Сингапурцу грозит более 20 лет тюрьмы за добычу криптовалюты в Amazon AWS и Google Cloud
Сингапурцу грозит более 20 лет тюрьмы за добычу криптовалюты в Amazon AWS и Google Cloud
Alexander Antipov
Хо Джун Цзя обвиняется в хищении персональных данных, а также вычислительных мощностей облачных сервисов.
29-летнему гражданину Сингапура Хо Джун Цзя, также известному под именем Мэтью Хо, предъявлены 14 обвинений в предполагаемой добыче криптовалюты с помощью фальшивых учетных записей электронной почты и похищенных вычислительных мощностей облачных сервисов Amazon AWS и Google Cloud.
Согласно обвинительному заключению, в период с октября 2017 года по февраль 2018 года после роста популярности и стоимости криптовалют обвиняемый проводил крупномасштабную кампанию по добыче криптовалюты с помощью мошенничества и кражи личных данных.
Подозреваемый использовал аккаунты для майнинга различных криптовалют, в том числе Bitcoin и Ethereum. Хо создал сеть фальшивых учетных записей электронной почты и использовал методы социальной инженерии для обмана провайдеров облачных вычислений, чтобы получить повышенные привилегии в аккаунте, увеличить вычислительную мощность компьютера и объем хранилища, а также уклонится от оплаты по счетам.
Вычислительные мощности использовались для майнинга криптовалюты, которую Хо затем использовал или обменивал на валюту на различных online-площадках. В течение нескольких месяцев злоумышленник использовал ресурсы облачных вычислений на $5 млн в рамках майнинга. Хо также использовал персональные данные одного из жителей Техаса, а также основателя технической компании в Индии для создания учетных записей в облачных сервисах Google, которые он аналогичным образом использовал для майнинга криптовалюты.
Суммарно по всем пунктам обвинения мужчине грозит более 20 лет тюремного заключения.
В нашем телеграм канале мы рассказываем о главных новостях из мира IT, актуальных угрозах и событиях, которые оказывают влияние на обороноспособность стран, бизнес глобальных корпораций и безопасность пользователей по всему миру. Узнай первым как выжить в цифровом кошмаре!
Поделиться новостью:
Как мы случайно сожгли $72 000 за два часа в Google Cloud Platform и чуть не обанкротились / Хабр
История о том, как мы оказались на грани банкротства, не успев даже запустить первый продукт, как нам удалось выжить и какие уроки мы извлекли.
В марте 2020 года, когда COVID поразил весь мир, наш стартап Milkie Way тоже сильно пострадал и почти закрылся. Мы сожгли 72 000 долларов во время изучения и внутреннего тестирования Cloud Run с Firebase в течение нескольких часов.
Я начал разработку сервиса Announce в ноябре 2019 года.
 Главная цель состояла в выпуске минимально функциональной первой версии продукта, поэтому код работал на простом стеке. Мы использовали JS, Python и развернули наш продукт на Google App Engine.
Главная цель состояла в выпуске минимально функциональной первой версии продукта, поэтому код работал на простом стеке. Мы использовали JS, Python и развернули наш продукт на Google App Engine.С очень маленькой командой мы сосредоточились на написании кода, разработке пользовательского интерфейса и подготовке продукта. Я практически не тратил времени на управление облаком — потратил ровно столько, чтобы поднять систему и обеспечить базовый процесс разработки (CI/CD).
Десктопный Announce
Первая версия была не очень удобной, но мы просто хотели выпустить версию для экспериментов, а потом уже работать над нормальной. В связи с COVID мы подумали, что сейчас хорошее время для запуска, поскольку государственные службы по всему миру могут использовать Announce для публикации оповещений.
Разве не здорово сгенерировать на платформе немного данных, когда пользователи ещё не закачали свою информацию? Эта мысль привела к появлению другого проекта Announce-AI для генерации контента. Богатые данные — это различные события, такие как оповещения о землетрясениях и, возможно, релевантные местные новости.
Богатые данные — это различные события, такие как оповещения о землетрясениях и, возможно, релевантные местные новости.
Для начала разработки Announce-AI мы использовали Cloud Functions. Поскольку наш бот для скрапинга был ещё на начальной стадии, мы решили взять эти легковесные функции. Но при масштабировании возникли проблемы, потому что у облачных функций тайм-аут около 9 минут.
И вдруг мы узнали о системе Cloud Run, у которой тогда был большой лимит бесплатного использования! Не разобравшись полностью, я попросил команду развернуть «тестовую» функцию Announce-AI в Cloud Run и оценить её производительность. Цель состояла в том, чтобы поиграться с Cloud Run для накопления опыта.
Google Cloud Run
Поскольку у нас очень маленький сайт, то для простоты мы использовали БД Firebase, так как у Cloud Run нет никакого хранилища, а деплой SQL Server или другую БД слишком чрезмерен для теста.
Я создал новый проект GCP ANC-AI Dev, настроил бюджет облачного биллинга на 7 долларов, сохранил проект Firebase по бесплатному плану (Spark). Худший вариант, который мы представляли, — это превышение ежедневного лимита Firebase.
Худший вариант, который мы представляли, — это превышение ежедневного лимита Firebase.
После некоторых модификаций мы подготовили код, сделали несколько запросов вручную, а затем оставили его работать.
В день тестирования всё прошло нормально, и мы вернулись к разработке Announce. На следующий день после работы ближе к вечеру я пошёл слегка вздремнуть. Проснувшись, я увидел несколько писем из Google Cloud, все с интервалом в несколько минут.
Первое письмо: автоматический апгрейд нашего проекта Firebase
Второе письмо: бюджет превышен
К счастью, на моей карте был установлен лимит в $100. Из-за этого платежи не прошли, а Google приостановил обслуживание наших аккаунтов.
Третье письмо: карта отклонена
Я вскочил с кровати, вошёл в биллинг Google Cloud и увидел счёт примерно на $5000. В панике начал щёлкать по клавишам, не понимая, что происходит. В фоновом режиме начал размышлять, как такое могло произойти и как оплатить счёт на $5000, в случае чего.
Проблема была в том, что с каждой минутой счёт продолжал расти.
Через пять минут он показывал $15 000 долларов, через 20 минут — $25 000. Я не понимал, когда цифры перестанут увеличиваться. Может, они будут расти до бесконечности?
Через два часа цифра остановилась на отметке чуть меньше $72 000.
К этому времени мы с командой были на телеконференции, я был в полном шоке и не имел абсолютно никакого понятия, что делать дальше. Мы отключили биллинг, закрыли все сервисы.
Поскольку во всех проектах GCP мы рассчитывались одной картой, все наши учётные записи и проекты были приостановлены.
Это произошло в пятницу вечером, 27 марта — за три дня до того, как мы планировали запустить первую версию. Теперь разработка остановилась, потому что Google приостановила все наши проекты, привязанные к одной карте. Мой боевой дух ниже плинтуса, а будущее компании казалось неопределённым.
Все наши облачные проекты приостановлены, разработка остановлена
Как только разум смирился с новой реальностью, в полночь я решил нормально разобраться, что же произошло. Я начал составлять документ с подробным расследованием инцидента… и назвал его «Глава 11» [это глава из закона о банкротстве — прим. пер.].
Я начал составлять документ с подробным расследованием инцидента… и назвал его «Глава 11» [это глава из закона о банкротстве — прим. пер.].
Двое коллег, участвовавших в эксперименте, тоже не спали всю ночь, исследуя и пытаясь понять, что произошло.
На следующее утро, в субботу 28 марта, я позвонил и написал письма десятку юридических фирм, чтобы записаться на приём или поговорить с адвокатом. Все они были в отъезде, но я смог получить ответ от одного из них по электронной почте. Поскольку детали инцидента настолько сложны даже для инженеров, объяснить это адвокату на простом английском языке было само по себе непросто.
Для нас как начинающего стартапа не было никакой возможности возместить $72 000.
К этому времени я уже хорошо изучил 7-ю и 11-ю главы закона о банкротстве и мысленно готовился к тому, что может произойти дальше.
В субботу после рассылки электронных писем юристам я начал дальше читать и просматривать каждую страницу документации GCP. Мы действительно совершали ошибки, но не было никакого смысла в том, что Google позволил нам резко потратить $72 000, если раньше мы вообще не делали никаких платежей!
GCP и Firebase
1.
 Автоматический апгрейд аккаунта Firebase на платный аккаунт
Автоматический апгрейд аккаунта Firebase на платный аккаунтМы такого не ожидали, и об этом нигде не предупреждалось при регистрации на Firebase. Наш биллинг GCP был подключён к исполнению Cloud Run, но Firebase шла под бесплатным планом (Spark). GCP просто ни с того ни с сего провела апгрейд на платный тариф и взяла с нас необходимую сумму.
Оказывается, этот процесс у них называется «глубокая интеграция Firebase и GCP».
2. Биллинговых «лимитов» не существует. Бюджеты запаздывают минимум на сутки
Выставление счетов GCP фактически задерживается как минимум на сутки. В большинстве документов Google предлагает использовать бюджеты и функцию автоматического отключения облака. Но к тому времени, когда сработает функция отключения или пользователю пришлют уведомление, ущерб уже будет нанесён.
Синхронизация биллинга занимает около суток, именно поэтому мы заметили счёт на следующий день.
3. Google должен был взять 100 долларов, а не 72 тысячи!
Поскольку с нашего аккаунта до сих пор не проходило никаких платежей, GCP должен был сначала взять плату в размере 100 долларов в соответствии с платёжной информацией, а при неуплате — прекратить услуги. Но этого не произошло. Я понял причину позже, но это тоже не по вине пользователя!
Но этого не произошло. Я понял причину позже, но это тоже не по вине пользователя!
Первый счёт для нас составил около $5000. Следующий на $72 тыс.
Порог выставления счетов для нашего аккаунта составляет $100
4. Не полагайтесь на панель управления Firebase!
Не только биллинг, но и обновление панели управления Firebase заняло более 24-х часов.
Согласно документации Firebase Console, цифры в панели управления могут «незначительно» отличаться от отчётов биллинга.
В нашем случае они отличались на 86 585 365,85%, или 86 миллионов процентных пунктов. Даже когда пришёл счёт, панель управления Firebase Console ещё показывала 42 000 операций чтения и записи в месяц (ниже дневного лимита).
Отработав шесть с половиной лет в Google и написав десятки проектных документов, отчётов с расследованиями событий и много другого, я начал составлять документ для Google, описывая инцидент и добавляя лазейки со стороны Google в отчёт. Команда Google вернётся на работу через два дня.
Поправка: некоторые читатели предположили, что я использовал свои внутренние контакты в Google. На самом деле я ни с кем не общался и выбрал путь, по которому пошёл бы любой нормальный разработчик или компания. Как и любой другой мелкий разработчик, я проводил бесчисленные часы в чате, за консультациями, составлением длинных электронных писем и сообщений об ошибках. В одной из следующих статей, посвящённой составлению отчётов об инцидентах, я покажу документы, которые отправил в Google.
Последний день в Google
Кроме того, нужно было понять наши ошибки и разработать стратегию развития продукта. Не все в команде знали об инциденте, но было совершенно ясно, что у нас большие неприятности.
В Google я сталкивался с человеческими ошибками ценой в миллионы долларов, но культура Google спасает сотрудников (за исключением того, что инженерам приходится потом сочинять длинные отчёты). На этот раз Гугла не было. На карту поставлен наш собственный маленький капитал и наша тяжёлая работа.
Стойкие Гималаи нам говорят…
Такой удар я получил первый раз. Это могло изменить будущее нашей компании и мою жизнь. Этот инцидент преподал мне несколько уроков бизнеса, в том числе самый важный — держать удар.
В то время у меня работала команда из семи инженеров и стажёров, и Google требовалось около десяти дней, чтобы ответить нам по поводу этого инцидента. Тем временем мы должны были возобновить разработку, найти способ обойти приостановку счетов. Несмотря на всё, мы должны были сосредоточиться на функциях и нашем продукте.
Стихотворение «Стойкие Гималаи нам говорят»
Почему-то у меня в голове постоянно крутилось одно стихотворение из детства. Это была моя любимая книга, и я помнил её слово в слово, хотя в последний раз читал более 15 лет назад.
Что мы на самом деле сделали?
Будучи очень маленькой командой, мы хотели как можно дольше воздержаться от расходов на аппаратное обеспечение. Проблема Cloud Functions и Cloud Run заключалась в тайм-ауте.
Один инстанс будет постоянно скрапить URL-адреса со страницы. Но через 9 минут наступит тайм-аут.
Тогда вскользь обсудив проблему, я за пару минут набросал на доске сырой код. Теперь понял, что у того кода была масса архитектурных недостатков, но тогда мы стремились к быстрым циклам исправления ошибок, чтобы стремительно учиться и пробовать новые вещи.
Концепт Announce-AI на Cloud Run
Чтобы преодолеть ограничение тайм-аута, я предложил использовать POST-запросы (с URL в качестве данных) для отправки заданий в инстанс и — запускать параллельно несколько инстансов, а не составлять очередь для одного. Поскольку каждый инстанс в Cloud Run скрапит только одну страницу, тайм-аут никогда не наступит, все страницы будут обрабатываться параллельно (хорошее масштабирование), а процесс высоко оптимизирован, поскольку использование Cloud Run происходит с точностью до миллисекунд.
Скрапер на Cloud Run
Если присмотреться, в процессе не хватает нескольких важных деталей.
- Происходит непрерывная экспоненциальная рекурсия: инстансы не знают, когда остановить работу, потому что оператора break не предусмотрено.
- У POST-запросов могут быть одни и те же URL. Если есть обратная ссылка на предыдущую страницу, то сервис Cloud Run застрянет в бесконечной рекурсии, но хуже всего то, что эта рекурсия умножается экспоненциально (максимальное количество инстансов было установлено на 1000!)
Как вы можете себе представить, это привело к ситуации, в которой 1000 инстансов делают запросы и записи в Firebase DB каждые несколько миллисекунд. Мы увидели, что по операциям чтения Firebase в какой-то момент проходило около 1 миллиарда запросов в минуту!
Сводка транзакций на конец месяца для GCP
116 миллиардов операций чтения и 33 миллиона записей
Экспериментальная версия нашего приложения на Cloud Run сделала 116 миллиардов операций чтения и 33 миллиона записей в Firestore. Ох!
