Python в три ручья: работаем с потоками (часть 1) | GeekBrains
В каких случаях вам нужна многопоточность, как реализовать её на Python и что нужно знать о глобальной блокировке GIL.
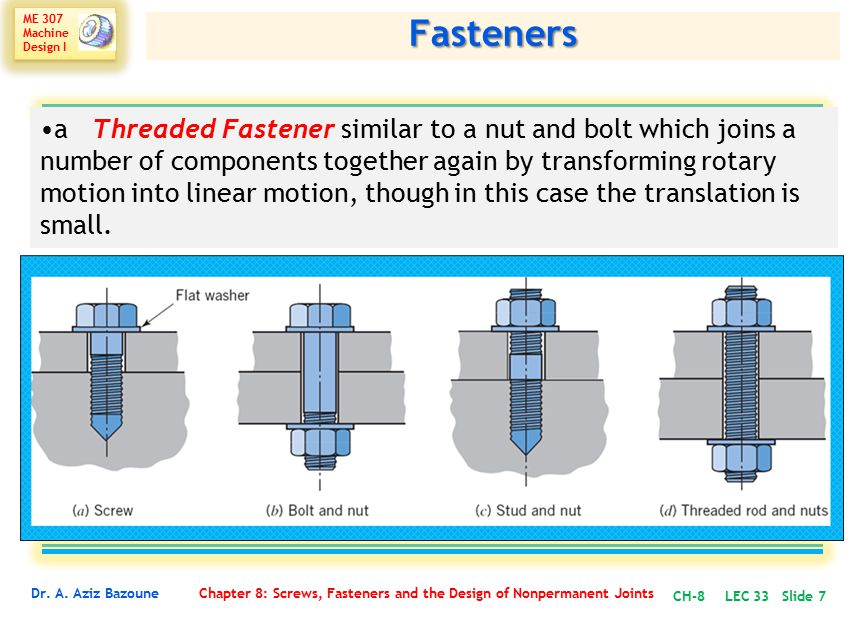
https://d2xzmw6cctk25h.cloudfront.net/post/1582/og_cover_image/b8f59e927c66e03053113b8036b95103
Из этой статьи вы узнаете, как с Python выполнять несколько операций одновременно и распределять нагрузку между ядрами процессора, какие особенности языка учитывать. Но главное — поймете, когда многопоточность в Python нужна, а когда только мешает.
Небольшое предупреждение для тех, кто впервые слышит о параллельных вычислениях. Что такое поток и чем он отличается от процесса, мы выяснили в статье «Внутри процесса: многопоточность и пинг-понг mutex’ом». Тогда мы приводили примеры на Java, но теоретические основы многопоточности верны и для Python. Совпадают, в том числе, механизмы синхронизации потоков: семафоры, взаимные исключения (mutex), условия, события. Поэтому сегодня сделаем акцент на особенностях Python, его механизмах и инструментах, связанных с многопоточностью.
Организовать параллельные вычисления в Python без внешних библиотек можно с помощью модулей:
- threading — для управления потоками.
- queue — для организации очередей.
- multiprocessing — для управления процессами.
Пока нас интересует только первый пункт списка.
Как создавать потоки в Python
Метод 1 — «функциональный»
Для работы с потоками из модуля threading импортируем класс Thread. В начале кода пишем:
from threading import Thread
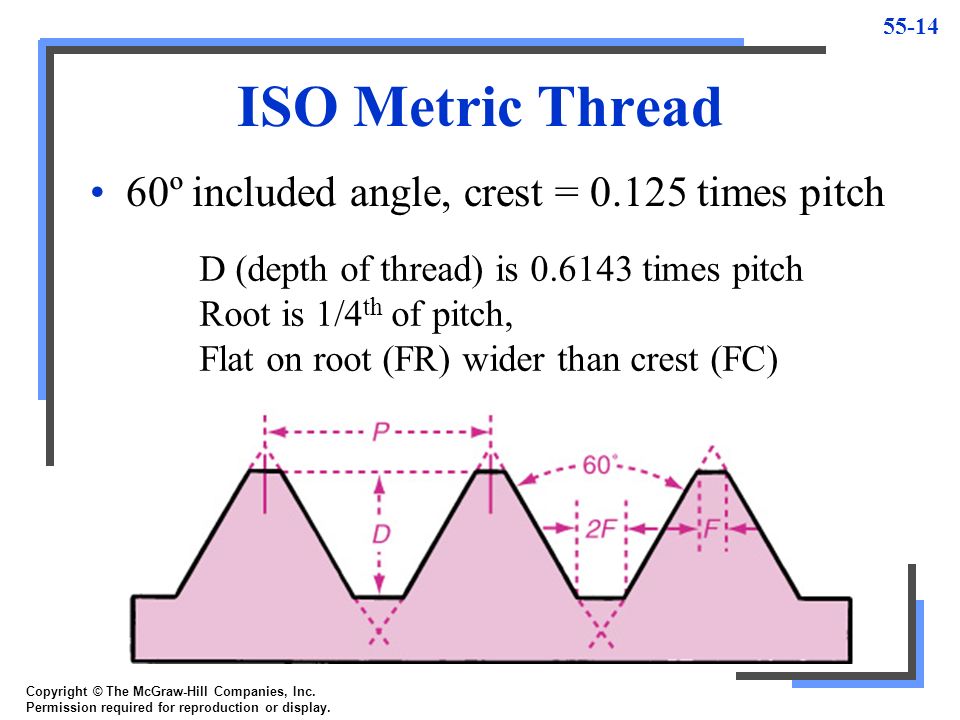
После этого нам будет доступна функция Thread() — с ней легко создавать потоки. Синтаксис такой:
variable = Thread(target=function_name, args=(arg1, arg2,))
Первый параметр target — это «целевая» функция, которая определяет поведение потока и создаётся заранее. Следом идёт список аргументов. Если судьбу аргументов (например, кто будет делимым, а кто делителем в уравнении) определяет их позиция, их записывают как args=(x,y).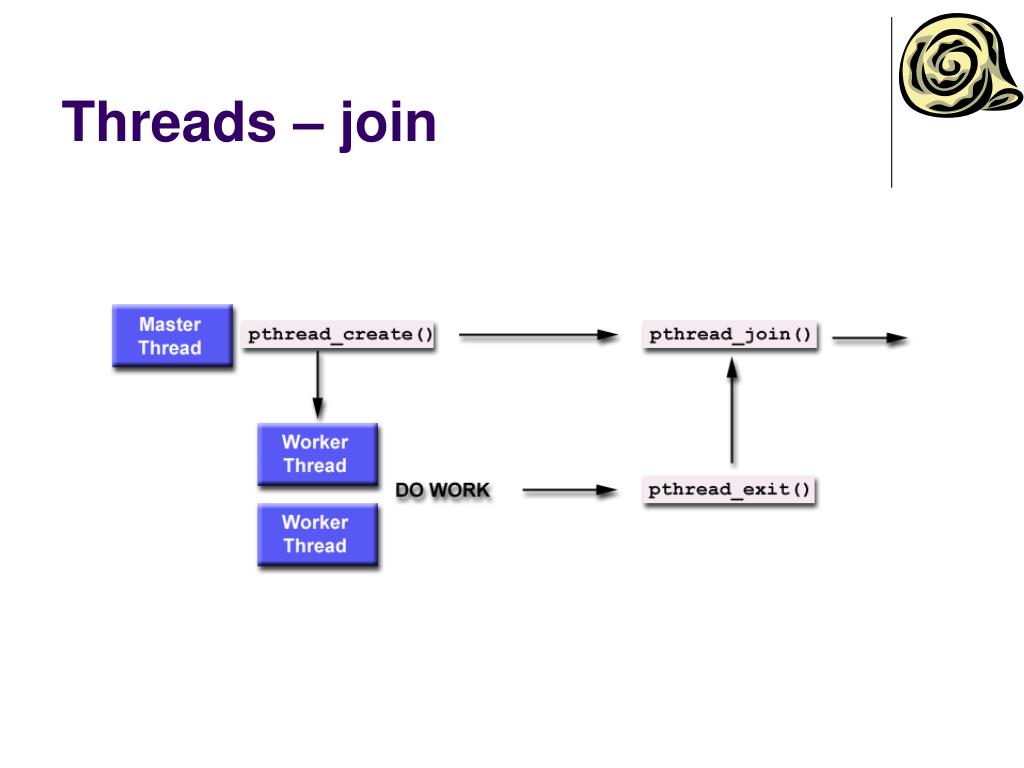 Если же вам нужны аргументы в виде пар «ключ-значение», используйте запись вида kwargs={‘prop’:120}.
Если же вам нужны аргументы в виде пар «ключ-значение», используйте запись вида kwargs={‘prop’:120}.
Ради удобства отладки можно также дать новому потоку имя. Для этого среди параметров функции прописывают name=«Имя потока». По умолчанию name хранит значение null. А ещё потоки можно группировать с помощью параметра group, который по умолчанию — None.
За дело! Пусть два потока параллельно выводят каждый в свой файл заданное число строк. Для начала нам понадобится функция, которая выполнит задуманный нами сценарий. Аргументами целевой функции будут число строк и имя текстового файла для записи.
Давайте попробуем:
#coding: UTF-8
from threading import Thread
def prescript(thefile, num):
with open(thefile, 'w') as f:
for i in range(num):
if num > 500:
f.write('МногоБукв\n')
else:
f.write('МалоБукв\n')
thread1 = Thread(target=prescript, args=('f1.txt', 200,))
thread2 = Thread(target=prescript, args=('f2.txt', 1000,))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
Что start() запускает ранее созданный поток, вы уже догадались. Метод join() останавливает поток, когда тот выполнит свои задачи. Ведь нужно закрыть открытые файлы и освободить занятые ресурсы. Это называется «Уходя, гасите свет». Завершать потоки в предсказуемый момент и явно — надёжнее, чем снаружи и неизвестно когда. Меньше риск, что вмешаются случайные факторы. В качестве параметра в скобках можно указать, на сколько секунд блокировать поток перед продолжением его работы.
Метод 2 — «классовый»
Для потока со сложным поведением обычно пишут отдельный класс, который наследуют от Thread из модуля threading. В этом случае программу действий потока прописывают в методе run() созданного класса. Ту же петрушку мы видели и в Java.
#coding: UTF-8 import threading class MyThread(threading.Thread): def __init__(self, num): super().__init__(self, name="threddy" + num) self.num = num def run(self): print ("Thread ", self.num), thread1 = MyThread("1") thread2 = MyThread("2") thread1.start() thread2.start() thread1.join() thread2.join()
 Thread):
def __init__(self, num):
super().__init__(self, name="threddy" + num)
self.num = num
def run(self):
print ("Thread ", self.num),
thread1 = MyThread("1")
thread2 = MyThread("2")
thread1.start()
thread2.start()
thread1.join()
thread2.join()
Thread):
def __init__(self, num):
super().__init__(self, name="threddy" + num)
self.num = num
def run(self):
print ("Thread ", self.num),
thread1 = MyThread("1")
thread2 = MyThread("2")
thread1.start()
thread2.start()
thread1.join()
thread2.join()
Стандартные методы работы с потоками
Чтобы управлять потоками, нужно следить, как они себя ведут. И для этого в threading есть специальные методы:
current_thread() — смотрим, какой поток вызвал функцию;
active_count() — считаем работающие в данный момент экземпляры класса Thread;
enumerate() — получаем список работающих потоков.
Ещё можно управлять потоком через методы класса:
is_alive() — спрашиваем поток: «Жив ещё, курилка?» — получаем true или false;
getName() — узнаём имя потока;
setName(any_name) — даём потоку имя;
У каждого потока, пока он работает, есть уникальный идентификационный номер, который хранится в переменной
thread1.start() print(thread1.ident)
Отсрочить операции в вызываемых потоком функциях можно с помощью таймера. В инициализаторе объектов класса Timer всего два аргумента — время ожидания в секундах и функция, которую нужно в итоге выполнить:
import threading
print ("Waiting...")
def timer_test():
print ("The timer has done its job!")
tim = threading.Timer(5.0, timer_test)
tim.start()
Таймер можно один раз создать, а затем запускать в разных частях кода.
Потусторонние потоки
Обычно Python-приложение не завершается, пока работает хоть один его поток. Но есть особые потоки, которые не мешают закрытию программы и останавливается вместе с ней. Их называют демонами (daemons). Проверить, является ли поток демоном, можно методом  Если является, метод вернёт истину.
Если является, метод вернёт истину.
Назначить поток демоном можно при создании — через параметр “daemon=True” или аргумент в инициализаторе класса.
thread0 = Thread(target=target_func, kwargs={‘x’:10}, daemon=True)
Не поздно демонизировать и уже существующий поток методом setDaemon(daemonic).
Всё бы ничего, но это даже не верхушка айсберга, потому что прямо сейчас нас ждут великие открытия.
Приключение начинается. У древнего шлюза
Питон слывёт дружелюбным и простым в общении, но есть у него причуды. Нельзя просто взять и воспользоваться всеми преимуществами многопоточности в Python! Дорогу вам преградит огромный шлюз… Даже так — глобальный шлюз (Global Interpreter Lock, он же GIL), который ограничивает многопоточность на уровне интерпретатора. Технически, это один на всех mutex, созданный по умолчанию. Такого нет ни в C, ни в Java.
Задача шлюза — пропускать потоки строго по одному, чтоб не летали наперегонки, как печально известные стритрейсеры, и не создавали угрозу работе интерпретатора.
Без шлюза потоки подрезали бы друг друга, чтобы первыми добраться до памяти, но это еще не всё. Они имеют обыкновение внезапно засыпать за рулём! Операционная система не спрашивает, вовремя или невовремя — просто усыпляет их в ей одной известный момент. Из-за этого неупорядоченные потоки могут неожиданно перехватывать друг у друга инициативу в работе с общими ресурсами.
Дезориентированный спросонок поток, который видит перед собой совсем не ту ситуацию, при которой засыпал, рискует разбиться и повалить интерпретатор, либо попасть в тупиковую ситуацию (deadlock). Например, перед сном Поток 1 начал работу со списком, а после пробуждения не нашёл в этом списке элементов, т.к. их удалил или перезаписал Поток 2.
Чтобы такого не было, GIL в предсказуемый момент (по умолчанию раз в 5 миллисекунд для Python 3.2+) командует отработавшему потоку: «СПАААТЬ!» — тот отключается и не мешает проезжать следующему желающему.
Благодаря шлюзу однопоточные приложения работают быстро, а потоки не конфликтуют. Но, к сожалению, многопоточные программы при таком подходе выполняются медленнее — слишком много времени уходит на регулировку «дорожного движения». А значит обработка графики, расчет математических моделей и поиск по большим массивам данных c GIL идут неприемлемо долго.
В статье «Understanding Python GIL»технический директор компании Gaglers Inc. и разработчик со стажем Chetan Giridhar приводит такой пример:
from datetime import datetime
import threading
def factorial(number):
fact = 1
for n in range(1, number+1):
fact *= n
return fact
number = 100000
thread = threading.Thread(target=factorial, args=(number,))
startTime = datetime.now()
thread.start()
thread.join()
endTime = datetime.now()
print "Время выполнения: ", endTime - startTime
Код вычисляет факториал числа 100 000 и показывает, сколько времени ушло у машины на эту задачу. При тестировании на одном ядре и с одним потоком вычисления заняли 3,4 секунды. Тогда Четан создал и запустил второй поток. Расчет факториала на двух ядрах длился 6,2 секунды. А ведь по логике скорость вычислений не должна была существенно измениться! Повторите этот эксперимент на своей машине и посмотрите, насколько медленнее будет решена задача, если вы добавите thread2. Я получила замедление ровно вдвое.
Глобальный шлюз — наследие времён, когда программисты боролись за достойную реализацию многозадачности и у них не очень получалось. Но зачем он сегодня, когда есть много- и очень многоядерные процессоры? Как объяснил Гвидо ван Россум, без GIL не будут нормально работать C-расширения для Python. Ещё упадёт производительность однопоточных приложений: Python 3 станет медленнее, чем Python 2, а это никому не нужно.
Что делать?
«Нормальные герои всегда идут в обход»
Шлюз можно временно отключить. Для этого интерпретатор Python нужно отвлечь вызовом функции из внешней библиотеки или обращением к операционной системе. Например, шлюз выключится на время сохранения или открытия файла. Помните наш пример с записью строк в файлы? Как только вызванная функция возвратит управление коду Python или интерфейсу Python C API, GIL снова включается.
Как вариант, для параллельных вычислений можно использовать процессы, которые работают изолированно и неподвластны GIL. Но это большая отдельная тема. Сейчас нам важнее найти решение для многопоточности.
Если вы собираетесь использовать Python для сложных научных расчётов, обойти скоростную проблему GIL помогут библиотеки Numba, NumPy, SciPy и др. Опишу некоторые из них в двух словах, чтобы вы поняли, стоит ли разведывать это направление дальше.
Numba для математики
Numba — динамически, «на лету» компилирует Python-код, превращая его в машинный код для исполнения на CPU и GPU. Такая технология компиляции называется JIT — “Just in time”. Она помогает оптимизировать производительность программ за счет ускорения работы циклов и компиляции функций при первом запуске.
Суть в том, что вы ставите аннотации (декораторы) в узких местах кода, где вам нужно ускорить работу функций.
Для математических расчётов библиотеку удобно использовать в связке c NumPy. Допустим, нужно сложить одномерные массивы — элемент за элементом.
def arr_sum (x , y):
result_arr = nupmy.empty_like ( x)
for i in range (len (x)) :
result_arr [i ] = x[i ] + y[i ]
return result_arr
Метод nupmy.empty_like() принимает массив и возвращает (но не инициализирует!) другой — соответствующий исходному по форме и типу. Чтобы ускорить выполнение кода, импортируем класс jit из модуля numba и добавляем в начало кода аннотацию @jit:
from numba import jit @jit def arr_sum(x,y):
Это скромное дополнение способно ускорить выполнение операции более чем в 100 раз! Если интересно, посмотрите замеры скорости математических расчётов при использовании разных библиотек для Python.
PyCUDA и Numba для графики
В графических вычислениях Numba тоже кое-что может. Она умеет работать с программной моделью CUDA, чтобы визуализировать научные данные и работу алгоритмов, выдавать информацию о GPU и др. Подробнее о том, как работают графический процессор и CUDA — здесь. И снова мы встретимся с многопоточностью.
При работе с многомерными массивами в CUDA, чтобы понять, какой поток сейчас работает с элементами массива, нужно отследить, кто и когда вызывает функцию ядра. Например, поток может определять свою позицию в сетке блоков и рассчитать соответствующий элемент массива:
from numba import cuda
@cuda.jit
def call_for_kernel(io_arr):
# Идентификатор потока в одномерном блоке
thread_x = cuda.threadIdx.x
# Идентификатор блока в одномерной сетке
thread_y = cuda.blockIdx.x
# Число потоков на блок (т.е. ширина блока)
block_width = cuda.blockDim.x
# Находим положение в массиве
t_position = thread_x + thread_y * block_width
if t_position < io_arr.size: # Убеждаемся, что не вышли за границы массива
io_arr[ t_position] *= 2 # Считаем
Главный плюс этого кода даже не в скорости исполнения, а в прозрачности и простоте. Снова сошлюсь на Хабр, где есть сравнение скорости GPU-расчетов при использовании Numba, PyCUDA и эталонного С CUDA. Небольшой спойлер: PyCUDA позволяет достичь скорости вычислений, сопоставимой с Cи, а Numba подходит для небольших задач.
Когда многопоточность в Python оправдана
Стоит ли преодолевать связанные c GIL сложности и тратить время на реализацию многопоточности? Вот примеры ситуаций, когда многопоточность несёт с собой больше плюсов, чем минусов.
- Для длительных и несвязанных друг с другом операций ввода-вывода. Например, нужно обрабатывать ворох разрозненных запросов с большой задержкой на ожидание. В режиме «живой очереди» это долго — лучше распараллелить задачу.
- Вычисления занимают более миллисекунды и вы хотите сэкономить время за счёт их параллельного выполнения. Если операции укладываются в 1 мс, многопоточность не оправдает себя из-за высоких накладных расходов.
- Число потоков не превышает количество ядер. В противном случае параллельной работы всех потоков не получается и мы больше теряем, чем выигрываем.

Когда лучше с одним потоком
- При взаимозависимых вычислениях. Считать что-то в одном потоке и передавать для дальнейшей обработки второму — плохая идея. Возникает лишняя зависимость, которая приводит к снижению производительности, а в случае ошибки — к ступору и краху программы.
- При работе через GIL. Это мы уже выяснили выше.
- Когда важна хорошая переносимость на разных устройствах. Правильно подобрать число потоков для машины пользователя — задача не из легких. Если вы пишете под известное вам «железо», всё можно решить тестированием. Если же нет — понадобится дополнительно создавать гибкую систему подстройки под аппаратную часть, что потребует времени и умения.
Анонс — взаимные блокировки в Python
Самое смешное, что по умолчанию GIL защищает только интерпретатор и не предохраняет наш код от взаимных блокировок (deadlock) и других логических ошибок синхронизации. Поэтому разводить потоки по углам, как и в Java, нужно принудительно — с помощью блокирующих механизмов. Об этом и о не упомянутых в статье компонентах модуля threading мы поговорим в следующий раз.
Глава 3. Работа с потоками в Python
В Главе 1, Расширенное введение в совместное и параллельное программирование, вы увидели
некий пример потоков, применяемых в совместной обработке и параллельном программировании. В этой главе вы получите некое введение в собственно
формальное определение потока, а также модуль threading из Python. . Мы рассмотрим некое число способов
работы с потоками в какой- то программе на Python, в том числе такие действия как создание новых потоков, синхронизацию потоков а также работу
при помощи многопоточными очередями с приоритетами, причём на конкретных примерах. Мы также обсудим основное понятие блокировки при
синхронизации потоков, а также мы реализуем некое многопоточное приложение с блокированием для лучшего понимания преимуществ синхронизации
потоков.
