| 1 | AMD Radeon Pro Vega 64X | для рабочих станций | 100.00 | 54.87 | 2019 | 366 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | NVIDIA GeForce GTX 1080 SLI (мобильная) | для ноутбуков | 74.40 | 72.93 | 2016 | 352 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | AMD Radeon RX 5700 XT 50th Anniversary | десктопная | 72.70 | 62.57 | 2019 | 409 USD | 225 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | NVIDIA TITAN Xp | десктопная | 70.37 | 71.66 | 2017 | 408 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | NVIDIA GeForce GTX 980 SLI (мобильная) | для ноутбуков | 62. 25 25 | 59.21 | 2015 | 301 USD | 330 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6 | NVIDIA Quadro P3000 (мобильная) | для мобильных рабочих станций | 59.94 | 60.13 | 2017 | 537 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 7 | NVIDIA GeForce GTX 1070 SLI | десктопная | 48.97 | 71.42 | 2016 | 539 USD | 300 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 8 | NVIDIA Tesla M40 24 GB | для рабочих станций | 43.07 | 47.05 | 2015 | 499 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9 | AMD Radeon Pro Vega 48 | для рабочих станций | 41.56 | 42.69 | 2019 | 671 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 10 | AMD Radeon Pro W6600 | для рабочих станций | 41. 41 41 | 51.99 | 2021 | 812 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 11 | NVIDIA GeForce RTX 2060 Super | десктопная | 41.30 | 61.66 | 2019 | 667 USD | 175 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 12 | NVIDIA GeForce GTX 1070 (мобильная) | для ноутбуков | 36.94 | 39.25 | 2016 | 379 USD | 120 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 13 | AMD Radeon Pro W5500 | для рабочих станций | 35.90 | 34.72 | 2020 | 612 USD | 125 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 14 | AMD Radeon RX 6600 XT | десктопная | 35.79 | 58.83 | 2021 | 724 USD | 160 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 15 | NVIDIA GeForce GTX 1060 3 GB | десктопная | 34.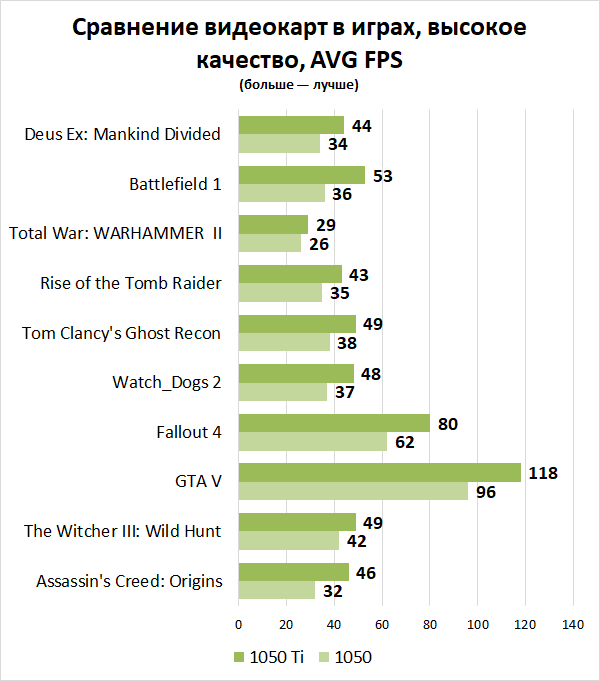 17 17 | 35.96 | 2016 | 363 USD | 120 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 16 | NVIDIA GeForce GTX 1650 (мобильная) | для ноутбуков | 33.89 | 26.13 | 2019 | 301 USD | 50 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 17 | NVIDIA GeForce GTX 1070 | десктопная | 32.24 | 50.33 | 2016 | 563 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 18 | NVIDIA GeForce GTX 1660 SUPER | десктопная | 32.11 | 47.60 | 2019 | 663 USD | 125 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 19 | NVIDIA GeForce GTX 1660 Super | десктопная | 32.11 | 47.60 | 2019 | 663 USD | 125 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 20 | NVIDIA GeForce GTX 1070 | десктопная | 31. | 50.33 | 2016 | 563 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 21 | NVIDIA GeForce RTX 2060 | десктопная | 31.62 | 52.06 | 2019 | 725 USD | 160 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 22 | AMD Radeon Pro Vega 20 | для мобильных рабочих станций | 31.49 | 22.29 | 2018 | 360 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 23 | AMD Radeon Pro W5700 | для рабочих станций | 31.10 | 56.27 | 2019 | 1143 USD | 205 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 24 | NVIDIA GeForce GTX 1660 | десктопная | 30.41 | 43.66 | 2019 | 645 USD | 120 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 25 | NVIDIA Titan X Pascal | десктопная | 30. 06 06 | 48.86 | 2016 | 596 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 26 | AMD Radeon RX 580 (мобильная) | для ноутбуков | 30.06 | 34.46 | 2017 | 410 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 27 | NVIDIA GeForce GTX 1080 Ti | десктопная | 29.84 | 67.80 | 2017 | 902 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 28 | NVIDIA GeForce GTX 1080 Ti | десктопная | 29.74 | 67.80 | 2017 | 902 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 29 | NVIDIA GeForce GTX 980 Ti | 29.62 | 52.04 | 2015 | 546 USD | 250 W | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 30 | NVIDIA GeForce GTX 1060 6 GB | десктопная | 28. 84 84 | 38.45 | 2016 | 475 USD | 120 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 31 | AMD Radeon RX 6600 | десктопная | 28.05 | 49.68 | 2021 | 771 USD | 132 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 32 | NVIDIA GeForce RTX 2080 Super | десктопная | 27.95 | 73.08 | 2019 | 1056 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 33 | NVIDIA Tesla M6 | для рабочих станций | 27.61 | 28.16 | 2015 | 350 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 34 | NVIDIA GeForce GTX 1080 | десктопная | 27.31 | 56.93 | 2016 | 748 USD | 180 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 35 | AMD Radeon RX 5700 XT | | 27. 17 17 | 63.19 | 2019 | 963 USD | 225 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 36 | NVIDIA GeForce GTX 1080 | десктопная | 27.09 | 56.93 | 2016 | 748 USD | 180 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 37 | NVIDIA TITAN V | десктопная | 26.71 | 64.23 | 2017 | 989 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 38 | AMD Radeon RX 6700 XT | | 26.12 | 70.40 | 2021 | 1081 USD | 230 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 39 | NVIDIA GeForce RTX 2070 Super Max-Q | для ноутбуков | 25.82 | 54.20 | 2020 | 812 USD | 80 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 40 | NVIDIA GeForce GTX 1650 SUPER | десктопная | 25. 49 49 | 37.39 | 2019 | 657 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 41 | NVIDIA GeForce RTX 3060 Ti | десктопная | 25.31 | 74.24 | 2020 | 1153 USD | 200 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 42 | NVIDIA GeForce RTX 2080 Super Max-Q | для ноутбуков | 24.97 | 52.41 | 2020 | 812 USD | 80 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 43 | NVIDIA GeForce RTX 3070 | десктопная | 24.84 | 82.27 | 2020 | 1262 USD | 220 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 44 | AMD Radeon RX 5700 | десктопная | 24.48 | 55.08 | 2019 | 938 USD | 180 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 45 | AMD Radeon RX 5700 | десктопная | 24. 48 48 | 55.08 | 2019 | 938 USD | 180 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 46 | AMD Radeon Pro WX 8200 | для рабочих станций | 23.91 | 51.69 | 2018 | 1346 USD | 230 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 47 | AMD Radeon RX 5600 XT | десктопная | 23.42 | 51.72 | 2020 | 924 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 48 | AMD Radeon Pro 5700 | для рабочих станций | 23.29 | 44.42 | 2020 | 1200 USD | 130 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 49 | AMD Radeon R9 Nano | десктопная | 22.99 | 31.83 | 2015 | 379 USD | 175 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 50 | NVIDIA GeForce RTX 3060 | десктопная | 22. 89 89 | 62.37 | 2021 | 1090 USD | 170 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 51 | NVIDIA GeForce GTX 1660 Ti (мобильная) | для ноутбуков | 22.88 | 38.17 | 2019 | 682 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 52 | AMD Radeon Pro WX 7100 | для рабочих станций | 22.81 | 29.28 | 2017 | 582 USD | 130 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 53 | AMD Radeon Vega Frontier Edition | десктопная | 22.27 | 51.99 | 2017 | 961 USD | 300 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 54 | NVIDIA GeForce RTX 3070 Ti | десктопная | 22.18 | 84.95 | 2021 | 1401 USD | 290 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 55 | NVIDIA GeForce GTX 1650 | десктопная | 22. 05 05 | 29.07 | 2019 | 555 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 56 | NVIDIA GeForce GTX 1660 Ti | десктопная | 21.91 | 44.17 | 2019 | 858 USD | 120 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 57 | NVIDIA GeForce GTX 980 | десктопная | 21.79 | 42.22 | 2014 | 536 USD | 220 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 58 | AMD Radeon RX 5600M | для ноутбуков | 21.49 | 28.01 | 2020 | 525 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 59 | AMD Radeon RX 580 | десктопная | 20.92 | 33.28 | 2017 | 574 USD | 185 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 60 | NVIDIA GeForce GTX TITAN X | десктопная | 20. 74 74 | 49.07 | 2015 | 711 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 61 | NVIDIA GeForce RTX 2080 | десктопная | 20.73 | 69.76 | 2018 | 1277 USD | 215 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 62 | NVIDIA GeForce GTX 980M SLI | для ноутбуков | 20.56 | 38.84 | 2014 | 499 USD | 200 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 63 | NVIDIA GeForce RTX 2080 Ti | десктопная | 20.24 | 81.45 | 2018 | 1450 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 64 | NVIDIA Quadro P5000 (мобильная) | для мобильных рабочих станций | 20.24 | 80.78 | 2017 | 2137 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 65 | NVIDIA GeForce RTX 2070 Super | десктопная | 20. 24 24 | 68.11 | 2019 | 1277 USD | 215 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 66 | AMD Radeon RX 6800 | десктопная | 20.15 | 77.89 | 2020 | 1410 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 67 | NVIDIA Quadro P2000 (мобильная) | для мобильных рабочих станций | 19.98 | 52.01 | 2017 | 1477 USD | 50 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 68 | NVIDIA Quadro P4000 Max-Q | для мобильных рабочих станций | 19.62 | 33.06 | 2017 | 803 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 69 | NVIDIA GeForce GTX 1050 Ti | десктопная | 19.47 | 23.75 | 2016 | 340 USD | 70 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 70 | NVIDIA GeForce GTX 1050 Ti | десктопная | 19.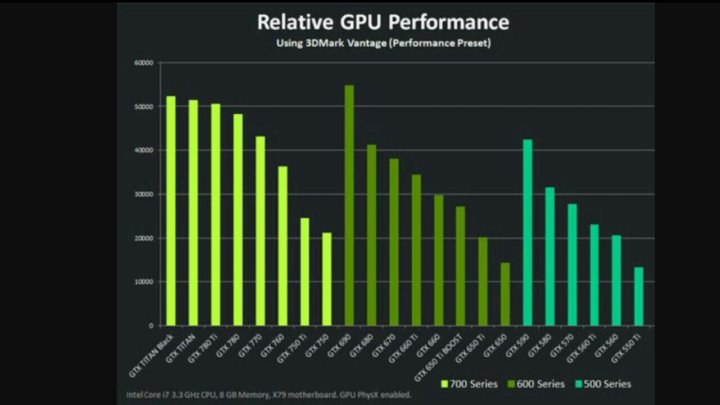 47 47 | 23.75 | 2016 | 340 USD | 70 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 71 | NVIDIA Quadro P1000 | для рабочих станций | 18.96 | 16.71 | 2017 | 301 USD | 47 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 72 | NVIDIA GeForce RTX 2070 | десктопная | 18.82 | 60.32 | 2018 | 1232 USD | 175 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 73 | NVIDIA Quadro M5000M | для мобильных рабочих станций | 18.30 | 25.93 | 2015 | 468 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 74 | NVIDIA GeForce GTX 780 Ti | десктопная | 18.15 | 34.56 | 2013 | 400 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 75 | AMD Radeon RX 6800 XT | десктопная | 18. 06 06 | 86.48 | 2020 | 1630 USD | 300 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 76 | NVIDIA Quadro P4000 (мобильная) | для мобильных рабочих станций | 17.78 | 36.83 | 2017 | 1053 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 77 | NVIDIA Quadro P4000 | для рабочих станций | 17.41 | 43.38 | 2017 | 1346 USD | 105 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 78 | NVIDIA Quadro RTX 3000 (мобильная) | для мобильных рабочих станций | 17.37 | 72.26 | 2019 | 2393 USD | 80 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 79 | NVIDIA Quadro P2000 Max-Q | для мобильных рабочих станций | 17.28 | 18.94 | 2017 | 426 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 80 | AMD Radeon RX 5500 | десктопная | 17. 17 17 | 32.56 | 2019 | 816 USD | 110 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 81 | AMD Radeon R9 FURY X | десктопная | 17.09 | 38.00 | 2015 | 670 USD | 275 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 82 | AMD Radeon RX 5500 XT | десктопная | 16.59 | 34.34 | 2019 | 877 USD | 130 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 83 | AMD Radeon Pro Vega 16 | для мобильных рабочих станций | 16.10 | 17.56 | 2018 | 511 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 84 | AMD Radeon RX 6900 XT | десктопная | 15.48 | 95.06 | 2020 | 1905 USD | 300 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 85 | AMD Radeon RX Vega 64 | десктопная | 15. 45 45 | 55.00 | 2017 | 1330 USD | 295 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 86 | NVIDIA Quadro M6000 24 GB | для рабочих станций | 15.09 | 47.45 | 2016 | 1503 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 87 | AMD Radeon Pro SSG | для рабочих станций | 14.93 | 39.37 | 2017 | 1499 USD | 350 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 88 | NVIDIA Quadro P4200 | для мобильных рабочих станций | 14.67 | 37.28 | 2018 | 1526 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 89 | NVIDIA Quadro RTX 5000 Max-Q | для мобильных рабочих станций | 14.54 | 52.76 | 2019 | 2130 USD | 80 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 90 | AMD Radeon Pro W6800 | для рабочих станций | 14. 32 32 | 72.01 | 2021 | 2800 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 91 | NVIDIA GeForce GTX 1050 | десктопная | 14.10 | 19.23 | 2016 | 342 USD | 60 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 92 | NVIDIA GeForce GTX 1050 | десктопная | 14.10 | 19.23 | 2016 | 342 USD | 60 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 93 | NVIDIA Quadro RTX 8000 | для рабочих станций | 13.90 | 73.62 | 2018 | 2920 USD | 260 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 94 | AMD Radeon R9 390X | десктопная | 13.62 | 35.71 | 2015 | 750 USD | 275 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 95 | NVIDIA Quadro T1000 (мобильная) | для мобильных рабочих станций | 13. 60 60 | 42.99 | 2019 | 1890 USD | 50 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 96 | NVIDIA Quadro RTX 4000 | для рабочих станций | 13.46 | 58.47 | 2018 | 2482 USD | 160 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 97 | NVIDIA GeForce GTX 1080 Max-Q | для ноутбуков | 13.43 | 38.28 | 2017 | 1008 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 98 | NVIDIA TITAN V CEO Edition | десктопная | 13.31 | 63.71 | 2018 | 1630 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 99 | NVIDIA GeForce GTX TITAN BLACK | десктопная | 13.21 | 34.20 | 2014 | 550 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 100 | AMD Radeon RX Vega 7 | для ноутбуков | 13. 05 05 | 15.38 | 2020 | 387 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 101 | NVIDIA GeForce RTX 3080 | десктопная | 12.90 | 92.05 | 2020 | 2077 USD | 320 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 102 | NVIDIA GeForce GTX 1060 Max-Q 6 GB | для ноутбуков | 12.80 | 36.59 | 2017 | 1010 USD | 80 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 103 | AMD Radeon RX Vega 56 | десктопная | 12.77 | 51.01 | 2017 | 1443 USD | 210 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 104 | NVIDIA GeForce GTX 960 | десктопная | 12.75 | 22.66 | 2015 | 331 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 105 | NVIDIA GeForce RTX 2080 Max-Q | для ноутбуков | 12. 73 73 | 52.11 | 2019 | 1268 USD | 80 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 106 | NVIDIA Quadro M4000 | для рабочих станций | 12.63 | 24.98 | 2015 | 603 USD | 120 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 107 | NVIDIA GeForce RTX 2070 Super Mobile | для ноутбуков | 12.49 | 64.34 | 2020 | 1443 USD | 115 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 108 | NVIDIA GeForce GTX 1650 Ti Mobile | для ноутбуков | 12.24 | 29.24 | 2020 | 892 USD | 50 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 109 | NVIDIA Quadro P5000 | для рабочих станций | 11.88 | 44.52 | 2016 | 1936 USD | 180 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 110 | AMD Radeon PRO WX 9100 | для рабочих станций | 11. 64 64 | 47.64 | 2017 | 2327 USD | 230 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 111 | NVIDIA GeForce RTX 3080 Ti | десктопная | 11.49 | 100.00 | 2020 | 2310 USD | 350 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 112 | AMD Radeon RX 570 | десктопная | 11.29 | 26.13 | 2017 | 733 USD | 120 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 113 | NVIDIA GeForce GTX 1660 Ti Max-Q | для ноутбуков | 11.12 | 33.06 | 2019 | 1037 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 114 | NVIDIA GeForce GTX 1050 Ti (мобильная) | для ноутбуков | 11.02 | 22.20 | 2017 | 545 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 115 | NVIDIA Quadro M5000 | для рабочих станций | 10. 83 83 | 35.62 | 2015 | 1300 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 116 | AMD Radeon R9 295X2 | десктопная | 10.79 | 31.54 | 2014 | 600 USD | 500 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 117 | AMD Radeon RX 5300 | десктопная | 10.79 | 27.56 | 2020 | 1037 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 118 | NVIDIA GeForce RTX 2060 (мобильная) | для ноутбуков | 10.65 | 42.58 | 2019 | 1250 USD | 115 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 119 | NVIDIA Quadro K6000 | для рабочих станций | 10.60 | 30.48 | 2013 | 731 USD | 225 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 120 | NVIDIA GeForce RTX 2070 Max-Q | для ноутбуков | 10. 51 51 | 45.58 | 2019 | 1311 USD | 80 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 121 | NVIDIA Quadro GP100 | для рабочих станций | 10.15 | 58.31 | 2016 | 2969 USD | 235 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 122 | NVIDIA Quadro M6000 | для рабочих станций | 10.10 | 42.27 | 2015 | 1733 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 123 | NVIDIA Quadro RTX 5000 | для рабочих станций | 9.94 | 61.00 | 2018 | 3283 USD | 230 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 124 | AMD Radeon RX 560X (мобильная) | для ноутбуков | 9.92 | 20.01 | 2017 | 520 USD | 65 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 125 | NVIDIA Quadro RTX 5000 (мобильная) | для мобильных рабочих станций | 9. 89 89 | 55.63 | 2019 | 3065 USD | 110 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 126 | NVIDIA Quadro M4000M | для мобильных рабочих станций | 9.75 | 25.10 | 2015 | 832 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 127 | AMD Radeon RX Vega 9 | для ноутбуков | 9.46 | 11.63 | 2017 | 302 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 128 | NVIDIA Quadro P2200 | для рабочих станций | 9.39 | 35.95 | 2019 | 2230 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 129 | NVIDIA GeForce RTX 2080 Super Mobile | для ноутбуков | 9.33 | 64.55 | 2020 | 1671 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 130 | AMD Radeon Pro 5300 | для рабочих станций | 9. 28 28 | 28.20 | 2020 | 1749 USD | 85 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 131 | NVIDIA Quadro RTX 4000 (мобильная) | для мобильных рабочих станций | 9.26 | 48.42 | 2019 | 2890 USD | 110 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 132 | NVIDIA GeForce GTX 980M | для ноутбуков | 9.20 | 27.42 | 2014 | 583 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 133 | NVIDIA Tesla T4 | для рабочих станций | 9.19 | 41.60 | 2018 | 2569 USD | 70 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 134 | AMD Radeon RX 5300M | для ноутбуков | 8.94 | 14.58 | 2019 | 525 USD | 85 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 135 | AMD Radeon RX Vega 8 (Ryzen 4000) | для ноутбуков | 8. 89 89 | 16.77 | 2020 | 631 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 136 | NVIDIA Quadro P6000 | для рабочих станций | 8.50 | 58.04 | 2016 | 3527 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 137 | AMD Radeon RX Vega M GH | для ноутбуков | 8.34 | 25.44 | 2018 | 1031 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 138 | NVIDIA Quadro M2000M | для мобильных рабочих станций | 8.24 | 13.37 | 2015 | 363 USD | 55 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 139 | AMD Radeon R9 370 | десктопная | 7.90 | 17.71 | 2015 | 380 USD | 110 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 140 | AMD Radeon RX 580 2048SP | десктопная | 7. 78 78 | 28.95 | 2018 | 1373 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 141 | NVIDIA GeForce GTX 970M SLI | для ноутбуков | 7.77 | 38.94 | 2014 | 1326 USD | 162 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 142 | NVIDIA GeForce GTX TITAN | десктопная | 7.70 | 31.98 | 2013 | 806 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 143 | AMD Radeon Pro WX Vega M GL | для мобильных рабочих станций | 7.59 | 22.69 | 2018 | 1359 USD | 65 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 144 | AMD Radeon RX 560 (мобильная) | для ноутбуков | 7.34 | 15.07 | 2017 | 468 USD | 55 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 145 | AMD FirePro W7100 | для рабочих станций | 7. 19 19 | 21.73 | 2014 | 660 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 146 | NVIDIA Quadro P3200 | для мобильных рабочих станций | 7.14 | 31.90 | 2017 | 2122 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 147 | AMD Radeon Pro 5500 XT | для рабочих станций | 7.10 | 31.09 | 2020 | 2499 USD | 125 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 148 | AMD FirePro W8100 | для рабочих станций | 7.01 | 27.13 | 2014 | 987 USD | 220 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 149 | AMD FirePro W4300 | для рабочих станций | 6.97 | 10.85 | 2015 | 332 USD | 50 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 150 | NVIDIA Quadro M5500 | для мобильных рабочих станций | 6. 92 92 | 29.69 | 2016 | 1700 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 151 | AMD Radeon Pro 5500M | для мобильных рабочих станций | 6.90 | 24.80 | 2019 | 1950 USD | 85 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 152 | NVIDIA Quadro M2000 | для рабочих станций | 6.74 | 14.94 | 2016 | 602 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 153 | NVIDIA GeForce GTX 1070 Max-Q | для ноутбуков | 6.56 | 26.07 | 2017 | 1244 USD | 115 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 154 | AMD Radeon R7 370 | десктопная | 6.50 | 16.67 | 2015 | 418 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 155 | NVIDIA TITAN RTX | десктопная | 6. 47 47 | 70.73 | 2018 | 2579 USD | 280 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 156 | NVIDIA Quadro T1000 | для рабочих станций | 6.44 | 24.32 | 2019 | 2048 USD | 50 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 157 | NVIDIA Quadro K5200 | для рабочих станций | 6.44 | 22.20 | 2014 | 753 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 158 | NVIDIA GeForce GTX 1650 Ti Max-Q | для ноутбуков | 6.42 | 23.42 | 2020 | 1183 USD | 50 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 159 | AMD Radeon PRO WX 2100 | для мобильных рабочих станций | 6.35 | 6.57 | 2018 | 343 USD | 35 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 160 | NVIDIA Quadro M3000M | для мобильных рабочих станций | 6. 29 29 | 21.24 | 2015 | 981 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 161 | AMD FirePro W7000 | для рабочих станций | 6.26 | 16.03 | 2012 | 337 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 162 | AMD Radeon RX Vega 6 (Ryzen 4000) | для ноутбуков | 6.16 | 13.88 | 2020 | 717 USD | − | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 163 | NVIDIA GeForce GTX 1650 Max-Q | для ноутбуков | 6.03 | 22.09 | 2019 | 1185 USD | 30 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 164 | AMD Radeon Pro VII | для рабочих станций | 6.00 | 63.21 | 2020 | 4876 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 165 | NVIDIA GeForce RTX 2070 (мобильная) | для ноутбуков | 5. 98 98 | 46.33 | 2019 | 1758 USD | 115 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 166 | NVIDIA Quadro P5200 | для мобильных рабочих станций | 5.91 | 45.39 | 2017 | 3894 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 167 | AMD Radeon R9 270X | десктопная | 5.82 | 18.42 | 2013 | 350 USD | 180 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 168 | AMD FirePro W7170M | для мобильных рабочих станций | 5.60 | 14.44 | 2015 | 600 USD | 100 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 169 | NVIDIA Quadro P2000 | для рабочих станций | 5.59 | 27.26 | 2017 | 2108 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 170 | NVIDIA GeForce GTX 1050 Ti Max-Q | для ноутбуков | 5. 59 59 | 20.64 | 2018 | 1140 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 171 | NVIDIA Quadro T2000 (мобильная) | для мобильных рабочих станций | 5.57 | 23.31 | 2019 | 2221 USD | 60 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 172 | AMD Radeon RX 560 | десктопная | 5.41 | 13.50 | 2017 | 596 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 173 | AMD Radeon Pro 5300M | для мобильных рабочих станций | 5.37 | 21.56 | 2019 | 2068 USD | 85 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 174 | AMD Radeon Pro WX 3200 | для мобильных рабочих станций | 5.30 | 9.50 | 2019 | 740 USD | 65 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 175 | NVIDIA GeForce RTX 3090 | десктопная | 5. 29 29 | 97.72 | 2020 | 3163 USD | 350 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 176 | NVIDIA Quadro K1200 | для рабочих станций | 5.27 | 10.76 | 2015 | 319 USD | 45 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 177 | NVIDIA GeForce RTX 2080 (мобильная) | для ноутбуков | 5.24 | 56.66 | 2019 | 2003 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 178 | NVIDIA GeForce RTX 2060 Max-Q | для ноутбуков | 5.24 | 36.67 | 2019 | 1680 USD | 65 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 179 | AMD FirePro W9000 | для рабочих станций | 5.24 | 23.02 | 2012 | 839 USD | 274 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 180 | NVIDIA RTX A2000 | десктопная | 5. 11 11 | 53.99 | 2021 | 2539 USD | 70 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 181 | AMD Radeon RX 560X | десктопная | 5.09 | 15.46 | 2018 | 907 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 182 | AMD Radeon RX 5500M | для ноутбуков | 5.00 | 15.19 | 2019 | 998 USD | 85 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 183 | AMD Radeon R9 270 | десктопная | 4.92 | 16.15 | 2013 | 317 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 184 | AMD Radeon Pro 455 | для мобильных рабочих станций | 4.71 | 11.67 | 2016 | 696 USD | 35 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 185 | NVIDIA GeForce GTX 690 | десктопная | 4. 67 67 | 21.01 | 2012 | 569 USD | 300 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 186 | AMD FirePro S7150 | для рабочих станций | 4.65 | 23.54 | 2016 | 1683 USD | 150 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 187 | AMD FirePro S10000 | для рабочих станций | 4.56 | 19.63 | 2012 | 699 USD | 375 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 188 | NVIDIA Quadro K2200 | для рабочих станций | 4.54 | 13.29 | 2014 | 418 USD | 68 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 189 | AMD Radeon Pro 555X | для мобильных рабочих станций | 4.42 | 12.13 | 2017 | 894 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 190 | NVIDIA GeForce GTX 860M SLI | для ноутбуков | 4.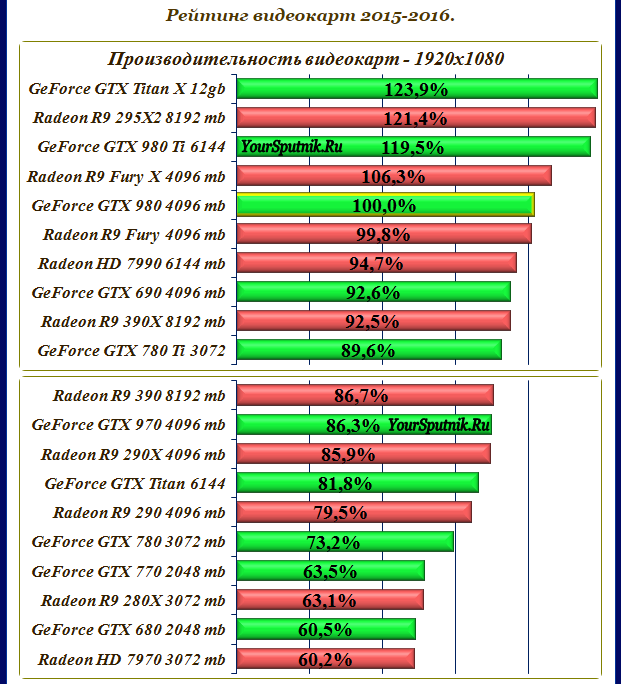 41 41 | 18.62 | 2014 | 489 USD | 120 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 191 | NVIDIA GeForce GTX TITAN Z | десктопная | 4.30 | 34.11 | 2014 | 1785 USD | 375 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 192 | AMD Radeon HD 7970 | десктопная | 4.30 | 19.68 | 2011 | 542 USD | 250 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 193 | AMD FirePro W9100 | для рабочих станций | 4.25 | 29.07 | 2014 | 1744 USD | 275 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 194 | AMD Radeon Pro 555 | для мобильных рабочих станций | 4.25 | 11.78 | 2017 | 894 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 195 | NVIDIA GeForce GTX 970M | для ноутбуков | 4. 24 24 | 22.03 | 2014 | 848 USD | 81 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 196 | AMD Radeon Pro WX 5100 | для рабочих станций | 4.24 | 20.95 | 2016 | 1797 USD | 75 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 197 | AMD FirePro S9050 | для рабочих станций | 4.20 | 14.67 | 2014 | 550 USD | 225 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 198 | AMD Radeon Pro Vega 56 | для рабочих станций | 4.19 | 45.79 | 2017 | 4999 USD | 210 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 199 | AMD Radeon RX 550 | десктопная | 4.15 | 10.24 | 2017 | 540 USD | 50 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 200 | AMD Radeon HD 7870 | десктопная | 4.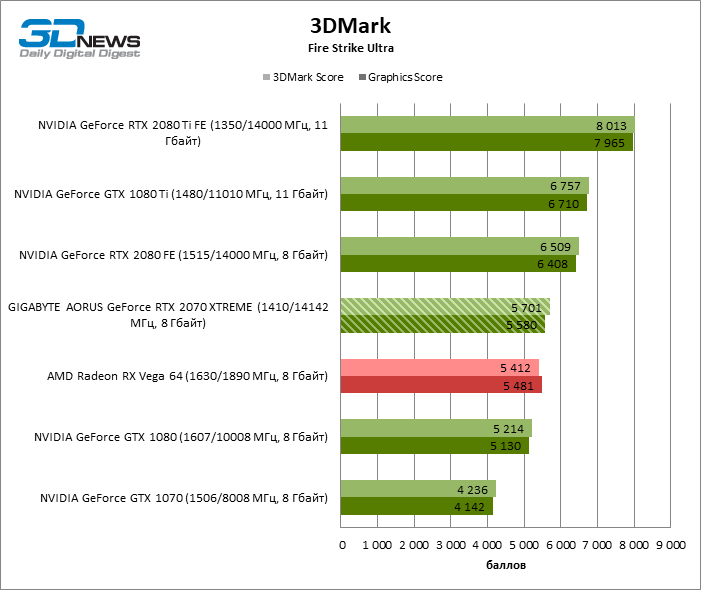 05 05 | 17.48 | 2012 | 452 USD | 200 W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
выбираем лучшие из девяти новых GPU / Хабр
Весной 2021 года NVIDIA представила новую линейку видеокарт RTX Ax000 и Ax0 на архитектуре Ampere, с тензорными ядрами третьего поколения. На тот момент в Selectel уже можно было арендовать
выделенные и облачные серверы с GPUTesla M60, T4, V100 и даже топовыми NVIDIA A100.