Стоимость операций чтения на Firebase:
$ (0.06 / 100,000) * 116,000,000,000 = $ 69,600
 06 / 100,000) * 116,000,000,000 = $ 69,600
06 / 100,000) * 116,000,000,000 = $ 69,60016 000 часов работы Cloud Run
После тестирования из остановки логов мы сделали вывод, что запрос умер, но на самом деле он ушёл в фоновый процесс. Поскольку мы не удалили сервисы (мы первый раз использовали Cloud Run, и тогда действительно не понимали этого), то несколько сервисов продолжали медленно работать.
За 24 часа все эти службы на 1000 инстансах отработали в общей сложности 16 022 часа.
Деплой ошибочного алгоритма в облаке
Уже обсуждалось выше. Мы действительно обнаружили новый способ бессерверного использования POST-запросов, который я не нашёл нигде в интернете, но задеплоили его без уточнения алгоритма.
Деплой Cloud Run с параметрами по умолчанию
При создании службы Cloud Run мы выбрали в ней значения по умолчанию. Максимальное число инстансов 1000, а параллелизм — 80 запросов. Мы не знали, что эти значения на самом деле наихудший сценарий для тестовой программы.
Если бы мы выбрали max-instances=2, затраты были бы в 500 раз меньше.
Если бы установили concurrency=1, то даже не заметили бы счёт.
Использование Firebase без полного понимания
Кое-что понимаешь только на опыте. Firebase — это не язык, который можно выучить, это контейнерная платформа. Её правила определены конкретной компанией Google.
Кроме того, при написании кода на Node.js нужно подумать о фоновых процессах. Если код уходит в фоновые процессы, разработчику нелегко узнать, что служба работает. Как мы позже узнали, это ещё и стало причиной большинства таймаутов наших Cloud Functions.
Быстрые ошибки и быстрые исправления — плохая идея в облаке
Облако в целом похоже на обоюдоострый меч. При правильном использовании он может быть очень полезен, но при неправильном — пеняй на себя.
Если посчитать количество страниц в документации GCP, то можно издать несколько толстенных томов. Чтобы всё понять, в том числе тарификацию и использование функций, требуется много времени и глубокое понимание, как работают облачные сервисы. Неудивительно, что для этого нанимают отдельных сотрудников на полный рабочий день!
Неудивительно, что для этого нанимают отдельных сотрудников на полный рабочий день!
Firebase и Cloud Run действительно мощны
На пике Firebase обрабатывает около миллиарда считываний в минуту. Это исключительно мощный инструмент. Мы играли с Firebase уже два-три месяца — и всё ещё открывали новые аспекты, но до того момента я понятия не имел, насколько мощная это система.
То же самое относится и к Cloud Run! Если установить количество параллельных процессов 60, max_containers == 1000, то при запросах по 400 мс Cloud Run может обрабатывать 9 миллионов запросов в минуту!
60 * 1000 * 2.5 * 60 = 9 000 000 запросов в минуту
Для сравнения, поиск Google обрабатывает 3,8 миллиона запросов в минуту.
Используйте мониторинг
Хотя
Google Cloud Monitoring не остановит биллинг, он отправляет своевременные оповещения (задержка 3-4 минуты). Поначалу не так просто освоить терминологию Google Cloud, но если вы потратите время, то панель мониторинга, оповещения и метрики немного облегчат вашу жизнь.
Эти метрики доступны только в течение 90 дней, у нас они уже не сохранились.
Фух, пронесло
Изучив наш длинный отчёт об инциденте, описывающий ситуацию с нашей стороны, после различных консультаций, бесед и внутренних обсуждений, Google простила нам счёт!
Спасибо тебе, Google!
Мы схватили спасательный круг и использовали эту возможность, чтобы завершить разработку продукта. На этот раз — с гораздо лучшим планированием, архитектурой и намного более безопасной реализацией.
Google, моя любимая технологическая компания, — это не просто отличная компания для работы. Это также отличная компания для сотрудничества. Инструменты Google очень удобны для разработчиков, имеют отличную документацию (по большей части) и постоянно расширяются.
(Примечание: это моё личное мнение как индивидуального разработчика. Наша компания никоим образом не спонсируется и не связана с Google).
После этого случая мы потратили несколько месяцев на изучение облака и нашей архитектуры. За несколько недель моё понимание улучшилось настолько, что я мог прикинуть стоимость скрапинга «всего интернета» с помощью Cloud Run с улучшенным алгоритмом.
За несколько недель моё понимание улучшилось настолько, что я мог прикинуть стоимость скрапинга «всего интернета» с помощью Cloud Run с улучшенным алгоритмом.
Инцидент заставил меня глубоко проанализировать архитектуру нашего продукта, и мы отказались от той, что была в первой версии, чтобы построить масштабируемую инфраструктуру.
Во второй версии Announce мы не просто создали MVP, мы создали платформу, на которой могли быстрыми итерациями разрабатывать новые продукты и тщательно тестировать их в безопасной среде.
Это путешествие заняло немало времени… Announce запущен в конце ноября, примерно через семь месяцев после первой версии, но он очень масштабируемый, берёт лучшее из облачных сервисов и высоко оптимизирован.
Мы также запустились на всех платформах, а не только в интернете.
Более того, мы повторно использовали платформу для создания нашего второго продукта — Point Address. Он тоже отличается масштабируемостью и хорошей архитектурой.
Google Alerts Users About Malicious Actors Using Cloud for Cryptocurrency Mining
14. 09.20 18:26 Егор Шетюк
09.20 18:26 Егор Шетюк
Понеслась
14.09.20 18:35 Константин В.В
Биток и эфир держу до лучших времён)
14.09.20 18:38 Попко Колян
ДОБРОГО
14.09.20 18:43 Даниил
Рига смотрит
14.09.20 18:46 Вадим Никулин
Всегда смотрю Вас!
14.09.20 18:55 Захар Трофимов
Минск на проводе
14. 09.20 18:56 Щука А
09.20 18:56 Щука А
Спасибо за ваш труд
14.09.20 19:01 Никита
Хай
14.09.20 19:06 Вячеслав Левков
Отложил биток на пенсию
14.09.20 19:13 Попков С.А.
Отличные эфиры у вас
14.09.20 19:20 Щука А
Привет из Москвы
14.09.20 19:25 Алексей С.
Всем РЕСПЕКТ
14. 09.20 19:27 Николай
09.20 19:27 Николай
Вперед криптаны
14.09.20 19:34 КРИПТАН
Слышно гуд
14.09.20 19:36 Егор Шетюк
Подарите книгу)))
14.09.20 19:44 Светлана П
миллионерам привет
14.09.20 19:48 Вячеслав Левков
Крипта скам=)
14.09.20 19:53 Тоха
Понеслась
14. 09.20 19:57 Носов А.А
09.20 19:57 Носов А.А
Рига смотрит
14.09.20 20:04 Прокоп
Донаты принемаете?
14.09.20 20:06 Носов А.А
спасибо
14.09.20 20:12 Юрий Ник
Тюмень рулит😁
14.09.20 20:18 Даниил
миллионерам привет
14.09.20 20:18 Нина
17$. Биток и эфир держу до лучших времён)
14. 09.20 20:24 Никита
09.20 20:24 Никита
18$. Задонатю вам баблишка)
14.09.20 20:25 Вячеслав Левков
Поможем парням лайками, я уже свой поставил
14.09.20 20:26 Павел Скоровойтов
Слава эфиру
14.09.20 20:35 Носов А.А
Привет, пацаны. Слышно, видно хорошо
14.09.20 20:36 Тоха
Шалом
14.09.20 20:44 Лена
Биток и эфир держу до лучших времён)
14. 09.20 20:47 Нина
09.20 20:47 Нина
ку-ку)
14.09.20 20:53 Попков С.А.
Все good. Ростем потихоньку и падаем, как всегда
14.09.20 20:58 Санек
Всем РЕСПЕКТ
14.09.20 21:01 Славка Орехов
Спасибо за ваш труд
14.09.20 21:10 Ваня А,
Привет, пацаны. Слышно, видно хорошо
14.09.20 21:13 Нина
ДОБРОГО
14. 09.20 21:20 Никита
09.20 21:20 Никита
Привет парни!
14.09.20 21:25 Егор Шетюк
Hello
14.09.20 21:27 Вячеслав Левков
ку-ку)
14.09.20 21:33 Попков С.А.
Тамбов с вами братва
14.09.20 21:37 Серега Бумер
Слава эфиру
14.09.20 21:42 Ваня А,
Подарите книгу)))
14. 09.20 21:50 Павел Скоровойтов
09.20 21:50 Павел Скоровойтов
Поможем парням лайками, я уже свой поставил
14.09.20 21:54 Захар Трофимов
Привет парни!
14.09.20 21:56 Санек
Отложил биток на пенсию
14.09.20 22:03 Носов А.А
Привет, пацаны. Слышно, видно хорошо
14.09.20 22:03 Попков С.А.
14$. Надо изучать Defi , интересно
14. 09.20 22:09 Николай
09.20 22:09 Николай
Поможем парням лайками, я уже свой поставил
14.09.20 22:14 Вадим Никулин
Я из РБ слежу за вами давно💰
14.09.20 22:17 Николай
Поможем парням лайками, я уже свой поставил
14.09.20 22:24 Лена
Я снова с вами)))
14.09.20 22:28 Носов А.А
Отложил биток на пенсию
14.09. 20 22:31 Серега Бумер
20 22:31 Серега Бумер
Тюмень рулит😁
14.09.20 22:40 Светлана П
Сморгонь 👍
14.09.20 22:43 Вадим Никулин
Отложил биток на пенсию
14.09.20 22:46 Николаев
Круто
14.09.20 22:53 Ваня А,
Люблю ваши трансляции, вы крутые!
14.09.20 22:58 Вячеслав Левков
Биток вперед!!!
14. 09.20 23:05 Носов А.А
09.20 23:05 Носов А.А
Привет всем с Украины!
14.09.20 23:06 Носов А.А
12$. здарова бандиты
14.09.20 23:09 Константин В.В
Отложил биток на пенсию
14.09.20 23:14 Прокоп
Екатеринбург на связи
14.09.20 23:18 Николаев
Круто
14.09.20 23:25 Тоха
здарова бандиты
14. 09.20 23:27 Попков С.А.
09.20 23:27 Попков С.А.
Отличные эфиры у вас
14.09.20 23:33 Лена
Поможем парням лайками, я уже свой поставил
14.09.20 23:39 Николаев
Доброе утречко
14.09.20 23:45 Лена
Как успехи?
14.09.20 23:49 Павел Скоровойтов
ку-ку)
14.09.20 23:51 Ваня А,
Привет, пацаны. Слышно, видно хорошо
Слышно, видно хорошо
14.09.20 23:57 Попков С.А.
Хомяки тут
15.09.20 00:01 Лысый Боб
Привет, пацаны. Слышно, видно хорошо
15.09.20 00:07 Санек
Слава эфиру
15.09.20 00:12 Щука А
Екатеринбург на связи
15.09.20 00:14 Нина
23$. Лайк
15. 09.20 00:16 Юрий Ник
09.20 00:16 Юрий Ник
Вперед криптаны
15.09.20 00:25 Лена
Биток и эфир держу до лучших времён)
15.09.20 00:26 Попков С.А.
Как успехи?
15.09.20 00:33 Попко Колян
Я из РБ слежу за вами давно💰
15.09.20 00:40 Даниил
миллионерам привет
15.09.20 00:50 Константин В.В
11$. Круто
Круто
17.09.20 15:31 Trident
купил билет на семинар который изначально планировался в субботу…. в пятницу не смогу послушать, гле посмотреть запись?
24.09.20 12:08 Серго1985
Как бабло зарабатывается??
15.10.20 09:16 Vyacheslav
отлично зарабатывается !)
15.10.20 09:16 Vyacheslav
у вас как?
09.02.21 10:40 ave2510
всем привет! кто то заходил в ю8д. ..?
..?
10.02.21 12:52 [email protected]
почему я на юнисвоп не вижу токен NTFI
16.02.21 18:27 Jessikagylu
Всем привет. А какой интернет вы используете для майнинга? Прочла интересную статью https://hashalot.io/blog/vyjdet-li-majning-za-limit-trafika-kakaya-skorost-interneta-nuzhna-dlya-majninga/ и задумалась над этим. Какие характеристики сети у вашего провайдера?
24.04.21 07:21 [email protected]
991532991
24.04.21 07:24 [email protected]
998991532991
24. 04.21 07:25 [email protected]
04.21 07:25 [email protected]
[email protected]
12.05.21 09:24 Calibr
Как купить доступ в закрытый чат?
18.06.21 11:05 007ja
Как войти на выбинар бесплатный в 11:00
13.07.21 19:13 ChicoChalk
Try changehero: https://changehero.io/
15.07.21 21:57 Alonzo
ребята нужна помощь не могу завести ton на кошелек ton cristal!
18. 07.21 00:04 Alonzo
07.21 00:04 Alonzo
ребят мне нужна помощь я не могу зайти в фермы !вроде делаю все как вы обьясняли но что то делаю не так нужна помощь
26.08.21 04:09 Noverlick
А значит надо оптимизировать алгоритм. Мы в Новерлик это сделали!
08.10.21 12:36 artem2121ro
Как принять участие?
18.11.21 16:42 wakawaka
test text
14.12.21 21:40 James Delic
Try Coinsbee. Ptatform which allows to buy gift cards for cryptocurrency www. coinsbee.com
coinsbee.com
Обзор майнинга в App Store с помощью R + Google Cloud Machine Learning
Дата публикации Sep 24, 2018
В этой статье описывается, как экспортировать данные из iTunes с помощью R и itunesr (поАбдул Маджед Раджа) с последующей визуализацией рейтингов и обзоров. В нем также рассказывается, как использовать googleLanguageR для перевода отзывов путем выполнения языковой обработки с помощью Google Cloud Machine Learning API перед проведением базового анализа настроений.
Зачем заботиться о рейтингах и обзорах приложений?
Обзоры содержат ценную информацию о том, что работает, а что нет, и поэтому следует рассматривать как золотую жилу. Отзывы могут быть единственным источником информации о том, почему приложение не работает. Поэтому, если кто-то спросит, зачем заботиться о бесплатной, ценной и незапрашиваемой обратной связи с пользователями 2018 года, вам лучше убедиться, что вы находитесь в нужном месте. Просто следите за своим поведением в Интернете, и вы найдете ответ.