Мы также обсудим основное понятие блокировки при
синхронизации потоков, а также мы реализуем некое многопоточное приложение с блокированием для лучшего понимания преимуществ синхронизации
потоков.
В этой главе будут обсуждены такие темы:
-
Собственно понятие потока в обсуждаемом контексте программирования совместной обработки в информатике
-
Базовый API модуля
threadingв Python -
Как создавать новый поток при помощи модуля
threading -
Концепция блокирования и как применять различные механизмы блокировки для синхронизации потоков
-
Основное понятие очереди в обсуждаемом контексте программирования совместной обработки и как применять модуль
Queueдля работы с объектами очереди в Python
Технические требования
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter03 -
Ознакомьтесь со следующими видеоматериалами Code in Action
Понятие потока
В области информатики, некий поток исполнения является наименьшим элементом
команд программирования (кода), который какой- то планировщик (обычно как часть операционной системы) может обрабатывать, а также управлять им.
В зависимости от конкретной операционной системы реализация потоков и процессов (которые мы обсудим в своей следующей главе) меняется, но поток
является обычно является неким элементом (компонентом) в каком- то процессе.
Сопоставление потоков и процессов
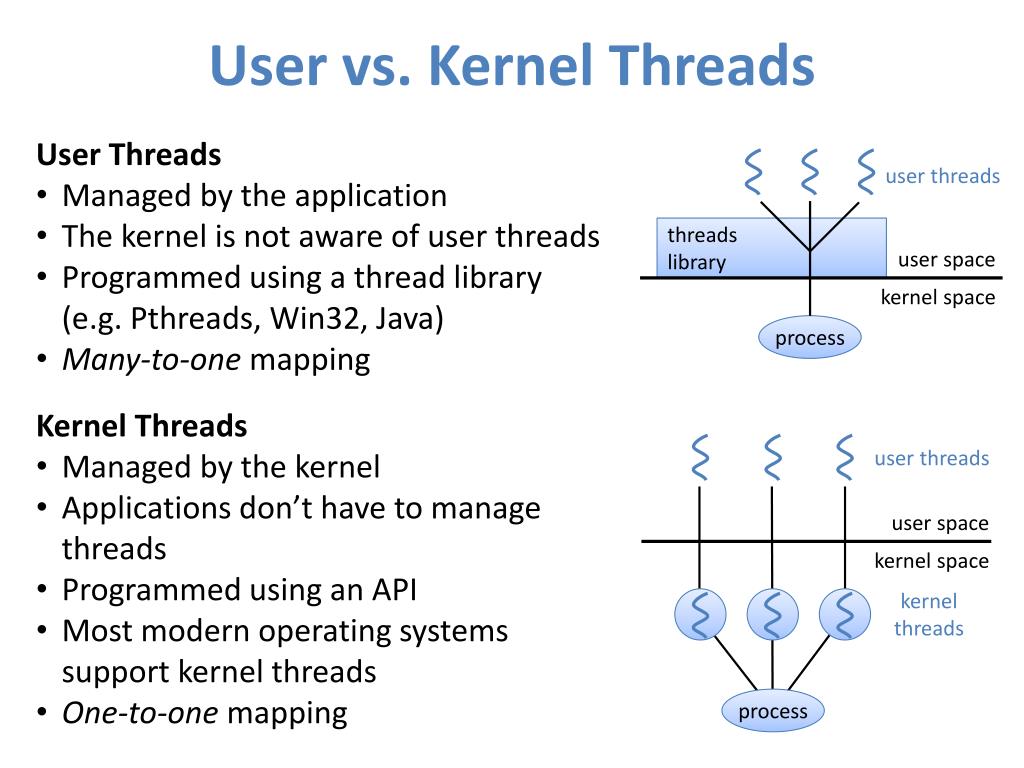
Внутри одного и того же процесса может буть реализовано более одного потока, скорее всего исполняющихся совместно и осуществляющих доступ/ разделяя одни и те же ресурсы. Потоки в одном и том же процессе совместно используют все последующие инструкции (свой код) и контекст (те значения, на которые ссылаются их переменные в любой определённый момент).
Основным ключевым отличием между этими двумя понятиями состоит в том, что некий поток обычно компонент какого- то процесса. Таким образом, один процесс может содержать множество потоков, которые могут исполняться одновременно. Потоки также обычно допускают совместное применение ресурсов, таких как память и данные, в то время как процессы крайне редко делают это. Короче говоря, некий поток является каким- то независимым компонентом вычислений, который аналогичен процессу, однако сам поток внутри некоего процесса может разделять адресное пространство и, тем самым, и собственно данные такого процесса:
Первые упоминания о применении потоков для переменного числа задач в мультипрограммировании OS/360, которая является снятой с производства системой пакетной обработки, датируемые 1967 годом после её разработки IBM. В то время разработчики именовали потоки задачами, а сам термин поток стал популярным позднее и приписывается Виктору А. Высоцкому, математику и научному сотруднику в области вычислений, который был директором- основателем Исследовательской лаборатории Digital в Кембридже.
Многопоточность
В информатике одиночный поток аналогичен традиционной последовательной обработке, исполняющей некую отдельную команду в определённый момент времени.
С другой стороны, многопоточность реализует более одного потока существующими и
исполняющимися в каком- то отдельном процессе, причём одновременно. За счёт разрешения множеству потоков осуществлять доступ к совместным ресурсам/
контекстам и исполняться независимо, такая техника может помогать приложениям ускоряться в своём исполнении независимых задач.
За счёт разрешения множеству потоков осуществлять доступ к совместным ресурсам/
контекстам и исполняться независимо, такая техника может помогать приложениям ускоряться в своём исполнении независимых задач.
Многопоточность изначально может достигаться двумя способами. В системах с единственным процессором, многопоточность обычно реализуется путём деления времени, техники, которая позволяет имеющемуся ЦПК переключаться между различным программным обеспечением, запущенным в различных потоках. При разделении времени, сам ЦПУ переключает своё исполнение настолько быстро и настолько часто, что пользователи обычно воспринимают что их программное обеспечение запущено параллельно (например, когда вы открываете две различные программы в одно и то же время в каком- то компьютере с единственным процессором):
В противоположность системам с единственным процессором, системы со множеством процессоров или ядер способны легко реализовывать многопоточность, причём исполняя каждый поток в каком- то отдельном процессоре или ядре и при этом одновременно. Кроме того, неким вариантом является и разделение времени, так как такие системы со множеством процессоров и множеством ядер могут иметь только один процессор/ одно ядро для переключения между задачами — хотя обычно это не самый практичный приём.
Многопоточные приложения имеют ряд преимуществ по сравнению с обычными последовательными приложениями; некоторые из них таковы:
-
Более быстрое время исполнения: Одним из основных преимуществ совместной обработки при многопоточности является достигаемое ускорение. Отдельные потоки в одной и той же программе мугут исполняться совместно или параллельно, когда они достаточно независимы друг от друга.
-
Быстрота отклика: Некая программа с единственным потоком за раз может обрабатывать только один кусочек ввода; тем самым, если её основной поток исполнения блокируется в какой- то задаче с длительным временем исполнения (например, некая часть ввода, которая требует интенсивных вычислений и обработки), вся программа целиком не будет способна продолжить прочий ввод и, следовательно, будет казаться замёрзшей.
Применяя отдельные потоки для осуществления вычислений и оставаясь исполняемой для получения ввода другого пользователя в
то же самое время, некая многопоточная программа может предоставлять гораздо лучшую отзывчивость. -
Эффективность в потреблении ресурсов: Как уже упоминалось ранее, множество потоков внутри одного и того же процесса могут совместно разделять одни и те же ресурсы и осуществлять к ним доступ. Вследствие этого, многопоточные программы могут обслуживать и обрабатывать множество запросов клиентов к данным для совместной обработки, используя значительно меньше ресурсов чем это потребовалось бы при применении однопотоковых или многопроцессных программ. Это также ведёт к более быстрому взаимодействию между потоками.
 Применяя отдельные потоки для осуществления вычислений и оставаясь исполняемой для получения ввода другого пользователя в
то же самое время, некая многопоточная программа может предоставлять гораздо лучшую отзывчивость.
Применяя отдельные потоки для осуществления вычислений и оставаясь исполняемой для получения ввода другого пользователя в
то же самое время, некая многопоточная программа может предоставлять гораздо лучшую отзывчивость.При этом многопточные программы также имеют и свои собственные недостатки, а именно:
-
Крушения: Даже хотя некий процесс может содержать множество потоков, отдельная недопустимая операция в пределах одного потока может отрицательно сказываться на имеющейся обработке всех прочих потоков в этом процессе и может вызывать в результате крушение всей программы целиком.
-
Синхронизация: Даже хотя разделение одних и тех же ресурсов может выступать неким преимуществом над обычным последовательным программированием или программами с множеством процессов, для такого совместного использования ресурсов также требуется аккуратное рассмотрение подробностей с тем, чтобы совместные данные вычислялись правильно и их обработка была корректной. Интуитивно непонятные проблемы, которые могут быть вызваны небрежной координацией потоков включают в свой состав взаимные блокировки, зависания и состояние конкуренции, каждое из которых будет обсуждено в последующих главах.
 w3.org/1999/xhtml»>
Некий пример на Python
w3.org/1999/xhtml»>
Некий пример на PythonЧтобы продемонстрировать само понятие запуска множества потоков в одном и том же процессе, давайте рассмотрим некий быстрый пример на Python.
Если у вас уже имеется выгруженным с нашей страницы в GitHub необходимый код для данной книги, проследуйте далее и переместитесь в папку
Chapter03. Давайте рассмотрим приводимый далее файл
Chapter03/my_thread.py:
# Chapter03/my_thread.py
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name, delay):
threading.Thread.__init__(self)
self.name = name
self.delay = delay
def run(self):
print('Starting thread %s.' % self.name)
thread_count_down(self.name, self.delay)
print('Finished thread %s.' % self.name)
def thread_count_down(name, delay):
counter = 5
while counter:
time.sleep(delay)
print('Thread %s counting down: %i...' % (name, counter))
counter -= 1
В этом файле мы применяем соответствующий модуль threading мз Python в качестве необходимой основы для
своего класса MyThread. Кадлый объект из этого класса имеет некое
name и параметр delay. Имеющаяся функция
run(), которая вызывается как только некий новый поток инициализирован и запущен, печатает какое- то
стартовое сообщение и, в свою очередь, вызывает соответствующую функцию thread_count_down(). Данная функция
ведёт обратный отсчёт с 5 до 0, а между итерациями засыпает на несколько
секунд, которые определены определяемым параметром задержки.
Основной момент в данном примере состоит в том чтобы показать имеющуюся природу совместной обработки через одновременный запуск более одного объектов
из нашего класса MyThread. Мы знаем, что как только каждый поток запускается, также стартует и обратный отсчёт
на основе времени. В традиционной последовательной программе отдельный обратный отсчёт будет исполняться обособленно, по- порядку (то есть, какой- то
новый обратный отсчёт не начнётся, пока не завершится текущий). Как вы обнаружите, все отдельные обратные отсчёты для обособленных потоков исполняются
совместно.
Мы знаем, что как только каждый поток запускается, также стартует и обратный отсчёт
на основе времени. В традиционной последовательной программе отдельный обратный отсчёт будет исполняться обособленно, по- порядку (то есть, какой- то
новый обратный отсчёт не начнётся, пока не завершится текущий). Как вы обнаружите, все отдельные обратные отсчёты для обособленных потоков исполняются
совместно.
Давайте рассмотрим следующий файл, Chapter03/example1.py:
# Chapter03/example1.py
from my_thread import MyThread
thread1 = MyThread('A', 0.5)
thread2 = MyThread('B', 0.5)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('Finished.')
Здесь мы выполнили инициализацию и запустили совместно два потока, причём каждый из них имеет в качестве параметра delay
0.5 секунд. Воспользовавшись своим интерпретатором Python запустите этот сценарий. Вы должны получить
следующий вывод:
> python example1.py
Starting thread A.
Starting thread B.
Thread A counting down: 5...
Thread B counting down: 5...
Thread B counting down: 4...
Thread A counting down: 4...
Thread B counting down: 3...
Thread A counting down: 3...
Thread B counting down: 2...
Thread A counting down: 2...
Thread B counting down: 1...
Thread A counting down: 1...
Finished thread B.
Finished thread A.
Finished.
В точности, как и ожидалось, полученный вывод сообщает нам, что наши два обратных отсчёта для имеющихся потоков исполнялись совместно; вместо того
чтобы завершить наш самый первый поток обратного отсчёта и затем запустить второй имеющийся поток обратного отсчёта, наша программа исполнила эти два
обратных отсчёта почти в одно и то же время. Без включения каких- то накладных расходов и различных объявлений, такая методика организации потоков позволяет
почти удвоить улучшение скорости для нашей предыдущей программы.
Без включения каких- то накладных расходов и различных объявлений, такая методика организации потоков позволяет
почти удвоить улучшение скорости для нашей предыдущей программы.
Имеется один дополнительный момент, который стоит принять во внимание в нашем предыдущем выводе. После самого первого обратного отсчёта под номером
5 мы можем заметить, что поток B в действительности обогнал поток A в исполнении, даже хотя мы и знаем, что поток A
был проинициализирован и запущен до потока B. Такое изменение на самом деле позволило потоку B завершиться ранее потока A. Это явление является
непосредственным результатом совместной работы при многопоточности; так как эти два потока были проинициализированы и запущены почти одновременно, имеется
большая вероятность что один поток опередит другой при исполнении.
Если вы запустили этот сценарий много раз, достаточно вероятно что вы получите отличающийся вывод в терминах порядка исполнения и завершения своих обратных
отсчётов. Ниже приводятся два фрагмента вывода, которые я получил запуская этот сценарий снова и снова. Самый первый вывод показывает некое единообразие и
неизменность порядка исполнения и завершения, при котором эти два обратных отсчёта были исполнены рука к руке. Второй же показывает некий вариант, при
котором поток A исполнился слегка быстрее чем поток B; даже завершившись до того, как поток B отсчитал число
1. Этот вариант вывода в дальнейшем проиллюстрирует тот факт, что наши потоки воспринимались и исполнялись со
стороны Python одинаково.
Следующий код показывает один возможный вывод нашей программы:
> python example1.py
Starting thread A.
Starting thread B.
Thread A counting down: 5...
Thread B counting down: 5...
Thread A counting down: 4...
Thread B counting down: 4...
Thread A counting down: 3...
Thread B counting down: 3. ..
Thread A counting down: 2...
Thread B counting down: 2...
Thread A counting down: 1...
Thread B counting down: 1...
Finished thread A.
Finished thread B.
Finished.
 ..
Thread A counting down: 2...
Thread B counting down: 2...
Thread A counting down: 1...
Thread B counting down: 1...
Finished thread A.
Finished thread B.
Finished.
..
Thread A counting down: 2...
Thread B counting down: 2...
Thread A counting down: 1...
Thread B counting down: 1...
Finished thread A.
Finished thread B.
Finished.
А вот ещё один возможный вывод:
> python example1.py
Starting thread A.
Starting thread B.
Thread A counting down: 5...
Thread B counting down: 5...
Thread A counting down: 4...
Thread B counting down: 4...
Thread A counting down: 3...
Thread B counting down: 3...
Thread A counting down: 2...
Thread B counting down: 2...
Thread A counting down: 1...
Finished thread A.
Thread B counting down: 1...
Finished thread B.
Finished.
Обзор имеющегося модуля потоков
Существует множество вариантов, когда дело доходит до реализации многопоточных программ в Python. Один из наиболее распространённых способов работы
с потоками в Python состоит в применении модуля threading. Прежде чем мы погрузимся в имеющуюся модель применения и
её синтаксис, вначале давайте изучим саму модель thread, которая первоначально была самым основным модулем
разработки на основе потока в Python.
Модуль thread в Python 2
Прежде чем приобрёл популярность модуль threading, первичным модулем разработки на основе потоков был
thread. Если вы используете более старые версии Python 2, имеется возможность применять этот модуль
«как есть». Тем не менее, согласно странице документации этого модуля, на самом деле этот модуль в Python 3 был переименован в
_thread.
Для тех читателей, которые работали с этим модулем thread для построения многопоточных приложений и
рассматривают возможность портации своего кода с Python 2 на Python 3, инструмент 2to3 может оказаться неким решением. Инструмент 2to3 обрабатывает
большинство выявленных несовместимостей между различными версиями Python, при этом производя синтаксический анализ получаемого исходного кода и
обходящего это исходное дерево для преобразования кода Python 2.x в код Python 3.x. Другой трюк для достижения преобразования состоит в изменении
своего импортируемого кода с
Инструмент 2to3 обрабатывает
большинство выявленных несовместимостей между различными версиями Python, при этом производя синтаксический анализ получаемого исходного кода и
обходящего это исходное дерево для преобразования кода Python 2.x в код Python 3.x. Другой трюк для достижения преобразования состоит в изменении
своего импортируемого кода с import thread на import _thread as thread
в вашей программе Python.
Основным свойством данного модуля thread является его скорость и достаточность метода создания нового потока
для исполнения функций: соответствующей функции thread.start_new_thread(). Кроме того, для целей
синхронизации предоставляются простые объекты блокировки (например, взаимные исключения — mutexes и семафоры — semaphores).
Модуль threading в Python 3
Старый модуль thread рассматривался разработчиками Python как утративший актуальность на длительное время, в
основном, по причине его функций на достаточно низком уровне и ограничении применения. С другой стороны, модуль
threading строится поверх имеющегося модуля thread , предоставляя более
простые способы для работы с потоками посредством мощных API верхнего уровня. Пользователи Python на самом деле одобрили применение этого нового
модуля threading вместо модуля thread в своих программах.
Кроме того, сам модуль thread рассматривает каждый поток как некую функцию; когда вызывается
thread.start_new_thread(), она на самом деле получает некую отдельную функцию в качестве своего основного
аргумента чтобы породить некий новый поток. Тем не менее, новый модуль threading разработан с целью предоставления
дружественного пользователю интерфейса для тех, кто исходит из парадигмы объектно- ориентированного программного обеспечения, трактуя каждый создаваемый
поток как некий объект.
В дополнение ко всей функциональности для работы с потоками, которые предоставляет модуль thread, новый модуль
threading поддерживает ряд дополнительных методов, как то:
-
threading.activeCount(): Эта функция возвращает общее число активных в настоящий момент времени объектов потока в данной программе -
threading.currentThread(): Данная функция возвращает общее число объектов потока в данном текущем потоке, управляемых стороной вызова -
threading.enumerate(): Функция возвращает список всех активных в настоящий момент объектов потока в данной программе
Следуя парадигме разработки объектно- ориентированного программного обеспечения, новый модуль threading
также предоставляет некий класс Thread, который поддерживает необходимую объектно- ориентированную
реализацию потоков. В данном классе поддерживаются такие методы:
-
run(): Этот метод исполняется когда инициализируется и запускается некий новый поток -
start(): Данный метод запускает инициализированный вызывающий объекта потока, вызывая соответствующий методrun() -
join(): Такой метод ожидает завершения соответствующего вызывающего объекта потока прежде чем продолжить исполнение оставшейся части программы -
isAlive(): Данный метод возвращает Булево значение, указываюшее исполняется ли в данный момент вызывающий объект потока -
getName(): Этот метод возвращает собственно название данного вызывающего объекта потока -
setName(): Этот метод устанавливает соответствующее название данного вызывающего объекта потока
 w3.org/1999/xhtml»> Создание нового потока в Python
w3.org/1999/xhtml»> Создание нового потока в PythonПредоставляя некий обзор нового модуля threading и его отличия от имеющегося старого модуля
thread в данном разделе, мы изучим ряд примеров создания новых потоков применяя эти инструменты в Python.
Как уже упоминалось ранее, новый модуль threading, вероятно, наиболее распространённый способ работы с
потоками в Python. Особые случаи требуют применения старого модуля thread, а может быть также и прочих
инструментов и нам важно быть способными выявлять такие ситуации.
Запуск потока при помощи thread
В модуле thread для исполнения функций совместно создаются новые потоки. Как мы уже упоминали, основным способом
для выполнения этого является применение функции thread.start_new_thread():
thread.start_new_thread(function, args[, kwargs])
Когда вызывается эта функция, для исполнения той функции, которая определены в передаваемых параметрах, порождается новый поток, а когда данная функция
завершает своё исполнение, возвращается значение идентификатора созданного потока. Значением параметра function
является название подлежащей исполнению функции, а перечень параметров args (который обязан пыть списком или
кортежем) содержит те аргументы, которые должны быть переданы в данную определяемую функцию. Необязательный параметр
kwargs, с другой стороны, содержит некий отдельный словарь дополнительных аргументов с ключевыми словами.
После того осуществляется возврат из порождённой функции thread.start_new_thread(), этот поток также втихую
завершится.
Давайте взглянем на некий пример использования модуля thread в программе Python. Если вы уже выгрузили
необходимый для данной книги код с нашей страницы GitHub, пройдите далее и переместитесь в папку Chapter03
к файлу Chapter03/example2.. В этом примере мы рассмотрим функцию
 py
pyis_prime(), которую мы уже применяли в своих предыдущих главах:
# Chapter03/example2.py
from math import sqrt
def is_prime(x):
if x Вы можете заметить, что результатом её вычисления данной функции is_prime(X) является совершенной другой
способ возвращения полученного результата; вместо возврата true или
false для указания является ли параметр x простым числом, данная
функция is_prime() непосредственно выводит этот результат на печать. Как мы уже сказали ранее, наша функция
thread.start_new_thread() исполняет полученную параметром функцию посредством порождения нового потока, но на практике
она возвращает значение получаемого идентификатора потока. Выводя на печать получаемый результат нашей функции
is_prime() мы обходим задачу получения доступа к самому результату данной функции в потоке модуля
thread.