Поскольку мы стараемся предоставлять клиентам только актуальное железо с современными технологиями, решили, что пора обновить линейку видеокарт. Предлагать все анонсированные NVIDIA видеокарты нерационально как для нас, так и для клиентов. Под катом расскажу, как мы выбирали лучших из лучших и поделюсь результатами нашего бенчмарка на тестовой сборке.
Подход, с помощью которого мы в Selectel выбираем железо — видеокарты, процессоры и другие комплектующие, — довольно прост. Мы предполагаем, что клиент хочет решить свои бизнес-задачи эффективно и с минимальными затратами. Соответственно, отталкиваемся от следующей формулы:
Соответственно, отталкиваемся от следующей формулы:
По ней же мы выбирали лидеров среди новых видеокарт.
Какие видеокарты рассматривали
Сравнивали девять GPU: видеокарты RTX от А2000 до А6000, А10, А16, А30, А40 и A100 PCIe. A2000 вышла только летом этого года, но это не помешало рассмотреть характеристики чипа и протестировать образец.Тут у нас «семья» RTX Ax000 — от старшей A5000 до младшей А2000.
Все участники тестирования — серверные видеокарты, десктопных GeForce RTX 3080 и 3090 в списке нет. Эти карты (а если быть точным, установка драйверов NVIDIA) запрещены к использованию в серверах в дата-центрах. Производитель строго следит за соблюдением ограничений: санкции за нарушение применяются не только к провайдеру, но и клиенту, который арендует сервер с десктопным железом или устанавливает на нем ПО NVIDIA.
Для оценки видеокарт мы отталкивались от нескольких характеристик, которые важны для решения задач, часто возникающих у клиентов. То есть смотрели на то, за что, вообще, берут эти GPU. Назначение ядер представлено в упрощенной форме, каждый тип влияет на производительность видеокарты.
То есть смотрели на то, за что, вообще, берут эти GPU. Назначение ядер представлено в упрощенной форме, каждый тип влияет на производительность видеокарты.
Среди них:
- Число ядер CUDA (для тех, кто не знает, это условное обозначение скалярных вычислительных блоков в видеочипах NVIDIA). Чем больше ядер, тем лучше карта справляется с работой с графикой и вычислениями в целом.
- Число тензорных ядер, которые динамически оптимизируют вычисления и здорово справляются с нагрузками, характерными для работы с ИИ, перемножением матриц для обучения нейросетей и анализа данных.
- Число RT (Ray Tracing) ядер, которые обеспечивают высокую точность рендеринга.
К слову, NVIDIA не всегда указывает точное количество CUDA, RT и тензорных ядер. Для сравнения мы использовали данные сторонних источников.
- Объем памяти.
- Пропускная способность памяти. Эти два пункта логично влияют на производительность видеокарты.
- Поддержка виртуальных GPU VDI.
 Этот пункт важен, поскольку инфраструктуру виртуальных рабочих столов нередко используют наши клиенты.
Этот пункт важен, поскольку инфраструктуру виртуальных рабочих столов нередко используют наши клиенты. - Энергопотребление. Это, скорее, пунктик для нас: для дата-центра этот показатель важен при выборе корпуса, питания для сервера и стойки.
 Этот пункт важен, поскольку инфраструктуру виртуальных рабочих столов нередко используют наши клиенты.
Этот пункт важен, поскольку инфраструктуру виртуальных рабочих столов нередко используют наши клиенты.Вот что получилось по цифрам:
Данные не предоставляются NVIDIA, взяты из открытых сторонних источников (pny.eu, techpowerup.com).
Какие выводы можно сделать из этой таблички
Для линейки RTX Ax000 характеристики растут почти линейно с ростом индекса модели.
A16 — это четыре видеокарты в одной. NVIDIA позиционирует устройство как специальное решение для VDI.
A30, на первый взгляд, менее производительная, чем A10, однако тип памяти HBM2 имеет большую пропускную способность. NVIDIA позиционирует A30 как решение для ИИ. По обоим устройствам компания не публикует данные по количеству тензорных и других ядер (характеристики получены из сторонних источников).
В сравнение с другими видеокартами в таблице, топовое решение A100 в форм-факторе PCIe имеет максимальную пропускную способность памяти и максимальное количество тензорных ядер, что ожидаемо. Очевидно, что основное назначение этой GPU — работа с искусственным интеллектом и сложными вычислениями. В линейке NVIDIA это самая производительная видеокарта на сегодняшний день, особенно версия с 80 ГБ памяти в форм-факторе SXM. Но последняя распаивается на плате, и из соображений унификации мы рассматривали только вариант в форм-факторе PCIe.
Очевидно, что основное назначение этой GPU — работа с искусственным интеллектом и сложными вычислениями. В линейке NVIDIA это самая производительная видеокарта на сегодняшний день, особенно версия с 80 ГБ памяти в форм-факторе SXM. Но последняя распаивается на плате, и из соображений унификации мы рассматривали только вариант в форм-факторе PCIe.
А сколько стоит
Следуя уже озвученной формуле по выбору комплектующих, рассмотрим цены. Сложно писать о них в 2021 году, который запомнился кризисом чипов и постоянными перебоями поставок.
Точных цифр не будет по двум причинам. Во-первых, это коммерческая тайна. Во-вторых, и это главное, с момента анонсирования карт весной цены успели измениться (и, уверен, продолжат меняться далее).
Будем использовать такой подход: примем за эталон GPU A5000 — его цена в сравнительной таблице будет равняться 1 «попугаю». Цены на остальные карты я представлю через отношение к цене A5000. A10 и A16 в близком ценовом диапазоне, поэтому «стоят» столько же.
На этом этапе соотношение цен и заявленных характеристик ожидаемо. Первый кандидат на добавление в линейку видеокарт Selectel, на роль младшей модели, – А2000. Также вызывает интерес паритет между A5000, A10 и A16.
Изнанка наших GPU.Перейдем к тестированию производительности претендентов.
Тестирование видеокарт
Проводить тесты оборудования — обычная практика для Selectel. Мы используем большое количество железа в различных продуктах компании, поэтому тестируем его как на совместимость друг с другом и ПО, так и на производительность.
Для этого у нас есть своя «лаборатория» — Selectel Lab. Некоторое оборудование мы даже предоставляем клиентам для бесплатного тестирования в их проектах. Из свежих примеров: отдаем на тест настоящего монстра DGX A100 c 8 одноименными видеокартами. Подробней о его бенчмарке можно прочитать по ссылке.
Для тестирования новых видеокарт мы собрали тестовые серверы с двумя мощными процессорами от Intel и достаточным количеством оперативной памяти.
Характеристики следующие:
- 2 × Intel® Xeon® Gold 6240: 18 ядер с частотой 2.6 ГГц
- 192–384 ГБ DDR4;
- 240–480 ГБ SSD SATA;
- 1 × выбранный GPU
Бенчмарки, которые мы выбрали:
GeekBench 5 — общий тест, моделирующий выполнение задач и определяющий производительность GPU.
AI-benchmark — тест производительности, который замеряет скорость обучения и применения различных нейронных сетей на задачах распознавания и классификации.
V-Ray Benchmark — тест для проверки скорости рендеринга.
ffmpeg NVENC — тест на производительность при транскодинге видео.
Результаты тестирования представлены в таблице. Выделили лидеров по каждому пункту.
На время написания статьи видеокарт A16 и RTX A6000 на руках у нас не было, поэтому в таблицу они не вошли. Их бенчмарк планируется позже.
Лидеры бенчмарка
По результатам тестирования A5000 побеждает по соотношению цены и качества. Лучший результат в OpenCL Compute Score, незначительно уступает более дорогим A40 и A100 в CUDA Compute Score и подойдет для работы с графикой. Второе место в AI-benchmark после A100. Лидер в V-Ray тесте на скорость рендеринга, лидер в тесте на транскодинг. Поддерживает VDI. Безоговорочно наш вариант, если сопоставить с таблицей цен.
Лучший результат в OpenCL Compute Score, незначительно уступает более дорогим A40 и A100 в CUDA Compute Score и подойдет для работы с графикой. Второе место в AI-benchmark после A100. Лидер в V-Ray тесте на скорость рендеринга, лидер в тесте на транскодинг. Поддерживает VDI. Безоговорочно наш вариант, если сопоставить с таблицей цен.
A2000 — в пять раз дешевле A5000, при этом демонстрирует приемлемые результаты бенчмарка для базовой модели. Не поддерживает VDI, но подходит для работы с графикой и задач ИИ.
A4000 — «середнячок» по производительности между A2000 и A5000, не поддерживает VDI, но в остальном выдерживает критику по соотношению цены и результатов бенчмарков.
A100, как я уже писал, — безоговорочный лидер для работы с искусственным интеллектом, обучением моделей, инференсом, анализом данных и сложными вычислениями. Оптимален для инфраструктуры удаленных рабочих столов.
Остальные GPU при сравнении бенчмарков и цены показали меньшие результаты.
Финал
На пьедестале победителей (которые, кстати, уже можно заказать на сайте) — четыре видеокарты.
 Нашей формуле соответствуют RTX A2000, RTX A4000, RTX A5000 и A100.
Нашей формуле соответствуют RTX A2000, RTX A4000, RTX A5000 и A100.Мы хотим предоставить клиентам свободу выбора: от недорогих серверов с одним GPU до кластеров с несколькими видеокартами на борту. Если нужен «крепкий» сервер для рендеринга, добавьте в него A2000 — выполнит работу на пять и не «съест» бюджет. А для амбициозных задач со сложными вычислениями, ИИ, крупными VDI-проектами есть сервер с восемью А100. Уже есть готовый конфиг. Несмотря на наш строгий отбор, мы готовы предоставить клиенту любую карту NVIDIA (кроме десктопных RTX 3080 и 3090, конечно).
Выбранные карты в наличии на складе, а это значит, что кастомный сервер с ними вы получите в течение пяти дней. Если подойдет уже собранный сервер с GPU, он будет готов для работы уже через 2-60 минут.
Технический обзор Surface Book 3 GPU — Surface
- Статья
- Чтение занимает 9 мин
Оцените свои впечатления
Да Нет
Хотите оставить дополнительный отзыв?
Отзывы будут отправляться в корпорацию Майкрософт. Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Отправить
Спасибо!
В этой статье
Введение
Surface Book 3, самый мощный пока выпущенный ноутбук Surface, интегрирует полностью модернизированные возможности вычислений и графики в свой знаменитый съемный форм-фактор. Под руководством четырехъядерного 10-го поколения Intel® Core™ i7 и NVIDIA® Quadro RTX™ 3000 графических процессоров (GPU) на 15-дюймовой модели, Surface Book 3 поставляется в широком диапазоне конфигураций для потребителей, творческих специалистов, архитекторов, инженеров и ученых данных. В этой статье объясняются основные различия между конфигурациями GPU для 13-дюймовых и 15-дюймовых моделей Surface Book 3.
Значительным дифференциатором Surface Book трех моделей является конфигурация GPU. Помимо интегрированного GPU Intel, встроенного во все модели, все устройства, кроме начального уровня 13,5-дюймового core i5, также оснащены дискретным GPU NVIDIA с max-Q Design, который включает функции, оптимизируя энергоэффективность для мобильных форм-факторов.
Встроенный в базу клавиатуры, дополнительный GPU NVIDIA предоставляет расширенные возможности визуализации графики и поставляется в двух основных конфигурациях: GeForce® GTX® 1650/1660 Ti для потребителей или творческих специалистов и Quadro RTX 3000 для творческих специалистов, инженеров и других бизнес-специалистов, которым необходимы расширенные графики или возможности глубокого обучения. В этой статье также описано, как оптимизировать использование GPUs приложения, указав, какие приложения должны использовать интегрированный iGPU по сравнению с дискретным GPU NVIDIA.
Surface Book 3 GPUs
В этом разделе описываются интегрированные и дискретные GPUs для Surface Book 3 моделей. Сведения о конфигурации всех моделей со ссылкой на приложение A: Surface Book 3 SKUs.
Сведения о конфигурации всех моделей со ссылкой на приложение A: Surface Book 3 SKUs.
Intel Iris™ Plus Graphics
Интегрированный GPU (iGPU), включенный во все модели Surface Book 3, включает более широкий графический движок и переработанный контроллер памяти с поддержкой LPDDR4X. Установленный в качестве вторичного GPU на большинстве Surface Book 3 моделей, Intel Iris Plus Graphics выполняет функции сингулярного GPU в основной модели i5 с диагональю 13,5 дюйма. Хотя номинально устройство начального уровня в строке Surface Book 3, оно предоставляет расширенные графические возможности, позволяющие потребителям, любителям и онлайн-создателям запускать новейшее программное обеспечение производительности, например Adobe Creative Cloud, или наслаждаться играми в 1080p.
NVIDIA GeForce GTX 1650
NVIDIA GeForce GTX 1650 с помощью дизайна Max-Q обеспечивает крупное обновление основного мультипроцессора потоковой передачи для более эффективного обработки сложной графики современных игр. Одновременное выполнение операций плавающей точки и многостройки повышает производительность в вычислительных нагрузках современных игр. Новая архитектура единой памяти с двукратным кэшом предшественника позволяет улучшить производительность сложных современных игр. Новые улучшения в области затенки повышают производительность, повышают качество изображения и обеспечивают новые уровни геометрической сложности.
Одновременное выполнение операций плавающей точки и многостройки повышает производительность в вычислительных нагрузках современных игр. Новая архитектура единой памяти с двукратным кэшом предшественника позволяет улучшить производительность сложных современных игр. Новые улучшения в области затенки повышают производительность, повышают качество изображения и обеспечивают новые уровни геометрической сложности.
NVIDIA GeForce GTX 1660 Ti
Чем быстрее GeForce GTX 1650, тем быстрее GeForce GTX 1660 Ti обеспечивает Surface Book 3 дополнительные улучшения производительности и включает в себя новый и обновленный кододер NVIDIA, что делает его лучше для потребителей, геймеров, живых стримеров и творческих специалистов.
Благодаря 6 ГБ графической памяти GDDR6, Surface Book 3 модели, оснащенные NVIDIA GeForce GTX 1660 TI, обеспечивают превосходные скорости на передовом программном обеспечении производительности бизнеса и популярных играх, особенно при запуске самых современных названий или livestreaming.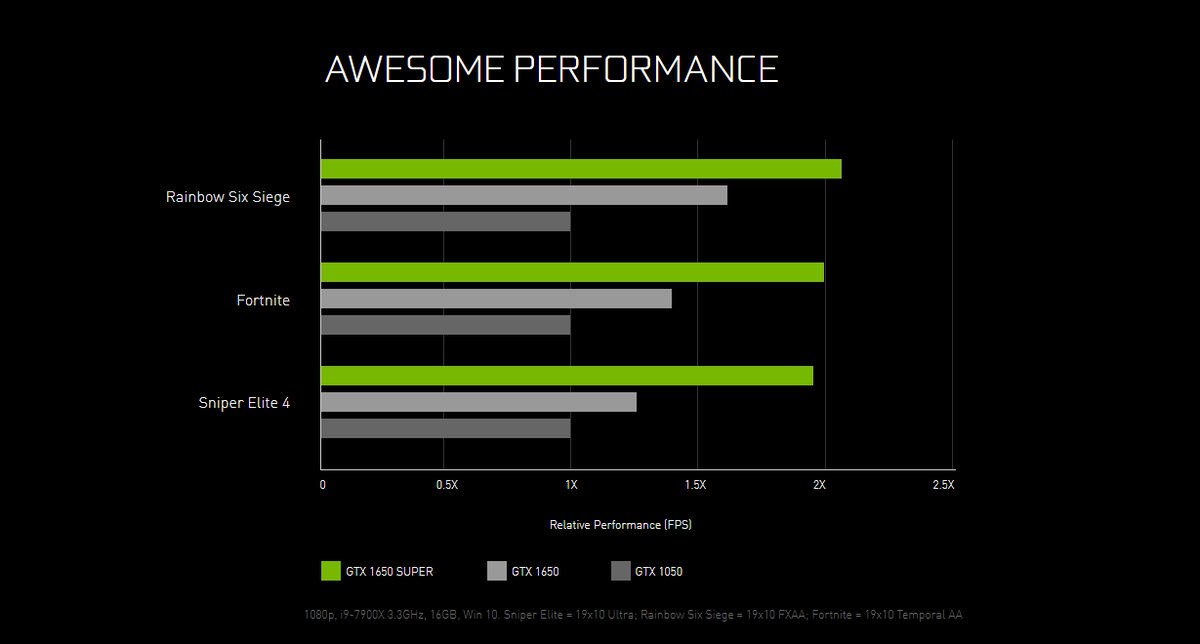 С необязательным SSD 2 TB (доступно только в США), 15-дюймовая модель с GeForce GTX 1660 Ti обеспечивает наибольшее хранилище любого устройства Surface Book 3.
С необязательным SSD 2 TB (доступно только в США), 15-дюймовая модель с GeForce GTX 1660 Ti обеспечивает наибольшее хранилище любого устройства Surface Book 3.
NVIDIA Quadro RTX 3000
NVIDIA Quadro RTX 3000 открывает несколько ключевых функций для профессиональных пользователей: отрисовку трассировки лучей и ускорение ИИ, а также расширенные показатели графики и вычислений. Сочетание 30 ядер RT, 240 ядер тенсора и 6 ГБ графической памяти GDDR6 позволяет использовать несколько расширенных рабочих нагрузок, включая рабочие процессы с питанием от «Аль», создание 3D-контента, усовершенствование редактирования видео, профессиональное вещание и рабочие процессы с несколькими приложениями. Enterprise оборудование и поддержка программного обеспечения интегрируют средства развертывания для максимального простоя и минимизации требований к ИТ-поддержке. Сертифицированные для самых современных программных средств в мире, драйверы Quadro оптимизированы для профессиональных приложений и настроены, протестированы и проверены для обеспечения сертификации приложений, стабильности, надежности, доступности и поддержки с расширенной доступностью продукта.
