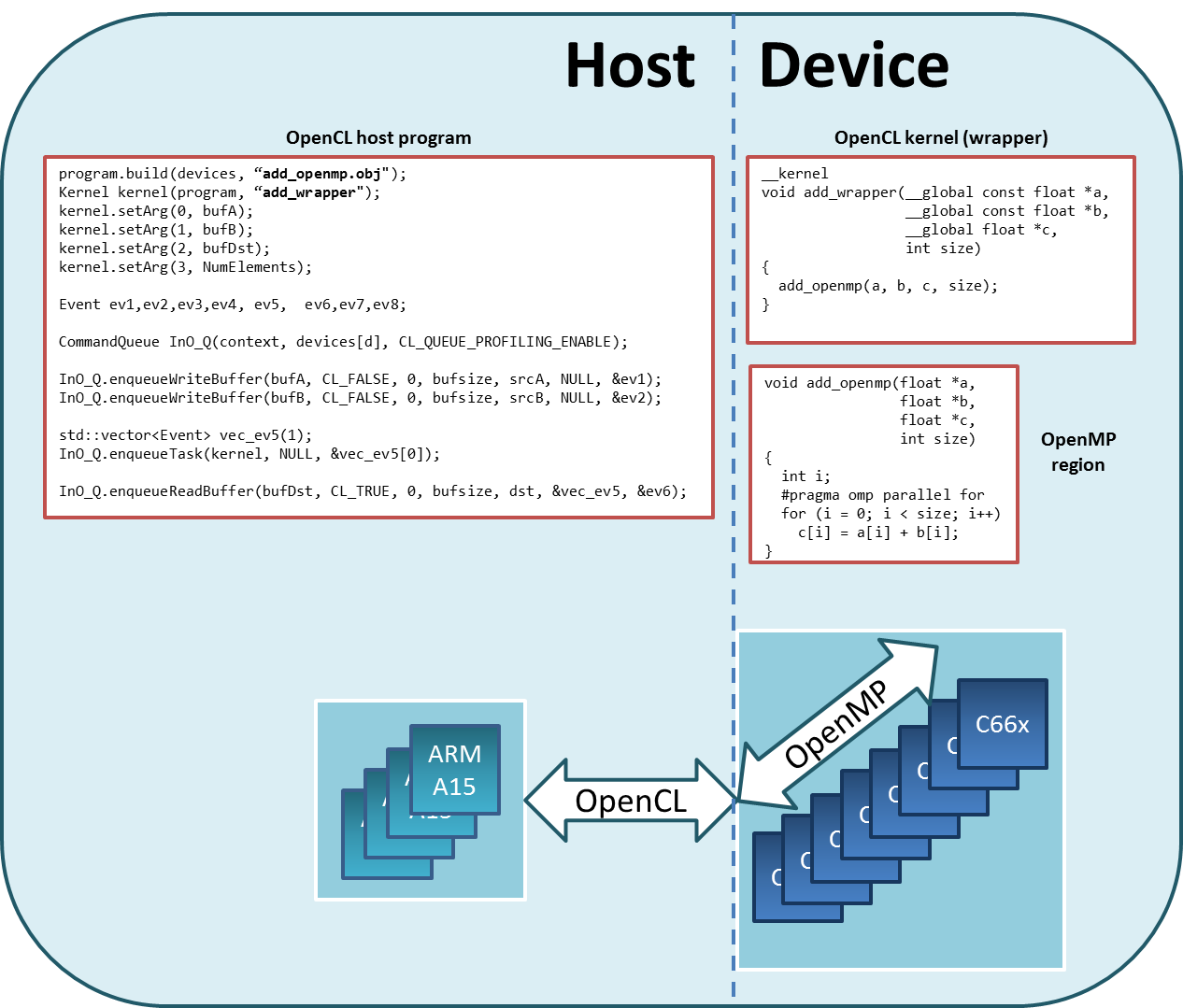
Windows 10: OpenCL и OpenGL Compatibility Pack, выпущенный Microsoft
На этой неделе Microsoft выпустила приложение OpenCL и OpenGL Compatibility Pack в свой магазин Microsoft Store, чтобы приложения могли работать на Windows 10 устройства, на которых не установлены драйверы оборудования OpenCL или OpenGL.
Если установлены драйверы DirectX 12, поддерживаемые приложения будут работать с аппаратным ускорением для повышения производительности.
Microsoft предоставляет информацию о приложении и самом проекте по его Блог разработчиков DirectX.
Команда проекта работает над слоями отображения OpenCL и OpenGL в Direct3D 12, чтобы представить поддержку «продуктивных и творческих приложений на основе OpenCL и OpenGL, для которых недоступны собственные драйверы». Конечный результат, которого команда пытается достичь с помощью реализации, улучшает совместимость приложений на Windows 10 устройства; другими словами: приложения, которые в настоящее время не работают из-за требований OpenCL или OpenGL, могут затем запускаться на Windows 10 ПК благодаря слоям отображения в DirectX.
Пакет совместимости, выпущенный Microsoft на этой неделе для приложений, использующих OpenCL версии 1.2 и ранее и OpenGL версии 3.3 и ранее.
Microsoft выпустила две версии пакета; один для стабильных версий Windows и более новая версия, доступная для устройств предварительной оценки.
Пакет совместимости также предоставляется для устройств ARM; это значит, что Windows 10 на устройствах ARM теперь могут запускать поддерживаемые приложения при установке пакета вместо того, чтобы полагаться на программную эмуляцию.
Основная загрузка доступна на Microsoft Store. Пользователям требуется учетная запись Microsoft, чтобы загрузить пакет совместимости в свои системы и установить его.
Windows пользователи, которые не хотят этого, могут получить официальный файл appx с помощью онлайн-генератора ссылок для Microsoft Store:
- Откройте веб-сайт генератора ссылок в Интернете в любом браузере: https://store.rg-adguard.net/
- Выберите ProductId в первом меню.

- Вставьте идентификатор 9nqpsl29bfff в поле рядом с ним.
- Выберите «Быстро», чтобы получить инсайдерскую версию (более свежую), или «Розничная», чтобы получить стабильную версию приложения.
- Найдите нужную загрузку в списке ссылок; он должен иметь расширение файла appx, и вам нужна правильная архитектура, например x64 для 64-битной версии Windows или arm для 32-битной системы ARM.
- После загрузки проверьте имя файла, чтобы убедиться, что он имеет расширение .appx.
- Если нет, щелкните его правой кнопкой мыши, выберите переименовать и добавьте в конец .appx.
- Дважды щелкните файл и следуйте диалогу установки.

Закрытие слов
Microsoft отмечает, что пакет совместимости полезен только для определенных приложений, но не перечисляет эти приложения на странице Microsoft Store или в блоге разработчиков. По словам Microsoft, версия Insider поддерживает больше приложений, но, поскольку неясно, какие именно, все сводится к методам проб и ошибок со стороны пользователя.
Вы можете установить пакет совместимости, протестировать свои приложения, чтобы увидеть, есть ли разница в производительности, и либо сохранить пакет совместимости, если он есть, либо удалить его, если нет.
(через Deskmodder)
Библиотеки. GPGPU | Ресурсный Центр Вычислительный Центр СПбГУ
Расположение библиотеки CUDA:
| 10.1 | /usr/local/CUDA/10.1.105/ |
| 9.0 | /usr/local/cuda/ |
| 8.0 | /usr/local/CUDA/8.0 |
| 7.0 | /usr/local/CUDA/7.0 |
| 6.0 | /usr/local/CUDA/6.0 |
Поддержка в компиляторах:
| Технология | Язык | Компилятор |
| CUDA | CUDA C | Nvidia: nvcc |
| CUDA Fortran | PGI: pgfortran | |
| OpenCL | OpenCL C | Nvidia: clcc |
| OpenACC | C, C++ и Fortran | PGI, GCC (>= 5. 0) 0) |
Содержание:
Введение в технологию GPGPU
GPGPU (англ. General-purpose computing for graphics processing units, неспециализированные вычисления на графических процессорах) — техника использования графического процессора видеокарты, который обычно имеет дело с вычислениями только для компьютерной графики, чтобы выполнять расчёты в приложениях для общих вычислений, которые обычно проводит центральный процессор. Это стало возможным благодаря добавлению программируемых шейдерных блоков и более высокой арифметической точности растровых конвейеров, что позволяет разработчикам ПО использовать потоковые процессоры для не-графических данных.
Реализации:
1) CUDA — технология GPGPU, позволяющая программистам реализовывать на языке программирования Си (а также C++/C#) алгоритмы, выполнимые на графических процессорах ускорителей GeForce восьмого поколения и новее. Технология CUDA разработана компанией Nvidia.
Технология CUDA разработана компанией Nvidia.
3) OpenCL — является языком программирования задач, связанных с параллельными вычислениями на различных графических и центральных процессорах.
5) OpenACC — стандарт, описывающий набор директив для написания гетерогенных программ, задействующих как центральный, так и графический процессор. Используется для распараллеливания программ на языках C, C++ и Fortran. Стандарт был создан группой, в которую вошли CAPS, Cray, NVIDIA и PGI.
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах Nvidia, и включать специальные функции в текст программы на Си. Архитектура CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью.
OpenCL (от англ. Open Computing Language — открытый язык вычислений) — фреймворк для написания компьютерных программ, связанных с параллельными вычислениями на различных графических и центральных процессорах, а также FPGA.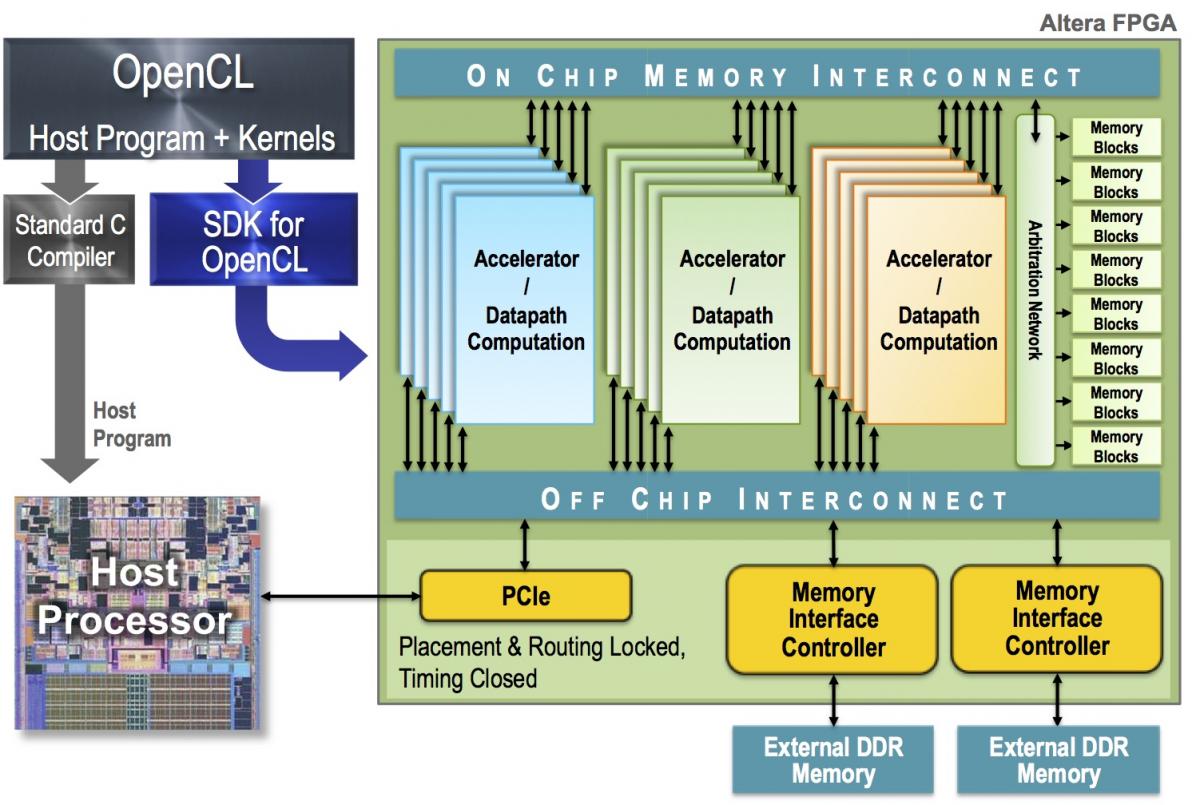 В OpenCL входят язык программирования, который основан на стандарте языка программирования Си C99, и интерфейс программирования приложений. OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является осуществлением техники GPGPU. OpenCL является полностью открытым стандартом, его использование не облагается лицензионными отчислениями.
В OpenCL входят язык программирования, который основан на стандарте языка программирования Си C99, и интерфейс программирования приложений. OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является осуществлением техники GPGPU. OpenCL является полностью открытым стандартом, его использование не облагается лицензионными отчислениями.
OpenACC (от англ. Open Accelerators) — программный стандарт для параллельного программирования, разрабатываемый совместно компаниями Cray, CAPS, Nvidia и PGI. Стандарт описывает набор директив компилятора, предназначенных для упрощения создания гетерогенных параллельных программ, задействующих как центральный, так и графический процессор[1][2].
Как и более ранний стандарт OpenMP, OpenACC используется для аннотирования фрагментов программ на языках C, C++ и Fortran. С помощью набора директив компилятора программист отмечает участки кода, которые следует выполнять параллельно или на графическом процессоре, обозначает какие из переменных являются общими, а какие индивидуальными для потока и т.
Пример 1 — сборка CUDA-программы при помощи компилятора nvcc и запуск на Nvidia Tesla k40 (кластер Huawei)
$ CUDA_PATH=/usr/local/cuda
$ CUDA_TEST_PATH=$CUDA_PATH/samples/1_Utilities/bandwidthTest/
$ export PATH=/usr/local/cuda/bin/:$PATH
$ CUDA_INC_PATH=/usr/local/cuda/samples/common/inc
$
$ nvcc $CUDA_TEST_PATH/bandwidthTest.cu -I$CUDA_INC_PATH
$
$ ./a.out
[CUDA Bandwidth Test] — Starting…
Running on…
Device 0: Tesla K40m
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 10152. 7
7
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 10269.2
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 183668.1
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
$
QGIS 🚀 — Поддержка OpenCL не обнаружена в смешанной системе CPU / GPU
Я немного обижен, что не подумал об этом раньше.
Не надо, ты просто победил меня вовремя, вот что я собирался предложить попробовать в следующий раз.
Длинная история:
- Чтобы поставлять QGIS с поддержкой OpenCL, нам нужно связать библиотеку OpenCL.dll, эта библиотека является просто загрузчиком для предоставленных поставщиком реализаций OpenCL, и она должна быть стандартной и независимой от поставщика.
- По этой причине мы поставляем нашу собственную версию OpenCL.dll, эта библиотека должна быть установлена в целевой системе, только если в системном каталоге нет OpenCL.dll (@ jef-n поправьте меня, если я ошибаюсь) .
- По какой-то непонятной причине на некоторых машинах наш OpenCL.dll не может распознать и загрузить реализации OpenCL поставщика, и это вызывает проблему «В вашей системе не обнаружены устройства, совместимые с OpenCL». В этих случаях поможет удаление QGIS OpenCL.dll, поскольку вместо него будет использоваться OpenCL.dll, предоставленный поставщиком.
Итак, во время Bucharest HF (и до этого) я попытался посмотреть, как другие проекты ОС (libreoffice и blender) справляются с этой проблемой, их решение заключается в использовании оболочки, загружающей OpenCL.dll во время выполнения [1], но, к сожалению, это оболочка не только устарела, но и использует C API, в то время как мы используем C++ API.
Мне понравился этот подход, мы могли бы создать QGIS и отправить его без связывания и предоставления OpenCL. dll, делегируя целевой машине загрузку (во время выполнения) реализации OpenCL.dll, обычно предоставляемую поставщиками.
dll, делегируя целевой машине загрузку (во время выполнения) реализации OpenCL.dll, обычно предоставляемую поставщиками.