В самой основной части нашей программы мы организуем цикл по некоторому перечню потенциальных кандидатов быть простыми числами и будем вызывать свою
функцию thread.start_new_thread() для вычисляющей функции is_prime() и
каждого числа из данного перечня следующим образом:
# Chapter03/example2.py
import _thread as thread
my_input = [2, 193, 323, 1327, 433785907]
for x in my_input:
thread.start_new_thread(is_prime, (x, ))
Вы можете обратить внимание, что в данном файле Chapter03/example2.py присутствует строка кода для получения
ввода от клиента в самом конце:
a = input('Type something to quit: \n')
Теперь давайте прокомментируем эту самую последнюю строку. Потом, когда мы исполним всю программу Python целиком, будет казаться, что наша программа
завершилась без вывода на печать каких- нибудь результатов; другими словами, наша программа завершилась прежде чем могут завершить своё исполнение её
потоки. Это происходит по той причине, что когда некий новый поток порождается из функции
Потом, когда мы исполним всю программу Python целиком, будет казаться, что наша программа
завершилась без вывода на печать каких- нибудь результатов; другими словами, наша программа завершилась прежде чем могут завершить своё исполнение её
потоки. Это происходит по той причине, что когда некий новый поток порождается из функции thread.start_new_thread()
для обработки числа из нашего входного списка, сама программа продолжает обходить циклом все последующие числа в то время как такие вновь созданные потоки
исполняются.
Поэтому, ко времени, когда наш интерпретатор Python достигнет самого конца своей программы, если никакой поток не завершил исполнение (в нашем случае,
такими являются все эти потоки), такой поток будет проигнорирован и прекращён и никакой вывод при этом не будет отображён на печати. Тем не менее, время от
времени одним из выходных данных является 2 is a prime number, что является выведенным на печать результатом до завершения
данной программы, так как обрабатывающий число 2 поток имеет возможность завершиться до данного момента.
Самая последняя строка кода является иным обходным манёвром для нашего модуля thread на этот раз чтобы решить
указанную выше проблему. Эта строка удерживает нашу программу от выхода вплоть до ввода пользователем любого нажатия клавиши для завершения всех запущенных
потоков (то есть, чтобы завершить обработку всех имеющихся в перечне входа чисел). Удалите комментарий с самой последней строки и выполните этот файл, в
результате вы получите свой вывод, который будет похож на следующее:
> python example2.py
Type something to quit:
2 is a prime number.
193 is a prime number.
1327 is a prime number.
323 is not a prime number.
433785907 is a prime number.
Как вы можете отметить, строка Type something to quit, которая соответствует самой последней строке кода из нашей
программы, была выведена прежде чем мы получили вывод из функции is_prime(); это согласуется с тем фактом, что данная
строка исполняется прежде чем все прочие потоки завершили своё исполнение, в большинстве вариантов. Я указываю именно «в большинстве вариантов»,
так как когда наш поток который обрабатывает самое первое данное на входе (число
Я указываю именно «в большинстве вариантов»,
так как когда наш поток который обрабатывает самое первое данное на входе (число 2) завершает исполнение прежде
чем интерпретатор Python достигает самой последней строки, наш вывод порой может выглядеть аналогично следующему:
> python example2.py
2 is a prime number.
Type something to quit:
193 is a prime number.
323 is not a prime number.
1327 is a prime number.
433785907 is a prime number.
Запуск потока с применением threading
Теперь вы знаете как запускать некий поток при помощи модуля thread, а также вы знаете о его ограничениях
и применении потоков на низком уровне, помимо потребности рассмотрения интуитивно не понятного обходного манёвра при работе с ним. В данном
подразделе мы изучим более предпочтительный модуль threading и его преимущества над
thread по отношению к реализации многопоточных программ в Python.
Чтобы создать и выполнить индивидуальную настройку какого- то нового потока при помощи нового модуля threading,
существуют определённые шаги, которые должны быть следующими:
-
В вашей программе определите некий подкласс общего класса
threading.Thread -
Внутри полученного подкласса перепишите установленный по умолчанию метод
__init__(self [,args])для добавления необходимых индивидуальных аргументов в этот класс -
Внутри этого же подкласса перепишите установленный по умолчанию метод
run(self [,args])для персонализации имеющегося поведения данного класса потоков при инициализации и запуске некоего нового потока
На самом деле вы уже видели некий пример в самом первом примере из данной главы.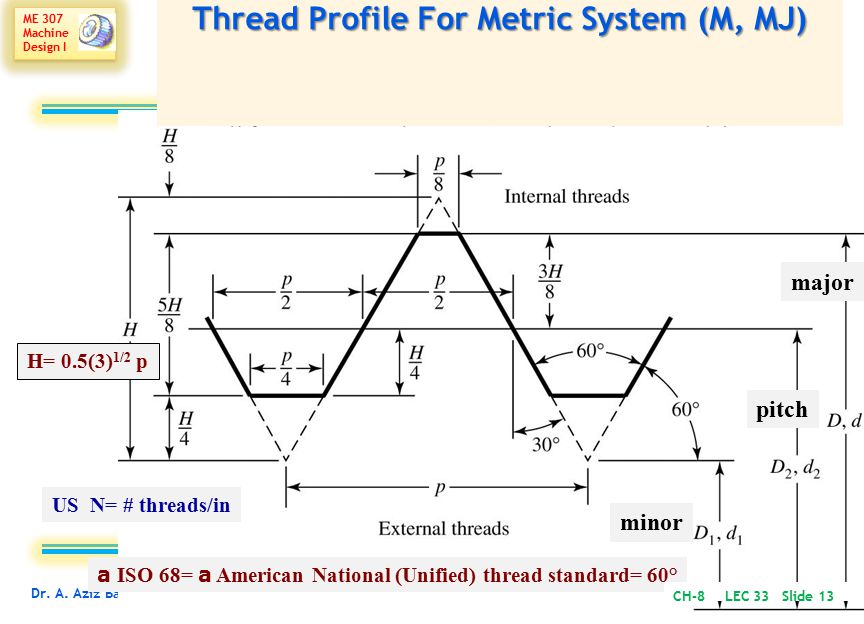 Чтобы напомнить, ниже приводится то что нам приходится применять
для индивидуализации какого- то подкласса
Чтобы напомнить, ниже приводится то что нам приходится применять
для индивидуализации какого- то подкласса threading.Thread для выполнения обратного отсчёта в пять шагов
с некой персональной задержкой между каждыми шагами:
# Chapter03/my_thread.py
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name, delay):
threading.Thread.__init__(self)
self.name = name
self.delay = delay
def run(self):
print('Starting thread %s.' % self.name)
thread_count_down(self.name, self.delay)
print('Finished thread %s.' % self.name)
def thread_count_down(name, delay):
counter = 5
while counter:
time.sleep(delay)
print('Thread %s counting down: %i...' % (name, counter))
counter -= 1
В своём следующем примере мы рассмотрим свою задачу выявления является ли задаваемое число простым. В этот раз мы реализуем некую многопоточную
программу Python посредством нового модуля threading. Перейдите в папку Chapter03
к файлу example3.py. Давайте вначале сосредоточимся на своём подклассе
MyThread:
# Chapter03/example3.py
import threading
class MyThread(threading.Thread):
def __init__(self, x):
threading.Thread.__init__(self)
self.x = x
def run(self):
print('Starting processing %i...' % x)
is_prime(self.x)
Всякий экземпляр нашего класса MyThread имеет некий параметр с названием x,
определяющий число- кандидат на то чтобы быть простым. Как вы можете заметить, когда инициализируется и запускается некий экземпляр этого класса
(а точнее, в функции run(self)), наша функция is_prime(), которая является
той же самой функцией проверки является ли число простым, которую мы применяли в своём предыдущем примере, причём с указанным параметром
x, а перед этим в нашей функции run() для указания на начало данного процесса
также выводится на печать некое сообщение.
В своей основной программе мы всё ещё имеем всё тот же список на вход для проверки на принадлежность к простым числам. Мы намерены пройти по всем
числам из этого перечня, порождая и запуская некий новый экземпляр данного класса MyThread с этим числом и
дописывая этот экземпляр MyThread в некий отдельный список. Такой список созданных потоков необходим по той
причине, поскольку после этого нам придётся вызвать метод join() для всех этих потоков, который удостоверит все эти
потоки успешно завершили своё исполнение:
my_input = [2, 193, 323, 1327, 433785907]
threads = []
for x in my_input:
temp_thread = MyThread(x)
temp_thread.start()
threads.append(temp_thread)
for thread in threads:
thread.join()
print('Finished.')
Отметим, что в отличии от того случая когда мы применяли старый модуль thread, на этот раз нам нет нужды
изобретать какой- то обходной манёвр чтобы гарантировать что все потоки успешно завершили своё исполнение. Опять же, это делается указанным методом
join(), который предоставляется новым модулем threading. Это всего
лишь один пример из множества преимуществ применения более мощного API верхнего уровня нового модуля threading,
относительно использования традиционного модуля thread.
Синхронизация потоков
Как вы видели в наших предыдущих примерах, новый модуль threading имеет множество преимуществ над своим
предшественником, традиционным модулем thread, с точки зрения функциональности и вызовов API верхнего уровня.
Даже хотя кое- кто рекомендует искушённым разработчикам Python знать как реализовывать многопоточные приложения при помощи обоих модулей, скорее всего,
для работы с потоками Python вы будете применять именно модуль threading. В данном разделе мы рассмотрим
использование модуля
В данном разделе мы рассмотрим
использование модуля threading при синхронизации потоков.
Понятие синхронизации потоков
Прежде чем мы перепрыгнем к некому реальному примеру на Python, давайте изучим само понятие синхронизации в информатике. Как вы уже видели в предыдущих главах, порой нежелательно иметь все порции программы исполняемыми параллельно. Фактически, в наиболее современных совместных программах, даже внутри некоторой совместной части, также необходима некая форма координации между различными потоками/ процессами.
Синхронизация потоков/ процессов является неким понятием из информатики, которое определяет различные механизмы гарантии того, что за раз не более одной одновременно исполняемого потока/ процесса может обработать и исполнить некую определённую часть кода; такая часть кода именуется критическим разделом и мы будем обсуждать его более подробно когда будем рассматривать распространённые проблемы при параллельном программировании в Главе 12, Взаимные блокировки и в Главе 13, Зависание.
В некоторой конкретной программе, когда какой- то поток осуществляет доступ/ исполняет соответствующий критический раздел данной программы, все
прочие потоки обязаны дожидаться пока этот поток не завершит исполнение. Наиболее типичной целью синхронизации потоков является избежание потенциальной
противоречивости данных при организации доступа множеством потоков разделяемых ими ресурсов; позволяя только одному потоку исполнять данный критический
раздел вашей программы за раз чтобы гарантировать что в многопоточном приложении не произойдёт никаких конфликтов с данными.
{Прим. пер.: пример, иллюстрирующий такой конфликт, приводится в нашем переводе раздела Ресторан Серийных ботов книги Asyncio в Python 3
Цалеба Хаттингха. }
}
Класс threading.Lock
Один из наиболее общих путей применения синхронизации потоков состоит в реализации некоторого механизма блокировки. В нашем модуле
threading, класс threading.Lock предоставляет некий образец и
интуитивно понятного подхода по созданию блокировок и работе с ними. Его основное использование включает в себя такие методы:
-
threading.Lock(): Этот метод инициализирует и возвращает некий объект блокировки. -
acquire(blocking): При вызове данного метода все имеющиеся потоки будут запущены синхронно (то есть, только один поток может исполнять данный критический раздел в определённый момент времени):-
Необязательный аргумент
blockingпозволяет нам определять должен ли данный текущий поток выполнять ожидание чтобы получить данную блокировку. -
Когда
blocking = 0, данный текущий поток не дожидается данной блокировки и просто возвращает0, если такая блокировка не может быть получена этим потоком или1в противоположном случае. -
Когда
blocking = 1, данный текущий поток выполняет блокирование и дожидается пока эта блокировка не освободится и получает её после этого.
-
-
release(): При вызове данного метода его блокирование высвобождается.
Некий пример на Python
Давайте рассмотрим некий конкретный пример. В этом примере мы будем просматривать свой файл Chapter03/example4.py.
Мы вернёмся обратно к своему примеру обратного отсчёта от пяти до одного, который уже рассматривали в самом начале данной главы; улучите момент
чтобы чтобы вернуться назад и вспомнить постановку задачи.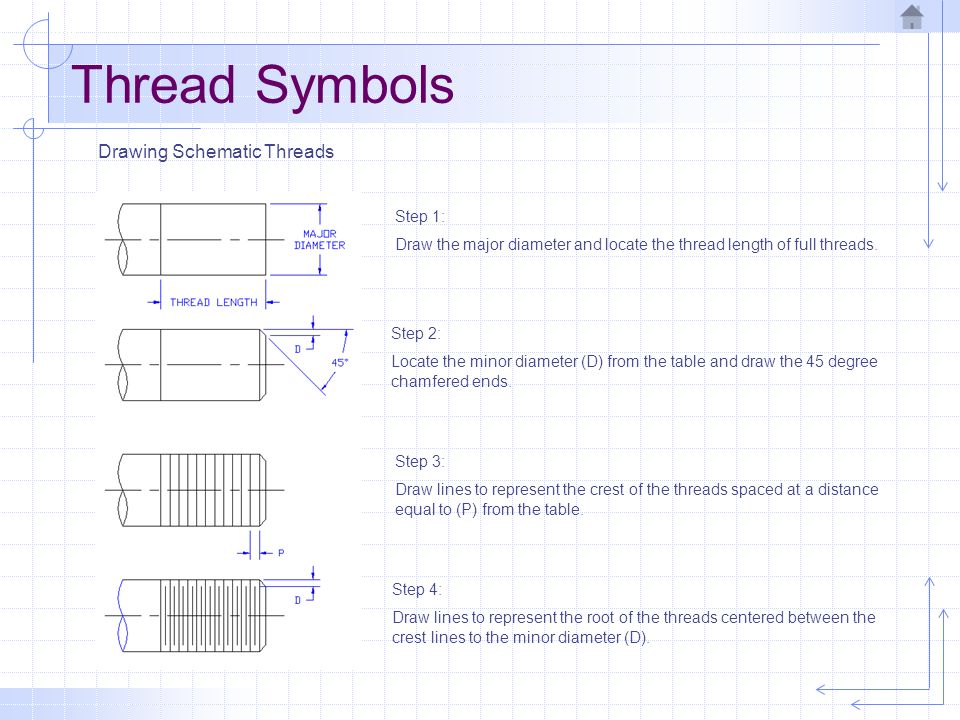 В данном примере мы отрегулируем свой класс
В данном примере мы отрегулируем свой класс MyThread
следующим образом:
# Chapter03/example4.py
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name, delay):
threading.Thread.__init__(self)
self.name = name
self.delay = delay
def run(self):
print('Starting thread %s.' % self.name)
thread_lock.acquire()
thread_count_down(self.name, self.delay)
thread_lock.release()
print('Finished thread %s.' % self.name)
def thread_count_down(name, delay):
counter = 5
while counter:
time.sleep(delay)
print('Thread %s counting down: %i...' % (name, counter))
counter -= 1
В противоположность самому первому примеру из этой главы, класс MyThread применяет некую блокировку объекта
(имя переменной которого имеет название thread_lock) внутри своей функции
run(). В частности, данный объект блокировки получается сразу перед вызовом функции
thread_count_down() (то есть когда начинается обратный отсчёт), а высвобождается этот блокируемый объект сразу
после её завершения. Теоретически, данная спецификация позволит изменять то поведение наших потоков, которое мы видели в самом первом примере; вместо
одновременного имеющегося обратного отсчёта наша программа теперь исполняет имеющиеся потоки по отдельности, и каждый последующий обратный отсчёт будет
иметь место после предыдущего.
Наконец, мы проинициализируем свою переменную thread_lock а также запустим два отдельных экземпляра класса
MyThread:
thread_lock = threading.Lock()
thread1 = MyThread('A', 0.5)
thread2 = MyThread('B', 0. 5)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('Finished.')
 5)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('Finished.')
5)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('Finished.')
Вывод будет таким:
> python example4.py
Starting thread A.
Starting thread B.
Thread A counting down: 5...
Thread A counting down: 4...
Thread A counting down: 3...
Thread A counting down: 2...
Thread A counting down: 1...
Finished thread A.
Thread B counting down: 5...
Thread B counting down: 4...
Thread B counting down: 3...
Thread B counting down: 2...
Thread B counting down: 1...
Finished thread B.
Finished.
Многопоточная очередь с приоритетами
Широко применяемым как в не параллельном, так и в совместном программировании понятием информатики является применение очередей. Некая очередь является абстрактной структурой данных, которая является коллекцией различных элементов для сопровождения некоего установленного порядка; эти элементы могут быть иными объектами в какой- то программе.
Взаимосвязь реального мира и программируемых очередей
Очереди являются интуитивно понятной концепцией, которая легко может быть соотнесена с повседневной практикой, например, когда вы стоите к стойке в одну линию в аэропорту. В реальной цепочке из людей вы наблюдаете следующее:
-
Люди обычно встают с одной стороны этой цепочки и покидают её с другой стороны.
-
Если персона A поступает в эту цепь перед персоной B, то персона A также покинет эту цепь до персоны B (если только у персоны B не более высокий приоритет).
-
Когда все разместятся в самолёте, в данной очереди никого не останется. Иными словами, данная цепь будет пустой.
В информатике очередь работает в значительной степени аналогичным образом:
-
Элементы могут добавляться в самый конец определённой очереди; эта задача называется постановкой в очередь (enqueue).
-
Элементы также могут удаляться из самого начала такой очереди; такая задача именуется извлечением из очереди (dequeue).
-
В очереди FIFO (First In First Out, первый пришёл- первый ушёл) тот элемент, что добавляется первым, также будет и удалён первым (отсюда и название, FIFO). Это является противоположностью другой распространённой структуре данных в информатике, именуемой стеком, в котором самый последний добавляемый элемент удаляется первым. Что также именуется как LIFO (Last In First Out, последний пришёл — первый ушёл).
-
Если внутри некоторой очереди были удалены все элементы, такая очередь будет пустой и не будет никакого способа удалять и далее элементы из такой очереди. Аналогично, если данная очередь достигает максимальной ёмкости по числу элементов, которые она может содержать, нет никакого способа добавлять какие бы то ни было элементы в данную очередь:
Модуль queue в Python предоставляет некую простую реализацию такой структуры данных очереди. Каждая очередь
из имеющегося класса queue.Queue может содержать определённое количество элементов и может иметь следующие методы
в качестве своего API верхнего уровня:
-
get(): Данный метод возвращает следующий элемент вызывая объектqueueи удаляя его из этого объектаqueue -
put(): Этот метод добавляет новый элемент в данный вызываемый объектqueue -
qsize(): Этот метод возвращает общее число текущих элементов в данном вызываемом объектеqueue(то есть его размер). -
empty(): Такой метод возвращает некое Булево значение, указывающее является ли вызываемый объектqueueпустым. -
full(): Данный метод возвращает некое Булево значение, указывающее является ли вызываемый объектqueueзаполненным.
Постановка в очереди в параллельном программировании
Обсуждаемое понятие очереди даже ещё более распространено в подобласти совместного программирования, в особенности когда нам необходимо реализовать некое фиксированное число потоков в нашей программе для взаимодействия с переменным числом совместных ресурсов.
В своих предыдущих примерах мы изучили назначение некой определённой задачи какому- то новому потоку. Это означает, что общее число задач,
которое необходимо обработать будет диктовать общее число потоков, которое следует породить нашей программе (Например, в своём файле
Chapter03/example3.py мы имели пять чисел в качестве наших входных данных и мы, следовательно, создали пять потоков —
каждый взял по одному числу из входных данных и обработал его.)
Порой не желательно иметь столько же потоков, сколько задач у нас имеется для обработки. Скажем, у вас имеется большое число подлежащих обработки, тогда было бы достаточно не эффективно порождать то же самое число потоков и иметь каждый поток исполняющим только одну задачу. Может дать больше преимуществ наличие фиксированного числа потоков (обычно именуемого неким пулом потоков), который мог бы работать с имеющимися задачами на основе кооперации.
Здесь на сцену выходит понятие очереди. У нас есть возможность спроектировать некую структуру, в которой наш пул потоков не будет сохранять какую бы
то ни было информацию относящуюся к задачам, которые ему следует исполнять, а вместо этого сами задачи хранятся в некоторой очереди (иными словами,
создают очередь задач), и соответствующие элементы из этой очереди будут питать персональных участников имеющегося пула потоков. По мере того как
выбранная задача завершается неким участником нашего пула потоков, если присутствующая очередь задач всё ещё содержит подлежащие обработке элементы,
тогда следующий элемент из этой очереди будет отправлен в тот поток, который только что освободился.
По мере того как
выбранная задача завершается неким участником нашего пула потоков, если присутствующая очередь задач всё ещё содержит подлежащие обработке элементы,
тогда следующий элемент из этой очереди будет отправлен в тот поток, который только что освободился.