Сравнение GPUs в Surface Book 3
GPUs NVIDIA обеспечивают пользователям большую производительность для игр, livestreaming и создания контента. Продукты GeForce GTX отлично подходит для геймеров и создателей контента. Продукты Quadro RTX ориентированы на профессиональных пользователей, обеспечивают большую производительность в играх и создании контента, а также добавляют следующие функции:
- Ускорение RTX для отслеживания лучей и ИИ. Это позволяет отрисовка объектов и сред с физическими точными тенями, отражениями и преломлями. А его аппаратные возможности ускоренного ИИ означает, что расширенные функции на основе ИИ в популярных приложениях могут работать быстрее, чем когда-либо ранее.
- Enterprise оборудования, драйверов и поддержки, а также сертификации приложений ISV.
- Функции ИТ-управления, включая дополнительный уровень специальных корпоративных средств для удаленного управления, которые помогают увеличить время простоя и свести к минимуму требования к ИТ-поддержке.

Если вы не засчитаете себя в рядах специалистов в области разработки, дизайна, архитектуры или науки о данных, Surface Book 3, оснащенные графическими возможностями NVIDIA GeForce, скорее всего, будут отвечать вашим потребностям. И наоборот, если вы уже работаете или хотите присоединиться к профессии, которая требует высокоразвитых возможностей графики в переносном форм-факторе, который позволяет работать из любого места, Surface Book 3 с Quadro RTX 3000 заслуживает серьезного внимания. Дополнительные сведения можно найти в техническом Surface Book 3 Quadro RTX 3000.
Таблица 1: Дискретные GPUs на Surface Book 3
| GeForce GTX 1650 | GeForce GTX 1660 Ti | Quadro RTX 3000 | |
|---|---|---|---|
| Целевые пользователи | Геймеры, любители и создатели в Интернете | Геймеры, творческие специалисты и создатели в Интернете | Творческие специалисты, архитекторы, инженеры, разработчики, специалисты по данным |
| Рабочий процесс | Графический дизайн Фотография Видео | Графический дизайн Фотография Видео | Рабочий процесс с питанием от al Сертификация приложений Видео с высоким уровнем повторной записи Pro вещания Рабочий процесс с несколькими приложениями |
| Ключевые приложения | Adobe Creative Suite | Adobe Creative Suite | Adobe Creative Suite Autodesk AutoCAD Dassault Systemes SolidWorks |
| Ускорение GPU | Обработка видео и изображений | Обработка видео и изображений | Отслеживание лучей + AI + 6K видео Pro вещания Enterprise поддержки |
Таблица2. Технические характеристики GPU на Surface Book 3
Технические характеристики GPU на Surface Book 3
| GeForce GTX 1650 | GeForce GTX 1660 Ti | Quadro RTX 3000 | |
|---|---|---|---|
| Ядра обработки NVIDIA CUDA | 1024 | 1536 | 1920 |
| NVIDIA Tensor Cores | Нет | Нет | 240 |
| NVIDIA RT Cores | Нет | Нет | 30 |
| Память GPU | 4 ГБ | 6 ГБ | 6 ГБ |
| Пропускная способность памяти (GB/sec) | До 112 | До 288 | До 288 |
| Тип памяти | GDDR5 | GDDR6 | GDDR6 |
| Интерфейс памяти | 128-bit | 192-bit | 192-bit |
| Boost clock MHz | 1245 | 1425 | 1305 |
| Базовые часы (MHz) | 1020 | 1245 | 765 |
| Отслеживание лучей в режиме реального времени | Нет | Нет | Да |
| Ускорение оборудования ИИ | Нет | Нет | Да |
| Аппаратный коддер | Да | Да | Да |
| Драйвер готовности к игре (GRD) | Да 1 | Да 1 | Да 2 |
| Драйвер Studio (SD) | Да 1 | Да 1 | Да 1 |
| Оптимальный драйвер для Enterprise (ODE) | Нет | Нет | Да |
| Драйвер новых функций Quadro (QNF) | Нет | Нет | Да |
API Microsoft DirectX 12, API Vulkan, Open GL 4. 6 6 | Да | Да | Да |
| Защита цифрового контента с высокой пропускной способностью (HDCP) 2.2 | Да | Да | Да |
| Повышение GPU NVIDIA | Да | Да | Да |
- Рекомендуется
- Поддерживается
Оптимизация мощности и производительности Surface Book 3
Windows 10 включает режим saver батареи с ползунком производительности, который позволяет повысить производительность приложения (сдвинув его вправо) или сохранить время автономной работы (сдвинув его влево). Surface Book 3 реализует эту функцию алгоритмически для оптимизации мощности и производительности в следующих компонентах:
- Регистры энергоэффективности ЦП (технология смены скорости Intel) и другие параметры настройки SoC для максимальной эффективности.
- Fan Maximum RPM с четырьмя режимами: тихой, номинальной, производительной и максимальной.
- Крышки мощности процессора (PL1/PL2).
- Ограничения IA Turbo процессора.

По умолчанию, когда батарея опускается ниже 20 процентов, saver батареи регулирует параметры, чтобы продлить срок службы батареи. При подключении к мощности Surface Book 3 по умолчанию для параметров «Лучшая производительность», чтобы обеспечить работу приложений в режиме высокой производительности на вторичном GPU NVIDIA, присутствуют во всех системах i7 Surface Book 3.
Использование параметров по умолчанию рекомендуется для оптимальной производительности при использовании в качестве ноутбука или отсоединения в режиме планшета или студии. Вы можете получить доступ к saver батареи, выбрав значок батареи справа от панели задач.
Режим игры
Surface Book 3 включает новый режим игры, который автоматически выбирает максимальные параметры производительности при запуске.
Сейф Detach
Новые в Surface Book 3, приложения, включенные для Сейф Detach, позволяют отключиться во время использования GPU приложения. Для поддерживаемых приложений, таких как World of Warcraft, ваша работа перемещается в iGPU.
Для поддерживаемых приложений, таких как World of Warcraft, ваша работа перемещается в iGPU.
Изменение параметров приложения, чтобы всегда использовать определенный GPU
Вы можете переключаться между энергосберегаемой, но все еще способной встроенной графикой Intel и более мощным дискретным GPU NVIDIA и связать GPU с определенным приложением. По умолчанию Windows 10 автоматически выбирает соответствующий GPU, назначая графически требующие приложения дискретным GPU NVIDIA. В большинстве случаев нет необходимости вручную настраивать эти параметры. Однако если вы часто отсоединяем и повторно отсоединяем дисплей от базы клавиатуры при использовании графического приложения, обычно необходимо закрыть приложение до отсоединения. Чтобы включить непрерывное использование приложения, не закрывая его каждый раз, когда вы отсоедините или повторно прикрепите дисплей, вы можете назначить его интегрированному GPU, хотя и с некоторой потерей производительности графики.
В некоторых случаях Windows 10 может назначить графически требующим приложения iGPU; например, если приложение не полностью оптимизировано для гибридной графики. Чтобы исправить это, можно вручную назначить приложение дискретным GPU NVIDIA.
Чтобы исправить это, можно вручную назначить приложение дискретным GPU NVIDIA.
Настройка приложений с помощью настраиваемых параметров каждого GPU:
Перейдите Параметры > **** > системный дисплей и выберите графические Параметры.
- Для настольной Windows выберите классический обзор приложенийи > **** найдите ее.
- Для приложения UWP выберите универсальное приложение, а затем выберите приложение из выпадаемого списка.
Выберите Добавить, чтобы создать новую запись в списке для выбранной программы, выберите Параметры для открытия спецификаций графики, а затем выберите нужный вариант.
Чтобы проверить, какой GPU используется для каждого приложения, откройте диспетчер задач, выберите Performance и просмотреть столбец GPU Engine.
Приложение A: Surface Book 3 SKUs
| Display | Процессор | Графический процессор | ОЗУ | Storage |
|---|---|---|---|---|
| 13,5-дюймовый | Четырехъядерный 10-й gen Core i5-1035G7 | Intel Iris™ Plus Graphics | 16 LPDDR4x | 256 ГБ |
| 13,5-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA GeForce GTX 1650.  Max-Q Design с 4 ГБ графической памяти GDDR5 Max-Q Design с 4 ГБ графической памяти GDDR5 | 16 LPDDR4x | 256 ГБ |
| 13,5-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA GeForce GTX 1650. Max-Q Design с 4 ГБ графической памяти GDDR5 | 32 LPDDR4x | 512 ГБ |
| 13,5-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA GeForce GTX 1650. Max-Q Design с 4 ГБ графической памяти GDDR5 | 32 LPDDR4x | 1 ТБ |
| 15-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA GeForce GTX 1660 Ti. Max-Q Design с графической памятью GDDR6 с 6 ГБ | 16 LPDDR4x | 256 ГБ |
| 15-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA GeForce GTX 1660 Ti. Max-Q Design с графической памятью GDDR6 с 6 ГБ | 32 LPDDR4x | 512 ГБ |
| 15-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA GeForce GTX 1660 Ti.  Max-Q Design с графической памятью GDDR6 с 6 ГБ Max-Q Design с графической памятью GDDR6 с 6 ГБ | 32 LPDDR4x | 1 ТБ |
| 15-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA GeForce GTX 1660 Ti. Max-Q Design с графической памятью GDDR6 с 6 ГБ | 32 LPDDR4x | 2 ТБ |
| 15-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA Quadro RTX 3000. Max-Q Design с графической памятью GDDR6 с 6 ГБ | 32 LPDDR4x | 512 ГБ |
| 15-дюймовый | Четырехъядерный 10-й gen Core i7-1065G7 | Графика Intel Iris Plus NVIDIA Quadro RTX 3000. Max-Q Design с графической памятью GDDR6 с 6 ГБ | 32 LPDDR4x | 1 ТБ |
Примечание
2TB SSD доступен только в США: Surface Book 3 15″ с NVIDIA GTX 1660Ti
Сводка
Созданная для производительности, Surface Book 3 включает различные конфигурации GPU, оптимизированные для выполнения определенных рабочих нагрузок и требований к использованию. Интегрированный графический GPU Intel Iris функционирует как единственный GPU на устройстве начального уровня Core i5 и как вторичный GPU на всех остальных моделях. GeForce GTX 1650 имеет крупное обновление основного потокового мультипроцессора для более эффективного запуска сложной графики. Чем быстрее GeForce GTX 1660 Ti Surface Book 3 с дополнительными улучшениями производительности, тем лучше для потребителей, геймеров, живых стримеров и творческих специалистов. Quadro RTX 3000 открывает несколько ключевых функций для профессиональных пользователей: отрисовку трассировки лучей и ускорение ИИ, а также расширенные показатели графики и вычислений.
Интегрированный графический GPU Intel Iris функционирует как единственный GPU на устройстве начального уровня Core i5 и как вторичный GPU на всех остальных моделях. GeForce GTX 1650 имеет крупное обновление основного потокового мультипроцессора для более эффективного запуска сложной графики. Чем быстрее GeForce GTX 1660 Ti Surface Book 3 с дополнительными улучшениями производительности, тем лучше для потребителей, геймеров, живых стримеров и творческих специалистов. Quadro RTX 3000 открывает несколько ключевых функций для профессиональных пользователей: отрисовку трассировки лучей и ускорение ИИ, а также расширенные показатели графики и вычислений.
Подробнее
Сравнение архитектуры процессоров Nvidia Ampere и Turing [GPU]
Опубликовано 15.09.2020, 13:50 · Комментарии:15
Turing и Ampere — это две передовые технологии графических процессоров от Nvidia, используемые в их видеокартах серии RTX. Обе эти архитектуры предлагают значительное улучшение по сравнению с более старых версий Nvidia, которые включают в себя Volta и Pascal. Эти два новейших графических процессоров (Turing и Ampere) имеют некоторое сходство друг с другом.
Эти два новейших графических процессоров (Turing и Ampere) имеют некоторое сходство друг с другом.
Ampere является более новой из двух и используется в видеокартах Nvidia последнего поколения, включая RTX 30 Series, а Turing обслуживает видеокарты RTX 20 Series. Архитектура Ampere поставляется с некоторыми новыми функциями и улучшениями по сравнению с архитектурой Turing GPU. Итак, чтобы помочь вам узнать о существенных различиях между этими видами графических процессоров, здесь я провожу общее сравнение двух типов процессоров по важным параметрам.
Архитектура графического процессора Turing
Тьюринг — непосредственный преемник графического процессора Volta. Архитектура построена по 12-нм техпроцессу и поддерживает GDDR5, HBM2 и память GDDR6. Tensor GPU поставляется с ядрами CUDA, RT Core и тензорными ядрами в одном чипе GPU (за исключением карт серии GTX 16). Это первая архитектура, поддерживающая трассировку лучей в реальном времени, которая используется для создания реалистичных изображений, теней, отражений и других сложных световых эффектов./data/SS2_m_1024_A.png)
Более того, архитектура Тьюринга также поддерживает DLSS (Deep Learning Super Sampling), которая представляет собой технологию на основе искусственного интеллекта, использующую тензорные ядра для увеличения частоты кадров в играх без ущерба для качества изображения или графики. Однако следует отметить, что для использования преимуществ этих двух технологий игра также должна поддерживать их (трассировку лучей и DLSS). Архитектура Turing GPU обеспечивает увеличение производительности до 6 раз по сравнению со старой архитектурой Pascal GPU, что является большим шагом вперед.
Графические карты на базе архитектуры Turing GPU включают GeForce RTX 20 Series и GTX 16 Series. Однако видеокарты Turing серии GeForce GTX 16 не поставляются с ядрами RT и тензорными ядрами. Видеокарты серии GeForce RTX 20 также поддерживают VirtualLink через разъем USB Type-C для подключения гарнитуры VR следующего поколения через порт USB Type-C для получения потрясающих впечатлений от виртуальной реальности. Архитектура Turing GPU также используется в видеокартах для рабочих станций, включая Quadro RTX 4000, Quadro RTX 5000, Quadro RTX 6000 и Quadro RTX 8000.
Архитектура Turing GPU также используется в видеокартах для рабочих станций, включая Quadro RTX 4000, Quadro RTX 5000, Quadro RTX 6000 и Quadro RTX 8000.
Архитектура графического процессора Ampere
Ampere является преемником от графического процессора Turing. Он построен по 8-нм техпроцессу и поддерживает высокоскоростную память GDDR6, HBM2 и GDDR6X. Память GDDR6X в настоящее время является самой быстрой графической памятью, которая может достигать скорости до 21 Гбит/с и обеспечивать пропускную способность до 1 ТБ/с. Архитектура Ампер обеспечивает значительное улучшение по сравнению с Тюрингом и поставляется с 2 — го поколения RT ядер и 3 — го поколения тензорных сердечников.
Эти новые ядра RT и Tensor обеспечивают примерно в 2 раза пропускную способность или производительность по сравнению с ядрами RT и Tensor предыдущего поколения, используемыми в архитектуре Turing. Это означает, что вы получаете значительный прирост производительности в играх и других приложениях, если игра или приложение поддерживает технологии Ray Tracing и AI.
Архитектура Ampere теперь поддерживает стандарт PCIe Gen 4, что вдвое увеличивает пропускную способность интерфейса PCIe Gen3. Архитектура поддерживает CUDA версии 8.0 и включает 2 потоковых мультипроцессора FP32, что означает двойную производительность FP32 по сравнению с Turing. Архитектура графического процессора Ampere поддерживает NVLink 3.0 для увеличения вычислительной мощности системы, использующей более одного графического процессора. Архитектура Ampere обеспечивает повышение производительности на ватт до 1,9 раза по сравнению с архитектурой Turing.
Еще одним отличным дополнением к Ampere является поддержка HDMI 2.1, который поддерживает сверхвысокое разрешение и частоту обновления, которая составляет 8K при 60 Гц и 4K при 120 Гц. Он также поддерживает Dynamic HDR, а общая пропускная способность, поддерживаемая HDMI 2.1, составляет 48 Гбит/с.
RTX IO — это еще одна новая функция, представленная в архитектуре Ampere, которая может снизить накладные расходы на ввод-вывод ЦП и значительно сократить время загрузки игры за счет распаковки игровых текстур/данных внутри памяти графического процессора с помощью графического процессора. Эта функция работает вместе с Microsoft Windows DirectStorage API. Графические карты, использующие архитектуру графического процессора Ampere, — это видеокарты серии RTX 30, в том числе GeForce RTX 3090, RTX 3080, RTX 3070.
Эта функция работает вместе с Microsoft Windows DirectStorage API. Графические карты, использующие архитектуру графического процессора Ampere, — это видеокарты серии RTX 30, в том числе GeForce RTX 3090, RTX 3080, RTX 3070.
Сравнение архитектур Nvidia Ampere и GPU Turing
Быстрое и краткое сравнение архитектур графических процессоров Ampere и Turing от Nvidia.
| Архитектура GPU | Ampere | Turing |
| Производитель | Nvidia | Nvidia |
| Процесс изготовления | 8 нм (Samsung) | 12 нм (TSMC) |
| Версия CUDA | 8 | 7,5 |
| RT ядра | 2-е поколение | 1-е поколение |
| Тензорные ядра | 3-е поколение | 2-е поколение |
| Потоковые мультипроцессоры | 2x FP32 | 1x FP32 |
| DLSS | DLSS 2. 0 0 |
DLSS 1.0 |
| Поддержка памяти | HBM2, GDDR6X | GDDR6, GDDR5, HBM2 |
| Поддержка PCIe | PCIe Gen 4 | PCIe Gen 3 |
| Кодировщик NVIDIA (NVENC) | Gen 7 | Gen 7 |
| Декодер NVIDIA (NVDEC) | Gen 5 | Gen 4 |
| DirectX 12 Ultimate | да | да |
| VR технология | да | да |
| Поддержка нескольких GPU | NVLink 3.0 | NVLink 2.0 |
| Энергоэффективность | Лучше, чем Turing | Лучше, чем Volta |
| Видео порты | HDMI 2.1, DisplayPort 1.4a | HDMI 2.0b, DisplayPort 1.4a |
| Графические карты | RTX 30 серии | Серия RTX 20, серия GTX 16 |
| Приложения | Игры, домашний пк, искусственный интеллект (AI) | Игры, домашний пк, искусственный интеллект (AI) |
Заключение
Что ж, архитектура графического процессора Ampere предлагает значительные улучшения, когда дело доходит до трассировки лучей и DLSS, но даже когда эти функции не используются, прирост производительности в Ampere больше, чем у Turing. Другим значительным дополнением к Ampere является поддержка PCIe Gen 4, которая предлагает гораздо более высокую пропускную способность и может оказаться весьма полезной в будущем.
Другим значительным дополнением к Ampere является поддержка PCIe Gen 4, которая предлагает гораздо более высокую пропускную способность и может оказаться весьма полезной в будущем.
AMD vs Nvidia: что лучше?
Авторы данного обзора решили сравнить AMD и Nvidia, дабы выяснить – кто же станет безусловным чемпионом. Для самых заядлых геймеров данное соперничество является не менее важно, чем, скажем, соперничество между донецким «Шахтёром» и киевским «Динамо», между «Кока-кола» и «Пепси», между «Marvel» и «DC Comics». Кто делает лучшие процессоры: AMD или Nvidia? В нашем обществе существует несколько распространённых представлений о сильных и слабых сторонах каждого из этих брендов, и данное сравнение призвано проверить все эти точки зрения.
Информация о компаниях
AMD
- Изначально компания получила известность в качестве производителя вычислительных процессоров (CPU), однако, затем плотно вошла на рынок графических процессоров (GPU).
- Присутствует на рынках CPU и GPU, занимая на них вторые позиции, в то время как первые позиции на этих рынках занимают Intel и Nvidia соответственно.
- Выпускает превосходную продукцию в нижнем и среднем классах.
- Удаётся запускать высокопроизводительные приложения.
- Вырабатывает большее количество тепла, поскольку использует большие массивы памяти для повышения производительности.

Nvidia
- С первых дней своего существования занимается GPU и по сей день видеокарты Nvidia занимают первую позицию в данном секторе.
- Заметное присутствие на рынке GPU и небольшое присутствие на рынке CPU.
- Выпускает отличные графические процессоры среднего и высокого класса.
- Создала единственный GPU, который действительно способен запускать высокопроизводительные приложения – такие, как игры 2K и 4K.
- Генерирует меньшую мощность и потребляет меньшее количество энергии.

Цена
В сообществе геймеров принято считать, что AMD предлагает лучшее соотношение цены и качества своих продуктов, чем Nvidia. И хотя в целом это справедливая оценка, на самом деле всё обстоит немного сложнее. В перечне основных моделей процессоры Nvidia часто стоят значительно дороже, чем их аналоги более раннего поколения. Но отчасти это можно объяснить тем фактом, что Nvidia совсем недавно сократила своё новое поколение Turing. Однако, трудно игнорировать тот факт, что RTX 2080 Ti стоит почти вдвое дороже GTX 1080 Ti, или то, что стандартный RTX 2080 стоит примерно 800 долларов.
Впрочем, на базовой конференции Nvidia прозвучало обещание компании снизить цены, так что вскоре всё может измениться. И Nvidia уже предлагает процессоры CPU стоимостью всего в 150 долларов. На данный момент AMD предлагает значительно более выгодные цены на большинство моделей, но ситуация может измениться, когда на рынке появится их процессор Navi следующего поколения, а Nvidia внесёт некоторые изменения в свою ценовую политику. Что касается высокопроизводительных игровых видеокарт, то здесь расхождение становится менее заметным. Высокопроизводительный AMD Radeon VII стоит всего на 100 долларов дешевле, чем его аналог от Nvidia несмотря на то, что он не совсем соответствует тем же ключевым параметрам.
Что касается высокопроизводительных игровых видеокарт, то здесь расхождение становится менее заметным. Высокопроизводительный AMD Radeon VII стоит всего на 100 долларов дешевле, чем его аналог от Nvidia несмотря на то, что он не совсем соответствует тем же ключевым параметрам.
Производительность
Nvidia Corporation может ставить премиальные цены на свои игровые видеокарты, но многие утверждают, что это их заслуженное право. Лучшие графические процессоры от Nvidia впечатляют и завораживают. RT 2080 Ti может стоить почти целое состояние, но на рынке более нет ничего подобного! Память GDDR6 объёмом 11 ГБ сочетается с новой трассировкой лучей и выборкой, управляемой искусственным интеллектом (подробнее об этом речь пойдёт ниже), и это делает её очень удобной для игр многих будущих поколений. И хотя Radeon VII выглядит в значительной степени сопоставимым с точки зрения своих характеристик, игроманы определённо заметят разницу, когда начнут использовать DirectX 12.
В общем, если говорить кратко, то процессоры Nvidia просто более мощные, особенно для игр. Они лучше работают в многозадачном режиме, способны выполнять исключительно сложные задачи и справляются с этим при значительно меньшем энергопотреблении. И хотя AMD предлагает больший объём памяти в линейке процессоров младших классов, это также означает, что они быстрее перегреваются, поэтому они просто не могут конкурировать друг с другом на более высоком уровне. И, несмотря на то, что разрыв в мощности постепенно сокращается, Nvidia по-прежнему имеет явное преимущество по этому показателю.
Победитель: NvidiaАдаптивная синхронизация
И Nvidia, и AMD любят использовать множество модных технологий, однако пользователям не следует упускать из виду адаптивную синхронизацию, представленную соответственно технологиями G-Sync и FreeSync. Данные технологии максимально используют частоту обновления монитора, чтобы уменьшить разрывы, обеспечить постоянство частоты кадров и, в целом, просто обеспечить более приятный игровой процесс. И поскольку две упомянутые выше технологии совместимы лишь с картами соответствующих производителей, разницу следует учитывать.
И поскольку две упомянутые выше технологии совместимы лишь с картами соответствующих производителей, разницу следует учитывать.
Здесь мнения пользователей и экспертов расходятся, поскольку две компании достигли совершенно различных результатов при реализации этих технологий. Мониторы G-Sync работают исключительно с мониторами, поддерживающими G-Sync, и это считается премиальной функцией, часто доступной лишь в более дорогих моделях. FreeSync, напротив, имеет более высокую совместимость и будет работать с большинством мониторов стоимостью от 130 долларов и выше. Но, как и в целом обстоит дело с этими двумя компаниями, технология AMD жертвует мощностью ради доступности. G-Sync – это лучший вариант, а более высокие стандарты, применяемые к мониторам G-Sync, означают, что они, как правило, действительно приносят в адаптивную синхронизацию всё, чего она стоит.
Победитель: ничья в зависимости от того, сколько денег вы готовы потратить.Программное обеспечение
Современные видеокарты – это нечто большее, чем просто устройство для отображения картинки на экране, а из этого следует, что наиболее продвинутые геймеры хотят настраивать их функциональность. Это означает, что программные платформы, которые использует каждая из компаний, также важны. Раньше победитель здесь был явным. Программное обеспечение Nvidia поставлялось с рядом полезных функций, которых просто не хватало AMD. Но в последние годы AMD сумела преодолеть этот пробел, и все меньше игровых компаний создают настройки, специально предназначенные для того или иного производителя видеокарт.