Просто следите за своим поведением в Интернете, и вы найдете ответ.
Основные идеи о важности рейтингов и обзоров приложений:
Разделение пользователя означает заботу о компании
Покупка нестандартного инструмента для анализа приложений или создание собственной платформы
Работа с аналитическим майнингом может быть сложной, но дает вам квалифицированную информацию, которая может помочь создать более качественные услуги и, как мы надеемся, повысить лояльность пользователей. Чтобы получить положительный эффект, вам нужен метод, как выполнить работу. К сожалению, App Store не помогает вам классифицировать положительные и отрицательные отзывы с течением времени. Кроме того, вам необходимо определить систематический процесс, в котором схожие отзывы группируются перед анализом. Распределение по категориям положительных и отрицательных отзывов, ошибки от квалифицированных улучшений UX или более широкие предложения функций увеличат эффективность и облегчат будущие приоритеты.
Итак, с чего начать? Либо вы платите за иногда дорогую подписку с помощью специального, но мощного инструмента, такого как Appbot, MobileAction, App Annie или SensorTower, либо сами создаете индивидуальное решение и экономите тысячи долларов. Вместо этого я бы использовал эти инструменты для экспорта исторических данных, а затем создал бы собственное решение для майнинга в Tableau или в качестве блестящего веб-приложения в R.
Отказ от ответственности:Недостатком App Store Connect является то, что вам разрешено экспортировать последние 500 отзывов для каждой страны / рынка и только рейтинги, связанные с обзором. Это повлияет на всю агрегированную отчетность, поскольку последние 500 обзоров в США могут быть собраны за одну неделю, но меньший рынок, такой как Венгрия, может охватывать наблюдения за предыдущие двенадцать месяцев. Можно сохранять промежуточные данные каждый день или неделю для сохранения исторических данных. Если нет, будьте осторожны с вашими выводами.
Плюсом создания гибкого решения является возможность перекрестной проверки данных и планирования автоматизированных задач на основе различных сценариев. Кроме того, сократив объем кода и визуализаций, вы можете в течение секунды бесплатно проводить исследования приложений.
Обзор аналитики с R и Itunesr
Почему выбирают R? R — это язык статистического программирования для качественного и количественного анализа, разработанный учеными с множеством библиотек для статистики, машинного обучения и обработки данных. Огромным преимуществом с R является возможность создавать интерактивные веб-приложения с R Markdown. Таким образом, это эффективный способ быстрого и интерактивного распространения данных в организации. Проверьте курсПрограммирование с R на Courseraесли вы совершенно новичок в R.
Я был вдохновлен Абдул Маджед Радж, который также является автором пакета itunesr после прочтенияАнализ iOS App Store iTunes Отзывы в R, Еще одним источником вдохновения для того, какие данные визуализировать и как, является статьяАнализ рейтингов и обзоров приложения PodCruncher на iTunesГригория Е Каневского.
Сегодня я использую itunesr для получения информации о приложениях для оценки производительности и определения приоритетов будущего развития. Но также, чтобы автоматизировать отрицательные рейтинги и подтолкнуть их непосредственно к Slack с Slackr. Я надеюсь, что вы сможете найти свои собственные творческие способы распространения данных проверок в вашей организации.
Я все еще начинающий пользователь R, поэтому я позволю себе растянуть принцип СУХОЙ (не повторяйся). Пожалуйста, будьте терпеливы.
Выбранные инструменты и пакеты для анализа и визуализации(iTunes, RStudio, Google Translate API, Google Cloud, ggplot2 & dplyr )Что именно мы ищем?
Изучение обзоров может быть сделано различными способами и методами. Наша цель — узнать, как на самом деле работает каждый рынок, проанализировав:
- Распределение рейтинга приложений
- Чувство пользователя (негатив / позитив)
- Средний рейтинг по версии приложения
- Средний рейтинг за день месяца
- Средняя длина символа обзора
- Перевод текста с помощью googleLanguageR
- Анализ текстовых настроений
Начните с загрузкири IDE,RStudio, Во-вторых, нам нужно собрать список всего необходимогоApple Store Коды страндля нашей визуализации рынка. Чтобы получить данные приложения, нам нужен идентификатор приложения iOS, который можно найти в URL-адресе iTunes. Просто Google ваш любимый приложение и скопируйте идентификатор.
Чтобы получить данные приложения, нам нужен идентификатор приложения iOS, который можно найти в URL-адресе iTunes. Просто Google ваш любимый приложение и скопируйте идентификатор.
Теперь установите и загрузите необходимые библиотеки. Вы можете сделать это в своем исходном коде, написав install (the-library), или щелкнуть Packages> Install из репозитория CRAN. itunesr может быть установлен непосредственно из CRAN, но я рекомендую установить последнюю версию разработки сGithubвместо.
# Install and load libraries
devtools::install_github("amrrs/itunesr")
remotes::install_github("ropensci/googleLanguageR")library(itunesr)
library(googleLanguageR)
library(openxlsx)
library(ggplot2)
library(writexl)
library(tidyr)
library(dplyr)
library(sentimentr)
library(scales)
library(tidyverse)
library(tidytext)
library(DataExplorer)# Spotify iOS App ID
appstoreID = 324684580# Get information about the Spotify App
getAttributes(appstoreID,'se')# Create this df for later purpose
df_App_allMarkets = NULL
ФункцияgetAttributesпредставляет заголовок приложения, разработчика, пакета, URL-адреса и категории в нашей консоли RStudio.
Хорошо, давайте пнуть это! Далее, мы собираемся создать пустой фрейм данных, который будет содержать последние 500 обзоров, которые Apple позволяет нам импортировать.(Spotify присутствует на65 рынков, но для этого примера я использовал только 12 из них), Затем мы устанавливаем переменные для второй и последней страницы обзора в iTunes перед созданием цикла for, который будет проходить через все обзоры с каждого рынка и связывать их вместе в один фрейм основных данных.
## 1. Prepare to loop through last 500 reviews per market# Spotify App Store Country Codes
appMarketsSpotify <- c("se", "us", "dk", "de", "hu", "it", "nl", "no", "br", "ca", "ch")# Each page has 51 reviews between each pagination
no_ratings <- 500 #500
no_reviews_per_page <- 51
ratings <- no_ratings/no_reviews_per_page# Round up pagination & set variables for second and last page
ratings <- ceiling(ratings) #round up to 10
reviewStartPage <- 2
reviewEndPage <- ratings
Следующий кусок кода будет проходить по каждой странице обзора для данного рынка, прежде чем объединить их вместе. Затем мы конвертируем переменную
Затем мы конвертируем переменнуюdf_App$Dateот POSIXt по умолчанию к дате, сортируйте и упорядочивайте столбцы по индексу перед созданием фрейма данных локального рынка в конце Наконец, мы связываем все фреймы данных вместе сrbind(df_App_allMarkets, df_App_Market).Вполне возможно, что вы получите дублированные обзоры, почему необходимо удалить их с помощью команды,unique(data frame)В зависимости от количества обзоров и рынков сценарий может занять несколько минут. ☕
## 2. Loop through all App markets and bind them togetherЦикл по каждому рынку и привязать все кадры данных к одному
for (appMarket in appMarketsSpotify) {# Creates a df with first review page (1)
df_App <- getReviews(appstoreID,appMarket,1)# Create a for loop and merge all tables in to one single df
for (page in reviewStartPage:reviewEndPage){
df_App <- rbind(df_App, getReviews(appstoreID,appMarket, page))
}# Convert 'Date' from POSIXt to Date and sort df by date (ascending)
df_App$Date <- as.
df_App <- df_App[order(df_App$Date),]# Reorder columns in our df by column index and add market suffix
df_App <- df_App[c(7, 4, 5, 1, 6, 2, 3)]
df_App$Market=appMarket# Create df for each local market
df_App_Market <- print(appMarket)
df_App_Market <- df_App# Bind all markets together into one single df
df_App_allMarkets <- rbind(df_App_allMarkets, df_App_Market)# Remove dublicated reviews
df_App_allMarkets <- unique(df_App_allMarkets)### End loop
}
 Date(df_App$Date)
Date(df_App$Date)Прежде чем визуализировать наш фрейм данных, давайте проверим размерность входного набора данных, чтобы понять, с чем мы имеем дело. Я использую библиотеку DataExplorer, чтобы провести быструю EDA нашего фрейма данных путем записи.plot_str(df_App_allMarkets)
Теперь давайте предварительно просмотрим и рассмотрим наш сводный фрейм данныхdf_App$Marketпросто написавView(df_App$Market)и нажмите ввод. Ниже Глобальной среды в RStudio GUI мы можем изучить наш фрейм данных, чтобы увидеть, что собрано 6908 наблюдений, разделенных на 8 столбцов.
Ниже Глобальной среды в RStudio GUI мы можем изучить наш фрейм данных, чтобы увидеть, что собрано 6908 наблюдений, разделенных на 8 столбцов.
Простой qplot, показывающий распределение рейтингов
Чтобы получить информацию о количестве отзывов на рынок, используйтеtable(df_App_allMarkets$Market)илиtable(df_App_allMarkets$Rating)изучить распределение рейтинга. Для графической визуализации сюжетных обзоров сqplot(df_App_allMarkets$Rating),
2.1 Экспорт фрейма данных в Excel
Возможно, нам потребуется вернуться и обработать наш фрейм данных позже, поэтому вместо того, чтобы периодически перезапускать приведенный выше скрипт, более эффективно экспортировать все рецензии в базу данных SQL, Excel или CSV-файл. Прежде чем сделать это, нам нужно внести некоторые незначительные изменения, например, изменить суффиксы стран на названия стран.
# Sort df by rating 1-5
df_App_allMarkets$Rating <- factor(df_App_allMarkets$Rating,
levels = c("1", "2", "3", "4", "5"))# Convert data types & rename country codes before visualization
df_App_allMarkets$Rating <- as.
df_App_allMarkets$Date <- as.Date(df_App_allMarkets$Date)df_App_allMarkets$Market <- revalue(df_App_allMarkets$Market,
c("se" = "Sweden",
"us" = "USA",
"de" = "Germany",
"hu" = "Hungary",
"it" = "Italy",
"nl" = "Netherlands",
"no" = "Norway",
"br" = "Brazil",
"ch" = "Switzerland",
"gb" = "Great Britain",
"ca" = "Canada",
"dk" = "Denmark"))
 numeric(df_App_allMarkets$Rating)
numeric(df_App_allMarkets$Rating)Теперь давайте использовать пакет Ropenxlsxэкспортировать df как файл Excel. ФайлAppStoreReviews.xlsxбудет храниться в вашем локальном рабочем каталоге. Если вы не уверены в своем домашнем пути, напишитеgetwd()и нажмите ввод.
#Save as Excel to back up collected reviewsСохраните локальный файл XLSX в качестве резервной копии на будущее
write_xlsx(df_App_allMarkets, path = ("AppStoreReviews.xlsx"), col_names = TRUE)
Теперь мы можем даже создавать запланированные задачи в R и добавлять новые обзоры в нашу основную таблицу либо локально на Google Drive.
ПоздравляюВы просто сэкономили сотни долларов за то, что не купили инструмент, который делает более или менее то же самое.
2.2 Визуализировать рейтинги и отзывы
Пришло время для визуализации, и мы собираемся использовать ggplot2 для дальнейшего изучения и, надеюсь, извлечем ценную информацию из наших собранных обзоров.N.Bчто мы работаем только с последними 500 отзывами на рынок и что все рейтинги связаны с уникальным обзором. Spotify Music имеет 4.7-звездочный рейтинг в App Store. Это на 20% выше, чем рейтинги с обзором, где средний рейтинг составляет 3,9,mean(df_App_allMarkets$Rating)Как упоминалось ранее, пользователи, пишущие обзоры, в основном чаще недовольны, чем те, кто только раздает оценки.
2.3 Отсутствие достаточного количества данных
Поскольку период времени для отправленных обзоров приложений Spotify на каждом рынке отличается, вы не можете сделать какие-либо существенные выводы на основе последних 500 обзоров. Если мы продолжим работу с нашей базой данных основных данных, мы заметим, что рынки с более частыми отзывами и оценками пользователей будут распределяться относительно неравномерно, чем рынки с меньшим количеством обзоров. Следовательно, мы должны быть осторожны с нашими предположениями при агрегировании данных со всех рынков. Давайте представим эту модель
Если мы продолжим работу с нашей базой данных основных данных, мы заметим, что рынки с более частыми отзывами и оценками пользователей будут распределяться относительно неравномерно, чем рынки с меньшим количеством обзоров. Следовательно, мы должны быть осторожны с нашими предположениями при агрегировании данных со всех рынков. Давайте представим эту модельqplot(df_App_allMarkets$Date).
Очевидно, что подавляющее большинство обзоров было сделано в течение последних 60 дней. На самом деле только в США было +500 отзывов за последние 7 дней. (Но это не обычное приложение, иди 🇸🇪).
Если вы получили всего около 200 отзывов на каждый рынок, чем вы в безопасности, но, как и в нашем случае, мы застряли с 166 952 отзывами и 2 858 871 оценками за последние 365 дней и поэтому настоятельно рекомендуем собрать больше данных. Поскольку цель этого поста — продемонстрировать принцип возможных, а не точных цифр, я сэкономил деньги на чем-то другом, кроме дорогих лицензий.
3.1 Распределение рейтинга приложений
Проблема:Нам нужно сравнить распределение рейтингов на каждом рынке, чтобы понять различия. Распространенная гипотеза о рейтингах заключается в том, что вы либо счастливый пользователь, либо злой хулитель, это будет отражать диаграммы, в которых вы видите большое количество 1- и 5-звездочных рейтингов.
Решение:Давайте рассмотрим распределение сgeom_bar.