Приводимая ниже схема иллюстрирует такую настройку:
Давайте рассмотрим быстрый пример на Python чтобы проиллюстрировать этот момент. Перейдите к соответствующему файлу
Chapter03/example5.py. В этом примере мы будем рассматривать задачу вывода всех положительных множителей некоторых
элементов в заданном списке положительных целых. Мы всё ещё придерживаемся своего класса MyThread, но
с некими настройками:
# Chapter03/example5.py
import queue
import threading
import time
class MyThread(threading.Thread):
def __init__(self, name):
threading.Thread.__init__(self)
self.name = name
def run(self):
print('Starting thread %s.' % self.name)
process_queue()
print('Exiting thread %s.' % self.name)
def process_queue():
while True:
try:
x = my_queue.get(block=False)
except queue.Empty:
return
else:
print_factors(x)
time.sleep(1)
def print_factors(x):
result_string = 'Positive factors of %i are: ' % x
for i in range(1, x + 1):
if x % i == 0:
result_string += str(i) + ' '
result_string += '\n' + '_' * 20
print(result_string)
# setting up variables
input_ = [1, 10, 4, 3]
# filling the queue
my_queue = queue.Queue()
for x in input_:
my_queue.put(x)
# initializing and starting 3 threads
thread1 = MyThread('A')
thread2 = MyThread('B')
thread3 = MyThread('C')
thread1. start()
thread2.start()
thread3.start()
# joining all 3 threads
thread1.join()
thread2.join()
thread3.join()
print('Done.')
 start()
thread2.start()
thread3.start()
# joining all 3 threads
thread1.join()
thread2.join()
thread3.join()
print('Done.')
start()
thread2.start()
thread3.start()
# joining all 3 threads
thread1.join()
thread2.join()
thread3.join()
print('Done.')
Тут имеется много на что стоит посмотреть, поэтому давайте разобьём эту программу на части меньшего размера. Во- первых, давайте рассмотрим свою ключевую функцию:
# Chapter03/example5.py
def print_factors(x):
result_string = 'Positive factors of %i are: ' % x
for i in range(1, x + 1):
if x % i == 0:
result_string += str(i) + ' '
result_string += '\n' + '_' * 20
print(result_string)
Эта функция берёт некий параметр, x, затем выполняет итерации по всем положительным числам между
1 и своим значением чтобы проверить является ли это число неким множителем
x. В конце выводится на печать форматированное сообщение, которое содержит всю необходимую информацию,
которая накопилась в нашем цикле.
В нашем новом классе MyThread, после того как некий новый экземпляр проинициализирован и запущен, будет
вызвана соответствующая функция process_queue(). Эта функция вначале попытается получить следующий
требуемый элемент из существующего объекта очереди, который содержится в переменной my_queue неким
образом без блокировки посредством вызова соответствующего метода get(block=False). Если произошла некая
исключительная ситуация queue.Empty (что указывает на то, что данная очередь не содержит значений), тогда мы
завершаем исполнение данной функции. В противном случае мы просто передаём тот элемент, что мы только что получили, в свою функцию
print_factors().
# Chapter03/example5.py
def process_queue():
while True:
try:
x = my_queue. get(block=False)
except queue.Empty:
return
else:
print_factors(x)
time.sleep(1)
 get(block=False)
except queue.Empty:
return
else:
print_factors(x)
time.sleep(1)
get(block=False)
except queue.Empty:
return
else:
print_factors(x)
time.sleep(1)
Переменная my_queue определяется в нашей основной функции как некий объект Queue
из модуля queue, который содержит все элементы в своём перечне input_:
# setting up variables
input_ = [1, 10, 4, 3]
# filling the queue
my_queue = queue.Queue(4)
for x in input_:
my_queue.put(x)
В оставшейся части своей основной программы мы просто инициируем и запускаем такие отдельные потоки пока все они не завершат свои соответствующие исполнения. В данном случае мы остановились на создании только трё потоков для имитации своей архитектуры, которую мы обсудили выше — некое фиксированное число потоков обработки очереди на входе, чьё число элементов может изменяться независимым образом:
# initializing and starting 3 threads
thread1 = MyThread('A')
thread2 = MyThread('B')
thread3 = MyThread('C')
thread1.start()
thread2.start()
thread3.start()
# joining all 3 threads
thread1.join()
thread2.join()
thread3.join()
print('Done.')
Запустите эту программу и получите следующий вывод:
> python example5.py
Starting thread A.
Starting thread B.
Starting thread C.
Positive factors of 1 are: 1
____________________
Positive factors of 10 are: 1 2 5 10
____________________
Positive factors of 4 are: 1 2 4
____________________
Positive factors of 3 are: 1 3
____________________
Exiting thread C.
Exiting thread A.
Exiting thread B.
Done.
В этом примере мы реализовали ту структуру, которую обсудили ранее: очередь задач, которая хранит все подлежащие исполнению задачи и некий пул потоков
(потоки A?\, B и C), которые взаимодействуют с имеющейся очередью для обработки её элементов.
Многопоточная очередь с приоритетами
Все элементы в некоторой очереди обрабатываются в том порядке, в котором они были добавлены в эту очередь; иными словами, самый первый добавленный в очередь элемент покидает эту очередь первым (FIFO). Даже хотя такая абстрактная структура данных и имитирует реальную жизнь во многих случаях, в зависимости от самого приложения и его целей, порой нам требуется переопределять/ изменять имеющийся порядок стоящих в очереди элементов динамически. Именно в такой ситуации удобным становится понятие очереди с приоритетами.
Абстрактная структура данных очереди с приоритетами аналогична уже обсуждённой структуре данных очереди (и даже вышеупомянутому понятию стека), но каждый имеющийся в некоторой очереди с приоритетами элемент, как предвосхищает её название, имеет некий связанный с ним приоритет; говоря иначе, когда некий элемент добавляется в очередь с приоритетами, требуется определить его приоритет. В отличии от обычной очереди, принцип выборки из очереди с приоритетами полагается на значение приоритета имеющихся элементов: те элементы, у которых приоритет выше, обрабатываются ранее конкурентов с меньшим приоритетом.
Данная концепция очереди с приоритетами используется в разнообразных различных приложениях — а именно, управлении полосой пропускания,
алгоритме Дейкстры, алгоритмах наилучшего первого поиска, и тому подобных. Каждое из таких приложений обычно применяет систему очков с конечным числом
значений/ функцию определения значения приоритета её элементов. Например, при управлении полосой пропускания, приоритетный обмен, такой как обмен в
потоках реального масштаба времени, обрабатывается с наименьшей задержкой и наименьшей вероятностью отказа. В алгоритмах наилучшего поиска, которые
применяются для нахождения кратчайшего пути между двумя определёнными узлами графа, реализуется очередь с приоритетами для отслеживания не обследованных
маршрутов; маршруты с более короткой оценочной длиной имеют более высокий приоритет в такой очереди.
Некое исполнение потока является самым малым элементом программирования команд. В информатике многопоточные приложения позволяют множеству потоков существовать внутри одного и того же процесса одновременно для реализации одновременной обработки и параллелизма. Многопоточность предоставляет различные преимущества во время исполнения, в виде способности к отклику, а также относительно действенности применения ресурсов.
Модуль threading в Python 3. который обычно рассматривается в качестве покрывающего более ранний модуль
thread, предоставляет эффективный, мощный и при этом представленный верхним уровнем API для работы с потоками
при реализации многопоточных приложений в Python, включая варианты для порождения новых потоков динамически, а также для синхронизации потоков
посредством различных механизмов.
Очереди и очереди с приоритезацией являются важными структурами данных в отрасли информатики, причём они являются существенным понятием в синхронной обработке и параллельном программировании. Они делают возможным для многопоточных приложений действенно исполнять и аккуратно завершать свои потоки, гарантируя то, что разделяемые ресурсы обрабатываются особым образом и при этом динамически.
В своей следующей главе мы обсудим более современные функции Python, оператор with и то, как он дополняет
использование многопоточного программирования в Python.
-
Что такое поток? В чём состоит ключевое отличие потока от процесса?
-
В чём состоят варианты, предоставляемые модулем
threadв Python? -
Что предлагают параметры, предлагаемые модулем
threadingиз Python? -
В чём состоит процесс создания новых потоков через модули
threadиthreading? -
Что стоит за основной идеей синхронизации потоков при помощи блокировки?
-
Что составляет процесс реализации синхронизации потоков с применением блокировки в Python?
-
В чём основная идея структуры данных очереди?
-
Что является основным приложением очередей для совместного программирования?
-
Что составляет центральное отличие между обычными очередями и очередями с приоритетами?
 w3.org/1999/xhtml»> Дальнейшее чтение
w3.org/1999/xhtml»> Дальнейшее чтениеДля получения дополнительных сведений воспользуйтесь следующими ссылками:
-
Наш перевод 2 издания Python Parallel Programming Cookbook, Джанкарло Законне, Packt Publishing Ltd, сентябрь 2019
-
Learning Concurrency in Python: Build highly efficient, robust, and concurrent applications, Элиот Форбс, Packt Publishing Ltd, 2017
-
Real-time concepts for embedded systems, Кинг Ли и Кэролайн Яо, CRC Press, 2003
Правила написания thread-safe UDF
James Arias-La Rheir
InterBase Technical Services
InterBase Software Corp. Основная задача при написании потоко-безопасных UDF – обеспечить корректное обращение к возвращаемым параметрам при многопользовательской работе. Особенности архитектуры SuperServer (IB 4.2 for NT, 5.0 for NT, Solaris, HP-UX) полностью исключают использование глобальных переменных в DLL (shared library) дл возврата результата функции, как это было принято в архитектуре Classic (IB 4.0).
Рассмотрим корректные варианты возврата параметров:
- FREE_IT: Этот аргумент используется в объявлении DECLARE EXTERNAL FUNCTION для того чтобы память, занятая внутри функции с помощю malloc() была освобождена IB. Объявление выходного параметра таким способом указывает серверу, что возвращаемое значение является указателем на буфер памяти, выделенный с помощю malloc, и сервер должен освободить эту память. Возвращаемое по такому принципу значение является thread-safe.
- Thread-local storage: Объявите переменные thread-local (threadvars в Delphi) для хранения входных и выходных значений UDF. Поскольку thread может быть использован сервером повторно для других целей (или обработки запросов другого пользователя), эти переменные нельзя использовать дл передачи данных другим threads или для хранения статический информации (используемой в другой UDF). Возвращаемое таким образом значение функции является thread-safe.
- RETURNS PARAMETER N: Этот аргумент используется в объявлении DECLARE EXTERNAL FUNCTION для указания, что возвращаемое значение UDF находитс во входном параметре с порядковым номером N (начиная с 1). Эта возможность непопулярна в ISC и не сертифицирована под 5.x (прим. КДВ – и даже в результате была вычеркнута из документации, хотя вполне неплохо работает). Использовать такой способ можно только на свой риск. Во всяком случае, длина выходного параметра не может быть больше длины соответствующего входного параметра. До версии 5.x такой способ передачи выходных параметров был thread-safe.
 Возвращаемое таким образом значение функции является thread-safe.
Возвращаемое таким образом значение функции является thread-safe.Важно отметить разницу между:
- Объявлением глобальной переменной и ее синхронизацией между threads.
и
- Объявлением переменной thread-local (threadvar).
Ядро IB Database будет корректно работать в случае B, поскольку операционна система заботится о сохранении значения переменной в пределах thread. Также IB копирует возвращаемое значение в отдельный участок памяти сразу после выполнения UDF; это также повышает безопасность переменных между нитями. За более подробной информацией по TLS обращайтесь к Win32.HLP или к книге «Windows для Профессионалов» Джефри Рихтера.
Gregory H. Deatz
Hoagland, Longo, Moran, Dunst & Doukas
Threadvar в Delphi работает нормально, и используется в FreeUDFLib. Однако совсем недавно было обнаружено, что на многопроцессорных компьютерах использование threadvar может привести к «падению» dll и скорее всего ibserver.exe. Чаще всего это происходит если объявить «объектный» тип как threadvar. В таком случае более надежной является прямая работа с TLSAlloc, TLSFree, TLSGetValue, TLSSetValue (и т.д.).
Данная проблема также была упомянута в Delphi Informant (август).
Кузьменко Д. В.
Epsylon Technologies
Хоть уважаемый James Arias-La Rheir и говорит, что функции с RETURNS PARAMETER лучше не использовать, я решил протестировать все варианты передачи и возврата строковых параметров.
Вообще способов может быть три:
1. возврат строки при помощи входного параметра – RETURNS PARAMETER . Этот способ не описан в документации и несколько неочевиден, т. к. вместо функции необходимо писать процедуру. Основное неудобство – хранимое в БД объявление функции не совпадает с объявленным, т. е. функция после создания выглядит как обычная функция с возвращаемым в виде строки параметром (а не номером параметра).
2. возврат строки, созданной внутри UDF при помощи malloc (FREE_IT). Этот способ с точки зрения производительности самый худший, поскольку память аллокируется и уничтожается при каждом вызове функции. Если функция обрабатывает значения 10000 записей, значит те же 10000 раз память будет захвачена и освобождена. С другой стороны, скорость таких операций намного выше, чем скорость получения записей с диска, поэтому влияние на скорость обработки данных будет минимальным. Обязательным является соответствие количества аллокируемой памяти внутри функции, и длина строки в объявлении функции в БД.
3. возврат строки, которая является входным параметром. Это «трюк», поскольку IB сам аллокирует память для входного параметра. Основные неудобства – размер выходной строки должен совпадать с размером входной, и невозможность использования этого метода если функция не содержит входных строковых параметров (или по типу эти параметры отличаются).
В случаях 1 и 3 память для передачи и получения результата UDF выделяется IB один раз в контексте клиентского соединения.
Для каждого случая была написана функция (см. функции function1, 2 и 3 соответственно в файле safeudf.zip). Тестировались функции следующим образом: из 3-х экземпляров Database Explorer одновременно выполнялся запрос
SELECT FUNCTION1(string) FROM EMPLOYEE, EMPLOYEE
WHERE FUNCTION1(string) <> stringгде string – уникальная строка для каждого экземпляра Database Explorer, но одинаковой длины (10 символов).
Тест показал абсолютную безопасность всех трех способов при работе в многопользовательских средах.Временные замеры показали, что быстрее всех выполнялась функция1 (4 мин 10 сек), чуть медленнее – функция3 (4 мин 17 секунд), и медленнее всех – функция2 (4 мин 57 секунд). Различие в скорости выполнения функций не является пропорциональным объему обрабатываемых данных. Поэтому можно сказать, что все три варианта могут быть успешно использованы.
 В том случае, если условие FUNCTION1(string) <> string по каким-то причинам нарушалось, ответ на запрос содержал бы минимум 1 строку. Это могло произойти только если результат функции перекрывался бы другим результатом функции. Такого у thread-safe функций произойти не может в принципе.
В том случае, если условие FUNCTION1(string) <> string по каким-то причинам нарушалось, ответ на запрос содержал бы минимум 1 строку. Это могло произойти только если результат функции перекрывался бы другим результатом функции. Такого у thread-safe функций произойти не может в принципе.Модуль threading на примерах
Модуль threading впервые был представлен в Python 1.5.2 как продолжение низкоуровневого модуля потоков. Модуль threading значительно упрощает работу с потоками и позволяет программировать запуск нескольких операций одновременно. Обратите внимание на то, что потоки в Python лучше всего работают с операциями I/O, такими как загрузка ресурсов из интернета или чтение файлов и папок на вашем компьютере.
Если вам нужно сделать что-то, для чего нужен интенсивный CPU, тогда вам, возможно, захочется взглянуть на модуль multiprocessing, вместо threading. Причина заключается в том, что Python содержит Global Interpreter Lock (GIL), который запускает все потоки внутри главного потока. По этой причине, когда вам нужно запустить несколько интенсивных операций с потоками, вы заметите, что все работает достаточно медленно. Так что мы сфокусируемся на том, в чем потоки являются лучшими: операции I/O.
Небольшое интро
Поток позволяет вам запустить часть длинного кода так, как если бы он был отдельной программой. Это своего рода вызов наследуемого процесса, за исключением того, что вы вызываете функцию или класс, вместо отдельной программы. Я всегда находил конкретные примеры крайне полезными. Давайте взглянем на нечто совершенно простое:
Я всегда находил конкретные примеры крайне полезными. Давайте взглянем на нечто совершенно простое:
import threading
def doubler(number):
"""
A function that can be used by a thread
"""
print(threading.currentThread().getName() + '\n')
print(number * 2)
print()
if __name__ == '__main__':
for i in range(5):
my_thread = threading.Thread(target=doubler, args=(i,))
my_thread.start()Здесь мы импортируем модуль threading и создаем обычную функцию под названием doubler. Наша функция принимает значение и удваивает его. Также она выводи название потока, который вызывает функцию и выводит бланк-строчку в конце. Далее, в последнем блоке кода, мы создаем пять потоков, и запускаем каждый из них по очереди.
Вам больше не придется долгими часами настраивать дорогостоящую рекламу в Фейсбуке и тратить на нее весомый бюджет. Сайт Avi1 готов помочь Вам купить ее по самым приятным ценам, и как можно быстрее развиться в данной социальной сети. Здесь Вам будут доступны пакетные предложения с разнообразными ресурсами: лайки, подписчики, друзья и пр.
Используя многопоточность можно решить много рутинных моментов. Например загрузка видео или другого материала в социальные сети, такие как Youtube или Facebook. Для развития своего Youtube канала можно использовать https://publbox.com/ru/youtube который возьмет на себя администрирование вашего канала. Youtube отличный источник заработка и чем больше каналов тем лучше. Без Publbox вам не обойтись.
Обратите внимание на то, что когда мы определяем поток, мы устанавливаем его целью на нашу функцию doubler, и мы также передаем аргумент функции. Причина, по которой параметр args выглядит немного непривычно, заключается в том, что нам нужно передать sequence функции doubler, и она принимает только один аргумент, так что нужно добавить запятую в конце, чтобы создать sequence одной из них. Обратите внимание на то, что если вы хотите подождать, пока поток определится, вы можете вызвать его метод join(). Когда вы запустите этот код, вы получите следующую выдачу:
Когда вы запустите этот код, вы получите следующую выдачу:
Thread-1
0
Thread-2
2
Thread-3
4
Thread-4
6
Thread-5
8Конечно, вам скорее всего не захочется выводить вашу выдачу в stdout. Это может закончиться сильным беспорядком. Вместо этого, вам нужно использовать модуль Python под названием logging. Это защищенный от потоков модуль и он прекрасно выполняет свою работу. Давайте немного обновим указанный ранее пример и добавим модуль logging, и заодно назовем наши потоки:
import logging
import threading
def get_logger():
logger = logging.getLogger("threading_example")
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler("threading.log")
fmt = '%(asctime)s - %(threadName)s - %(levelname)s - %(message)s'
formatter = logging.Formatter(fmt)
fh.setFormatter(formatter)
logger.addHandler(fh)
return logger
def doubler(number, logger):
"""
A function that can be used by a thread
"""
logger.debug('doubler function executing')
result = number * 2
logger.debug('doubler function ended with: {}'.format(result))
if __name__ == '__main__':
logger = get_logger()
thread_names = ['Mike', 'George', 'Wanda', 'Dingbat', 'Nina']
for i in range(5):
my_thread = threading.Thread(
target=doubler, name=thread_names[i], args=(i,logger))
my_thread.start()Самое большое изменение в этом коде – это добавление функции get_logger. Эта часть кода создаст логгер, который настроен на дебаг. Это сохранит log в нынешнюю рабочую папку (другими словами, туда, откуда запускается скрипт) и затем мы настраиваем формат каждой линии на логированный. Формат включает временной штамп, название потока, уровень логгирования и логгированое сообщение. В функции doubler мы меняем наши операторы вывода на операторы логгирования.
Обратите внимание на то, что мы передаем логгер в функцию doubler, когда создаем поток. Это связанно с тем, что если вы определяет объект логгирования в каждом потоке, вы получите несколько singletons и ваш журнал будет содержать множество повторяющихся строк. В конце мы называем наши потоки, создав список наименований, и затем устанавливаем каждый поток на особое наименование, использую параметр name. Когда вы запустите этот код, вы должны получить лог файл со следующим содержимым:
Это связанно с тем, что если вы определяет объект логгирования в каждом потоке, вы получите несколько singletons и ваш журнал будет содержать множество повторяющихся строк. В конце мы называем наши потоки, создав список наименований, и затем устанавливаем каждый поток на особое наименование, использую параметр name. Когда вы запустите этот код, вы должны получить лог файл со следующим содержимым:
Эта выдача достаточно понятная, так что давайте пойдем дальше. Я хочу разобрать еще один вопрос в этой статье. Мы поговорим о наследовании класса под названием threading.Thread. Давайте снова рассмотрим предыдущий пример, только вместо вызова потока напрямую, мы создадим свой собственный подкласс. Вот обновленный код:
import logging
import threading
class MyThread(threading.Thread):
def __init__(self, number, logger):
threading.Thread.__init__(self)
self.number = number
self.logger = logger
def run(self):
"""
Run the thread
"""
logger.debug('Calling doubler')
doubler(self.number, self.logger)
def get_logger():
logger = logging.getLogger("threading_example")
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler("threading_class.log")
fmt = '%(asctime)s - %(threadName)s - %(levelname)s - %(message)s'
formatter = logging.Formatter(fmt)
fh.setFormatter(formatter)
logger.addHandler(fh)
return logger
def doubler(number, logger):
"""
A function that can be used by a thread
"""
logger.debug('doubler function executing')
result = number * 2
logger.debug('doubler function ended with: {}'.format(result))
if __name__ == '__main__':
logger = get_logger()
thread_names = ['Mike', 'George', 'Wanda', 'Dingbat', 'Nina']
for i in range(5):
thread = MyThread(i, logger)
thread.setName(thread_names[i])
thread. start() start()
start()В этом примере мы только что унаследовали класс threading.Thread. Мы передали число, которое хотим удвоить, а также передали объект логгированмя, как делали это ранее. Но на этот раз, мы настроим название потока по-другому, вызвав функцию setName в объекте потока. Нам все еще нужно вызвать старт в каждом потоке, но запомните, что нам не нужно определять это в наследуемом классе. Когда вы вызываете старт, он запускает ваш поток, вызывая метод run. В нашем классе мы вызываем функцию doubler для выполнения наших вычислений. Выдача сильно похожа на ту, что была в примере ранее, за исключением того, что я добавил дополнительную строку в выдаче. Попробуйте сами и посмотрите, что получится.