Это означает, что программные платформы, которые использует каждая из компаний, также важны. Раньше победитель здесь был явным. Программное обеспечение Nvidia поставлялось с рядом полезных функций, которых просто не хватало AMD. Но в последние годы AMD сумела преодолеть этот пробел, и все меньше игровых компаний создают настройки, специально предназначенные для того или иного производителя видеокарт.
Однако, ни в коем случае не следует говорить о том, что GeForce Experience от Nvidia перестал впечатлять. Обновления драйверов выполняются автоматически, и вы можете делать снимки экрана и транслировать видео прямо через его интерфейс. И несмотря на то, что AMD уже начала включать в свое программное обеспечение всё больше функций оптимизации игр (и, надо сказать, она неплохо с этим справляется), они всё ещё пытаются догнать своего более опытного в этом деле конкурента. Автоматизация оптимизации GeForce Experience является исключительной и представляет собой отличный способ получить наилучшие впечатления от игры, не будучи техническим специалистом.
Тем не менее, в новейшей версии AMD Radeon Software Adrenalin имеется несколько интересных хитрых настроек. Программа не только предлагает автоматический разгон, но также позволяет транслировать игры прямо на ваше мобильное устройство, включая поддержку возможностей виртуальной реальности.
Победитель: Nvidia, однако, её статус победителя висит на волоске.Специальные функции
Если говорить об универсальных функциях, то здесь компания AMD проделала огромную работу для того, чтобы догнать Nvidia. Однако, это было в прошлом. Появление поколения Тьюринга принесло с собой два фундаментальных изменения в правилах игры: трассировку лучей и выборку, управляемую искусственным интеллектом. Первое обеспечивает беспрецедентный уровень детализации при отображении света, и, хотя он ещё не слишком активно реализован в играх нынешнего поколения, демо-варианты, которые Nvidia представила на выставке CES, были просто потрясающими. Но наибольший импульс может дать ядро искусственного интеллекта Тьюринга. Благодаря машинному обучению данный искусственный интеллект может интуитивно улучшить качество графики на основе анализа совместного опыта.
Благодаря машинному обучению данный искусственный интеллект может интуитивно улучшить качество графики на основе анализа совместного опыта.
Это та ситуация, когда расчёт времени был преимуществом для Nvidia. Впрочем, ходят слухи о том, что последующие AMD видеокарты будут использовать трассировку лучей. Однако, данные видеокарты ещё не выпущены, и до сих пор нет никакой информации о сложном искусственном интеллекте, который входит в новейшие процессоры Nvidia. И несмотря на то, что ни одна из этих технологий ещё не получила широкого распространения в игровом сообществе, можно ожидать, что вскоре всё изменится, поскольку разработчики смогут работать с ними более комфортно, а в следующем поколении консолей могут быть реализованы наши ожидания, связанные с кросс-совместимыми играми.
Победитель: NvidiaКлючевые различия между AMD и Nvidia
Давайте обсудим основные ключевые различия между AMD и Nvidia.
- Производительность: Radeon была оригинальным продуктом ATI (Array Technology Inc), а ATI являлась главным конкурентом Nvidia. После того, как AMD приобрела ATI, на рынке GPU появилось два ведущих игрока: Nvidia и AMD. Бренд Radeon взял верх над GeForce и стал их конкурентом. Компании AMD принадлежит меньшая доля рынка GPU – подобно тому, как ей принадлежит меньшая доля на рынке CPU, где она конкурирует с Intel. Контрольным показателем при сравнении производительности графических процессоров может быть количество кадров, обработанных за заданный промежуток времени, и скорость запуска таких игр, как Crysis. И в том, и в другом случае показатели не являются одинаковыми для разных моделей одного бренда и могут различаться.
- Аппаратное обеспечение: Nvidia использует передовые технологии и широко известна благодаря своей превосходной производительности. В процессе работы видеокарт производства данной компании вырабатывается меньшее количество тепла, поскольку потребляется меньше электроэнергии. AMD компенсирует эти пробелы своей вычислительной мощностью, используя больше памяти и потребляя больше энергии. Это был пробел, который AMD закрыла в своих новых продуктах.
- Технология: Nvidia использует ядра CUDA (объединённая вычислительная архитектура устройства), а AMD использует процессоры Stream. Между этими двумя ядрами не наблюдается серьёзных различий в производительности.
- Программное обеспечение: Точно настроенное программное обеспечение оказывает влияние на производительность и позволяет закрывать пробелы в аппаратном обеспечении. Обе компании часто обновляют драйверы, при этом Nvidia демонстрирует немного большую последовательность и стабильность. Если не учитывать этих различий, можно сказать, что в этой области компании работают на равных условиях.
- Потоковая передача и запись: Если не считать некоторого улучшения качества видео в процессе потоковой передачи и записи в случае с Nvidia, оба игрока находятся на одном уровне.
- Подстановка вертикальной синхронизации: Эта функция позволяет избежать срывов картинки на экране за счёт синхронизации частоты обновления монитора с частотой кадров. И AMD Freesync, и Nvidia Gsync предоставляют свои решения, которые сопоставимы по своей производительности. Freesync – лучшее решение по стоимости, а Gsync – по общей производительности.
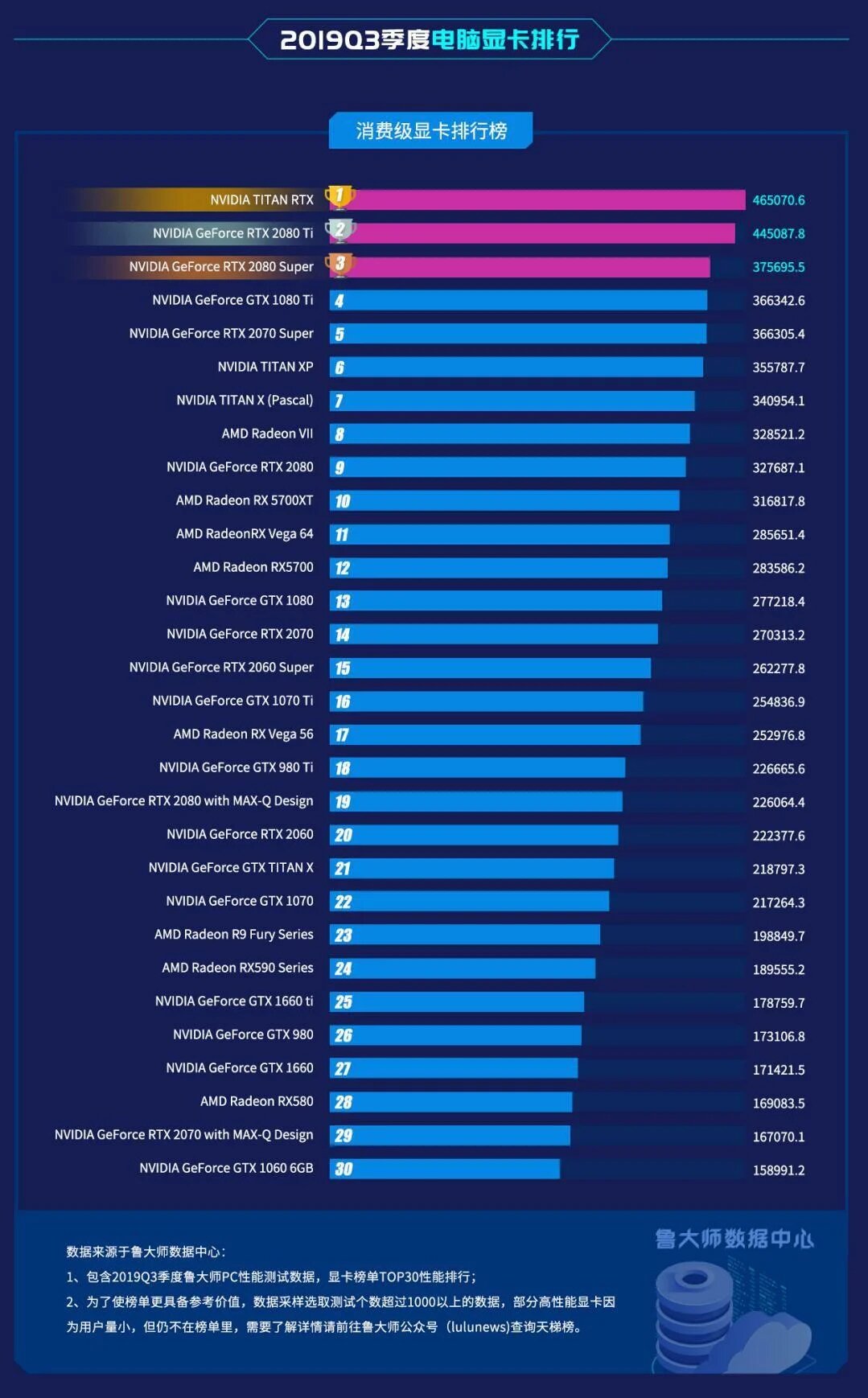 После того, как AMD приобрела ATI, на рынке GPU появилось два ведущих игрока: Nvidia и AMD. Бренд Radeon взял верх над GeForce и стал их конкурентом. Компании AMD принадлежит меньшая доля рынка GPU – подобно тому, как ей принадлежит меньшая доля на рынке CPU, где она конкурирует с Intel. Контрольным показателем при сравнении производительности графических процессоров может быть количество кадров, обработанных за заданный промежуток времени, и скорость запуска таких игр, как Crysis. И в том, и в другом случае показатели не являются одинаковыми для разных моделей одного бренда и могут различаться.
После того, как AMD приобрела ATI, на рынке GPU появилось два ведущих игрока: Nvidia и AMD. Бренд Radeon взял верх над GeForce и стал их конкурентом. Компании AMD принадлежит меньшая доля рынка GPU – подобно тому, как ей принадлежит меньшая доля на рынке CPU, где она конкурирует с Intel. Контрольным показателем при сравнении производительности графических процессоров может быть количество кадров, обработанных за заданный промежуток времени, и скорость запуска таких игр, как Crysis. И в том, и в другом случае показатели не являются одинаковыми для разных моделей одного бренда и могут различаться.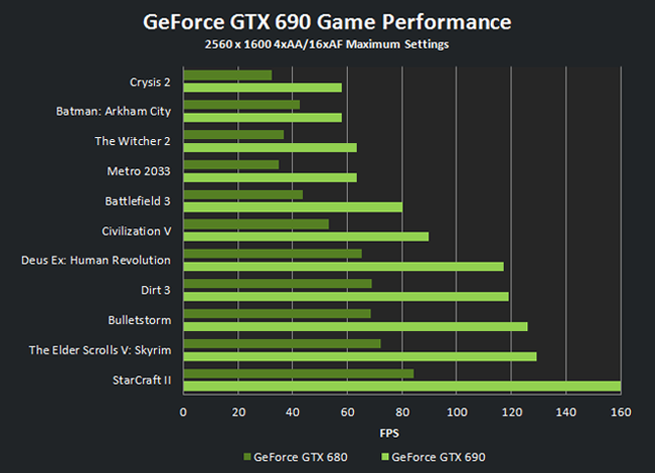 Это был пробел, который AMD закрыла в своих новых продуктах.
Это был пробел, который AMD закрыла в своих новых продуктах.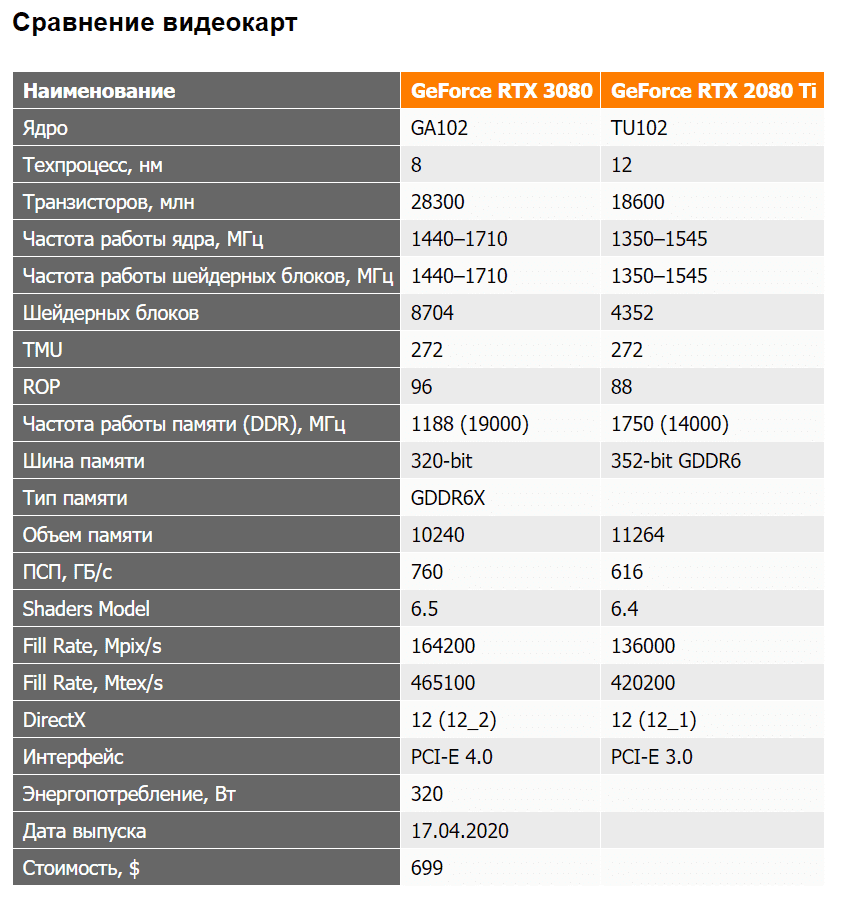 И AMD Freesync, и Nvidia Gsync предоставляют свои решения, которые сопоставимы по своей производительности. Freesync – лучшее решение по стоимости, а Gsync – по общей производительности.
И AMD Freesync, и Nvidia Gsync предоставляют свои решения, которые сопоставимы по своей производительности. Freesync – лучшее решение по стоимости, а Gsync – по общей производительности.Вердикт
Так кто же из них является победителем? Никто. Несмотря на то, что Nvidia может быть признана лидером в большинстве категорий, ценовая политика AMD также имеет большое значение. Игровая видеокарта Nvidia высшего класса обойдётся довольно дорого, и покупателю также может понадобиться вложить большие инвестиции в надёжный процессор, материнскую плату и монитор, чтобы получить максимальную отдачу от видеокарты. В общем, если вы желаете получать всё самое лучшее, покупайте Nvidia. Если же вы можете обходиться без продукции наивысшего класса, AMD может предложить вам фантастические решения, особенно в случае с видеокартами стоимостью менее 200 долларов.
Скорее всего, в ближайшие годы различия между продуктами этих двух брендов будут только уменьшаться. AMD сделала несколько многообещающих шагов на рынке high-end, а Nvidia уже пообещала в ближайшие месяцы снизить цены на свою продукцию.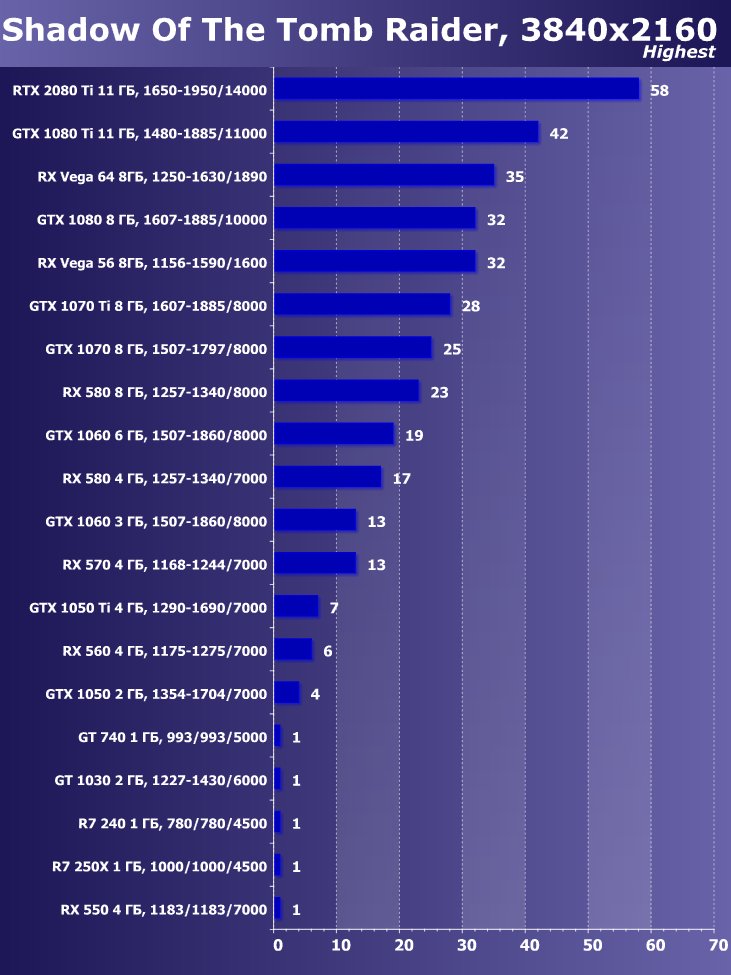 Внимательно следите за рынком, поскольку выпуск следующего поколения AMD действительно откроет путь к следующей битве эпохи процессорных войн.
Внимательно следите за рынком, поскольку выпуск следующего поколения AMD действительно откроет путь к следующей битве эпохи процессорных войн.
Сравнение эффективности CPU и GPU реализаций некоторых комбинаторных алгоритмов на задачах обращения криптографических функций | Булавинцев
TOP500 Supercomputer Site URL:http://www.top500.org (дата обращения: 01.01.2015)
Lee, V. W. Debunking the 100X GPU vs. CPU myth: an evaluation of throughput computing on CPU and GPU / V. W. Lee et al //ACM SIGARCH Computer Architecture News. — ACM, 2010. — Vol. 38, No. 3. — P. 451–460.
Flynn, M. Some computer organizations and their effectiveness / M. Flynn // Computers, IEEE Transactions on. — 1972. — Vol. 100, No. 9 — P. 948–960.
CUDA C Best Practices Guide — CUDA SDK v.6.0 — NVIDIA corp. — 2014. URL: http://docs.nvidia.com/cuda (дата обращения: 15.07.2014)
Percival, C. The scrypt Password-Based Key Derivation Function. — IETF Draft — 2012 / C.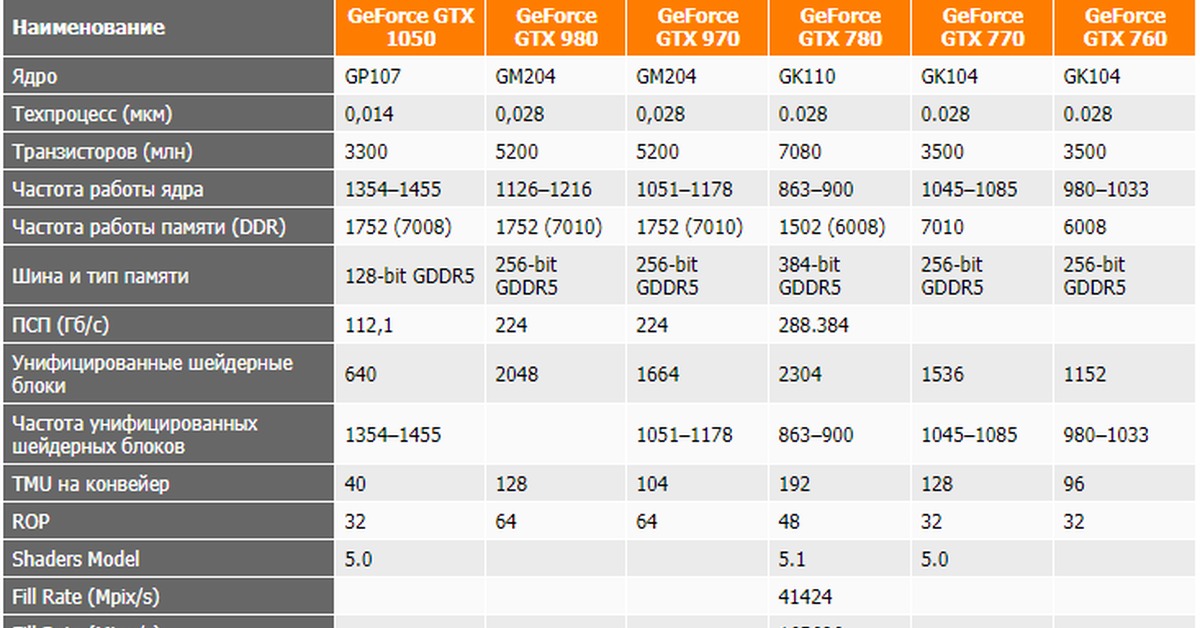 Percival, S. Josefsson URL: http://tools.ietf.org/html/josefsson-scrypt-kdf-00.txt (дата обращения: 30.11.2012)
Percival, S. Josefsson URL: http://tools.ietf.org/html/josefsson-scrypt-kdf-00.txt (дата обращения: 30.11.2012)
Nohl, K. Attacking phone privacy / K. Nohl // Black Hat USA. — 2010. URL: https://srlabs.de/blog/wp-content/uploads/2010/07/Attacking.Phone_.Privacy_Karsten.Nohl_1.pdf (дата обращения: 01.01.2015)
Mironov, I. Applications of SAT solvers to cryptanalysis of hash functions / I. Mironov, L. Zhang // Theory and Applications of Satisfiability Testing-SAT 2006. — Springer Berlin Heidelberg, 2006. — P. 102–115.
Semenov, A. Parallel logical cryptanalysis of the generator A5/1 in BNB-Grid system / A. Semenov et al // Parallel Computing Technologies. — Springer Berlin Heidelberg, 2011. — P. 473–483.
Biryukov, A. Real Time Cryptanalysis of A5/1 on a PC / A. Biryukov, A. Shamir , D. Wagner // Fast Software Encryption. — Springer Berlin Heidelberg, 2001. — P. 1–18.
Goliс, J. D. Cryptanalysis of alleged A5 stream cipher / J.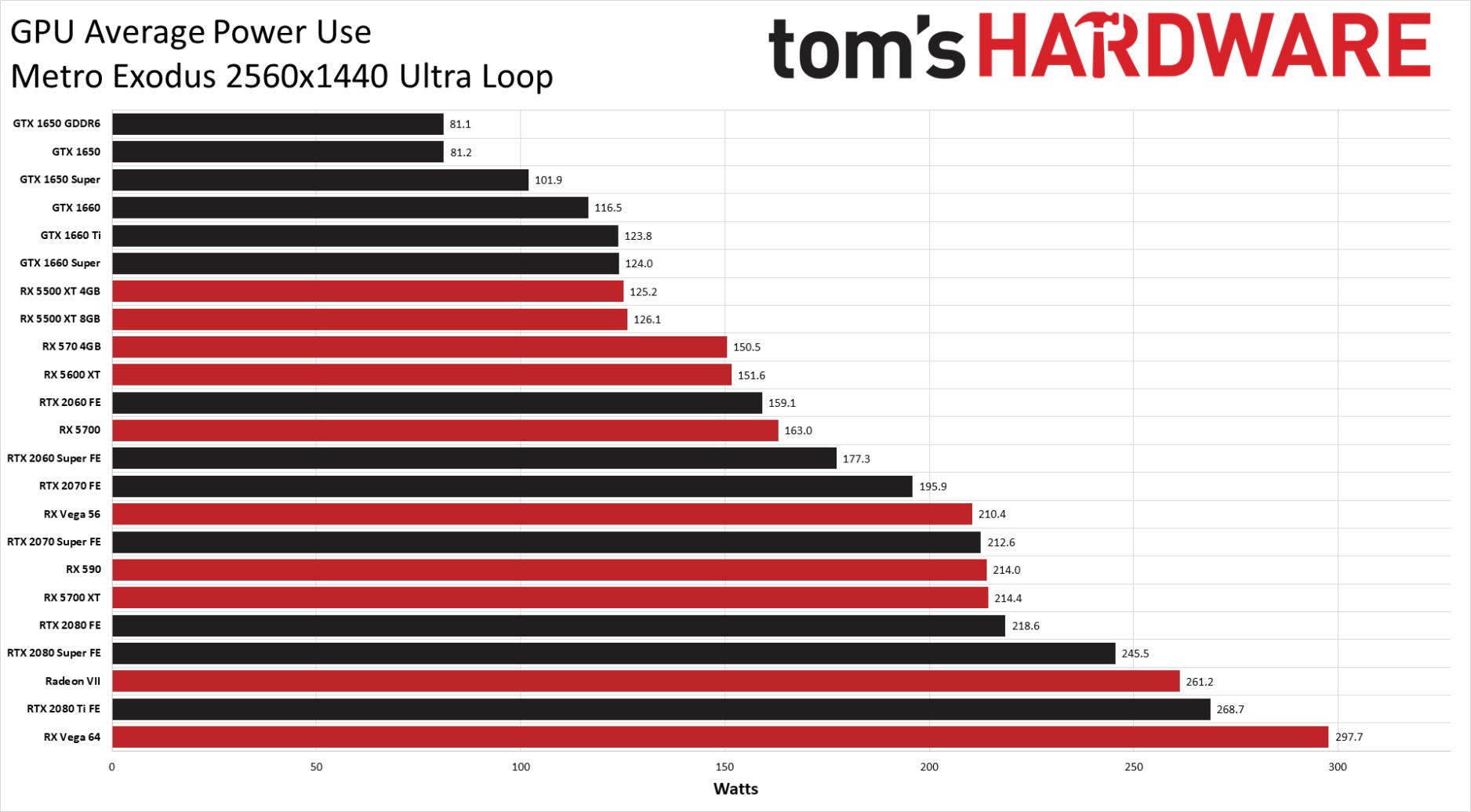 D. Goliс // Advances in Cryptology—EUROCRYPT’97. — Springer Berlin Heidelberg, 1997. — P. 239–255.
