывает ассоциация), вычислять количество ассоциаций для объекта и обеспечивать функциональность, подобную разбиению на страницы.В документе представлены примеры шаблонов запросов, таких как получение «50 последних комментариев к отметкам Алисы» или «сколько отметок на мосту GG?». Запросы в этом API возвращают несколько ассоциаций и вызывают этот тип результата списком ассоциаций .
Архитектура
Архитектура TAO содержит два уровня: уровень хранения и уровень кэширования .
Уровень хранения
Уровень хранения (как следует из названия) сохраняет графические данные в MySQL: Facebook инвестировал значительный объем ресурсов в свои развертывания MySQL, о чем свидетельствуют их механизм хранения MyRocks и другие сообщения в своем техническом блоге.. На уровне хранения есть два ключевых технических момента: сегментов и таблиц , используемых для хранения самих данных графика.
Данные графа разделены на сегментов (представленных как база данных MySQL), и сегменты сопоставлены с одним из многих серверов баз данных. Объекты и ассоциации для каждого шарда хранятся в отдельных таблицах.
Уровень кэша
Уровень кэша оптимизирован для запросов чтения и сохраняет результаты запросов в памяти. На уровне кэша есть три ключевых идеи: кэш-серверов , уровней кеш-памяти и уровней лидер / подчиненный .
Клиенты передают запросы чтения и записи кеш-серверам . Каждый кэш-сервер обслуживает запросы для набора сегментов на уровне хранения и кэширует объекты, ассоциации и размер списков ассоциаций (с помощью шаблонов запросов, упомянутых в разделе API выше).
Уровень кэша представляет собой набор из серверов кеширования , которые могут отвечать на запросы для всех сегментов — количество серверов кеширования на каждом уровне настраивается, как и отображение запроса на сервер кеширования.
Уровни кэша можно настроить как лидеров или последователей . Независимо от того, является ли уровень кэша лидером или подчиненным , это влияет на его поведение:
- Следующие уровни могут обслуживать запросы чтения без связи с ведущим (хотя они пересылают промахи чтения и запросы записи на соответствующие кэш-серверы на ведущем уровне).
- Уровни лидеров взаимодействуют со слоем хранения (путем чтения и записи в / из базы данных), а также с подчиненными уровнями кеш-памяти .В фоновом режиме ведущий уровень отправляет сообщения об обновлении кэша на ведомых уровней (что в конечном итоге приводит к согласованности, упомянутой ранее в этом обзоре).
Масштабирование
Для работы в больших масштабах TAO необходимо было выйти за пределы одного региона. Система достигает этой цели, используя конфигурацию главный / подчиненный для каждого шарда базы данных.
В конфигурации главный / подчиненный каждый сегмент имеет один ведущий уровень кэша и множество ведомых уровней кэша.Данные на уровне хранения для каждого сегмента асинхронно реплицируются из главного региона в подчиненные регионы.
Основное различие между конфигурацией с одним регионом, описанной выше, и конфигурацией с несколькими регионами заключается в поведении уровня лидера , когда он получает записи. В конфигурации с одним регионом ведущий уровень всегда пересылает записи на уровень хранения . Напротив, ведущий уровень в многорегиональной конфигурации TAO записывает на уровень хранения , только если ведущий уровень находится в главном регионе .Если уровень лидера не находится в главной области (это означает, что он находится в подчиненном регионе!), Тогда уровень лидера должен перенаправить запись в главную область . Как только основная область подтверждает запись, подчиненная область обновляет свой локальный кэш с результатом записи.
Заключение
TAO — это графическая база данных, работающая в огромном масштабе. Система была построена на растущих потребностях Facebook и имела ограниченную поддержку транзакций. В документе упоминается ограниченное поведение, подобное транзакциям, но не приводятся важные детали.В следующей статье этой серии обсуждается, как транзакции были добавлены в систему, при этом сохранялась производительность для существующих приложений и предоставлялась возможность добровольного обновления для новых приложений.
Как всегда, не стесняйтесь обращаться в Twitter с любыми отзывами или предложениями на бумаге. До следующего раза
.