Замки и Синхронизация
Когда у вас в распоряжении более одного потока, тогда вам, возможно, понадобится понять, как избежать конфликтов. Под этим я имею ввиду то, что вы можете использовать случай, где более одного потока нуждаются в доступе к одном и тому же ресурсу в одно и то же время. Если вы не думаете о таких проблемах и соответственном планировании, тогда вы можете столкнуться с самыми худшими проблемами в крайне неудобное время, и, как правило, в момент выпуска кода.
Решение проблемы – это использовать замки. Замок предоставлен модулем Python threading и может держать один поток, или не держать поток вообще. Если поток пытается acquire замок на ресурсе, который уже закрыт, этот поток будет ожидать до тех пор, пока замок не откроется. Давайте посмотрим на практичный пример одного кода, который не имеет никакого замочного функционала, но мы попробуем его добавить:
import threading
total = 0
def update_total(amount):
"""
Updates the total by the given amount
"""
global total
total += amount
print (total)
if __name__ == '__main__':
for i in range(10):
my_thread = threading.Thread(target=update_total, args=(5,))
my_thread. start() start()
start()Мы можем сделать этот пример еще интереснее, добавив вызов time.sleep. Следовательно, проблема здесь в том, что один поток может вызывать update_total и перед тем, как он обновится, другой поток может вызвать его и тоже попытается обновить его. В зависимости от порядка операций, значение может быть добавлено единожды. Давайте добавим замок к функции. Существует два способа сделать эта. Первый – это использование try/finally, если мы хотим убедиться, что замок снят. Вот пример:
import threading
total = 0
lock = threading.Lock()
def update_total(amount):
"""
Updates the total by the given amount
"""
global total
lock.acquire()
try:
total += amount
finally:
lock.release()
print (total)
if __name__ == '__main__':
for i in range(10):
my_thread = threading.Thread(target=update_total, args=(5,))
my_thread.start()Здесь мы просто вешаем замок, перед тем как сделать что-либо другое. Далее, мы пытаемся обновить total и finally, мы снимаем замок и выводим нынешний total. Мы можем упростить данную задачу, используя оператор Python под названием with:
import threading
total = 0
lock = threading.Lock()
def update_total(amount):
"""
Updates the total by the given amount
"""
global total
with lock:
total += amount
print (total)
if __name__ == '__main__':
for i in range(10):
my_thread = threading.Thread(target=update_total, args=(5,))
my_thread.start()Как вы видите, нам больше не нужны try/finally, так как контекстный менеджер, предоставленный оператором with, сделал все это за нас. Конечно, вы можете обнаружить, что пишите код там, где необходимы несколько потоков с доступом к нескольким функциям. Когда вы впервые начнете писать конкурентный код, вы можете сделать что-нибудь на подобии следующего:
import threading
total = 0
lock = threading. Lock()
def do_something():
lock.acquire()
try:
print('Lock acquired in the do_something function')
finally:
lock.release()
print('Lock released in the do_something function')
return "Done doing something"
def do_something_else():
lock.acquire()
try:
print('Lock acquired in the do_something_else function')
finally:
lock.release()
print('Lock released in the do_something_else function')
return "Finished something else"
if __name__ == '__main__':
result_one = do_something()
result_two = do_something_else() Lock()
def do_something():
lock.acquire()
try:
print('Lock acquired in the do_something function')
finally:
lock.release()
print('Lock released in the do_something function')
return "Done doing something"
def do_something_else():
lock.acquire()
try:
print('Lock acquired in the do_something_else function')
finally:
lock.release()
print('Lock released in the do_something_else function')
return "Finished something else"
if __name__ == '__main__':
result_one = do_something()
result_two = do_something_else()
Lock()
def do_something():
lock.acquire()
try:
print('Lock acquired in the do_something function')
finally:
lock.release()
print('Lock released in the do_something function')
return "Done doing something"
def do_something_else():
lock.acquire()
try:
print('Lock acquired in the do_something_else function')
finally:
lock.release()
print('Lock released in the do_something_else function')
return "Finished something else"
if __name__ == '__main__':
result_one = do_something()
result_two = do_something_else()Этот код хорошо работает в данном случае, но подразумевается, что у вас есть несколько потоков, вызывающих обе эти функции. Пока один поток работает над функциями, второй может, в свою очередь, обновлять данные и вы получите некорректный результат. Проблема в том, что вы сначала можете не заметить, что с результатами что-то неладное. Как найти решение этой проблеме? Давайте в ней разберемся. Первое, к чему можно прийти, это повесить замок на двух вызовах функций. Давайте попробуем обновить указанный ранее пример, чтобы получить что-то вроде следующего:
import threading
total = 0
lock = threading.RLock()
def do_something():
with lock:
print('Lock acquired in the do_something function')
print('Lock released in the do_something function')
return "Done doing something"
def do_something_else():
with lock:
print('Lock acquired in the do_something_else function')
print('Lock released in the do_something_else function')
return "Finished something else"
def main():
with lock:
result_one = do_something()
result_two = do_something_else()
print (result_one)
print (result_two)
if __name__ == '__main__':
main()Когда вы запустите этот код, вы увидите, что он просто висит. Причина в том, что мы просто указываем модулю threading повесить замок. Так что когда мы вызываем первую функцию, она видит, что замок уже висит и блокируется. Это будет длиться до тех пор, пока замок не снимут, что никогда и не случится, так как это не предусмотрено в коде. Хорошее решение в данном случае – использовать re-entrant замок. Модуль threading предоставляет такой, в виде функции RLock. Просто замените строку lock = threading.Lock() на lock = threading.RLock() и попробуйте перезапустить код. Теперь он должен заработать. Если вы хотите попробовать код выше но добавить в него потоки, то мы можем заменить call на main следующим образом:
Так что когда мы вызываем первую функцию, она видит, что замок уже висит и блокируется. Это будет длиться до тех пор, пока замок не снимут, что никогда и не случится, так как это не предусмотрено в коде. Хорошее решение в данном случае – использовать re-entrant замок. Модуль threading предоставляет такой, в виде функции RLock. Просто замените строку lock = threading.Lock() на lock = threading.RLock() и попробуйте перезапустить код. Теперь он должен заработать. Если вы хотите попробовать код выше но добавить в него потоки, то мы можем заменить call на main следующим образом:
if __name__ == '__main__':
for i in range(10):
my_thread = threading.Thread(target=main)
my_thread.start()Так мы запустим основную функцию в каждом потоке, что в свою очередь приведет к вызову остальных двух функций. В конце вы получите достаточно крупную выдачу.
Таймеры
Модуль threading включает в себя один очень удобный класс, под названием Timer, который вы можете использовать запуска действия, спустя определенный отрезок времени. Данный класс запускает собственный поток и начинают работу с того же метода start(), как и обычные потоки. Вы также можете остановить таймер, используя метод cancel. Обратите внимание на то, что вы можете отменить таймер еще до того, как он стартовал. Однажды у меня был случай, когда мне нужно было наладить связь с под-процессом, который я начал, но мне нужен было обратный отсчет. Несмотря на существования ряда различных способов решения этой отдельной проблемы, моим любимым решением всегда было использование класса Timer модуля threading. Для этого примера мы взглянем на применение команды ping. В Linux, команда ping будет работать, пока вы её не убьете. Так что класс Timer становится особенно полезным для мира Linux. Вот пример:
import subprocess
from threading import Timer
kill = lambda process: process.kill()
cmd = ['ping', 'www.google.com']
ping = subprocess.Popen(
cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
my_timer = Timer(5, kill, [ping])
try:
my_timer.start()
stdout, stderr = ping.communicate()
finally:
my_timer.cancel()
print (str(stdout))Здесь мы просто настраиваем лямбду, которую мы можем использовать, чтобы убить процесс. Далее мы начинаем нашу работу над ping и создаем объект Timer. Обратите внимание на то, что первый аргумент – это время ожидания в секундах, затем – функция, которую нужно вызвать и аргумент, который будет передан функции. В нашем случае, наша функция – это лямбда, и мы передаем её список аргументов, где список содержит только один элемент. Если вы запустите этот код, он будет работать примерно 5 секунд, после чего выведет результат пинга.
Другие Компоненты Потоков
Модуль threading также включает в себя поддержу других объектов. Например, вы можете создать семафор, который является одним из древнейших синхронизационных примитивов в компьютерной науке. Семафор управляет внутренним счетчиком, который будет декрементируется когда вы вызываете acquire и увеличивается, когда вы вызываете release. Счетчик разработан таким образом, что он не может падать ниже нуля. Так что если так вышло, что вы вызываете acquire когда он равен нулю, то он заблокируется.
Еще один полезный инструмент, который содержится в модуле, это Event. С его помощью вы можете получить связь между двумя потоками, используя сигналы. Мы рассмотрим примеры применения Event в следующей статье. Наконец-то, в версии Python 3.2 был добавлен объект Barrier. Это примитив, который управляет пулом потока, при этом не важно, где потоки должны ждать своей очереди. Для передачи барьера, потоку нужно вызвать метод wait(), который будет блокировать до тех пор, пока все потоки не сделают вызов. После чего все потоки пройдут дальше одновременно.
Связь потоков
Существует ряд случаев, когда вам нужно сделать так, чтобы потоки были связанны друг с другом. Как я упоминал ранее, вы можете использовать Event для этой цели. Но более удобный способ – использовать Queue. В нашем примере мы используем оба способа! Давайте посмотрим, как это будет выглядеть:
import threading
from queue import Queue
def creator(data, q):
"""
Creates data to be consumed and waits for the consumer
to finish processing
"""
print('Creating data and putting it on the queue')
for item in data:
evt = threading.Event()
q.put((item, evt))
print('Waiting for data to be doubled')
evt.wait()
def my_consumer(q):
"""
Consumes some data and works on it
In this case, all it does is double the input
"""
while True:
data, evt = q.get()
print('data found to be processed: {}'.format(data))
processed = data * 2
print(processed)
evt.set()
q.task_done()
if __name__ == '__main__':
q = Queue()
data = [5, 10, 13, -1]
thread_one = threading.Thread(target=creator, args=(data, q))
thread_two = threading.Thread(target=my_consumer, args=(q,))
thread_one.start()
thread_two.start()
q.join()Давайте немного притормозим. Во первых, у нас есть функция creator (также известная, как producer), которую мы используем для создания данных, с которыми мы хотим работать (или использовать). Далее мы получаем еще одну функцию, которую мы используем для обработки данных, под названием my_consumer. Функция creator использует метод Queue под названием put, чтобы добавить данные в очередь, затем потребитель, в свою очередь, будет проверять, есть ли новые данные и обрабатывать их, когда такие появятся. Queue обрабатывает все закрытия и открытия замков, так что лично вам эта участь не грозит.
В данном примере мы создали список значений, которые мы хотим дублировать. Далее мы создаем два потока, один для функции creator/producer, второй для consumer (потребитель). Обратите внимание на то, что мы передаем объект Queue каждому потоку, что является прямо таки магией, учитывая то, как обрабатываются замки. Очередь начнется с первого потока, который передает данные второму. Когда первый поток передает те или иные данные в очередь, он также передает их к Event, после чего дожидается, когда произойдет события, чтобы закончить. Далее, в функции consumer, данные обрабатываются, и после этого вызывается метод настройки Event, который указывает первому потоку, что второй закончил обработку, так что он может продолжать. Последняя строка кода вызывает метод join объекта Queue, который указывает Queue подождать, пока потоки закончат обработку. Первый поток заканчивает, когда ему больше нечего передавать в Queue.
Подведем итоги
Мы рассмотрели достаточно много материала. А именно:
- Основы работы с модулем threading
- Как работают замки
- Что такое Event и как его можно использовать
- Как использовать таймер
- Внутрипотоковая связь с использованием Queue/Event
Теперь вы знаете, как использовать потоки, и в чем они хороши. Надеюсь, вы найдете им применение в своем собственном коде!
Unix2019b/Библиотека pthreads — iRunner Wiki
Основы Pthreads
Библиотека pthreads определяет набор типов, функций, констант для языка C. Заголовочный файл называется pthread.h.
Там около сотни функций, все начинаются на pthread_, могут быть отнесены к четырём группам:
- Thread management — creating, joining threads etc.
- Mutexes
- Condition variables
- Synchronization between threads using read/write locks and barriers
Важно: функции не выставляют значение errno. Большинство функций библиотеки спроектированы так, что возвращают 0 в случае успеха и код ошибки (положительное число) в случае неудачи.
Само по себе errno реализуется не просто как глобальная переменная, а как макрос, который раскрывается в thread-specific-переменную. Поэтому обрабатывать ошибки POSIX-функций через errno в разных потоках можно безопасно, состояния гонки при этом не возникает.
Пример
Из википедии.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#define NUM_THREADS 5
void* perform_work(void* argument) {
int passed_in_value;
passed_in_value = *((int*) argument);
printf("Hello World! It's me, thread with argument %d!\n", passed_in_value);
return NULL;
}
int main(int argc, char** argv) {
pthread_t threads[NUM_THREADS];
int thread_args[NUM_THREADS];
int result_code;
unsigned index;
// create all threads one by one
for (index = 0; index < NUM_THREADS; ++index) {
thread_args[ index ] = index;
printf("In main: creating thread %d\n", index);
result_code = pthread_create(&threads[index], NULL, perform_work, &thread_args[index]);
assert(!result_code);
}
// wait for each thread to complete
for (index = 0; index < NUM_THREADS; ++index) {
// block until thread 'index' completes
result_code = pthread_join(threads[index], NULL);
assert(!result_code);
printf("In main: thread %d has completed\n", index);
}
printf("In main: All threads completed successfully\n");
exit(EXIT_SUCCESS);
}Сборка
Требуется указание флага pthread [1].
$ gcc main.c -pthread
Этот флаг включает макросы а-ля _REENTERANT и велит линковать программу с libpthread.so.
Создание и завершение потоков
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
void pthread_exit(void *retval);
int pthread_join(pthread_t thread, void **retval);Потоки создаются функцией pthread_create.
- Первый параметр этой функции представляет собой указатель на переменную типа pthread_t, которая служит идентификатором создаваемого потока.
- Второй параметр, указатель на переменную типа pthread_attr_t, используется для передачи атрибутов потока.
- Третьим параметром функции должен быть адрес функции потока. Эта функция играет для потока ту же роль, что функция main() – для главной программы.
- Четвертый параметр функции pthread_create() имеет тип void *. Этот параметр может использоваться для передачи значения, возвращаемого функцией потока.
Вскоре после вызова pthread_create() функция потока будет запущена на выполнение параллельно с другими потоками программы. Таким образом, собственно, и создается новый поток. Если в ходе создания потока возникла ошибка, функция pthread_create() возвращает ненулевое значение, соответствующее номеру ошибки.
Функция потока должна иметь сигнатуру вида
void* func_name(void* arg)
Имя функции, естественно, может быть любым. Аргумент arg — это тот самый указатель, который передаётся в последнем параметре функции pthread_create(). Функция потока может вернуть значение, которое затем будет проанализировано заинтересованным потоком, но это не обязательно. Завершение функции потока происходит если:
- функция потока вызвала функцию pthread_exit;
- функция потока достигла точки выхода;
- поток был досрочно завершен другим потоком.
Функция pthread_exit представляет собой потоковый аналог функции _exit. Аргумент, значение типа void *, становится возвращаемым значением функции потока.
Как (и кому?) функция потока может вернуть значение, если она не вызывается из программы явным образом? Для того чтобы получить значение, возвращенное функцией потока, нужно воспользоваться функцией pthread_join. У этой функции два параметра.
- Первый параметр – это идентификатор потока.
- Второй параметр имеет тип «указатель на нетипизированный указатель». В этом параметре функция pthread_join() возвращает значение, возвращенное функцией потока.
Конечно, в многопоточном приложении есть и более простые способы организовать передачу данных между потоками. Основная задача функции pthread_join() заключается, однако, в синхронизации потоков. Эта функция позволяет вызвавшему ее потоку дождаться завершения работы другого потока. Вызов функции pthread_join() приостанавливает выполнение вызвавшего ее потока до тех пор, пока поток, чей идентификатор передан функции в качестве аргумента, не завершит свою работу. Если в момент вызова pthread_join() ожидаемый поток уже завершился, функция вернет управление немедленно.
Функцию pthread_join() можно рассматривать как эквивалент waitpid() для потоков, но с некоторыми отличиями.
- Все потоки одноранговые, среди них отсутствует иерархический порядок, в то время как процессы образуют дерево и подчинены иерархии родитель — потомок.
- Нельзя дать указание одному «ожидай завершения любого потока», как это возможно с вызовом waitpid(-1, &status, options).
- Также невозможно осуществить неблокирующий вызов pthread_join().
Отсоединение потока
Любому потоку по умолчанию можно присоединиться вызовом pthread_join() и ожидать его завершения. Однако в некоторых случаях статус завершения потока и возврат значения нам не интересны. Все, что нам надо, это завершить поток и автоматически выгрузить ресурсы обратно в распоряжение ОС. В таких случаях мы обозначаем поток отсоединившимся и используем вызов pthread_detach().
#include <pthread.h> int pthread_detach(pthread_t thread);
При удачном завершении pthread_detach() возвращает код 0, ненулевое значение сигнализирует об ошибке.
Если поток отсоединён, его уже не перехватить с помощью вызова pthread_join(), чтобы получить статус завершения. Также нельзя отменить его отсоединенное состояние.
Примитивы синхронизации
Предполагается, что студенты ранее знакомились с примитивами синхронизации на первом-втором курсе, поэтому изложение будет очень кратким.
Mutex
Мьютексы — это простейшие двоичные семафоры, которые могут находиться в одном из двух состояний — отмеченном или неотмеченном (открыт и закрыт соответственно). Задача мьютекса — защита объекта от доступа к нему других потоков, отличных от того, который завладел мьютексом. В каждый конкретный момент только один поток может владеть объектом, защищённым мьютексом. Если другому потоку будет нужен доступ к переменной, защищённой мьютексом, то этот поток блокируется до тех пор, пока мьютекс не будет освобождён.
Цель использования мьютексов — защита данных от повреждения в результате асинхронных изменений (состояние гонки), однако могут порождаться другие проблемы (например взаимные блокировки).
Мьютекс в pthreads имеет тип pthread_mutex_t (переменная этого типа занимает 24 байта на 32-битных системах и 40 байт на 64-битных).
Поддерживаются следующие основные операции.
pthread_mutex_init — инициализация. Поскольку в C нет конструкторов, то такая функция выполняет его роль. Другим способом проинициализировать мьютекс перед использованием является применение специального инициализатора [2]:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
По стандарту такой инициализатор подходит только для глобальных переменных. Если его использовать для обычной локальной переменной на стеке, то код скомпилируется, но теоретически на каких-то платформах может работать неверно (если макрос раскрывается в вызов непотокобезопасной функции).
pthread_mutex_lock — операция захвата мьютекса. Если мьютекс занят, функция блокируется до тех пор, пока мьютекс не станет доступен. В случае успеха возвращает ноль.
pthread_mutex_unlock — операция освобождения ранее захваченного мьютекса.
Мьютексы в pthreads бывают разных типов (обычный, рекурсивный, с проверкой ошибок). Это можно настраивать, передавая аргумент в функцию init. Например, созданный с опцией PTHREAD_MUTEX_RECURSIVE мьютекс обладает свойством подсчёта локов. Когда поток захватывает мьютекс, счётчик выставляется в 1. Каждый последующий захват этого же мьютекса этим же потоком приводит к увеличению счётчика на единицу, о освобождение — к уменьшению на единицу.
Condition variable
Условная переменная — примитив синхронизации, обеспечивающий блокирование одного или нескольких потоков до момента поступления уведомления от другого потока о выполнении некоторого условия или до истечения максимального промежутка времени ожидания. Условные переменные используются вместе с ассоциированным мьютексом.
Мьютекс не позволяет нескольким потокам обращаться к общей переменной одновременно. Условная переменная позволяет одному потоку сообщать другим потокам об изменении состояния переменной (или другого общего ресурса) и позволяет другим потокам ждать такого уведомления (блокироваться до наступления события).
В pthreads используется тип данных pthread_cond_t.
pthread_cond_init выполняет инициализацию условной переменной. Или же можно использовать
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
pthread_cond_signal запускает один из потоков, которые в настоящий момент ожидают на данной условной переменной. Если таких потоков нет, ничего не происходит, сигнал теряется. Если их несколько, то разблокируется ровно один, но это может быть любой поток.
pthread_cond_broadcast запускает все потоки, ожидающие на этой условной переменной.
pthread_cond_wait принимает не только условную переменную, но и мьютекс. Мьютекс должен быть заранее захвачен. Функция атомарно разблокирует мьютекс и ждёт, пока условная переменная не будет просигнализирована. Ожидание не потребляет тактов процессора. Наконец, когда ожидание завершено, перед возвратом управления мьютекс заново захватывается. Типичная последовательность действий выглядит так:
pthread_mutex_lock(mutex);
while (!predicate) {
pthread_cond_wait(cvar);
}
pthread_mutex_unlock(mutex);Атомарность, заложенная в функцию wait, гарантирует, что какой-то другой поток не может захватить мьютекс и сигнализировать условную переменную до того, как текущий поток начал ожидать сигнала на этой условной переменной.
Может возникнуть вопрос, вызывать сначала pthread_cond_signal, потом pthread_mutex_unlock, или наоборот. На самом деле можно делать и так и так. В литературе замечают, что чаще для лучшей производительности лучше сначала отпускать мьютекс, потом сигнализировать, чтобы не случалось лишних пробуждений и переключений контекста, но в зависимости от реализации разницы может и не быть [3].
При ожидании на условной переменной возможны так называемые ложные пробуждения (англ. spurious wakeups) [4]. То есть, согласно стандарту, функция может вернуть управление даже в случае, когда никто не вызывал signal. Поэтому wait всегда нужно вызывать в цикле, проверяя на каждой итерации выполнение нужного условия.
Пример: производители и потребители
Пример из Википедии.