### App rating distribution per marketggplot(df_App_allMarkets, aes(x=as.factor(Rating), fill=as.factor(Rating))) +Распределение рейтинга приложений (1–5) на рынок
geom_bar(col="white")+
theme_bw() +
labs(title="App rating distrubution per market",
x="Ratings 1-5", y="No of Ratings")+theme(plot.title = element_text(family = "Circular Std", color="black", face="bold", size=22, hjust=0))+scale_fill_manual("Ratings", values = c("1" = "#DA393B", "2" = "#EE6D45", "3" = "#F7E458", "4" = "#68E194", "5" = "#5F9CEF"))+
facet_wrap(~Market, scales = 'free_x')
Insights:Оценки в 1 или 5 звезд, кажется, являются самыми популярными рейтингами для раздачи. Наиболее довольные пользователи находятся в Венгрии, Швеции, Норвегии и Италии. Однако большинство неудовлетворенных пользователей находятся в Бразилии, Канаде, Германии и Швейцарии. Я бы проанализировал, почему так много венгерских пользователей с радостью раздают 5-звездочные рейтинги и выполняет анализ ключевых слов для всех 1-звездочных рейтингов в Германии. Кроме того, постройте линейный график со средними рейтингами по неделям, чтобы понять историческое развитие.
Наиболее довольные пользователи находятся в Венгрии, Швеции, Норвегии и Италии. Однако большинство неудовлетворенных пользователей находятся в Бразилии, Канаде, Германии и Швейцарии. Я бы проанализировал, почему так много венгерских пользователей с радостью раздают 5-звездочные рейтинги и выполняет анализ ключевых слов для всех 1-звездочных рейтингов в Германии. Кроме того, постройте линейный график со средними рейтингами по неделям, чтобы понять историческое развитие.
3.2 Чувство пользователя (отрицательное / положительное)
Проблема:Сравнение 12 разных рынков на одном и том же графике с рейтингом 1–5 звезд может быть затруднено. Итак, давайте избавимся от всех нейтральных 3-звездочных рейтингов и разберем их по количеству отрицательных (1–2 звезды) и положительных (4–5 звезд) оценок.
Решение:Сначала создайте новый фрейм данных на основеdf_App_allMarkets.Затем мы преобразуем переменную Rating из числового значения в символ, прежде чем заменить оценки положительными и отрицательными символами. Наконец, выведите результат в виде доли от общего объема для каждого рынка.
Наконец, выведите результат в виде доли от общего объема для каждого рынка.
### User feeling for each market# Create a new df based on df_App_allMarketsРаспределение между отрицательными и положительными оценками
df_Ratings_Simplified <- data.frame("Date" = df_App_allMarkets$Date, "Rating" = df_App_allMarkets$Rating, "AppVersion" = df_App_allMarkets$App_Version, "Market" = df_App_allMarkets$Market)# Convert ratings to vector and replace ratings with text
df_Ratings_Simplified$Rating <- as.character(df_Ratings_Simplified$Rating)# Remove all ratings with 3-stars from df
df_Ratings_Simplified <- df_Ratings_Simplified[!df_Ratings_Simplified$Rating == "3", ]# Replace 1-2 star ratings with text Negative, and 4-5 stars with text Positivedf_Ratings_Simplified$Rating[df_Ratings_Simplified$Rating == '1']
<- 'Negative'+df_Ratings_Simplified$Rating[df_Ratings_Simplified$Rating == '2']
<- 'Negative'+df_Ratings_Simplified$Rating[df_Ratings_Simplified$Rating == '4']
<- 'Positive'+df_Ratings_Simplified$Rating[df_Ratings_Simplified$Rating == '5']
<- 'Positive'# Plot user feelings for each market
ggplot(df_Ratings_Simplified, aes(Rating, group = Market)) +
geom_bar(aes(y = .
geom_text(aes( label = scales::percent(..prop..), y= ..prop.. ), size = 4, stat= "count", vjust = -0.4) +theme_bw() +
theme(legend.position="none")+
scale_fill_manual("Ratings", values = c("1" = "#ED5540", "2" = "#68E194"))+
labs(y = "Rating", fill="Rating") +
scale_y_continuous(labels=scales::percent, limits = c(0, 1)) +ylab("relative frequencies") +
xlab("Procent") + labs(title="User feeling per market", x="Reviews", y="Amount")+
labs(caption = "(Negative = 1-2 stars, Positive = 4-5 stars)")+facet_wrap(~Market, scales = 'free_x')
 .prop.., fill = factor(..x..)), stat="count") +
.prop.., fill = factor(..x..)), stat="count") + Insights:Не менее важно понимать мотивы и разницу между довольными и разочарованными пользователями. Результат кажется одинаковым для каждого рынка, за исключением пользователей в США, Канаде, Бразилии и Германии, которые более недовольны. Анализируя эти обзоры, вы можете найти сходства.
3.3 Чувство пользователя в будний день
Проблема:Положительные или отрицательные оценки могут быть легко сегментированы для представления данных за месяц, неделю или за день. Если нам нужно понять, когда публикуются обзоры и как различаются чувства пользователей в течение недели, мы можем сделать это, визуализируя ощущения за будний день.
Решение:Сначала мы конвертируем нашу переменную дату (2018–08–23) в день недели, например, Суббота. Затем мы отображаем результаты в виде столбчатой диаграммы с накоплением, показывающей количество положительных и отрицательных отзывов, включая общее количество. Если вам нужно сравнить разницу между рынками, просто раскомментируйте последний ряд ниже.
### Plot feelings by weekday
df_Ratings_Feeling_Week <- df_Ratings_Simplified
df_Ratings_Feeling_Week$Date <- format(as.Date(df_Ratings_Feeling_Week$Date), '%A')ggplot(df_Ratings_Feeling_Week, aes(x = as.factor(Date), fill = Rating, label = Rating)) +
geom_bar(stat = "count")+
theme_bw() +
scale_fill_manual("Ratings", values = c("Positive" = "#68E194", "Negative" = "#ED5540"))+
theme(plot.
xlab("Procent")+
labs(title="User feeling per weekday", x="Weekday", y="Ratings")+
labs(caption = "(Negative = 1-2 stars, Positive = 4-5 stars)")+
scale_x_discrete(limits=c("Måndag","Tisdag","Onsdag","Torsdag","Fredag","Lördag","Söndag"))#facet_wrap(~Market, scales = 'free_x')
 title = element_text(family = "Circular Std", color="black", face="bold", size=26, hjust=0)) +ylab("relative frequencies")+
title = element_text(family = "Circular Std", color="black", face="bold", size=26, hjust=0)) +ylab("relative frequencies")+Insights:В будние дни равномерное распределение. Количество обзоров приводится по средам и воскресеньям, а доля отрицательных и положительных комментариев за небольшим исключением даже по понедельникам распределяется.
3.4 Средние оценки по версии приложения
Проблема:Чтобы понять, насколько хорошо толпа получила каждый релиз с его функциями, мы можем построить средний рейтинг для каждой версии приложения по рынку.
Решение:Сначала мы агрегируем все оценки по версии приложения и рассчитываем средние оценки со средним значением. Затем мы переименовываем столбцы и сортируем рейтинги по возрастанию. Наконец, удалите строки с нулевым рейтингом, в нашем случае строки 10, 11, 12, 16, 22 и 38. Затем постройте результат.
Затем мы переименовываем столбцы и сортируем рейтинги по возрастанию. Наконец, удалите строки с нулевым рейтингом, в нашем случае строки 10, 11, 12, 16, 22 и 38. Затем постройте результат.
### Average ratings per App versionГрафик, показывающий средний рейтинг приложения, отсортированный по версии и рейтингу
# Creates a df with mean values for each app version
df_MeanRatingsVersion <- aggregate(df_App_allMarkets$Rating ~ df_App_allMarkets$App_Version, df_App_allMarkets, mean)# Rename df columns
names(df_MeanRatingsVersion)[1]<- "Version"
names(df_MeanRatingsVersion)[2]<- "Rating"# Sort by ratings ascending
df_MeanRatingsVersion$Version <- factor(df_MeanRatingsVersion$Version, levels = df_MeanRatingsVersion$Version[order(-df_MeanRatingsVersion$Rating)])# Strip specific rows and round mean values
df_MeanRatingsVersion <-
df_MeanRatingsVersion[-c(10, 11, 12, 16,22,38), ]df_MeanRatingsVersion$Rating <-
round(df_MeanRatingsVersion$Rating, digits = 2)# Plot average ratings for each app version
ggplot(df_MeanRatingsVersion, aes(x = Version, y = Rating, label=Rating)) +
geom_bar(fill = "#29E58E", stat = "identity")+
geom_text(position = 'identity', stat = 'identity', size = 4, vjust = -0.theme_bw() +
labs(title="Average ratings for each App Version", size=60) +
labs(x="App Version", y="Avg. Rating")
 4)+
4)+Insights:Надеемся, что история, основанная на данных выше, будет лучше рассказана человеком внутри Spotify, чем снаружи. Несмотря на это, сложно понять, имеет ли рейтинг какое-либо отношение к конкретной версии приложения на момент проверки или имеет более общий характер. Однако, глядя на средний рейтинг в долгосрочной перспективе, мы видим, что средний рейтинг увеличивается со временем.
3.5 Средний рейтинг за день месяца
Проблема:В зависимости от категории вашего приложения и чувствительности к циклическому поведению может быть интересно узнать, меняются ли средние рейтинги в течение каждого месяца. Например, важно изучить, существует ли какая-либо связь между высоким уровнем использования и высокими / низкими рейтингами?
Решение:График среднего рейтинга для каждого дня месяца. Начнем подсчитывать среднюю оценку и переименовывать столбцы. Затем мы конвертируем даты в день месяца с
Начнем подсчитывать среднюю оценку и переименовывать столбцы. Затем мы конвертируем даты в день месяца сPOSIXltи разделить дни и рейтинги на отдельные столбцы. Круглые рейтинги до 1 цифры, чем график данных
### Calculate average ratings for each day and change column namesГрафик, показывающий, как меняется ежемесячный рейтинг в течение месяца
df_MeanRatingsDays <- aggregate(df_App_allMarkets$Rating ~ df_App_allMarkets$Date, df_App_allMarkets, mean)
names(df_MeanRatingsDays)[1]<- "Date"
names(df_MeanRatingsDays)[2]<- "Rating"# Convert dates to day of month
df_MeanRatingsDays$Date <- unclass(as.POSIXlt(df_MeanRatingsDays$Date))$mday# Split Day of month and avg. rating to separate columns
df_MeanRatingsDays <- aggregate(df_MeanRatingsDays$Rating ~ df_MeanRatingsDays$Date, df_MeanRatingsDays, mean)
names(df_MeanRatingsDays)[1]<- "Day"
names(df_MeanRatingsDays)[2]<- "Rating"# Round Ratings to 1 digit
df_MeanRatingsDays$Rating <-
round(df_MeanRatingsDays$Rating, digits = 1)# Plot mean ratings for each day of month
ggplot(df_MeanRatingsDays, aes(x = Day, y = Rating, label = Rating))+
geom_bar(fill = "#29E58E", stat = "identity")+
theme_bw() +
geom_text(position = 'identity', stat = 'identity', size = 4, vjust = -0.
theme(plot.title = element_text(family = "Circular Std", color="black", face="bold", size=26, hjust=0)) +
labs(x="Day of Month", y="Avg. Rating")+scale_x_discrete(limits=df_MeanRatingsDays$Day)+
scale_y_continuous(limits = c(0,5))
 4)+labs(title="Average ratings by day of month", size=60) +
4)+labs(title="Average ratings by day of month", size=60) +Insights:Никаких захватывающих идей, чтобы построить что-то, кроме того, что оно довольно равномерно распределено, что является лишь признаком того, что определенный день месяца не влияет на средний рейтинг. Если вы работаете в сфере финансов или здравоохранения, картина может выглядеть иначе. Я также рекомендовал бы изучать рейтинги по времени дня, дням недели и месяцам.
3.6 Средняя длина символа обзора
Наш следующий график может быть лучше определен как EDA (исследовательский анализ данных), чем решение проблем, но я хотел посмотреть, есть ли какие-либо различия между длиной обзора для каждого рынка, рассматривая как плотность, так и среднюю длину обзора. Поскольку мы уже знаем распределение рейтинга по рынкам, было бы интересно посмотреть, соответствует ли оно длине обзора.
Поскольку мы уже знаем распределение рейтинга по рынкам, было бы интересно посмотреть, соответствует ли оно длине обзора.
Итак, начнем с подсчета длины каждого обзора, а затем средней длины по рынку. Затем мы переименовываем наши столбцы и объединяем их с фреймом основных данных, а затем округляем числа, а затем строим график плотности обзора, включая среднюю длину по рынку. (Теперь вы можете дышать)
### Count length of reviews and create a sorted df_App_allMarkets$Review <- as.character(df_App_allMarkets$Review)Участок разделен по рынку, показывая среднюю длину обзора
df_App_allMarkets$ReviewLength <- nchar(df_App_allMarkets$Review)# Count the average review lenght for each market
df_MeanLengthMarket <- aggregate(df_App_allMarkets$ReviewLength ~ df_App_allMarkets$Market, df_App_allMarkets, mean)names(df_MeanLengthMarket)[1]<- "Market"
names(df_MeanLengthMarket)[2]<- "AvgReviewLength"df2_App_allMarkets <-
merge(df_App_allMarkets,df_MeanLengthMarket, by = "Market")# Round numbers before visualizing
df2_App_allMarkets$AvgReviewLength <- round(df2_App_allMarkets$AvgReviewLength, digits = 2)ggplot(data=df2_App_allMarkets, aes(x=ReviewLength)) +
geom_density(aes(y = .
geom_vline(aes(xintercept = df2_App_allMarkets$AvgReviewLength), linetype = "dashed", size = 0.5)+facet_wrap(~Market, scales = 'free')+
geom_text(data=df2_App_allMarkets, mapping=aes(x=AvgReviewLength, y=2, label=AvgReviewLength), check_overlap = TRUE, size=5, angle=0, vjust=1, hjust=-0.5)+
ylim(0,5)+
xlim(5,600)+theme_minimal()+
labs(title="Review Character Length", subtitle = "The average length per review for each market", x="Review Length", y="")+
theme(plot.title = element_text(family = "Circular Std", color="black", face="bold", size=22, hjust=0)) +
theme(axis.title = element_text(family = "Circular Std", color="black", face="bold", size=12)) +
theme(plot.subtitle = element_text(family = "Helvetica", color="black", face="plain", size=14))+
theme(strip.text = element_text(face="bold", size=12)) +
theme(panel.border = element_blank(), panel.grid.major = element_blank(),
panel.grid.
