Ускоритель вычислений Tesla V100 является абсолютным рекордсменом в добыче криптовалют
Как известно, Tesla V100 является одним из самых быстрых ускорителей вычислений из присутствующих на рынке, и создавшая его компания NVIDIA также это наверняка знала, устанавливая на него цену в немалые $8000. Такие ускорители используются для различных задач, вроде работы с искусственным интеллектом или глубинного обучения, однако использовать их можно и для других, более приземлённых задач.
Например, YouTube-канал BuriedONE Cryptomining решил протестировать данный ускоритель в добыче криптовалют. Конечно, сам ускоритель Tesla V100 покупать не было смысла, поэтому для тестов был использован сервер облачного вычислительного сервиса Amazon AWS, который как раз использует эти новые ускорители NVIDIA на базе Volta.
Результат тестирования вполне ожидаемый Tesla V100 показала лучшие результаты в мире в добыче различных криптовалют. В расчёте на одну видеокарту, конечно же. В добыче популярного Ethereum новинка достигла результата в 94 МХэш/с, а для сравнения результат разогнанной Titan V составляет 77 МХэш/с. В добыче Zcash результат составит 950 Сол/с, Monero – 1670 Хэш/с, и наконец в Litecoin – 769 МХэш/с.
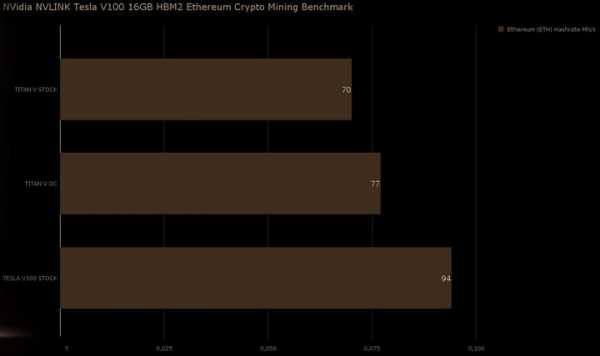
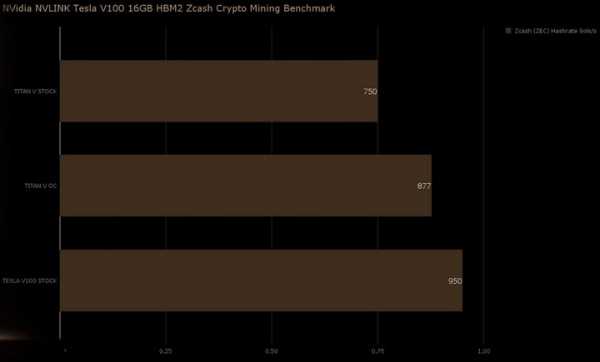
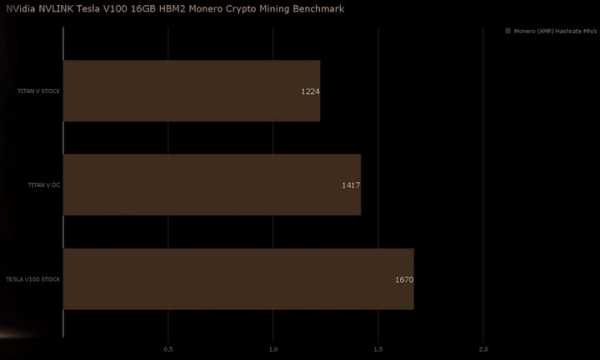
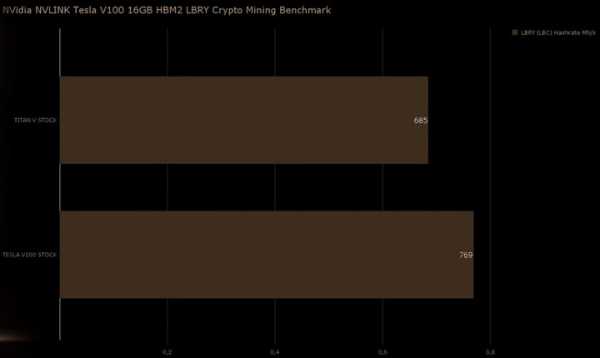
Представленные выше результаты хоть и являются рекордными, но представляют они лишь академический интерес. Очевидно, что «копать» на ускорителе Tesla V100 крайне не выгодно, как минимум из-за цены в $8000, а также не стоит забывать и о его энергопотреблении. В конце отметим, что в скором времени нам обещаны результаты тестирования системы сразу с восемью ускорителями Tesla V100.
overclockers.ru
Nvidia Tesla V100 — текущий рекордсмен в майнинге Ethereum
28.01.2018 Компьютеры