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define STORAGE_MIN 10
#define STORAGE_MAX 20
/* Разделяемый ресурс */
int storage = STORAGE_MIN;
pthread_mutex_t mutex;
pthread_cond_t condition;
/* Функция потока потребителя */
void *consumer(void *args)
{
puts("[CONSUMER] thread started");
int toConsume = 0;
while(1) {
pthread_mutex_lock(&mutex);
/* Если значение общей переменной меньше максимального,
* то поток входит в состояние ожидания сигнала о достижении
* максимума */
while (storage < STORAGE_MAX) {
pthread_cond_wait(&condition, &mutex);
}
toConsume = storage-STORAGE_MIN;
printf("[CONSUMER] storage is maximum, consuming %d\n", toConsume);
/* "Потребление" допустимого объема из значения общей
* переменной */
storage -= toConsume;
printf("[CONSUMER] storage = %d\n", storage);
pthread_mutex_unlock(&mutex);
}
return NULL;
}
/* Функция потока производителя */
void *producer(void *args)
{
puts("[PRODUCER] thread started");
while (1) {
usleep(200000);
pthread_mutex_lock(&mutex);
/* Производитель постоянно увеличивает значение общей переменной */
++storage;
printf("[PRODUCER] storage = %d\n", storage);
/* Если значение общей переменной достигло или превысило
* максимум, поток потребитель уведомляется об этом */
if (storage >= STORAGE_MAX) {
puts("[PRODUCER] storage maximum");
pthread_cond_signal(&condition);
}
pthread_mutex_unlock(&mutex);
}
return NULL;
}
int main(int argc, char *argv[])
{
int res = 0;
pthread_t thProducer, thConsumer;
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&condition, NULL);
res = pthread_create(&thProducer, NULL, producer, NULL);
if (res != 0) {
perror("pthread_create");
exit(EXIT_FAILURE);
}
res = pthread_create(&thConsumer, NULL, consumer, NULL);
if (res != 0) {
perror("pthread_create");
exit(EXIT_FAILURE);
}
pthread_join(thProducer, NULL);
pthread_join(thConsumer, NULL);
return EXIT_SUCCESS;
}Thread-Local Storage
Чтобы создать переменную, локальную для каждого потока, нужно при объявлении глобальной или локальной статической переменной использовать спецификатор __thread.
static __thread char buf[MAX_ERROR_LEN];
При этом каждый поток получит свою копию.
В стандарте C11 добавили аналогичный спецификатор _Thread_local.
Потокобезопасность
Функция называется потокобезопасной (thread-safe), если она может безопасно вызываться несколькими потоками одновременно; и наоборот, если функция не является потокобезопасной, то мы не можем вызывать ее из одного потока, пока она выполняется в другом потоке.
Функция называется реентерабельной (reentrant), если она разработана таким образом, что несколько вызовов могут безопасно выполняться одновременно. Это важно даже в однопоточных программах, так как выполнение может быть прервано обработкой сигнала.
Из одного понятия не следует другое понятие. Примеры.
ThreadSanitizer
ThreadSanitizer (или TSan) — детектор состояния гонки (data race) для C и С++. Гонки являются одним из наиболее распространённых и трудных для отладки типов ошибок в параллельных системах. Гонка наблюдается, когда два потока одновременно обращаются к одной и той же переменной и по крайней мере одно из обращений — запись.
Темы против сопрограмм в Котлине
Соблазнительно думать, что порождение большего количества потоков может помочь нам выполнять больше задач одновременно. К сожалению, это не всегда так.
Создание слишком большого количества потоков может на самом деле сделать приложение неэффективным в некоторых ситуациях; потоки — это объекты, которые накладывают накладные расходы во время размещения объектов и сборки мусора.
Чтобы преодолеть эти проблемы,Kotlin introduced a new way of writing asynchronous, non-blocking code; the Coroutine.
Подобно потокам, сопрограммы могут работать одновременно, ожидать и общаться друг с другом, с той разницей, что их создание намного дешевле, чем потоки.
3.1. Контекст сопрограммыПрежде чем представлять конструкторы сопрограмм, которые Kotlin предоставляет «из коробки», мы должны обсудить контекст сопрограмм.
Сопрограммы всегда выполняются в некотором контексте, который представляет собой набор различных элементов.
Основными элементами являются:
Job — моделирует отменяемый рабочий процесс с несколькими состояниями и жизненным циклом, который завершается его завершением.
Dispatcher — определяет, какой поток или потоки использует соответствующая сопрограмма для своего выполнения. С диспетчеромwe can a confine coroutine execution to a specific thread, dispatch it to a thread pool, or let it run unconfined
Мы увидим, как указать контекст, когда будем описывать сопрограммы на следующих этапах.
3.2. launchсlaunch function is a coroutine builder which starts a new coroutine without blocking the current thread и возвращает ссылку на сопрограмму как объектJob:
runBlocking {
val job = launch(Dispatchers.Default) {
println("${Thread.currentThread()} has run.")
}
}У него есть два необязательных параметра:
context — контекст, в котором выполняется сопрограмма, если не определена, она наследует контекст отCoroutineScope, из которого она запускается.
start — параметры запуска сопрограммы. По умолчанию сопрограмма немедленно запланирована для выполнения
Обратите внимание, что приведенный выше код выполняется в общем фоновом пуле потоков, потому что мы использовалиDispatchers.Default w, который запускает его вGlobalScope.
В качестве альтернативы мы можем использоватьGlobalScope.launch w, который использует тот же диспетчер:
val job = GlobalScope.launch {
println("${Thread.currentThread()} has run.")
}Когда мы используемDispatchers.Default илиGlobalScope.launch, мы создаем сопрограмму верхнего уровня. Несмотря на то, что он легкий, он все же потребляет некоторые ресурсы памяти во время работы.
Вместо запуска сопрограмм вGlobalScope, как мы обычно делаем с потоками (потоки всегда глобальные), мы можем запускать сопрограммы в конкретной области выполняемой операции:
runBlocking {
val job = launch {
println("${Thread.currentThread()} has run.")
}
}В этом случае мы запускаем новую сопрограмму внутри построителя скорутинrunBlocking (который мы опишем позже) без указания контекста. Таким образом, сопрограмма унаследует контекстrunBlocking.
3.3. asyncсЕще одна функция, которую Kotlin предоставляет для создания сопрограммы, —async.
Функцияasync создает новую сопрограмму и возвращает будущий результат как экземплярDeferred<T>:
val deferred = async {
[email protected] "${Thread.currentThread()} has run."
}deferred — это неблокируемое отменяемое будущее, которое описывает объект, который действует как прокси для результата, который изначально неизвестен.
Как иlaunch,, мы можем указать контекст, в котором будет выполняться сопрограмма, а также параметр запуска:
val deferred = async(Dispatchers.Unconfined, CoroutineStart.LAZY) {
println("${Thread.currentThread()} has run.")
}В этом случае мы запустили сопрограмму с использованиемDispatchers.Unconfined, которая запускает сопрограммы в вызывающем потоке, но только до первой точки приостановки.
Обратите внимание, чтоDispatchers.Unconfined хорошо подходит, когда сопрограмма не использует процессорное время и не обновляет общие данные.
In addition, Kotlin provides Dispatchers.IO that uses a shared pool of on-demand created threads:
val deferred = async(Dispatchers.IO) {
println("${Thread.currentThread()} has run.")
}Dispatchers.IO рекомендуется, когда нам нужно выполнять интенсивные операции ввода-вывода.
3.4. runBlockingсРанее мы рассматривалиrunBlocking, но теперь давайте поговорим о нем более подробно.
runBlocking — это функция, которая запускает новую сопрограмму и блокирует текущий поток до его завершения.
В качестве примера в предыдущем фрагменте мы запустили сопрограмму, но никогда не ждали результата.
Чтобы дождаться результата, мы должны вызвать метод приостановкиawait():
// async code goes here
runBlocking {
val result = deferred.await()
println(result)
}await() — это то, что называется функцией приостановки. Suspend functions are only allowed to be called from a coroutine or another suspend function. По этой причине мы заключили его в вызовrunBlocking.
Мы используемrunBlocking в функцияхmain и в тестах, чтобы мы могли связать код блокировки с другим кодом, написанным в стиле приостановки.
Подобно тому, как мы это делали в других сборщиках сопрограмм, мы можем установить контекст выполнения:
runBlocking(newSingleThreadContext("dedicatedThread")) {
val result = deferred.await()
println(result)
}Обратите внимание, что мы можем создать новый поток, в котором мы можем выполнить сопрограмму. Тем не менее, выделенный поток является дорогим ресурсом. И, когда больше не нужно, мы должны выпустить его или, что еще лучше, использовать его во всем приложении.
Класс Thread . Язык программирования Python
Экземпляры класса threading.Thread представляют потоки Python–программы. Задать действия, которые будут выполняться в потоке, можно двумя способами: передать конструктору класса исполняемый объект и аргументы к нему или путем наследования получить новый класс с переопределенным методом run(). Первый способ был рассмотрен в примере выше. Конструктор класса threading.Thread имеет следующие аргументы:
Thread(group, target, name, args, kwargs)
Здесь group — группа потоков (пока что не используется, должен быть равен None), target — объект, который будет вызван в методе run(), name — имя потока, args и kwargs — последовательность и словарь позиционных и именованных параметров (соответственно) для вызова заданного в параметре target объекта. В примере выше были использованы только позиционные параметры, но то же самое можно было выполнить и с применением именованных параметров:
import threading
def proc(n):
print «Процесс», n
p1 = threading.Thread(target=proc, name=»t1″, kwargs={«n»: «1»})
p2 = threading.Thread(target=proc, name=»t2″, kwargs={«n»: «2»})
p1.start()
p2.start()
То же самое можно проделать через наследование от класса threading.Thread с определением собственного конструктора и метода run():
import threading
class T(threading.Thread):
def __init__(self, n):
threading.Thread.__init__(self, name=»t» + n)
self.n = n
def run(self):
print «Процесс», self.n
p1 = T(«1»)
p2 = T(«2»)
p1.start()
p2.start()
Самое первое, что необходимо сделать в конструкторе — вызвать конструктор базового класса. Как и раньше, для запуска потока нужно выполнить метод start() объекта–потока, что приведет к выполнению действий в методе run().
Жизнью потоков можно управлять вызовом методов:
• start() Дает потоку жизнь.
• run() Этот метод представляет действия, которые должны быть выполнены в потоке.
• join([timeout]) Поток, который вызывает этот метод, приостанавливается, ожидая завершения потока, чей метод вызван. Параметр timeout (число с плавающей точкой) позволяет указать время ожидания (в секундах), по истечении которого приостановленный поток продолжает свою работу независимо от завершения потока, чей метод join был вызван. Вызывать join() некоторого потока можно много раз. Поток не может вызвать метод join() самого себя. Также нельзя ожидать завершения еще не запущенного потока. Слово «join» в переводе с английского означает «присоединить», то есть, метод, вызвавший join(), желает, чтобы поток по завершении присоединился к вызывающему метод потоку.
• getName() Возвращает имя потока. Для главного потока это «MainThread».
• setName(name) Присваивает потоку имя name.
• isAlive() Возвращает истину, если поток работает (метод run() уже вызван, но еще не завершился).
• isDaemon() Возвращает истину, если поток имеет признак демона. Программа на Python завершается по завершении всех потоков, не являющихся демонами. Главный поток демоном не является.
• setDaemon(daemonic) Устанавливает признак daemonic того, что поток является демоном. Начальное значение этого признака заимствуется у потока, запустившего данный. Признак можно изменять только для потоков, которые еще не запущены.
В модуле Thread пока что не реализованы возможности, присущие потокам в Java (определение групп потоков, приостановка и прерывание потоков извне, приоритеты и некоторые другие вещи), однако они, скорее всего, будут созданы в недалеком будущем.
Аргументы потоковой передачи Python
Функции с аргументами действительно полезны. Можно запускать функции в разделите потоки и по-прежнему укажите аргументы для функции. я покажу тебе как.
В моем введение в потоки Python Я не передаю аргументы ни одной из функций, которые я выполняю в ступенях. Есть два способы передачи аргументов в Python, я расскажу об обоих.
Список аргументов
Первый тип аргумента — простой. Те, которые только что перечислены
с функцией, например name в примере ниже:
def greet (имя):
напечатайте "Привет,% s!" % имя
greet ("Monty") # распечатки -> 'Привет, Монти!'
В следующем примере запускается функция countTo , чтобы считать до 4 на два.
разная скорость:
#! / Usr / bin / python
импорт потоков, время
def countTo (x, задержка):
для i в диапазоне (x):
распечатать я
время.сон (задержка)
Поток # 4hz аналогичен запуску `countTo (4,0.25)`
thread4hz = threading.Thread (цель = countTo, args = (4,0.25))
# 10hz thread - это то же самое, что и запуск `countTo (4,0.1)`
thread10hz = threading.Thread (цель = countTo, args = (4,0.1))
thread4hz.start ()
thread10hz.start ()
В чем секрет? Когда вы создаете поток, передайте свой список аргументов
как аргументы .
Аргументы ключевого слова
Python также позволяет указывать аргументы ключевого слова:
def вычитание (x = 0, y = 0):
вернуть x-y
вычесть (x = 5, y = 2) # = 3
вычесть (x = 2, y = 5) # = -3
Как использовать аргументы ключевого слова с потоком? Вот так:
#! / Usr / bin / python
импорт потоков, время
def countTo (x = 4, задержка = 0.1):
для i в диапазоне (x):
распечатать я
time.sleep (задержка)
# Используйте аргументы ключевого слова в потоке 4 Гц
thread4hz = threading.Thread (target = countTo, kwargs = dict (x = 3, задержка = 0,25))
# Используйте аргументы defualt
thread10hz = threading.Thread (цель = countTo)
thread4hz.start ()
thread10hz.start ()
Вам нужно передать словарь в параметр потока kwargs конструктор.
Это должно дать вам гораздо больше гибкости при вызове функций в отдельных потоки.Обязательно прочтите о блокировка резьбы и очереди задач для большего многопоточная информация.
Python Multi-threading Tutorial — Python Примеры
Многопоточность в Python
Многопоточность — это концепция одновременного выполнения разных частей кода. Поток — это объект, который может работать на процессоре индивидуально со своим собственным уникальным идентификатором, стеком, указателем стека, программным счетчиком, состоянием, набором регистров и указателем на блок управления процессом процесса, в котором живет поток.
В этом руководстве мы изучим на примерах, как реализовать многопоточность в программировании на Python.
threading Модуль используется для многопоточности в Python.
Создание потока
Чтобы создать поток, вы можете использовать класс threading.Thread (). Синтаксис класса Thread ():
threading.Thread (group = None, target = None, name = None, args = (), kwargs = {}, *, daemon = None) - оставить группа как Нет.
- target — это вызываемый объект, вызываемый методом run () класса Thread.
- name — это имя потока, которое вы можете указать и использовать позже в программе.
- args — кортеж аргументов для целевого вызова.
- kwargs — словарь аргументов ключевого слова для целевого вызова.
- демон не None, будет установлен как демон.
Начать поток
После того, как вы создали поток с помощью класса Thread (), вы можете запустить его с помощью Thead.start () метод.
t1 = нарезание резьбы. Резьба ()
t1.start () Дождаться завершения потока
Вы можете настроить счетчик программ основного процесса на ожидание завершения определенного потока. Все, что вам нужно сделать, это вызвать метод join () для объекта Thread.
t1.join () Выполнение в основной программе ожидает здесь, в этом операторе, пока t1 не завершит свое целевое выполнение.
Пример — многопоточность Python с двумя потоками
В следующем примере мы будем выполнять многопоточность с двумя потоками.Каждый поток выполняется параллельно другому и выполняется всякий раз, когда ему доступны ресурсы обработки.
Чтобы полностью продемонстрировать это поведение, мы запустим в каждом потоке функцию, которая печатает единицы и двойки.
Программа Python
импорт потоков
def print_one ():
для i в диапазоне (10):
печать (1)
def print_two ():
для i в диапазоне (10):
печать (2)
если __name__ == "__main__":
# создать темы
t1 = threading.Thread (цель = print_one)
t2 = заправка.Тема (цель = print_two)
# начать цепочку 1
t1.start ()
# начать поток 2
t2.start ()
# ждем, пока поток 1 не будет полностью выполнен
t1.join ()
# ждем, пока поток 2 не будет полностью выполнен
t2.join ()
# оба потока полностью выполнены
print («Готово!») ВыполнитьВывод
1
1
1
2
2
2
1
1
2
1
2
2
2
2
2
2
1
1
1
1
Выполнено! Вы могли заметить, что после того, как поток 1 выполнил цикл for для трех итераций, поток 2 получил ресурсы и начал выполнение.Очень маловероятно предсказать, сколько времени поток может получить для выполнения.
Пример — многопоточность с аргументами, переданными потокам
В нашем предыдущем примере мы запускали потоки только с их целевыми объектами. Теперь мы передадим им некоторые аргументы. Кроме того, вы можете вызывать одну и ту же цель для разных потоков.
Программа Python
импорт потоков
def print_x (x, n):
для i в диапазоне (n):
печать (х)
если __name__ == "__main__":
# создать темы
t1 = заправка.Тема (цель = print_x, args = (1, 5,))
t2 = threading.Thread (цель = print_x, args = (2, 10,))
# начать цепочку 1
t1.start ()
# начать поток 2
t2.start ()
# ждем, пока поток 1 не будет полностью выполнен
t1.join ()
# ждем, пока поток 2 не будет полностью выполнен
t2.join ()
# оба потока полностью выполнены
print («Готово!») ВыполнитьВывод
1
1
1
2
2
2
2
1
2
1
2
2
2
2
2
Выполнено! Резюме
В этом руководстве примеров Python мы узнали, как реализовать многопоточность в программировании на Python с помощью хорошо подробных примеров.
11.3.2 Параметры
11.3.2 Параметры
Динамическое связывание: параметризация в The Racket Guide вводит параметры.
См. Параметры для получения основной информации о модель параметров. Параметры соответствуют сохраненной нити жидкости в Scsh [Gasbichler02].
Для параметризации кода, удобного для потоков и продолжения, используйте параметризацию. Форма параметризации вводит ячейка свежей нити для динамической протяженности ее тела выражения.
Когда создается новый поток, параметризация для нового начальное продолжение потока — это параметризация создатель темы. Поскольку ячейка потока каждого параметра сохраняется, новый поток «наследует» значения параметров его создающий поток. Когда продолжение перемещается из одного потока в другой, настройки, введенные с параметризацией эффективно двигаться с продолжением.
Напротив, прямое присвоение параметру (путем вызова процедура параметра со значением) изменяет значение в ячейке потока, и поэтому изменяет настройку только для текущего нить.Следовательно, что касается диспетчера памяти, значение, изначально связанное с параметром через параметризация остается достижимой, пока продолжается достижимо, даже если параметр изменен.
Возвращает новую процедуру параметра. Значение параметра инициализируется значением v во всех потоках.
Если охранник не #f, он используется в качестве процедуры защиты параметра. Охранник процедура принимает один аргумент. Всякий раз, когда процедура параметра применяется к аргументу, аргумент передается охраннику процедура.Результат, возвращаемый защитной процедурой, используется как новое значение параметра. Процедура защиты может вызвать исключение для отклонить изменение значения параметра. Охранник не применяется к исходной версии.
Аргумент name используется как имя процедуры параметра как сообщает имя-объекта.
Изменено в версии 7.4.0.6 базы пакетов: Добавлен аргумент имени.
(параметризация ([параметр-выражение значение-выражение] …) тело … +)
Результат параметризованного выражения является результатом последнее тело. Параметры-выражения определяют параметры для установки, а значения-выражения определяют соответствующие значения для установки при оценке тела. Параметры-выражения и значения-выражения оцениваются слева направо (чередуются), и тогда параметры привязываются в продолжении к сохраненному потоку ячейки, содержащие значения выражений значений; результат каждого параметра-выражения проверяется параметром? непосредственно перед его связыванием.Последнее тело в хвосте положение по отношению ко всей форме параметризации.
За пределами динамического экстента параметризованного выражения, параметры остаются привязанными к другим ячейкам потока. Таким образом, эффективно старые настройки параметров восстанавливаются при выходе управления из параметризовать выражение.
Если продолжение захвачено во время оценки параметризовать, эффективно вызывая продолжение повторно вводит параметризацию, поскольку параметризация связаны с продолжением через знак продолжения (см. Знаки продолжения) с использованием закрытого ключа.
Примеры:
(параметр * ((параметр-выражение значение-выражение) …) тело … +)
Возврат процедура параметра, которая устанавливает или извлекает то же значение, что и параметр, но с:
защита применяется при настройке параметра (перед любым защита, связанная с параметром), и
перенос, применяемый при получении значения параметра.
См. Также шаперон-процедуру, которую также можно использовать для охраны параметры процедуры.
Возвращает #t, если v — процедура параметра, #f иначе.
Возвращает #t, если параметры процедуры a и b всегда изменяйте один и тот же параметр с одними и теми же охранниками (хотя, возможно, и с другими шаперонами), #f в противном случае вызывает преобразователь (через хвостовой вызов) с параметризацией как текущая параметризация.Использование файлов параметров — CIAO 4.13
Использование синтаксиса @@
Если это однократная ситуация, вы можете настроить файл параметров, скопируйте его в отдельное место, а затем наведите инструмент на эту копию.