D. Goliс // Advances in Cryptology—EUROCRYPT’97. — Springer Berlin Heidelberg, 1997. — P. 239–255.
Kumar, S. Breaking ciphers with COPACOBANA—a cost-optimized parallel code breaker / S. Kumar et al. // Cryptographic Hardware and Embedded Systems-CHES 2006. — Springer Berlin Heidelberg, 2006. — P. 101–118.
Kwan, M. Reducing the Gate Count of Bitslice DES / M. Kwan //IACR Cryptology ePrint Archive. — 2000. — Vol. 2000. — P. 51.
John the Ripper password cracker — 2013 URL: http://www.openwall.com/john/ (дата обращения: 02.07.2014)
Davis, M. A machine program for theorem-proving / M. Davis, G. Logemann, D. Loveland // Communications of the ACM. — 1962. — Vol. 5, No. 7. — P. 394–397.
Moskewicz, M. W. Chaff: Engineering an efficient SAT solver / M. W. Moskewicz et al. //Proceedings of the 38th annual Design Automation Conference. — ACM, 2001. — P. 530–535.
Marques-Silva, J. P. GRASP: A search algorithm for propositional satisfiability / J. P Marques-Silva, K. A. Sakallah // Computers, IEEE Transactions on. — 1999. — Vol. 48, No. 5. — P. 506–521.
P Marques-Silva, K. A. Sakallah // Computers, IEEE Transactions on. — 1999. — Vol. 48, No. 5. — P. 506–521.
Blumofe, R. D. Scheduling multithreaded computations by work stealing / R. D. Blumofe, C. E. Leiserson //Journal of the ACM (JACM). — 1999. — Vol. 46, No. 5. — P. 720–748.
Backus, J. Can programming be liberated from the von Neumann style?: a functional style and its algebra of programs / J. Backus // Communications of the ACM. — 1978. — Vol. 21, No. 8. — P. 613–641.
Molka, D. Memory performance and cache coherency effects on an Intel Nehalem multiprocessor system / D. Molka et al. // PACT’09. 18th International Conference on Parallel Architectures and Compilation Techniques. — IEEE, 2009. — P. 261–270.
Een, N. MiniSat: A SAT solver with conflict-clause minimization / N. Een, N. Sörensson // Proceedings of the International Symposium on the Theory and Applications of Satisfiability Testing (2005) — 2005. — Vol. 5 — P.55
Сравнение систем виртуализации — VMware, Hyper-V, KVM, Xen — Datahouse.
 ru
ruVMware против Microsoft Hyper-V
- Гипервизор Hyper-V не поддерживает технологию, которая используется для проброса аппаратных USB-портов, что не позволяет подключать, например, аппаратные лицензионные ключи 1С к виртуальным машинам. Данные технологии обычно называются USB Redirection или USB Passthrough. Microsoft предлагает использовать вместо этого Discrete Device Assignment (DDA).
- Hyper-V не умеет «на лету» добавлять CPU, вам придётся осуществлять добавление в offline режиме через остановку сервиса, что вызовет простой (DownTime).
- Количество гостевых операционных систем, которые могут работать внутри виртуальной машины, у Hyper-V значительно меньше VMware, поэтому рекомендуется проверить актуальный список, если вам требуется запустить раритетного гостя.
- Стоит признать, что Hyper-V позволяет уменьшать размер диска, а не только увеличивать, как VMware, но на практике, к сожалению, аппетиты только растут и чаще всего виртуальный сервер будет требовать всё больше занятого места.
- Microsoft первой реализовала в своём гипервизоре Hyper-V технологию VM-GenerationID, которая пригодится администраторам службы каталогов, использующим сложные схемы Active Directory со множеством контроллеров в виртуальных средах. Благодаря VM-GenerationID можно избежать множества проблем при откате к старому снимку или при восстановлении её из резервной копии. Стоит отметить, что VMware также реализовала поддержку VM-GenerationID с версии vSphere 5.0 Update 2.

VMware против Red Hat KVM
После того, как KVM стал частью ядра Linux, он автоматически стал «генеральной линией партии» (mainline) в вопросе «а что выбрать для создания виртуализации средствами Linux». Заметьте, что Red Hat сделала ставку на KVM и в версии Red Hat Enterprise Linux 6.0 полностью исключил Xen, сделав окончательный выбор.
Эта борьба двух Linux-проектов, которые завязли в братской войне, шла на пользу VMware и Hyper-V, так как KVM и Xen отбирали долю рынка у друг друга, а не у конкурентов.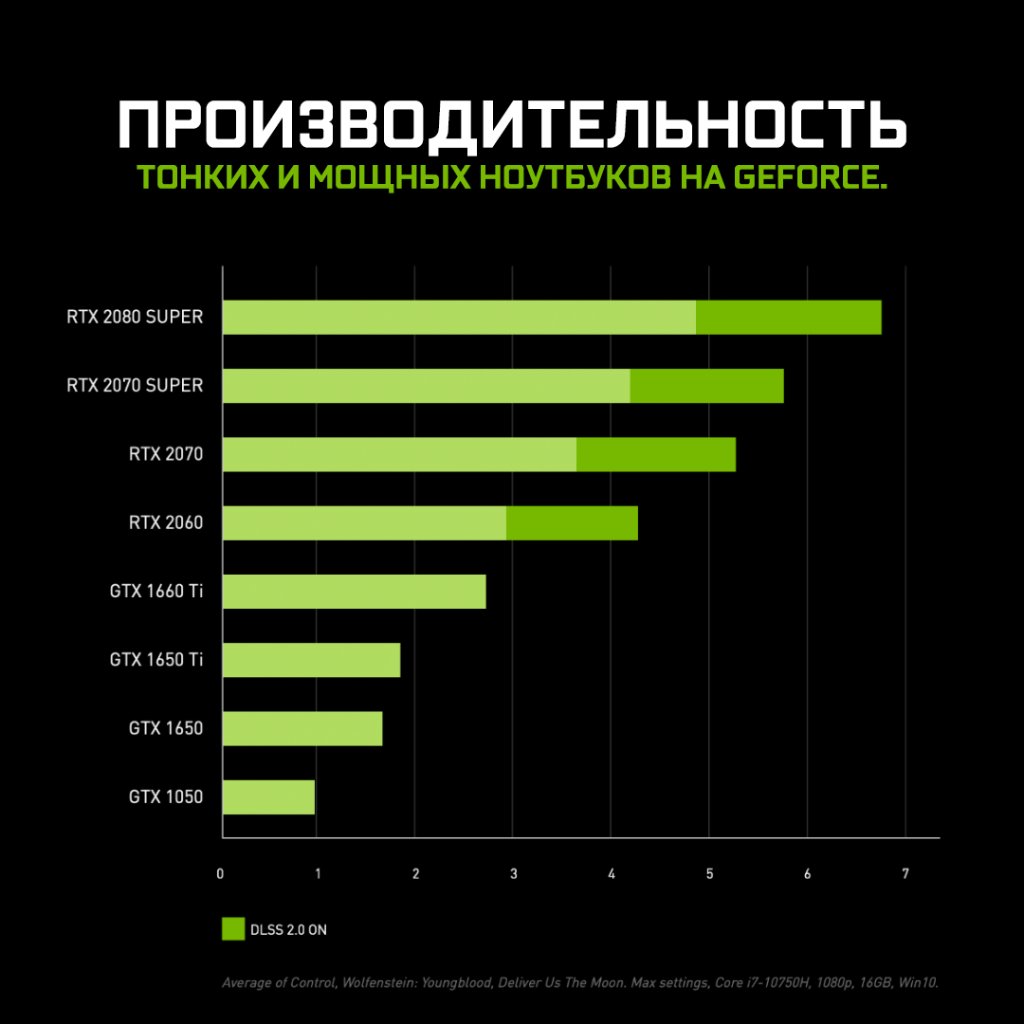
К минусам KVM часто относят:
- Отсутствие более развитых средств управления (как у конкурентов)
- Менее стабильную работу для задач с мощным и интенсивным вводом-выводом (I/O)
Традиционно к плюсам KVM относят неприхотливость к аппаратной части сервера, буквально — «если Linux работает на нём, то всё будет хорошо». Адепты свободного софта могут прочесть исходные коды гипервизора. Благодаря KVM можно получить недорогую виртуальную среду.
VMware против Citrix Xen
Citrix Xen одно время мог похвастать паравиртуализацией, которая требует модифицировать гостевую операционную систему, что невозможно для закрытых систем типа MS Windows, для более быстрой работы и снижения накладных расходов (overhead) на виртуализацию. Но с той поры прошло много лет, и все игроки на рынке виртуализации и аппаратного обеспечения приблизили работу гостя к производительности схожей «как на голом железе», что нивелирует плюсы паравиртуализации. А контейнеры и вовсе отобрали лавры быстрого гостя для UNIX- и Linux-гостей.
А контейнеры и вовсе отобрали лавры быстрого гостя для UNIX- и Linux-гостей.
Citrix с Xen подвергся усилению конкуренции со стороны решений с открытым кодом от KVM и OpenStack, а также отсутствию поддержки поставщиков и сообщества, в отличие от KVM и OpenStack.
На сегодняшний день одной из сильных сторон можно назвать продвинутые возможности по предоставлению внутри виртуальной машины 3D аппаратной акселерации GPU от производителей Intel, AMD, NVIDIA.
К особенностям гипервизора можно отнести:
- Проброс топовых GPU внутрь гостя GPU Pass-through (для конкретного виртуального гостя — конкретный GPU в физическом сервере)
- GPU Virtualization — возможность множеству виртуальных машин получить доступ к GPU хоста, что лучше, чем программная эмуляция
- vGPU Live Migration — позволяет виртуальной машине перемещаться между хостами без потерь с доступом к GPU
Такие технологии очень востребованы в секторах Computer-Aided Design (CAD) и Computer-Aided Manufacture (CAM), что позволяет виртуализировать рабочее место специалистов по компьютерному моделированию, чертёжников, проектировщиков и т.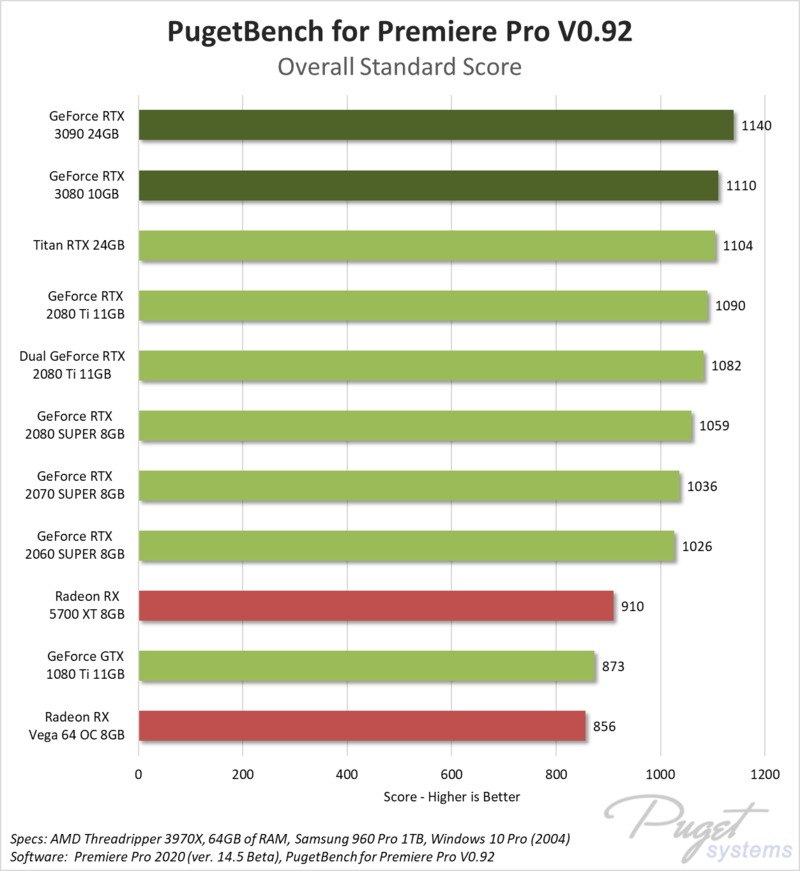 д.
д.
AMD против Nvidia: полное сравнение
AMD против Nvidia: объяснение основных различий
Любители компьютеров и сборщики компьютерных игровых систем хорошо осведомлены о долгой, продолжающейся войне за господство на рынке видеокарт. Двумя титанами, сражавшимися на протяжении десятилетий, были Nvidia и AMD, также называемые «Зеленой командой» и «Красной командой». Advanced Micro Devices (AMD) обычно рассматривались как выбор для бюджетных сборок, но у AMD были моменты, когда выпуск новых продуктов временно опережал высококлассные предложения от Nvidia.
Хотите ли вы выбрать новую видеокарту или узнать больше об этих двух компаниях, в следующем руководстве мы сравним их и продукты, которые они предлагают в настоящее время.
AMD против NVIDIA: сторона по боковым сравнении
| NVIDIA | Advanced Micro Devices (AMD) | ||
|---|---|---|---|
| Company Founding Date | апреля 1993 г. | 9001 мая 1, 1969||
| категории продуктов | GPU, мобильная графика, чипсетки материнской платы, суперкомпьютеры для материнской платы | Процессоры для потребителей, GPU, мобильные процессоры, Профессиональные процессоры, серверы CPU | |
| Флагманский график продукта | GeForce RADEON 3090 | RADEON RX 6900 XT | |
| Технология адаптивной синхронизации | G-Sync | G-Sync | REESEYNC |
| NVIDIA RAYON | NVIDIA RADEON 6000 Series | Radeon 6000 Series | |
| Основатель | Jensen Huang | Jerry Sanders | |
| Драйверы видеокарты | GeForce Experience, панель управления Nvidia | Radeon Ad реналин |
 Sapphire производит графические карты с высокой эффективностью охлаждения.
Sapphire производит графические карты с высокой эффективностью охлаждения.AMD против Nvidia: 5 фактов, которые нужно знать
- AMD, несмотря на свою привлекательность для бюджетных сборщиков, является гораздо более зрелой компанией, чем Nvidia, поскольку она была основана почти на 25 лет раньше, чем Nvidia.
- Видеокарты обеих компаний очень близки по производительности, но серия Nvidia RTX гораздо лучше справляется с трассировкой лучей и сверхвысоким разрешением.
- Продукты Nvidia в основном представляют собой решения для обработки графики, в то время как AMD производит большую часть потребительских процессоров на компьютерном рынке вместе со своими популярными графическими процессорами.
- Графические процессоры Nvidia также используются для расширенных приложений в системах искусственного интеллекта и глубокого обучения с помощью технологии Nvidia CUDA.
- Помимо потребительских процессоров и графических процессоров, AMD также производит оперативную память и твердотельные жесткие диски.

Линейки продуктов Nvidia
Nvidia наиболее известна на потребительском рынке своими популярными графическими процессорами GeForce (GPU), но они также производят технологические продукты для множества других приложений.Чип Nvidia Tegra — это вычислительное решение для мобильных устройств, а Tesla — их процессор для научных и инженерных приложений. Nvidia Drive — это серия технологий для автономных беспилотных транспортных средств, а nForce — технология набора микросхем, которая взаимодействует с системными процессорами на популярных потребительских материнских платах.
Графические процессоры Nvidia также используются в научных исследованиях и суперкомпьютерах. API CUDA (Compute Unified Device Architecture) — это технология, которая поддерживает большое количество ядер графического процессора для параллельной обработки.Лаборатории и исследовательские группы используют CUDA в обширных системах нейронных сетей для поддержки передовых проектов глубокого обучения и искусственного интеллекта.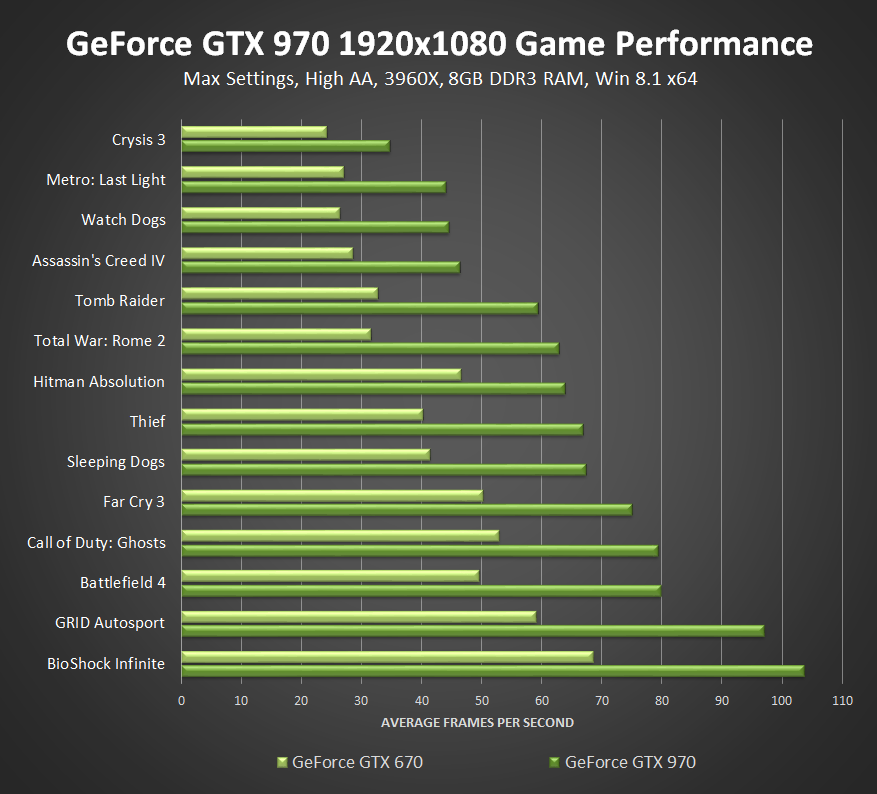
Линейки продуктов AMD
AMD (Advanced Micro Devices) — компания-производитель полупроводников, производящая широкий спектр микрочипов. Они хорошо известны своими популярными линейками графических процессоров и системных процессоров. AMD рассматривается потребителями как хороший вариант для обеспечения производительности при бюджете от низкого до среднего, но их высокопроизводительные видеокарты и процессоры иногда конкурируют с высокопроизводительными продуктами Nvidia.
AMD предлагает обширную линейку процессоров и гибридных процессоров, включая бренд Athlon для бюджетных ПК, серию A для ноутбуков, Ryzen для высокопроизводительных настольных компьютеров и Ryzen Threadripper для профессионального программного обеспечения и высококлассных сборщиков для энтузиастов. Линейки продуктов для чипов AMD GPU включают популярные Radeon, Mobility Radeon, Radeon Pro для рабочих станций и Radeon Instinct для серверов и приложений машинного обучения. AMD также производит оперативную память и твердотельные жесткие диски.
Сравнение игровой производительности в различных ценовых категориях
Обе компании выпускают графические продукты, предназначенные для трех основных ценовых диапазонов на рынке, которые делятся на категории «бюджетный», «средний» и «энтузиаст».”
Для недорогих или «бюджетных» моделей ценовая категория в 200 долларов является целью для идеального соотношения цены и качества. Конкурирующими продуктами двух компаний в этом ценовом диапазоне являются GeForce GTX 1660 от Nvidia и RX 5500 XT от AMD. Графический процессор Nvidia повышает тактовую частоту памяти выше, чем у продукта AMD, но карта AMD имеет 8 ГБ видеопамяти по сравнению с 6 ГБ на GTX 1660 от Nvidia. В целом, с лучшими графическими драйверами GeForce GTX 1660 немного превосходит AMD RX 5500 XT.
На среднем уровне, где большинство компьютерных геймеров рассчитывают использовать свое развлекательное программное обеспечение, цена составляет около 400 долларов. Две конкурирующие карты на этом уровне — это RTX 3060 от Nvidia и RX 6700 XT от AMD. Карта от AMD работает лучше, чем продукт от Nvidia, но стоит немного дороже.
Карта от AMD работает лучше, чем продукт от Nvidia, но стоит немного дороже.
В высокопроизводительных продуктах стоимостью 700 долларов и выше основными конкурирующими картами для сравнения являются AMD RX 6800 XT и Nvidia RTX 3080. трассировка лучей включена и в сверхвысоком разрешении.Учитывая, что трассировка лучей широко не используется в современных играх, AMD, кажется, предлагает лучшую ценность на уровне энтузиастов. Однако выбор сильно зависит от вариантов использования, поэтому окончательный вердикт несколько равен.
Nvidia Geforce GTX 1660 Ti Tuf Gaming и его карта на белом фоне. Nvidia — ведущая компания в мире графических процессоров.Возможности улучшения графики
Обе компании, помимо базовой мощности рендеринга, обладают солидным набором технологий, повышающих реалистичность видеоконтента.Подход Nvidia в этом отношении является более проприетарным, часто создавая технологии, которые работают только с оборудованием Nvidia, тогда как AMD стремится создавать функции, которые могут использоваться продуктами других производителей оборудования, включая продукты Nvidia.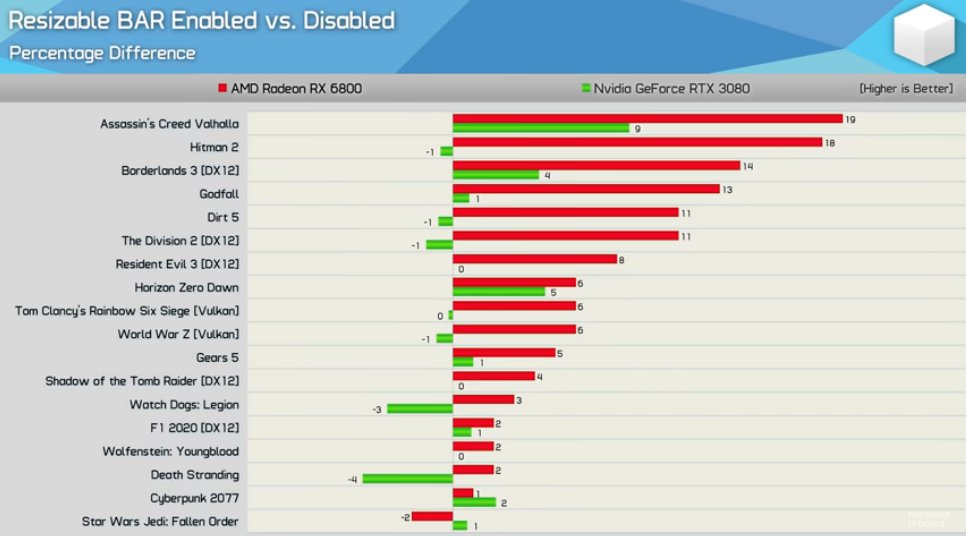
Одной из примечательных функций графических решений Nvidia является Ampere, функция, которая обеспечивает Nvidia Broadcast для потоковой передачи и другого видеоконтента. Используя искусственный интеллект, Nvidia Broadcast позволяет стримерам и вещателям заменять фон человека, который находится в камере, на пользовательскую среду.Эта функция также может отфильтровывать шумы из аудиоканала трансляции.
Функции улучшения игр, которые работают только с Nvidia, включают DLSS, что означает суперсэмплинг с глубоким обучением, который использует ИИ для улучшения рендеринга в играх и повышения производительности. Основные графические карты Nvidia также поддерживают PhysX, технологию, которая увеличивает вычислительную мощность системы для имитации физики в игровом мире.
Последние функции AMD больше ориентированы на игры.Contrast Adaptive Sharpening (CAS) улучшает качество игр на мониторах с высоким разрешением. FidelityFX — это новая функция, которая позволяет большему количеству геймеров играть в разрешении 4K, тогда как их аппаратное обеспечение обычно не может адекватно работать в сверхвысоком разрешении. Затенение с переменной скоростью — это функция, которая интеллектуально выбирает, в каких областях видеоизображения сосредоточить больше энергии для детализации, обеспечивая более высокую эффективность производительности.
Затенение с переменной скоростью — это функция, которая интеллектуально выбирает, в каких областях видеоизображения сосредоточить больше энергии для детализации, обеспечивая более высокую эффективность производительности.
AMD против Nvidia: что выбрать?