 .count..), color="#1F3161", fill = "#68E193", alpha=0.6) +
.count..), color="#1F3161", fill = "#68E193", alpha=0.6) + minor = element_blank(), axis.line = element_line(colour = "black"))
minor = element_blank(), axis.line = element_line(colour = "black"))И да, это похоже на совпадение между высокими оценками и несколькими персонажами. Из того, что мы знали раньше, было то, что США, Канада, Бразилия и немцы были наиболее недовольны, и ожидаем, что от Бразилии те рынки с самой высокой средней длиной символов. Кроме того, наши счастливые туристы в Венгрии, похоже, не могут сказать ничего больше, чем «tökéletes» и «hibátlan».
Распределение длины обзора для каждого рейтингаЧтобы усилить гипотезу о том, что отрицательным пользователям есть что сказать, и наоборот, давайте удалимgeom_vlineи переключиться сfacet_wrapвRating,
Совершенно очевидно, что счастливые пользователи могут сказать меньше, хотя однозвездные оценщики пишут меньше слов, таких как «дерьмо», «дерьмовое приложение» и т. Д. Пользователям, раздающим 2-3 звезды, на самом деле стоит прочитать, поскольку они часто мотивируют свои оценки. Анализируя менее популярное приложение, следите за длинными отзывами с высокими оценками. Эти отзывы могут быть поддельными.
Анализируя менее популярное приложение, следите за длинными отзывами с высокими оценками. Эти отзывы могут быть поддельными.
4.1 Перевод отзывов с помощью googleLanguageR
В наших письменных обзорах можно найти больше золота, чем просто средняя длина в рейтинге. Для проведения анализа текста и базового анализа настроений мы должны перевести письменные отзывы со всех двенадцати рынков на английский язык. Это можно сделать через API Google Cloud Machine Learning с пакетомgoogleLanguageRавторМарк Эдмонсон. Следоватьаутентифицировать руководствопрежде чем идти дальше.
Google отличный и все, но ничего не бесплатно, поэтому прежде чем переводить +100.000 отзывов, убедитесь, что вы знаете о расходах. В моем случае мне дали несколько бесплатных кредитов, но если вы этого не сделаете, я бы рекомендовал вместо этого выбрать случайную выборку ваших данных, как я сделал ниже.
Перевод отзывов с помощью Google Cloud Machine Learning APIСначала загрузите и запустите файл аутентификации * . json из своего домашнего каталога, затем выберите размер выборки и создайте новый вектор данных рецензирования, который будет переведен перед переводом. (N.B. это может занять несколько минут).
json из своего домашнего каталога, затем выберите размер выборки и создайте новый вектор данных рецензирования, который будет переведен перед переводом. (N.B. это может занять несколько минут).
### Prepare for translation of market reviews with Google Translate# Include Gooogle Cloud Service Identity
gl_auth("API Translate-xxxxxxxxxxxx.json")# Sample 5000 random rows
df2_App_allMarkets_sample <- sample_n(df2_App_allMarkets, 5000)
View(df2_App_allMarkets_sample)# Convert Reviews to character vector
text <- as.character(df2_App_allMarkets_sample$Review)# Create a new df from translated reviews (automatic lang.detection)
df_Translation <- gl_translate(text, target = "en")# Add english translated reviews to original df
df2_App_allMarkets_sample$Review_translated <- df_Translation$translatedText
Для предварительного просмотра и проверки результатов напишите:head(df2_App_allMarkets_sample$Review_translated, 10)
4.2 Выполнить анализ настроений с помощью sentimentr
Sentimentr предназначен для быстрого вычисления настроения полярности текста на уровне предложений и при необходимости агрегирования по строкам. Давайте продолжим и проведем анализ настроений, где каждому переведенному отзыву будет присвоен положительный или отрицательный балл. Наконец, мы связываем эти оценки настроения вместе с нашим фреймом основных данных для будущих графиков.
Давайте продолжим и проведем анализ настроений, где каждому переведенному отзыву будет присвоен положительный или отрицательный балл. Наконец, мы связываем эти оценки настроения вместе с нашим фреймом основных данных для будущих графиков.
## 4. Perform sentiment analysis on each review# Create a copy of df2_App_allMarkets_sample
df_ReviewSentiment <- df2_App_allMarkets_sample# Check names of the columns and drop those not needed
names(df_ReviewSentiment)
df_ReviewSentiment <- subset(df_ReviewSentiment, select = -
c(Author_URL, Author_Name, ReviewLength, Title))# Add translated reviews in our data frame
df_ReviewSentiment$ReviewTranslated <-
as.character(df2_App_allMarkets_sample$Review_translated)# Perform sentiment analysis and round values
df_ReviewSentiment$reviews_sentiment <- reviews_sentiment %>%
sentiment_by(by=NULL)df_ReviewSentiment$reviews_sentiment <-
round(df_ReviewSentiment$reviews_sentiment, digits = 2)
Чтобы проверить отзывы с наивысшей сентиментальной оценкой:head(df_ReviewSentiment$reviews_sentiment, 3)и самый низкий:tail(df_ReviewSentiment$reviews_sentiment, 3).
4.3 Подтвердить сентиментальный балл с помощью рейтинга
Из вышеприведенной картины все кажется полностью функциональным, но проведение сентиментального анализа гораздо сложнее, чем это. Поэтому возникает вопрос: в какой степени мы можем предсказать рейтинг клиента на основании его письменного мнения?
Давайте проверим, соответствуют ли наши рейтинги среднему сентиментальному баллу из наших письменных обзоров.
# Correlate sentiment score with ratingsggplot(df_ReviewSentiment, aes(Rating, reviews_sentiment$ave_sentiment, group = Rating)) +Boxplot, показывающий распределение обзора для каждого рейтинга
geom_boxplot(fill="#29E58E") +
theme_minimal()+
labs(title="App reviews sentiment score per market", y="Average sentiment score")+
geom_jitter(shape=16, size=0.7, position=position_jitter(0.3))
Квадратный график — это метод для графического изображения групп числовых данных через их квартиль. Это помогает нам визуализировать среднюю оценку и каждый отзыв как отдельное место. Возможно, это не квалифицируется как нечто искусное, что можно поставить на стену, но результат удовлетворительный. Хотя мы получили слишком много 5-звездных выбросов с оценками ниже нуля, средняя оценка коррелирует с оценками звезд. Кроме того, распределение отзывов, близкое к среднему, понятно, что хорошо.
Это помогает нам визуализировать среднюю оценку и каждый отзыв как отдельное место. Возможно, это не квалифицируется как нечто искусное, что можно поставить на стену, но результат удовлетворительный. Хотя мы получили слишком много 5-звездных выбросов с оценками ниже нуля, средняя оценка коррелирует с оценками звезд. Кроме того, распределение отзывов, близкое к среднему, понятно, что хорошо.
4 3 Просмотрите оценку настроений для каждого рынка
Чтобы полностью понять, как восприятие приложения меняется с течением времени, мы можем визуализировать среднюю оценку настроения в наших данных обзора приложений от первого собранного обзора до последнего для каждого рынка. Если это ваша метрика полюсной звезды, я бы порекомендовал отслеживать среднюю оценку настроений и использовать пакет AnomalyDetection из Twitter для отправки аварийных сигналов, когда оценка падает до определенного обоснованного порога.
(N.B, будьте осторожны с вашими рекомендациями, так как период отличается на каждом рынке. Проверьте шкалу Х, прежде чем повышать свой голос).
Проверьте шкалу Х, прежде чем повышать свой голос).
# App reviews sentiment scoreВизуализация оценки настроения по дате и рынку
ggplot(test, aes(x = Date, y = reviews_sentiment$ave_sentiment, fill=Market)) +
geom_smooth(colour="black", size=1) +
theme_bw() +
theme_minimal()+
labs(title="App reviews sentiment score per market",
subtitle = "Time period differs due to the amount of reviews in the near future",
x="Date",
y="Reviews Sentiment Scores")+
facet_wrap(~Market, scales = "free_x")
4.4 Анализ текста — Как разбить отзывы на ценные идеи
Чтобы полностью понять суть каждого обзора и то, как каждое слово влияет на общее восприятие приложения, нам нужно разбить обзорные предложения на слова. Это можно сделать с помощью так называемой токенизации. В процессе токенизации некоторые символы, такие как знаки препинания и стоп-слова, отбрасываются, чтобы превратить шум в сигнал.
Чего мы хотим достичь:
- Разделить предложения на отдельные слова
- Удалить стоп-слова
- Сюжет 100 самых распространенных слов
- Добавить оценки чувств к словам
- Сюжет самые негативные и позитивные слова
- Создайте облако слов, показывающее поляризацию
# Create a new data frame with only words
TranslatedText <- as.
TranslatedText <- data_frame(line = 1:5000, text = TranslatedText)# Split reviews to individual words - "Tokenization"
tidy_df <- TranslatedText %>%
unnest_tokens(word, text)# Remove stop words
data(stop_words)tidy_df <- tidy_df %>%
anti_join(stop_words)tidy_df %>%
count(word, sort = TRUE)
 vector(df_Translation$translatedText)
vector(df_Translation$translatedText)# Visualize words that occur +100 timesКак часто каждое слово встречается в обзоре
tidy_df %>%
count(word, sort = TRUE) %>%
filter(n > 100) %>%
mutate(word = reorder(word, n)) %>%ggplot(aes(word, n)) +
theme_minimal()+
labs(title="Words that occur more than 100 times", subtitle = "Occurring individual words in our sampled reviews", x="", y="Contribution to sentiment")+
geom_col() +
xlab(NULL) +
coord_flip()
Не удивительно, что такие слова, как «приложение», «музыка», «Spotify» и «песни» встречаются чаще. Но что более интересно, так это то, что «премия», кажется, горячая тема, а также «оплата» и «раздражает». Я бы отфильтровал все отзывы, где встречаются эти слова, а затем провел бы дальнейший анализ.
Но что более интересно, так это то, что «премия», кажется, горячая тема, а также «оплата» и «раздражает». Я бы отфильтровал все отзывы, где встречаются эти слова, а затем провел бы дальнейший анализ.
Теперь давайте разделим эти слова на две отдельные группы, положительные и отрицательные, с помощью лексикона bing.
# Add sentiment scores to each wordГрафик, показывающий наиболее часто встречающиеся негативные и позитивные слова
get_sentiments("bing")bing_word_counts <- tidy_df %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
ungroup()bing_word_countsbing_word_counts %>%
group_by(sentiment) %>%
top_n(25) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%# Visualize the distrubution of word sentiment
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
theme_minimal()+
labs(title="Distribution of word sentiment", subtitle = "Words that contribute to positive and negative sentiment", x="", y="Contribution to sentiment")+
facet_wrap(~sentiment, scales = "free_y") +
coord_flip()
Я позволю вам проанализировать этот вопрос, но интересно видеть, что у людей принципиально разные представления о приложении. Было бы интересно изучить противоположности и посмотреть, как они меняются со временем.
Было бы интересно изучить противоположности и посмотреть, как они меняются со временем.
Наконец, мы будем использовать те же данные, но с визуализацией облака слов, в котором частота одного слова отражается размером.
library(reshape2)
library(wordcloud)# Word cloud showing 200 words
tidy_df %>%
anti_join(stop_words) %>%
count(word) %>%
with(wordcloud(word, n, use.r.layout=FALSE,max.words = 200))# Word cloud showing 200 words by sentiment score
tidy_df %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
acast(word ~ sentiment, value.var = "n", fill = 0) %>%
comparison.cloud(colors = c("#D9383A", "#68E193"),
use.r.layout=FALSE,
max.words = 200)
Несмотря на то, что есть возможности для улучшения работы с разными размерами каждого слова, довольно легко понять, какие слова используются чаще всего. Эти облака могут быть разделены по рынку и / или версии приложения, чтобы следить за изменениями и тенденциями.
Я потерял тебя где-то посередине или тебе удалось прочитать весь пост? Независимо от того, я был бы очень рад вашим отзывам и мыслям о рейтингах и обзоре майнинга.
Фредрик Седерлеф,
Руководитель отдела цифровой аналитики и исследований пользователей в Коллекторском банке
Оригинальная статья
хакеров используют взломанные аккаунты Google Cloud для майнинга криптовалюты
Google предупреждает, что киберпреступники взламывали учетные записи Google Cloud Platform (GCP) для майнинга криптовалюты.
Интернет-гигант утверждает, что злоумышленники иногда загружали программное обеспечение для майнинга криптовалюты в течение всего 22 секунд после взлома облачных учетных записей.
Майнинг криптовалюты — это ресурсоемкая деятельность, в то время как вознаграждение за майнинг продолжает снижаться на фоне роста вычислительных затрат.Однако клиенты Google Cloud имеют доступ к обновляемой вычислительной мощности по цене, что делает их незащищенные облачные ресурсы целевыми киберпреступниками.
Google опубликовал выводы в своем первом отчете Threat Horizons, созданном недавно созданной группой действий по кибербезопасности, которая пытается объединить коллективную аналитическую информацию об угрозах для получения более действенной информации.
Хакеры используют самые взломанные аккаунты Google Cloud для добычи криптовалюты
Google обнаружил, что из 50 недавно взломанных экземпляров Google Cloud 86% использовались для майнинга криптовалюты.
Хакеры использовали еще 10% взломанных экземпляров Google Cloud для сканирования Интернета на предмет уязвимых систем и 8% для атаки других целей. Злоумышленники использовали 6% аккаунтов для размещения вредоносного ПО, 4% для размещения нелегального контента, 2% для запуска DDoS-ботов и 2% для рассылки спама.
Злоумышленники использовали ресурсы CPU / GPU на скомпрометированных экземплярах Google Cloud для майнинга криптовалюты или хранилища для майнинга Chia.
Google объяснил взлом учетных записей Google Cloud недостаточной гигиеной безопасности, в том числе слабыми паролями или их отсутствием и неправильной конфигурацией. Согласно отчету, злоумышленники использовали неэффективные методы обеспечения безопасности или уязвимое стороннее программное обеспечение в (75%) инцидентов. Почти в половине (48%) случаев у скомпрометированных экземпляров Google Cloud не было пароля для учетных записей или подключений API. Более чем в четверти (26%) случаев злоумышленники использовали уязвимое стороннее программное обеспечение, установленное владельцем. Аналогичным образом, 12% атак были связаны с неправильной конфигурацией облачных экземпляров или стороннего программного обеспечения, а 4% — из-за утечки учетных данных.