Я и @ jef-n потратили много времени, пытаясь использовать тот же подход для QGIS (сначала переключившись на C API, а затем адаптировав C ++ API для использования оболочки clew ) но он оказался очень нестабильным (разбился), и нам пришлось отказаться от этого подхода (также из-за нехватки времени).
Я, честно говоря, не знаю, как действовать сейчас, мне сложно найти решение, в основном потому, что мне никогда не удавалось воспроизвести эту проблему на моих локальных машинах разработки, а также потому, что я не обычный пользователь Windows или опытный разработчик Windows (не говоря уже о том, что мое время — очень ограниченный ресурс).
[1] https://github.com/martijnberger/clew
vulkan — В OpenCL, Вулкан Sycl
как в OpenCL относится к вулкан ?
Они оба трубопровода сепары работать с хоста на GPU и GPU на хост с использованием очереди, чтобы сократить расходы на связь, используя несколько потоков. Совместимая с DirectX-и OpenGL не может?
Совместимая с DirectX-и OpenGL не может?
Как первый релиз 28 августа 2009 года. Более широкой аппаратной поддержки. Указатели разрешено, но только, чтобы использоваться в устройстве. Вы можете использовать локальную память разделяется между потоками. Гораздо проще для начала всем привет. Имеет API накладные для команды, если они не являются устройства очередь. Вы можете выбрать неявная синхронизация нескольких устройств или явного управления. Ошибки в основном закреплены за 1,2, но я не’т знаем о версии 2.0.
Вулкан: первый выпуск 16 февраля 2016(но прогресс с 2014 года). Узкий аппаратной поддержки. Может Спир-V ручки указатели? Может быть, не? Нет локальной памяти? Трудно начать Здравствуй, мир. Меньше API служебные. Вы можете выбрать неявного управления несколькими устройствами? Еще багги для Dota-2 игры и некоторые другие игры. Используя оба графика и расчета трубопроводов в то же время может скрывать еще больше задержки.
если OpenCL был вулкан, то она была скрыта от общественности в течение 7-9 лет. Если они могли бы добавить его, почему же’t они делают это для OpenGL?(возможно из-за давления на PhysX/CUDA технологии?)
Если они могли бы добавить его, почему же’t они делают это для OpenGL?(возможно из-за давления на PhysX/CUDA технологии?)
Vulkan это рекламируется как вычислительный и графический API, однако я нашли очень мало ресурсов для вычислительных часть — почему ?
Для этого нужно больше времени, как в OpenCL.
Вы можете проверить информацию о вычислительные шейдеры здесь:
https://www.khronos.org/registry/vulkan/specs/1.0/xhtml/vkspec.html#fundamentals-floatingpoint
Вот пример системы частиц, управляемых вычислительных шейдеров:
https://github.com/SaschaWillems/Vulkan/tree/master/computeparticles
ниже этого, есть слишком raytracers и обработки изображений примеры.
Вулкан имеет преимущества производительности по сравнению с OpenGL. Это же верно и для Вулкан против в OpenCL?
- Вулкан не’т необходимость синхронизации для другой API. Его команды буферы синхронизации между commandqueues.
- В OpenCL необходимо синхронизировать с OpenGL или DirectX (или вулкан?) прежде чем использовать общий буфер(КЛ-гл или ДХ-ХЛ взаимодействия буферов). В этом есть накладные расходы и нужно скрыть его, используя буфер обмена и конвейеризации. Если нет общего буфера существует, он может работать по совместительству на современном оборудовании с OpenGL или DirectX.

OpenCL-это печально известную, чтобы быть медленнее, чем на CUDA
Он был, но сейчас его зрелого и вызовы CUDA, тем более с гораздо более широкой аппаратной поддержки от всех игровых графических процессоров для ПЛИС при использовании версии 2.1, например, в будущем Intel может поставить ПЛИС в сердечник i3 и включить его для (софт-х86 ядра ИС) количество ядер процессора модель сокращает разрыв между производительности GPU и CPU для обновления своего процессора PhysX в играх или просто пусть для OpenCL физики осуществления сформировать его и использовать не менее %90 плашк-уголок вместо софт-ядро’s на %10-%20 эффективно используется площадь.
С таким же ценой, графические процессоры AMD можно вычислить быстрее на OpenCL и с таким же вычислительные мощности процессора Intel igpus потребляют меньше энергии. (редактировать: за исключением, когда алгоритмы чувствительны к производительности кэша, где Nvidia имеет превосходство)
Кроме того, я написал SGEMM ядра OpenCL и работать на HD7870 в 1,1 терафлопс и проверили интернете видела SGEMM henchmark на GTX680 для одинаковой производительности с помощью популярных название на CUDA!(соотношение цен на gtx680/hd7870 было 2). (правка: для NVIDIA’ы СС3.0 Не’т использовать кэш L1 при чтении глобальных массивов и мое ядро было чисто местной/общей памяти + некоторые регистры и»плиточный»)смотрите
не SYCL использует OpenCL для внутренне или использовать вулкан ? Или это использование ни и вместо этого полагаются на низком уровне, конкретного поставщика API для быть реализовано ?
Здесь
https://www.khronos.org/assets/uploads/developers/library/2015-iwocl/Khronos-SYCL-May15. pdf
pdf
говорит
предлагает методы для решения задач, которые не имеют в OpenCL(пока!)
запасной вариант осуществления процессора отлаживаемого!
поэтому он может вернуться к чисто резьбовое исполнение(по аналогии с Java’ы aparapi).
доступ к объектам OpenCL от объектов SYCL можно построить объекты SYCL от объекта в OpenCL
взаимодействие с OpenGL остается в SYCL
- использует те же структуры/типы
он использует технологии OpenCL(может не напрямую, но с модернизированным связи водителя?), она развивается параллельно в OpenCL, но может переход на резьбу.
от самых маленьких в OpenCL 1.2 встроенное устройство для самых продвинутых в OpenCL 2.2 ускорители
OpenCL. Использование графического процессора видеокарты для рендеринга. — Дневник злостного критика-рецидивиста
Эх, как-то невнимательно я просматривал настройки Adobe Premiere Pro. Когда в настройках проекта я пытался выбрать в качестве средства рендеринга аппаратное GPU-ускорение, видео пропадало, а в окне вывода оно хоть и было, но при начале рендеринга тут-же вываливалась ошибка. При этом я лишь бегло просмотрел этот выбор, и слово в скобках названия пункта прочитал как OpenGL (а не OpenCL), потому что только оно было мне знакомо. Ну, думаю, да, моя видеокарта поддерживает OpenGL на аппаратном уровне, я это читал в её спецификации, так почему ж аппаратное ускорение не работает? Ну, и рендерил на основном процессоре, который разогнал для этой цели с 3,4 до 4,7 ГГц.
Когда в настройках проекта я пытался выбрать в качестве средства рендеринга аппаратное GPU-ускорение, видео пропадало, а в окне вывода оно хоть и было, но при начале рендеринга тут-же вываливалась ошибка. При этом я лишь бегло просмотрел этот выбор, и слово в скобках названия пункта прочитал как OpenGL (а не OpenCL), потому что только оно было мне знакомо. Ну, думаю, да, моя видеокарта поддерживает OpenGL на аппаратном уровне, я это читал в её спецификации, так почему ж аппаратное ускорение не работает? Ну, и рендерил на основном процессоре, который разогнал для этой цели с 3,4 до 4,7 ГГц.В свете последних событий с поломкой моего DVD-рекордера, и переходом на оцифровку TV-тюнером, я внимательнее отнёсся к минимизации потерь видеоинформации во всей цепочке оцифровки. Я настроил тюнер на максимальную резкость и определил, что максимальное сохранение деталей без замыливания происходит именно при работе кодека MPEG2 с максимально возможным для тюнера битрейтом 15000 кбит/с. Кроме того, напомню, что видеомагнитофон также был настроен на воспроизведение видео без искажений (специальный режим в JVC для перезаписи).
Единственная галочка, улучшающая видеоизображение, осталась стоять только в драйвере TV-тюнера, осуществляющего видеозахват. Она практически не мылила картинку, но в то же время превращала некую зелёную кашу лесного массива в нормальные деревья. На геометрически ровных объектах эта галочка вела себя по разному — что-то улучшала, что-то чуть искажала. Я подумал, что драйвер как никто другой знает особенности работы своего TV-тюнера, и поэтому, возможно, он лучше всех справится с первичным улучшением видеоизображения. Возможно, я не прав, но стоящую по умолчанию в драйвере галочку я решил не трогать.
Поскольку все остальные «улучшайзеры» были отключены, итоговая картинка получилась хотя и резкой, как я хотел, но несколько зашумленной, и я стал искать в Adobe Premiere Pro инструмент, способный качественно уменьшить шумы, сохраняя тем не менее резкость картинки. Штатный фильтр меня не очень устроил, и я нашёл в Интернете рекомендацию использовать плагин Denoicer III. В описании я прочитал, что он использует в своей работе аппаратное ускорение OpenCL. Вот тут то я заметил кое-что и насторожился. Что за CL? Знаю только GL!
Вот тут то я заметил кое-что и насторожился. Что за CL? Знаю только GL!
После ознакомительного чтения об OpenCL оказалось, что это альтернативная библиотека параллельных расчётов. Если OpenGL (Open Graphics Library) была чисто графической библиотекой, то OpenCL (Open Computing Language) — это более универсальный фреймворк. Как гласит Википедия, «Цель OpenCL состоит в том, чтобы дополнить открытые отраслевые стандарты для трёхмерной компьютерной графики и звука OpenGL и OpenAL возможностями GPU для высокопроизводительных вычислений». Хм, но вроде OpenGL вообще внутри GPU сидит… ну ладно. Короче говоря, OpenCL может работать как на графическом процессоре, так и на центральном (на графическом, конечно, быстрее).
Тем не менее, я не стал ставить OpenCL, а сразу поставил Denoicer III и он сразу заработал. Видимо, в системе стоял какой-то вариант OpenCL для центрального процессора, либо использовались какие-то внутренние функции фильтра. Я снизил шумы на видео и включил рендеринг. И он заработал оооочень медленно. При этом, что странно, ядра процессора были загружены наполовину, а не целиком, как раньше.
И он заработал оооочень медленно. При этом, что странно, ядра процессора были загружены наполовину, а не целиком, как раньше.
Я подумал, что наверное, надо всё-таки поставить в систему OpenCL. И вот, лазия по сайтам, я выяснил, что OpenCL можно скачать как для главного процессора, так и для видеокарты. Причём OpenCL вроде как уже имеется в составе драйверов моей видеокарты! Я решил обновить драйверы видеокарты и попробовать снова включить аппаратное ускорение, что и было сделано. И вот тут-то я и увидел, что в качестве средства рендеринга предлагается вовсе не OpenGL, как я думал раньше, а именно OpenCL! Дрожащей рукой я выбрал аппаратное ускорение… И ВСЁ ЗАРАБОТАЛО!
Оказывается, у меня банально стоял устаревший драйвер видеокарты, который, возможно, был не совсем совместим с новой версией Adobe Premiere Pro СС v12.0.
Я попробовал отрендерить видео, причём на максимальных настройках, и оно отрендерилось быстрее раза в три, чем оно рендерилось на обычных настройках и без всяких фильтров на основном процессоре. Что называется, век живи — век учись… Что интересно, все ядра и потоки процессора при этом были загружены равномерно, но только на 50%.
Что называется, век живи — век учись… Что интересно, все ядра и потоки процессора при этом были загружены равномерно, но только на 50%.
Вообще, конечно, драйверы надо было обновить первым делом, перед всей этой оцифровкой. Но я почему-то считал, что, во-первых, они у меня достаточно свежие, а во-вторых, смутил меня этот OpenCL, прочтённый, как OpenGL, который жёстко прошит в видеокарте и, по идее, не должен зависеть от смены драйверов.
P.S.:
Вот интересно… похоже, видеокарта не справляется с рендерингом мелких быстродвижущихся сцен. Примерно раз в секунду на таких сценах мелкие дальние изображения превращаются на полсекунды в мерцающие квадратики. Выглядит это как периодическое и неравномерное дрожание картинки, а при нажатии на паузу как пикселизация квадратами. Причём это происходит только когда рендеринг идёт достаточно долго. Если я те же сцены рендерю выборочно, то такого почему-то не происходит.
В конце получасового видео у меня действие перемещается внутрь помещения с однородными стенами и крупными предметами, и глюк прекращается. Неужели придётся таки рендерить на основном процессоре?
Неужели придётся таки рендерить на основном процессоре?
Основному процессору доступна память 16 гигов, а графическому на карте ATI HD 7850 всего 2 гига. Может, в этом дело?
Сейчас поставлю ряд экспериментов. Рендерю сейчас центральным процессором при тех же настройках и фильтрах. Сравню. Ещё возможно, я неправильно применил шумодав. Я его применил к уже отмасштабированному эпизоду. Думаю, надо было открыть вложенный эпизод, имеющий начальное, меньшее разрешение, и применить шумодав к нему. Попробую тоже. Но уже завтра, когда отрендерится текущее видео.
Microsoft выпустила пакет совместимости OpenCL и OpenGL для Windows 10
Оставьте ответ
Microsoft выпустила новый пакет расширения для Windows 10, который добавляет новый уровень совместимости с DirectX. Он позволяет приложениям OpenCL и OpenGL работать на ПК с Windows 10, на котором по умолчанию не установлены драйверы оборудования OpenCL и OpenGL.
Если установлен драйвер DirectX 12, поддерживаемые приложения будут работать с аппаратным ускорением для повышения производительности. Этот пакет поддерживает приложения, использующие OpenCL версии 1.2 и ранее и OpenGL версии 3.3 и ранее.
Этот пакет поддерживает приложения, использующие OpenCL версии 1.2 и ранее и OpenGL версии 3.3 и ранее.
как изменить поля в документах Google
Microsoft поставляет две версии этого пакета. Публичный доступен в Магазине, а другой доступен для участников программы предварительной оценки Windows. Последний поддерживает больше приложений из коробки.
как добавить устройство в Google Play
Пакет предоставляет новый бэкэнд D3D12 для проекта Mesa с открытым исходным кодом для поддержки OpenCL и OpenGL.Создав слои сопоставления OpenCL и OpenGL, Microsoft сможет обеспечить аппаратное ускорение для множества приложений с помощью только драйвера DX12, никаких других драйверов не требуется.
Только определенные приложения могут использовать этот пакет совместимости. Участники программы предварительной оценки Windows могут получить версию этого пакета для участников программы предварительной оценки, которая позволяет использовать его большему количеству приложений.
Участники программы предварительной оценки Windows могут получить версию этого пакета для участников программы предварительной оценки, которая позволяет использовать его большему количеству приложений.
Вы можете получить его здесь:
OpenCL ™ и OpenGL® Compatibility Pack
Для этого пакета требуется Windows 10 версии 19041.488 или более поздней, Xbox One, DirectX 12 и доступен для платформ ARM, ARM64, x64 и x86.
как показать пинг в лол
OpenCL, Vulkan, Sycl
как OpenCL относится к вулкану ?
они оба трубопровода сепары работы с хоста на GPU и GPU на хост с использованием очереди, чтобы сократить расходы на связь с помощью нескольких потоков. Directx-opengl не может?
OpenCL: первоначальный релиз 28 августа 2009 года. Более широкая аппаратная поддержка. Указатели разрешены, но только для использования в устройстве. Можно использовать локальную память, совместно используемую потоками.
Гораздо проще начать hello world. Имеет api накладные расходы для команд, если они не находятся в очереди на стороне устройства. Можно выбрать неявную синхронизацию нескольких устройств или явное управление. Ошибки в основном закреплены за 1.2, но я не знаю о версии 2.0.Вулкан: первоначальный релиз 16 февраля 2016 года (но прогресс с 2014 года). Более узкая аппаратная поддержка. Может ли SPIR-V обрабатывать указатели? А может, и нет? Нет опции локальной памяти? Трудно начать Привет мир. Меньше API служебные. Можно ли выбрать неявное управление несколькими устройствами? Все еще багги для игры Dota-2 и некоторых других игр. Использование графики и вычислительного конвейера одновременно может скрыть еще большую задержку.