С выходом AMD RADEON RX VEGA в сети не утихают слухи, что именно эта карта может выдавать 70-100 мегахешей при майнинге Ethereum, однако на текущий момент эти сведения не подтверждаются тестами на последних доступных драйверах. Поэтому позиции текущего лидера Nvidia Tesla V100 в майнинге Ethereum с результатом в 80Mh/s остаются на первом месте.
Nvidia Tesla V100 это профессиональное устройство для расчетов, построенное на основе GPU Volta, которую ждут в потребительском сегменте не ранее 2018 года.
Основные особенности Nvidia Tesla V100 и ее предшественников:
Из особенностей следует отметить использование памяти HBM2 как это сделала AMD в своей Веге, правда ширина памяти здесь полноценная в 4096 Бит. Сам чип GV100 выполнен по нормам 12нм и содержит 5120 ядер FP32 (аналог CUDA ядер в потребительских видеокартах) и 2560 ядер для расчетов FP64. Производительность в расчетах FP32 15 Терафлопс и 7,5 Терафлопс для FP64, что на 50% больше чем у чипов предыдущего поколения.
К слову сказать предыдущее поколение Nvidia Tesla P100 выдает на алгоритме Dagger Hashimoto (Ethereum) 69-72 Mh/s, с использованием исходных кодов майнера Genoil/cpp-ethereum c компилированием под архитектуру ppc64el. Другими словами Теслы не совместимы с кодом х86 для обычных компьютеров и на них нельзя запустить более производительные в майнинге майнеры от Claymores, т.к. код майнера закрыт и скомпилировать под архитектуру ppc64el может только сам автор этих майнеров.
Обсуждение по использованию в одной связке 4-х Nvidia Tesla P100 с общим хешрейтом 275Mh/s и энергопотреблением в 1кВт можно прочесть на этой ветке Reddit.
Что на счет новичка, то иноформации по производительности Nvidia Tesla V100 еще меньше, но мельком проскакивают сообщения на профильных форумах, что эти карты выдают не менее 80 Mh/s при майнинге эфира и энергопотреблении в районе 150Вт.
Учитывая эти показатели Nvidia Tesla V100 это самый производительный для майнинга Ethereum инструмент как в натуральном выражении так и по энергоэффективности (менее 2Вт на Mh/s), однако все впечатление портит его цена ( от 5.000$ за Nvidia Tesla P100 ) и плохая доступность в розничной продаже.
Обсудить на форуме
Комментарии:
Добавить комментарий
teora-holding.ru
Сервер для задач глубокого обучения Nvidia DGX-2 построен на GPU Tesla V100
Тема графических применений продукции NVIDIA на конференции GTC 2018 уже давно перестала быть главной. Хотя немалую часть ключевого выступления главы компании занимала трассировка лучей в реальном времени и автомобильная тематика, не обошёл он стороной и самую важную тему для NVIDIA на GTC — применение в системах искусственного интеллекта и глубокого обучения, в частности. Технологии калифорнийской компании шагнули далеко за рамки ускорения рендеринга и обработки визуальных данных, и главной для них сейчас является вычислительная платформа для ускорения глубокого обучения.