Согласно отчету, злоумышленники использовали неэффективные методы обеспечения безопасности или уязвимое стороннее программное обеспечение в (75%) инцидентов. Почти в половине (48%) случаев у скомпрометированных экземпляров Google Cloud не было пароля для учетных записей или подключений API. Более чем в четверти (26%) случаев злоумышленники использовали уязвимое стороннее программное обеспечение, установленное владельцем. Аналогичным образом, 12% атак были связаны с неправильной конфигурацией облачных экземпляров или стороннего программного обеспечения, а 4% — из-за утечки учетных данных.
Минимальное время между развертыванием уязвимого облачного экземпляра и взломом было менее 30 минут. В 40% случаев хакеры взломали экземпляры менее чем через 8 часов после развертывания.
Google предположил, что злоумышленники регулярно сканировали IP-адреса на предмет уязвимых облачных экземпляров. По словам исследователей, злоумышленники сканировали диапазон IP-адресов Google Cloud вместо конкретных экземпляров пользователей.
В 58% инцидентов хакеры загружали программное обеспечение для майнинга криптовалюты на взломанные экземпляры в течение 22 секунд.Google утверждает, что злоумышленники автоматизировали развертывание программного обеспечения для майнинга криптовалюты без вмешательства человека.
Google отметил, что человеческое реагирование на такие инциденты невозможно, и рекомендовал внедрить автоматический механизм реагирования. Точно так же клиенты облачных сред должны избегать развертывания уязвимых экземпляров в качестве первой линии защиты.
Команда Google по анализу угроз также обнаружила киберпреступников, использующих новую тактику для злоупотребления сервисами Google Cloud в гнусных целях.Например, они подписались на бесплатные пробные проекты, зарегистрировав поддельные компании, чтобы получить стартовые кредиты и получить доступ к ресурсам облачных вычислений Google.
Тем временем российские национальные злоумышленники APT28 или Fancy Bear также использовали учетные записи Google Gmail для проведения крупномасштабной фишинговой кампании с более чем 12 000 фишинговых сообщений. Точно так же северокорейские хакеры выдавали себя за сотрудников Samsung, нацеленных на южнокорейских технических работников с поддельными вакансиями.
Точно так же северокорейские хакеры выдавали себя за сотрудников Samsung, нацеленных на южнокорейских технических работников с поддельными вакансиями.
Как защитить учетные записи Google Cloud
Исследователи посоветовали клиентам Google Cloud включить различные меры безопасности для защиты своих экземпляров от майнинга криптовалюты и других облачных угроз.
Команда посоветовала клиентам провести аудит своих опубликованных проектов, чтобы убедиться, что они не раскрывают учетные данные безопасности. Кроме того, они должны проверять загруженный код, чтобы избежать установки обновлений, отравленных атаками «человек посередине» (MITM).
# Хакеры использовали аккаунты Google #Cloud, используя слабые пароли или отсутствие паролей, неправильную конфигурацию или уязвимое программное обеспечение для майнинга #cryptocurrency. # кибербезопасность #respectdataНажмите, чтобы написать твит Точно так же они должны добавить уровень безопасности, чтобы сделать скомпрометированные учетные данные непригодными для использования, требуя многофакторной аутентификации.
хакеров могут использовать взломанные учетные записи Google Cloud для установки программного обеспечения для майнинга менее чем за 30 секунд: Report
В отчете, направленном на оценку угроз для пользователей облака, группа действий по кибербезопасности Google заявила, что некоторые злоумышленники используют «плохо настроенные» учетные записи для добычи криптовалюты.
В среду команда Google заявила, что из 50 проанализированных инцидентов, которые скомпрометировали облачный протокол Google, 86% были связаны с крипто-майнингом. Хакеры использовали скомпрометированные учетные записи в облаке для доступа к ресурсам отдельных центральных или графических процессоров, чтобы добывать токены или использовать пространство для хранения при добыче монет в сети Chia.
Однако команда Google сообщила, что многие атаки не ограничивались одним вредоносным действием, таким как майнинг криптовалют, но также являлись отправными точками для проведения других взломов и выявления других уязвимых систем. По словам группы по кибербезопасности, участники обычно получали доступ к облачным учетным записям в результате «плохой практики обеспечения безопасности клиентов» или «уязвимого стороннего программного обеспечения».
По словам группы по кибербезопасности, участники обычно получали доступ к облачным учетным записям в результате «плохой практики обеспечения безопасности клиентов» или «уязвимого стороннего программного обеспечения».
«Несмотря на то, что кража данных не являлась целью этих взломов, остается риск, связанный с компрометацией облачных активов, поскольку злоумышленники начинают использовать различные формы злоупотреблений», — заявила группа действий по кибербезопасности.«Общедоступные облачные экземпляры с выходом в Интернет были открыты для сканирования и атак методом грубой силы».
Скорость атак также заслуживает внимания. Согласно анализу Google, в большинстве проанализированных инцидентов хакеры смогли загрузить программное обеспечение для майнинга криптовалют на взломанные учетные записи в течение 22 секунд. Google предположил, что «первоначальные атаки и последующие загрузки были событиями по сценарию, не требующими вмешательства человека», и сказал, что почти невозможно вручную вмешаться, чтобы остановить такие инциденты, как только они начнутся.
Связано: Google блокирует 8 «обманчивых» криптографических приложений из Play Store
Атака на облачные учетные записи нескольких пользователей с целью получения доступа к дополнительным вычислительным мощностям не является новым подходом к незаконному майнингу криптовалют. «Криптоджекинг», как его называют многие в космосе, имел несколько громких инцидентов, включая взлом Capital One в 2019 году с целью предположительно использовать серверы пользователей кредитных карт для майнинга криптовалюты. Однако криптоджекинг на основе браузера, а также майнинг криптовалюты после получения доступа через загрузку ложных приложений также по-прежнему являются проблемой для многих пользователей.
Google предупреждает пользователей о злоумышленниках, использующих облако для майнинга криптовалют — Bitcoin News
Google предупредил пользователей об использовании его платформы Google Cloud злоумышленниками для майнинга криптовалют. В своем последнем отчете Cloud Threat Intelligence под названием «Горизонты угроз», который предоставляет пользователям информацию о безопасности, компания сообщила, что 86% скомпрометированных экземпляров на платформах Google Cloud использовались для майнинга криптовалют. Большинство скомпрометированных учетных записей были защищены слабыми паролями или вообще не имели пароля.