 Гораздо проще начать hello world. Имеет api накладные расходы для команд, если они не находятся в очереди на стороне устройства. Можно выбрать неявную синхронизацию нескольких устройств или явное управление. Ошибки в основном закреплены за 1.2, но я не знаю о версии 2.0.
Гораздо проще начать hello world. Имеет api накладные расходы для команд, если они не находятся в очереди на стороне устройства. Можно выбрать неявную синхронизацию нескольких устройств или явное управление. Ошибки в основном закреплены за 1.2, но я не знаю о версии 2.0.если в opencl был вулкан, то он был скрыт от общественности в течение 7-9 лет. Если они могли добавить его, почему они не сделали этого для opengl?(может быть, из-за давления physx/cuda?)
Vulkan рекламируется как вычислительный и графический api, однако я найдено очень мало ресурсов для вычислительной части-почему это ?
ему нужно больше времени, как и opencl.
вы можете проверить информацию о вычислительных шейдерах здесь:
https://www.khronos.org/registry/vulkan/specs/1.0/xhtml/vkspec.html#fundamentals-floatingpoint
вот пример системы частиц, управляемой вычислительными шейдерами:
https://github.com/SaschaWillems/Vulkan/tree/master/computeparticles
ниже этого есть raytracers и примеры обработки изображений тоже.
Вулкан имеет преимущества производительности над OpenGL. То же самое верно для Вулкан против OpenCl?
- Vulkan не нужно синхронизировать для другого API. Его о синхронизации буферов команд между commandqueues.
- OpenCL необходимо синхронизировать с opengl или directx (или vulkan?) перед использованием общего буфера (буферы взаимодействия cl-gl или dx-cl). Это накладные расходы, и вы должны скрывать это используя буфер обмена и конвейеризации. Если общий буфер не существует, он может работать одновременно на современном оборудовании с opengl или directx.
OpenCL печально известен тем, что медленнее, чем CUDA
Это было, но теперь его зрелые и проблемы cuda, особенно с гораздо более широкой аппаратной поддержкой от всех игровых графических процессоров до fpgas с использованием версии 2.1, например, в будущем Intel может поместить fpga в Core i3 и включить его для (soft-x86 core ip) многоядерный процессор модель, закрывающая разрыв между производительностью gpu и процессором, чтобы обновить игровой опыт cpu-physx или просто позволить реализации физики opencl сформировать его и использовать по крайней мере %90 die-area вместо эффективно используемой области %10-%20 мягкого ядра.
С такой же ценой, графические процессоры AMD могут вычислять быстрее на opencl и с такой же вычислительной мощностью Intel igpus рисовать меньше мощности.
кроме того, я написал ядро SGEMM opencl и запустил на HD7870 в 1.1 Tflops и проверил интернет, а затем увидел SGEMM henchmark на GTX680 для той же производительности, используя популярное название на CUDA!(соотношение цены gtx680/hd7870 было 2).
использует ли SYCL OpenCL внутри или может ли он использовать vulkan ? Или нет? используйте ни то, ни другое и вместо этого полагается на низкий уровень, API поставщика быть реализованным ?
здесь
https://www.khronos.org/assets/uploads/developers/library/2015-iwocl/Khronos-SYCL-May15.pdf
говорит
предоставляет методы для работы с целями, которые не имеют В OpenCL(пока!)
резервная реализация CPU отлаживается!
таким образом, он может вернуться к чистой потоковой версии(аналогичной aparapi java).
можно получить доступ к объектам OpenCL из объектов SYCL Может создавать объекты SYCL из объекта OpenCL
взаимодействие с OpenGL остается в SYCL — Использует то же самое структуры/типа
он использует opencl(возможно, не напрямую, но с обновленной связью драйверов?), он развивается параллельно opencl, но может возвращаться к потокам.
от самого маленького встроенного устройства OpenCL 1.2 до самого продвинутого В OpenCL 2.2 ускорители
5
автор: huseyin tugrul buyukisik
Как узнать, когда вам нужен OpenCL — Sweetcode.io
Было время, когда практически все приложения выполнялись только одним типом устройства: процессором. Это время закончилось. С момента выпуска OpenCL 1.0 в 2009 году у разработчиков появился простой способ перенести выполнение приложений на другие типы устройств или, в некоторых случаях, по-новому использовать ЦП для выполнения программного обеспечения.
Это, конечно, не означает, что каждое приложение должно использовать OpenCL.Очевидно, что мы живем в мире, где центральные процессоры остаются основными процессорами для большинства стандартных приложений.
Однако при правильном использовании и правильном развертывании OpenCL может изменить правила игры. Он обеспечивает уровни скорости и эффективности, которые были просто невозможны в более ранние годы истории вычислений.
Имея это в виду, вы можете задаться вопросом, когда именно вам следует использовать OpenCL. Каковы основные преимущества и варианты использования OpenCL, а также примеры ситуаций, когда OpenCL не дает значительных преимуществ?
В этой статье рассматриваются эти вопросы.Он начинается с обзора того, что такое OpenCL и какие реализации доступны. Затем рассматриваются основные варианты использования OpenCL и в заключение приводится несколько примечательных примеров широкомасштабного использования OpenCL сегодня.
Что такое OpenCL?
Основное определение OpenCL: это платформа для написания программного обеспечения, которое может выполняться на различных типах вычислительных устройств.
Попросите уличного разработчика рассказать вам, что означает OpenCL, и вы можете получить ответ о написании приложений, которые выполняются с использованием графических процессоров, а не центральных процессоров.
На самом деле OpenCL — это нечто большее, чем просто перенос выполнения на GPU. OpenCL позволяет писать и развертывать приложения, использующие для обработки несколько типов устройств. К ним относятся не только графические процессоры, но и центральные процессоры (которые, опять же, могут эффективно использоваться в сочетании с OpenCL в определенных сценариях), цифровые сигнальные процессоры (DSP) и другие типы аппаратных ускорителей.
По этой причине правильным определением OpenCL является: структура для создания приложений, которые могут выполняться на разнородных вычислительных устройствах.В этом контексте гетерогенный относится к разнообразному набору аппаратных компонентов, способных выполнять вычисления. Он включает в себя гораздо больше, чем просто графические процессоры.
Также важно помнить, что сам OpenCL является просто спецификацией. Существует несколько реализаций OpenCL как от поставщиков оборудования, так и от поставщиков программного обеспечения. Вообще говоря, приложение, использующее OpenCL, совместимо с любой реализацией платформы, хотя в некоторых случаях реализации OpenCL включают специальные расширения, которые поддерживаются не всеми реализациями.
Вообще говоря, приложение, использующее OpenCL, совместимо с любой реализацией платформы, хотя в некоторых случаях реализации OpenCL включают специальные расширения, которые поддерживаются не всеми реализациями.
Когда использовать OpenCL
OpenCL очень широко поддерживается на различных программных платформах и аппаратных устройствах. Его синтаксис, похожий на C, также прост в освоении для большинства программистов, которые уже знают последний язык (то есть для большинства программистов, учитывая, что C является вторым по популярности языком программирования). Все это означает, что вы можете использовать OpenCL в самых разных ситуациях.
Однако настоящий вопрос для разработчиков заключается в том, следует ли вам использовать OpenCL.Хотя OpenCL редко мешает выполнению приложения, в некоторых случаях он дает больше преимуществ, чем в других.
Вот критерии, которые следует учитывать при принятии решения об использовании OpenCL.
Поддерживается ли ваше целевое оборудование? Это первый и самый очевидный вопрос. Вы должны убедиться, что устройства, на которых будет развернуто ваше программное обеспечение OpenCL, поддерживают OpenCL.
Вы должны убедиться, что устройства, на которых будет развернуто ваше программное обеспечение OpenCL, поддерживают OpenCL.
Скорее всего, да. Большинство современных графических и центральных процессоров, предназначенных для стандартных потребительских устройств, поддерживают OpenCL.Поддержка может быть менее тщательной, если вы имеете дело со специализированными типами устройств. Но в любом случае информацию о поддержке OpenCL обычно легко найти в спецификациях устройств, с которыми вы работаете.
Поддерживают ли его целевые программные среды?Второй очевидный вопрос, который следует задать, заключается в том, поддерживают ли программные среды, на которые вы ориентируетесь, OpenCL. Здесь также все основные современные программные платформы (включая Windows, macOS, Android, Linux и FreeBSD) совместимы с OpenCL, и большинство из них поставляется с предустановленным OpenCL.
Если вы создаете программное обеспечение OpenCL для другого типа среды или среды, в которой вы не можете рассчитывать на то, что драйверы OpenCL будут доступны по умолчанию (что может иметь место на некоторых телефонах Android, например, если поставщик решит не предоставить OpenCL по умолчанию), вам может потребоваться предоставить драйверы OpenCL вместе с программным обеспечением, которое вы создаете. Как правило, это достаточно легко сделать, хотя в этом случае вам также следует учитывать, насколько сложными будут установки драйверов OpenCL для конечных пользователей и как вы можете упростить для них процесс установки.
Как правило, это достаточно легко сделать, хотя в этом случае вам также следует учитывать, насколько сложными будут установки драйверов OpenCL для конечных пользователей и как вы можете упростить для них процесс установки.
Основная причина, по которой OpenCL позволяет выполнять приложения быстрее, чем в стандартной среде на основе ЦП, заключается в том, что OpenCL позволяет одновременно использовать множество вычислительных устройств. Перенос выполнения приложений на такие устройства, как GPU, полезен не потому, что отдельные вычислительные мощности внутри GPU быстрее, чем в CPU, а потому, что GPU обычно содержат гораздо больше ядер, чем стандартный CPU.Следовательно, они обеспечивают более быстрое выполнение, поскольку вы можете запускать больше потоков приложений одновременно.
Чтобы эффективно использовать большее количество ядер, к которым OpenCL предоставляет вам доступ, ваш код должен быть написан с поддержкой параллелизма, что означает возможность одновременного запуска нескольких процессов или задач.
Если вы пишете приложение с нуля, его разработка для параллельной архитектуры обычно вполне возможна. Но если вы пытаетесь добавить код OpenCL в существующее приложение, реализация кода таким образом, чтобы в полной мере использовать поддержку распараллеливания устройств, на которые вы ориентируетесь, может оказаться более сложной задачей.
Ваши данные не будут узкими местами между устройствамиРаспространенной проблемой при использовании OpenCL являются узкие места. Узкие места возникают, когда вы не можете достаточно быстро передавать данные между устройствами, выполняющими код OpenCL, и «хост-устройством» вашей системы, которым обычно является стандартный ЦП. Узкие места возникают из-за того, что шина, соединяющая эти два компонента, не может поддерживать высокую скорость передачи.
Есть вещи, которые вы можете сделать, чтобы смягчить эту проблему, например, асинхронная передача данных, которая снижает риск возникновения узких мест за счет более эффективного перемещения данных. Вы также можете обойти это ограничение, запустив код OpenCL на устройстве, на которое вообще не нужно передавать данные. Это одна из распространенных причин запуска OpenCL на ЦП, а не на ГП, поскольку ЦП может обращаться к стандартной системной памяти быстрее, чем ГП.
Вы также можете обойти это ограничение, запустив код OpenCL на устройстве, на которое вообще не нужно передавать данные. Это одна из распространенных причин запуска OpenCL на ЦП, а не на ГП, поскольку ЦП может обращаться к стандартной системной памяти быстрее, чем ГП.
Но если шина, с которой вам нужно работать, слишком медленная, обходные пути не помогут. Суть: прежде чем принять решение об использовании OpenCL, ознакомьтесь со спецификациями системы, с которой вы работаете, чтобы убедиться, что они не оставят вас узким местом.Кроме того, подумайте о типе приложения, которое вы пишете, и о том, как часто вам нужно будет перемещать данные между устройствами и хостами.
Вы знаете CКак отмечалось выше, синтаксис OpenCL основан на синтаксисе C, поэтому, если вы знаете C (или C++, если на то пошло), написание кода OpenCL не должно быть особенно сложным.
Имейте также в виду, что не все ваши приложения должны быть написаны на OpenCL, чтобы использовать преимущества OpenCL. Вы можете использовать OpenCL в сочетании практически с любым языком программирования, написав немного кода ядра OpenCL.
Вы можете использовать OpenCL в сочетании практически с любым языком программирования, написав немного кода ядра OpenCL.
Варианты использования OpenCL
Как выглядят реальные варианты использования OpenCL? Вот несколько примеров:
- OCR : Оптическое распознавание символов, или OCR, требует больших вычислительных ресурсов. OpenCL может значительно повысить производительность приложений OCR при условии, что приложения используют преимущества параллелизма.
- Распознавание изображений . Идентификация шаблонов или объектов на изображениях для таких целей, как распознавание лиц, — еще одна ресурсоемкая задача, для решения которой может пригодиться OpenCL.
- Майнинг биткойнов . Если вы много знаете о биткойнах, вы знаете, что процесс майнинга биткойнов требует огромной вычислительной мощности — настолько большой, что майнинг биткойнов с использованием стандартных процессоров сегодня нецелесообразен. По этой причине было создано множество приложений OpenCL для майнинга биткойнов.
- Изменение размера изображения . Изменение размера изображений — еще одна ресурсоемкая операция, которая может выиграть от OpenCL .
Что такое OpenCL?.OpenCL — это инструмент, который позволит вам… | Бернардо Родригес. Проверьте это для большего содержания.
Как и многие другие, я стараюсь проводить свободное время во время карантина продуктивно. Я решил, что пришло время заняться тем, что меня давно интересовало: программирование GPU. Если вы погуглите эту тему, вы обнаружите, что есть несколько технологий, которые могут помочь вам воспользоваться преимуществами вашего графического процессора.Ради всех я не буду приводить сравнение этих технологий, так как их полно в сети. Что я могу сказать, так это то, почему я решил изучать OpenCL, а не его аналоги.
Как я читал, OpenCL часто не обеспечивает оптимальной производительности по сравнению с другими (например, CUDA), однако это открытый стандарт, поддерживаемый десятками крупных компаний.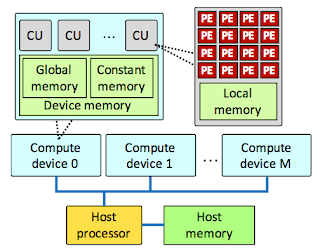 Мне это казалось чем-то более общим и открыто принятым в индустрии.
Мне это казалось чем-то более общим и открыто принятым в индустрии.
Я ни в коем случае не эксперт в этом вопросе.Однако я хотел бы поделиться тем, что я узнал, пытаясь использовать OpenCL в одном из моих проектов.
[Khronos Group] Некоторые примеры из обширного списка сторонников OpenCL (https://www.khronos.org/opencl/)Как сообщает Khronos Group, разработчики OpenCL и других открытых стандартов, таких как OpenGL:
OpenCL™ (Open Computing Language) — это открытый бесплатный стандарт для кросс-платформенного параллельного программирования различных ускорителей, используемых в суперкомпьютерах, облачных серверах, персональных компьютерах, мобильных устройствах и встроенных платформах.
Это мало что объясняет, кроме общего коммерческого описания. Давайте сломаем это. OpenCL — это инструмент, позволяющий выполнять параллельные вычисления общего назначения на графических процессорах или других совместимых аппаратных ускорителях . Это включает в себя перемещение данных, выполнение фактической работы и получение результатов.
Это включает в себя перемещение данных, выполнение фактической работы и получение результатов.
OpenCL — это открытая спецификация, также называемая стандартом. Среди прочего, он определяет язык программирования, модель программирования и обоснование.Однако в нем не упоминается, как реализовать их на аппаратном или даже программном обеспечении; это нормально, и именно поэтому его можно считать кросс-платформенным стандартом. Разработчики приложений и оборудования договариваются об абстрактном интерфейсе, в котором встречаются их миры; еще одно хорошее применение развязанных систем.