Здесь мы настраиваем два файла параметров — один с использованием гауссовский с сигмой 3 пикселя в каждом направлении (/tmp/aconvolve.g3.par), а другой с значение сигмы установлено на 5 пикселей (/tmp/aconvolve.g5.par). Затем мы запускаем два копии беседы с этим человеком файлы параметров, установив режим «h» чтобы избежать запросов автоматических параметров.
unix% punlearn aconvolve unix% pset aconvolve infile = img.fits method = fft unix% pset aconvolve outfile = img.sm3.подходит unix% pset aconvolve kernelspec = "lib: gauss (2,5,1,3,3)" unix% cp `paccess aconvolve` /tmp/aconvolve.g3.par unix% pset aconvolve outfile = img.sm5.fits unix% pset aconvolve kernelspec = "lib: gauss (2,5,1,5,5)" unix% cp `paccess aconvolve` /tmp/aconvolve.g5.par unix% aconvolve @@ / tmp / aconvolve.g3.par mode = h & unix% aconvolve @@ / tmp / aconvolve.g5.par mode = h &
Предостережение: синтаксис @@ может не работать со скриптами, такими как dmgti и wavdetect. Поскольку скрипты обычно запускаются несколько инструментов CIAO, все еще может быть гонка условия, если переменная среды не набор.
Изменение переменной среды PFILES
Более надежное решение — запускать каждую копию инструмента. с переменной среды PFILES, установленной на другой локальный каталог. Предполагая, что по умолчанию Настройка PFILES после запуска CIAO выглядит так:
unix% echo $ PFILES / home / имя пользователя / cxcds_param4; / soft / ciao / contrib / param: / soft / ciao / param:
и вы хотите использовать каталоги «/ home / username / cxcds_param1 /» и «/ home / username / cxcds_param2 /», затем вы можно сказать:
unix% setenv PFILES "/ home / username / cxcds_param1; / soft / ciao / contrib / param: / soft / ciao / param" unix% punlearn aconvolve unix% pset aconvolve infile = img.подходит метод = fft unix% pset aconvolve outfile = img.sm3.fits unix% pset aconvolve kernelspec = "lib: gauss (2,5,1,3,3)" unix% aconvolve mode = h & unix% setenv PFILES "/ home / username / cxcds_param2; / soft / ciao / contrib / param: / soft / ciao / param" unix% punlearn aconvolve unix% pset aconvolve infile = img.fits method = fft unix% pset aconvolve outfile = img.sm5.fits unix% pset aconvolve kernelspec = "lib: gauss (2,5,1,5,5)" unix% aconvolve mode = h &
Хотя в целом это лучший подход, чем предыдущий внушение, оно влечет за собой последствия необходимо помнить, в каком каталоге файлов параметров вы в настоящее время используют.
Необязательно использовать абсолютный путь, когда установка PFILES; часто имеет смысл использовать относительный путь. Например, если вы установите для PFILES значение
./param:/home/username/cxcds_param4;/soft/ciao/contrib/param:/soft/ciao/param
тогда библиотека параметров будет искать файл сначала в подкаталоге param / папки рабочий каталог, затем в cxcds_param4 / подкаталог вашего домашнего каталога и, наконец, доступ к системной копии по умолчанию в CIAO распределение, $ ASCDS_INSTALL (здесь установлено значение / soft / ciao).
Установка каталога файла параметров на текущий рабочий каталог, например «.» (точка), это специальный дело. Если вы хотите поместить файлы в текущий рабочий каталог, вы должны включить косую черту («./») в переменная PFILES:
./:/home/username/cxcds_param4;/soft/ciao/contrib/param:/soft/ciao/param
Назовите элемент (отверстие) с его параметрами / описанием резьбы
Они могут показаться модными и дорогими лицензиями, но если компания внедрила Catia и не использует KWE (если у них нет минимум 1 лицензия KWA и PKT и достаточное количество KT1 для обхода) повторно использовать знания и передовой опыт, они выбрасывают деньги.Это кажется дорогим с точки зрения бюджета на программное обеспечение, но это не так. требуется значительная экономия времени в день, чтобы окупиться. Но хуже было бы иметь лицензии и оставить их неиспользованными. Такое тоже бывает. Но, черт возьми, большинство компаний даже не слишком часто используют Power Copy, и это включены бесплатно. Деньги на столе.
Возвращаясь к технической проблеме, я понимаю, как это может быть реализовано некрасиво быстро для английских юнитов.
Да, можно использовать описание потока.
Только то, что это не очевидно, если у вас толстая шина бар аэропорта, потому что Описание темы не указано как атрибут Дыры на панели Обозревателя языков.
Однако он отображается в списке параметров и может быть получено с помощью
aHole-> GetAttributeString («` Тема Описание` «)
вот код действия:
let desc (Список)
let counts (Список)
let Hole (Список)
let hole (Отверстие)
let desc (String)
let have (Boolean)
let indx (целое число)
let cnt (целое число)
let holeDesc (строка)
отверстий = Body.2 -> Запрос («Hole», «x.Threaded == true»)
для внутренних отверстий
{
holeDesc =
Hole-> GetAttributeString («» Описание потока «)
cnt = 0
indx = 0
have = false
для desc inside descs
{
indx = indx + 1
если desc ==
holeDesc
{
есть =
правда
cnt =
counts-> GetItem (indx)
cnt =
cnt + 1
counts-> SetItem (cnt, indx)
}
}
если есть == false
{
descs-> Добавить (holeDesc)
cnt = 1
counts-> Append (cnt)
}
отверстие.Name = «HOLE_» + holeDesc + «.» +
ToString (cnt)
}
threading — Потоковый параллелизм — документация Python 3.9.2
Исходный код: Lib / threading.py
Этот модуль конструирует высокоуровневые поточные интерфейсы поверх нижнего
level _thread module. См. Также модуль очереди .
Изменено в версии 3.7: Этот модуль раньше был необязательным, теперь он всегда доступен.
Примечание
Хотя они не перечислены ниже, имена camelCase , используемые для некоторых
методы и функции в этом модуле из серии Python 2.x по-прежнему
поддерживается этим модулем.
Детали реализации CPython: В CPython из-за глобальной блокировки интерпретатора только один поток
может выполнять код Python сразу (даже если некоторые ориентированные на производительность
библиотеки могут преодолеть это ограничение).
Если вы хотите, чтобы ваше приложение лучше использовало вычислительные
ресурсы многоядерных машин рекомендуется использовать многопроцессорность или одновременная обработка.Futures.ProcessPoolExecutor .
Однако многопоточность по-прежнему является подходящей моделью, если вы хотите запустить
одновременное выполнение нескольких задач, связанных с вводом-выводом.
Этот модуль определяет следующие функции:
-
нарезание резьбы.active_count() Возвращает количество активных в настоящее время
объектов Thread. Вернувшийся count равно длине списка, возвращаемого функциейenumerate ().
-
нарезание резьбы.текущая резьба() Вернуть текущий объект
Thread, соответствующий потоку вызывающего объекта. контроля. Если поток управления вызывающего абонента не был создан черезthreadingmodule, фиктивный объект потока с ограниченной функциональностью вернулся.
-
нарезание резьбы.кроме крюка( args , /) Обрабатывать неперехваченное исключение, вызванное потоком
.запустить ().Аргумент args имеет следующие атрибуты:
exc_type : Тип исключения.
exc_value : значение исключения, может быть
Нет.exc_traceback : Отслеживание исключения, может быть
Нет.поток : поток, вызвавший исключение, может быть
Нет.
Если exc_type —
SystemExit, исключение автоматически игнорируется.В противном случае исключение распечатывается наsys.stderr.Если эта функция вызывает исключение, вызывается
sys.excepthook ()для справиться.threading.excepthook ()можно переопределить, чтобы контролировать, насколько неперехваченным обрабатываются исключения, вызванныеThread.run ().Сохранение exc_value с использованием настраиваемого обработчика может создать ссылочный цикл. Это должен быть очищен явно, чтобы прервать контрольный цикл, когда исключение больше не нужно.
Сохранение нити с использованием настраиваемого крючка может воскресить его, если он установлен на объект, который дорабатывается. Избегайте хранения нити после пользовательской крючок завершается, чтобы избежать воскрешения объектов.
-
нарезание резьбы.get_ident() Вернуть «идентификатор потока» текущего потока. Это ненулевое целое число. Его значение не имеет прямого значения; он задуман как волшебное печенье будет использоваться e.грамм. для индексации словаря данных, специфичных для потока. Нить идентификаторы могут быть переработаны, когда поток завершается, а другой поток созданный.
-
нарезание резьбы.get_native_id() Возвращает собственный интегральный идентификатор потока текущего потока, назначенного ядром. Это целое неотрицательное число. Его значение может использоваться для однозначной идентификации этого конкретного потока в масштабе всей системы. (до тех пор, пока поток не завершится, после чего значение может быть переработано ОС).
Доступность: Windows, FreeBSD, Linux, macOS, OpenBSD, NetBSD, AIX.
-
нарезание резьбы.перечислить() Вернуть список всех
объектов Thread, которые в настоящее время активны. Список включает в себя демонические потоки, объекты фиктивных потоков, созданныеcurrent_thread ()и основной поток. Исключает завершенные потоки и темы, которые еще не были запущены.
-
нарезание резьбы.main_thread() Вернуть основной объект
Thread. В нормальных условиях основной поток — это поток, из которого интерпретатор Python был началось.
-
нарезание резьбы.settrace( func ) Установите функцию трассировки для всех потоков, запущенных из модуля
threading. func будет переданsys.settrace ()для каждого потока перед егоrun () вызывается метод.
-
нарезание резьбы.setprofile( func ) Задайте функцию профиля для всех потоков, запускаемых из модуля
threading. func будет переданsys.setprofile ()для каждого потока, прежде чем егоrun () вызывается метод.
-
нарезание резьбы.размер_стека([ размер ]) Возвращает размер стека потоков, используемый при создании новых потоков.Необязательный размер аргумент определяет размер стека, который будет использоваться для последующего создания потоков и должен быть 0 (использовать платформу или настроен по умолчанию) или положительный целочисленное значение не менее 32 768 (32 КБ). Если размер не указан, 0 используется. Если изменение размера стека потоков неподдерживаемый, возникает ошибка
RuntimeError. Если указанный размер стека недопустимый, возникаетValueErrorи размер стека не изменяется. 32 КБ в настоящее время является минимальным поддерживаемым значением размера стека, чтобы гарантировать достаточное пространство стека для самого интерпретатора.Обратите внимание, что некоторые платформы могут иметь особые ограничения на значения размера стека, такие как требование минимальный размер стека> 32 КиБ или требуется выделение в количестве, кратном системе размер страницы памяти — дополнительную информацию см. в документации по платформе. информации (обычно страницы 4 КиБ; использование кратного 4096 размера стека предлагаемый подход при отсутствии более конкретной информации).Доступность: Windows, системы с потоками POSIX.
Этот модуль также определяет следующую константу:
-
нарезание резьбы.TIMEOUT_MAX Максимальное значение, разрешенное для параметра тайм-аута функций блокировки (
Lock.acquire (),RLock.acquire (),Condition.wait ()и т. Д.). Указание тайм-аута больше этого значения вызоветОшибка переполнения.
Этот модуль определяет ряд классов, которые подробно описаны в разделах ниже.
Дизайн этого модуля частично основан на потоковой модели Java.Тем не мение,
где Java делает блокировки и условные переменные основным поведением каждого объекта,
в Python они являются отдельными объектами. Класс Python Thread поддерживает
подмножество поведения Java-класса Thread; в настоящее время нет
приоритеты, нет групп потоков, и потоки не могут быть уничтожены, остановлены,
приостановлено, возобновлено или прервано. Статические методы класса Thread Java,
при реализации отображаются в функции уровня модуля.
Все методы, описанные ниже, выполняются атомарно.
Локальные данные потока
Локальные данные потока — это данные, значения которых зависят от потока. Справляться
локальных данных потока, просто создайте экземпляр локального (или
подкласс) и сохраните на нем атрибуты:
mydata = threading.local () mydata.x = 1
Значения экземпляра будут разными для разных потоков.
- класс
нарезание резьбы.местный Класс, представляющий локальные данные потока.
Для получения дополнительных сведений и подробных примеров см. Строку документации
_threading_localмодуль.
Объекты потока
Класс Thread представляет собой действие, которое выполняется в отдельном
поток управления. Есть два способа указать действие: передавая
вызываемый объект в конструктор, или переопределив run () метод в подклассе. Никаких других методов (кроме конструктора) быть не должно.
переопределено в подклассе.Другими словами, только отменяет __init __ () и run () методов этого класса.
После создания объекта потока его активность должна быть запущена путем вызова
метод потока start () . Это вызывает run () метод в отдельном потоке управления.
Как только активность потока запущена, он считается «живым». Это
перестает быть живым, когда его метод run () завершается — либо
обычно или вызывая необработанное исключение. is_alive () проверяет, жив ли поток.
Другие потоки могут вызывать метод join () потока. Это блокирует
вызывающий поток, пока поток, чей метод join () не будет
вызов прекращен.
У потока есть имя. Имя можно передать конструктору и прочитать или
изменено с помощью атрибута name .
Если метод run () вызывает исключение, threading.excepthook () вызывается для его обработки.По умолчанию, threading.excepthook () молча игнорирует SystemExit .
Поток можно пометить как «поток демона». Значение этого флага
что вся программа Python завершается, когда остаются только потоки демона. В
начальное значение наследуется от создающего потока. Флаг можно установить
через свойство daemon или конструктор daemon аргумент.
Примечание
Потоки демона внезапно останавливаются при завершении работы.Их ресурсы (такие
как открытые файлы, транзакции с базой данных и т. д.) могут быть выпущены неправильно.
Если вы хотите, чтобы ваши потоки корректно останавливались, сделайте их недемоническими и
используйте подходящий механизм сигнализации, например, событие .
Есть объект «основной поток»; это соответствует начальному потоку управление в программе Python. Это не поток демона.
Существует вероятность создания «фиктивных объектов потока». Это
объекты потока, соответствующие «чужеродным потокам», которые являются потоками управления
запущен вне модуля потоковой передачи, например, непосредственно из кода C.Дурачок
объекты потока имеют ограниченную функциональность; они всегда считаются живыми и
демонический, и не может быть join () ed. Они никогда не удаляются,
так как невозможно обнаружить завершение чужих потоков.
- класс
нарезание резьбы.Thread( group = None , target = None , name = None , args = () , kwargs = {} , * , daemon = None ) Этот конструктор всегда следует вызывать с ключевыми аргументами.Аргументы являются:
группа должна быть
Нет; зарезервировано для будущего продления, когдаРеализован класс ThreadGroup.target — это вызываемый объект, который должен быть вызван методом
run (). По умолчаниюНет, что означает, что ничего не вызывается.имя — имя потока. По умолчанию уникальное имя создается из сформируйте «Резьба- N », где N — маленькое десятичное число.
args — это кортеж аргументов для целевого вызова. По умолчанию
().kwargs — словарь аргументов ключевого слова для целевого вызова. По умолчанию
{}.Если нет
Нет, демон явно устанавливает, является ли поток демоническим. ЕслиНет(по умолчанию), демоническое свойство наследуется от текущий поток.Если подкласс переопределяет конструктор, он должен обязательно вызвать конструктор базового класса (
Thread.__init __ ()), прежде чем делать что-либо еще для нить.Изменено в версии 3.3: Добавлен аргумент daemon .
-
начало() Запустить активность потока.
Он должен вызываться не более одного раза для каждого объекта потока. Он организует метод объекта
run (), который будет вызываться в отдельном потоке контроля.Этот метод вызовет
RuntimeError, если вызывается более одного раза. на том же объекте потока.
-
пробег() Метод, представляющий активность потока.
Вы можете переопределить этот метод в подклассе. Стандартный пробег
()вызывает вызываемый объект, переданный конструктору объекта как аргумент цели , если таковой имеется, с принятыми позиционными аргументами и аргументами ключевого слова из аргументов args и kwargs соответственно.
-
присоединиться( тайм-аут = нет ) Подождите, пока поток не завершится.Это блокирует вызывающий поток до тех пор, пока поток, чей метод
join ()называется, завершается — либо обычно или через необработанное исключение — или до тех пор, пока необязательный истекло время ожидания.Когда присутствует аргумент тайм-аут , а не
Нет, он должен быть число с плавающей запятой, определяющее тайм-аут для операции в секундах (или их части). Посколькуjoin ()всегда возвращаетNone, вы должны позвонитьis_alive ()послеjoin ()к решить, произошел ли тайм-аут — если поток все еще жив,join ()истекло время ожидания вызова.Если аргумент тайм-аут отсутствует или
Нет, операция будет блокировать, пока поток не завершится.Поток может быть
join ()ed много раз.join ()вызываетRuntimeError, если предпринята попытка чтобы присоединиться к текущему потоку, поскольку это вызовет тупик. Это также ошибкаjoin ()потока до его запуска и попытки сделать это вызывают то же исключение.
-
название Строка, используемая только для идентификации.У него нет семантики. Одно и то же имя может быть присвоено нескольким потокам. Начальное название задается конструктор.
-
getName() -
setName() Старый API геттера / сеттера для
name; использовать его непосредственно как свойство вместо этого.
-
идент. «Идентификатор потока» этого потока или
Нет, если поток не было начато. Это ненулевое целое число.См.get_ident ()функция. Идентификаторы потока могут быть повторно использованы при выходе из потока и создается другой поток. Идентификатор доступен даже после поток завершился.
-
native_id Собственный интегральный идентификатор потока этого потока. Это неотрицательное целое число или
Нет, если поток не было начато. См. Функциюget_native_id (). Это представляет собой идентификатор потока (TID), присвоенный поток ОС (ядро).Его значение может использоваться для однозначной идентификации этот конкретный поток общесистемный (пока поток не завершится, после чего значение может быть переработано ОС).Примечание
Подобно идентификаторам процессов, идентификаторы потоков действительны (гарантированно уникальны. общесистемный) с момента создания потока до был прекращен.
Доступность: требуется функция
get_native_id ().
-
is_alive() Вернуть, активен ли поток.
Этот метод возвращает
Trueнепосредственно перед методомrun (). запускается до тех пор, пока не завершится методrun (). В Функция модуляenumerate ()возвращает список всех активных потоков.
-
демон Логическое значение, указывающее, является ли этот поток потоком демона (True) или нет (Ложь). Это должно быть установлено до вызова
start (), в противном случае возникаетRuntimeError.Его начальное значение наследуется из создающей нити; основной поток не является потоком демона и поэтому все потоки, созданные в основном потоке, по умолчаниюдемон=Ложь.Вся программа Python завершается, когда не остается никаких живых потоков, не являющихся демонами.
-
isDaemon() -
наборDaemon() Старый API для получения и установки для
daemon; использовать его непосредственно как свойство вместо этого.
-
Заблокировать объекты
Примитивная блокировка — это примитив синхронизации, который не принадлежит
конкретный поток, когда он заблокирован. В Python в настоящее время это самый низкий уровень
доступен примитив синхронизации, реализуемый непосредственно _thread модуль расширения.
Простая блокировка находится в одном из двух состояний: «заблокировано» или «разблокировано». Он создан
в разблокированном состоянии. Он имеет два основных метода: collect (), и выпуск () .Когда состояние разблокировано, получить () изменяет состояние на заблокированное и немедленно возвращается. Когда состояние заблокировано, Acquire () блокируется до вызова release () в другом
поток изменяет его на разблокированный, затем вызов acqu () сбрасывает его
заблокирован и возвращается. Метод release () должен быть
вызывается в заблокированном состоянии; он меняет состояние на разблокировано и возвращает
немедленно. Если предпринята попытка разблокировать разблокированный замок, RuntimeError будет возбуждено.
также поддерживают протокол управления контекстом.
Когда более одного потока заблокировано в Acquire () ожидает
состояние, чтобы превратиться в разблокирован, только один поток продолжается, когда release () вызов сбрасывает состояние на разблокировку; какой из ожидающих потоков продолжается
не определен и может отличаться в зависимости от реализации.
Все методы выполняются атомарно.
- класс
нарезание резьбы.Замок Класс, реализующий примитивные объекты блокировки.Как только поток получил блокировка, последующие попытки получить ее блокируют, пока она не будет снята; любой поток может освободить его.
Обратите внимание, что
Lockна самом деле является заводской функцией, которая возвращает экземпляр наиболее эффективной версии поддерживаемого конкретного класса Lock у платформы.-
получить( блокировка = Истина , тайм-аут = -1 ) Получите блокировку, блокирующую или неблокирующую.
При вызове с блокирующим аргументом установлено значение
Истинно(по умолчанию), блокировать, пока блокировка не будет разблокирована, затем установите для него значение заблокировано и вернитеTrue.При вызове с блокирующим аргументом установлено значение
Ложь, не блокировать. Если вызов с блокировкой установлен наИстинныйбудет заблокирован, вернетЛожьнемедленно; в противном случае установите блокировку на заблокированный и вернитеTrue.При вызове с положительным значением аргумента тайм-аут с плавающей запятой значение, блокируется максимум на количество секунд, указанное в тайм-аут и пока блокировка не может быть получена.Тайм-аут аргумент
-1указывает неограниченное ожидание. Запрещено указывать таймаут когда блокирует ложно.Возвращаемое значение —
Истина, если блокировка получена успешно,Ложь, если нет (например, если истекло время ожидания ).Изменено в версии 3.2: Новый параметр тайм-аут .
Изменено в версии 3.2: Получение блокировки теперь может прерываться сигналами POSIX, если базовая реализация потоковой передачи поддерживает его.
-
выпуск() Разблокируйте фиксатор. Это можно вызвать из любого потока, а не только из потока который приобрел замок.
Когда замок заблокирован, сбросьте его до разблокированного и верните обратно. Если какие-либо другие темы заблокированы, ожидая разблокировки замка, разрешите ровно один из них продолжать.
При вызове разблокированной блокировки возникает
RuntimeError.Нет возвращаемого значения.
-
заблокировано() Вернуть истину, если блокировка получена.
-
Объекты RLock
Повторяющаяся блокировка — это примитив синхронизации, который может быть получен многократно. раз по той же теме. Внутри он использует концепцию «владения потоком». и «уровень рекурсии» в дополнение к заблокированному / разблокированному состоянию, используемому примитивом замки. В заблокированном состоянии какой-то поток владеет блокировкой; в разблокированном состоянии, ни один поток не владеет им.