Для большинства людей, читающих это, вопрос в основном актуален для выбора лучшей видеокарты для вашего бюджета и вычислительных потребностей.В настоящее время геймеры могут обнаружить, что высокопроизводительные карты Nvidia обеспечивают лучшую производительность при разрешении 4K, хотя графические процессоры AMD в целом работают немного лучше в других случаях использования.
Если вы планируете играть во множество игр нового поколения с трассировкой лучей, Nvidia в настоящее время является лучшим вариантом. Для бюджетных сборок лучше всего подойдет GeForce GTX 1660 от Nvidia. Суть в том, что видеокарта является крупной покупкой для большинства потребителей, поэтому не принимайте решение, не изучив, какая карта лучше всего соответствует вашим потребностям и вашему бюджету.
графических процессоров на Compute Engine | Документация по вычислительному движку | Облако Google
Compute Engine предоставляет графические процессоры (GPU), которые вы можете добавить к экземплярам вашей виртуальной машины (ВМ). Вы можете использовать эти графические процессоры для ускорения конкретные рабочие нагрузки на ваши экземпляры, такие как машинное обучение и данные обработка.
Если у вас есть рабочие нагрузки с интенсивным использованием графики, такие как 3D-визуализация, 3D-рендеринг или виртуальные приложения, вы можете создавать виртуальные рабочие станции, которые используют Технология NVIDIA® GRID®.Для получения информации о графических процессорах для приложений с интенсивным использованием графики приложения, см. Графические процессоры для графических рабочих нагрузок.
В этом документе содержится обзор графических процессоров в Compute Engine, а также
информацию о работе с графическими процессорами см. на следующих ресурсах:
на следующих ресурсах:
Попробуйте сами
Если вы новичок в Google Cloud, создайте учетную запись, чтобы оценить, как Compute Engine работает в реальном мире сценарии.Новые клиенты также получают бесплатные кредиты в размере 300 долларов США для запуска, тестирования и развертывание рабочих нагрузок.
Попробуйте Compute Engine бесплатноВведение
Compute Engine предоставляет графические процессоры NVIDIA®
для ваших экземпляров в транзитном режиме, чтобы экземпляры вашей виртуальной машины
имеют прямой контроль над графическими процессорами и связанной с ними памятью.
Для вычислительных рабочих нагрузок модели графических процессоров доступны на следующих этапах:
- NVIDIA® A100: общедоступный
- NVIDIA® T4:
nvidia-tesla-t4: общедоступный - NVIDIA® V100:
nvidia-tesla-v100: общедоступный - NVIDIA® P100:
nvidia-tesla-p100: общедоступный - NVIDIA® P4:
nvidia-tesla-p4: Общедоступный - NVIDIA® K80:
nvidia-tesla-k80: общедоступный
Для графических рабочих нагрузок доступны модели графических процессоров следующих стадий:
- Виртуальные рабочие станции NVIDIA® T4:
nvidia-tesla-t4-vws: Общедоступный - Виртуальные рабочие станции NVIDIA® P100:
nvidia-tesla-p100-vws: общедоступный - Виртуальные рабочие станции NVIDIA® P4:
nvidia-tesla-p4-vws: Общедоступный
Информацию о графических процессорах для виртуальных рабочих станций см. Графические процессоры для графических рабочих нагрузок.
Графические процессоры для графических рабочих нагрузок.
Вы можете подключать графические процессоры только к инстансам с предопределенный или пользовательские типы машин. GPU не поддерживаются на с общим ядром или оптимизированные для памяти типы машин.
Вы также можете добавить локальные твердотельные накопители к графическим процессорам. Для список поддерживаемых локальных SSD по типам GPU и регионам см. Локальная доступность SSD по регионам и зонам GPU.
Цены
Большинство устройств с графическим процессором получают скидки на постоянное использование аналогично vCPU. Почасовые и месячные цены на устройства с графическим процессором см. Страница с ценами на GPU.
моделей графических процессоров
Графические процессоры NVIDIA® A100
Для запуска графических процессоров NVIDIA® A100 необходимо использовать
оптимизированный для ускорителя (A2)
тип аппарата.
Каждый тип машины A2 имеет фиксированное количество GPU, количество виртуальных ЦП и объем памяти.
Примечание. Чтобы просмотреть доступные регионы и зоны для графических процессоров в Compute Engine, см. Регионы GPU и доступность зон.| Модель графического процессора | Тип машины | графических процессоров | Память графического процессора | Доступные виртуальные ЦП | Доступная память |
|---|---|---|---|---|---|
| NVIDIA® A100 | a2-highgpu-1g | 1 ГП | 40 ГБ HBM2 | 12 виртуальных ЦП | 85 ГБ |
а2-хайгпу-2г | 2 графических процессора | 80 ГБ HBM2 | 24 виртуальных ЦП | 170 ГБ | |
а2-хайгпу-4г | 4 графических процессора | 160 ГБ HBM2 | 48 виртуальных ЦП | 340 ГБ | |
а2-хайгпу-8г | 8 графических процессоров | 320 ГБ HBM2 | 96 виртуальных ЦП | 680 ГБ | |
а2-мегагпу-16g | 16 графических процессоров | 640 ГБ HBM2 | 96 виртуальных ЦП | 1360 ГБ |
Другие доступные модели графических процессоров NVIDIA®
Виртуальные машины с меньшим количеством графических процессоров ограничены максимальным числом виртуальных ЦП. В целом более высокое число
GPU позволяет создавать инстансы с большим количеством виртуальных ЦП и
объем памяти.
В целом более высокое число
GPU позволяет создавать инстансы с большим количеством виртуальных ЦП и
объем памяти.
| Модель графического процессора | графических процессоров | Память графического процессора | Доступные виртуальные ЦП | Доступная память |
|---|---|---|---|---|
| NVIDIA® T4 | 1 ГП | 16 ГБ GDDR6 | 1–24 виртуальных ЦП | 1 — 156 ГБ |
| 2 графических процессора | 32 ГБ GDDR6 | 1–48 виртуальных ЦП | 1 — 312 ГБ | |
| 4 графических процессора | 64 ГБ GDDR6 | 1–96 виртуальных ЦП | 1 — 624 ГБ | |
| NVIDIA® P4 | 1 ГП | 8 ГБ GDDR5 | 1–24 виртуальных ЦП | 1 — 156 ГБ |
| 2 графических процессора | 16 ГБ GDDR5 | 1–48 виртуальных ЦП | 1 — 312 ГБ | |
| 4 графических процессора | 32 ГБ GDDR5 | 1–96 виртуальных ЦП | 1 — 624 ГБ | |
| NVIDIA® V100 | 1 ГП | 16 ГБ HBM2 | 1–12 виртуальных ЦП | 1 — 78 ГБ |
| 2 графических процессора | 32 ГБ HBM2 | 1–24 виртуальных ЦП | 1 — 156 ГБ | |
| 4 графических процессора | 64 ГБ HBM2 | 1–48 виртуальных ЦП | 1 — 312 ГБ | |
| 8 графических процессоров | 128 ГБ HBM2 | 1–96 виртуальных ЦП | 1 — 624 ГБ | |
| NVIDIA® P100 | 1 ГП | 16 ГБ HBM2 | 1–16 виртуальных ЦП | 1 — 104 ГБ |
| 2 графических процессора | 32 ГБ HBM2 | 1–32 виртуальных ЦП | 1 — 208 ГБ | |
| 4 графических процессора | 64 ГБ HBM2 | 1–64 виртуальных ЦП 1–96 виртуальных ЦП | 1 — 208 ГБ 1 — 624 ГБ | |
| NVIDIA® K80 | 1 ГП | 12 ГБ GDDR5 | 1–8 виртуальных ЦП | 1–52 ГБ |
| 2 графических процессора | 24 ГБ GDDR5 | 1–16 виртуальных ЦП | 1 — 104 ГБ | |
| 4 графических процессора | 48 ГБ GDDR5 | 1–32 виртуальных ЦП | 1 — 208 ГБ | |
| 8 графических процессоров | 96 ГБ GDDR5 | 1–64 виртуальных ЦП | 1 — 416 ГБ 1 — 208 ГБ |
- Более подробное описание зон см. Регионы и зоны. Платы
- NVIDIA® K80® содержат по два графических процессора каждая. Цена на К80 Графические процессоры — это отдельные графические процессоры, а не плата.
 Регионы и зоны.
Регионы и зоны.Графические процессоры NVIDIA® GRID® для графических рабочих нагрузок
Если у вас есть графические рабочие нагрузки, такие как 3D-визуализация, вы можете создавать виртуальные рабочие станции, использующие платформу NVIDIA® GRID®. Справочную информацию о NVIDIA® GRID® см. Обзор ГРИД.
Когда вы выбираете GPU для виртуальной рабочей станции, NVIDIA® GRID® лицензия добавлена к вашей виртуальной машине.Для получения дополнительной информации о ценах см. Страница с ценами на GPU.
Чтобы настроить виртуальную рабочую станцию NVIDIA® GRID®, вам необходимо создать виртуальную машину с включенной виртуальной рабочей станцией и установите драйвер GRID.
После создания виртуальной рабочей станции вы можете подключиться к ней с помощью удаленного
настольный протокол, такой как Teradici® PCoIP или VMware® Horizon View.
| Модель графического процессора | графических процессоров | Память графического процессора | Доступные виртуальные ЦП | Доступная память |
|---|---|---|---|---|
| Виртуальная рабочая станция NVIDIA® T4 | 1 ГП | 16 ГБ GDDR6 | 1–24 виртуальных ЦП | 1 — 156 ГБ |
| 2 графических процессора | 32 ГБ GDDR6 | 1–48 виртуальных ЦП | 1 — 312 ГБ | |
| 4 графических процессора | 64 ГБ GDDR6 | 1–96 виртуальных ЦП | 1 — 624 ГБ | |
| Виртуальная рабочая станция NVIDIA® P4 | 1 ГП | 8 ГБ GDDR5 | 1–16 виртуальных ЦП | 1 — 156 ГБ |
| 2 графических процессора | 16 ГБ GDDR5 | 1–48 виртуальных ЦП | 1 — 312 ГБ | |
| 4 графических процессора | 32 ГБ GDDR5 | 1–96 виртуальных ЦП | 1 — 624 ГБ | |
| Виртуальная рабочая станция NVIDIA® P100 | 1 ГП | 16 ГБ HBM2 | 1–16 виртуальных ЦП | 1 — 104 ГБ |
| 2 графических процессора | 32 ГБ HBM2 | 1–32 виртуальных ЦП | 1 — 208 ГБ | |
| 4 графических процессора | 64 ГБ HBM2 | 1–64 виртуальных ЦП 1–96 виртуальных ЦП | 1 — 208 ГБ 1 — 624 ГБ |
Пропускная способность сети и GPU
Использование более высокой пропускной способности сети может повысить производительность распределенных
рабочие нагрузки. Для получения дополнительной информации см.
Пропускная способность сети и графические процессоры.
Для получения дополнительной информации см.
Пропускная способность сети и графические процессоры.
графических процессоров на вытесняемых инстансах
Вы можете добавить графические процессоры к вытесняемым экземплярам ВМ. по более низким спотовым ценам на графические процессоры. графические процессоры прикрепленные к вытесняемым экземплярам, работают как обычные графические процессоры, но сохраняются только в течение жизнь экземпляра. Выгружаемые экземпляры с графическими процессорами следуют тому же процесс упреждения как и все вытесняемые экземпляры.
Рассмотрите возможность запроса выделенной квоты Preemptible GPU для использования GPU на
упреждающие экземпляры.Для получения дополнительной информации см.
Квоты для вытесняемых экземпляров ВМ.
Во время обслуживания вытесняемые экземпляры с графическими процессорами вытесняются
по умолчанию и не может быть перезапущен автоматически. Если вы хотите воссоздать свой
случаях после того, как они были вытеснены, используйте
группа управляемых экземпляров.
Управляемые группы экземпляров воссоздают ваши экземпляры, если виртуальный ЦП, память и
Ресурсы графического процессора доступны.
Если вы хотите воссоздать свой
случаях после того, как они были вытеснены, используйте
группа управляемых экземпляров.
Управляемые группы экземпляров воссоздают ваши экземпляры, если виртуальный ЦП, память и
Ресурсы графического процессора доступны.
Если вы хотите получить предупреждение перед тем, как ваш экземпляр будет вытеснен, или хотите настроить ваш экземпляр для автоматического перезапуска после обслуживания, используйте стандартный экземпляр с GPU.Для стандартных экземпляров с графическими процессорами Google предоставляет предварительное уведомление за час до упреждения.
Compute Engine не взимать плату за графические процессоры, если их экземпляры вытесняются в первом через минуту после того, как они начнут работать.
Инструкции по автоматическому перезапуску стандартного экземпляра см. Обновление параметров для экземпляра.
Чтобы узнать, как создавать вытесняемые экземпляры с подключенными графическими процессорами, прочтите
Создание ВМ с подключенными графическими процессорами.
Резервирование графических процессоров со скидками за обязательное использование
Чтобы зарезервировать ресурсы графического процессора в определенной зоне, см. Резервирование зональных ресурсов.Для обязательного использования по сниженным ценам на графические процессоры требуется резервирование.
Сравнительная таблица GPUОзнакомьтесь с этим разделом, чтобы узнать больше о таких факторах, как производительность. спецификации, доступность функций и идеальные типы рабочих нагрузок, которые лучше всего подходят для различных моделей графических процессоров, доступных в Compute Engine.
Максимальное количество ЦП и памяти, доступное для любой модели графического процессора, зависит от
зона, в которой работает ресурс GPU. Для получения дополнительной информации о памяти см.
Ресурсы ЦП, а также доступный регион и зоны,
см. список графических процессоров.
Общее сравнение
| Метрическая система | А100 | Т4 | В100 | Р4 | Р100 | К80 |
|---|---|---|---|---|---|---|
| Память | 40 ГБ HBM2 при 1,6 ТБ/с | 16 ГБ GDDR6 при 320 ГБ/с | 16 ГБ HBM2 при 900 ГБ/с | 8 ГБ GDDR5 при 192 ГБ/с | 16 ГБ HBM2 при 732 ГБ/с | 12 ГБ GDDR5 при 240 ГБ/с |
| Межблочное соединение | Полноячеистая сеть NVLink @ 600 ГБ/с | Н/Д | Кольцо NVLink @ 300 ГБ/с | Н/Д | Н/Д | Н/Д |
| Поддержка удаленных рабочих станций GRID | ||||||
| Лучше всего использовать для | ML Обучение, Инференс, HPC | ML Inference, Training, Remote Visualization Workstations, Video Transcoding | ML Обучение, Инференс, HPC | Рабочие станции удаленной визуализации, вывод машинного обучения и транскодирование видео | ML Training, Inference, HPC, удаленные рабочие станции визуализации | ML Инференс, Обучение, HPC |
| Цена | Чтобы сравнить цены на GPU для различных моделей GPU и регионов, доступных в Compute Engine,
см. цены на GPU. цены на GPU. | |||||
Сравнение производительности
| Метрическая система | А100 | Т4 | В100 | Р4 | Р100 | К80 |
|---|---|---|---|---|---|---|
| Производительность вычислений | ||||||
| ФП64 | 9,7 терафлопс | 0,25 терафлопс 1 | 7,8 терафлопс | 0,2 терафлопс 1 | 4.7 терафлопс | 1,46 терафлопс |
| ФП32 | 19,5 терафлопс | 8,1 терафлопс | 15,7 терафлопс | 5,5 терафлопс | 9,3 терафлопс | 4,37 терафлопс |
| ФП16 | 18,7 терафлопс | |||||
| INT8 | 22 ВЕРХА 2 | |||||
| Производительность тензорного ядра | ||||||
| ФП64 | 19.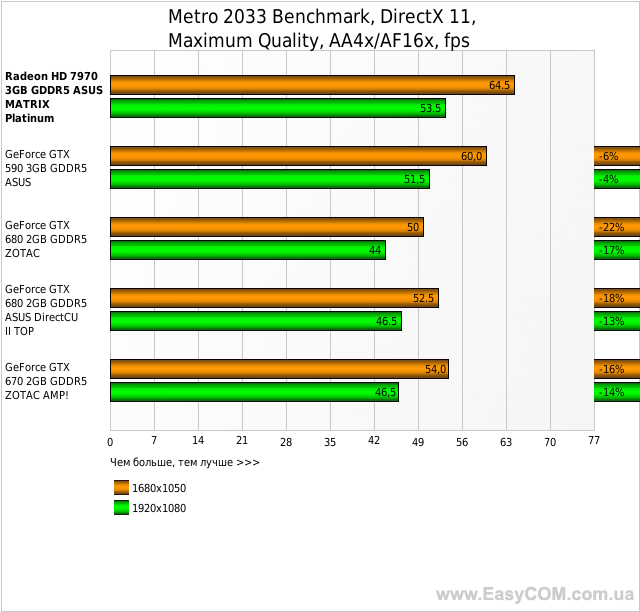 5 терафлопс 5 терафлопс | |||||
| ТФ32 | 156 терафлопс | |||||
| Смешанная точность FP16/FP32 | 312 терафлопс 3 | 65 терафлопс | 125 терафлопс | |||
| INT8 | 624 ВЕРХ 2 | 180 ВЕРХ. 2 | ||||
| INT4 | 1248 ВЕРХ 2 | 260 ТОП 2 | ||||
1 Чтобы обеспечить правильную работу кода FP64, небольшое количество FP64 аппаратные блоки включены в архитектуру GPU T4 и P4.
2 тераопераций в секунду.
3 Для обучения смешанной точности NVIDIA A100 также поддерживает bfloat16 тип данных.
Ограничения
Для виртуальных машин с подключенными графическими процессорами применяются следующие ограничения:
Если вы хотите использовать графические процессоры NVIDIA® K80 с вашими виртуальными машинами, виртуальные машины не могут используйте платформы ЦП Intel Skylake или более поздних версий.
Графические процессорыв настоящее время поддерживаются только с N1 или N1 общего назначения. типы машин A2, оптимизированные для ускорителей.
Вы не можете подключить графические процессоры к виртуальным машинам с типы машин с общим ядром.
ВМ с подключенными графическими процессорами должны остановка для мероприятий по обслуживанию хоста, но может автоматический перезапуск. События обслуживания хоста в Compute Engine имеют периодичность один раз в две недели но может иногда запускаться чаще. Вы должны настроить свой рабочие нагрузки для аккуратной обработки этих событий обслуживания. Конкретно, длительные рабочие нагрузки, такие как машинное обучение и высокопроизводительные вычисления (HPC) должны обрабатывать прерывание событий обслуживания хоста.Для получения дополнительной информации см. Обработка событий обслуживания хоста GPU.
Для защиты систем и пользователей Compute Engine новые проекты имеют глобальная квота GPU, которая ограничивает общее количество GPU, которые вы можете создать в любая поддерживаемая зона.
Когда вы запрашиваете квоту GPU, вы должны запросить квоту
для моделей графических процессоров, которые вы хотите создать в каждом регионе, и дополнительный
глобальная квота на общее количество графических процессоров всех типов во всех зонах.ВМ с одним или несколькими графическими процессорами имеют максимальное количество виртуальных ЦП для каждый GPU, который вы добавляете к экземпляру.Например, каждый Графический процессор NVIDIA® K80 позволяет использовать до восьми виртуальных ЦП и до 52 ГБ памяти в типе вашего экземпляра машины. Видеть доступные диапазоны vCPU и памяти для разных конфигураций GPU, см. список графических процессоров.
Графическим процессорам для правильной работы требуются драйверы устройств. Графические процессоры NVIDIA работают на Compute Engine должна использоваться минимальная версия драйвера. Чтобы получить больше информации о версиях драйверов см. Требуемые версии драйверов NVIDIA.
ВМ с определенной моделью подключенного графического процессора покрываются Соглашение об уровне обслуживания Comp Engine, только если эта подключенная модель графического процессора общедоступна и поддерживается более чем в одной зоне в одном регионе.
Соглашение об уровне обслуживания Compute Engine не распространяется на модели графических процессоров в
следующие зоны:- NVIDIA® A100:
- NVIDIA® T4:
-
австралия-юго-восток1-a -
европа-запад3-б -
южная америка-восток1-c
-
- NVIDIA® V100:
- NVIDIA® P100:
-
австралия-юго-восток1-c -
европа-запад4-а
-
- NVIDIA® K80:
Compute Engine поддерживает одновременную работу 1 пользователя на каждый GPU.

 Когда вы запрашиваете квоту GPU, вы должны запросить квоту
для моделей графических процессоров, которые вы хотите создать в каждом регионе, и дополнительный
глобальная квота на общее количество графических процессоров всех типов во всех зонах.
Когда вы запрашиваете квоту GPU, вы должны запросить квоту
для моделей графических процессоров, которые вы хотите создать в каждом регионе, и дополнительный
глобальная квота на общее количество графических процессоров всех типов во всех зонах. Соглашение об уровне обслуживания Compute Engine не распространяется на модели графических процессоров в
следующие зоны:
Соглашение об уровне обслуживания Compute Engine не распространяется на модели графических процессоров в
следующие зоны:Что дальше?
На этой странице описывается поддержка GPU AMBER 16.