Производители оборудования будут заботиться только о реализации оборудования и публикации драйверов, совместимых с какой-либо версией спецификации OpenCL. Между тем, разработчики приложений с удовольствием будут использовать программную модель, предложенную той же спецификацией, и она будет гарантированно корректно работать на оборудовании.
Вы, наверное, заметили, что ранее я упоминал драйверы. Думайте о драйвере как об уровне аппаратной абстракции, написанном в программном обеспечении с целью обработки (от имени пользователя/разработчика) внутренних операций конкретного устройства. Эти драйверы чаще всего реализуются самими производителями оборудования и, следовательно, являются проприетарными. Из-за этого разные реализации OpenCL, например. AMD против Nvidia может дать разные результаты; некоторые драйверы более отточены, чем другие.
Думайте о драйвере как об уровне аппаратной абстракции, написанном в программном обеспечении с целью обработки (от имени пользователя/разработчика) внутренних операций конкретного устройства. Эти драйверы чаще всего реализуются самими производителями оборудования и, следовательно, являются проприетарными. Из-за этого разные реализации OpenCL, например. AMD против Nvidia может дать разные результаты; некоторые драйверы более отточены, чем другие.
Поскольку OpenCL является абстрактным стандартом, не только графические процессоры могут быть совместимы с OpenCL. Теоретически все, что реализует спецификацию OpenCL, будет запускать программу OpenCL. Черт возьми, вы даже можете разработать свой собственный аппаратный ускоритель, совместимый с OpenCL, на FPGA. В конце концов, стандарт бесплатный.
[Khronos Group] Как организованы приложения OpenCL (https://www.khronos.org/opencl/)- OpenCL имеет свой собственный язык , но не бойтесь, поскольку он по сути является подмножеством C99. Начиная с OpenCL 2.1 также есть спецификация для другого диалекта, основанного на подмножестве C++14. Если вы знаете C, у вас все будет хорошо.
- OpenCL превосходит приложений с параллельными данными, требующих больших вычислительных ресурсов . Если ваш код сильно зависит от данных или доступа к памяти, возможно, OpenCL не даст вам соответствующего прироста производительности.
- Тот же код работает на любом устройстве OpenCL .
- Код OpenCL скомпилирован во время выполнения .
- Вам нужно смоделировать вашу задачу, чтобы она соответствовала модели программирования OpenCL .Будьте осторожны при определении параллелизма данных.
 Начиная с OpenCL 2.1 также есть спецификация для другого диалекта, основанного на подмножестве C++14. Если вы знаете C, у вас все будет хорошо.
Начиная с OpenCL 2.1 также есть спецификация для другого диалекта, основанного на подмножестве C++14. Если вы знаете C, у вас все будет хорошо.В следующий раз мы обсудим модель программирования OpenCL. А пока, счастливого кодирования !
Материалы Khronos Group
Введение в OpenCL
Анонс пакета совместимости OpenCL™ и OpenGL® для Windows 10 на ARM
Анджела Цзян
Ранее в этом году мы объявили о партнерстве с Collabora для создания слоев отображения OpenCL и OpenGL в DirectX 12 с целью поддержки большего количества приложений для повышения производительности и творчества на основе OpenCL и OpenGL, для которых родные драйверы недоступны. С тех пор мы добились огромного прогресса, и сегодня мы рады рассказать больше о проекте и поделиться одним конкретным примером использования: Photoshop в Windows 10 на ARM.
С тех пор мы добились огромного прогресса, и сегодня мы рады рассказать больше о проекте и поделиться одним конкретным примером использования: Photoshop в Windows 10 на ARM.
В сентябре главный директор по продуктам Windows + Devices Панос Панай рассказал в своем блоге о том, как партнеры по приложениям внедряют Windows 10 на ARM. Сегодня Adobe выпустила бета-версию Photoshop, изначально созданную для ARM64, чтобы разработчики могли использовать свои подключаемые модули Photoshop для Windows на ARM. Разработчикам потребуется платная подписка на Photoshop, чтобы найти и установить эту бета-версию через приложение Creative Cloud для настольных ПК.
Мы рады сообщить, что мы сотрудничаем с Adobe, чтобы обеспечить ускорение графического процессора в Photoshop на ARM с использованием слоев отображения OpenCL и OpenGL. Слои сопоставления теперь доступны для загрузки в Microsoft Store как OpenCL™ и OpenGL® Compatibility Pack . Когда вы устанавливаете пакет совместимости вместе с драйвером Qualcomm DirectX 12, собственная версия Photoshop для ARM может использовать пакет совместимости, чтобы воспользоваться преимуществами возможностей графического процессора на вашем устройстве ARM:
. Что входит в пакет совместимости OpenCL и OpenGL?
Что входит в пакет совместимости OpenCL и OpenGL? В отличие от традиционного приложения, которое вы найдете в Магазине, этот пакет совместимости на самом деле не является приложением, поэтому вы не найдете его в меню «Пуск».Вместо этого это набор DLL, все из которых созданы проектами с открытым исходным кодом.
Пакет совместимости OpenCL и OpenGL включает реализацию OpenGL ICD и стек компилятора OpenCL из проекта Mesa, а также реализацию OpenCL ICD из нашего собственного репозитория с открытым исходным кодом. Стек компилятора OpenCL использует еще больше компонентов с открытым исходным кодом: он использует Clang/LLVM 10.0, проект SPIRV-LLVM-Translator и проект SPIRV-Tools перед преобразованием OpenCL SPIR-V в формат Mesa NIR и, наконец, в формат D3D DXIL.
Код Mesa в настоящее время получен из ответвления. Мы будем работать с сообществом Mesa, чтобы внести этот новый драйвер в ближайшие месяцы — следите за обновлениями.
Каким системным требованиям я должен соответствовать, чтобы иметь возможность использовать пакет совместимости OpenCL и OpenGL?Чтобы использовать пакет совместимости на вашем устройстве Windows на ARM, вам необходимо выполнить два требования:
- Версия вашей ОС должна быть 19041. 488 или выше. На практике это означает, что вы должны использовать последнюю версию обновления Windows 10 от мая 2020 г. (версия 2004), или последнюю версию обновления Windows 10 от октября 2020 г. (версия 20h3), или последнюю сборку программы предварительной оценки.
- Пакет совместимости OpenCL и OpenGL должен быть установлен на вашем устройстве ARM. Вы можете загрузить его из Microsoft Store. Вы также можете проверить, какую версию пакета совместимости вы установили, выбрав «Настройки» > «Приложения» > «Приложения и функции» > «Пакет совместимости OpenCL и OpenGL» > «Дополнительные параметры».
 488 или выше. На практике это означает, что вы должны использовать последнюю версию обновления Windows 10 от мая 2020 г. (версия 2004), или последнюю версию обновления Windows 10 от октября 2020 г. (версия 20h3), или последнюю сборку программы предварительной оценки.
488 или выше. На практике это означает, что вы должны использовать последнюю версию обновления Windows 10 от мая 2020 г. (версия 2004), или последнюю версию обновления Windows 10 от октября 2020 г. (версия 20h3), или последнюю сборку программы предварительной оценки.Кроме того, чтобы пакет совместимости поддерживал ускорение графического процессора, вам потребуется установить новейший драйвер DirectX 12.
Какие версии OpenCL и OpenGL поддерживает пакет совместимости? Как упоминалось в нашем первоначальном объявлении, пакет совместимости OpenCL и OpenGL будет поддерживать приложения, использующие OpenCL версии 1. 2 и более ранней, а также OpenGL версии 3.3 и более ранней.
2 и более ранней, а также OpenGL версии 3.3 и более ранней.
Пакет совместимости OpenCL и OpenGL в настоящее время доступен только для использования с родной версией Photoshop для ARM.Мы изучаем возможность добавления поддержки дополнительных приложений позднее.
Если вы в восторге от того, что ваши любимые приложения OpenCL и OpenGL работают на вашем устройстве Windows на ARM, и не хотите ждать, у нас есть хорошие новости: инсайдеры Windows на всех каналах могут загрузить инсайдерскую версию пакета совместимости, который позволяет большему количеству приложений использовать его. Фактически все приложения, использующие OpenCL версии 1.2 и более ранних версий и OpenGL версии 3.3 и более ранних версий, могут использовать инсайдерскую версию пакета обеспечения совместимости.
Могу ли я использовать пакет совместимости OpenCL и OpenGL в моей системе x64? Мы рекомендуем использовать собственные драйверы OpenCL и OpenGL в вашей системе x64. Пакет совместимости OpenCL и OpenGL предназначен для поддержки большего количества приложений OpenCL и OpenGL в средах, где собственные драйверы недоступны, например в Windows на ARM. Если вы устанавливаете пакет совместимости в среде, где уже доступны собственные драйверы OpenCL и OpenGL, уровни отображения OpenCL и OpenGL будут иметь следующее поведение:
Пакет совместимости OpenCL и OpenGL предназначен для поддержки большего количества приложений OpenCL и OpenGL в средах, где собственные драйверы недоступны, например в Windows на ARM. Если вы устанавливаете пакет совместимости в среде, где уже доступны собственные драйверы OpenCL и OpenGL, уровни отображения OpenCL и OpenGL будут иметь следующее поведение:
- Слой отображения OpenGL не будет использоваться.Вместо этого будет использоваться родной драйвер OpenGL.
- Уровень отображения OpenCL будет указан последним в списке платформ OpenCL. Приложение выбирает используемую платформу OpenCL, и вполне вероятно, что будет выбран собственный драйвер OpenCL.
Мы хотели бы услышать от вас, используете ли вы общедоступную версию или инсайдерскую версию пакета совместимости.Самый простой способ поделиться с нами своими проблемами и предложениями — использовать Центр отзывов и включить «Пакет совместимости OpenCL и OpenGL» в заголовок отзыва.
Продукт основан на опубликованной спецификации Khronos и был представлен и, как ожидается, пройдет процесс соответствия Khronos. Текущий статус соответствия можно найти на сайте www.khronos.org/conformance.
OpenCL и логотип OpenCL являются товарными знаками Apple Inc., используемыми Khronos с разрешения. Полная информация о лицензии доступна на веб-сайте Apple (https://developer.apple.com/softwarelicensing/opencl/).
OpenGL® и овальный логотип являются товарными знаками или зарегистрированными товарными знаками Hewlett Packard Enterprise в США и/или других странах мира.
OpenCL против CUDA: что лучше поддерживает приложения?
Итак, теперь перейдем к OpenCL, платформе GPGPU с открытым исходным кодом. Мы уже упоминали, что если ваше программное обеспечение поддерживает и OpenCL, и CUDA, выберите CUDA, но что, если OpenCL — единственный выбор?
Проще говоря, если OpenCL — ваш единственный вариант, сделайте это. Например, Final Cut Pro X поддерживает только OpenCL, и мы обычно рекомендуем нашим пользователям устанавливать карты AMD OpenCL в свои системы, если они используют популярное приложение для редактирования видео. В целом интеграция OpenCL, как правило, не такая тесная, как CUDA, но OpenCL по-прежнему дает значительный прирост производительности при использовании, и это намного лучше, чем вообще не использовать GPGPU.
Например, Final Cut Pro X поддерживает только OpenCL, и мы обычно рекомендуем нашим пользователям устанавливать карты AMD OpenCL в свои системы, если они используют популярное приложение для редактирования видео. В целом интеграция OpenCL, как правило, не такая тесная, как CUDA, но OpenCL по-прежнему дает значительный прирост производительности при использовании, и это намного лучше, чем вообще не использовать GPGPU.
Как мы уже говорили ранее, карты Nvidia также используют платформу OpenCL, но в настоящее время они не так эффективны, как карты AMD (однако они быстро догоняют).Поэтому, если все приложения, которые вы используете, основаны исключительно на OpenCL и не имеют поддержки CUDA, например Final Cut Pro X, мы рекомендуем вам оснастить вашу систему графическим процессором OpenCL AMD.
Если приложения, которые вы используете, разделяют свою поддержку между CUDA и OpenCL, мы рекомендуем использовать последнюю карту Nvidia. С настройкой Nvidia вы получите максимальную отдачу от своих приложений с поддержкой CUDA, сохраняя при этом хорошие возможности OpenCL в приложениях без CUDA.
С настройкой Nvidia вы получите максимальную отдачу от своих приложений с поддержкой CUDA, сохраняя при этом хорошие возможности OpenCL в приложениях без CUDA.
Например, Nvidia GTX 780 значительно ускорит все ваши вычисления на основе CUDA, но при этом наберет 1700 баллов в LuxMark Sala (тест OpenCL), что значительно ускорит работу приложений, основанных на OpenCL, таких как Final Cut Pro X. Еще более новый графический процессор Nvidia, такой как GTX 980 набирает 2600 баллов в LuxMark Sala, что выше, чем у AMD R9 280X (который набирает 2400 баллов), что дает вам лучшее из обоих миров. Если вы используете Adobe CC или другие приложения с поддержкой CUDA, а также эксклюзивное программное обеспечение OpenCL, такое как Final Cut Pro X, Nvidia GTX 780 и 980 являются надежными решениями.
Здесь мы кратко перечислим ряд приложений с поддержкой GPGPU, с какими фреймворками они работают и, если опубликовано, как GPGPU используется в приложении. Обратите внимание, что этот список не является исчерпывающим, он просто содержит основные приложения и соответствующую легкодоступную информацию. Здесь Nvidia предоставляет собственный список приложений с ускорением CUDA. Для OpenCL может быть немного сложнее выяснить, какие приложения поддерживают платформу, Google обычно является лучшим методом.
Обратите внимание, что этот список не является исчерпывающим, он просто содержит основные приложения и соответствующую легкодоступную информацию. Здесь Nvidia предоставляет собственный список приложений с ускорением CUDA. Для OpenCL может быть немного сложнее выяснить, какие приложения поддерживают платформу, Google обычно является лучшим методом.
- 1 Adobe After Effects CC
- CUDA SUPMENT
- 3D RAY TRACE
- Multi GPU
- OpenCL поддержка
- 01
- Adobe Photoshop CC
3
- CUDA CUDA SUPPER
- 30 EFFICE В Mercury Graphics Engine
5
- CUDA CUDA SUPPER
5
- CUDA SUPMENT
- 1 Adobe After Effects CC
0
0
0
1- CUDA Support
- Mercury Воспроизведение двигателя для редактирования видео в реальном времени и ускоренного рендеринга
5
- OpenCL поддержки
5
- CUDA Support
- Adobe SpeedGrade CC
- Cuda Support
- CUDA Оценка и отделка
- CUDA Оценка и отделка
- Cuda Support
- 1 Autodesk Maya
3
- CUDA SOPECTION
- Увеличение модели
- Большие сцены
5
- поддержка OpenCl 9010 5
- CUDA SOPECTION
- Avid Media Composer
- CUDA Поддержка
- Быстрее видеоэффекты
- Уникальный стерео 3D возможности
- CUDA Поддержка
- Avid Motion графика
- Blackmagic DaVinci Resolve
- CUDA Поддержка
- Цветовая коррекция в реальном времени
- Re-Time De-No-Noising
5
- OpenCL CORM
- Real-Time Color Correction
5
- CUDA Поддержка
- Final Cut Pro X
- OpenCL Support
- Real -time FX редактирование – нет необходимости рендерить временную шкалу
- Более быстрое общее воспроизведение и производительность временной шкалы
- Ускоренный рендеринг сторонних эффектов
- Нет перекодирования AVCHD или других сложных кодеков в редактируемый ProRes
- OpenCL Support
- 0 -X
- Поддержка CUDA
- Ускоренные погибшие
- поддержки для 2 GPU
5
- Поддержка CUDA
- OPENCL SPEECT
- NO CESPORES Устраненные
- только поддержки 1 GPU
5
-
- Red Giant Magic Pullet выглядит
- SONY Vegas Pro
- CUDA Поддержка
- Быстрее видео эффекты и кодирование
- OpenCL Поддержка
- Литейный Гиерон
- The Foundry NUKE & NUKEX
- Заготовя MARI
- CUDA Support
- Увеличение моделей сложности при интерактивных ставках
5
- Убедитесь, что ваш компьютер поддерживает OpenCL, как описано выше.