В своем последнем отчете Cloud Threat Intelligence под названием «Горизонты угроз», который предоставляет пользователям информацию о безопасности, компания сообщила, что 86% скомпрометированных экземпляров на платформах Google Cloud использовались для майнинга криптовалют. Большинство скомпрометированных учетных записей были защищены слабыми паролями или вообще не имели пароля.
Облако Google, используемое для майнинга криптовалюты
Софтверный гигант Google предупреждает пользователей о злоумышленниках, использующих взломанные учетные записи Google Cloud для майнинга криптовалюты. Учетные записи Google Cloud имеют доступ к вычислительной мощности, которую можно легко перенаправить для выполнения вредоносных задач. Согласно первому отчету «Горизонты угроз», выпущенному Google для повышения осведомленности о недостатках безопасности в своей платформе, 86% скомпрометированных учетных записей используются для этой цели.
В отчете говорится, что майнинг криптовалюты в облаке приводит к высокому использованию мощности процессора и / или графического процессора. Он также ссылается на майнинг альтернативных криптовалют, таких как Chia, которые используют пространство для хранения в качестве ресурса для майнинга.
Он также ссылается на майнинг альтернативных криптовалют, таких как Chia, которые используют пространство для хранения в качестве ресурса для майнинга.
Причины и способы устранения
Первой причиной компрометации исследованных экземпляров Google Cloud была низкая безопасность из-за различных проблем. Одной из этих проблем был слабый или несуществующий пароль для доступа к платформе или отсутствие проверки API в экземпляре.Без применения основных мер безопасности злоумышленник может легко завладеть этими платформами. Другие облачные платформы также сталкиваются с аналогичными проблемами.
Большинство исследованных экземпляров загрузили ПО для майнинга криптовалюты менее чем за 22 секунды после взлома. Это показывает, что существуют систематические атаки на эти незащищенные экземпляры с единственной целью — использовать их для этой цели. Кроме того, злоумышленники, похоже, активно отслеживают эти незащищенные экземпляры Google, учитывая, что 40% незащищенных экземпляров были скомпрометированы в течение восьми часов после развертывания. Google заявил:
Google заявил:
Это говорит о том, что пространство общедоступных IP-адресов регулярно сканируется на наличие уязвимых экземпляров Cloud. Вопрос не в том, будет ли обнаружен уязвимый экземпляр Облака, а в том, когда.
Для снижения этих рисков в отчете пользователям рекомендуется следовать основным передовым методам обеспечения безопасности и внедрять анализ контейнеров и веб-сканирование — инструменты, которые будут проверять систему на наличие слабых мест в системе безопасности с использованием различных методов, таких как сканирование.
Что вы думаете об использовании экземпляров Google для майнинга криптовалюты злоумышленниками? Расскажите нам в комментариях ниже.
Серджио Гощенко
Серхио — криптовалютный журналист из Венесуэлы. Он описывает себя опоздавшим к игре и вступившим в криптосферу, когда в декабре 2017 года произошел рост цен. Имея опыт работы в области компьютерной инженерии, живя в Венесуэле и находясь под влиянием бума криптовалюты на социальном уровне, он предлагает другую точку зрения.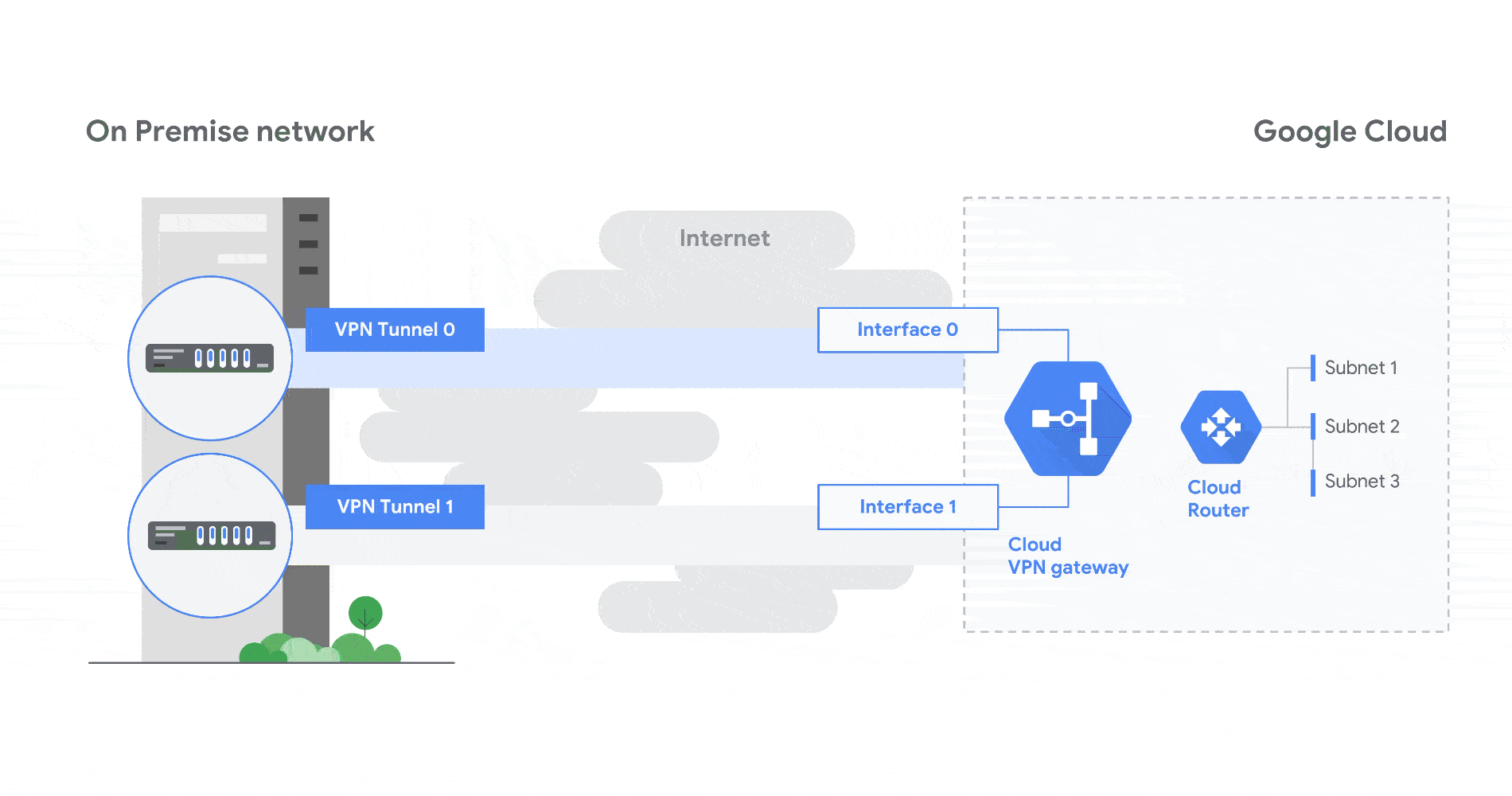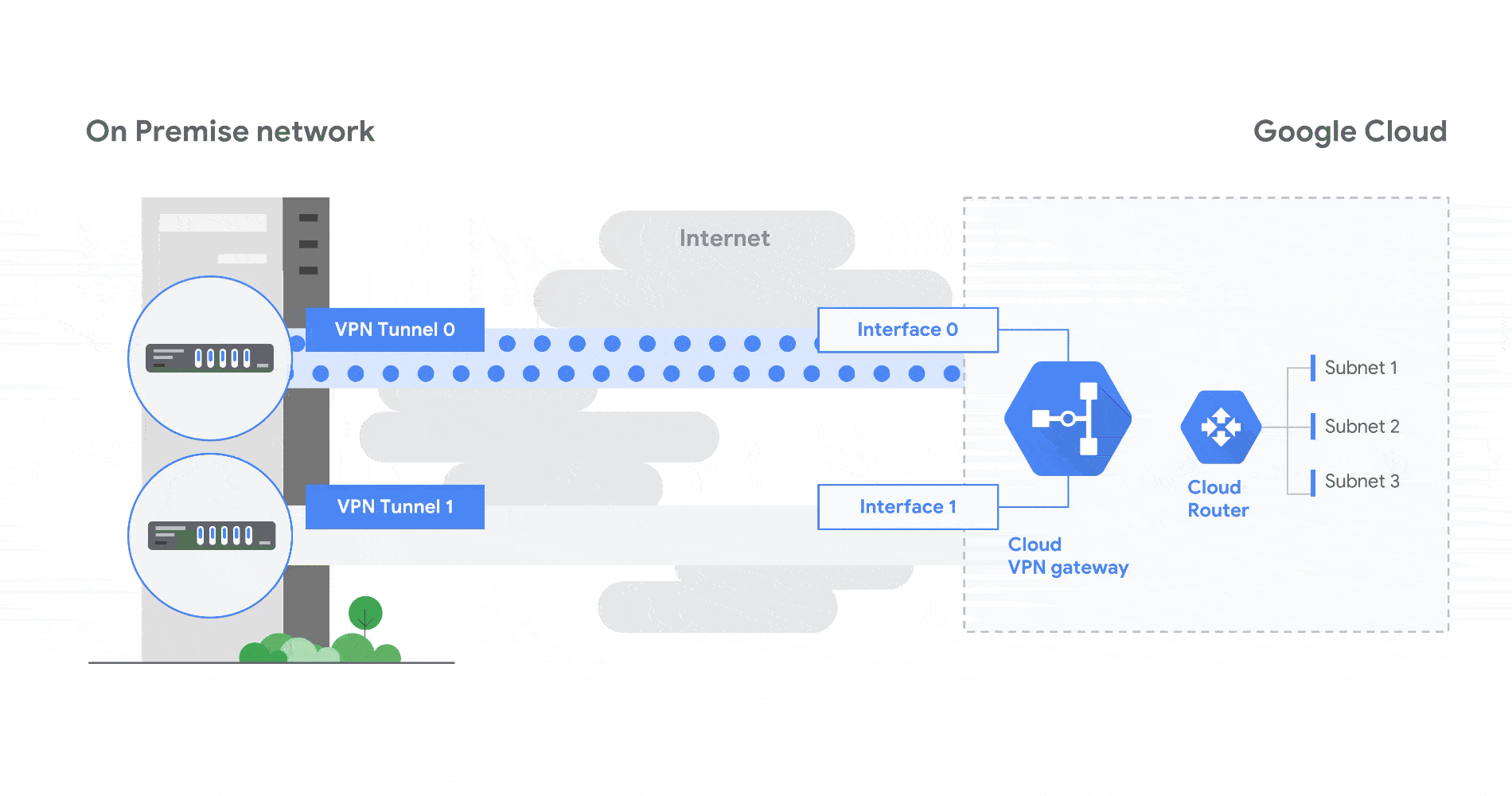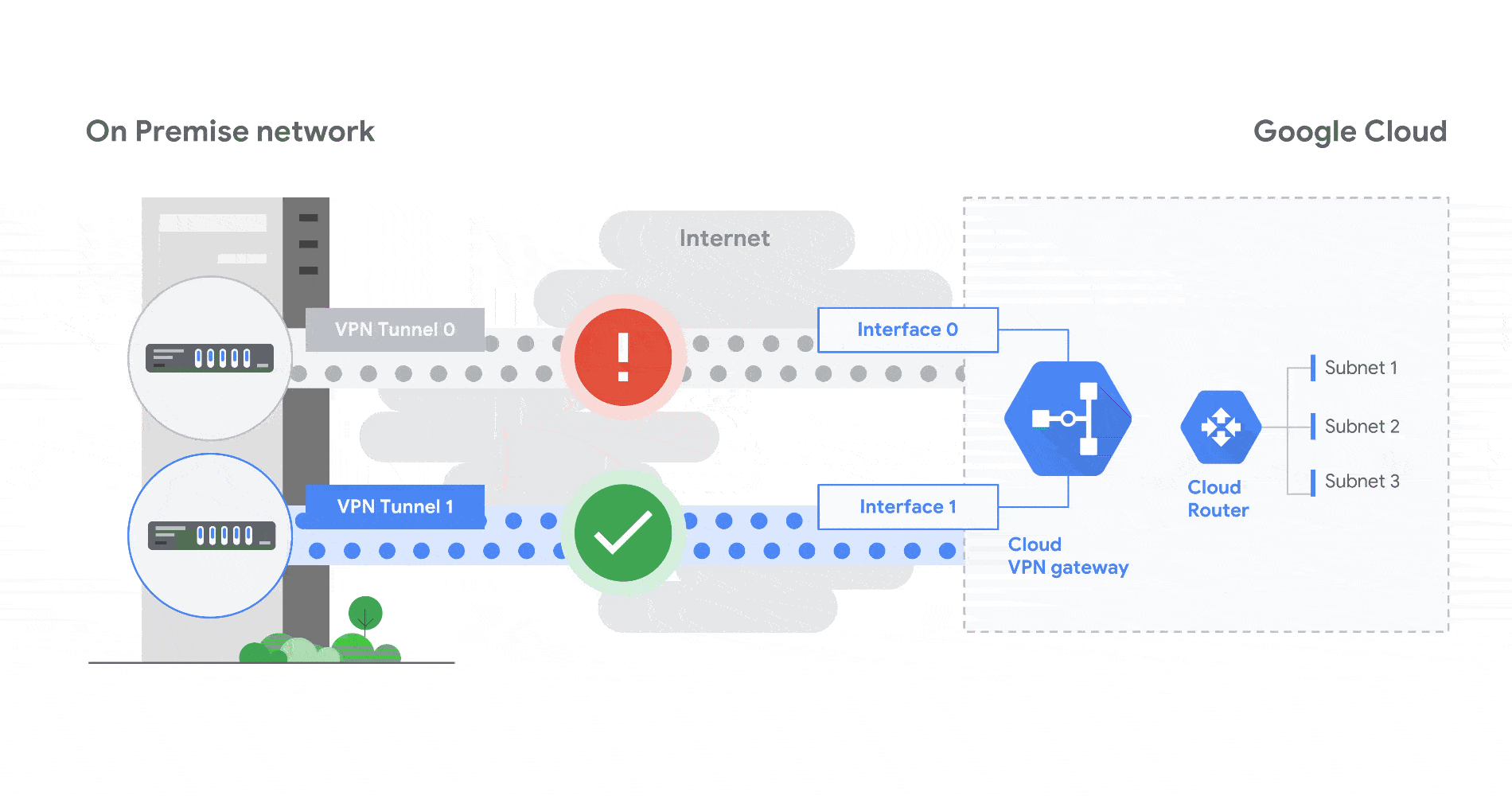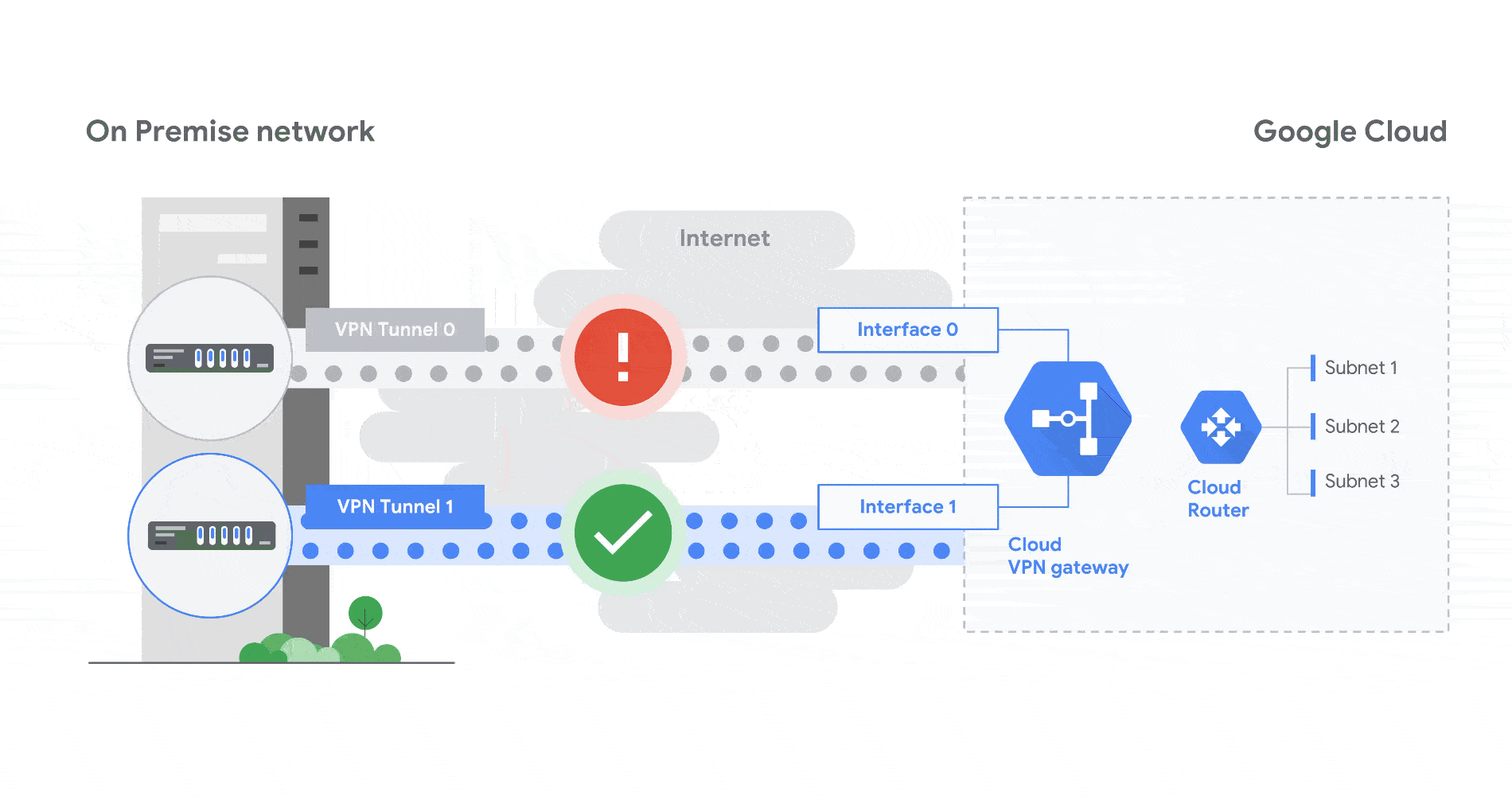 об успехе криптовалюты и о том, как он помогает тем, кто не обслуживается и не обслуживается банковскими услугами.
об успехе криптовалюты и о том, как он помогает тем, кто не обслуживается и не обслуживается банковскими услугами.
Изображение предоставлено : Shutterstock, Pixabay, Wiki Commons
Заявление об ограничении ответственности : Эта статья предназначена только для информационных целей. Это не прямое предложение или ходатайство о покупке или продаже, а также рекомендация или одобрение каких-либо продуктов, услуг или компаний. Bitcoin.com не предоставляет инвестиционных, налоговых, юридических или бухгалтерских консультаций. Ни компания, ни автор не несут ответственности, прямо или косвенно, за любой ущерб или убытки, вызванные или предположительно вызванные или в связи с использованием или использованием любого контента, товаров или услуг, упомянутых в этой статье.
Другие популярные новости
На случай, если вы пропустили
Подавляющее большинство скомпрометированных экземпляров Google Cloud Platform выполняются криптомайнерами
Логотип Google Cloud виден на ноутбуке в офисе Google в Германии 31 августа 2021 года в Берлине, Германия. (Фото Шона Гэллапа / Getty Images)
(Фото Шона Гэллапа / Getty Images)Google Cloud в среду сообщил, что злоумышленники недавно взломали 50 экземпляров Google Cloud Platform, около 86% из которых использовались для майнинга криптовалюты.
Согласно анализу Google, в 58% случаев программное обеспечение для майнинга криптовалюты было загружено в систему в течение 22 секунд после взлома.
«Это говорит о том, что первоначальные атаки и последующие загрузки были событиями по сценарию, не требующими вмешательства человека», — сказал Google Cloud. «Возможность вручную вмешаться в такие ситуации для предотвращения эксплуатации практически невозможна. Лучшей защитой было бы не развертывать уязвимую систему или не иметь автоматических механизмов реагирования.”
Подробности, опубликованные Google Cloud, являются частью первого выпуска его отчета Threat Horizons, подготовленного после сопоставления информации, полученной от Google Threat Analysis Group, Google Cloud Security and Trust Center и других внутренних групп Google.
Независимо от того, нацелены ли они на майнинг криптовалюты или нет, автоматические атаки, при которых большинство взломов выполняется в течение нескольких секунд, действительно подчеркивают важность опережения злоумышленников, сказал Янив Бар-Даян, соучредитель и генеральный директор Vulcan Cyber.Бар-Даян сказал, что, как указывает Google Cloud, этого лучше всего добиться либо путем проверки того, что системы не уязвимы, либо путем развертывания механизмов автоматического реагирования.
«Управление киберрисками — важнейший компонент любой эффективной стратегии безопасности, и организациям необходимо найти способ расширить свои существующие усилия, чтобы охватить все свои активы, включая облачную инфраструктуру», — сказал Бар-Даян. «Автоматизация — отличный инструмент, помогающий организациям выявлять и устранять уязвимые системы до того, как они могут быть скомпрометированы.Без него знание того, на чем следует сосредоточить усилия по смягчению последствий, занимает слишком много времени, поэтому так много уязвимых систем продолжают развертываться. И до тех пор, пока организации не начнут последовательно развертывать стратегии для эффективного определения приоритетов и снижения рисков до того, как уязвимости могут быть использованы, эти типы атак будут продолжать вызывать серьезные проблемы ».
И до тех пор, пока организации не начнут последовательно развертывать стратегии для эффективного определения приоритетов и снижения рисков до того, как уязвимости могут быть использованы, эти типы атак будут продолжать вызывать серьезные проблемы ».