Эпизод 3: Сравнение производительности собственного графического процессора с виртуализированным графическим процессором и масштабируемость виртуализированных графических процессоров для машинного обучения В нашем третьем эпизоде производительности машинного обучения с vSphere 6. Машинное обучение с виртуализированными графическими процессорами Производительность — одна из самых больших проблем, которая удерживает пользователей высокопроизводительных вычислений (HPC) от выбора виртуализации в качестве решения для развертывания приложений HPC, несмотря на преимущества виртуализации, такие как снижение затрат на администрирование, эффективность использования ресурсов, энергосбережение и безопасность.Однако с постоянным развитием технологий виртуализации разрыв в производительности между «голым железом» и виртуализацией почти исчез, и в некоторых случаях использования виртуализированные приложения могут достигать более высокой производительности, чем работающие на «голом железе», благодаря интеллектуальному и высокооптимизированному использованию ресурсов. Сравнение виртуального графического процессора с физическим графическим процессором Чтобы понять влияние машинного обучения на графические процессоры с использованием виртуализации на производительность, мы использовали приложение для моделирования сложного языка, предсказывающее следующие слова по истории предыдущих слов с помощью рекуррентной нейронной сети (RNN) с 1500 единицами долговременной кратковременной памяти (LSTM) на слой в наборе данных Penn Treebank (PTB) [2, 3], который имеет:
Мы протестировали три корпуса:
Виртуальная машина в последних двух случаях имеет 12 виртуальных ЦП (вЦП), 60 ГБ ОЗУ и 96 ГБ хранилища SSD. Тест был реализован с использованием TensorFlow [4], который также использовался для реализации других тестов машинного обучения в наших экспериментах. Мы использовали CUDA 7.5, cuDNN 5.1 и CentOS 7.2 как для собственных, так и для гостевых операционных систем. Эти тестовые случаи выполнялись на сервере Dell PowerEdge R730 с двумя 12-ядерными процессорами Intel Xeon E5-2680 v3, разъемами 2,50 ГГц (24 физических ядра, 48 логических с включенной гиперпоточностью), 768 ГБ памяти и твердотельным накопителем (1,5 ТБ). . На этом сервере также было две карты NVIDIA Tesla M60 (каждая с двумя графическими процессорами), всего 4 графических процессора, каждый из которых имел 2048 ядер CUDA, 8 ГБ памяти, 36 x H.264 видео 1080p 30 потоков и может поддерживать от 1 до 32 виртуальных графических процессоров GRID с профилями памяти от 512 МБ до 8 ГБ. Эта экспериментальная установка использовалась для всех тестов, представленных в этом блоге (рис. 1 ниже). Рис. 1. Сравнение конфигураций испытательного стенда для собственного графического процессора и виртуального графического процессора Результаты на рис. GPU по сравнению с CPU в среде виртуализации Одним из важных преимуществ использования графического процессора является сокращение продолжительного времени обучения задачам машинного обучения, что позволило повысить результаты исследований и разработок в области ИИ в последние годы. Во многих случаях это помогает сократить время выполнения с недель/дней до часов/минут.Мы иллюстрируем это преимущество на рисунке 3 (ниже), где показано время обучения с vGPU и без него для двух приложений:
Из результатов видно, что время обучения RNN на PTB с CPU было в 7,9 раз больше, чем время обучения с vGPU (рис. 3-a). Время обучения CNN на MNIST с процессором составило 10.в 1 раз выше, чем при обучении vGPU (рис. 3-б). Виртуальная машина, используемая в этом тесте, имеет 1 виртуальный графический процессор, 12 виртуальных ЦП, 60 ГБ памяти, 96 ГБ хранилища SSD, а тестовая установка аналогична описанной выше. Рис. 3. Нормализованное время обучения PTB, MNIST с vGPUи без него Как показывают результаты тестирования, мы можем успешно запускать приложения машинного обучения в виртуализированной среде vSphere 6, и его производительность аналогична времени обучения приложений машинного обучения, работающих в собственная конфигурация (не виртуализированная) с использованием физических графических процессоров. А как насчет сквозного сценария? Как приложение машинного обучения работает на виртуальной машине vSphere 6 с использованием сквозного доступа к физическому графическому процессору по сравнению с использованием виртуализированного графического процессора? Мы представляем наши выводы в следующем разделе. Сравнение ввода-вывода DirectPath и GRID vGPU Мы оцениваем производительность, масштабируемость и другие преимущества ввода-вывода DirectPath и GRID vGPU. Мы также предоставляем некоторые рекомендации по лучшим вариантам использования каждого виртуального графического процессора. Производительность Чтобы сравнить производительность ввода-вывода DirectPath и GRID vGPU, мы сравнили их с RNN на PTB и CNN на MNIST и CIFAR-10. CIFAR-10 [8] представляет собой приложение для классификации объектов, которое распределяет изображения RGB размером 32×32 пикселя по 10 категориям: самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик. MNIST — приложение для распознавания рукописного ввода. И CIFAR-10, и MNIST используют сверточные нейронные сети. Языковая модель, используемая для предсказания слов, основана на истории с использованием рекуррентной нейронной сети.Используемый набор данных — The Penn Tree Bank (PTB). Результаты на рис. 4 (выше) показывают сравнительную производительность двух решений виртуализации, в которых производительность ввода-вывода DirectPath несколько выше, чем у GRID vGPU. Это улучшение связано с тем, что сквозной механизм ввода-вывода DirectPath добавляет минимальные накладные расходы рабочим нагрузкам на основе графического процессора, выполняемым внутри виртуальной машины. На рисунке 4-a скорость ввода-вывода DirectPath примерно на 5 % выше, чем у GRID vGPU для MNIST, и они имеют одинаковую производительность с PTB.Для CIFAR-10 ввод-вывод DirectPath может обрабатывать примерно на 13 % больше изображений в секунду, чем GRID vGPU. Мы используем изображения в секунду для CIFAR-10, потому что это часто используемый показатель для этого набора данных. Виртуальная машина в этом эксперименте имеет 12 виртуальных ЦП, 60 ГБ видеопамяти и один графический процессор (ввод-вывод DirectPath или виртуальный графический процессор GRID). Масштабируемость Мы рассматриваем два типа масштабируемости: пользовательскую и графическую. Масштабируемость пользователя В облачной среде несколько пользователей могут совместно использовать физические серверы, что помогает лучше использовать ресурсы и экономить средства.Наш тестовый сервер с 4 графическими процессорами может поддерживать до 4 пользователей, нуждающихся в графическом процессоре. Кроме того, у одного пользователя может быть четыре ВМ с vGPU. Количество виртуальных машин, работающих на одну машину в облачной среде, как правило, велико для увеличения использования и снижения затрат [9]. Рабочие нагрузки машинного обучения, как правило, гораздо более ресурсоемкие, и использование наших тестовых систем с 4 графическими процессорами только для 4 пользователей отражает это. Рисунок 5. Масштабирование количества ВМ с vGPU на CIFAR-10 На Рисунке 5 (выше) представлена масштабируемость пользователей на CIFAR-10 от 1 до 4, где каждый использует виртуальную машину с одним GPU, и мы нормализуем количество изображений в секунду до этого случая DirectPath I/O — 1 VM (рис. Масштабируемость GPU Для приложений машинного обучения, которым необходимо создавать очень большие модели или в которых наборы данных не помещаются в один графический процессор, пользователи могут использовать несколько графических процессоров для распределения рабочих нагрузок между ними и дальнейшего ускорения задачи обучения. Мы демонстрируем эффективность использования нескольких графических процессоров в vSphere путем сравнительного анализа рабочей нагрузки CIFAR-10 и использования метрики количества изображений в секунду (изображений в секунду) для сравнения производительности CIFAR-10 на виртуальной машине с различным количеством графических процессоров при масштабировании от 1 до 4 графических процессоров. Из результатов на рис. 6 (ниже) мы обнаружили, что количество изображений, обрабатываемых в секунду, улучшается почти линейно с количеством графических процессоров на хосте (рис. Как выбрать между DirectPath I/O и GRID vGPU Для ввода/вывода DirectPath Из приведенных выше результатов видно, что DirectPath I/O и GRID vGPU имеют аналогичную производительность и низкие накладные расходы по сравнению с производительностью собственного графического процессора, что делает их хорошим выбором для приложений машинного обучения в виртуализированных облачных средах. Для GRID vGPU Когда каждому пользователю требуется один графический процессор, GRID vGPU может быть хорошим выбором. Эта конфигурация обеспечивает более высокую степень консолидации виртуальных машин и использует преимущества виртуализации: .
Заключение Наши тесты показывают, что виртуализированные рабочие нагрузки машинного обучения в vSphere с vGPU обеспечивают производительность, близкую к производительности «голого железа». Каталожные номера
God of War — собственное разрешение, NVIDIA DLSS и AMD FSR, тесты и сравнения Только что снято эмбарго на обзоры God of War, и мы наконец-то можем поделиться своими первыми техническими мыслями об этом долгожданном релизе для ПК. Для этих тестов мы использовали Intel i9 9900K с 16 ГБ памяти DDR4 на частоте 3800 МГц и NVIDIA RTX 3080. Мы также использовали 64-разрядную версию Windows 10 с драйвером GeForce 497.29. God of War не имеет встроенного инструмента для тестирования. Поэтому мы сравнили одну из областей открытия. Наша эталонная сцена — это когда Кратос и Атрей начинают охотиться на оленя. Эта область имеет множество объемных эффектов и, похоже, нагружает графический процессор больше, чем все предыдущие сцены. Ниже вы можете найти несколько сравнительных скриншотов между Native 4K (слева), качеством NVIDIA DLSS (в центре) и AMD FSR (справа). God of War использует множество эффектов постобработки и имеет действительно мягкое изображение (даже в родном разрешении). Таким образом, DLSS может выглядеть четче, чем исходное 4K, тогда как FSR может выглядеть почти так же хорошо, как исходное 4K. NVIDIA DLSS кажется более четким, чем AMD FSR, и работает немного лучше на нашей RTX3080. Однако мы заметили некоторые странные артефакты с DLSS (которых не было ни в родном разрешении, ни в FSR).Например, взгляните на цепочку для фонарей в конце нашего видео. Как вы можете видеть, в нем больше алиасинга, и при перемещении камеры наблюдается сильное мерцание. Эта мерцающая проблема напомнила нам о похожей проблеме, которую мы видели в Call of Duty: Vanguard. Мы уже сообщили об этом NVIDIA, поэтому надеемся, что зеленая команда сможет решить эту проблему с помощью будущей версии DLSS. Из-за этих проблем с мерцанием мы рекомендуем запускать игру в исходном разрешении (и использовать фильтр повышения резкости).Для тех, кому интересно, наша RTX3080 смогла запустить игру с постоянными 60 кадрами в секунду на высоких настройках в родном 4K (настройка выше исходных настроек/настроек PS4). Кроме того, вы можете использовать FSR вместе с фильтром повышения резкости. С точки зрения производительности, DLSS обеспечивает повышение производительности на 20-25%. Это ниже, чем то, что мы видели в других играх.Тем не менее, как с DLSS, так и с FSR, наша RTX3080 смогла запустить игру в 4K/Ultra с постоянными 60 кадрами в секунду. Более того, что довольно удивительно, AMD FSR почти так же быстр, как NVIDIA DLSS. Наш анализ производительности ПК (в котором мы будем тестировать больше графических процессоров как от NVIDIA, так и от AMD) будет запущен позже на этой неделе, так что следите за обновлениями! Джон Пападопулос Джон — основатель и главный редактор DSOGaming. Он фанат компьютерных игр и активно поддерживает моддинг и инди-сообщества.До создания DSOGaming Джон работал над многочисленными игровыми сайтами. Хотя он заядлый игрок на ПК, его игровые корни можно найти на консолях. Глубокое обучение GPU Benchmarks 2020 | Рабочие станции для глубокого обучения, серверы, облачные сервисы на GPUОбзор современных высокопроизводительных графических процессоров и ускорителей вычислений, которые лучше всего подходят для задач глубокого и машинного обучения.Включены последние предложения от NVIDIA: поколение графических процессоров Ampere. Также оценивается производительность установок с несколькими графическими процессорами, таких как четырехъядерная конфигурация RTX 3090.Обзор протестированных графических процессоров Хотя мы протестировали лишь небольшую часть всех доступных графических процессоров, мы думаем, что охватили все графические процессоры, которые в настоящее время лучше всего подходят для обучения и разработки в области глубокого обучения благодаря их вычислительным возможностям и памяти, а также их совместимости с текущими платформами глубокого обучения.
Получение максимальной производительности от TensorflowБыли предприняты некоторые меры, чтобы получить максимальную производительность от Tensorflow для бенчмаркинга. Размер партииОдним из наиболее важных параметров оптимизации рабочей нагрузки для каждого типа графического процессора является использование оптимального размера пакета.Размер пакета указывает, сколько параллельных размножений сети выполняется, результаты каждого размножения усредняются по пакету, а затем результат применяется для корректировки весов сети. Лучший размер пакета с точки зрения производительности напрямую связан с объемом доступной памяти графического процессора . Больший размер пакета повысит параллелизм и улучшит использование ядер графического процессора. Но размер пакета не должен превышать доступную память графического процессора , так как в этом случае должны сработать механизмы подкачки памяти и снизить производительность, иначе приложение просто аварийно завершает работу с исключением «недостаточно памяти». Большой размер партии в некоторой степени не оказывает отрицательного влияния на результаты обучения, напротив, большой размер партии может иметь положительный эффект для получения более обобщенных результатов. Примером может служить BigGAN, где для достижения наилучших результатов предлагается размер пакета до 2048. Еще одна интересная информация о влиянии размера партии на результаты обучения была опубликована OpenAI. Тензорный поток XLAФункция повышения производительности Tensorflow, которая некоторое время назад была объявлена стабильной, но по-прежнему отключена по умолчанию, — это XLA (ускоренная линейная алгебра).Он выполняет оптимизацию графа сети, динамически компилируя части сети в определенные ядра, оптимизированные для конкретного устройства. Это может дать выигрыш в производительности от 10% до 30% по сравнению со статическими ядрами Tensorflow для разных типов слоев. Эта функция может быть включена простой опцией или флагом среды и будет иметь прямое влияние на производительность выполнения. Обучение с плавающей запятой 16 бит / смешанное точное обучениеЧто касается заданий логического вывода, то для повышения производительности предоставляется более низкая точность с плавающей запятой и еще более низкое 8- или 4-битное целочисленное разрешение.В большинстве ситуаций обучения 16-битная точность с плавающей запятой также может применяться для задач обучения с незначительной потерей точности обучения и может значительно ускорить выполнение заданий обучения. Применение 16-битной точности с плавающей запятой не так уж тривиально, поскольку модель должна быть настроена для ее использования. Поскольку не все этапы вычислений должны выполняться с более низкой битовой точностью, смешивание различных битовых разрешений для вычислений называется «смешанной точностью». Полный потенциал обучения смешанной точности будет лучше изучен с помощью Tensor Flow 2.X и, вероятно, станет тенденцией развития для улучшения производительности фреймворка глубокого обучения. Мы предоставляем тесты для 32-битной и 16-битной точности с плавающей запятой в качестве эталона для демонстрации потенциала. Тест глубокого обученияМодель визуального распознавания ResNet50 в версии 1.0 используется для нашего теста. Как классическая сеть глубокого обучения с ее сложной 50-уровневой архитектурой с различными сверточными и остаточными слоями, она по-прежнему является хорошей сетью для сравнения достижимой производительности глубокого обучения.Поскольку он используется во многих бенчмарках, доступна близкая к оптимальной реализация, обеспечивающая максимальную производительность графического процессора и показывающая пределы производительности устройств. Среда тестирования Для тестирования мы использовали наш сервер AIME A4000. Это продуманная среда для запуска нескольких высокопроизводительных графических процессоров, обеспечивающая оптимальное охлаждение и возможность запуска каждого графического процессора в слоте PCIe 4. Поколение NVIDIA Ampere использует PCIe 4.0 удваивает скорость передачи данных до 31,5 ГБ/с на ЦП и между графическими процессорами. Возможность подключения оказывает заметное влияние на производительность глубокого обучения, особенно в конфигурациях с несколькими графическими процессорами. Кроме того, AIME A4000 обеспечивает сложное охлаждение, необходимое для достижения и поддержания максимальной производительности. Технические характеристики для воспроизведения наших тестов:
Сценарии Python, используемые для теста, доступны на Github по адресу: Tensorflow 1.x Benchmark .Производительность одного графического процессора Результатом наших измерений является среднее изображение в секунду, которое можно обучить при выполнении 100 пакетов с заданным размером пакета. Поколение NVIDIA Ampere явно лидирует, а A100 рассекречивает все остальные модели. При обучении с плавающей запятой 16-битной точности ускорители вычислений A100 и V100 увеличивают свое преимущество. Но также RTX 3090 может более чем удвоить производительность по сравнению с 32-битными вычислениями с плавающей запятой. Ускорение графического процессора по сравнению с центральным процессором увеличивается здесь до 167 раз по сравнению с 32-ядерным процессором, что делает вычисления на графическом процессоре не только возможными, но и обязательными для высокопроизводительных задач глубокого обучения. Эффективность обучения глубокому обучению с несколькими графическими процессорамиСледующим уровнем производительности глубокого обучения является распределение рабочих и учебных нагрузок между несколькими графическими процессорами.AIME A4000 поддерживает до 4 графических процессоров любого типа. Глубокое обучение хорошо масштабирует на нескольких графических процессорах. Таким образом, каждый GPU вычисляет свой пакет для обратного распространения для применяемых входных данных среза пакета. Затем результаты каждого графического процессора обмениваются и усредняются, а веса модели корректируются соответствующим образом и должны распределяться обратно на все графические процессоры. Что касается обмена данными, то для сбора результатов партии и корректировки весов перед запуском следующей партии происходит пиковая скорость обмена данными. В то время как графические процессоры работают над пакетом, обмен данными между графическими процессорами не происходит или не происходит вообще. В этом стандартном решении для масштабирования нескольких графических процессоров необходимо убедиться, что все графические процессоры работают с одинаковой скоростью, иначе самый медленный графический процессор будет узким местом , которого должны ждать все графические процессоры! Поэтому смешивание разных типов GPU бесполезно . С AIME A4000 достигается хороший масштабный коэффициент 0,88, поэтому каждый дополнительный GPU добавляет около 88% своей возможной производительности к общей производительностиЭффективность обучения в перспективеЧтобы получить лучшее представление о том, как измерение количества изображений в секунду преобразуется во время обработки и ожидания при обучении таких сетей, мы рассмотрим реальный вариант обучения такой сети с большим набором данных. Например, набор данных ImageNet 2017 состоит из 1 431 167 изображений.Для однократной обработки каждого изображения набора данных, так называемой 1 эпохи обучения, на ResNet50 потребуется около:
Обычно требуется не менее 50 периодов обучения, чтобы можно было получить результат для оценки после:
Это показывает, что правильная настройка может изменить продолжительность задачи обучения с недель до одного дня или даже нескольких часов. В большинстве случаев, вероятно, желательно время тренировки, позволяющее проводить тренировку в течение ночи, чтобы получить результаты на следующее утро. ВыводыMixed Precision может ускорить обучение более чем в 2 разаОсобенность, на которую стоит обратить внимание с точки зрения производительности, — переключение тренировки с точности с плавающей запятой 32 на тренировку со смешанной точностью.Получение повышения производительности путем настройки программного обеспечения в зависимости от ваших ограничений, вероятно, может быть очень эффективным шагом для удвоения производительности. Масштабирование нескольких GPU более чем возможноМасштабирование производительности глубокого обученияс несколькими графическими процессорами хорошо масштабируется как минимум для 4 графических процессоров: 2 графических процессора часто могут превзойти следующий более мощный графический процессор с точки зрения цены и производительности. Это верно, например, при сравнении 2 x RTX 3090 с NVIDIA A100. Лучший графический процессор для глубокого обучения?Как и в большинстве случаев, на вопрос нет однозначного ответа.Производительность, безусловно, является наиболее важным аспектом графического процессора, используемого для задач глубокого обучения, но не единственным. Так что это сильно зависит от ваших требований. Вот наши оценки наиболее перспективных графических процессоров для глубокого обучения: .RTX 3080Он обеспечивает максимальную отдачу от затраченных средств. Если вы ищете экономичное решение, установка с 4 графическими процессорами может занять место в высшей лиге с затратами на приобретение менее одного самого высокопроизводительного графического процессора. Но имейте в виду, что объем доступной памяти графического процессора уменьшился, так как у RTX 3080 на 1 ГБ памяти меньше, чем у давней конфигурации памяти GTX 1080 TI и RTX 2080 TI с 11 ГБ памяти.Вероятно, это приводит к необходимости уменьшить размер пакета по умолчанию для многих приложений. Может быть RTX 3080 TI устранит это узкое место? RTX 3090RTX 3090 в настоящее время является реальным шагом вперед по сравнению с RTX 2080 TI. Благодаря своей сложной памяти объемом 24 ГБ и явному увеличению производительности по сравнению с RTX 2080 TI он устанавливает предел для этого поколения графических процессоров для глубокого обучения. Установка с двумя RTX 3090 может превзойти установку с четырьмя RTX 2080 TI по времени цикла глубокого обучения, с меньшим энергопотреблением и более низкой ценой. NVIDIA A100Если требуется максимальная производительность независимо от цены и максимальная плотность производительности, NVIDIA A100 — лучший выбор: она обеспечивает максимальную вычислительную производительность во всех категориях. A100 значительно улучшил производительность по сравнению с Tesla V100, что делает соотношение цены и качества более приемлемым. Кроме того, более низкое энергопотребление 250 Вт по сравнению с 700 Вт установки с двумя RTX 3090 при сопоставимой производительности достигает диапазона, при котором при постоянной полной нагрузке разница в затратах на электроэнергию может стать фактором, который следует учитывать. Кроме того, что касается решений, требующих виртуализации для работы под гипервизором, например, для служб аренды облачных вычислений, в настоящее время это лучший выбор для высококлассных задач обучения глубокому обучению. Четырехъядерная установка NVIDIA A100, как это возможно с AIME A4000, катапультирует один из них в область вычислений HPC с производительностью петафлопс. 2019. Все права защищены. Карта сайта | ||||||||
 здесь.
здесь.  98
98 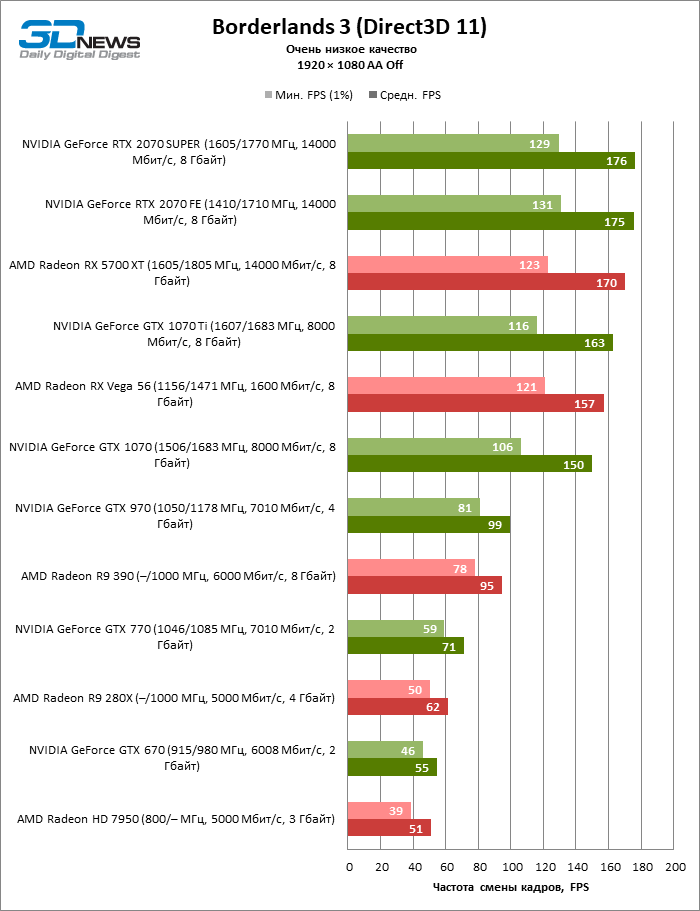
 1 МБ)
1 МБ) без ущерба для производительности первой работы со времён шины PCI-E
и ядра процессора уже полностью загружены. ЯНТАРЬ отличается. Во время
один GPU запускает процессор, а шина PCI-E практически не используется.Таким образом, у вас есть
выбор запуска одного MD на нескольких графических процессорах, чтобы
максимизировать пропускную способность при одном расчете, или, альтернативно, вы
может выполнять четыре полностью независимых задания по одному на каждом графическом процессоре. В этом
случае, когда каждый отдельный запуск, в отличие от многих других кодов GPU MD, будет
бежать на полной скорости. По этой причине совокупная пропускная способность AMBER на
экономически эффективные узлы с несколькими графическими процессорами значительно превосходят другие коды
которые полагаются на постоянную связь ЦП с ГП.
без ущерба для производительности первой работы со времён шины PCI-E
и ядра процессора уже полностью загружены. ЯНТАРЬ отличается. Во время
один GPU запускает процессор, а шина PCI-E практически не используется.Таким образом, у вас есть
выбор запуска одного MD на нескольких графических процессорах, чтобы
максимизировать пропускную способность при одном расчете, или, альтернативно, вы
может выполнять четыре полностью независимых задания по одному на каждом графическом процессоре. В этом
случае, когда каждый отдельный запуск, в отличие от многих других кодов GPU MD, будет
бежать на полной скорости. По этой причине совокупная пропускная способность AMBER на
экономически эффективные узлы с несколькими графическими процессорами значительно превосходят другие коды
которые полагаются на постоянную связь ЦП с ГП.  На следующем графике показано относительное соотношение цена/качество.
на графический процессор GTX1080 для текущих графических процессоров GeForce и Tesla по ценам
по состоянию на январь 2018 г. Чем меньше, тем лучше .
На следующем графике показано относительное соотношение цена/качество.