- Получите заголовки и библиотеки OpenCL, включенные в SDK OpenCL, у вашего любимого поставщика.
- Начать писать код OpenCL.
- Сообщите компилятору, где расположены заголовки OpenCL.
- Установите OpenCL.dll-файл.
- Обновите драйверы вашего устройства.
- Переустановите программу.
- Запустите проверку на вирусы.
5
5
Round-Up
Довольно ясно, что GPGPU является ходом в правильном направлении для всех профессиональных пользователей. При поддержке это дает огромные преимущества производительности для приложений, особенно когда они работают с изображениями и видео.
При поддержке это дает огромные преимущества производительности для приложений, особенно когда они работают с изображениями и видео.
В настоящее время CUDA и OpenCL являются ведущими платформами GPGPU. CUDA — это закрытый фреймворк Nvidia, он не поддерживается в таком количестве приложений, как OpenCL (тем не менее, поддержка по-прежнему широка), но там, где он интегрирован, высококачественная поддержка Nvidia обеспечивает непревзойденную производительность. OpenCL имеет открытый исходный код и поддерживается в большем количестве приложений, чем CUDA. Однако поддержка часто бывает тусклой, и в настоящее время она не обеспечивает такого же повышения производительности, как CUDA.
По нашему мнению, графические процессоры Nvidia (особенно более новые) обычно являются лучшим выбором для пользователей, поскольку имеют встроенную поддержку CUDA, а также высокую производительность OpenCL, когда CUDA не поддерживается. Единственная ситуация, в которой мы бы рекомендовали графический процессор AMD профессионалам, — это когда они используют исключительно приложения, поддерживающие OpenCL и не имеющие опции CUDA.
Если вы ищете систему Mac Pro 5,1 на базе CUDA/OpenCL, перейдите на нашу страницу Mac Pro, чтобы собрать систему, или напишите нам по адресу [email protected]
Где находится OpenCL DLL?
Где находится DLL OpenCL?
Если вы используете 64-битную версию, файл OpenCL.dll должен находиться по пути C:\Windows\SysWOW64. После того, как вы получите новый файл OpenCL, вам необходимо зарегистрировать его.
Как узнать, установлен ли OpenCL в Windows 10?
¶ Выполнение команды clocl –version отобразит версию установленного компилятора OpenCL. Выполнение команды ls -l /usr/lib/libOpenCL* отобразит библиотеки OpenCL, установленные на устройстве.
Как включить OpenCL в Windows 10?
Основные шаги будут следующими:
OpenCL умер?
OpenCL де-факто умер в пользу CUDA, а затем некоторые члены Khronos сформировали HSA Foundation, но он тоже умер, так что теперь мы находимся на том месте, где у нас есть AMD ROCm/HIP и Intel oneAPI/DPC++ (SYCL со специфическими расширениями Intel) .
Что лучше OpenCL или Cuda?
По общему мнению, если ваше приложение поддерживает и CUDA, и OpenCL, используйте CUDA, так как это даст более высокие результаты производительности. Если вы включите OpenCL, можно использовать только 1 графический процессор, однако при включении CUDA для GPGPU можно использовать 2 графических процессора.
Использует ли nuke GPU?
Nuke 12.0 включает в себя новые инструменты с ускорением на графическом процессоре, интегрированные с Cara VR, для решения задач камеры, сшивания и исправления с обновлениями до самых последних стандартов.Оптимизации, включенные в этот выпуск, появляются во всем программном обеспечении, в основном для повышения производительности, особенно при работе в масштабе.
Cuda только для Nvidia?
В отличие от OpenCL, графические процессоры с поддержкой CUDA доступны только у Nvidia.
Cuda C или C++?
CUDA C — это, по сути, C/C++ с несколькими расширениями, которые позволяют выполнять функции на графическом процессоре, используя множество потоков параллельно.
Может ли AMD GPU запускать Cuda?
CUDA был разработан специально для графических процессоров NVIDIA.Следовательно, CUDA не может работать на графических процессорах AMD. Графические процессоры AMD не смогут запускать двоичные файлы CUDA (.cubin), поскольку эти файлы специально созданы для используемой вами архитектуры графических процессоров NVIDIA.
Является ли Cuda графическим процессором?
CUDA — это платформа параллельных вычислений и модель программирования, разработанная Nvidia для общих вычислений на собственных графических процессорах (графических процессорах). CUDA позволяет разработчикам ускорить работу ресурсоемких приложений за счет использования мощности графических процессоров для распараллеливаемой части вычислений.
Стоит ли изучать Cuda?
Важно ли изучать CUDA для глубокого обучения? Нет, не совсем. Мы реализовали некоторые стандартные и модифицированные архитектуры глубокого обучения без CUDA на обычных машинах с процессором. Однако наличие процессора GPU и работа с ним с использованием CUDA значительно ускоряет работу.
Как узнать, поддерживает ли моя видеокарта CUDA?
Вы можете убедиться, что у вас есть графический процессор с поддержкой CUDA, в разделе «Адаптеры дисплея» в диспетчере устройств Windows.Здесь вы найдете название производителя и модель вашей видеокарты. Если у вас есть карта NVIDIA, указанная на http://developer.nvidia.com/cuda-gpus, этот графический процессор поддерживает CUDA.
Может ли Cuda работать на процессоре?
Если вы хотите запускать коды CUDA, скомпилированные с помощью CUDA 5.5, вам понадобится графический процессор с поддержкой CUDA. Если вы хотите использовать старые наборы инструментов CUDA, вы можете установить один из различных эмуляторов, например этот. Или вы можете установить очень старый (например, ~ CUDA 3.0) набор инструментов cuda, который может запускать коды CUDA на ЦП.
Или вы можете установить очень старый (например, ~ CUDA 3.0) набор инструментов cuda, который может запускать коды CUDA на ЦП.
Могу ли я запустить Cuda без графического процессора?
Ответ на ваш вопрос ДА. Драйвер компилятора nvcc не связан с физическим наличием устройства, поэтому вы можете компилировать коды CUDA даже без графического процессора с поддержкой CUDA. Конечно, в обоих случаях (без GPU или GPU с другой архитектурой) вы не сможете успешно запустить код.
Поддерживает ли GTX 1050 Cuda?
GTX 1050 имеет ту же функциональность CUDA, что и GTX 1080 Ti, несмотря на то, что у нее на 21% больше ядер CUDA и на 22% больше видеопамяти.
Что такое ядра Cuda в видеокартах?
ядра CUDA — это параллельные процессоры, точно так же, как ваш процессор может быть двух- или четырехъядерным устройством, графические процессоры nVidia содержат несколько сотен или тысяч ядер. Ядра отвечают за обработку всех данных, которые вводятся в графический процессор и из него, выполняя расчеты игровой графики, которые визуально разрешаются для конечного пользователя.
Имеют ли значение ядра Cuda для игр?
Использование графической карты с ядрами CUDA даст вашему ПК преимущество в общей производительности, а также в играх.Больше ядер CUDA означает более четкую и реалистичную графику. Просто не забудьте принять во внимание и другие особенности видеокарты.
Сколько ядер у видеокарты?
ЦПимеют 1,2,4,6,8 ядер или более. То же самое, у графических процессоров их от сотен до тысяч. Вот почему лучшая видеокарта имеет примерно в 80 раз большую вычислительную мощность, чем четырехъядерный процессор. Разница в том, что они специфичны для типа и сгруппированы (см. ответ выше).
Какая видеокарта имеет больше всего ядер Cuda?
Вариантс большим графическим процессором: для карт, имеющих до 8192 ядер CUDA и до 24 ГБ ОЗУ….Большие карты GPU.
| Плата графического процессора | ядра CUDA | ОЗУ |
|---|---|---|
| GeForce GTX Titan-X | 3072 | 12 ГБ |
| GeForce RTX 3090 | 10496 | 24 ГБ |
| GeForce RTX 3080 | 8704 | 10 ГБ |
| GeForce RTX 2080 Ti | 4352 | 11 ГБ |
Какая видеокарта самая быстрая?
Поиск
| Ранг | Устройство | MSRP Цена |
|---|---|---|
| 1 | NVIDIA GeForce RTX 3090 DirectX 12. 00 00 | $1499 |
| 2 | AMD Radeon 6900 XT DirectX 12.00 | $999 |
| 3 | AMD Radeon RX 6800 XT DirectX 12.00 | 649 $ |
| 4 | NVIDIA Quadro RTX A6000 DirectX 12.00 | н/д |
Какая самая мощная видеокарта в мире 2020?
NVIDIA ТИТАН В
Стоит ли обновлять 1080 до RTX 2080?
Очень доволен обновлением 1080->2080, это определенно заметно.В основном с настройками, которые я использовал с 1080, чтобы все работало гладко, 2080 кадров в секунду могут соответствовать или даже превышать частоту обновления монитора. Если у вас есть монитор 4K или вы хотите добиться 144 кадров в секунду на ультра настройках, тогда RTX 2080 имеет больше смысла.
Что означает GT для Nvidia?
гигатексель затенение
Как исправить, что программа не запускается из-за отсутствия OpenCL DLL на вашем компьютере?
Как исправить OpenCL.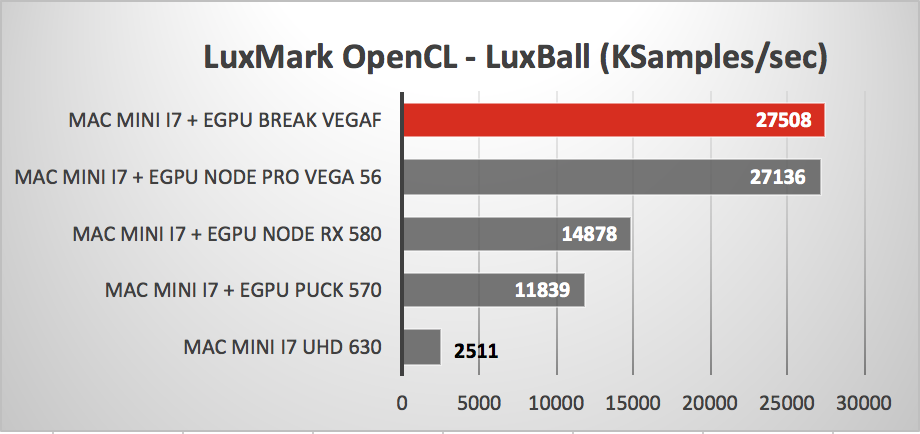 dll отсутствует или не найден
dll отсутствует или не найден
Как установить OpenCL в Windows?
Заменит ли Vulkan OpenCL?
Vulkan — это вычислительный API не больше, чем OpenGL. У него могут быть вычислительные шейдеры, но их функциональность ограничена. То, что вы можете делать в вычислительной операции OpenCL, просто недоступно в OpenGL/Vulkan CS. Vulkan имеет преимущества в производительности по сравнению с OpenGL.
Поддерживает ли Blender GPU AMD?
OpenCL поддерживается для рендеринга GPU с видеокартами AMD. Blender поддерживает рендеринг GPU на видеокартах с GCN поколения 2 и выше.
Поддерживает ли AMD OpenCL?
Созданный как часть AMD GPUOpen, ROCm (Radeon Open Compute) представляет собой проект Linux с открытым исходным кодом, построенный на OpenCL 1.2 с языковой поддержкой 2. 0. Система совместима со всеми современными CPU и APU AMD (фактически частично GFX 7, GFX 8 и 9), а также Intel Gen7.5+ процессоров (только с PCI 3.0).
0. Система совместима со всеми современными CPU и APU AMD (фактически частично GFX 7, GFX 8 и 9), а также Intel Gen7.5+ процессоров (только с PCI 3.0).
Является ли OpenCL устаревшим?
Спустя десятилетие с момента своего создания экосистема вычислений на GPU претерпевает изменения: интерес NVIDIA сдерживается тем фактом, что у них уже есть свой очень успешный API CUDA, драйверы AMD OpenCL в беспорядке, Apple отказалась от OpenCL и переходит на собственный проприетарный Металлический API.
Может ли OpenCL работать на процессоре?
Приложение OpenCL может работать на одноядерном ЦП, но обычно многоядерные системы предназначены для повышения общей производительности системы.OpenCL также может работать на FPGA.
В чем разница между OpenGL и OpenCL?
Основное различие между OpenGL и OpenCL заключается в том, что OpenGL используется для программирования графики, а OpenCL — для гетерогенных вычислений. OpenGL позволяет писать программы для выполнения графических операций, а OpenCL позволяет писать программы для гетерогенных систем, состоящих из нескольких процессоров.
Vulkan лучше, чем OpenGL?
Vulkan — это малозатратный кроссплатформенный API для 3D-графики и вычислений.Vulkan нацелен на высокопроизводительные приложения для 3D-графики в реальном времени, такие как видеоигры и интерактивные медиа. По сравнению с OpenGL, Direct3D 11 и Metal, Vulkan предлагает более высокую производительность и более сбалансированное использование процессора и графического процессора.
Работает ли Vulkan на Nvidia?
NVIDIA тесно сотрудничала с Khronos Group, создателями Vulkan, на протяжении всей его разработки, и на сегодняшний день Vulkan поддерживает все графические карты Kepler и Maxwell под управлением Windows 7 или более поздней версии или Linux.Принцип Талоса работает на Вулкане.
Как получить Vulkan в Windows 10?
Если вы используете Windows 10, используйте Windows-I, чтобы открыть приложение «Параметры». Выберите «Приложения» > «Приложения и функции» и введите Vulkan в поле поиска на странице.
Стоит ли использовать Vulkan r6?
Vulkan API предоставляет преимущества по сравнению с DirectX 11, которые могут помочь Rainbow Six Осада улучшить графическую производительность. Более того, Vulkan как более новый API имеет преимущества, которые помогут снизить затраты на ЦП и ГП, а также поддержку более современных функций, которые могут открыть двери для более новых и интересных вещей в будущем.
Более того, Vulkan как более новый API имеет преимущества, которые помогут снизить затраты на ЦП и ГП, а также поддержку более современных функций, которые могут открыть двери для более новых и интересных вещей в будущем.
CUDA vs OpenCL — Run:AI
Аппаратное обеспечение
Существует три основных производителя графических ускорителей: NVIDIA, AMD и Intel.
NVIDIA в настоящее время доминирует на рынке, занимая наибольшую долю. NVIDIA предоставляет комплексные вычислительные и вычислительные решения для мобильных графических процессоров (Tegra), графических процессоров для ноутбуков (GeForce GT), графических процессоров для настольных компьютеров (GeForce GTX) и графических процессоров для серверов (Quadro и Tesla).
Этот широкий спектр аппаратного обеспечения NVIDIA можно использовать как с CUDA, так и с OpenCL, но производительность CUDA на NVIDIA выше, поскольку он был разработан с учетом аппаратного обеспечения NVIDIA.
Сопутствующее содержание: ознакомьтесь с нашим подробным руководством о CUDA на NVIDIA
AMD создает графические процессоры Radeon для встроенных решений и мобильных систем, ноутбуков и настольных компьютеров, а также графические процессоры Radeon Instinct для серверов. OpenCL — это основной язык, используемый для обработки графики на графических процессорах AMD.
Intel предлагает интегрированные в процессоры графические процессоры. OpenCL может работать на этих графических процессорах, но, хотя его достаточно для ноутбуков, он не обеспечивает конкурентоспособной производительности для вычислений общего назначения.
Помимо GPU, вы можете запускать код OpenCL на CPU и FPGA/ASIC. Это основная тенденция использования OpenCL в интегрированных решениях.
Операционные системы
CUDA может работать в Windows, Linux и MacOS, но только на оборудовании NVIDIA.
Приложения OpenCL могут работать практически в любой операционной системе и на большинстве типов оборудования, включая FPGA и ASIC.