Сарью Найяр, генеральный директор Gurucul, сказал, что Google Cloud сообщает, что атаки на облачные экземпляры являются сценариями, поэтому злоумышленники ищут определенные дыры в безопасности, а не нацелены на атаки, а затем используют эти дыры для загрузки и выполнения программного обеспечения для майнинга криптовалют.
«Пользователи облака в целом должны понимать свои обязанности по обеспечению безопасности и понимать, как структурировать свое программное обеспечение для выполнения этих обязанностей», — сказал Найяр. «И активно искать незаконную деятельность; должно быть достаточно легко заметить, что определенные облачные экземпляры более активны, чем должны быть. Поскольку злоумышленники используют автоматизированные методы для поиска и использования этих экземпляров, пользователи этих экземпляров также должны использовать автоматизацию, чтобы найти их и устранить атаку. Пользователям стоило выполнять чьи-то вычисления в облаке, что делало это потенциально дорогостоящим взломом.
Пользователям стоило выполнять чьи-то вычисления в облаке, что делало это потенциально дорогостоящим взломом.
Гаррет Граек, генеральный директор YouAttest, сказал, что реальный ключ к защите наших систем от любого злонамеренного или злонамеренного использования — будь то криптомайнеры, программы-вымогатели или кража данных PII — состоит в том, чтобы гарантировать, что наши системы обеспечивают нулевое доверие к сетям. и управление идентификацией пользователей.
«Мы должны внимательно следить за трафиком и использованием наших ресурсов», — сказал Граек. «Связь с командованием и контролем должна быть идентифицирована и немедленно остановлена, как и изменения, которые злоумышленники вносят в нашу личность для повышения привилегий.”
Virtual GPU Miner (Google Cloud)
Запуск майнера GPU в этом примере выполняется с помощью Google Cloud.
В консоли перейдите к Compute Engine >>> Экземпляры виртуальных машин в главном меню в левом верхнем углу.
Создайте новый экземпляр.
Требования:
Зона: asia-southeast1-b (или любой другой регион, поддерживающий майнеры на GPU)
Тип машины: Custom , 6 CPU , 10 GB и 1 Nvidia Tesla P4
ОС: Debian GNU / Linux 10
Тип диска: Постоянный диск SSD
Размер диска: 100 ГБ
Настройки брандмауэра: разрешить HTTP-трафик
ПРИМЕЧАНИЕ. Если вы впервые используете Google Cloud, после создания вы можете столкнуться с ошибкой, требующей увеличения пределов квоты графического процессора.Вы можете сделать это, следуя этому решению Stack Overflow.
Затем, чтобы открыть порты на вашей виртуальной машине, вам нужно будет создать правило межсетевого экрана. Вы можете перейти туда, перейдя в VPC Network >>> Firewall из главного меню. Оказавшись там, создайте новое правило брандмауэра, которое будет соответствовать сетевому тегу, который был создан ранее в настройках брандмауэра:
Оказавшись там, создайте новое правило брандмауэра, которое будет соответствовать сетевому тегу, который был создан ранее в настройках брандмауэра:
Обязательно заполните поля точно так же, как указано выше.
Включите и создайте правило. Как только вы это сделаете, ваши порты будут открыты для просмотра мультивселенной, создаваемой вашим майнером (см. В конце этого руководства).
SSH в вашу виртуальную машину с помощью собственного терминала и введите следующие команды:
sudo apt update -y
sudo apt install -y git net-tools vim tmux lshw jq wget curl ca-сертификаты apt-transport-https gnupg2 общие свойства программного обеспечения
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key добавить -
sudo add-apt-repository "deb [arch = amd64] https://download.docker.com/linux/debian buster стабильный"
sudo apt update -y
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
sudo systemctl запустить докер
экспорт DEBIAN_FRONTEND = не интерактивный
apt -y install linux-headers - $ (uname -r) build-essential
echo blacklist nouveau> /etc/modprobe. d/blacklist-nvidia-nouveau.conf
перезагрузка systemctl
sudo apt install -y Linux-заголовки-4.19.0-10-облако-amd64
sudo su root
wget http://us.download.nvidia.com/tesla/440.33.01/NVIDIA-Linux-x86_64-440.33.01.run
chmod + x NVIDIA-Linux-x86_64-440.33.01.run
./NVIDIA-Linux-x86_64-440.33.01.run -s
# -s - это беззвучный режим, предотвращающий надоедливые всплывающие окна и вопросы.
# после выполнения этой команды вы можете увидеть два сообщения ERROR.Не стесняйтесь игнорировать и двигаться дальше
 d/blacklist-nvidia-nouveau.conf
перезагрузка systemctl
sudo apt install -y Linux-заголовки-4.19.0-10-облако-amd64
sudo su root
wget http://us.download.nvidia.com/tesla/440.33.01/NVIDIA-Linux-x86_64-440.33.01.run
chmod + x NVIDIA-Linux-x86_64-440.33.01.run
./NVIDIA-Linux-x86_64-440.33.01.run -s
# -s - это беззвучный режим, предотвращающий надоедливые всплывающие окна и вопросы.
# после выполнения этой команды вы можете увидеть два сообщения ERROR.Не стесняйтесь игнорировать и двигаться дальше
d/blacklist-nvidia-nouveau.conf
перезагрузка systemctl
sudo apt install -y Linux-заголовки-4.19.0-10-облако-amd64
sudo su root
wget http://us.download.nvidia.com/tesla/440.33.01/NVIDIA-Linux-x86_64-440.33.01.run
chmod + x NVIDIA-Linux-x86_64-440.33.01.run
./NVIDIA-Linux-x86_64-440.33.01.run -s
# -s - это беззвучный режим, предотвращающий надоедливые всплывающие окна и вопросы.
# после выполнения этой команды вы можете увидеть два сообщения ERROR.Не стесняйтесь игнорировать и двигаться дальше
Пока все еще находится в [электронная почта защищена] из более ранней команды sudo su root на шаге 2:
распределение = $ (. / Etc / os-release; echo $ ID $ VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key добавить -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl перезапустить докер
перезагрузка sudo
# это обязательный шаг, который завершит вашу сессию, поэтому откройте новую сессию, чтобы продолжить
sudo su root
docker run --gpus все nvidia / cuda: 10. 0-base nvidia-smi
# этот шаг проверяет, установлен ли докер и распознает ваш графический процессор.
 0-base nvidia-smi
# этот шаг проверяет, установлен ли докер и распознает ваш графический процессор.
0-base nvidia-smi
# этот шаг проверяет, установлен ли докер и распознает ваш графический процессор.
🚧
ПРИМЕЧАНИЕ
Следующее репозиторий GitHub поддерживается независимыми членами нашего сообщества, не связанными с Overline. Используйте по своему усмотрению.
git clone https://github.com/trick77/bcnode-gpu-docker bcnode-gpu-docker && cd $ _
./build-images.sh
vim ./config
# обновить значения "miner key" и "scookie" в этом файле,
🚧
Эфемерное хранилище / снимок БД
Использование этого снимка рекомендуется только в том случае, если вы хотите ускорить процесс синхронизации.
Мы НАСТОЯТЕЛЬНО поощряем пользователей майнить полную мультицепную базу данных с нуля, если это возможно.
apt install unzip
wget https://community.multichains.org/_easysync_db.zip && . /import-db.sh ./_easysync_db.zip
 /import-db.sh ./_easysync_db.zip
/import-db.sh ./_easysync_db.zip
./start.sh
Вот и все! ниже приведены некоторые команды для использования после запуска майнера.
Для просмотра журналов:
журналы докеров sudo -f bcnode --tail 100
Для остановки майнера *:
судо./cleanup.sh
Чтобы повторно получить последний снимок БД:
sudo wget https://community.multichains.org/_easysync_db.zip
sudo ./import-db.sh ./_easysync_db.zip
Чтобы повторно загрузить последний образ докера:
sudo ./build-images.sh
Для перезапуска майнера после остановки *:
sudo ./start.sh
Для просмотра вашей мультивселенной:
Перейдите к [YOUR.EXTERNAL.IP]: 3000 в своем браузере.
* ПРИМЕЧАНИЕ. Для выполнения этих команд вам необходимо находиться в каталоге tmp / bcnode-gpu-docker /.
Осторожно! Плохие люди используют Google Cloud для майнинга Crypto
ДЖАКАРТА — Софтверный гигант Google предупреждает пользователей о злоумышленниках, использующих их взломанные учетные записи Google Cloud для майнинга криптовалют. У этой учетной записи Google Cloud есть доступ к вычислительной мощности, которую можно легко использовать для выполнения вредоносных задач.
Согласно первому отчету « Threat Horizons », выпущенному Google для повышения осведомленности о недостатках безопасности в своей платформе, для этой цели использовалось 86% скомпрометированных учетных записей.
В отчете, цитируемом bitcoinnews.com, говорится, что майнинг криптовалюты в облаке приводит к высокой загрузке ЦП и / или графического процессора. Это также относится к майнингу альтернативных криптовалют, таких как Chia, который использует пространство для хранения в качестве ресурса майнинга.
Причины и способы устранения
Первой причиной компрометации проверенных экземпляров Google Cloud является низкая безопасность из-за различных проблем. Одна из этих проблем — слабый или несуществующий пароль для доступа к платформе или отсутствие проверки API в экземпляре.
Без базовых мер безопасности злоумышленники могут легко получить контроль над этой платформой. Другие облачные платформы также сталкиваются с аналогичными проблемами.
Большинство экземпляров, изученных программным обеспечением для майнинга криптовалют, могут быть загружены менее чем за 22 секунды после взлома. Это указывает на систематическую атаку со стороны этих незащищенных экземпляров Облака.
Кроме того, злоумышленники, похоже, активно отслеживают эти небезопасные экземпляры Google, учитывая, что 40% небезопасных экземпляров были взломаны в течение восьми часов после развертывания.Google сообщает:
«Это означает, что пространство общедоступных IP-адресов регулярно сканируется на наличие уязвимых экземпляров облака. Вопрос не в том, будет ли обнаружен уязвимый экземпляр Облака, а в том, когда ».
Вопрос не в том, будет ли обнаружен уязвимый экземпляр Облака, а в том, когда ».
Чтобы уменьшить этот риск, в отчете рекомендуется, чтобы пользователи следовали основным передовым методам обеспечения безопасности и внедряли анализ контейнеров и веб-сканирование — инструменты, которые исследуют уязвимости системы безопасности с использованием различных методов, таких как сканирование.
Версии на английском, китайском, японском, арабском, французском и испанском языках создаются системой автоматически.Поэтому при переводе все еще могут быть неточности, пожалуйста, всегда выбирайте индонезийский в качестве основного языка. (система поддерживается DigitalSiber.id)
хакеров, использующих взломанные учетные записи Google Cloud для добычи криптовалюты
Злоумышленники используют ненадлежащим образом защищенные экземпляры Google Cloud Platform (GCP) для загрузки программного обеспечения для майнинга криптовалюты в скомпрометированные системы, а также злоупотребляют своей инфраструктурой для установки программ-вымогателей, проведения фишинговых кампаний и даже создания трафика на видео YouTube для манипулирования подсчетом просмотров.
«В то время как облачные клиенты продолжают сталкиваться с различными угрозами в приложениях и инфраструктуре, многие успешные атаки происходят из-за плохой гигиены и отсутствия базовой реализации контроля», — подчеркнула группа действий по кибербезопасности (CAT) Google в своем недавнем отчете Threat Horizons. опубликовано на прошлой неделе.
Из 50 недавно скомпрометированных экземпляров GCP 86% из них использовались для майнинга криптовалюты, в некоторых случаях в течение 22 секунд после успешного взлома, а 10% экземпляров использовались для сканирования других общедоступных хостов в Интернете с целью выявляли уязвимые системы, и 8% экземпляров использовались для нанесения ударов по другим объектам.Около 6% экземпляров GCP использовались для размещения вредоносных программ.
В большинстве случаев несанкционированный доступ был связан с использованием слабых паролей или их отсутствия для учетных записей пользователей или подключений API (48%), уязвимостей в стороннем программном обеспечении, установленном в облачных экземплярах (26%), и утечке учетных данных в Проекты GitHub (4%).
Другой заметной атакой была фишинговая кампания Gmail, запущенная APT28 (также известная как Fancy Bear) в конце сентября 2021 года, в ходе которой была отправлена рассылка электронной почты более чем 12000 владельцев учетных записей, в основном в США.С., Великобритания, Индия, Канада, Россия, Бразилия и ЕС. наций с целью украсть их верительные грамоты.
Кроме того, Google CAT сообщил, что наблюдал, как злоумышленники злоупотребляли бесплатными облачными кредитами, используя пробные проекты и выдавая себя за фальшивые стартапы для перекачки трафика на YouTube. В другом инциденте группа злоумышленников, поддерживаемая правительством Северной Кореи, маскировалась под рекрутеров Samsung, чтобы рассылать фальшивые вакансии сотрудникам нескольких южнокорейских компаний по информационной безопасности, которые продают решения для защиты от вредоносных программ.
«В электронных письмах был PDF-файл, якобы содержащий описание должности в Samsung; однако PDF-файлы были искажены и не открывались в стандартном PDF-ридере», — заявили исследователи. «Когда цели ответили, что не могут открыть описание вакансии, злоумышленники ответили вредоносной ссылкой на вредоносное ПО, якобы являющееся« Secure PDF Reader », хранящимся на Google Диске, которое теперь заблокировано».
«Когда цели ответили, что не могут открыть описание вакансии, злоумышленники ответили вредоносной ссылкой на вредоносное ПО, якобы являющееся« Secure PDF Reader », хранящимся на Google Диске, которое теперь заблокировано».
Google связал атаки с тем же злоумышленником, который ранее в этом году нацелился на специалистов по безопасности, занимающихся исследованиями и разработками уязвимостей, чтобы украсть эксплойты и организовать дальнейшие атаки на уязвимые цели по своему выбору.
«Ресурсы, размещенные в облаке, обладают преимуществом высокой доступности и доступа в любом месте и в любое время», — говорится в сообщении Google CAT. «В то время как ресурсы, размещенные в облаке, оптимизируют работу персонала, злоумышленники могут попытаться воспользоваться повсеместным характером облака для компрометации облачных ресурсов. Несмотря на растущее внимание общественности к кибербезопасности, тактики целевого фишинга и социальной инженерии часто оказываются успешными».
.