на графический процессор GTX1080 для текущих графических процессоров GeForce и Tesla по ценам
по состоянию на январь 2018 г. Чем меньше, тем лучше . 004, вырезать=8.,
нтт=1, tаутр=10,0,
темп0=300.0,
нтб=2, нтп=1, баростат=2,
выход = 1,
/
004, вырезать=8.,
нтт=1, tаутр=10,0,
темп0=300.0,
нтб=2, нтп=1, баростат=2,
выход = 1,
/ 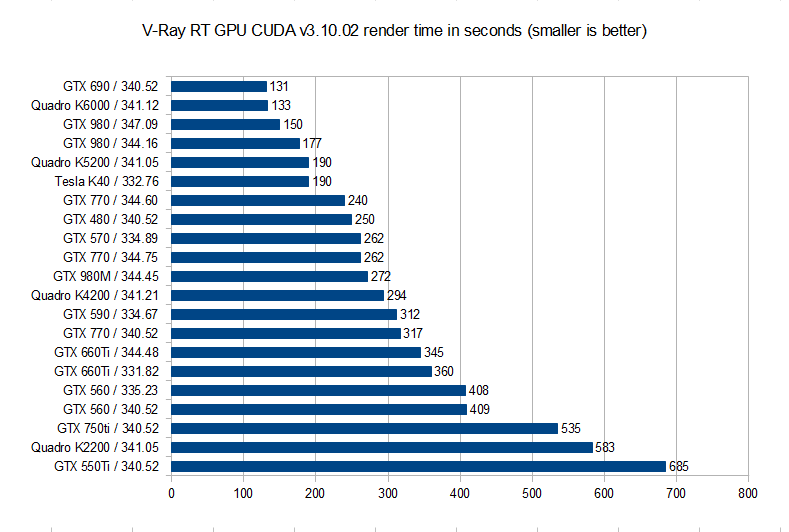 002, вырезать=8.,
нтт=1, tаутр=10,0,
темп0=300.0,
нтб=2, нтп=1, баростат=2,
выход = 1,
/
002, вырезать=8.,
нтт=1, tаутр=10,0,
темп0=300.0,
нтб=2, нтп=1, баростат=2,
выход = 1,
/  002, вырезать=8.,
нтт=1, tаутр=10,0,
темп0=300.0,
нтб=2, нтп=1, баростат=2,
выход = 1,
/
002, вырезать=8.,
нтт=1, tаутр=10,0,
темп0=300.0,
нтб=2, нтп=1, баростат=2,
выход = 1,
/ 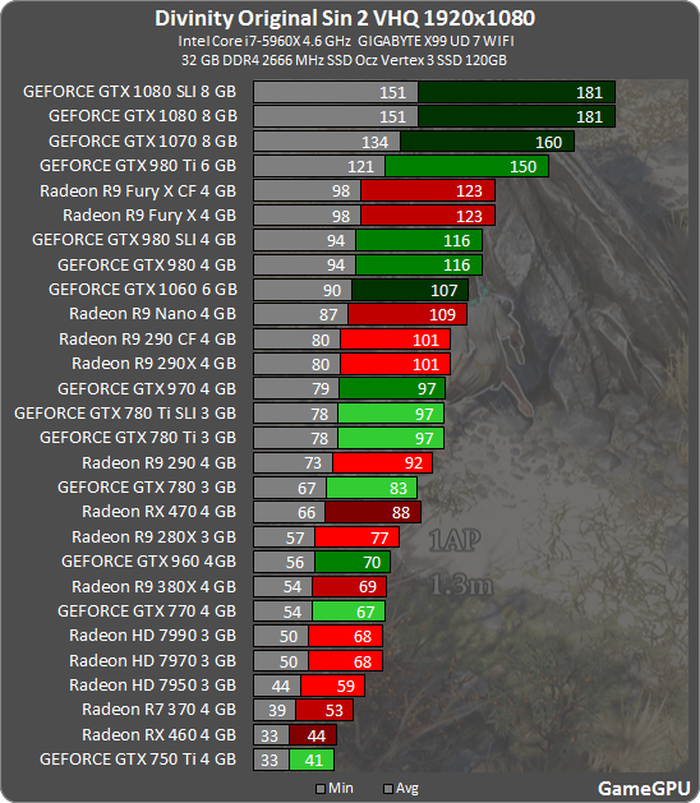 002, вырезать=8.,
нтт=1, tаутр=10,0,
темп0=300.0,
нтб=2, нтп=1, баростат=2,
выход = 1,
/
002, вырезать=8.,
нтт=1, tаутр=10,0,
темп0=300.0,
нтб=2, нтп=1, баростат=2,
выход = 1,
/  0, темп0=325.0,
нтпр=1000, нтвкс=1000, нтвр=50000,
нтб=0, игб=1,
разрез=9999., rgbmax=9999.,
/
0, темп0=325.0,
нтпр=1000, нтвкс=1000, нтвр=50000,
нтб=0, игб=1,
разрез=9999., rgbmax=9999.,
/  0,nscm=0,
0,nscm=0,  x мы сравним виртуальный графический процессор с физическим графическим процессором. Кроме того, мы расширяем результаты производительности рабочих нагрузок машинного обучения с использованием ввода-вывода VMware DirectPath (сквозной) по сравнению с виртуальным графическим процессором NVIDIA GRID, которые были частично рассмотрены в предыдущих эпизодах:
x мы сравним виртуальный графический процессор с физическим графическим процессором. Кроме того, мы расширяем результаты производительности рабочих нагрузок машинного обучения с использованием ввода-вывода VMware DirectPath (сквозной) по сравнению с виртуальным графическим процессором NVIDIA GRID, которые были частично рассмотрены в предыдущих эпизодах: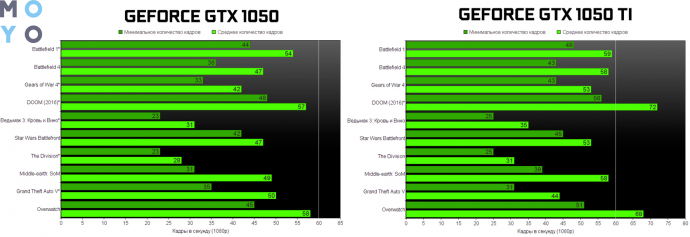 гипервизоры. Например, предыдущее исследование [1] показывает, что приложения векторной машины, работающие в виртуализированном кластере из 10 серверов, имеют лучшее время выполнения, чем работающие на «голом железе».
гипервизоры. Например, предыдущее исследование [1] показывает, что приложения векторной машины, работающие в виртуализированном кластере из 10 серверов, имеют лучшее время выполнения, чем работающие на «голом железе».
 2 (ниже) показывают относительное время выполнения операций ввода-вывода DirectPath и GRID vGPU по сравнению с собственным графическим процессором. Виртуализация приводит к увеличению накладных расходов на 4 % — производительность операций ввода-вывода DirectPath и GRID vGPU аналогична.Эти результаты согласуются с предыдущими исследованиями производительности виртуальных графических процессоров со сквозным подключением, где накладные расходы в большинстве случаев составляют менее 5% [5, 6].
2 (ниже) показывают относительное время выполнения операций ввода-вывода DirectPath и GRID vGPU по сравнению с собственным графическим процессором. Виртуализация приводит к увеличению накладных расходов на 4 % — производительность операций ввода-вывода DirectPath и GRID vGPU аналогична.Эти результаты согласуются с предыдущими исследованиями производительности виртуальных графических процессоров со сквозным подключением, где накладные расходы в большинстве случаев составляют менее 5% [5, 6].

 5-a).Как и в предыдущем сравнении, DirectPath I/O и GRID vGPU демонстрируют сравнимую производительность по мере увеличения количества ВМ с GPU. В частности, разница в производительности между ними составляет 6–10 % для изображений в секунду и 0–1,5 % для загрузки ЦП. Эта разница несущественна по сравнению с преимуществами, которые дает vGPU. Из-за своей гибкости и эластичности это хороший вариант для рабочих нагрузок машинного обучения. Результаты также показывают, что два решения линейно масштабируются с количеством виртуальных машин как с точки зрения времени выполнения, так и использования ресурсов ЦП.Виртуальные машины, используемые в этом эксперименте, имеют 12 виртуальных ЦП, 16 ГБ памяти и 1 графический процессор (ввод-вывод DirectPath или виртуальный графический процессор GRID).
5-a).Как и в предыдущем сравнении, DirectPath I/O и GRID vGPU демонстрируют сравнимую производительность по мере увеличения количества ВМ с GPU. В частности, разница в производительности между ними составляет 6–10 % для изображений в секунду и 0–1,5 % для загрузки ЦП. Эта разница несущественна по сравнению с преимуществами, которые дает vGPU. Из-за своей гибкости и эластичности это хороший вариант для рабочих нагрузок машинного обучения. Результаты также показывают, что два решения линейно масштабируются с количеством виртуальных машин как с точки зрения времени выполнения, так и использования ресурсов ЦП.Виртуальные машины, используемые в этом эксперименте, имеют 12 виртуальных ЦП, 16 ГБ памяти и 1 графический процессор (ввод-вывод DirectPath или виртуальный графический процессор GRID). В vSphere приложения, которым требуется несколько графических процессоров, могут использовать транзитный ввод-вывод DirectPath для настройки виртуальных машин с любым количеством графических процессоров.Эта возможность ограничена для приложений CUDA, использующих виртуальный графический процессор GRID, поскольку для вычислений CUDA допускается только 1 виртуальный графический процессор на виртуальную машину.
В vSphere приложения, которым требуется несколько графических процессоров, могут использовать транзитный ввод-вывод DirectPath для настройки виртуальных машин с любым количеством графических процессоров.Эта возможность ограничена для приложений CUDA, использующих виртуальный графический процессор GRID, поскольку для вычислений CUDA допускается только 1 виртуальный графический процессор на виртуальную машину. 6-a).В то же время их загрузка ЦП также увеличивается линейно (рис. 6-b). Этот результат показывает, что рабочие нагрузки машинного обучения хорошо масштабируются на платформе vSphere. В случае приложений машинного обучения, которым требуется больше графических процессоров, чем может поддерживать физический сервер, мы можем использовать модель распределенных вычислений с несколькими распределенными процессами, использующими графические процессоры, работающие на кластере физических серверов. При таком подходе можно использовать как ввод-вывод DirectPath, так и виртуальный графический процессор GRID для повышения масштабируемости с очень большим количеством графических процессоров.
6-a).В то же время их загрузка ЦП также увеличивается линейно (рис. 6-b). Этот результат показывает, что рабочие нагрузки машинного обучения хорошо масштабируются на платформе vSphere. В случае приложений машинного обучения, которым требуется больше графических процессоров, чем может поддерживать физический сервер, мы можем использовать модель распределенных вычислений с несколькими распределенными процессами, использующими графические процессоры, работающие на кластере физических серверов. При таком подходе можно использовать как ввод-вывод DirectPath, так и виртуальный графический процессор GRID для повышения масштабируемости с очень большим количеством графических процессоров. Для приложений, которые требуют короткого времени обучения и используют несколько графических процессоров для ускорения задач машинного обучения, ввод-вывод DirectPath является подходящим вариантом, поскольку это решение поддерживает несколько графических процессоров на виртуальную машину.Кроме того, DirectPath I/O поддерживает более широкий спектр устройств с графическим процессором и, таким образом, может предоставить пользователям более гибкий выбор графического процессора.
Для приложений, которые требуют короткого времени обучения и используют несколько графических процессоров для ускорения задач машинного обучения, ввод-вывод DirectPath является подходящим вариантом, поскольку это решение поддерживает несколько графических процессоров на виртуальную машину.Кроме того, DirectPath I/O поддерживает более широкий спектр устройств с графическим процессором и, таким образом, может предоставить пользователям более гибкий выбор графического процессора. Использование решений GRID для машинного обучения и 3D-графики позволяет облачным службам мультиплексировать графические процессоры среди большего числа одновременных пользователей, чем количество физических графических процессоров в системе. Это контрастирует с вводом-выводом DirectPath, который представляет собой решение с выделенным графическим процессором, в котором количество одновременных пользователей ограничено количеством физических графических процессоров.
Использование решений GRID для машинного обучения и 3D-графики позволяет облачным службам мультиплексировать графические процессоры среди большего числа одновременных пользователей, чем количество физических графических процессоров в системе. Это контрастирует с вводом-выводом DirectPath, который представляет собой решение с выделенным графическим процессором, в котором количество одновременных пользователей ограничено количеством физических графических процессоров.
 В: Учеб. 22-го симпозиума по высокопроизводительным вычислениям (2014 г.).
В: Учеб. 22-го симпозиума по высокопроизводительным вычислениям (2014 г.). 5ГБ
5ГБ 5 ГБ
5 ГБ God of War поддерживает как NVIDIA DLSS, так и AMD FSR. Поэтому мы решили сначала поделиться нашими тестами DLSS/FSR.
God of War поддерживает как NVIDIA DLSS, так и AMD FSR. Поэтому мы решили сначала поделиться нашими тестами DLSS/FSR.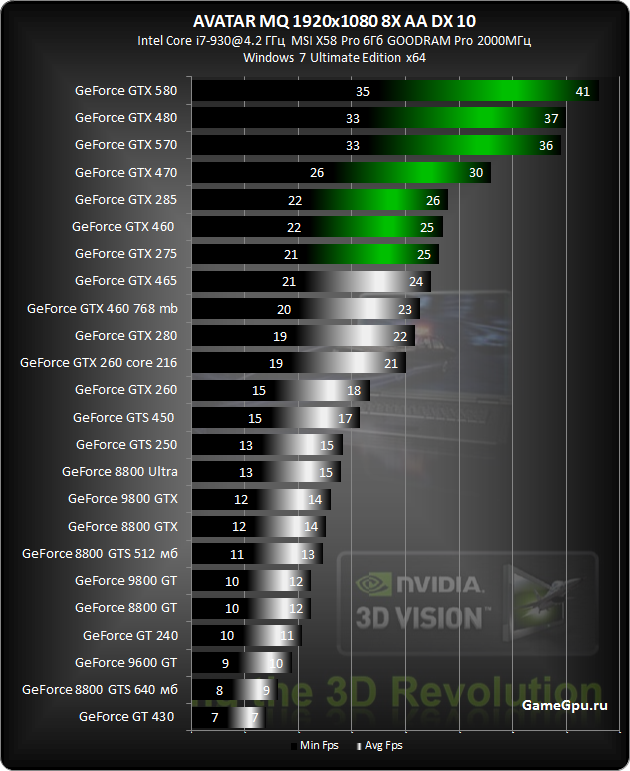
 Обычно мы рекомендуем использовать DLSS, так как он более четкий, чем родное разрешение и FSR. Тем не менее, эти мерцающие проблемы могут сильно отвлекать, даже в режиме качества.
Обычно мы рекомендуем использовать DLSS, так как он более четкий, чем родное разрешение и FSR. Тем не менее, эти мерцающие проблемы могут сильно отвлекать, даже в режиме качества. Джон любил и до сих пор любит 16-битные консоли и считает SNES одной из лучших консолей. Тем не менее, платформа ПК победила его над консолями. В основном это произошло благодаря компании 3DFX и ее культовой графической карте Voodoo 2, посвященной 3D-ускорителю. Джон также написал дипломную работу на тему «Эволюция графических карт для ПК». Контактное лицо: Электронная почта
Джон любил и до сих пор любит 16-битные консоли и считает SNES одной из лучших консолей. Тем не менее, платформа ПК победила его над консолями. В основном это произошло благодаря компании 3DFX и ее культовой графической карте Voodoo 2, посвященной 3D-ускорителю. Джон также написал дипломную работу на тему «Эволюция графических карт для ПК». Контактное лицо: Электронная почта 
 Он оснащен тем же ядром Turing ™ , что и Titan RTX, с 576 тензорными ядрами, обеспечивающими производительность 130 тензорных терафлопов и 24 ГБ сверхбыстрой памяти GDDR6 ECC.
Он оснащен тем же ядром Turing ™ , что и Titan RTX, с 576 тензорными ядрами, обеспечивающими производительность 130 тензорных терафлопов и 24 ГБ сверхбыстрой памяти GDDR6 ECC. Как и Titan RTX, он имеет 24 ГБ памяти GDDR6X.
Как и Titan RTX, он имеет 24 ГБ памяти GDDR6X. Один A100 преодолевает барьер производительности Peta TOPS.
Один A100 преодолевает барьер производительности Peta TOPS.
 Как включить XLA в своих проектах читайте здесь.
Как включить XLA в своих проектах читайте здесь.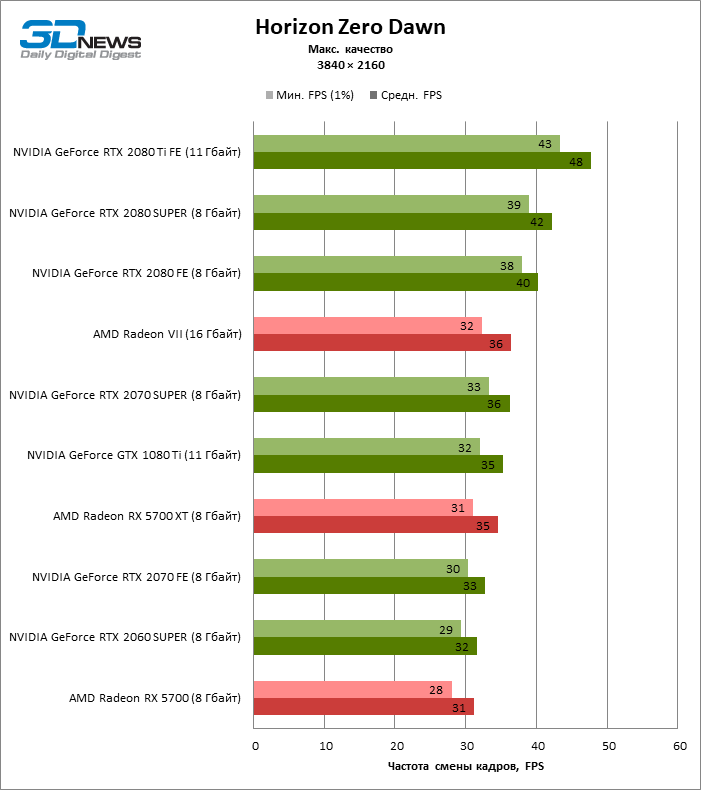
 0 x16, напрямую подключенном к ЦП.
0 x16, напрямую подключенном к ЦП.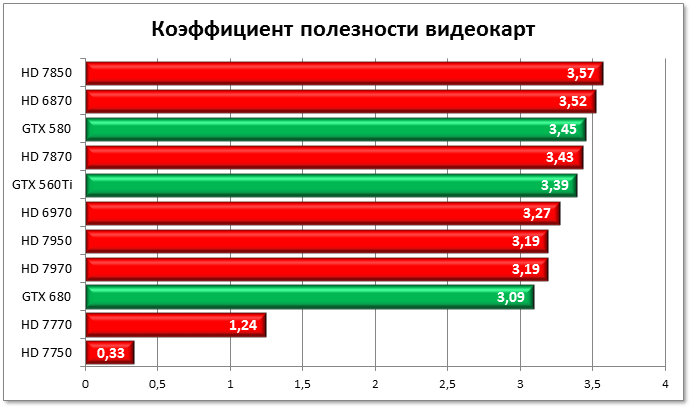
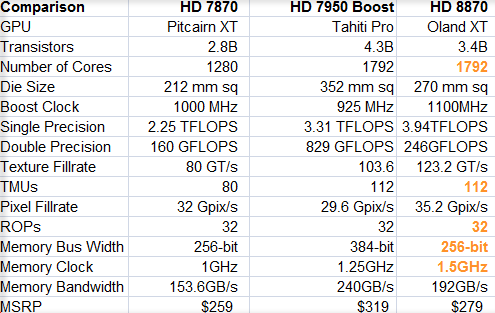 Метод выбора для масштабирования с несколькими GPU, по крайней мере, в 90% случаев, заключается в распределении пакета по GPU. Таким образом, эффективный размер пакета представляет собой сумму размера пакета каждого используемого графического процессора.
Метод выбора для масштабирования с несколькими GPU, по крайней мере, в 90% случаев, заключается в распределении пакета по GPU. Таким образом, эффективный размер пакета представляет собой сумму размера пакета каждого используемого графического процессора.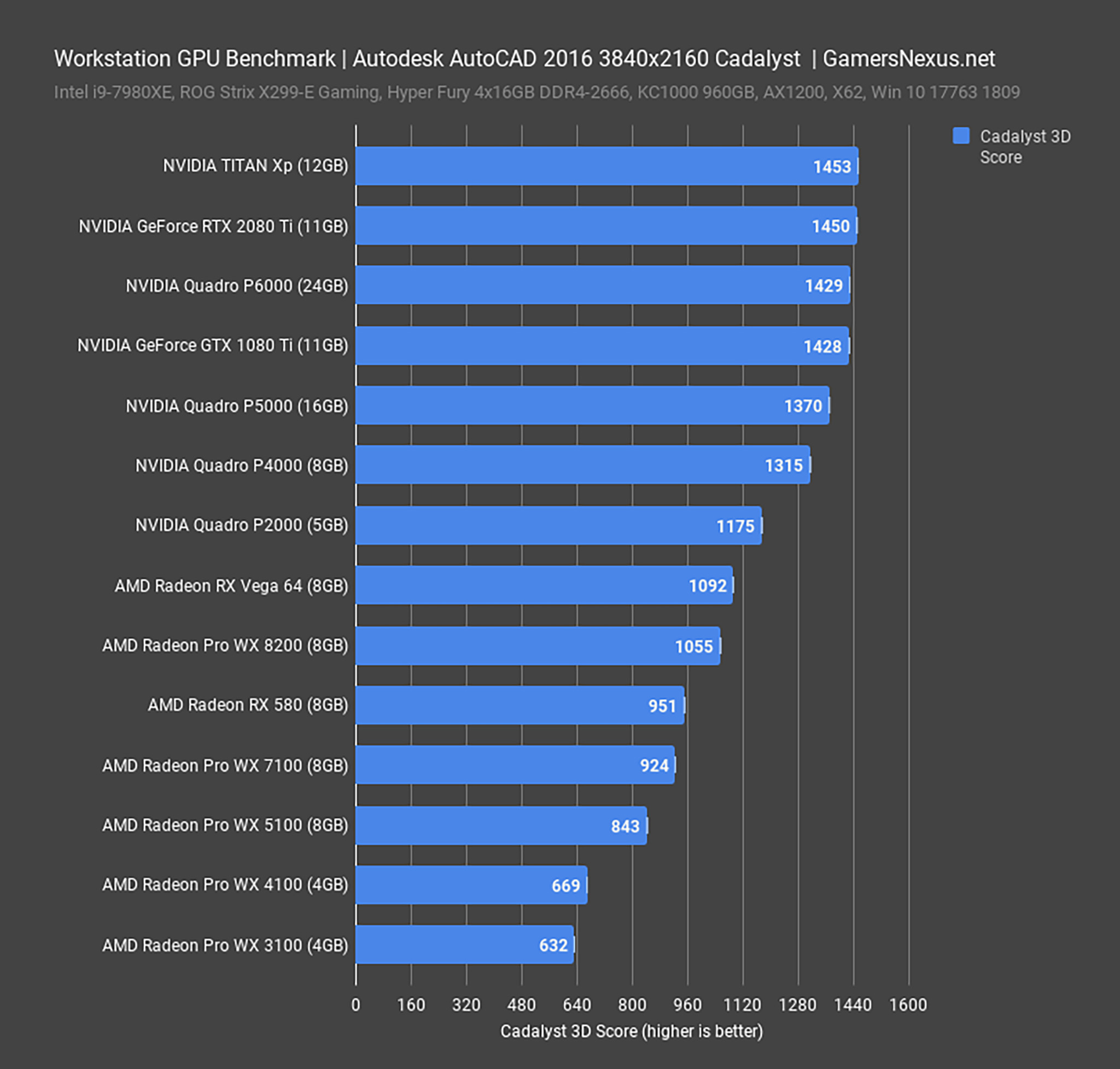
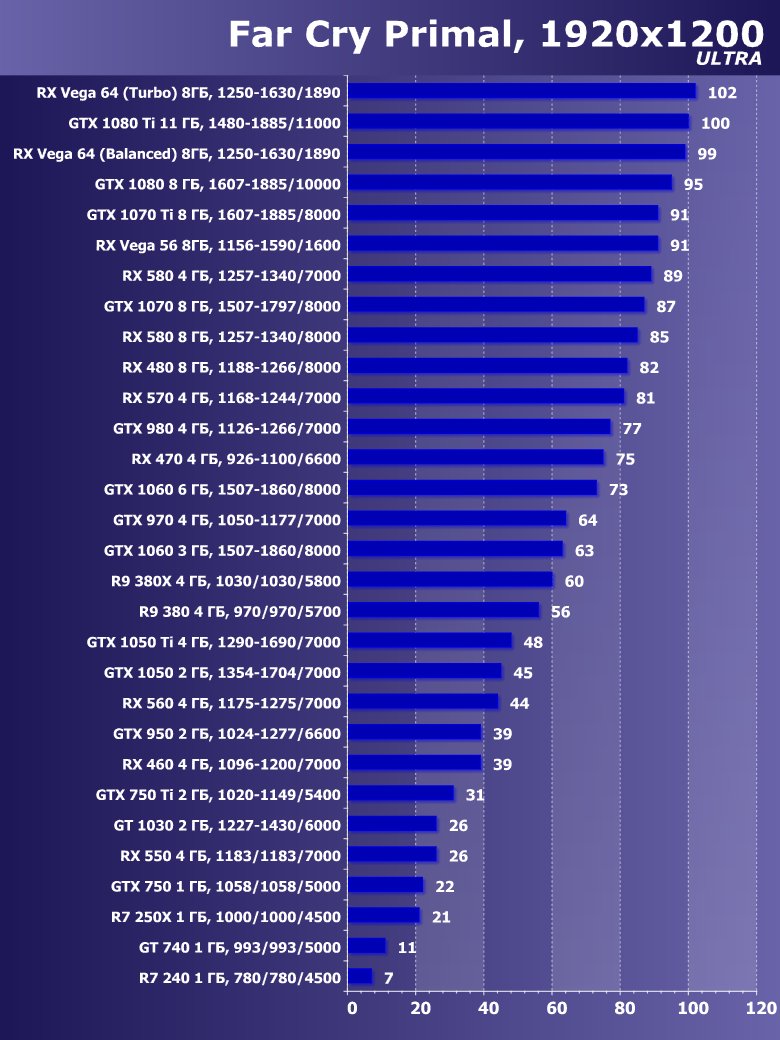 5 минут
5 минут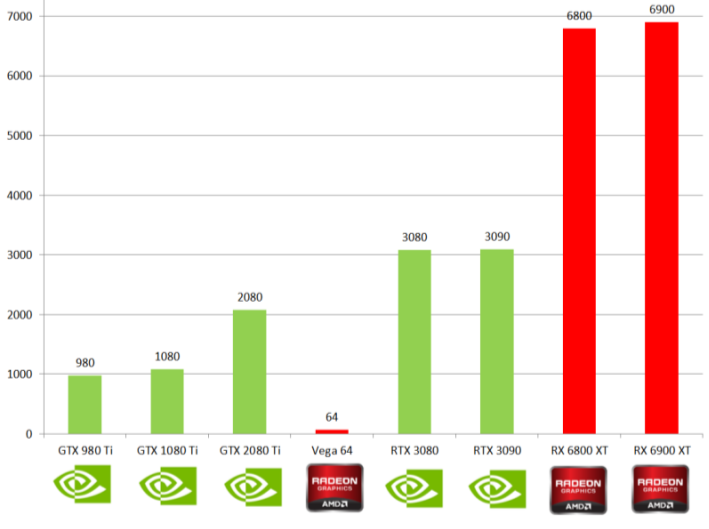 5 часов
5 часов