Программное обеспечение и сообщество
NVIDIA занимается коммерциализацией и развитием платформы CUDA.NVIDIA разработала такие инструменты, как CUDA Toolkit, NVIDIA Performance Primitives (NPP), Video SDK и Visual Profiler, а также обеспечила интеграцию с Microsoft Visual Studio и другими популярными платформами. CUDA имеет обширную экосистему сторонних инструментов и библиотек. Новейшие аппаратные функции NVIDIA быстро поддерживаются в наборе инструментов CUDA.
Деятельность сообщества AMD более ограничена. AMD создала CodeXL Toolkit, который предоставляет полный спектр инструментов программирования OpenCL.
Модель программирования
CUDA не является языком или API.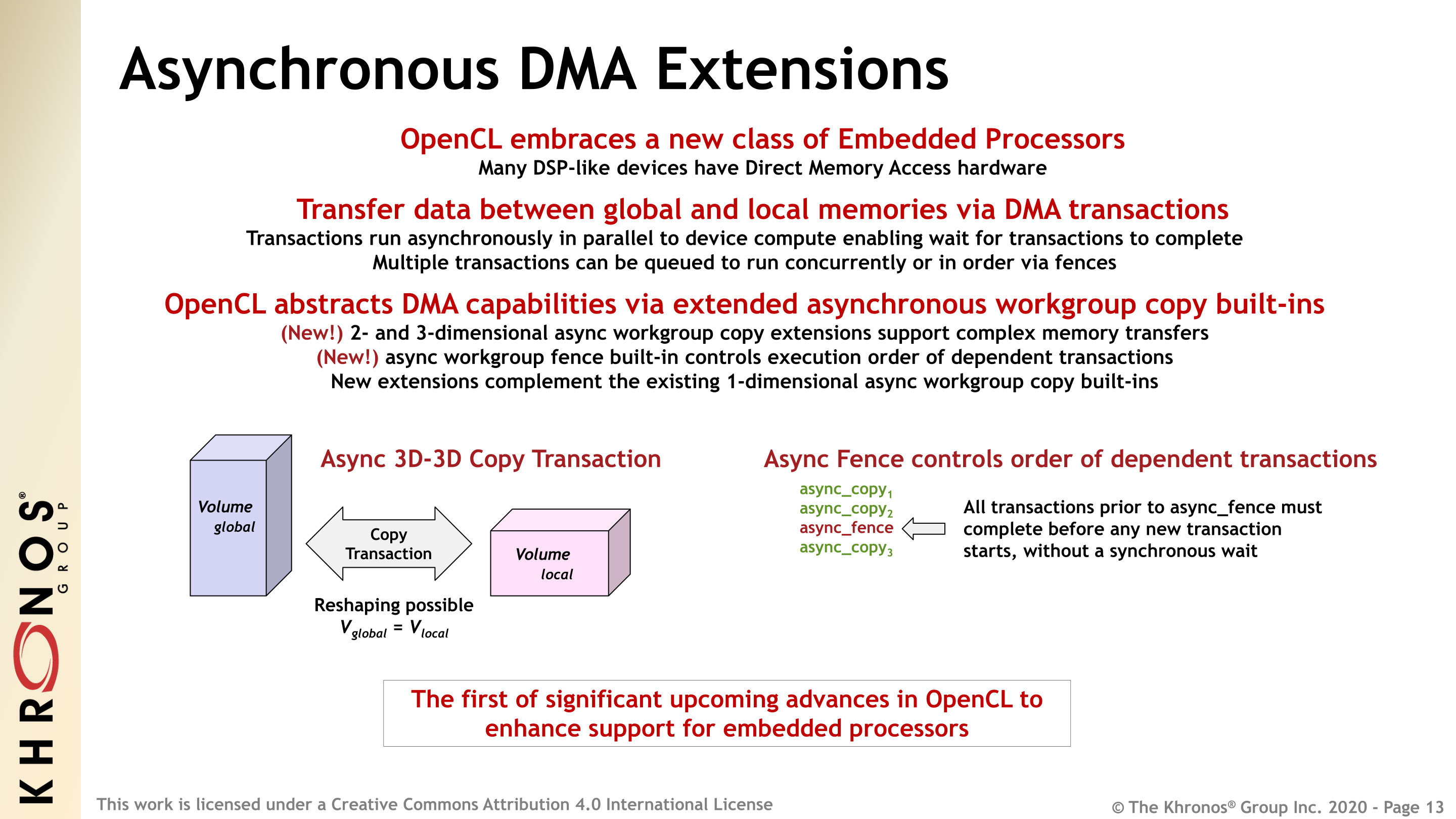 Это платформа и модель программирования для параллельных вычислений, которые ускоряют вычисления общего назначения с использованием графических процессоров. Разработчики по-прежнему могут писать программы на C или C++ и включать распараллеливание с помощью ключевых слов CUDA.
Это платформа и модель программирования для параллельных вычислений, которые ускоряют вычисления общего назначения с использованием графических процессоров. Разработчики по-прежнему могут писать программы на C или C++ и включать распараллеливание с помощью ключевых слов CUDA.
OpenCL не позволяет писать код на C++, но вы можете работать в среде, напоминающей язык программирования C, и работать напрямую с ресурсами графического процессора.
Нажатие кнопки сброса в Compute Frameworks
За последние 15 лет эволюция вычислений на GPU, а теперь, в более широком смысле, различных форм высокопараллельных вычислений, пошла по интересному пути.В то время как графические процессоры стали более широко использоваться в качестве ускорителей общего назначения, многие предсказывали и достигли цели в значительной степени, то, как мы пришли к этому, было интересным путем. Развитие процессоров застопорилось, параллельные архитектуры и целые компании взлетали и падали, самые мощные в мире суперкомпьютеры теперь включают графические процессоры в качестве ядра своей вычислительной мощности, и никто не предвидел грядущую революцию в области глубокого обучения, пока она уже не случилась с нами.
Большую часть последних полутора десятилетий на этом ландшафте стояла OpenCL, открытая платформа Khronos для программирования графических процессоров и других ускорителей вычислений.Первоначально созданный Apple и широко принятый в отрасли в целом, OpenCL был первой (и до сих пор наиболее последовательной) попыткой создать общий API для параллельного программирования. Извлекая уроки из ранних усилий поставщиков и создавая более широкий стандарт, который мог бы использовать каждый, OpenCL был адаптирован для всего, от встроенных процессоров и DSP до графических процессоров, потребляющих полкиловатт энергии.
В целом OpenCL успешно справляется с поставленными задачами по созданию общей (и в значительной степени переносимой) платформы вычислительного программирования.Он не только поддерживается на широком спектре оборудования, но и невероятно актуален даже для текущих событий: это API-ускоритель, используемый проектом Folding@Home, самым мощным в мире вычислительным кластером, который интенсивно используется для исследования вариантов лечения для пандемия COVID-19.
В то же время, как и никто не мог точно предсказать эволюцию рынка параллельных вычислений, не всегда все шло по плану Khronos и рабочей группы OpenCL, возглавляющей его разработку.Как мы уже несколько раз за последний год упоминали в различных статьях, OpenCL находится в довольно шатком состоянии на рабочем столе ПК, его изначальном доме. Спустя более десяти лет с момента своего создания экосистема вычислений на GPU раскололась: интерес NVIDIA сдерживается тем фактом, что у них уже есть свой очень успешный API CUDA, драйверы AMD OpenCL в беспорядке, Apple отказалась от OpenCL и переходит на собственный проприетарный Metal. API. Как ни странно, единственным поставщиком, проявляющим реальный интерес к OpenCL в настоящее время, является, как ни странно, Intel.В то же время OpenCL так и не получил широкого распространения на мобильных устройствах, несмотря на его эпизодическое использование и тот факт, что они получают все более мощные графические процессоры и другие блоки параллельной обработки.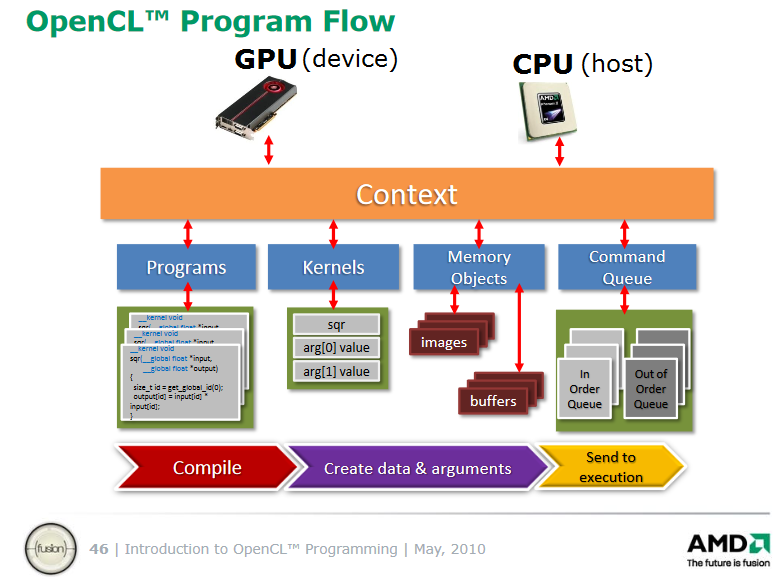
Итак, сегодня Khronos делает то, для чего, я не уверен, есть параллели в вычислительной индустрии — и, конечно же, ничего подобного в вычислительной экосистеме GPU никогда не было: фреймворк делает большой шаг назад. Стремясь перезагрузить экосистему, как любит это называть группа, сегодня Khronos представляет OpenCL 3.0, последняя версия их API вычислений. Приняв близко к сердцу некоторые с трудом заработанные (и тяжело выученные) уроки, группа повернула время вспять для OpenCL, вернув основной API к форку OpenCL 1.2.
В результате все, что разработано как часть OpenCL 2.x, теперь стало необязательным: поставщики могут (и, как правило, будут) продолжать поддерживать эти функции, но эти функции больше не требуются для соответствия основной спецификации. Вместо того, чтобы поддерживать каждую функцию OpenCL, независимо от того, насколько полезной или бесполезной она может быть для данной платформы, будущее API будет зависеть от поставщиков, выбирающих, какие дополнительные функции они хотели бы поддерживать поверх ядра.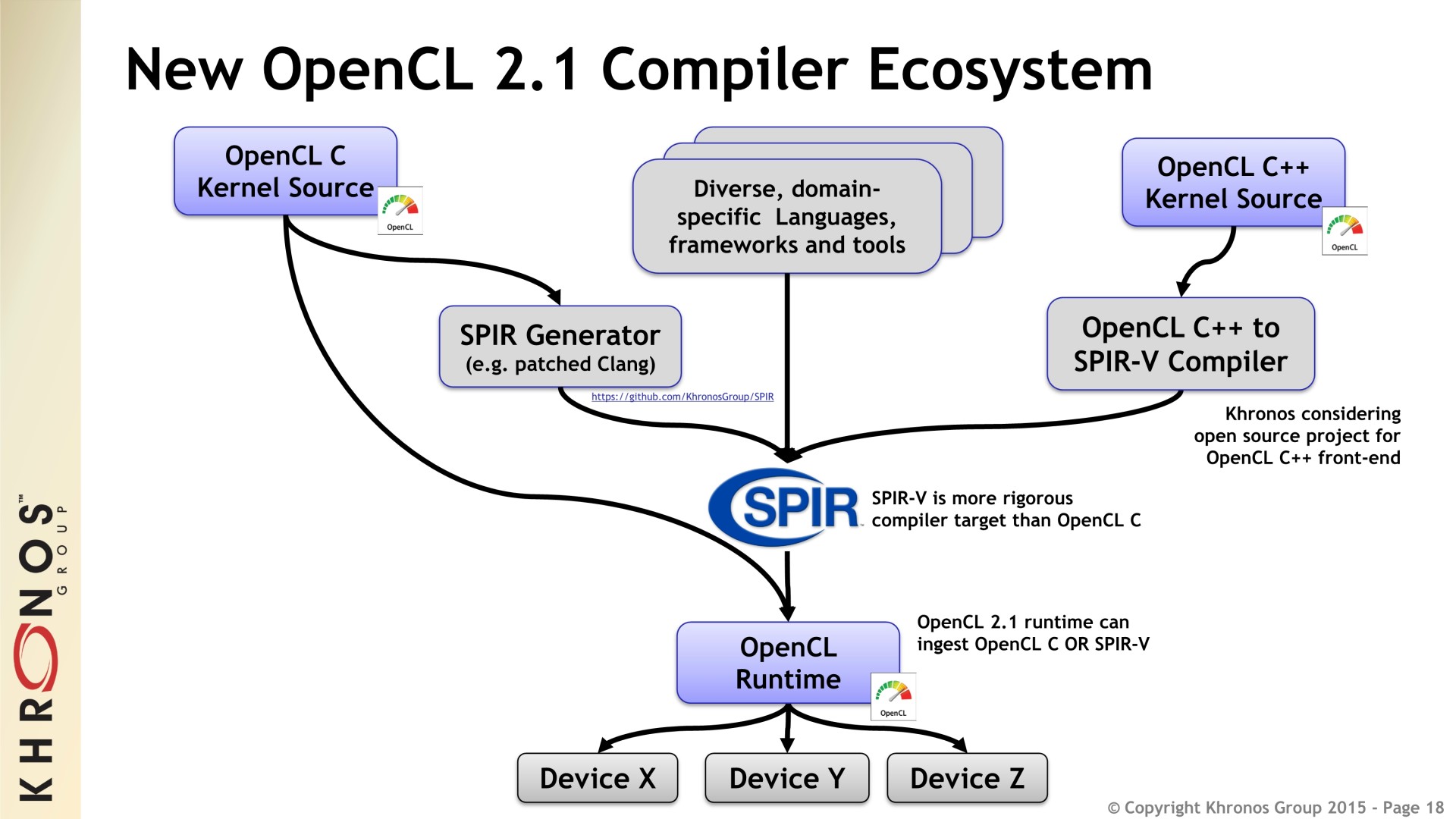 ОпенКЛ 1.2-производная спецификация.
ОпенКЛ 1.2-производная спецификация.
Политика и лижет
В целом объявление OpenCL 3.0 дает много поводов для распаковки. Но, возможно, лучше всего начать с понимания процесса разработки OpenCL и того, кто является пользователями OpenCL. Напомним, Khronos — это отраслевой консорциум. Сама организация не имеет реальной власти — это просто набор компаний — и, поскольку она не является держателем платформы, как Microsoft или Apple, группа не может никому навязывать технологические изменения.Вместо этого сила усилий Khronos заключается в том, что он получает широкую отраслевую поддержку своих стандартов, включая опыт и интересы многих поставщиков по всей экосистеме.
Проблема совместного подхода, однако, заключается в том, что он требует, по крайней мере, определенной степени гармонии и согласия между участвующими компаниями. Если не может быть достигнуто соглашение о том, что делать дальше, то проект не может двигаться вперед. Или, если полученный продукт никого не устраивает, продукт может быть полностью пропущен. Установление отраслевых стандартов в конечном итоге является политическим вопросом, даже если речь идет о технологическом стандарте.
Установление отраслевых стандартов в конечном итоге является политическим вопросом, даже если речь идет о технологическом стандарте.
В каком-то смысле это проблема, с которой столкнулся OpenCL. Самая последняя версия спецификации, OpenCL 2.2, была выпущена еще в 2017 году. Важно отметить, что она представила язык ядра OpenCL C++, наконец, обеспечив поддержку более современного объектно-ориентированного языка для API, который изначально был основан на C. критично, однако, три года спустя никто не принял OpenCL 2.2 . Ни NVIDIA, ни AMD, ни Intel, ни уж точно ни один из производителей встраиваемых устройств.
Каким бы важным шагом вперед ни был OpenCL 2.2 (и 2.1 до него), факт в том, что никто не был особенно доволен состоянием OpenCL после версий 1.2 и 2.0. В результате он теряет актуальность и больше не соответствует целям проекта. Проект OpenCL пытался угодить всем с помощью версии 2.x, но в итоге не удовлетворил никого.
ОпенКЛ 3.