Миллионы серверов и компьютеров по всему миру становятся всё производительнее, но для того, чтобы сделать их умнее, нужно научиться использовать все возможности: качественное распознавание голоса, понимание естественной речи и многое другое — кстати, обработка визуальных данных сюда тоже входит. Президент компании Дженсен Хуанг, выступая перед 8500 разработчиками, бизнесменами, учёными и прессой, опубликовал целую серию анонсов, укрепляющих вычислительную deep learning платформу компании.
NVIDIA с каждым годом значительно улучшает возможности и производительность своей платформы для глубокого обучения, серьёзно превосходя все ожидания, что открывает новые возможности по применению их платформы и революционных изменений в различных сферах: медицине, транспорте, науке и многих других. Даже если не говорить о важных программных объявлениях, среди которых адаптация большинства облачных сервисов, то одним из самых интересных аппаратных анонсов стало объявление нового вычислительного решения Tesla V100, использующего удвоенный до 32 ГБ объём начиповой HBM2-памяти, который актуален в большом количестве требовательных к объёму и скорости памяти задач глубокого обучения. Удвоенный объём памяти позволит обучать большие по размеру модели и получить преимущество в задачах, которые были ограничены ранее памятью объёмом в 16 ГБ.
Новое вычислительное решение Tesla V100 32GB доступно со дня анонса, а такие известные производители как Cray, Hewlett Packard Enterprise, IBM, Lenovo, Supermicro и Tyan начнут распространять системы на основе Tesla V100 32GB во втором квартале текущего года. Сервис Oracle Cloud Infrastructure также уже анонсировал планы по предложению возможностей новой Tesla V100 32GB в облаке во второй половине года.

А совместно с совершенно новой технологией межчиповых соединений NVIDIA NVSwitch, соединяющей до 16 ускорителей Tesla V100 в единое устройство с производительностью подсистемы памяти в 2,4 терабайта/с, возможности таких систем и вовсе будут казаться безграничными. NVSwitch расширяет возможности NVLink и предлагает в 5 раз большую пропускную способность по сравнению с лучшими из PCI-Express свитчей и это позволяет создавать системы с большим количеством соединённых друг с другом GPU в них.

Нейросети становятся всё более сложными, растут их размер и наборы данных. Также появились некоторые новые техники, требующие большего количества GPU, соединённых друг с другом для обмена данными и синхронизации. Такие операции требуют передачи большого объёма данных и высокой пропускной способности. Новое решение компании убирает предыдущие ограничения по скорости передачи данных между чипами и позволяет использовать наборы данных большего размера при всё более ресурсоёмких нагрузках, включающих параллельную тренировку нейросетей.
Каждый из NVSwitch содержит 18 портов NVLink (50 ГБ/с на порт), на базовой плате их шесть штук вместе с восемью GPU Tesla V100, и две эти базовые платы могут объединяться в одно целое. Каждый из восьми GPU на одной плате соединён с каждым из шести NVSwitch одиночным NVLink каналом, а восемь портов каждого чипа NVSwitch используются для обмена данными с другой базовой платой. Соответственно, каждый из восьми GPU на плате с другими процессорами «общается» на скорости в 300 ГБ/с.

Неудивительно, что NVIDIA сразу же анонсировала готовое самое произодительное решение на основе Tesla V100 и NVSwitch, предназначенное для задач глубокого обучения — NVIDIA DGX-2. Это первый одиночный сервер с вычислительной производительностью в два петафлопа, заменяющий 300 обычных серверов, занимающих 15 стоек в датацентрах при в 60 раз меньшем размере и в 18 раз большей энергоэффективности.


DGX-2 — это первая система, использующая NVSwitch и позволяющая 16-ти процессорам системы использовать общую память. На такой системе разработчики могут тренировать нейросети на более сложных и больших массивах данных, используя более комплексные модели глубокого обучения. В результате новая система DGX-2 в некоторых задачах может быть в несколько раз раз быстрее DGX-1 на основе всё той же архитектуры Volta, представленной в сентябре. Новинка включается в линейку продуктов DGX и становится на вершину этой серии вычислительных систем NVIDIA.

Кроме анонсов аппаратных решений на тему deep learning, была объявлена улучшенная поддержка ускоренных на GPU задач глубокого обучения. В частности, получило поддержку новых версий такое ПО как: CUDA, TensorRT, NCCL и cuDNN, новый набор Isaac software developer kit для тренировки роботов. Также было объявлено о тесной работе с ведущими разработчиками облачных сервисов и об оптимизации всех распространённых фреймворков под возможности новой вычислительной платформы NVIDIA.
www.ixbt.com