Чтобы заблокировать блокировку, поток вызывает свой метод acqu () ; это
возвращается, когда поток владеет блокировкой.Чтобы разблокировать блокировку, поток вызывает
его метод release () . приобретение () / выпуск () пары вызовов могут быть вложенными; только последний выпуск () ( () крайней пары) сбрасывает блокировку в разблокированное состояние и
позволяет продолжить работу другому потоку, заблокированному в acqu () .
Реентерабельные блокировки также поддерживают протокол управления контекстом.
- класс
нарезание резьбы.RLock Этот класс реализует объекты реентерабельной блокировки.Повторная блокировка должна быть выпущен потоком, который его приобрел. Как только поток получил повторная блокировка, тот же поток может получить ее снова без блокировки; в поток должен освобождать его каждый раз, когда он его получает.
Обратите внимание, что
RLockна самом деле является заводской функцией, которая возвращает экземпляр наиболее эффективной версии конкретного поддерживаемого класса RLock у платформы.-
получить( блокировка = Истина , тайм-аут = -1 ) Получите блокировку, блокирующую или неблокирующую.
При вызове без аргументов: если этот поток уже владеет блокировкой, увеличить уровень рекурсии на единицу и немедленно вернуться. В противном случае, если другой поток владеет блокировкой, блокируйте, пока блокировка не будет разблокирована. Как только замок разблокирован (не принадлежит ни одному потоку), затем захватить владение, установить уровень рекурсии к одному и вернуться. Если заблокировано более одного потока, ожидая блокировки разблокирован, только один может получить право владения замком. В этом случае нет возвращаемого значения.
При вызове с параметром , блокирующим аргумент , установленным в значение true, выполните те же действия, что и при вызывается без аргументов и возвращает
True.При вызове с блокирующим аргументом установлено значение false, не блокировать. Если звонок без аргумента будет блокироваться, немедленно вернуть
False; в противном случае сделайте то же самое, что и при вызове без аргументов, и возвращаетTrue.При вызове с положительным значением аргумента тайм-аут с плавающей запятой значение, блокируется максимум на количество секунд, указанное в тайм-аут и пока блокировка не может быть получена.Вернуть
True, если блокировка было получено, false, если истекло время ожидания.Изменено в версии 3.2: Новый параметр тайм-аут .
-
выпуск() Снять блокировку, уменьшая уровень рекурсии. Если после декремента это ноль, сбросить блокировку на разблокировку (не принадлежит ни одному потоку), и если любой другой потоки заблокированы, ожидая разблокировки блокировки, разрешите ровно один из них, чтобы продолжить.Если после декремента уровень рекурсии все еще ненулевое значение, блокировка остается заблокированной и принадлежит вызывающему потоку.
Вызывайте этот метод, только если вызывающий поток владеет блокировкой. А
RuntimeErrorвозникает, если этот метод вызывается при блокировке. разблокирован.Нет возвращаемого значения.
-
Состояние объектов
Условная переменная всегда связана с какой-либо блокировкой; это может быть передается или один будет создан по умолчанию.Передача одного полезна, когда несколько переменных условия должны использовать одну и ту же блокировку. Замок является частью объект условия: вам не нужно отслеживать его отдельно.
Условная переменная подчиняется протоколу управления контекстом:
использование с оператором получает связанную блокировку на время
закрытый блок. приобретают () и release () методы также вызывают соответствующие методы
связанная блокировка.
Другие методы должны вызываться с удерживаемой связанной блокировкой.В wait () Метод снимает блокировку, а затем блокируется до тех пор, пока
другой поток пробуждает его, вызывая notify () или notify_all () . После пробуждения ждать () повторно получает замок и возвращается. Также можно указать тайм-аут.
Метод notify () пробуждает один из потоков, ожидающих
переменная условия, если таковая ожидает. notify_all () пробуждает все потоки, ожидающие переменной условия.
Примечание: методы notify () и notify_all () не отпускайте замок; это означает, что пробужденная нить или нити будут
не возвращаться из своего вызова wait () немедленно, а только когда
поток, который вызвал notify () или notify_all () наконец отказывается от владения замком.
Типичный стиль программирования с использованием условных переменных использует блокировку для
синхронизировать доступ к некоторому общему состоянию; темы, которые заинтересованы в
конкретное изменение состояния вызовите wait () несколько раз, пока они
увидеть желаемое состояние, в то время как потоки, которые изменяют состояние, вызывают notify () или notify_all () при их изменении
состояние таким образом, чтобы оно могло быть желаемым состоянием для одного
официантов.Например, следующий код является общим
Ситуация производитель-потребитель с неограниченной буферной емкостью:
# Потребление одного предмета
с резюме:
пока не an_item_is_available ():
cv.wait ()
get_an_available_item ()
# Произвести один предмет
с резюме:
make_an_item_available ()
cv.notify ()
Цикл и необходим для проверки условий приложения
потому что wait () может вернуться через произвольно долгое время,
и условие, которое вызвало вызов notify () , может
больше не верны.Это присуще многопоточному программированию. В wait_for () Метод может использоваться для автоматизации условия
проверка и упрощает вычисление таймаутов:
# Потребление предмета
с резюме:
cv.wait_for (an_item_is_available)
get_an_available_item ()
Чтобы выбрать между notify () и notify_all () ,
подумайте, может ли одно изменение состояния быть интересным только для одного или нескольких
ожидающие потоки. Например. в типичной ситуации производитель-потребитель, добавив один
элемент в буфер необходимо только для того, чтобы разбудить один потребительский поток.
- класс
нарезание резьбы.Условие( блокировка = Нет ) Этот класс реализует объекты переменных условий. Условная переменная позволяет одному или нескольким потокам ждать, пока они не будут уведомлены другим потоком.
Если указан аргумент lock , а не
None, это должен быть аргументLockилиRLockобъект, и он используется в качестве базовой блокировки. Иначе, создается новый объектRLock, который используется в качестве базовой блокировки.Изменено в версии 3.3: изменена с фабричной функции на класс.
-
получить( * аргументы ) Получите базовую блокировку. Этот метод вызывает соответствующий метод на лежащий в основе замок; возвращаемое значение — это то, что возвращает этот метод.
-
выпуск() Снять базовую блокировку. Этот метод вызывает соответствующий метод на лежащий в основе замок; нет возвращаемого значения.
-
ждать( тайм-аут = нет ) Подождите, пока не появится уведомление или пока не истечет время ожидания. Если вызывающий поток имеет не получил блокировку при вызове этого метода,
RuntimeErrorподнятый.Этот метод освобождает базовую блокировку, а затем блокирует ее до тех пор, пока не будет пробуждается вызовом
notify ()илиnotify_all ()для того же условная переменная в другом потоке или до необязательного тайм-аута происходит.После пробуждения или истечения времени ожидания он повторно устанавливает блокировку и возвращается.Когда присутствует аргумент тайм-аут , а не
Нет, он должен быть число с плавающей запятой, определяющее тайм-аут для операции в секундах (или их части).Когда базовая блокировка — это
RLock, она не снимается с использованием его методrelease (), так как он может фактически не разблокировать блокировку когда он был получен несколько раз рекурсивно. Вместо этого внутренний используется интерфейс классаRLock, что действительно его разблокирует даже если он был получен рекурсивно несколько раз.Другой внутренний затем используется интерфейс для восстановления уровня рекурсии, когда блокировка повторно приобретен.Возвращаемое значение —
Истина, если не истек заданный тайм-аут , в котором если этоЛожь.Изменено в версии 3.2: ранее метод всегда возвращал
Нет.
-
wait_for( предикат , тайм-аут = Нет ) Подождите, пока условие не станет истинным. предикат должен быть вызываемый, результат которого будет интерпретирован как логическое значение. Может быть предусмотрен тайм-аут , дающий максимальное время ожидания.
Этот служебный метод может вызывать
wait ()несколько раз, пока предикат выполняется или пока не истечет время ожидания. Возвращаемое значение — последнее возвращаемое значение предиката и будет оценивать какЛожь, если истекло время ожидания метода.Игнорирование функции тайм-аута, вызов этого метода примерно эквивалентен письмо:
без predicate (): резюме.ждать()Следовательно, применяются те же правила, что и для
wait (): Блокировка должна быть удерживается при вызове и повторно приобретается при возврате. Предикат оценивается с удерживаемым замком.
-
уведомить( n = 1 ) По умолчанию пробуждает один поток, ожидающий этого условия, если таковой имеется. Если вызывающий поток не получил блокировку при вызове этого метода,
RuntimeErrorвозникает.Этот метод пробуждает не более n потоков, ожидающих выполнения условия Переменная; это не работает, если нет ожидающих потоков.
Текущая реализация пробуждает ровно n потоков, если не менее n потоки ждут. Однако полагаться на такое поведение небезопасно. Будущая оптимизированная реализация может иногда пробуждать более чем n ниток.
Примечание: пробужденный поток фактически не возвращается из своего
wait ()звоните, пока он не сможет восстановить блокировку. Посколькуnotify ()не отпустите блокировку, ее вызывающий должен.
-
notify_all() Разбудить все потоки, ожидающие этого условия.Этот метод действует как
notify (), но пробуждает все ожидающие потоки вместо одного. Если вызывающий поток не получил блокировку при вызове этого метода,RuntimeErrorвозникает.
-
Семафорные объекты
Это один из старейших примитивов синхронизации в истории компьютеров.
наука, изобретенная ранним голландским ученым-компьютерщиком Эдсгером В. Дейкстра (он
использовали имена P () и V () вместо collect () и выпуск () ).
Семафор управляет внутренним счетчиком, который уменьшается на каждый collect () вызов и увеличивается с каждым вызовом release () вызов. Счетчик никогда не может опуститься ниже нуля; когда получить () обнаруживает, что он равен нулю, блокирует, ожидая, пока какой-нибудь другой поток вызовет выпуск () .
Семафоры также поддерживают протокол управления контекстом.
- класс
нарезание резьбы.Семафор(значение = 1 ) Этот класс реализует семафорные объекты.Семафор управляет атомарным счетчик, представляющий количество вызовов
release ()минус количествоPurchase ()вызовов плюс начальное значение. МетодPurchase ()блокирует при необходимости до тех пор, пока не сможет вернуться без отрицательного значения счетчика. Если не указан, значение по умолчанию равно 1.Необязательный аргумент дает начальное значение для внутреннего счетчика; Это по умолчанию
1. Если заданное значение меньше 0,ValueErrorподнятый.Изменено в версии 3.3: изменена с фабричной функции на класс.
-
получить( блокировка = Истина , тайм-аут = Нет ) Получить семафор.
При вызове без аргументов:
Если внутренний счетчик больше нуля при входе, уменьшите его на one и немедленно верните
True.Если внутренний счетчик равен нулю при входе, блокировка до пробуждения вызовом
выпуск ().Однажды проснувшись (а счетчик больше чем 0), уменьшите счетчик на 1 и вернитеTrue. Ровно один поток будет пробуждаться при каждом вызовеrelease (). В порядок, в котором пробуждаются потоки, не следует полагаться.
При вызове с блокировкой для установлено значение false, не блокировать. Если звонок без аргумента будет блокироваться, немедленно вернуть
False; в противном случае сделайте то же самое, что и при вызове без аргументов, и вернутьTrue.При вызове с таймаутом , отличным от
Нет, он будет заблокирован на Максимальный таймаут секунд. Если получение не завершится успешно в этот интервал вернетЛожь. В противном случае вернитеTrue.Изменено в версии 3.2: Новый параметр тайм-аут .
-
выпуск( n = 1 ) Освободить семафор, увеличив внутренний счетчик на n .Когда это был нулевым при входе, и другие потоки ждут, когда он станет больше чем снова ноль, пробуждает n этих потоков.
Изменено в версии 3.9: добавлен параметр n для одновременного освобождения нескольких ожидающих потоков.
-
- класс
нарезание резьбы.BoundedSemaphore(значение = 1 ) Класс, реализующий ограниченные семафорные объекты. Ограниченный семафор проверяет убедитесь, что его текущее значение не превышает его начальное значение.Если это так,
ValueErrorвозникает. В большинстве случаев семафоры используются для защиты ресурсы с ограниченными возможностями. Если семафор отпущен слишком много раз это признак ошибки. Если не указан, значение по умолчанию равно 1.Изменено в версии 3.3: изменена с фабричной функции на класс.
Семафор ПримерСемафоры часто используются для защиты ресурсов с ограниченной емкостью, например, сервер базы данных.В любой ситуации, когда размер ресурса фиксирован, вам следует использовать ограниченный семафор. Перед созданием любых рабочих потоков ваш основной поток инициализирует семафор:
maxconnections = 5 # ... pool_sema = BoundedSemaphore (значение = maxconnections)
После создания рабочие потоки вызывают методы получения и выпуска семафора. когда им нужно подключиться к серверу:
с pool_sema:
conn = connectdb ()
пытаться:
# ... использовать соединение ...наконец-то:
conn.close ()
Использование ограниченного семафора снижает вероятность того, что ошибка программирования приводит к тому, что семафор высвобождается больше, чем полученный, остается незамеченным.
Объекты событий
Это один из простейших механизмов связи между потоками: один поток сигнализирует о событии, и другие потоки его ждут.
Объект события управляет внутренним флагом, которому можно присвоить значение true с помощью параметра set () и сбросьте значение false с помощью clear () метод.Метод wait () блокируется, пока флаг не станет истинным.
- класс
нарезание резьбы.Событие Класс, реализующий объекты событий. Событие управляет флагом, который может быть установлен на true с помощью метода
set ()и сбросить до false с помощьюclear ()метод. Методwait ()блокируется, пока флаг не станет истинным. Флаг изначально ложный.Изменено в версии 3.3: изменена с фабричной функции на класс.
-
is_set() Вернуть
Истинатогда и только тогда, когда внутренний флаг истинен.
-
комплект() Установить для внутреннего флага значение true. Все потоки ждут, когда это станет правдой пробуждаются. Потоки, которые вызывают
wait ()после установки флага, будут не блокировать вообще.
-
прозрачный() Сброс внутреннего флага на ложное. Впоследствии потоки, вызывающие
wait ()будет блокироваться до тех пор, пока не будет вызванset ()для установки внутреннего флаг снова в истинное значение.
-
ждать( тайм-аут = нет ) Блокировать до тех пор, пока внутренний флаг не станет истинным. Если внутренний флаг установлен на вход, немедленно возвращайся. В противном случае блокируйте, пока другой поток не вызовет
set (), чтобы установить флаг в истинное значение или до тех пор, пока не истечет необязательный тайм-аут.Если присутствует аргумент тайм-аута, а не
Нет, он должен быть число с плавающей запятой, определяющее тайм-аут для операции в секундах (или их части).Этот метод возвращает
Trueтогда и только тогда, когда для внутреннего флага установлено значение истина, либо до вызова ожидания, либо после начала ожидания, поэтому он будет всегда возвращатьИстинно, кроме случаев, когда задан тайм-аут и операция время вышло.Изменено в версии 3.1: ранее метод всегда возвращал
Нет.
-
Объекты таймера
Этот класс представляет действие, которое следует запускать только после определенного количества
времени прошло — таймер. Таймер является подклассом Thread и как таковой также служит примером создания настраиваемых потоков.
Таймеры запускаются, как и потоки, путем вызова их start () метод. Таймер можно остановить (до того, как его действие начнется), вызвав cancel () метод. Интервал ожидания таймера до
выполнение его действия может не совпадать с интервалом, указанным в
Пользователь.
Например:
def привет ():
print ("привет, мир")
t = Таймер (30.0, привет)
t.start () # через 30 секунд будет напечатано "hello, world"
- класс
нарезание резьбы.Таймер( интервал , функция , args = нет , kwargs = нет ) Создайте таймер, который будет запускать функцию с аргументами args и ключевым словом arguments kwargs , после интервала прошло секунд. Если args равно
None(по умолчанию), то будет использоваться пустой список.Если kwargs равноNone(по умолчанию), то будет использоваться пустой dict.Изменено в версии 3.3: изменена с фабричной функции на класс.
-
отменить() Остановить таймер и отменить выполнение действия таймера. Это будет работают только в том случае, если таймер все еще находится в стадии ожидания.
-
Заградительные объекты
Этот класс предоставляет простой примитив синхронизации для использования с фиксированным номером.
потоков, которым нужно ждать друг друга.Каждый из потоков пытается пройти
барьер путем вызова метода wait () и будет блокироваться до тех пор, пока
все потоки выполнили вызовов wait () . На этой точке,
потоки освобождаются одновременно.
Барьер можно использовать повторно любое количество раз для одного и того же количества потоков.
В качестве примера приведем простой способ синхронизации клиентского и серверного потоков:
b = Барьер (2, тайм-аут = 5)
def server ():
start_server ()
b.wait ()
в то время как True:
соединение = accept_connection ()
process_server_connection (соединение)
def client ():
б.ждать()
в то время как True:
соединение = make_connection ()
process_client_connection (соединение)
- класс
нарезание резьбы.Барьер( сторон , действие = нет , тайм-аут = нет ) Создать объект барьера для сторон количество ниток. Действие , когда при условии, вызывается одним из потоков, когда они вышел. тайм-аут — значение тайм-аута по умолчанию, если для метод
wait ().-
ждать( тайм-аут = нет ) Пройдите через шлагбаум. Когда все потоки, участвующие в барьере, вызвали В этой функции все они запускаются одновременно. Если таймаут при условии, что он используется вместо того, что было предоставлено классу конструктор.
Возвращаемое значение — целое число в диапазоне от 0 до 903 12 сторон — 1, разные для каждого потока. Это можно использовать для выбора потока для выполнения каких-то специальных ведение домашнего хозяйства, e.г .:
я = барьер.wait () если я == 0: # Только один поток должен это напечатать print («преодолел барьер»)Если конструктору было предоставлено действие , один из потоков будет позвонили до того, как его выпустили Если этот вызов вызывает ошибку, шлагбаум переводится в разрушенное состояние.
Если время вызова истекло, шлагбаум переводится в неработающее состояние.
Этот метод может вызвать исключение
BrokenBarrierError, если барьер нарушен или сброшен, пока поток ожидает.
-
сброс() Вернуть барьер в пустое состояние по умолчанию. Любые потоки, ожидающие его получит исключение
BrokenBarrierError.Обратите внимание, что для использования этой функции может потребоваться внешний синхронизация, если есть другие потоки, состояние которых неизвестно. Если барьер сломан, может быть лучше просто оставить его и создать новый.
-
прервать() Привести шлагбаум в сломанное состояние.Это вызывает любые активные или будущие вызывает
wait ()для отказа сBrokenBarrierError. Использовать это, например, если один из потоков необходимо прервать, чтобы избежать взаимоблокировки заявление.Может быть предпочтительнее просто создать барьер с разумной тайм-аут значение для автоматической защиты от одного из идущих потоков наперекосяк.
-
партий Количество нитей, необходимое для прохождения барьера.
-
нет ожидания Число потоков, ожидающих в данный момент в барьере.
-
сломано Логическое значение
Истинно, если барьер находится в сломанном состоянии.
-
- исключение
нарезание резьбы.BrokenBarrierError Это исключение, подкласс
RuntimeError, возникает, когдаОбъект Barrierсброшен или сломан.
Использование блокировок, условий и семафоров в
с оператором Все объекты, предоставленные этим модулем, которые имеют acqu (), и release () методы могут использоваться в качестве менеджеров контекста для с утверждение. Метод Acquire () будет вызываться, когда блок
input, и release () будет вызываться при выходе из блока. Следовательно,
следующий фрагмент:
с some_lock:
# сделай что-нибудь...
эквивалентно:
some_lock.acquire ()
пытаться:
# сделай что-нибудь...
наконец-то:
some_lock.release ()
В настоящее время Замок , RLock , Состояние ,
Объекты Semaphore и BoundedSemaphore могут использоваться как с диспетчерами контекста операторов.
Переменные передачи JMeter между группами потоков
В этом руководстве по JMeter мы рассмотрим, как мы можем совместно использовать и передавать переменные между группами потоков.
При разработке сложных сценариев JMeter, скорее всего, у вас будет несколько групп потоков. Каждая группа потоков будет выполнять разные запросы.
Хороший пример этого — когда нам нужно аутентифицировать пользователей с помощью токенов на предъявителя. Одна группа потоков выполняет аутентификацию и сохраняет токен. Другой группе потоков необходимо получить доступ к этому токену и использовать его в другом запросе.
Следовательно, нам нужен механизм для передачи переменных между группами потоков.
Передача переменных между группами потоков в JMeter
В этом примере наш план тестирования будет иметь две группы потоков.Первая группа потоков делает запрос GET к веб-службе. Затем мы используем плагин JSON Extractor для анализа ответа JSON.
Используя JSONPath, мы извлекаем значение для определенного ключа и сохраняем его как переменную JMeter.
Вот так выглядит наш запрос JMeter:
Результат вышеуказанного запроса дает следующий ответ в формате JSON:
и наш JSONPath для извлечения первого URL-адреса выглядит так:
Значение запроса JSONPath сохраняется как first_url .Эта переменная доступна только в той же группе потоков, и мы можем получить ее значение, используя $ {first_url} . Теперь, как мы собираемся сделать эту переменную доступной через другие группы потоков?
Ответ — использовать BeanShell Assertion для сохранения переменной как глобального свойства. Таким образом, мы можем передавать переменные между группами потоков.
Чтобы добавить утверждение BeanShell, щелкните правой кнопкой мыши План тестирования> Добавить> Утверждение> Утверждение BeanShell
В нашем утверждении BeanShell мы можем ввести следующий код
$ {__ setProperty (first_url, $ {first_url})};
Теперь в группе потоков 2 мы можем получить доступ к этой переменной напрямую, используя $ {__ property (first_url)} , как показано ниже:
Или мы можем использовать препроцессор BeanShell для управления переменной:
В препроцессоре BeanShell мы можем получить доступ к переменной, переданной из другой группы потоков, используя props.