/unikla_roadmapa_amd_pro_sektor_embedded_2013_01.png) 0: Идти вперед, идя назад
0: Идти вперед, идя назадИтак, если OpenCL 2.x в значительной степени игнорировался, как можно снова сделать OpenCL актуальным? Для Khronos и рабочей группы OpenCL ответ заключается в том, чтобы вернуться к тому, что сработало. Лучше всего работал OpenCL 1.2.
Впервые представленный в 2011 году, OpenCL 1.2 был последним выпуском OpenCL 1.x. По современным стандартам API это очень примитивно: он основан на чистом C и не поддерживает такие вещи, как разделяемая виртуальная память или промежуточный язык представления SPIR-V.Но в то же время это еще и последняя версия API, которая не включает в себя кучу хлама, который кому-то где-то не нужен. Это чистый, довольно низкоуровневый API для параллельных вычислений для разработчиков из самых разных областей, от встроенных устройств до самых мощных графических процессоров.
В конечном счете, рабочая группа OpenCL смогла договориться о том, что OpenCL 1.2 должен стать ядром новой спецификации, а все остальное, выпущенное после него, каким бы полезным в некоторых случаях оно ни было, недостаточно полезно для того, чтобы его использовать. быть обязательным во всех реализациях.Именно это и происходит с OpenCL 3.0. Новейшая версия OpenCL наследует версию 1.2 и делает ее новой базовой спецификацией, в то время как все остальные функции, выходящие за ее пределы, удаляются из основной спецификации и становятся необязательными.
быть обязательным во всех реализациях.Именно это и происходит с OpenCL 3.0. Новейшая версия OpenCL наследует версию 1.2 и делает ее новой базовой спецификацией, в то время как все остальные функции, выходящие за ее пределы, удаляются из основной спецификации и становятся необязательными.
Именно этот сброс Khronos и рабочая группа намерены дать OpenCL новый путь вперед. Несмотря на то, что время повернулось почти на девять лет назад, OpenCL и близко не подходит к завершению своего развития. Но его прежняя жесткая, монолитная природа также удерживала его от развития, потому что путь вперед был только один.Если поставщик был доволен OpenCL 1.2, но хотел, например, пару дополнительных функций 2.1, то для соответствия спецификации ему нужно было реализовать всю базовую спецификацию 2.1; В OpenCL 1.x/2.x не было механизма частичного соответствия. Это было все или ничего, и ряд поставщиков выбрали «ничего».
OpenCL 3.0, напротив, специально структурирован таким образом, чтобы поставщики могли использовать те части, которые им нужны, и только те части.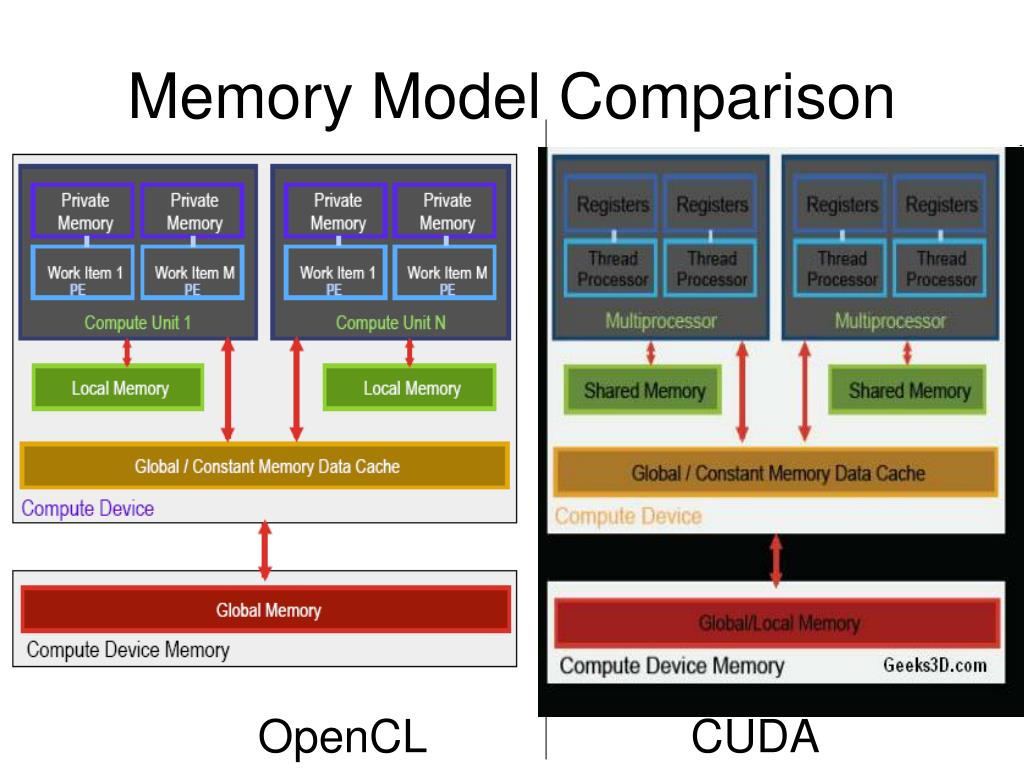 Как упоминалось ранее, фактическим ядром спецификации является OpenCL 1.2, с дополнительной поддержкой функциональных запросов, а также некоторыми «второстепенными точками входа для улучшенной переносимости приложений». Поверх этого, в свою очередь, накладывается все остальное: все функции OpenCL 2.x, а также новые функции OpenCL 3.0. Все эти дополнительные функции являются необязательными, что позволяет поставщикам платформ выбирать, какие дополнительные функции они хотели бы поддерживать, если таковые вообще имеются.
Как упоминалось ранее, фактическим ядром спецификации является OpenCL 1.2, с дополнительной поддержкой функциональных запросов, а также некоторыми «второстепенными точками входа для улучшенной переносимости приложений». Поверх этого, в свою очередь, накладывается все остальное: все функции OpenCL 2.x, а также новые функции OpenCL 3.0. Все эти дополнительные функции являются необязательными, что позволяет поставщикам платформ выбирать, какие дополнительные функции они хотели бы поддерживать, если таковые вообще имеются.
Например, поставщик встраиваемых систем может очень близко придерживаться того, что было в OpenCL 1.2, а затем внедрить несколько функций, таких как асинхронные расширения DMA и совместно используемая виртуальная память.В то же время крупный разработчик зеленого дискретного графического процессора может принять большую часть OpenCL 2.x, но исключить поддержку этой общей виртуальной памяти, что не очень полезно для дискретного ускорителя. И тогда третий поставщик в середине может захотеть внедрить диспетчеризацию устройств, но не SPIR-V. В конечном счете, OpenCL 3.0 дает поставщикам платформ возможность выбирать те функции, которые им нужны, по сути адаптируя OpenCL к их конкретным желаниям.
В конечном счете, OpenCL 3.0 дает поставщикам платформ возможность выбирать те функции, которые им нужны, по сути адаптируя OpenCL к их конкретным желаниям.
Как оказалось, это очень похоже на то, как Хронос боролся с Вулканом, который в последние годы был гораздо более успешным.Предоставление поставщикам некоторой гибкости в том, что реализует их API, позволило Vulkan быть растянутым от мобильных устройств до настольных компьютеров, поэтому есть некоторые очень четкие, реальные доказательства того, что эта структура может работать. И именно такого успеха хотела бы видеть и рабочая группа OpenCL.
В конечном счете, с точки зрения Хроноса, трудности OpenCL за последние полвека или около того были вызваны попыткой сделать его всем для всех и в то же время сохранить его монолитный характер.То, что нужно специалистам по встраиваемым системам, отличается от того, что нужно парням с CPU/APU, а то, что нужно этим ребятам, все еще отличается от того, что нужно ребятам с dGPU — и мы до сих пор не добрались до таких вещей, как FPGA и более эзотерические способы использования OpenCL. Таким образом, чтобы обеспечить свое будущее, OpenCL должен отказаться от монолитной конструкции и вместо этого быть адаптируемым к широкому спектру устройств и рынков, для обслуживания которых предназначен фреймворк.
Таким образом, чтобы обеспечить свое будущее, OpenCL должен отказаться от монолитной конструкции и вместо этого быть адаптируемым к широкому спектру устройств и рынков, для обслуживания которых предназначен фреймворк.
Путь вперед
Копнув немного глубже, давайте кратко рассмотрим, что такое OpenCL 3.0 означает для разработчиков, поставщиков платформ и пользователей, что касается разработки программного обеспечения и совместимости.
Несмотря на значительные изменения в философии разработки, OpenCL 3.0 спроектирован так, чтобы быть максимально совместимым с предыдущими версиями. Для разработчиков и пользователей, поскольку основная спецификация основана на OpenCL 1.2, приложения 1.2 будут работать без изменений на любом устройстве OpenCL 3.0. В то же время для приложений OpenCL 2.x эти приложения также будут работать без изменений на OpenCL 3.0, а также до тех пор, пока эти устройства поддерживают любые используемые функции 2.x. Что, разумеется, не означает, что вы собираетесь запускать приложение OpenCL 2. 1 во встроенной системе в ближайшее время; но на ПК и других системах, где уже работают приложения OpenCL 2.1, ожидается, что они не перестанут работать под OpenCL 3.0.
1 во встроенной системе в ближайшее время; но на ПК и других системах, где уже работают приложения OpenCL 2.1, ожидается, что они не перестанут работать под OpenCL 3.0.
Причина этого различия снова сводится к необязательному включению функций. Поставщикам платформ, разрабатывающим среду выполнения OpenCL 3.0, не обязательно поддерживать версию 2.x функции, но от них тоже не нужно отказываться; они могут (продолжать) поддерживать дополнительные функции по своему усмотрению. На самом деле, новая спецификация требует от держателей платформ относительно немногого в том, что касается соблюдения основных требований. Драйверы OpenCL 1.2 и 2.x нуждаются в некоторых изменениях для соответствия требованиям 3.x, но в основном это связано с поддержкой новых функциональных запросов OpenCL. Таким образом, поставщики смогут выпустить драйверы версии 3.0 в короткие сроки.
В дальнейшем основное внимание будет уделяться разработчикам приложений, правильно использующим запросы функций. Поскольку функции OpenCL 2.x являются необязательными, всем приложениям, использующим дополнительные функции 2.x/3.0, настоятельно рекомендуется использовать запросы функций, чтобы сначала убедиться, что необходимые функции доступны; как минимум, приложение может затем изящно завершить работу, а не более серьезный сбой из-за вызова функции, которой не существует. Таким образом, хотя программное обеспечение OpenCL 2.x будет продолжать работать как есть, разработчикам рекомендуется обновлять свои приложения для выполнения функциональных запросов.
Поскольку функции OpenCL 2.x являются необязательными, всем приложениям, использующим дополнительные функции 2.x/3.0, настоятельно рекомендуется использовать запросы функций, чтобы сначала убедиться, что необходимые функции доступны; как минимум, приложение может затем изящно завершить работу, а не более серьезный сбой из-за вызова функции, которой не существует. Таким образом, хотя программное обеспечение OpenCL 2.x будет продолжать работать как есть, разработчикам рекомендуется обновлять свои приложения для выполнения функциональных запросов.
Теперь, после всего сказанного, следует отметить, что, поскольку куча ранее требовавшихся OpenCL 2.x были сделаны необязательными, это означает, что поставщики платформ могут отказаться от них, если захотят. Говоря с Khronos, не похоже, что это произойдет — по крайней мере, не с поставщиками оборудования для ПК — но, тем не менее, это вариант, который они признают. Там, где его, скорее всего, увидят (если вообще где-нибудь), так это во встроенном пространстве и тому подобном, где поставщики уже медлили с такими функциями, как SPIR-V.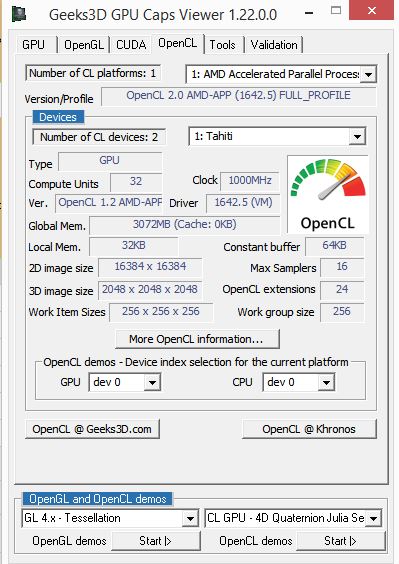
Наконец, хотя в реальном мире влияние этого будет нулевым, также стоит отметить, что OpenCL 2.2 так и не был принят, стандарт OpenCL 3.0 технически что-то оставляет позади. OpenCL C++, представленный в версии 2.2, не был включен в спецификацию OpenCL 3.0 даже в качестве дополнительной функции. Вместо этого рабочая группа OpenCL полностью отказывается от него.
На смену OpenCL C++ приходит проект C++ for OpenCL, который, несмотря на схожесть названий, является полностью отдельным проектом. Различия довольно малы с точки зрения программирования, но, по сути, C++ для OpenCL создается с многоуровневым подходом.В этом случае используется Clang/LLVM для компиляции кода в SPIR-V, который затем можно запускать на более низких уровнях стека выполнения OpenCL, как и другой код. И, конечно же, SYCL от Khronos по-прежнему обеспечивает программирование на C++ с одним исходным кодом для параллельных вычислений. Следует отметить, что SYCL основан на OpenCL 1.2, так что этот переход довольно незаметен.
Что нового в OpenCL 3.0: расширения асинхронного DMA и SPIR-V 1.3
Помимо серьезного возврата к базовой спецификации, OpenCL также включает в себя некоторые новые, дополнительные функции, в которые могут вникнуть разработчики и поставщики платформ.Главными среди них являются расширения асинхронного DMA, которые в конечном итоге станут особенно вкусным пряником для поставщиков платформ, которые до сих пор придерживались OpenCL 1.2.
Предназначенный для предоставления операций прямого доступа к памяти в OpenCL для устройств с аппаратным обеспечением DMA, асинхронный DMA — это именно то, что говорит само название: поддержка асинхронного выполнения передач DMA. Это позволяет выполнять транзакции DMA одновременно с вычислительными ядрами, в отличие от синхронных операций, которые обычно могут выполняться только между другими операциями вычислительного ядра.Это включает в себя возможность запуска нескольких операций прямого доступа к памяти одновременно друг с другом.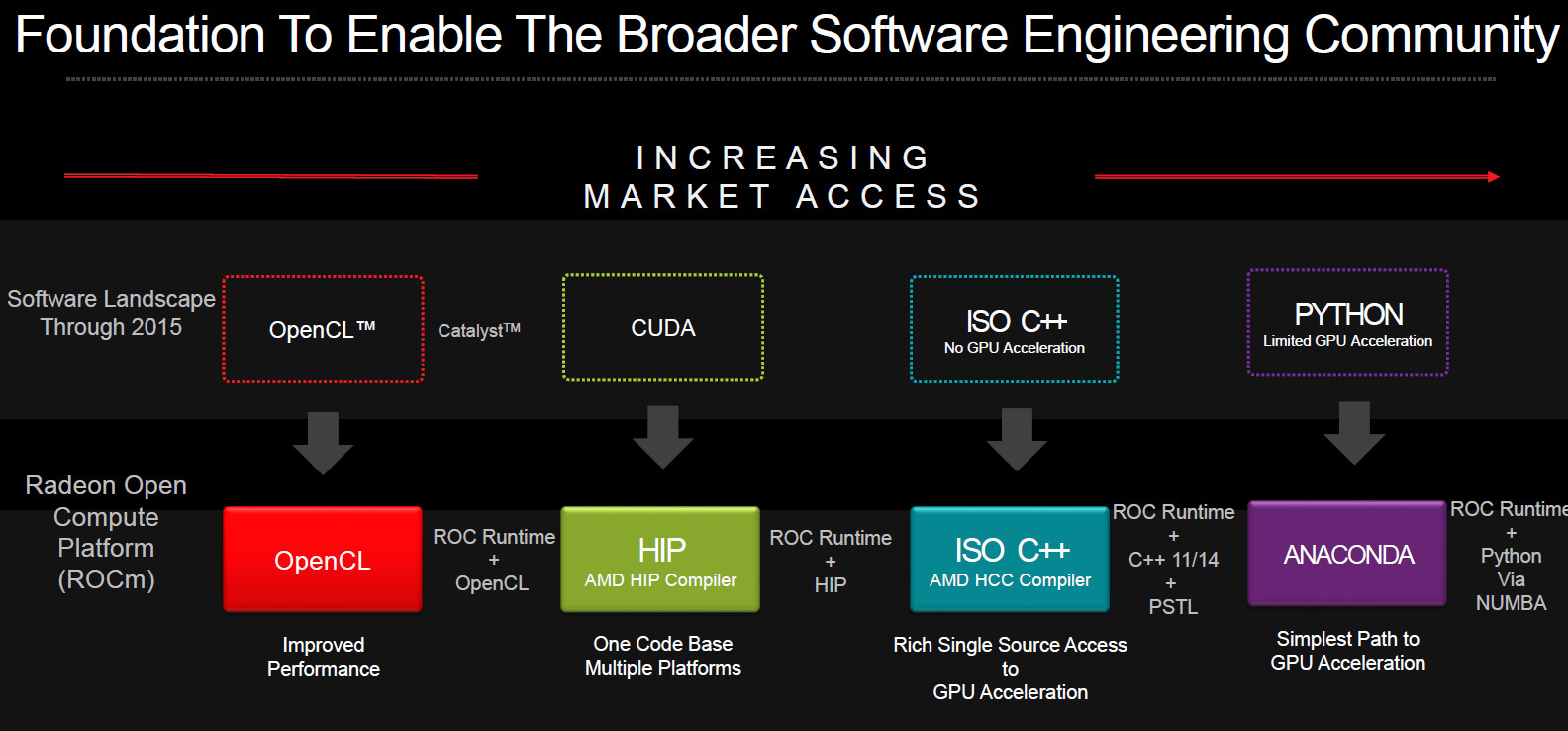
Эта функция особенно примечательна возможностью передачи 2D- и 3D-памяти, то есть сложных структур памяти, которые более совершенны, чем простые 1D (линейные) структуры памяти. Как и следовало ожидать, это предназначено для использования с изображениями и подобными данными, которые изначально являются двухмерными/трехмерными структурами.
Между тем, OpenCL 3.0 также представляет поддержку SPIR-V 1.3 для OpenCL.Это опять-таки дополнительная функция для владельцев платформ, которая делает OpenCL немного более современным в плане поддержки SPIR-V, а основная версия SPIR-V теперь имеет версию 1.5. По правде говоря, я не уверен, насколько актуальна опция поддержки 1.3 в данный момент, однако, поскольку она является частью спецификации Vulkan 1.1 — и действительно, многие улучшения в ней по сравнению с 1.2 сосредоточены на графике — в дальнейшем он будет играть более важную роль в усилении взаимодействия между Vulkan и OpenCL.
Что дальше для OpenCL?
Наконец, в рамках капитального ремонта OpenCL для версии 3.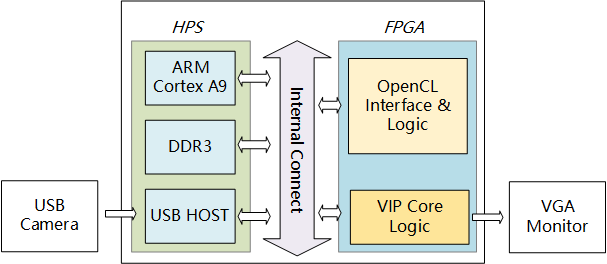 0, Khronos и рабочая группа OpenCL также излагают свои планы относительно будущего развития OpenCL. Очищая доску и перемещая так много функций в необязательные, это дает рабочей группе новую свободу добавлять в OpenCL столько пользователей, сколько считает нужным. И, следуя их новой философии, более фрагментарно.
0, Khronos и рабочая группа OpenCL также излагают свои планы относительно будущего развития OpenCL. Очищая доску и перемещая так много функций в необязательные, это дает рабочей группе новую свободу добавлять в OpenCL столько пользователей, сколько считает нужным. И, следуя их новой философии, более фрагментарно.
Значительной частью, как всегда, будет дальнейшее развитие базовой спецификации OpenCL. В то время как 3.0 отматывает все назад, план не состоит в том, чтобы поддерживать спецификацию ядра версии 1.2 навсегда.Скорее, как и в других проектах Khronos, цель рабочей группы по-прежнему состоит в том, чтобы перенести широко распространенные и хорошо протестированные расширения в ядро. Чтобы еще раз добавить дополнительные слои к луковице, как бы, но гораздо более разумно и размеренно, чем это было в разработке OpenCL 2.x.
Тем временем одной из высокоприоритетных функций для будущих версий будет то, что группа называет гибким профилем, что является еще одной функцией, ориентированной на встроенные приложения.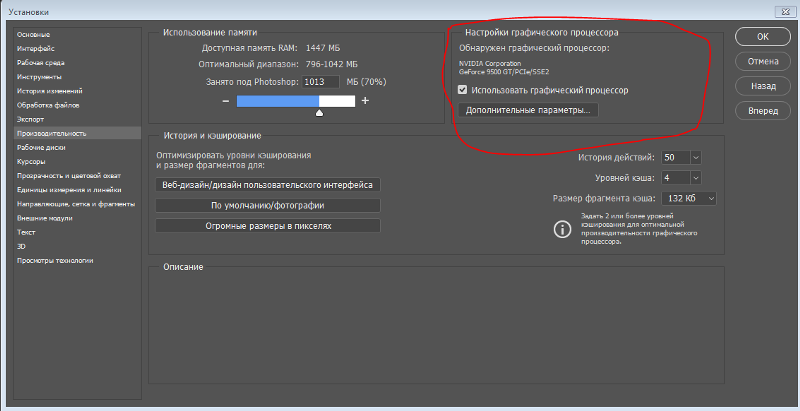 Интересно, что в некоторых отношениях это еще более урезанная версия OpenCL, позволяющая производителям вырезать еще больше функций, чтобы точно соответствовать возможностям их оборудования.Например, можно удалить режимы точности с плавающей запятой, такие как одинарная точность IEEE, которые обычно требуются в OpenCL 1.2/3.0, а также некоторые вызовы API. Помимо дальнейшего упрощения для некоторых разработчиков, это сделало бы OpenCL более подходящим для сред со строгими требованиями к сертификации безопасности (например, в автомобильной промышленности), поскольку меньший набор функций OpenCL было бы намного проще проверить и пройти сертификацию.
Интересно, что в некоторых отношениях это еще более урезанная версия OpenCL, позволяющая производителям вырезать еще больше функций, чтобы точно соответствовать возможностям их оборудования.Например, можно удалить режимы точности с плавающей запятой, такие как одинарная точность IEEE, которые обычно требуются в OpenCL 1.2/3.0, а также некоторые вызовы API. Помимо дальнейшего упрощения для некоторых разработчиков, это сделало бы OpenCL более подходящим для сред со строгими требованиями к сертификации безопасности (например, в автомобильной промышленности), поскольку меньший набор функций OpenCL было бы намного проще проверить и пройти сертификацию.
Тем временем, на другом конце спектра, Khronos снова рассматривает идею наборов функций для OpenCL, чтобы помочь разработчикам программного обеспечения лучше ориентироваться в различиях между основными платформами.Хотя характер OpenCL 3.0 с большим количеством опций делает его относительно мелкозернистым, он также в некоторой степени ухудшает переносимость — разработчик не может рассчитывать на другую реализацию OpenCL 3.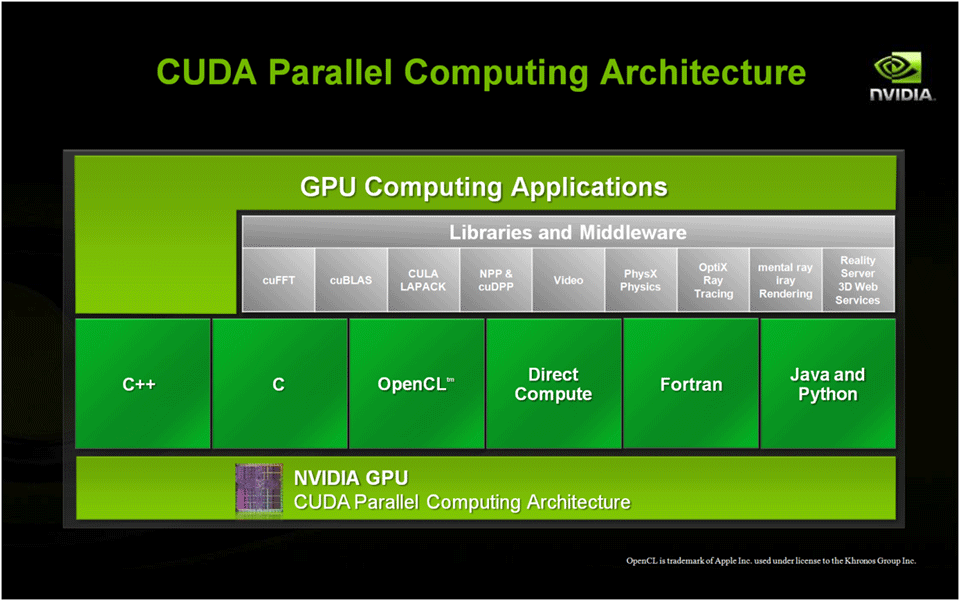 0, которая должна иметь что-то большее, чем то, что требует основная спецификация 1.2-eqsue. . Таким образом, в отличие от наборов графических функций для графических процессоров, наборы функций OpenCL позволили бы отрасли провести некоторую стандартизацию — скажем, профиль ПК с многочисленными современными функциями, а затем профиль машинного обучения с поддержкой меньшего числа функций, более актуальных только для глубокого анализа. обучающие операции.
0, которая должна иметь что-то большее, чем то, что требует основная спецификация 1.2-eqsue. . Таким образом, в отличие от наборов графических функций для графических процессоров, наборы функций OpenCL позволили бы отрасли провести некоторую стандартизацию — скажем, профиль ПК с многочисленными современными функциями, а затем профиль машинного обучения с поддержкой меньшего числа функций, более актуальных только для глубокого анализа. обучающие операции.
Группа также ищет новые возможности для многоуровневых подходов, когда поддержка OpenCL не является (и, вероятно, никогда не будет) встроенной частью платформы. Это еще одна концепция, взятая из сборника игр Vulkan, где есть уровни, доступные для запуска Vulkan на таких платформах, как Metal от Apple. У OpenCL уже есть активный проект для запуска поверх Vulkan — clspv и clvk — который использовался в мобильных устройствах, чтобы помочь Adobe переносить и повторно использовать свой код OpenCL с рабочего стола Premiere на Premiere Rush, не требуя обширной перезаписи.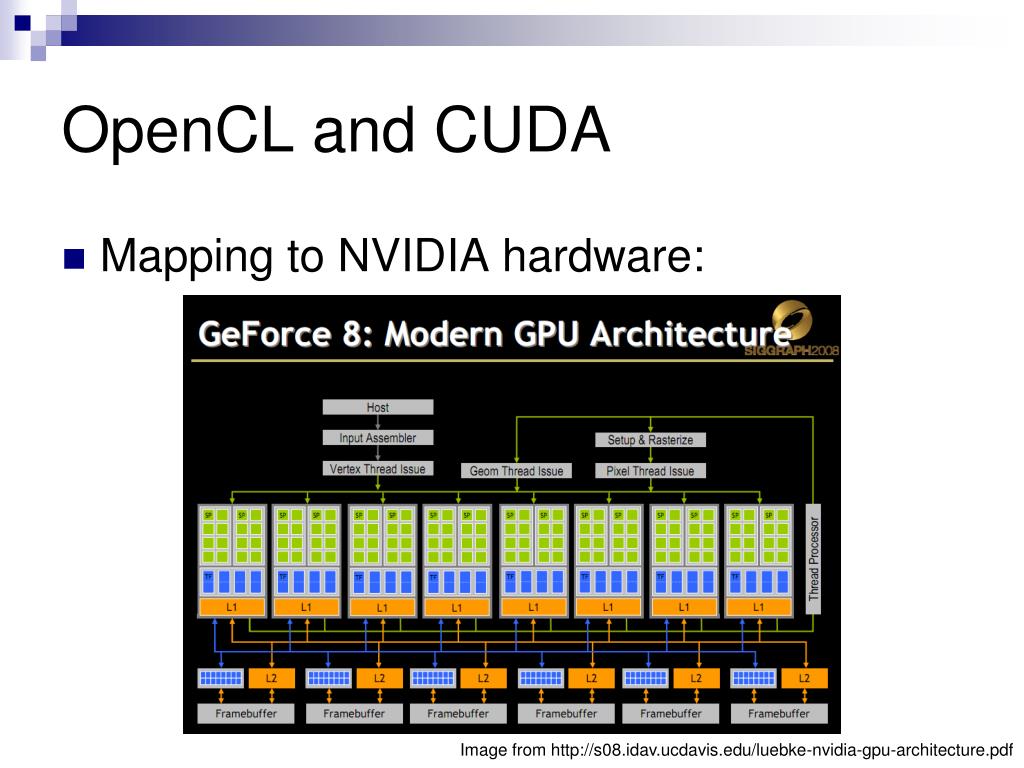 Тем временем Microsoft также поддерживает проект OpenCL, (Open)CLOn12, в котором будет реализована поддержка OpenCL 1.2 поверх DirectX 12.
Тем временем Microsoft также поддерживает проект OpenCL, (Open)CLOn12, в котором будет реализована поддержка OpenCL 1.2 поверх DirectX 12.
Но большой вопрос о многоуровневости, который Khronos задает прямо сейчас, вращается вокруг OpenCL для платформ Apple. Первоначальный автор OpenCL не продвинулся дальше поддержки OpenCL 1.2, и они пометили эту функцию как устаревшую. Так что, если OpenCL продолжит работать на платформах Apple, не говоря уже о поддержке новых версий 2.x и 3.x — тогда необходимо будет добавить новую поддержку в качестве уровня более высокого уровня. Так что, хотя в настоящее время нет проекта OpenCL over Metal, кажется, что его запуск — лишь вопрос времени, если, конечно, Khronos сможет найти достаточно заинтересованных сторон для проекта. Группа добилась большого успеха с MoltenVK, их слоем Vulkan-over-Metal, поэтому проект OpenCL хорошо вписался бы в это.
Наконец, даже сам Vulkan является своего рода потенциальным проектом для рабочей группы OpenCL. Возврат к основной спецификации означает, что совместимость Vulkan/OpenCL сделала шаг назад, и рабочая группа хотела бы продвинуть это вперед. В идеале OpenCL должен иметь возможность работать в том же наборе памяти, что и Vulkan, а также импортировать и экспортировать семафоры явным образом.
Возврат к основной спецификации означает, что совместимость Vulkan/OpenCL сделала шаг назад, и рабочая группа хотела бы продвинуть это вперед. В идеале OpenCL должен иметь возможность работать в том же наборе памяти, что и Vulkan, а также импортировать и экспортировать семафоры явным образом.
OpenCL 3.0: предварительная версия сегодня, формализация через несколько месяцев?
Но прежде чем что-либо из этого может официально произойти, Khronos и рабочая группа OpenCL приложат все усилия, чтобы получить OpenCL 3.0 за дверь. Хотя сегодня группа представляет OpenCL 3.0, стандарт все еще является предварительным — он раскрывается разработчикам и широкой публике, чтобы получить отзывы до полной формализации. И, учитывая текущее состояние OpenCL 2.x, группа стремится как можно скорее завершить работу над OpenCL 3.0.
В общем, Хронос надеется, что они смогут добиться ратификации стандарта через несколько месяцев. Наряду с получением согласия участников и разработчиков, для финализации также потребуется, чтобы OpenCL 3.